Aprendizado de máquina e abandono escolar: análise preditiva para apoio à tomada de decisão / Alex Marques de Souza. Esta pesquisa trata da utilização do Machine Learning (ML) como ferramenta para auxiliar gestores escolares na verificação e combate à evasão escolar.
Problema de Pesquisa
Dessa forma, estuda as formas pelas quais as máquinas são capazes de executar tarefas que seriam executadas por humanos, bem como a programação utilizada nos computadores, construída por regras previamente estipuladas que autorizam os computadores a tomar decisões com base nos dados disponíveis. Este estudo torna-se significativo não apenas para apoiar a análise de dados sobre taxas de evasão, mas também para permitir que os modelos analíticos aqui desenvolvidos sirvam de base para outras questões associadas aos dados acadêmicos e administrativos como referência para outras instituições de ensino.
Motivação e Justificativa
Lacuna a ser Explorada
O estudo possibilitou a comunicação com conceitos interdisciplinares como recuperação de informação, organização e representação da informação. Portanto, as áreas de Ciência da Computação, Ciência da Informação, Aprendizado de Máquina e Inteligência Artificial fizeram parte do objeto de estudo.
Objetivos
Objetivo geral
Objetivos específicos
Contribuições
Adequação do Projeto de Mestrado e a Linha de Pesquisa
Estrutura da Dissertação
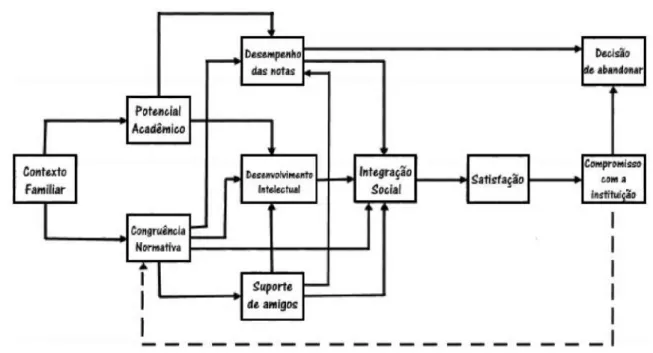
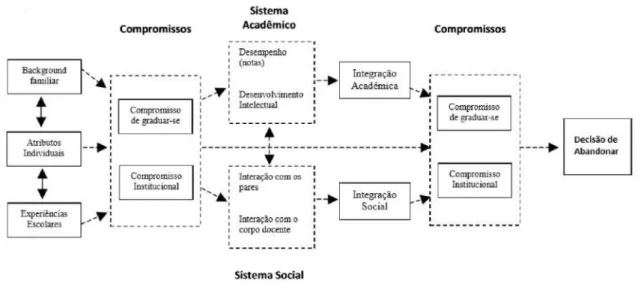
Evasão Escolar
- Tipos de evasão
- Modelos de evasão
- Causas de evasão
- Questões financeiras e a evasão
Desistência da instituição: A evasão da instituição refere-se à saída do curso e da instituição para outra instituição de ensino superior. Evasão do sistema: A evasão do sistema é um pouco mais grave, pois além do aluno abandonar o curso e a instituição desistir totalmente de estudar.
