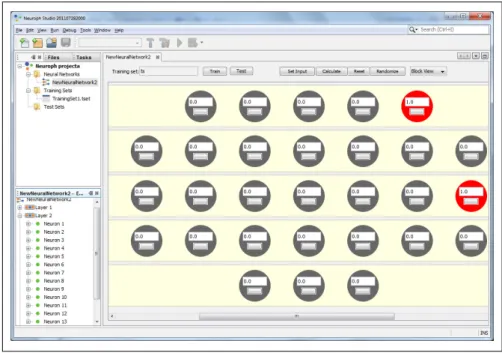
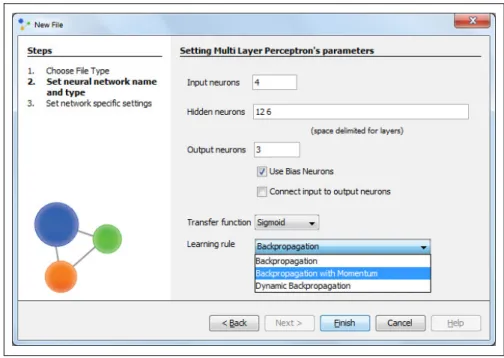
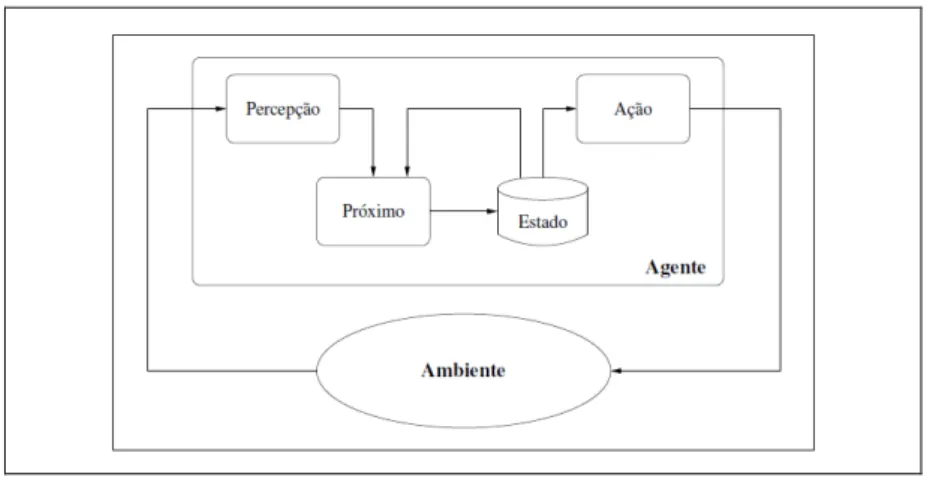
Todos os dias, pesquisadores e desenvolvedores de jogos trabalham para melhorar a qualidade do comportamento dos personagens controlados por computador. Apesar do alto nível de inteligência que a pesquisa sobre imitação comportamental busca mapear, nem todos os estudos abordam todas as ações dos personagens.
PROBLEMA DE PESQUISA
Solução Proposta
Utilizando DrussGT e DustBunny como oponentes, foram realizados confrontos entre os agentes com mapeamento do comportamento humano, as técnicas determinísticas utilizadas em DrussGT e DustBunny, além de um terceiro personagem controlado por um jogador humano para comparações de qualidade durante as avaliações. Os grupos são escolhidos por estarem ligados à área de tecnologia ou diretamente ligados à área de jogos.
Delimitação de Escopo
Justificativa
OBJETIVOS
Objetivo Geral
Objetivos Específicos
METODOLOGIA
Metodologia da Pesquisa
O problema de pesquisa possui abordagem qualitativa, pois visa avaliar a percepção dos jogadores através de questões sobre sua percepção, mensuração entre diferentes abordagens de jogos utilizando valores estatísticos dos resultados de comparações entre agentes no jogo para avaliação. O trabalho é classificado como pesquisa exploratória, pois realiza estudos para comparar diferentes abordagens aplicadas aos agentes, o que permite identificar a proporção de melhorias na qualidade da IA com o agente RNA através da imitação do comportamento humano.
Procedimentos Metodológicos
Para cada batalha foi avaliado o nível de percepção atribuído ao agente com o comportamento humano. As avaliações foram divididas entre 3 abordagens distintas: agente com mapeamento do comportamento humano, agentes determinísticos e ator humano.
ESTRUTURA DA DISSERTAÇÃO
Esta seção trata dos principais temas de interesse desta pesquisa, os quais estão divididos nos seguintes tópicos: os fundamentos a respeito das Redes Neurais Artificiais utilizadas no trabalho; os fundamentos e o tratamento determinístico da implementação tradicional em jogos baseados em regras; a definição e perfis de Agentes Inteligentes; e a definição das ferramentas utilizadas no experimento.
REDES NEURAIS
- Estrutura da rede
- Aprendizado supervisionado
- Tipos de Redes Neurais
- Rede Perceptron
- Rede Multi layer Perceptron (MLP)
- Treinamento a partir de padrões comportamentais
- Conjuntos de treinamentos desbalanceados
- Método de treinamento
O conjunto de dados utilizado para o treinamento e o tipo de problema a ser respondido devem ser levados em consideração para a aplicação do algoritmo de treinamento adequado. Na etapa de treinamento da rede, os exemplos contidos no conjunto de dados pertencentes a uma determinada classe permitem que a rede realize o reconhecimento de padrões.

