Science, Netherlands Stefania Bandini University of Milano-Bicocca, Italy Olga Bandman Russian Academy of Sciences Thomas Casavant University of Iowa, USA Pierpaolo Degano University of Pisa, Italy. Mateo Valero Technical University of Catalonia, Spain Roman Wyrzykowski Technological University of Czestochowa, Poland Laurence T.
Parallel Programming Tools
Cellular Automata
Application
Strassen’s Communication-Avoiding Parallel Matrix Multiplication Algorithm
1 Introduction
In a previous publication, we have proposed an implementation of Strassen's algorithm specifically designed for wormhole-routed, 2D, all-port, torus connection networks [3]. In this paper, we present a new communication-avoiding matrix multiplication algorithm for the same architecture based on a variant of Strassen's formulation.
2 Problem Statement and Previous Work
Unlike some recent proposals on the same topic, we treat the topological aspects of the algorithm in detail and provide specific conflict-free routing models that are useful in reducing the total number of messages. Thus, given the widening gap between network latency and processor speed, it is becoming increasingly important to reduce the number of messages and the length of messages contained in an application.
3 The Proposed Algorithm
The Basic 2 × 2 Multiplication Algorithm
3. To calculate the elements of product matrix C, an additional communication step is required (Figure 2). The latency (L) and bandwidth (B) costs for the base case can be calculated as follows.

Performing Recursion
The steps for the first phase of the algorithm, and associated latency and bandwidth costs are provided in Table 1. A BFS divides the 7 subproblems between the processors, so that 1/7 of the processors work on each.

4 Performance Analysis
The level at which the recursive call to Strassen's algorithm must terminate due to communication overhead is called the cutoff point. If (n− >k ω), we invoke (l= − −n k ω) Strassen's recursions and then return to local computation of submatrices.
5 Conclusions and Future Work
If (n− ≤k ω), we only execute the basic case of the Strassen algorithm (i.e. the first level of the Strassen algorithm without any recursion) and the 7 processors perform the local matrix multiplication of the 2(n k−)2×2(n k− )2 matrix only once . The above inequality is satisfied when the local classical matrix multiplication takes longer time compared to the recursive call of Strassen's algorithm.
Timed Resource Driven Automata Nets for Distributed Real-Time Systems Modelling
1 Introduction
Meanwhile, TRDA networks have a relatively simple and natural syntax and can be efficiently translated into widely used formats. We demonstrated the modeling capabilities of the formalism and proved that TRDA-nets can be embedded (up to temporal bisimulation equivalence) in temporal automata as well as temporal Petri nets, so that TRDA-nets combine the advantages of both formalisms.
2 Preliminaries
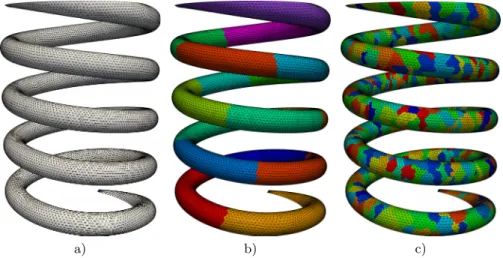
A source-driven automaton (RDA) is a tupleA= (SA, TA, lA), where SA is a finite set of states, TA ⊆SA×SA is a transition relation, and lA:TA → Li is a transition label. Ak) with types of Ω as described above, and a system net SN over a set Ω of types, set Const of constants, and a set Π of Ω-typed gates.
3 Timed RDA-Nets
The set of all constants (all timed automaton states) is defined as Const=defWConst∪FConst. Continuous part of the model is concentrated at the object level - time constraints are imposed.
4 Modelling and Verification with TRDA-Nets
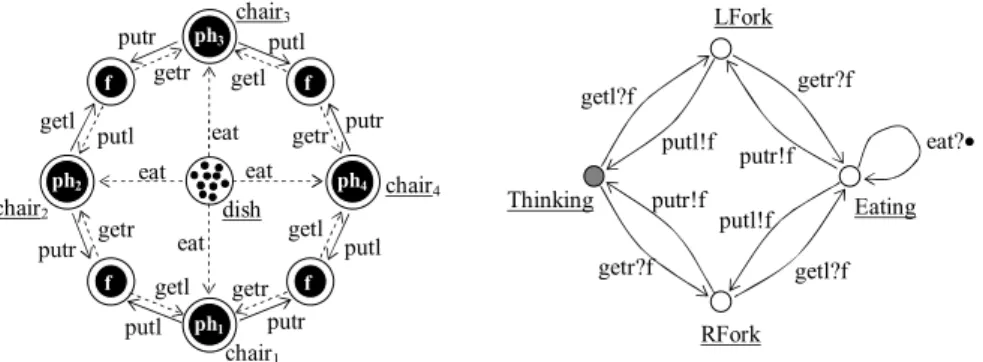
As we have shown, TRDA nets can be a convenient modeling formalism for distributed dense-time systems. TRDA Networks for Modeling Real-Time Distributed Systems 23 Consider a specific use case — the cigarette smoker problem.

