ESCOLA DE ECONOMIA DE SÃO PAULO
RICARDO PIRES DE SOUZA SANTOS
MODELANDO CONTÁGIO FINANCEIRO ATRAVÉS DE
CÓPULAS
SÃO PAULO
MODELANDO CONTÁGIO FINANCEIRO ATRAVÉS DE
CÓPULAS
Dissertação apresentada à Escola de Economia da
Fundação Getúlio Vargas, para a obtenção de Título
de Mestre em Economia.
Orientador: Prof. Dr. Pedro Luiz Valls Pereira
Pires de Souza Santos, Ricardo.
Modelando Contágio Financeiro através de Cópulas / Ricardo Pires de
Souza Santos - 2010.
94 f.
Orientador: Pedro Luiz Valls Pereira
Dissertação (mestrado) - Escola de Economia de São Paulo.
1. Crise financeira. 2. Mercado financeiro -- Previsão. 3. Mercado
financeiro – Modelos matemáticos. 4. Cópulas (Estatística matemática). I.
Valls, P. (Pedro). II. Dissertação (mestrado) - Escola de Economia de São
Paulo. III. Título.
aqui tratada, por sua competência, atenção criteriosa e indispensável prestada em todas as etapas desta Tese de Mestrado. Pelo tempo dispensado às discussões semanais, pela oportunidade de crescimento e aprendizado no trabalho conjunto e pela con…ança em mim depositada.
Aos profesores Dr. Emerson Fernandes Marçal e Dr. Ricardo Ratner Rochman que participaram da banca de quali…cação com comentários e sugestões para a melhoria do trabalho e pela ajuda fora da banca.
Aos professores Dr. Luiz Koodi Hotta e Dr. Emerson Fernandes Marçal que participaram da banca de defesa com suas críticas e sugestões para a melhoria da dissertação.
Aos meus pais e irmãos, que sempre me deram apóio e força, valorizando meus potenciais. Em particular agradeço ao meu pai pelas sugestões e ajuda na etapa …nal da dissertação.
À Cynthia Rieder por seu sorriso e alegria, que mesmo morando do outro lado do oceano, me incentivou constantemente.
Aos amigos e colegas de mestrado: Hugo, Felipe, Eduardo, Priscila, Perosa, Dárcio, Politi, Serigati, Luiz Fernando, Barbi e outros, pela convivência nesses dois anos. Em particular agradeço ao Leonardo Correia, pelas conversas …adas sobre econometria fora da sala de aula.
A todos os amigos, professores e pessoas que, direta ou indiretamente, con-tribuíram para a execução desse trabalho.
À Cynthia
aos meus pais, José Carlos e Zuleima,
Sumário
Lista de Figuras iv
Lista de Tabelas v
I Teoria 1
1 Introdução 2
2 Contágio …nanceiro 5
2.1 De…nições de contágio …nanceiro . . . 7
2.2 Testes empíricos sobre contágio . . . 11
2.3 Contágio …nanceiro no Brasil . . . 12
3 Introdução à cópulas 14 3.1 Cópulas . . . 16
3.1.1 Transformação Integral de probabilidade . . . 17
3.2 Teorema de Sklar . . . 18
3.3 Funções cópulas . . . 19
3.4 Copulas especiais . . . 23
3.5 Métodos de estimação . . . 26
3.5.1 Máxima Verossimilhança Exata . . . 27
3.5.2 Inferência para as Marginais . . . 28
3.5.3 Máxima Verossimilhança Canônica . . . 29
3.6 Exemplo ilustrativo . . . 30
4 Medidas de Dependência 33 4.1 Correlação de Pearson (coe…ciente de correlação linear) . . . 36
4.2 Correlação de Spearman . . . 38
4.3 Tau de Kendall . . . 39
4.4 Dependência quantílica . . . 41
4.5 Dependência das caudas . . . 41
5 Cópulas condicionais 45
5.1 Cópulas condicionais . . . 46
5.2 Cópulas condicionais orientadas a observações . . . 48
II Análise Empírica 52 6 Testando a hipótese de contágio …nanceiro 53 6.1 Dados . . . 53
6.2 Estatísticas descritivas dos retornos . . . 55
6.2.1 Períodos de análise . . . 63
6.3 Modelos para as distribuições marginais . . . 64
6.4 Modelos para as cópulas . . . 69
6.4.1 Cópula gaussiana . . . 69
6.4.2 Cópula SJC . . . 75
7 Conclusão 86
Lista de Figuras
3.1 Diagrama de dispersão das funções cópulas gaussiana (coluna esquerda) e as respectivas distribuições bivariadas (coluna direita) construídas a partir
desta copula e distribuições marginais N(0;1). . . 22
3.2 Diagrama de dispersão das funções cópulas Joe-Clayton (coluna esquerda) e as respectivas distribuições bivariadas (coluna direita) construídas a partir desta copula e distribuições marginais N(0;1). . . 24
3.3 Cópulas especiais: C ,C+ eC? . . . 25
3.4 Diagrama de dispersão de distribuições geradas a partir de diversas cópulas e distribuições marginais padrão N(0;1) . . . 31
5.1 Distância mínima do ponto (u1;t; u2;t) em relação à diagonal principal (de-pendência positiva perfeita). . . 49
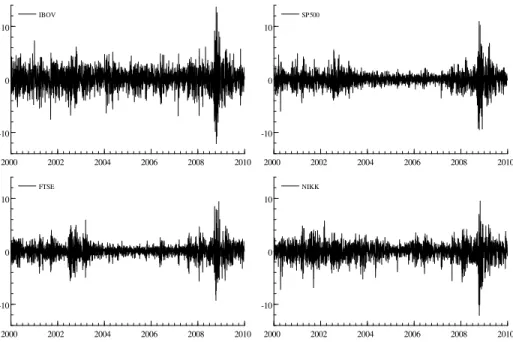
6.1 Índices de mercados selecionados . . . 54
6.2 Retornos (logarítmicos) diários . . . 56
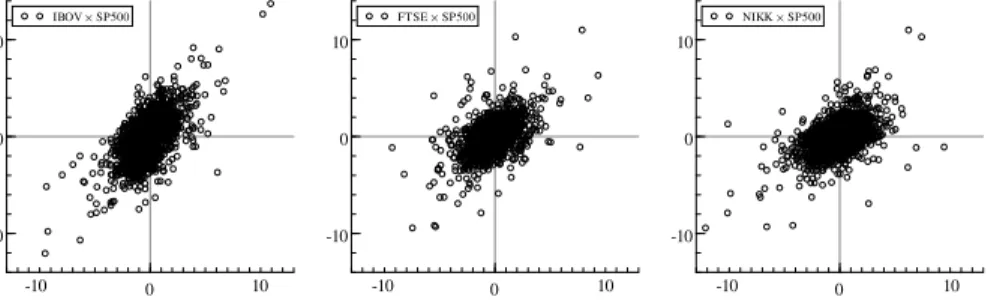
6.3 Diagrama de dispersão dos retornos diários . . . 60
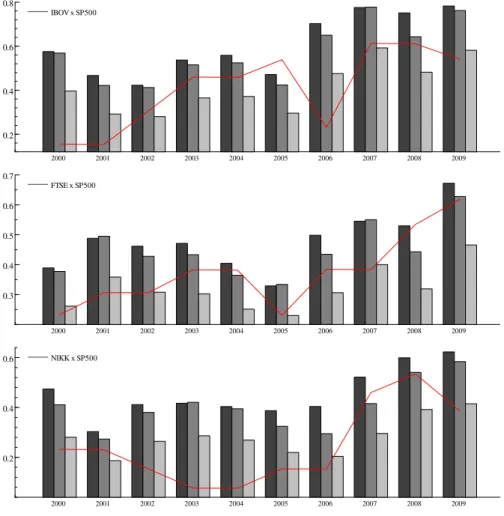
6.4 Medidas de associação - (escuro), S (médio), K (claro) e (linha) . . . 62
6.5 Média anual dos retornos (logarítmicos) diários . . . 63
6.6 Distribuiçãot-student assimétrica . . . 66
6.7 Copula gaussiana - coe…ciente de correlação linear t . . . 71
6.8 Copula gaussina - correlação linear t com a presença de quebra estrutural . 76 6.9 Copula SJC - Dependência das caudas superior U (verde, escala esquerda) e inferior L (azul, escala direita) . . . . 80
6.10 Copula SJC – dependência da cauda superior U com a presença de quebra estrutural . . . 83
Lista de Tabelas
3.1 Medidas de dependência para distribuições conjuntas obtidas a partir das
funções copulas e de distribuições marginaisN(0,1) . . . 32
6.1 Estatísticas Descritivas dos Retornos Diários . . . 59
6.2 Modelos ARMAst-GARCH para as distribuições marginais . . . 67
6.3 Estimativas dascopulas condicionais: gaussiana . . . 73
Parte I
Capítulo 1
Introdução
As medidas de dependência entre mercados …nanceiros exercem notável in‡uência
e são de extensa aplicação. Administradores de carteiras exploram as correlações entre
mercados de modo a se bene…ciar da diversi…cação internacional. Formuladores de política
monitoram a dependência entre mercados …nanceiros a …m de avaliar a possibilidade de
contágio …nanceiro.
