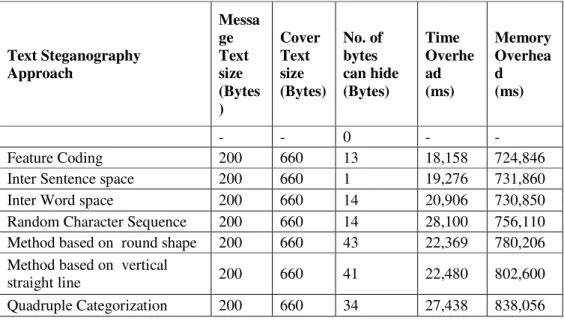
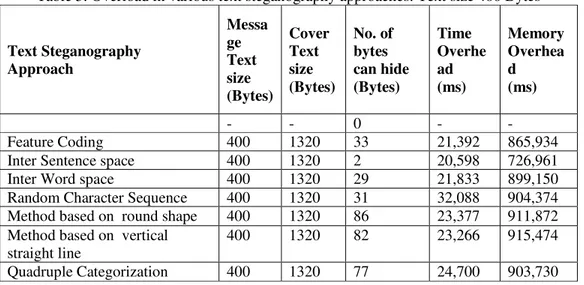
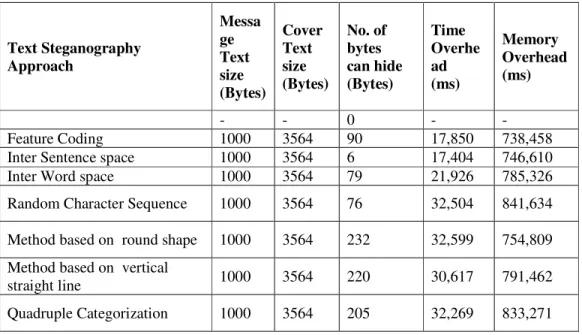
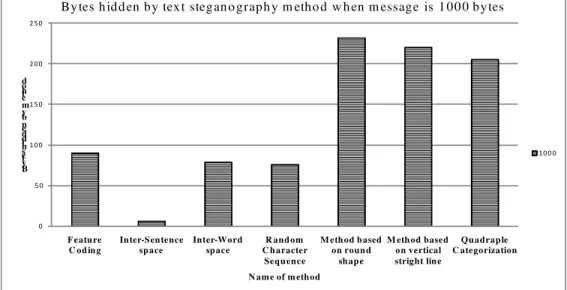
Experimenting with the Novel Approaches in Text Steganography
Texto
Imagem


Documentos relacionados
In this connection, the present study aims to present an epidemiological analysis of accidents involving scorpions in Brazil, in the period from 2000 to
Basically, it is necessary to verify the solution before putting them in the ground as well as it is necessary to run the simulation in parallel with the real system (or slightly
O trabalho artístico realizado em contextos prisionais - os atores sociais em interação sobre o seu território (a instituição total) - as relações entre os grupos de reclusos e
À semelhança de outros países europeus (cf. Guerassimoff-Pina, 2006, Sáiz López, 2005), os indivíduos pouco qualificados cuja imigração têm uma base
This was observed in cultivated soils for the ultramaphic rock and the mining by-products, which had a higher production of root dry matter (Figure 1b), providing higher content
A avaliação das condições para a concessão da liberdade condicional é, como já referido, objeto de uma intervenção partilhada por duas equipas: a equipa dos serviços de tratamento
Therefore, both the additive variance and the deviations of dominance contribute to the estimated gains via selection indexes and for the gains expressed by the progenies
The attacks on science come from many sources. From the outside, science is beset by post-modernist analysis that sees no truth, only “accounts”; it is beset by environmentalist
