FAM´
ILIAS ESTRUTURADAS DE MODELOS
COM MODELO BASE ORTOGONAL
Teoria e Aplica¸
c˜
oes
Disserta¸c˜ao apresentada para obten¸c˜ao do Grau de Doutor em Matem´atica com
especializa¸c˜ao em Estat´ıstica pela Universidade Nova de Lisboa, Faculdade de
Ciˆencias e Tecnologia.
Lisboa
Sendo este o espa¸co reservado para referir as pessoas que realmente me ajudaram
e apoiaram neste trabalho, come¸co pelo meu orientador, o Professor Doutor Jo˜ao
Tiago Mexia. Foi com ele que tudo isto come¸cou. Foi ele que me trouxe para o
mundo da investiga¸c˜ao, primeiro com o mestrado e agora com o doutoramento e
os projectos em que estive e continuo envolvida, dando in´ıcio a uma nova fase da
minha vida profissional onde me sinto melhor que nunca. Apesar do grande n´umero
de doutoramentos orientados pelo Prof. Mexia durante todo o per´ıodo em que se
processou o meu doutoramento, ele esteve quase sempre dispon´ıvel para responder
`as minhas d´uvidas, para me orientar no caminho a seguir e para em pouco tempo
dar um retorno sobre o material que lhe ia entregando. Mais do queO Professor, o Prof. Mexia ´e um grande amigo com a ajuda do qual sei que posso contar noutras
situa¸c˜oes.
A segunda pessoa que quero referir, ´e sem d´uvida, o meu colega do Centro de
Ma-tem´atica e Aplica¸c˜oes (CMA) e grande amigo Miguel Fonseca, sempre disposto para
discutir comigo as m´ultiplas quest˜oes que iam surgindo ao longo de todo processo.
Quero agradecer tamb´em a todos os outros meus colegas que diariamente ou
com alguma frequˆencia se encontram na sala do CMA, e que contribuem para o
bom ambiente de trabalho que a´ı se vive, o qual proporcionou a realiza¸c˜ao do meu
doutoramento.
co-orientador na ´area da hidrologia e coordenador do projecto de PTDC/AGR-AAM/
71649/2006 -“Gest˜ao do risco em secas: Identifica¸c˜ao, monitoriza¸c˜ao, caracteriza¸c˜ao,
predi¸c˜ao e mitiga¸c˜ao”do qual sou bolseira de investiga¸c˜ao. Gra¸cas a ele tive
finan-ciamento durante o ´ultimo ano de doutoramento e tive tamb´em a oportunidade de
estar inserida neste projecto e de ter publicado nas melhores revistas internacionais
da ´area da hidrologia. Obrigado por acreditar em mim.
Al´em disso gostava tamb´em de agradecer `a Professora Doutora Alexandra
Ri-beiro minha co-orientadora e coordenadora do projecto de investiga¸c˜ao POCTI/
32927/AGR/2000 - “Removal of Cu, Cr, As and creosote from impregnated wood
waste aiming its recycling”, no qual tiveram origem os dados que serviram de base
ao trabalho de aplica¸c˜ao apresentado no capitulo 9 desta disserta¸c˜ao.
Por fim dedico esta disserta¸c˜ao `a minha fam´ılia: aos meus pais, porque a eles
devo grande parte do que sou, ao meu marido Jo˜ao Paulo que sempre me incentivou
a seguir em frente e a procurar uma actividade profissional em que me sentisse
realizada e ao meu pequenino Daniel, a luz que ilumina a minha vida e que d´a
As fam´ılias estruturadas de modelos (f.e.m.) s˜ao constitu´ıdas por modelos
elementa-res que corelementa-respondem aos tratamentos do modelo base, o qual pode ser ortogonal de
efeitos fixos com cruzamento-encaixe de factores. Por sua vez, os modelos
elemen-tares podem ser regress˜oes lineares m´ultiplas nas mesmas vari´aveis, considerando
homocedasticidade entre as regress˜oes ou ent˜ao modelos log-lineares ajustados a
tabelas de contingˆencia. No tratamento das f.e.m., numa primeira fase,
condensa-se a informa¸c˜ao contida nos vectores de obcondensa-serva¸c˜oes correspondentes aos modelos
elementares nas respectivas estat´ısticas suficientes e na segunda fase aplicam-se os
algoritmos desenvolvidos para o modelo base aos resultados obtidos na primeira fase.
Dado um modelo ortogonal λ = Pmi=1Xiαi associado a uma ´algebra de Jor-dan comutativa, diz-se que y = Lλ+ e ´e um modelo L-ortogonal se os vecto-res coluna de L forem linearmente independentes. No caso n˜ao equilibrado das f.e.m. com regress˜oes m´ultiplas, L ser´a uma matriz diagonal por blocos da forma L= D( ˇX1, ...,Xˇc), onde Xˇj s˜ao as matrizes das regress˜oes individuais as quais di-ferem de tratamento para tratamento. Desta forma, ultrapassa-se a restri¸c˜ao usual
requerendo que todas as regress˜oes tenham a mesma matriz de modelo.
Trˆes aplica¸c˜oes a dados reais s˜ao apresentadas. Nas duas primeiras, aplicam-se
as f.e.m. com modelos log-lineares `a hidrologia, atrav´es da an´alise de transi¸c˜oes
entre classes de seca. Na terceira, analisam-se dados de experiˆencias de remo¸c˜ao
Structuralized family of models (s.f.m.) are constituted by unit models
correspon-ding to the treatments of the base model, which can be orthogonal of fixed effects
with cross-nesting. On its side, the unit models can be multiple linear regressions
on the same variables, considering homoscedasticity between regressions or then,
log-linear models fitted to contingency tables. Following the treatment of s.f.m., in
a first step, information inside the observation vectors correspondent to unit models
is condensate in sufficient statistics and in second step, the algorithms developed for
the base model are applied to the results obtained in the first fase.
Given a orthogonal model λ =Pmi=1Xiαi associated to a commutative Jordan algebra, it is said thaty=Lλ+eis aL-orthogonal model if the column vectors the matrixLare linearly independent. In the no-balanced case of the s.f.m. with multi-ple regressions,Lwill be a diagonal by blocks matrix of the formL=D( ˇX1, ...,Xˇc), whereXˇj are the model matrices of the individuais regressions which can differ from treatment to treatment. In this way, the usual restriction requiring all regressions
to have the same model matrix is overcame.
Three applications to real data are presented. In the two first applications,
s.f.m. with loglinear unit models are applied to hydrology, through the analysis of
transitions between drought classes. In the third one, data originated in experiments
of electrodialytic removal of heavy metals are analyzed using the non-balanced case
v → vector (letra min´uscula a negrito) 0 → vector nulo
1 → vector de 1’s
Y → vector aleat´orio (letra mai´uscula a negrito) A → matriz (letra mai´uscula a negrito)
On → matriz nula de ordem n In → matriz identidade de ordem n Jn → matriz de 1’s de ordemn AT → matriz transposta de A A−1
→ matriz inversa de A
