Escola Superior de Tecnologia de Tomar
Ricardo Marques António
Microsserviços para Reconhecimento de
Emoção em Música
Relatório de Projeto de Mestrado
Orientado por:
Professor Renato Panda, Instituto Politécnico de Tomar Professor Luís Oliveira, Instituto Politécnico de Tomar
Relatório apresentado ao Instituto Politécnico de Tomar para cumprimento dos requisitos necessários
à obtenção do grau de Mestre em Engenharia Informática – Internet das Coisas
i
“Aos que sempre me apoiaram e acreditaram em mim, um muito obrigado.” Ricardo António
iii
RESUMO
O reconhecimento de emoção em música (MER) é uma área de investigação que tem ganho notoriedade nas últimas décadas. Sabemos hoje que a música transmite emoções aos ouvintes, sendo este facto explorado para os mais diversos fins, como o entretenimento, cinema, desporto ou terapia. Por esta razão, investigadores na área de MER têm estudado a possibilidade de criar sistemas capazes de reconhecer de forma automática a emoção presente num sinal musical áudio. Este processo é extremamente complexo, tocando diversas áreas como a psicologia, com as taxonomias de emoção, mas também de ciência da computação, com processamento de sinal e aprendizagem automática, assim como a área da música. Desta forma, grande parte dos avanços permanece ainda fechada no meio académico, existindo poucos ou nenhuns sistemas deste tipo disponíveis.
Este projeto visou criar um protótipo sistema robusto e escalável que sirva para demonstrar o conceito de um sistema de MER. Para isso junta os vários conceitos do estado da arte na área com metodologias modernas de engenharia de software, originando um sistema que obtém o áudio de vídeos do YouTube, sumariza o mesmo em características e classifica-o em quatro emoções distintas: alegria, agressividade, tristeza e tranquilidade. Foram desenvolvidos microsserviços distintos que implementam estas funcionalidades, através de uma arquitetura que os torna independentes, escaláveis, robustos e de alto desempenho. Este sistema vem contribuir também para a área de MER, pois facilita a divulgação da mesma fora do meio académico.
v
ABSTRACT
Music Emotion Recognition (MER) is a research area that has gained notoriety in recent decades. We know today that music transmits emotions to listeners, and this fact is exploited for various purposes, such as entertainment, cinema, sports or therapy.
For this reason, researchers in the area of REM are studying the possibility of creating systems that can automatically recognize the emotion present in an audio musical signal. This is an extremely complex process, touching many areas such as psychology, with the taxonomies of emotion, but also computer science, with signal processing and automatic learning, as well as the area of music.
In this way most advances remain closed in the academic world, with few or no such systems available.
This project aimed to create a robust and scalable prototype system that serves to demonstrate the concept of a MER system. For this, it joins several state-of-the-art concepts in the area with modern software engineering methodologies, that origins a system that obtains audio from You Tube videos, summarizes it into characteristics and classifies it into four distinct emotions: joy, aggressiveness, sadness and tranquility. Distinct microservices have been developed that implement these functionalities through an architecture that makes them independent, scalable, robust and high performance.
This system also contributes to the MER area as it facilitates the divulgation outside the academic world.
vii
AGRADECIMENTOS
Este trabalho não teria sido possível sem a presença de um conjunto de pessoas na minha vida, pelo que lhes dedico este trabalho como forma de gratidão por todo o apoio, suporte e amor que me deram durante as fases mais complicadas deste ano extremamente difícil. Para os meus pais Hélder e Irene, o meu irmão Tiago e a minha namorada Sílvia. O meu muito obrigado.
Ao Professor Doutor Renato Panda pelo suporte, incentivo e disponibilidade que sempre me ofereceu. Pelo tempo e apoio que me deu nas fases mais árduas do projeto e também durante este ano difícil, um especial obrigado.
Um obrigado também ao Professor Doutor Luís Oliveira e à professora Doutora Ana Cristina Lopes pelo apoio e disponibilidade durante este árduo ano.
Aos professores do Mestrado de Engenharia Informática do Instituto Politécnico de Tomar um obrigado pela partilha de conhecimento e disponibilidade demonstradas durante os dois anos de mestrado.
Finalmente, aos meus colegas David Bernardo, Diogo Mendes, Luís Nunes, Pedro Dias e Rafael Escudeiro um obrigado pelo apoio prestado e a total disponibilidade em ajudar.
ix
ÍNDICE
RESUMO ... iii ABSTRACT ... v AGRADECIMENTOS ... vii ÍNDICEÍNDICE DE FIGURAS ... ixÍNDICE DE FIGURAS ... xiii
ÍNDICE DE TABELAS ... xv
GLOSSÁRIO ... xvii
Capítulo 1 Introdução ... 1
1.1. Organização do Relatório ... 3
Capítulo 2 Estado da Arte ... 5
2.1. Contexto do Panorama Atual ... 6
2.2. Plataformas de Streaming ... 6 2.2.1. Spotify ... 6 2.2.2. Apple Music ... 7 2.2.3. YouTube Music ... 8 2.2.4. Tidal ... 8 2.2.5. MOODetector ... 8 2.2.6. Shazam ... 9
Índice Microsserviços para Reconhecimento de Emoção em Música
2.2.7. Considerações Finais sobre Plataformas de Streaming ... 10
2.3. Taxonomias da Emoção ... 10
2.3.1. Conceptualização Categórica da Emoção ... 11
2.3.2. Conceptualização Dimensional da Emoção ... 12
2.3.3. Considerações Finais ... 13
2.4. Abordagem Típica dos Sistemas de MER ... 14
2.4.1. Conjuntos de Dados ou Datasets ... 16
2.4.2. Frameworks para Tratamento do Sinal Áudio ... 17
2.4.3. Algoritmos de Aprendizagem Computacional ... 22
2.4.4. Implementações de Máquinas de Vector de Suporte (SVM) ... 28
Capítulo 3 Planeamento e Desenvolvimento ... 31
3.1. Arquitetura Geral do Sistema ... 31
3.2. Mecanismos de Orquestração de Containers ... 38
3.2.1. Docker ... 38
3.2.2. Kubernetes ... 41
3.3. Mecanismos de Comunicação entre Processos ... 42
3.3.1. Apache Kafka ... 43
3.3.2. Open Message Queue ... 44
3.3.3. RabbitMQ ... 46
Microsserviços para Reconhecimento de Emoção em Música Índice
xi
3.4. Linguagens Utilizadas nos Microsserviços ... 48
3.4.1. Python ... 48
3.4.2. JavaScript ... 49
3.4.3. Ruby ... 50
3.4.4. MATLAB ... 51
3.4.5. Considerações finais ... 51
Capítulo 4 Desenvolvimento da Solução ... 53
4.1. Aplicação Web ... 55
4.2. Comunicação entre Microserviços ... 57
4.3. Extração de Vídeo e Conversão Áudio ... 58
4.4. Extração de Características Musicais... 60
4.5. Classificação Emocional do Sinal Áudio ... 63
4.5.1. Treino do Modelo de Classificação ... 63
4.5.2. Processo de Previsão de Emoção ... 65
4.5.3. Precisão do Sistema de Classificação ... 66
4.6. Trabalho Futuro ... 66
Capítulo 5 Conclusão ... 69
xiii
ÍNDICE DE FIGURAS
Figura 1 - Arquitetura Geral da Solução ... 3
Figura 2 - Expressões Faciais usadas nas emoções básicas de Ekman ... 11
Figura 3 - Círculo de adjetivos de Hevner ... 12
Figura 4 - Representação de emoções através do espaço Valence-Arousal, segundo o modelo de Russell ... 13
Figura 5 - Estratégia de aprendizagem computacional supervisionada aplicada em MER . 16 Figura 6 – Exemplo de uma árvore de decisão ... 24
Figura 7 - k-Nearest Neightbour ... 25
Figura 8 - SVM, processo de maximização da margem ... 26
Figura 9 - Arquitetura Geral da Solução ... 33
Figura 10 - Arquitetura Monolítica e Arquitetura de Microsserviços ... 37
Figura 11 - Aplicações executadas em containers de Docker ... 39
Figura 12 - Arquitetura de Apache Kafka ... 44
