Vera Liliana Pereira Leite
Business Intelligence no estudo das
Pneumonias e da sua incidência em Portugal
Vera Liliana Pereira Leite
4
Business Intellig
ence no es
tudo das
Pneumonias e da sua incidência em P
or
Dissertação de Mestrado
Ciclo de Estudos Integrados Conducentes ao
Grau de Mestre em Engenharia de Comunicações
Trabalho efetuado sob a orientação do
Professora Doutora Maribel Yasmina Santos
Vera Liliana Pereira Leite
Business Intelligence no estudo das
“Devemos acreditar que temos um dom para alguma coisa e que, custe o que custar, havemos de consegui-la.”
AGRADECIMENTOS
Não podia encerrar este capítulo da minha vida sem agradecer às pessoas que fizeram parte dele e que contribuíram para o meu sucesso.
Agradeço à minha orientadora Professora Doutora Maribel Santos, pela disponibilidade sempre demonstrada para comigo. Obrigada pela sua simpatia e ternura. Certamente que vou recordá-la sempre com muito carinho.
À Fundação Portuguesa do Pulmão por cederem parte dos dados necessários à realização deste trabalho, em especial ao Presidente da fundação, Dr. Teles de Araújo e ao Dr. Carvalheira Santos pela sua disponibilidade no esclarecimento das dúvidas que surgiram. Quero agradecer também à fundação o convite para participar no V Congresso da Fundação Portuguesa do Pulmão realizado em Junho do presente ano.
Aos meus queridos pais que sempre me apoiaram e continuam a apoiar em tudo aquilo a que me proponho. Durante estes 6 anos sempre me fizeram acreditar que eu era capaz, sem nunca me deixarem baixar os braços nos momentos mais difíceis. Tudo o que sou hoje devo-lhes sem dúvida a eles.
Quero agradecer aos meus amigos, principalmente àqueles que me acompanharam ao longo do meu percurso académico e que partilharam comigo as mesmas angústias e as mesmas alegrias, nomeadamente à Margarida, à Adriana e à Marta.
Por último, mas não menos importante, quero deixar um obrigada ao Nuno pela pessoa especial que é na minha vida e pelo apoio que sempre me deu desde o primeiro dia. Obrigada por sempre acreditares nas minhas capacidades, obrigada pela tua ajuda quando as coisas corriam menos bem, obrigada por vibrares sempre com as minhas conquistas.
RESUMO
A cada dia que passa, o volume de dados proveniente de várias fontes, tem vindo a aumentar de forma muito acentuada. No seio das organizações, a dificuldade em processar o grande volume de dados que estas vêm armazenando influenciou o aparecimento dos sistemas de Business Intelligence. Estes surgiram com o objetivo de auxiliar as organizações na recolha, análise e compreensão dos dados, de forma a extrair informação capaz de dar suporte ao processo de tomada de decisão.
Das inúmeras áreas onde a aplicação de sistemas de Business Intelligence permite tirar partido das vantagens da sua implementação, destaca-se neste documento a área da saúde. O estudo de padrões de incidência de uma determinada doença permite perceber algumas das suas características e fatores que podem contribuir para a sua evolução. Nesta dissertação é abordada a doença respiratória que representa a principal causa de morte e internamento em Portugal, a Pneumonia.
Apesar da frequência com que chegam às unidades hospitalares pacientes com sintomas de pneumonia, é uma doença da qual ainda pouco se conhece acerca da sua origem, bem como das condições que podem influenciar o seu desenvolvimento. Relativamente aos fatores que podem estar na origem das pneumonias, existe a suspeita de que o fumo libertado durante o deflagrar dos incêndios pode estar na causa de algumas das pneumonias assistidas, sendo também uma questão abordada.
Assim, neste documento é proposta uma solução e posterior implementação de um sistema de Business Intelligence capaz de armazenar os dados recolhidos pelas unidades hospitalares e cedidos pela Fundação Portuguesa do Pulmão, dados demográficos relativos aos censos realizados em 2011, assim como dados relativos aos incêndios deflagrados em Portugal num Data Warehouse. Este serve de suporte à aplicação de ferramentas de análise de dados como Dashboards e algoritmos de Data Mining que permitiram a identificação de padrões nos dados e modelos preditivos das Pneumonias.
Os resultados obtidos permitiram estudar determinados indicadores possibilitando identificar os pacientes que apresentam maior risco de contrair Pneumonia, bem como identificar padrões desta doença, e construir modelos preditivos. Relativamente ao estudo de uma possível relação entre as Pneumonias e os incêndios foi possível identificar determinados concelhos em Portugal que apresentam uma forte ligação entre os dois fenómenos.
ABSTRACT
The volume of data that is collected from different data sources is increasing every day. Organizations are facing several difficulties in the analysis of such volumes of data. To help them to storage and analyze useful information, business intelligence systems provide the appropriate conceptual and technological framework. These systems emerged aiming to help organizations to collect, analyze and understand the data in order to extract information that can support the decision-making process.
Although numerous areas can benefit from the application of business intelligence systems, this document focuses on the healthcare domain. The study of patterns of incidence of pneumonia in Portugal allows us to understand some of the characteristics of this disease and, also, to verify its evolution. This dissertation approaches the respiratory disease that is the leading cause of death and admissions in hospitals in Portugal, pneumonia.
Despite the frequency with which patients arrive to hospital units with symptoms of pneumonia, pneumonia is a disease of which little is known about its origin, as well as the conditions that may influence its development. Between the factors that may be at the origin the pneumonia or that can potentiate the disease, there is the suspicion that the smoke released during the deflagration of fires may be the cause of some of the verified cases.
This work proposes the design and implementation of a Business Intelligence system, relying in a Data Warehouse,that is capable of storing data about patients with pneumonia, demographic data collected in the 2011 Portugal census and collected by hospitals and assigned by the Portuguese Lung Foundation, as well as data about forest fires in Portugal. The system integrates data analytics techniques like Dashboards and Data Mining algorithms, enabling the identification of patterns in data and predictive models of pneumonia.
The results obtained showed the usefulness of the system, providing several insights about the incidence of the disease and identified allowed to study indicators allowing to identify patients with higher risk of getting pneumonia as well as to identify patterns of this disease, and building predictive models. The study of a possible relationship between pneumonia and forest fires, as a strong correlation between the two events was verified in municipalities in Portugal.
