Escola de Engenharia Departamento de Inform´atica
Jo˜ao Pedro N´obrega Rei
Study, Selection and Evaluation of an
IoT Platform for Data Collection and
Analysis for medical sensors
Escola de Engenharia Departamento de Inform´atica
Jo˜ao Pedro N´obrega Rei
Study, Selection and Evaluation of an
IoT Platform for Data Collection and
Analysis for medical sensors
Master dissertation
Master Degree in Medical Informatics
Dissertation supervised by
Professor Doutor Ant ´onio Lu´ıs Sousa Francisco Cruz
In the first place, I would like to express my gratitude to professor Ant ´onio Lu´ıs Sousa, my master thesis’ adviser, for the opportunity to work in this area. I am really grateful for all the help and comprehension during the development of this dissertation.
To my lab colleagues in the HASLab group, I am really thankful for the integration and constant support in everything I needed. I would like to express my gratitude especially to Francisco Cruz, for all the help and guidance during my work in the lab.
I am also grateful to my family, for making all of this possible and always supporting me during my journey. Everything I have ever achieved, I owe it to you.
I would like to express my gratitude, in particular, to Joana, for being always by my side, in every victory and every defeat, not only during this master thesis, but almost my entire academic journey. Thank you for your patience, your comprehension and for being the most incredible person I know.
And finally, to my closest friends, thank you for always being there. I am grateful for all your patience and unconditional support.
Every day, huge amounts of data are generated in the healthcare environments from se-veral sources, such as medical sensors, EMRs, pharmacy and medical imaging. All of this data provides a great opportunity for big data applications to discover and understand pat-terns or associations between data, in order to support medical decision-making processes. Big data technologies carry several benefits for the healthcare sector, including preventive care, better diagnosis, personalized treatment to each patient and even reduce medical costs. However, the storage and management of big data presents a challenge that traditional data base management systems can not fulfill. On the contrary,NoSQLdatabases are distributed and horizontally scalable data stores, representing a suitable solution for handling big data. Most of medical data is generated from sensor embedded devices. The concept ofIoT, in the healthcare environment, enables the connection and communication of those devices and other available resources over the Internet, to perform or help in healthcare activities such as diagnosing, monitoring or even surgeries. IoT technologies applied to the health-care sector aim to improve the access and quality of health-care for every patient, as well as to reduce medical costs.
This master thesis presents the integration of both big data and IoT concepts, by deve-loping an IoT platform designed for data collection and analysis for medical sensors. For that purpose, an open source platform, Kaa, was deployed with both HBase and Cassandra as NoSQLdatabase solutions. Furthermore, a big data processing engine, Spark, was also implemented on the system.
From the results obtained by executing several performance experiments, it is possible to conclude that the developed platform is suitable for implementation on an healthcare environment, where huge amounts of data are rapidly generated. The results also made it possible to perform a comparison between the performance of the platform with Cassandra and HBase, showing that the last one presents slightly better results in terms of the average response time.
Atualmente, uma grande quantidade de dados ´e gerada todos os dias em ambientes hospitalares provenientes de diversas fontes, como por exemplo sensores m´edicos, registos eletr ´onicos, farm´acias e imagens m´edicas. Todos estes dados proporcionam uma grande oportunidade para aplicac¸ ˜oes de big data, permitindo revelar e interpretar padr ˜oes ou associac¸ ˜oes entre os dados de forma a auxiliar no processo de tomada de decis˜ao m´edica. As tecnologias de big data comportam diversos benef´ıcios para o sector de sa ´ude, incluindo a prestac¸˜ao de cuidados preventivos, diagn ´osticos mais eficientes, tratamento personalizado para cada paciente e at´e mesmo reduzir os custos m´edicos. No entanto, o armazenamento e a gest˜ao da big data apresenta um desafio que os sistemas de gest˜ao de base de dados tradicionais n˜ao s˜ao capazes de ultrapassar. N˜ao obstante, as bases de dadosNoSQL repre-sentam uma soluc¸˜ao de armazenamento de dados distribu´ıda e escal´avel horizontalmente, sendo, portanto, apropriadas para lidar com big data.
Uma grande parte dos dados m´edicos ´e gerada atrav´es de dispositivos embebidos com sensores. O conceito de IoT, no ambiente das unidades de sa ´ude, permite a conex˜ao e comunicac¸˜ao desses dispositivos e outros recursos dispon´ıveis atrav´es da Internet, de forma a realizar ou auxiliar nas atividades de sa ´ude, como por exemplo o diagn ´ostico, a monitorizac¸˜ao ou at´e mesmo em cirurgias. As tecnologias IoT visam melhorar o acesso e qualidade dos cuidados de sa ´ude para todos os pacientes, bem como reduzir os custos na prestac¸˜ao dos mesmos.
Esta tese de mestrado apresenta, assim, a integrac¸˜ao de ambos os conceitos de big data e IoT, propondo o desenvolvimento de uma plataforma projetada para a recolha e an´alise de dados de sensores m´edicos. Para essa finalidade, foi utilizada uma plataforma IoT de c ´odigo aberto, Kaa, juntamente com duas bases de dados NoSQL, HBase e Cassandra. Adicionalmente, foi tamb´em implementado um mecanismo de processamento de dados, tamb´em de c ´odigo aberto, o Spark.
Com base nos resultados obtidos atrav´es da realizac¸˜ao de diversas experiˆencias de avaliac¸˜ao de desempenho, foi poss´ıvel concluir que a plataforma desenvolvida ´e adequada para a implementac¸˜ao em ambientes de prestac¸˜ao de cuidados de sa ´ude, onde grandes quan-tidades de dados s˜ao rapidamente geradas. Os resultados permitiram tamb´em realizar uma comparac¸˜ao entre o desempenho da plataforma com Cassandra e com HBase, realc¸ando que esta ´ultima apresenta resultados ligeiramente melhores em termos do tempo m´edio de resposta.
