101 Figura 4.9 – Tempo de treino em função dos grupos e todos os dados. a) Ponto de partida; (b) arranjo estável; 125 Figura 7.3 - Valores de MSE e R para os modelos baseados em LM-ANN considerando os modelos treinados com dados não lineares, a cor de cada curva representa um experimento diferente: (a) MSE da linha de base; (b) R para o ponto de partida. 127 Figura 7.5 - Valores de MSE e R para modelos baseados em LSTM considerando modelos treinados com dados não lineares: (a) MSE para linha de base; (b) R para o ponto de partida.
INTRODUÇÃO
Indústria de Alumínio
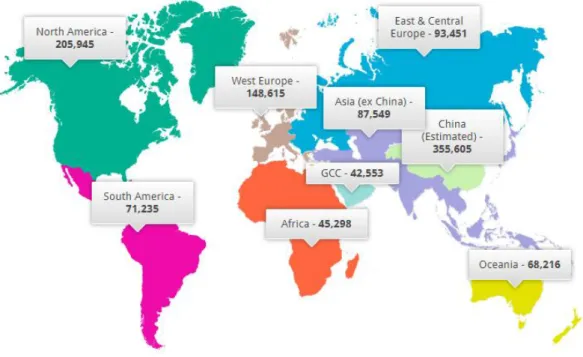
A Figura 1.3 mostra a quantidade de alumínio produzida (em milhões de toneladas) por região do globo no período de janeiro de 1980 a julho de 2019. Em uma planta de produção de alumínio existem centenas de fornos eletrolíticos e eles estão dispostos em série, portanto, recebem corrente elétrica constante da ordem de 180 kA, mas este valor pode variar de fábrica para fábrica. Fluoreto de alumínio: é uma das matérias primas constantemente consumidas pelo forno eletrolítico para a produção do alumínio primário.
Revisão da Literatura
- Revisão sistemática nos periódicos da CAPES
- Revisão sistemática no TMS Light Metals
- Revisão sistemática no repositório de trabalhos acadêmicos das universidades
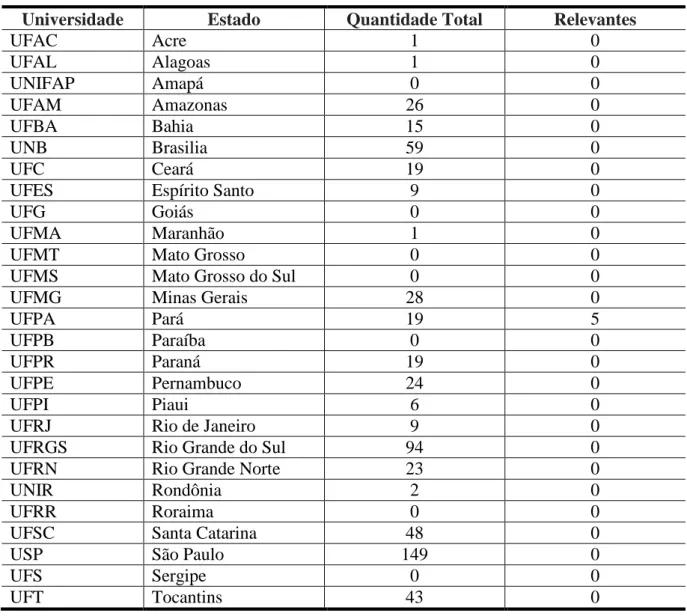
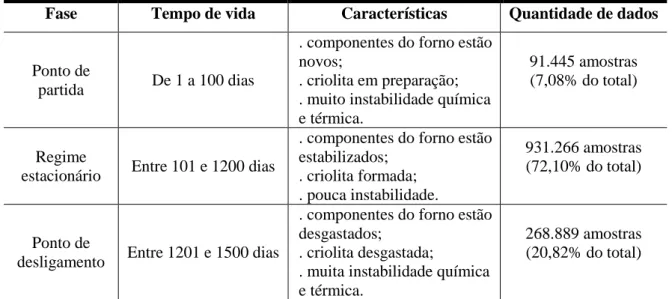
No entanto, 124 foram descartados porque atenderam aos critérios de rejeição (tabela 1.2), que eram inadequados para responder à pergunta de pesquisa nº 1. 41 Tabela 1.7 – Correspondência de trabalhos de repositórios de universidades federais. especificamente no escopo da tese. 42 Tabela 1.8 - Resumo das dissertações do repositório da UFPA correspondentes. especificamente no escopo da tese. conclusão) AM Referência(s) Técnica(s).