A+ → matriz inversa generalizada de Moore-Penrose de A ⊗ → produto de Kronecker entre matrizes
Car(A) → caracter´ıstica da matrizA
Det(A) → determinante da matriz A
R(A) → Espa¸co imagem da matriz A
V⊥/W → Complemento ortogonal do sub-espa¸co V relativamente a W vV → projec¸c˜ao ortogonal de v sobre o sub-espa¸coV
Q(V) → Matriz de projec¸c˜ao ortogonal sobre o sub-espa¸co V
⊞ → Soma directa ortogonal de sub-espa¸cos
E(X) → Valor esperado da vari´avel aleat´oria X V(X) → Variˆancia da vari´avel aleat´oriaX
COV(X;Y) → Covariˆancia entre a vari´avel aleat´oria X e Y
E(Y) → Vector m´edio do vector aleat´orio Y
COV(Y) → Matriz de covariˆancia do vector aleat´orioY
COV(X;Y) → Matriz de covariˆancia cruzada dos vectores aleat´oriosX e Y D(d1, ..., dn) → Matriz diagonal com elementos principais d1, ..., dn
Pr() → Probabilidade
UMVUE → Uniforme minimal variance unbiased estimator
BLUE → Best linear unbiased estimator
1. Introdu¸c˜ao. . . 1
2. Defini¸c˜oes e Resultados Preliminares . . . 7
2.1 Matrizes Ortogonais Estandardizadas, Diagonalizadoras Ortogonais e Matrizes Uniformizadoras . . . 7
2.2 Sub-Espa¸cos e ´Algegras . . . 9
2.3 Matrizes Inversas Generalizadas de Moore-Penrose . . . 10
2.4 Matrizes de Projec¸c˜ao Ortogonal . . . 11
2.5 Produto de Kronecker entre Matrizes . . . 12
2.6 Vector M´edio, Matriz de Covariˆancia e Matriz de Covariˆancia Cruzada 14 2.7 Estat´ısticas Suficientes, Completas e Estimadores UMVUE . . . 16
2.8 Testes de Hip´oteses . . . 20
2.9 Vectores Normais e Testes F . . . 23
2.10 Modelos de Regress˜ao M´ultipla . . . 26
2.10.1 Introdu¸c˜ao . . . 26
2.10.2 Estima¸c˜ao dos Coeficientes da Regress˜ao . . . 29
2.10.3 Testes de Hip´oteses para Modelos de Regress˜ao M´ultipla . . . 34
2.11 Modelos Log-Lineares e Tabelas de Contingˆencia . . . 38
3. ´Algebras de Jordan Comutativas . . . 43
3.1 Primeiros Resultados . . . 43
3.2 Gera¸c˜ao de ´Algebras de Jordan Comutativas . . . 48
3.3 Opera¸c˜oes Bin´arias . . . 52
4. Modelos Lineares Ortogonais . . . 55
4.1 Modelos Associados a uma ´Algebra de Jordan Comutativa . . . 55
4.2 Estimadores UMVUE . . . 60
4.3 Inferˆencia para o Modelo de Efeitos Fixos . . . 61
4.4 Vectores Estim´aveis e Testes F para os Efeitos Fixos . . . 64
4.5 Constru¸c˜ao de Modelos . . . 65
4.5.1 Modelos para Encaixe . . . 65
4.5.2 Modelos para Cruzamento-Encaixe . . . 68
5. Fam´ılias Estruturadas de Modelos: Caso Equilibrado . . . 71
5.1 Generalidades . . . 71
5.2 Modelo Base . . . 72
5.3 Modelos Elementares . . . 74
5.3.1 Regress˜oes M´ultiplas . . . 75
5.3.2 Modelos Log-Lineares . . . 79
6. Modelos L-Ortogonais para Efeitos Fixos . . . 85
6.1 Projec¸c˜oes e Estat´ısticas . . . 85
6.2 Inferˆencia . . . 87
6.3 Um Primeiro Exemplo . . . 91
6.4.1 Estrutura . . . 94
6.4.2 Inferˆencia . . . 97
7. An´alise de Transi¸c˜oes entre Classes de Seca utilizando Fam´ılias Estruturadas de Modelos Log-lineares . . . 101
7.1 Introdu¸c˜ao . . . 101
7.2 Dados . . . 102
7.3 Ajustamento de Modelos Log-lineares com Duas Dimens˜oes . . . 103
7.4 An´alise . . . 105
7.5 Resultados e Conclus˜oes . . . 111
8. An´alise de Diferen¸cas Significativas ao N´ıvel das Ocorrˆencias de Seca no Sul de Portugal . . . 115
8.1 Introdu¸c˜ao . . . 115
8.2 Dados . . . 115
8.3 An´alise da Homogeneidade . . . 117
8.4 Modelo Base “Two-Way” . . . 119
8.5 Resultados e Conclus˜oes . . . 121
9. Modela¸c˜ao Regressional da Remo¸c˜ao Electrodial´ıtica de Metais Pesados de Res´ıduos de Madeira . . . 127
9.1 Introdu¸c˜ao . . . 127
9.2 Experiˆencias e Dados . . . 127
9.3 Modela¸c˜ao da Evolu¸c˜ao Temporal das Concentra¸c˜oes de Cu, Cr e As nos Electr´olitos . . . 130
9.3.1 An´alise Regressional . . . 133
10. Conclus˜oes e Trabalho Futuro . . . 143
Apˆendice 153
A. Tabelas Anexas ao Capitulo 7 . . . 155
B. Tabelas Anexas ao Capitulo 8 . . . 159
2.1 Tabela de contingˆencia com 2 dimens˜oes . . . 41
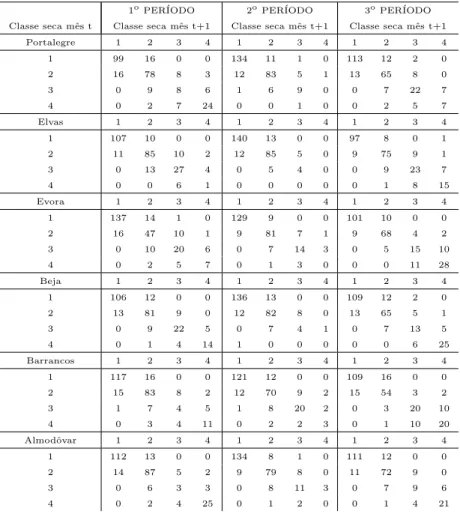
7.1 Classifica¸c˜ao das classes de seca segundo o SPI . . . 102
7.2 Tabelas de contingˆencia com duas dimens˜oes: frequˆencias observadas para Portalegre, Elvas, ´Evora, Beja, Barrancos e Almodˆovar . . . 103
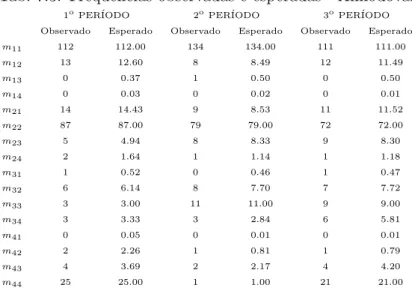
7.3 Frequˆencias observadas e esperadas - Almodˆovar . . . 106
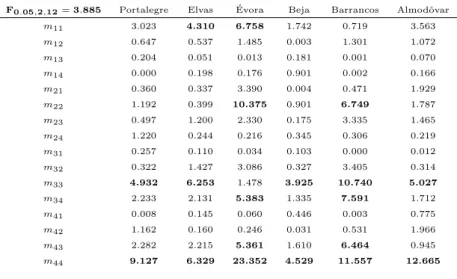
7.4 Resultado das compara¸c˜oes m´ultiplas de Scheff´e para Almodˆovar . . . 111
7.5 Valores da estat´ısticaF para Portalegre, Elvas, ´Evora, Beja, Barran-cos e Almodˆovar . . . 112
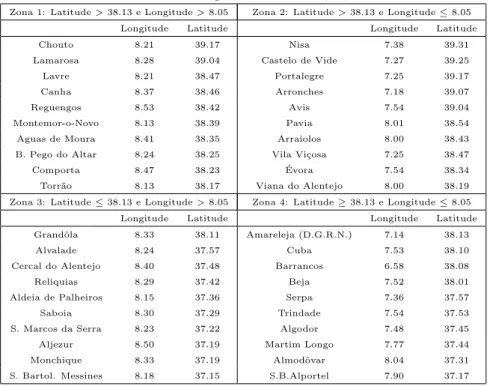
8.1 Defini¸c˜ao das zonas 1, 2, 3 e 4 . . . 116
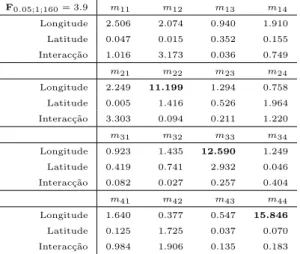
8.2 Valores das estat´ısticasF(h) para as diferentes frequˆencias esperadas do n´umero de transi¸c˜oes entre classes de seca . . . 124
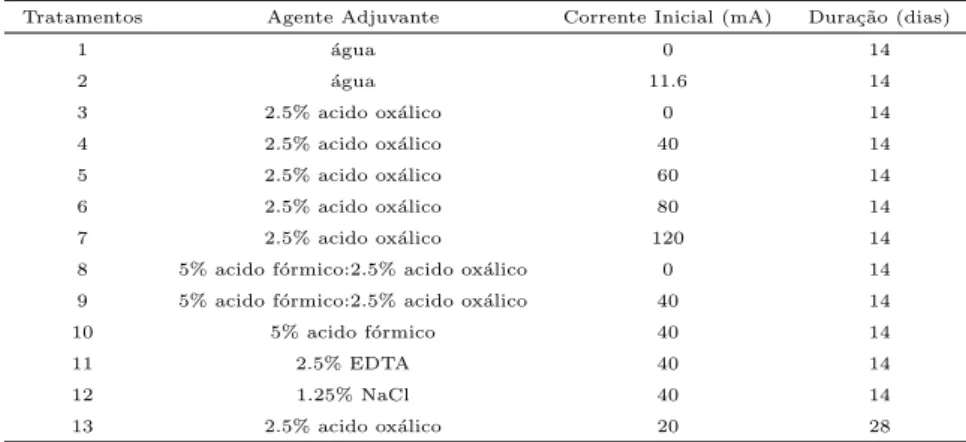
9.1 Tratamentos (condi¸c˜oes experimentais) . . . 129
9.2 Estimadores dos coeficientes das regress˜oes para o Cobre, Cr´omio e Ars´enio . . . 133
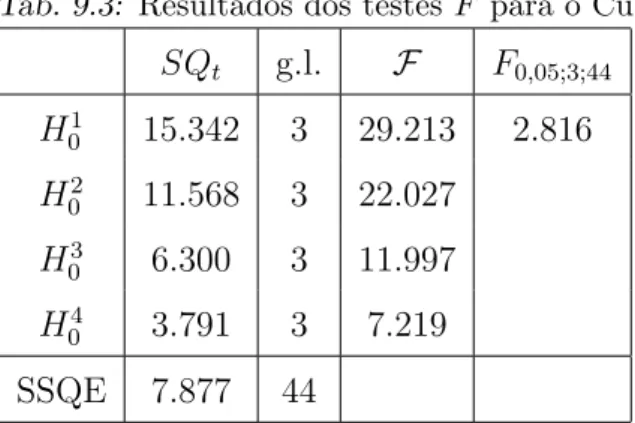
9.3 Resultados dos testes F para o Cu . . . 136
9.4 Resultados do m´etodo de Scheff´e para o Cu . . . 137
9.5 Resultados dos testes F para o Cr . . . 138
9.6 Resultados do m´etodo de Scheff´e para o Cr . . . 138
9.8 Resultados do m´etodo de Scheff´e para o As . . . 140
9.9 Resultados do m´etodo de Boferroni para o As . . . 140
A.1 Valores para os estimadores dos parˆametros dos modelos de
quasi-associa¸c˜ao ajustados `as tabelas de contingˆencia e respectivos desvios
residuais das 6 esta¸c˜oes. . . 156
A.2 Resultado das compara¸c˜oes m´ultiplas de Scheff´e para Portalegre,
El-vas, ´Evora . . . 157
A.3 Resultado das compara¸c˜oes m´ultiplas de Scheff´e para Beja, Barrancos
e Almodˆovar . . . 158
B.1 Tabelas de contingˆencia para zona 1 e 2 . . . 160
B.2 Tabelas de contingˆencia para zona 3 e 4 . . . 161
B.3 Estimadores dos parˆametros dos modelos de quasi-associa¸c˜ao
ajusta-dos `as tabelas de contingˆencia e respectivos desvios residuais das 40
esta¸c˜oes. . . 162
As combina¸c˜oes de n´ıveis dos factores que intervˆem num modelo correspondem aos
tratamentos. Uma fam´ılia de modelos ´e estruturada quando os respectivos modelos
correspondem aos tratamentos doutro modelo. Diz-se que este ´ultimo ´e o modelo
base para o destingir dos modelos constituintes da fam´ılia estruturada, modelos esses
designados de modelos elementares.
