UNIVERSIDADE DE TRÁS-OS-MONTES E ALTO DOURO
Reconhecimento Expressões Faciais
Fernando Gil Abreu Mesquita da Costa Orientador
Professor Doutor Paulo Alexandre Cardoso Salgado (Professor Associado da UTAD)
Dissertação de Mestrado em Engenharia Electrotécnica de Computadores
Gostaria de expressar os meus sinceros agradecimentos ao Professor Doutor Paulo Salgado da Universidade de Trás os Montes e Alto Douro pela oportunidade de trabalho num tema que tem tanto de interessante como de importante. A sua orientação e suporte foram uma fonte constante de encorajamento ao longo da realização desta dissertação.
Tem sido uma grande honra e prazer trabalhar sobre a sua supervisão. As suas valiosas sugestões e feedback ao longo da dissertação, foram de uma enorme importância para a conclusão do trabalho atempadamente. O seu tremendo conhecimento acerca deste tópico, foram de uma extrema utilidade para a conclusão desta dissertação .
Também gostaria de expressar os meus agradecimentos a todos os meus colegas de Licenciatura e Mestrado em Engenharia Electrotécnica pela sua amizade e companheirismo
Finalmente, gostaria de agradecer à minha família, pela força e continuo suporte, que me
iii
Resumo
A expressão facial é uma forma de comunicação não-verbal que permite a partilha de sentimentos e emoções, numa linguagem subentendida entre seres humanos.
A detecção facial e reconhecimento automático de expressões baseia-se no processamento de imagem e reconhecimento de padrões. O desenvolvimento nestas áreas deve-se a avanços multidisciplinares recentes, desde a aquisição e processamento digital de imagem, caracterização e reconhecimentos de padrões, e da compreensão dos mecanismos de interacção pessoa-máquina, entre muitos outros domínios.
O objectivo desta dissertação é realizar o reconhecimento de faces e respectivas expressões e reprodução desta informação ao utilizador.
Para tal, são necessários realizar várias tarefas preliminares, tais como a localização da face caracterização de suas partes relevantes. Isto foi alcançado criando um algoritmo baseado no artigo escrito por Yi-chi Liu e outros, cujo trabalho descreve uma forma simples e de baixo consumo computacional, para a detecção da zona facial numa imagem complexa. Esta tarefa é realizada através da detecção do tom de pele no espaço de cor YCbCr.
A imagem obtida da zona facial é então processada e através do algoritmo da analise em componentes principiais (PCAs) é reduzida aos seus componentes principais. São depois criados os eigenfaces para cada personagem de modo à redução do espaço das imagens adquiridas, e para utilização por método de caracterização facial.
Por fim é proposto um método que, através da comparação entre a imagem tratada e a imagem original, a identificar a quem corresponde a face e a respectiva expressão.
iv Este trabalho prova ser possível caracterizar as expressões faciais com recurso a técnicas estatísticas, sendo que esta dissertação é um primeiro passo na procura de novos métodos de reconhecimento facial.
v
Abstract
Facial expression is a form of nonverbal communication which allow the sharing of feelings and emotions, in a known language among humans.
The detection and automatic recognition of facial expressions is based on image processing and pattern recognition. The development in these areas is due to recent multi-disciplinary advances, from the acquisition and procession of the image, characterization and recognition of patterns and the understanding of the mechanism related to the interaction man-machine, along other domains.
The aim of this dissertation is the recognition of faces and their expressions and reproduction of this information to the user.
For this it is necessary to do several preliminary tasks such as, the location of the face and the characterization of their relevant parts.. This was achieved by creating an algorithm based on the article written by Liu Yi-chi and others, work that describes a simple and low computer load on face detection in a complex image. This task is obtained by detecting skin tone using the YCbCr color space.
The image obtained of the facial zone is then processed by an algorithm of principal component analysis (PCA) and is reduced to its main components. After that is created the eigenfaces for which person to reduce the space of images, and for the use of the method of facial characterization.
Finally, is proposed a method that, using the comparison between the treated image and the original image, can identify to whom those the face correspond and which expression.
