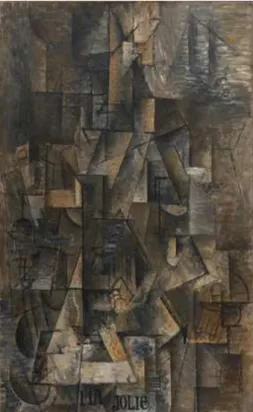UNIVERSIDADE PRESBITERIANA MACKENZIE
PROGRAMA DE P ´
OS-GRADUAC
¸ ˜
AO EM
ENGENHARIA EL´
ETRICA
Ricardo Ribani
RECOMENDAC
¸ ˜
OES DE OBRAS DE ARTE BASEADAS EM
CONTE ´
UDO
Disserta¸c˜ao apresentada ao Programa de P´os-Gradua¸c˜ao em Engenharia El´etrica da Univer-sidade Presbiteriana Mackenzie, como requisito para obten¸c˜ao do T´ıtulo de Mestre em Enge-nharia El´etrica.
Orientador: Prof. Dr. Maur´ıcio Marengoni
R482r
Ribani, Ricardo
Recomendações de obras de arte baseadas em conteúdo. / Ricardo Ribani – São Paulo, 2015.
68 f.: il.; 30 cm
Dissertação (Programa de Pós-Graduação (Stricto Sensu) em Engenharia Elétrica) - Universidade Presbiteriana Mackenzie - São Paulo, 2015.
Orientador: Mauricio Marengoni Bibliografia: f. 53-57
1. Sistemas de recomendações. 2. Visão computacional. 3. Recuperação de imagens. 4. Bag of keypoints. 5. Pontos de interesse. 6. Inteligência artificial. I.Título.
Agradecimentos
Agrade¸co, primeiramente a Deus, por me conduzir at´e aqui.
Agrade¸co ao meu professor Mauricio Marengoni por direcionar os meus estudos, pelo incentivo, por acreditar que eu era capaz e por ser um exemplo profissional pra mim.
Aos meus pais por terem me dado educa¸c˜ao, por me ensinarem os valores da vida e me direcionarem a cada dia para ser uma pessoa melhor.
Aos meus irm˜aos, por estarem sempre ao meu lado, me ajudarem e acreditarem.
Agrade¸co `a minha noiva pelo companheirismo e compreens˜ao nos momentos mais dif´ıceis.
Aos meus amigos que sempre acreditaram em mim.
`
A CAPES e ao Mackpesquisa pela bolsa concedida.
”Quando vocˆe quer alguma coisa, todo o
universo conspira para que vocˆe realize o
seu desejo.”
RESUMO
Os sistemas de recomenda¸c˜oes est˜ao cada dia mais presentes no meio digital. Com a crescente quantidade de informa¸c˜oes e a populariza¸c˜ao da internet, cada vez mais as pessoas tem acesso a grandes acervos multim´ıdia. Com isso, consequentemente o usu´ario se encontra muitas vezes em situa¸c˜oes de d´uvida ao fazer uma escolha. Com o objetivo de auxiliar o usu´ario a fazer suas escolhas, o presente trabalho apresenta um estudo em torno dos sistemas de recomenda¸c˜oes baseados em conte´udo de imagens. Este estudo engloba uma abordagem a respeito de algoritmos de recupera¸c˜ao de imagens, al´em da aplica¸c˜ao de conceitos de vis˜ao computacional e inteligˆencia artificial, como t´ecnicas para reconhecimento de padr˜oes. Al´em do estudo te´orico, este trabalho teve como objetivo a cria¸c˜ao de um sistema computacional aplicado a um banco de dados de imagens de obras de arte. Uma aplica¸c˜ao que utiliza uma interface desenvolvida para telefones celulares, no qual o usu´ario pode capturar a imagem de uma obra atrav´es da cˆamera do celular e baseado nessa obra o sistema gera uma recomenda¸c˜ao de outra dentro do mesmo banco de dados, considerando parˆametros configur´aveis como estilo, gˆenero ou cores.
ABSTRACT
With the growing amount of multimedia information, the recommender systems have be-come more present in digital systems. Together with the growth of the internet, more and more people have access to large multimedia collections and consequently the user is often in doubt situations when making a choice. In order to help the user to make their own choices, this research presents a study around the content-based recommender systems applied to art paintings. Here are included approaches on image retrieval algo-rithms, computer vision and artificial intelligence concepts such as techniques for pattern recognition. One of the goals of this research was the creation of a software for mobile phones, applied to an art paintings database. The application uses an interface developed for mobile phones, where the user can point the phone’s camera to a painting and based on this painting the system generates a recommendation of another painting in the same database, considering some parameters such as style, genre or color.
Sum´
ario
1 INTRODUC¸ ˜AO 1
1.1 Motiva¸c˜ao . . . 1
1.2 Objetivo . . . 2
1.3 Trabalhos Relacionados . . . 3
1.4 Estrutura da Disserta¸c˜ao . . . 4
2 CARACTER´ISTICAS DOS MOVIMENTOS DE ARTE ESTUDADOS 5 3 REFERENCIAL TE ´ORICO 11 3.1 Recupera¸c˜ao de Imagens . . . 11
3.2 Pontos de Interesse . . . 13
3.2.1 SIFT - Scale Invariant Feature Transform . . . 13
3.2.1.1 Detec¸c˜ao dos pontos de interesse . . . 14
3.2.1.2 Refinamento dos pontos localizados . . . 15
3.2.1.3 Descri¸c˜ao dos pontos de interesse . . . 18
3.2.2 SURF - Speeded-Up Robust Features . . . 20
3.2.2.1 Detec¸c˜ao dos pontos de interesse . . . 20
3.2.2.2 Descri¸c˜ao dos pontos de interesse . . . 22
3.2.3 ORB - Oriented FAST and Rotated BRIEF . . . 24
3.3 Bag of Keypoints . . . 25
3.3.1 Constru¸c˜ao de um vocabul´ario de palavras universal . . . 27
3.3.1.1 Extra¸c˜ao dos pontos caracter´ısticos . . . 27
3.3.1.2 Agrupamento dos pontos utilizando k-means . . . 27
3.3.1.3 Gera¸c˜ao do descritor visual para cada imagem . . . 28
3.3.2 Constru¸c˜ao de um vocabul´ario adaptado por classe . . . 29
3.4 Descritor de Cores Dominantes . . . 30
3.5 M´etrica para an´alise da precis˜ao no sistemas de recomenda¸c˜oes . . . 31
4 DESENVOLVIMENTO DO SISTEMA 32 4.1 Acervo . . . 32
4.2 Arquitetura . . . 34
4.3.1 Gera¸c˜ao do Descritor baseado no Bag of Keypoints . . . 36
4.3.2 Gera¸c˜ao do Descritor de Cores Dominantes . . . 38
4.4 Processo Online . . . 41
4.4.1 Reconhecimento do Quadro . . . 41
4.4.2 Indexa¸c˜ao e Recomenda¸c˜ao . . . 43
5 EXPERIMENTOS E RESULTADOS 46
6 CONCLUS ˜OES E TRABALHOS FUTUROS 51
Lista de Figuras
1 Modelo b´asico do sistema de recomenda¸c˜oes. . . 2
2 Voca¸c˜ao de S˜ao Mateus, obra de Michelangelo Merisi da Caravaggio. . . 6
3 Trˆes de Maio de 1808, obra de Francisco de Goya. . . 7
4 Montanha, obra de Basuki Abdullah. . . 7
5 Impress˜ao, Sol Nascente, obra de Claude Monet. . . 8
6 O terra¸co do caf´e `a noite, obra de Vincent Van Gogh. . . 9
7 ”Ma Jolie”, obra de Pablo Picasso. . . 10
8 Pirˆamide de escalas gerada pelo algoritmo SIFT . . . 15
9 Ponto de m´aximo ou m´ınimo detectado pelo SIFT . . . 16
10 Pontos detectados pelo algoritmo SIFT. . . 18
11 Descritor do ponto de interesse do SIFT. . . 20
12 Representa¸c˜ao do c´alculo da imagem integral. . . 21
13 Filtros utilizados nas matrizes de convolu¸c˜ao do SURF. . . 22
14 Pirˆamide de escalas utilizada nos filtros do SURF. . . 22
15 Filtros da transformada de Haar utilizados pelo SURF. . . 23
16 Atribui¸c˜ao da orienta¸c˜ao do ponto no algoritmo SURF. . . 23
17 Descritor do ponto de interesse do SURF. . . 24
18 Representa¸c˜ao da gera¸c˜ao do dicion´ario de palavras visuais. . . 26
19 Representa¸c˜ao do agrupamento realizado pelo algoritmo k-means. . . 28
20 Exemplos de Retratos dos movimentos Barroco, Realismo e Romantismo. . 33
21 Exemplos de Paisagens dos movimentos Barroco, Realismo e Romantismo. 33 22 Exemplos de Retratos dos movimentos Expressionismo e Impressionismo. . 33
23 Exemplos de Paisagens dos movimentos Expressionismo e Impressionismo. 33 24 Exemplos de Retratos do movimento Cubismo. . . 33
25 Exemplos de Paisagens do movimento Cubismo. . . 34
26 Vista do processo de recupera¸c˜ao de imagens dividido em fase offline e online. 35 27 Exemplo de paisagem do movimento barroco (classe 1). . . 37
28 Histograma de paisagem do movimento barroco. . . 37
29 Exemplo de retrato do movimento barroco (classe 2). . . 38
30 Histograma de retrato do movimento barroco. . . 38
32 Imagem quantizada com 24 cores. . . 39
33 Imagem resultante com 8 cores dominantes. . . 40
34 Histograma resultante com as 8 cores dominantes. . . 40
35 Imagem do sistema buscando o quadro na imagem capturada. . . 41
36 Imagem do sistema no momento que o quadro ´e identificado. . . 42
37 Processo de reconhecimento do quadro capturado pelo celular. . . 43
38 Representa¸c˜ao b´asica de escolha da recomenda¸c˜ao a partir da indexa¸c˜ao. . 44
39 Configura¸c˜ao dos parˆametros de recomenda¸c˜oes. . . 45
40 Apresenta¸c˜ao da recomenda¸c˜ao ao usu´ario. . . 45
41 Gr´afico de precis˜oes do algoritmo SURF. . . 47
42 Gr´afico de precis˜oes do algoritmo SIFT. . . 47
43 Exemplos de resultados para 4 recomenda¸c˜oes (wp = 1 e wc = 0). . . 49
44 Resultados utilizando o descritor de bag of keypoints (wp = 1 e wc = 0). . . 49
45 Resultados utilizando o descritor de cores dominantes (wp = 0 ewc = 1). . 49
Lista de Tabelas
1 N´umero de imagens inclu´ıda em cada classe. . . 34
2 Valores de precis˜ao utilizando o algoritmo SURF. . . 46
3 Valores de precis˜ao utilizando o algoritmo SIFT. . . 47
4 Tempos m´edios de processamento para gera¸c˜ao das recomenda¸c˜oes. . . 48
1
INTRODUC
¸ ˜
AO
O termo recomenda¸c˜ao est´a presente h´a tempos na sociedade e pode ser observado em diversos contextos. Desde a pr´e-hist´oria, o homem das cavernas observava os alimentos que outras pessoas consumiam para saber se eram bons, o que pode-se considerar um tipo de recomenda¸c˜ao (KONSTAN; EKSTRAND, 2013). Em outros contextos, o termo recomenda¸c˜ao pode ser interpretado como conselho, padr˜ao ou normas a serem seguidas. O conceito de recomenda¸c˜oes passou a ter tamb´em o contexto de filtro, com o objetivo de auxiliar as pessoas a encontrar informa¸c˜oes relevantes em meio a uma grande massa de da-dos. Os sistemas de recomenda¸c˜oes tornaram-se uma ´area importante de pesquisas, desde suas primeiras apari¸c˜oes sobre filtros colaborativos em meados de 1990 (ADOMAVICIUS; TUZHILIN, 2005).
