UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE CENTRO DE CIÊNCIAS EXATAS E DA TERRA
DEPARTAMENTO DE INFORMÁTICA E MATEMÁTICA APLICADA PROGRAMA DE PÓS-GRADUAÇÃO EM SISTEMAS E COMPUTAÇÃO
Otimização em comitês de classificadores: Uma
abordagem baseada em filtro para seleção de
subconjuntos de atributos
Laura Emmanuella Alves dos Santos Santana
Laura Emmanuella Alves dos Santos Santana
Otimização em comitês de classificadores: Uma
abordagem baseada em filtro para seleção de
subconjuntos de atributos
Tese de doutorado submetida ao Programa de Pós-Graduação em Sistemas e Computa-ção do Departamento de Informática e Mate-mática Aplicada da Universidade Federal do Rio Grande do Norte como parte dos requi-sitos para a obtenção do grau de Doutor em Ciência da Computação.
Orientador:
Profa. Dra. Anne Magály de Paula Canuto
Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial Especializada do Centro de Ciências Exatas e da Terra – CCET.
Santana, Laura Emmanuella Alves dos Santos.
Otimização em comitês de classificadores: uma abordagem baseada em filtro para seleção de subconjuntos de atributos / Laura Emmanuella Alves dos Santos Santana. – Natal, RN, 2012.
168 f. : il.
Orientador(a): Profa. Dra. Anne Magály de Paula Canuto.
Tese (Doutorado) – Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Departamento de Informática e Matemática Aplicada. Programa de Pós-Graduação em Sistemas e Computação.
1. Inteligência artificial – Tese. 2. Seleção de atributos – Tese. 3. Comitês de classificadores – Tese. 4. Metaheurística – Tese. 5. Algoritmos genéticos – Tese. I. Canuto, Anne Magály de Paula. III. Título.
LAURA EMMANUELLA ALVES DOS SANTOS SANTANA
Otimização em comitês de classificadores: Uma abordagem
baseada em filtro para seleção de subconjuntos de atributos
Esta Tese foi julgada adequada para a obtenção do título de doutor em Ciência da Computação e aprovada em sua forma final pelo Programa de Pós-Graduação em Sistemas e Computação do Departamento de Informática e Matemática aplicada da Universidade Federal do Rio Grande do Norte.
Profa. Dra. Anne Magály de Paula Canuto – UFRN Orientadora
Prof. Dr. Martin Alejandro Musicante – UFRN Coordenador do Programa
Banca Examinadora
Profa. Dra. Anne Magály de Paula Canuto – UFRN Presidente
Profa. Dra. Elizabeth Ferreira Gouvea – UFRN
Prof. Dr. Adrião Duarte Doria Neto – UFRN
Prof. Dr. André Carlos Ponce Ferreira de Carvalho – USP
Prof. Dr. Cleber Zanchetin – UFPE
i
Aos meus pais, José Sávio Santana (in me-moriam) e Teodora Alves Santana, pela
ii
Agradecimentos
Agradeço a Deus por ter me permitido realizar o doutorado. Sou imensamente grata por todas as oportunidades que me foram dadas de crescimento intelectual e moral.
À minha família agradeço por todo auxílio prestado, pela compreensão e apoio em todos os momentos. Em especial à minha mãe, Teodora Alves Santana, aos meus sogros, José Gilson de Oliveira e Rejane Moema Sousa de Oliveira, e ao meu esposo, George Gilson Sousa de Oliveira, por me ajudarem incondicionalmente a cuidar de nossa pequenina Lívia, me permitindo concluir o doutorado dentro do prazo estabelecido.
Agradeço à minha orientadora, Anne Magály de Paula Canuto, pelos conhecimentos transmitidos e pela atenção dispensada. À professora Elizabeth Ferreira Gouvêa Goldbarg que me recebeu como aluna ouvinte em sua disciplina de Tópicos Avançados em Algoritmos Experimentais sendo muito atenciosa e prestativa.
A todos os amigos que de alguma forma, direta ou indireta, me ajudaram, em especial à Ligia Maria Moura e Silva, que trabalhou comigo nos primeiros passos desta pesquisa, Thatiana Cunha Navarro de Souza que me forneceu material e foi também muito atenciosa e Diego Silveira Costa Nascimento por me ajudar com o LATEX.
iii
“O que sabemos é uma gota, o que ignoramos é um oceano”
iv
Resumo
A aplicação tradicional da seleção de atributos em diversas áreas como mineração de dados, aprendizado de máquina e reconhecimento de padrões visa melhorar a acurácia dos modelos construídos com a base de dados, ao retirar dados ruidosos, redundantes ou irrelevantes, e diminuir o custo computacional do modelo, ao encontrar um subconjunto representativo dos dados que diminua sua dimensionalidade sem perda de desempenho. Com o desenvolvimento das pesquisas com comitês de classificadores e a verificação de que esse tipo de modelo possui melhor desempenho que os modelos individuais, dado que os classificadores base sejam diversos, surge uma nova aplicação às pesquisas com seleção de atributos, que é a de encontrar subconjuntos diversos de atributos para a construção dos classificadores base de comitês de classificadores. O presente trabalho propõe uma abordagem que maximiza a diversidade de comitês de classificadores através da seleção de subconjuntos de atributos utilizando um modelo independente do algoritmo de aprendiza-gem e de baixo custo computacional. Isso é feito utilizando metaheurísticas bioinspiradas com critérios de avaliação baseados em filtro.
v
Abstract
Traditional applications of feature selection in areas such as data mining, machine lear-ning and pattern recognition aim to improve the accuracy and to reduce the computational cost of the model. It is done through the removal of redundant, irrelevant or noisy data, finding a representative subset of data that reduces its dimensionality without loss of per-formance. With the development of research in ensemble of classifiers and the verification that this type of model has better performance than the individual models, if the base classifiers are diverse, comes a new field of application to the research of feature selection. In this new field, it is desired to find diverse subsets of features for the construction of base classifiers for the ensemble systems. This work proposes an approach that maximizes the diversity of the ensembles by selecting subsets of features using a model independent of the learning algorithm and with low computational cost. This is done using bio-inspired metaheuristics with evaluation filter-based criteria.
vi
Sumário
Lista de Figuras xi
Lista de Tabelas xiv
1 Introdução 1
1.1 Considerações Iniciais . . . 1
1.2 Motivação . . . 5
1.3 Objetivos . . . 6
1.4 Organização do Trabalho . . . 7
2 Classificação de Padrões 9 2.1 Considerações Iniciais . . . 9
2.2 Classificação de Padrões . . . 11
2.3 Algoritmos de Aprendizado de Máquina: Indutores . . . 13
2.3.1 Árvore de Decisão: Paradigma de Aprendizado Simbólico . . . 13
2.3.2 Naive Bayes: Paradigma de Aprendizado Estatístico . . . 17
2.3.3 K – Vizinhos mais Próximos: Paradigma de Aprendizado Baseado em Exemplos . . . 18
Sumário vii
2.5 Combinação de Classificadores . . . 22
2.6 Diversidade em Comitês de Classificadores . . . 27
3 Seleção de Atributos 30 3.1 Considerações Iniciais . . . 30
3.2 Seleção de Atributos como um Problema de Busca . . . 32
3.2.1 Definição do ponto inicial da busca . . . 33
3.2.2 Procedimento da busca . . . 33
3.2.3 Avaliação da solução encontrada . . . 36
3.2.4 Critério de parada . . . 38
3.2.5 Validação da solução encontrada . . . 38
4 Metaheurísticas 40 4.1 Considerações Iniciais . . . 40
4.2 Algoritmos Genéticos . . . 43
4.3 Colônia de Formigas . . . 51
4.4 Nuvem de Partículas . . . 55
4.5 Otimização Multiobjetivo . . . 59
4.6 Algoritmos Genéticos Multiobjetivo . . . 62
4.7 Colônia de Formigas Multiobjetivo . . . 65
4.8 Nuvem de Partículas Multiobjetivo . . . 68
5 Trabalhos Relacionados 72 5.1 Considerações Iniciais . . . 72
Sumário viii
5.3 Seleção de Atributos com Colônia de Formigas . . . 76
5.4 Seleção de Atributos com Nuvem de Partículas . . . 76
5.5 Considerações Finais . . . 78
6 Metodologia dos Experimentos 79 6.1 Considerações Iniciais . . . 79
6.2 Bases de Dados Utilizadas . . . 79
6.2.1 Image Segmentation . . . 80
6.2.2 SCOP: Structural Classification of Proteins . . . 80
6.2.3 Breast Cancer Wisconsin (Diagnostic) . . . 81
6.2.4 Gaussian3 . . . 81
6.2.5 Simulated6 . . . 82
6.2.6 Ionosphere . . . 82
6.2.7 LIBRASMovement . . . 82
6.2.8 SONAR . . . 82
6.2.9 SPECTF . . . 83
6.3 A Seleção de Atributos . . . 83
6.3.1 Critérios de avaliação das soluções candidatas . . . 84
6.3.1.1 Correlação Interclassificadores . . . 85
6.3.1.2 Correlação Intraclassificadores . . . 87
6.3.1.3 Correlação Interclassificadores + Intraclassificadores . . . 89
6.3.2 Metaheurísticas . . . 89
6.3.2.1 Algoritmo Genéticos . . . 89
Sumário ix
6.3.2.3 Nuvem de Partículas . . . 94
6.3.2.4 Critério para escolha da melhor solução não dominada en-contrada . . . 98
6.3.3 Seleção Aleatória dos Atributos . . . 99
6.4 Validação da Busca . . . 99