O presente trabalho testa a hipótese de contágio …nanceiro entre quatros mercados
selecionados seguindo-se a metodologia de cópulas.
A hipótese da ocorrência de contágio …nanceiro entre mercados desenvolveu-se
principalmente a partir de crises …nanceiras que ocorreram na década de 90. O corpo
teórico que abrange tal hipótese consiste na identi…cação dos canais de transmissão
inter-nacional do choque e na avaliação de sua estabilidade durante os períodos de crise,i.e. da
sua intensidade na transmissão de choques. No presente estudo, contágio …nanceiro será
país especí…co. Tal de…nição se encaixa na classe de de…nições de contágio, identi…cada e
denominada por Rigobon (2002) deshift-contagion. A presença do fenômeno, portanto, será
evidenciada por meio de uma quebra estrutural do comportamento padrão da dependência
entre os mercados. De acordo com Forbes e Rigobon (2002), o uso desta de…nição apresenta
a vantagem da não necessidade de explicitação do canal de transmissão do choque.
A vantagem da modelagem do contágio …nanceiro por meio de funções copulas é
evidente, posto que ambos tomam as medidas de dependência como protagonista de seus
corpos teóricos. A teoria de copulas é uma metodologia de modelagem de distribuições
multivariadas. Como alicerce principal, admite que toda distribuição multivariada pode ser
decomposta em uma estrutura para as distribuições marginais e uma estrutura de
dependên-cia, representada pelas funções cópulas que, por sua vez, "ligam"as distribuições marginais
numa estrutura única. A metodologia sobressai-se outras abordagens alternativas,e.g.
val-ores extremos, por modelar toda a distribuição conjunta das variáveis, fornencendo além
de medidas de locação e dispersão, e.g. média e variância, outras medidas de dependência
como dependências de cauda e correlações de postos.
Não se questiona o extraordinário avanço dos instrumentos …nanceiros e do setor de
tecnologia de informação, que reduziram as barreiras para a movimentação da informação
e pode-se inferir que os mercados …nanceiros, de forma geral, estejam mais interligados.
Entretanto, não é possível a…rmar que estes mercados estejam mais suscestíveis a contágio
…nanceiro. De acordo com o Global Financial Report, FMI (2008), com a recente crise
do Subprime, iniciada nos Estados Unidos, a hipótese de descolamento1 (que pode ser
interpretada como hipótese de não-contágio) das economias emergentes foi posta a teste.
Este trabalho compreende um bloco teórico, onde são apresentados os fundamentos
econômicos e estatísticos que abrangem o tema e que, em um segundo bloco empírico,
servirão para o desenvolvimento dos modelos e testes necessários para se testar a hipótese
da evidência de contágio. No capítulo 2 é feita uma concisa revisão bibliográ…ca acerca da
teoria de contágio …nanceiro expondo, inclusive, de…nições e alguns estudos sobre contágio
…nanceiro envolvendo o Brasil. O capítulo 3 apresenta a teoria da metodologia de cópulas,
destacando sua …nalidade para modelagem de distribuições multivariadas. O capítulo 4
introduz algumas medidas de dependência, objeto de estudo na teoria de contágio, e destaca
as suas propriedades e …nalidades. Por …m, a teoria de cópulas condicionais e o método
para modelagem do fenômeno contágio são tratados no capítulo 5. Os capítulos 6 e 7
abrangem a parcela empírica desta dissertação, os princípios, testes e procedimentos até
Capítulo 2
Contágio …nanceiro
Encontra-se na literatura uma série de de…nições e formas de se mensurar o
fenô-meno do contágio …nanceiro, ao qual necessariamente está subjacente uma crise …nanceira
(choque). Devido às diferentes arquiteturas …nanceira-internacionais de cada país, seus
diferentes arranjos institucionais e à própria inerente complexidade das crises …nanceiras,
encontra-se uma grande variedade de estudos e modelos para se explicar o fenômeno do
contágio (Marçalet al. (2010)).Dessa forma, os resultados dos diferentes trabalhos
tornam-se de difícil comparação, di…cultando a apretornam-sentação aqui de um corpo teórico único e
consolidado.
De acordo com Edwards (2000), a literatura sobre contágio desenvolveu-se a partir
das crises …nanceiras da década de 90, que se espalharam para os países emergentes. Mesmo
antes da crise …nanceira mexicana de 1995, estudos e investigações relacionados ao tema
já constituíam parte da literatura econômica. Em pesquisa realizada pelo mesmo autor no
apresentava-se no abstract e/ou título, apenas 17 datavam de épocas anteriores à 1990.
No que se refere-se às principais crises …nanceiras dos últimos anos, encontram-se
trabalhos sobre contágio aplicados à crise do México de 1995 (desvalorização do peso
mex-icano em dezembro de 1994), à crise asiática de 1997 (desvalorização da moeda tailandesa
em julho de 1997), à crise russa de 1998 (com a declaração de moratória do país em agosto
de 1998), à desvalorização do Real em janeiro de 1999, às quedas das ações das empresas de
tecnologia ao …m de 2000, à crise argentina em 2001 (com o colapso docurrency board em
dezembro de 2001), e mais recentemente à crise do Subprime em 2007 com a subseqüente
quebra do Banco Lehman Brothers no segundo semestre de 2008.
Ressalta-se que muito embora o fenômeno contágio tenha se iniciado a partir de
crises …nanceiras em mercados emergentes, não se restringe apenas a estes. É possível
encontrar uma série de estudos acerca de contágio …nanceiro entre países desenvolvidos,
como por exemplo, sobre a crise do Exchange Rate Mechanism em 1992, que atingiu vários
países da Europa (ver Giavazzi, et al. (2000)).
Segundo Rigobon (2002), acredita-se que o estudo do contágio começou com as três
grandes crises …nanceiras de meados dos anos 90 (mexicana, asiática e russa) que colocaram
vários países em desenvolvimento sob intenso estresse …nanceiro. Ainda, o autor a…rma que
a propagação das crises da Ásia e da Rússia, diferentemente da crise mexicana, ainda é de
difícil explicação tendo-se como base apenas as teorias1 existentes sobre o assunto.
2.1
De…nições de contágio …nanceiro
Embora não exista uma concordância clara que re…ra-se à de…nição de contágio e à
sua identi…cação empírica/cientí…ca, pode-se estabelecer certa identidade comum em todas
as suas de…nições: crises econômicas em fase inicial podem propagar-se para outros países
por meio do aumento das conexões entre os países envolvidos (Rigobon (2002)).
Claessens et al. (2000) de…nem contágio como a propagação de perturbações
no mercado de um país para o mercado de um outro país, evidenciadas por meio de
co-movimentos nas taxas de câmbio, preços de ações, ‡uxos de capitais e spreads soberanos.
Entre as de…nições apresentadas em Pericoli e Massimo (2003) está a que considera
contágio …nanceiro um aumento signi…cante da probabilidade de crise em um país,
condi-cional a uma crise em outro país. Trata-se esta da de…nição também utilizada no estudo
de Eichengrenn et al. (1996) que pretenderam veri…car se a ocorrência da crise cambial em
país aumenta a probabilidade de ataques especulativos em outros países. Após análise, nos
últimos trinta anos, de vintes países industrializados os autores encontraram evidências de
que o canal de transmissão de comércio entre países aumenta a probabilidade de contágio
durante crise cambiais.
Como apontado por Pericoli e Massimo (2003), qualquer corpo teórico sobre
con-tágio deve ser capaz de i) identi…car quais são os canais de transmissão internacional do
choque e ii) veri…car se estes são estáveis, i.e. se há descontinuidades nesses canais, se há
canais ativos apenas em períodos de crise, etc.
Seguindo a taxionomia adotada por Rigobon (2002), é possível agrupar as distintas
A primeira classe de contágio – shift contagion – engloba todas as de…nições
rela-cionadas a aumentos signi…cativos dos mecanismos de propagação de choques entre países.
Nestas, as transmissões de choques durante períodos de estabilidade econômica são
admiti-das como um canal estável de propagação. Intuitivamente, havendo aumento de intensidade
na transmissão dos choques durante os períodos de crise econômica em relação aos períodos
de estabilidade, esse aumento pode ser considerado contágio. Assim, as relações entre
mer-cados podem ser mensuradas por diversas estatísticas como a correlação entre os retornos
de ativos …nanceiros, a probabilidade de um ataque especulativo e a transmissão de choques
ou volatilidade.
Nota-se que esta classe de de…nições encara o fenômeno do contágio como um
aumento na intensidade das relações entre os países, sem focar em como essa mudança
ocorre. As de…nições de Claessenset al. (2000) e Eichengrennet al. (1996) situam-se aqui.
A segunda classe de contágio – contágio puro – foca no tipo de mecanismo de
propagação que transmite o choque. O princípio base dessas de…nições é considerar apenas
os choques que não são transmitidos pelos canais padrões de transmissão (e.g. relações
comerciais) e que, portanto, não podem ser explicados pelos fundamentos econômicos, como
contágio. Assim, a presença de contágio …ca evidenciada pelos excessos de transmissão de
choques que não são explicados pelos fundamentos econômicos-…nanceiros do país.