vi This work has proven to be possible to characterize facial expression using statistical techniques, being that this dissertation is a first step in the search for new methods for facial recognition Key-words: facial recognition, facial expression, PCA, eigenface
vii
Lista de Figuras
ILUSTRAÇÃO 1:MODELO DE DETECÇÃO DA EXPRESSÃO FACIAL... 7
ILUSTRAÇÃO 2:AS SEIS EXPRESSÕES FACIAIS BÁSICAS.FONTE:EKMAN E FRIESEN [33] ... 13
ILUSTRAÇÃO 3:AJUSTE DE AAM EM TRÊS ITERAÇÕES A PARTIR DA POSIÇÃO INICIAL.FONTE:EDWARDS E OUTROS [37] ... 17
ILUSTRAÇÃO 4:EXEMPLOS TÍPICOS DE FACES UTILIZADAS NO ESTUDO DE EDWARDS E OUTROS [37] ... 18
ILUSTRAÇÃO 5:EXEMPLO DA APLICAÇÃO DE FILTROS DE GABOR A UMA IMAGEM ... 19
ILUSTRAÇÃO 6:EXEMPLO DA APLICAÇÃO DE GFK AO ROSTO.FONTE:HONG E OUTROS [17] ... 19
ILUSTRAÇÃO 7:PARÂMETROS DE ACÇÃO SUGERIDOS POR HUANG E OUTROS FONTE:HUANG E HUANG [2] ... 20
ILUSTRAÇÃO 8:REDUÇÃO DE DIMENSIONALIDADE ATRAVÉS DA IMPLEMENTAÇÃO DE PCA.FONTE:HUANG E OUTROS [2] 20 ILUSTRAÇÃO 9:POSICIONAMENTO DE GRELHA SOBRE IMAGEM FACIAL.FONTE:LYONS E OUTROS [38] ... 21
ILUSTRAÇÃO 10:SVM-MARGEM MÁXIMA ENTRE OS VECTORES DE DADOS.FONTE:LU E OUTROS [29] ... 22
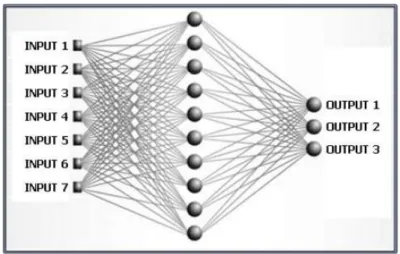
ILUSTRAÇÃO 11:EXEMPLO DE REDE NEURONAL ... 23
ILUSTRAÇÃO 12:EXEMPLO DE REDE DE HOPFIELD COM 4 NEURÓNIOS.FONTE:YONEYAMA E OUTROS [26] ... 24
ILUSTRAÇÃO 13:EXEMPLO DE UMA FUNÇÃO DE ACTIVAÇÃO DE SIGMOID.FONTE:PADGETT E COTTRELL [22] ... 25
ILUSTRAÇÃO 14:AJUSTAMENTO AO OLHO: CARACTERÍSTICAS-MODELO.FONTE:PANTIC E ROTHKRANTZ [3] ... 27
ILUSTRAÇÃO 15[28] ... 28
ILUSTRAÇÃO 16:DETERMINAÇÃO DE EXPRESSÕES EM SEQUÊNCIAS DE IMAGENS.FONTE:ESSA E PETLAND [30] ... 29
ILUSTRAÇÃO 17:ESTIMAÇÃO DO MOVIMENTO ATRAVÉS DE ALGORITMOS DE FLUXO.FONTE:OTSUKA E OHYA [46] ... 30
ILUSTRAÇÃO 18:UTILIZAÇÃO DE PDVD PARA ACOMPANHAR MOVIMENTOS FACIAIS.FONTE:COHEN E OUTROS [49] ... 32
ILUSTRAÇÃO 19:MODELO CANDIDE.FONTE:KOTSIA E OUTROS [52] ... 33
ILUSTRAÇÃO 20:MODELO GERAL ... 38
ILUSTRAÇÃO 21:COMPENSAÇÃO DE LUZ ... 42
ILUSTRAÇÃO 22:COMPENSAÇÃO DE LUZ ... 42
ILUSTRAÇÃO 23:DETECÇÃO DO TOM DE PELE ... 43
ILUSTRAÇÃO 24:DETECÇÃO DO TOM DE PELE ... 44
ILUSTRAÇÃO 25:DETECÇÃO DA FACE ... 45
viii
ILUSTRAÇÃO 27:INTERFACE ... 55
ILUSTRAÇÃO 28:RESULTADOS EXPERIMENTAIS ... 56
ILUSTRAÇÃO 29:RESULTADOS EXPERIMENTAIS ... 56
ILUSTRAÇÃO 30:RESULTADOS EXPERIMENTAIS ... 58
ix
Lista de tabelas
TABELA 1:LISTA DE 46AUS ... 15
TABELA 2:ANALISE GLOBAL DOS MÉTODOS ... 37
TABELA 3:RESULTADOS OBTIDOS ... 55
TABELA 4:RESULTADOS EXPERIMENTAIS ... 57
x
Lista de Abreviaturas
PCA (Principal Component Analisis) LBT (Local Binnary Pattern)
PPBTF (Pixel Pattern Based Texture Feature) FACS (Facial Action Coding System)
AU (Action Units)
AAM (Active Appearance Models) GFK (General Face Knowlodge) AP (Action Parameters)
LDA (Linear Discriminant Analysis) SVM (Support Vector Machines) HMM (Hidden Markov Model)
EHMM (Embedded Hidden Markov Model) PBVD (Piecewise Bezier Volume Deformation) MU (Motion Unit)
EM (Expectation Maximization) NB (Naïve Bayes)
TAN (Tree- Augmented Naïve Bayes)
xi
Índice
Resumo iii
Abstract v
Lista de Figuras vii
Lista de tabelas ix Lista de Abreviaturas x Índice xi Capitulo I 1 1.Introdução 1 1.1 Objectivo 2 1.2 Organização do Documento 3 Capitulo II 5 2. Estado da arte 5 2.1 Detecção da face 8
2.2 Extracção das características faciais 10
2.3 Classificação de expressões faciais 13
2.4 Análise Global 35
Capitulo III 38
3. Trabalho realizado 38
3.1 Espaço de imagens 39
3.2 Detecção facial 40
xii
3.4 Detecção de expressões faciais 53