1 i n t r o d u c t i o n 1
1.1 Context and Motivation 1
1.2 Objectives 2 1.3 Contributions 3 1.4 Document Structure 3 2 l i t e r at u r e r e v i e w 4 2.1 Introduction 4 2.2 Big Data 5 2.2.1 Overview 5
2.2.2 Big Data in Healthcare 7
2.2.3 Storage and Analytics Solutions for Big Data 9
2.3 Apache Software Foundation Projects 13
2.3.1 Apache Hadoop 13 2.3.2 Apache HBase 16 2.3.3 Apache Cassandra 19 2.3.4 Apache Spark 22 2.4 Internet of Things 23 2.4.1 Overview 23 2.4.2 IoT in Healthcare 25
2.4.3 Ambient Assisted Living (AAL) 26
2.4.4 IoT Platforms 30
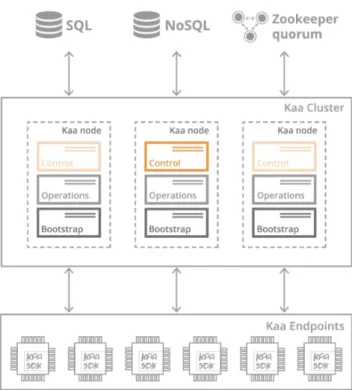
2.5 Kaa IoT Platform 31
2.5.1 Overview 31 2.5.2 Architecture 33 2.5.3 Applications 35 2.6 Summary 35 3 r e s e a r c h m e t h o d o l o g y 37 3.1 Introduction 37
3.2 Design Science Research 37
3.3 Practical Application 38 4 t h e p r o b l e m a n d i t s c h a l l e n g e s 40 4.1 Introduction 40 4.2 Proposed Approach 41 4.3 System Architecture 42 iv
5 p l at f o r m d e v e l o p m e n t 45
5.1 Decisions 45
5.2 Implementation 47
5.2.1 Central Platform Development 47
5.2.2 HBase Log Appender Development 47
5.2.3 Client Application Development 50
5.2.4 Data Processing Application Development 50
5.3 Summary 52
6 c a s e s t u d i e s / experiments 53
6.1 Experiment setup 53
6.1.1 First scenario - Limits of the platform 54 6.1.2 Second scenario - Constant write only applications 54 6.1.3 Third scenario - Constant write and streaming applications 55 6.1.4 Fourth scenario - Constant write, streaming and analytic
applica-tions 55
6.2 Results 56
6.2.1 First scenario results 56
6.2.2 Second scenario results 58
6.2.3 Third scenario results 63
6.2.4 Fourth scenario results 66
6.3 Summary 68
7 c o n c l u s i o n 70
7.1 Conclusions 70
Figure 1 5V’s of big data 6
Figure 2 CAP Theorem 11
Figure 3 Hadoop Distributed File System (HDFS) 14
Figure 4 HBase Data Model 17
Figure 5 Cassandra workflow of read and write operations 21
Figure 6 Apache Spark supported tools 22
Figure 7 Remote patient monitoring 27
Figure 8 Kaa middleware platform overview 32
Figure 9 Kaa platform architecture overview 34
Figure 10 Proposed architecture 41
Figure 11 System architecture for data collection, processing and analytics 43 Figure 12 Data storage solutions overview in default Kaa platform 46 Figure 13 HBase log appender configuration schema 48
Figure 14 Vital signs dashboard 51
Figure 15 Thermometer dashboard 51
Figure 16 Average number of stored samples per number of sensors 56 Figure 17 Average response time in milliseconds per number of sensors 57 Figure 18 Average response time for an input of 2000 sensors during 10 minutes 59 Figure 19 Number of samples in queue for an input of 2000 sensors during 10
minutes 59
Figure 20 Average response time for an input of 6000 sensors during 10 minutes 60 Figure 21 Number of samples in queue for an input of 6000 sensors during 10
minutes 61
Figure 22 Average response time for an input of 9000 sensors during 10 minutes 62 Figure 23 Number of samples in queue for an input of 9000 sensors during 10
minutes 62
Figure 24 Average response time for an input of 6000 sensors during 10 minutes
with a data streaming application 64
Figure 25 Number of samples in queue for an input of 6000 sensors during 10 minutes with a data streaming application 65
Figure 26 Average response time for an input of 6000 sensors during 10 minutes
in a real world scenario 66
Figure 27 Number of samples in queue for an input of 6000 sensors during 10
6LoWPANIPv6-based Low-power Wireless Personal Area Network AALAmbient Assisted Living
APIApplication Programming Interface
CAPConsistency, Availability and Partition Tolerance CQL Cassandra Query Language
DSR Design Science Research EMRs Eletronic Medical Records GFSGoogle File System
HDFS Hadoop Distributed File System
HIPAAHealth Insurance Portability and Accountability Act ICUIntensive Care Unit
IoT Internet of Things IP Internet Protocol
ITInformation Technology JSONJavaScript Object Notation m-healthmobile-health
MVCCMulti-Version Concurrency Control NoSQL Not Only SQL
RDBMSRelational Database Management System RDDResilient Distributed Dataset
RFIDRadio Frequency Identification SDK Software Development Kit SQLStructured Query Language UIUser Interface
WALWrite-Ahead-Log
WSNWireless Sensor Network
1
I N T R O D U C T I O N
The present dissertation explores the development of a platform for data collection and analysis for medical sensors, based on the concept of the Internet of Things. Section 1.1 presents a brief contextualization and motivation of this master thesis’ topic, followed by its main goals in Section 1.2. Section 1.3 presents some contributions of this project and, finally, Section1.4exposes the document’s structure.
1.1 c o n t e x t a n d m o t i vat i o n
The presence of embedded sensors in everyday life objects is rapidly increasing. Smart-phones and wearable devices are just two examples of recent technologies that enable to bridge the gap between physical and cyber worlds [1]. Nowadays, there is an increasing
interest in wearable sensors and there are already several devices available on the market for fitness, activity awareness and even personal healthcare [2].
Over the years, the access, affordability and quality of healthcare have always represented a problem around the world. In fact, a large number of people do not receive the quality care they need, either by geographical disadvantages or the high costs of medical care [3].
This way, researchers have been considering the application of smartphones and wearable technologies in the healthcare sector for remote health monitoring and clinical management of patients’ physiological information [2]. Through the mobile application, sensors, medical
devices and remote monitoring products, it is possible to improve the quality of care and reduce medical costs, as well as connecting people with healthcare providers [3,4].
The concept of Internet of Things (IoT) enables the integration and communication of these network-connected devices to provide information concerning the health status of a patient in real time to the healthcare professionals [4]. Any device integrated in an IoT
system is uniquely addressed and identifiable at any time and anywhere through the In-ternet [2]. These systems provide several benefits especially in the management of chronic
diseases and remote monitoring systems, as well as reducing visits to the hospital and me-dical costs [4–6]. Additionally, by integrating all the available data from theIoT devices in
decision-support systems, it is possible to provide better prognosis and treatments, early
interventions and life-style recommendations to improve the quality of the patient’s health status [2].
Healthcare data is not only produced at an exponential rate but it also grows in diversity. Most of the data generated by medical devices and sensors is unstructured and, thus, re-quires different data storage mechanisms than the traditional database management sys-tems. Furthermore, in order to analyze that huge amount of data, solutions based on cloud computing are also required [5].
Although there are already some IoT solutions on the market, the ambiguity and tech-nical challenges are still prevailing, highlighting the deployment of an intelligentIoT-based healthcare platform that involves big data management as one of the biggest challenges [7]. This thesis aims to study the features required for that purpose, as well as to deploy
and evaluate an IoT platform for data collection and analysis for medical sensors, using appropriate mechanisms for data storage.
1.2 o b j e c t i v e s
Having in mind the context and motivation for this master thesis, presented in Section 1.1, some objectives were established in order to conduct its whole development process. In the initial stage, it was necessary to gather a great amount of information, from different and heterogeneous sources, concerning the required components and issues for the imple-mentation of the IoTplatform in the healthcare sector. Afterwards, it was fundamental to design and deploy the system architecture and, finally, proceed with the platform evalu-ation process. Therefore, three main goals were established for this project:
• Assess the adoption of anIoTplatform in the healthcare environment for storage and analysis of data for medical sensors:
– Collect and analyze bibliographic documents about IoT applications, big data and database solutions in the healthcare sector.
– Identification of the components required for building a platform to collect large amounts of data from medical sensors.
– Identification of potential applications and medical sensors to integrate into the platform.
– Identification of potential processing and analytic open source frameworks to integrate into the platform.
– Study and selection of anIoTopen source platform suitable for healthcare envir-onments.
• Design and implement a system architecture for an IoT platform for storage and analysis of data for medical sensors:
– Design of the system architecture proposed, based on the IoTplatform selected, database solutions suitable for medical sensors and analytic applications.
– Implementation of the designed system.
• Evaluate the performance of the developed platform:
– Design and configuration of the experiments for the assessment process.
– Representation and discussion of the results obtained from the assessment of the platform performance, based on the designed experiments.