Figura 13 - Arquitetura do OpenMQ ... 45
Figura 14 - Arquitetura geral do RabbitMQ ... 47
Figura 15 - Solução Final com tecnologias utilizadas ... 55
Figura 16 - Página principal da aplicação Web ... 56
Índice de Figuras Microsserviços para Reconhecimento de Emoção em Música
xiv
Figura 18 - Fluxo de produção e consumo dos microsserviços ... 58 Figura 19 - Diagrama de funcionamento do microsserviço de extração e conversão de vídeo ... 60 Figura 20 - Diagrama de funcionamento do microsserviço de extração de características 62 Figura 21 - Processo de extração das características das músicas do dataset ... 63 Figura 22 - Processo de treino do modelo e obtenção do scaler ... 64 Figura 23 - Diagrama de funcionamento do microsserviço de classificação ... 65
xv
ÍNDICE DE TABELAS
Tabela 1 - Comparação das diferentes ferramentas de extração de características ... 22 Tabela 2 - Instâncias com dados de entrada e suas correspondentes saídas ... 23 Tabela 3 - Comparação dos diferentes algoritmos de classificação supervisionada ... 27
xvii
GLOSSÁRIO
Arousal CD-ROM
Excitação – energia e nível de estimulação
Compact Disk Read-Only Memory - Memória só de leitura em Disco
Compactado
Feature Qualquer característica específica que permite descrever/diferenciar algo, por exemplo a cor dos olhos, batidas por minuto, duração de algo
Framework Conjunto de bibliotecas e ferramentas
Playlist Lista de Músicas
MER Music Emotion Recognition - Reconhecimento de emoção em música
MIR Music Information Retrieval - Recolha de informação em música
Streaming Transmissão contínua de dados
Valence Valência – estados positivos ou negativos relacionados com o sentimento
1
Capítulo 1
Introdução
A música tem estado presente na história da nossa espécie desde que há memória. Normalmente associada ao entretenimento, a música tem vários outros fins onde é utilizada e a prova disso é a sua utilização em acontecimentos marcantes, como cerimónias religiosas, aniversários, eventos desportivos ou até os hinos de países. Isto acontece porque a música é muito mais que um conjunto de alterações de pressão de ar, tendo a capacidade de transmitir várias emoções (Juslin, 2013), proporcionando bem-estar pessoal e social e tendo várias utilizações nas mais diversas áreas do dia-a-dia. Por outro lado, “nunca houve uma tão vasta coleção de música a ser criada e a ouvida diariamente” (Chen, 2012) e a principal razão deve-se à facilidade com que, atualmente, esta pode ser acedida através da Internet.
Ao longo do tempo, os métodos de gravação e distribuição de música têm vindo a evoluir, desde os formatos analógicos, como o vinil e cassetes, até aos formatos digitais compactos, como CD-ROM. Atualmente é comum ouvir música através dos serviços de streaming como o Spotify1 ou YouTube2. Estes serviços disponibilizam catálogos de milhões de músicas dos mais diferentes géneros, nacionalidades e eras. Esta oferta gera um grande problema de excesso de informação, pois uma tão vasta coleção de músicas é difícil de consultar utilizando os métodos de pesquisa típicos, normalmente com base no título da música, artistas ou outros meta-dados definidos manualmente (Chen, 2012). Em alternativa a estas pesquisas, estes serviços dispõem de várias playlists, mas estas são por norma criadas por outros utilizadores ou geradas com base nos históricos de reproduções e não no conteúdo do sinal musical. No entanto, tendo a música um papel tão importante ao nível de transmissão de emoções, seria interessante explorar esta informação automaticamente, como por exemplo fazendo a catalogação automática (sem intervenção humana) das músicas através do sentimento que elas nos transmitem. Alguns destes serviços, por vezes,
1https://www.spotify.com/pt/
Capítulo 1. Introdução Microsserviços para Reconhecimento de Emoção em Música
2
já suportam alguma pesquisa por “moods” (humores), permitindo por exemplo procurar músicas felizes. No entanto, por norma a base desta pesquisa não é feita através da análise do sinal de áudio, mas sim através de etiquetas que foram atribuídas por outros utilizadores (por exemplo no last.fm3).
Surge então a área de reconhecimento de emoções em música (MER), um campo de investigação ainda em aberto, ou seja, no qual ainda existem diversas questões em aberto, que tem vindo a ser abordado nas últimas décadas pela comunidade científica na área de extração/recuperação de informação musical (Music Information Retrieval, MIR). O processo em si é complexo pois lida com diferentes áreas como: psicologia (emoção) e ciência da computação (processamento de áudio e inteligência artificial). Alguns dos estudos científicos publicados, como o realizado por (Panda & Pedro Paiva), deram origem a protótipos e ferramentas que servem de conceitos. Este processo, por norma, segue um processo semelhante ao ilustrado na Figura 5 (disponível na página 16, onde é descrito de forma mais aprofundada), e passa pela análise e processamento de sinais de áudio de um conjunto de dados de treino devidamente etiquetados emocionalmente, a fim de extrair as suas características musicais, utilização de mecanismos de reconhecimento automático para treinar um modelo capaz de reconhecer padrões entre as características extraídas e respetivas etiquetas emocionais, e utilização do modelo gerado para obter (prever) a classificação emocional de uma nova música através das características extraídas desta nova música.
Sendo assim, o objetivo deste projeto consiste em desenvolver um protótipo web capaz de reconhecer emoções em música/vídeos do YouTube. Para tal, este deve seguir a abordagem típica usada no estado da arte de MER. Dada a complexidade computacional associada a determinadas tarefas (como o processamento áudio e classificação), o sistema deve ser escalável, robusto e bem organizado para que seja possível alterar cada um dos módulos facilmente. Como ilustrado na Figura 1, a abordagem recai na utilização de uma arquitetura de microsserviços isolados, em que cada um é independente e responsável
Microsserviços para Reconhecimento de Emoção em Música Capítulo 1. Introdução
3
apenas por efetuar uma tarefa específica (ex. classificação). Ao contrário do processo tradicional, onde as tarefas são executadas de forma síncrona, numa sequência de eventos bem definida, estes serviços comunicam através de uma fila de mensagens que tem como base um mecanismo de produção/consumo. Assim, cada microsserviço aguarda uma nova tarefa específica para si na fila de mensagens (consumo), desencadeada através da criação de uma nova mensagem. Depois de realizar a tarefa, o microsserviço publica uma nova mensagem na fila e volta ao estado de espera de uma mensagem. Esta abordagem permite tornar cada uma das tarefas assíncronas e independentes, podendo até serem executadas várias réplicas de um mesmo microsserviço caso a sua tarefa seja mais demorada.
Figura 1 - Arquitetura Geral da Solução
1.1. Organização do Relatório
O presente relatório está organizado da seguinte forma: o capítulo 1 apresenta uma introdução de alto nível do trabalho realizado, no capítulo 2 é abordado o estado de arte na área e descrito o processo de reconhecimento emocional em música. De seguida, o capítulo
Capítulo 1. Introdução Microsserviços para Reconhecimento de Emoção em Música
4
3 descreve a arquitetura do sistema implementado e as tecnologias utilizadas. No capítulo 4 apresentamos a informação relativa ao processo de implementação do sistema. Por fim, o capítulo 5 finaliza este trabalho, traçando a conclusão e algumas ideias para trabalho futuro.