No que diz respeito `a teoria desenvolvida nesta disserta¸c˜ao ir´a considerar-se o
caso em que:
1. O modelo base ´e de efeitos fixos com cruzamento-encaixe completo e
equili-brado de 2 ou mais factores e est´a associado a uma ´algebra de Jordan
comu-tativa A, e
2. Os modelos elementares podem corresponder a regress˜oes lineares nas mesmas
vari´aveis ou a modelos log-lineares ajustados a tabelas de contingˆencia.
As fam´ılias estruturadas de modelos correspondem a uma formaliza¸c˜ao dos modelos
regressionais m´ultiplos introduzidos em Mexia (1987). Desde ent˜ao, alguns
desen-volvimentos particulares e aplica¸c˜oes tˆem sido efectuados, nomeadamente na tese de
Moreira (2004) onde foram contempladas as situa¸c˜oes de multicolinariedade e
hete-rocedasticidade dos modelos de regress˜ao m´ultipla para um modelo base de efeitos
fixos com 1 factor e correspondente aplica¸c˜ao `a remo¸c˜ao electrodial´ıtica de metais
dos delineamentos regressionais m´ultiplos quando o delineamento base ´e de
quadra-dos latinos, blocos casualizaquadra-dos e planos completos, respectivamente. Tamb´em foi
extendida a teoria delineamentos regressionais ao caso em que o modelo base ´e um
plano factorial de base 2 em Domingues (1997) e factorial de base prima em Oliveira
(2005).
No tratamento de fam´ılias estruturadas de modelos tender´a a seguir-se uma
es-trat´egia que agora ir´a procurar pˆor-se em evidˆencia. Assim, numa primeira fase,
come¸car-se-´a por condensar a informa¸c˜ao contida nos vectores de observa¸c˜oes
cor-respondentes aos modelos elementares nas respectivas estat´ısticas suficientes e numa
segunda fase aplicar-se-ao os algoritmos desenvolvidos para o modelo base aos
re-sultados obtidos na primeira fase.
Em primeiro lugar, admite-se que os modelos elementares s˜ao indexados por
i = 1, ..., c, tˆem vectores de observa¸c˜ao yi e vectores de parˆametros relevantes φi, com co n´umero de tratamentos do modelo base.
Concretize-se para o caso dos modelos regressionais m´ultiplos. Neste caso, φi
ser´a composto pelo vector dos coeficientes da regress˜aoβie pela variˆanciaσ2
i. Muitas vezes admite-se a homocedasticidade, i.e., σ2
i = σ2, i = 1, ..., c, ou seja a variˆancia do erro n˜ao varia de modelo elementar para modelo elementar. Quando se tem
yi ∼N Xˇiβi, σ2Ini
onde Xˇi ´e a matriz do modelo regressional do tipo ni×k, as estat´ısticas suficientes ser˜ao
˜
βi = XˇTi Xˇi + ˇ
XTi yi, i= 1, ..., c e
SQEi =yTi yi −yTi Xˇiβ˜i, i= 1, ..., c
caso regular, para o qual se admite Xˇi =Xˇ, i= 1, ..., c e sup˜oe-se que Xˇ ´e do tipo
n×(k+ 1) com vectores coluna linearmente independentes. Tem-se ent˜ao,
˜
βi = XˇTXˇ−1XTyi ∼N βi, σ2(XˇTXˇ)−1
independente de
SQEi =yiTyi−yTi Xˇβ˜i ∼σ2χ2n−k−1. Os pares β˜i, SQEi
, i = 1, ..., c conter˜ao toda a informa¸c˜ao transportada pelos vectores das observa¸c˜oes.
Nos modelos regressionais m´ultiplos est´a-se interessado em coeficientes
individu-ais da regress˜ao, ou nas suas combina¸c˜oes lineares. Sendoao vector dos coeficientes duma combina¸c˜ao linear, faz-se
ˇ
yi =aTβ˜i e
SSQE = c X
i=1
SQEi ∼σ2χ2g′
comg′ =c(n−k−1). Al´em disso vemE(ˇy
i) = aTβi = ˇµi eV(ˇyi) =σ2aT(XˇTXˇ)−1a. Ordenem-se os tratamentos do modelo base mediante os ´ındices i =i(j) = 1, ..., c. Seja ˇyo vector cujas componentes s˜ao os valores ˇyi reordenados pelos ´ındicesi. Este vector ser´a normal e ir´a constituir para o modelo base, o vector de observa¸c˜oes para
o qual vem
E(ˇyi) = ˇµ
com ˇµ o vector cujas componentes s˜ao as combina¸c˜oes lineares ˇµi, com ´ındices
i= 1, ..., c, dosβi. Aplicando o algoritmo correspondente ao modelo base a ˇy pode-se estudar a influˆencia dos factores do modelo bapode-se nos valores das combina¸c˜oes
No que diz respeito `a estrutura da disserta¸c˜ao que segue, come¸ca-se por
apresen-tar resultados preliminares de forma a ter-se uma disserta¸c˜ao auto-suficiente. Estes
resultados ser˜ao de natureza alg´ebrica e de natureza estat´ıstica. Os resultados de
natureza alg´ebrica referir-se-˜ao principalmente `as ´algebras de Jordan comutativas e
opera¸c˜oes bin´arias sobre ´algebras de Jordan. Estas ´algebras s˜ao espa¸cos vectoriais
constitu´ıdos por matrizes sim´etricas que comutam e que cont´em os quadrados das
respectivas matrizes sim´etricas. As mesmas s˜ao utilizadas para estudar modelos
normais ortogonais [5], [7] e [2].
Os resultados mais importantes de natureza estat´ıstica referir-se-˜ao a estat´ısticas
suficientes e completas, estimadores UMVUE, testes de hip´oteses, vectores normais
e ao tratamento das regress˜oes lineares e modelos log-lineares.
Segue-se o tratamento de modelos ortogonais associados a ´algebras de Jordan
comutativas, come¸cando pelo caso usual
y= w X
j=1
Xjαj+e
com os αj, j = 1, ..., m vectores fixos, os αj, j =m+ 1, ..., w e e vectores normais independentes com valores m´edios nulos e matrizes de covariˆancia σ2
jIcj, j = m+
1, ..., weσ2I
nrespectivamente. Como adiante ser´a visto, admitida a normalidade do modelo, consegue-se obter estat´ısticas suficientes e completas que permitem obter
estimadores UMVUE podendo-se, em seguida, estudar-se a inferˆencia para os para
modelos de efeitos fixos. No seguimento constro˜em-se os modelos para o
cruzamento-encaixe de factores.
Com vista a conjugar a teoria dos modelos regressionais m´ultiplos com os
mo-delos ortogonais associados a ´algebras de Jordan comutativas, deparou-se com a
do caso n˜ao equilibrado, relativo aos modelos regressionais m´ultiplos, com modelo
base de efeitos fixos, caso esse em que as matrizes Xˇj poder˜ao n˜ao ser iguais para todos os tratamentos.
Para pˆor em evidˆencia a versatilidade e potˆencia das t´ecnicas desenvolvidas
apresentam-se aplica¸c˜oes a duas situa¸c˜oes bem distintas:
• An´alise de transi¸c˜oes entre classes de seca na hidrologia, e
• Experiˆencias de remo¸c˜ao electrodial´ıtica de metais pesados na remedia¸c˜ao am-biental.
Na primeira e segunda aplica¸c˜oes os modelos elementares s˜ao log-lineares e na
2.1
Matrizes Ortogonais Estandardizadas, Diagonalizadoras
Ortogonais e Matrizes Uniformizadoras
Dado um n´umero inteiro s considerem-se as matrizes ortogonais
Ps =
1 √
s1 sT
...
Ts
em queTs´e uma sub-matriz dePsconstitu´ıda pelas linhas dePsmenos a primeira. As linhas de Ts s˜ao vectores de contrastes mutuamente ortogonais de norma um. Vectores de contrastes s˜ao vectores cujas componentes s˜ao os coeficientes duma
combina¸c˜ao linear sendo a soma das componentes desse vector nula. As matrizesPs assim definidas s˜ao chamadas ortogonais estandardizadas. Estas matrizes s˜ao muito utilizadas para analisar a ac¸c˜ao de factores com n´ıveis quantitativos [18].
Sendo A uma matriz sim´etrica de ordem k, existem matrizes ortogonais P de ordemk tais que
PAPT =D(r1, r2, ..., rk)
ser˜ao vectores pr´oprios ortonormados de A associados aos valores pr´oprios com o mesmo ´ındice [35].
Se A for definida positiva ter-se-´a rj >0, j = 1, ..., k, estando definida a matriz G0 =D(r−11/2, r−
1/2 2 , ..., r−
1/2 k )P que ´e solu¸c˜ao da equa¸c˜ao matricial
MAMT =Ik.
As solu¸c˜oes desta equa¸c˜ao ser˜ao as matrizesuniformizadoras de A, representando-se a respectiva familia por U(A). Em particular G0 ser´a a uniformizadora directa deA.
Mostra-se que, ver [14],
• G∈ U(A)⇐⇒A−1 =GTG
• seG∈ U(A) com M regular tem-se GM−1 ∈ U(MAMT);
• seG∈ U(A), G′ ∈ U(A) se e s´o se G′G−1 for uma matriz ortogonal. Assim, G∈ U(A) se e s´o se G=PG0, com P ortogonal.