Capitulo IV 54
4. Avaliação e resultados experimentais 54
4.1 Avaliação da detecção facial 54
4.2 Avaliação dos eigenfaces 57
Capitulo V 60
5. Conclusão 60
5.1 Conclusões finais e Discussão 61
Capitulo VI 63
Reconhecimento de expressões faciais 1
Capitulo I
1.IntroduçãoO ser humano tem uma grande facilidade em reconhecer e distinguir expressões faciais. Muitas destas expressões têm características que as tornam universalmente compreensíveis entre pessoas de diferentes proveniências e culturas. A expressão facial é, assim, um dos métodos mais poderosos e eficientes para partilha de emoções e intenções entre as pessoas.
Desde o início da computação, um dos principais objectivos nas áreas das tecnologias de informação, é dotar o computador de um comportamento inteligente. Conferir aos sistemas computacionais um comportamento humano é um objectivo entusiasmante, o que tem conduzido a investigações e desenvolvimento de inúmeros estudos.
A detecção facial e reconhecimento automático de expressões surge como um desafio esperado, mas igualmente complexo, na sequência de estudos realizados no âmbito da análise de imagem e reconhecimento de padrões.
O desenvolvimento destes estudos pode trazer melhorias significativas na área da interacção pessoa-máquina, tornando-se ao mesmo tempo um precioso contributo para a ciência comportamental, psicologia e medicina.
Na área das interfaces utilizador, dada a natureza da sua aplicabilidade, é necessário encontrar uma solução tecnológica e analítica que para além da capacidade de oferecer uma resposta a tempo real, seja capaz de caracterizar comportamentalmente e emocialmente o agente interactuante humano. Na prática esta tarefa torna essencial o balanço de encontrar um bom
Reconhecimento de expressões faciais 2 método de classificação de expressões e uma boa rapidez de resposta por parte do sistema, com a utilização de recursos moderados
1.1 Objectivo
O principal objectivo deste trabalho é o de propor um método capaz de efectuar o reconhecimento de expressões faciais e reproduzir esta informação numa interface utilizador. O processamento da imagem, que consiste na detecção do rosto, extracção de características de interesse e classificação da expressão, tem em conta diversos estudos relevantes na área.
Uma das técnicas utilizadas é a chamada Análise dos Componentes Principais (ou PCA - Principal Component Analysis), e é esta técnica a inspiradora do método aqui apresentado. Entretanto, para capacitar um computador de tal habilidade, precisamos treiná-lo com a utilização de imagens de referência. Sendo que estas possuem geralmente um tamanho relativamente grande, e sendo necessárias inumeras imagens visando o aumento da robustez do sistema, torna-se bastante difícil a criação de métodos com os quais se possa trabalhar em tempo real. Tal circunstância resulta do elevado custo de processamento e da elevada quantidade de dados envolvidos. A utilização de eigenfaces proporciona reduzir a dimensionalidade dos dados de treino e permite de contornar o problema recém citado, sendo sua descrição e implementação algorítmica e de programação um dos objectivos deste trabalho. Actualmente diversas pesquisas têm sido conduzidas de modo a aperfeiçoar o método eigenfaces e seus algoritmos. Este esforço encontra-se em diversas publicações técnicas, onde
Reconhecimento de expressões faciais 3 são apresentados derivadas da transformada PCA, sejam o da modelagem de densidade,
eigenfeatures da similaridade Bayesiana, entre outros [Cendrillon e Lovell, 1999].