6.5 Testes Estatísticos . . . 101
7 Resultados dos Experimentos 104 7.1 Considerações Iniciais . . . 104
7.2 Resultados utilizando Nuvem de Partículas . . . 106
7.3 Resultados utilizando Algoritmos Genéticos . . . 112
7.4 Resultados utilizando Colônia de Formigas . . . 116
7.5 Conclusões da Primeira Fase da Análise . . . 120
7.6 Mono-objetivo: Minimização da Correlação Interclassificadores . . . 123
7.7 Mono-objetivo: Minimização da correlação intraclassificadores . . . 126
7.8 Biobjetivo: Minimização simultânea da correlação inter e intraclassificadores 126 7.9 Conclusões da Segunda Fase da Análise . . . 128
7.10 Análise sobre a Interseção dos Atributos . . . 131
7.11 Conclusões da Terceira Fase da Análise . . . 138
7.12 Análise sobre os Comitês de Classificadores . . . 138
7.12.1 Métodos de Combinação . . . 138
7.12.2 Estrutura dos Comitês . . . 141
7.13 Conclusões da Quarta Fase da Análise . . . 141
Sumário x
8.1 Considerações Iniciais . . . 144
8.2 Conclusões Obtidas . . . 145
8.3 Trabalhos Futuros . . . 149
Referências 151 Apêndice A -- Resultados dos Métodos de Combinação 164 A.1 Image . . . 164
A.2 SCOP . . . 165
A.3 Breastcancer . . . 165
A.4 Gaussian3 . . . 166
A.5 Ionosphere . . . 166
A.6 LIBRAS . . . 167
A.7 Simulated6 . . . 167
A.8 Sonar . . . 168
xi
Lista de Figuras
2.1 Fases de aprendizagem e reconhecimento de padrões . . . 12
2.2 Árvore de decisão para diagnóstico de um paciente . . . 14
2.3 Rede neural artificial . . . 20
2.4 Divisão dos dados de uma base em quatro folds . . . 22
2.5 Diversidade entre classificadores em um domínio H . . . 23
2.6 Sistemas multiclassificador modular . . . 24
2.7 Sistemas multiclassificador paralelo . . . 25
2.8 Exemplo do método soma em um sistema com dois classificadores traba-lhando com uma base que possui duas classes possíveis . . . 25
2.9 Exemplo do método voto em um sistema com três classificadores em uma base que possui duas classes possíveis . . . 26
3.1 Processo de busca por um subconjunto de atributos . . . 32
3.2 Exemplo de espaço de busca por subconjuntos de atributos . . . 33
3.3 Ordem de exploração do espaço de busca utilizando uma busca em profun-didade . . . 34
3.4 Ordem de exploração do espaço de busca utilizando uma busca em largura 35 3.5 Modelo embbeded . . . 38
3.6 Modelo baseado em filtro e wrapper . . . 39
4.1 Região factível . . . 41
Lista de Figuras xii
4.3 Função unimodal . . . 42
4.4 Ilustração de uma roleta formada a partir dos valores de aptidão de uma população com cinco soluções candidatas . . . 48
4.5 Ilustração do método de torneio binário . . . 49
4.6 Recombinação de um par de cromossomos com 2 pontos de troca . . . 49
4.7 Mutação de um cromossomo . . . 50
4.8 Formação da trilha de feromônios . . . 52
4.9 Rotas para comida . . . 53
4.10 Movimento de uma partícula . . . 57
4.11 Soluções não dominadas no espaço objetivo . . . 61
4.12 Fluxograma do NSGAII . . . 64
6.1 Ilustração do cálculo do coeficiente de correlação interclassificadores . . . . 86
6.2 Ilustração do cálculo do coeficiente de correlação intraclassificadores . . . . 88
6.3 Representação cromossômica para um comitê com três classificadores e uma base de dados com quatro atributos . . . 90
6.4 Representação da formiga para um comitê com três classificadores e uma base de dados com quatro atributos . . . 91
6.5 Atualização do vetor velocidade para um comitê com três classificadores e uma base de dados com quatro atributos . . . 96
6.6 Atualização da posição da partícula . . . 97
7.1 Ilustração de uma seleção de atributos com interseção para um comitê com 3 classificadores . . . 131
Lista de Figuras xiii
xiv
Lista de Tabelas
6.1 Bases de dados utilizadas . . . 83
6.2 Combinações dos classificadores base nos comitês . . . 101
7.1 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo PSO mono-objetivo em suas versões para minimização da correlação inter e intraclassificadores . . . 107
7.2 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo PSO biobjetivo, para minimização simultânea das correlações inter e intraclassificadores . . . 109
7.3 Comparação dos sistemas com melhor desempenho nas versões mono-objetivo e biobjetivo do PSO . . . 110 7.4 Comparação dos sistemas com melhor desempenho com seleção de atributos
feita pelo PSO e dos sistemas sem seleção de atributos . . . 111
7.5 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo AG mono-objetivo em suas versões para minimização da correlação inter e intraclassificadores . . . 113
7.6 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo AG biobjetivo, para minimização simultânea das correlações inter e intraclassificadores . . . 114
7.7 Comparação dos sistemas com melhor desempenho nas versões mono-objetivo e biobjetivo do AG . . . 115
Lista de Tabelas xv
7.9 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo ACO mono-objetivo em suas versões para minimização da correlação inter e intraclassificadores . . . 118
7.10 Acurácia média e desvio padrão dos sistemas com seleção de atributos feita pelo ACO biobjetivo, para minimização simultânea das correlações inter e intraclassificadores . . . 119
7.11 Comparação dos sistemas com melhor desempenho nas versões mono-objetivo e biobjetivo do ACO . . . 121 7.12 Comparação dos sistemas com melhor desempenho com seleção de atributos
feita pelo ACO e os sistemas sem seleção de atributos . . . 122
7.13 Comparação dos sistemas de classificação com seleção de atributos mono-objetivo: correlação interclassificadores . . . 124
7.14 Porcentagem dos casos em que os sistemas utilizando o PSO e o AG para minimização da correlação interclassificadores foram estatisticamente supe-riores em relação aos sistemas utilizando os demais métodos . . . 125
7.15 Comparação dos sistemas de classificação com seleção de atributos mono-objetivo: correlação intraclassificadores . . . 127
7.16 Porcentagem dos casos em que os sistemas utilizando o PSO e o AG para minimização da correlação intraclassificadores foram estatisticamente supe-riores em relação aos sistemas utilizando os demais métodos . . . 128
7.17 Comparação dos sistemas de classificação com seleção de atributos biobjetivo129 7.18 Porcentagem dos casos em que os sistemas utilizando o PSO e o AG para
minimização simultânea das correlações inter e intraclassificadores foram estatisticamente superiores em relação aos sistemas utilizando os demais métodos . . . 130
Lista de Tabelas xvi
7.20 Coeficiente de correlação de Pearson entre a quantidade média de atribu-tos repetidos e o erro do comitê para o caso da seleção de atribuatribu-tos com minimização da correlação interclassificadores . . . 133
7.21 Porcentagem média (e desvio padrão) da interseção de atributos para o caso da seleção de atributos com minimização da correlação intraclassificadores 134
7.22 Coeficiente de correlação de Pearson entre a quantidade média de atribu-tos repetidos e o erro do comitê para o caso da seleção de atribuatribu-tos com minimização da correlação intraclassificadores . . . 135 7.23 Coeficiente de correlação de Pearson entre a quantidade média de atributos
repetidos e o erro do comitê para o caso da seleção de atributos biobjetivo 135
7.24 Porcentagem média (e desvio padrão) da interseção de atributos para o caso da seleção de atributos biobjetivo, primeira versão . . . 136
7.25 Porcentagem média (e desvio padrão) da interseção de atributos para o caso da seleção de atributos biobjetivo, segunda versão . . . 137
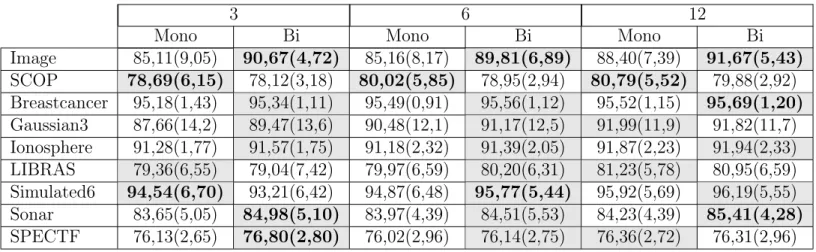
7.26 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo . . . 139
7.27 Acurácia média e desvio padrão dos comitês homogêneos e heterogêneos com seleção de atributos mono-objetivo e biobjetivo . . . 142
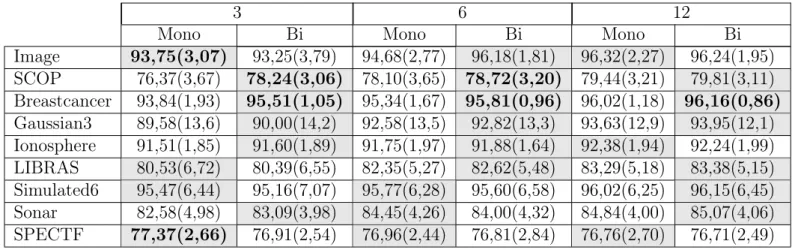
A.1 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a baseimage . . . 164
A.2 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a base SCOP . . . 165
A.3 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a baseBreastcancer . . . 165 A.4 Acurácia média e desvio padrão dos métodos de combinação com seleção de
Lista de Tabelas xvii
A.5 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a baseIonosphere . . . 166
A.6 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a base LIBRAS . . . 167
A.7 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a baseSimulated6 . . . 167
A.8 Acurácia média e desvio padrão dos métodos de combinação com seleção de atributos mono-objetivo e biobjetivo para a base Sonar . . . 168
1
Capítulo 1
Introdução
1.1
Considerações Iniciais
1.1 Considerações Iniciais 2
consequente aumento de sua acurácia, que é o assunto central deste trabalho.