A principal vantagem desta segunda classe com relação a primeira (shift
conta-gion), segundo Rigobon (2002), está em sua de…nição extensa de contágio. Nas de…nições
pertencentes acontágio puro, os mecanismos de transmissão de choques são explicitamente
Na prática, entretanto, a vantagem pode tornar-se incoveniente, posto que a implementação
empírica necessária para testar essa classe de de…nições é consideravelmente mais complexa
do que no caso do shift contagion. Na maior parte dos estudos relacionados a contágio
puro, o contágio é tratado como o resíduo de uma regressão (i.e. a propagação que não
é explicada pelos canais explicitamente modelados). Assim, se algum canal relevante de
transmissão não for considerado na especi…cação, as conclusões da análise empírica poderão
ser viesadas.
No presente estudo, contágio …nanceiro é de…nido como o aumento signi…cante
das conexões entre mercados após choque em um país especí…co, nos moldes da classe de
shift-contagion. Dessa forma, a presença de contágio …nanceiro se provará por meio de uma
quebra (estrutural) do comportamento padrão dessas relações entre países. De acordo com
Forbes e Rigobon (2002), o uso desta de…nição apresenta a vantagem da não necessidade
de explicitação do canal de transmissão do choque. E dado a extensa literatura sobre
canais de propagação internacional de choques, ao de…nir-se contágio como retro-proposto,
evita-se a necessidade de mensuração e diferenciação desses diversos canais de transmissão
de choques. Tal proveito deverá estender-se também a questões empíricas, posto não ser
possível observar todos os canais de transmissão de choques entre países (a de…nição em
questão contorna tal restrição ao considerar toda informação disponível pelas observações
em períodos de estabilidade econômica).
Patton (2009) identi…ca, porém, uma relevante di…culdade enfrentada ao se utilizar
essa de…nição, visto que a mesma exige a proposição de um ponto de referência para o que
antes de se testar a hipótese da ocorrência de contágio.
Outra limitação, apresentada por Rigobon (2002), reside no fato de a de…nição
aqui pretendida ser aplicável apenas no sentido a…rmativo e não no sentido restritivo. Em
outras palavras, a presença de um aumento da intensidade dos co-movimentos nos preços
de mercados, condicionada a uma crise ocorrendo em um país especí…co, é manifestação
de contágio …nanceiro. Já a ausência dessa mudança nos canais de transmissão não pode
ser considerada uma evidência da inexistência de contágio. Segundo o autor, a de…nição,
portanto, não permite testar a ausência de contágio …nanceiro uma vez que não explicita
um canal especí…co de transmissão de choques.
Por …m, vale ressaltar - princípio básico da teoria sobre investimento - que grande
parte dos distúrbios econômicos são idiossincráticos a cada país, de modo que os
merca-dos de ações em diferentes países devem apresentar, relativamente, baixas correlações. A
correlação entre mercados nacionais é um dos principais elementos para administração de
carteiras internacionais e a diversi…cação internacional entre mercados permite reduzir o
risco total dessas carteiras sem, aparentemente, sacrifícios sobre o retorno. Entretanto, se
as correlações entre mercados aumentam após um choque negativo,i.e. em períodos onde os
benefícios da diversi…cação do risco são mais demandados, a evidência do fenômeno contágio
…nanceiro pode ser interpretada como contrária à e…cácia da diversi…cação internacional,
2.2
Testes empíricos sobre contágio
Como visto na seção anterior, uma teoria sobre contágio deve ser capaz de
iden-ti…car os canais de transmissão do choque e veri…car se estes são estáveis ou ativos apenas
em períodos de crise.
As di…culdades econométricas enfrentadas na modelagem de contágio devem-se
basicamente ao fato do fenômeno ser, muitas vezes, mensurado com variáveis de freqüência
diária, por exemplo retornos dos mercados de ações, taxas de juros, spread soberano e
taxas de câmbio. Dentre os problemas que essas variáveis apresentam, Rigobon (2001)
aponta para os seguintes: viés de omissão, simultaneidade, heteroscedasticidade condicional
e incondicional, correlação serial, não linearidade e a não normalidade.
Tomando-se como exemplo os retornos diários sob a ótica do mercado …nanceiro,
estes apresentam heteroscedasticidade condicional e incondicional, correlação serial e são
não-normais. Sob a perspectiva macroeconômica, retornos internacionais são
simultanea-mente determinados e estão constantesimultanea-mente sujeitos a choques comuns e não observáveis
como mudanças de expectativa do investidor e choques de liquidez.
Dentre as principais metodologias para se mensurar contágio …nanceiro,
encontram-se na literatura estudos envolvendo o coe…ciente de correlação linear, modelos de
compo-nentes principais, regressões lineares, modelos logit-probit e, mais recentemente, os
mod-elos GARCH multivariados, regressões quantílicas e a modelagem por cópulas. Uma
re-comendável revisão bibliográ…ca de algumas metodologias utilizadas para mensurar o
2.3
Contágio …nanceiro no Brasil
Entre os primeiros trabalhos realizados sobre o tema, destaca-se, dentro do propósito
aqui pretendido, o de Baig e Goldfajn (2000), que examina a ocorrência de contágio na crise
russa com relação ao Brasil, através da análise dos spreads de títulos Brady e índices de
mercado de ações. Os autores, dotando-se de uma técnica de ajuste dos coe…cientes de
correlação, proposta por Forbes e Rigobon (2002), concluem a ocorrência do contágio, por
meio de uma parada súbita no ‡uxo de capitais para Brasil e Rússia, sob o mecanismo de
propagação do mercado de títulos da dívida.
O estudo de Mendes (2005) se destingue por utilizar uma metodologia semelhante
à empregada neste estudo. A autora procura, por meio da teoria de cópulas, evidências de
excesso de co-movimentos entre mercados que não sejam, necessariamente, explicados por
teorias econômicas. A análise é feita para sete mercados de ações da América Latina, Ásia
e África. Dentre os resultados encontrados, destaca-se o aumento de dependência durante
perdas conjuntas, para os pares de países Argentina e México e Brasil e México.
Em Marçal e Valls Pereira (2008), testa-se a hipótese de contágio …nanceiro no
mercado de títulos soberanos de quatros países emergentes (Brasil, Argentina, México e
Rússia) durante as crises da década de 90. O teste é feito a partir de diferentes modelos
de volatilidade multivariada. Os resultados evidenciaram que as estruturas de volatilidade
não foram constantes durantes as crises …nanceiras do período.
No recente trabalho de Marçal et al. (2010), os autores seguem percurso ainda
mais rigoroso ao analisarem a presença de contágio …nanceiro condicionada aos fundamentos
foi muito bem exposto no trabalho de Pesaran e Pick (2003). Nele, os autores investigam
as condições sob as quais o fenômeno do contágio pode ser diferenciado de movimentos de
interdependência2.
Em Marçal et al. (2010), a partir da utilização de modelos multivariados DCC,
testa-se a hipótese de contágio entre os países da América Latina e Ásia durante as crises
…nanceiras ocorridas entre 1994 e 2003. Entre os resultados, os autores apresentam
ev-idências de contágio regional na América Latina e Ásia, e contágio …nanceiro da Ásia para
América Latina. Os resultados apontam ainda para os Estados Unidos como vetor de
con-tágio para os países da América Latina e o Japão, como vetor de concon-tágio para países da
Ásia e América Latina.
Por …m, vale a menção ao recente estudo feito por Souza e Tabak (2009), como
ex-emplo ilustrativo da aplicabilidade da teoria de contágio …nanceiro. Estes autores estendem
a de…nição de contágio para investigar sua ocorrência entre os mercados bancários, durante
a crise do Subprime. Considerando uma amostra de 48 países e realizando testes com base
na metodologia proposta por Forbes e Rigobon (2002), os autores criaram umranking dos
países que mais sofreram contágio. No que se aplica ao Brasil, concluem que, de maneira
geral, o efeito do contágio sobre os bancos brasileiros foi limitado.
Capítulo 3
Introdução à cópulas
A teoria de cópulas está diretamente ligada à teoria de modelagem de distribuições
multivariadas e, portanto, ao conceito de dependência.
Com efeito, toda distribuição multivariada possui informações sobre as distribuições
marginais e sobre as relações de dependência entre as variáveis.
Por de…nição, a distribuição bivariada das variáveis de interesse Y1,Y2 é dada por F(y1; y2) = P(Y1 y1; Y2 y2). De acordo com Trivedi e Zimmer (2007), as seguintes
propriedades são necessárias e su…cientes para queF(y1; y2)seja uma distribuição conjunta
contínua pela direita:
limyj! 1F(y1; y2) = 0 paraj= 1;2.
limyj!1F(y1; y2) = 1 paraj= 1;2.
Peladesigualdade retangular, para todo(a1; b1)e(a2; b2)coma1 a2eb1 b2, temos
As duas primeiras propriedades garantem 0 F 1, enquanto que a última trata-se simplesmente da versão bidimensional da propriedade análoga de uma função
uni-dimensional não decrescente1.
A partir da distribuição conjunta F(y1; y2), as distribuições marginais F1(y1) e F2(y2) das variáveisY1 e Y2, respectivamente, são obtidas por:
F1(y1) =P(Y1 y1) =P(Y1 y1 eY2 1)
= lim
y2!1
F(y1; y2)
F2(y2) =P(Y2 y2) =P(Y1 1 eY2 y2)
= lim
y1!1
F(y1; y2):
(3.1)
A distribuição marginal de uma variável é, portanto, obtida pelo limite da outra variável
na distribuição conjunta (o que pela de…nição de distribuição conjunta equivale a dizer que
a ocorrência da outra variável é garantida).