Tendo as matrizes sim´etricas que comutam especial interesse nesta disserta¸c˜ao,
apresenta-se o seguinte resultado
Proposi¸c˜ao 2.1.1. SejamA1, ...,Am matrizes k×k sim´etricas. Ent˜ao existe uma matriz ortogonal P tal que para cada i, PTA
iP = Di ´e uma matriz diagonal cu-jos elementos principais s˜ao os valores pr´oprios de Ai se e s´o se AiAj = AjAi para todos os pares (i, j), i, j = 1, ..., m, isto ´e, se e s´o se as matrizes A1, ...,Am comutarem.
2.2
Sub-Espa¸cos e ´
Algegras
SendoVum sub-espa¸co vectorial pr´oprio do espa¸coW ⊆Rn, o conjunto dos vectores de W ortogonais a todos os vectores de V constituem um sub-espa¸co denominado complemento ortogonal de V relativamente a W. Sendo V⊥/W o complemento ortogonal deV relativamente a W, todo o vector de W ser´a a soma dum vector de V com um vector de V⊥/W, sendo W a soma directa ortogonal de V com V⊥/W, visto essa decomposi¸c˜ao ser ´unica. QuandoW =Rkpˆor-se-´aV⊥/W =V⊥, tendo-se (V⊥)⊥ =V.
Recorde-se que um sub-espa¸co W ⊆ Rn ´e a soma directa dos sub-espa¸cos V1 e V2 se todo o vector v ∈ W tiver uma decomposi¸c˜ao ´unica v = v1 +v2 com vj ∈ Vj, j = 1,2. Se todo o vector de V1 for ortogonal a todo o vector de V2, ent˜ao V1 e V2 ser˜ao sub-espa¸cos ortogonais cuja soma directa ortogonal ser´a W. vj ser´a a projec¸c˜ao ortogonal dev sobre Vj, j = 1,2.
Segundo Seber(1980), dada a matrizAdo tipon×k, o seusub-espa¸co imagem ser´a
R(A) ={v:v=Au} enquanto que o seusub-espa¸co nulidade ser´a
N(A) = {u:Au=0} tendo-se
R(AT) =N(A)⊥.
Recorde-se agora tamb´em a defini¸c˜ao de ´algebra. Uma ´algebra A ´e um espa¸co linear equipado com uma opera¸c˜ao bin´aria∗, usualmente chamada deproduto, para o qual as propriedades seguintes se verificam para todos osα∈R e a,b,c∈ A:
• (a+b)∗c=a∗c+b∗c; • α(a∗b) = (αa)∗b=a∗(αb).
Al´em do mais, uma ´algebra A ´eassociativase e s´o se, para todos os a,b,c∈ A, (a∗b)∗c=a∗(b∗c)
e ´ecomutativa se e s´o se, para todos os a,b∈ A, a∗b =b∗a.
Sublinhe-se que as propriedades associativa e comutativa n˜ao s˜ao necess´arias para
que um espa¸co linear seja uma ´algebra.
2.3
Matrizes Inversas Generalizadas de Moore-Penrose
Qualquer que seja a matriz A existe uma e uma s´o matriz A+ tal que, ver [30], 1)AA+A=A
2)A+AA+=A+ 3) AA+T =AA+ 4) A+AT =A+A
.
A matriz A+ denomina-se a inversa de Moore-Penrose de A. Se A for regular A+=A−1. Por outro lado, sendo A sim´etrica k×k com Car(A) = l < k, pode-se sempre ordenar os vectores linha de uma matrizP diagonalizadora ortogonal de A de forma a ter-se
PAPT =D(r1, r2, ..., rl,0, ...,0) com r1, r2, ..., rl os valores pr´oprios n˜ao nulos de A, tendo-se
e
A+=PTD(r−1
1 , ..., r−l 1,0, ...,0)P.
2.4
Matrizes de Projec¸c˜
ao Ortogonal
DadoW um espa¸co vectorial soma directa ortogonal dos sub-espa¸cosV1eV2, definiu-se atr´as a projec¸c˜ao ortogonalvVj de v∈ W sobreVj, j = 1,2. Ter-se-´a ainda
vVj =Q(Vj)v, j = 1,2
com Q(Vj) a matriz de projec¸c˜ao ortogonal sobre Vj, j = 1,2. Verifica-se facilmente que
Q(V⊥) = I
n−Q(V) vindo
vV⊥ =v−vV = (I−Q(V))v.
Recorde-se ainda que Q ´e matriz de projec¸c˜ao ortogonal se e s´o se for idempotente e sim´etrica.
De seguida ir˜ao ser recordados alguns resultados bem conhecidos sobre matrizes
de projec¸c˜ao ortogonal [14].
Proposi¸c˜ao 2.4.1. Dada a matriz X do tipo n×k e tomando-se Ω = R(X)
ℵ=R(XT) as matrizes de projec¸c˜ao ortogonal sobre Ω e ℵ ser˜ao
Q(Ω) =X(XTX)+XT Q(ℵ) = (XTX)+(XTX)
Proposi¸c˜ao 2.4.2. Para v∈Ω tem-se
Q(Ω)v=v Q(Ω⊥)v=0.
Proposi¸c˜ao 2.4.3. Dado um vector v, o vector u ∈ Ω que minimiza kv−uk2 ´e vΩ.
Proposi¸c˜ao 2.4.4. Fazendo v = (XTX)+XTz com z um vector arbitr´ario tem-se zΩ =Xv, ou seja zΩ ∈R(X).
2.5
Produto de Kronecker entre Matrizes
Dadas as matrizes A= [ai,j] do tipom×n eBdo tipop×q, o respectivoproduto de Kronecker´e dado pela matriz por blocos de ordem mp×nq
A⊗B =
a11B a12B · · · a1nB
a21B a22B · · · a2nB · · · ·
am1B am2B · · · amnB
. (2.1)
Verifica-se facilmente que, estando definidos os produtos usuais A1A2 e B1B2, se tem
(A1⊗B1)(A2⊗B2) = (A1A2)⊗(B1B2) (2.2)
(A⊗B)T =AT ⊗BT.
tem-se
1u⊗1v =1uv Iu⊗Iv =Iuv Ju⊗Jv =Juv
vendo-se ainda que o produto⊗de matrizes ortogonais, ortogonais estandardizadas, sim´etricas, idempotentes d´a respectivamente matrizes ortogonais, ortogonais
estan-dardizadas, sim´etricas, idempotentes. Daqui resulta que o produto ⊗ de matrizes de projec¸c˜ao ortogonal d´a matrizes de projec¸c˜ao ortogonal.
SendoD(γ1) e D(γ2) matrizes diagonais cujos elementos principais s˜ao as
com-ponentes do vectores γ1 e γ2 respectivamente, tem-se
D(γ1)⊗D(γ2) =D(γ1⊗γ2). (2.3) Dadas as matrizes sim´etricas M1 e M2, existem matrizes ortogonais P1 e P2 e matrizes diagonaisD(γ1) e D(γ2) tais que
PjMjPTj =D(γj), j = 1,2.
Os elementos principais deD(γj), j = 1,2 s˜ao os valores pr´oprios deMj correspondendo-lhes, como vectores pr´oprios, os vectores linha dePj, j = 1,2 (sec¸c˜ao 2.1). Ter-se-´a ent˜ao, atendendo a (2.2) e a (2.3):
(P1⊗P2) (M1⊗M2) (P1⊗P2)T = P1M1PT1
⊗ P2M2PT2
=D(γ1⊗γ2) (2.4)
pelo que os valores pr´oprios de M1 ⊗M2 ser˜ao os produtos dos valores pr´oprios de M1 e M2 e os vectores pr´oprios s˜ao os vectores linha de P1 ⊗ P2. Como a caracter´ıstica de uma matriz sim´etrica ´e o n´umero dos seus valores pr´oprios n˜ao
nulos, vˆe-se que
Sendo o determinante deMj, j = 1,2 o produto dos seus valores pr´oprios, o mesmo acontecendo para o determinante de M1⊗M2, ter-se-´a
Det(M1 ⊗M2) =Det(M1)Det(M2). (2.6) Por outro lado, ver [38], para qualquer matriz Vj tem-se
Car(Vj) =Car(VjVTj), j = 1,2 e como
(V1⊗V2) (V1⊗V2)T = V1VT1
⊗ V2VT2
ter-se-´a
Car(V1⊗V2) = 2 Y
j=1
Car VjVTj
= 2 Y
j=1
Car(Vj). (2.7) ´
E ainda f´acil de verificar que, ver [38],
m X
i=1
aiVi !
⊗ n X
j=1
bjUj !
= m X
i=1 n X
j=1
aibj(Vi ⊗Uj) (2.8)
e utilizando (2.2), tem-se
(V1⊗V2)+ =V+1 ⊗V+2. (2.9) Em particular se V1 e V2 forem regulares tem-se tamb´em
(V1⊗V2)−1 =V1−1⊗V−21. (2.10)
2.6
Vector M´
edio, Matriz de Covariˆ
ancia e Matriz de Covariˆ
ancia
Cruzada
Um vector aleat´orio ser´a um vector cujas componentes s˜ao vari´aveis aleat´orias
en-quanto que uma matriz aleat´oria ser´a uma matriz cujos elementos s˜ao vari´aveis
Dado um vector aleat´orio X= X1 ... Xn
ovector m´edio de X ter´a como componentes os valores m´edios das componentes deX, assim
E(X) =
E(X1) ...
E(Xn)
quando estes valores m´edios est˜ao definidos. Analogamente os elementos da matriz
m´edia de uma matriz aleat´oria ser˜ao os valores m´edios, supostos definidos, dos
elementos da matriz aleat´oria. Em particular a matriz da covariˆancia do vector aleat´orio X ser´a
COV(X) = Eh(X−E(X)) (X−E(X))Ti =
V (X1) . . . COV (X1, Xn)
... . .. ...
