In addition, we demonstrate multi-agent reinforcement learning (MARL) scenarios by combining our simulator with RLlib, an open source library for reinforcement learning, and a custom OpenAI Gym environment. Our results show that our simulator can solve scenarios involving millions of drivers, far exceeding the demand for Porto.
Context
Motivation
A scalable simulator capable of accurately capturing the intricacies of competition for resources in a traffic flow environment is an excellent tool for researchers to design and prototype modern urban mobility solutions. With a mesoscopic simulator, we can achieve a balance between scale and detail, taking advantage of the strengths of the micro and macroscopic models that best suit our needs.
Objectives
Additionally, we can incorporate MARL to capture the choices drivers must make when sharing a road network. Although many simulators already target the mesoscopic range, there is still much to contribute at this scale, especially when combined with MARL.
Document Structure
Chapters 5 and 6 contain a collection of details regarding the implementation of the simulator and the MARL components, respectively. This chapter provides an overview of the research topics dealt with in the thesis and aims to briefly review some key concepts that are inextricably linked to the work developed.
Traffic simulation
Microscopic models are focused on representing in detail all dynamics and interactions of the vehicles. Therefore, it allows us to improve the scalability of our system by significantly reducing the level at which we simulate the environment, but by keeping the drivers modeled individually, exchanging the physics-based properties of the vehicles with aggregate measurements, which allows us to explicitly to study driver behavior [ 8].
![Figure 2.2: Microscopic, mesoscopic and macroscopic simulation model example[67]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17604643.4190512/17.892.215.726.657.855/figure-microscopic-mesoscopic-and-macroscopic-simulation-model-example.webp)
Game Theory
The purpose of the mesoscopic scale is to represent an intermediate approach between micro and macro by exploiting some features of both, providing a very flexible model as one could approximate either of the original models. When characterizing traffic flow in an aggregate manner, an important issue is the effect of road capacity on travel time, which is often estimated using volume delay functions (VDFs)[51].
Reinforcement Learning
In the second case, we now see that several agents take actions independently, which when combined produce the next state of the environment, which is then given to each agent, along with the specific reward for each agent, and the cycle begins again. . However, the curse of dimensionality calls into question the feasibility of this solution for large-scale scenarios due to the exponential growth of the action state space.
![Figure 2.3: Interaction between agent and environment in reinforcement learning [59]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17604643.4190512/20.892.201.730.163.360/figure-interaction-agent-environment-reinforcement-learning.webp)
Summary
Another robust baseline algorithm for various RL problems is the Advantage Actor-Critic (A2C) developed by DeepMind [39], which aims to improve the efficiency of the original actor-critic algorithm by using multiple environments in parallel to allow This chapter shows a collection of relevant research carried out in our areas of interest, namely simulation, multi-agent reinforcement learning in the context of urban mobility and some parallel uses of game theory in the modeling of traffic.
Multi-Agent Reinforcement Learning
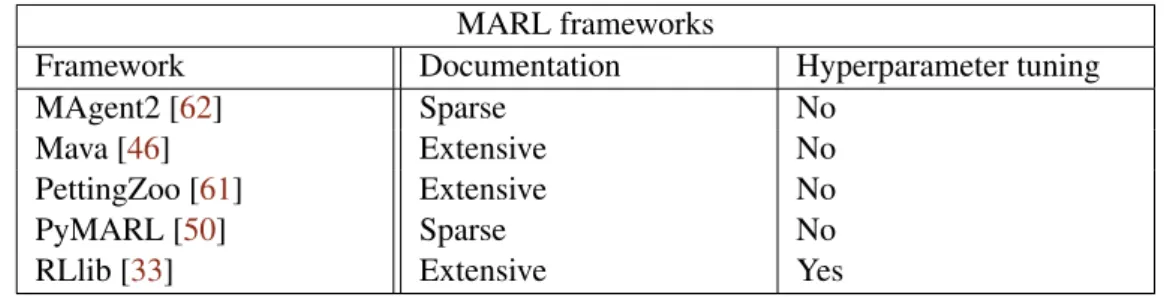
A study of available frameworks for multi-agent reinforcement learning was also conducted to help inform the decision on which platform to develop and train our agents. Both of these platforms are designed exclusively for multi-agent reinforcement learning, but do not provide the learning algorithms themselves.
Traffic Simulation Models
23] recently presented a scalable Meso-Macro traffic simulation model that can be a useful testbed for multi-agent reinforcement learning tasks, as the proposed simulator far outperforms SUMO, approximately by a factor of 20, enabling simulations with millions of drivers . in extended networks. The solution has not yet been made open source, but the authors mention plans to implement an open source "gym fashion environment" in the future. It includes studies of vehicle emission models and different traffic assignment problems where ecological objectives, traffic signal control optimization and implementation of emission-oriented dynamic road pricing greatly influence route choice.