Justificativa
Objetivos
- Originalidade da tese
Agrupamento de dados, com base no conhecimento de especialistas do processo de produção de alumínio primário, usado para criar modelos neurais que representam fornos semelhantes. Aplicação da técnica de deep learning, LSTM, no contexto industrial de produção de alumínio primário;.
Organização da Tese
FABRICAÇÃO DO ALUMÍNIO PRIMÁRIO
- Forno eletrolítico
- Influência dos materiais químicos usados no eletrólito
- Layout da Linha de Produção
- Sistemas de Controle em Forno Eletrolítico
- Aquisição, Armazenamento e Disponibilização dos Dados do Processo de
- Uso de Modelagem Baseada em Dados para Forno Eletrolítico
- Considerações Finais
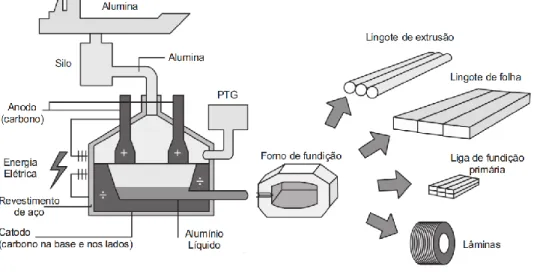
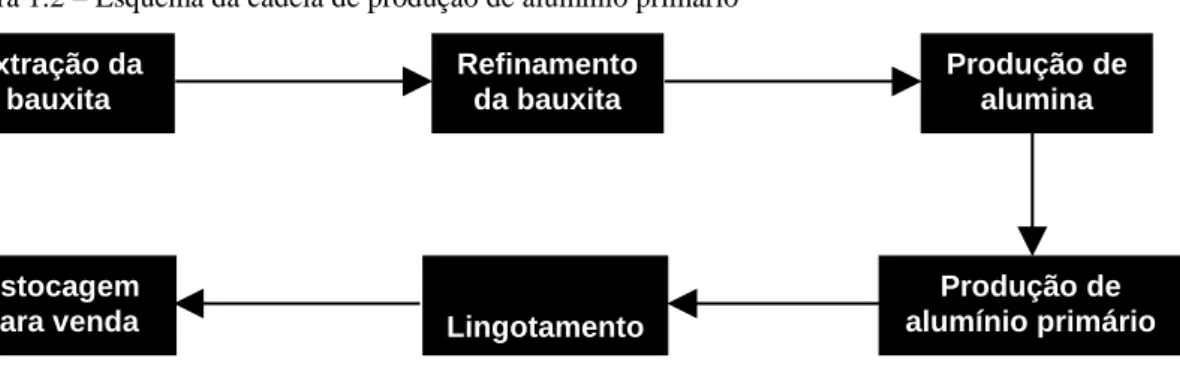
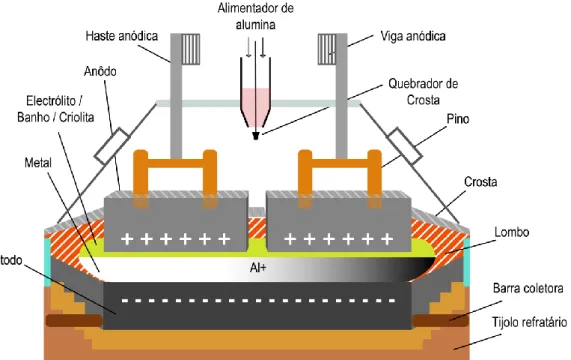
A criolita usada na produção de alumínio é sintetizada artificialmente (da equação 2.2) ou reutilizada de um forno eletrolítico que entrou em colapso. Portanto, a criolita é mais um subproduto do processo de produção de alumínio primário do que uma matéria-prima. A próxima seção mostra como os fornos são dispostos na principal planta de fundição de alumínio.