1.3 c o n t r i b u t i o n s
The application ofIoTtechnologies on the healthcare sector, along with big data storage and analytic solutions, represents one of the most promising applications nowadays. By developing anIoT platform designed for data collection and analytics for medical sensors, this master thesis is contributing to the spread of this concept as a reliable and beneficial solution to take into account for the healthcare sector.
A major contribution of this master thesis was the development and integration of a component to establish the connection between HBase data store and Kaa platform. The source code of this contribution was accepted and integrated in the platform source code, through GitHub, by the development team of Kaa.
1.4 d o c u m e n t s t r u c t u r e
This master thesis is organized in seven chapters. This introductory chapter contextuali-zes the reader on the subject in study, as well as its motivations and objectives. A literature review on the main concepts and technologies addressed in this project is presented on Chapter2. Chapter3exposes the research methodology adopted, while Chapter4presents the proposed approach and the system architecture for the platform development. Chapter 5 addresses the decision making and implementation processes in the deployment of the platform. Chapter6is dedicated to the assessment of the platform performance, highlight-ing the experimental setup, the obtained results and the respective discussion. The funda-mental conclusions of this master thesis and the prospects for future work are presented in Chapter7.
2
L I T E R AT U R E R E V I E W
This chapter describes the theoretical foundations and scientific concepts concerning the development of this thesis, as well as the state of the art and literature review. Firstly, in Section2.1, it is presented a brief introduction containing the major subjects of this chapter. Section2.2presents the concept of nowadays big data, its challenges and opportunities in healthcare environments and, finally, the emerging big data technologies. Subsequently, Section 2.3 presents in detail the Apache Software Foundation projects relevant for this dissertation. Section 2.4 discusses the concept of Internet of Things and its relationship with big data, highlighting the applications and benefits in the healthcare industry and making reference to security requirements and existing platforms. Finally, Section 2.5 is dedicated to the Kaa platform overview, which is the IoTplatform deployed in this thesis project.
2.1 i n t r o d u c t i o n
Nowadays, healthcare organizations already store their medical records in electronic data-bases and there are even advances towards data transparency by making that stored data usable, searchable and actionable by the healthcare sector as a whole [8]. As healthcare data
is rapidly increasing, healthcare providers and data scientists now have access to promising new threads of knowledge, called ”big data” as result of not only its volume but also its complexity and diversity [8,9]. The analysis of this data, in order to obtain useful insight,
allows healthcare providers to deliver higher quality care and reduce costs. [8,10]. Many
innovative companies in the private sector are already building applications and analytic tools that help patients, physicians and other healthcare stakeholders to identify value and new opportunities based on all this emerging data [8,10].
However, there are some obstacles in healthcare systems that big data has to overcome in order to succeed [11, 12]. Patient privacy needs to be protected as more information
becomes public and big data systems need to be carefully developed to satisfy storage and analytic requirements [8,11,13]. Thus, new data management systems have been developed
to face these challenges such as Hadoop [14], an open source framework that helps solve
problems related to storage and access to data and allows very fast parallel processing; HBase [15], an open source distributed database that is built on top of Hadoop’s file system;
and Cassandra database [16], that can store millions of columns in a single row and does
not require prior knowledge of data formatting [13,17]. Additionally, for big data analytics
purposes Spark [18] is one of the most widely used open source processing frameworks
[19].
One of the major sources of big data is theInternet of Things(IoT). This concept is based on the integration of everyday objects with sensing and networking capabilities to commu-nicate with all devices or services over the Internet [20]. This way, healthcare represents
one of the most potential and attractive areas for the implementation of IoT solutions, es-pecially in remote health monitoring, fitness programs, chronic diseases and elderly care. In addition to the possibility of applying big data analytics on the huge amount of data ge-nerated by these systems,IoTapplications in healthcare are also expected to reduce medical costs, provide specialized treatments and increase the users’ quality of life [21]. In order
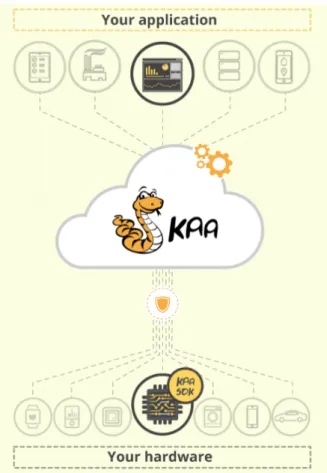
to achieve those goals, many IoTplatforms integrated with cloud based storage solutions, such as Kaa [22], have been developed. [1,23].
2.2 b i g d ata
2.2.1 Overview
Everyday, web and databases are overloaded with huge amounts of data in some way that by 2025 the forecast is that the Internet will exceed the brain capacity of everyone liv-ing in the whole world [17]. Data can be generated by different kinds of sources such as
online transactions, emails, videos, audio, images, click streams, logs, posts, search queries, health records, social networks, science data, sensors and smartphones [24]. Advances in
digital sensors, communications, high-speed network connections and computation tech-nologies contribute to a massive increase of this data, thus creating huge data collections [17,25]. In addiction, the development and deployment of business-related data standards,
electronic data interchange formats, business databases and information systems improved the creation, storage, communication and utilization of all that data [25]. This phenomenon
is known as big data [17].
In August 2012, a report delivered to the U.S. Congress defined the concept of big data as “large volumes of high velocity, complex, and variable data that require advanced tech-niques and technologies to enable the capture, storage, distribution, management and ana-lysis of the information” [10]. In fact, big data is commonly characterized by the following
• Volume: Huge amount of data is generated every second. All this data enforces the need of advanced tools to store and process efficiently all the information [9,17].
• Variety: Data does not have a fixed structure. It can be highly structured (data from relational databases), semi-structured (web, social media, sensor source) or even un-structured (audio, video, clicks) [9,13,17].
• Velocity: The term ”velocity” includes not only the speed of incoming data but also the speed that data flows in the system. It involves data streaming, structured records creation, data processing speed and availability for access and delivery [12,13,17].
• Value: The value refers to the purpose and potential of big data such as human de-cision support, discovering needs, segmenting populations or enabling new business models, products or services [17,26].
• Veracity: It is associated to the uncertainty of data, which can be caused by incon-sistencies, model approximations, incompleteness or even fraud. With many forms of big data, sometimes there is a lack of quality and accuracy [9,17,26].
Figure 1: Representation of the 5V’s characteristic of big data: Volume, Variety, Velocity, Value and Veracity [27].
In the last years, big data analytics have become of major interest and value for both academic and business communities. It is usually referred as the techniques, technologies, systems, practices, methodologies and applications that analyze critical data to obtain new discoveries and insight of relevance to the organizations [12,25]. The analysis of big data
provides useful information that help in making judgments, suggestions, supports or de-cisions for the stakeholders. In fact, extracting insight from big data may be useful in economic sectors, as well as improve the productivity and competitiveness of enterprises
and public sectors, creating huge benefits for both providers and costumers [28]. Several
key application fields of big data such as enterprises, finances and online social-networks are introduced in [28]. In the same way, some promising areas of analytic applications such
as e-commerce and market intelligence, e-government and politics, science and technology, smart health and well-being and security and public safety are presented and discussed in [25]. In [24] it is presented the potential of big data in some different sectors, highlighting
the healthcare industry as one of the most important and emerging technologies for the next years [10,12,13,24].
2.2.2 Big Data in Healthcare
The term ”big data” in healthcare is related to all electronic health datasets that are difficult to process with traditional medical software and require some advanced data man-agement tools [10, 12]. Healthcare data has increased massively not only because of the
volume but also because of the data diversity and speed at which it is generated and must be recorded. In 2012, it was estimated to be equal to 500 petabytes (1015bytes) and it is ex-pected to reach 25,000 petabytes in 2020 [29]. It includes clinical information from sources
like physician’s written notes, medical imaging, laboratory, pharmacy, Eletronic Medical Records (EMRs), sensors (such as vital signs monitoring devices), biometric data and even smartphone health applications [10,12].
