To use any of the C/Stat/Library functions, you must first write a program in C to call the function. Care should be taken to avoid using the same data space in separate threads calling functions in C/Stat/Library.
Naming Conventions
A discussion of error types is provided in the "User Errors" section of the reference material. Do not select a name that begins with "imsls_" in any combination of upper or lower case letters.
Error Handling, Underflow, and Overflow
Printing Results
Missing Values
Basic Statistics
Routines
Simple Summary Statistics
Usage Notes
If IMSLS_MEDIAN is specified, medians are calculated and stored in an additional row (row number 14) in the returned simple statistics matrix. IMSLS_RETURN_USER, float simple_statistics[] (Output) User-supplied string containing the statistics matrix.
IMSLS_T_TEST, int *df, float *t, float *p_value, IMSLS_T_TEST_NULL, float mean_hypothesis_value, IMSLS_CONFIDENCE_VARIANCE, float confidence variance, IMSLS_CI_VARIANCE, float *lower_limit, . float *upperbound, .. IMSLS_CHI_SQUARED_TEST, int *df, float *chi_squared, float *p_value, . The chi-square statistic for the two-sided test regarding the population variance is given by.
Argument lower_limit contains the lower confidence limit, and upper_limit contains the upper limit for the mean of the first population minus the mean of the second, assuming equal variances. Argument lower_limit contains the approximate lower confidence limit, and upper_limit contains the approximate upper limit for the ratio of the variance of the first population to the second.
Argument n is the address of the pointer to an internally allocated array of length n_cells containing the number of observations (rows) in each group. All cells have a frequency of at least 1, i.e. there is no 'missing cell'. The list_cells array can be considered “parallel” to table_unbalanced because row i of list_cells is the set of n_keys values describing the cell for which row i is.
Regression
- Multivariate Linear Regression—Model Fitting Generate regressors for a general
The imsls_f_regression function (page 64) fits both the simple and multiple linear regression models using a quick Data transformation and includes an option to exclude the intercept β0. The imsls_f_poly_regression function (page 132) fits a polynomial regression model with the ability to determine the extent of the model and also produces summary information.
Column 1 Column 2 Column 3
The functions in this chapter are designed to handle the linear dependence of the regressors; i.e. the. In the non-complete rank case, not all linear combinations of the regression coefficients can be estimated.
Nonlinear Regression Model
A negative diagonal element means the row corresponds to a linearly independent constraint imposed on the regression parameters by AB = Z in a constrained model. This represents an arbitrary constraint imposed to obtain a solution for the regression coefficients.
Weighted Least Squares
Summary Statistics
The p-value associated with the test is the probability that F is greater than that calculated assuming the model and the null hypothesis. The square root of s2(s = anova_table[12]) is often called the estimated standard deviation of the model error.
Tests for Lack-of-Fit
The estimated variance of ei is (1 – hi)s2/wi, where s2 is the mean square residual from the fitted regression. The Cook's distance for the ith case is a measure of how much an individual case affects the estimated regression coefficients.
Transformations
The i-th jackknife residual or deleted residual involves the difference between yi and its predicted value, based on the data set where the i-th case is deleted. When the responses are non-normal and their distribution is known, a transformation of the responses can often be chosen so that the transformed responses closely meet the regression model assumptions.
Alternatives to Least Squares
For example, by taking natural logarithms on both sides of the equation, the exponential model. The square-root transform for counts with a Poisson distribution and the arc-sine transform for binomial proportions are common examples. When fitting regression models, any observation that contains NaN for the independent, dependent, weight, or frequency variables is omitted from the calculation of the regression parameters.
Regressors for an effect (source of variation) consisting of a single classification variable are created using indicator variables. The first NVAR effects correspond to the x columns, so the first effect corresponds to the first x column, the second effect corresponds to the second x column, .., the NVAR effect corresponds to the NVAR column of x (ie x[NVAR − 1]). Regressors for the one-way model (default model order) are created using the IMSLS_ALL dummy method (the default dummy method).
IMSLS_X_COL_DIM, int x_col_dim, IMSLS_Y_COL_DIM, int y_col_dim, IMSLS_N_DEPENDENT, int n_dependent, .. IMSLS_IDO, int ido, IMSLS_ROWS_ADD, or IMSLS_ROWS_DELETE, IMSLS_INTERCEPT or IMSLS_NO_INTERCEPT,. Address of a pointer to the internally allocated array containing the estimated means of the independent variables. By default, the total sum of squares is the sum of the squares of the deviations of yi from the mean.