Uma planta de produção de alumínio primário consiste em centenas ou mesmo milhares de fornos eletrolíticos. Com base nessas informações, pode-se observar novamente a complexidade do processo de produção do alumínio primário. A frequência de aquisição da maioria das variáveis que controlam o comportamento dos fornos é diária (24 horas), pois o processo de produção do alumínio primário é essencialmente químico e, portanto, lento.
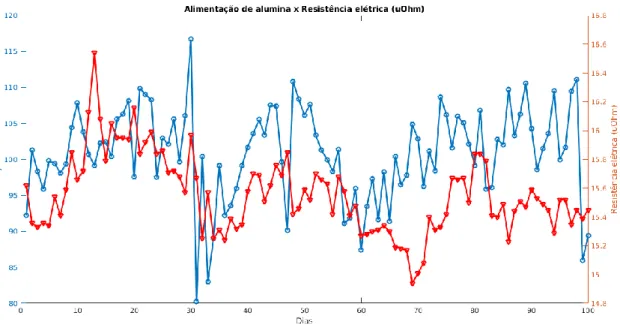
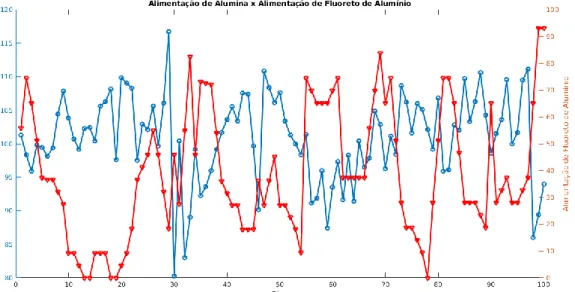
A Figura 2.10 mostra a relação entre as alimentações de alumina e fluoreto de alumínio. Isso acontece porque o processo de produção do alumínio primário é complexo e dezenas de outros fatores interferem em seu funcionamento. Portanto, é essencial entender como funciona o processo de produção de alumínio primário antes de aplicar o.
Devido à complexidade do processo de produção de alumínio primário, é interessante usar modelos baseados em dados para medir as variáveis mais importantes do processo, uma vez que esse processo é não linear, variante no tempo e dinâmico com parâmetros distribuídos.
MATERIAL E MÉTODOS
Base de dados
- Pré-processamento dos dados
- Escolha das variáveis de entrada do modelo
- Agrupamento de dados baseado no conhecimento dos especialistas
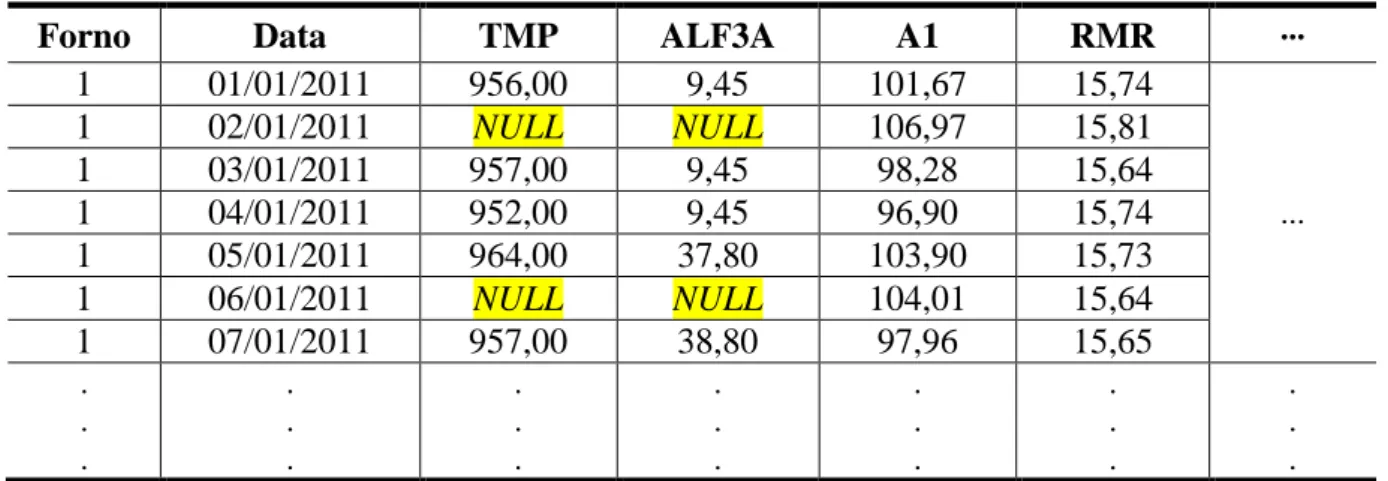
45 ALF3Ah Quantidade de AlF3 adicionada - kg histórico/Vários FORNOS 46 ALF3Am Quantidade de AlF3 adicionada - manutenção kg/Vários FORNOS. Para identificar isso, foi calculada a razão entre os valores zero da variável e o total das amostras, a tabela 3.2 mostra as razões. O operador não insere dados no sistema de computador para armazenar no banco de dados.
