Classificador probabilístico baseado no teorema de Bayes
Score do termo
Score final do termo
Cálculo da Acurácia
Cálculo da Precisão
Cálculo da Revocação
Cálculo da medida F1
INTRODUÇÃO
- MOTIVAÇÃO E JUSTIFICATIVA
- TEMA E DELIMITAÇÃO
- OBJETIVOS
- Objetivo Geral
- Objetivos Específicos
- RELEVÂNCIA E APLICABILIDADE
- METODOLOGIA
- TRABALHOS RELACIONADOS
- ESTRUTURA DO TRABALHO
O campo de estudo que analisa as opiniões e sentimentos das pessoas em textos é chamado de análise de sentimento (MEDHAT et al., 2014). Neste contexto, este trabalho limita-se a analisar o desempenho de predição de um modelo não supervisionado para análise de sentimentos em dados não estruturados (textos), para posteriormente ser desenvolvido um sistema de apoio à decisão (SentiWordNet) com base neste modelo estudado. O principal objetivo desta monografia é analisar a capacidade preditiva de um modelo não supervisionado para análise de sentimentos em textos (SentiWordNet), modelo que servirá de base para o desenvolvimento de um sistema de apoio à decisão.
A segunda fase do trabalho consistirá em dois experimentos realizados com o objetivo de analisar a eficácia de um modelo não supervisionado para análise de sentimentos.
UMA PANORÂMICA NA ANÁLISE DE SENTIMENTOS
- ORIGEM E CONCEITOS DESSA ÁREA
- ALGUNS MÉTODOS UTILIZADOS NA MINERAÇÃO DE OPINIÃO
- SentiWordNet
- SentiStrength
- LIWC
- APLICAÇÕES DA ANÁLISE DE SENTIMENTOS
- Análise de Sentimento em Sistemas de Recomendação
- Detecção de Mensagens de Ódio
- Análise de Sentimento na Política
- DESAFIOS DA ANÁLISE DE SENTIMENTOS
- Sentimentos implícitos e sarcasmos
- Dependência de domínio
- Expectativas frustradas
- Pragmática
- Conhecimento de mundo
- Detecção de subjetividade
- Identificação de entidade
- Negação
O objetivo da análise de sentimento é determinar a intensidade dos sentimentos e a polaridade das frases capturadas da web (PANG; LEE; VAITHYA-NATHAN, 2002). Segundo Xu (2010), a mineração de opinião ou análise de sentimento são campos que englobam técnicas computacionais que tentam entender opiniões e sentimentos em textos e analisam grandes quantidades de dados para auxiliar as pessoas na tomada de decisões. Embora a opinião seja um conceito muito amplo, a análise de sentimento se concentra principalmente nas emoções positivas e negativas.
ALGUNS MÉTODOS UTILIZADOS NA MINERAÇÃO DE OPINIÃO Nesta seção mostraremos alguns estudos e métodos criados para realizar a análise de sentimentos em textos. Os léxicos são usados para o problema de análise de sentimento para tentar resolver o problema dos classificadores, que geralmente reside no alto custo de treinamento. Outro fator importante na classificação é a capacidade de analisar textos em diferentes idiomas, inclusive o português, mas não com a precisão do inglês.
LIWC é uma ferramenta de análise de texto que estima componentes emocionais, cognitivos e estruturais de um determinado texto com base no uso de dicionários contendo palavras e suas respectivas categorias. Podemos usar a análise de sentimento nos mais diversos setores do mercado consumidor, como avaliar produtos, descobrir atitudes e tendências do consumidor para fortalecer campanhas de marketing, encontrar opiniões sobre temas populares ou também avaliar filmes, etc. Esta seção tem como objetivo listar alguns dos principais ramos da análise de sentimento.
Oliveira e Bermejo (2017) realizaram um estudo para identificar como a análise de sentimentos, baseada em textos extraídos de mídias sociais, pode ser um instrumento público de medição do desempenho do governo, para contribuir com a avaliação da administração pública. Lidar com negações no contexto de uma frase é um dos maiores desafios da análise de sentimentos.