Além disso muitos projectos já vêm utilizando eigenfaces para o processamento de imagens em geral, como detecção de faces [Turk e Pentland, 1991], ou apenas dos olhos [Marques, Orlans e Piszcz, 2003], ou dos pontos principais de uma face, como nariz, boca, etc. [Liou, 1997]
Ao longo desta tese encontraremos a descrição do método, apresentando uma série de testes realizados em bases de dados contendo imagens de faces humanas,. Foi deste trabalho construir um sistema computacional, implementado na plataforma Matlab, com um conjunto de rotinas e procedimentos completos capazes de processarem e responderem automaticamente, quando uma nova imagem facial lhe é fornecida. Assim, foi construído uma base de imagens, cuja caracterização facial é previamente conhecida. Após a fase de treino o sistema implementado é capaz de discernir, ao receber uma nova imagem, se essa contém uma face humana e qual expressão facial correspondente.
1.2 Organização do Documento
Este documento é organizado da seguinte forma:
No capítulo 2 é analisado o trabalho que tem vindo a ser desenvolvido nos últimos anos na área em estudo. São tidos em conta os vários passos na detecção de expressões faciais, desde a detecção do rosto numa imagem arbitrária até à extracção de elementos faciais relevantes e
Reconhecimento de expressões faciais 4 subsequente classificação da expressão correspondente. São explorados trabalhos que utilizam imagem estática e dinâmica (vídeo) e estudadas as diversas abordagens à classificação. É feito um estudo comparativo do trabalho que tem vindo a ser desenvolvido nesta área de modo a procurar uma direcção a tomar de acordo com os requisitos para o trabalho a implementar. O capítulo 3 apresenta o trabalho realizado e justificadas as decisões tomadas na implementação do sistema e seus métodos. São apresentadas considerações importantes sobre a sua concretização prática e discutidas as diversas alternativas existentes. É descrito em detalhe o processo de detecção e normalização facial, bem como a forma como é efectuada a extracção das características necessárias à classificação da expressão.
O capítulo 4 apresenta os resultados obtidos no contexto do presente estudo. São expostas as métricas adoptadas para medir o desempenho do classificador, bem como os resultados dos testes efectuados. É também feita uma análise dos resultados destes testes.
No capítulo 5 são enunciadas as conclusões do presente trabalho, tal como os seus pontos fortes e fracos, sendo apontada uma direcção para futuro trabalho de investigação que poderá advir deste.
No capítulo 6 estão referenciados as diferentes fontes de informação utilizadas para esta dissertação
Reconhecimento de expressões faciais 5
Capitulo II
2. Estado da arteNas ultimas duas décadas, o reconhecimento de expressões faciais tem despertado o interesse da comunidade científica, devido as suas potencialidades para a criação de interfaces baseados no comportamento ser humano.
O reconhecimento de expressões faciais tem um papel importante para criar um interface homem-computador que pode ser usado em várias aplicações, tais como na realidade virtual, na videoconferência, para traçar o perfil do utilizador e satisfação do consumidor, e variados serviços Web, além de que facilita a interligação entre o homem e o computador.
Para o ser humano, reconhecer expressões é um processo simples, rápido e pouco propício a erros. Com efeito, logo nos primeiros anos de vida aprendemos a avaliar a emoção, depreendíveis da análise dos elementos do rosto.
No caso de um sistema computacional, este processo envolve uma série de restrições e, consequentemente, implica o uso de um conjunto de técnicas e algoritmos relativamente complexos.
O reconhecimento automático de expressões faciais deve ter em conta factores como a luminosidade do meio ambiente, a posição do utilizador em relação à câmara e as características do próprio utilizador como a presença de pêlos faciais e óculos.
Reconhecimento de expressões faciais 6 Conforme a sua aplicação, surgem outros requisitos tem de se ter em conta, nomeadamente a nível temporal, caso se pretenda criar um sistema capaz de processar vídeo em tempo real, ao invés de imagens estáticas.
Os trabalhos desenvolvidos nesta área dividem o reconhecimento facial em três fases .
_ Detecção do rosto numa imagem arbitrária – O utilizador encontra-se normalmente perante uma câmara num ambiente relativamente controlado. No entanto, é plausível que estejam presentes diversos artefactos exteriores ao rosto. Para que o processamento seja eficaz e eficiente, é necessário eliminar informação desnecessária. Esta fase identifica uma zona como sendo a região da face do utilizador, após o que apenas esta área será processada nas fases seguintes;
_ Detecção das características faciais – Este passo consiste em, dada uma imagem facial, extrair as características que são relevantes à classificação da expressão. Normalmente, é dada mais ênfase às sobrancelhas, olhos, nariz e boca.
_ Classificação da expressão – Tendo disponível a informação correspondente à localização das características faciais do rosto na imagem, é possível proceder à classificação da expressão. Esta fase, que pode basear-se em diversos métodos de classificação, desde os mais simples aos mais complexos.