Inicialmente, foi realizada a seleção dos registros do banco de dados relacional disponibilizado por meio da linguagem Structured Query Language (SQL). A Tabela 3.5 mostra os principais inputs associados às variáveis de output escolhidas para criar os modelos estimadores. 68 Tabela 3.5 – Lista das variáveis de entrada com os valores de R em relação às saídas ID Variável Abreviação Unidade Delay R c/.
O agrupamento de dados (na prática de fornos) foi realizado com a ajuda dos engenheiros de processo da fábrica, que possuem conhecimento e experiência em relação à planta de produção. Os diferentes comportamentos também podem ser verificados quando o conjunto de dados de cada grupo é analisado estatisticamente.
Modelagem neural
- Backpropagation
- Levenberg-Marquardt
- Aspectos importantes da RNA pós-treinamento
- Redes de memória de longo prazo (RMLP) ou Long Short-Term Memory (LSTM)
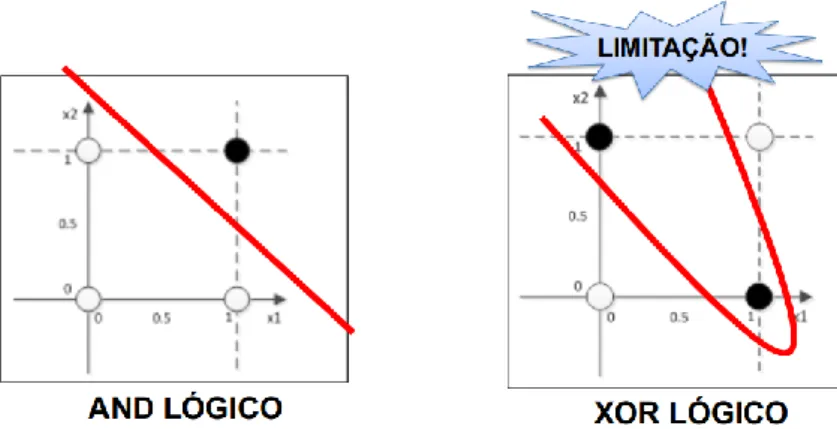
O processo de aprendizado de uma RNA com grande taxa de erro, e conforme as iterações de treinamento são realizadas e os pesos são alterados, a taxa de erro começa a diminuir conforme a rede assimila o conhecimento contido na essência do banco de dados. Resumidamente, os algoritmos de treinamento trabalham para minimizar o erro alterando os pesos a cada iteração, dependendo da taxa de erro. A taxa de aprendizado controla a taxa de treinamento: quanto mais próximo de um, mais rápido o treinamento tende a acontecer.