No que tange às relações de dependência, pelo Teorema de Bayes temos que:
F(y1; y2) =F1j2(y1jy2)F2(y2) =F2j1(y2jy1)F1(y1)
Para f1(y1); f2(y2) > 0.Para o caso exclusivo de variáveis independentes, F1j2(y1jy2) =
P(Y1 y1) =F1(y1)ou F2j1(y2jy1) =P(Y2 y2) =F2(y2) e, portanto: F(y1; y2) =F1(y1)F2(y2)
Assim, a distribuição conjunta de um vetor de variáveis independentes está determinada
somente pelas distribuições marginais de cada variável. Para o caso de não independência
entre variáveis, a distribuição conjunta se caracterizará não só pelas distribuições marginais
como também por uma estrutura de dependência entre as variáveis.
A modelagem da distribuição multivariada por cópulas permite isolar dessa
estru-tura de dependência a estruestru-tura das distribuições marginais, permitindo, como apontado por
McNeil, et al. (2005), uma modelagem das distribuições multivariadas do “especí…co para
o geral”. Parte-se da investigação das distribuições marginais que, via de regra, oferecem
ao pesquisador uma gama maior de informações comparativamente à distribuição conjunta.
A teoria de cópulas possibilita a combinação das distribuições marginais com uma
variedade de modelos de dependência representados pelas funções cópulas. Para simpli…car
a exposição, a teoria apresentada focará apenas nas distribuições bivariadas, muito embora
seja aplicável também a dimensões maiores.
3.1
Cópulas
Antes de apresentar o Teorema de Sklar – base para a teoria de cópulas e pelo
qual se faz a ligação entre a função cópula e a distribuição conjunta – será de…nida a função
cópula.
Uma função cópula bidimensional C é uma função de[0;1]2 ![0;1]que satisfaz as seguintes propriedades:
C(u1;0) =C(0; u2) = 0, para todou1,u2 2[0;1]
C(u1;1) =u1 e C(1; u2) =u2, para todou1,u2 2[0;1]
Para todo (a1; b1) e (a2; b2), onde a1 a2 e b1 b2, é válido
A partir da de…nição acima, e graças à similaridades com as propriedades que
uma distribuição conjunta deve atender, pode-se interpretar uma função cópula como uma
função que associa o plano unitário (no caso bidimensional) ao intervalo unitário. Ou
alternativamente, e de acordo com Nelsen (2006), cópulas são distribuições conjuntas cujas
distribuições marginais são uniformes no intervalo (0;1).
3.1.1 Transformação Integral de probabilidade
Uma função cópula possui informações, a respeito da distribuição conjunta, que
não pertencem às distribuições marginais. O isolamento das informações contidas nas
dis-tribuições marginais é obtido pela transformação integral de probabilidade, também
con-hecida como transformação quantílica.
Seja Fi a função de distribuição de uma variável Yi, a função quantílica de Fi é
de…nida para todo u2(0;1)pela sua inversa generalizada2, como segue
Fi (u) = inffyi2R:Fi(yi) ug (3.2)
Assim, a transformação integral de probabilidade assegura que Yi distribui-se de forma
Fi. De…nindo as variáveis aleatórias U1 e U2 como Ui Fi(Yi), então Ui distribui-se
uniformemente no intervalo unitário(0;1). Vale ressaltar que a recíproca também é válida,
i.e. seUi U nif orme(0;1)então paraYi Fi (Ui), temos Yi Fi.
2A inversa generalizada
F é a função inversa F 1, quando
3.2
Teorema de Sklar
Como já mencionado, a estrutura de dependência entre as variáveis de um vetor é
completamente descrita por sua distribuição conjunta. A abordagem por cópulas permite
o isolamento das distribuições marginais de cada variável e de mais uma estrutura de
de-pendência, a partir da distribuição conjunta. Tal separação está assegurada por meio de
um dos mais importantes pilares que fundamentam esta teoria, conhecido como Teorema
de Sklar. Pelo Teorema de Sklar (1959), é possível obter a distribuição conjunta de um
vetor de variáveis a partir da função cópula e das transformações das variáveis em suas
respectivas distribuições marginais uniformes, como segue:
F(y1; y2) =P(Y1 y1; Y2 y2)
=P(U1 F1(y1); U2 F2(y2))
=C(F1(y1); F2(y2))
(3.3)
Para uma melhor visualização da separação da estrutura de dependência e das
distribuições marginais, convém apresentar uma versão do Teorema de Sklar em termos de
funções de densidade de probabilidade.
Sejaf a função de densidade conjunta das variáveisY1 eY2;efi, suas respectivas
funções de densidade marginais, por de…nição:
f(y1; y2) =
@F(y1; y2) @y1@y2
Como foi visto, pelo Teorema de Sklar,F(y1; y2) =C(F1(y1); F2(y2))e, portanto:
f(y1; y2) =
Utilizando a regra da cadeia e substituindou1 por Fi(yi)para i= 1;2;tem se que
f(y1; y2) = @C@y(1u1@y;u22)f1(y1)f2(y2)
=c(u1; u2)f1(y1)f2(y2)
(3.4)
onde c( ) é a função de densidade cópula3. Pela representação acima, sob a hipótese
de independência entre as variáveis que compõem a distribuição conjunta, infere-se que
c(u1; u2) = 1 e, portanto,f(y1; y2) =f1(y1)f2(y2).
Assim, a função cópula contém informações, sobre a distribuição conjunta, que não
estão presentes nas distribuições marginais. Ao converter-se, por meio da transformação
quantílica, as variáveisY1 eY2 em variáveis uniformes, a informação das distribuições
mar-ginais será …ltrada, posto que U1 e U2 serão uniformes (0;1), independente de F1 e F2.
Segundo Patton (2002), por essa razão a função cópula também é conhecida como função
de dependência.
3.3
Funções cópulas
Essa seção apresenta de maneira sucinta alguns tipos de funções cópulas. Antes,
porém serão exibidos dois exemplos para obtenção das funções cópulas a partir do método
de …ltragem das informações das distribuições marginais.
Através da própria de…nição da função cópula C( ), como uma distribuição
con-junta com marginais uniformes, pelo Teorema de Sklar tem-se que,
C(u1; u2) =F F1 1(u1); F2 1(u2) (3.5)
A partir dessa equivalente representação do Teorema de Sklar, é possível obter-se a função
cópula dada uma distribuição conjunta.
Supondo Y1 e Y2 duas variáveis aleatórias que distribuem-se conjuntamente como
uma distribuição logística (Gumbel) bivariada,
F(y1; y2) = 1 +e y1 +e y2 1
Como foi visto, equação 3.1, as distribuições marginais podem ser obtidas por meio de
Fj(yj) = limyi!1F(y1; y2), para i =6 j e, portanto, Fi(yi) = (1 +e yi) para i = 1;2.
Assim, pela transformação quantílica, u1 =F1(y1) e u2 =F2(y2). As funções inversas são
dadas porFi 1(ui) = log ui 1 1 parai= 1;2. Em vista disso e, através da distribuição
conjuntaF(y1; y2)e das funções inversasF1 1(u1)eF2 1(u2), é possível determinar a função
cópula logística (Gumbel) bivariada, pela equação 3.5, onde
C(u1; u2) =F F1 1(u1); F2 1(u2)
= u1u2
u1+u2 u1u2
O mesmo princípio pode ser aplicado para determinar a função cópulagaussiana.
Supondo Y1 e Y2 duas variáveis que se distribuem conjuntamente como uma distribuição
gaussiana bivariada, com coe…ciente de correlação linear ,i.e.
F(y1; y2) = (y1; y2)
As distribuições marginais serão distribuições gaussianas univariadas, i.e. F1(y1) = (y1)
eF2(y2) = (y2). Assim, pela transformação quantílica,y1 = 1(u1) ey2 = 1(u2). A
representação da cópula gaussiana é dada por
CG(u1; u2) =F F1 1(u1); F2 1(u2)
= 1(u
A cópula gaussiana é, portanto, a função de dependência associada a uma normal
bivariada, e embora não possua uma fórmula fechada, sua forma funcional é dada por
CG(u1; u2j ) =
Z 1(u
1)
1
Z 1(u
2)
1
1
2 p1 2exp
(
s2 2 st+t2
2 (1 2)
)
dsdt (3.6)
onde 2( 1;+1). Assim à medida que o coe…ciente de correlação linear se aproxima dos limites de seu domínio, a dispersão das variáveis uniformes u1 e u2 no quadrado unitário
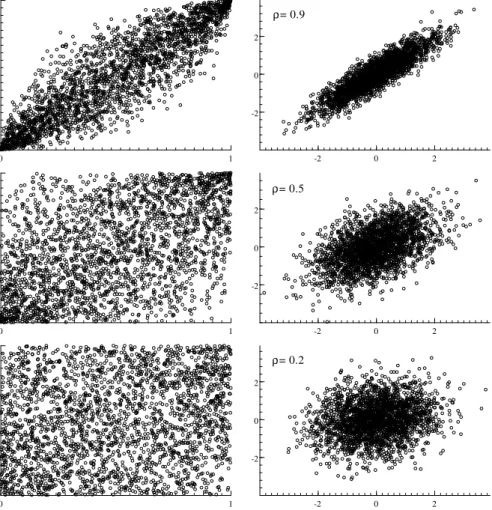
diminui. A Figura 3.1 apresenta diferentes distribuições conjuntas construídas a partir de
marginais normais padrão e a cópula gaussiana.