SISTEMAS BASEADOS EM REGRAS
Isso prova que mesmo utilizando uma abordagem simples como o RBS requer atenção dos desenvolvedores para que possa ser utilizado adequadamente, pois no caso de um sistema com muitas regras, gerenciar todos os recursos pode eventualmente se tornar muito difícil. As características dos personagens construídos com abordagem determinística são importantes para que os experimentos deste trabalho possam avaliar as características em que o personagem com abordagem não determinística é mais perceptível.

AGENTES INTELIGENTES
Autonomia e aprendizagem
A autonomia refere-se ao princípio básico de que agentes inteligentes podem realizar suas ações de forma independente, com base em suas próprias iniciativas, sem a necessidade de serem controlados. Almeida (2004) menciona que os agentes podem ser considerados autônomos quando realizam suas ações sem a presença do usuário, simplesmente com base em um perfil de preferência previamente construído.
Mapeamento de perfil em Agentes
Essa série de objetivos menores deve ser levada em consideração no mapeamento do perfil do jogador para que essas características possam ser observadas após o treino. A definição do perfil do jogador neste trabalho visa identificar o nível de habilidade dos jogadores para que os dados possam ser avaliados corretamente nas comparações realizadas durante os experimentos.
FERRAMENTA PARA SIMULAÇÃO
- Requisitos da ferramenta
- Ferramentas Pesquisadas
- Comparativo entre as ferramentas
- ROBOCODE
Esta seção descreverá o processo de seleção de uma ferramenta de teste e simulação. Além disso, a ferramenta deve fornecer um arquivo de log para que as ações dos agentes possam ser mapeadas para treinamento. Além disso, Jarts faz uma comparação entre ferramentas de simulação semelhantes às definidas no projeto e identifica as vantagens do Jarts sobre elas (ARMBRUSTER, 2007).