1.1
Motiva¸c˜
ao
Com a crescente quantidade de dados e acervos multim´ıdia, cada vez mais as pessoas se encontram em situa¸c˜oes de d´uvidas ao fazer uma sele¸c˜ao de conte´udo. Por exemplo, ao alugar um filme online o usu´ario acessa um conjunto de informa¸c˜oes, mas nem todo o conte´udo ´e relevante. Uma recomenda¸c˜ao em meios digitais, pode ser baseada em informa¸c˜oes do perfil do usu´ario, nas avalia¸c˜oes feitas por este usu´ario, nas avalia¸c˜oes feitas por outros usu´arios com perfil similar ou pode ser baseada no conte´udo (ADOMAVICIUS; TUZHILIN, 2005).
No contexto de obras de arte, pode-se citar os museus com grandes acervos dispon´ıveis para visita¸c˜ao. Muitas vezes, a grande quantidade de obras dispon´ıveis faz com que o usu´ario perca muito tempo visitando coisas que n˜ao s˜ao de seu interesse. Usando um sistema de recomenda¸c˜oes, a visita¸c˜ao dessas cole¸c˜oes pode se tornar mais interativa e agrad´avel para um visitante regular, mostrando-lhe as pinturas relevantes de acordo com o seu interesse, assim como auxiliando o usu´ario a encontrar conte´udo mais rapidamente, ganhando tempo e explorando informa¸c˜oes antes desconhecidas por ele.
1.2
Objetivo
O objetivo geral da pesquisa consiste em criar um algoritmo de recupera¸c˜ao de imagens que ser´a utilizado para gerar recomenda¸c˜oes de obras de arte, no qual o usu´ario ir´a informar a imagem de uma obra por meio da cˆamera de um celular, em seguida ser´a considerado o conte´udo desta imagem e a partir disso ser´a recomendada outra obra ou uma lista de obras de arte dentro do mesmo acervo. J´a o objetivo espec´ıfico consiste em gerar descritores para as imagens automaticamente de acordo com determinadas caracter´ısticas, como cor e textura. Atrav´es destes descritores ser´a poss´ıvel classificar e indexar as imagens de acordo com sua relevˆancia no contexto, ou seja, de acordo com a imagem passada na consulta, conforme representado na Figura 1. Tamb´em ser´a considerado o perfil do usu´ario, que ir´a conter avalia¸c˜oes de outros itens j´a visitados por ele.
Figura 1: Modelo b´asico do sistema de recomenda¸c˜oes.
1.3
Trabalhos Relacionados
Hill et al. (1995) explicam um problema relacionado a novos usu´arios em um sistema de recomenda¸c˜oes, esses ainda n˜ao possuem informa¸c˜oes suficientes para receber uma recomenda¸c˜ao de acordo com suas preferˆencias ou avalia¸c˜oes. Apresentam um m´etodo, o qual utiliza as escolhas de outras pessoas como filtros ou guia para fazer recomenda¸c˜oes a novos usu´arios. Ainda no mesmo ano, Shardanand e Maes (1995) descrevem um sistema chamadoRingoque faz recomenda¸c˜oes musicais de ´albuns e artistas de acordo com o perfil do usu´ario. Explicam que o sistema mant´em uma base de conhecimento das preferˆencias do usu´ario e cruzam essas informa¸c˜oes com os perfis de outros usu´arios, a partir disso, quando um deles avalia uma m´usica ´e poss´ıvel saber se esta ser´a ou n˜ao recomendada ao outro.
Adomavicius e Tuzhilin (2005) explicavam que o interesse em pesquisas nesta ´area crescia e que havia muito trabalho a ser feito. Empresas como Amazon.com, MovieLens, AdaptiveInfo.com, TiVo System e Netflix j´a implementavam sistemas de recomenda¸c˜oes em seus sistemas de vendas de produtos e servi¸cos.
No modelo de S´anchez et al. (2012), s˜ao utilizados dois bancos de dados, um de anota¸c˜oes sobre a imagem, que armazena caracter´ısticas gerais da imagem e outro de avalia¸c˜oes de usu´arios, que armazena informa¸c˜oes de gosto e avalia¸c˜oes do usu´ario. Neste sistema, o processo de classifica¸c˜ao das imagens ´e feito de forma offlineou desconectado. Quando uma nova imagem ´e inserida no banco de dados, ´e executado um processo de classifica¸c˜ao perceptiva que extrai as caracter´ısticas da imagem e as armazena no banco de dados de anota¸c˜oes de imagens. Para obter informa¸c˜oes e classificar as imagens, ´e utilizado o padr˜ao MPEG-7 (SALEMBIER; SIKORA, 2002), este padr˜ao possui cinco tipos de descritores (cor, textura, forma, movimento e outros), por´em, no modelo de S´anchez et al. (2012) s˜ao utilizados apenas cor e textura. Ele utiliza combina¸c˜oes entre esses parˆametros para descrever melhor a imagem, al´em de incluir um novo parˆametro descritor das caracter´ısticas de ilumina¸c˜ao.
79,8% com grupos formados a partir das caracter´ısticas de cores, sem citar movimentos de (YELIZAVETA; TAT-SENG; IRINA, 2005). Outro trabalho apresenta um sistema para classificar os movimentos de arte onde a pintura ´e classificada em cinco movimentos, um filtro de gabor ´e utilizado para extra¸c˜ao de caracter´ısticas em escala de cinza, um histograma de cores no espa¸co HSV para descrever as cores e um algoritmo de apren-dizado AdaBoost, atingindo a precis˜ao de 68,3% (ZUJOVIC et al., 2009). Um resultado not´avel apresenta uma precis˜ao de at´e 90% para a classifica¸c˜ao de obras de arte utilizando seis descritores de cores diferentes em conjunto com umSupport Vector Machine, classifi-cando pinturas de arte dentro de 3 movimentos art´ısticos diferentes (GUNSEL; SARIEL; ICOGLU, 2005).
No presente trabalho, foram obtidos resultados expressivos utilizando-se apenas dois descritores: um descritor de pontos caracter´ısticos e um descritor de cores dominantes. Um ponto crucial para a obten¸c˜ao de bons resultados foi a realiza¸c˜ao de uma pesquisa so-bre hist´oria da arte, a fim de obter um entendimento mais profundo soso-bre as caracter´ısticas visuais presentes em cada movimento. A partir desse estudo foi poss´ıvel agrupar adequa-damente as obras, tal como identificar padr˜oes presentes em cada movimento e qual a influˆencia hist´orica que estes geraram em outros movimentos.
1.4
Estrutura da Disserta¸c˜
ao
2
CARACTER´ISTICAS DOS MOVIMENTOS DE
ARTE ESTUDADOS
Pinturas feitas em certos movimentos de arte como barroco, realismo e romantismo, possuem propriedades visuais muito similares. O movimento barroco foi desenvolvido inicialmente na Europa entre o final do s´eculo 16 e at´e o s´eculo 18 (PROEN¸cA, 2003). Segundo Farthing (2010), o termo barroco era inicialmente depreciativo e este movimento estava associado principalmente `a arte feita sob encomenda para a Igreja Cat´olica. ´E caracterizado pela decora¸c˜ao pesada, design complexo por´em sistem´atico e a aplica¸c˜ao abundante de luzes e sombras.
Proen¸ca (2003) fala que as pinturas deste movimento possuem um elemento que atra-vessa o plano na diagonal com um forte contraste em claro e escuro, como exemplo a obra ”Voca¸c˜ao de S˜ao Mateus”, de Caravaggio (Figura 2). A luz que ilumina a cena vem da direita e n˜ao de uma janela que aparece no fundo, como seria natural. ´E que, nesse caso, a luz dirige a aten¸c˜ao do observador para o grupo de figuras sentadas em volta da mesa. O contraste de luz e sombra valoriza a tridimensionalidade, pois os corpos ganham volume e a variedade das cores dominui.
O movimento do romantismo surgiu em seguida, no s´eculo 19, apresentando carac-ter´ısticas muito similares ao movimento barroco, com tra¸cos bem realistas e ainda man-tendo o elemento de contraste entre claro e escuro na diagonal, o que acentua o sentimento dram´atico da cena (PROEN¸cA, 2003). O romantismo exerceu tamb´em uma enorme in-fluˆencia na arte americana, em especial na pintura de paisagens. Esse movimento marcou o come¸co de um longo per´ıodo de guerras sangrentas em toda a Europa, enfatiza a exas-pera¸c˜ao das emo¸c˜oes, a turbulˆencia da psicologia humana e a for¸ca da natureza.
