Uma metodologia híbrida para análise de dados estruturados e não estruturados para subsidiar a tomada de decisão em segurança pública. METODOLOGIA ANALÍTICA HÍBRIDA DE DADOS ESTRUTURADOS E NÃO ESTRUTURADOS DE SUPORTE AO PROCESSO DE DECISÃO V.
OBJETIVOS
Objetivo Geral
No entanto, verificou-se que não há uma combinação de dados estruturados e não estruturados que permita ampliar a análise da segurança pública. A integração de dados não estruturados com dados estruturados oferece a possibilidade de expansão do banco de dados, incorporando conteúdos gerados por usuários UGC em redes sociais e outras plataformas, permitindo que as análises sejam mais precisas e com melhores níveis de precisão do algoritmo de aprendizado de máquina.
Objetivos Específicos
JUSTIFICATIVA
Por outro lado, buscamos contribuir com conteúdo inédito para a literatura, oferecendo novos métodos de integração de dados a partir de uma metodologia híbrida que considera dados estruturados e dados não estruturados. A literatura, que será explicada no Capítulo 2, dispõe de meios que permitem a análise de dados estruturados e instrumentos que permitem a análise de dados não estruturados, mas não existe uma metodologia capaz de analisar esses dados simultaneamente.
MATERIAIS E MÉTODOS
O DS.Security possibilita a inovação na captura, processamento e análise de dados, capacitando a análise de grandes volumes de dados em tempo real, ao mesmo tempo em que aumenta a precisão dos algoritmos de aprendizado de máquina. Como resultado, o DS.Security e a metodologia híbrida de análise de dados receberão um segundo prêmio em 2021, Melhor Ph.D.
ESTRUTURA DA TESE
SEGURANÇA PÚBLICA BRASILEIRA
A tecnologia da informação (TI) é entendida como a aplicação da tecnologia para resolver problemas organizacionais ou de negócios em grande escala. A tecnologia da informação visa permitir que os órgãos governamentais envolvidos com a segurança pública identifiquem ações que visem à redução da incidência de crimes, permitindo que a população tenha uma sensação de segurança em seu ambiente.
BIG DATA E USER GENARETED CONTENT (UGC)
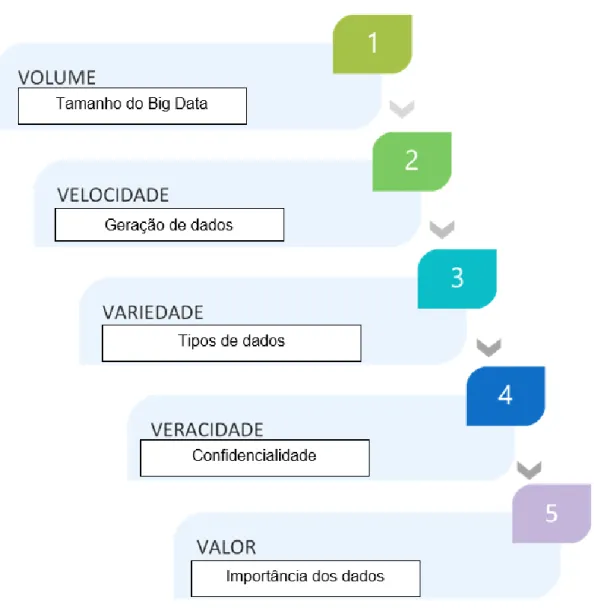
O Big Data serve para analisar os dados à medida que são criados, sem a necessidade de armazená-los em bancos de dados. Na Figura 1 é possível identificar a relação entre os 5 Vs do Big Data, considerando tanto o volume de dados quanto os tipos de dados existentes.
MACHINE LEARNING (APRENDIZAGEM DE MÁQUINA)
Decision Trees (Árvore de Decisão)
Cada nó de decisão implementa uma função de teste fm(x) com um valor de saída discreto que se torna a entrada para o próximo nó de decisão e assim por diante. O nó raiz geralmente divide o domínio de entrada em duas partes semelhantes, os nós subsequentes novamente dividem o domínio de entrada em duas partes semelhantes e assim por diante. Com esta estratégia é possível mapear os valores de entrada e descobrir os valores de saída com n iterações.