Estes paços essenciais, visando o reconhecimento fácil e das suas expressões, está resumido na figura 1
Reconhecimento de expressões faciais 7
Ilustração 2.1: Modelo de detecção da expressão facial Ilustração 1: Modelo de detecção da expressão facial
Reconhecimento de expressões faciais 8 2.1 Detecção da face
O ser humano tem facilidade em reconhecer uma face mesmo nos casos em que a iluminação é desfavorável ou a pessoa se encontra a uma grande distância. A maior parte dos estudos realizados neste campo é feita em ambientes controlados, com luminosidade constante e em que a face é apresentada frontalmente e a uma distância constante da câmara. Os sistemas de detecção facial existentes seguem diversas abordagens. No caso do ser humano, segundo Bruce [1], a presença de características e a relação destas entre si é muitas vezes mais importante do que as características individuais. O modelo mental humano segue uma abordagem holística, na medida em que a face é vista como um todo e não como um conjunto de características individuais, como acontece no caso da aproximação analítica.
Existem numerosos estudos que exploram este problema. No que diz respeito à detecção de um rosto em imagens faciais, Huang e Huang [2], bem como Pantic e Rothkrantz [3], seguem abordagens holísticas. O primeiro estudo obtém a estimativa da localização da face através de um detector de contornos e opta pela adopção de um modelo representativo da face, enquanto que o segundo utiliza duas vistas do utilizador (de frente e de perfil), detectando o contorno facial através da detecção de perfil e da utilização de modelos de cor.
Por outro lado, Kimura e Yachida[4] e H. Kobayashi e F. Hara[5], optaram por utilizar uma abordagem analítica. No primeiro estudo, começaram por localizar o centro dos olhos e da boca, e através desses pontos é feita a normalização e é possível modelar a face, enquanto que no segundo, é utilizado a distrbuição do brilho numa face através de uma câmara em modo monocromático, o que permite localizar as íris dos olhos, e a localização das outras características é obtida utilizando localizações relativas de características faciais.
Reconhecimento de expressões faciais 9 Em termos da detecção facial em sequências de imagens, podemos sub-dividir os estudos realizados em dois grandes grupos: baseada em características e baseada em aparência. No primeiro caso, utiliza-se essencialmente a cor do rosto como característica de interesse. De facto, mesmo entre diferentes grupos étnicos, a tonalidade da tez acaba por localizar-se num intervalo relativamente apertado de valores. O estudo de Saber e Tekalp [6] define regiões de pele através de um classificador que assinala os pixéis candidatos a pertencerem a uma região do rosto, adaptando posteriormente um modelo elíptico a cada região disjunta. Vezhnevets [7] propõe a aglomeração de pixéis segundo a probabilidade de pertencerem a um rosto, agrupando-os numa região aproximadamente elíptica, a que posteriormente aplica um modelo deformável ou adaptativo até obter a imagem facial. No caso da detecção baseada em aparência, o rosto é encarado como um padrão em termos de intensidades de pixéis, como referem Sung e Poggio [8]. Neste tipo de abordagem, os padrões faciais são distinguidos de padrões não faciais através da sub-divisão de uma imagem em janelas de menor dimensão. Os estudos de Rowley e outros [9] e Pham e outros [10] realizam detecção facial através de redes neuronais em imagens em escala de cinzentos. Viola e Jones [11] propõem a utilização do algoritmo AdaBoost, que selecciona as características mais representativas num grande espaço de amostragem e sub-divide a imagem em janelas, sendo estas sujeitas a testes em cascata em que são rejeitadas caso não correspondam a imagens faciais. Neste método baseiam-se os estudos de Bartlett e outros [12] e Zhan e outros [13], que têm desempenho em tempo real, sendo que o primeiro utiliza funções de Haar, computacionalmente leves, e o segundo serve-se de uma combinação eficiente de classificadores extremamente simples (método de amplificação ou boosting). Mais recentemente, também o estudo de Cao e Tong [14] e de Lu e outros [15] adoptam, para a detecção do rosto, o método proposto por Viola e Jones [11].
Existem aproximações à detecção facial em sequências de imagens que não se incluem nos grupos anteriores. O método proposto por Pentland e outros [16] baseia-se na obtenção de blobs
Reconhecimento de expressões faciais 10 de movimento, em que cada blob passível de representar uma cabeça humana é avaliado como uma imagem única. Ainda, Hong e outros [17] exploram um sistema PersonSpotter para fazer o rastreamento da cabeça de um indivíduo, baseando-se em filtros preditivos para estimar a cabeça e respectiva velocidade num dado instante.
2.2 Extracção das características faciais
Existem três aproximações principais a este problema: holística, analítica e uma combinação de ambas, que resulta numa aproximação híbrida. Os métodos baseados em modelos adequam-se às abordagens holísticas, enquanto que os métodos baseados em características são maioritariamente usados conjuntamente com abordagens analíticas. Terzopoulos e Waters [18], bem como Black e Yacoob [19], representam a face como uma estrutura com uma dada textura ou um modelo espacio-temporal de movimento. Métodos baseados em modelos estão intimamente relacionados com este tipo de aproximação.