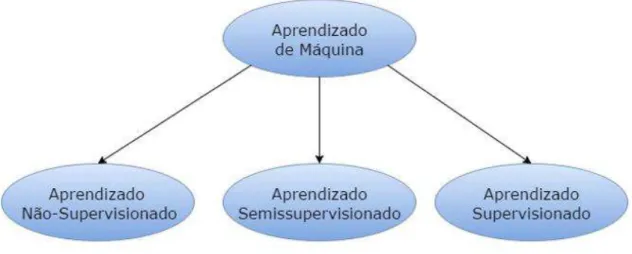
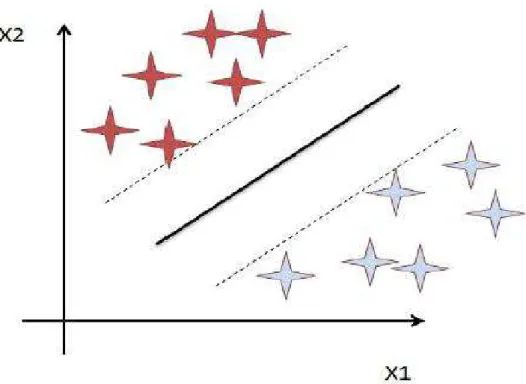
Machine Learning
Aprendizagem supervisionada
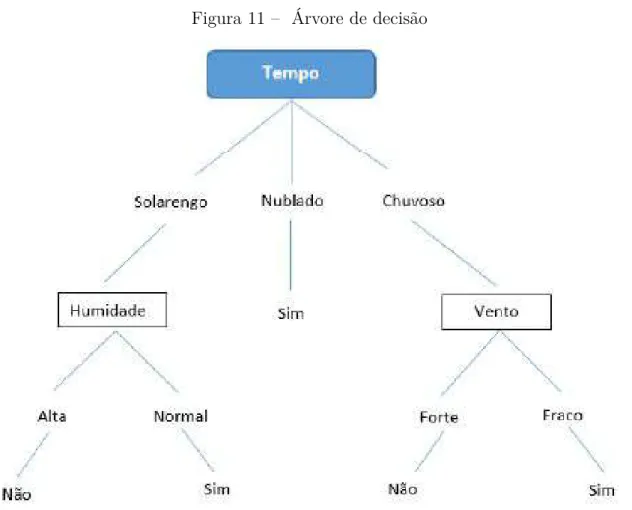
- Árvore de decisão
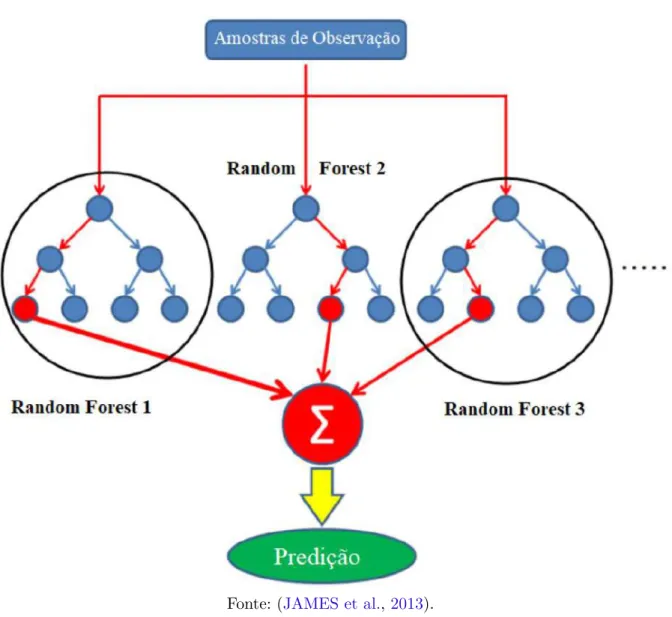
- Floresta aleatória
- Máquina de vetores de suporte
- Redes neurais artificiais
- Regressão logística
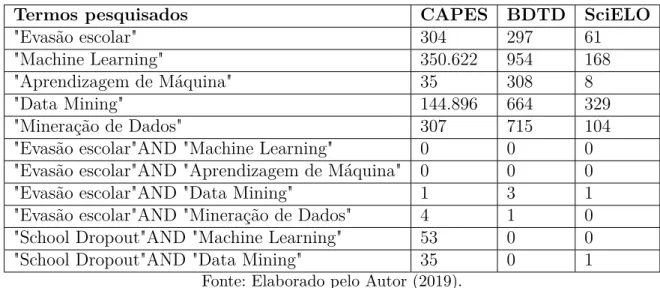
Num estudo realizado por Karamouzis et al.(2008), os autores concentraram-se na previsão da taxa de aceitação dos estudantes durante os primeiros dois anos de graduação. Alguns trabalhos como Coelho et al. 2016), alcançou 87% de precisão com o algoritmo de classificação Árvore de Decisão.