Os comitês de classificadores são sistemas para classificação de padrões baseados na combinação das saídas de um conjunto de diferentes classificadores, chamados nesse con-texto de classificadores base. Essa combinação tem como objetivo conseguir uma classifi-cação mais exata, com menos erros. O aumento de desempenho tende a ocorrer se forem respeitados critérios de diversidade entre os classificadores componentes do sistema, nesse caso, a diversidade é percebida se os erros dos classificadores base não coincidem, isto é, se os classificadores base não cometem sempre os mesmos erros, nesse caso, diz-se que os classificadores generalizam de forma diferente.
Deve-se observar que não é necessária a construção de um comitê de classificadores se o classificador individual não comete erros. Entretanto, se o classificador comete erros será preciso complementá-lo com outros classificadores que não cometam os mesmos erros (KUNCHEVA, 2004). Desta forma, o resultado final após a combinação de suas respostas pode ser correto. Sendo assim, a diversidade na saída dos classificadores base é um requisito vital para o sucesso de um comitê. Intuitivamente, espera-se que os classificadores base do comitê sejam tão corretos quanto possível e no caso de cometerem erros que ocorram em padrões diferentes (KUNCHEVA, 2004).
Essa diversidade pode ser promovida a partir de alguns parâmetros dos comitês de classificadores, tais como:
• Arquitetura interna dos classificadores base: A diversidade pode ser alcançada através do uso de diferentes parâmetros de ajuste inicial dos algoritmos de aprendizagem. Isso permite a construção de classificadores base a partir do mesmo algoritmo de aprendizagem, mas que generalizam de forma diferente;
• Estrutura do modelo: A diversidade em um comitê de classificadores pode ser promo-vida aumentando-se a quantidade de classificadores base e a variedade dos algoritmos de aprendizagem, utilizados para construir esses classificadores;
1.1 Considerações Iniciais 3
iguais, porém com informações diferentes, ou seja, com atributos diferentes. Esse procedimento permite que os classificadores aprendam o mesmo conceito sob visões diferentes, generalizando de forma diversa.
Neste último caso, existem métodos como o bagging (BREIMAN, 1996) e o boosting (SCHAPIRE et al., 1998) que são bastante utilizados para construção de comitês, onde os
classificadores base são formados a partir de padrões diferentes (QUINLAN, 1996; BAUER; KOHAVI, 1999; DIETTERICH, 2000). É ainda nesse contexto de construção de comitês de classificadores diversos a partir dos dados de treinamento que pode-se usar a seleção de atributos. Nesse caso, a seleção de diferentes subconjuntos de atributos a partir da base de dados original para a construção dos classificadores base pode favorecer a diversidade e consequente acurácia do comitê criado. Trabalhos como os de (KUNCHEVA, 1993; OPITZ, 1999;TSYMBAL; PECHENIZKIY; CUNNINGHAM, 2005a) iniciaram essa forma de lidar com a seleção de atributos em comitês de classificadores, isto é, ao invés de selecionar um único subconjunto de atributos para todos os componentes do comitê, visando unicamente a retirada de dados prejudiciais ao processo de aprendizagem e a redução do custo compu-tacional para a construção do modelo, vários subconjuntos de atributos são selecionados e cada classificador base é construído com um subconjunto diferente, promovendo também diversidade ao comitê construído com os dados selecionados.
A seleção de atributos é intrinsecamente um problema de busca e otimização, onde o espaço de busca é o conjunto com todos os atributos disponíveis e deseja-se encontrar um ou mais subconjuntos representativos dos dados que diminua sua dimensionalidade sem perda de desempenho. O problema da seleção de subconjuntos de atributos pode ser definido como segue. SejaXo conjunto original de atributos da base de dados, espaço de busca, com tamanho q. O objetivo do problema de seleção de subconjuntos de atributos é encontrar um conjunto X0
= nX10, X20 , ..., Xn0
o
, onde n é a quantidade de classificadores base, de forma que cada subconjunto de X0 possua tamanho
q0
i < q e X
0
i ⊆ X. Para isto, uma função f(X0
) é aplicada como critério de avaliação do conjunto que deve ser maximizada ou minimizada, de acordo com o problema.
1.1 Considerações Iniciais 4
acurácia do classificador para avaliar a solução encontrada. Na outra abordagem, chamada embbeded, o processo de busca pelo subconjunto de atributos é realizado internamente pelo próprio algoritmo de aprendizagem. A abordagem independente do classificador é cha-mada filtro e utiliza alguma medida de importância que considera características gerais do conjunto de dados para avaliar a solução encontrada.
Em determinados problemas a estratégia de busca e otimização pode empregar um método exato, que garante encontrar a solução ótima para o problema, porém tem uma modelagem matemática complexa e pode gastar um tempo proibitivo para gerar uma solução ótima, ou ainda executar um processo exaustivo ou heurístico. A busca exaustiva avalia todas as possíveis soluções do problema, no caso de seleção de atributos a busca exaustiva deve avaliar todos os possíveis subconjuntos de atributos. Para se executar uma busca exaustiva por um subconjunto de atributos ótimo deve-se considerar todas as 2q combinações possíveis paraqatributos. O número de combinações cresce exponencialmente fazendo com que a busca exaustiva se torne impraticável para valores altos de q e até mesmo para valores moderados de q (YU, 2003). Dessa forma, a busca heurística é mais realista que a busca exaustiva, e apesar de não garantir encontrar a solução ótima, é capaz de encontrar uma solução útil, próximo da ótima, em um tempo aceitável. Dentre os algoritmos de busca heurística, existem os algoritmos determinísticos, cujas execuções geram sempre as mesmas soluções, e os algoritmos não-determinísticos ou estocásticos, que se utilizam de uma aleatoriedade que evita os mínimos locais, gerando soluções diferentes a cada execução.
Dentre os algoritmos de busca heurística estocástica generalistas, também chamados de metaheurísticas, o mais trabalhado na área de seleção de atributos é o Algoritmo Gené-tico, com trabalhos que datam do final dos anos 80 (SIEDLECKI; SKLANSKY, 1989; YANG; HONAVAR, 1998; KUDO; SKLANSKY, 2000; OH; LEE; MOON, 2002; FROHLICH; CHAPELLE; SCHOLKOPF, 2003; OH; LEE; MOON, 2004; HUANG; WANG, 2006). Mais recentemente os algoritmos de Colônia de Formigas (AL-ANI, 2005; BELLOet al., 2005; GAO; YANG; WANG,
2005; SIVAGAMINATHAN; RAMAKRISHNAN, 2007; ROBBINS et al., 2007; CHIANG; CHIANG; LIN, 2008; KANAN; FAEZ, 2008; AGHDAM; GHASEM-AGHAEE; BASIRI, 2009) e de Nuvens de Partículas (CORREA; FREITAS; JOHNSON, 2006; CHáVEZet al., 2007; CORREA; FREITAS;
1.2 Motivação 5
YUet al., 2008;SHEN; MEI; YE, 2009) começaram a ser aplicados à seleção de atributos, sem
ter sido ainda empregados no contexto de comitês de classificadores.