Figura 2: Voca¸c˜ao de S˜ao Mateus, obra de Michelangelo Merisi da Caravaggio.
Fonte: www.wikiart.org, acessado em 02/11/2014.
2010). Proen¸ca (2003) cita que observando essa pintura pode-se notar, pelo jogo de luz e sombra, que se trata de uma composi¸c˜ao diagonal. A luz concentrada sobre o homem de camisa branca, com bra¸cos abertos e levantados, nos d´a certeza da morte iminente e j´a vivida pelos companheiros jogados no ch˜ao.
Figura 3: Trˆes de Maio de 1808, obra de Francisco de Goya.
Fonte: www.wikiart.org, acessado em 02/11/2014.
Figura 4: Montanha, obra de Basuki Abdullah.
Fonte: www.wikiart.org, acessado em 02/11/2014.
determinado sentimento em suas pinturas atrav´es de efeitos de luz e pinceladas marcantes. Outra caracter´ıstica desse movimento est´a no uso da cor, que comparado aos movimentos anteriores, apresenta mais cores e tons variados devido a evolu¸c˜ao das tintas e t´ecnicas de misturas de cores. Um dos artistas mais famosos deste movimento foi o francˆes Claude Monet (PROEN¸cA, 2003) e um exemplo de obra impressionista ´e a obra ”Impress˜ao, Sol Nascente” (Figura 5), primeira obra de Monet. Foi tamb´em a primeira obra a ser cha-mada de impressionista, possui pinceladas marcantes, sobrepostas e sem muita mistura de cores.
Segundo Farthing (2010), os artistas impressionistas se propunham a capturar a im-press˜ao do momento passada pelo efeito da luz. Diz ainda que para os olhos do s´eculo 19, estas obras passavam aspecto de inacabadas e foram recebidas com esc´arnio em suas primeiras exposi¸c˜oes.
Figura 5: Impress˜ao, Sol Nascente, obra de Claude Monet.
Fonte: www.wikiart.org, acessado em 02/11/2014.
pin-tor holandˆes Vincent Van Gogh (PROEN¸cA, 2003). Os artistas p´os-impressionistas em geral se afastaram do naturalismo do impressionismo, eles usaram cores vivas, camadas grossas de tinta, temas cotidianos e pinceladas expressivas que enfatizavam as formas geom´etricas, por´em ainda haviam t´ecnicas de pinturas e uma inspira¸c˜ao baseada no mo-vimento impressionista. Por exemplo, na obra ”O terra¸co do caf´e `a noite” de Vincent Van Gogh (Figura 6), onde o artista utiliza t´ecnicas aprendidas com os expressionistas, mas com cores muito mais vivas e superf´ıcies vigorosamente trabalhadas.
Figura 6: O terra¸co do caf´e `a noite, obra de Vincent Van Gogh.
Fonte: www.wikiart.org, acessado em 02/11/2014.
domi-naram boa parte das obras iniciais do movimento, como ´e poss´ıvel observar na obra ”Ma Jolie”, de Pablo Picasso (Figura 7).
Figura 7: ”Ma Jolie”, obra de Pablo Picasso.
3
REFERENCIAL TE ´
ORICO
O conceito de recomenda¸c˜ao e o conceito de recupera¸c˜ao de imagens est˜ao diretamente ligados, afinal para gerar recomenda¸c˜oes ´e necess´ario fazer uma consulta em um banco de dados. ´E preciso recuperar os itens utilizando alguma medida de similaridade, de forma que estes sejam indexados de acordo com sua relevˆancia no contexto, para ent˜ao recomendar o item mais relevante (ADOMAVICIUS; TUZHILIN, 2005). Como estamos falando em imagens ´e necess´ario encontrar uma forma de medir visualmente a similaridade entre elas. Foram estudados algoritmos de detec¸c˜ao de pontos de interesse em conjunto com o conceito debag of keypoints, que juntos apresentam uma solu¸c˜ao para representar as imagens em forma de descritores.
3.1
Recupera¸c˜
ao de Imagens
Em diversas situa¸c˜oes quando procuramos uma determinada imagem, n˜ao sabemos expressar em palavras o que desejamos. Por exemplo, ao procurar um retrato em uma cole¸c˜ao, qualquer forma de descrever textualmente o retrato ”perfeito” ser´a diferente do imaginado. Esta tarefa pode se tornar mais simples e retornar resultados pr´oximos do desejado quando passamos uma imagem de referˆencia e procuramos encontrar outras similares a essa. Uma forma de fazer isso ´e utilizando uma interpreta¸c˜ao visual da imagem, indexando e recuperando uma lista a partir disso (DATTA et al., 2008). O mesmo conceito pode ser aplicado para a gera¸c˜ao de recomenda¸c˜oes, que ser˜ao geradas com base em outra imagem que o usu´ario demonstrou interesse.
Chang et al. (2012) caracterizam recupera¸c˜ao de imagens como o processo de buscar e recuperar imagens em um extenso banco de dados. Dizem ainda, que os bancos de dados de imagens crescem cada vez mais r´apido em complexidade e diversidade, est˜ao cada vez mais acess´ıveis devido ao uso da internet, de cˆameras fotogr´aficas digitais e principal-mente celulares com cˆamera e acesso a internet. Apresentam tamb´em a recupera¸c˜ao de imagens baseada em conte´udo como alternativa a busca textual e falam sobre a extra¸c˜ao de caracter´ısticas. Explicam que t´ecnicas de minera¸c˜ao de dados s˜ao utilizadas para essa tarefa, como por exemplo a t´ecnica de agrupamento (clusteriza¸c˜ao) por meio do algoritmo
k-means, que facilita o processo e reduz o custo computacional.
Valle e Cord (2009) explicam que a solu¸c˜ao de anota¸c˜oes em imagens ainda ´e longe do ideal por ser computacionalmente cara, lenta e inconsistente. Portanto, apresentam a recupera¸c˜ao baseada em conte´udo como uma alternativa interessante que n˜ao precisa de palavras chave para realizar a consulta e nem metadados diretamente gravados nas imagens. Apresentam ainda dois tipos de aplica¸c˜oes dentro deste contexto: a classifica¸c˜ao semˆantica, que necessita de um aprendizado atrav´es de uma lista de imagens para cada categoria; e uma recupera¸c˜ao interativa da informa¸c˜ao onde o usu´ario participa com sua opini˜ao sobre o resultado, essa forma ´e chamada de relevance feedback.
Segundo Valle e Cord (2009), um grande impedimento enfrentado no estudo da recu-pera¸c˜ao de imagens ´e chamado desemantic gapou espa¸co semˆantico. Os autores explicam que esse espa¸co consiste em uma diferen¸ca entre a codifica¸c˜ao dos dados brutos da imagem (como valores de pixels e sub-imagens) e a representa¸c˜ao de como os usu´arios desejam recuperar as informa¸c˜oes (conceitos complexos como ”pessoa”, ”carro” ou ”cachorro”). Datta et al. (2008) tamb´em falam sobre este problema e o colocam como a diferen¸ca entre caracter´ısticas de baixo n´ıvel e alto n´ıvel. Em algumas aplica¸c˜oes, a similaridade visual ´e mais cr´ıtica do que a similaridade semˆantica. Para tentar superar este problema de interpreta¸c˜ao, as informa¸c˜oes passaram a ser representadas atrav´es de descritores, que possuem uma representa¸c˜ao mais rica dos dados brutos da imagem. Estes descritores aparecem em diversas formas: cor, textura, formas, mapas de gradiente, etc.
relevante de imagens. Chang et al. (2012) escrevem que a escolha das caracter´ısticas afeta diretamente os resultados da consulta e que algum pr´e-processamento pode ser necess´ario para reduzir a quantidade de ru´ıdo. Utilizam uma combina¸c˜ao de duas caracter´ısticas, um histograma de contraste e um histograma de cores m´edias extra´ıdas de sub-imagens da imagem. Valle e Cord (2009) citam diversos detectores de pontos de interesse que podem ser utilizados como extratores de caracter´ısticas para descrever e recuperar imagens, entre eles o SIFT (LOWE, 2004) e o SURF (BAY et al., 2008), que ser˜ao detalhados na se¸c˜ao 3.2.
3.2
Pontos de Interesse
Ser˜ao descritos aqui, dois algoritmos de identifica¸c˜ao de pontos de interesse, o algo-ritmo SIFT, criado por Lowe (1999), e o algoalgo-ritmo SURF, criado por Bay et al. (2008). Ambos ser˜ao utilizados para a cria¸c˜ao de palavras visuais atrav´es do conceito deBag of Keypoints, onde estes pontos de interesse ir˜ao formar palavras visuais, para uma poste-rior classifica¸c˜ao desta imagem. A diferen¸ca de desempenho entre os dois algoritmos j´a foi apresentada em algumas pesquisas (VALGREN; LILIENTHAL, 2010; SALEEM; BAIS; SABLATNIG, 2012), por´em o objetivo de testar os dois algoritmos ´e verificar se existem diferen¸cas na precis˜ao dos resultados ao utiliz´a-los para fazer recupera¸c˜ao de imagens.
3.2.1 SIFT - Scale Invariant Feature Transform
3.2.1.1 Detec¸c˜ao dos pontos de interesse Segundo Lowe (1999), na etapa de de-tec¸c˜ao dos pontos de interesse, o algoritmo procura identificar pontos no espa¸co de escala da imagem respeitando as varia¸c˜oes de transla¸c˜ao, rota¸c˜ao, escala e com o m´ınimo de distor¸c˜ao e ru´ıdo. S˜ao selecionados os pontos de m´axima e m´ınima de uma fun¸c˜ao de diferen¸ca de gaussianas aplicada neste espa¸co de escalas, que pode ser obtido construindo uma pirˆamide de imagens com amostragens entre os n´ıveis. Al´em disso, o algoritmo identifica pontos em regi˜oes de grande varia¸c˜ao na imagem, que s˜ao considerados pontos particulares para caracteriza¸c˜ao desta imagem, como pontos de alto contraste.