Em termos de imagens estáticas, o estudo de Hong e outros [17], baseado em modelos, utiliza a framework PersonSpotter, que se baseia em dois grafos distintos, um mais esparso e outro mais denso, para localizar a face e suas características, respectivamente. Vezhnevets e outros [20] propõem um método também baseado em modelos, em que se obtêm as posições dos olhos através da análise de variações dos canais de vermelho da imagem e dos lábios através de modelos iterativos de cor e de pele.
Os estudos realizados por Bassili [21] e Bruce [1], baseados em características, sugerem que a descrição dos movimentos de pontos relacionados com os principais elementos faciais e análise das relações entre estes podem clarificar as propriedades principais de uma dada face. Estes resultados incentivaram uma série de trabalhos de investigação que seguiram uma aproximação
Reconhecimento de expressões faciais 11 analítica do problema, dos quais o estudo de Padgett e Cottrell [22] é um dos percursores. Kobayashi e Hara [5] estudam a distribuição de brilho na face, cruzando linhas verticais entre os principais pontos da mesma. Saber e Tekalp [6] localizam os olhos através de algoritmos de cor, utilizando estes dados para aproximar, através de funções de custo, a posição dos outros elementos do rosto. Pantic e Rothkrantz [3] utilizam uma aproximação bi-dimensional da face, através do uso das vistas frontal e de perfil, sendo usados múltiplos detectores para cada característica facial e decidido o melhor destes. Yang e outros [23] exploram uma implementação bi-dimensional do algoritmo Principal Components Analysis (PCA) para representar imagens faciais, o que implica a criação de uma matriz de covariâncias a partir das matrizes originais da imagem, cujos vectores próprios são usados na extracção de características. Turhal e outros [24] propõem um algoritmo em duas etapas que consiste numa evolução do anterior, baseando-se numa decomposição da matriz de covariâncias, em que se obtêm os vectores e valores próprios, sendo que a extracção de características faciais é feita através do uso de N vectores próprios correspondentes aos N maiores valores próprios.
Existem ainda soluções híbridas, em que um conjunto de pontos faciais determina a posição inicial para uma template que modela a face, como refere o estudo de Lam e Yan [25]. Yoneyama e outros [26] calculam o fluxo óptico entre imagens através da aplicação de uma grelha rectangular sobre a imagem normalizada de uma dada face, determinando o fluxo para cada uma das regiões da grelha e comparando as imagens sucessivas, localizando assim as características faciais.
No que diz respeito a sequências de imagens, o estudo de Black e Yacoob [19] baseia-se em diversos modelos parametrizados de fluxo para estimar movimento, sendo que os parâmetros resultantes são tratados recorrendo a um esquema de regressão baseado no brilho da imagem. Malciu e Preteux [27] seguem uma aproximação baseada em modelos deformáveis para fazer o rastreamento da boca e dos olhos em sequências arbitrárias de vídeo, consistindo a deformação
Reconhecimento de expressões faciais 12 dos modelos em mapeamentos geométricos bi-dimensionais. Mais recentemente, Cao e Tong [14] apostam na utilização de um operador Local Binary Pattern (LBP) para a detecção de características faciais. Este operador, definido como a medida de textura invariante em escala de cinzentos, é obtido através da textura numa dada região e sua vizinhança. Além de apresentar invariância a alterações monotónicas de níveis de cinzento, é computacionalmente simples, permitindo bons desempenhos temporais.
Alguns dos métodos baseados em características são o estudo de Cohn e outros [28] e de Zhan e outros [13]. O primeiro define pontos à volta das principais características faciais que possibilitam o cálculo, através das alterações entre as várias imagens, de vectores de fluxo que permitem localizar as características-chave. O segundo serve-se da aplicação de filtros de Gabor, que consistem em sinusoidais complexas modeladas por funções Gaussianas bidimensionais, a um conjunto de pontos de referência (normalizados a partir de testes efectuados sobre um conjunto de imagens faciais), para extrair os elementos-chave do rosto. Mais recentemente, o estudo de Lu e outros [29] assenta numa nova representação de características, Pixel-Pattern-Based Texture Feature (PPBTF). Este método discriminativo baseado em aparência para extracção de elementos faciais tem por base a utilização de um mapa de padrões. Este mesmo mapa é gerado a partir de uma dada imagem, sendo que cada pixel das arestas e do fundo é associado a uma dada classe de padrões-modelo, o que permite encarar imagens faciais como uma composição de micro-padrões. Este método, além de rápido, é capaz de trabalhar sobre condições de iluminação variáveis.