OBJETIVO PRINCIPAL DA REVISÃO SISTEMÁTICA
PROTOCOLO DE REVISÃO SISTEMÁTICA
- Objetivo
- Questões de pesquisa
- Fontes de dados
- Critérios de inclusão e exclusão
- Síntese dos dados
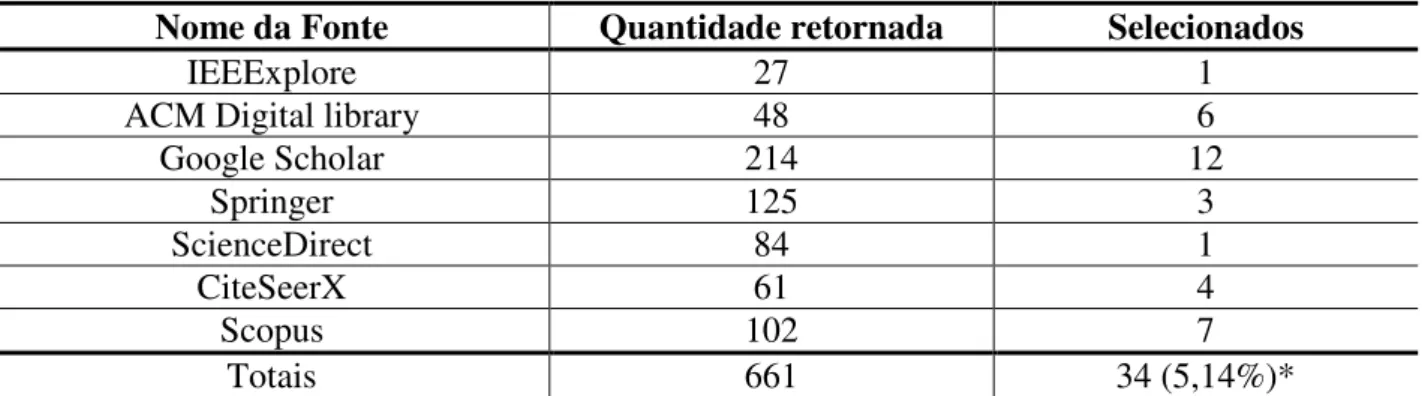
A string final usada para o Google Scholar é vista assim:. jogos) AND (humano OR interativo) AND ('imitação de aprendizagem' OR comportamento OR imitação OR imitação OR aprendizagem) AND (IA ou 'inteligência artificial' OR agentes). A string final usada para CiteSeer pode ser vista assim:. jogos) AND (humano OR interativo) AND ('imitação de aprendizagem' OR comportamento OR imitação OR aprendizagem) AND (IA ou 'inteligência artificial'). Os dados extraídos foram apresentados de acordo com os critérios especificados para análise de dados no protocolo de revisão sistemática.

ANÁLISE COMPARATIVA
- Estudos Selecionados
- Foco dos estudos
- Abrangência
- Metodologia Utilizada
- Classificação dos resultados obtidos
Os dados de publicação por ano mostram que 70,59% dos estudos selecionados foram realizados nos últimos anos. Além de descrever com base nos artigos selecionados, a visão geral visa mapear a participação e determinar a frequência de publicação dos estudos selecionados mais relevantes (Q1). Os dados de publicação por ano mostram que 70,59% dos estudos selecionados foram realizados nos últimos 6 anos.
CONSIDERAÇÕES
Comparação de áreas por grau de similaridade para o desempenho de uma determinada tarefa 1 (5,88%) Após a exibição dos estudos mapeados, que realizaram uma comparação por áreas gráficas (Comparação de áreas graficamente para o desempenho de uma determinada tarefa), destacam-se, que representam 23,52% dos estudos selecionados. características do movimento de forma mais clara, tornando a comparação mais objetiva. Os métodos mais utilizados foram aqueles que visam comparar os resultados entre agentes treinados e jogadores (uma métrica de pontos para a realização de uma determinada tarefa), o que representa 29,41% dos estudos selecionados. Durante a extração dos dados foram observados os principais pontos de trabalho relacionados ao processo de mapeamento, e esses dados foram extraídos apenas para descrever com mais clareza os detalhes dos estudos.
DEFINIÇÕES DAS VARIÁVEIS PARA MAPEAMENTO
- Robocode como ferramenta de simulação
- Estrutura do Agente
- Método de extração de dados
- Definição das variáveis de Movimentação
- Definição das variáveis de Controle da Torre
Ângulo relativo ao oponente (sensor 1): O método getBearing() do Robocode agora indica a posição relativa ao oponente através de ângulos positivos de até 180º (para leituras feitas quando o oponente está à direita do robô) e ângulos negativos. até -180º (quando localizado à esquerda); Ângulo da arma em relação ao oponente (sensor 1): Para obter o ângulo da arma em relação ao oponente, foi criado o método getGunAngle(). Distância relativa ao adversário (sensor 3): A distância é calculada a partir das coordenadas relativas ao adversário.