Para detectar os pontos de m´axima e m´ınima ´e necess´ario criar uma pirˆamide de escalas. J´a que a fun¸c˜ao gaussiana ´e separ´avel, s˜ao feitos dois passos da convolu¸c˜ao em 1-dimens˜ao da gaussiana na horizontal e na vertical (Equa¸c˜ao 1). Primeiramente ´e feita uma convolu¸c˜ao da imagem de entrada I(x, y) com a gaussiana G(x, y, σ) (Equa¸c˜ao 2), obtendo-se uma imagem A. Em seguida ´e feita mais uma convolu¸c˜ao incremental com o mesmo valor de σ, obtendo-se uma imagem B. A fun¸c˜ao com a diferen¸ca das gaussianas ´e obtida subtraindo a imagem B da imagem A.
G(x, y, σ) = 1 2πσ2e
−(x2+y2)
2σ2 (1)
A(x, y, σ) = G(x, y, σ)∗I(x, y) (2)
No primeiro trabalho proposto por Lowe (1999), ´e feita a convolu¸c˜ao da fun¸c˜ao de diferen¸ca das gaussianas com a imagem, D(x, y, σ), que pode ser calculada a partir da diferen¸ca de duas escalas pr´oximas separadas por um fator k (Equa¸c˜ao 3).
D(x, y, σ) = (G(x, y, kσ)−G(x, y, σ))∗I(x, y)
=B(x, y, kσ)−A(x, y, σ)
(3)
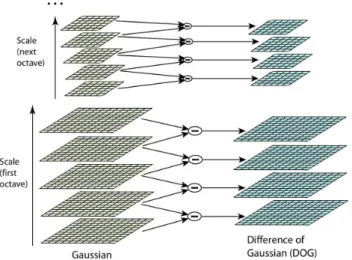
Para gerar a pr´oxima oitava da pirˆamide de escalas, ´e necess´ario redimensionar a imagem B utilizando uma interpola¸c˜ao bilinear, reduzindo a resolu¸c˜ao da imagem pela metade. A pirˆamide com a diferen¸ca das gaussianas ´e calculada novamente para essa oitava. ´E feita a convolu¸c˜ao da imagem com a gaussiana, produzindo uma lista de imagens no espa¸co de escalas. As imagens adjacentes s˜ao subtra´ıdas para gerar a diferen¸ca das gaussianas. Para cada oitava, a resolu¸c˜ao da imagem ´e reduzida pela metade e o processo ´e repetido para essa oitava (LOWE, 2004), conforme apresentado na Figura 8.
Figura 8: Pirˆamide de escalas gerada pelo algoritmo SIFT
Fonte: (LOWE, 2004)
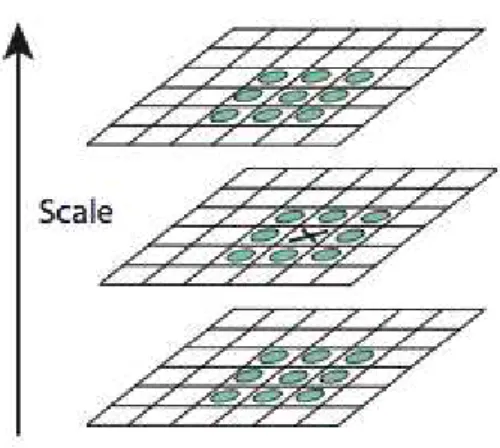
Com a pirˆamide de escalas montada, Lowe (2004) explica que os pontos de m´aximo e m´ınimo s˜ao determinados comparando cada pixel na pirˆamide com seus oito pixels vizinhos no mesmo n´ıvel. Se esse ponto for m´aximo ou m´ınimo neste n´ıvel, ent˜ao a localiza¸c˜ao do pixel mais pr´oximo ´e calculada no n´ıvel abaixo da pirˆamide e comparado com os nove pixels adjacentes neste n´ıvel, caso o valor continue sendo maior ou menor, ent˜ao o teste se repete para o n´ıvel acima. Sendo assim, o pixel ´e selecionado como um candidato se seu valor for maior ou menor que todos os 26 pixels vizinhos, considerando a escala acima e abaixo (Figura 9).
refina-Figura 9: Ponto de m´aximo ou m´ınimo detectado pelo SIFT
Fonte: (LOWE, 2004)
mento dos pontos de acordo com sua escala e proximidade de localiza¸c˜ao. O objetivo desse processo ´e descartar pontos que apresentam baixo contraste ou que podem caracterizar algum tipo de ru´ıdo na imagem, apresentando melhoras na estabilidade e na etapa de correla¸c˜ao. Este conceito ´e feito utilizando uma expans˜ao em s´eries de Taylor da fun¸c˜ao do espa¸co de escalasD(x, y, σ), de forma que a o ponto de origem seja deslocado de acordo com a Equa¸c˜ao 4.
D(x) =D+ ∂D
T
∂x x+ 1 2x
T∂
2
D
∂x2 x (4)
Onde D e suas deriva¸c˜oes s˜ao estimados no ponto e x= (x, y, σ)T ´e o deslocamento a
descartados.
ˆ x=−∂
2 D ∂x2 −1 ∂D ∂x (5)
D(ˆx) =D+1 2
∂DT
∂x xˆ (6)
Al´em de descartar os pontos de baixo contraste, Lowe (2004) apresenta ainda um refinamento em rela¸c˜ao as bordas presentes na imagem. Se a diferen¸ca das gaussianas tiver um pico mal definido, ainda podem aparecer pontos de ru´ıdo ao logo dessas bor-das. Lowe (2004) define como um pico mal definido uma curvatura principal grande ao longo da borda, por´em uma curvatura pequena na dire¸c˜ao perpendicular. Essa curvatura perpendicular pode ser calculada aplicando uma matriz hessiana na localiza¸c˜ao do ponto:
H =
2
4
Dxx Dxy
Dxy Dyy 3
5 (7)
Os autovalores de H s˜ao proporcionais a curvaturas principais de D. Vamos considerar αo autovalor com maior magnitude eβo autovalor de menor magnitude. Ent˜ao, ´e poss´ıvel calcular a soma dos autovalores no tra¸cado de H a partir do produto do determinante:
T r(H) = Dxx+Dyy =α+β,
Det(H) = D+xxDyy−(Dxy)
2
=αβ (8)
Quando o valor deste determinante ´e negativo, significa que a curvatura possui sinais diferentes e ent˜ao o ponto ´e descartado por n˜ao ser considerado um extremo. Agora, consideremosr como sendo o valor da taxa entre o maior e o menor valor dos autovalores, ou seja α=rβ. Ent˜ao:
T r(H)2
Det(H) =
(α+β)2
αβ =
(rβ+β)2
αβ2 =
(r+ 1)2
r (9)
Para verificar se a taxa da curvatura est´a abaixo de um valor de corter, basta aplicar:
T r(H)2
Det(H) <
(r+ 1)2
Lowe (2004) utiliza um valor de r = 10 para eliminar os pontos com uma taxa de curvatura maior que 10, resultando em uma quantidade ainda menor de pontos, conforme apresentado na figura 10 respectivamente: (a) imagem original; (b) imagem com todos os pontos candidatos detectados; (c) pontos eliminados de acordo com localiza¸c˜ao e proxi-midade com outros pontos; (d) imagem com os pontos eliminados de acordo com a taxa de curvatura ao longo das bordas.
(a) (b)
(c) (d)
Figura 10: Pontos detectados pelo algoritmo SIFT.
Fonte: (LOWE, 2004)
12) do gradiente. A escala considerada para a imagem ser´a a escala mais pr´oxima onde o ponto L(x,y) foi detectado.
m(x, y) = p(L(x+ 1, y)−L(x−1, y))2+ (L(x, y+ 1)
−L(x, y−1))2 (11)
θ(x, y) = tan−1
((L(x, y+ 1)−L(x, y−1))/L(x+ 1, y)−L(x−1, y))) (12)
Um histograma das orienta¸c˜oes ´e formado contendo 36 posi¸c˜oes, que representam os 360 graus em torno do ponto detectado. O valor de pico do histograma corresponde a orienta¸c˜ao dominante do gradiente naquele ponto (LOWE, 2004).
Os parˆametros obtidos at´e agora apresentam informa¸c˜oes locais em duas coordenadas (posi¸c˜ao, escala e rota¸c˜ao). Entretanto, devido a varia¸c˜oes de ilumina¸c˜ao ou varia¸c˜oes em 3 dimens˜oes para fazer o reconhecimento de um objeto ´e necess´ario que o ponto seja descrito de uma forma mais detalhada. Lowe (2004) primeiramente obt´em todas as magnitudes e orienta¸c˜oes de gradiente nos pontos em torno do ponto detectado utilizando a escala equivalente na pirˆamide.
Para que a etapa de correla¸c˜ao seja invariante a rota¸c˜ao, todas as orienta¸c˜oes de gradiente s˜ao rotacionadas em rela¸c˜ao a orienta¸c˜ao do ponto detectado. O descritor resultante ´e ilustrado na figura 11, onde s˜ao calculadas a magnitude e a orienta¸c˜ao em cada ponto em torno do ponto de interesse. A imagem a direita mostra 4 histogramas em 2x2 sub-regi˜oes, onde o tamanho de cada seta corresponde a magnitude do gradiente. Nos experimentos do autor os valores calculados para cada ponto s˜ao sumarizados em 8 histogramas a partir de 4x4 sub-regi˜oes, resultando em um vetor de descri¸c˜ao de 128 posi¸c˜oes.
Figura 11: Descritor do ponto de interesse do SIFT.
Fonte: (LOWE, 2004)
3.2.2 SURF - Speeded-Up Robust Features
Desenvolvido a partir do legado iniciado pelo seu antecessor direto, o SIFT (LOWE, 1999), o algoritmo SURF (Speeded-Up Robust Features) foi desenvolvido por Bay et al. (2008) e possui as mesmas etapas que o SIFT: a etapa de detec¸c˜ao de pontos de interesse, descri¸c˜ao destes pontos e correla¸c˜ao.