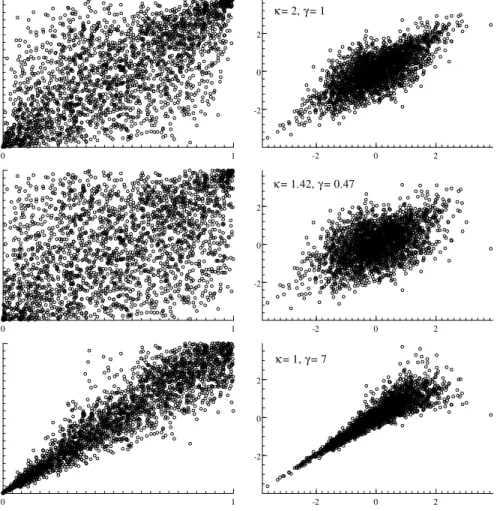
Outro exemplo de função cópula é a Joe-Clayton, também conhecida como cópula
BB7 de Joe (1997). Essa função cópula é construída a partir da transformação de Laplace
da cópula Clayton, e sua especi…cação é dada por
CJC(u1; u2j ; ) = 1 1
n
[1 (1 u1) ] + [1 (1 u2) ] 1
o 1 1
(3.7)
onde 1e >0. Dentre as propriedades dessa função cópula, destaca-se que ela converge para a cópula Clayton4para = 1, e para ! 1ou ! 1a funçãoC
JC atinge a fronteira
superior de Fr·echet-Hoe¤ding5. Outra propriedade útil dessa função é o fato de que e
são diretamente relacionados com as medidas de dependência de cauda, que captam o
comportamento de variáveis aleatórias durante eventos extremos. O comportamento de
e sobre a distribuição conjunta, construída a partir de marginais normais-padrão, é
apresentado na Figura 3.2.
Nota-se que, para ambas funções cópulas, o efeito de diferentes valores do(s)
parâmetro(s) de dependência sobre a distribuição das variáveis uniformes no quadrado
4A cópula Clayton é de…na como
CC(u1; u2j ) = u1 +u2 1 1=
0 1 1
-2 0 2
-2 0 2
ρ= 0.9
0 1
1
-2 0 2
-2 0 2
ρ= 0.5
0 1
1
-2 0 2
-2 0 2
ρ= 0.2
unitário. No caso de dependência positiva, quanto maior a direção do parâmetro para
a dependência entre as variáveis, mais próximo o par(u1; u2)estará da diagonal principal.
3.4
Copulas
especiais
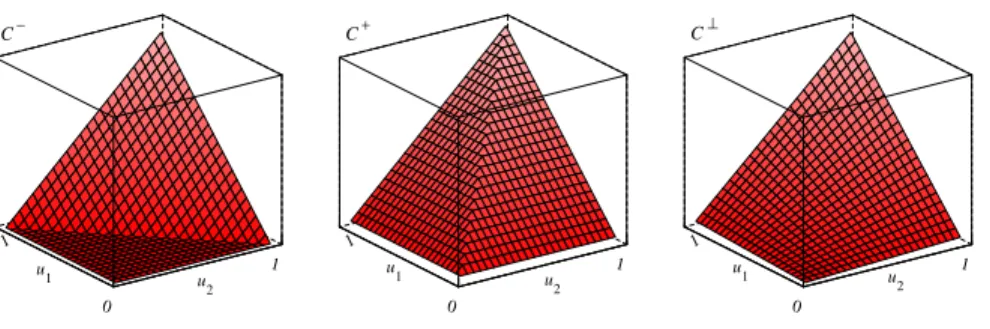
Um importante resultado na teoria de cópulas, conhecido como Fronteiras de
Fr·echet-Hoe¤ding, garante que toda função cópula possui uma fronteira inferior e
supe-rior, que são aqui denotadas por C e C+, respectivamente. O resultado permite para
qualquer ponto (u1; u2)2[0;1]2, que
C (u1; u2) C(u1; u2) C+(u1; u2) (3.8)
ondeC (u1; u2) = max [u1+u2 1;0]eC+(u1; u2) = min [u1; u2]. O conhecimento dessas
fronteiras é importantíssimo na escolha da função cópula. Segundo Trivedi e Zimmer (2007),
uma propriedade desejável de uma cópula é que esta cubra todo o espaço amostral entre os
limites superior e inferior, de modo a permitir, à medida que o parâmetro de C(u1; u2) se
aproxime do limite inferior (superior) de seu domínio, que a função cópula se aproxime da
fronteira inferior (superior). Entretanto, devido às suas formas funcionais, algumas funções
cópulas apresentam restrições que as impedem de alcançar uma ou ambas as fronteiras.
Outra cópula merecedora de destaque é a cópula produto, denotada por C?. A
cópula produto é o resultado obtido quando as distribuições marginais são independentes.
Sua forma funcional é dada porC?=u1u2. Nota-se que sua respectiva função de densidade
0 1 1
-2 0 2
-2 0 2
κ= 2,γ= 1
0 1
1
-2 0 2
-2 0 2
κ= 1.42,γ= 0.47
0 1
1
-2 0 2
-2 0 2
κ= 1,γ= 7
Uma função cópula que incluaC ,C+eC?é chamada decompreensiva. A Figura
3.3 apresenta a distribuição conjunta das três cópulas.
Por …m, vale ainda mencionar a função cópula sobrevida Cb(u1; u2). A função
sobrevida de uma distribuição bivariadaF(y1; y2) é denotada porF(y1; y2) e implica em
F(y1; y2) =P(Y1 > y1; Y2 > y2) (3.9)
Em …nanças, não é raro o interesse sobre o tempo remanescente de um instrumento
…nanceiro, como exemplo, na administração de risco de crédito, a modelagem do tempo para
o default de uma cesta de crédito.
Supondo, pelo Teorema de Sklar, a função cópula implícita emF(y1; y2) dada por C( ), então
F(y1; y2) =P(Y1 y1; Y2 y2)
= 1 P(Y1 > y1; Y2 > y2)
= 1 F1(y1) F2(y2) +F(y1; y2)
u2
u1
C−
0
1 1
u2
u1
C+
0
1 1
u1
u2
C⊥
0
1 1
Assim, é possível representar F(y1; y2) por
F(y1; y2) =F1(y1) +F2(y2) 1 +C(F1(y1); F2(y2))
=F1(y1) +F2(y2) 1 +C 1 F1(y1);1 F2(y2)
A função cópulasobrevidaCbda funçãoF(y1; y2)pode ser obtida a partir da “representação”
sobrevida do Teorema Sklar, onde F(y1; y2) =C Fb 1(y1); F2(y2) e
b
C(u1; u2) =u1+u2 1 +C(1 u1;1 u2)
De acordo com Nelsen (2006), a cópula sobrevida não deve ser confundida com uma
dis-tribuição conjunta sobrevida C para duas variáveis uniforme u1 e u2, cuja distribuição é
uma cópulaC,i.e.
C(u1; u2) =F(u1; u2)
=P(U1> u1; U2 > u2)
A relação entre as cópulas C e Cb é dada por C(u1; u2) = Cb(1 u1;1 u2). A
função C é utilizada quando se deseja “inverter” a direção da função cópula e, portanto, inverter a relação de dependência da distribuição.
3.5
Métodos de estimação
Esta seção apresenta as principais abordagens presentes na referente literatura
para se estimar os parâmetros da função cópula. A principal metodologia de estimação
utilizada é o método da máxima verossimilhança (ML). Dentre as principais propriedades
do estimador de máxima verossimilhança, encontram-se a consistência, e…ciência assintótica
Um método alternativo, porém não muito utilizado na prática, é a estimação
dos parâmetros a partir do método de momentos generalizados (GMM). Tal método, não
necessita de hipóteses explícitas sobre as distribuições dos erros, contudo requer as condições
de momentos6.
Sob o princípio da máxima verossimilhança, a estimação pode ser feita por meio
de três abordagens distintas: MVE (Máxima Verossimilhança Exata), IM (Inferência para
as Marginais) e MVC (Máxima Verossimilhança Canônica).
3.5.1 Máxima Verossimilhança Exata
Seja fy1;t; y2;tgTt=1 uma amostra aleatória de duas variáveis de interesse com T
observações. Pelo Teorema de Sklar, a distribuição conjunta dessas variáveis é descrita por
C(F1(y1;t); F2(y2;t)). A função log-verossimilhança é obtida a partir da equação 3.4 e dada
por
L( ) =
T
X
t=1
lnc(F1(y1;t); F2(y2;t)j c) + T
X
t=1
lnf1(y1;tj 1) +
T
X
t=1
lnf2(y2;tj 2) (3.10)
onde, é um vetor de parâmetros que inclui os parâmetros da cópula e das distribuições
marginais. O estimador MV –bM V E – é determinado por
bM V E = arg max
2 L
( )
Por onde é possível mostrar, Davidson e MacKinnon (1993), que sob certas condições de
reg-ularidades o estimador é consistente, assintoticamente e…ciente e assintoticamente normal,
i.e.
p
T bM V E 0 ! N 0;I 1( 0)
onde, I( 0) é a matrix de informação de Fisher e 0 o verdadeiro valor do parâmetro.