TABELA DE CONTEÚDOS
Agradecimentos ... vii
Resumo ... ix
Abstract ... xi
Tabela de Conteúdos ... xiii
Lista de Figuras ... xv
Lista de Tabelas ... xxi
Lista de Acrónimos e Abreviaturas ... 25
1 Introdução ... 1 1.1 Enquadramento e Motivação ... 1 1.2 Finalidade e Objetivos ... 2 1.3 Estrutura do Documento ... 3 2 Revisão Bibliográfica... 5 2.1 Business Intelligence ... 5 2.1.1 Processo de ETL ... 8 2.1.2 Data Warehouse ... 10
2.2 Descoberta de Conhecimento em Bases de Dados... 14
2.3 Data Mining... 17
2.4 Técnicas de Data Mining ... 22
2.4.1 Métodos de Clustering ... 22
2.4.1.1 Métodos de particionamento ... 23
2.4.1.2 Hierárquico ... 25
2.4.1.4 Grelha ... 29
2.4.2 Árvores de decisão ... 31
3 Sistema de Business Intelligence para o estudo das Pneumonias e dos Incêndios ... 33
3.1 Arquitetura do Sistema ... 33
3.2 Base de dados relacional ... 35
3.3 Data Warehouse ... 44
4 Data Analytics ... 57
4.1. Dashboards e indicadores analíticos ... 57
4.2. Componente de Data Mining ... 85
5 Conclusão e Trabalho Futuro ... 93
6 Referências ... 97
A Anexo: Análise dos dados das Pneumonias ... 101
A.1 Perspetiva geral dos dados ... 101
A.2 Análise à qualidade dos dados ... 108
B Anexo: Análise dos dados dos Incêndios ... 129
B.1 Perspetiva geral dos dados ... 129
B.2 Análise à qualidade dos dados ... 136
C Anexo: “Codificação e definição das categorias das causas” ... 165
LISTA DE FIGURAS
Figura 2.1: Arquitetura da infraestrutura tecnológica de apoio ao Business Intelligence (Han et
al., 2012). ... 7
Figura 2.2: Arquitetura de um sistema de ETL (Vassiliadis et al., 2002). ... 9
Figura 2.3: Exemplo de ligação da tabela de factos às respetivas dimensões. ... 12
Figura 2.4: Representação de um cubo, segundo três dimensões: Tempo, Localização, Classe de idades. ... 13
Figura 2.5: Etapas do processo de DCBD segundo Santos e Ramos (Santos & Ramos, 2006). 15 Figura 2.6: Processo de DCBD segundo Han etl al. (Han et al., 2012). ... 17
Figura 2.7: Exemplo gráfico da classificação de dados. (a) Conjunto de dados de treino; (b) Função de classificação de dados (Kantardzic, 2011). ... 19
Figura 2.8: Exemplo gráfico de clustering. (a) Conjunto de dados de treino; (b) descrição de clusters (Kantardzic, 2011). ... 20
Figura 2.9: Exemplo gráfico da sumariação de dados. (a) Conjunto de dados de treino; (b) Descrição formalizada (Kantardzic, 2011). ... 21
Figura 2.10: Exemplo gráfico do modelo de dependências. (a) Conjunto de dados de treino; (b) Dependências locais descobertas (Kantardzic, 2011). ... 22
Figura 2.11: Clustering de um conjunto de objetos com base no método k-means (Han et al., 2012). ... 24
Figura 2.12: Clustering hierárquico do conjunto de objetos {a, b, c, d, e} (Ester, Kriegel, Sander, & Xu, 1998). ... 26
Figura 2.13: Conjunto de objetos (Ester et al., 1996). ... 27
Figura 2.14: Alcance por densidade e ligação por densidade num agrupamento baseado em densidade (Han et al., 2012). ... 28
Figura 2.15: Estrutura hierárquica do algoritmo de Clustering STING. ... 29
Figura 2.16: Exemplo de uma árvore de decisão. ... 32
Figura 3.3: Diagrama Entidades e Relacionamentos que descreve os dados dos pacientes. ... 37
Figura 3.4: Excerto da informação contida na tabela Incendio. ... 40
Figura 3.5: Diagrama Entidades e Relacionamentos que descreve os dados dos incêndios. ... 41
Figura 3.6: Modelo multidimensional do Data Warehouse. ... 45
Figura 3.7: Excerto da informação contida na tabela Incidencia_Pneumonias. ... 46
Figura 3.8: Excerto da informação contida na tabela Incidencia_Incendios. ... 48
Figura 3.9: Excerto da informação contida na tabela Incidencia_Patologias. ... 48
Figura 3.10: Excerto da informação contida na tabela Dados_Estatisticos. ... 49
Figura 3.11: Ambiente de trabalho da ferramenta Talend Open Studio for Data Quality. ... 54
Figura 3.12: Ambiente de trabalho da ferramenta Talend Open Studio For Data Integration. .... 55
Figura 4.1: Dashboard para a análise de incidência de pneumonias. ... 58
Figura 4.2: Dashboard para a caracterização geo-espacial das pneumonias e dos incêndios em Portugal Continental.. ... 58
Figura 4.3: Evolução da incidência de pneumonias entre 2002 e 2011. ... 59
Figura 4.4: Evolução da incidência de vítimas mortais derivada de pneumonia entre 2002 e 2011. ... 59
Figura 4.5: Distribuição da incidência de vítimas mortais por género. ... 60
Figura 4.6: Distribuição da incidência de vítimas mortais por classe de idades. ... 60
Figura 4.7: Distribuição da incidência de vítimas mortais por sexo e classe de idades. ... 61
Figura 4.8: Distribuição da incidência de pneumonia por género. ... 61
Figura 4.9: Distribuição da incidência de pneumonia por idade. ... 62
Figura 4.10: Distribuição da incidência de pneumonia por tempo de internamento. ... 63
Figura 4.11: Distribuição da incidência de pneumonia por tempo de internamento. ... 63
Figura 4.12:Distribuição da incidência de determinada patologia em pacientes com pneumonia. ... 64
Figura 4.13: Distribuição da incidência de determinada patologia em pacientes com pneumonia por classes de idade. ... 65
Figura 4.14: Distribuição da incidência de vítimas mortais por patologia. ... 65
Figura 4.15: Distribuição da incidência de pneumonias por trimestre. ... 66
Figura 4.16: Evolução da ocorrência de incêndios entre 2002 e 2011. ... 66
Figura 4.17: Distribuição do tipo de incêndios. ... 67
Figura 4.19: Distribuição da classificação de incêndios. ... 68
Figura 4.20: Distribuição da ocorrência de incêndios por trimestre ... 69
Figura 4.21: Média dos dias de internamento distribuída pelos distritos e concelhos de Portugal continental. ... 71
Figura 4.22: Média do número de reingresso distribuída pelos distritos e concelhos de Portugal continental. ... 71
Figura 4.23: Métrica correspondente ao cálculo da incidência de pneumonia na população residente. ... 73
Figura 4.24: Incidência de pneumonias em Portugal continental na população em geral. ... 73
Figura 4.25: Métrica correspondente ao cálculo da incidência de pneumonia na população residente com 65 ou mais anos de idade. ... 74
Figura 4.26: Incidência de pneumonias em Portugal continental na população com 65 e mais anos de idade. ... 75
Figura 4.27: Distribuição por concelho do número de pneumonias e incêndios no ano de 2002. ... 75
Figura 4.28: Métrica correspondente à normalização dos dados. ... 76
Figura 4.29: Número de casos de pneumonia nos anos de 2007 e 2008. ... 79
Figura 4.30: Número de casos de pneumonia nos anos de 2010 e 2011. ... 80
Figura 4.31: Número de casos de pneumonia nos anos de 2002 e 2003. ... 81
Figura 4.32: Número de casos de pneumonia no ano de 2005 e 2006. ... 83
Figura 4.33: Número de casos de pneumonia no ano de 2005 e 2006. ... 84
Figura 4.34: Árvore de decisão para prever a mortalidade atendendo aos atributos de entrada: sexo, classe_idade e classe_d_internamento. ... 86
Figura 4.35: Árvore de decisão para prever a mortalidade atendendo aos atributos de entrada: sexo, classe_idade, classe_d_internamento e distrito. ... 87
Figura 4.36: Clustering dos atributos: classe_idade, patologia, flag_vitima_mortal... 89
Figura 4.37: Clustering dos atributos: classe_d_internamento, classe_idade, flag_vitima_mortal. ... 90
Figura 4.38: Clustering dos atributos: classe_d_internamento, patologia, flag_vitima_mortal. ... 91
Figura A.1: Diagrama Entidades e Relacionamentos que descreve os dados dos pacientes. ... 104
Figura A.3: Valores distintivos relativos ao atributo sexo. ... 109
Figura A.4: Cálculo da moda do atributo sexo. ... 109
Figura A.5: Estatísticas relativas ao atributo ano_internamento. ... 110
Figura A.6: Valores relativos ao atributo ano_internamento. ... 111
Figura A.7: Estatísticas relativas ao atributo idade. ... 111
Figura A.8: Deteção de valores inválidos relativo ao atributo idade. ... 112
Figura A.9: Identificação do valor inválido relativo ao atributo idade. ... 112
Figura A.10: Distribuição das idades tendo em conta os atributos: ano_internamento, sexo e cod_distrito do paciente. ... 113
Figura A.11: Distribuição total das idades dos pacientes. ... 114
Figura A.12: Cálculo da média tendo em conta os atributos ano_internamento, sexo e cod_distrito. ... 114
Figura A.13: Estatísticas relativas ao atributo data_nascimento. ... 115
Figura A.14: Identificação do valor inválido relativo ao atributo data_nascimento. ... 116
Figura A.15: Estatísticas relativas ao atributo dias_internamento. ... 117
Figura A.16: Deteção de um valor inválido relativo ao atributo dias_internamento. ... 117
Figura A.17: Identificação do valor inválido encontrado relativo ao atributo dias_internamento. ... 118
Figura A.18: Estatísticas relativas ao atributo cod_distrito. ... 119
Figura A.19: Identificação dos valores inválidos encontrados relativo ao atributo cod_distrito. 119 Figura A.20: Cálculo da moda para o atributo cod_distrito com valor inválido apresentado acima. ... 120
Figura A.21: Cálculo da moda para o atributo cod_distrito com valor inválido apresentado acima. ... 121
Figura A.22: Estatísticas relativas ao atributo cod_concelho. ... 122
Figura A.23: Identificação dos valores inválidos encontrados relativo ao atributo cod_concelho. ... 122
Figura A.24: Cálculo da moda para o atributo cod_concelho com valor inválido apresentado acima. ... 123