5
Capítulo 2
Estado da Arte
Nesta secção é apresentada uma revisão do estado da arte na área do reconhecimento emocional em música. Nesse sentido, a secção 2.1 serve para dar um contexto do panorama atual, seguida da descrição de algumas das plataformas de streaming existentes no mercado de forma a perceber como é feita a procura de músicas, na secção 2.2. São também apresentados alguns protótipos desenvolvidos no âmbito de projetos de investigação que implementam funcionalidades de MER. Na secção 2.3 são abordadas as diferentes taxonomias de emoção, ou seja, os métodos propostos e aceites pela comunidade científica para identificar e representar as várias emoções. Na secção 2.4 é exposto o processo aprendizagem computacional relacionada com MER. A aprendizagem computacional é um processo estruturado que passa por três partes distintas:
• Obtenção de um conjunto de dados verdadeiros (ground truth), isto é, escolha de um dataset;
• Extração de características musicais a partir do sinal áudio, realizado através de algumas frameworks de tratamento do sinal de áudio;
• Reconhecimento de padrões entre as características extraídas do conjunto de dados e respetivas etiquetas, para a classificação futura de novos exemplos (Panda R. E., 2019). Este processo recorre a algoritmos de aprendizagem de máquina e bibliotecas que os aplicam;
Diversos trabalhos, como os realizados por (Panda, Malheiro, & Paiva, 2018) e (Yang, Lin, Su, & H. Chen) têm vindo a ser apresentados seguindo esta abordagem, utilizando não apenas sinais de áudio, mas também texto das líricas, como (Malheiro, Panda, Gomes, & Pedro Paiva), variando datasets e classificadores. A Figura 5 (localizada na página 18) demonstra todo o processo pelo qual é necessário passar para obter um resultado. Para uma visão histórica, consultar o capítulo 3.2 de (Panda R. E., 2019).
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
6
2.1. Contexto do Panorama Atual
A área de investigação que aborda o reconhecimento de emoção em música tem vindo a crescer ao longo das últimas décadas, servindo-se do conhecimento produzido em várias áreas científicas, especialmente aquelas relacionadas com a extração e recolha de informação em sinais de áudio e a aprendizagem computacional (Panda, Malheiro, & Paiva, 2018). Os avanços neste tópico de investigação, juntamente com o rápido crescimento das plataformas de streaming de música, vão levando a que haja cada vez mais interesse por parte da indústria em desenvolver ferramentas que permitem a extração e recolha de informação de um sinal de áudio para auxiliar na análise e catalogação das bases de dados musicais. Estas aplicações atuais que têm como base o streaming de música oferecem, na sua maioria, uma catalogação baseada em meta-dados definidos manualmente, como os artistas, álbuns, géneros musicais, entre outros (Chen, 2012), excluindo aqueles originados pelo tratamento do sinal áudio em relação ao sentimento transmitido.
2.2. Plataformas de Streaming
Existem várias plataformas que fornecem serviços automatizados de busca e organização de músicas. Porém, como referido anteriormente, esta catalogação é normalmente feita através de etiquetas definidas manualmente por humanos, tais como o título da música, nome do álbum ou autor, sendo que mesmo nestes casos é ainda incomum a catalogação da música pela emoção transmitida. Alguns exemplos destes são listados de seguida.
2.2.1. Spotify
O Spotify é uma plataforma de streaming de música, com uma versão gratuita e outra paga. Está disponível para telefone, computador, tablet, entre outros, e fornece milhões de
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
7
faixas e álbuns. Permite pesquisar músicas através de metadados como o nome da música ou álbum e organizar e filtrar através ordem alfabética, do título da música, do artista ou do álbum, entre outros campos. A aplicação permite navegar pelas listas de música dos amigos, de artistas ou celebridades, e permite ainda criar uma estação de rádio ou ouvir a lista de música sugerida diariamente4. Esta playlist diária é baseada nos diferentes géneros
de música ouvidos pelo utilizador. Existe ainda uma categoria “Mood”, em que é composta por diversas playlists geradas pelo sistema, por exemplo “Chill total”, “Hits felizes”, “canta no carro”5. No entanto, estas categorias são por norma geradas com base em padrões de leitura dos utilizadores, género musical e outras e não necessariamente uma emoção em específico.
2.2.2. Apple Music
A Apple Music é uma plataforma de streaming fornecida pela Apple, disponível no iTunes e também disponível para dispositivos iOS e Android. Disponibiliza atualmente 50 milhões de músicas e a sua audição pode ser feita com o dispositivo offline através do seu download. Permite pesquisar através do nome da música ou álbum, criar listas de reprodução e ouvir as listas de músicas que são sugeridas pela Apple Music, baseadas no que o utilizador tem ouvido. Também é possível criar um perfil, seguir amigos e ouvir as playlists que eles partilham. A aplicação permite ainda seguir as letras da música e ver as músicas mais tocadas. Este serviço tem três planos de pagamento, sendo que cada um é gratuito durante os três primeiros meses6.
4https://www.spotify.com/pt/about-us/contact/
5https://open.spotify.com/genre/mood-page
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
8
2.2.3. YouTube Music
YouTube Music é uma plataforma desenvolvida pelo YouTube para desktop, iOS e Android, que fornece “álbuns oficiais, músicas, vídeos, remixes, performances ao vivo e muito mais”7. Esta plataforma permite a pesquisa de música através de álbuns, nomes de artista, nomes da música e até pesquisa pela letra da música ou sua descrição. Este processo de pesquisa através da letra ou descrição é realizada através de inteligência artificial8.
2.2.4. Tidal
Tidal é uma plataforma pertencente aos artistas: Alicia Keys, Arcade Fire, Beyoncé, Calvin Harris, Claudia Leite, Clifford “T.I” Harris, Coldplay, Daft Punk, Deadmau5, Jack White, Jason Aldean, J. Cole, Kanye West, Madonna, Nicki Minaj, Rihanna, Jay Z, Damian Marley, Indochine, Lil Wayne e Usher. Esta plataforma tem como objetivo “aproximar os artistas dos seus fans através de conteúdo único e experiências exclusivas”9. A Tidal tem
60 milhões de músicas e acima de 250 mil vídeos de alta qualidade. Permite a pesquisa de músicas através do nome, álbum, artista ou até algumas palavras-chave presentes na música10.
2.2.5. MOODetector
Para além dos serviços de streaming comerciais existentes hoje no mercado, existem também alguns protótipos de sistemas MER disponibilizados por alguns grupos de
7https://music.youtube.com/
8https://music.youtube.com/
9https://tidal.com/whatistidal
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
9
investigação. Estas são por norma pequenas provas de conceito com funcionalidade limitada, que foram criadas por forma a mostrar ao público em geral as possibilidades que o campo de MER oferece. Um desses casos é o MOODetector, uma aplicação protótipo desenvolvida pela equipa de MIR do Centro de Investigação em Informática e Sistemas da Universidade de Coimbra, reconhecendo a emoção de uma música e deteção de variações da emoção desta ao longo do tempo. O protótipo utiliza para extração de características a biblioteca Marsyas (introduzida na secção 0). “Realizado para ser utilizado como um típico reprodutor de música, permite a procura de música instantaneamente através do nome da música ou artista, organização de músicas através do nome da música, artista, valores de “arousal” e “valence” e permite ainda observar estatísticas relacionadas com as músicas já analisadas” (Cardoso, Panda, & Pedro Paiva). Além destas funcionalidades todas, a biblioteca faz detenção de humor nas músicas ou ao longo da música, estimando os valores de “arousal” e “valence”. Esta ferramenta sofre, no entanto, de alguns problemas de estabilidade de desempenho, estando o mecanismo de classificação emocional ainda a ser corrigido numa nova versão de nome MOODetector Reloaded.
2.2.6. Shazam
Para além da área de MIR existem hoje diversas aplicações que fazem abordagens semelhantes com outros fins. Um dos exemplos mais conhecidos é o Shazam, uma aplicação disponível para dispositivos móveis que faz identificação automática de músicas com base em apenas alguns segundos. O método funcional do Shazam é baseado na ideia de criar uma impressão digital para cada música. O processo de criação da impressão digital é o processo no qual se obtém hashs de tokens de reprodução. Depois, a impressão digital resultante, é procurada na base de dados de músicas até serem encontradas algumas impressões parecidas. Essas impressões são avaliadas e a música resultante é que a tem mais pontos comuns com a impressão digital recolhida11.
