Furthermore, ensuring high quality of service in such a peer-to-peer network requires careful system design. The dissertation consists of game-theoretic models of decentralized (peer-to-peer) radio spectrum sharing solutions (P2P, distributed network of functionally equal peers) and game-theoretic models.
Research background
Related work
Research goals
Motivation
The second part of the dissertation is focused on radio spectrum allocation, studying auction-based management schemes in a distributed manner. We let the participants exchange the acquired resources among themselves in a distributed design without the intervention of a central auctioneer.
Methodology
Game theory
The combination of universal cooperation leading to optimal overall utility, an individual incentive to defect, and rational behavior provides the essential tension that results in the tragedy of the commons [81] without properly designed incentive schemes. Neither of these conditions is likely to be achievable in a practical distributed system, where not only the preferences of individual peers but also their identities may be unknown [12].
Incentive mechanism design
Regarding economic efficiency, besides the lack of information about the identities and preferences of the individual participants, which is necessary for the calculation of the optimal allocation of resources and costs in a distributed system, an additional challenging issue is the complicated economic modeling of individuals. Currency has a well-defined uniform valuation for each participant and supports flexibility in terms of the time and amount of counter-contribution for any given resource.
Matching Theory
Distributed Algorithmic Mechanism Design (DAMD) focuses on enabling compatibility solutions for web applications in a decentralized manner. When such a system has no centralized authority with full knowledge of the decision-making system, this becomes a DAMD problem, combining computer science with the design of compatible incentive mechanisms in economics.
Outline of the dissertation
The second part of the thesis examines the possibility of allocating radio spectrum between several applicants dynamically in a distributed manner. This means that any arbitrary part of the data can be retrieved immediately by the data owner, guaranteeing low access latency.
Backup versus storage in a P2P system
Furthermore, since the backup service accepts a local copy of the data from the user, recovery of the backup is only required when the locally stored copy is lost. We strive to relieve users of payments, our data transfer scheduling policies keep data center bandwidth and storage costs to a minimum.
Focus of the work
- Replication
- Erasure coding
- Maintaining redundancy
- Feasibility of P2P storage
To maintain the stability of the backed up data, the degree of redundancy, i.e., the amount of additional data in the P2P system that guarantees that a backup operation is considered complete and secure, should be chosen wisely. If none of these choices are provided in one location, repairing a single encrypted fragment imposes the transfer of an amount of data equal to the size of the backup object to the system.
Data placement
- Central or distributed mapping
- Peer monitoring
- Fairness
- Incentives
Each peer belonging to the same group has a consistent view of the attributed partition. Consequently, peer heterogeneity in terms of the amount of resources they dedicate to the system must be taken into account by an additional system layer to elicit their cooperation.
Reliability of the system
Data transfers
Security
The purpose of a P2P backup system is to securely store data for users on remote peers. In this case, TTB and TTR depend only on the amount of backup data and on the bandwidth capacity and availability of the data owner.
Redundancy scheme
- Data structure
- Adaptive redundancy rate
- Redundancy maintenance scheme
- Assisted repairs
In fact, introducing backup objects and storing their fragments independently is analogous to allowing remote peers to have multiple fragments of the entire backup data. The scheme determines the adaptive redundancy level for each user individually and adjusts it according to the stored remote peers of each of them.
Grouping peers by design
From this point, the tracker starts to restore the redundancy of the online peer if its eDLP exceeds a threshold, calculated for a time window set to the eTTR of the data center in addition to 2×w. On the other hand, while the peer selection mechanisms result in cooperation incentives, the benefits of the scheme are offset by a loss in efficiency due to the stricter peer selection norms.
Assisted backup
Data center storage
On the contrary, the centralized nature of the data center means that the cost-sensitive user never stores more thank-you fragments in it. As soon as the backup phase is complete, a "hybrid" reordering phase, slightly modified from a pure P2P setup, begins with the fragments on the remote peers and in the data center.
Data placement during backup
Thus, chunks are transferred to the data center when the backup operation on remote peers temporarily fails. If the availability and bandwidth limitations of remote peers cease to exist, more fragments are uploaded to them and the data center is unloaded in the meantime.
User satisfaction
Our payment consists of two terms, value of service and cost of effort; the latter is the difference between the chosen grade and the peer's effortless grade. Instead, our heuristic value function reflects the attributes of the partners with their number and the worst grade among them.
The exchange game
Propositions 6.2.2 and 6.2.3 characterize the theoretical inefficiency of the backup phase due to the unavailability of external peers. The good performance of applying higher k is partly due to the growing involvement of the data center.