MODELO DE TREINAMENTO SUBDIVIDIDO EM TAREFAS
Movimentação
Sempre que o adversário contra-atacava (veio em direção ao robô) ou o robô estava muito próximo do adversário, eram realizadas manobras defensivas. Localização do Inimigo: Foram realizadas manobras para que o inimigo estivesse sempre próximo do campo de visão do robô. A cada movimento do inimigo na tentativa de escapar da linha de visão, eram realizadas manobras para localizar esse adversário.
Controle da Torre
Reações em relação ao cenário: A tarefa foi feita para evitar balançar o robô, pois ele ignora os limites do cenário nas demais tarefas. O objetivo da tarefa não era evitar a colisão, mas sim bloqueá-la, pois a colisão ocorre nas partidas disputadas pelo jogador. Este agente pode evitar ser encurralado, localizar o inimigo no campo de batalha, atacar e recuar de acordo com a situação de batalha, semelhante àquela que o jogador treina.
CICLO DE OBTENÇÃO DOS DADOS DE TREINAMENTO
Uma vez configurada a interface de leitura com o ANNRobot, diversas batalhas foram realizadas para cada uma das tarefas de movimentação e controle da torre. Respostas relacionadas ao cenário: 100 lutas realizadas para equilibrar o número de exemplos das demais tarefas de movimentação; Com base na quantidade de exemplos gerados em cada tarefa de movimento, foram obtidos exemplos relacionados ao cenário, sempre na tentativa de equilibrar a quantidade de exemplos gerados com as tarefas anteriores.
TRATAMENTO DOS DADOS PARA TREINAMENTO
Exemplos fora da faixa de valores foram analisados para obter sua representatividade em relação ao número total de exemplos gerados. Nesta etapa, exemplos relacionados às paredes da cena foram atribuídos ao arquivo de tarefas de movimento. Para tanto, foram duplicados os exemplos gerados no arquivo e acrescentados sensores e atuadores associados às paredes do cenário.
PROCESSO DE TREINAMENTO
Estrutura da Rede e Algoritmos de treinamento para Controle da Torre
Para controlar a torre foram definidas 5 entradas baseadas nos sensores e 3 saídas baseadas nos atuadores. Após o treinamento, a rede foi aplicada ao robô para observar as ações de controle da torre que ele realizava. A aplicação da rede utilizando a interface ANNRobot é demonstrada na Seção 4.6, enquanto os resultados das observações referentes às ações de controle da torre são descritos na Seção 4.7.

UTILIZAÇÃO DA REDE TREINADA
Durante o treinamento da rede responsável pelo controle da torre foram realizadas 287 iterações, que levaram aproximadamente 2 minutos para serem executadas, resultando em um MSE de 0,3. Na tarefa de controle da torre, embora a mira e o disparo sejam realizados em tempo real, o ângulo de rotação da torre é baseado no controle do mouse e não possui um ângulo definido. Porém, o valor utilizado para o movimento da torre foi baseado no número de FPS (frames por segundo) para que a cada leitura do Robocode, o movimento da arma fosse realizado de forma suave, como ao realizar ângulos baixos que não possuem o FPS move a arma em câmera lenta.
ANÁLISE DO AGENTE TREINADO
Tarefa de Perseguição e Defesa realizada em todas as batalhas Localização do inimigo Tarefa realizada em todas as batalhas Reações ao cenário Não há bloqueio em todas as batalhas. Tarefa de chute realizada em todas as partidas Outra observação importante está ligada à avaliação do comportamento, onde determinadas características observadas no agente treinado podem refletir nos resultados. Porém, em determinadas situações entre as partidas observadas, o agente cometeu erros de chute mesmo com o adversário parado, o que não aconteceu com o jogador.