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
10
2.2.7. Considerações Finais sobre Plataformas de Streaming
Como verificado, existem várias plataformas de streaming de música e todas estas têm ajudado no rápido desenvolvimento de novos mecanismos de MIR. No entanto, é difícil encontrar alguma aplicação comercial que forneça um serviço idêntico ao que se pretende com este trabalho, mesmo os sistemas que aplicam algum reconhecimento de emoção em música são por norma conceitos académicos e pouco estáveis. O principal objetivo destas plataformas passa pela disponibilização da música ou de vídeo com boa qualidade, tentando agradar ao utilizador pela sugestão playlists mais específicas. Devido a isso, é normal que no futuro venham a incluir também elas mecanismos de pesquisa emocional. Atualmente, estes serviços utilizam etiquetas definidas manualmente, como os nomes dos artistas, títulos da música, géneros musicais, álbuns. Em alternativa, oferecem listas de reprodução criadas por utilizadores ou com base no histórico de consumo dos seus utilizadores, excluindo na sua maioria a análise do sinal de áudio. Tendo isto em conta, este trabalho tem como objetivo a criação de um sistema protótipo que junte a parte do streaming de música e o tratamento de sinal de áudio disponibilizando informação emocional. Para tal segue a ideia inicial da plataforma MOODetector (pois esta já utiliza inteligência artificial para reconhecimento de emoção no sinal áudio), utilizando, no entanto, o áudio disponibilizado pelo serviço de streaming, seguindo uma abordagem de desenvolvimento mais robusta e que permita posteriormente incluir modelos emocionais mais fiáveis.
2.3. Taxonomias da Emoção
Para nós humanos identificar uma música como alegre ou triste é algo inato. Este processo é, no entanto, algo subjetivo, uma vez que um mesmo estímulo é por vezes identificado com emoções distintas por diferentes pessoas. Assim, o primeiro passo para qualquer sistema de MER é escolher uma taxonomia de emoção a utilizar no sistema, pois os resultados do processo de classificação serão representações das emoções segundo esta. As
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
11
várias taxonomias propostas na área da psicologia dividem-se em duas conceptualizações distintas.
2.3.1. Conceptualização Categórica da Emoção
A conceptualização categórica da emoção utiliza um conjunto de palavras, por exemplo tristeza ou felicidade, para reconhecer a emoção. Existem diversos modelos deste tipo, como por exemplo as emoções básicas propostas por Ekman (Ekman), que utilizam expressões faciais para categorização, como a Figura 2, e o círculo de adjectivos de Hevner [Hevner’s Adjective Circle], criado por Kate Hevner (Hevner), que categoriza a emoção através de conjuntos de adjetivos divididos em vários grupos, como representado na Figura 3.
Figura 2 - Expressões Faciais usadas nas emoções básicas de Ekman12
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
12
Figura 3 - Círculo de adjetivos de Hevner13
2.3.2. Conceptualização Dimensional da Emoção
A conceptualização dimensional da emoção aborda a emoção como “escalável e medível por descritores contínuos ou simplesmente por métricas multidimensionais” (E. Kim, et al., 2010), isto é, a categorização de emoção através de valores representados em planos dimensionais. Entre os vários modelos que existem, o mais utilizado é o modelo circumplexo de emoção de Russell [Russell’s Circumplex Model of Emotion], representado na Figura 4, que utiliza quatro quadrantes, definidos pelos eixos de valência (valence) e pela excitação (arousal), que representam no quadrante 1 as emoções felizes, no quadrante
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
13
2 as emoções ansiosas ou agressivas, no quadrante 3 para as depressivas e no quadrante 4 as emoções calmas.
Figura 4 - Representação de emoções através do espaço Valence-Arousal, segundo o modelo de Russell14
2.3.3. Considerações Finais
Existem vários modelos em cada uma das duas abordagens, categóricas e dimensionais. As categóricas têm a vantagem de serem mais fáceis, próximos do que nós humanos estamos habituados a usar. Por outro lado, são mais limitados por dividirem um conjunto grande em N categorias, não permitindo por exemplo distinguir músicas dentro de uma categoria (100 músicas tagged como alegre são todas iguais para efeitos de pesquisa).
Os modelos dimensionais resolvem este problema, já que cada ponto num mapa 2 ou 3D representa uma emoção diferente. No entanto estes modelos levantam um novo conjunto de problemas: são computacionalmente mais complexos e também são mais complexos
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
14
para nós humanos, pois não estamos habituados a usar A e V para demonstrar a nossa emoção.
Assim, como o âmbito deste trabalho é criar um conceito de software, foi seguido o modelo categórico com os 4 quadrantes de Russell, e utilizado o dataset do conjunto de dados do paper: (Panda, Malheiro, & Paiva, Novel audio features for music emotion recognition, 2018).
2.4. Abordagem Típica dos Sistemas de MER
À semelhança de outros problemas de recuperação de informação (information retrieval), um sistema de reconhecimento de emoções em música contém por norma 3 partes distintas, tal como representado na Figura 5: construção de um conjunto de dados etiquetado emocionalmente (dataset), processamento e análise do sinal áudio e aprendizagem automática.
Na criação do dataset, um conjunto de exemplos musicais é selecionado e etiquetado emocionalmente por um conjunto de voluntários, seguindo a taxonomia selecionada. De seguida, os ficheiros áudio são processados através de algoritmos que irão fazer a extração e sumarização das suas características (por exemplo, o número médio de batidas por minuto), integrando os dados temporais (por exemplo em média e desvio-padrão) e preparando-os para descartar os possíveis valores que poderão reduzir a eficiência do modelo.
A fase de aprendizagem computacional pode ser dividida em 3 partes: treino, teste e classificação. O processo de treino é “uma representação matemática de um processo da vida real”15, neste caso a identificação de padrões entre características do sinal e etiquetas
emocionais que permitam a classificação de uma emoção, e é gerado na fase de treino
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
15
através do processamento de um algoritmo de aprendizagem sobre as características (ou features) de um dataset. Este processo é por norma realizado apenas com um subconjunto das músicas do dataset original, sendo as restantes reservadas para testar a precisão do classificador gerado.
A fase de testes é realizada depois de obtido um modelo treinado, onde as músicas do dataset que não foram utilizadas no treino do classificador são agora fornecidas ao modelo treinado a fim de obter a sua classificação emocional. Esta classificação prevista é comparada com a etiqueta real, obtendo um valor de precisão do classificador, o que nos permite por exemplo afirmar que o modelo é capaz de acertar em 60% das previsões. Posteriormente, o processo de classificação em ambiente real passa pela obtenção de um novo sinal de áudio, extração das suas características (as mesmas utilizadas no processo de treino do modelo) e finalmente a classificação emocional utilizando o melhor modelo obtido no processo anterior. Esta classificação é uma classe resultante do processamento do modelo sobre as características extraídas do sinal.
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
16
Figura 5 - Estratégia de aprendizagem computacional supervisionada aplicada em MER16 As secções seguintes apresentam detalhe adicional sobre cada uma das fases ilustradas.