5 Conclusion
Here, we have used many features of our tool to verify some properties of the hashed time behavior of the system under consideration. Chang, L., He, X., Lian, J., Shatz, S.: Application of the nested Petri net modeling paradigm in the coordination of sensor networks with mobile agents.
Appendix
There are two main classes of preconditioners: explicit, which only applies matrix-vector multiplication, and implicit, which requires a solution of linear auxiliaries based on the incomplete decomposition of the original matrix. As a result, implicit preconditioners work much faster and are better than linearly dependent on the convergence of the geometric size of the problem.
2 Conjugate Gradient and Preconditioners
Other kinds of complicated explicit preconditioners (such as approximate reverse) also propagate information slowly due to the limited stencil size and also belong to the O(N) class. For these reasons, simple explicit preconditioners remain attractive in some cases due to good parallelization properties.
3 Optimization and Parallelization of Explicit Preconditioners
Parallelization properties of preconditioners for CG methods 29 The multiplication of the symmetrically stored sparse matrix by a vector is more complex compared to the original storage scheme. For long domains, it is recommended that network nodes be numbered along the short dimensions.
4 Implicit Preconditioners for Regular Domains
The next reverse exchange is done in the reverse order, from the center outwards. Each subdomain is divided into 2 parts in the j direction (see lower left octant divided between threads 0 and 1).

5 Implicit Preconditioners for Unstructured Grids
Therefore, the parallelization potential of the above method can be estimated to be at most 32 or 64. Twisted factorization of the sparse matrix (left, middle); illustration of the parallel Gaussian elimination (right).

6 Conclusion
The table shows that the performance gain when using the existing*4 data format is 1.28. The computation speed of the test problem on the more advanced Intel Sandy Bridge EP processor can be increased approximately 1.5 times in accordance with the increase in memory access speed.
Transitive Closure of a Union of Dependence Relations for Parameterized Perfectly-Nested
Loops
For example, the proposed technique can be used in the Floyd-Warshall algorithm [1] for computing the transitive closure of relations representing self-dependencies required at each iteration in this algorithm.
2 Related Work
Transitive Closure of a Union of Dependency Relations 39 All the algorithms mentioned above can take a lot of time and memory for computing the transitive closure of a connection that describes all the dependencies in a loop. This makes it impossible to apply parallelization techniques based on transitive closure of dependency relationships [2,3] to real-life code.
3 Background
This is why there is a great need in the development of algorithms for the calculation of transitive closure that are characterized by reduced computational complexity compared to known techniques. Different operations on relations are allowed, such as intersection (∩), union (∪), difference (-), domain of relation (domain(R)), range of relation (range(R)), relation application (R(S) ) ), positive transitive closure R+, transitive closureR∗.
4 Approach to Computing Transitive Closure
Replacing the Parameterized Vector with a Linear Combination of Constant Vectors
Each element of vector space V can be uniquely expressed as a finite linear combination of the basis dependence distance vectors belonging to B. Replace each parameterized dependence distance vector in Dn×m by a linear combination of vectors with constant coordinates.