Stable fixtures problem
Stable stratification
Grade improvement
We make the following claim on the association of effortlessness and equilibrium grades, and hence we show that effortlessness grade rankings essentially predetermine the equilibrium grade rankings, and hence joint capacities. Proposition 5.6.2 claims that players join cliques, driven by their payoffs based on the size and worst class member of the clique.
Random scheduling without full information
The original problem, ie. finding the optimal schedule that minimizes the time to transfer N fragments can be solved by performing O(logT)max-flow calculations. Since it is a Bernoulli process, the expected number of time slots T for the transmission of n fragments is E(T) = 1−un, since the mean of the associated binomial distribution is t(1−u).
Evaluation of random scheduling
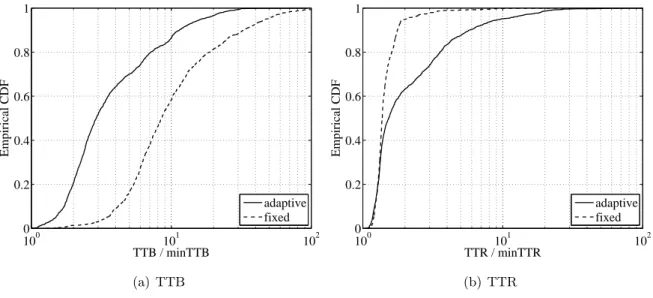
In addition, with a larger set of remote peers, randomization performance approaches optimal regardless of the number of fragments to transfer. In Figure 7.3(b), we show the distribution of theminT T BandminT T R defined in Definition 4.1.2: each user's amount of backed-up data divided by its actual upload and download capacity.

Fixed and adaptive redundancy rates
Prompt data availability and TTR
Plotted eTTR values are calculated when crashes occur, and compared to the subsequent measured TTR. However, as the redundancy rate increases (fixed rate), the eTTR approaches the measured TTR in most cases.
Adaptive redundancy rate scheme
The eTTR provides a fairly good estimate of the TTR: in some cases it is too pessimistic (ratio of TTR to eTTR is around 0.6), and appears to be inaccurate by a factor of more than 2 in 25% of the cases. optimistic . The former period is double the length of the predetermined time period after which peers are notified by the tracker of the crash of a peer, which was offline for the time being, indicated as w in section 4.2.
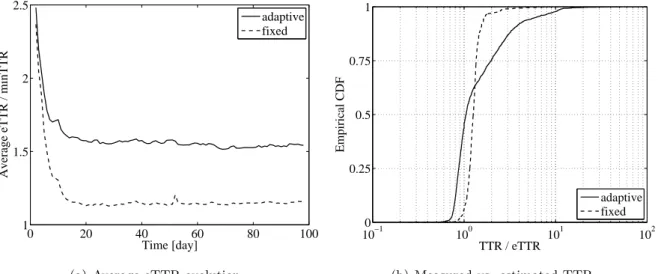
Data loss results
Even after uploading fragments from peers, most cases of data loss are due to low data redundancy. It is therefore significantly lower when adaptive rates are applied (Figure 7.9(b)), constituting an advantage of the adaptive scheme.
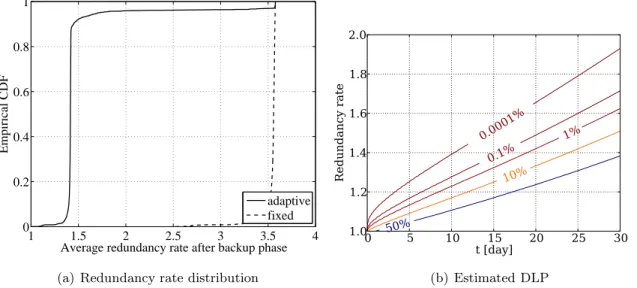
Evaluation of a grouped P2P system
The grade distribution in the system and in the separate classes is shown in Figure 7.10. We show the storage load on peers and on the data center per classes in figures 7.11(b) and 7.12(a) respectively.
Evaluation of scheduling policies
Effects of discrete scheduling
Results of assisted backup
The TTR is slightly longer in schemes where the data center plays a less important role in the backup phase (Figure 7.15(a)). Backup uploads and supported repair-related transfers (from remote peers to restore the backup object) make up the inbound traffic of the data center (Figure 7.16(b)).

System setting discussion
Fragment size
With k= 256, most fragments must be stored in the data center (Figure 7.18(d)), making the redundancy rate very low, although at the same time increasing costs. Anything that remains in the data center at the end of the simulations will remain unsaved in an unsupported case.

Simulated user parameters
The scalability of the system, i.e. similar TTB, DLP and TTR results and costs, regardless of how many peers the system has, is ensured if the peers are sufficient in number to distribute the encrypted fragments, which, in turn, is determined by system design through k. We conclude that short booking times are crucial, much more than the reliability of the P2P system itself.
Fairness
In this section we present our second prize policy and the directing role of the government. Given the complexity of node exclusion problems, we use Assumption 11.3.4 in the next section.