2.4.1. Conjuntos de Dados ou Datasets
Um dataset é um conjunto de dados devidamente estruturados, balanceados e credíveis, composto pelo sinal de áudio e pela sua anotação, previamente dada por um humano, que irá ser utilizado com o intuito de treinar um modelo de classificação. Esta anotação pode
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
17
ser obtida utilizando dados discretos (por exemplo etiquetas de emoção: triste, calma, entre outras) ou então valores contínuos (por exemplo os valores de excitação (“arousal”) ou valência (“valence”) de uma música. Apesar de parecer uma tarefa simples, é extremamente complicado encontrar um bom conjunto de dados para podermos utilizar na área de MER, uma vez que é uma tarefa complexa e intensiva em termos de recursos (voluntários), ainda mais considerando que nem sempre há um consenso acerca de emoções, como referido por (Chen, 2012). A maior parte dos projetos utilizam conjuntos de dados desenvolvidos pelos próprios colaboradores dos projetos, despendendo muito tempo para a realização de um conjunto de entradas válidas (no nosso caso músicas), resultando em conjuntos pequenos, não excedendo normalmente 1000 entradas (Chen, 2012). Tendo um conjunto de dados pequeno torna o processo de aprendizagem menos robusto e generalizável.
De entre os conjuntos que poderiam ser utilizados, a escolha recaiu sobre um dataset proposto por MOODetector (Panda, Malheiro, & Paiva, 2018), composto por 900 excertos musicais de 30 segundos, cada um etiquetado segundo uma taxonomia categórica, utilizando uma das “quatro classes emocionais pertencentes ao modelo circumplex de emoção de Russell [Russell’s Circumplex Model of Emotion]. Este conjunto foi validado por um método semiautomático (anotações AllMusic17, juntamente com uma validação humana mais simples), para reduzir os recursos necessários para construir um dataset completamente manual)” (Panda, Malheiro, & Paiva, 2018).
2.4.2. Frameworks para Tratamento do Sinal Áudio
Ao entrarmos no processo de recolha ou recuperação de informações de uma música, a extração de características de um sinal áudio é extremamente importante para todo o processo. As características são informações que são extraídas de um sinal áudio para que
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
18
depois possam ser analisadas e se consiga obter um padrão, através de inteligência artificial (Moffat, Ronan, & D. Reiss, 2015). Estas características são a base de muitas pesquisas no campo do reconhecimento de emoção em música, mas também de outros campos de MIR como o de efeitos digitais de áudio (Panda R. E., 2019). Alguns exemplos simples destas características são o zero crossing rate, onde é verificado o número de vezes que o sinal passa pelo eixo dos x, ou por exemplo informação sobre o número de batidas por minuto. Pondo de parte todos os problemas acerca da definição e representação de uma emoção que aparecem na criação do dataset, também o processamento de sinal introduz novas dificuldades. Nomeadamente o facto de existir muita informação transmitida num sinal de áudio que ainda hoje é difícil de extrair utilizando um sistema computacional. Por outro lado, de entre as várias características, é difícil saber quais as melhores para identificar uma emoção.
Ao longo das décadas foram propostos vários algoritmos de processamento de sinal, que atualmente são agrupados em frameworks áudio. Algumas destas têm como principal objetivo serem mais intuitivas para utilizador (educacionais), enquanto outras foram desenvolvidas com o foco na eficiência computacional, por exemplo para serem utilizadas na indústria, ou são simples conceitos académicos (Panda R. E., 2019).
De seguida, serão apresentadas de forma breve algumas das frameworks que são mais vulgarmente utilizadas. Para uma explicação mais detalhada sobre estas consultar (Moffat, Ronan, & D. Reiss, 2015).
Essentia
Essentia é uma biblioteca open-source desenvolvida em C++ para análise de áudio e recolha de informação do sinal áudio. Implementa uma coleção de vários algoritmos, entre os quais as funções típicas, como filtros, para o processamento de sinal digital, caraterização estatística de dados e grande conjunto de descritores musicais espetrais, temporais, tonais e de alto nível. É multiplataforma e focada na robustez, velocidade
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
19
computacional e utilização de pouca memória. Esta biblioteca também permite a utilização de comandos e extensões em Python, o que leva ao desenvolvimento e obtenção de resultados muito rapidamente18.
jMir
jMir é um conjunto de aplicações open-source implementadas em Java para a investigação na área de MIR. Pode ser utilizado para estudar música em diversos formatos, desde gravações áudio, codificações simbólicas como o MIDI e transcrições líricas, podendo também extrair (data mining) informações culturais da Internet. Inclui também ferramentas para gerir e criar perfis com base em largas listas de músicas e verificar áudio quanto a erros de produção. O jMir inclui também software para extrair características, aplicar algoritmos de aprendizagem computacional, aplicar verificadores de erros heurísticos e analisar meta-dados. O principal objetivo do jMir é providenciar software para investigação em classificação automática de música e análise de similaridade19.
LibROSA
LibROSA é uma biblioteca desenvolvida em Python para análise de música e áudio que “fornece os componentes necessários para criar sistemas de MIR”20. Como referido pelos criadores desta biblioteca (McFee, et al., 2015), os principais objetivos desta são: ter uma curva de aprendizagem reduzida para investigadores mais familiarizados com MATLAB, garantir a padronização de interfaces, nomes de variáveis e configurações de parâmetros em várias funções de análise, manter compatibilidade com versões anteriores da biblioteca, assim como com implementações de referência existentes e ter um código legível,
18https://essentia.upf.edu/documentation/
19http://jmir.sourceforge.net/
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
20
documentação completa e testes exaustivos. Como a área de MIR está em constante evolução, é reconhecido que as implementações do LibROSA podem não representar o estado da arte a cada momento. Consequentemente, as funções são desenhadas para serem modulares, permitindo que os utilizadores se sirvam destas para implementar as suas próprias funções quando for necessário. Uma explicação mais detalhada está disponível em (McFee, et al., 2015).
Marsyas
Marsyas, acrónimo para Music Analysis, Retrieval and Synthesis for Audio Signals é uma framework de software open-source em C++ para processamento de áudio com ênfase específico nas aplicações MIR21. A framework oferece um conjunto de blocos básicos como filtros, transformadas, acumuladores, entre outros, que podem ser combinados em sequência ou paralelamente, que permitem implementar novos algoritmos de forma flexível e providenciar boa performance. Oferece também um conjunto de aplicações de demonstração das suas funcionalidades. Num entanto esta flexibilidade torna a framework mais complexa, não tendo documentação suficiente para mitigar este problema 22.
MIR Toolbox
MIR Toolbox é um conjunto integrado de funções (toolbox) escritas em MATLAB, dedicado à extração de características musicais como tonalidade, ritmo, timbre, melodia, entre outras, em sinais de áudio. O objetivo é oferecer uma implementação fácil de usar dos vários algoritmos computacionais na área de MIR. O design é baseado numa estrutura modular: os diferentes algoritmos estão decompostos em diferentes estágios, formalizados utilizando um pequeno conjunto de mecanismos elementares. Esses blocos de construção
21http://marsyas.info/
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
21
formam o vocabulário básico desta ferramenta, que pode ser livremente articulado de diferentes maneiras novas e originais. Esses mecanismos elementares integram muitas vezes diferentes variantes propostas por abordagens alternativas de diferentes investigadores, que os utilizadores podem selecionar e parametrizar. Esta ferramenta foi inicialmente desenvolvida no contexto do projeto Brain Tuning23, financiado pela União
Europeia. O objetivo principal foi investigar a relação entre as características musicais e emoção induzida pela música e atividade neuronal apresentada”24. O facto de ser escrita em MATLAB e mais virada para a investigação torna-a uma das frameworks mais pesadas em termos computacionais, não tendo o desempenho equivalente às alternativas em C++.
Considerações Finais
Existem hoje diversas frameworks disponíveis para extrair características do sinal áudio. Essas características podem ser, por exemplo, de baixo nível, isto é, aquelas que estão mais perto do sinal áudio ou por exemplo alto nível, que estão mais longe do sinal áudio, estando por isso mais perto do que nós humanos percebemos e retiramos de uma música. Estas frameworks têm sido usadas em diversos estudos ao longo das últimas décadas, estando as principais características destas resumidas na Tabela 1. Com base nos resultados decidimos escolher a framework Essentia para este projeto, devido à grande panóplia funcionalidades principais que fornece. Além disso tem vantagens em termos de desempenho, devido ser desenvolvida em C++, é open-source, pode ser invocada utilizando Python e não é necessário MATLAB para utilizar. Para informações mais detalhadas acerca das comparações destas frameworks, consultar (Moffat, Ronan, & D. Reiss, 2015).