Visto isso, a abordagem MVE segue o mesmo princípio do método de máxima
verossimilhança, ou seja, os parâmetros das distribuições marginais e da função cópula são
estimados conjuntamente. Uma desvantagem, apontada por Bouyé et al. (2000) e
Pat-ton (2002), …ca evidente ao utilizar-se a abordagem MVE para distribuições com grandes
dimensões. O método torna-se computacionalmente intensivo, uma vez que a
maximiza-ção é feita numericamente – não há solumaximiza-ção analítica para a maximizamaximiza-ção da funmaximiza-ção
log-verossimilhança. Outra desvantagem da abordagem MVE se deve ao fato de que os
parâmet-ros da cópula são estimados sob hipóteses acerca das distribuições das marginais.
3.5.2 Inferência para as Marginais
A abordagem IM, proposta por Joe (1997), tem como princípio a própria teoria de
cópulas. Nessa abordagem há uma separação do vetor de parâmetros em parâmetros
es-pecí…cos para as distribuições marginais( 1 e 2)e em parâmetros comuns para a estrutura
de dependência ( c).
Da equação 3.10, a função log-verossimilhança é dada por
L( ) =
T
X
t=1
lnc(F1(y1;t); F2(y2;t)j c) + T
X
t=1
lnf1(y1;tj 1) +
T
X
t=1
lnf2(y2;tj 2)
Sendo a função log-verossimilhança composta por dois termos aditivos, um envolvendo a
função de densidade da cópula e outro envolvendo a função de densidade das marginais, a
estimação de é feita em dois estágios:
Estimação dos parâmetros das distribuições marginais,i.e.
bi= arg max
i2
T
P
t=1
Estimação dos parâmetros da função cópula, condicionada nas estimativas obtidas
para as marginais, i.e.
bc = arg max
c2
T
X
t=1
lnc F1 y1;tjb1 ; F2 y2;tjb2 j c
Assim, o estimador de máxima verossimilhança na abordagem IMF é dado por
bIM = b1,b2,bc , onde bc=f b1,b2 . É possível demonstrar que esse estimador é também
consistente, assintoticamente e…ciente e assintoticamente normal,i.e.
p
T b 0 ! N 0;V 1( 0)
onde V 1( 0) é a inversa da matriz de informação de Godambe7, construída a partir da
funçãoscore da função log-verossimilhança.
3.5.3 Máxima Verossimilhança Canônica
Diferentemente das abordagens EML e IMF, a abordagem CML não depende de
hipóteses sobre as distribuições das marginais para estimar os parâmetros c da função
cópula. A transformação das observações (y1;t; y2;t) em variáveis uniformes (u1;t; u2;t) é
feita utilizando-se as funções de distribuições empíricas FT
j (y), onde
FjT (y) = 1
T+ 1
T
X
t=1
I(Yj;t y) (3.11)
ondeI( )é uma função indicadora. Após tal transformação, os parâmetros da função cópula
são determinados por
bc = arg max
c2
T
X
t=1
lnc(ub1;t;ub2;tj c)
O estimador para c é chamado de estimador Omnibus8. A matrix de informação de
Go-dambe ou a matriz de covariância semi-paramétrica, dada em Genestet al. (1995), podem
ser usadas para inferência. De acordo com Genest et al. (1995), bM V C é consistente, assintoticamente e…ciente e assintoticamente normal.
3.6
Exemplo ilustrativo
Para …nalizar esse capítulo vale apresentar, através de um exemplo, a grande
‡ex-ibilidade que a teoria de cópulas nos fornece para a modelagem de distribuições conjuntas.
A Figura 3.4 apresenta diversas distribuições bivariadas construídas com distribuições
mar-ginais normais-padrão e com diferentes especi…cações de funções cópulas, calibradas de
modo a representar uma distribuição conjunta com coe…ciente de correlação linear igual a
0.5.
Pode-se claramente observar que o conhecimento das distribuições marginais
nor-mais e do coe…ciente de correlação linear não é su…ciente para descrever uma distribuição
conjunta9. Por exemplo, no caso da distribuição gerada a partir de uma cópula Clayton,
observa-se uma disposição das observações mais “a…ada” no quadrante negativo, indicando
uma maior dependência para eventos conjuntamente negativos do que positivos. Por outro
lado, a distribuição gerada a partir de uma cópula Gumbel, apresenta essa mesma
dis-posição “a…ada”, no quadrante positivo direito, evidenciando uma maior associação para
eventos conjuntamente positivos. A distribuição gerada por uma cópula t-student apre-8Ou pseudo estimador de verossimilhança.
0 -2.5
0.0 2.5
Copula Normal,ρ= 0.5
0.0185 0.037 0.0555 0.074 0.0925 0.111 0.1295 0.148 0.1665 0.0185 0.037 0.05550.0740.0925 0.1110.12950.148 0.1665 0.0185 0.037 0.0555 0.074 0.0925 0.111 0.1295 0.148 0.1665 0.0185 0.037 0.0555 0.074 0.0925 0.111 0.1295 0.148 0.1665 0 -2.5 0.0 2.5
Copulat-student,ρ= 0.5,ν= 3
0.022 0.044 0.066 0.088 0.11 0.132 0.154 0.176 0.198 0.022 0.044 0.066 0.088 0.11 0.1320.154 0.1760.198 0.022 0.044 0.066 0.088 0.11 0.132 0.154 0.176 0.198 0.022 0.044 0.066 0.088 0.11 0.132 0.154 0.176 0.198 0 -2.5 0.0 2.5
Copula Clayton,θ= 1
0.019 0.038 0.057 0.076 0.095 0.114 0.133 0.152 0.171 0.019 0.038 0.057 0.0760.095 0.1140.1330.152 0.171 0.019 0.038 0.057 0.076 0.095 0.114 0.133 0.152 0.171 0.019 0.038 0.057 0.076 0.095 0.114 0.133 0.152 0.171 0 -2.5 0.0 2.5
Copula Gumbel,δ= 1.5
0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0.0195 0.039 0.05850.078 0.0975 0.1170.1365 0.1560.1755 0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0 -2.5 0.0 2.5
Copula Joe-Clayton,κ= 1.42,γ= 0.47
0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0.0195 0.039 0.0585 0.0780.09750.117 0.1365 0.156 0.1755 0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0.0195 0.039 0.0585 0.078 0.0975 0.117 0.1365 0.156 0.1755 0 -2.5 0.0 2.5
Copula Plackett,ψ= 5
0.0215 0.043 0.0645 0.086 0.1075 0.129 0.1505 0.172 0.1935 0.0215 0.043 0.06450.0860.10750.1290.15050.1720.1935 0.0215 0.043 0.0645 0.086 0.1075 0.129 0.1505 0.172 0.1935 0.0215 0.043 0.0645 0.086 0.1075 0.129 0.1505 0.172 0.1935
Tabela 3.1: Medidas de dependência para distribuições conjuntas obtidas a partir das funções copulas e de distribuições marginaisN(0,1)
Dependência Dependência
Correlação da Cauda Quantílica (5%)
cópula Parâmetros Linear Superior Inferior Superior Inferior
Gaussiana( ) 0.5 0.50 0.00 0.00 0.24 0.24
t-student( ; ) 0.5 3 0.50* 0.31 0.31 0.37* 0.37*
Clayton ( ) 1 0.50* 0.00 0.50 0.10 0.51
Gumbel ( ) 1.5 0.50* 0.41 0.00 0.44 0.17
Joe Clayton ( ; ) 1.42 0.47 0.50* 0.37 0.23 0.38 0.32
Plackett( ) 5 0.50 0.00 0.00 0.18 0.18
Obs: Valores com * foram baseados nas simulações feitas em Patton (2002) e (2009).
senta contornos "a…ados"nos quadrantes positivos e negativos, indicando uma simetria de
dependência para eventos conjuntamente negativos e positivos.
Embora as distribuições conjuntas apresentem um coe…ciente de correlação linear
igual a 0.5, pode-se notar pela Tabela 3.1 que a estrutura de dependência em cada função
cópula, carrega medidas de dependência10 com valores distintos uns dos outros. Como
exemplo, pode-se notar que a cópula Normal não apresenta dependência da cauda inferior e
posterior e as dependências quantílicas são iguais em ambas as caudas. Já a cópula Gumbel,
apresenta dependência na cauda superior e dependência quantílica assimétrica.
Capítulo 4
Medidas de Dependência
Esta seção introduz de…nições e propriedades acerca das medidas de associação
utilizadas no presente trabalho. Antes, porém, são exibidas algumas propriedades básicas
que uma medida deve atender para medir adequadamente a associação entre quaisquer duas
variáveis aleatórias.