Florestas Aleatórias
Conforme visto na Figura 6, uma random forest é composta por várias árvores, ou seja, um conjunto de árvores, e cada árvore é composta por uma determinada amostra extraída de um conjunto de dados, sendo que esta amostra é um terço reservado para o treinamento do algoritmo e a parte restante para realizar a classificação. É semelhante a outros métodos, como árvores de decisão e florestas aleatórias, mas usa informações adicionais sobre os dados para melhorar a precisão preditiva.
Naive Bayes
SVM é um algoritmo de aprendizado de máquina que cria um modelo a partir de entradas de treinamento, mapeando-as no espaço multidimensional e usando regressão para encontrar um hiperplano, que é uma superfície do espaço n-dimensional que divide o espaço multidimensional em duas metades, o que separa melhor duas classes de entradas. Porém, em termos práticos, a capacidade computacional limita o número de entradas que podem ser utilizadas. Se, por exemplo, N entradas forem usadas para um SVM específico - o valor inteiro de N pode variar de um a infinito - a máquina deve mapear cada conjunto de entradas no espaço N-dimensional e encontrar um hiperplano N-1-dimensional que melhor separar os dados de treinamento (INGO & ANDREAS, 2008).
ESTUDOS RELACIONADOS
Este modelo computacional permite a análise e classificação de infrações penais com base em dados estruturados ou não estruturados. Portanto, trabalhos relacionados à análise de dados não estruturados produzem análises robustas e eficientes em segurança pública. Esta metodologia permite o desenho de uma base de dados que inclui dados estruturados e não estruturados.
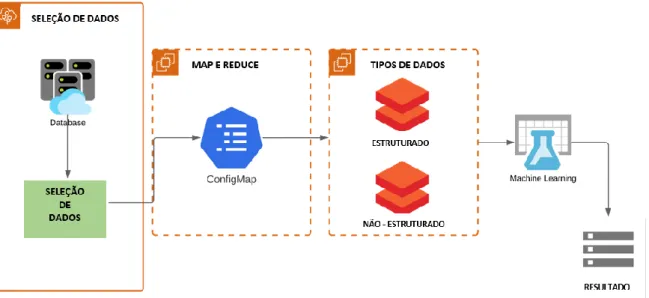
FRAMEWORK PARA ANÁLISE DE DADOS ESTRUTURADOS
Na etapa de refinamento, os dados são refinados para evitar possíveis erros associados à captura de dados. Esse agrupamento permite que o Hadoop mapeie e reduza o banco de dados refinado com base na correspondência de padrões entre os dados. O Hadoop inicia esse processo com a formação do cluster e armazena os dados consultados na etapa anterior em um banco de dados local ou na nuvem.
FRAMEWORK PARA ANÁLISE DE DADOS NÃO ESTRUTURADOS
Para integrar essas três fontes de dados em um único SGBD, que neste caso foi utilizado o Mongo DB por ser um banco de dados não estruturado, utiliza-se a priori um software de integração chamado Pentaho Data Integration, que funciona como extração, transformação e carregamento. – Ferramenta de carregamento (ETL) e permite a integração de vários bancos de dados em um único repositório. Esta etapa pode ser realizada via script, onde há definição direta de domínios diretamente em qualquer sistema gerenciador de banco de dados ou a partir de algoritmos. Esta etapa permite que os arquivos estejam em formatos adequados para verificação, enquanto refina os dados para identificar erros.