Figura A.25: Estatísticas relativas ao atributo cod_freguesia. ... 124
Figura A.26: Identificação dos valores inválidos encontrados relativo ao atributo cod_freguesia. ... 124
Figura A.27: Cálculo da moda para o atributo cod_freguesia com valor inválido apresentado
acima. ... 125
Figura A.28: Estatísticas relativas ao atributo sigla_hospital. ... 126
Figura A.29: Estatísticas relativas ao atributo flag_vitima_mortal. ... 127
Figura A.30: Valores relativos ao atributo flag_vitima_mortal. ... 127
Figura A.31: Estatísticas relativas ao atributo cod_patologia. ... 128
Figura B.1: Diagrama Entidades e Relacionamentos que descreve os dados dos incêndios. ... 132
Figura B.2: Estatísticas relativas ao atributo ano. ... 136
Figura B.3: Valores relativos ao atributo ano. ... 137
Figura B.4: Estatísticas relativas ao atributo tipo_incendio. ... 137
Figura B.5: Cálculo da moda para o atributo tipo_incendio. ... 138
Figura B.6: Valores relativos ao atributo tipo_incendio... 139
Figura B.7 Estatísticas relativas ao atributo cod_dtccfr... 139
Figura B.8: Identificação dos valores inválidos relativo ao atributo cod_dtccfr. ... 140
Figura B.9: Estatísticas relativas ao atributo latitude. ... 141
Figura B.10: Estatísticas relativas ao atributo longitude. ... 142
Figura B.11: Estatísticas relativas ao atributo cod_causa. ... 143
Figura B.12: Valor mínimo e máximo relativos ao atributo cod_causa. ... 144
Figura B.13: Estatísticas relativas ao atributo tipo_causa. ... 144
Figura B.14: Valores relativos ao atributo tipo_causa. ... 145
Figura B.15: Estatísticas relativas ao atributo flag_reacendimento. ... 145
Figura B.16: Valores relativos ao atributo flag_reacendimento. ... 146
Figura B.17: Estatísticas relativas ao atributo flag_falso_alarme. ... 146
Figura B.18: Valores relativos ao atributo flag_falso_alarme. ... 147
Figura B.19: Estatísticas relativas ao atributo data_alerta. ... 147
Figura B.20: Valor máximo e mínimo do atributo data_alerta. ... 148
Figura B.21: Estatísticas relativas ao atributo hora_alerta. ... 148
Figura B.22: Valor máximo e mínimo para o atributo hora_alerta. ... 149
Figura B.23: Estatísticas relativas ao atributo data_intervencao. ... 150
Figura B.24: Valor máximo e mínimo para o atributo data_intervencao. ... 150
Figura B.26: Estatísticas relativas ao atributo hora_intervencao. ... 151
Figura B.27: Valor máximo e mínimo para o atributo hora_intervencao. ... 152
Figura B.28: Estatísticas relativas ao atributo data_extincao. ... 153
Figura B.29: Valor máximo e mínimo para o atributo data_extincao. ... 153
Figura B.30: Valores inválidos relativos ao atributo data_extincao. ... 154
Figura B.31: Estatísticas relativas ao atributo hora_extincao. ... 154
Figura B.32: Valor máximo e mínimo para o atributo hora_extincao. ... 155
Figura B.33: Estatísticas relativas ao atributo a_agricola. ... 156
Figura B.34: Valor máximo e mínimo para o atributo a_agricola. ... 156
Figura B.35: Estatísticas relativas ao atributo a_mato. ... 157
Figura B.36: Valor máximo e mínimo para o atributo a_mato. ... 157
Figura B.37: Estatísticas relativas ao atributo a_povoamento. ... 158
Figura B.38: Valor máximo e mínimo para o atributo a_povoamento. ... 158
Figura B.39: Estatísticas relativas ao atributo a_total. ... 159
Figura B.40: Valor máximo e mínimo para o atributo a_total. ... 159
Figura B.41: Estatísticas relativas ao atributo a_espaco_florestal. ... 160
Figura B.42: Valor máximo e mínimo para o atributo a_espaco_florestal. ... 160
Figura B.43: Estatísticas relativas ao atributo agricola. ... 161
Figura B.44: Valores relativos ao atributo agricola. ... 161
Figura B.45: Estatísticas relativas ao atributo fogaco. ... 162
Figura B.46: Valores relativos ao atributo fogacho. ... 162
Figura B.47: Estatísticas relativas ao atributo incendio. ... 163
Figura B.48: Valores relativos ao atributo incendio. ... 163
Figura B.49: Estatísticas relativas ao atributo queimada. ... 164
LISTA DE TABELAS
Tabela 3.1: Atributos da entidade Paciente. ... 38
Tabela 3.2: Atributos da entidade Distrito. ... 38
Tabela 3.3: Atributos da entidade Concelho. ... 39
Tabela 3.4: Atributos da entidade Freguesia. ... 39
Tabela 3.5: Atributos da entidade Hospital. ... 39
Tabela 3.6: Atributos da entidade Patologia... 39
Tabela 3.7: Atributos da entidade Patologia-Paciente. ... 40
Tabela 3.8: Atributos da entidade Incendio. ... 42
Tabela 3.9: Atributos da entidade Distrito. ... 43
Tabela 3.10: Atributos da entidade Concelho. ... 43
Tabela 3.11: Atributos da entidade Freguesia. ... 43
Tabela 3.12: Atributos da entidade Causa. ... 43
Tabela 3.13: Atributos da entidade Tipo_Incendio. ... 44
Tabela 3.14: Atributos da entidade Classificacao. ... 44
Tabela 3.15: Tabela de factos Incidencia_Pneumonias. ... 46
Tabela 3.16: Tabela de factos Incidencia_Incendios. ... 47
Tabela 3.17: Tabela de factos Incidencia_Patologias. ... 48
Tabela 3.18: Tabela de factos Dados_Estatisticos. ... 49
Tabela 3.19: Tabela de dimensão Individuo. ... 50
Tabela 3.20: Tabela de dimensão Local. ... 50
Tabela 3.21: Tabela de dimensão Hospital. ... 51
Tabela 3.22: Tabela de dimensão Tempo_Mes. ... 51
Tabela 3.23: Tabela de dimensão Tempo_Ano. ... 51
Tabela 3.24: Tabela de dimensão Patologias. ... 52
Tabela 3.25: Tabela de dimensão Incendio. ... 52
Tabela 3.27: Tabela de dimensão Causa. ... 53 Tabela 3.28: Tabela de dimensão Tipo_Incendio. ... 53 Tabela 4.1: Lista de concelhos obtidos com valores de correlação iguais ou superiores a 0,7. . 78 Tabela 4.2: Valores tidos em conta no cálculo da correlação obtida para o concelho de Portel no ano de 2007, para o número de pneumonias e área ardida. ... 79 Tabela 4.3: Valores tidos em conta no cálculo da correlação obtida para o concelho de Oliveira de Frades no ano de 2010, para o número de pneumonias e área ardida. ... 80 Tabela 4.4: Valores tidos em conta no cálculo da correlação obtida para o concelho de Alandroal no ano de 2002, para o número de pneumonias e área ardida... 81 Tabela 4.5: Lista de concelhos obtidos com valores de correlação iguais ou superiores a 0,7. . 82 Tabela 4.6: Valores tidos em conta no cálculo da correlação obtida para o concelho de Marvão no ano de 2005, para o número de pneumonias e área ardida... 83 Tabela 4.7: Valores tidos em conta no cálculo da correlação obtida para o concelho de Alter do Chão no ano de 2005, para o número de pneumonias e área ardida. ... 84 Tabela A.1: Tabela com os atributos contidos nos ficheiros excel relativos às pneumonias. .... 102 Tabela A.2: Tabela com a seleção dos atributos considerados para análise. ... 103 Tabela A.3: Atributos da entidade Paciente. ... 105 Tabela A.4: Atributos da entidade Distrito. ... 105 Tabela A.5: Atributos da entidade Concelho. ... 106 Tabela A.6: Atributos da entidade Freguesia. ... 106 Tabela A.7: Atributos da entidade Hospital. ... 106 Tabela A.8: Atributos da entidade Patologia. ... 106 Tabela A.9: Atributos da entidade Patologia-Paciente. ... 107 Tabela A.10: Atributos relevantes para o cálculo da moda. ... 109 Tabela A.11: Atributos relevantes para o cálculo da moda. ... 113 Tabela A.12: Atributos relevantes para o cálculo da média. ... 114 Tabela A.13: Tabela com os valores correctos para o atributo dias_internamento. ... 118 Tabela A.14: Exemplo de um registo com valor inválido relativo ao atributo cod_distrito. ... 120 Tabela A.15: Exemplo de um registo com valor inválido relativo ao atributo cod_distrito. ... 121 Tabela A.16: Exemplo de um registo com valor inválido relativo ao atributo cod_concelho. .... 123 Tabela A.17: Exemplo de um registo com valor inválido relativo ao atributo cod_freguesia. ... 125 Tabela B.1: Tabela com os atributos contidos nos ficheiros relativos aos incêndios. ... 130
Tabela B.2: Tabela com os atributos considerados na análise ... 131 Tabela B.3: Atributos da entidade Incendio. ... 133 Tabela B.4: Atributos da entidade Distrito... 134 Tabela B.5: Atributos da entidade Concelho. ... 134 Tabela B.6: Atributos da entidade Freguesia. ... 134 Tabela B.7: Atributos da entidade Causa. ... 134 Tabela B.8: Atributos da entidade Tipo_Incendio. ... 135 Tabela B.9: Atributos da entidade Classificacao. ... 135 Tabela B.10: Atributos relevantes para o cálculo da moda. ... 138 Tabela B.11: Exemplo de um registo com valor inválido relativo ao atributo cod_dtccfr. ... 140
LISTA DE ACRÓNIMOS E ABREVIATURAS
FPP Fundação Portuguesa do Pulmão
ETL Extraction, Transformation, Load
EIS Executive Information Systems
OLAP On-Line Analitycal Processing
DCBD Descoberta de Conhecimento em Bases de Dados
KDD Knowledge Discovery in Databases
PAM Partitioning Around Medoids
CLARA Clustering Large Applications
DBSCAN A Density-Based Clustering Method Based on Connected Regions with Sufficiently High Density
OPTICS Ordering Points to Identify the Clustering Structure
DENCLUE Density-based Clustering
STING Statistical Information Grid
CLIQUE Clustering Inquest
VBA Visual Basic for Applications
1
INTRODUÇÃO
Neste primeiro capítulo é feito o enquadramento do tema da dissertação bem como da motivação que levou à realização da mesma. Para além disso é descrita a finalidade e os objetivos que são tencionados alcançar com a realização desta dissertação. Por fim, é apresentada a estrutura que constituí o documento.
