SPACE IN LANGUAGE: EMBODIED EVIDENCE OF SPACE-LANGUAGE INTERACTION
132
0
0
Texto
Imagem

+7


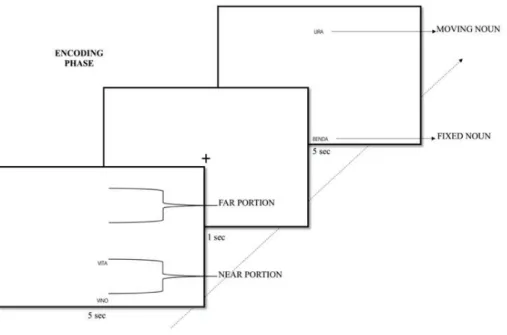

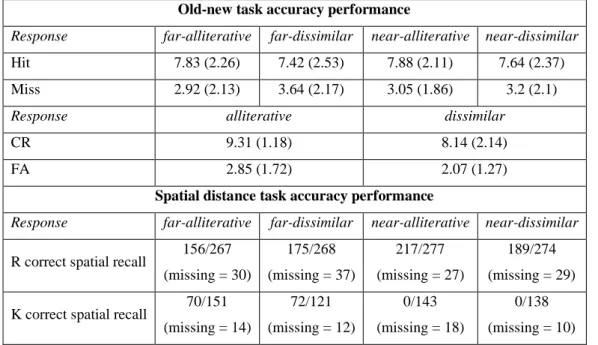
Documentos relacionados
Meu histórico eu fui muito bem assim, há uns quatro semestres atrás assim, eu corria de todas essas disciplinas, eu não aguento mais esse negócio de discutir, de sentar