Em Nelsen (2006), é possível encontrar duas métricas de associação que de…nem
duas classes de medidas: a métrica da concordância ( ) e a métrica dadependência ( ). O
autor lista uma série de propriedades que uma medida deve atender para pertencer a cada
uma das métricas. O conceito de concordância é a mais básica de…nição de associação entre
duas variáveis aleatórias. Sejam(x1; y1) e (x2; y2), dois pares de observações das variáveis
aleatórias contínuas X e Y. Os pares são
Concordantes, se(x1 x2) (y1 y2)>0
Discordantes, se(x1 x2) (y1 y2)<0
análoga, a discordância implica que x1 x2 e y1 y2 possuem sinais opostos.
Uma diferença entre as medidas de dependência e as medidas de concordância é
dada no intervalo na qual elas estão de…nidas, onde ( )2[ 1;+1]e ( )2[0;+1]. Nota-se que essa propriedade permite que as medidas de concordância indiquem qual a “direção” da
associação entre as variáveis. Já as medidas de dependência apenas mostram se as variáveis
são funcionalmente dependentes ou não.
Outra característica marcante que distingue as medidas de concordância das
medi-das de dependência é a falta de reciprocidade entre a (in)dependência medi-das variáveis aleatórias
e a medida ser nula. Uma medida de concordância é igual a 1ou +1se as duas variáveis
forem perfeitamente dependentes e igual a zero se elas forem independentes. Entretanto,
o inverso não será necessariamente verdadeiro, i.e. ( ) = 1, 1, ou 0 não implica
var-iáveis perfeitamente dependentes ou independentes. Em outras palavras, independência e
dependência perfeita são condições su…cientes, porém não necessárias, para que a medida de
concordância seja igual a 1,1ou0. Por outro lado, nas medidas de dependência a recíproca
é legítima,i.e. a medida será nula se e somente se as variáveis forem independentes.
Em Embrechts et al. (2002), são listadas algumas propriedades, consideradas
pelos autores, necessárias à uma medida para que esta possa medir de forma adequada a
associação entre variáveis aleatórias. Seja ( ) uma medida de dependência1 que designa
um número real para qualquer par de variáveis aleatórias então, de acordo com os autores,
as propriedades desejáveis dessa medida são:
i. (Y1; Y2) = (Y2; Y1) (simetria)
ii. 1 (Y1; Y2) +1 (normalização)
iii. (Y1; Y2) = +1,Y1,Y2 são co-monotônicas
(Y1; Y2) = 1,Y1,Y2 são contra-monotônicas2
iv. ParaT :R!Ruma transformação estritamente monotônica no domínio de Y:
(Y1; Y2) =
8 > > < > > :
(T(Y1); Y2), paraT crescente
(T(Y1); Y2), paraT decrescente
Fica evidenciado que o índice de correlação linear satisfaz apenas as propriedades
i e ii. As medidas obtidas a partir das correlações de posto satisfazem as propriedades i a
iv, se as variáveis forem contínuas. Os autores frisam que as propriedades acima são apenas
uma seleção e a lista pode ser alterada e/ou estendida. Como exemplo de extensão, eles
adicionam a propriedade referente à independência: (Y1; Y2) = 0 $ Y1; Y2 são
indepen-dentes. Entretanto, pode-se mostrar que essa adição contradiz a propriedade iv, de não
alteração da medida sobre transformações monotônicas. Como foi apresentado no capítulo
3, a metodologia de cópulas permite decompor a distribuição em uma estrutura composta
pelas distribuições marginais e uma estrutura exclusiva para as relações de dependência
en-tre as variáveis pertencentes à distribuição multivariada. Sendo assim e como indicado logo
abaixo, muitas das medidas de associação podem ser determinadas diretamente a partir da
função cópulaC.
Dentre as medidas de concordância, destacam-se a correlação de Spearman e o tau
de Kendall. Ambas são medidas de correlação entre os postos (ranking) das variáveis, ao
2Duas variáveis serão co-monotônicas (i.e. terão dependência positiva perfeita), se elas possuem a copula
C+ e serão contra-monotônicas (i.e. dependência negativa perfeita)se elas possuírem a copula
invés de seus valores efetivos e, por isso, são também conhecidas como correlações de posto
(rank correlation). Conseqüentemente, tais medidas não são alteradas por transformações
crescentes entre as variáveis. Como pode ser visto abaixo, a correlação de Pearson, mais
conhecida como coe…ciente de correlação linear, é uma medida de concordância aplicável
apenas a variáveis que possuam distribuições elípticas3. Dentre as medidas de dependência,
destacam-se a dependência quantílica e a dependência de caudas.
4.1
Correlação de Pearson (coe…ciente de correlação linear)
O coe…ciente de correlação linear é freqüentemente usado como medida de
de-pendência entre duas variáveis. Seja Y1 e Y2, duas variáveis aleatórias com variâncias
…nitas e não nulas, a correlação entre elas é de…nida por
= p Cov(Y1; Y2)
var(Y1)pvar(Y2)
(4.1)
onde,Cov(Y1; Y2) =E(Y1Y2) E(Y1)E(Y2). O estimador amostral da correlação de
Pear-son é obtido a partir das contrapartidas amostrais da covariância e variância das variáveis
aleatórias.
A medida de Pearson, embora possa ser escrita a partir das funções cópulas, ela
terá o seu valor como função do tipo de distribuição marginal, pois
cov(Y1; Y2) =
Z Z
D
(F(y1; y2) F1(y1)F2(y2))dy1dy2
=
Z 1
0
Z 1
0
(C(u1; u2) u1u2)dF1 1(u1)dF2 1(u2)
ondeD é o domínio em que Y1 eY2 são de…nidas.
Embora o coe…ciente de correlação linear seja a medida mais popular utilizada
para medir a associação entre duas variáveis, ele apresenta várias de…ciências. Além disso,
as variáveis precisam atender a uma série de requisitos para que o coe…ciente de correlação
linear seja de fato uma medida de concordância. O estudo de Embrechtset al. (2002) relata
com maiores detalhes sobre a de…ciência do coe…ciente. Dentre suas limitações, os autores
citam:
A variância de ambas as variáveis deve ser …nita para que o coe…ciente seja de…nido.
Conseqüentemente, o estimador não é apropriado para medir dependência em
dis-tribuições com cauda pesadas4.
Correlação nula não implica independência, a não ser que o par (X; Y) se distribua
como uma normal bivariada. Nesse caso o coe…ciente de correlação linear é
represen-tativo da estrutura de dependência da distribuição.
Correlação não é invariante sob todas as transformações crescentes das variáveis, mas
somente sob as lineares, i.e. (aX+b; cY +d) = sign(a c) (X; Y). Um exemplo
de transformação estritamente crescente não válida é a transformação logarítmica,i.e.
log (X) e log (Y) terão, geralmente, correlação diferente deX,Y.
Dependência perfeita positiva ou negativa entre as variáveis não implica,
necessari-amente, que o valor numérico do coe…ciente é igual a 1 ou 1. O exemplo clássico
encontrado nos livros textos de estatísticas é X; X2 = 0, mesmo queXeX2sejam
perfeitamente dependentes.
4.2
Correlação de Spearman
A correlação de Spearman é uma medida não-paramétrica de associação baseada
em dados ordenados (ranked). Sejam(X1; Y1),(X2; Y2) e(X3; Y3)três pares independentes
de variáveis aleatórias com uma função de distribuição comum. A correlação de Spearman
( S) é de…nida como uma proporção da diferença entre a probabilidade de concordância e a probabilidade de discordância entre os pares(X1; Y1) e (X2; Y3),i.e.
S = 3 (P[(X1 X2) (Y1 Y3)>0] P[(X1 X2) (Y1 Y3)<0]) (4.2)
Como foi dito antes, as medidas de associações podem ser diretamente obtidas a
partir das funções cópulas e, no caso da correlação de Spearman, sua representação …ca
como segue:
S= 12
Z 1
0
Z 1
0
u1u2dC(u1; u2) 3 (4.3)
Nota-se que a integral acima é apenas o valor esperado do produto de duas variáveis
uni-formes em (0;1), cuja distribuição conjunta é dada pela cópula C e, portanto, pode ser reescrita como
S = 12 E(U1U2) 3
= E(U1U2) 1=4
1=12 =
Ep(U1U2) E(U1)E(U2)
var(U1)
p
var(U2)
onde a última igualdade deve-se ao fato de que E(U) = 12 e var(U) = 121. Nota-se, assim,
que a sua forma é idêntica à da correlação linear, o que justi…ca inclusive o seu nome.
O estimador da correlação de Spearman é dado por
bS=
12
n(n2 1)
n
X
i=1
posto(xi)
n+ 1
2 posto(yi)
n+ 1
onde o posto (rank) de uma observação representa sua posição em uma amostra ordenada.
Outra fórmula representativa do estimador da correlação de Spearman é obtida utilizando
di=posto(xi) posto(yi), onde
bS = 1
6 Pni=1d2i n(n2 1)
onde bS é um estimador viesado de S, porém, pode-se mostrar que, Balakrishnan e Lai
(2009),
E(bS) = (n 2) S+ 3 K
(n 1) ! S, paran! 1
onde K é o tau de Kendall (de…nido na próxima seção).
4.3
Tau de Kendall
O tau de Kendall também é uma medida de correlação de posto. Sejam (X1; Y1) e
(X2; Y2)dois pares de variáveis aleatórias identicamente e independentemente distribuídas,
o tau de Kendall K entre as variáveis é de…nido pela diferença entre a probabilidade de
concordância e a probabilidade de discordância entre os pares(X1; Y1) e (X2; Y2),i.e.