All this amount of data creates a great opportunity for data scientists, allowing them to discover and understand patterns and associations between data to support medical decision-making [10, 26, 30]. Therefore, data analytics applications take advantage of that
data in order to extract useful insight to provide several benefits including preventive care, by detecting diseases or possible complications at earlier stages when it is possible to treat them more efficiently; better diagnosis and personalized treatment to each patient; under-standing and managing population health; predicting and/or estimating length of stay of patients, individuals at risk for medical complications or who will likely not benefit from surgery; and medical fraud detection [30]. By aggregating and integrating big data it is
possible to extract deep knowledge about patient similarities and connections to provide personalized care for each individual patient derived not only from hisEMRsinformation but also from his similarities with millions of other patients. This opens new opportunities for proactive medicine, actively managing diseases, empowering the patients and reduction of readmission rates [30]. With all this data-driven approach, healthcare is moving from a
disease-centered model towards a patient-centered model. In the first model, physician’s and healthcare professional’s decision making is based on clinical expertise and medical evidence. In the patient-centered model, the patient receives services focused on individual
needs and preferences, or in other words, personalized care to benefit from accurate and better services [26,30].
In addiction, applying advanced analytics based on healthcare data and patient-centered model also results in higher quality care at lower costs. McKinsey, a worldwide manage-ment consulting firm, estimated that big data analytics can save more than $300 billion per year only in U.S. healthcare [10,31]. The list below presents some areas where applying big
data analysis could help reduce waste and improve efficiency:
• Clinical operations: Extracting insight from data could help determine the best way for each patient diagnosis and treatment at lower costs [10,32].
• Research and development: Using statistical tools and analyzing clinical trials and patient records could help improving clinical trial designs and patient recruitment in order to reduce trial failures and speed new treatments to market [10,13].
• Public health: Analyzing disease patterns, outbreaks and transmission improve pub-lic health surveillance and speed response [9,10,13].
• Evidence based-medicine: AnalyzingEMRsdata and patient data could help predict-ing patients at risk for disease or readmission, and thus, providpredict-ing more efficient care [9,10,25].
• Remote monitoring: Analyzing real-time large volumes of data from healthcare cen-ters or home devices enables safety monitoring and prediction of any complication, reducing costs associated with patient readmission [9,10,25,32].
• Patient profile analytics: Analyzing patient profile and characteristics makes it pos-sible to identify individuals who would benefit from preventive care or lifestyle changes in order to avoid possible future complications and interventions [9,10,13].
Due to nowadays’ large stream of data, from various sources and in many different forms, big data projects need to be carefully planned to set up the right goals and realistic expectations. Their success depends on the ability to develop efficient systems for integ-rating and processing all the information available [12,17]. Furthermore, there are several
challenges surrounding the concept of big data in healthcare like confidentiality and data security, storage, access to information, data reliability, interoperability and data manage-ment [11,12,33]. Concerning patient’s privacy, in some healthcare organizations data may
be shared only after de-identification, which prevents direct and indirect identification of the patient [33]. In U.S., according to theHealth Insurance Portability and Accountability
Act (HIPAA) there are many data elements that need to be removed to assure patient’s privacy, such as names, geographic data, dates and contacts. In [33] there are listed all the
restricted data elements in accordance with HIPAA. As for data storage, reliability, access and management there have been developed and tested several solutions [28].
2.2.3 Storage and Analytics Solutions for Big Data
In order to handle big data challenges for developing storage and analytics solutions, it is crucial to understand all its implications. For that purpose, big data management can be split in four steps [17,34]:
• Acquisition: The system architecture has to acquire high speed of data from several different sources and diverse access protocols. If there is a need to filter the incoming data, this step is where it should be done.
• Organization: The system architecture must be able to parse data with different formats and extract the actual information that it contains. After that, data has to be integrated and stored in the right location, such as data warehouses, data marts, NoSQLdatabases, etc.
• Analyze: This step comprises running queries, modeling and building algorithms in order to extract new insights from data.
• Decision: By interpreting the results from the Analyze step, it is possible to make valuable and efficient decisions.
From this point of view, to be able to benefit from all the advantages of big data, it implies having an infrastructure capable of handling the steps above efficiently. That means this in-frastructure should be linearly scalable, able to handle high throughput data, fault tolerant, auto recoverable and with high degree of parallelism and distributed data processing [17].
Traditional data management systems were based on the Relational Database Manage-ment System (RDBMS) [34]. However, these systems require structured data which is not
suitable for handling big data, where large amounts of semi-structured and unstructured data can be rapidly generated [35]. Furthermore,RDBMSs are strictly designed with a lack
of scalability and expandability, compromising the system performance when dealing with huge amounts of data. In sum, traditionalRDBMSs could not handle the huge volume and heterogeneity of big data, so other solutions have been proposed [34,35].
Cloud Computing
According to the National Institute of Standards and Technology, cloud computing is a ”model for enabling convenient, on-demand network access to a shared pool of
configur-able computing resources (e.g. network, servers, storage, applications and services) that can be rapidly provisioned and released with a minimal management effort or service pro-vider interaction” [36]. This way, cloud computing provides the underlying engine needed
to perform distributed data-processing of multiple datasets, characteristic of big data [37].
lower operating and maintenance costs, as well as lower business risks [38]. These
proper-ties make cloud computing one of the most promising solutions for big data in healthcare as they provide a solution for interoperability problems and healthcare data sharing, pro-cessing and management [39].
In order to succeed in cloud environments, a cloud data management system requires [38]:
• Scalability and high performance, due to the continuous growth of data that need to be stored, users and data throughput.
• Elasticity, since cloud applications can face fluctuations in access patterns. • Fault tolerance, because of the possibility of some machine’s failure. • Security and privacy, since data is stored in third-party resources.
• Availability, as applications cannot afford extended periods of downtime.
As it has been previously stated, traditionalRDBMSs do not meet the requirements above. In order to address this issue, a new family of scalable databases, called NoSQL, has been developed in the last decade [36,38].
NoSQL Databases
For permanent storage and management of large volume of data, NoSQL databases proved to be a good option [34]. NoSQL stands for ”Not Only SQL”, highlighting that
Structured Query Language(SQL) is not a crucial point in these systems [35,38]. In fact,
ap-plications such as big data analytics, business intelligence and social networking require too much effort from SQL-like centralized databases, pushing them over their limits. NoSQL systems are distributed, horizontally scalable, non-relational databases designed for large-scale data storage and processing [40]. The term ”horizontally scalable” means that the
system has the ability to distribute both the data and the load of the operations over many servers without sharing RAM or disk among them [41]. NoSQL data stores also offer
flexible schemas or can even be schema-free, allowing to handle a wide variety of data structures. The horizontal scalability, the schema flexibility, the high availability and fault tolerance of these databases make them especially suitable for use as cloud management systems [38].