Ele é capaz de determinar um conjunto de pesos ótimos usando uma técnica de otimização conhecida como método do gradiente descendente, usando o erro quadrado como uma função de custo. As subseções a seguir apresentam dois algoritmos de treinamento mais robustos e comumente usados em RNAs. LM é um método de gradiente de segunda ordem baseado no método dos mínimos quadrados para modelos não lineares e pode aumentar a eficiência do BP no estágio de treinamento da RNA.
Um dos sinais do overtraining é que na fase de treino o erro é muito baixo, mas na fase de teste é alto. A primeira etapa na operação de um LSTM é decidir quais informações serão removidas do estado da célula. Conforme a Figura 3.18, o próximo passo é multiplicar o antigo estado por ft, esquecendo os valores anteriores (Ct-1), e depois somar a multiplicação entre ele e Ct. para atualizar o estado.
A Figura 3.19 descreve esse processo: primeiro, um sigmoide é calculado para decidir quais partes do estado da célula constituirão a saída.
Descrição dos experimentos
Verifica-se que houve uma melhora de cerca de 91% na acurácia do modelo segundo o índice RMSE. A Tabela 3.8 mostra a divisão do conjunto de dados completo para o processo de modelagem: para cada fase ou para todos os conjuntos de dados; três algoritmos de aprendizado diferentes; 32 seções diferentes (grupos/clusters) ou todo o conjunto de dados e três saídas, que inicialmente resultaram em 891 modelos diferentes. Cada modelo baseado em BP-RNA e LM-RNA foi treinado dez vezes, pois os pesos iniciais da rede neural são aleatórios, de acordo com uma função de densidade de probabilidade gaussiana.
Para modelos baseados em LSTM, ele é treinado apenas uma vez, pois não há uma grande variação nos resultados, ou seja, a aleatoriedade inicial mencionada anteriormente não afeta o desempenho final do modelo (Apêndice A). A definição do número de neurônios na camada oculta e das funções de transferência nas camadas oculta e de saída foi empírica (tentativa e erro). Foram realizados testes considerando 128 neurônios na camada oculta e a alteração da função de transferência resultou em uma pequena variação no MSE de treinamento, validação e teste de 0,5%.
Os modelos estimadores baseados em LSTM foram gerados de acordo com os seguintes parâmetros, também definidos por tentativa e erro. Ao contrário das ANNs, o LSTM não é afetado pela aleatoriedade dos pesos iniciais, distribuição de dados e outros parâmetros arbitrários. Número de neurônios na camada de saída: 1 (portanto, um LSTM para cada variável de saída);
A porcentagem de dados usada para treinar os modelos foi de 80%, o restante foi usado para testá-los.

Considerações finais
RESULTADOS
- Evolução do treinamento dos modelos
- Tempo de treinamento dos modelos
- Medidas de desempenho dos modelos
- Análises comparativas entre os valores reais os valores estimados pelos modelos
A Figura 4.2 ilustra a evolução do treinamento, validação e teste, considerando a variável de saída TMP e os dados do conjunto "ponto de partida". Os modelos baseados em LSTM geraram gráficos semelhantes à evolução do RNA-BP, como pode ser visto na Figura 4.3, que mostra a evolução do treinamento com referência à variável de saída TMP e ao conjunto de dados "start point". A Figura 4.4 mostra os valores de MSE e R, onde a linha azul é a média, para os modelos derivados da técnica ARN-LM.
A Figura 4.5 mostra que os valores de MSE e R são maiores que os encontrados no RNA-LM, além disso a variação entre os diferentes modelos também é maior. A Figura 4.7 revela os valores de MSE e R dos modelos criados a partir de todos os dados, ou seja, sem agrupamento, considerando os algoritmos ANN-LM e ANN-BP. Os modelos baseados em BP-RNA e LM-RNA consideraram a divisão dos dados em 70% para teste, 15% para validação e 15% para teste.