Com o objetivo de reduzir drasticamente o custo computacional, Bay et al. (2008) utilizam o conceito de imagens integrais, apresentado por Viola e Jones (2004). O uso de imagens integrais resulta em um r´apido tempo de processamento ao utilizar filtros de convolu¸c˜ao no formato de caixa. Uma imagem integral IP(w) na posi¸c˜ao w = (x, y), representa a soma de todos os valores dos pixels em uma regi˜ao retangular entre a origem ew.
IP(w) =
i≤x X
i=0
j≤y X
j=0
I(i, j) (13)
Com todos os valores da imagem integral calculados, s˜ao necess´arias apenas 3 opera¸c˜oes simples para sumarizar as intensidades dos pixels em uma ´area retangular da imagem, independente de tamanho (Figura 12).
Figura 12: Representa¸c˜ao do c´alculo da imagem integral.
Fonte: (BAY et al., 2008)
original e que serve como uma etapa para supress˜ao de pontos n˜ao m´aximos. Os pontos s˜ao escolhidos de acordo com o determinante dessa matriz hessiana. Dado um ponto w= (x, y) em uma imagem I, a matriz hessianaH(w, σ) no ponto w e na escala σ ser´a:
H(w, σ) =
2
4
Lxx(w, σ) Lxy(w, σ)
Lxy(w, σ) Lyy(w, σ) 3
5 (14)
Onde, Lxx(w, σ) representa a convolu¸c˜ao da derivada parcial de segunda ordem da
gaussiana com a imagem I no ponto w e na dire¸c˜ao horizontal, ou seja, a derivada de x em rela¸c˜ao a x que mostra o quanto a fun¸c˜ao varia na dire¸c˜ao horizontal, j´a Lyy(w, σ)
indica a varia¸c˜ao para a dire¸c˜ao vertical eLxy(w, σ) a varia¸c˜ao na diagonal. Atrav´es disso
ser´a poss´ıvel descrever a curvatura local necess´aria para sele¸c˜ao dos pontos.
Figura 13: Filtros utilizados nas matrizes de convolu¸c˜ao do SURF.
Fonte: (BAY et al., 2008)
Assim como no algoritmo SIFT (LOWE, 1999), o SURF (BAY et al., 2008) utiliza uma pirˆamide de escalas para detectar as varia¸c˜oes de diferentes magnitudes na imagem, ou seja, os pontos s˜ao detectados em diferentes escalas que representam diferentes valores deσ. No entanto, o SIFT gera uma pirˆamide de escalas para a imagem, j´a o SURF gera uma pirˆamide de escalas para os filtros utilizados (Figura 14). O filtro de tamanho 9x9 mostrado na figura 13, representa a menor escala da pirˆamide e equivale a um valor de σ= 1,2.
Figura 14: Pirˆamide de escalas utilizada nos filtros do SURF.
Fonte: (BAY et al., 2008)
Para verificar se o ponto ser´a considerado um ponto de interesse, o SURF aplica uma supress˜ao de n˜ao-m´aximos em torno de uma vizinhan¸ca de 3 pixels para cada lado, onde no total s˜ao verificados os 26 pixels nas dire¸c˜oes X e Y e nas escalas superior e inferior, assim como ´e feito no algoritmo SIFT (Figura 9). Aplicando esse processo de detec¸c˜ao dos pontos, ser˜ao capturados os pontos com grandes varia¸c˜oes de intensidade.
1999). A partir desta regi˜ao ´e realizada a extra¸c˜ao da orienta¸c˜ao dominante da imagem, que torna o algoritmo invariante a rota¸c˜ao.
Segundo Bay et al. (2008), para encontrar o vetor que descreve a distribui¸c˜ao de intensidades na regi˜ao de pixels vizinhos ao ponto de interesse, o algoritmo faz uma convolu¸c˜ao com dois filtros que representam as dire¸c˜oes X e Y, apresentados na figura 15, onde a parte escura possui o valor -1 e a parte clara possui o valor +1. Utiliza-se o conceito de imagens integrais e um vetor de 64 posi¸c˜oes para obter um processamento mais r´apido.
Figura 15: Filtros da transformada de Haar utilizados pelo SURF.
Fonte: (BAY et al., 2008)
Assim que as respostas para os filtros s˜ao calculadas em torno do ponto de interesse, estas s˜ao representadas como pontos no espa¸co, com a resposta horizontal e vertical ao longo da abcissa e ordenada. A orienta¸c˜ao dominante ´e sumarizada percorrendo uma vizinhan¸ca circular com um intervalo deπ/3 em torno do ponto de interesse. O vetor com maior valor define a orienta¸c˜ao do ponto de interesse, conforme apresentado na figura 16.
Figura 16: Atribui¸c˜ao da orienta¸c˜ao do ponto no algoritmo SURF.
Fonte: (BAY et al., 2008)
que indica a orienta¸c˜ao. O atributo de cada posi¸c˜ao ´e considerado mais uma vez realizando a convolu¸c˜ao com os filtros X e Y (Figura 15) e somam-se os resultados da dire¸c˜ao destes quadrantes. Em um grid quadrado com 4x4 sub-regi˜oes em torno do ponto, ´e calculada a resposta da transformada de Haar e cada 2x2 sub-divis˜oes de cada quadrado corresponde ao campo atual do descritor. Essas s˜ao as somasdx, |dx|,dye|dy|, calculadas em rela¸c˜ao a orienta¸c˜ao do grid. Com isso, para cada ponto de interesse tem-se um vetor de 64 posi¸c˜oes descrevendo a forma como a imagem varia nesse ponto, conforme apresentado na figura 17.
Figura 17: Descritor do ponto de interesse do SURF.
Fonte: (BAY et al., 2008)
3.2.3 ORB - Oriented FAST and Rotated BRIEF
Segundo Rublee et al. (2011), o algoritmo ORB (Oriented FAST and Rotated BRIEF) foi apresentado visando ser uma alternativa eficiente ao SIFT e ao SURF em rela¸c˜ao ao tempo de processamento, principalmente no contexto de aplica¸c˜ao em dispositivos m´oveis, por trabalhar com descritores bin´arios e por ter sido desenvolvido a partir da motiva¸c˜ao de fazer reconhecimento de imagem em dispositivos com baixo processamento de GPU.
Para a etapa de detec¸c˜ao, a proposta desse algoritmo baseia-se nas t´ecnicas apresen-tadas pelo algoritmo FAST (ROSTEN; DRUMMOND, 2006) e introduz uma vers˜ao in-variante a rota¸c˜ao, denominadaoFAST, al´em de apresentar a possibilidade de invariˆancia em rela¸c˜ao a escala. O detector FAST implementado no ORB utiliza um filtro Harris
para rejeitar bordas e ´e considerado um dos m´etodos mais eficientes para detectar cantos e arestas.
J´a na etapa de descri¸c˜ao, a proposta utiliza as t´ecnicas do algoritmo BRIEF (CA-LONDER et al., 2010), que apresenta um simples descritor bin´ario a partir da imagem suavizada. O desempenho deste descritor ´e parecido com o SIFT, por´em este ´e mais sens´ıvel a rota¸c˜ao. De modo geral, a t´ecnica pode ser entendida como um refinamento do componente de orienta¸c˜ao no algoritmo FAST e uma implementa¸c˜ao da caracter´ıstica de invariˆancia a rota¸c˜ao no algoritmo BRIEF.
3.3
Bag of Keypoints
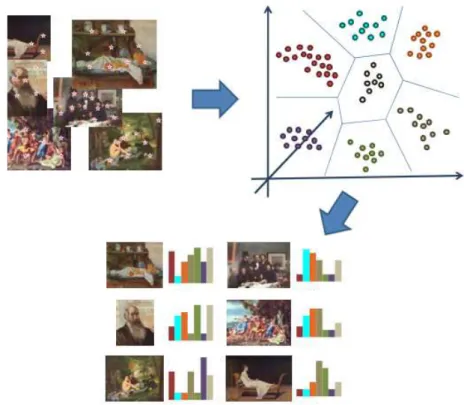
Um conceito para categoriza¸c˜ao visual de imagens ´e apresentado por Csurka et al. (2004). Neste conceito, as caracter´ısticas locais da imagens s˜ao quantizadas para classificar um objeto ou imagem dentro de uma determinada classe. OBag of Keypoints´e baseado na proposta deBag of Words, nessa representa¸c˜ao um documento textual ´e descrito como um histograma com o n´umero de ocorrˆencias de cada palavra. Perronnin (2008) explica que de forma similar, essa quantiza¸c˜ao pode ser aplicada a imagens, onde ao inv´es contabilizar dados textuais, s˜ao contabilizados dados visuais.
a imagem. Procura-se ent˜ao reduzir o espa¸co semˆantico entre as caracter´ısticas locais e as informa¸c˜oes interpretadas pelo conhecimento humano. Partindo desse principio, Csurka et al. (2004) e Perronnin (2008) apresentam uma forma de descrever e classificar cada uma das imagens utilizando caracter´ısticas locais (pontos de interesse). Os pontos detectados s˜ao descritos e agrupados para gerar um dicion´ario de palavras visuais (Figura 18). Esse dicion´ario corresponde a um histograma com o n´umero de ocorrˆencias de um determinado padr˜ao na imagem. Com uma categoriza¸c˜ao apropriada do conte´udo, ´e poss´ıvel medir a similaridade entre imagens e assim gerar recomenda¸c˜oes.
Figura 18: Representa¸c˜ao da gera¸c˜ao do dicion´ario de palavras visuais.
Fonte: (VALLE; CORD, 2009)
Segundo Liu (2013), a principal diferen¸ca entre o Bag of Words e o Bag of Keypoints
3.3.1 Constru¸c˜ao de um vocabul´ario de palavras universal
Csurka et al. (2004) explicam que a gera¸c˜ao do descritor visual consiste em trˆes fases:
• Detec¸c˜ao e descri¸c˜ao dos pontos de interesse ou keypoints contidos em todas as imagens;
• Gera¸c˜ao do vocabul´ario de palavras atrav´es de um algoritmo de agrupamento, no caso, o k-means;
• E por ´ultimo uma contagem de quantas vezes cada palavra aparece na imagem, formando um vetor caracter´ıstico que descreve a imagem.