COV(Xn, X1) · · · V (Xn)
supondo-se as variˆancias V(Xj), j = 1, ..., n e as covariˆancias COV(Xj, Xi), j, i = 1, ...n, j 6=i todas definidas. Uma matriz de covariˆancia ´e sempre sim´etrica.
Dado o par (X;Y) de vectores aleat´orios de ordem n e m respectivamente, a respectiva matriz de covariˆancia cruzada ser´a
COV(X;Y) = Eh(X−E(X)) (Y−E(Y))Ti =
COV (X1, Y1) . . . COV (X1, Ym)
... . .. ...
COV(Xn, Y1) · · · COV (Xn, Ym) .
Utilizando a linearidade do operador E mostra-se facilmente que
• E(AX+a) =AE(X) +a
• COV(AX+a) = ACOV(X)AT
• COV(AX+a;BX+b) =ACOV(X)BT
• COV(AX+a;BY+b) =ACOV(X;Y)BT
onde AeB s˜ao matrizes do tipor×n es×m, respectivamente eae bvectores de ordem r e s respectivamente. Al´em disso, como
X+Y = [I:I] X
Y
e COV(X,Y) ´e a matriz nula quando X e Y s˜ao independentes, pode-se mostrar ent˜ao que
COV(X+Y) = COV(X) +COV(Y).
2.7
Estat´ısticas Suficientes, Completas e Estimadores UMVUE
Represente-se porEn o espa¸co amostral constitu´ıdo por todas as amostras poss´ıveis de dimens˜ao n. Seja x uma amostra de dimens˜ao n que ser´a vista como uma realiza¸c˜ao vector aleat´orioX, tendo-se Pr(X ∈ En) = 1. As probabilidade associadas a X podem ser determinadas pela respectiva distribui¸c˜ao F(x|θ) = Pr(X ≤ x|θ), com θ um parˆametro a variar no espa¸co param´etrico Ω. A fun¸c˜ao densidade de
Dada uma parti¸c˜ao de En em conjuntos Ci, disjuntos dois a dois, atendendo ao teorema da probabilidade total, tem-se
F(x|θ) =X i
Pr(X∈ Ci|θ) Pr(X6x|X ∈ Ci,θ) = X
i
Pr(X∈ Ci|θ)F(x|Ci,θ) (2.11)
com
F(x|Ci,θ) = Pr(X6x|X∈ Ci, θ).
Uma parti¸c˜ao diz-sesuficientequando as distribui¸c˜oes condicionais n˜ao dependem deθ, tendo-se
F(x|θ) = X i
Pr(X∈ Ci|θ)F(x|Ci). (2.12)
Uma estat´ıstica T(x) ser´a uma qualquer fun¸c˜ao escalar ou vectorial definida no espa¸co amostral. As imagens inversas dadas porT(x) constituem uma parti¸c˜ao deEn. Se a parti¸c˜ao induzida por uma estat´ıstica for suficiente, ent˜ao a estat´ıstica ser´a suficiente. Por outras palavras, T(x) ser suficiente significa que T(x) contem toda a informa¸c˜ao acerca de θ que est´a contida na amostra, podendo proporcionar
uma redu¸c˜ao de dados sem perda de informa¸c˜ao.
Um importante crit´erio de suficiˆencia ´e dado pela
Proposi¸c˜ao 2.7.1. Teorema da Factoriza¸c˜ao
A estat´ıstica T(x) ´e suficiente se e s´o se existirem fun¸c˜oes n˜ao negativas g e h tal que
f(x|θ) =g(T(x)|θ)h(x) onde h(x) n˜ao depende de θ.
A seguir apresenta-se a demonstra¸c˜ao para o caso discreto, no entanto a tese
Demonstra¸c˜ao. Admita-se que se verifica a factoriza¸c˜ao. QuandoT(x) =t, ter-se-´a Pr(T(x) = t|θ) = X
x∈T−1(t)
f(x|θ) = X
x∈T−1(t)
g(T(x)|θ)h(x) =g(t|θ) X
x∈T−1(t)
h(x)
vindo para x∈T−1(t)
Pr(X=x|T=t,θ) = P r[(X=x)∩(T=t)|θ] Pr(T=t|θ) =
Pr(X=x|θ) Pr(T=t|θ) = g(t|θ)h(x)
g(t|θ) P
x′∈T−1(t′)
h(x′) =
h(x) P
x′∈T−1(t′)
h(x′)
o que mostra que as distribui¸c˜oes condicionais n˜ao dependem de θ, pelo que a
estat´ıstica ser´a suficiente.
Inversamente, por um lado igualmente se tem
Pr(X=x|T=t,θ) = Pr(X=x|θ) Pr(T=t|θ) =
f(x|θ) Pr(T=t|θ) e por outro
Pr(X=x|T=t,θ) =h(x)
onde h(x) n˜ao depende de θ por T(x) ser suficiente. Basta pois fazer g(t|θ) = Pr(T=t|θ) para concluir que se tem a factoriza¸c˜ao.
Por outro lado, se para uma qualquer fun¸c˜ao g deT se tiver
E(g(T)|θ) = 0, ∀θ ∈Ω =⇒ Pr (g(T) = 0|θ) = 1, ∀θ ∈Ω,
T(x) ser´a uma estat´ıstica completa. Tem-se ainda
Proposi¸c˜ao 2.7.2. Se X tem distribui¸c˜ao pertencente `a familia exponencial de dimens˜ao s ou seja se
f(x|θ) = b(θ)h(x) exp s X
i=1
ondeb e li s˜ao fun¸c˜oes do parˆametroθ e Ti s˜ao estat´ısticas e al´em disso se um pro-duto cartesiano de intervalos n˜ao degenerados estiver contido no espa¸co param´etrico Ω, a estat´ıstica T(x) = [T1(x)...Ts(x)] ser´a suficiente e completa.
Demonstra¸c˜ao. Ver [13], [12] e [38].
Um estimador dum parˆametro ser´a uma estat´ıstica cujos valores s˜ao “apro-xima¸c˜oes” aos verdadeiros valores do parˆametro. Entre as propriedades
convenien-tes que um estimador pode ter est´a serUMVUE(estimador centrado de variˆancia uniformemente m´ınima). Diz-se que ˜g(X) ´e UMVUEdeg(θ) se for centrado, i.e.
E(˜g(X)) =g(θ)
e se para todoθ se tem
V(˜g(X)|θ)≤V(ˆg(X)|θ) onde ˆg(X) ´e qualquer outro estimador centrado deg(θ).
Como se ir´a ver, as estat´ısticas suficientes e completas s˜ao ´uteis para se obter
UMVUE’s. Com efeito tem-se o
Proposi¸c˜ao 2.7.3. Teorema de Rao-Blackwell
Seja g uma fun¸c˜ao convexa e gˆ um estimador centrado de g(θ). Dada a estat´ıstica suficiente T(x)
• g˜(t) = E(ˆg(X)|T(x) = t) ´e fun¸c˜ao da estat´ıstica suficienteT(x) =t mas n˜ao ´e fun¸c˜ao de θ;
• g˜(T(x))´e um estimador centrado de g(θ); • V(˜g|θ)≤V(ˆg|θ) para todo o θ.
e o
Proposi¸c˜ao 2.7.4. Teorema de Blackwell-Lehmann-Scheff´e
Se T for uma estat´ıstica suficiente e completa e existir um estimador centrado ˆg
para g(θ), ˜g(t) =E(ˆg(X)|T(x) = t) ser´a estimador UMVUE de g(θ).
Demonstra¸c˜ao. Atendendo ao teorema de Rao-Blackwell, sabe-se que ˜g ´e estimador centrado de g e a variˆancia deste nunca excede a variˆancia de ˆg. Supondo agora que existia um outro estimador centrado ˇg parag, devido mais uma vez ao teorema Rao-Blackwell, sabe-se que ˇ˜g(t) = E(ˇg(X)|T =t) ´e fun¸c˜ao de t mas n˜ao de g(θ), sendo estimador centrado de g e V(ˇ˜g|θ)≤V(ˇg|θ).
Como T´e estat´ıstica suficiente e completa e g(t) se ˜g(t) s˜ao fun¸c˜oes de tcom o mesmo valor m´edio, qualquer que seja θ, ter-se-´a Pr(˜g(T) = ˇg(T)|θ) = 1, qualquer que sejaθ, o que estabelece a tese.
2.8
Testes de Hip´
oteses
Atrav´es de um teste de hip´oteses, pretende-se, de um modo geral, tomar uma decis˜ao
ou fazer uma escolha de entre duas hip´oteses alternativas, baseada na informa¸c˜ao
conhecida. Nesta sec¸c˜ao apenas ser˜ao abordados os testes de hip´oteses param´etricos,
para os quais a decis˜ao ´e feita relativamente a um parˆametro desconhecido θ
per-tencente a um conjunto conhecido Θ em que
θ ∈Θ0∨θ ∈Θ1, com Θ0,Θ1 ⊂Θ e Θ0∩Θ1 =∅.
Portanto, a escolha ser´a feita de entre a hip´otese
H0 :θ ∈Θ0
designada de hip´otese nula a outra hip´otese poss´ıvel
designada de hip´otese alternativa.
Considere-se uma amostraX = [X1, ..., Xn]T de vari´aveis aleat´orias independen-tes e identicamente distribu´ıdas, pertencenindependen-tes a uma classe de densidades
F={fθ(.) :θ∈Θ}.
Os testes de hip´oteses s˜ao regras criadas para tomar uma decis˜ao e aos quais est˜ao
associados um risco e uma perda.
Defina-se φ(x) a regra de decis˜ao, que tomar´a o valor 0 se a H0 for aceite e o valor 1 se esta for rejeitada em favor deH1.
