UNIVERSIDADEFEDERALDO RIO GRANDE DO NORTE
UNIVERSIDADEFEDERAL DORIOGRANDE DONORTE CENTRO DETECNOLOGIA
PROGRAMA DEPÓS-GRADUAÇÃO EMENGENHARIAELÉTRICA E DECOMPUTAÇÃO
Br-IndustrialExpert
Um framework para análise da dependabilidade de
infraestruturas críticas
Daniel Enos Cavalcanti Rodrigues de Macedo
Orientador: Prof. Dr. Luiz Affonso Henderson Guedes de Oliveira (DCA/UFRN)
Dissertação de Mestrado apresentada ao Programa de Pós-Graduação em Engenharia Elétrica e de Computação da UFRN (área de concentração: Engenharia de Computação) como parte dos requisitos para obtenção do título de Mestre em Ciências.
UFRN / Biblioteca Central Zila Mamede Catalogação da Publicação na Fonte Macedo, Daniel Enos Cavalcanti Rodrigues de.
Br-IndustrialExpert: um framework para análise da dependabilidade de infraestruturas críticas / Daniel Enos Cavalcanti Rodrigues de Macedo.
– Natal, RN, 2014. 57 f. : il.
Orientador: Prof. Dr. Luiz Affonso Henderson Guedes de Oliveira.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Tecnologia. Programa de Pós-Graduação Engenharia Elétrica e da Computação.
1. Infraestruturas críticas - Dissertação. 2. Árvores de Falhas - Dissertação. 3. Dependabilidade - Dissertação. 4. Framework - Dissertação. 5. Ambientes industriais - Dissertação. I. Oliveira, Luiz Affonso Henderson Guedes de. II. Universidade Federal do Rio Grande do Norte. III. Título.
Agradecimentos
Fazer um mestrado é o experimentar de novos desafios, o amadurecimento do pensar, uma explosão de sentimentos. Ao longo do caminho, encontra-se a chuva, o sol, as flores e o espinho. Para um viajante que cruza o caminho, o final pode parecer uma vitória soli-tária, mas engana-se. A conclusão não teria ocorrido sem a ajuda de pessoas especiais que contribuíram e me ajudaram ao longo de toda essa caminhada. Agradeço primeiramente a Deus, pelo amor e carinho com que tem cuidado de mim todos os dias da minha vida e me orientado nos momentos mais difíceis. A minha família que tem me encorajado e apoiado a alcançar meus sonhos.
A Raquel França de Oliveira, minha amiga e companheira que me deu forças e apoio mesmo nos momentos de maior ausência.
Aos meus orientadores de pesquisas científicas Prof. Luiz Affonso e Prof. Ivanovitch que marcaram minha vida acadêmica, como exemplos de profissionais dedicados a suas profissões e comprometidos com a verdadeira missão de lecionar.
Aos companheiros de trabalho do Laboratório de Informática Industrial e da AutoS-mart Sistemas de Automação Inteligentes que são exemplos de engenheiros e profissio-nais.
Resumo
A demanda para o desenvolvimento de novas ferramentas que facilitem o projeto, monitoramento, manutenção e comissionamento de infraestruturas críticas é permanente. A complexidade do ambiente industrial, por exemplo, exige que estas ferramentas apre-sentem funcionalidades bastante flexíveis, informando dados valiosos para os projetistas ainda na fase de pré-projeto. Adicionado a estes fatores, sabe-se que os processos in-dustriais apresentam requisitos de dependabilidade rígidos, uma vez que falhas podem provocar perdas econômicas, danos ambientais e riscos de vida aos operários. A utili-zação de uma ferramenta que habilite a avaliação de falhas nas infraestruturas críticas poderia mitigar esses problemas. Nesse sentido, o referido trabalho apresenta o desenvol-vimento de umaframeworkpara análise da dependabilidade de infraestruturas críticas. A
proposta permite a modelagem das infraestruturas críticas, mapeando seus componentes em uma Árvore de Falha. Em seguida, o modelo matemático gerado é utilizado para aná-lise da dependabilidade da infraestrutura, baseando-se nas falhas de equipamentos e suas interligações. Finalmente, cenários típicos de ambientes industriais são utilizados para a validação da proposta.
Abstract
There is a growing need to develop new tools to help end users in tasks related to the design, monitoring, maintenance and commissioning of critical infrastructures. The complexity of the industrial environment, for example, requires that these tools have fle-xible features in order to provide valuable data for the designers at the design phases. Furthermore, it is known that industrial processes have stringent requirements for depen-dability, since failures can cause economic losses, environmental damages and danger to people. The lack of tools that enable the evaluation of faults in critical infrastructures could mitigate these problems. Accordingly, the said work presents developing a fra-mework for analyzing of dependability for critical infrastructures. The proposal allows the modeling of critical infrastructure, mapping its components to a Fault Tree. Then the mathematical model generated is used for dependability analysis of infrastructure, relying on the equipment and its interconnections failures. Finally, typical scenarios of industrial environments are used to validate the proposal.
Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas v
Lista de Publicações vii
Lista de Acrônimos e Abreviaturas ix
1 Introdução 1
1.1 Objetivos . . . 3
1.2 Contribuições . . . 3
1.3 Organização da dissertação . . . 4
2 Dependabilidade: Estado da Arte 7 2.1 Principais conceitos . . . 7
2.1.1 Falha . . . 7
2.1.2 Defeito . . . 8
2.1.3 Erros . . . 9
2.1.4 Dependabilidade . . . 10
2.2 Medidas fundamentais . . . 11
2.2.1 Modelos para taxas de defeitos . . . 11
2.2.2 Medidas de Análise Quantitativa . . . 13
3 Árvore de Falhas 23 3.1 Composição da Árvore de Falhas . . . 23
3.1.1 Análise de Árvores de Falhas . . . 25
4 Frameworkpara Análise da Dependabilidade 29 4.1 Br-MathExpert . . . 29
4.2 Br-FaultTreeExpert . . . 31
4.3 Br-IndustrialExpert . . . 32
4.3.1 Editor de infraestruturas genéricas . . . 33
4.3.2 Gerador de Árvore de Falhas . . . 34
4.4 Conjunto de Cortes Minimais . . . 37
5 Estudo de casos 43 5.1 Estudo de Caso 1 . . . 43
5.2 Estudo de Caso 2 . . . 47
5.3 Estudo de Caso 3 . . . 49
6 Conclusão e Trabalhos Futuros 53
Lista de Figuras
2.1 Relação entre falhas, erros e defeitos. . . 9
2.2 Relação entre a densidade de defeitos f(t)e a taxa de defeitosz(t). . . 12
2.3 Estados do sistema na visão da confiabilidade. . . 14
2.4 Estados do sistema na visão da disponibilidade. . . 18
2.5 Comportamento do sistema para diversos instantes de tempo. . . 19
3.1 Diagrama de uma Árvore de Falhas e os seus principais componentes: eventos básicos (A,B,C,D,E), portas lógicas (or1, or2, and1, and2) e evento topo. . . 24
3.2 Portas lógicas mais comuns. . . 24
3.3 Execução do MOCUS na Árvore de Falha da Figura 3.1. . . 26
3.4 Árvore de Falhas com evento repetido. . . 27
3.5 Análise de um nó repetido. . . 27
4.1 Visão geral da arquitetura para avaliação da dependabiliade de infraestru-turas industriais críticas . . . 30
4.2 Hierarquia estrutural utilizada na arquitetura proposta. . . 30
4.3 Modelo hieráquico com Cadeia de Markov e Árvore de Falha. . . 31
4.4 Interface gráfica doBr-FaultTreeExpert . . . 32
4.5 Interface de configuração para estruturas genéricas noBr-IndustrialExpert. 34 4.6 Condição de falha para uma rede de dispositivos i considerado: (i) fa-lhas de hardware; (ii) fafa-lhas de link; (iii) ausência de camnhos entre o servidor/centralizador e o dispositivo; (iv) estrutura de dados adotada. . . 35
4.7 Condição de falha da rede (i) e sua estrutura de dados respectiva(ii). . . . 36
4.8 Exemplo de um sistema/processo. . . 37
4.9 Árvore de Falha baseada no exemplo da Fig. 4.8 considerando falhas de hardware permanente. . . 37
4.10 Árvore de Falhas baseada no exemplo da Fig. 4.8 considerando falhas em links permanentes. . . 37
4.11 Topologia utilizada para exemplificar a geração do conjunto de cortes
mí-nimos. . . 39
4.12 Simplificação utilizada na geração do conjunto de cortes mínimos. . . 42
5.1 Sistema de controle de nível de água. . . 43
5.2 Modelagem do processo de controle de nível de água no Br-IndustrialExpert. 44 5.3 Processo de controle de nível de água modelado em uma Árvore de Falha. 45 5.4 Análise de confiabilidade para o sistema de tanques. . . 46
5.5 Br-Industrial Process Expert’sEditor de Rede. . . 47
5.6 Analise de sensibilidade considerando a confiabilidade do sistema. . . 48
5.7 Esquema de rede de escoamento de óleo. . . 49
5.8 Confiabilidade do processo de escoamento de óleo. . . 50
5.9 Disponbilidade do processo de escoamento de óleo. . . 50
Lista de Tabelas
2.1 Medidas de confiabilidade para taxas de defeitos típicas. . . 17
5.1 Taxas de falha e reparo dos eventos. . . 45 5.2 Taxas de falha e reparo dos eventos. . . 46 5.3 Analise de sensibilidade considerando a disponibilidade do sistema. . . . 48 5.4 Taxas de falha e reparo dos eventos. . . 50
Lista de Publicações
Ivanovitch Silva, Rafael Leandro, Daniel Macedo, Luiz Affonso Guedes, A dependa-bility evaluation tool for the Internet of Things, Computers & Electrical Engi-neering, Volume 39, Issue 7, October 2013, Pages 2005-2018, ISSN 0045-7906, http://dx.doi.org/10.1016/j.compeleceng.2013.04.021.