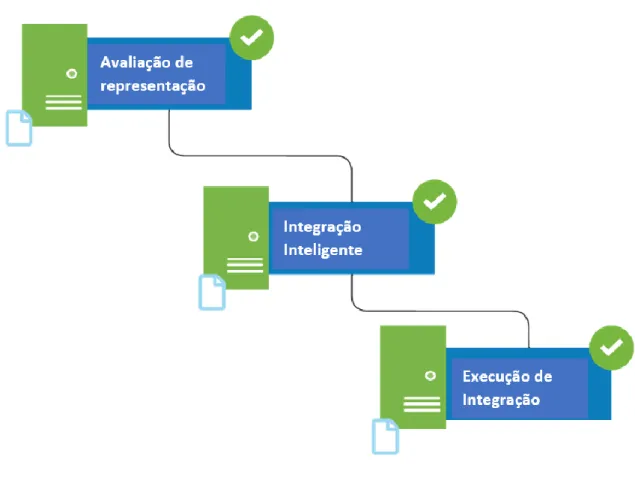
INTEGRAÇÃO DE DADOS
Como existem dois bancos de dados, a ideia é combiná-los em um único banco de dados estruturado. Esta fase especifica cada chave de integração que corresponde aos atributos do banco de dados por meio do construtor de metadados. Por fim, a etapa de execução da integração extrai, transforma e carrega os dados para realizar a agregação de dados em um único repositório de dados.
VISÃO GERAL DO DS.SECURITY
DS.Security Back-End
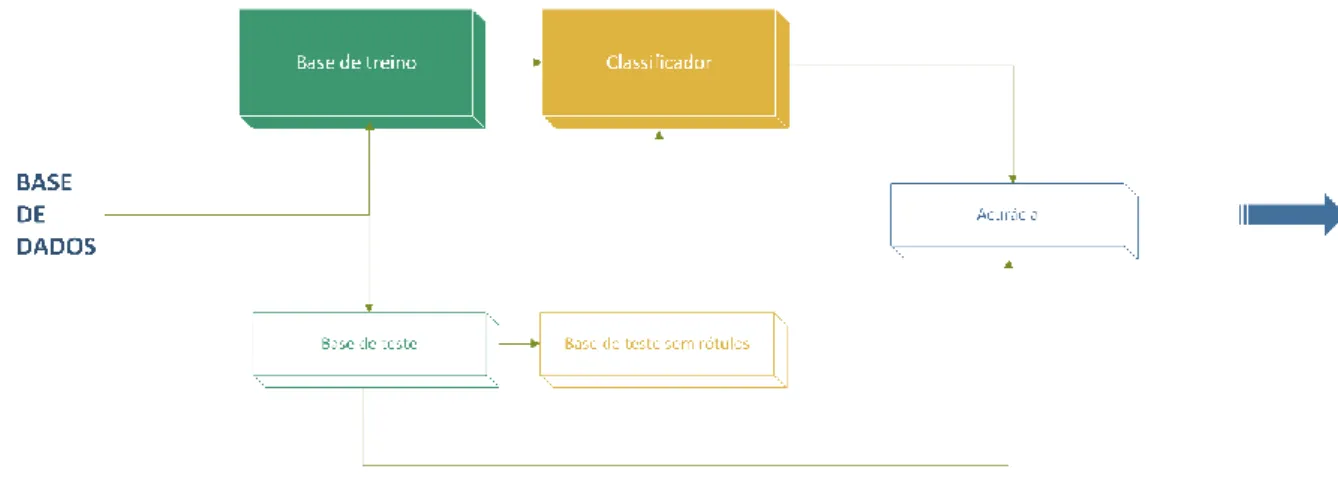
A DS.Security possui um sistema baseado na metodologia híbrida apresentada no capítulo anterior que atua como intermediário entre o usuário final e a coleta de dados (Figura 12). Depois de escolher um modelo, uma metodologia híbrida de análise de dados entra imediatamente em ação para analisar e incorporar dados estruturados e não estruturados obtidos de várias plataformas.
DS.Security Front-End
Além disso, o usuário poderá identificar com qual banco de dados irá trabalhar dentre os disponíveis, e escolher o algoritmo de aprendizado de máquina desejado e os atributos que o modelo levará em conta. Além disso, o usuário determinará, dentre as disponíveis, com qual banco de dados irá trabalhar, bem como qual algoritmo de aprendizado de máquina será utilizado para realizar esta classificação. Além disso, o usuário poderá especificar com qual banco de dados irá trabalhar e quais atributos o modelo levará em conta dentre os disponíveis.
