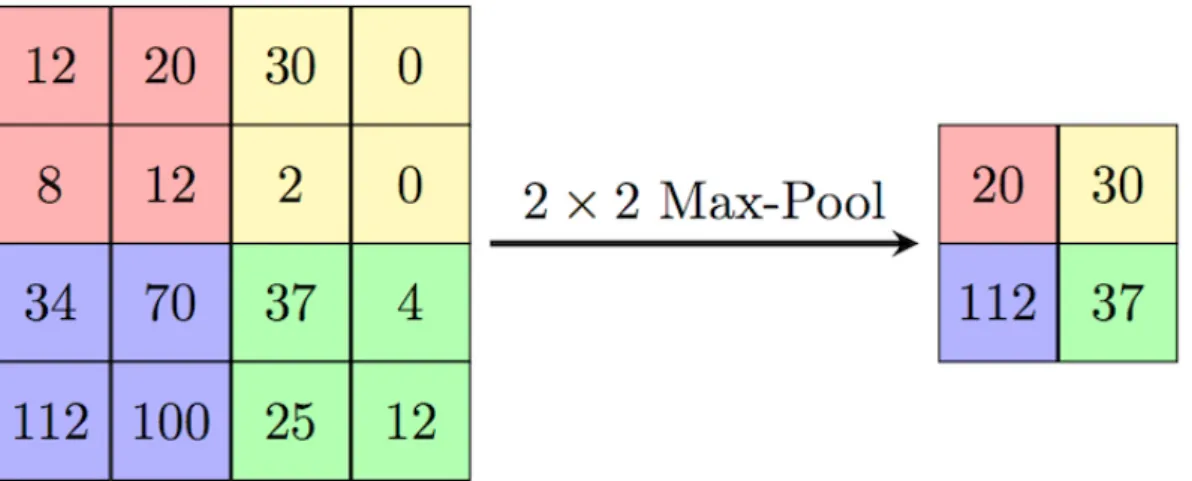No dia sete de janeiro de dois mil e vinte e dois, às 08h00, de forma não presencial, por meio do aplicativo Google Meet (meet.google.com/ndd-qmhj-yay), o sessão de defesa de trabalho de conclusão de curso do candidato ao Curso de Graduação em Engenharia de Controle e Automação, Antonio de Barros Naddeo Meirelles Ferreira, intitulado "OTIMIZAÇÃO MULTIO-OBJETIVO BASEADA EM MODELOS DE SUBSTITUIÇÃO PARA COMPRESSÃO DE REDES NEURAIS ARTIFICIAIS". Aproveitando esta consideração, este trabalho propõe uma metodologia para otimizar a escolha dos parâmetros envolvidos na compressão de uma rede neural artificial através de modelos de substituição. Para resolver esses e outros problemas relacionados ao tamanho das RNAs, tentativas têm sido feitas nos últimos anos para criar redes neurais efetivas e compactas, seja por meio de novas arquiteturas ou por meio de métodos de compressão de modelos.
Apesar do alto custo computacional, o trabalho demonstra a compressão de uma rede em 60% com um aumento significativo em sua precisão. TensorFlow (ABADI et al., 2015), sendo uma biblioteca de aprendizado de máquina, fornece implementações de código para compressão de redes neurais artificiais. Porém, o que se observa na literatura e na indústria de software é um avanço considerável nos métodos de compressão de RNA, porém sem uma discussão sobre o impacto dos hiperparâmetros de compressão nas características da rede comprimida.
No entanto, a compressão de uma rede é demorada e pode inviabilizar o uso de métodos de otimização direta, pois esses métodos geralmente requerem muitas avaliações de solução para resultados satisfatórios.

Objetivos gerais e específicos
Com base nessa limitação do número de avaliações da função de compressão, é utilizada uma abordagem de otimização por meio de modelos de substituição, que se mostra uma boa solução para otimizar problemas com altos custos de avaliação. Para a avaliação do algoritmo proposto, foram realizados testes de compressão das redes ResNet50 e VGG16 e os resultados comparados com as soluções encontradas utilizando o algoritmo evolutivo NSGA-II (Deb et al., 2002) como otimizador, onde as restrições quanto avaliação da função de compressão permaneceu a mesma.
Organização do texto
Redes Convolucionais
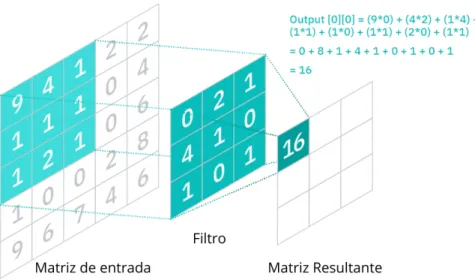
Redes neurais convolucionais são uma categoria de arquitetura onde a RNA utiliza, em pelo menos uma de suas camadas, a operação de convolução ao invés da multiplicação de matrizes observadas em camadas densas (DEEP. .,2021). Em uma camada convolucional, as conexões de um neurônio ocorrem apenas com uma pequena região dos neurônios da camada anterior, chamada de campo receptivo, conforme mostra a Figura 3. Em uma camada convolucional, os neurônios também compartilham os mesmos pesos, esta matriz de pesos compartilhados é chamado de filtro ou nuclear.