Macedo, D.; Silva, I.; Guedes, L.A.; Portugal, P.; Vasques, F., "A framework for de-pendability evaluation of industrial processes,"Emerging Technologies & Factory Automation (ETFA), 2013 IEEE 18th Conference on , vol., no., pp.1,4, 10-13 Sept. 2013, doi: 10.1109/ETFA.2013.6648117.
Silva, I ; Macedo, Daniel ; Guedes, L. A. A dependability evaluation for Internet of Things incorporating redundancy aspects. In: ICNSC, 2014, Maiami.
Macedo, Daniel ; Silva, I. ; Guedes, L. A. . Uma Ferramenta para Análise de Dependa-bilidade de Processos Industriais. In: Simpósio Brasileiro de Automação Inteligente (SBAI), 2013, Fortaleza. Simpósio Brasileiro de Automação Inteligente (SBAI), 2013.
SANTOS, A. ; Macedo, Daniel ; Silva, I. ; Guedes, L. A. ; Dória Neto, A. D . Ferra-menta para Gerenciamento de Redes Industriais WIRELESSHART. In: Simpósio Brasileiro de Automação Inteligente (SBAI), 2013, Fortaleza. Simpósio Brasileiro de Automação Inteligente (SBAI), 2013.
Silva, I ; Macedo, Daniel ; Guedes, L. A. . Uma Metodologia para Modelagem e Ava-liação da Dependabilidade de Redes Industriais Sem Fio. In: Abrisco, 2013, Rio de Janeiro. Associação Brasileira de Análise de Risco, Segurança de Processos e Confiabilidade. Rio de Janeiro: Abrisco, 2013.
Silva, P. A. F. ; Silva, I ; Macedo, Daniel ; Robson, A. ; Guedes, L. A. . Ferramenta para Análise de Confiabilidade e Risco de Processos Industriais via Redes Bayesianas. In: Abrisco, 2013, Rio de Janeiro. Associação Brasileira de Análise de Risco, Segurança de Processos e Confiabilidade. Rio de Janeiro: Abrisco, 2013.
Nobre, L. Silva, P. A. F. ; Silva, I ; Macedo, Daniel ; Robson, A. ; Guedes, L. A. Análise de confiabilidade de processos industriais via Redes Bayesianas. In: CBA, 2014, Belo Horizonte.(aprovado)
Lista de Acrônimos e Abreviaturas
CCF Falhas em modo comum
FT Árvores de Falhas
FTA Análise de Árvores de Falhas
ME Br-MarkovExpert
MTBF Tempo médio entre defeitos
MTTF Tempo médio de funcionamento até a ocorrência de um defeito
MTTR Tempo médio até o sistema reparar um defeito
Capítulo 1
Introdução
O ambiente industrial é conhecido por ser bastante conservador em relação à adoção de novas tecnologias. Fazendo uma comparação com a área de redes de computadores, vemos que uma infraestrutura de Tecnologia da Informação e Comunicação (TIC) tem um tempo de vida médio de 2 a 3 anos, enquanto que a mesma estrutura na área indus-trial apresenta um tempo de vida médio de aproximadamente 10 anos [Silva 2013]. Essa realidade ocorre principalmente devido à confiabilidade e à segurança já válidas em tec-nologias legadas. Em um ambiente industrial, falhas nos equipamentos podem resultar em perdas econômicas e, principalmente, provocar danos irreparáveis ao meio ambiente e operadores. Nesse sentido, é de suma importância o desenvolvimento de ferramen-tas para análise da dependabilidade1 das infraestruturas críticas dos ambientes
industri-ais [Krishnamurthy et al. 2005, Cinque et al. 2007, Xing et al. 2012].
Infraestruturas críticas podem ser desde processos químicos, serviços de Tecnologia da Informação (TI), redes de comunicação a fatores humanos. Do ponto de vista da modelagem de sistemas, as infraestruturas críticas podem ser mapeadas em uma estrutura de rede, constituindo assim um grafo. A teoria dos grafos é um ramo da matemática que estuda as relações entre os objetos de um determinado conjunto. Um grafo é formado por um conjunto não vazio de objetos, denominados vértices e por um conjunto de pares não ordenados de vértices, chamado arestas. Em uma refinaria por exemplo, podemos mapear os dutos de fluxo de óleo como as arestas e os vasos de armazenamento de óleo e de separação como os vértices.
A estimativa da dependabilidade das infraestruturas críticas durante as fases iniciais de planejamento e projeto pode antecipar importantes decisões, tais como o comportamento das falhas do sistema em caso de falhas, disponibilidade e criticidade dos equipamentos,
1A definição de dependabilidade será formalmente apresentada nas próximas seções. Nesse momento,
2 CAPÍTULO 1. INTRODUÇÃO
dentre outras métricas. Essa análise pode ser obtida quantitativamente através de modelos matemáticos, tais como Árvore de Falhas 2, Cadeias de Markov, Redes Petri e Redes Bayesianas.
A análise da dependabilidade de sistemas baseados em grafos é um problema clás-sico na literatura [AboElFotoh & Colbourn 1989]. A teoria já desenvolvida pode ser utilizada na estimação da dependabilidade das infraestruturas críticas em ambientes in-dustriais. O problema pode ser classificado em três abordagens: k-terminal, 2-terminal ou todos-terminal. Vamos assumir um grafo com N dispositivos e um conjunto de K
dispositivos (K ⊂N e |K|<|N|). K é um conjunto composto por um dispositivo
cen-tralizador eK-1 dispositivos de campo. Definindo um dispositivo centralizador s∈K, o
problemak-terminalé expressado como a probabilidade de que exista pelo menos um
ca-minho/ligação despara cada dispositivo de campo incluso emK. O problema2-terminal
é o caso ondeK = 2, ao passo que o problema de todos-terminalé o caso em que|K|= |N|.
Uma tentativa para criar uma metodologia para avaliar a dependabilidade de estrutu-ras baseadas em grafos foi realizada em [Cinque et al. 2007]. Os autores mapearam uma Rede de Sensores Sem Fio (RSSF) em uma estrutura de grafo. Os sensores assumem o papel dos vértices enquanto que os enlaces de comunicação entre os diversos sensores as-sumem o papel de arestas do grafo. Um modelo baseado no formalismo de Redes de Petri Estocásticas e Generalizadas foi desenvolvido para análise das falhas transientes. Para introduzir o conceito de arquitetura de modelos, os mesmos autores estenderam o traba-lho anterior [Cinque et al. 2007] criando uma proposta dinâmica capaz de especializar o estudo descrito em Di Martino et al. (2012). Todavia, ambos os trabalhos não permitem a configuração de condições de falhas mais complexas envolvendo eventos independentes. Adicionalmente, métricas clássicas de dependabilidade não são suportadas, por exemplo, confiabilidade, disponibilidade e criticidade de dispositivos.
Recentemente, uma importante contribuição para avaliação da dependabilidade em grafos foi proposta em Xing et al. (2012). A ideia principal é avaliar a influência de falhas em modo comum. Os autores propõem um esquema baseado em Diagramas de Decisão Binária (DDB) para avaliação de grafos com uma quantidade de componentes superior a 20 dispositivos. Todavia, o modelo não suporta condições genéricas de falha, tampouco uma análise de importância dos dispositivos. Tal trabalho foi desenvolvido visando especificamente o estudo de Redes de Sensores Sem Fio Industriais (RSSFI), no entanto, seus algoritmos podem ser generalizados para outras infraestruturas como processos químicos e refinarias.