Em qualquer processo de decis˜ao existem associados erros. Nos testes de hip´oteses
em que existe hip´otese nula e alternativa existem 2 tipos de erro:
1. Erro tipo I: Probabilidade de rejeitar H0 quandoH0 ´e verdadeira; 2. Erro tipo II: Probabilidade de aceitar H0 quando H1 ´e verdadeira.
Associado a um teste de hip´oteses existe tamb´em uma regi˜ao de aceita¸c˜ao
R0 ={x:φ(x) = 0} e umaregi˜ao cr´ıtica
R1 ={x:φ(x) = 1}. O tamanho dum teste ´e dado pelo
sup θ∈Θ
Pr(X∈R1)
o qual representa, de facto, o valor m´aximo que o erro tipo I pode assumir. Nos
testes de hip´oteses a ser utilizados tem-se
sup θ∈Θ
ondeqrepresenta on´ıvel de significˆanciaescolhido para um teste, que usualmente pode assumir os valores 0.1, 0.05 e 0.01. Ao inverso, pode ser obtido o mais pequeno
n´ıvel de significˆancia abaixo do qual a hip´otese nula seria rejeitada. A esse valor
chama-se “p-value”.
A potˆencia dum testepara algum θ ∈Θ1 ´e dada por
P ot= Pr(X∈R1) e a fun¸c˜ao potˆencia de um teste φ por
P otφ(θ) = Pr(X ∈R1),θ∈Θ.
A fun¸c˜ao potˆencia dum teste d´a, em fun¸c˜ao do parˆametro, a probabilidade de se rejeitar a hip´otese nula, ou por outras palavras descreve a eficiˆencia dum teste a
detectar o afastamento dos dados da hip´otese nula.
Nesse sentido, pretende-se pois maximizar a fun¸c˜ao potˆencia. Para tal, tomando
φ(x) =
0, x∈R0 1, x∈R2 h´a que maximizar
P otφ(θ) = E(φ(x)),∀θ ∈Θ1 sujeito `a condi¸c˜ao
E(φ(x))≤q,∀θ∈Θ0.
Quando Θ0 e Θ1 tˆem apenas um elemento, a solu¸c˜ao ´e dada pela
Proposi¸c˜ao 2.8.1. (Lema Fundamental de Neyman-Pearson). Seja Θ0 = θ0 e Θ1 =θ1, ent˜ao existe uma constante c tal que
1. φ(x) =
0, fθ1(x)
fθ0(x)
< c
1, fθ1(x)
fθ0(x)
> c
2. θ =θ0 ⇒E(φ(X)) =q;
eφ ´e o mais potente teste paraH0 :θ =θ0 vs. H1 :θ =θ1 ao n´ıvel de significˆancia
q. Al´em disso, se φ∗ for um teste mais potente ent˜ao se satisfaz 1. tamb´em satisfaz 2. com probabilidade 1.
Demonstra¸c˜ao. Ver [13].
Nos testes de hip´oteses ´e imposs´ıvel escolher a melhor regra de decis˜ao. A solu¸c˜ao
para este problema poder´a ser restringir a classe de regras de decis˜ao de modo que
estas retenham propriedades desej´aveis. Uma dessas propriedades ´e serem testes
n˜ao distorcidos. Um teste φ tal que
P otφ(θ)≤q,∀θ ∈Θ0
P otφ(θ)≥q,∀θ ∈Θ1
diz-sen˜ao distorcido, isto ´e, a potˆencia do teste para θ ∈Θ1 ´e sempre maior que o erro tipo I. Quando P otφ(θ0) = q, a probabilidade de rejeitar H0 quando H1 ´e verdadeira ´e maior que a probabilidade de rejeitar H0 quando H0 ´e verdadeira.
2.9
Vectores Normais e Testes F
DadoY um vector aleat´orio de ordemn a respectiva fun¸c˜ao geradora de momentos ser´a
ϕY(u) =E
euTY
sendo f´acil de se verificar que
ϕAY+b(v) =eb
Tv
Sendo
E(Y) =µ
COV(Y) = M se a fun¸c˜ao geradora de momentos de Y for
ϕY(u) = eµ
Tu+1
2uTMu (2.13)
o vector aleat´orioY, ver [14], ser´a normal escrevendo-se Y ∼N(µ,M).
Utilizando a express˜ao (2.13) ´e f´acil de mostrar que
AY+a∼N(Aµ+a,AMAT).
Dado agora Y ∼ N(µ, σ2I
n), kYk2 ser´a, ver [14], o produto por σ2 dum qui-quadrado com n graus de liberdade e parˆametro de n˜ao centralidade
δ= 1
σ2 kµk 2
escrevendo-se
kYk2 ∼σ2χ2n,δ.
Seja agora S ∼σ2χ2
m independente de Y F = kYk
2
n S/m
ter´a, ver [14], distribui¸c˜ao F com n e m graus de liberdade e parˆametro de n˜ao centralidade δ, escrevendo-se
F ∼Fn,m,δ. Em particular se µ=0, δ = 0, vindo
e portantoF ter´a distribui¸c˜ao F central, escrevendo-se
F ∼Fn,m.
Mais geralmente, ver [14], seY ∼N(µ, σ2M) com Car(M) = l≤n tem-se (Y−b)TM+(Y−b)∼σ2χ2l,δ
com
δ = (µ−b)
TM+(µ−b)
σ2 eb um vector qualquer, e se SQ∼σ2χ2
m for independente deY, ter-se-´a que F = m
l
(Y−b)TM+(Y−b)
SQ ∼Fl,m,δ.
F ser´a a estat´ıstica de um teste de hip´oteses F com l e m graus de liberdade para testar a hip´otese
H0 :µ=b.
Em particular se b=µ ou seja se H0 se verificar, δ= 0, vindo (Y−µ)TM+(Y−µ)∼σ2χ2l
logo
F′ = m
l
(Y−µ)TM+(Y−µ)
SQ ∼Fl,m
ou seja F′ tem distribui¸c˜ao F central com l e m graus de liberdade. Sendo F1−q,l,m o quantil para a probabilidade 1−q deFl,m tem-se
Pr [F′ ≤F
1−q,l,m] = 1−q ou seja, como δ = 0 tem, neste caso, P ot = Pr [F′ > F
1−q,l,m,] = q donde o teste ser´a n˜ao distorcido. Como consequˆencia, as desigualdades
(µ−Y)TM+(µ−Y)≤lF1−q,l,m
definem elips´oides de confian¸ca n´ıvel 1−q paraµ, isto ´e, a probabilidade deµestar coberto pelo elips´oide anterior ´e 1−q, donde o teste F de n´ıvel q n˜ao rejeita a H0 se e s´o se b pertencer ao elips´oide de confian¸ca n´ıvel 1−q atr´as definido. Diz-se, neste caso, que o teste goza de dualidade[15] e [17].
Quando M´e definida positiva, M+ =M−1 tamb´em ´e definida positiva, vindo
δ = (µ−b)
TM−1(µ−b)
σ2 ,
podendo reescrever-se a hip´otese nula como H0 :δ= 0, uma vez que
µ=b⇐⇒δ = 0.
Neste caso, o teste ´e estritamente n˜ao distorcido [14].
2.10
Modelos de Regress˜
ao M´
ultipla
2.10.1 Introdu¸c˜ao
Quando se tem uma vari´avel resposta y que depende de k vari´aveis independentes ou vari´aveis controladas x1, x2, ..., xk, a rela¸c˜ao entre estas vari´aveis ´e caracterizada por um modelo matem´atico, chamado modelo regressional.
O modelo regressional pode ser linear
y=α0+α1x1+α2x2+...+αkxk+ǫ (2.14)
ou n˜ao linear, como por exemplo exponencial, logar´ıtmico, etc. A equa¸c˜ao (2.14)
representa um modelo regressional m´ultiplo linear, dado que se trata duma fun¸c˜ao
vari´aveis controladas xi, i 6= j s˜ao mantidas constantes e ǫ representa a vari´avel aleat´oria erro do modelo, para o qual usualmente se assume ǫ∼N(0, σ2).
Considere-se o caso mais geral, para o qual se disp˜oe de n >(k+ 1) observa¸c˜oes
y1, y2, ..., yn para a vari´avel resposta y. A cada observa¸c˜ao yi corresponde um valor
xij, para a j-´esima vari´avel controlada, j = 0, ..., k,i= 1, ..., n. O modelo regressio-nal multi-linear pode ser ent˜ao escrito em termos de valores observados tomando-se
yi = k X
j=0
αjxij +ǫi, i= 1,2, ..., n; j = 0, ..., k (2.15)
onde os ǫ1, ..., ǫn s˜ao os erros aleat´orios n˜ao correlacionados entre si. A equa¸c˜ao (2.15) pode ser escrita na forma matricial
y=Xα+ǫ (2.16)
onde y= y1 ... yn
representa o vector das observa¸c˜oes,
α= α0 ... αk
´e o vector dos coeficientes da regress˜ao,
o vector dos erros aleat´orios e
X=
1 x11 · · · x1k 1 x21 . . . x2k
... ... 1 xn1 · · · xnk
´e a matriz do modelo do tipon×(k+ 1), isto ´e, a matriz dos valores das vari´aveis controladas, havendo nesta matriz uma coluna por vari´avel controlada.
As vari´aveis controladas poder˜ao estar relacionadas entre si como ,por exemplo,
numa regress˜ao polinomial, onde estas s˜ao potˆencias duma mesma vari´avel base.
Caso exista dependˆencia linear entre as vari´aveis controladas est´a-se perante uma
situa¸c˜ao de multicolinariedade, em que Car(X) ´e inferior ao n´umero de vari´aveis controladas. Considerando a situa¸c˜ao mais geral admitir-se-´a que p = Car(X) ≤
k+ 1.