Esses trabalhos, em geral, utilizam uma abordagemwrapper, onde a acurácia do classi-ficador é utilizada como critério de avaliação das soluções encontradas. Essa abordagem é comumente escolhida pelo fato de obter, frequentemente, melhores resultados que a abor-dagem filtro, já que a seleção de atributos é otimizada para o algoritmo de aprendizagem utilizado. No entanto, desde que o algoritmo de aprendizagem é empregado para avaliar todo e qualquer subconjunto de atributos considerado, esse modelo tem um custo computa-cional alto, podendo-se tornar proibitivo para casos em que a base de dados contém muitos atributos. Além disso, desde que o processo de seleção de atributos é fortemente acoplado ao algoritmo de aprendizagem, o modelo wrapper é menos geral que o filtro, tendo que ser executado novamente quando se muda de um algoritmo para outro (HALL, 1999).
Dessa forma, considerando que as vantagens do modelo filtro para a seleção de atributos podem superar suas desvantagens, o presente trabalho apresenta uma abordagem baseada em filtro para seleção de subconjuntos de atributos a fim de maximizar a diversidade de comitês de classificadores.
1.2
Motivação
1.3 Objetivos 6
A maioria das pesquisas que envolvem seleção de subconjuntos de atributos para cons-trução de comitês de classificadores utiliza uma abordagem wrapper, onde a acurácia do classificador é utilizada como função de ajuste do algoritmo de busca. Essa abordagem obtém bons resultados, porém é dependente do algoritmo de aprendizagem, ou seja, deve ser executado novamente sempre que se desejar modificar o algoritmo, além disso, tem um custo computacional alto, podendo ser proibitiva para casos em que a base de dados contém muitos atributos.
Sendo assim, a motivação principal deste trabalho é definir uma abordagem indepen-dente do algoritmo de aprendizagem e de baixo custo computacional que otimize a diversi-dade de comitês de classificadores. Isso será feito utilizando metaheurísticas com inspiração biológica, que são algoritmos de fácil implementação, baixo custo computacional e eficientes na determinação de soluções subótimas.
1.3
Objetivos
O objetivo principal deste trabalho é otimizar comitês de classificadores, maximizando sua diversidade, através da seleção de subconjuntos de atributos diversos. Esta seleção será feita utilizando uma abordagem baseada em filtro, ou seja, independente do classificador, que a torna mais generalista, já que não é necessário executar novamente caso se queira mudar o algoritmo de aprendizagem, além de ter um custo computacional mais baixo que os modelos wrapper. Serão utilizados para a seleção, metaheurísticas com inspiração biológica, que são algoritmos de fácil implementação, com baixo custo computacional e eficientes na determinação de soluções subótimas.
As metaheurísticas utilizadas são: Algoritmos Genéticos, Colônia de Formigas e Nu-vem de Partículas, em versões mono-objetivo e biobjetivo. Uma análise comparativa dos resultados obtidos apresenta a diferença no desempenho entre:
• Comitês sem seleção de atributos x Comitês com seleção de atributos;
1.4 Organização do Trabalho 7
• Algoritmos Genéticos x Colônia de Formigas x Nuvem de Partículas; • Metaheurísticas mono-objetivo x Metaheurísticas biobjetivo.
Pretende-se, ainda, determinar se existe uma relação entre a interseção de atributos nos subconjuntos selecionados e a acurácia do comitê, ou seja, determinar se a quantidade de atributos que se repetem em cada subconjunto influencia o desempenho do comitê, desde que isso poderia torna-lo menos diverso.
Com este trabalho pretende-se contribuir com as pesquisas sobre comitês de classifi-cadores, apresentando uma ferramenta para melhorar seu desempenho, a partir da seleção de subconjuntos diversos de atributos para construção dos classificadores base, utilizando uma abordagem baseada em filtro que permite que esta ferramenta seja generalista em relação aos algoritmos de classificação, ou seja, a seleção feita pode ser empregada com qualquer algoritmo de aprendizagem sem a necessidade de uma nova execução, além de ter um custo computacional baixo.
Os trabalhos publicados em Santana, Silva e Canuto (2009), Santana et al. (2010), Santana, Silva e Canuto (2011) apresentam parte dos resultados desta pesquisa.
1.4
Organização do Trabalho
Este trabalho está organizado do seguinte modo:
Capítulo 1: Introdução
O capítulo introdutório contextualiza este trabalho, apresentando os objetivos e motivação para sua realização.
Capítulo 2: Classificação de Padrões
Este capítulo traz informações sobre a área de aprendizado de máquina, apresentando alguns algoritmos utilizados para classificação de padrões. Aborda ainda a questão da combinação de classificadores, apresentando alguns métodos de combinação e tratando sobre a questão da diversidade em comitês de classificadores.
1.4 Organização do Trabalho 8
Este capítulo aborda a seleção de atributos como um problema de busca, enfatizando os passos básicos para a realização do processo de busca.
Capítulo 4: Metaheurísticas
Este capítulo traz informações sobre otimização e apresenta as metaheurística que são utilizadas neste trabalho, algoritmos genéticos, colônia de formigas e nuvem e partículas. O capítulo aborda ainda a questão da otimização multiobjetivo e sua implementação através das metaheurísticas anteriormente tratadas.
Capítulo 5: Trabalhos Relacionados
Este capítulo apresenta uma revisão da literatura, citando trabalhos que realizaram se-leção de atributos em sistemas de classificação de padrões, enfatizando os trabalhos que utilizaram algoritmos genéticos, colônia de formigas e nuvem de partículas.
Capítulo 6: Metodologia dos Experimentos
Este capítulo trata dos detalhes da implementação e execução dos experimentos, apresenta as bases de dados, as funções de avaliação e os parâmetros utilizados pelas metaheurísticas. Apresenta ainda os métodos utilizados para validação da seleção de atributos e o teste estatístico utilizado para analisar a diferença entre os sistemas.
Capítulo 7: Resultados
Este capítulo apresenta os resultados encontrados e faz uma análise comparativa entre os modelos implementados.
Capítulo 8: Conclusão
9
Capítulo 2
Classificação de Padrões
2.1
Considerações Iniciais
Entre os anos de 1943 e 1956, alguns pesquisadores deram início ao campo de pesquisa hoje conhecido como Inteligência Artificial (IA), dentre os trabalhos iniciais estão as redes neurais artificiais de McCulloch e Pitts (MCCULLOCH; PITTS, 1943), a aprendizagem de Hebb (HEBB, 1949) e o teste de Turing (TURING, 1950).
2.1 Considerações Iniciais 10
FILHO; JOTA, 1998); engenharia do petróleo (DOKAISANY; VICE; HALLECK, 2000); enge-nharia de produção (MAIAet al., 2002); metalurgia (VIANA; PATARO, 1998); segurança do trabalho (EVSUKOFF; GENTIL, 2005); ciências médicas e biológicas (COSTA, 2004); setor financeiro (CARVALHO et al., 2002). Como qualquer tecnologia, no entanto, as técnicas de
IA devem ser aplicadas apenas em situações onde as técnicas tradicionais e diretas são insuficientes.
Dentro do campo de estudo da Inteligência Artificial existe uma área responsável por fazer com que o sistema computacional adquira conhecimento, ou seja, aprenda de forma automática, chamada Aprendizado de Máquina. Os estudos nessa área visam desenvolver técnicas que permitam ao sistema computacional adquirir conhecimento sobre um domínio desejado através de amostras desse domínio. Ou seja, a partir da conexão de informações sobre objetos conhecidos de um domínio, o sistema deve inferir conhecimento, podendo, então, tomar decisões a respeito de outros objetos ainda não conhecidos.
Diferentes algoritmos utilizando técnicas e paradigmas diversos foram desenvolvidos para captação de conhecimento em Aprendizado de Máquina. Estes diferentes algoritmos podem ser classificados como supervisionados ou não supervisionados, de acordo com o conhecimento prévio que se tem sobre as amostras do domínio estudado, chamadas de exemplos, instâncias ou padrões de treinamento, utilizadas para a construção do conheci-mento.
Sendo assim, diz-se que um algoritmo de Aprendizado de Máquina é supervisionado quando ele recebe amostras do domínio e informações sobre o que essas amostras repre-sentam naquele domínio, enquanto que os algoritmos não supervisionados recebem apenas as amostras do domínio, sem ter nenhuma informação a priori do que essas amostras es-tão representando no domínio tratado. Uma breve explanação do funcionamento destes algoritmos é dada a seguir:
2.2 Classificação de Padrões 11
dados os valores x de um novo exemplo, predizer o valor y correspondente (LEE; MONARD; WU, 2005). No caso dos valores y pertencerem a um conjunto discreto de classes, a tarefa de aprendizado é chamada de classificação, tratada neste trabalho. Se os valores de y pertencerem a um conjunto contínuo, o aprendizado é tratado como regressão.
• Os algoritmos de aprendizado não supervisionados, por sua vez, recebem como en-trada apenas os valores dex, não sendo conhecidas as classes dos exemplos de treina-mento, ou seja, os valores de y. Neste caso, o indutor analisa os exemplos fornecidos agrupando-os de acordo com algum critério de semelhança, formando grupos, tam-bém chamados de clusters. A partir destes agrupamentos, o algoritmo induz uma hipótese h, que deverá predizer os valores de y de novos padrões apresentados ao sistema, ondey serão os clusters gerados.