1.1 Enquadramento e Motivação
Estudos revelam que a quantidade de informação no mundo dobra a cada 20 meses, o que se reflete num aumento veloz no tamanho e número de base de dados. “Em 1989, o número total de bases de dados no mundo foi estimado em cinco milhões” (Frawley, Shapiro, & Matheus, 1992).
No seio das organizações, a dificuldade em processar o grande volume de dados que estas vêm armazenando influenciou o aparecimento dos sistemas de Business Intelligence. Estes surgiram com o objetivo de auxiliar as organizações na recolha, análise e compreensão dos dados, de forma a extrair informação capaz de dar suporte ao processo de tomada de decisão.
São inúmeras as áreas de aplicação que podem tirar partido das vantagens da implementação de um sistema de Business Intelligence, como por exemplo a área das telecomunicações. Tendo em conta a concorrência neste sector, a implementação de um sistema deste tipo pode ajudar as operadoras a tornarem-se mais competitivas oferecendo serviços mais atractivos e eficientes (Normile, n.d.).
Em concreto neste documento a área de aplicação que merece destaque é a área da saúde. A Fundação Portuguesa do Pulmão (FPP) em parceria com o Departamento de Sistemas de Informação da Universidade do Minho têm vindo a desenvolver trabalhos de investigação no domínio das doenças respiratórias, motivados pelo facto de estas constituírem uma das principais causas de morbilidade, incapacidade de longa duração e mortalidade.
Segundo dados do relatório, publicado em 2013, do Observatório Nacional das Doenças Respiratórias, em 2012 morreram por doenças respiratórias 13.908 portugueses, havendo a acrescentar a esse número 4.012 óbitos por cancros da traqueia, brônquios e pulmão. Isto significa que em 2012 morreram por doenças do foro respiratório 50 portugueses por dia (Carvalheira Santos et al., 2013)
Do conjunto de doenças respiratórias as pneumonias representam a principal causa de morte e internamento em Portugal constituindo um sério problema, como tem vindo a referir a FPP em todos os Relatórios do Observatório Nacional das Doenças Respiratórias, publicados anualmente desde 2005 (Dr. Teles de Araújo, n.d.). O mesmo autor refere ainda que, segundo dados divulgados pela OMS, constatam que nos 28 países que constituem a União Europeia, a mortalidade média por pneumonia é de 13,0 por 100.000 habitantes. Em Portugal o valor é de 26,6 por 100.000 (apenas ultrapassada pelo Reino Unido e Eslováquia). O que significa que, por dia, morrem cerca de 15 portugueses com pneumonia. A situação torna-se ainda mais grave, uma vez que não se tem assistido a uma diminuição no número de internamentos por pneumonia, nem no número de óbitos. Antes pelo contrário os números mostram, em 5 anos, uma tendência para se agravarem: os óbitos aumentaram 16,7% e os internamentos 14,1%.
Apesar da frequência com que chegam às unidades hospitalares pacientes com sintomas de pneumonia, é uma doença da qual ainda pouco se conhece acerca da sua origem, bem como das condições que podem influenciar o seu desenvolvimento.
Relativamente aos fatores que podem estar na origem das pneumonias, a FPP suspeita que o fumo libertado durante o deflagrar dos incêndios pode estar na causa de algumas das pneumonias assistidas.
A realidade preocupante das pneumonias e a desconfiança da FPP relativa a uma possível causa-efeito entre o fumo dos incêndios e as pneumonias motivou a realização deste projeto de dissertação a partir do qual se pretende dar um contributo importante nesta área.
1.2 Finalidade e Objetivos
Este projeto de dissertação tem como objetivo propor uma solução e posterior implementação de um sistema de Business Intelligence capaz de armazenar os dados recolhidos pelas unidades hospitalares, bem como dos dados relativos a incêndios deflagrados em Portugal num Data Warehouse. Este servirá de suporte à aplicação de técnicas de análise de dados como
Dashboards que permitirão a identificação de padrões de incidência, e os algoritmos de Data Mining que permitirão a identificação de modelos preditivos.
O trabalho desenvolvido ao longo deste projeto de dissertação incidiu na realização dos seguintes objetivos, previamente definidos:
Definição da arquitetura do sistema de Business Intelligence a implementar, caracterizando os componentes necessários e as tecnologias a utilizar;
Exploração dos dados das pneumonias disponibilizados pela FPP e dos dados relativos aos incêndios, de forma a proceder à limpeza de possíveis erros nos dados e transformações necessárias;
Definição do modelo de dados das bases de dados relacionais que permitirão a migração dos dados para um Data Warehouse;
Definição do modelo de dados do Data Warehouse que servirá de suporte ao armazenamento de dados e respetivas implementações;
Análise dos dados recorrendo a ferramentas de Dashboard e algoritmos de Data Mining para a identificação de padrões e tendências nos dados.
1.3 Estrutura do Documento
A estrutura deste documento encontra-se dividida em cinco capítulos e quatro anexos. No primeiro capítulo é feita uma introdução ao tema da dissertação, bem como a sua motivação e objetivos que se pretendem alcançar. Por fim, é apresentada a estrutura adotada na elaboração deste documento, finalizando assim este capítulo.
O segundo capítulo incide sobre a revisão bibliográfica realizada, sistematizando o enquadramento teórico dos conceitos e fundamentos relevantes que estão na base do trabalho desenvolvido.
O sistema de Business Intelligence implementado é apresentado no capítulo três recorrendo à descrição dos componentes que compõem a arquitetura do sistema.
No capítulo quatro são apresentadas as análises realizadas ao conjunto de dados recorrendo à implementação de Dashborads e técnicas de Data Mining. Os Dashboards permitem a análise de um conjunto de indicadores que caracterizam os dados em questão. As
técnicas de Data Mining permitem obter modelos preditivos resultantes da aplicação de árvores de decisão e de padrões de incidência a partir de algoritmos de clustering.
Por fim, no capítulo 5 são apresentadas as respetivas conclusões acerca do trabalho realizado, bem como sugestões de trabalho futuro.
Tal como referido, para além dos cinco capítulos que integram a estrutura do documento, fazem também parte quatro anexos que correspondem aos relatórios da qualidade dos dados, quer das pneumonias como dos incêndios, bem como informações adicionais.