1.1. OBJETIVOS 3
A partir da discussão acima se torna claro que os trabalhos já desenvolvidos na lite-ratura têm fornecido apenas uma solução parcial para o problema visado, uma vez que a maioria deles é focado em situações muito específicas. Adicionalmente, esses tra-balhos são muito restritivos no que diz respeito à definição das condições de falha na infraestrutura, métricas de confiabilidade, topologia e aspectos de reconfiguração. A fer-ramenta proposta neste trabalho utiliza-se de uma metodologia que não é uma aborda-gem nova, visto que o problema da dependabilidade em grafos já foi avaliado na litera-tura [AboElFotoh & Colbourn 1989], no entanto, a metodologia adotada visa eliminar a maioria das limitações dos trabalhos anteriores. Além disso, os trabalhos analisados geram seus próprios modelos de dependabilidade, o que dificulta a generalização dos re-sultados.
1.1 Objetivos
Considerando a importância inerente das infraestruturas críticas em ambientes indus-triais e também a necessidade de novas instalações (redes de comunicação cabeadas e sem fio, processos químicos, monitoramento de dutos, etc), a presente dissertação tem como objetivo principal o desenvolvimento de um framework para criação de infraestruturas
industriais críticas mais resilientes e compatíveis com os requisitos orçamentários. O fra-meworkproposto pode ser considerado uma ferramenta de projeto, cujo foco principal é a
dependabilidade das aplicações. Oframeworkpermite a escolha da topologia (forma com
que os equipamentos se conectam) a ser adotada, indicar os dispositivos mais críticos e realizar análise de sensibilidade. A proposta é baseada no formalismo matemático de Ár-vores de Falhas, considerando-se falhas permanentes, e falhas em modo comum (eventos independentes).
1.2 Contribuições
A principal contribuição da dissertação é propor umframeworkpara avaliar a
4 CAPÍTULO 1. INTRODUÇÃO
tanque de estocagem, etc). Adicionalmente, como contribuições secundárias, a adaptação de um algoritmo originalmente aplicado à teoria de grafos para a geração dos cortes míni-mos de uma Árvore de Falha, que viabiliza computacionalmente o emprego dessa técnica infraestruturas e dimensões tipicamente encontradas em instalações industriais reais.
A proposta inclui vários aspectos, sendo flexível e adaptável para diferentes tipos de cenários. Quando comparada com outras soluções encontradas na literatura, as principais vantagens doframeworkproposto nesta dissertação são:
• Suporte para infraestruturas industriais genéricas;
• Condições de falhas que podem ser configuradas de uma maneira flexível, desde um simples dispositivo até um grupo de dispositivos;
• Processos de defeitos e reparos podem ser caracterizados usando diferentes tipos de distribuições estatísticas;
• Análise de defeitos em modo comum;
• Falhas em hardware(equipamentos) e enlaces de comunicação (interação entre os
equipamentos);
• Possibilidade de obtenção de diferentes tipos de métricas para um mesmo modelo (confiabilidade, disponibilidade, tempo médio entre falhas, medidas de criticali-dade);
• Desenvolvimento de uma linguagem de programação para modelagem e cálculo da dependabilidade de infraestruturas industriais;
• Protocolo de comunicação baseado em plug-inspara a análise da dependabilidade
baseada em Árvores de Falhas;
• Implementação de umsoftwareincorporando todas as contribuições anteriores.
Para complementar a proposta, foram desenvolvidas ferramentas desoftware
genéri-cas para a análise de Árvore de Falhas e Cadeias de Markov de tempo discreto permitindo que outras aplicações gerem seus modelos e possam analisa-los. O desenvolvimento da ferramenta para análise de Cadeia de Markov foi feito para analisar redundâncias em dis-positivos em trabalho futuros.
1.3 Organização da dissertação
1.3. ORGANIZAÇÃO DA DISSERTAÇÃO 5
Capítulo 2
Dependabilidade: Estado da Arte
Dependabilidade é um tema intrinsecamente relacionado à indústria. Falhas nas in-fraestruturas críticas podem provocar a parada parcial ou até mesmo total de uma planta industrial, resultando em perdas econômicas e riscos iminentes aos operários. Esse ca-pítulo tem como objetivo principal descrever os principais conceitos relacionados com análise da dependabilidade de infraestruturas críticas industriais. Técnicas de redundân-cia e análises quantitativas também serão abordadas.
2.1 Principais conceitos
2.1.1 Falha
O primeiro conceito sobre dependabilidade a ser descrito é a própriafalha(fault). A
definição de falha é simples e clara, é um tipo de evento que pode conduzir a um erro. Uma falha está ativa quando ela causa um erro, caso contrário ela está dormente. Na indústria, alguns exemplos de falhas são: deterioração física dos componentes de hardware, erros operacionais, decisões equivocadas ainda na fase de projeto e envelhecimento de software.
Classificação
Avizienis et al. (2004) classificou as falhas para três principais grupos: falhas de pro-jeto, falhas físicas e falhas de operação. As falhas de projeto incluem todas as falhas que ocorrem durante a fase de desenvolvimento dos sistemas, enquanto que as falhas físicas são aquelas que afetam ohardwaredos equipamentos. Por fim, as falhas de operação são
todas as falhas que ocorrem durante a utilização dos sistemas.
8 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
pela ação do homem, a qual pode incluir a falha por omissão (ausência de ações quando na verdade ações deveriam ter sido tomadas) ou falha por comissionamento (quando ações erradas conduzem a falhas). Outros exemplos são descritos abaixo:
• Falhas maliciosas: introduzidas com o objetivo de alterar o funcionamento do sis-tema.
• Falhas não maliciosas: introduzidas sem o objetivo malicioso. • Falhas deliberadas: ocorrem devido a más decisões.
• Falhas não deliberadas: ocorrem devido a erros.
• Falhas de configuração: a configuração errada dos parâmetros conduzem para fa-lhas.
2.1.2 Defeito
O próximo conceito a ser descrito sobre análise da dependabilidade é o defeito ( fai-lure). A manifestação de eventos que ocorre quando o sistema desvia do serviço correto
é chamado defeito. Em outras palavras, defeitos ocorrem quando erros são propagados dentro do sistema.
Um ponto de grande importância é a identificação das possíveis causas dos defeitos. Isso pode ser realizado mais facilmente baseado na caracterização/classificação dos di-versos tipos de defeitos. Avizienis et al. (2004) caracteriza os defeitos em quatro pontos de vistas: domínio, detectabilidade, consistência e consequências.
No primeiro ponto de vista, o domínio dos defeitos são classificados em três classes principais:
• Defeitos de conteúdo: a natureza da informação (numérica ou não numérica) trans-mitida desvia da especificação correta.
• Defeitos temporais: a duração do serviço desvia da implementação correta (muito rápido ou muito lento).
• Defeitos de conteúdo e temporais: nenhum serviço é entregue ou caso o serviço seja entregue ele desvia da sua implementação correta.
2.1. PRINCIPAIS CONCEITOS 9
dos defeitos quando eles realmente ocorrem. Ambos problemas conduzem o sistema para um estado de degradação, onde apenas algumas funcionalidades são operacionais.
A consistência dos defeitos é um ponto de vista que apresenta um significado muito próximo com a detectabilidade dos defeitos. Esse conceito está relacionado com a capa-cidade de observação dos usuários em relação aos defeitos. Quando um serviço incorreto é percebido por todos os usuários do sistema, o defeito é chamado consistente. Por outro lado, quando apenas alguns usuários percebem que um defeito ocorreu, este é chamado de inconsistente.
Finalmente, o último ponto de vista proposto por Avizienis et al. (2004) é a con-sequência dos defeitos. Esse conceito caracteriza a severidade que um defeito pode causar. Quando as consequências são comparadas com os benefícios fornecidos pelo funciona-mento correto do sistema, os defeitos são chamados de benignos, caso contrário eles são chamados de catastróficos.
Na metodologia proposta nesta dissertação, assumem-se os defeitos de conteúdo e temporais. Adicionalmente, todos os defeitos são sinalizados e observados para/pelos usuários. Em relação à severidade dos defeitos, dependendo do cenário a ser avaliado, ambos os defeitos benignos e catastróficos são suportados pela proposta apresentada aqui.
2.1.3 Erros
Erro é um conceito básico em análise da dependabilidade, o qual caracteriza um estado incorreto de parte do sistema. Erros podem causar defeitos, enquanto que as causas dos erros são as falhas. Os defeitos surgem quando os erros são propagados no sistema. Note que a parte do sistema que contém erros pode nunca ser usada, dessa forma o defeito poderá nunca ocorrer. A relação completa entre falhas, erros e defeitos é descrita na Figura 2.1.
Falha
... Ativação
Erro Propagação Defeito Causa Falha ...
Figura 2.1: Relação entre falhas, erros e defeitos.
10 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
algoritmo de controle não foi capaz, por exemplo, de enviar o sinal correto para o desblo-queio de uma válvula (defeito).
Em relação à classificação, os erros são caracterizados conforme sua detectabilidade. Um erro é detectável quando sua evidência é indicada através de um comportamento peculiar do sistema ou através de mensagens/alarmes. Por outro lado, quando o erro é presente, porém, não detectáveis, sua denominação é erro latente. No contexto desta dissertação, todos os erros são considerados detectáveis.