DESCOBERTA DE CONHECIMENTO EM TEXTO (KDT)
- MINERAÇÃO DE TEXTOS – CONCEITOS E DEFINIÇÕES
- RECUPERAÇÃO DE INFORMAÇÃO
- APRENDIZAGEM DE MÁQUINA
- Naive Bayes (NB)
- Support Vector Machines (SVM)
- PROCESSAMENTO DE LINGUAGEM NATURAL
- O PROCESSO DE MINERAÇÃO DE TEXTO
- Coleta
- Pré-processamento
- Indexação
- Mineração ou Processamento
- Análise
Para melhor contextualizar o leitor com os aspectos relacionados ao processo KDT, as seções seguintes irão discutir esses processos e, finalmente, a seção 3.5 apresentará o processo de mineração de texto completo. Belkin e Croft (1987) definem o processo de RI como um processo de localização de itens de informação que foram objetos de armazenamento, com a finalidade de dar ao usuário acesso a itens de informação, objetos de uma solicitação. O processo de recuperação da informação é baseado na coleta, representação, armazenamento, organização e acesso do usuário.
Em geral, o processo do sistema de informação possui aspectos linguísticos e objetos textuais, portanto necessita de uma correta interpretação dos elementos incluídos, o que garante uma recuperação de qualidade. O processo de aprendizagem inclui a aquisição de novas formas de conhecimento: o desenvolvimento de habilidades motoras e cognitivas (por meio de instrução ou prática), a organização de novos conhecimentos (apresentações eficazes) e a descoberta de novos fatos e teorias por meio da observação e experimentação. Uma desvantagem do aprendizado de máquina supervisionado no contexto da análise de sentimento é que deve haver vários exemplos de texto já classificados para formar um corpo de treinamento confiável (SILVA, LIMA, BARROS, 2012; QIU et al., 2009).
SVM é uma técnica recente (da década de 90) utilizada no processo de reconhecimento de padrões e regressão linear. Um dos motivos é que os dados podem não estar disponíveis em um formato adequado para serem usados no processo de mineração de texto. A etapa de pré-processamento costuma ter um alto custo computacional, e um planejamento organizado e cuidadoso nesta etapa é fundamental para se obter um bom desempenho no processo de mineração de texto (WEISS et al., 2005).
Na prática, envolve a seleção, configuração e execução de um ou mais algoritmos de mineração de conhecimento. A etapa final do processo de mineração de texto é responsável por avaliar e interpretar os padrões extraídos.

DESCRIÇÃO DOS EXPERIMENTOS
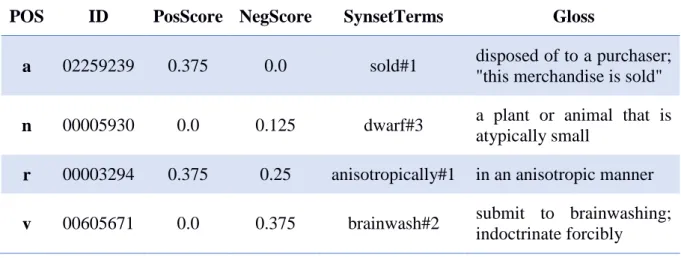
- DICIONÁRIO LÉXICO
- O CLASIFICADOR
- CONSTRUÇÃO DO CORPUS
- PREPARAÇÃO DOS DADOS
- MÉTRICAS DE AVALIAÇÃO
Trask (2008) conceitua léxico como um conjunto de palavras que compõem a linguagem, ou seja, é o vocabulário de uma língua. Algumas redes sociais fornecem uma API (Application Programming Interface) para que os estudos ou coletas de dados possam ser realizados de forma simplificada, o que garante que os dados que circulam e são coletados estão associados a uma conta de desenvolvedor e sob uma série de condições de responsabilidade da rede social. Os dados do Twitter são a fonte mais abrangente de conversas públicas ao vivo em todo o mundo.
Uma vez que os dados estejam disponíveis, ou seja, finalizada a etapa de coleta dos tweets, o próximo passo é realizar o pré-processamento desses dados. A balança de ministros escalou para votar a condenação contra o presidente Michel Temer (PMDB) no Congresso. Depois de acompanhar atentamente na Câmara dos Deputados a votação do pleito da Procuradoria-Geral da República contra o presidente Michel Temer.
A acurácia indica a porcentagem de sentenças classificadas corretamente, ou seja, a soma de acertos de todas as classes dividida pelo número total de sentenças classificadas. A precisão é calculada para cada classe separadamente e mostra a porcentagem de sentenças classificadas corretamente para aquela classe. Ou seja, basta dividir os acertos de uma classe pelo número de itens classificados como pertencentes a essa classe.
Considerando que a revocação é calculada exatamente pelo número total de sentenças classificadas corretamente para uma classe sobre o número total de sentenças dessa classe no banco de dados. Para cada classe marcada manualmente como "Positiva", existem instâncias separadas que são classificadas corretamente pelo método (TP - Verdadeiro Positivo) e aquelas que são classificadas como.