NoSQL database storing mechanisms follow the concept of CAP theorem, formulated by Eric Brewer in 2000, which stands for Consistency, Availability and Partition Tolerance [40, 42]. It postulates that only two of the previous three properties can be fully achieved
Figure 2: TheCAPtheorem states that only a combination of two of the following properties can be fully achieved simultaneously: consistency, availability and partition tolerance [42]. Consistency means having a single up-to-date instance of data [38]. This way, all clients
who read from the database will always see the latest version of data [36, 40]. Availability
implies data to be accessible at the moment that it is requested [38]. This means that all
clients always find at least one copy of the requested data, even if some machines in the cluster are down [40]. Finally, partition tolerance refers to the capability of the system to
tolerate network partitions [38]. This means the database still can perform read and write
operations when some parts of the system are completely inaccessible [36]. Regarding the
different concerns ofNoSQLdatabases, there are three possible scenarios [42]:
• Concerned about consistency and availability: Mainly use of replication approach to ensure data consistency and availability. Some examples include Vertica [43], Aster
Data [44] and Greenplum [45].
• Concerned about consistency and partition tolerance: Data is stored in distributed nodes and these systems privilege the assurance of data consistency instead of avail-ability. Some examples include BigTable [46], HBase [15] and MongoDB [47].
• Concerned about availability and partition tolerance: This kind of systems priv-ileges data availability over consistency. Some examples include Voldemort [48],
CouchDB [49] and Cassandra [16].
NoSQLdatabases can also be classified as key-value databases, document databases and column-oriented databases [42,50]. In key-value databases, data is stored as key-value pairs
[50]. The key identifies uniquely the value, and it is used to store and retrieve the value into
and out the data store. The value is opaque to the data store, so it can be used to store any arbitrary data. However, due to this property, these data stores cannot perform data-level querying [38]. Some examples of these databases include Dynamo, Voldemort and Redis
[40]. Document databases are especially suitable for applications where the input data can
be represented in a document format [38]. Data is stored and organized as a collection
of documents with any number of fields and length [50]. Those documents are usually
represented using JavaScript Object Notation (JSON) or some derived format [38]. These
data stores are not particularly concerned about high performance write operations, but to ensure big data storage and good query performance [42]. Typical document databases are
CouchDB and MongoDB [41,42]. Finally, most of column-oriented databases derived from
Google Bigtable. In Bigtable, datasets consist of several rows where each row is addressed by a unique key. Each row is comprised by a set of column families and each column family is comprised by one or more columns [38]. The full description of Bigtable is
presen-ted in [46]. The deployment of column-oriented databases in an architecture with data
compression and parallel processing can provide high performance of data analysis and business intelligence processing [42]. Some examples of these data stores include Google’s
Bigtable, HBase (which is the direct open source implementation of Bigtable concepts) and Cassandra [38,41,42].
Big Data Technologies
Nowadays, most of big data platforms and frameworks are based on distributed storage of data, which, unlike traditional systems, stores blocks of very large files across multiple nodes. These storage systems are designed to run on low-cost hardware and provide high availability and streaming access to data [35]. In this perspective, Hadoop has been a
revolutionary technology in the realm of computer science [51].
Apache Hadoop is an open source framework that allows distributed processing of huge datasets across clusters [31]. It has not only gained significant importance in business
intelligence and analytics [25], but also has become common in healthcare industry [9,31].
In fact, it is the most widely applied technology in big data systems as it helps to overcome important challenges like storage and access, management of overheads (associated with the large datasets) and fast parallel processing [13]. Hadoop’s main infrastructure consists
in its default distributed file system and MapReduce [35,52].
MapReduce is a programming paradigm introduced by Google in order to process huge amounts of data [35]. Some use cases of MapReduce framework in healthcare industry
include finding optimal parameters for lung texture classification using machine learning algorithms, content-based medical imaging indexing and wavelet analysis for solid texture classification [31].
Despite providing high scalability across many servers in Hadoop cluster, MapReduce does not perform very well with intensive input-output tasks [31]. Apache Spark is another
computing engine that can be integrated in Hadoop cluster for data processing. It supports in-memory computing, which allows to query data much faster than disk-based engines
like Hadoop’s MapReduce [53]. In fact, for performing analytics on continuous streams
of data, Spark proves to be very useful due to its capabilities to compute on streaming data with machine learning algorithms and graphic tools for visualization. This way, it is possible to perform both real-time and retrospective analysis of incoming data [31].
Currently, software and hardware vendors like IBM [54], Cloudera [55] and Dell EMC
[56] offer tools, platforms and services for big data analytics based on Hadoop architecture
[57]. Other big data technologies, including the previous mentionedNoSQLdatabases, are
presented and described in [17] and [10]. Some big data tools such as Apache Zookeeper
[58] for managing resources and Apache Flume [59] for data integration are presented
in [35]. Actually, many Apache Software Foundation projects are developed to meet the
requirements of big data systems.
2.3 a pa c h e s o f t wa r e f o u n d at i o n p r o j e c t s
2.3.1 Apache Hadoop
The first version of Hadoop was created in 2004 by Doug Cutting, who named the project after his son’s stuffed elephant. In January 2008, it became a top-level Apache Software Foundation project [60]. The Apache Hadoop project is responsible for developing
open-source software for reliable, scalable and distributed computing. Hadoop software library is a framework that provides distributed storage and processing of large datasets across clusters of computers using simple programming models. It is designed to scale up from one to thousands servers and to detect and handle failures [14]. The storage is provided by
Hadoop Distributed File System (HDFS) and the processing and analysis by MapReduce. There are other components that can be integrated in Hadoop, but these two are considered its kernel [61].
Hadoop Distributed File System
HDFS is an open-source fault-tolerant distributed file system, inspired by Google File System (GFS), that supports large data storage and management [60, 62]. It is designed to
be deployed on low-cost hardware and to provide high throughput access to application data [14].HDFSstores data in blocks, typically with size of 64MB, and each block is stored
as a separate file in the local file system [35, 63]. The reason for this large size of blocks is
to reduce the number of disk seeks [52,61].
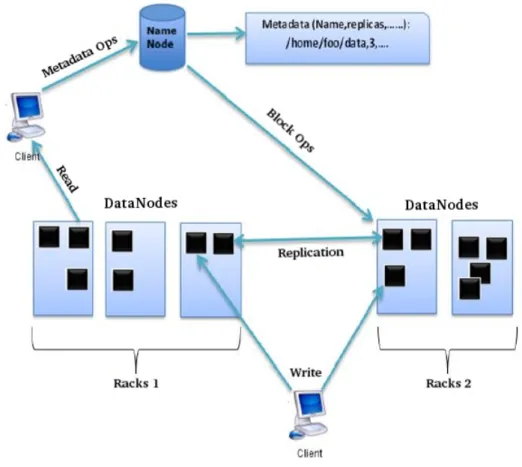
The HDFS cluster has a master/slave architecture [62, 64]. It consists of a single
Name-Node, which is considered the master server, and several DataNodes, usually one per node in the cluster [64]. The NameNode is a centralized service operating on one node in the cluster
system namespace. It deals with clients requests to perform file system operations, such as open, close, rename and delete [63]. NameNode does not store HDFS data. Instead, it
maintains a mapping between theHDFS file name, a list of blocks in the file and the Data-Nodes that store those blocks [63]. This way, NameNode acts as the arbitrator and repository
of HDFS metadata [14]. DataNodes are responsible for handling read and write requests
from clients and perform operations such as block creation, deletion, and replication when the NameNode requests. They retrieve blocks not only when they are told to, but they also report back to the NameNode the lists of blocks they are storing, periodically, in order to keep it up to date on their current status [65]. Note that although it is the NameNode that
manages the namespace and block operations, clients are addressed to DataNodes in order to read or write data [63]. TheHDFSarchitecture is represented in Figure 3.