Tecnologia da Informação na Educação
Caracterização da Instituição Objeto da Pesquisa
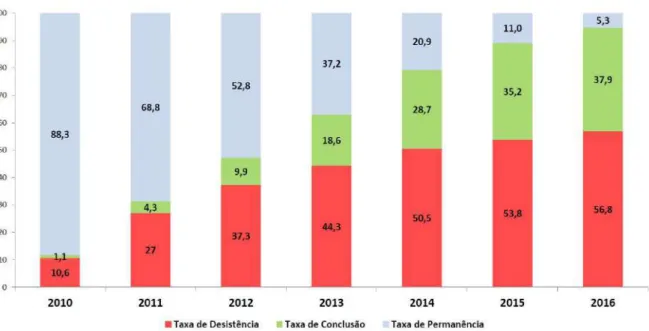
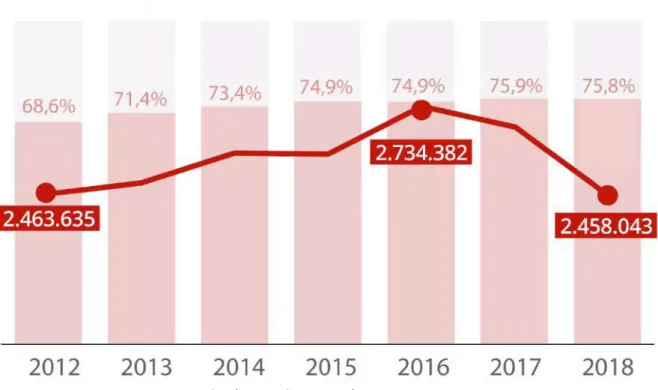
Com números como esse, é preciso mais atenção para garantir que a taxa de evasão não aumente. Ao entender cada uma das situações, agora é possível analisar a taxa de evasão com base nos relatórios gerais da instituição referentes aos anos de 2017 e 2018. Com a soma dessas situações e o recálculo, os valores chegam a uma taxa de evasão de aproximadamente 23,15%.
A soma dessas situações e a partir do recálculo dos valores chega a uma taxa de evasão de aproximadamente 23,25%. Analisando os dados com base nas inscrições realizadas por ano, de 2009 a 2018, a taxa de evasão aumenta significativamente em alguns casos.

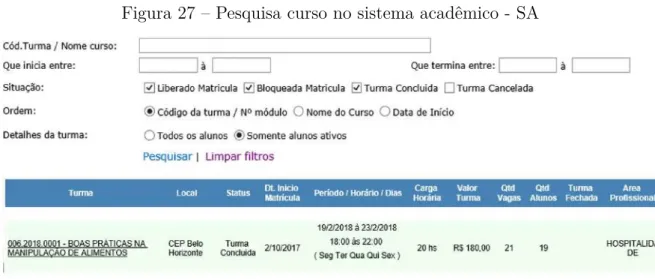
Sistema Acadêmico - SA
Você tem a opção de clicar naquela turma consultada, conforme seta e obter mais informações sobre a turma solicitada. Os dados dos alunos são bastante extensos pois a instituição necessita de alguma informação para reportar ao DN e auditorias que ocorrem com frequência. Este capítulo descreve a metodologia de pesquisa utilizada neste estudo para atingir os objetivos propostos, caracterização da pesquisa, procedimentos de coleta e análise de dados, desenvolvimento de ferramenta e metodologia.
Caracterização da Pesquisa
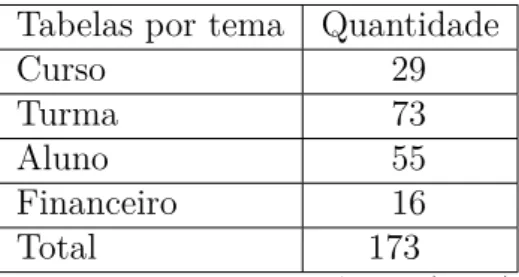
Para atingir o objetivo geral foi necessário recuperar as informações por meio de buscas nas bases de dados da instituição. Identificar quais dados e informações, de acordo com o panorama bibliográfico, estão presentes nas bases de dados do sistema acadêmico. Coleta de dados: Este é um momento crucial para o resultado final, pois a quantidade e a qualidade das informações determinam o quão preditivo será o modelo de ML.
Seleção de modelo: Existem vários modelos de ML, cada um destinado a cumprir uma função específica. Melhoria dos parâmetros: com o objetivo de melhorar sempre a qualidade e eficiência do modelo de ML utilizado, esta etapa identifica valores que afetam diretamente a precisão do modelo e o tempo de treinamento necessário.