23http://braintuning.fi/
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
22
Essentia jMir LibROSA Marsyas MIR
Toolbox
Características de alto nível
Sim Não Sim Sim Sim
Características de baixo nível
Sim Sim Sim Sim Sim
Filtros Sim Não Não Não Sim
Reamostragem Sim Sim Sim Sim Sim
APIs C/C++ Python R Java Python C/C++ Python Java MATLAB
Tabela 1 - Comparação das diferentes ferramentas de extração de características25
2.4.3. Algoritmos de Aprendizagem Computacional
Depois da recolha de informações do sinal áudio, a continuação do projeto passa por dar inteligência ao sistema. A inteligência artificial tem vindo cada vez mais a ser utilizada no nosso dia-a-dia nas mais diversas áreas. Aprendizagem computacional é uma área de inteligência artificial que tem como objetivo a “fornecer a um sistema a habilidade de automaticamente aprender e melhorar a sua experiência sem ser explicitamente
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
23
programado” (Expert System, s.d.), através de aprendizagem supervisionada (existência de dados etiquetados) ou não supervisionada. Este trabalho segue a abordagem de classificação proposta em (Panda, Malheiro, & Paiva, Novel audio features for music emotion recognition, 2018), que tem por base a aprendizagem supervisionada, isto é, neste tipo de aprendizagem os dados de entrada para treinar o modelo de classificação contêm etiquetas ou classes (Tabela 2), ao contrário da linguagem não supervisionada (B. Kotsiantis, 2007).
Característica 1 Característica 2 …. Característica N Class
xxxx x xx Feliz
xxxx x xx Feliz
xxxx x xx Triste
…. …. …. ….
Tabela 2 - Instâncias com dados de entrada e suas correspondentes saídas26
Dentro da aprendizagem computacional supervisionada existem vários algoritmos que são abordados de seguida. Uns baseados na lógica, como Árvores de Decisão, outros baseados em aprendizagem estatística, como os k Vizinhos Mais Próximos (kNN, k-Nearest Neighbour) ou as Máquinas de Vetores de Suporte (SVM, Support Vector Machines).
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
24 Árvores de Decisão
Árvores de Decisão, exemplificado na Figura 6, são “árvores que classificam instâncias fazendo uma organização baseada no valor das características” (B. Kotsiantis, 2007), isto é, um método baseado em tomadas de decisão. O seu funcionamento passa pela existência de nós conectados por ramos, em que cada nó representa uma característica e os ramos são os seus possíveis valores. Utilizando como exemplo a Figura 6, a condição começa no nó raiz, at1 e existem três caminhos possíveis, os ramos a1, b2 e c1. A partir do nó raiz vai-se tomando uma decisão consoante o valor dos ramos. Caso na característica at1 se verifique o ramo (valor) a1, então a decisão continua para a característica at2. Se por outro lado a característica at1 verifique as condições b1 ou c1 o resultado de classificação será “Não”.
Figura 6 – Exemplo de uma árvore de decisão27
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
25 k-Vizinhos Mais Próximos (KNN)
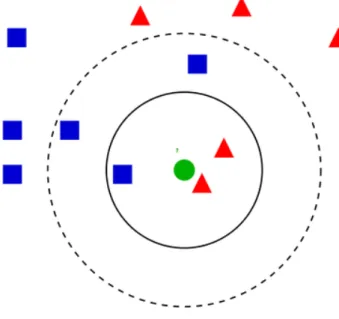
k-Nearest Neighbour (kNN), exemplificado na Figura 7, é “baseado no princípio de que as instâncias de um conjunto de dados geralmente existirão muito próximas a outras instâncias que possuem propriedades semelhantes” (B. Kotsiantis, 2007). Este algoritmo utiliza um conjunto de eixos que representam as características, por exemplo o eixo dos X poderia ser batidas por minuto e dos Y a duração do som. Neste referencial de N dimensões são colocados os casos de treino. A classificação de um novo exemplo é dada através da sua colocação no espaço, sendo-lhe atribuída uma etiqueta igual à que estiver em maioria entre os seus k vizinhos mais próximos. Por exemplo, na Figura 7, a instância verde é o ponto sem etiqueta, que tem uma certa posição em relação a uns eixos. Existem instâncias de cor azul e vermelhas que já foram etiquetadas. Se o número de vizinhos (k) for 3, a etiqueta resultante da classificação da instância verde vai ser a mesma que as instâncias vermelhas, caso seja 5, a etiqueta vai ser a mesma das instâncias azuis.
Figura 7 - k-Nearest Neightbour28
28 Retirado de
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
26 Máquinas de Vectores de Suporte (SVM)
Máquinas Vetores de Suporte (SVM), representado na Figura 8, são um dos algoritmos de aprendizagem mais utilizados atualmente. Baseia-se na “noção de “margem” - um dos lados do híper-plano que separa duas classes de dados” (B. Kotsiantis, 2007), isto é, o algoritmo tenta encontrar uma linha, denominada híper-plano, que consiga separar o mais possível as classes através da maximização das margens (B. Kotsiantis, 2007). Para melhor compreensão do algoritmo ver a secção 7, na página 260 de (B. Kotsiantis, 2007).
Figura 8 - SVM, processo de maximização da margem29
Considerações Finais
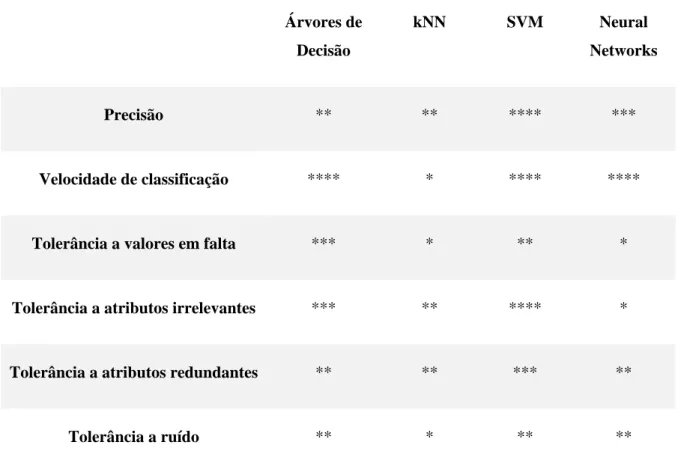
Como se pode verificar na Tabela 3, os algoritmos kNN e SVM são dos que obtêm melhores resultados. Isto deve-se à precisão que cada um deles tem e à tolerância demonstrada a valores considerados “outliers”, isto é, valores que podem trazer imprecisão ao sistema quer por serem valores atípicos, quer por redundância de valores. Porém, como demonstrado em (B. Kotsiantis, 2007), o algoritmo kNN demonstra algumas lacunas quer
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
27
termos de espaço necessário para o armazenamento necessário para a classificação, quer em termos de processamento necessário para tentar obter um bom valor de k. Devido a isso e suportado também pela opção tida em (Panda, Malheiro, & Paiva, Novel audio features for music emotion recognition, 2018) a escolha irá recair sobre o algoritmo SVM. Existia também a opção da utilização de algoritmos de aprendizagem profunda (deep learning), porém estes algoritmos têm como base enormes conjuntos de dados anotados e estes tipos de datasets não existem atualmente, pelo que a utilização destes algoritmos só poderá ser considerada futuramente. Para melhor compreensão sobre o funcionamento dos algoritmos e sobre as suas vantagens e desvantagens, consultar (B. Kotsiantis, 2007).