Figure 3: Architecture and workflow of Hadoop Distributed File System (HDFS). The NameNode manages metadata operations and gives instructions on block operations to DataNodes. When clients send operations requests to HDFS, the NameNode addresses them to the respective DataNode in order to perform read or write operations. Adapted from [35]. Without the NameNode, the file system cannot be used because there would be no way of knowing how to reconstruct the files from the blocks on the DataNodes. Thus, it is extremely
important to make sure the NameNode is resilient to failure. Hadoop provides two ways for achieving that. First, Hadoop can be configured so that the NameNode writes its persistent state to multiple file systems in order to backup all metadata information. Second, Hadoop can also run a secondary NameNode that is responsible for merging the namespace image periodically. It keeps a copy of the merged namespace which can be used in the event of the NameNode failing [61].
HDFSis designed to store huge amounts of data across machines in a large cluster in a reliable way [14]. Thus, it implements an automatic replication system for granting
fault-tolerance [63]. The number of replicas is configurable through the replication factor
prop-erty onHDFSconfiguration. Each file is stored as a sequence of blocks, which are replicated under that replication factor [14].HDFSreplication is also transparent to the client
applica-tion. When a block is written in one DataNode, it echos the data to a second one, and so on until the desired number of replicas have been achieved. When the NameNode receives the list of stored blocks from each DataNode, it will verify if each block is sufficiently replicated. In case of failure, the NameNode instructs DataNodes to make additional replicas [63].
Data corruption can occur in any system due to faults in storage devices, network faults or even buggy software. In order to prevent that, HDFSimplements checksum verification mechanisms on its contents for granting data integrity. When a client creates an HDFSfile, it computes a checksum for each block and stores them in a separate hidden file in the same HDFSnamespace. Then, when a client retrieves file contents, it verifies that the data received matches the checksum previously stored [14].
MapReduce
Hadoop MapReduce is the most popular open-source implementation of the MapReduce framework introduced by Google [66]. MapReduce provides a powerful parallel
program-ming technique for distributed processing of data on clusters. The fundamental method of this programming paradigm is to break down the complex big data problems into small units of work and process them in parallel [24]. MapReduce, as the name suggests,
ex-presses the fact that two different functions are performed: Map and Reduce [17,52]. The
Map function is applied on the input data in order to produce a set of intermediate results in the form of < key, value> pairs [17,63]. Then, the records for any given key (possibly
spread across many nodes in the cluster) are aggregated at the node running the reducer for that key. This step involves data transfer between machines, so the Reduce stage is blocked from progressing until all the data from the Map stage has been transferred to the appropri-ate machine [60]. Finally, the Reduce function merges all the intermediate values associated
with the same key [17]. Those two functions can run independently on each<key, value>
define the Map and Reduce functions and the framework takes care of everything else, such as failover and parallelism mechanisms [66].
In Hadoop cluster, a job corresponds to a MapReduce program and it is executed by subsequently breaking it down into small parts called tasks. When a node in the cluster receives a job, it divides it and runs it in parallel with other nodes. This procedure is led by JobTracker [17]. The JobTracker receives the MapReduce job from the user application
and splits it into tasks. Subsequently, it assigns those tasks to TaskTrackers on DataNodes. Lastly, the TaskTracker of each DataNode executes the assigned task on its data. JobTracker is responsible for the coordination of the process and, thus, it is in continuous communication with TaskTrackers, which periodically report the task status [35,63]. When Hadoop detects
task failures, it restarts the task in another healthy node, granting the fault-tolerance of the system [60].
Despite being a simple programming model, restricted to the usage of key-value pairs, there is a surprising number of tasks and algorithms that fits into this framework [60].
2.3.2 Apache HBase
HBase is an Apache Hadoop-based project modeled on Google’s BigTable database [60].
The architecture of BigTable can be found on [46]. HBase can be defined as a distributed,
sparse, persistent and multidimensional sorted map [15,67]:
• Distributed: Data is stored in multiple nodes across the cluster.
• Sparse: Usually a record has many columns and some of them may have null data. HBase can efficiently save the space in sparse data.
• Persistent: Data is written and saved in the cluster. • Multidimensional: A row can have multiple columns. • Map: Data is stored in form of key-value pairs.
• Sorted: The key is stored in a sorted way for faster read and write optimization.
HBase is a column-oriented database built on top of the HDFS [68]. Therefore, the
is-sues surrounding data replication, node failure and data distribution across the nodes are handled by the HDFS[50,69]. HBase is designed to provide random real-time read/write
access to very large datasets [60,61].
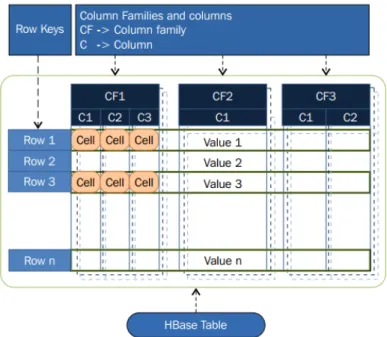
Data Model
• Row: Each table comprises a set of rows where each row is identified through a unique row key. This is just a logical representation since the data is not stored physically in row, but in columns. In HBase a row consists of its row key and one or more columns associated with their values.
• Column: A column consists of a column family and a column qualifier delimited by a ”:” character ( family:qualifier ).
• Column family: Column families physically stores a set of columns and their respect-ive values. Each column family has a set of storage properties that can be configured, such as compression, cache in memory, etc. Every row in a table has the same column families, however a row might not store anything in a given column family.
• Column qualifier: A column qualifier addresses the data on the column family. Column qualifiers are mutable and different rows can have different sets of column qualifiers.
• Cell: A cell is the basic quantum of information in HBase. It is addressed by a row key, column family and column qualifier and contains a value and a timestamp, which represents the value’s version. Each cell is associated with a timestamp, allowing to manage different versions of data for the same row key.
Figure 4: Logical representation of HBase data model. An HBase table consists in a set of rows where each row comprises a row key and one or more column families. Each column family groups one or more column qualifiers (simply referred as columns). The cell represents the basic unit of information, as it is addressed by a row key, a column family and a column qualifier [67].
All table accesses are performed using row keys [60]. Rows are sorted alphabetically by
row keys, so lexicographically adjacent keys will be stored in the same area of physical stor-age [72]. For this reason, the design of the row key is crucial [15]. HBase stores everything
as uninterpreted bytes. This means that any arbitrary array of bytes (not necessarily human-readable) can be used as a name for a column family or even a key for a row [50]. Both
column families and qualifiers may be arbitrary strings, but column families are usually defined statically at the table schema creation, while column qualifiers can be added at any time [60,72].
Architecture
Column family’s data are stored in multiple files and in multiple regions, where each re-gion comprises a particular range of a table’s rows [61]. In order to manage them, HBase’s
master server assigns multiple regions to a region server. In addition, HBase uses Zoo-keeper to manage the coordination and resources needed to be highly available in a distri-buted environment [67]. In sum, HBase system architecture consists in a Zookeeper cluster,
a master server and region servers. [71,73].
The master server, designated as HMaster, is the administrator of the HBase cluster. It is responsible for cluster monitoring and management, assigning regions to the regions servers and handling failover and load balancing by re-assigning those regions [67,74].
The region servers run on DataNodes of theHDFSand are responsible for managing the regions, splitting data in regions and coordinating and serving read and write requests [67,74]. Regions have a previously configured maximum size. When the data grows more
than that size, region servers split that region in two equal regions, maintaining the high velocity of read and write operations over data [67].