As Equações 2.2 e 2.3 descrevem uma camada convolucional com uma entrada bidimensional, onde I denota a matriz de entrada e K denota o filtro de camada. O filtro de camadas convolucionais permite reconhecer o mesmo padrão em diferentes locais da matriz de entrada. Além do cálculo da convolução e da função de ativação dos neurônios 2.2 e 2.3, as camadas convolucionais são geralmente seguidas por camadas de agrupamento.
Uma camada pooling, como uma camada convolucional, tem cada unidade conectada a apenas uma região da camada anterior, conforme mostrado na Figura 4. A diferença entre as camadas é que uma camada pooling não possui pesos para cada conexão, ela é definida por função matemática, geralmente o valor médio ou máximo.
Treinamento de uma rede neural artificial
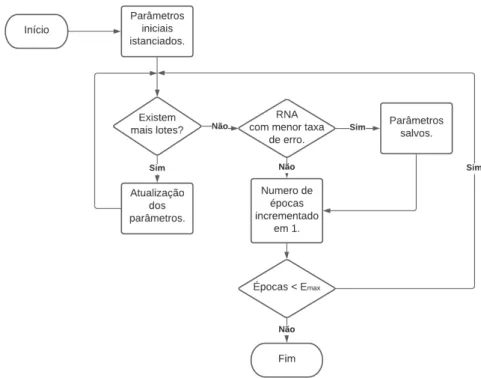
21 Durante o treinamento, uma parte ou conjunto de dados de entrada é enviado para a rede. Com os resultados gerados pela RNA e os resultados esperados, é possível calcular o erro da rede e atualizar os pesos e bias com um algoritmo de otimização de forma a minimizar este erro (DEEP. .,2021). Uma etapa de treinamento ocorre quando a rede é alimentada com um conjunto de dados e tem seus parâmetros atualizados.
O conjunto de etapas necessárias para usar todos os dados de treinamento é chamado de período de treinamento. Após cada época de treinamento, os parâmetros são salvos se o erro calculado for menor que a época anterior.
Métodos de compressão de Redes Neurais
Poda
- Cronograma por esparsidade constante
- Cronograma por Decaimento Polinomial
A poda de RNA é uma técnica para reduzir o número de parâmetros de uma rede neural, apresentada pela primeira vez por Cun, Denker e Solla (1989). Outras abordagens omitem todas as conexões com um neurônio, removendo-o da rede, e táticas mais agressivas podem até remover camadas inteiras de uma rede. Esta será a estratégia de poda utilizada neste trabalho, implementada no módulo Model Optimization da biblioteca TensorFlow (ABADI et al., 2015).
Embora a remoção possa ser aplicada a uma rede treinada, a remoção de pesos pode ter um grande impacto negativo na precisão. Portanto, a poda é aplicada em paralelo com o treinamento ou retreinamento da rede, onde as camadas são podadas gradualmente, permitindo que a rede se recupere a cada etapa de poda. Durante o treinamento da rede, a cada passo de ∆tp, definido como a frequência de poda, uma porção da matriz de pesos das camadas é zerada até que a mais esparsa seja atingida.
Pruning Frequency(∆t): Define o número de etapas de treinamento entre execuções de poda na rede. Com os parâmetros de poda definidos, as próximas subseções irão descrever os esquemas de poda utilizados. Nesse algoritmo, a dispersão de uma determinada camada aumenta em porcentagens constantes a cada etapa de remoção.
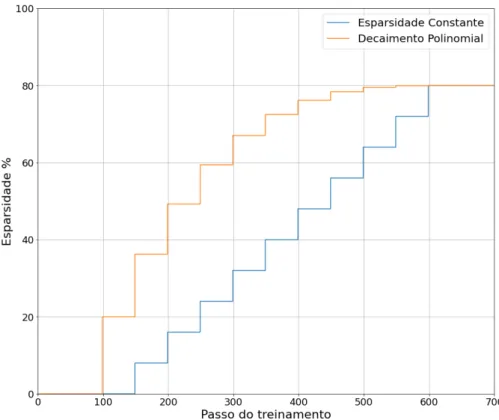
A Equação 2.4 define a dispersão de uma matriz de pesos em uma etapa de treinamento onde o número de etapas de poda é dado pela Equação 2.5. A esparsidade definida pelo decaimento polinomial é dada pelos mesmos parâmetros do esquema de poda constante e pela esparsidade,si, para a primeira iteração da poda0, bem como o dgrip do polinômio, definido pela equação 2.6. A Figura 6 ilustra a evolução da dispersão da rede durante o treinamento usando os dois esquemas de poda.