Desta forma, os algoritmos de Aprendizado de Máquina adquirem conhecimento a par-tir do raciocínio indutivo, ou seja, obtém conclusões genéricas sobre um conjunto particular de exemplos através da classificação, regressão ou agrupamento dos dados.
2.2
Classificação de Padrões
Classificação de padrões é o processo de atribuição de rótulos discretos, também cha-mados de classes, a objetos, padrões ou amostras de um domínio, onde esses objetos são descritos por um conjunto de medidas chamadas de atributos ou características ( KUN-CHEVA, 2004).
2.2 Classificação de Padrões 12
2.3 Algoritmos de Aprendizado de Máquina: Indutores 13
Em outras palavras, o processo de classificação inicia-se com a construção dos classi-ficadores, a partir de algoritmos de aprendizado e de um conjunto de exemplos, objetos pertencentes ao domínio de conhecimento que se quer aprender. Estes classificadores serão utilizados na determinação das classes de novos exemplos, inferindo, assim, conhecimento sobre o domínio tratado, como pode ser visto na Figura 2.1.
Como dito anteriormente, diferentes algoritmos utilizando técnicas e paradigmas di-versos foram desenvolvidos para captação de conhecimento em Aprendizado de Máquina, a próxima seção apresenta alguns algoritmos pertencentes aos principais paradigmas de aprendizado para que se tenha uma visão geral da área. Os algoritmos que serão descritos foram utilizados na fase experimental deste trabalho.
2.3
Algoritmos de Aprendizado de Máquina: Indutores
Os algoritmos de aprendizagem podem pertencer a diversos paradigmas, tais como: Simbólico, Estatístico, Baseado em Exemplos e Conexionista. As próximas subseções apre-sentam algoritmos pertencentes a estes quatro paradigmas e que foram utilizados na fase experimental deste trabalho.
2.3.1
Árvore de Decisão: Paradigma de Aprendizado Simbólico
Os sistemas de aprendizado simbólico buscam aprender construindo representações simbólicas de um conceito através da análise de exemplos e contraexemplos desse conceito. A principal característica deste paradigma é que as representações obtidas são de fácil com-preensão e facilmente interpretáveis em linguagem natural. As representações simbólicas estão tipicamente na forma de alguma expressão lógica, árvore de decisão, regras ou rede semântica (MONARD; BARANAUSKA, 2002).
2.3 Algoritmos de Aprendizado de Máquina: Indutores 14
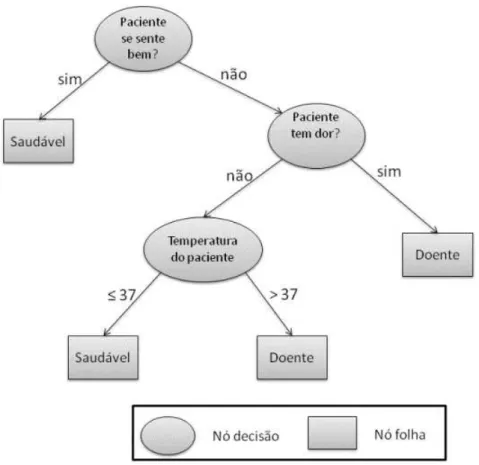
Sendo assim, uma árvore de decisão é uma estrutura de dados definida recursivamente como um nó folha que corresponde a uma classe ou um nó decisão que contém um teste sobre algum atributo. Para cada resultado possível para o teste existe uma aresta que conduz a uma subárvore. A Figura 2.2 traz uma ilustração sobre isto, neste exemplo existem três nós decisão e dois nós folha, que são as classes do problema.
Figura 2.2: Árvore de decisão para diagnóstico de um paciente
A construção da árvore, fase de aprendizagem do algoritmo, pode ser entendida como segue:
1. Escolhe-se um atributo para particionar o conjunto de exemplos da base de dados (definição do atributo para o teste de um nó decisão);
2.3 Algoritmos de Aprendizado de Máquina: Indutores 15
3. Para cada nó:
(a) Se todos os exemplos da base que podem ser agrupados nesse nó são da mesma classe, associar esta classe ao nó (definição de um nó folha);
(b) Se não houver exemplos que se encaixem no valor desse nó, associar o nó a uma classe determinada a partir de alguma outra informação, como a classe mais frequente do nó pai (nó superior), por exemplo;
(c) Caso contrário, repetir os passos de 1 a 3 para os exemplos que ainda não foram associados a nenhum nó folha.
Sendo assim, o ponto mais importante na construção da árvore de decisão é o critério utilizado para escolher o atributo que deve particionar o conjunto de exemplos a cada iteração. Existem muitos critérios na literatura e todos concordam em dois pontos:
• Uma divisão que mantém a proporção das classes em todas as partições não tem utilidade, por exemplo, se um nó decisão que possui 10 exemplos de cada classe é particionado em dois nós, cada um com 5 exemplos de cada classe, essa divisão não trouxe nenhum benefício na discriminação das classes do problema;
• Uma divisão cujas partições possuem todos os exemplos de uma mesma classe tem utilidade máxima.
Alguns desses critérios para escolha dos atributos utilizam medidas como as citadas abaixo:
• Medidas baseadas na proporção de exemplos por classes, analisando a diferença dessa proporção entre o nó corrente e os nós descendentes. Esse tipo de medida valoriza a pureza das partições;
• Medidas baseadas na proporção de exemplos por classes, analisando a diferença dessa proporção apenas entre os nós descendentes. Esse tipo de medida valoriza a dispari-dade entre as partições;
2.3 Algoritmos de Aprendizado de Máquina: Indutores 16
Já na fase de reconhecimento de uma árvore de decisão, a classificação de um padrão se inicia pela raiz da árvore, e esta árvore é percorrida até que se chegue a um nó fo-lha. Em cada nó de decisão será feito um teste que irá direcionar o padrão para uma subárvore (ABREU, 2006). Em geral, o procedimento de uma árvore de decisão na fase de reconhecimento é similar ao apresentado no Algoritmo 1.
Algoritmo 1 Fluxo básico de uma árvore de decisão na fase de reconhecimento 1: SejaS uma base de dados;
2: Apresente um padrão pao nó inicial da árvore, nó raiz; 3: while um nó folha não for alcançado do
4: Apresente o padrão pao próximo nó decisão da árvore;
5: /* De acordo com o resultado do teste lógico usado pelo nó, a árvore ramifica-se para um dos nós seguintes */
6: end while
Alguns algoritmos de árvore de decisão utilizam uma técnica chamada Poda para me-lhorar o desempenho do classificador construído. A Poda reduz o número de nós decisão, a fim de evitar que a árvore fique superajustada (do inglês, overfitting) aos dados de trei-namento utilizados na sua construção. Os algoritmos baseados em árvore de decisão mais utilizados na literatura são:
• CART (Classification and Regression Tree) (BREIMAN, 1984): Este algoritmo pode ser utilizado para classificação ou regressão dos dados, ou seja, os rótulos da classe podem ser discretos ou contínuos. Executa uma partição binária dos dados a cada iteração, aplicando comumente o índice gini (Raileanu 2000) como critério de parti-ção;
• ID3 (Iterative Dichotomiser 3) (QUINLAN, 1986): Trabalha apenas com dados que possuem valores discretos. Utiliza o cálculo da entropia, medida de desordem, para escolher os atributos que particionarão o conjunto de dados;
2.3 Algoritmos de Aprendizado de Máquina: Indutores 17
2.3.2
Naive Bayes
: Paradigma de Aprendizado Estatístico
Esse paradigma de aprendizado utiliza modelos estatísticos para encontrar uma boa aproximação do domínio que se deseja aprender. Como regra geral, técnicas estatísticas tendem a focar tarefas em que todos os atributos são contínuos ou ordinais, onde ordinais são atributos discretos, mas ordenáveis. Muitas dessas técnicas também são paramétricas, ou seja, assumem alguma forma de modelo e buscam encontrar valores apropriados para os parâmetros do modelo a partir dos dados. Por exemplo, um classificador linear assume que as classes podem ser expressas como combinação linear dos valores dos atributos, e então procura uma combinação linear particular que forneça a melhor aproximação sobre o conjunto de dados (MONARD; BARANAUSKA, 2002).
Entre os algoritmos estatísticos destaca-se o de aprendizado bayesiano, naive bayes (MITCHELL, 1997), que faz uso de fórmulas estatísticas e cálculo de probabilidades para realizar a classificação. O classificador naive bayes possui aprendizado supervisionado e baseia-se na aplicação do teorema de bayes, Equação (2.1), para o cálculo das probabi-lidades necessárias à classificação. Para calcular a classe mais provável de um padrão, calcula-se a probabilidade de todas as possíveis classes e, no fim, escolhe-se a classe com maior probabilidade como rótulo para o padrão que está sendo classificado.