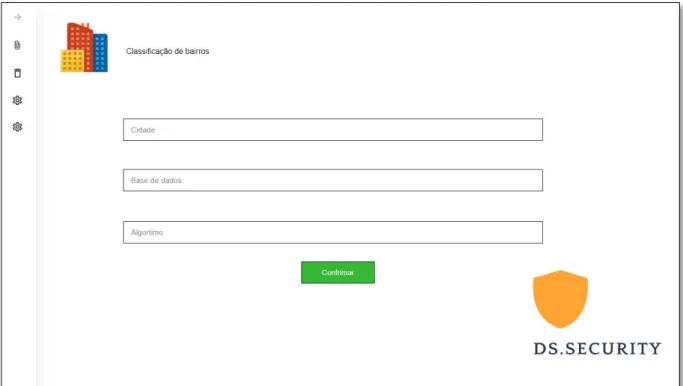
CONFIGURAÇÃO DA BASE DE DADOS
Após o procedimento, é incluído um novo atributo (quantidade) que vai identificar o número de homicídios em determinada região e reduzir o banco de dados. No que diz respeito à compilação da base de dados não estruturada para este estudo de caso, foram absorvidos dados das plataformas CityCopy, Onde Fui Roubado e Twitter. Frases, localização, tipo de crime e horários são armazenados em um banco de dados não estruturado chamado Mongo DB.
ESTUDO DE CASO
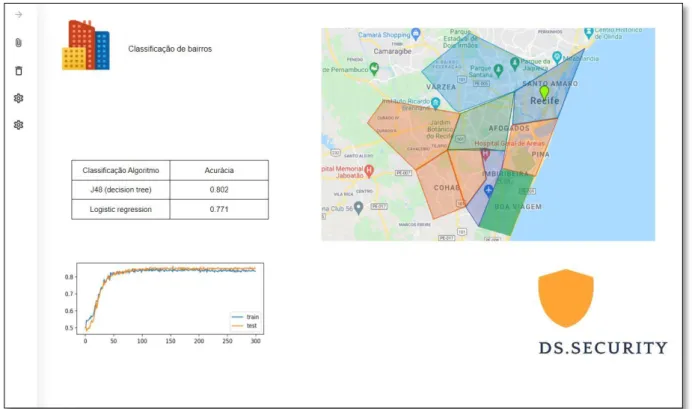
O primeiro modelo consistia em dados estruturados, enquanto o segundo modelo era composto por dados não estruturados e estruturados (ou seja, nossa metodologia proposta; Tabela 2). Por outro lado, o teste F1 Score no algoritmo J48 atingiu 0,810, resultado semelhante ao identificado pela precisão balanceada, o que demonstra o bom desempenho do algoritmo na base de dados baseada na metodologia híbrida de análise de dados. O teste F1 Score no algoritmo Random Forest deu 0,815, resultado semelhante ao resultado de precisão balanceada, o que também comprova o bom desempenho desse algoritmo no conjunto de dados correspondente.
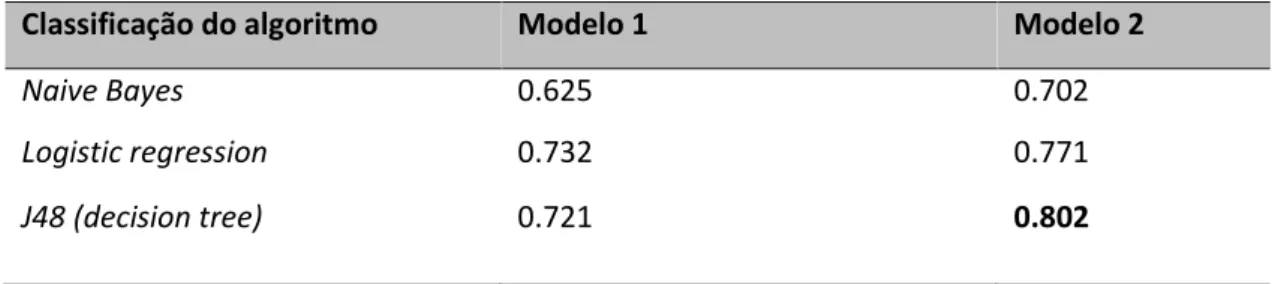
RESULTADOS E DISCUSSÕES
Dessa forma, esses algoritmos possuem características relacionadas ao problema enfrentado pela secretaria de segurança pública local. Esse resultado pode mudar constantemente conforme o banco de dados recebe novos dados, pois é um sistema em tempo real. Um SVM requer o uso de um conjunto de dados de treinamento de entrada e saída para construir o modelo SVM que pode ser usado para classificar novos dados.