2
REVISÃO BIBLIOGRÁFICA
Neste capítulo é feito o enquadramento teórico dos conceitos e fundamentos relevantes associados ao tema desta dissertação e que estiveram na base de todo o trabalho realizado.
Inicialmente são apresentados um conjunto de fundamentos teóricos associados a sistemas de Business Intelligence, nomeadamente de Data Warehousing, processo de Extraction, Transformation, Loading (ETL), Descoberta de Conhecimento em Bases de Dados (DCBD) e por fim Data Mining.
2.1
Business Intelligence
O conceito Business Intelligence foi introduzido pelo Gartner Group1 em meados da
década de 90. No entanto, há milhares de anos atrás Fenícios, Persas, Egípcios e outros Orientais já utilizavam, à sua maneira, o princípio de Business Intelligence quando cruzavam informações provenientes da natureza, nomeadamente o comportamento das marés, períodos de seca e de chuvas, entre outras, para benefício próprio (Sidemar, 2007).
O conceito atual de Business Intelligence começou na década de 70, quando foram disponibilizados no mercado alguns produtos de Business Intelligence para a análise de negócios, passando a estar presente nas organizações através de diferentes sistemas. Com a evolução das tecnologias e sistemas de informação e as consequentes mudanças nas organizações surgiu, na década de 80, o conceito Executive Information Systems (EIS). Este conceito corresponde a uma tecnologia computorizada que permite ajudar os executivos na tomada de decisão estratégica, fornecendo o acesso fácil e rápido a dados relevantes, necessários para atingir os objetivos estratégicos de uma organização, como o controlo e acompanhamento da mesma (Turban, Sharda, Aronson, & King, 2009).
Na década de 90, começaram a ser comercializados produtos tecnológicos que possuíam estas características aliadas à introdução de outros recursos, passando a ser chamados de ferramentas de Business Intelligence (Turban et al., 2009).
Os sistemas de Business Intelligence, segundo Watson e Wixom (Watson & Wixom, 2007), sugiram com o objetivo de auxiliar as organizações na recolha, compreensão e exploração dos seus dados de forma a extrair informação capaz de dar suporte à tomada de decisão.
Este suporte permite às organizações tomadas de decisões mais rápidas e eficazes culminando em benefícios inevitáveis. Turban et al. (Turban et al., 2009) afirmam que relatórios recentes efectuados por analistas da área mostram que, nos próximos anos, milhões de pessoas usarão ferramentas visuais de Business Intelligence e de análise, diariamente.
Os sistemas de Business Intelligence incluem vários softwares para o processo de ETL, Data Warehousing, consulta de bases de dados e relatórios, On-Line Analitycal Processing (OLAP), Data Mining e de visualização (Gangadharan & Swami, 2004).
Na literatura é possível encontrar diferentes arquiteturas da infraestrutura tecnológica de apoio ao Business Intelligence, das quais se destaca a arquitetura proposta por Han et al. (Han, Kamber, & Pei, 2012)(Han et al., 2012)(Han et al., 2012)(Han et al., 2012)(Han et al., 2012). Esta arquitetura é composta por três níveis: o nível do servidor de Data Warehouse, o nível de servidor OLAP e o nível de ferramentas de análise que disponibilizam informação relevante para a tomada de decisão (Figura 2.1).
Figura 2.1: Arquitetura da infraestrutura tecnológica de apoio ao Business Intelligence (Han et al., 2012).
O nível do servidor de Data Warehouse integra o Data Warehouse da organização e/ou diversos Data Marts. Uma organização pode optar pela implementação de um Data Warehouse,
são carregados para estas estruturas normalmente no processo de ETL a partir de várias fontes de dados internas ou externas à organização. Este processo engloba ferramentas de software cuja função é a extração, limpeza, transformação e carregamento dos dados. O processo de ETL é abordado na subsecção 2.1.1.
Este nível contém ainda uma base de dados de metadados, que armazena informações sobre o Data Warehouse e seu conteúdo. Metadados representam dados sobre dados, que quando usados num Data Warehouse representam os dados que definem objetos do Data Warehouse. O nível intermédio integra o servidor OLAP que permite a análise multidimensional dos dados. O servidor OLAP pode ser implementado segundo um modelo ROLAP, MOLAP ou então HOLAP que diferem entre si no tipo de armazenamento. O conceito de Data Warehouse e OLAP são abordados na subsecção 2.1.2.
Por último, o nível superior representa o nível dos resultados que integra um conjunto de ferramentas de análise que permitem fazer questões sobre os dados, consultas ad-hoc, dashboards, gerar relatórios ou identificar tendências e padrões úteis nos dados (Data Mining).
2.1.1 Processo de ETL
As ferramentas de Extração, Transformação e Carregamento de dados, desempenham um papel fundamental nos sistemas de Business Intelligence, sendo responsáveis pela preparação dos dados e posterior carregamento para o Data Warehouse.
Na Figura 2.2 é descrita a arquitetura de um sistema de ETL, segundo Vassiliadis et al. (Vassiliadis, Simitsis, & Skiadopoulos, 2002). No nível inferior da referida arquitetura, encontram-se as fontes de dados envolvidas em todo o processo, enquanto no nível superior, estão representadas as operações exercidas sobre os dados.
Extração Transformação e Limpeza Carregamento e Refrescamento
Dados Área de estágio dos dados Data Warehouse
Figura 2.2: Arquitetura de um sistema de ETL (Vassiliadis et al., 2002).
No nível inferior esquerdo observam-se as fontes de dados operacionais, normalmente bases de dados relacionais, mas também outras fontes de dados como arquivos de texto, entre outras. Os dados das diversas fontes são extraídos recorrendo a ferramentas adequadas e temporariamente armazenados na área de estágio dos dados (Data Staging Area - DSA). Nesta área ocorre o processo transformação e limpeza dos dados para posteriormente serem carregados para o Data Warehouse. No processo de carregamento, os dados que se encontram na DSA são carregados para o Data Warehouse.
Na Figura 2.2 encontram-se ferramentas e utilitários de back-end intervenientes no processo de ETL que permitem carregar e refrescar o Data Warehouse. Das principais funções que caracterizam estas ferramentas e utilitários destacam-se:
Extração de dados - Esta fase caracteriza-se pela extração de dados adquiridos de várias fontes, como bases de dados relacionais, arquivos de texto, ficheiros excel, entre outros, incluindo sistemas operacionais.
Transformação de dados - Uma vez que os dados extraídos podem advir de sistemas diferentes, às vezes é necessário padronizar os diferentes formatos.
Limpeza de dados - É realizada a limpeza e validação dos dados extraídos, de forma a corrigir valores inconsistentes, omissos ou inválidos.
Carregamento - Nesta fase os dados limpos e transformados são carregados para um Data Warehouse.
Refrescamento – É feito através do carregamento para o Data Warehouse dos novos dados existentes nas fontes de dados, atualizando-o.
Vassiliadis et al. (Vassiliadis et al., 2002) refere que para determinados autores as ferramentas de ETL e limpeza de dados requerem pelo menos um terço do esforço e orçamento num projeto de Data Warehouse, ao passo que outros, nomeadamente Demarest (Demarest, 1997) consideram que, no que diz respeito ao tempo de desenvolvimento de um projeto de Data Warehouse, este pode consumir 80% do tempo total. Ainda, Inmon (Inmon, 2000) acrescenta que o processo ETL tem custos que podem rondar os 55% do tempo total de execução do projeto de Data Warehouse. A qualidade das soluções de Business Intelligence é proporcional à qualidade dos dados de entrada, ou seja, quanto maior for a qualidade dos dados melhor será a qualidade das soluções de Business Intelligence obtidas. Dados inconsistentes ou de baixa qualidade podem levar a tomadas de decisões erradas (Daniel, Casati, Palpanas, & Leksiy, 2008). Desta forma, são compreensíveis os custos associados ao processo de ETL num sistema de Business Intelligence.
2.1.2 Data Warehouse
Um Data Warehouse é um repositório de informação válida e consistente que serve para facilitar a análise dos grandes conjuntos de dados normalmente existentes nas organizações e a consequente tomada de decisão.