AGA = A
Note that the coef_covariances argument can only be used to obtain the variances and covariances of the estimable functions of the regression coefficients, i.e. The estimated standard errors of the estimated regression coefficients (stored in column 1 of coef_t_tests) are calculated as the square roots of the corresponding diagonal entries in coef_covariances. When R is nonsingular and derived from an unconstrained regression fit, coef_covariance is the estimated variance-covariance matrix.
IMSLS_POINTWISE_CI_POP_MEAN, floating **lower limit, floating** upper limit, .. IMSLS_POINTWISE_CI_POP_MEAN_USER, floating lower limit[], floating upper limit[],. Address of a pointer to an internally allocated array of length n_predict containing the standardized residues. Address of a pointer to an internally allocated array of length n_predict containing the DFFITS statistics.
A hypothesis Hβ = g is partially testable if the intersection of the row space H (denoted by ℜ(H)) and the row space of X (ℜ(X)) is not essentially empty and is a good subset of ℜ(H) , i.e.,. The method replaces Hp in the partially testable hypothesis Hpβ = gp by a matrix H whose rows form a basis for the intersection of the row space of Hp and the row space of X. For the general case of the multivariate model Y = Xβ + ε with possible linear equality constraints on the regression parameters.
Array from now to now showing the sums of squares and cross products attributable to the hypothesis. The function imsls_f_hypothesis_scph calculates the matrix of sums of squares and cross products for the general linear hypothesis HβU = G for the multivariate general linear model Y = Xβ + ε. The sum of squares and cross-product matrix, scph, is then calculated by calling imsls_f_hypothesis_scph to test that the third independent variable is present in the model (determined by the specification of h).
The imsls_f_hypothesis_test function calculates test statistics and p-values for the general linear hypothesis HβU = G for a multivariate general linear model. The error sum of squares and the cross product matrix for the hypothesis HβU = G calculated by imsls_f_hypothesis_test is. Finally, the function imsls_f_hypothesis_test is called to calculate the p-value for the test statistic (Wilk's lambda).
IMSLS_COEF_STATISTICS_USER, int index_coefficients[], floatcoefficients[], .. IMSLS_INPUT_COV, int n_observations, floatcov[], 0). Argument index_variables is the address of a pointer to the internally allocated array of length nsize + 1 (where nsize equals max_subset_size if optional argument IMSLS_R_SQUARED is specified; otherwise nsize equals n_candidates) containing the locations in independent_variables of the first element each subset size. Here n equals the sum of the frequencies (or n_rows if . IMSLS_FREQUENCIES is not specified) and SST is the total sum of squares.
IMSLS_SWEPT_USER, int swept[], IMSLS_HISTORY_USER, float history[], IMSLS_COV_SWEPT_USER, float *covs .. IMSLS_INPUT_COV, int n_observations, float *cov, 0). A user-assigned array of length n_candidate + 1 with information identifying the independent variables in the model. In this case, several calls to imsls_f_regression_stepwise are made (using the optional arguments . IMSLS_FIRST_STEP, IMSLS_INTERMEDIATE_STEP, .., IMSLS_LAST_STEP).
IMSLS_SSQ_LOF_COL_DIM, int ssq_lof_col_dim, IMSLS_X_MEAN, float *x_mean, .. IMSLS_X_VARIANCE, float *x_variance, IMSLS_ANOVA_TABLE, float **anova_table, IMSLS_ANOVA_TABLE_USER, float anova_table[], IMSLS_DF_PURE_ERROR, int *df_error, IMSLS_SSQ_PURE_DIM ERROR, float *ssq_pure_error, IMSLS_RESIDUAL, float * * residue,. The imsls_f_poly_regression function calculates regression coefficient estimates in a polynomial (curvilinear) regression model. In addition to calculating the fit, imsls_f_poly_regression calculates some summary statistics.

Array upper_limit is the address of a pointer to an internally allocated array of length n_forecast. IMSLS_DELETED_RESIDUAL, float **deleted_residual (Output) Address of a pointer to an internally allocated array of length n_predict containing the deleted residues. Address of a pointer to an internally allocated array of length n_predict containing the Cook's D statistics.