Para o processo de classifica¸c˜ao ´e proposta mais uma etapa, que consiste em enviar o histograma extra´ıdo da imagem para uma m´aquina de aprendizado que determina a categoria a qual a imagem pertence (CSURKA et al., 2004). Os autores apresentam resultados utilizando as m´aquinas de aprendizadoSupport Vector MachineeNaive Bayes, por´em esta etapa n˜ao ser´a utilizada neste trabalho, visto que o objetivo est´a na indexa¸c˜ao para gerar recomenda¸c˜oes e n˜ao na categoriza¸c˜ao da imagem. As etapas para a gera¸c˜ao do dicion´ario de palavras visuais ser˜ao detalhadas a seguir.
3.3.1.1 Extra¸c˜ao dos pontos caracter´ısticos A primeira etapa do processo con-siste na detec¸c˜ao e descri¸c˜ao dos pontos de interesse, Csurka et al. (2004) utilizam o algoritmo SIFT (LOWE, 1999; LOWE, 2004) que possui as propriedades de ser inva-riante a rota¸c˜ao, escala e ilumina¸c˜ao. Neste trabalho, tamb´em ser˜ao feitos testes com o algoritmo SURF (BAY et al., 2008), que ´e um algoritmo mais moderno e apresenta avan¸cos no tempo de processamento em rela¸c˜ao ao SIFT. Inicialmente, todos os pontos s˜ao detectados em todas as imagens e colocados juntos em um grupo ´unico. Tanto o al-goritmo SIFT como o SURF possuem parˆametros que devem ser ajustados para detectar mais ou menos pontos. Estes ajustes ser˜ao discutidos mais a frente na fase implementa¸c˜ao.
e ir´a indicar a quantidade de palavras visuais existente no vocabul´ario (CSURKA et al., 2004; PERRONNIN, 2008; VALLE; CORD, 2009). A quantidade de palavras poder´a afetar a distˆancia entre o descritor de cada imagem ao comparar a similaridade visual, portanto o ajuste do valork tamb´em ser´a experimentado na fase de implementa¸c˜ao.
Ap´os definida a quantidade de palavras, o algoritmo converge todos os pontos infor-mados parakcentros de massa, de acordo com a figura 19. Cada centro de massa, indica uma palavra no vocabul´ario que ser´a utilizada para gerar o histograma de acordo com sua proximidade em rela¸c˜ao aos pontos. Csurka et al. (2004) explicam que a quantidade de palavras contidas neste vocabul´ario deve ser grande o suficiente para distinguir as carac-ter´ısticas que classificam a imagem, mas n˜ao t˜ao grande ao ponto de distinguir pequenas varia¸c˜oes, como por exemplo de um ru´ıdo.
Figura 19: Representa¸c˜ao do agrupamento realizado pelo algoritmo k-means.
Fonte: http://scikit-learn.org/0.5/modules/clustering.html
acessado em 15/05/2014
incrementado obtendo-se o histograma, em seguida os valores s˜ao normalizados. Este ser´a o vetor caracter´ıstico que descreve a imagem para os pontos de interesse extra´ıdos.
3.3.2 Constru¸c˜ao de um vocabul´ario adaptado por classe
Assim como apresentado por Csurka et al. (2004), Perronnin (2008) explica que a categoriza¸c˜ao visual gen´erica de imagens ´e um problema de classifica¸c˜ao de padr˜oes que consiste em aplicar etiquetas a imagens com base em seu conte´udo. Por´em, Perronnin (2008) aborda o uso de grupos espec´ıficos de palavras para cada classe, onde para exem-plificar a diferen¸ca na classifica¸c˜ao entre gatos e cachorros ´e utilizado um histograma universal e um histograma espec´ıfico para a classe. Nesse caso a imagem de um cachorro, no histograma do classificador de cachorro, ir´a apresentar valores maiores no vocabul´ario espec´ıfico do que no universal. J´a no histograma do classificador de gato, os valores do vocabul´ario universal ser˜ao maiores do que do vocabul´ario espec´ıfico.
Perronnin (2008) enfatiza o uso da palavra ”gen´erico” para mostrar que as imagens possuem informa¸c˜oes comuns para todas as classes e mais importante que estas, existem caracter´ısticas espec´ıficas para cada uma, que facilitam a categoriza¸c˜ao visual dentro de cada classe. Por exemplo, s˜ao estas caracter´ısticas espec´ıficas que nos auxiliam a iden-tificar a diferen¸ca entre uma caneca e um copo, ambos possuem caracter´ısticas similares (gen´ericas), mas o que diferencia uma classe da outra, s˜ao atributos particulares de cada uma. Por´em, a pr´atica de dividir os vocabul´arios por classe se torna impratic´avel para uma grande quantidade de classes, visto que o tamanho do vocabul´ario cresce linearmente com esta quantidade, tornando o custo computacional muito alto devido ao tamanho do histograma gerado.
de dados sempre ter´a uma taxa de acerto maior do que uma imagem fora do mesmo, exatamente pelo fato do agrupamento ter sido feito a partir das imagens contidas no banco de dados. No entanto, ´e poss´ıvel classificar uma imagem fora do banco de dados com uma boa taxa de acerto, j´a que os pontos caracter´ısticos tendem a estar pr´oximos para imagens dentro das mesmas categorias.
A partir da classifica¸c˜ao visual de imagens e visando gerar recomenda¸c˜oes baseadas no conte´udo de uma imagem, temos um caminho que nos leva ao problema de recupera¸c˜ao de imagens baseado em conte´udo. Para efetuar uma consulta em uma lista de imagens ´e necess´ario uma indexa¸c˜ao, que por sua vez deve ser baseada em alguma informa¸c˜ao da imagem. Os histogramas gerados pelo Bag of Keypoints apresentam uma boa descri¸c˜ao para indexar as imagens, desde que a extra¸c˜ao das caracter´ısticas seja feita de acordo com a informa¸c˜ao buscada e desde que os parˆametros para gera¸c˜ao do vocabul´ario sejam aplicados corretamente, como por exemplo a quantidade de palavras visuais que ser´a utilizada e os parˆametros para o detector de pontos de interesse (DATTA et al., 2008).
3.4
Descritor de Cores Dominantes
Por analisar apenas varia¸c˜oes de intensidade em pontos espec´ıficos da imagem, os algoritmos que foram utilizados trabalham com imagens em escalas de cinza (LOWE, 2004; BAY et al., 2008). No entanto, a informa¸c˜ao de cor ´e uma caracter´ıstica muito importante quando falamos em obras de arte, ela adiciona beleza as imagens e fornece uma informa¸c˜ao muito valiosa para ser utilizada na recupera¸c˜ao de imagens baseada no conte´udo (YELIZAVETA; TAT-SENG; IRINA, 2005).
Para melhorar a descri¸c˜ao visual das obras de arte, tamb´em foi utilizado um descritor de cores dominantes baseado na t´ecnica apresentada por Krishnan, Banu e Christiyana (2007), onde os autores criam uma categoriza¸c˜ao pr´e-determinada do espa¸co de cores e em seguida aplicam um conceito similar ao Bag of Keypoints para gerar uma tabela de frequˆecia, que indica a frequˆencia de cada cor na imagem. Por fim, essa tabela ´e ordenada de forma decrescente para identificar as cores dominantes na imagem.
as imagens presentes nesse banco de dados, ao inv´es de utilizar categorias pr´e-definidas como no trabalho de Krishnan, Banu e Christiyana (2007). Essa categoriza¸c˜ao mais dinˆamica permitiu uma melhor distribui¸c˜ao das categorias no espa¸co de cores e para isso foi utilizado o algoritmo k-means. As etapas para gera¸c˜ao desse descritor ser˜ao melhor detalhadas no cap´ıtulo 4.
3.5
M´
etrica para an´
alise da precis˜
ao no sistemas de recomenda¸c˜
oes
Para avaliar a qualidade dos resultados no sistema de recomenda¸c˜oes, foi utilizada uma m´etrica muito comum no estudo de recupera¸c˜ao de imagens, explicada por Herlocker et al. (2004). Foi utilizada a medida de precis˜ao para medir a qualidade das informa¸c˜oes recuperadas e avaliar se os itens retornados na pesquisa s˜ao realmente os itens esperados.
A medida de precis˜ao indica a quantidade de itens relevantes que foram retornados na consulta ou recomendados, de acordo com a quantidade total de itens retornados, explica Herlocker et al. (2004). O valor da precis˜ao´e definido por:
P = tp tp+fp
, (15)
onde tp representa a quantidade verdadeiros positivos, ou seja, de itens relevantes e fp ´e
4
DESENVOLVIMENTO DO SISTEMA
Com uma base te´orica formada sobre os conceitos necess´arios, foram elaboradas duas aplica¸c˜oes computacionais: uma aplica¸c˜ao para computadores desktop com Windows, que executa a primeira etapa do sistema; e uma aplica¸c˜ao para dispositivos m´oveis da plataforma Android, que executa a segunda etapa na qual o usu´ario efetivamente utiliza o sistema. Foi utilizada a biblioteca OpenCV, uma biblioteca de software livre voltada a aplica¸c˜oes de vis˜ao computacional e c´alculos matem´aticos complexos (OPENCV, 2014). As linguagens de programa¸c˜ao utilizadas foram Java, C e C++.
A primeira etapa consiste em listar as imagens do acervo e aplicar as t´ecnicas de recupera¸c˜ao de imagens descritas na se¸c˜ao 3.1. Tamb´em foi utilizado o conceito de Bag of Keypoints, descrito na se¸c˜ao 3.3, para gerar os descritores que por sua vez foram utilizados para indexar a lista e apresentar o resultado ordenado. Como pr´e-requisito para a implementa¸c˜ao do Bag of Keypoints, foram testados os algoritmos de detec¸c˜ao e descri¸c˜ao de pontos de interesse SIFT e SURF, descritos na se¸c˜ao 3.2.