CONFIGURAÇÃO DA BASE DE DADOS
Conforme declarado no Capítulo 2, SVM é um método de aprendizado de máquina que tenta obter dados de entrada e classificá-los em uma de duas categorias.
ESTUDO DE CASO
Nível de crimes
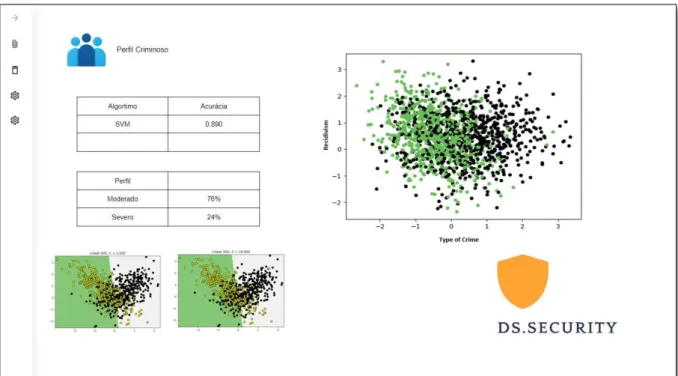
Além disso, esse nível é determinado por fatores demográficos, incluindo ensino fundamental ou médio, ter nascido em um bairro não violento e ausência de reincidência. As pessoas que se enquadram no nível 2 cometem crimes considerados mais graves, como roubos e homicídios. Os fatores demográficos que impulsionam esse nível incluem baixa escolaridade, nascimento em bairros violentos e famílias que cometeram crimes.
Aplicação do algoritmo de SVM
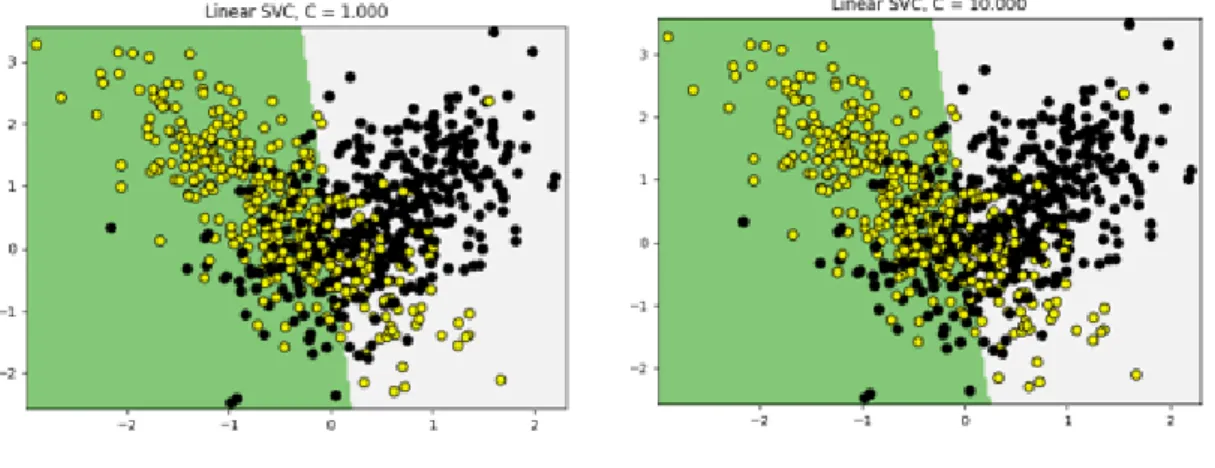
Os pontos pretos na Figura 9 indicam pontos de dados pertencentes à categoria grave e os círculos amarelos representam pontos de dados pertencentes à categoria moderada. Cada um dos pontos de dados individuais tem um valor de entrada exclusivo de 1, representado por sua posição no eixo x, e um valor de entrada exclusivo de 2, representado por sua posição no eixo y. O SVM então usa essa linha divisória para classificar novos pontos de dados na Categoria 1 ou na Categoria 2.