Illustrating Example
As we proved in subsection 4.1, the task of replacing parameterized vectors with a linear combination of vectors with constant coordinates can be performed in O. The task of identifying a set of linearly independent columns of the matrix A, A∈Zn×k with constant coordinates to find the basis can be done in polynomial time by the Gaussian elimination algorithm.
5 Experiments
Results of experiments on the proposed approach to the calculation of transitive closure (eg: 1 – exact result, 0 – too close approximation; Δt: difference between the calculation time of the transitive closure of the known correspondence technique and that of the presented approach). The calculation of the transitive closure time with the presented approach is from 3.2 to 275 times smaller than that obtained by known implementations.

6 Conclusions
Transitive conclusion of the union of dependency relations 49 Analyzing the results presented in Table 2, we can conclude that the approach to calculating the transitive conclusion presented in the paper seems to be the least time-consuming compared to all known approaches implemented by the author. . Wlodzimierz, B., Tomasz, K., Marek, P., Beletska, A.: An iterative algorithm for computing the transitive closure of the union of parametrized relations of affine integers.
Cliff-Edge Consensus: Agreeing on the Precipice
This problem of collective agreement can be thought of as a new type of specialized consensus, where nodes bordering a collapsed region (i.e. nodes on the rock edge) want to agree on the extent of this cracked region (the abyss of our title) . The solution must be scalable, and must work especially in networks of arbitrary size, i.e. it must only involve nodes in the vicinity of an accident region, and never the complete system. ii) Due to continuous failures, nodes may disagree on the extent of a crash region, but as they do so, they will also disagree on who should even participate in the agreement, since both what must be agreed (the crash region), and who must agree on it (the nodes bordering the region) are irreparably dependent on each other.
2 The Problem
Overview
Paper Organization: We first present the clff-edge consensus problem in Section 2, and then proceed to describe our solution (Section 3). However, due to persistent crashes, nodes bordering the same crashed region may have different views on the size of their region, and thus have different views on who should be involved in a protocol run.
System Model and Assumptions
If Madrid is slow to detect the Paris crash, it could try to agree on F1 with only London and Rome, while Berlin will try to involve all nodes bordering F3 in deciding on F3. More precisely, a faulty domain is a region in which all nodes are faulty, but whose border nodes are correct.
Convergent Detection of Crashed Regions: Specification
We say that two defective domains F0 and Fnare in the same defective cluster, notedclustered(F0, Fn), if they are transitively adjacent1, i.e. the originality of the problem lies in the two remaining properties: CD6 (View Convergence) and CD3 (Locality).
3 A Cliff-Edge Consensus Protocol
Preliminaries: Failure Detector, Multicast, Region Ranking Our algorithm uses a perfect failure detector provided in the form of a
Algorithm
Because a node may be involved in multiple conflicting consensus instances simultaneously, messages related to conflicting views are also collected and processed. If a node becomes aware of a conflicting view with a lower rank (line 26), it sends a special rejection vector to this view's border nodes, then ignores any message related to this view (lines 28-31) .
Proof of Correctness
Similarly, the same guard proposed = ⊥ in line 12 means that a node cannot start a new consensus instance before completing the current one (RemarkN2). First, let us assume that the last view Vqmax proposed by q failed and q does not discover any new collided nodes (C2).