Além disso, é importante mencionar que, para modelos baseados em RNA correta, a distribuição foi para cada grupo de dados, ou seja, para o ponto de partida (considerando os primeiros cem dias): os primeiros 70 dias (70%) foram usados para treinamento, o dia 71 ao dia 85 (15%) foi usado para validação e o dia 86 ao dia 100 (15% restante) para teste. Através da figura 4.10 é possível verificar a comparação entre os valores medidos pelos sensores ou analisados em laboratório (dados reais) e os valores estimados pelos modelos baseados em RNA-BP e LSTM para o forno número 5, que faz parte da sala número 1, para todos os grupos de dados e todas as datas. A Figura 4.11 mostra a comparação entre dados reais e estimados considerando modelos baseados em RNA-LM e LSTM.
Portanto, modelos baseados em LSTM são mais precisos do que aqueles baseados em ARN-LM.

CONSIDERAÇÕES FINAIS
Trabalhos futuros
Testar outros métodos de seleção de variáveis de entrada para os modelos neurais propostos e considerar o índice de atrito do alumínio como variável de entrada, pois os engenheiros de processo constantemente analisam esse parâmetro e afirmam que ele interfere no comportamento do forno; Se a fábrica permitir, ela será integrada às bases de dados existentes em seu parque tecnológico, permitindo que as avaliações sejam feitas em tempo real, com rapidez e alta precisão. Estudos sobre o processo Hall-Heroult de extração eletrolítica de alumínio, Revista da Sociedade Brasileira de Química, vol.
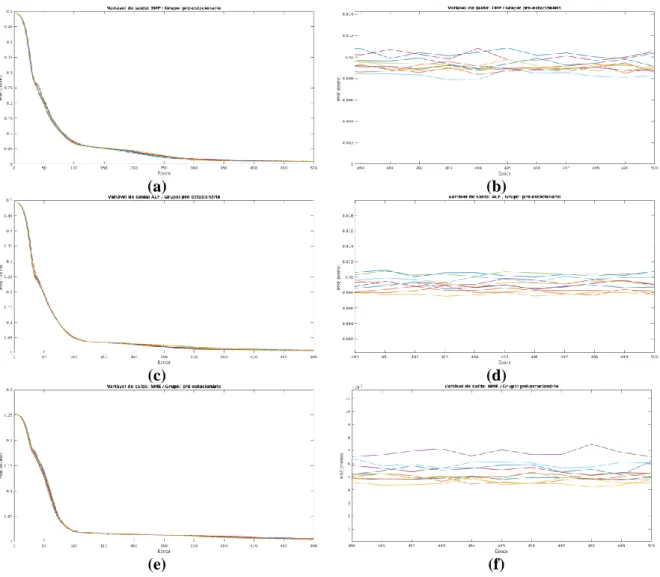
Para demonstrar que os modelos baseados em LSTM diferem muito pouco entre si, mesmo levando em consideração a aleatoriedade no processo de treinamento, dez experimentos diferentes foram realizados no mesmo conjunto de dados (grupo pré-estacionário) e a variação indicada é mostrada . para a Figura 6.1 abaixo, onde cada linha representa um experimento. Esta seção apresenta os resultados obtidos assumindo que a imputação de dados ausentes foi realizada usando a Equação 7.1, que é uma função pseudoaleatória e não linear dada por . Após a substituição dos dados nulos, foram gerados histogramas das variáveis de entrada e saída do modelo (Figura 7.2).
Em seguida, modelos neurais baseados em LM-RNA, BP-RNA e LSTM foram criados com os mesmos parâmetros de treinamento informados no Capítulo 3 (Materiais e Métodos). Como o tempo total de treinamento – considerando todas as técnicas e todos os grupos de dados – é muito grande, optou-se por usar apenas o grupo de dados. A Figura 7.3 mostra os valores de MSE e R, onde a linha azul é a média, para os modelos derivados pela técnica de RNA-LM.
A curva vermelha tracejada é de LM-RNA (Figura 7.6a) e BP-RNA (Figura 7.6b), pode-se notar que essas duas técnicas geraram resultados muito semelhantes.