P(h/D) = P(D/h)∗P(h)
P(D) (2.1)
Onde:
P(h) é a probabilidade a priori da classe h;
P(D) é a probabilidade a priori dos dados de treinamento D;
P(h/D) é a probabilidade de h dado D (Probabilidade Condicional);
P(D/h) é a probabilidade de D dado h (Probabilidade Condicional).
2.3 Algoritmos de Aprendizado de Máquina: Indutores 18
As principais vantagens do aprendizado estatístico, especialmente o aprendizado baye-siano, são: O fato de poder embutir nas probabilidades calculadas o conhecimento de domínio que se tem e o fato da classificação se basear em evidências fornecidas. Por outro lado, a desvantagem reside justamente no seu caráter estatístico, ou seja, muitas probabi-lidades devem ser calculadas e isto pode ocasionar um alto custo computacional.
Algoritmo 2 Fluxo básico do Naive Bayes na fase de reconhecimento
Dado uma base de dados S com P padrões, cada padrão com x atributos, podendo pertencer a i classes;
2: Calcula-se a probabilidade de cada uma das classes ocorrerem, independentemente dos valores dos atributos:
P(classe) = (numero de casos da classe)/(nmero total de casos);
4: for cada padrão da base de dados do
Calcule a probabilidade de cada um dos atributos do padrão em relação a cada possível classe:
6: P(atributox/classei) = numero de casos da classeicom atributo x numero total de casos da classei
Calcule a probabilidade de cada classe ocorrer dado os valores de todos os atributos que compõem o padrão:
8: P(classe/padrao) = P(atributo/classe)∗P(classe) end for
2.3.3
K
– Vizinhos mais Próximos: Paradigma de Aprendizado
Baseado em Exemplos
Esse paradigma busca classificar exemplos nunca vistos por meio de exemplos similares conhecidos. Esse tipo de aprendizado é também denominadolazy. Sistemaslazynecessitam manter os exemplos na memória para classificar novos exemplos.
2.3 Algoritmos de Aprendizado de Máquina: Indutores 19
O k-NN gera um classificador onde o aprendizado é baseado na analogia, ou seja, clas-sifica exemplos nunca vistos por meio de exemplos similares conhecidos. Para determinar a classe de um elemento que não pertença ao conjunto de treinamento, o classificador k-NN procurakelementos do conjunto de treinamento que estejam mais próximos deste elemento desconhecido, ou seja, que tenham a menor distância. Estes k elementos são chamados de k vizinhos mais próximos. Verifica-se quais são as classes desses k vizinhos e a classe mais frequente será atribuída à classe do elemento desconhecido. Os vizinhos mais próximos a um padrão, em geral, são definidos em termos de distância euclidiana, Equação (2.2).
d(xi, xj) =
qX
(pi−pj)2 (2.2)
Onde,
d(xi, xj) é a distância entre os padrõesi e j;
pi epj são os atributos componentes dos padrões xi e xj.
2.3.4
Redes Neurais Artificiais: Paradigma de Aprendizado
Co-nexionista
As redes neurais artificiais são construções matemáticas simplificadas inspiradas no modelo biológico do sistema nervoso. A representação de uma rede neural envolve unidades altamente interconectadas, neurônios, e por esse motivo o nome conexionismo é utilizado para descrever a área de estudo (MONARD; BARANAUSKA, 2002).
2.3 Algoritmos de Aprendizado de Máquina: Indutores 20
Figura 2.3: Rede neural artificial
Na fase de treinamento, aprendizagem, os neurônios da camada de saída competem para serem os vencedores, ou seja, sempre que é apresentado um padrão à rede neural, cada neurônio desta camada apresenta à saída da rede um valor entre 0 e 1 que indica a confiabilidade do padrão pertencer àquela classe.
Cada neurônio possui associado a si um vetor de pesos que o interliga aos demais neurô-nios, e o aprendizado nada mais é do que modificações sucessivas nesses pesos de forma que a rede classifique as entradas corretamente. Dizemos que a rede neural aprendeu quando ela passa a reconhecer todas as entradas apresentadas durante a fase de treinamento.
Um dos algoritmos de aprendizado conexionista mais utilizados na literatura são as redes neurais MLP,Multilayer Perceptron, que são redes do tipoPercetron (ROSENBLATT, 1958) que podem ter várias camadas intermediárias. O algoritmo de treinamento comu-mente utilizado nas redes neurais do tipo MLP é obackpropagation (RUMELHART; HINTON; WILLIAMS, 1986).
2.4 Amostragem dos Dados 21
padrão particular. Se esta não estiver correta, o erro é calculado. O erro é propagado a partir da camada de saída até a camada de entrada, e os pesos das conexões das unidades das camadas internas vão sendo modificados conforme o erro é retropropagado (HAYKIN, 2001).
2.4
Amostragem dos Dados
Para que se possa estimar a precisão ou o erro de um algoritmo de aprendizado de má-quina em uma determinada tarefa, faz-se necessário testar os classificadores construídos. Esse teste normalmente é feito utilizando-se amostras de dados fora do conjunto utilizado para a construção dos classificadores. Sendo assim, é necessário que o conjunto de exemplos seja dividido pelo menos em duas partes: conjunto de treinamento, utilizado para cons-truir o classificador, e conjunto de teste, utilizado para testar o classificador construído e determinar sua acurácia. Existe vários métodos propostos na literatura para se realizar essa divisão do conjunto de dados, um dos métodos mais simples é oholdout que divide os conjunto em uma porcentagem fixa de p exemplos para treinamento e (1−p) para teste (MONARD; BARANAUSKA, 2002).
Porém, nem sempre a quantidade de exemplos é suficiente para tornar esse tipo de divisão dos dados satisfatória e outros métodos buscam minimizar esse problema, como é o caso do k-fold cross validation. Esse método é um dos mais utilizados na literatura para realizar a amostragem dos dados em algoritmos de aprendizado de máquina. Seu funcionamento é dado como segue: Os exemplos são aleatoriamente divididos em k par-tições mutuamente exclusivas, chamadas folds, de tamanho aproximadamente igual a n/k exemplos, onde n é a quantidade total de exemplos. O algoritmo de indução é treinado com (k −1) folds e testado com o fold remanescente. Esse processo é repetido k vezes, cada vez considerando um fold diferente para teste. A acurácia final é dada pela média das acurácias calculadas em cada um dos k folds (MONARD; BARANAUSKA, 2002). Esse método é comumente utilizado comk igual a 10.
2.5 Combinação de Classificadores 22
Figura 2.4: Divisão dos dados de uma base em quatro folds
2.5
Combinação de Classificadores
O desempenho dos classificadores gerados no processo de aprendizagem depende de alguns fatores, como o domínio no qual está sendo aplicado o indutor, a quantidade de exemplos de treinamento e a relevância das características, atributos, desses exemplos. Esses fatores afetam de maneira diversa as hipóteses geradas por algoritmos de classifi-cação diferentes. Ou seja, as diferenças existentes entre os classificadores, diferenças nos algoritmos utilizados em sua construção, fazem com que estes classificadores apresentem desempenhos diferentes de acordo com alguns fatores, como quantidade de exemplos e relevância das características que compõem esses exemplos. Desta forma, alguns classifica-dores possuem bons desempenhos com poucos exemplos, enquanto outros precisam de um número maior de exemplos para conseguir fazer com que o sistema adquira conhecimento de forma adequada. Assim como, alguns classificadores trabalham bem com redundância de informação, enquanto outros não. Ou seja, em geral, todos os algoritmos de classificação possuem seus pontos fortes e fracos.
2.5 Combinação de Classificadores 23
Dessa forma, sistemas multiclassificadores (SMC), são sistemas para classificação de padrões baseados na combinação das saídas de um conjunto de diferentes classificadores, chamados nesse contexto de classificadores base. Essa combinação tem como objetivo conseguir uma classificação mais exata, com menos erros. O aumento de desempenho tende a ocorrer se forem respeitados critérios de diversidade entre os classificadores componentes do sistema, nesse caso, a diversidade é percebida se os erros dos classificadores base não coincidem, isto é, se não cometem sempre os mesmos erros. Para ilustrar isso, Dietterich (1997) apresenta o seguinte exemplo: Dado um SMC com três classificadores h1, h2e h3
e um novo exemplo a ser classificado, x. Se os três classificadores são idênticos, então quando h1(x) está errado, h2(x) e h3(x) também estarão errados. Entretanto se os erros
dos classificadores não são coincidentes, então quando h1(x) está errado, h2(x) e h3(x)
podem estar certos e a combinação de suas respostas pode classificar x corretamente.
Figura 2.5: Diversidade entre classificadores em um domínio H
2.5 Combinação de Classificadores 24
diversos entre si, maior o espaço de busca coberto, aumentando a probabilidade de obter uma boa aproximação a partir da combinação das saídas dos classificadores base.