Árvores de Decisão kNN SVM Neural Networks Precisão ** ** **** *** Velocidade de classificação **** * **** ****
Tolerância a valores em falta *** * ** *
Tolerância a atributos irrelevantes *** ** **** *
Tolerância a atributos redundantes ** ** *** **
Tolerância a ruído ** * ** **
Tabela 3 - Comparação dos diferentes algoritmos de classificação supervisionada30
Capítulo 2. Estado da Arte Microsserviços para Reconhecimento de Emoção em Música
28
2.4.4. Implementações de Máquinas de Vector de Suporte (SVM)
Uma vez escolhido o algoritmo é necessário escolher de uma biblioteca que forneça a sua implementação. Surgem então duas grandes referências a LIBSVM e Scikit-Learn que serão abordadas a seguir.
LIBSVM
LIBSVM é um software integrado para classificação, regressão e estimação da distribuição [support vector classification, regression and distribution estimation]. Suporta também classificação multi-classe. LIBSVM fornece uma interface de programação de aplicações simples, que os programadores podem facilmente utilizar nos seus próprios programas31. O
código fonte está possível em C++ e Java, e a biblioteca tem extensões para Python, R, MATLAB, Perl, Ruby, Weka, Common LISP, entre outras.
Scikit-Learn
Scikit-Learn é um módulo em Python que integra um conjunto vasto de algoritmos de aprendizagem computacional que são parte do estado da arte para problemas classificação, supervisionada ou não, média escala. Este módulo pretende trazer a aprendizagem computacional aos não especialistas, utilizando para isso uma linguagem de alto nível (Python). A ênfase do projeto é posta na facilidade de uso, performance, documentação e consistência da API. Exige poucas dependências de outro software e é distribuída com a
Microsserviços para Reconhecimento de Emoção em Música Capítulo 2. Estado da Arte
29
licença BSD para que possa ser utilizada tanto por estudantes académicos como fins comerciais”32.
Considerações Finais
Ambos os softwares que fazem implementação de SVM são extremamente completos, fornecendo muitas funcionalidades para a implementação do algoritmo SVM. Porém, a biblioteca Scikit-Learn incorpora a biblioteca em C++ do LibSVM e, ao contrário das outras bibliotecas, é compilada, o que permite que tenha mais eficiência. Além disso, os bindings para Python do software Scikit-Learn têm menos 40% de overhead que os bindings originais do SVM (Pedregosa, et al.).
31
Capítulo 3
Planeamento e Desenvolvimento
A solução proposta passa pelo desenvolvimento de um sistema de reconhecimento emocional em música áudio organizado seguindo uma arquitetura de microsserviços, com a comunicação entre estes a ser realizada através de um serviço de filas de mensagens, que são consumidas também por uma aplicação Web. Neste capítulo, é abordado o planeamento da solução final, as tecnologias consideradas e o seu processo de desenvolvimento. Na secção 3.1 é abordada a arquitetura utilizada para o desenvolvimento do projeto. De seguida, na secção 3.2, são abordadas as diferentes soluções existentes para a orquestração de containers. Na secção 3.3 são abordados os mecanismos de comunicação entre processos. Para terminar este capítulo, a secção 3.4 apresenta as linguagens de programação que foram consideradas para a implementação do sistema.
3.1. Arquitetura Geral do Sistema
Como abordado anteriormente, um dos problemas da área de MER passa por haver poucas aplicações reais que tenham como objetivo principal de fazer tratamento do áudio e utilizá-lo para obter uma classificação da emoção presente neste. Entre as possíveis razões para isto, estão a complexidade do tema e o facto de ser ainda hoje um problema em aberto, onde novos avanços vão sendo propostos, mas ainda longe de produzirem uma solução robusta para situações reais. Torna-se por isso necessário desenvolver uma solução que considere estes problemas e que seja fácil de se adaptar a eventuais mudanças. Parte deste objetivo é conseguido através da utilização de certos conceitos de engenharia de software e metodologias de desenvolvimento Agile. Pressupõe-se o desenvolvimento de uma solução robusta, escalável e capaz de suportar todo o processo pesado de tratamento de sinal, como extração de características e extração do áudio, sem que interfira com o restante funcionamento da aplicação. Para cumprir estes requisitos obtendo o melhor
Capítulo 3. Planeamento e Desenvolvimento Microsserviços para Reconhecimento de Emoção em Música
32
resultado possível, o primeiro passo necessário consiste em identificar qual a melhor arquitetura a escolher para o projeto.
A definição de arquitetura geral da solução consiste numa “descrição do sistema que ajuda a entender como o sistema se comportará”33. As várias tarefas do sistema a desenvolver
têm requisitos de tempo e processamento bastante díspares, pois têm vários passos complexos e distintos, uns mais demorados que outros. Por exemplo, o tempo que demora a extrair características de um sinal áudio é bastante maior que o necessário para obter a classificação tendo um modelo já treinado. Desta forma, um cenário ideal seria ter estas tarefas divididas em blocos isolados e independentes, cada um responsável exclusivamente pela sua tarefa. Como ilustrado pela Figura 9, é necessário que exista um elemento central, por exemplo uma fila de mensagens, com o objetivo de permitir a comunicação entre a aplicação Web e os vários componentes que fazem o tratamento do sinal áudio. Assim, existem duas abordagens que foram tomadas em conta: a arquitetura tradicional (monolítica), caracterizada pelo desenvolvimento num só bloco, ou a arquitetura de microsserviços, caracterizada pelo desenvolvimento de vários blocos.
Microsserviços para Reconhecimento de Emoção em Música Capítulo 3. Planeamento e Desenvolvimento
33
Figura 9 - Arquitetura Geral da Solução
A arquitetura tradicional, ou monolítica, é a abordagem típica presente, hoje em dia, em sistemas comuns e caracteriza-se por “uma aplicação com uma única base de código/repositório, por normal grande, que oferece dezenas ou centenas de funcionalidades usando interfaces diferentes como páginas HTML, serviços Web e/ou serviços REST” (Villamizar, Castro, Verano Merino, & Casallas, 2015). Isto é, como referido naFigura 10, todos os diferentes componentes pertencem uma única aplicação sob uma única plataforma. Esta abordagem está vastamente disseminada pela indústria, mas com o surgimento de computação para a nuvem esta arquitetura tem vindo a ser substituída pela utilização de microsserviços, pois a sua manutenção e gestão torna-se dispendiosa, especialmente quando se trata de aplicações complexas com as características anteriormente referidas. A arquitetura tradicional tem, no entanto, vários pontos a favor, como por exemplo a facilidade de desenvolvimento, em especial no início do projeto, facilidade em testar o sistema e facilidade em colocar o trabalho desenvolvido em
Capítulo 3. Planeamento e Desenvolvimento Microsserviços para Reconhecimento de Emoção em Música
34
produção (Haq, 2018). Os problemas principais aparecem mais tarde, com o crescimento da aplicação, na dificuldade de manutenção e deteção/correção de erros e na sua escalabilidade (Haq, 2018). Nesta arquitetura, cada vez que é adicionada uma nova funcionalidade ou é necessária uma atualização, torna-se necessário voltar a fazer a implementação (deploy) da aplicação completa novamente para o servidor, carregando todos os módulos e bibliotecas que lhe pertencem (Haq, 2018). Este processo por norma demora algum tempo, o que pode levar a que a aplicação tenha disrupções (seja colocada offline) durante esse tempo. Nesta arquitetura, também quando há congestionamento ou algum erro, a execução da aplicação é interrompida ou torna-se mais lenta, levando a que o sistema esteja parado algum tempo. A manutenção da aplicação e deteção de erros torna-se um processo cada vez mais complexo, que aumenta com a quantidade de funcionalidades que vão surgindo à medida que a aplicação vai crescendo (Haq, 2018). Com o crescimento da aplicação, também os recursos utilizados serão cada vez mais, levando a que seja necessário escalar a aplicação. Escalar uma aplicação seguindo uma arquitetura tradicional é por norma uma tarefa difícil, sendo a abordagem tipicamente escolhida a de escalar horizontalmente (Haq, 2018), isto é, adicionando mais máquinas com a aplicação (réplicas) e utilizando um balanceador de carga para fazer a gestão de pedidos. Existem situações em que tal não é possível, sendo necessário escalar a aplicação verticalmente, isto é, dando mais recursos à máquina onde está alojada a aplicação. No caso deste projeto, o desenvolvimento seria de uma aplicação sobre um só bloco que seria responsável pela transferência de vídeos, extração e conversão para áudio, recolha de características e classificação. Estes processos são algo pesados do ponto de vista computacional, pelo que cada vez que o sistema os estivesse a executar resultaria em tempos de espera. Como já referido, uma solução para este problema passa pela utilização de várias máquinas correndo a aplicação e de um balanceador de carga que distribuía novos pedidos pelas várias máquinas disponíveis, diminuindo o tempo de espera e mantendo a aplicação operacional. Tal abordagem apresenta diversas desvantagens, sendo a maior o custo associado. Existia também a opção da utilização de threads para todas as tarefas de processamento, distribuindo (paralelizando) o processamento das tarefas numa mesma máquina pelos vários núcleos de processamento e garantindo que a aplicação continua a responder. No entanto, a gestão de threads é um processo complexo e quando um
Microsserviços para Reconhecimento de Emoção em Música Capítulo 3. Planeamento e Desenvolvimento
35
problema causa a falha na parte do processamento, por norma toda a aplicação falha. Existem ainda todos os outros problemas anteriormente referidos, como a complexidade no tratamento de erros, manutenção ou implementação que contribuem para aumentar a dificuldade desta opção. Devido a isso, torna-se necessária a escolha de uma outra arquitetura que permita repartir toda a aplicação em pequenos serviços independentes e isolados, responsáveis pela execução das tarefas distintas como a extração da música e conversão para áudio, recolha de características e classificação.