RESULTADOS E DISCUSSÕES
- RESULTADOS DO PRIMEIRO EXPERIMENTO
- RESULTADOS DO SEGUNDO EXPERIMENTO
- CONSIDERAÇÕES FINAIS DESSE CAPÍTULO
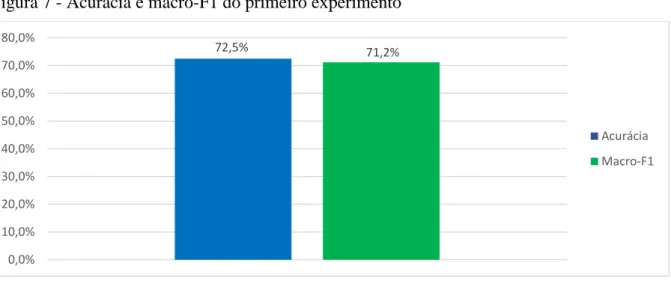
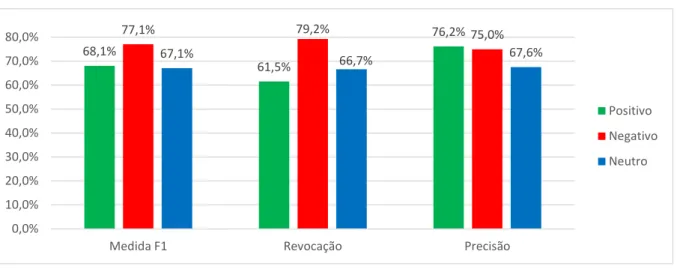
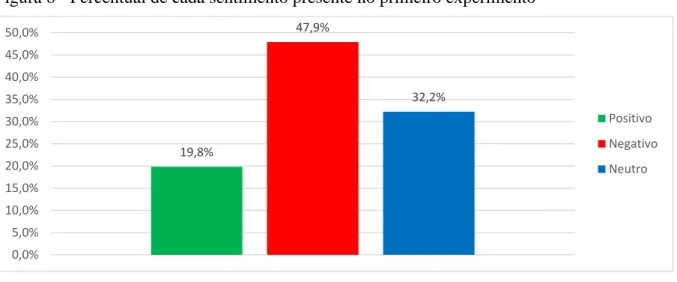
Podemos observar que, de maneira geral, o modelo obteve um bom resultado, se considerarmos que uma abordagem não supervisionada tem uma média de 72% de precisão e nosso modelo alcançou uma precisão de 72,5% enquanto a macro-F1 foi de 71,2%. . A Figura 7 mostra os resultados para precisão, recall e medida F1 para os sentimentos: positivo, negativo e neutro. Na figura 8 podemos analisar as polaridades de cada contexto, nela, como esperado, notamos que a polaridade, quando se refere ao contexto da denúncia, domina os comentários negativos chegando a 57,4%, enquanto os comentários positivos são apenas 5%.
A Figura 9 apresenta os resultados individuais, para cada contexto (#FicaTemer, . #ForaTemer e Denúncia), de acurácia e macro-F1. Aqui podemos ver que não houve uma diferença muito grande, quanto à acurácia e macro-F1, entre os contextos analisados. Em comparação, este cenário produziu um resultado significativamente mais equilibrado do que o mesmo cenário do experimento anterior na Figura 5.
Na Figura 11, focando apenas na precisão e macro-F1 para o segundo experimento, podemos ver que há uma melhora significativa em relação ao experimento anterior da Figura 6, que alcançou 63,9% de precisão e 59,8% de macro F1. A Figura 12 mostra os resultados para precisão, recordação e medida F1 para os sentimentos: positivo, negativo e neutro em relação ao segundo experimento. Nesta fase do trabalho, foram apresentados os resultados obtidos ao utilizar o recurso lexical SentiWordNet para o problema de classificação automática de sentimentos no contexto da política.
Os resultados obtidos com os dois experimentos podem ser considerados satisfatórios, pois segundo (WIEBE et al., 2006) e (GOLDEN, 2011) a capacidade humana de avaliar corretamente a subjetividade de um texto varia de 72% a 85%, e a a precisão média dos dois experimentos aqui apresentados foi de 74,2%. Os resultados apresentados neste trabalho foram semelhantes aos já obtidos em outros trabalhos da área, como em (OHANA; TIERNEY, 2009) e (CAVALCANTI, 2011), que obtiveram média de 65,85 usando SentiWordNet em seus experimentos % e 76 % de acerto respectivamente em (KHAN; BASHIR; QAMAR, 2013), que obtiveram 74,2% de acerto ao realizar experimentos com dados do Twitter.