Um sistema multiclassificador é, portanto, formado por um conjunto de classificadores base e uma função para combinação das saídas desses classificadores. A escolha dessa função, ou mecanismo, nem sempre é trivial e influencia diretamente o desempenho final do sistema (ABREU, 2006).
De acordo com sua arquitetura interna, um sistema multiclassificador pode ser mo-dular ou paralelo. Os primeiros dividem a tarefa final do sistema em subtarefas, criando especialistas. Cada especialista executa uma subtarefa e o módulo combinador utiliza as soluções dessas subtarefas para determinar a saída final do sistema. A Figura 2.6 ilustra um sistema multiclassificador modular, onde S1, S2, ..., Sn são as soluções encontradas por cada classificador.
Figura 2.6: Sistemas multiclassificador modular
Os sistemas multiclassificadores paralelos, também conhecidos como ensembles ou co-mitês, utilizam uma combinação redundante, pois todos os classificadores base executam a mesma tarefa. Essa forma de combinação explora a ideia de que a diferença existente entre os classificadores base pode extrair informações complementares sobre os exemplos a serem classificados. Este foi o tipo de sistema multiclassificador utilizado neste traba-lho. A Figura 2.7 apresenta a ideia de um sistema multiclassificador paralelo, comitê de classificadores.
classifica-2.5 Combinação de Classificadores 25
Figura 2.7: Sistemas multiclassificador paralelo
dores componentes do sistema na construção da resposta final, ou seja, a classificação final resulta da opinião coletiva dos classificadores participantes. Pode-se citar como exemplos os seguintes métodos:
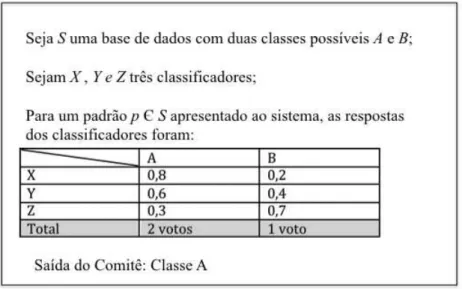
• Soma (KITTLER; ALKOOT, 2003): O método Soma é um método de combinação linear das saídas dos classificadores componentes do sistema. Funciona de maneira que quando apresentado um padrão de entrada para os classificadores, os valores das saídas correspondentes a cada classe de cada classificador são somados e a classe vencedora é aquela que possuir o maior valor absoluto. A Figura 2.8 apresenta um exemplo para este método.
2.5 Combinação de Classificadores 26
• Soma Ponderada: O método da soma ponderada funciona da mesma forma que o
método da soma, acrescentando, porém, um peso para a saída de cada classificador. Dessa forma, classificadores com maiores desempenhos segundo algum critério são mais considerados do que outros. Esse critério pode ser a taxa de classificação correta sobre o conjunto de treinamento ou sobre um conjunto de avaliação.
• Voto (KUNCHEVA, 2004): O método do Voto é um método de combinação não-linear das saídas dos classificadores componentes do sistema. Neste método, quando um padrão de entrada é apresentado para os classificadores, cada um deles vota na classe que ele achar que é a correta. A classe vencedora é aquela que possuir o maior número de votos, como pode ser visto na Figura 2.9.
Figura 2.9: Exemplo do método voto em um sistema com três classificadores em uma base que possui duas classes possíveis
2.6 Diversidade em Comitês de Classificadores 27
classificadores base, fase de treinamento. Os dois folds remanescentes são utilizados para validação e teste dos classificadores base. As saídas dos classificadores base para os exem-plos de validação e teste são utilizadas para realizar o treinamento e teste do combinador, respectivamente.
Já na estratégia de combinação baseada em seleção, a resposta final do sistema é dada pelo classificador base mais capacitado para o padrão de entrada dado. Um método de seleção que tem sido bastante utilizado é o Classificador de Seleção Dinâmica (Dynamic Classifier Selection – DCS) (GIACINTO; ROLI, 1999), que utiliza análise de competência para cada classificador, dado um padrão de entrada por ele classificado.
Essa análise de competência é dada pela proporção de acertos de cada classificador para oskpadrões mais parecidos com o padrão atual e que foram rotulados com a mesma classe pelo classificador em questão. Por exemplo, dado um padrão de entradaxpara classificação em um sistema com dois classificadores base e um módulo combinador DCS. O classificador 1 atribuixà classeAe o classificador 2 atribuixà classeB. A competência do classificador 1 será a média de acertos dele para os 10 (por exemplo) padrões mais parecidos com x e que foram rotulados por ele como sendo da classeA. Para o classificador 2 será a média de acertos dele para os 10 padrões mais parecidos com x e que foram rotulados por ele como sendo da classe B.
Dessa forma, o classificador que tiver a maior proporção de padrões classificados cor-retamente é o mais competente segundo o DCS para classificar o padrão de entrada dado.
2.6
Diversidade em Comitês de Classificadores
2.6 Diversidade em Comitês de Classificadores 28
• Algoritmos de aprendizagem iguais com parâmetros diferentes: Nesta abordagem,
a diversidade pode ser alcançada através do uso de diferentes parâmetros de ajuste inicial dos algoritmos de aprendizagem. Sendo assim, mesmo construindo um comitê homogêneo, ou seja, um comitê formado por um mesmo tipo de classificador, pode-se obter um comitê diverso, pois os parâmetros do algoritmo de aprendizagem foram inicializados com valores diferentes, construindo, assim, modelos diferentes. Em uma rede neural, por exemplo, isso significaria variar os pesos e topologia do modelo de rede neural;
• Algoritmos de aprendizagem diferentes: Nesta abordagem, a diversidade pode ser al-cançada através do uso de diferentes algoritmos de aprendizagem, ou seja, diferentes tipos de classificadores, são os chamados comitês heterogêneos. Por exemplo, normal-mente um comitê que é composto de rede neural e árvore decisão é mais diversificado que um comitê composto apenas de redes neurais ou apenas de árvores decisão;
• Conjuntos de dados diferentes na construção do classificador: Nesta abordagem, a diversidade pode ser alcançada através da utilização de estratégias de aprendizagem, tais como Bagging e Boosting que selecionam conjuntos de exemplos distintos para cada classificador ou a utilização de métodos de distribuição de atributos. Dessa forma, os classificadores componentes do comitê generalizarão de forma diversa, visto que os estímulos de entrada são distintos.
Neste trabalho todas as estratégias supracitadas foram aplicadas, tendo como foco principal a seleção de subconjuntos de atributos diversos para cada classificador.
Existem propostas para avaliar quantitativamente a diversidade entre classificadores e isso pode ajudar na escolha dos componentes mais diversos para a construção de um co-mitê. Porém, nenhuma dessas medidas é aceita uniformemente, pois ainda não foi provada nenhuma relação formal entre as métricas e o erro total do comitê. Segundo (KUNCHEVA, 2004) as métricas podem ser divididas em dois grupos:
2.6 Diversidade em Comitês de Classificadores 29
a medida de desacordo que mede a probabilidade de dois classificadores discorda-rem de suas decisões e a medida de dupla falta que mede a probabilidade de dois classificadores estarem errados em suas decisões;
• Medidas sem paridade: Mede a diversidade considerando todos os classificadores juntos, calculando diretamente um valor para o comitê. Essas métricas se baseiam em entropia ou na correlação de cada classificador com a saída média de todos os classificadores.
30
Capítulo 3
Seleção de Atributos
3.1
Considerações Iniciais
Intuitivamente, quanto maior o número de atributos em uma base de dados, maior o poder discriminatório do classificador e a facilidade de extrair modelos de conhecimento da base, porém, na prática isso nem sempre é verdade, por dois motivos principais. Primeiro porque muitos algoritmos de aprendizagem sofrem da maldição da dimensionalidade, ou seja, o tempo computacional do algoritmo aumenta de forma considerável e indesejável com o aumento no número de atributos, dificultando a construção do modelo. Segundo porque a presença de atributos ruidosos, irrelevantes ou redundantes na base de dados pode confundir o algoritmo de aprendizagem, ajudando a esconder as distribuições de pequenos conjuntos de atributos realmente relevantes, prejudicando, assim, a construção de um classificador acurado (PAPPA, 2002). Isso acontece porque nem sempre uma base de dados é construída visando uma tarefa específica, como a classificação de padrões, por exemplo, e pode, portanto, possuir atributos que não são importantes e não contribuem para tal tarefa.
3.1 Considerações Iniciais 31
dos dados para sua posterior aplicação em tarefas como mineração dos dados, aprendizado de máquina, reconhecimento de padrões, estatística, etc., tendo como principal objetivo selecionar um subconjunto de atributos relevantes dentre todos os atributos disponíveis para a tarefa proposta.
Neste ponto, a questão é definir o que é um atributo relevante. Em geral um atributo é dito relevante se ele é capaz de distinguir exemplos pertencentes a classes diferentes. Na literatura existem várias definições formais para atributos relevantes, classificando-os como atributos fracamente relevantes ou fortemente relevantes. Em Kohavi e John (1997) são definidas duas notações para relevância:
• Relevância forte: Um atributo xi é fortemente relevante se a sua remoção gera uma degradação no desempenho do classificador.