IMSLS_THETA_GUESS, float theta_guess[], IMSLS_JACOBIAN, void jacobian(), IMSLS_THETA_SCALE, float theta_scale[], IMSLS_GRADIENT_EPS, float gradient_eps, IMSLS_STEP_EPS, float step_eps, .. IMSLS_SSE_REL_EPS, float sse_rel_eps, IMSLS_ SSE_ABS _EPS, float sse_abs_eps, IMSLS_MAX_STEP, float max_step,. IMSLS_MAX_ITERATIONS, int max_itn, .. IMSLS_MAX_SSE_EVALUATIONS, int max_sse_eval, IMSLS_MAX_JACOBIAN_EVALUATIONS, int max_jacobian, IMSLS_TOLEANCE, float tolerance,. The imsls_f_nonlinear_regression function is designed so that the values of the function f(xi; θ) are calculated one by one by a user-supplied function.
IMSLS_WEIGHTS, float weight, IMSLS_ACC, float acc, .. IMSLS_MAX_SSE_EVALUATIONS, int *max_sse_eval, IMSLS_PRINT_LEVEL, int print_level,. IMSLS_STOP_INFO, int *stop_info, .. IMSLS_ACTIVE_CONSTRAINTS_INFO, int *n_active, int **active_indexes, float **multiplier, IMSLS_ACTIVE_CONSTRAINTS_INFO_USER, int *n_active, . int indices_active[], float multiplier[], IMSLS_PREDICTED, float **predicted,. Address of a pointer to an internally allocated real array of length n_observations containing the residuals in the approximate solution.
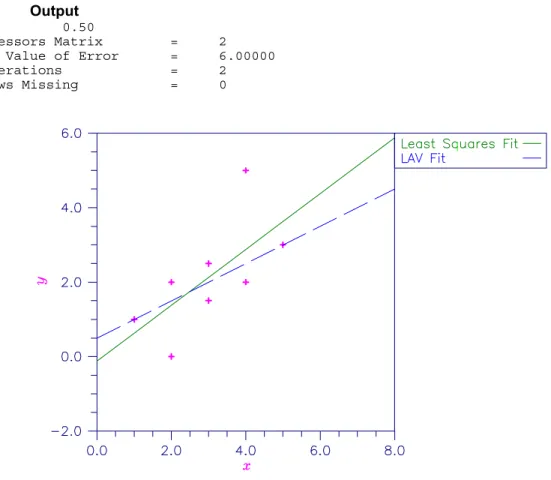
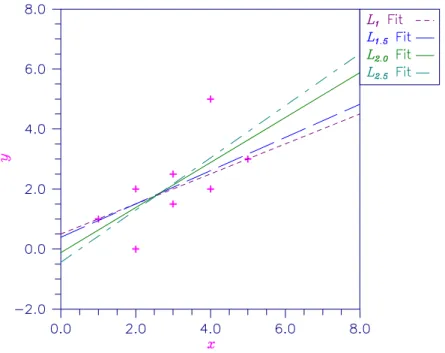
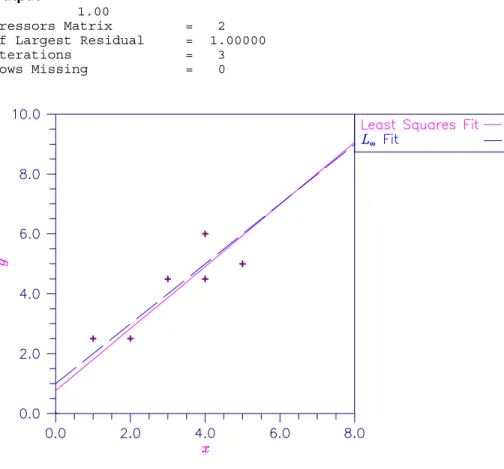
Lnorm_regression
Correlation and Covariance
Common multivariate correlation and covariance measures for continuous random variables are produced using the imsls_f_covariances routine.
3 Crude cross products, means, variances and covariances are calculated as in the case of missing_value_method = 2. If missing_value_method is 0, observations with missing values are not included in n_observations; otherwise, all observations are included, except observations with missing weight or frequency values. If missing_value_method is 0, observations with missing values are not included in sum_wt.