4.1
Acervo
Para implementar a solu¸c˜ao proposta, um banco de dados de pinturas foi montado a partir do site www.wikiart.org, que cont´em pinturas disponibilizadas a partir de uma licen¸ca p´ublica, organizadas por artista, gˆenero e movimento. As imagens obtidas foram analisadas dentro de seis movimentos de arte: Barroco, Romantismo, Realismo, Impres-sionismo, Expressionismo e Cubismo. Dentro de cada movimento existem imagens de paisagens e retratos, formando uma cole¸c˜ao com um total de 240 obras de arte.
apre-sentada na tabela 1.
Figura 20: Exemplos de Retratos dos movimentos Barroco, Realismo e Romantismo.
Figura 21: Exemplos de Paisagens dos movimentos Barroco, Realismo e Romantismo.
Figura 22: Exemplos de Retratos dos movimentos Expressionismo e Impressionismo.
Figura 23: Exemplos de Paisagens dos movimentos Expressionismo e Impressionismo.
Figura 25: Exemplos de Paisagens do movimento Cubismo.
Tabela 1: N´umero de imagens inclu´ıda em cada classe.
Classe Movimentos de Arte (Estilo) Gˆenero Imagens
1
Barroco Realismo Romantismo
Paisagem 40
2
Barroco Realismo Romantismo
Retrato 40
3 Expressionismo
Impressionismo Paisagem 40
4 Expressionismo
Impressionismo
Retrato 40
5 Cubismo Paisagem 40
6 Cubismo Retrato 40
4.2
Arquitetura
Baseado na divis˜ao feita por Valle e Cord (2009) e conforme apresentado na figura 26, as etapas do sistema foram divididas em duas fases:
• Offline: Etapa executada de forma autom´atica, ou seja, sem a interven¸c˜ao do usu´ario. Deve ser processada antes que se possa utilizar o sistema e tamb´em a cada vez que uma nova imagem for inclu´ıda no acervo. Consiste no processamento de todas as imagens para gera¸c˜ao do vocabul´ario, do descritor baseado emkeypoints
• Online: Consiste na fase em que o usu´ario utiliza o sistema, ou seja, quando o usu´ario passar uma imagem solicitando uma recomenda¸c˜ao o sistema carrega o descritor desta imagem, que ´e chamada de query. Em seguida ´e realizado um processo de
matching entre o descritor daquery e de todas as imagens do acervo, ordenando-as de forma crescente em rela¸c˜ao a distˆancia entre os descritores.
Figura 26: Vista do processo de recupera¸c˜ao de imagens dividido em fase offline e online.
Fonte: Autor
4.3
Processo
Offline
necess´ario definir o valor de k, ou seja, a quantidade de palavras visuais que se deseja ter no vocabul´ario. Esse valor foi definido empiricamente e o resultado dos testes ser´a apresentados no cap´ıtulo 5.
4.3.1 Gera¸c˜ao do Descritor baseado no Bag of Keypoints
Nos testes feitos para a gera¸c˜ao do descritor de Bag of keypoints, foi identificado que havia uma necessidade de ter uma quantidade uniforme de pontos de interesse. Ao utilizar os parˆametros pr´e-configurados no OpenCV para os detectores do SIFT e do SURF, a quantidade de pontos detectados era muito diferente entre uma imagem e outra, princi-palmente ao analisar imagens de diferentes classes e diferentes tamanhos. Por exemplo, um quadro cubista apresentava muitos mais pontos do que um quadro do movimento barroco. Essa diferen¸ca gerou um problema no momento de aproximar cada ponto a uma palavra no vocabul´ario e fazer a contagem das palavras visuais. O histograma gerado ficava disperso para as imagens com muitos pontos, resultando em um n´umero maior de falsos positivos.
Para resolver essa quest˜ao a quantidade de pontos foi normalizada para 500 pontos por imagem, alterando o parˆametro de m´aximo n´umero de pontos para o SIFT e a m´ınima hessiana no SURF. Isso tamb´em resolveu o problema de imagens com diferentes tamanhos, j´a que os algoritmos s˜ao invariantes a escala. A quantidade fixa de pontos definiu bem o padr˜ao detectado, gerando um descritor que caracteriza melhor cada uma das classes e reduzindo o n´umero de falsos positivos.
Na primeira configura¸c˜ao, que utiliza um vocabul´ario universal, os pontos de todas as imagens foram extra´ıdos e agrupados viak-means uma ´unica vez para todas as imagens. O vocabul´ario gerado foi armazenado fisicamente em um arquivo no disco para ficar dispon´ıvel na faseonline.
em um arquivo para ficarem dispon´ıveis na fase online. Finalmente os vocabul´arios fo-ram utilizados para gerar o descritor de cada imagem presente no acervo com base nos
keypoints.
Com todos os descritores gerados, foi poss´ıvel validar o conceito de vocabul´ario adap-tado apresenadap-tado por Perronnin (2008), onde a parte do descritor adaptada para deter-minada classe apresentou uma quantidade maior de palavras quando a imagem analisada est´a dentro desta classe, por exemplo no caso da Figura 27, ´e poss´ıvel perceber que a quantidade de palavras presentes na classe 1 ´e maior do que a distribui¸c˜ao entre as outras classes (Figura 28). J´a no caso da Figura 29, ´e poss´ıvel perceber que a quantidade de palavras da classe 2 ´e maior do que nas outras classes (Figura 30).
Figura 27: Exemplo de paisagem do movimento barroco (classe 1).
Figura 29: Exemplo de retrato do movimento barroco (classe 2).
Figura 30: Histograma de retrato do movimento barroco.
4.3.2 Gera¸c˜ao do Descritor de Cores Dominantes
A gera¸c˜ao do descritor de cores dominantes ´e feita na fase offline e est´a dividida em trˆes passos:
• Cria¸c˜ao de uma paleta de vinte e quatro cores baseando-se em todas as imagens do acervo;
• Quantiza¸c˜ao das cores de cada imagem de acordo com os valores da paleta;
Para a gera¸c˜ao da paleta de cores, todas as imagens do acervo foram processadas e foi extra´ıdo o valor RGB de cada pixel em todas as imagens. Estes valores foram inclu´ıdos em um vetor ´unico e agrupados utilizando o algoritmok-meanscom um valor dek= 24. Com isso, cada valor convergido pelo algoritmo resultou em um valor RGB, ou seja, resultando em uma paleta de vinte e quatro cores RGB.
Com a paleta de cores definida, o pr´oximo passo foi a quantiza¸c˜ao de cada uma das imagens. Cada pixel em cada imagem foi aproximado a um dos 24 valores existentes na paleta utilizando a t´ecnica de KNN, gerando um histograma que mostra quantas vezes cada cor da paleta aparece na imagem. A imagem original ´e apresentada na Figura 31 e ap´os quantizada, foi obtida uma imagem com uma quantidade reduzida de cores, que ´e apresentada na Figura 32.
Figura 31: Imagem RGB original com todas as cores.
Figura 32: Imagem quantizada com 24 cores.
e a imagem resultante ´e apresentada na Figura 33. Um histograma com as mesmas 24 posi¸c˜oes que representa o descritor das cores dominantes e seus respectivos percentuais ´e apresentado na Figura 34.
Figura 33: Imagem resultante com 8 cores dominantes.
4.4
Processo
Online
4.4.1 Reconhecimento do Quadro
Antes da etapa de recupera¸c˜ao das imagens e gera¸c˜ao da recomenda¸c˜ao, ´e necess´ario que o usu´ario informe a imagemquery ao sistema, esse processo ´e feito na faseonline, ou seja, acontece no momento em que o usu´ario utiliza o sistema. O usu´ario aponta a cˆamera do celular para o quadro conforme a Figura 35 e o sistema reconhece o quadro presente no frame capturado, mostrando ao usu´ario as informa¸c˜oes daquele quadro, conforme a Figura 36.
Figura 35: Imagem do sistema buscando o quadro na imagem capturada.
Fonte: Autor
Um m´etodo para reconhecer a imagem utilizando pontos de interesse consiste em detectar e descrever todos os pontos de interesse de todas as imagens e armazen´a-los em um banco de dados, em seguida ´e feita a extra¸c˜ao e descri¸c˜ao dos pontos na imagem do frame capturado pela cˆamera do celular. A partir de ent˜ao ´e feito um processo de correla¸c˜ao entre os descritores doframe e todos os descritores armazenados no banco de dados, onde para cada descritor doframe´e encontrado um descritor no banco de dados e a respectiva imagem recebe um voto, ao final ´e retornada a imagem com maior quantidade de votos (VALLE; CORD, 2009). Este m´etodo foi implementado para o reconhecimento do quadro presente noframe utilizando o algoritmo ORB e suas etapas s˜ao apresentadas na Figura 37. Como o sistema proposto n˜ao faz uma proje¸c˜ao de objetos virtuais no
Figura 36: Imagem do sistema no momento que o quadro ´e identificado.
Fonte: Autor
pontos detectados foram o suficiente para encontrar o quadro no banco de dados.
Os pontos detectados noframe utilizando o ORB, s˜ao descritos e correlacionados com os pontos ORB que foram armazenados no banco de dados durante a fase offline para cada imagem. Em seguinda ´e realizada uma vota¸c˜ao e retornada a imagem que possui maior quantidade de votos, ou seja, que possui mais pontos correspondidos com os pontos do frame. Quando a imagem ´e capturada pela cˆamera do celular, a obra de arte a ser identificada pode estar presente ou n˜ao. O usu´ario pode estar caminhando pelo museu com o aplicativo ligado e n˜ao necess´ariamente apontando para uma obra de arte. Para evitar que o sistema identifique de forma errada uma imagem em cadaframe, foi necess´ario aplicar um threshold, eliminando as correla¸c˜oes que possuam uma quantidade de votos menor que 15.
Figura 37: Processo de reconhecimento do quadro capturado pelo celular.
Fonte: Autor
4.4.2 Indexa¸c˜ao e Recomenda¸c˜ao
Ap´os o reconhecimento do quadro no frame, temos o seu identificador no banco de dados e este ser´a o identificador da imagem query para a gera¸c˜ao da recomenda¸c˜ao. A partir disso ´e poss´ıvel recuperar os descritores debag of keypoints e de cores dominantes, que consistem em vetores de tamanho fixo para cada imagem armazenada no banco de dados.