2.1.4 Dependabilidade
Dependabilidade é um conceito muito interessante que é discutido amplamente na li-teratura [Avizienis & Laprie 1986, Laprie 1995, Avizienis et al. 2004, Petre et al. 2011]. Existem diversas definições para o termo dependabilidade. Na definição original [Avizienis & Laprie 1986], dependabilidade é a capacidade de entregar serviços que podem ser jus-tificadamente confiáveis. Na definição de Petre et al. (2011), o termo dependabilidade é usado para descrever que um sistema pode ser confiável sob determinadas condições operacionais por um período de tempo específico. A definição de dependabilidade as-sumida nesta dissertação, considerando que todo sistema pode falhar, é a habilidade de um sistema evitar falhas nos serviços mais críticos [Avizienis et al. 2004]. Dependabili-dade pode ser também caracterizada por um conceito integrado combinando os seguintes atributos:
• Confiabilidade: exprime a ideia de continuidade do serviço correto. Em outras palavras, a probabilidade de um defeito não ocorrer em um determinado período de tempo.
• Integridade:o serviço não pode ser modificado sem autorização. • Manutenabilidade: capacidade de ser reparado ou sofrer manutenção.
• Disponibilidade: habilidade em fornecer o serviço correto quando solicitado. Em outras palavras, a probabilidade do sistema estar operacional quando solicitado. • Segurança:ausência de consequências catastróficas para os usuários do sistema.
2.2. MEDIDAS FUNDAMENTAIS 11
2.2 Medidas fundamentais
Sem perda de generalidade, a dependabilidade dos sistemas pode ser avaliadas baseando-se em duas medidas fundamentais [J. Muppala 2000]: confiabilidade e a disponibilidade. A confiabilidade é uma medida cuja relevância está direcionada para os sistemas com alta sensibilidade em caso de defeitos, ou seja, sistemas cujo os serviços não podem ser interrompidos (sistemas orientados à missão, por exemplo). Exemplos desses sistemas in-cluem controladores de aviões, missões espaciais, sistemas intrusivos (marcapasso, cora-ção artificial), sistemas balísticos e protecora-ção de reatores nucleares. Por outro lado, quando sistemas apresentam tolerância a pequenas interrupções, a medida de disponibilidade é mais indicada para avaliar a dependabilidade. Processos industriais e de telecomunica-ções incluem-se nesses sistemas [Portugal 2004]. A seguir, as medidas confiabilidade e disponibilidade serão descritas formalmente.
2.2.1 Modelos para taxas de defeitos
Devido à sua relação intrínseca com as medidas confiabilidade e disponibilidade, os modelos para taxas de defeitos serão os primeiros a serem descritos aqui. Vamos assumir um sistema composto porN dispositivos, os quais se encontram operacionais no instante t =0. Falhas ocorrem à medida que os dispositivos são utilizados ao longo do tempo.
O número de dispositivos operacionais em um instante de tempot é definido pela
fun-çãon(t). Baseando-se neste cenário, vamos definir o primeiro conceito: a densidade de defeitos f(t).
A densidade de defeitos expressa a taxa global da ocorrência de defeitos. Como des-crito na equação 2.1, f(t)é definida em um intervalo de tempo∆t e representa a relação
entre o número de defeitos ocorridos naquele intervalo de tempo (considerando o número total de dispositivos do sistema) dividido pelo intervalo de tempo transcorrido.
f(t) = n(t)−n(t+∆t)
N∆t (2.1)
De maneira análoga, se estamos interessados em calcular a percentagem de defeitos ocorridos até o instantet, então estaremos calculando a função de distribuição acumulativa
dos defeitosF(t). Sendo assim, de acordo com sua definição,F(t)é dada por:
F(t) =
Z u
12 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
A relação simétrica deF(t), a qual representa a porcentagem de dispositivos
operaci-onais no instantet, pode também ser facilmente encontrada, cujo valor é dado por:
1−F(t) = n(t)
N (2.3)
Outra definição bastante importante é ataxa de defeitos z(t)(também conhecida como
hazard rate). z(t)corresponde à taxa instantânea em que os defeitos ocorrem. Como
des-crito na equação 2.4,z(t)corresponde ao número de defeitos ocorridos em um intervalo∆t
(considerando a quantidade de dispositivos operacionais no inicio do intervalo) dividido pelo tamanho do intervalo de tempo.
z(t) = n(t)−n(t+∆t)
n(t)∆t (2.4)
f(t)
z(t)
Tempo
Tempo
T
1T
2Defeitos aleatórios
(vida útil) Desgate Período
inicial
Figura 2.2: Relação entre a densidade de defeitos f(t)e a taxa de defeitosz(t).
As funções f(t)ez(t)podem ser utilizadas para caracterizar a ocorrência de defeitos nos componentes do sistema. Durante o período inicial (após a fabricação ou início do sistema) defeitos nos componentes podem ser observados principalmente devido a erros de fabricação ou utilização incorreta. Nesse período é esperado que as funções f(t)ez(t)
2.2. MEDIDAS FUNDAMENTAIS 13
enquanto que f(t)diminui lentamente semelhante a uma função exponencial [Shooman
2002]. Nesse período os defeitos estão relacionados com as condições ambientes em que o sistema está inserido. Finalmente, quando a utilização do sistema ultrapassar a vida útil, observa-se um aumento natural da taxa de defeitos z(t). Esse comportamento provoca uma aumento imediato, porém curto, na densidade de defeitos f(t). Um resumo da relação entre f(t)ez(t)é descrito na Figura 2.2. Devido ao comportamento descrito porz(t), esta função também é conhecido como “curva da banheira”.
A taxa de defeitos z(t) descrita na Figura 2.2 apresenta uma aproximação razoável para o comportamento dos defeitos. Entretanto, esse comportamento não pode ser ge-neralizado. Por exemplo, para os componentes eletrônicos,z(t)apresenta um comporta-mento constante, enquanto que para os componentes mecânicosz(t)é estritamente cres-cente [Shooman 2002]. Na prática, devido à dificuldade em encontrar os valores reais correspondentes às ocorrências dos defeitos,z(t)é mapeado em modelos analíticos. Tais
modelos seguem distribuições de probabilidades que são escolhidas e configuradas de acordo com o comportamento observado dos sistemas. As distribuições Exponencial (z(t)
constante) e Weibull (z(t)apresenta comportamento similar ao da Figura 2.2) são bastante
utilizadas nesses modelos. Adicionalmente, a configuração das distribuições estatísticas utilizadas nos modelos insere um item a mais de dificuldade na modelagem, pois os parâ-metros a serem utilizados devem ser os mais fieis possível ao modelo real. Entretanto, na prática seria necessário observar comportamentos dos defeitos em sistemas semelhantes para a obtenção de parâmetros mais fidedignos. Uma alternativa é obter os parâmetros em bases de dados já compiladas por várias organizações, como por exemplo oMilitary Handbook - Reliability Prediction of Electronic Equipment (MIL-HDBK-217F)(1991) ou
OREDA (1983).
2.2.2 Medidas de Análise Quantitativa
14 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
seguir alguns aspectos de cada uma delas e em que situações elas são empregadas.
Confiabilidade
Conceitualmente, confiabilidade é definida como a probabilidade de um defeito do sistema não ter ocorrido no intervalo [0,t[. Este conceito foi descrito inicialmente na equação 2.3. Nesta seção iremos definir formalmente o conceito confiabilidade de forma similar ao descrito em Shooman (1990). A ideia é descrever confiabilidade em função da taxa de defeitosz(t).
Sem perda de generalidade vamos assumir que o sistema apresenta dois estados (con-forme descrito na Figura 2.3): operacional e o defeituoso. A transição do estado ope-racional para o defeituoso é vinculada à função z(t). Vamos assumir também a variável
aleatória T como sendo o tempo até o sistema entrar para o estado defeituoso. F(t) e
f(t) são respectivamente a função de distribuição acumulativa (equação 2.5) e a função
de densidade de probabilidade (equação 2.6) deT, ou seja:
z(t)
Operacional Defeituoso
Figura 2.3: Estados do sistema na visão da confiabilidade.