Segundo Innon (Inmon, 2002), Data Warehouse é uma base de dados orientado por assuntos, integrado, variante no tempo e não volátil, que tem por objetivo dar suporte aos processos de tomada de decisão. Compreendendo melhor as suas principais características:
Orientado por assunto - Cada organização possui o seu próprio conjunto de assuntos de interesse. Estes sistemas oferecem uma visão clara e precisa de um determinado assunto, excluindo os dados que não revelam importância no processo de tomada de decisão;
Integrado - Como já referido um Data Warehouse é normalmente construído a partir de múltiplas fontes heterogéneas de dados, como bases de dados relacionais da organização. Para garantir a consistência dos dados são aplicadas técnicas de limpeza e integração dos dados;
Não voláteis - Os dados são carregados uma única vez para o Data Warehouse e a partir desse momento só podem ser acedidos para processamento de consultas, não podendo ser apagados nem alterados pelos utilizadores;
Variante no tempo - O Data Warehouse contém dados não atualizáveis relativos a um momento específico.
Um Data Warehouse é uma base de dados que é mantido separadamente das bases de dados operacionais da organização e que permite a agregação de informação proveniente de várias fontes, para posteriormente consolidar numa única estrutura de dados, de forma a facilitar a análise desses dados.
Como já referido anteriormente, um Data Warehouse integra a informação relativa a um determinado assunto ou assuntos da organização, ou seja, é caracterizada a organização e não parte dela. Por outro lado, sempre que o âmbito é mais específico, um subconjunto específico de dados da organização é armazenado numa arquitetura designada Data Mart ao invés de Data Warehouse. A escolha de uma destas arquiteturas a utilizar passa por analisar as necessidades da organização no que diz respeito ao âmbito da cobertura de informação para a tomada de decisão (Santos & Ramos, 2006).
Relativamente à estrutura de sistemas de Data Warehouse, esta é concebida através de modelação multidimensional. Esta modulação assenta em 2 princípios: simplicidade na estrutura do modelo de dados permitindo uma fácil compreensão e utilização e um bom desempenho no processamento de consultas. O modelo de dados multidimensional visualiza os dados como um cubo, permitindo que estes sejam modelados e visualizados em múltiplas dimensões. Um cubo é definido segundo factos e dimensões.
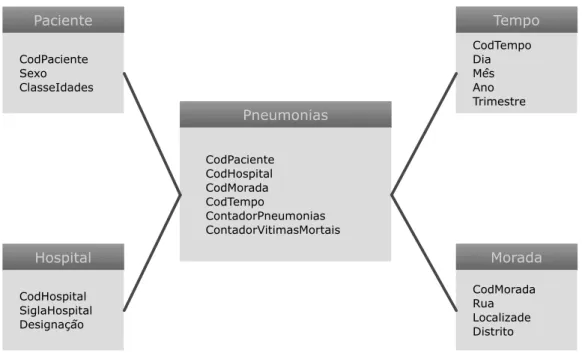
As tabelas de factos correspondem ao assunto que se pretende analisar, normalmente uma componente do negócio: incidência de pneumonias (aplicando ao tema desta dissertação). Os factos estão associados a acontecimentos. Estes acontecimentos são atributos numéricos que representam determinada métrica ou medida do processo de negócio: ContadorPneumonias, ContadorVítimasMortais. Para além dos atributos numéricos, integram também um conjunto de chaves estrangeiras que relacionam as tabelas de factos com as
dimensões que lhe estão associadas. Segundo Santos e Ramos (Santos & Ramos, 2006) estas tabelas contêm uma grande quantidade de registos, ocupando normalmente mais de 95% do espaço ocupado pelo Data Warehouse.
As tabelas de dimensões integram um conjunto diversificado de atributos que possibilitam a análise dos indicadores de negócio presentes na tabela de factos. Estes atributos integram, habitualmente, as descrições que permitem contextualizar as métricas em análise. Cada uma das tabelas possui uma chave primária que permite a ligação às tabelas de factos ou entre tabelas de dimensão. Ao contrário das tabelas de factos, as tabelas de dimensão armazenam uma pequena quantidade de registos.
A Figura 2.3 apresenta um exemplo de um esquema de Data Warehouse onde se pretende analisar a incidência de pneumonias ao longo das dimensões Paciente, Hospital, Tempo e Morada. Os factos a explorar encontram-se na tabela Pneumonias representados pelos atributos ContadorPneumonias, que armazena o número total de pacientes com pneumonia e ContadorVítimasMortais, que armazena o número de vítimas mortais com pneumonia durante o período de internamento.
Figura 2.3: Exemplo de ligação da tabela de factos às respetivas dimensões.
Relativamente à exploração de um Data Warehouse, existem atualmente diversas tecnologias que podem ser utilizadas para este fim. As mais comuns são a tecnologia OLAP e o Data Mining. Paciente Tempo Pneumonias Morada Hospital CodPaciente Sexo ClasseIdades CodTempo Dia Mês Ano Trimestre CodMorada Rua Localizade Distrito CodHospital SiglaHospital Designação CodPaciente CodHospital CodMorada CodTempo ContadorPneumonias ContadorVitimasMortais
A tecnologia OLAP fornece aos utilizadores finais, meios para explorar e analisar grandes quantidades de dados, envolvendo cálculos complexos, seus relacionamentos, e apresentação visual dos resultados em diferentes perspetivas (Khan & Quadri, 2012).
Esta tecnologia permite criar cubos de dados multidimensionais definidos por dimensões e factos que permitem analisar a informação sob diferentes perspetivas (Rao, Zhang, Yu, Li, & Chen, 2003).
A Figura 2.4 apresenta um cubo no qual um dos factos (ContadorPneumonias) representados no esquema da Figura 2.3 é analisado segundo três dimensões: Tempo, Localidade (concretizada pela dimensão Morada) e Classe de idades (concretizada pela dimensão Paciente). 4º Trimestre 2º Trimestre 3º Trimestre 1º Trimestre Guimarães Braga Famalicão Viana do Castelo [0-4] [5-9] [10-19] [20-24] Classe de idades Local ização T e m p o 1000 500 1250 250 50 700 10 90 2000 579 1400 1250 90 40 100 15 890 20 55 104 201 100 99 16 601 504 60 100 605 788 98 109
Figura 2.4: Representação de um cubo, segundo três dimensões: Tempo, Localização, Classe de idades.
Os servidores OLAP podem ser divididos em três tipos tendo em conta a forma de armazenamento:
Rolap - São servidores intermediários que operam entre uma base de dados relacional e as ferramentas de front-end utilizadas para a análise dos dados.
Molap - Estes servidores suportam uma visão multidimensional dos dados através de um mecanismo de armazenamento também ele multidimensional.
Holap - A abordagem OLAP combina a tecnologia ROLAP e MOLAP, beneficiando da grande escalabilidade do ROLAP e a velocidade de processamento do MOLAP.
Como já referido, para além das ferramentas OLAP, o Data Mining constitui outra forma de explorar informação armazenada num Data Warehouse. Este processo identifica padrões ou tendências nos dados que podem representar informação útil para as organizações. Na secção 2.3 é analisada com maior grau de detalhe.
2.2 Descoberta de Conhecimento em Bases de Dados
Com uma produção de dados cada vez maior, surge a necessidade de transformar esses mesmos dados em informação e conhecimento úteis.
Esta necessidade de compreender dados, por vezes complexos e semanticamente ricos é transversal a todas as áreas: negócios, ciência, engenharia, saúde, entre outras e tem vindo a assumir cada vez mais relevância no dia-a-dia das organizações e da sociedade. Assim, tem-se tornado urgente o aparecimento de novas técnicas e ferramentas computacionais capazes de ajudar o ser humano no processo de DCBD.
Ao longo dos anos, o processo de descoberta de padrões/modelos úteis em dados recebeu várias designações, Descoberta de Conhecimento em Base de Dados, Data Mining, Extração de Conhecimento, Descoberta de Informação, Coleta de Informação e Processamento de Padrões entre Dados (U. Fayyad, Piatetsky-Shapiro, & Smyth, 1996b). A DCBD é um processo complexo de extração de conhecimento a partir de grandes bases de dados recorrendo a algoritmos de Data Mining para encontrar padrões úteis nos dados. Por outro lado, Data Mining é considerada uma etapa que intervém em todo este complexo processo e que consiste na aplicação de algoritmos específicos para extrair padrões/modelos em dados.
Segundo Han et al. (Han et al., 2012) muitas vezes os termos Data Mining e DCBD são tratados como sinónimos. Alternativamente, outros autores veem o Data Mining simplesmente como uma etapa essencial no processo de descoberta de conhecimento. Frawley et al. (Frawley et al., 1992) definem o processo de DCBD como "o processo não trivial de identificação de padrões válidos e potencialmente úteis percetíveis a partir dos dados".
Este processo ao contrário da análise de dados tradicional é um processo interativo, uma vez que exige a participação do utilizador em praticamente todas as etapas e iterativo, na medida em que é possível ocorrerem retrocessos a etapas anteriores.
