Estimação paramétrica e não-paramétrica em modelos de markov ocultos
Texto
Imagem
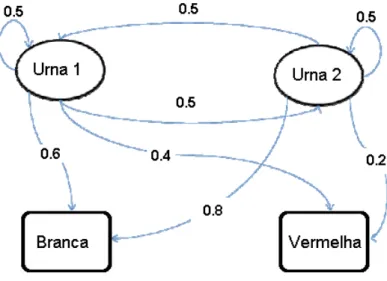

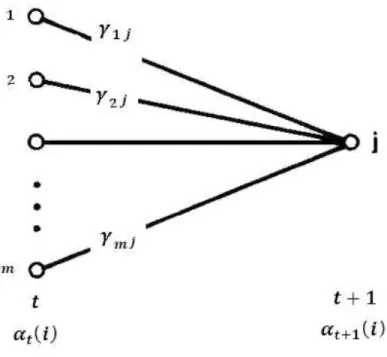
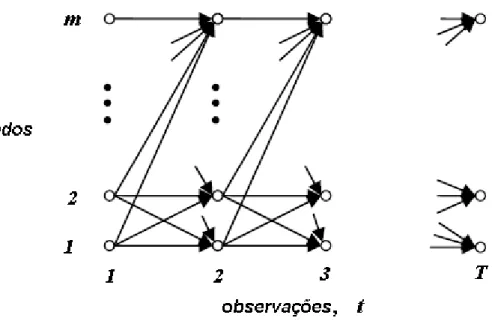
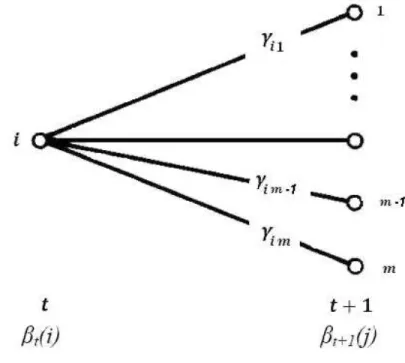
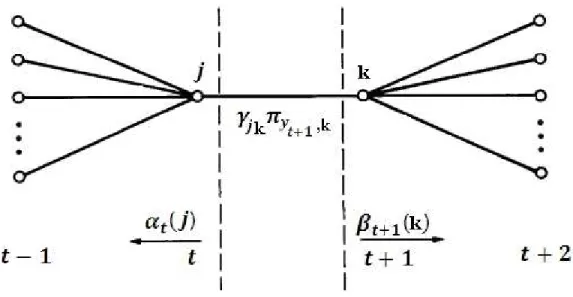
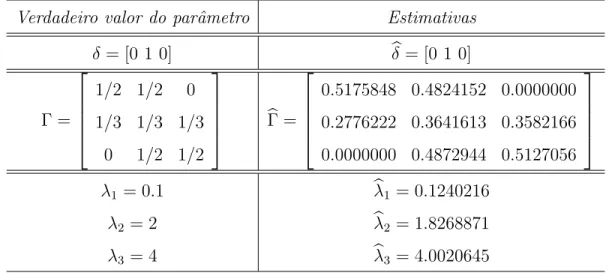
Documentos relacionados
As contribui¸ c˜ oes pioneiras para a ´ area de Redes Neurais (RN) (tamb´ em denominadas redes neuronais, de neurˆ onio), foram as de McCulloch e Pitts (1943), que introduziram a
Inferˆ encia Frequentista, Inferˆ encia Bayesiana Data Mining, Neural Networks, Data Science Statistical Learning, Machine Learning... Aprendizado
O m´ etodo do fator principal est´ a intimamente relacionado com a t´ ecnica utilizada na an´ alise de componentes principais.. Na pr´ atica, as comunalidades e as variˆ
Mais comumente, os dados envolvem valores de v´ arias vari´ aveis, obtidos da observa¸ c˜ ao de unidades de investiga¸ c˜ ao que constituem uma amostra de uma popula¸ c˜ ao. A
Para evitar isso, vocˆ e pode mover os dois comandos do preˆ ambulo para algum lugar ap´ os o comando \tableofcontents ou definitivamente n˜ ao us´ a-los, porque vocˆ e ver´ a que
A an´ alise de dados amostrais possibilita que se fa¸ ca inferˆ encia sobre a distribui¸ c˜ ao de probabilidades das vari´ aveis de interesse, definidas sobre a popula¸ c˜ ao da
Em geral, cada linha da matriz de dados corresponde a uma unidade de investiga¸c˜ ao (e.g. uni- dade amostral) e cada coluna, a uma vari´ avel. Uma planilha bem elaborada
A an´ alise de dados amostrais possibilita que se fa¸ ca inferˆ encia sobre a distribui¸ c˜ ao de probabilidades das vari´ aveis de interesse, definidas sobre a popula¸ c˜ ao da