Quantização
O custo da compressão
Otimização Multiobjetivo
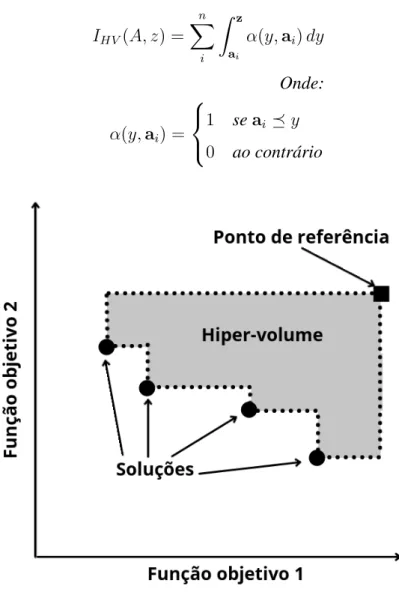
Hiper-Volume
Problema de otimização modelos substitutos
Algoritmo de otimização por modelos substitutos
Métodos de seleção de infill points
- Seleção Aleatória (RD)
- Distância no espaço de busca (SD)
- Densidade no espaço de objetivos (OD)
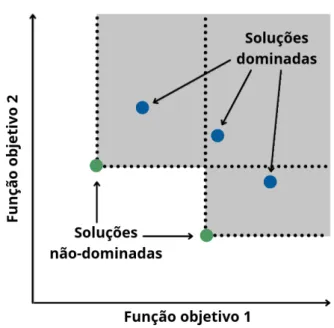
Considerando AP F = [f1, ...,fm] o conjunto que constitui a fronteira de Pareto do conjunto A, o ponto de preenchimento selecionado é aquele que minimiza a equação. O próximo capítulo apresenta formalmente a modelagem do problema de compressão multiobjetivo, utilizando os conceitos introduzidos na Seção 2.2 e neste capítulo. Esta seção apresenta a modelagem de um problema de compressão de rede neural, a modelagem do algoritmo usado para otimizar problemas multiobjetivos a partir de modelos substitutos e, finalmente, os experimentos realizados.
O problema de compressão de Redes Neurais Artificiais
Das variáveis de projeto, x0x1 são variáveis binárias que definem a aplicação ou não do respectivo método de compressão (x0 para corte e x1 para quantização). x2 é um vetor de variáveis, com comprimento igual ao número de tipos de camadas que modelamM possui, como camada dobrada ou densa, onde cada posição indica a aplicação ou não de corte no respectivo tipo de camada. x3 é novamente um vetor com tamanho igual a x2 e armazena valores reais entre 0 e 1 indicando a porcentagem de esparsidade final para cada tipo de camada. As variáveis x4 e x5 referem-se ao processo de poda, onde x4 é uma variável binária que indica o tipo de escalonamento utilizado para a poda da rede, onde 0 indica o uso de decaimento constante e 1 decaimento polinomial.
Implementação do Algoritmo Proposto
Implementação do problema de compressão
Implementação do otimizador por modelos substitutos
Experimentos Computacionais
Experimento de Benchmark
Experimento de Compressão
Experimentos de Benchmark
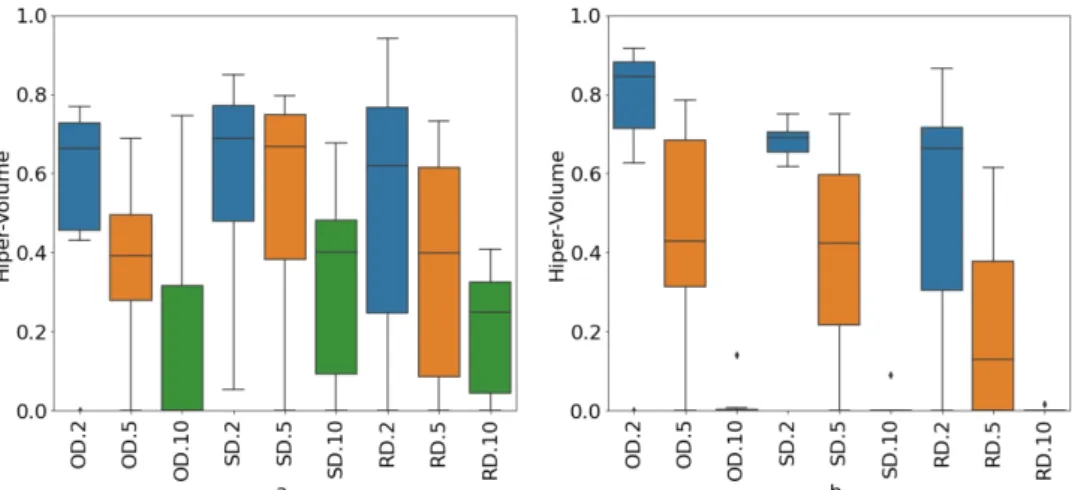
E como no experimento anterior, a densidade no espaço objetivo acaba sendo o melhor método de seleção. Os resultados também demonstram que testar com uma população menor e com mais gerações fornece soluções melhores e mais concisas em todas as execuções. Neste experimento, a superioridade dos parâmetros de teste b é indiscutível se observarmos que todos os diagramas da Figura 12.b são melhores que os diagramas equivalentes da Figura 12.a.