4 Related Work
Scalability here means that the cost depends only on the "volume" of knowledge to be built, independent of the actual size of the system, which is a strong feature of very large systems. A further challenge could be to explore how the notion of predicate-based regions and the properties of appropriate consensus protocols to deal with unstable properties could be developed.
Hybrid Multi-GPU Solver
Based on Schur Complement Method
Efficient use of GPUs in the Schur complement method depends on optimal distribution of computation between CPUs and GPUs and optimal decomposition of matrices. In this paper, the Schur complement method is designed as a hybrid numerical method for hybrid platforms.
2 The Schur Complement Method
In Algorithm 1, we present a sequential algorithm of the Schur complement method (the number of processors np= 1 and nΩ> np) and analyze its computational cost. In this work, we present a hybrid implementation of the Schur complement method that combines different matrix storage formats, PCG solvers, and heterogeneous computing devices.
3 Analysis of Matrix Storage Formats for the Schur Complement Method
The DCSR format is more convenient than the CSR format for the triangular decomposition of the matrices AII. For band matrices, the execution time for constructing the Schur complement is about 80% of the total time.

4 The Efficiency of the Parallel Schur Complement Method
Construction of the Schur Complement Matrix
The inversion of the AII matrix is one of the most expensive operations in the construction of the Schur complement matrix. Introducing this level of parallelization speeds up the construction of the Schur complement proportionally to the number of computing modules.
Solution of the Schur Complement System on GPU
After the conjugate gradient method completes, the array, which stores the approximation of the solution vector, is copied to CPU memory. To calculate the vector coordinates, from 2 to 32 threads are used, depending on the sparsity of the matrix.
Solving the Interface System on Multi-GPU and Cluster-GPU To solve the interface system (3) on Multi-GPU, a block algorithm of the conju-
The results in Table 4 show that the GPU algorithm of the conjugate gradient method significantly accelerates the solution of the interface system. The hybrid implementation of the Schur complement method presented in this paper allowed us to distribute the computations between CPU and GPU in a balanced manner.

An implementation of the functional data flow paradigm is the Pythagorean (Parallel Informational and Functional AlGORthmic) language [5]. So the development of formal verification methods for functional data flow programs is current.
2 The Description of the Formal System
Using forward tracing rules, when inference rules are applied from top to bottom of the data flow graph (from input values to output). Using backtracking rules, when inference rules are applied from the bottom up of the data flow graph (from the result to the input values).
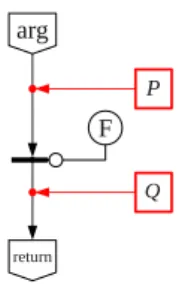
3 The Analysis of Recursion Correctness
4 An Example of a Recursive Function Correctness Proof
Formal verification of programs in the Pifagor language 85. 2. The data flow graph of the Hoare triple for function fact. Then, according to the inductive assumption, the function facttriple for the argument of the recursive call is correct:.

5 Conclusions
Formal verification of programs in the Pythagorean language 89 There is only multiplication "*" in the code part of the triple (11). This formula is identically true, which means that the initial Hoare triple (3) is also true and this in turn implies the correctness of the program fact.
Machine-Specific Interconnects
It is therefore necessary to understand the low-level behavior of system interconnection and apply such knowledge to application implementations in a more educated manner. The scalability of the suites is limited to thousands of cores, which is not applicable for a large-scale management-class facility.
2 Evaluation Environments
Eureka is a 100-node computing cluster, which is primarily used for data preparation, data analysis and visualization. Magellan is the 100-node compute cluster, which is used for data analysis and visualization of data obtained on Mira.
3 Experiments
- Messaging Rate
- Point-to-Point Communication Latency
- Aggregate Node Bandwidth
- Bisection Bandwidth
- Collectives Latency
- Halo Exchange Latency
- Overlapping Computation with Communication
At the BG/Q node, each node has nine nearest neighbors because the "E" direction of the torus always has size 2. For the farthest pair of tasks, the tasks are placed on the nodes with the longest path between and delay. , in addition to the above factors, depends on the partition size and routing protocol properties.