F(t) =P(T ≤t) (2.5)
f(t) = d
dtF(t) (2.6)
De acordo com a teoria de processos estocásticos [Papoulis & Pillai 2002], a probabi-lidade de um evento (defeito) ocorrer no intervalo[t,t+∆t]é dado por:
P(t<T ≤t+∆t) =F(t+∆t)−F(t) (2.7)
Estendendo essa definição para a probabilidade condicional, podemos calcular a probabi-lidade de ocorrer um defeito no intervalot+∆t, sabendo-se que o sistema estava
2.2. MEDIDAS FUNDAMENTAIS 15
P(t<T ≤t+∆t|t<T) = P(t <T ≤t+∆t)
P(T >t) =
F(t+∆t)−F(t)
1−F(t) (2.8)
Dividindo ambos os lados da equação 2.8 por∆t e calculando o limite∆t →0, pode-se obter a seguinte conclusão: a probabilidade de ocorrer um defeito no intervalo t+∆t,
sabendo que o sistema estava operacional no instantet, é similar à relação da densidade
de probabilidade do defeito pela confiabilidade do sistema (equação 2.9).
lim
∆t→0
P(t<T ≤t+∆t|t<T)
∆t = ∆limt→0
F(t+∆t)−F(t)
∆t ·
1 1−F(t)
= d
dtF(t)·
1 1−F(t)
= f(t)
1−F(t) (2.9)
Através de algumas manipulações matemáticas (considerando-se as equações 2.1, 2.3 e 2.4) é possível relacionar a funçãoz(t)com a equação 2.9. O procedimento é descrito na
equação 2.10.
z(t) = lim
∆t→0
n(t)−n(t+∆t)
n(t)∆t
= lim
∆t→0
n(t)−n(t+∆t)
∆t ·
1
n(t)
= N·f(t)· 1
n(t)
= f(t)
1−F(t) (2.10)
Assim, temos condições de definir formalmente o conceito confiabilidade. Baseado na definição do início desta seção, a confiabilidadeR(t)de um sistema pode ser descrita como o complemento da função de probabilidade acumulativa dos defeitos.
R(t) = P(T >t) =1−F(t) (2.11)
16 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
f(t) = d
dtF(t) =
d
dt(1−R(t)) =−R
′(t) (2.12)
z(t) = f(t)
1−F(t)=
−R′(t)
R(t) =−
d
dtlnR(t) (2.13)
Finalmente, encontramosR(t)calculando a integral em ambos os lados da equação 2.13 e elevando a constante matemática neperiana (e) ao resultado. A equação 2.14 comprova
a intrínseca relação entre a taxa de defeitos e a confiabilidade do sistema.
Z t
0 z(u)du = −lnR(t)
R(t) = exp
−
Z t
0 z(u)du
(2.14)
Medidas de valores médios
Uma outra forma de avaliar a confiabilidade do sistema é através dos valores mé-dios/esperados (E(t)) das distribuições de defeitos. Em geral, o tempo médio de
funciona-mento até a ocorrência de um defeito (MTTF) é a medida mais utilizada [Shooman 1990]. Baseado na teoria de probabilidade [Papoulis & Pillai 2002] e na equação 2.12 podemos definir o MTTF através da seguinte relação:
MT T F = E(t) =
Z ∞
0 t f(t)dt
= −
Z ∞
0 t
d
dtR(t)dt
= −
Z ∞
0 tdR(t)
= −tR(t)
∞
0 +
Z ∞
0 R(t)dt
=
Z ∞
0 R(t)dt (2.15)
Exemplos de confiabilidade para algumas taxas de defeitos
2.2. MEDIDAS FUNDAMENTAIS 17
o parâmetro do modelo éλ, que nesse caso representa o número de defeitos por unidade de tempo. Em relação à taxa de defeitos com comportamento linearmente crescente, o parâmetro do modelo éK, o qual representa a amplitude das curvas. Percebe-se que estes
dois modelos anteriores são casos particulares do modelo Weibull (m=0 corresponde ao modelo com taxas constante enquanto quem=1 ao modelo com taxas linearmente crescente). O parâmetro m é conhecido como fator de aspecto devido influenciar no
comportamento da curva. Adicionalmente, para o cálculo do MTTF no modelo Weibull é necessário a utilização da funçãogamma(Γ(x) =
Z ∞
0 e
−ttx−1dt).
Tabela 2.1: Medidas de confiabilidade para taxas de defeitos típicas.
Funções Taxa de defeitos
Constante Crescente Weibull
z(t) λ Kt Ktm
f(t) λe−λt Kte−Kt2/2 Ktme−Ktm+1/(m+1) F(t) 1−e−λt 1−eKt2/2 1−e−Ktm+1/(m+1) R(t) e−λt eKt2/2 e−Ktm+1/(m+1)
MTTF λ1 q π
2K
Γ[(m+2)/(m+1)] [K/(m+1)]1/(m+1)
Distribuição Exponencial Rayleigh Weibull
Disponibilidade
Conceitualmente, disponibilidade é definida como a probabilidade do sistema estar operacional no instante de tempot. Similar à definição da confiabilidade, vamos
assu-mir que o sistema apresenta dois estados (conforme descrito na Figura 2.4): operacional e o defeituoso. A transição do estado operacional para o defeituoso é vinculada à taxa de defeitosz(t). Nesse novo modelo, após a ocorrência de um defeito o sistema poderá ser reparado (manutenção). A transição do estado defeituoso para o operacional é vincu-lado à taxa de reparação µ(t)1. Seµ(t)é zero (sistema não reparável), então o conceito
disponibilidade iguala-se à definição de confiabilidade.
De forma geral, a disponibilidade de um sistema pode ser classificada em três ti-pos: instantânea, média e assintótica. A disponibilidade instantâneaA(t)é aplicada para qualquer instante de tempot e sempre é igual ou superior à confiabilidade R(t) do sis-tema [Grottke et al. 2008]. A(t) depende do modelo e distribuições utilizadas paraz(t)
e µ(t). Assumindo-se o modelo de confiabilidade da Figura 2.4 e considerando-se z(t)
18 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
z(t)
Operacional Defeituoso
μ(t)
Figura 2.4: Estados do sistema na visão da disponibilidade.
e µ(t) constantes, cujos valores são respectivamente λ e µ, pode-se provar [Rausand &
Hsyland 2004] queA(t)é dada por:
A(t) = µ
µ+λ+ λ
µ+λe
−(λ+µ)t (2.16)
Por outro lado, a disponibilidade média Am(t) avalia a porcentagem de tempo pelo
qual o sistema ficou operacional no intervalo (0,t]. Formalmente,Am(t) é definida pela
seguinte relação:
Am(t) =
1
t Z t
0 A(τ)dτ (2.17)
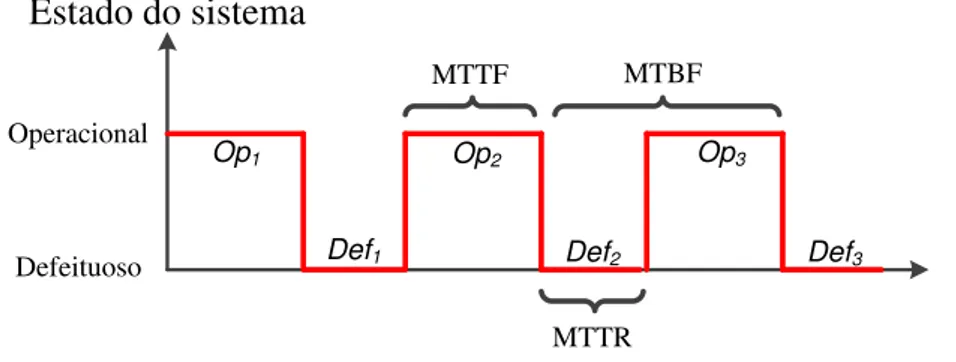
Outra questão importante é a avaliação da operacionalidade do sistema considerando um instante de tempot muito grande. Na prática consideramost →∞. Nesse caso, esta-remos calculando a disponibilidade assintótica do sistemaA∞. Para melhor compreender
essa definição vamos supor o comportamento do sistema como descrito na Figura 2.5. O sistema opera corretamente por vários períodos de tempo e, em caso de defeitos, re-paros são realizados. O MTTF e o tempo médio entre defeitos (MTBF) são definidos, respectivamente, como o tempo médio até o sistema reparar um defeito e o tempo médio entre defeitos. Assumindo-se quen períodos ocorreram, podemos encontrar A∞ através
da equação 2.18.
A∞ = lim
t→∞=
1
n
∑
iOpi
1
n(
∑
iOpi+
∑
iDe fi)
= MT T F
2.2. MEDIDAS FUNDAMENTAIS 19
Estado do sistema
Operacional
Defeituoso
Op1
Def1
Op2 Op3
MTTF MTBF
MTTR
Def2 Def3
Figura 2.5: Comportamento do sistema para diversos instantes de tempo.
Percebe-se queA∞depende apenas do MTTF e do tempo médio até o sistema reparar um
defeito (MTTR) do sistema. Assim, não existe dependência em relação a natureza das distribuições das taxas de defeitos e reparos.
Birnbaum
A medida Birnbaum IB(i|t)é uma métrica que descreve a importância da
confiabili-dade de um componente [Birnbaum & Saunders 1969]. Esta medida é definida como a derivada parcial da confiabilidade do sistema em relação à confiabilidade do componente
i, cujo valor é dado por:
IB(i|t) = ∂R(t)
∂Ri(t)
para i=1,2, . . . ,n (2.19)
SeIB(i|t)é grande, uma pequena variação na confiabilidade do componentei irá
re-sultar em um mudança considerável na confiabilidade do sistema. O componente i é
considerado crítico para o sistema se quando o componente i falhar, o sistema também
falha. Sendo assim, a medida Birnbaum é também interpretada como a probabilidade do componenteiser crítico para o sistema no instantet [Rausand & Hsyland 2004].