Game Theory in Traffic
Gap analysis
Summary
Problem Statement
Proposed Solution
In the second step, the DynamiCITY Learn component was developed and both DynamiCITY SimandDinamiCITY Learn components were used in the proposed multi-agent reinforcement learning approach, which is the answer to point 2 above. Nevertheless, from a high-level perspective, this approach allows users to apply reinforcement learning algorithms to a collection of agents to train them to complete their assigned journeys as quickly as possible. This is done by having the agents map out their paths, and when they have all completed their journey, a call is made to the simulator to evaluate the results of the actions taken.
Validation
With these values, more than 15 agents on the shortest path result in a travel time for the last vehicles to enter above that of the longest path. For each network, there is a file that describes the structure and properties of the network, such as the nodes and links, a file with an HB matrix that contains the demand between each pair of nodes, and finally a file with the best-known solution for the scenario. This solution consists of the power allocated to each edge to produce the lowest total travel time.

Summary
As such, we cover its defining features, a brief overview of the tools used to facilitate the development phase, an in-depth explanation of the program's inputs and outputs, functional and non-functional requirements that describe its purpose, and finally , some insight into how the simulator was implemented.
Mesoscopic Model
Event Driven
Software Description
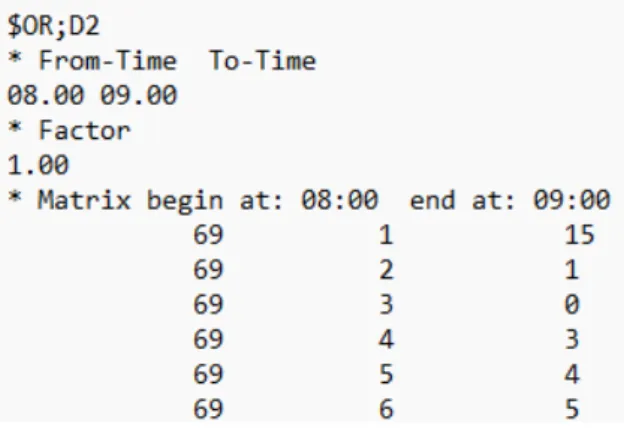
The most relevant part of the file is the matrix itself, and the three displayed values correspond to the starting TAZ, the target TAZ and the number of incoming vehicles, respectively. The result of the simulation of the previously defined example can be displayed in two different ways. It shows, as shown in Figure 5-5, how much time each driver spends on each step of the route and the current measured at that edge before the driver entered it.
Requirements
Implementation
Regarding the characteristics of the edge itself, we store the maximum allowed speed, the known capacity of the edge, its length and the VDFs to be used during the travel time estimation. Edges contain a queue representing the edge flow, which is updated only when requested. We take the origin node from one of the source ends and the destination node from one of the sink ends.
Summary
This chapter serves to show the full process of converting our problem into an environment suitable for learning algorithms. To do this, we outline the step-by-step steps to move from single- to multi-agent reinforcement learning and the challenges encountered during the process. After selecting RLlib as the library to work with, we chose to model our problem in an Open AI Gym environment, as RLlib fully supports these kinds of environments and allows for their use right out of the box.
Single-agent Environment
First we need to translate the action, an integer, into an edge to add it to the agent's route. If the agent has not yet reached their destination, another reward is given, intended to encourage the agent in the right direction, but made to be impervious to exploitation. For each step of an agent, we measure the shortest path distance between the node where the agent was before and after performing its action.
Multi-agent Environment
The last change was minimal and resulted in these operations being easy to perform when all agents had completed their last step before the call to the simulator. So the final solution was to check at every step that all agents had completed their route. If so, we launch the simulator subprocess1 and assign the resulting rewards to all agents.
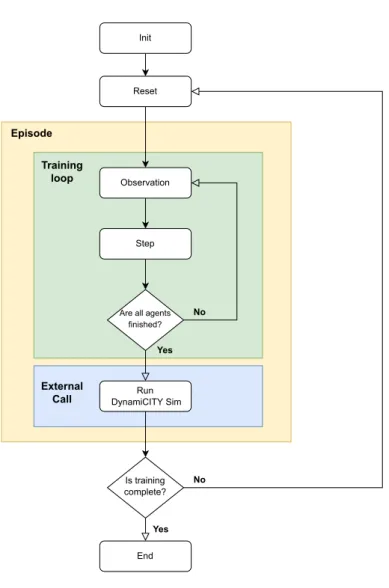
Training Process
We advise the reader to consult the official documentation2 for a full explanation of the remaining parameters. We select some preliminary metrics to print after each iteration to provide a quick summary of the results. To allow a better understanding of what our agents are doing throughout the experiment, we collect the state of the network each time a simulation occurs.