4 Conclusion and Future Work
The research used ALCF resources at Argonne National Laboratory, which is supported by the US Office of Science. The authors would like to thank Bob Walkup and Daniel Faraj of IBM, and Kevin Harms of ALCF for their assistance with this study.
Multi-core Implementation of Decomposition-Based Packet Classification Algorithms *
Modern multi-core optimized microarchitectures [7], [8] offer a number of new and innovative features that can improve memory access performance. Specifically, we use decomposition-based approaches on state-of-the-art multi-core processors and make a thorough comparison for different implementations.
2 Background
Multi-field Packet Classification
Efficient parallel algorithms are also needed on multi-core processors to improve the performance of network applications. In this paper, we focus on improving the performance of packet classification with respect to throughput and latency on multi-core processors.
Related Work
However, the decomposition-based approaches on the latest multi-core processors have not been well studied and evaluated.
3 Algorithms
- Linear Search
- Set Representation
- BV Representation Another representation for
- Summary of various approaches
Thus, for the partial result represented using a set of rule IDs, all rule IDs are listed in ascending (or descending) order. In all five areas; we only reassert the rule with 3.5 High Applications In summary, we have four typical results represented as ru recorded in sets of rule IDs (R (4) Searching the rank tree with B .

4 Performance Evaluation and Summary of Results
- Experimental Setup
- Data Movement
- Throughput and Latency
- Search Latency and Merge Latency
- Cache Performance
Number of L2 cache misses per 1K packets on the AMD processor 4.6 Number of threads per core (T). The number of threads per core also impacts the performance for all four approaches.

5 Conclusion and Future Work
Liu, D., Hua, B., Hu, X., Tang, X.: A high performance packet sorting algorithm for any core and multithreaded network processor. Jiang, W., Prasanna, V.K.: A parallel split-array architecture for high-performance multi-match packet sorting using FPGA.
Slot Selection Algorithms in Distributed Computing with Non-dedicated and Heterogeneous Resources
Thus, during each cycle of the batch scheduling of work [6] two problems must be solved: 1) the selection of an alternative set of slots (alternatives) that meet the requirements (resource, time and cost);. The novelty of the proposed approaches consists in the allocation of a number of alternative sets of slots (alternatives).
2 General Scheme and Slot Selection Algorithms
AEP Scheme
In this paper, we propose algorithms for efficient slot selection based on user-defined criteria that have linear complexity on the number of available slots during the job batch scheduling cycle. The time length of an allocated window W is defined by the execution time of the task using the slowest CPU node.

AEP Implementation Examples
It is easy to provide the implementation of the algorithm to find a window with the minimum total execution cost. Implementing this window selection algorithm at each step of the AEP scheme allows finding an appropriate window with the smallest possible runtime at the given scheduling interval.
3 Experimental Studies of Slot Selection Algorithms
Algorithms and Simulation Environment
In each experiment, a generation of a distributed environment consisting of 100 CPU nodes was performed. A relatively high number of generated nodes was chosen to allow CSA to find more alternative slots.
Experimental Results
The level of the initial resource load with the local and high-priority jobs at the scheduling interval [0;. 5 clearly shows the average working duration of the algorithms depending on the number of available CPU nodes (the values are taken from Table 1). The CSA curve is not represented since its working time is incomparably longer than AEP-like algorithms.).