Criticalidade
A medida de criticalidade ICR(i|t) é uma métrica adequada para priorizar ações de manutenção [Rausand & Hsyland 2004]. Esta medida é definida como a probabilidade de o componenteiser crítico no instantet e ele ter falhado nesse instante, sabendo que o
sistema falhou no instantet. Sua definição é descrita pela seguinte equação:
ICR(i|t) = I
B(i|t)(1−R i(t))
20 CAPÍTULO 2. DEPENDABILIDADE: ESTADO DA ARTE
Em outras palavras, a criticalidade é a probabilidade do componente i ter causado uma
falha no sistema sabendo-se que o sistema está em falha no instantet.
Fussel-Vesely
A medida Fussel–VeselyIFV(i|t)é uma métrica que descreve como um componente
pode contribuir para o defeito de um sistema dado que o componente não é critico [Rausand & Hsyland 2004]. Esta medida é definida como a probabilidade de que pelo menos um conjunto de cortes mínimos, que contenha o componente i, tenha falhado no instantet,
sabendo-se que o sistema falhou nesse mesmo instante. Sua definição é descrita por:
IFV(i|t)≈ m
∑
j=1(1−Rj(t))
1−R(t) , (2.21)
onde Rj(t) é a função de confiabilidade do conjunto de cortes mínimos j que contém o
componentei, enquanto que mé a quantidade de cortes mínimos que contém o
compo-nentei.
RAW
RAW(Risk Achievement Worth) também é chamado fator de aumento de risco. Ele
mede o aumento da probabilidade de falha do sistema assumindo o pior caso de falha do componente. É um indicador da importância de manter o nível atual de confiabilidade para o componente. Sua equação é dada na Equação 2.22.
RAW(i|t) =Rs|i(t)/Rs(t) (2.22)
Na Equação 2.22, o termoRs|i representa a probabilidade do sistema falhar dado que
o eventoifalhou e o termoRs representa a probabilidade do sistema falhar.
RRW
O RRW (Risk Reduction Worth) é chamado também fator de diminuição de risco. Ele
2.2. MEDIDAS FUNDAMENTAIS 21
RRW(i|t) =Rs(t)/Rs|i(t) (2.23)
Na Equação 2.23, o termoRs|irepresenta a probabilidade do sistema falhar dado que
Capítulo 3
Árvore de Falhas
A evolução tecnológica tem permitido o desenvolvimento de sistemas/processos in-dustriais cada vez mais robustos. As novas tecnologias permitem a criação de novas apli-cações que antes não eram possíveis com as soluções legadas [Silva et al. 2013]. Em ge-ral, a complexidade das aplicações é abstraída dos operadores, facilitando sua utilização e adoção no mercado. Por outro lado, a complexidade inerente das novas aplicações devem também garantir os requisitos de dependabilidade. Assim, existe a necessidade de criar sistemas que avaliem sistemas, como é o caso da avaliação da dependabilidade. Neste capítulo, iremos introduzir um dos principais formalismos matemáticos para a avaliação da dependabilidade de sistemas/processos, nomeadamente Árvores de Falhas. Através da análise de Árvore de Falhas é possível avaliar qualitativamente ou quantitativamente a dependabilidade de sistemas/processos. Esse formalismo matemático é utilizado em di-versas áreas da engenharia, como as indústrias aeroespaciais, química, nuclear, petróleo e gás [Majdara & Wakabayashi 2009].
3.1 Composição da Árvore de Falhas
Árvore de Falhas é um formalismo matemático que representa em formato de dia-grama lógico a relação entre os componentes de um determinado sistema/processo e os seus respectivos modos de falhas que levam aos defeitos [Ferdous et al. 2007].
Para construir o diagrama de uma Árvore de Falhas é necessário inicialmente identifi-car o defeito que se deseja analisar. De acordo com a literatura [Limnios 2007], o defeito em uma Árvore de Falhas é mapeado em um evento especial chamado eventotopo. A
partir do eventotopoé possível expandir a árvore, combinado as causas (eventos básicos
24 CAPÍTULO 3. ÁRVORE DE FALHAS
Topo
A B C
D E and1
or1 or2
and2
Figura 3.1: Diagrama de uma Árvore de Falhas e os seus principais componentes: eventos básicos (A,B,C,D,E), portas lógicas (or1, or2, and1, and2) e evento topo.
As portas lógicas representam a combinação de dois ou mais eventos. Essas portas se assemelham às portas lógicas booleanas, no entanto suas expressões lógicas podem receber valores no intervalo [0,1]. As principais portas utilizadas são OR, ANDeNOT.
Outra porta lógica também muito utilizada é aK-OU T-N. Nessa porta, a falha acontece
se pelo menos k de n entradas ocorrerem, para k≤n. Os símbolos de cada porta são
apresentados na Figura 3.2.
A B C
(a)
A B C
(b)
A C
(c)
C
B A
(d)
Figura 3.2: Portas lógicas mais comuns.
3.1. COMPOSIÇÃO DA ÁRVORE DE FALHAS 25
3.1.1 Análise de Árvores de Falhas
O diagrama de uma Árvore de Falhas não é suficiente para a compreensão de como um conjunto de eventos pode acarretar erro em um sistema. Para isso existem métodos que provêm a análise de Árvores de Falhas, trazendo assim uma série de informações que serão aplicadas em tomadas de decisão para prevenção e correção de erros. Existem dois tipos de análise: a qualitativa e a quantitativa. A seguir são apresentadas as características e o significado de cada métrica.
Análise Qualitativa
A análise qualitativa busca remover redundâncias da Árvore de Falhas, dessa forma, preocupa-se com a equação analítica que representa a Árvore de Falha. Assim, utiliza álgebra booleana para convertê-las em expressões lógicas, manipulando as relações dos eventos através das portas lógicas para eliminar eventos repetidos ou redundantes. As expressões que representam a saídaT de cada porta lógica, a partir da relação das entradas AeBsão mostradas a seguir:
• PortaOR:T =A+B
• PortaAND:T =A.B
• PortaNOT:T =A¯
Dito isso, pode-se definir, para Árvores de Falhas coerentes 1, o conjunto de cortes minimais, do inglêsminimal cut set. Um cut set é um conjunto de eventos básicos que
influenciam diretamente o eventotopo. Se ocut setocorre o eventotopotambém ocorre.
Adicionalmente,minimal cut seté umcut setque não pode ser reduzido.
Algoritmo MOCUS
Remover redundâncias e encontrar o corte mínimo de uma Árvore de Falhas pode tornar-se uma uma tarefa custosa se realizada manualmente. O desafio se torna ainda maior para árvores de falhas de grandes dimensões (maior que 10 portas lógicas). Assim, diversos algoritmos foram propostos na literatura para encontrar os cortes mínimos de uma Árvore de Falhas de forma automática. Um dos principais algoritmos é o MOCUS (Method for Obtaining Cut Sets) [Limnios 2007]. Nesse algoritmo uma matriz é cons-truída, percorrendo a Árvore de Falha a partir do evento topo até os eventos da árvore. Os passos do algoritmo MOCUS são descritos no Algoritmo 1.
26 CAPÍTULO 3. ÁRVORE DE FALHAS
Algoritmo 1:Mocus
Iniciar a matriz de entrada;
Expandir as portas lógicas adequadamente conforme o tipo;
Se a porta lógica é uma AND, cada entrada será inserida em coluna na matriz; se a porta lógica é um OR, cada entrada será inserida como uma linha da matriz;
Repita o passo 2 até que a matriz seja composta apenas de eventos básicos; Remova redundâncias entre as linhas e as colunas;
A matriz resultante é convertida em uma Árvore de Falhas formada apenas por um corte mínimo. Os eventos de uma linha são combinados em uma porta AND, e todas as
linhas são combinadas em uma única porta OR, que levará ao evento topo. A principal aplicação dessa análise é a de simplificar a Árvore de Falhas, de modo a facilitar sua a compreensão.
Um exemplo do algoritmo pode ser visualizo na Figura 3.3. O resultado final do algoritmo fornece ocut setcom a seguinte expressãoC∗D+C∗E+A∗B.
Topo
or2
and2
and1
and2
A B
A B
Or1
C
A B
C E
C D
TopoA B C
D E and1
or1 or2
and2
Figura 3.3: Execução do MOCUS na Árvore de Falha da Figura 3.1.
Análise Quantitativa
A análise quantitativa considera os valores de probabilidade dos eventos, utilizando-os para o cálculo de diversas medidas. Um exemplo de uso dessa análise é o cálculo da probabilidade de ocorrência de falha no evento topo, que é feita a partir das relações dos eventos através das portas lógicas. Cada porta possui uma equação associada, como mostra as equações 3.1, 3.2, 3.3 e 3.4:
• PortaOR:
F(t) =1− n
∏
i=13.1. COMPOSIÇÃO DA ÁRVORE DE FALHAS 27
• PortaAND:
F(t) = n
∏
i=1(Fi(t)) (3.2)
• PortaK-OUT-N:
F(t) = n
∑
i=1
n i
F(t)i(1−F(t))n−i (3.3)
• PortaNOT:
F(t) =1−Fi(t) (3.4)
Fazer uso dessa análise traz o benefício de oferecer resultados numéricos, que auxi-liam na avaliação do sistema e antecipação na correção de erros.