RESULTADOS E DISCUSSÕES
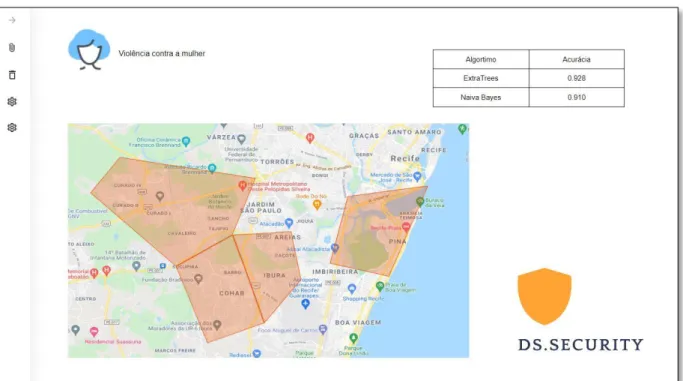
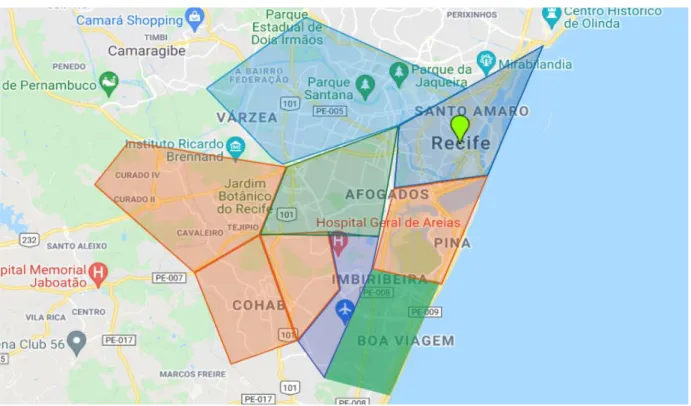
É um modelo que visa classificar os bairros que consideram violência contra a mulher. A classificação final leva em consideração os quatro bairros com maior risco de violência contra a mulher em uma semana. As áreas em vermelho representam bairros com maior probabilidade de crimes contra mulheres.
PRINCIPAIS CONTRIBUIÇÕES E POTENCIAIS DE USO DESTE ESTUDO
Este estudo também constatou que os dados oficiais fornecidos pelos departamentos de segurança pública são essenciais para ampliar a análise e, consequentemente, obter resultados mais precisos. Este trabalho amplia a discussão da política de segurança pública enquanto avança DSSs que incorporam ML, AI e UGC. As ações de segurança pública podem ser direcionadas para minimizar o crime e aumentar a sensação geral de segurança.
LIMITAÇÕES E TRABALHOS FUTUROS
Entretanto, outras análises podem ser realizadas para subsidiar outras decisões de segurança pública. Abordagem Híbrida Baseada em SARIMA e Redes Neurais Artificiais para Descoberta de Conhecimento Aplicada à Previsão da Taxa de Criminalidade, In: CONFERÊNCIA INTERNACIONAL DE INFORMAÇÃO EMPRESARIAL. Um sistema de visualização interativa para análise de dados criminais no estado do Rio de Janeiro, In: 19ª CONFERÊNCIA INTERNACIONAL DE SISTEMAS DE INFORMAÇÃO EMPRESARIAL.