Apache Zookeeper is a distributed, open-source coordination service for distributed ap-plications that is also part of the Apache Software Foundation [58]. It offers filesystem-like
access with directories and files (called znodes) that distributed systems can use to negoti-ate ownerships, register servers and other coordination services [73]. The znodes are not
designed for general data storage but to map the metadata used for coordination purposes. However, Zookeeper allows clients to store some useful information for metadata or con-figuration in distributed systems [75]. Every region server creates its own znode, which
the HMaster uses to discover available servers [73]. At the creation time, a session with an
associated timeout is initialized. If Zookeeper does not receive anything from its session for more than that timeout, the session is closed and the client is considered faulty [75]. With
this mechanism, HBase uses Zookeeper to monitor all region servers and recover them in case of failure [67].
As for concurrency control, HBase implementsMulti-Version Concurrency Control(MVCC). In MVCC, when data is updated, it does not overwrite the old data, but instead it adds a
new version for the update and marks it as the current. With this approach, a read oper-ation can retrieve not only the current version data but also data from previous versions [38]. The maximum number of versions allowed can be configured in column families’
properties.
HBase provides strong consistency for both read and write, which means that when write requests are confirmed, the same data is visible to all subsequent read requests [38].
For reads, the clients cannot read any record that is inconsistent, until that inconsistency is fixed. As for writes, HBase does not write updates to disk instantly [76]. It first saves all the
updates in aWrite-Ahead-Log(WAL) stored in hard drive and then it performs in-memory data replication across the nodes, increasing this way the write throughput. Periodically it flushes the in-memory structure to disk creating an immutable index-organized data file, designated HFile [69,76]. For this reason,WALproves to be extremely important to recover
data in case of any failure [67].
2.3.3 Apache Cassandra
Cassandra was integrated in Apache Software Foundation projects in March 2010, after being open-sourced by Facebook in July 2008 [77,78]. Since its early deployments involved
storing social network data such as user activity updates, reviews and application statistics, it is optimized to provide high performance writes [78]. Cassandra is defined as a
distrib-uted, scalable, highly available, fault tolerant column-oriented database that is influenced by Amazon’s Dynamo infrastructure and Google’s BigTable data model [77,78].
Data Model
In Cassandra, a database schema is represented by a keyspace, which is the namespace that contains all data objects, such as tables [79]. A keyspace is defined by a name and a set
of attributes, like replication factor, replica placement strategy and column families [78].
Cassandra tables are represented by a distributed multidimensional map indexed by a key. It contains the following dimensions [78,80,81]:
• Row: Each row is identified by a string key of arbitrary length and contains one or more column families.
• Column family: A column family consists of columns and super columns. Cassandra stores column families in separate files on disk, so it is important to define related columns in the same column family.
• Column: A column is the most basic unit of data structure and it consists in a tuple containing a name, a value and a timestamp. Cassandra uses the column timestamp
to determine the most recent data. It is also possible to have different number of columns for different rows.
• Super column: Super columns provide another level of nesting to the regular column family structure. Each super column consists in a name and a map of sub-columns. Cassandra is considered to be schema-free. Despite the keyspace and the column families being fixed at the database creation, the columns can be added to a family at any time [78, 81]. Similarly to HBase, Cassandra represents its data structures in sparse multidimensional
hashtables, meaning that different keys can have different numbers of columns [78].
In order to perform queries over the tables, Cassandra makes use of theCassandra Query Language(CQL), which has aSQL-like syntax [79].
Architecture
Cassandra has a peer-to-peer distributed architecture [81]. Contrary to the master/slave
architecture of HBase, it is a decentralized system, meaning that all nodes of the cluster are structurally identical and function the same way [78]. Thus, Cassandra has no single point
of failure (such as the master node failure), which contributes to the high availability of the system [81].
Since there is no master node, Cassandra uses a gossip protocol so that each node can have state information about the other nodes in the cluster [78]. Gossip is a peer-to-peer
communication protocol where nodes exchange messages about their state and the state of other nodes they know about. This way, each node quickly obtains information about the state of all other nodes in the cluster. Every gossip message has a version associated with it, allowing only the old state information to be updated [81]. This process runs every second
and it is also responsible for detecting failures. Cassandra uses an accrual detection mech-anism to calculate a per-node threshold based on network conditions, workload and other conditions that might affect the node’s response [78, 81]. Through the gossip mechanism,
this method can determine if one node is up or down, allowing Cassandra to avoid routing client requests to unresponsive nodes [80,81]. When a node failure occurs, the other nodes
will keep trying to gossip with it to see if it is recovered, unless the administrator explicitly removes the failing node [81].
Similarly to HBase, Cassandra provides a replication mechanism to ensure reliability and fault-tolerance [81]. The number of times data is replicated across the cluster is defined by
the replication factor [80]. The way that those replicas are distributed across the cluster is
determined by the replica placement strategy. Both replication factor and replica placement strategy are set at the keyspace definition [81].
Despite being focused on availability, it does not mean that consistency is dismissed. In fact, Cassandra has a ”tuneable consistency”, which means it is possible to decide the
level of consistency required, in balance with the level of availability [78]. The consistency
level can be set by the client and specifies how many replicas in the cluster must handle the requested operation in order to be considered successful [78]. Three well known consistency
levels in Cassandra are [76,78,81]:
• ONE: This is the default value. It only needs a response from one replica for both read and write requests. For read, the response may not always contain the most recent data. A background thread is created to check the same data on the other replicas, and if there is any outdated, a read repair is performed. As for write, the operation is considered successful when at least one replica is written.
• ALL: This level perform writes and reads on all replicas and fail if there is any un-responsive replica. It provides stronger consistency at the cost of availability, due to synchronous blocking operations that wait for all nodes to be successfully updated. • QUORUM: For write operations, it must be performed successfully on more than a
half of the replicas. For read operations, it must return data with the most recent timestamp after more than a half replicas have responded.
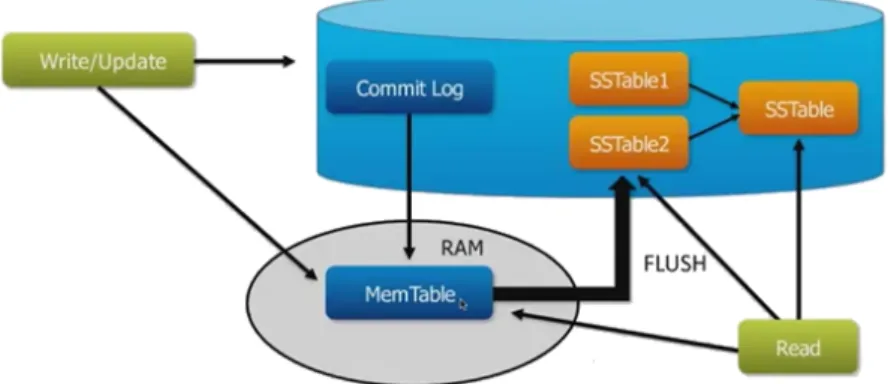
Cassandra architecture allows any node in the cluster to be read or written [81]. When
data is written to the cluster, it will be first written to a commit log, which provides durabil-ity of data in case of some unexpected shutdown [16]. A write is not considered successful
until it is written in that commit log [78]. Afterwards, the data is written to an in-memory
structure called memtable. When the memory usage of memtables exceeds a configured threshold or the commit log approaches its maximum size, the contents of the memtable are flushed onto disk in an immutable file called SSTable [16,78]. As for reads, Cassandra will
check the requested data in the memtables first [78]. All this process is presented in Figure
5.
Figure 5: Cassandra workflow for read and write operations. Data is written first in the commit log to ensure durability, and then in the memtable. When the memtable reaches its maximum capacity, data is flushed into SSTables. As for read operations, data is sought first in the memtables and then in the SSTables [82].