Nós repetidos
As equações 3.1, 3.2, 3.3 e 3.4 podem ser utilizadas diretamente apenas quando a árvore não possui eventos repetidos. Nós repetidos são eventos que ocorrem na Árvore de Falha por duas ou mais vezes, apresentando um comportamento de dependência. A Figura 3.4 apresenta um exemplo de de uma Árvore de Falha com evento repetido (M3).
Falha
P1 M1 M3 P2 M2 M3
Figura 3.4: Árvore de Falhas com evento repetido.
Falha
P1 M1 P2 M2
Falha
P1 P2
(a) M3 falhou (b) M3 não falhou
Figura 3.5: Análise de um nó repetido.
28 CAPÍTULO 3. ÁRVORE DE FALHAS
Assim, a probabilidade final do sistema será a soma das probabilidades calculadas nas duas situações, ponderadas pela probabilidade de ocorrência de cada uma, conforme a Equação 3.5:
F(t) =P(N)∗N1+ (1−P(N))∗N2 (3.5)
OndeP(N)é a probabilidade de ocorrência do evento repetido eN1eN2são as
Capítulo 4
Framework
para Análise da
Dependabilidade
Confome descrito em capítulos anteriores, diversos modelos matemáticos podem ser utilizados para analisar a dependabilidade de sistemas/processos. Nessa dissertação, es-tamos interessados em utilizar tais modelos para a análise da dependabilidade de infraes-truturas industriais críticas.
A ideia principal é criar umaframeworkque centralize, de forma transparente e
gené-rica, os diversos modelos matemáticos descritos anteriormente. Baseado nessa estrutura desoftware, a aplicação para análise da dependabilidade pode ser construída de forma
fle-xível, permitindo inclusive a incorporação de novos formalismos matemáticos de forma transparente ao usuário.
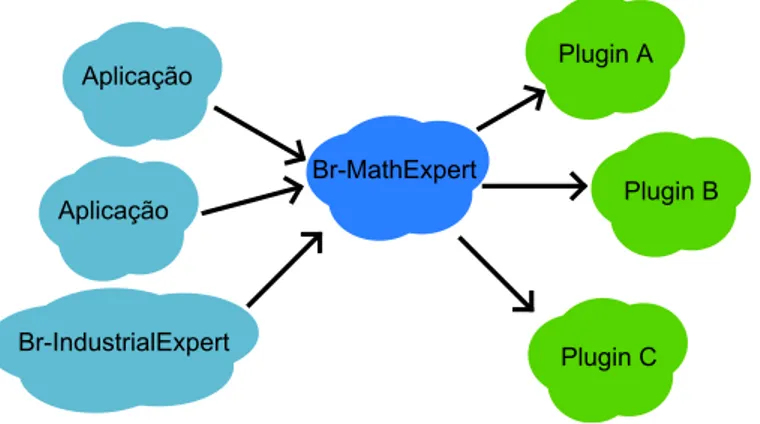
Na infraestrutura mostrada na Figura 4.1, uma aplicação sempre funciona como um cliente, cujo servidor é o Br-MarkovExpert (ME). Adicionalmente, o ME também fun-ciona como cliente, solicitando serviços aos plug-ins. De forma análoga, os plug-ins
podem atuar como clientes (solicitando serviços de outrosplug-insvia ME) ou servidores
(esperando requisições do ME).
4.1 Br-MathExpert
O Br-MathExpert é um gerenciador de plugins matemáticos. Sua responsabilidade
é interfacear uma aplicação (por exemplo, o Br-IndustrialExpert) com esses modelos.
Para isso, oBr-MathExpert fornece serviços em SOAP, JAVA-RMI e SOCKET. Através
desses serviços as aplicações se conectam ao Br-MathExpert e lhe enviam o código de
descrição do modelo matemático que se deseja analisar, conforme ilustrado na Fig. 4.2. A partir desse momento oBr-MathExperté responsável pela comunicação com os plug-ins
30 CAPÍTULO 4. FRAMEWORKPARA ANÁLISE DA DEPENDABILIDADE
Plugin B Plugin A
Plugin C Br-MathExpert
Aplicação
Aplicação
Br-IndustrialExpert
Figura 4.1: Visão geral da arquitetura para avaliação da dependabiliade de infraestruturas industriais críticas
Br-IndustrialExpert
FaultTreeExpert
MathProcessExpert
4.2. BR-FAULTTREEEXPERT 31
A grande vantagem para o desenvolvedor das aplicações que utilize essa arquitetura é ter acesso aos modelos de forma transparente, sem preocupação com a forma em que eles foram desenvolvidos ou programados. Para os desenvolvedores dos plug-ins, o serviço
é disponibilizado sem exposição do código fonte do programa e com a possibilidade de também usar de forma transparente outrosplug-ins. Além disso, essa arquitetura viabiliza
um desacoplamento do sistema em unidades menores de processamento, permitindo a exploração do espaço de projeto com técnicas de paralelismo.
A interação entre osplug-insocorre a partir de modelos hierárquicos. O uso de
mode-los hierárquicos matemáticos não é novo na literatura [Sahner, Puliafito & Trivedi 1996]. Nesses modelos, um formalismo pode incorporar ou usar dados estatísticos gerados por outro modelo. Por exemplo, uma técnica comum para se analisar a dependabilidade sobre redundâncias é o uso de Cadeias de Markov, conforme descrito em [Macedo, Silva & Guedes 2013]. Portanto, ao invés dos eventos carregarem uma distribuição estatística que os represente (por exemplo, exponencial ou binomial), eles terão uma Cadeia de Markov e sua distribuição será a análise desse modelo. Na Fig. 4.3 é apresentado de maneira ilustrativa o modelo hierárquico desse exemplo.
Figura 4.3: Modelo hieráquico com Cadeia de Markov e Árvore de Falha.
Em relação aosplug-ins, já foram realizados implementações para os seguintes
forma-lismos matemáticos: Cadeias de Markov de Tempo Discreto, Árvores de Falhas, Árvores de Falhas Dinâmicas e Redes Bayesianas. Oplug-in Br-FaultTreeExpert, criado para o
formalismo de Árvores de Falhas, foi a base para aplicação desenvolvida nessa dissertação e será explicado em mais detalhes na próxima seção.
4.2 Br-FaultTreeExpert
Criado para atender o modelo de Árvore de Falhas, oBr-FaultTreeExpertfaz as
aná-lises descritas na Seção 2.2.2. Assim como a maioria dos softwares dessa categoria, o Br-FaultTreeExperttem a capacidade de armazenar árvores em um arquivo para
32 CAPÍTULO 4. FRAMEWORKPARA ANÁLISE DA DEPENDABILIDADE
Como se pode deduzir pela Fig. 4.4, pode-se descrever uma Árvore de Falhas através da interface principal, escolhendo-se os nós e suas conexões, ou através do código de descrição, o mesmo usado no modoplug-indoBr-MathExpert (Algoritmo 2).
Em relação à análise de dependabilidade, pode-se escolher o processamento tanto através do cut set quanto sem ele. Essa configuração permite ao usuário identificar o
ganho de desempenho com o uso de algoritmos de otimização. Outro ponto interessante em relação aocut seté que o usuário pode visualizar a forma da árvore simplificada por
esse algoritmo.
Ainda em relação a Fig. 4.4, pode-se verificar dois nós diferentes. O primeiro é cha-mado de box event. Esse nó tem as mesmas funções e propriedades de um evento, com
a particularidade de atuar forma hierárquica. Portanto, ao invés de apontar uma função estatística diretamente, obox eventaponta para outro modelo.
Figura 4.4: Interface gráfica doBr-FaultTreeExpert
Como mencionado na Seção 4.1, para ser plugi-in do Br-MathExpert, é necessário
uma linguagem de descrição capaz de descrever o modelo matemático. É através dessa linguagem que a aplicação descreve o que precisa ser analisado. No Algoritmo 2, é mostrado um exemplo de código capaz de descrever a Árvore de Falha da Fig. 3.1.