Como j´a foi referido, ´e usual admitir-se que os erros aleat´orios ǫi, i= 1, ..., n tˆem valor m´edio nulo e variˆancia σ2, sendo tamb´em independentes entre si, donde
COV(ǫ) = σ2In.
Contudo, dado que, na pr´atica, existem situa¸c˜oes de correla¸c˜ao entre os erros, mais
uma vez considerar-se-´a o caso geral em que
COV(ǫ) =σ2C onde Cuma matriz conhecida e regular.
O modelo (2.15) representa um caso particular deste modelo.
Para o modelo em quest˜ao ter-se-´a, portanto, y normal com
E(y) = Xα=µ
COV(y) =σ2C
Perante a ausˆencia de homocedasticidade no modelo, ou seja de igualdade e
independˆencia de variˆancias entre as vari´aveis aleat´orias, h´a que realizar uma
trans-forma¸c˜ao em y, chamada redu¸c˜ao da heterocedasticidade, de forma a obter-se a homocedasticidade.
Com G∈ U(C), tome-se
y′ =Gy X′ =GX
(2.17)
atendendo aos resultados sobre matrizes uniformizadoras, ver [14], obt´em-se
E(y′) =X′α
COV(y′) = GTCOV(y)G=σ2GTCG=σ2I n passando a ter-se o modelo homoced´astico
y′ =X′α+ǫ′. (2.18)
2.10.2 Estima¸c˜ao dos Coeficientes da Regress˜ao
O m´etodo dos m´ınimos quadrados ´e o m´etodo mais usualmente utilizado para a
estima¸c˜ao dos coeficientes da regress˜ao. Este m´etodo consiste na obten¸c˜ao de valores
para os coeficientesαj tais que a soma dos quadrados dos res´ıduos seja minimizada, ou seja, encontra-se o vectorαˆ estimador deα que minimiza
ky′−X′αk2. (2.19)
Para encontrar o vectorαˆ, ir´a ser utilizado um instrumento de ´algebra matricial de grande importˆancia na estat´ıstica, que ´e o de matriz de projec¸c˜ao ortogonal.
Tome-se
e recorde-se que as matrizes de projec¸c˜ao ortogonal sobreℵ e Ω s˜ao, ver sec¸c˜ao 2.4,
Q(Ω) =X′(X′TX′)+X′T Q(ℵ) = (X′TX′)+(X′TX′)
(2.20)
Ora como o vector X′αˆ que minimiza (2.19) ´ey′
Ω =Q(Ω)y′ (proposi¸c˜ao 2.4.3), atendendo `a primeira das express˜oes (2.20) vem
X′αˆ =X′(X′TX′)+X′Ty′
donde
ˆ
α= (X′TX′)+X′Ty′. (2.21) Como y´e normal, αˆ ser´a tamb´em normal com
E(αˆ) = (X′TX′)+X′TE(y′) = (X′TX′)+X′TX′α=Q(ℵ)α=αℵ (2.22) pelo queαˆ n˜ao ´e necessariamente um estimador centrado deα. Contudo, os vectores estim´aveis v˜ao permitir ultrapassar a limita¸c˜ao anterior [14].
Um vector λ = Aα diz-se estim´avel se existir um estimador linear centrado
λ∗ =By deλ.
Tem-se ent˜ao Aα= E(λ∗) = E(By) = BX′α para todo o α, logo A =BX′ e AT =X′TBT. Dondeλ ´e estim´avel se e s´o se os vectores linha deA pertencerem a ℵ.
Observe-se agora que, se c∈ ℵ, tem-se E(cTαˆ) =cTα
ℵ=cTQ(ℵ)α= Q(ℵ)Tc T
α= (Q(ℵ)c)T α=cTα
uma vez que as matrizes de projec¸c˜ao ortogonal s˜ao sim´etricas e a projec¸c˜ao
Por fim, pelo conhecido Teorema de Gauss-Markov, ver [14], os estimadores da formaA ˆαs˜ao BLUE (Estimadores Lineares Centrados ´Optimos) deAαos quais tˆem variˆancia m´ınima quando comparados com outros estimadores lineares centrados
deAα [15].
Atendendo `as propriedades das inversas generalizadas de Moore-Penrose tem-se
ainda
COV(αˆ) = (X′TX′)+X′TCOV(y′)X′(X′TX′)+ = (X′TX′)+X′T(σ2I
n)X′(X′TX′)+
=σ2(X′TX′)+X′TX′(X′TX′)+=σ2(X′TX′)+
(2.23)
portanto, o modelo ajustado ter´a a forma
ˆ
y′ =X′αˆ =y′
Ω. (2.24)
Uma vez ajustado o modelo ´e frequentemente necess´ario estimarσ2, para a qual se tem o estimador centrado
ˆ
σ2 = SQE
n−p (2.25)
em que
SQE =ky′−yˆ′k2
=ky′−y′Ωk2
representa a soma dos quadrados dos res´ıduos. Ora recorde-se que
y′−y′
Ω =y′Ω⊥ = (In−Q(Ω))y′ =Q(Ω⊥)y′
(sec¸c˜ao 2.4) pelo que
SQE =ky′ Ω⊥k
2
=Q(Ω⊥)y′2 =y′TQ(Ω⊥)TQ(Ω⊥)y′ dadoQ(Ω⊥) ser idempotente e sim´etrica, logo
SQE=y′TQ(Ω⊥)y′ =y′T(I
vindo por fim
SQE=y′Ty′−y′TX′αˆ. (2.26) Um resultado importante ´e do Teorema de Fisher, ver [14], o qual estabelece que, quando y´e normal,αˆ ´e independente de SQE e
SQE ∼σ2χ2n−p.
Um outro resultado referente `as matrizes uniformizadoras de C estabelece que GTG=C−1, ver [14], vindo
X′TX′ =XTGTGX=XTC−1X X′Ty′ =XTGTGy=XTC−1y y′TX′ =yTGTGX=yTC−1X y′Ty′ =yTGTGy=yTC−1y obtendo-se para (2.21), (2.23) e (2.26) as express˜oes
ˆ
α= XTC−1X+XTC−1y (2.27)
COV(αˆ) = σ2 XTC−1X+ (2.28)
SQE =yTC−1y
−yTC−1X ˆα (2.29)
donde se conclui que, na realidade, estas express˜oes podem ser calculadas sem haver
necessidade de efectuar a transforma¸c˜ao (2.17), bastando para tal inverter a matriz
C.
De referir que, caso se tenha COV(y) = σ2I
n e n˜ao haja multicolinariedade, tendo-seCar(X) = k+ 1,XTX´e regular, logo (XTX)+ = (XTX)−1 vindo portanto
ˆ
α= (XTX)−1XTy (2.30)
COV(αˆ) = σ2(XTX)−1 (2.32)
SQE =yTy−yTX ˆα (2.33)
ˆ
σ2 = SQE
n−k−1. (2.34)
Uma medida estat´ıstica para o ajustamento do modelo regressional `as observa¸c˜oes
´e dada pelo coeficiente de determina¸c˜ao m´ultipla
R2 = 1− SQE
SQT; 06R
2 61
em queSQT representa soma dos quadrados dos res´ıduos para a m´edia, dada por
SQT = n X
i=1 (y′
i −y¯′) 2
a qual ´e ainda dada por
SQT = n X
i=1
y′2
i −ny¯′2 =y′ T
y′ −ny¯′2 (2.35)
com
¯
y′ = n P i=1
y′2 i
n .
Este coeficiente mede a frac¸c˜ao da varia¸c˜ao total entre observa¸c˜oes da vari´avel
de-pendente que ´e explicada pela regress˜ao. Para atender ao n´umero de vari´aveis
controladas pode substituir-seR2 por
R2adj = 1−
SQE/( n−p)
SQT/( n−1)
(2.36)
de forma a considerar-se menos bom um ajustamento conseguido aumentando muito
2.10.3 Testes de Hip´oteses para Modelos de Regress˜ao M´ultipla
Testam-se hip´oteses acerca dos parˆametros de modelos de regress˜ao m´ultipla com o
objectivo de medir a sua significˆancia, ou seja a sua utilidade para o modelo.
Como base de partida para construir os testes admite-se que y∼N(Xα, σ2C), passando a ter-se, ap´os redu¸c˜ao da heterocedasticidade, y′ ∼ N(X′α, σ2I
n) e ex-press˜oes para αˆ, COV(αˆ) e SQE independentes da uniformizadora de C.
As hip´oteses a serem testadas em geral s˜ao da forma
H0 :ψ=ψ0
onde ψ = Aα, com A uma matriz cujos vectores linha pertencem a ℵ e ψ0 um vector de R(A).
Dado que as componentes de ψ s˜ao estim´aveis, ψˆ=A ˆα ser´a um vector normal com
E(ψˆ) = E(A ˆα) =Aα=ψ
COV(ψˆ) =ACOV(αˆ)AT =σ2A XTC−1X+AT
independente de SQE, uma vez que αˆ ´e independente de SQE, logo A ˆα tamb´em o ´e.
Com h=CarA XTC−1X+AT, atendendo aos resultados apresentados na sec¸c˜ao 2.9, tem-se
(ψˆ−ψ0)T A XTC−1X+AT+(ψˆ
−ψ0)∼σ2χ2h,δ (2.37)
onde
δ =
(ψ−ψ0)T A XTC−1X+AT+(ψ−ψ 0)
σ2
σ2χ2
n−p por ser fun¸c˜ao deψˆ, tem-se
F = n−p
h
(ψˆ−ψ0)T A XTC−1X+AT+(ψˆ−ψ 0)
SQE ∼Fh,n−p,δ
o que permite utilizarF como estat´ıstica de testeF para testar a hip´oteseH0 :ψ =
ψ0.