Em termos de abordagens híbridas, o estudo proposto por Essa e Pentland [30] combina a extracção de características próprias através do algoritmo PCA à aplicação de modelos de fluxo para estimar o movimento facial. Kimura e Yachida [31] obtêm um campo de potencial correspondente a uma dada imagem, ao qual aplicam um modelo cuja deformação permite localizar os principais elementos faciais.
Reconhecimento de expressões faciais 13 2.3 Classificação de expressões faciais
Em relação à classificação de expressões, estudamos nesta secção o desempenho de sistemas que consideram imagens e o de sistemas que exploram sequências de imagens.
O problema da classificação da expressão facial é encarado fazendo a distinção entre imagens ou sequências de imagens. No primeiro caso, encontram-se abordagens baseadas em modelos, redes neuronais ou regras. No último, existem métodos baseados em modelos, em regras ou híbridos. São ainda apresentadas algumas considerações a ter em conta neste contexto.
Ekman e Friesen, nos estudos [32] e [33], dividiram as expressões faciais em seis grandes classes de emoções básicas: alegria, tristeza, surpresa, repugnância, cólera e medo, ilustradas na ilustração 2
Alguns autores consideram o estado neutro como uma sétima classe de emoções. Cada emoção básica é definida tendo em conta a expressão facial que caracteriza essa emoção univocamente. No entanto, esta representação tornou-se bastante limitativa. Efectivamente é comum, para o ser humano, a manifestação de várias emoções em simultâneo o que, consequentemente, resulta numa mistura entre várias destas expressões básicas.
De modo a tentar vencer este problema, Ekman e Friesen desenvolveram um sistema, o Facial Action Coding System (FACS) [33], que permite a especificação precisa da morfologia e
Reconhecimento de expressões faciais 14 dinâmica de movimentos faciais. Baseado em conhecimentos de anatomia, vídeos e fotografias ilustrativos de como a contracção de cada músculo facial desempenha um papel na alteração de expressão de um dado indivíduo, este sistema tornou-se uma das maiores referências nesta área. O FACS define 46 Action Units (AUs), conforme apresentado na tabela 1, que correspondem a um conjunto de músculos que definem um dado movimento independente da face. Cada expressão pode ser sub-dividida em N AUs, tendo cada uma destas um significado associado. As diferentes combinações de diversas AUs leva a uma vastíssima quantidade de expressões faciais a serem caracterizadas e estudadas, sendo possível então obter, através do uso do FACS, bastante informação. No entanto, tem vindo a ser executado manualmente, recorrendo a peritos deste sistema, o que leva a um gasto exacerbado de recursos. Algumas das tentativas na área do reconhecimento de expressões faciais têm como objectivo uma automatização deste processo, como os estudos realizados por Cohn e outros [28], Essa e Pentland [30] e Pantic e Rothkrantz [3]. Contudo, muitos destes centraram-se numa automatização parcial, em que são seleccionadas manualmente as principais características faciais para reconhecimento, como os estudos de Donato e outros [34] e Kaiser e outros [35].
Reconhecimento de expressões faciais 15
Referencia Acção
1 Elevação da parte interior das sobrancelhas 2 Elevação da parte exterior das sobrancelhas 4 Depressão das sobrancelhas
5 Elevação da pálpebra superior 6 Elevação da bochecha
7 Compressão das pálpebras 9 Enrugamento do nariz 10 Elevação do lábio superior
11 Aumento de profundidade da região nasolabial 12 Alongamento dos cantos da boca
13 Inchador de bochechas 14 Fazedor de covinhas
15 Depressão dos cantos da boca 16 Depressão do lábio inferior 17 Elevação do queixo
18 Contracção extrema de ambos os lábios 19 Lingua para fora
20 Esticador dos lábios 21 Endurecedor de Pescoço 22 Afunilador dos lábios 23 Endurecedor de Lábio 24 Pressionador de Lábio 25 Separador de Lábios 26 Queda de Mandibula 27 Esticador da boca 28 Sucção dos lábios 29 Projecção de mandíbula
30 Movimentação Lateral da mandibula 31 Jaw clencher 32 Mordida do lábio 33 Inflar da bochecha 34 Bufar da bochecha 35 Sucção da bochecha 36 Arquemanto da Lingua 37 Limpeza do lábio 38 Dilatador das narinas 39 Compressor das narinas 41 Depressão das palpebras 42 Fenda
43 Olhos fechados 44 Olhos semicerrados 45 Piscar de olhos 46 Piscar de um só olho Tabela 1: Lista de 46 AUs
Reconhecimento de expressões faciais 16 Segundo Ekman [36], uma característica ainda não explorada pelos sistemas de reconhecimento automático de expressões faciais é o facto de o ser humano atribuir diferentes pesos aos diversos grupos musculares da face. As expressões correspondentes aos músculos superiores prevalecem sobre as expressões da parte inferior da face quando esta avaliação é feita por um ser humano.