2.3.4 Apache Spark
Apache Spark can be defined as a ”fast and general-purpose cluster computing system” [18]. It provides high-level Application Programming Interface(API) in several
program-ming languages, such as Java, Scala, Python and R [18,53]. Spark is by far one of the most
widely used open source processing frameworks for big data [19,83].
This computing system has a batch processing model similar to MapReduce, which con-sists in dividing a large dataset into several small sets for subsequent parallel processing [84]. However, Spark engine supports in-memory computing, which provides faster data
processing compared to traditional disk-based engines [53]. In fact, this in-memory
pro-cessing capability proved to be much faster than Hadoop’s MapReduce that was mentioned in Section2.3.1[53,84]. Thus, this framework is commonly designed for scalable
MapRe-duce computing across distributed systems [85].
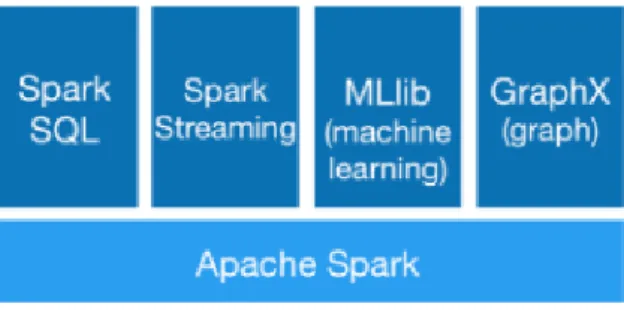
Apache Spark also provides a set of high-level tools (Figure 6) such as Spark SQL forSQL and structured data processing, Spark Streaming for stream processing, MLlib for machine learning and GraphX for graph processing [18,53].
Figure 6: Apache Spark supported tools include SparkSQL, Spark Streaming, MLib and GraphX. The documentation for each element can be found in its website [18].
The Spark framework consists in a spark master node and one or more workers. The master is responsible for initializing the spark driver that manages all the workers, which, on its turn, are responsible for the execution of parallel processing operations [85]. The
main abstraction that Spark provides is a Resilient Distributed Dataset (RDD), which is a collection of objects partitioned across the cluster that can be manipulated and processed in parallel [18,86]. RDDs are fault tolerant and able to automatically recover from failures
2.4 i n t e r n e t o f t h i n g s
2.4.1 Overview
The first steps of the Internet revolution led to the interconnection between people all over the world. Nowadays, the next revolution aims to create smart environments by es-tablishing network connections between everyday objects. Mark Weiser, who is considered to be the father of ubiquitous computing, defined a smart environment as ”the physical world that is richly and invisibly interwoven with sensors, actuators, displays, and compu-tational elements, embedded seamlessly in the everyday objects of our lives, and connected through a continuous network” [87]. To bring this concept to reality, a new technology has
been developed over the years: the Internet of Things(IoT) [87].
IoT can be simply defined as the integration of all networked devices and sensors to provide information in real-time and allow interaction with people who use them [4]. It
is based on the integration ofInformation Technology (IT), which is related to the storage and processing of data, and Communication Technology, which includes communication protocols and technologies [6]. The term ”Internet of Things” was used for the first time
by Kevin Ashton in the supply chain management context, in 1999 [87, 88]. Nowadays,
with the present capability of Internet,IoTaims to create a new paradigm where computer systems interact with sensors and devices that see, hear and sense the surrounding envir-onment, without the intervention of humans, in order to make real use of that information [88].
TheIoTconcept is based on ”things”, also designated as smart objects, that are built and developed in order to be identifiable, communicate and interact with every entity of the system [89]. In fact, they are considered the active participants of the system, since they
are responsible to communicate with each other and with the surrounding environment by sharing data and reacting to the physical world events with or without user interven-tion [87]. Hence, IoT entities can be seen as providers and/or consumers of data related
to the real world [89]. They can be grouped in three main classes: devices attached to
objects for identification purposes; sensors and actuators for external access and control of objects’ properties and functions; and finally, sensor-enabled devices such as wearables and smartphones. IoT platforms should support these different classes in order to assure the interoperability of the system, integrating every device or sensor in their network infra-structures [1].
One of the major breakthroughs concerning embedded communication in the IoT sys-tems was theRadio Frequency Identification(RFID) technology [87]. This concept is based
on microchips attached to antennas for wireless communication of data that allows auto-matic identification of the object they are attached to, similar to electronic barcodes [87,90].
In its first steps,IoTonly considered objects tagged with this technology. Nowadays, it cov-ers many other technologies such as distributed sensor networks, sensor-enabled devices and other smart objects capable to interact with physical world [1]. Communication
tech-nologies are generally divided in long-range and short-range techtech-nologies. The first group refers mainly to the regular long distance communication solutions like Internet and mo-bile phones while the second group includes wireless technologies such as Bluetooth,RFID, Wi-Fi, Infrared and ZigBee [7,21]. The comparison of these different short distance
commu-nication techniques is presented in [7]. Another technology for short-range communication
that is worth mentioning in theIoTcontext is theWireless Sensor Network(WSN) [87]. The
WSNs consist of a large number of efficient, low cost and low power sensors that enables the collection, processing and analysis of valuable information gathered in several environ-ments [87, 88]. Usually there is one or more base stations, designated by gateways, that
act like a data sink to the network sensors and connect them to the physical world [88].
Sensor networks are useful specially for monitoring the status of things, as they provide a better awareness of the surrounding environment [90]. At last, an ongoing trend is to adopt
IP-based sensor networks, using IPv6-based Low-power Wireless Personal Area Network (6LoWPAN) [21].
In sum, sensors and devices are responsible to interface with the physical world, either by sensing data or triggering actions on the physical world [89]. An IBM report estimated
that by 2020 there will be 212 billion sensor-enabled objects available and 30 billion of them will be connected to networks [1]. According to Cisco, that number is even greater, having
estimated 50 billion of network-connected devices by 2020 [6]. By making all these devices
and sensors communicate and sharing information with each other, IoTplatforms make it possible to collect and analyze new data streams faster and more accurately [91]. In this
point of view, it is generated a massive amount of data, usually semi-structured or unstruc-tured, that is useful only when it is analyzed, for example with big data analytic tools. In fact, IoT and big data are two inter-dependent technologies. The widespread deployment of IoT leads to a fast increasing in volume and diversity of data, thereby providing great opportunities for the development of big data applications [28].
Similarly to big data applications, one of the most critical challenges in the widespread adoption of IoT applications is the security issue. IoT solutions should provide mechan-isms of confidentiality, privacy and authenticity in order to be adopted by stakeholders. Data represents one of the fundamental features in these systems, so data confidentiality is needed to guarantee that only authorized entities are able to access and modify them [20, 89]. This is achieved mainly by implementing an access control mechanism, such as
Role-Based Access Control, and an authentication process (with an identity management system) [89]. Furthermore, not all data should be available. Privacy rules aim to define
![Figure 1 : Representation of the 5 V’s characteristic of big data: Volume, Variety, Velocity, Value and Veracity [ 27 ].](https://thumb-eu.123doks.com/thumbv2/123dok_br/17268675.788991/16.892.307.640.572.865/figure-representation-characteristic-volume-variety-velocity-value-veracity.webp)
![Figure 2 : The CAP theorem states that only a combination of two of the following properties can be fully achieved simultaneously: consistency, availability and partition tolerance [ 42 ].](https://thumb-eu.123doks.com/thumbv2/123dok_br/17268675.788991/21.892.343.609.150.418/combination-following-properties-simultaneously-consistency-availability-partition-tolerance.webp)