Com os resultados obtidos e discutidos nesta seção, podemos prosseguir para os testes de compressão. 36 no espaço objetivo com 2 pontos de preenchimento porque esta configuração dá os melhores resultados e é concisa durante a execução nos experimentos de referência.
Experimentos de Compressão de Redes Neurais Artificiais
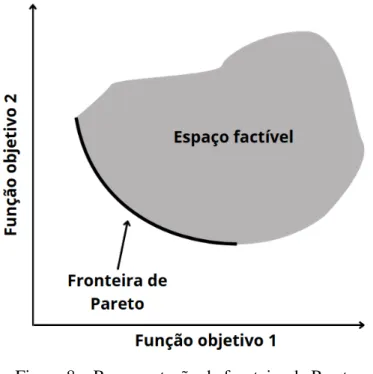
- Fronteira de Pareto
- Soluções por método
- Cronogramas de Poda
- Frequência de Poda
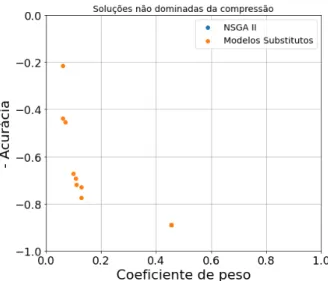
Para entender o comportamento dos algoritmos em relação às preferências de aplicação para os métodos de compressão, esta seção demonstra todos os resultados da compressão, dominada e não dominada, separados pelo método de compressão utilizado. 39 Conforme mostrado na Figura 16, ao contrário do que se observa ao comprimir NSGA-II para ResNet50, este algoritmo repetiu muitas soluções usando apenas quantização para comprimir VGG16, sem explorar a região mais à esquerda do gráfico. Apesar da variação de métodos de compactação semelhantes para usar NSGA-II e modelos substitutos na compactação ResNet50, uma grande diferença nos resultados é observada para VGG16.
A Figura 17 apresenta as soluções usando a poda do experimento de compressão de rede ResNet50 separada pelo cronograma de poda. Comparando os resultados dos dois otimizadores de compressão ResNet50, ambos os cronogramas atingem uma redução de tamanho de rede de até 15% de seu tamanho original com quedas de precisão semelhantes. No entanto, a utilização de modelos alternativos mostra que o esquema utilizado parece alterar pouco o resultado da compressão VGG16, conforme mostra a Figura 18 à esquerda.
E se compararmos os melhores resultados de compressão das duas redes, vemos que o decaimento constante é preferível para a compressão Resnet50, enquanto o VGG16 parece sentir pouca diferença entre os métodos, isso pode indicar que o cronograma ideal está mais ligado à arquitetura da rede do que um descoberta genérica para todas as redes. A Figura 19 ilustra a frequência de corte com base em uma escala de cores para cada solução de compactação de rede ResNet50. Comparando os gráficos de compressão do ResNet50, embora ambos os otimizadores prefiram baixas frequências, nota-se que o uso de modelos substitutos também explora algumas soluções com altas frequências.
Porque no campo do aprendizado de máquina, onde os parâmetros do modelo estão sendo constantemente aprimorados, sejam ANN ou não, usar métodos de compressão de ANN com parâmetros estáticos ou apenas aleatórios parece ilógico. Embora a compactação de ambas as redes tenha apresentado resultados significativos, os parâmetros de compactação escolhidos nas melhores soluções diferem entre as redes, como a diferença na frequência de poda. Enquanto a literatura indica o uso de altas frequências de poda, os resultados da compressão ResNet50 mostraram que o oposto pode ser melhorado, enquanto a compressão VGG16 suporta o uso de altas frequências.
Trabalhos Futuros
Este trabalho surgiu para tentar entender o impacto da compressão em uma rede neural artificial. E o uso da otimização por modelos substitutos se mostrou promissor, obtendo soluções diferentes e melhores do que o uso do NSGA-II em ambas as redes estudadas. O que os resultados e comparações da compressão das redes testadas indicam é que os parâmetros envolvidos na compressão estão fortemente ligados à rede comprimida.