Para cada um dos tipos de descritores, de bag of keypoints e de cores dominantes, foi feita uma correla¸c˜ao entre aquerye as imagens no banco de dados utilizando um algoritmo de for¸ca bruta. Foram testadas duas m´etricas de distˆancia dispon´ıveis no OpenCV: a distˆancia L1 (Manhattan) e a distˆancia L2 (Euclidiana). A m´etrica escolhida foi a distˆancia deManhattan, que apresentou melhores resultados em rela¸c˜ao a Euclidiana, conforme j´a apresentado anteriormente por outros autores (KOKARE; CHATTERJI; BISWAS, 2003).
Foi calculado um valor de distˆancia para cada imagem no banco de dados em rela¸c˜ao aquery e em seguida as imagens foram ordenadas por essa distˆancia em ordem crescente. A imagem query sempre estar´a contida na cole¸c˜ao, portanto ´e esperado que a primeira imagem recuperada seja ela pr´opria e que a distˆancia em rela¸c˜ao aquery seja igual a zero. A segunda imagem recuperada ser´a a pintura a ser recomendada ao usu´ario, conforme apresentado na Figura 38.
Figura 38: Representa¸c˜ao b´asica de escolha da recomenda¸c˜ao a partir da indexa¸c˜ao.
Fonte: Autor
e outro para as cores dominantes. Para considerar os pontos de interesse e as cores domi-nantes em um ´unico resultado na consulta, o ´ındice de cada caracter´ıstica foi integrado combinando os valores de distˆancia. Para isso foi utilizado o c´alculo apresentado por Jain e Vailaya (1996). Considerando Q a imagem query e I uma imagem na cole¸c˜ao, Dp ser´a
a distˆancia entre Q e I com base nos pontos de interesse. Dc ser´a a distˆancia com base
nas cores dominantes e a distˆancia total Dt ser´a:
Dt =
wpDp +wcDc
wp+wc
(16)
onde wp e wc s˜ao os pesos para pontos de interesse (gˆenero/estilo) e cores dominantes,
respectivamente.
Para permitir uma intera¸c˜ao maior do usu´ario com o sistema, ´e poss´ıvel alterar os valores dewp ewc a partir da interface do sistema antes da gera¸c˜ao da recomenda¸c˜ao,
Figura 39: Configura¸c˜ao dos parˆametros de recomenda¸c˜oes.
Fonte: Autor
Figura 40: Apresenta¸c˜ao da recomenda¸c˜ao ao usu´ario.
5
EXPERIMENTOS E RESULTADOS
Os primeiros testes foram executados utilizando tanto o algoritmo SURF como o SIFT, com o objetivo de comparar as precis˜oes entre eles para a gera¸c˜ao das recomenda¸c˜oes. O experimento tamb´em consiste em fazer uma verifica¸c˜ao de qual o n´umero adequado de palavras visuais que devem existir no vocabul´ario, alterando empiricamente os valores de 250 a 4000. Para este teste, o peso para o descritor de cores dominantes foi definido para wc = 0. A medi¸c˜ao foi feita passando todas as imagens presentes no banco de dados
como query, uma por uma e avaliando a precis˜ao para uma recomenda¸c˜ao. Como cada obra possui uma informa¸c˜ao de estilo e gˆenero, a precis˜ao foi medida por: estilo, gˆenero, apenas um dos dois (OR) e para os dois (AND). Os resultados para essa configura¸c˜ao s˜ao apresentados na Tabela 2 para o SURF e na Tabela 3 para o SIFT.
Tabela 2: Valores de precis˜ao utilizando o algoritmo SURF.
Palavras Visuais Estilo Gˆenero AND OR 250 0,8410 0,6778 0,5941 0,9247 500 0,8828 0,7406 0,6778 0,9456
1000 0,9080 0,8117 0,7448 0,9749 1500 0,9205 0,8117 0,7699 0,9623 2000 0,9247 0,8243 0,7699 0,9791 3000 0,9665 0,8452 0,8368 0,9749 4000 0,9665 0,8912 0,8828 0,9749
Figura 41: Gr´afico de precis˜oes do algoritmo SURF.
Tabela 3: Valores de precis˜ao utilizando o algoritmo SIFT.
Palavras Visuais Estilo Gˆenero AND OR 250 0,7782 0,7824 0,6527 0,9079 500 0,8745 0,8912 0,8117 0,9540 1000 0,9498 0,9331 0,9038 0,9791 1500 0,9665 0,9498 0,9372 0,9791
2000 0,9749 0,9582 0,9582 0,9749 3000 0,9874 0,9707 0,9707 0,9874 4000 0,9874 0,9623 0,9623 0,9874
Foi poss´ıvel perceber que os valores de precis˜ao para os SIFT crescem de acordo com a quantidade de palavras visuais do vocabul´ario. Para a caracter´ıstica de estilo, essa precis˜ao come¸ca a estabilizar em torno de 1000 palavras visuais com 0,9498 de precis˜ao e para o gˆenero em torno de 2000 mil palavras com 0,9582 de precis˜ao, conforme ´e poss´ıvel observar no gr´afico da Figura 42. Como ´e de conhecimento que o custo computacional aumenta de acordo com a quantidade de palavras, foi medido o tempo m´edio de processamento para a gera¸c˜ao da recomenda¸c˜oes com 1000 e com 2000 palavras. Os resultados s˜ao apresentados na Tabela 4 e considerando a diferen¸ca de apenas 0,008 segundos no tempo de processamento, foi escolhido o valor de 2000 palavras visuais.
Tabela 4: Tempos m´edios de processamento para gera¸c˜ao das recomenda¸c˜oes.
Palavras Visuais 1000 2000 Tempo (segundos) 0,025 0,033
Quando a primeira recomenda¸c˜ao j´a foi vista pelo usu´ario, o sistema deve recomendar a segunda imagem e assim por diante. Devido a isso tamb´em foi medida a precis˜ao para uma quantidade maior de recomenda¸c˜oes. Ainda utilizando o algoritmo SIFT, para esse teste foram utilizadas 2000 palavras visuais e foram recuperadas 4 imagens. Os resultados s˜ao apresentados na Tabela 5 e na Figura 43.
Tabela 5: Precis˜ao para 4 recomenda¸c˜oes por estilo e gˆenero.
Estilo Gˆenero AND OR 0,9559 0,9487 0,9299 0,9738
Na Figura 44 ´e poss´ıvel perceber que os resultados recuperados est˜ao de acordo com estilo e gˆenero, mas n˜ao de acordo com as cores. Para avaliar a precis˜ao de acordo com o descritor de cores dominantes, o peso para o ´ındice do descritor de bag of keypoints foi configurado para wp = 0 e o peso do descritor de cores dominantes para wc = 1. Os
resultados s˜ao apresentados na Figura 45.
Finalmente, os pesos foram alterados de forma que ambos os ´ındices para cada carac-ter´ıstica, entrebag of keypointse cores dominantes, fossem integrados. Os valores parawp
ewc foram alterados empiricamente e os resultados foram avaliados observando as cores e
Figura 43: Exemplos de resultados para 4 recomenda¸c˜oes (wp = 1 e wc = 0).
Figura 44: Resultados utilizando o descritor de bag of keypoints (wp = 1 e wc = 0).
recomenda¸c˜oes, estes pesos podem ser ajustados de acordo com a preferˆencia do usu´ario por estilo/gˆenero ou cores. Os valores padr˜ao escolhidos foram wp = 0,8 e wc = 0,2,
por´em estes valores podem ser alterados pelo usu´ario atrav´es da interface do sistema. Os resultados de recomenda¸c˜oes para essa configura¸c˜ao s˜ao apresentados na Figura 46. Devido a inferˆencia do descritor de cores a precis˜ao foi reduzida, por´em ainda manteve-se um valor de 0,9540 para estilo ou gˆenero.
6
CONCLUS ˜
OES E TRABALHOS FUTUROS
Com os primeiros testes foi poss´ıvel perceber que o uso de um vocabul´ario adaptado para cada classe se mostrou mais eficiente do que o vocabul´ario universal. A resposta para esse problema ´e que alguns pontos s˜ao similares entre as classes e ao utilizar um vocabul´ario ´unico, algumas palavras s˜ao compartilhadas por imagens de diferentes classes, aumentando o n´umero de falsos positivos. Ao usar um vocabul´ario adaptado s˜ao geradas duas palavras separadas para cada classe, permitindo que os pontos detectados sejam atribu´ıdos `a palavra da respectiva classe, o que melhorou muito a precis˜ao.
Tamb´em foi poss´ıvel comparar a precis˜ao na recupera¸c˜ao de imagens utilizando dois algoritmos diferentes para a gera¸c˜ao dobag of keypoints. Foram obtidos melhores resulta-dos para o algoritmo SIFT em rela¸c˜ao ao SURF, apesar deste segundo ser mais recente. Recomenda-se para trabalhos futuros executar os mesmos testes para diversos outros al-goritmos de detec¸c˜ao e descri¸c˜ao de pontos de interesse, tal como verificar o que pode-se melhorar dentro destes algoritmos de forma que se tenha melhores precis˜oes na aplica¸c˜ao de recupera¸c˜ao de imagens baseadas em conte´udo.
O m´etodo proposto apresentou bons resultados para recomenda¸c˜oes e recupera¸c˜ao de obras de arte a partir de um banco de dados com base no conte´udo. Utilizando apenas um descritor de pontos de interesse combag of keypointsfoi poss´ıvel obter ´otimos valores de precis˜ao chegando a 0,9749 com 2000 palavras visuais para pelo menos uma das duas caracter´ısticas entre estilo e gˆenero (OR). Ao combinar o descritor de pontos de interesse com o descritor de cores dominantes, foi poss´ıvel melhorar a similaridade visual das imagens recuperadas.
A divis˜ao adequada das obras de arte tamb´em foi um passo muito importante, onde o estudo dos movimentos de arte e suas caracter´ısticas foi fundamental. Nos testes, foi poss´ıvel concluir que a escolha do n´umero de palavras visuais no vocabul´ario ´e muito importante e deve ser adequada de acordo com o tipo de imagens utilizadas.