O processo global de DCBD é constituído por diferentes fases, que segundo Santos e Ramos (Santos & Ramos, 2006) incluem a seleção de dados, o tratamento dos dados, o
pré-processamento dos dados, o Data Mining e por fim a interpretação dos resultados. Cada uma destas fases é descrita com mais detalhe de seguida.
Figura 2.5: Etapas do processo de DCBD segundo Santos e Ramos (Santos & Ramos, 2006).
Seleção dos dados
Nesta fase é feita a seleção dos dados armazenados em diversos repositórios de dados tendo em conta os atributos que se considerem úteis, permitindo assim eliminar aqueles que não têm interesse no processo de descoberta de conhecimento, normalmente aqueles que têm caráter meramente informativo.
Tratamento dos dados
Nesta fase procede-se à limpeza de registos duplicados, corrompidos ou inconsistentes.
Os registos duplicados são normalmente originados por negligência na introdução dos dados, pelo incorreto fornecimento dos mesmos ou por erros de digitação. Por exemplo, pode ocorrer que os mesmos dados de um utilizador estarem contidos em diferentes registos e este utilizador ser considerado como duas pessoas distintas.
Esta fase é parte crucial no processo de DCBD, pois a qualidade dos dados vai influenciar os resultados a obter pelos algoritmos de Data Mining.
Pré-processamento dos dados
Esta fase passa essencialmente pela redução do espaço de pesquisa, utilizando métodos de redução ou transformação para diminuir o número de variáveis envolvidas no processo. Esta redução é conseguida transformando atributos com valores contínuos em atributos com valores discretos, nomeadamente através da substituição de idades por faixas etárias (Santos & Ramos, 2006). Com isto, pretende-se melhorar o desempenho dos algoritmos de análise na fase posterior, de Data Mining.
Data Mining
A partir da seleção de algoritmos e técnicas adequadas, procede-se à análise dos dados provenientes da fase anterior de Pré-processamento dos dados. “Não há um método de Data
certa forma uma arte." (U. Fayyad et al., 1996b). O processo de Data Mining raramente fica completo apenas pela aplicação de um único algoritmo, pelo que normalmente são combinados dois ou mais, de acordo com as tarefas a executar.
Interpretação dos resultados
Procede-se à análise dos resultados obtidos pela aplicação de algoritmos de Data Mining. Se os modelos encontrados satisfizerem o interesse do utilizador são então aplicados a novos conjuntos de dados, caso contrário é necessário identificar a razão pelo qual isso sucedeu. Para tal, provavelmente é necessário retroceder a fases anteriores do processo para alterar decisões tomadas ou então incluir novos dados na análise. O processo é posteriormente retomado, de forma a identificar novos modelos resultantes das alterações efetuadas.
Literaturas mais recentes apresentam um modelo do processo DCBD com algumas diferenças relativamente à versão inicial apresentada por Fayyad et al. (U. M. Fayyad, Piatetsky-Shapiro, Smyth, & Uthurusamy, 1996). É exemplo disso a recente versão apresentada por Han et al. (Han et al., 2012), em que o processo de DCBD é constituído por 7 fases, como mostra a Figura 2.6. Estas fases incluem a limpeza dos dados, a integração dos dados, a seleção dos dados, a transformação dos dados, o Data Mining, a avaliação do padrão e por fim a apresentação dos resultados. Cada uma destas fases é descrita com mais detalhe de seguida. Limpeza dos dados
Eliminação de ruído e dados inconsistentes. Integração dos dados
As várias fontes de dados são combinadas. Seleção dos dados
É feita a seleção dos dados armazenados em diversos repositórios para posterior análise.
Transformação
Os dados são transformados e consolidados de forma adequada para a aplicação do processo de Data Mining através da realização de operações de resumo ou agregação.
Data Mining
Aplicação de algoritmos para extrair padrões dos dados. Avaliação dos modelos
Identificação de padrões interessantes, isto é padrões que representam conhecimento para o utilizador.
Apresentação dos resultados
Técnicas de representação e visualização de conhecimento são usadas para apresentar o conhecimento extraído aos utilizadores de forma compreensível.
Figura 2.6: Processo de DCBD segundo Han etl al. (Han et al., 2012).
Depois de apresentadas as fases do processo de descoberta de conhecimento, é de seguida descrita com maior detalhe a fase de Data Mining na qual algoritmos de análise são aplicados sobre os dados.
2.3
Data Mining
Data Mining é considerada a principal etapa do processo de DCBD. Consiste na procura de relacionamentos, modelos ou padrões potencialmente importantes que estão implícitos nos dados armazenados em bases de dados, Data Warehouses, ou outros repositórios de dados.
Fayyad et al. (U. Fayyad et al., 1996b) definem o Data Mining como sendo “uma etapa do processo DCBD que consiste em aplicar algoritmos de descoberta e análise de dados que, sob as limitações de eficiência computacional aceitável, produzem uma enumeração particular de padrões sobre os dados”.
Para que o Data Mining cumpra o seu propósito, ou seja, a descoberta de conhecimento relevante, é importante estabelecer metas bem definidas. Essas metas, ainda segundo Fayyad et al. (U. Fayyad, Piatetsky-Shapiro, & Smyth, 1996a) são definidas em função dos objetivos associados com a utilização do sistema, podendo ser de dois tipos:
Verificação - o sistema está limitado quanto à verificação de hipóteses definidas pelo utilizador.
Descoberta - o sistema é responsável por encontrar de forma automática novos padrões. Este pode, ainda, ser subdividido em previsão e descrição:
Previsão - localiza padrões com a finalidade de prever o comportamento futuro de variáveis ou de novos conjuntos de dados.
Descrição - procura encontrar padrões, compreensíveis pelo utilizador, que descrevam os dados de maneira concisa e resumida, apresentando propriedades gerais interessantes acerca dos mesmos.
Os objetivos de previsão e descrição são alcançados através das seguintes tarefas de Data Mining: classificação, segmentação, sumarização e modelação de dependências (U. M. Fayyad et al., 1996). Cada uma destas tarefas é de seguida descrita com mais detalhe.
Classificação
Classificação é o processo de procura de um modelo ou função que mapeia um conjunto de dados em classes ou categorias predefinidas (U. Fayyad et al., 1996a).
O processo de classificação de dados é dividido em duas fases: treino e teste (Beniwal & Arora, 2012)(Han et al., 2012). Na primeira fase, é identificado um modelo de classificação a partir do conjunto de dados de treino, recorrendo à análise dos registos contidos no mesmo. Na segunda fase, o modelo obtido é usado para classificar sendo assim aplicado ao conjunto de dados de teste permitindo verificar o seu desempenho na classificação de dados desconhecidos. Para que o modelo seja utilizado para classificar novos dados, a sua precisão tem de ser considerada aceitável, o que depende do domínio de aplicação em causa. A precisão do modelo é determinada com base na quantidade de registos classificados corretamente, comparando o
valor real disponível armazenado no conjunto de dados de teste, com o valor previsto pelo modelo (classe identificada pelo modelo para o registo) (Santos & Ramos, 2006).
A classificação de dados é considerada uma tarefa de aprendizagem supervisionada, uma vez que o atributo e as classes que vão levar ao processo de classificação de dados são conhecidos a priori.
Um exemplo de aplicação da classificação de dados é a concessão de crédito bancário a clientes de uma determinada instituição bancária. Os clientes são divididos em classes para a avaliação de concessão de crédito tendo como base alguns atributos, nomeadamente idade, montante salarial, entre outras. Posteriormente, um novo cliente pode ser enquadrado, automaticamente, numa classe de crédito específica, de acordo com os fatores indicados.
Na Figura 2.7 estão representadas amostras que pertencem a diferentes classes, uma representada pelo símbolo “◦” e outra pelo, “*”.
O resultado final da classificação de dados é a linha apresentada na Figura 2.7b. Aplicando esta função, a cada nova amostra, mesmo sem uma saída conhecida, ou seja, a classe a que pertence, estas podem ser classificadas corretamente.
Figura 2.7: Exemplo gráfico da classificação de dados. (a) Conjunto de dados de treino; (b) Função de classificação de dados (Kantardzic, 2011).
Em relação ao tipo de dados, a classificação é utilizada para prever valores discretos ou contínuos. Sempre que o processo de Data Mining inclua a previsão de atributos com valores contínuos, estamos perante uma tarefa de regressão ou estimação. Estimar permite identificar uma função matemática que calcula o valor desconhecido de uma variável, com base no valor dado de uma outra variável (Santos & Ramos, 2006).