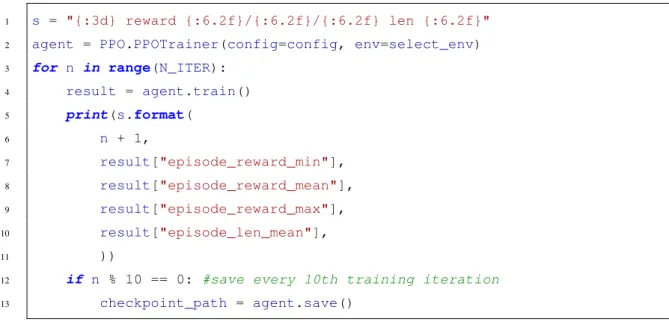
Software Description
Edges with throughput below their capacity are colored green, indicating that the drivers are not experiencing any network delays, while edges with higher throughput become progressively redder. In addition, we use the last episode to collect all the metrics needed for a direct comparison not only with the results available in the transport network repository, but also with the hypothetical scenario of assigning the shortest route to all drivers.
Summary
Simulator Experiments
In addition, we made simulations while studying the effect of increasing both the number of vehicles and steps in conjunction, which can be seen in the heat map depicted in Figure 7.4, which further helps to show the agreement between these two variables in terms of to observe their effect. in the performance of the simulator. We should mention that to achieve the presented result, we applied a factor of 6 in the number of trips generated between each OD pair. This value was encountered manually to get a result that corresponds to our idea of the traffic felt in the city during these hours.
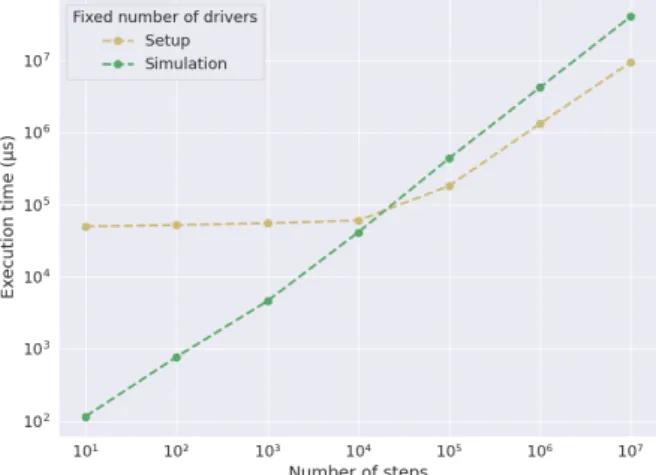
Reinforcement Learning Experiments
T t – total time spent in the network by all drivers E – number of links in the network. This leads us to the train_batch_sizeparameter, which dictates the size of the sample collected from the environment or the number of steps between all agents. This led us to set thetrain_batch_sizeparameter as twice the product of the number of agents by the horizon defined.
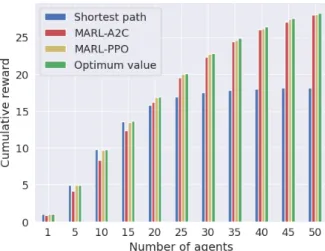
Summary
Finally, for the gamma parameter, which corresponds to the discount factor of the MDP, we kept a high value of 0.95, since we want our agents to value the rewards in the future, especially because the most important reward comes from the simulator, which is only attributed in the last step. One of the biggest challenges of our time is the ever-growing need for good, reliable and efficient means of transport. To tackle this challenge, we started by performing a state-of-the-art analysis of traffic simulations, looking for current mesoscopic solutions that could match our needs in terms of integration with a multi-agent reinforcement learning system to tackle traffic task problems .
Main Contributions
Our results show that we have met the scalability requirement for the simulator, capable of handling simulations with millions of vehicles and that although our results on the MARL experiments in the Sioux Falls network are still far from the optimum solution, we feel we there is still room for improvement and that this method shows potential to capture the decision-making processes of drivers in traffic.
Future Work
In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1774–. Multi-Agent Reinforcement Learning for Markov Routing Games: A New Modeling Paradigm for Dynamic Traffic Allocation. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 905-913, London, UK, July 2018.
![Figure 2.1: Distinction between simulation types [54]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17604643.4190512/16.892.285.655.870.1034/figure-distinction-between-simulation-types.webp)
![Figure 2.4: Multiple agents in the same environment [42]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17604643.4190512/21.892.248.691.244.507/figure-multiple-agents-environment.webp)


![Figure 4.6: Sioux Falls network[19]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17604643.4190512/32.892.309.618.721.1068/figure-sioux-falls-network.webp)