4.3 Br-IndustrialExpert
Nomeado deBR-IndustrialExpert, o principal objetivo da ferramenta proposta neste
permi-4.3. BR-INDUSTRIALEXPERT 33
Algoritmo 2:Código de descrição da Árvore de Falha Fig. 3.1. event A repairFaultRate 1.0 2.0;
// Cria o evento A com taxa de falha 2.0 e taxa de reparo 1.0
1 event B repairFaultRate 1.0 2.0; 2 event C repairFaultRate 1.0 2.0; 3 event D repairFaultRate 1.0 2.0; 4 event E repairFaultRate 1.0 2.0; 5 and porta_and A B;
// Cria uma porta lógica chamada de porta_and que liga os eventos A e B
6 or porta_or D E;
7 and porta_and_1 C porta_or;
8 or porta_or_1 porta_and porta_and_1;
9 terminal porta_or_1 reliability 1.0 0.0 10.0;
// Define o topo da Árvore de Falha conectado a porta_or_1 e pede para analisar a confiabilidade do tempo 0 ao tempo 10 com passo 1
tindo o desenvolvimento de aplicações industriais tolerantes a falhas e a manutenção do sistema/processo de forma mais eficiente. Nas próximas subseções será mostrado como o usuário da ferramenta descreve uma infraestrutura genérica e os algoritmos de mapea-mento para uma Árvore de Falhas otimizada.
4.3.1 Editor de infraestruturas genéricas
O editor de infraestruturas genéricas define as abstrações da infraestrutura, uma das características mais importantes da ferramenta de análise da dependabilidade. Primeira-mente, o sistema/processo é organizado como um grafo G(V,E)com nvértices (V) ek
arestas (E). Os vértices representam dispositivos e as arestas do grafo representam as
ligações (links) entre os dispositivos. A interface gráfica do usuário (GUI) é mostrada na
34 CAPÍTULO 4. FRAMEWORKPARA ANÁLISE DA DEPENDABILIDADE
Figura 4.5: Interface de configuração para estruturas genéricas noBr-IndustrialExpert.
4.3.2 Gerador de Árvore de Falhas
Esta seção descreve os passos a serem seguidos para construir uma Árvore de Falha baseada em um sistema/processo mapeado como um grafo. O primeiro passo é determi-nar as condições que podem levar a um defeito no sistema/processo. São considerados três possibilidades para uma falha de dispositivo: (i) ohardwarefalha; (ii) um conjunto de linksfalham; (iii) não há nenhum caminho entre o dispositivo e o servidor/centralizador
(problema de conectividade). Como descrito na Seção 1, as condições (i) e (ii) não podem ser acessadas simultaneamente porque falhas permanentes delinkocorrem mais
frequen-temente que as de hardware. Por outro lado, a condição (iii) tem uma influência direta
nas condições (i) e (ii). Então, isso deve ser avaliado pelos dois casos, um para condição (i) e outro para condição (ii).
Todos as condições de falhas do dispositivo são descritas na Figura 4.6. Para fa-lhas de hardwarepermanente, um dispositivoié representado pelo evento devi. Para as
falhas delinkpermanente, um link jé representado pelo eventolinkj. O eventocpi
(pro-blema de conectividade) representa condição de falhas (iii). Esse evento é apenas ativado quando todos caminhos entre o dispositivoie o serveridor/centralizador tem falhado.
Fi-nalmente, um caminho k é considerado falho se pelo menos um dispositivo (hardware)
ou um link ao longo do caminho tem falhado. Este comportamento é representado pelo
neces-4.3. BR-INDUSTRIALEXPERT 35
sária a adoção de uma estrutura de dados com base em vetores dinâmicos (Fig. 4.6-iv). De acordo como o tamaho da rede, a estrutura cresce dinamicamente.
and
devi_Path1 ... devi_Pathn
cpi
or
devi ... devj
devi_Pathm
(iii) (i)
linkk ... linkp
devi_Pathm
(ii) or dev dev1 Path1 Path Pathn
1 2 3 4 5
1 8 5
(iv) cp1 dev k ... cpk
Figura 4.6: Condição de falha para uma rede de dispositivosi considerado: (i) falhas de
hardware; (ii) falhas de link; (iii) ausência de camnhos entre o servidor/centralizador e o dispositivo; (iv) estrutura de dados adotada.
Note que algum esforço é necessário para encontrar todas as cominações que levam a o eventocpi. Para isso, é necessário que a pesquisa de todos os caminhos entre o
ser-vidor/centralizador e o dispositivo destinoi(eventodevi). Os caminhos são encontrados
realizando uma busca em profundidade (BP) na matriz de adjacência A do grafo G. Todos os passos para gerar o eventocpisão descritos no Algoritmo 3.
Algoritmo 3:Algoritmo para gerar o eventocpde um dispositivo destino.
Algoritmo:gerar_cp(graph,dev)
Output: O eventocppara o dispositivo destino(dev).
// Encontrar todos caminhos entre o dispositivo destino e o servidor/centralizador do grafo
1 all_paths←DFS(graph,dev);
2 fori←1;i<all_paths.size();i++do
3 dev.path[i]←all_paths[i];
4 cp←dev; 5 returncp
O segundo passo para a geração da Árvore de falhas é definir quais combinações de dispositivos podem levar o sistema/processo a um defeito. Esta configuração é represen-tada pelo eventon f c(condição de falha do sistemas/processo) na Fig. 4.7. A ferramenta
proposta nesta dissertação suporta qualquer combinação que possa ser expressada através de operadores booleanos (and, or). Uma combinação de dispositivos que levam a falha
do sistema/processo é definido comon f c_andj, onde jé a identificação da combinação.
Este evento é representado pela porta lógica and da condição de falha dos dispositivos.
36 CAPÍTULO 4. FRAMEWORKPARA ANÁLISE DA DEPENDABILIDADE
sistema/processo é representada pela porta lógicaorde todas as cominações que levam a
falha do sistema/processo.
or nfc
cpi
...
and...
nfc_and1 nfc_andn
cpk
and
...
nfc
cp1cp3
cpi ... cpk
nfc_andn
nfc_and1
(i)
(ii)
Figura 4.7: Condição de falha da rede (i) e sua estrutura de dados respectiva(ii).
A geração do eventon f cé descrita no Algoritmo 4, onde a estrutura de dados é
aná-loga à representada na Fig. 4.7-ii. Deve-se enfatizar que a condição de falha do sis-tema/processo é um parâmetro de entrada da ferramenta. Assim, o principal objetivo do Algoritmo 4 é ligar este parâmetro de entrada (n f c_input) ao dado gerado pelo método generate_cp (Algoritmo 3). n f c_input e n f c compartilham a mesma estrutura, a
dife-rença é que a forma armazena apenas rótulos.
Algoritmo 4:Algoritmo para gerar o eventon f c.
Algoritmo:generate_nfc(graph,nfc_input)
Output: O evento topo da Árvore de Falha (eventn f c).
// Encontrar todos dispositivos que envolve a condição de falha
do sistema/processo e seu evento espectivo cp
1 fori←1;i<nfc_input.number_devices();i++do
2 device←nfc_input.get_device(i);
3 cp[i]←generate_cp(graph,device);
// Realocar cada label i no nfc_input pelo seu respectivo evento cpi
4 forj←1;j<nfc_input.number_combinations();j++do
5 fork←1;nfc_input.combination[j].size();k++do
6 target←nfc_input.combination[j].at(k);
7 position←indexOf(cp,target);
8 nfc.combination[j].at(k)←cp[position];
9 returnnfc
4.4. CONJUNTO DE CORTES MINIMAIS 37
sistema/processo (cason f c) é definido como o seguinte:device1+device2+device3. Em
outras palavras, o sistema/processo falha se pelo menos um dispositivo falhar. A Árvore de Falha para falhas permanentes de hardware e falhas permanentes no link são descritas nas Figs. 4.9 e 4.10, respectivamente. Note que, em ambos os casos, device 3tem dois
caminhos para o servidor/centralizador (eventosDev3_Path1 andDev3_Path2), enquanto
que os dispositivos device2 e device3 tem apenas um caminho (eventos Dev1_Path1 e Dev2_Path1, respectivamente). Se em um dado momento a operação boleana tem apenas
um entrada, a outra entrada é adicionada com uma constante apropriada. Para a porta lógica and, a constante 1 (tudo verdade) é adicionada. Por sua vez, para a porta or, a
constante 0(tudo f also)é adicionada.
Device 1 Device 3 Device 2 Server/Sink Link 1 Link 2 Link 4 Link 3
Figura 4.8: Exemplo de um sistema/processo.
and
or
Dev3 Dev1 Server or
Dev3 Dev2 Server Dev3_Path1 Dev3_Path2 and
or
Server Dev2_Path1
1 (all true)
Dev2 and
or
Server Dev1_Path1
1 (all true)
Dev1
or
cp 1 cp 3
cp 2 nfc
Figura 4.9: Árvore de Falha baseada no exemplo da Fig. 4.8 considerando falhas de hardware permanente.
and or Link3 Link1 or Link4 Link2 Dev3_Path1 Dev3_Path2 and or
0 (all false) Dev2_Path1
1 (all true)
Link2 and
or
0 (all false) Dev1_Path1
1 (all true)
Link1
or
cp 1 cp 3
cp 2 nfc
Figura 4.10: Árvore de Falhas baseada no exemplo da Fig. 4.8 considerando fa-lhas em links permanentes.