4 Conclusions and Future Work
Toporkov, V., Yemelyanov, D., Toporkova, A., Bobchenkov, A.: Ressource Co-allocation Algorithms for Job Batch Scheduling in Dependable Distributed Computing. Toporkov, V., Bobchenkov, A., Toporkova, A., Tselishchev, A., Yemelyanov, D.: Slot Selection and Co-allocation for Economic Scheduling in Distributed Computing.
Determination of Dependence of Performance from Specifications of Separate Components
Within the boundaries of the project, the experimental prototype of a personal hybrid computer system is created. For this purpose, the experimental prototype of a personal hybrid computer system was created at a preparatory stage and on its basis research was conducted into the dependence of actual performance on specifications of individual components of system hardware.
2 Personal Hybrid Computing System
Obtained results allowed to evaluate the level of influence of separate components on the performance of the personal hybrid computer system and to ensure the regularity of the chosen direction for the creation of the personal hybrid computer system, also results determined in a basis for the creation process of an experimental prototype personal hybrid computing system.
3 Testing. Analysis Results
Dependence of performance of experimental prototype personal hybrid computing system with 3 GPU processors from RAM clock frequency. Test results of performance dependence of experimental prototype of personal hybrid computer system from PCI-Express bus bandwidth.

4 Conclusion
It is possible to draw a conclusion: the rate of the PCI-Express bus does not have a significant impact on the performance of the personal hybrid computing system.
Design of Distributed Parallel Computing Using by MapReduce/MPI Technology
We develop our parallel computing on mpiJava [16] so that the MAPREDUCE technology is also implemented using Java and can be easily integrated with virtual platforms on Java Virtual Machine (JVM). This article consists of the following sections: mathematical model of pressure field distributions in 3D anisotropic porous media and creating a parallel computer algorithm (in MPI), building discrete models (on Model Driven Architecture - MDA), realizing experimental computing and discussing the results.
2 Mathematical Model
The main problem in this field is to provide efficient load balancing on existing resources and high reliability of the distributed computing systems. Due to the complexity of the computational domain structures (anisotropic and inhomogeneous porous medium), we choose the problem of oilfield pressure calculation for 3D cases of high-performance computing and visualization.
3 MAPREDUCE/MPI Platform
Further, use MPI technology with the second level of decomposition - "micro cube" (map level 2) of dimension (N/4∗N/4∗N/4). Calculate the Proc 3D MPI values for the "microcube" at the selected nodes and assign it as a new object.

4 Discrete Models of Distributed Parallel Computations on MDA
5 Computational Experiment
The next step in a cluster configuration process, we have generated the RSA key pair on the cluster master node. As you can see in the figures, the proposed system realizes the distributed parallel computing algorithm faster than the sequential program on one node.

6 Related Work
Next is a problem (1) - (3) to find the values of pressure field distributions in 3D anisotropic porous medium with various regimes of oil production with parallel computer algorithm inN. Design of Distributed Parallel Computing Using MapReduce/MPI 147 scalability of algorithms and their adaptation for wide classes of scientific problems is still open.
7 Summary
Diaz, J., Munoz-Caro, C., Nino, A.A.: Exploring parallel programming models and tools in the multi- and many-core era. Pandey, S., Buyya, R.: Scheduling workflow applications based on parallel data collection from multiple sources in distributed computer networks.
PowerVisor: A Toolset for Visualizing Energy Consumption and Heat Dissipation Processes in Modern
Processor Architectures
2 Modern Processors: Architecture and Simulation
3 PowerVisor Implementation
The power trace file contains information (in text form) about power consumption in different processor blocks. The heat trace file contains information (in text form) about heat dissipation in different processor blocks.