Efficiency
Perspectives
We build a self-organizing scheme in which the participants, that is, the wireless service providers, manage the allocation of their frequency bands at arbitrary time. Radio spectrum exploitation is historically regulated by government authorities, e.g. the Federal Communications Commission in the US.
Focus of the work
The authors also provide a linear programming formulation of spectrum allocation with feasibility constraints: maximum service vs. deduce the latter from physical interference models so that it yields an almost optimal allocation.
Distributed allocation
Spectrum auctions
The proposed system focuses on dynamic allocation stability, which is achieved through admission control and disturbance-aware demand shaping. The authors show the existence of a Nash equilibrium of bidding strategies in the case of two users.
Secondary spectrum usage
Node description
If two nodes share the same spectrum part within the same region and the technological connection is zero, they do not interfere with each other at all, but if it is the largest, the spectrum is destroyed for one of the nodes. The cumulative effect of combining geographic and radio technologies between any two nodes operating on the same spectrum with given transmission powers is simply the product of three factors, and these factors may also be asymmetric.
Interference model
With ui we denote the utility of the frequency slot for node i ∀i∈ I; its value is based on the expected income of the node, provided that it gets the necessary spectrum quality of the qi slot bands to run its service. We assume that the total utility of the node is homogeneously divided into the required frequency slots.
Distributed allocation — one-way exclusion
If the newcomer's allocation includes buyout attempts, the excluding node(s) pay off the interfering node(s) on the frequency slot, but the non-interfering nodes, i.e. exclusion is one-way. Real offers and utilities are direct consequences of system rules; this aspect is evaluated in the next section.
Pricing directives
- Second-price auctions
- Utility-based pricing and rationality
- Incentive compatibility
- Fairness and efficiency
If the new node's bid is higher, it pays the lower bid to the authority and the frequency lessee's node is shut down. Therefore, the defined usefulness also depends on the time remaining until the end of the actual period.
Node exclusion strategies and their consequences
- Node exclusion problem
- Insights about exclusions in a simplified scenario
- The saturation of a frequency slot
- Queuing model of a frequency slot
Proposition 11.3.6 Optimizing the set of perturbing nodes described by Assumption 11.3.4 is an NP-complete problem. Proposition 11.3.7 After the cumulative disturbance reaches αfmin at the frequency slot f, it will not drop to lower values simply due to exclusions.
Frequency band selection algorithms
The frequency band selection and node-exclusion algorithm
However, by design it tries to exclude nodesj in ascending order of their "interference prices" (uj−cj . ωfji ) if the frequency slot is overinterfered in i. Furthermore, if it succeeds in lowering its perceived interference level below its threshold αfi, it is assumed to resist exclusion attempts in the ascending order of αfj of old nodes, thereby implicitly excluding them or raising their cost until i is definitively bought out on every frequency slot.
Optimization heuristics
Implemented heuristic algorithms
As in the previous example, we try to analyze the frame effects in very interference-friendly (like UWB) and extremely uninterference-friendly (like DVB-T) nodes. We determine the interference thresholds based on the various characteristics of the radio technique included in the simulation, thus setting the set of α (in Table 12.3).
Evaluation metrics
We give the geographical (ǫ = 640 within the given area) and technological coupling parameters of [78] (in Table 12.2 the row technologies cause the depicted perturbation of the column technologies); interference parameters are given by these multiplicative values. Node utilities (in Table 12.4) are chosen in favor of our framework's performance representation.
Simulation results
12.3(d)), the difference is less noticeable in Figure 12.3(f), despite the fact that type-4 nodes are penalized even more severely in the latter case. Based on the peer selection preferences caused by the payout, we showed that matches arise between peers with similar grades.

Distributed dynamic spectrum allocation
Hierarchical codes: How to make erasure codes attractive to peer-to-peer storage systems. -TO-PEER BACKUP ALGORITHMS 138. pu: number of maximum parallel uploads to external peers. peer, fr rag, comp): an upload job described by the remote peer, the fragment, and the transfer completion percentage.
Maximum flow problem formulation of data transfer scheduling
Backup and retrieval inefficiency with synthetic online phases
Backup and retrieval inefficiency with correlated online phases
Number of online peers
Peer behavior inputs
Peer connectivity inputs
Online redundancy with fixed-rate
Analysis of adaptive-, and fixed-rate redundancy schemes
Fixed and adaptive redundancy schemes
Redundancy rates and data losses
Fatal fraction of peer crashes with adaptive-rates (top) and fixed-rates (bottom) . 65
Distribution of grades
Fairness in grouped peer selection
Cost of fairness in grouped peer selection
Uplink underutilization
Benefits of assisted backup
Data center involvement in different data placement schemes
Data center traffic
Redundancy rate distribution with different fragment sizes
Fragment size analysis
Nodes in the second scenario
Authority income and node lifetimes with different frequency band selection strate-
Authority income and node lifetimes with different frequency band selection strate-