A arquitetura de microsserviços é uma arquitetura “inspirada pela computação orientada a serviços que tem vindo a ganhar popularidade” (Dragoni, et al.). A ideia da utilização desta arquitetura, ilustrada na Figura 10, passa pela criação de pequenos serviços independentes que comunicam através de mensagens. Normalmente, a implementação destes microsserviços é realizada sobre containers (pacote de software leve e autónomo que inclui tudo o que é necessário para correr uma aplicação) e são orquestrados através de ferramentas como o Docker34 ou Kubernetes35, abordados mais á frente no capítulo 3.2. Uma vez que a computação para nuvem se tem tornado uma das maneiras mais viáveis de disponibilizar aplicações e de utilizar containers, várias empresas têm vindo a modificar o seu paradigma no desenvolvimento mudando de arquiteturas monolíticas para arquitetura de microsserviços. A arquitetura de microsserviços fornece grandes benefícios em termos de desenvolvimento contínuo e manutenção de grandes aplicações, uma vez que é mais fácil incluir novas mudanças, substituindo os módulos de um sistema (containers) se estes forem independentes, sem ter de tornar o sistema indisponível. A arquitetura apresenta diversas outras vantagens como a facilidade de aplicação de testes devido aos serviços serem pequenos (embora possa ser mais complicado testar a aplicação de forma automatizada como um todo), facilidade de implementação por serem independentes, torna mais fácil isolar erros, isto é, caso um serviço falhe não interfere com a execução dos outros serviços, permite a atualização ou modificação de casa serviço sem comprometer o resto dos serviços. Acrescenta flexibilidade na escolha de tecnologias utilizadas em cada
34https://www.docker.com/
Capítulo 3. Planeamento e Desenvolvimento Microsserviços para Reconhecimento de Emoção em Música
36
serviço, permitindo escolher a melhor solução a ser utilizada para um dado objetivo/tarefa. Isto é, permite que, por exemplo, o desenvolvimento de um serviço seja feito em JavaScript correndo sobre Node.js e outro utilize Python ou outra linguagem qualquer, uma vez que são independentes e comunicam através de mensagens. Esta abordagem é ainda fácil escalar tanto horizontalmente (mais nós) como verticalmente (mais recursos em cada nó) (Haq, 2018). “Escalar aplicações monolíticas é sempre mais difícil do que escalar microsserviços porque numa é necessário escalar toda a aplicação e fazer a implementação de todo o código em vez de dimensionar a parte da aplicação que exige mais recursos” (Kalske, Makitalo, & Mikkonen, 2018). Resumindo, ao escalar uma aplicação monolítica fornecemos mais recursos (verticalmente) ou duplicamos a funcionalidade (horizontalmente) de toda aplicação, mesmo que seja só uma tarefa específica da aplicação a necessitar de mais processamento. Ao passo que numa solução de microsserviços são dados mais recursos apenas ao serviço específico que esteja a necessitar. Porém, a arquitetura de microsserviços também tem alguns problemas. Alguns desses problemas devem-se ao facto de se lidar com a complexidade de criar um sistema distribuído. Apesar de ser fácil testar os serviços independentes, torna-se mais difícil testar a funcionalidade dos mesmo como um todo em relação a uma aplicação monolítica. São necessários mecanismos de comunicação entre serviços e, uma vez que estamos a executar vários serviços distintos sobre vários containers, que por sua vez executam sobre máquinas (físicas ou virtuais), o consumo de memória aumenta (Haq, 2018).
Microsserviços para Reconhecimento de Emoção em Música Capítulo 3. Planeamento e Desenvolvimento
37
Figura 10 - Arquitetura Monolítica e Arquitetura de Microsserviços36
Concluindo, ambas as arquiteturas apresentadas têm os seus prós e contras. No entanto, dada a oferta crescente de soluções de computação para a nuvem e considerando as especificidades deste projeto, torna-se muito mais acertada a utilização de uma arquitetura de microsserviços, quer em termos de custos, quer em termos de gestão, manutenção e desenvolvimento contínuo da aplicação. Caso seja necessário alterar algum dos serviços do sistema, por exemplo para adicionar uma nova tecnologia, atualizar bibliotecas ou alterar a própria abordagem implementada, basta preparar e atualizar o serviço em causa, ficando as suas tarefas em espera na fila de mensagens ou resolvidas por outro nó caso haja replicação. Por outro lado, caso haja erros ou congestionamento nos serviços, o normal funcionamento da aplicação não irá ser tão comprometido, bastando lançar novos serviços, algo difícil de obter com arquitetura monolítica.
36 Figura retirada de
Capítulo 3. Planeamento e Desenvolvimento Microsserviços para Reconhecimento de Emoção em Música
38
3.2. Mecanismos de Orquestração de Containers
Para a implementação do sistema usando microsserviços é necessária a utilização de um mecanismo que permita a execução de containers. Os containers (contentores) são uma “unidade padrão de software que permite o encapsulamento de uma aplicação, incluindo o seu código e todas as dependências deste, para que seja utilizada de maneira rápida e confiável em vários ambientes de computação diferentes”37. A utilização deste tipo de soluções tem vindo a aumentar devido à sua flexibilidade, baixo peso computacional, facilidade na sua manutenção e mudança ao longo do tempo (mutação), portabilidade e associação a outros containers.
Existem hoje dois principais mecanismos que permitem a gestão e orquestração de containers – Docker e Kubernetes. O mecanismo escolhido para o desenvolvimento deste projeto foi o Docker pelo estado de maturidade, pelas funcionalidades e pela sua extensa documentação disponível.
3.2.1. Docker
O Docker é uma plataforma que permite desenvolver e executar aplicações, independentemente do ambiente computacional, utilizando para isso containers. Estes containers são independentes e a plataforma fornece diversas políticas de configuração, tais como a opção de reinício caso um container falhe ou até em caso de falha do próprio Docker. Como representado na Figura 11, o Docker assenta sobre o sistema operativo da máquina e consiste em docker engine, um mecanismo para a criação e gestão de containers e docker hub38, um repositório para gerir e partilhar imagens dos containers. No
caso do Docker engine, este pode ser executado em modo normal ou em enxame (swarm).
37https://www.docker.com/resources/what-container