4 Example Study with PowerVisor
A Toolkit for Visualizing Energy Consumption and Heat Dissipation Processes 153 From these examples, one can easily observe the level of non-uniform heating in different parts of the processor, indicating the non-uniform use of those parts during application runs. On the other (software) side of the problem, the visual data of power consumption and heat dissipation can be useful for the code optimization efforts to provide a more balanced use of various resources in processors.
5 Concluding Remarks
It can be shown that different combinations of benchmarks (or loads) lead to different patterns of power consumption and heat distribution across the different blocks of the processor, which can provide clues to processor designers for better layout designs of the CPUs. This data can also be used in efforts to improve the power and cooling units of new processors.
SVM Regression Parameters Optimization Using Parallel Global Search Algorithm
This paper introduces a new method for the selection of SVM regression parameters based on optimization of the cross-validation error function using a parallel global search algorithm. The paper is organized as follows: the second part presents an optimization problem for SVM regression parameters; part three describes the basic parallel global search algorithm [5] and its modifications that increase parallel computing efficiency; section four demonstrates the success of the described approach based on model problems, and discusses the possibility of applying the approach to large-scale cluster systems.
2 Optimization of SVM Regression Algorithm Parameters
Virtually the only way to solve problems of the mentioned class within a reasonable time is the development of parallel algorithms and their implementation on high performance computer systems. The idea of the method is to randomly divide the training set into S subsets {Gs,s=1,..,S}, train the model on (S−1) subsets and use the remaining subset to to calculate test error.
3 Parallel Global Search Algorithm
2.Inform the rest of the processors about the start of the trial at point y (blocking of k point y); k. The choice of the point xq+1, q≥1, for each subsequent attempt on processor l is determined by the following rules.
4 Computational Experiment
Optimization of a Function of Two Variables: Comparison with the Exhaustive Search
Optimization of SVM Regression Parameters Using Parallel Global Search Algorithm 163 The algorithm was run with the following parameters: search accuracy. As the problem dimension increases, the gap in the number of iterations performed and thus the gap in solution time will only increase.
Optimization of a Function of Two Variables: Efficiency of the Algorithm and Its Modifications When Using Parallel Computing
The total number of iterations performed by the parallel version of the algorithm before stopping criteria was reached was 1550 (to achieve the same accuracy with the exhaustive search would require 10000 iterations), optimum value found was 0.006728. Running time of the algorithms (optimization of a function of two variables) Implementation Scans Cores on scan Time (hours).
Optimization of a Function of Three Variables: Efficiency of the Algorithm and Its Modifications When Using Parallel Computing
SVM Regression Parameters Optimization Using Parallel Global Search Algorithm 165 The results demonstrate a linear acceleration in the number of used nodes and cores. More cluster nodes can be used in the case of a larger number of SVM parameters (which depends on used kernel).
5 Conclusions
Wang, Y., Liu, Y., Ye, N., Yao, G.: The Parameter Selection for SVM Based on Improved Chaos Optimization Algorithm. In this paper, we develop a formal theory of contracts that supports the verification of service compliance.
2 Motivating Example
The second step shows that the customer's request has been accepted by the broker via a communication. The index R of the arrows shows that the transitions depend on the services in the repositoryR. The index π is a vector of functions, called a plan, that indicates how the requests are bound to services.

3 Programming Model
Network and Plan)
- Statically Checking Validity
In this case, the previous session is restored after the new one ends. The client's history is updated with the closing frames of all policies that are still active in Hj and now no longer make sense (computed via the auxiliary functionΦ) and the closing frames of the policies imposed during the session.
4 Checking Service Compliance
Compliance)
The immutable property Pinv only examines the current state without looking at all past history, ie. Pinv ={s0s1s2.
5 Verifying Services Secure and Unfailing
Partitioning for Parallel Scientific Applications on Dedicated Heterogeneous HPC Platforms
In this work, we address the problem of implementing data partitioning algorithms in data-parallel applications for dedicated heterogeneous platforms. The framework provides a number of general data partitioning algorithms based on computational performance models.
2 Existing Data Partitioning Software
In Section 3, we discuss the main challenges in optimizing data-parallel applications for heterogeneous platforms and formulate the features of a framework for data partitioning based on computational models. In the following section, we discuss the main challenges of software implementation of heterogeneous data-parallel applications and define the features of a framework for data partitioning based on computational models.
3 Optimisation of Data-Parallel Applications for Heterogeneous Platforms
Algorithms implemented in Zoltan [3], PaGrid [1] reduce the execution time of the application by using some cost function. This information can be obtained from the benchmarks that assess the performance of the application on the devices.
4 New Framework for Model-Based Data Partitioning