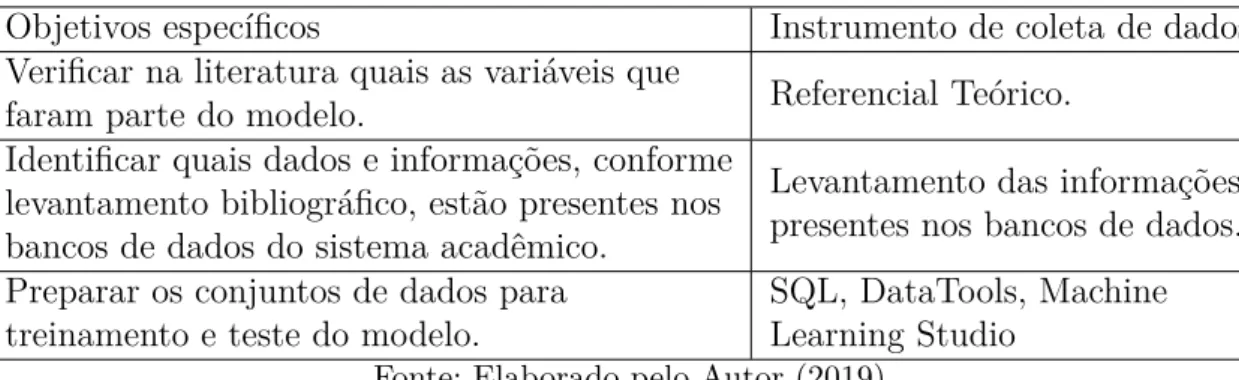
CRISP-DM
Previsão: é quando a máquina de ML pode ser usada com eficácia para responder às perguntas para as quais foi treinada. Preparação de dados: esta etapa teve como objetivo preparar e transformar atributos para tornar o conjunto de dados adequado para servir de entrada para algoritmos de mineração de dados. Avaliação: Esta fase da metodologia procurou avaliar se os modelos finais gerados foram validados e se o conhecimento adquirido com esses modelos foi utilizado na fase de implementação.
Portanto, procurou-se analisar os modelos com base nos parâmetros de qualidades e objetivos comerciais do projeto de mineração. Implementação: Nesta fase do projeto procuramos descrever como o conhecimento adquirido no projeto de mineração de dados pode ser aplicado na organização nas suas atividades diárias.
Compreensão do Negócio
Determinar os objetivos do negócio
Avaliar a situação
Dado que esta base de dados contém informações académicas, financeiras e pessoais sobre os alunos e responsáveis pelas finanças, o autor compromete-se a manter a confidencialidade das informações nela contidas, ressalvando-se que é responsável por não divulgar ou repassar quaisquer dessas informações a terceiros. . . Os dados são utilizados apenas para efeitos de realização da investigação e não serão divulgadas informações pessoais ou que permitam a identificação pessoal dos alunos. Todas as informações extraídas do banco de dados e utilizadas para a publicação do estudo foram informações estatísticas e agregadas, o que não permite a identificação individual dos alunos.
Uma limitação do estudo foi o tamanho da base de dados do SA, que é muito grande. De acordo com os critérios para sucesso do resultado, constatou-se que os modelos gerados deveriam ter uma eficiência de pelo menos 75% na classificação correta.
Ferramentas e técnicas
Esta ferramenta será muito útil considerando que todo o processo de carregamento, ou seja, todas as tabelas relacionadas ao processo de bypass que fazem parte do banco de dados SA serão copiadas para nosso ambiente de estudo utilizando SSIS. Por ser uma ferramenta que faz parte do Azure, o modelo pode ser publicado como um serviço online e consumido por aplicativos personalizados ou ferramentas de BI, como o Power BI. O Azure MLS fornece um espaço de trabalho visual e comunicativo para criar, testar e iterar um modelo de análise preditiva.
Arraste e solte conjuntos de dados e módulos analíticos em telas interativas para criar um teste, conforme mostrado na Figura 28. Não é necessária programação, basta conectar visualmente os conjuntos de dados e módulos para construir seu modelo de análise preditiva.
Compreensão dos Dados
- Coleta de dados
- Descrição dos dados
- Exploração dos dados
- Qualidade dos dados
O objetivo desta etapa foi examinar detalhadamente todos os dados copiados para o banco de dados DataMartEvasao. Neste sentido, verificou-se a necessidade de unir essas tabelas em uma tabela contendo todos os dados antes de realizar a descrição dos dados, para não descrever dados que não poderiam ser utilizados e assim não perder tempo e trabalho. . SQL Server para realizar uma exploração mais detalhada dos dados, onde foi possível identificar os registros e seus aspectos, permitindo uma descrição detalhada de todos os dados (realizada na tarefa anterior).