K =P[(X1 X2) (Y1 Y2)>0] P[(X1 X2) (Y1 Y2)<0] (4.5)
A de…nição de K acima é equivalente a K =cov[sign(X1 X2); sign(Y1 Y2)]5, e sua
representação em termos da função cópulaC é dada por
K = 4
Z 1
0
Z 1
0
C(u1; u2)dC(u1; u2) 1 (4.6)
PorR1 0
R1
0 C(u1; u2)dC(u1; u2)ser equivalente a
R1
0
R1
0 C(u1; u2)c(u1; u2)du1du2, a expressão
4.6 pode ser representada por K= 4 E[C(U1; U2)] 1.
5A função
Dada uma amostra, com tamanho n, de duas variáveis aleatórias X e Y, seja c o número de pares concordantes edo número de pares discordantes, o estimador amostral do tau de Kendall é dado por
bK =
c d c+d =
c d
n
2
= 2
n(n 1)
X
i<j
sign[(Xi Xj) (Yi Yj)] (4.7)
Diferentemente do estimador da correlação de Spearman, bK é um estimador não
viesado de K. Segundo Balakrishnan e Lai (2009), bK e bS são, relativamente ao b,
estimadores menos sensíveis à presença de outliers.
Embora sejam K e S medidas de probabilidades de concordância e
discordân-cia entre as variáveis aleatórias, dada uma distribuição, seus valores numéricos podem ser
freqüentemente diferentes. Ainda, de acordo com Balakrishnan e Lai (2009), há vários
ex-emplos indicando que uma relação precisa entre as duas medidas não existe para qualquer
distribuição bivariada. Porém é possível obter limites entre as duas medidas, como segue
3 K 1
2 S
1+2 K 2K
2 , para K 0
2
K+2 K 1
2 S 1 32 K, para K <0
De acordo com Gibbons (1993), a vantagem do tau de Kendall sobre a correlação
de Spearman reside na sua simples interpretação como a diferença, na amostra, entre a
proporção de pares concordantes e pares discordantes. Embora ambas medidas K e S
meçam o grau de associação entre variáveis, a de…nição da correlação de Spearman não
explicita, claramente, qual o tipo de associação entre as variáveis. O autor ainda destaca
que, mesmo que = S = K = 0:5, o valor 0:5 deve ser intrepretado de três maneiras
4.4
Dependência quantílica
A dependência quantílica está relacionada à medida de Coles et al. (1999) e mede
a probabilidade de duas variáveis estarem ambas abaixo ou acima de um terminado quantil
de suas distribuições univariadas, i.e. sendo " o limiar inferior e "+ o limiar superior, a
dependência quantílica superior e inferior entre as duas variáveis é dada por
("+) =P Y1 > F1 1("+)jY2 > F2 1("+)
(" ) =P Y1 F1 1(" )jY2 F2 1(" )
(4.8)
Pela equação 4.8, percebe-se que a dependência quantílica é uma medida
direta-mente associada ao conceito econômico de Valor em Risco (VaR) e pode ser representada
equivalentemente por
("+) =P[Y1 > V aRY1("+)jY2 > V aRY2("+)]
(" ) =P[Y1 V aRY1(" )jY2 V aRY2(" )]
ou seja, a dependência quantílica é representada como a probabilidade de ambas as variáveis
ultrapassarem seus valores em risco.
Pela transformação de probabilidade integral é possível obter a representação da
medida em termos da função cópulaC, onde
(u) =
8 > > < > > :
P(U1 > ujU2 > u) =
b
C(u;u)
u =
1 2u+C(u;u)
1 u , parau >1=2
P(U1 ujU2 u) = C(u;uu ), parau 1=2
4.5
Dependência das caudas
Diferentemente das outras medidas apresentadas até agora, a medida de
bi-variadas. Sendo U1, U2 duas variáveis aleatórias distribuídas uniformemente no intervalo
unitário (0;1) a dependência das caudas é de…nida como o limite das dependências quan-tílicas, com o limiarudirecionando-se aos extremos zero (no caso de dependência da cauda
inferior) ou 1 (dependência da cauda superior),i.e.
U = lim
u!1 P(U1 > ujU2 > u) = limu!1 P(U2> ujU1> u)
L= lim
u!0+P(U1 ujU2 u) = limu!0+P(U2 ujU1 u)
(4.9)
Do mesmo modo apresentado até agora para as demais medidas, U e Lpodem ser obtidas
diretamente a partir da função cópulaC, onde:
U = lim
u!1
C(u;u)
1 u = limu!1
1 2u+C(u;u) 1 u
L= lim
u!0+
C(u;u)
u
Assim se U 2(0;1]então a cópula C apresenta dependência na cauda superior e
C não terá dependência na cauda superior se U = 0. Similarmente, se L2(0;1], a cópula
C possui dependência na cauda inferior e para L = 0, a cópula C não tem dependência
na cauda inferior. Portanto, sempre que U, L2(0;1], as variáveis aleatóriasY
1 e Y2 são
assintoticamente dependentes nas caudas superior e inferior. No caso em que U, L = 0,
as variáveis são assintoticamente independentes nas caudas superior e inferior.
4.6
Outras medidas de associação
Entre outras medidas que merecem destaque e possuem aplicabilidade na
mode-lagem …nanceira estão o índice de Gini, a Dependência do Quadrante Positivo (DQP) e o
O índice de Gini de duas variáveis aleatórias, cuja função cópula éC, é dado por
= 2
Z 1
0
Z 1
0
(ju1+u2 1j ju1 u2j)dC(u1; u2) (4.10)
O índice de Gini é, do mesmo modo que o tau de Kendall e a correlação de Spearman, uma
medida de associação baseada na métrica da concordância. O trabalho de Sun e Wu (2009)
usa uma versão condicional do índice como medida de dependência entre o índice S&P500
e o VIX6.
O beta de Blomqvist também é uma medida de associação que segue a métrica
da concordância e avalia a dependência no centro da distribuição, dado pelas medianas das
distribuições marginais. Por essa razão o beta de Blomqvist também é conhecido como
o coe…ciente de correlação mediana. Assim, sendo (ye1;ye2) as medianas de duas variáveis
aleatórias, o índice de dependência é dado por
= 2P[(Y1 ye1) (Y2 ye2)>0] 1 = 4C
1 2;
1
2 1 (4.11)
Pode-se notar que, no caso de independência, C( ) =C?( ) = u1u2 e, portanto,
= 0 seY1 e Y2 forem independentes. O beta de Blomqvist, por medir a dependência em
torno da mediana e por esta última ser uma medida de locação mais robusta à presença
de outliers, é também utilizado para modelagem …nanceira. O trabalho de Harvey (2008)
utiliza, além da dependência de cauda, o beta de Blomqvist para detectar a presença de
contágio …nanceiro entre os mercados de Hong Kong e da Coreia do Sul, durante o ataque
especulativo de 1997.
Por …m, destaca-se a Dependência do Quadrante Positivo (DQP), uma associação
uma medida de dependência. SejamY1eY2duas variáveis aleatórias, elas serão dependentes
no quadrante positivo, se
P(Y1 > y1; Y2 > y2) P(Y1 > y1)P(Y2> y2) (4.12)
o que, em termos da função cópula, é representada por C C?. Assim se as variáveis
aleatórias representam perdas …nanceiras, a dependência do quadrante positivo implicará
em uma perda simultânea maior sob dependência entre as variáveis do que sob variáveis
independentes. Se as variáveis se distribuem de acordo com uma distribuição F( ), então a DQP implica que
F(y1; y2) F1(y1)F2(y2) para todo (y1; y2)2R2
PeloTeorema de Bayes, a desigualdade da DQP implica emP(Y1 y1jY2 y2) P(Y1 y1),
ou equivalentemente, P(Y2 y2jY1 y1) P(Y2 y2). O trabalho de Mendes (2005)
uti-liza uma variação desta última desigualdade para analisar a presença de contágio entre sete
principais índices de mercados no mundo.
Para …nalizar a seção, vale frisar que embora o termo dependência, visto em Nelsen
(2006), envolva um conceito fechado, com propriedades especí…cas, ele é usado no presente
Capítulo 5
Cópulas
condicionais
Esta seção tem como objetivo fazer a conexão entre as teorias de contágio
…nan-ceiro e a de cópulas, i.e. como se faz possível a modelagem de contágio com cópulas. A
aplicação de cópulas para séries de tempo possui duas abordagens distintas: uma delas se
concentra na cópula de uma seqüencia de observações de série de tempo univariada, e.g. na
distribuição conjunta de (Yt; Yt+1; :::; Yt+n) para capturar eventuais dependências entre as
observações de uma mesma série. Essa abordagem nos leva a considerar modelos de séries
de tempo não lineares. A segunda abordagem se concentra na aplicação de modelos de
séries de tempo multivariados, onde o …m é modelar a distribuição conjunta de um vetor
aleatório Yt = (Y1;t; Y2;t:::; Yk;t) condicional a algum conjunto de informação . Essa
se-gunda abordagem nos leva à de…nição de cópulas condicionais (ou variantes no tempo) e é,