Um exemplo de aplicação desta tarefa pode ser, estimar a probabilidade de um paciente sofrer de determinada patologia, dado o resultado de um conjunto de exames realizados.
(a)
(a)
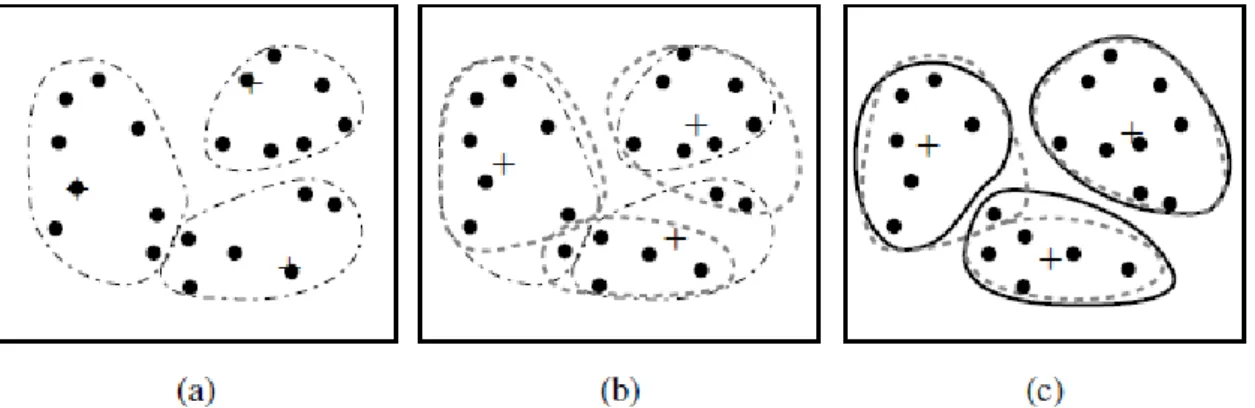
Segmentação
A segmentação ou clustering é responsável por agrupar objetos tendo em conta as suas similaridades em diferentes clusters ou segmentos.
Os clusters formados são baseados no princípio de que os objetos que o constituem devem ser o mais similares possíveis entre si e dissimilares em relação a objetos de outros clusters. Assim, quando se pretende formar clusters seleciona-se um conjunto de atributos que se achem relevantes e em função da similaridade desses atributos são formados os clusters. Estes atributos utilizados para descrever os objetos, são na maioria das vezes comparados utilizando medidas de distância (Han et al., 2012).
A diferença básica entre o clustering e a classificação de dados reside no facto de que no clustering não existem classes predefinidas para classificar os dados em estudo, ou seja, estas são dinamicamente criadas a partir das similaridades entre os objetos, ao contrário da classificação. Deste modo, o clustering representa uma tarefa de aprendizagem não supervisionada.
A Figura 2.8a mostra os dados iniciais para aplicação da tarefa de clustering, os quais são agrupados em três clusters, como mostra a Figura 2.8b, em função da similaridade de atributos escolhidos previamente. Com base nos resultados do processo de clustering, cada novo objecto pode ser atribuído a um dos clusters encontrados anteriormente, usando para tal o critério de similaridade com os objetos constituintes de cada cluster.
Figura 2.8: Exemplo gráfico de clustering. (a) Conjunto de dados de treino; (b) descrição de clusters (Kantardzic, 2011).
Diversos algoritmos de clustering podem ser utilizados na identificação de clusters nos dados. Na secção 2.4 são abordados alguns deles.
Sumariação
Sumariação envolve métodos capazes de encontrar uma descrição compacta para um determinado conjunto ou subconjunto de dados2. Um dos exemplos mais simples de sumariação
é a determinação da média e desvio-padrão de uma amostra (U. Fayyad et al., 1996a).
As tarefas de sumariação são frequentemente utilizadas na análise exploratória de dados, permitindo identificar um conjunto de valores ou descrições capazes de descrever os dados analisados.
Se a descrição é compacta, como apresentado na Figura 2.9b, essa informação pode simplificar e, portanto, melhorar o processo de tomada de decisão num determinado domínio.
Figura 2.9: Exemplo gráfico da sumariação de dados. (a) Conjunto de dados de treino; (b) Descrição formalizada (Kantardzic, 2011).
Modelo de Dependências
O Modelo de Dependência tem como objetivo encontrar um modelo que descreve dependências significativas entre variáveis. Existem dois níveis de modelos de dependência: estruturado e quantitativo. O nível estruturado específica geralmente em forma de gráfico, quais as variáveis que dependem localmente de outras variáveis. O nível quantitativo específica o grau de dependência, usando para tal uma escala numérica.
Na Figura 2.10b é possível identificar duas relações diferentes no conjunto dos dados de treino. Uma relação elipsoidal encontrada para um subconjunto e uma relação linear para outro subconjunto dos dados de treino representados na Figura 2.10a. Estes tipos de modelação são especialmente úteis em grandes conjuntos de dados que descrevem sistemas muito complexos.
Figura 2.10: Exemplo gráfico do modelo de dependências. (a) Conjunto de dados de treino; (b) Dependências locais descobertas (Kantardzic, 2011).
Um exemplo de aplicação de um modelo de dependências, inclui a análise do histórico de vendas de um híper ou supermercado, com o objetivo de se encontrar produtos que tendem a ser adquiridos na mesma compra, como café e leite. Os resultados desta análise podem ser úteis na elaboração de catálogos e layout de prateleiras para que produtos adquiridos na mesma compra, fiquem próximos uns dos outros.
2.4 Técnicas de
Data Mining
Existe uma grande variedade de técnicas de Data Mining, as quais assentam em diferentes algoritmos criados para a extração de conhecimento. As técnicas distinguem-se essencialmente pela forma de representação do modelo, bem como, pelo algoritmo de procura dos parâmetros internos do mesmo (Armando, 2007). São exemplo de técnicas de Data Mining: algoritmos de clustering, árvores de decisão, as regras de associação, as redes neuronais artificiais, a regressão linear, algoritmos genéricos, entre outras.
Nas próximas subsecções são abordados os métodos de clustering bem como as árvores de decisão, devido à sua popularidade e clareza de exposição dos resultados.
2.4.1 Métodos de Clustering
Existe uma grande variedade de algoritmos de clustering descritos na literatura. A escolha do algoritmo a utilizar depende essencialmente do tipo de dados disponíveis e do objetivo que se pretende alcançar.
Normalmente para uma determinada tarefa de clustering, aplicam-se diferentes algoritmos sobre os mesmos dados e analisam-se os clusters obtidos, de forma a escolher o algoritmo que produziu clusters mais adequados à aplicação a que se destinam os dados.
Os métodos de clustering podem ser classificados nas seguintes categorias apresentadas em seguida.
2.4.1.1 Métodos de particionamento
Dado um conjunto de dados D, com n objetos e k o número de clusters pretendidos, os algoritmos de particionamento organizam os objetos em k partições, em que cada partição representa um cluster, tal que k<=n.
Os algoritmos de particionamento mais conhecidos e utilizados são o Means e o k-Medoids, em que cada cluster é representado pelo centro de gravidade do cluster, denominado de centróide, caso se trate do algoritmo k-means, ou por um dos objetos do cluster localizado perto do centro, no caso do algoritmo k-medoid (Ester et al., 1998). Cada objeto é atribuído ao cluster mais próximo, cluster ao qual a distância entre o objeto e o centróide é menor. A divisão obtida tenta maximizar a semelhança intracluster, ou seja, entres objetos dentro do mesmo cluster e minimizar a semelhança intercluster, entre clusters diferentes.
K-means
O algoritmo k-means tem como parâmetro de entrada k, que representa o número de clusters em que os n objetos de um conjunto são particionados, de modo que a semelhança entre os objetos que constituem um cluster seja elevada, e em contrapartida uma semelhança entre diferentes clusters baixa. A semelhança de clusters é medida em relação ao valor médio dos objetos num cluster.
O algoritmo k-means procede da seguinte forma (Han et al., 2012):
1. São selecionados aleatoriamente k objetos, cada um dos quais representa inicialmente o centro ou a média do cluster (centróide).
2. Cada um dos restantes objetos é atribuído ao cluster mais semelhante, com base na distância entre o objeto e o centróide do cluster. O objeto é inserido no cluster ao qual obteve menor distância, ou seja, maior semelhança.
3. Após a primeira iteração, efetua-se o cálculo do novo centroíde de cada cluster. Este processo repete-se até a função de critério convergir.