Ao analisar a tabela14, foi possível constatar que os dados apresentam um bom nível de qualidade em termos de dados faltantes, pois todos os atributos possuem 0%. Por fim, deve-se destacar que o número de registros é grande o suficiente para utilizar todos os algoritmos de mineração disponíveis no MLS.
Preparação dos Dados
- Seleção de dados
- Limpeza de dados
- Construção de dados
- Integração de dados
- Formatação de dados
Havia preocupação se o número de registros seria suficiente, já que os algoritmos de ML geralmente exigem uma quantidade razoável. Felizmente conseguimos criar um conjunto de dados com número suficiente de atributos e registros para analisar o perfil do aluno. Valores dos registros criados Turma que terminou em 2007 a 2023 Objetivo Saber em que ano começou a turma e associá-la.
Os dados foram discriminados de acordo com o tipo de necessidade especial que o aluno indicou no formulário no momento da matrícula. Esta tarefa teve como objetivo transformar os dados para melhorar o desempenho dos algoritmos de ML. Para tanto, foram realizados testes em todos os 32 atributos selecionados para a base de dados final.
Modelagem
Avaliação
Implementação
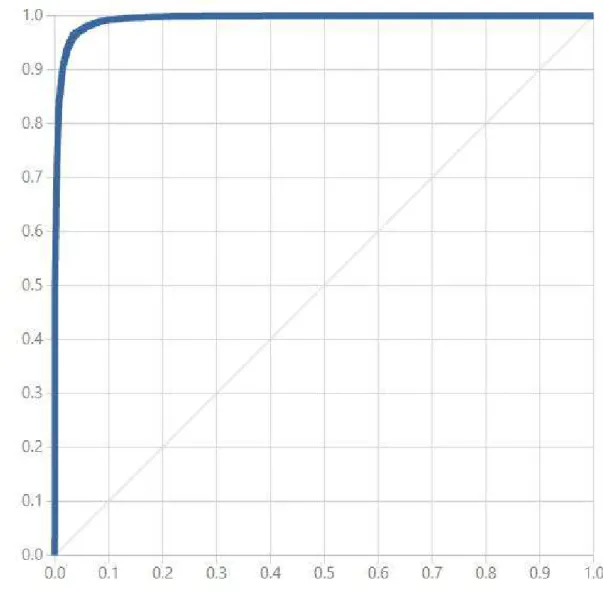
Conforme visto na tabela 15, é possível concluir que o algoritmo que obteve melhor desempenho na métrica Precisão é a Árvore de Decisão de Duas Classes.
Algoritmo Two-Class Support Vector Machine
Verdadeiros positivos (TP): indicaram a quantidade de registros que foram classificados como “descartados corretamente”, ou seja, a resposta do avaliador foi que o aluno foi descartado e o aluno foi de fato descartado. Verdadeiro negativo (TN): indicou a quantidade de itens que foram classificados como “não evadido corretamente”, ou seja, a resposta do classificador foi que o aluno não se esquivou e o aluno não se esquivou de fato. Falso positivo (FP): indicou a quantidade de itens que foram classificados como “evitados incorretamente”, ou seja, a resposta do classificador foi que o aluno evitou, mas o aluno não evitou.
Falso negativo (FN): indicou o número de registros classificados como “não desistiu incorretamente”, ou seja, a resposta do classificador foi que o aluno não está evadido, mas o aluno está evadido. No banco de dados, ela respondeu à seguinte pergunta: de todos os alunos classificados como positivos, qual percentual é realmente positivo.
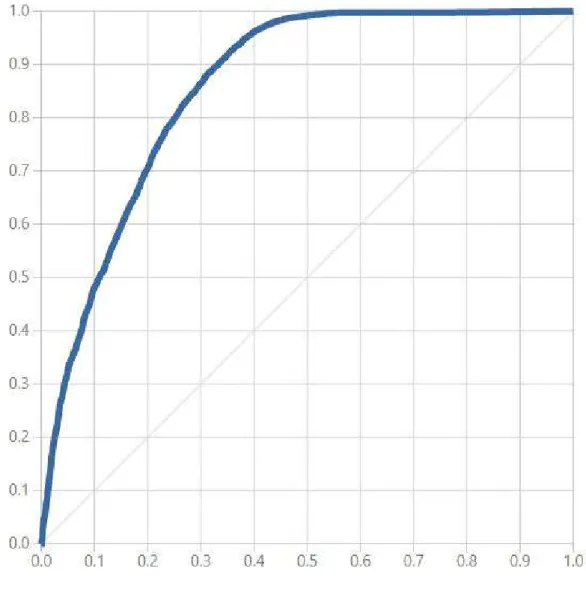
Algoritmo Two-Class logistic Regression
Conforme mostrado na matriz de confusão do modelo, o algoritmo classificou corretamente 5.202 registros de desistências e 15.004 registros de não desistências, ou seja, considerando que a base de dados contém 10.000 desistências, o algoritmo governa para mais de 50% dos registros gerados, o que pode ser considerado bom.