• Relevância fraca: Um atributoxi é de fraca relevância se ele não for fortemente rele-vante e existir um subconjunto de atributosV em que o desempenho do classificador usando V ∪xi é superior ao desempenho do mesmo classificador utilizado somente sobre subconjunto V.
Existem ainda atributos que não possuem relevância fraca e nem forte, por isso, denominam-se irrelevantes e não devem ser selecionados. Essa forma de se determinar a relevância dos atributos é feita sob uma avaliação individual dos atributos de uma base de dados e somente remove os atributos irrelevantes, já que espera-se que atributos re-dundantes tenham a mesma importância na discriminação das classes. Pode-se, porém, avaliar a relevância de um subconjunto de atributos como um todo, e nesse caso, retirar não somente os atributos irrelevantes como os redundantes (HUEI, 2005). Para isso, alguma medida de avaliação deve ser adotada para determinar se um subconjunto é melhor que outro. Várias medidas foram propostas na literatura para definir a importância dos atri-butos, quer por avaliação individual, quer por avaliação do subconjunto. Algumas dessas medidas serão comentadas na próxima seção.
3.2 Seleção de Atributos como um Problema de Busca 32
desempenho. O problema pode ser formalmente definido como segue. Seja X o conjunto original de atributos da base de dados, espaço de busca, com tamanho q. O objetivo do problema de seleção de atributos é encontrar um conjunto X0 com tamanho
q0, onde
X0
⊆X. Para isto, uma funçãof(X0
)é aplicada como critério de avaliação do subconjunto e deve ser maximizada, como mostra a Equação (3.1). Esse critério de avaliação é a medida de importância do subconjunto de atributos e pode ser a acurácia do classificador, por exemplo.
f(X0
) = maxf(Z), onde Z ⊆Xe|Z|=q0
(3.1)
3.2
Seleção de Atributos como um Problema de Busca
Como dito anteriormente, a tarefa de seleção de atributos pode ser descrita como um problema de busca onde cada etapa identifica um subconjunto de atributos possíveis dentro do espaço de busca e essa solução encontrada deve ser avaliada segundo algum critério. Em Blum e Langley (1997) foi sugerido que o processo de busca por subconjuntos de atributos deve seguir quatro passos básicos: Definição do ponto inicial no espaço de busca; Definição do procedimento da busca; Definição da estratégia de avaliação das soluções encontradas e Critério de parada da busca. Podemos acrescentar aqui um quinto passo: Validação da solução encontrada. A Figura 3.1 apresenta um gráfico com os passos básicos do processo de seleção de atributos.
3.2 Seleção de Atributos como um Problema de Busca 33
As próximas subseções apresentam cada um dos passos para a seleção de atributos.
3.2.1
Definição do ponto inicial da busca
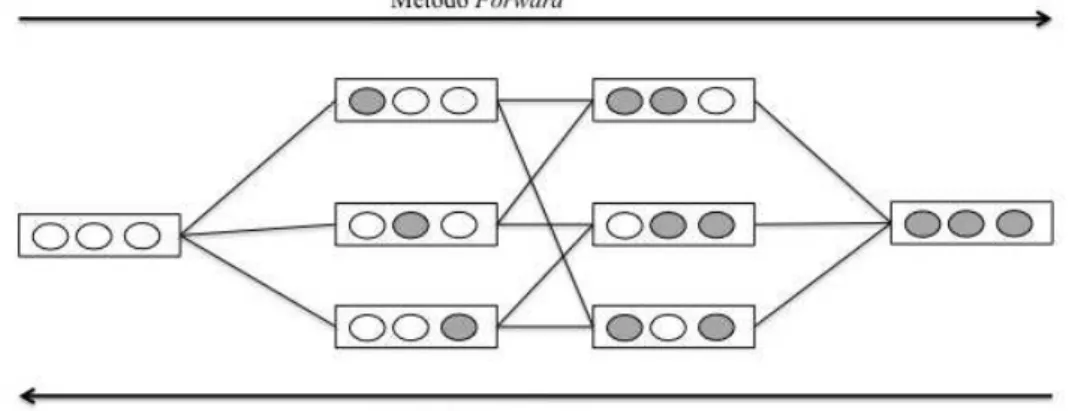
O ponto inicial no espaço determina a direção da busca. Como mostra a Figura 3.2 a busca pode começar com uma solução vazia e ir sucessivamente adicionando os atributos (Método Forward) ou pode começar com uma solução que possua todos os atributos e ir sucessivamente retirando os atributos (Método Backward). A busca pode ser também bidirecional, ou seja, pode-se processar simultaneamente duas buscas, uma em cada direção e parar quando uma das buscas encontrar a melhor solução ou quando ambas chegarem ao centro do espaço de busca. A busca pode ainda iniciar com uma solução qualquer no espaço de busca.
Figura 3.2: Exemplo de espaço de busca por subconjuntos de atributos
3.2.2
Procedimento da busca
3.2 Seleção de Atributos como um Problema de Busca 34
caso de seleção de atributos a busca exaustiva deve avaliar todos os possíveis subconjuntos de atributos. Os algoritmos de busca exaustiva podem, por exemplo, empregar alguma técnica de busca não informada como a busca em profundidade ou a busca em largura para definir a ordem de exploração do espaço de busca.
Figura 3.3: Ordem de exploração do espaço de busca utilizando uma busca em profundidade
Essas técnicas podem ser definidas como segue: Seja o espaço da busca pelo melhor subconjunto de atributos de uma base de dados representado por um grafo onde cada nó representa uma solução para o problema, semelhante ao espaço apresentado na Figura 3.2. A busca em profundidade avalia cada solução começando da raiz, ponto inicial da busca, e explora cada um de seus ramos até os nós não terem mais sucessores. A medida que esses nós são expandidos a busca retorna ao nó seguinte mais raso que ainda tem sucessores inexplorados, como mostra a Figura 3.3. Já a busca em largura expande todos os nós em uma dada profundidade no espaço de busca, antes que todos os nós do nível seguinte sejam expandidos, como mostra a Figura 3.4. Uma busca exaustiva retornará a solução dentre todas as soluções possíveis com melhor desempenho no processo de avaliação.
3.2 Seleção de Atributos como um Problema de Busca 35
Figura 3.4: Ordem de exploração do espaço de busca utilizando uma busca em largura
a mesma solução em todas as execuções que sigam o mesmo critério de avaliação e parada, já os estocásticos retornam soluções diversas devido à aleatoriedade embutida no algoritmo, tendo, por isso, a vantagem de evitar mínimos locais.
Os algoritmos de busca podem trabalhar de forma sequencial, ou seja, construindo uma única solução ao longo de sua execução, ou de forma paralela, analisando múltiplas soluções no processo de escolha. No primeiro caso, o espaço de busca pode ser representado por um grafo onde cada nó é um atributo e ao longo do processo de busca o algoritmo adiciona ou remove um atributo ao conjunto selecionado, formando assim a solução final. Já no caso paralelo, o espaço de busca pode ser definido como um grafo onde cada nó é um subconjunto de atributos e o algoritmo decide se um nó é melhor ou pior que outro, seguindo um caminho por ele determinado.
3.2 Seleção de Atributos como um Problema de Busca 36
representando todos os atributos e a cada iteração um atributo é removido da solução atual até que não se consiga melhorar a qualidade da solução encontrada (PAPPA, 2002). Já as buscas sequenciais flutuantes para frente e para trás executam uma quantidade l de vezes o algoritmo de busca sequencial para frente e em seguida uma quantidade m de vezes o algoritmo de busca sequencial para trás, onde l e m são atualizados dinamicamente, sendo a primeira bottom up e a segundatop down.
Dentre os métodos determinísticos paralelos pode-se citar os algoritmos best-first e beam first, esses algoritmos seguem sempre pelo caminho que parece o mais promissor em um dado momento, seu procedimento é dado da seguinte maneira: todas as possíveis soluções em um nível do grafo, isto é, a uma distância k do nó raiz, são avaliadas e a melhor delas é escolhida para ser expandida, ou seja, todas as soluções a partir dela que estejam um nível mais baixo na árvore de busca serão avaliadas. A busca volta a um nível mais alto caso pareça mais promissor. O algoritmo beam search é uma versão restrita do primeiro que limita a quantidade de soluções candidatas que serão avaliadas.
Os algoritmos de busca heurística estocásticos são aqueles que apresentam alguma aleatoriedade embutida em seu procedimento de busca que permite os saltos no espaço de busca. Dentre eles estão os Algoritmos Genéticos e Simulated Anneling. Este tópico será tratado no Capítulo 4.
3.2.3
Avaliação da solução encontrada
Sendo o subconjunto de atributos selecionado utilizado para a construção dos classi-ficadores, pode-se avaliar a solução encontrada pelo algoritmo de busca de duas maneiras distintas:
1. Critério de avaliação independente do classificador