ANTARES
- ARQUITETURA GERAL DO SISTEMA
- TECNOLOGIAS ENVOLVIDAS
- PRINCIPAIS TELAS DO SISTEMA
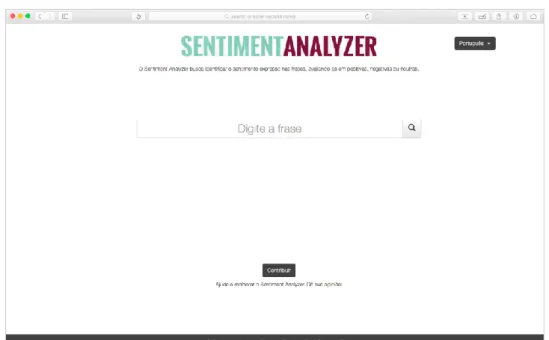
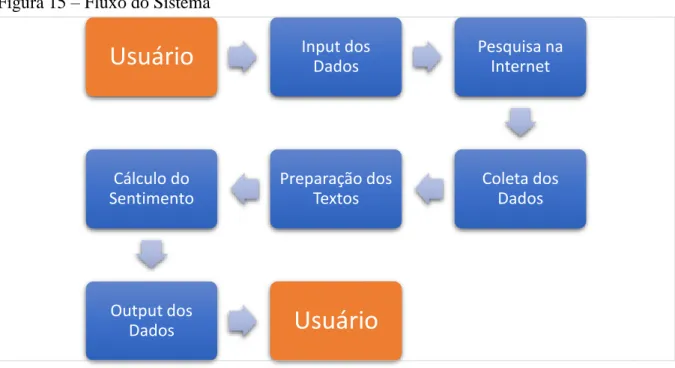
Para avaliar os sentimentos contidos nos textos extraídos, é necessário realizar um pré-processamento (seção 4.4), uma das etapas mais importantes de um sistema de análise de sentimentos, pois é nesse momento que todos os dados são preparados aplicando técnicas para fazer o texto mais interpretável para o analista. Ao final de todas as etapas, o software apresenta ao usuário o resultado de todo o processo em forma de gráficos e tabelas com um resumo dos textos encontrados, bem como o sentimento ligado a cada um deles. Por se tratar de uma aplicação web, o desenvolvimento do protótipo utilizou paradigmas de desenvolvimento para este fim, como linguagem de programação e frameworks para desenvolvimento de aplicações web.
Foi efetuada a codificação das camadas que efetuam a pesquisa online e recolha de todos os dados necessários à análise, o pré-processamento dos textos captados e a classificação de sentimentos, bem como a comunicação entre a aplicação e a base de dados. feitas na linguagem PHP Programming Guide 23 (um acrônimo recursivo para "PHP: Hypertext Preprocessor"). Houve também a preocupação de desenvolver uma plataforma user-friendly. A arquitetura é distribuída em pacotes que são divididos de acordo com a finalidade de utilização das classes, visando a fácil criação, manutenção e compartilhamento das camadas do sistema.
Desta forma, a lógica da aplicação fica isolada da interface do usuário, permitindo ao desenvolvedor alterar, editar e testar cada parte do sistema separadamente. O framework também facilita a realização de testes para desenvolvimento web, o que evita possíveis erros (BRANAS, 2014). ChartJS é uma biblioteca JavaScript poderosa e livre de dependências que ajuda a criar gráficos da web usando o elemento HTML canvas.
Nesta tela, o usuário pode inserir o nome do produto, serviço ou empresa que deseja analisar, a partir da qual o usuário é redirecionado para a tela onde é feito um resumo da análise (Figura 17). A interface possui diversos tipos de resumos dos dados analisados, como gráficos e tabelas que detalham os cálculos realizados e mostram alguns tweets analisados, bem como o sentimento predominante sobre o objeto pesquisado.
CONCLUSÃO
- RECOMENDAÇÕES PARA TRABALHOS FUTUROS
- CONSIDERAÇÕES FINAIS
Análise de sentimento de tweets relacionados aos protestos ocorridos no Brasil entre junho e agosto de 2013. Realização do 37º Encontro Anual de Linguística Computacional da Association for Computational Linguistics. Análise de sentimento em comentários de aplicativos móveis: explorando o impacto do pré-processamento.
Politwi: Descoberta precoce de novos tópicos políticos no Twitter e o impacto na análise de sentimento em nível de conceito. Análise comparativa de métodos de análise de sentimentos usando tweets em português, Belo Horizonte, 2016.