Algoritmo Two-Class Locally-Deep VSM
Este algoritmo apresentou valor baixo de 0,662 para a métrica Precison, valor também considerado baixo para este estudo.
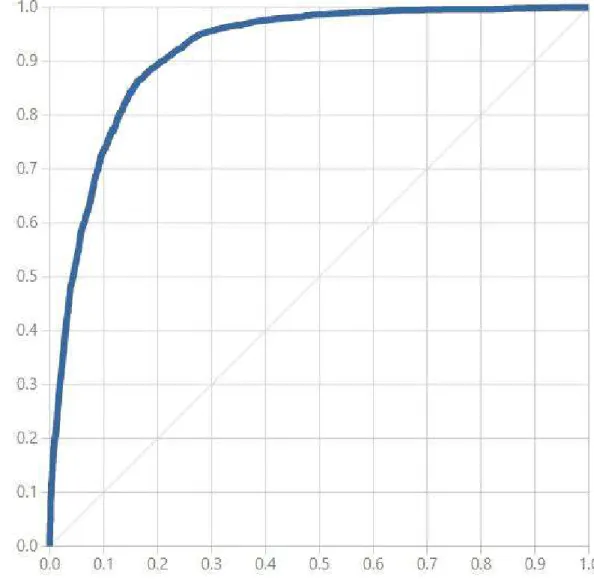
Algoritmo Two-Class Decision Jungle
Algoritmo Two-Class Neural Network
Ao analisar os valores de FP e FN na Matriz de Confusão, notou-se que atingiram valores muito baixos, 626 e 853 respectivamente.
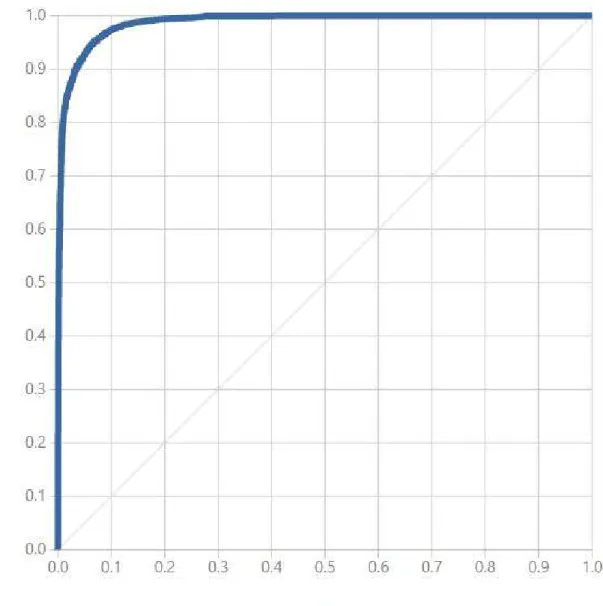
Algoritmo Two-Class Boosted Decision Tree
Nota-se que esse atributo não agregou muito na construção do conjunto de dados, pois a instituição possui período de matrícula e a maioria dos alunos matricula-se nesse período. Optamos por remover este atributo do nosso conjunto de dados porque quase todos os registros estão vazios (nulos). Devido à quantidade de registros diferentes não foi possível utilizar este atributo, pois não retornou nenhuma informação relevante nos primeiros testes que realizamos.
Devido à quantidade de registros diferentes, não foi possível utilizar este atributo por não fornecer informações relevantes. Analisando esse atributo, optamos por não utilizá-lo, pois 95% dos dados preenchidos são de estudantes do estado de Minas Gerais. Como já estamos utilizando o atributo vlrturmagrade, não utilizaremos este atributo pois os valores são os mesmos.
Devido à grande diversidade de registros, não foi possível utilizar esse atributo, pois ele não forneceu informações adequadas nos primeiros testes que realizamos.