Por outro lado, quandoψ =ψ0,δ = 0, vindo
F0 = n−p
h
(ψˆ−ψ)TA XTC−1X+AT+(ψˆ−ψ)
SQE ∼Fh,n−p
ou seja F tem distribui¸c˜ao F central, logo estes testes s˜ao n˜ao distorcidos (sec¸c˜ao 2.9). O testeF de n´ıvelqn˜ao rejeitaH0 se e s´o se o vectorψ0 pertencer ao elips´oide de confian¸ca de n´ıvel 1−q
(ψˆ−ψ)T A XTC−1X+AT+(ψˆ
−ψ)≤hF1−q,h,n−p
SQE
(n−p)
ondeF1−q,h,n−p ´e o quantil de probabilidade n´ıvel 1−q de Fh,n−p. Neste caso diz-se que o teste F goza de dualidade. Equivalentemente, a hip´otese H0 ´e rejeitada ao n´ıvelq se e s´o se
F > F1−q,h,n−p.
Se se tiver A XTC−1XAT+ = A XTC−1XAT−1, pode-se testar directa-mente a hip´otese H0 : δ = 0 e o teste ser´a estritamente n˜ao distorcido (sec¸c˜ao 2.9).
Em particular, fazendo A = Ik+1 e ψ0 = 0, facilmente se vˆe que est´a a ser testada a hip´otese
H0 :α0 =α1 =...=αk = 0
H1 :αj 6= 0 pelo menos para um j
Testa-se esta hip´otese para saber se, de facto, existe uma rela¸c˜ao linear entre a
vari´avel respostay e o conjunto de vari´aveis controladasx1, ..., xk . RejeitarH0 im-plica que pelo menos uma das vari´aveisxj, j = 1, ..., k ´e significativamente diferente de zero e logo contribui significativamente para o modelo, estando-se portanto na
presen¸ca de uma rela¸c˜ao linear.
Quando a matriz A ´e uma matriz linha cT e c∈ ℵ, vem ψ =cTα e a hip´otese a testar ser´a
H0 :ψ =ψ0
ent˜ao ˆψ =cTαˆ ser´a uma vari´avel aleat´oria normal com valor m´edio ψ e
V( ˆψ) =σ2cT XTC−1X+cT
logo F0 com as devidas substitui¸c˜oes ter´a distribui¸c˜ao F com 1 e n−p graus de liberdade, obtendo-se a partir da´ı os intervalos de confian¸ca para ψ
( ˆψ−ψ)T cT XTC−1X+c+( ˆψ−ψ)≤F
1−q,1,n−p
SQE
(n−p) ou, equivalentemente,
" ˆ
ψ − s
F1−q,1,n−p cT (XTC−1X)+c
SQE
n−p; ˆψ+
s
F1−q,1,n−p cT (XTC−1X)+c
SQE
n−p
#
ou seja tamb´em neste caso os testes F gozam de dualidade.
Como particularidade interessante tem-se que a raiz quadrada da estat´ıstica F
t0 =
ˆ
ψ−ψ0 q
cT (XTC−1X)+cSQE n−p
(2.38)
se a ´unica componente n˜ao nula de c for a j-´esima e for igual a 1, tem-se ψ =
αj. Fazendo ψ0 = 0, os resultados anteriores corresponder˜ao agora a intervalos de confian¸ca para αj e ao teste bilateral para
H0 :αj = 0, j = 0, ..., k
contra
H1 :αj 6= 0, j = 0, ..., k reduzindo-se neste caso a estat´ısticat0 a
t0 = ˆ
αj q
wjjSQEn−p
onde wjj representa o elemento da linha j e coluna j da matriz W = (XTC−1X)+. A hip´oteseH0 ser´a rejeitada ao n´ıvel de significˆancia q se
|t0|> t1−q/2,n−p
em que t1−q/2,n−p representa o quantil de probabilidade de n´ıvel 1− q/2 de cada uma das caudas da distribui¸c˜ao t-Student. A rejei¸c˜ao de H0 indica pois que αj ´e significativamente diferente de zero e, portanto, a vari´avel xj deve ser mantida no modelo. Se pelo contr´arioH0 n˜ao for rejeitada, conclui-se que a vari´avelxj pode ser eliminada do modelo.
Este testet serve pois para testar hip´oteses acerca dos coeficientes da regress˜ao individualmente, sendo ´util para determinar a importˆancia de uma determinada
vari´avel controlada no modelo. Dependendo do caso, um modelo pode ser mais
eficiente se se adicionar uma ou mais vari´aveis controladas ou, pelo contr´ario, se se
eliminar alguma(s) das j´a existentes.
2.11
Modelos Log-Lineares e Tabelas de Contingˆ
encia
Os modelos log-lineares descrevem padr˜oes de associa¸c˜ao entre vari´aveis categ´oricas
e s˜ao utilizados para modelar as contagens por c´elula em tabelas de contingˆencia
[1]. O modelo amostral de Poisson para contagens ´e usualmente usado em tabelas
de contingˆencia e assume que as contagens s˜ao realiza¸c˜oes de vari´aveis aleat´orias
independentes de Poisson.
Suponha-se que se tem (n1, ..., nN) contagens emN c´elulas duma tabela de con-tingˆencia (frequˆencias observadas) com n =Pini. Como j´a foi referido, assume-se que (n1, ..., nN) s˜ao realiza¸c˜oes de vari´aveis independentes com distribui¸c˜ao de Pois-son com parˆametros mi = E(ni), chamados de frequˆencias esperadas, aos quais correspondem probabilidades πi, i= 1, ..., N. A fun¸c˜ao de probabilidade para cada um dos ni, i= 1, ..., N ´e
exp(−mi)mnii
ni!
(2.39)
satisfazendo V(ni) =E(ni) =mi. O modelo log-linear ´e definido por
logmi = s X
j=1
xijθj, i= 1, ..., N (2.40)
ou na forma matricial
logm=Xθ (2.41)
onde m ´e o vector cujas componentes s˜ao os mi, n o vector com componentes ni,
i = 1, ..., N, X = [xij], i = 1, ..., N, j = 1, ..., s ´e a matriz do modelo contendo os valores das vari´aveis expl´ıcitas para as N c´elulas e θ ´e o vector cujas componentes s˜ao os parˆametros do modelo θj, j = 1, ..., s.
Nos modelos log-lineares para amostras de Poisson independentes, a estima¸c˜ao
que neste caso a fun¸c˜ao de verosimilhan¸ca ´e dada por
L(m) = N Y
i=1
exp(−mi)mnii
ni!
(2.42)
donde o logaritmo da fun¸c˜ao de verosimilhan¸ca que interessa maximizar ´e dado por
logL(m) = N X
i=1
nilogmi− N X
i=1
mi = N X i=1 ni s X j=1
xijθj ! − N X i=1 exp s X j=1
xijθj !
.
(2.43)
Derivando, obt´em-se
∂logL(m)
∂θj =
N X
i=1
nixij − N X
i=1
mixij (2.44)
dado que mi = exp[Psj=1xijθj]. Para obter os estimadores da m´axima verosimi-lhan¸ca ˆθj de θj, j = 1, ..., s, igualam-se essas derivadas a zero. Obt´em-se, deste modo, em nota¸c˜ao matricial, as equa¸c˜oes
XTn=XTmˆ (2.45)
ondemˆ tem componentes ˆmi = exp[Psj=1xijθˆj],i= 1, ..., N.
Na estima¸c˜ao por m´axima verosimilhan¸ca, a matriz de informa¸c˜ao (INF) ´e a variˆancia de∂logL(m)/∂θj. Ora a matriz de informa¸c˜ao ´e dada pelo pela sim´etrica do valor esperado da matriz Hessiana. Sendo a matriz Hessiana constitu´ıda pelos
elementos
∂2logL(m)
∂θjθk
=− N X i=1 xij ∂mi ∂θk =− N X i=1 xij ( ∂ ∂θk " exp( s X h=1
xihθh) #)
=− N X
i=1
xijxikmi (2.46)
os quais n˜ao dependem das frequˆencias observadas n, vem
onde D(mˆ) ´e a matriz diagonal cujos elementos principais s˜ao as componentes de ˆ
m [1].
Para um n´umero fixo de c´elulas, o estimador da m´axima verosimilhan¸ca θˆtem distribui¸c˜ao assimptoticamente normal, com valor m´edio θ e matriz de covariˆancia
igual a INF−1 [1]. Donde, para amostras de Poisson, a matriz de covariˆancia esti-mada de θˆ´e
\
COV(θˆ) = XTD(mˆ)X−1. (2.48) Para cada c´elulai, duma tabela de contingˆencia, o res´ıduo estandardizado ´e dado por
ei =
ni−mˆi ˆ
m1/2i . (2.49)
Quando o modelo se ajusta bem, os ei, i = 1, ..., N s˜ao assimptoticamente normais com valor m´edio nulo e variˆancias assimpt´oticas inferiores a 1 [1].
Seja e = [e1, ..., eN]T, ent˜ao a estat´ıstica de Pearson X2 =eTe tem distribui¸c˜ao assimpt´otica qui-quadrado comN −s graus de liberdade. Por outras palavras, X2 tem distribui¸c˜ao qui-quadrado aproximada, com graus de liberdade iguais ao n´umero
de c´elulas da tabela de contingˆencia menos o n´umero de parˆametros linearmente
independentes estimados do modelo [1].
Nos modelos log-lineares a “bondade” do ajustamento ´e dada pelo desvio residual
G2 = 2 N X
i=1
nilog(ni/mˆi). (2.50)
Supondo queπi >0, i= 1, ..., N quando o modelo se ajusta bem en→ ∞, o desvio residual, ver [1], distribui-se assimptoticamente como um qui-quadrado com N −s
graus de liberdade, o que ´e o mesmo que dizer queG2 converge em distribui¸c˜ao para um qui-quadrado com N −s graus de liberdade, ver [32], pondo-se