AVALIAÇÃO DO COMPORTAMENTO MAPEADO
Instrumento de avaliação
Em cada uma das seções apresentadas, dois robôs aparecem em batalha até que um deles seja destruído. O avaliador responde a perguntas sobre o comportamento de um dos bots em cada uma das batalhas apresentadas para indicar se ele acredita que o bot avaliado é um jogador humano ou um personagem artificial. Em cada uma das páginas onde são apresentados os vídeos e questões sobre a avaliação do comportamento, o avaliador também recebe um campo adicional para comentários para que possa explicar sua escolha.
Design do experimento
Na utilização do questionário foi solicitada a avaliação de um robô por vez para adequar o experimento ao framework utilizado, onde apenas um dos agentes é avaliado em cada jogo. Os questionários foram elaborados para trabalhar com escalas de níveis comportamentais para que esses dados numéricos possam ser utilizados na avaliação estatística. Os questionários foram elaborados para trabalhar com escalas de níveis de comportamento que possam ser utilizadas em avaliação estatística.

CONSIDERAÇÕES
Para responder às questões desta pesquisa, foram realizados experimentos com 3 grupos de pessoas da área de tecnologia. Os grupos foram definidos apenas pela sua relação com o domínio da tecnologia ou diretamente com o domínio do jogo, a fim de obter amostras com participantes em diferentes níveis de experiência de jogo. Considerando os níveis de experiência, são analisadas as classificações (entre mais humanas ou mais artificiais) de cada um dos personagens com cada uma das abordagens definidas para o teste (abordagem de rede neural artificial, determinística e controlada pelo próprio jogador).
ÁNALISE DAS RESPOSTAS
Tal como a questão principal, a questão sobre os níveis de experiência dos jogadores também é apresentada numa escala ordinal com 5 opções. Com este resultado foi possível identificar que existe uma diferença significativa entre os níveis de experiência para alguns cruzamentos (que incluem todas as batalhas). A partir disso é possível confirmar que o nível influenciou a avaliação do comportamento realizado, portanto os testes foram realizados levando em consideração os diferentes níveis de experiência.

COMPARAÇÃO ENTRE AS ABORDAGENS
A Tabela 23 mostra os resultados obtidos para cada abordagem entre jogadores menos experientes, e a Tabela 24 mostra os resultados entre jogadores mais experientes. Tal como acontece com os jogadores menos experientes, os valores medianos mostram que os jogadores mais experientes tenderam a ser indecisos e não atribuíram valores significativos a um nível mais humano ou artificial para nenhuma das abordagens. Por outro lado, os valores de significância resultantes para jogadores mais experientes ficaram mais próximos do nível de significância aceito.

RESPOSTAS COMPLEMENTARES
Avaliação do robô controlado pelo jogador humano versus o robô com a abordagem RNA Tabela 30. Avaliação do robô com a abordagem RNA versus o robô controlado pelo jogador humano Tabela 31. Alguns dos comentários sobre o agente com a abordagem RNA apresentados na Tabela 31 reforçam as semelhanças identificadas com o jogador humano.

CONSIDERAÇÕES
Aos jogadores mais experientes foram atribuídos níveis de comportamento estatisticamente significativos na batalha entre a abordagem ANN e o DustBunny determinístico. Esta informação é consistente com os resultados obtidos, uma vez que no cruzamento entre a abordagem determinística DussGT e a abordagem RNA as avaliações do nível de comportamento foram muito mais próximas. Essas observações indicaram que um dos objetivos, que era mapear as ações do jogador no agente com uma abordagem de RNA, foi identificado durante as avaliações.
SUBJETIVIDADE, VIESES E OUTRAS AMEAÇAS
Dissertação (Graduação em Ciência da Computação) – Programa de Pós-Graduação em Computação, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2007. In: Sexta Conferência Internacional sobre Computação Bioinspirada: Teorias e Aplicações (BIC-TA '11), Washington, EUA. Dissertação (Pós-Graduação em Ciência da Computação) – Programa de Pós-Graduação em Computação, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2000.