Algumas questões a resolver têm que ver com a capacidade de um sistema:
Reconhecer expressões faciais independentemente de características fisionómicas;
Ser robusto à caracterização de expressões tendo em conta que a intensidade de demonstração de um dado sentimento varia de indivíduo para indivíduo.
Neste passo do reconhecimento de expressões existe uma clara distinção entre o tratamento de imagens estáticas e de sequências de imagens. Uma sequência de imagens minimiza o erro associado a este processo, uma vez que é possível visualizar uma expressão desde o estado neutro até à sua maior amplitude, regressando à expressão neutra.
2.3.1 Trabalho existente
Nesta secção vai ser apresentado alguns exemplos dos métodos de classificação que já existe, tanto para imagens estáticas, como para sequência de imagens. No primeiro existem 3 tipos distintos de métodos, métodos baseado em modelos, métodos baseados em redes neuronais e métodos baseados em regras. Por outro lado, para sequência de imagens existem 2 tipos de métodos, sendo eles o método baseado em modelos e o método baseado em regras.
Reconhecimento de expressões faciais 17
Imagens estáticas
Métodos baseados em Modelos
Edwards e outros [37] apresentam uma framework que utiliza Active Appearance Models (AAMs) para reconhecimento facial, cujo objectivo é identificar o indivíduo independentemente da posição e luminosidade.
Um AAM contém um modelo estatístico da forma e aparência de nível de cinzento do objecto. Para ajustar o modelo à imagem a analisar, é necessário procurar parâmetros que minimizem a diferença entre ambos, o que implica alguma dificuldade, dado o número potencialmente elevado de parâmetros existentes. Normalmente, o ajustamento é feito em dois passos: numa fase de treino, o AAM sintetiza um modelo linear correspondente à relação entre desfasamentos de parâmetros e resíduos induzidos; na fase de procura, mede os resíduos e usa este modelo para corrigir os parâmetros actuais, melhorando iterativamente a adaptação do modelo. Um exemplo do funcionamento de algoritmos baseados em AAM pode observar-se na ilustração 3.
Considerando que um conjunto de parâmetros pode ser o suficiente para descrever e interpretar uma dada imagem, neste estudo cria-se uma template pormenorizada de uma face-objectivo, de modo a modelar essa mesma face o mais realisticamente possível.
Reconhecimento de expressões faciais 18 Obtiveram-se resultados de 40,6% de taxa de sucesso para reconhecimento de expressões faciais em imagens com diferentes condições de luminosidade e posições do rosto, como as representadas na ilustração 4.
Hong e outros [17] utilizam uma galeria para auxiliar a caracterização de uma dada expressão. Uma galeria pessoal caracteriza-se pela existência de imagens de um dado indivíduo relativas às seis expressões básicas, conjuntamente com a expressão neutra. A face da pessoa a analisar é associada à mais semelhante que existe na galeria, sendo esta utilizada para caracterizar a expressão da faceobjectivo. Parte do princípio que duas pessoas com fisionomias aproximadamente similares têm uma maneira semelhante de expressar a mesma emoção. Este método combina filtros de Gabor com o método Elastic Graph Matching, que consiste num processo simples para comparar grafos com imagens e gerar novos grafos para descrever as características visuais básicas de uma imagem. Um filtro de Gabor enquadra-se na categoria de filtros lineares, em que a resposta impulsiva é definida pela combinação de uma função harmónica com uma função Gaussiana. As Gabor Wavelets, sinusóides moduladas através de Gaussianas, são usadas nos filtros de Gabor para representar dilatações e rotações, resultando num espaço de Gabor. Os filtros de Gabor são bastante eficientes para detectar a localização de linhas e arestas em imagens, como pode observar-se na ilustração 5.
Reconhecimento de expressões faciais 19 Esta aproximação provou ser eficiente independentemente de variações de luminosidade do meio. Foram ainda usadas estruturas de General Face Knowledge (GFK), que constituem uma pequena galeria de imagens cujos grafos são criados através de nós colocados em pontos-chave da imagem, como ilustrado na ilustração 6.
Quando o grafo da face objectivo é criado, este é comparado com os da galeria até ser encontrada a face que melhor corresponde à inicial. Este método tem uma taxa de sucesso de cerca de 89%.
Ilustração 5: Exemplo da aplicação de filtros de Gabor a uma imagem
Reconhecimento de expressões faciais 20 Huang e Huang [2] descrevem 10 Action Parameters (AP), que se baseiam no diferencial entre uma face neutra e uma face com uma dada expressão. Estas AP substituem ou são conjugações de algumas AUs do sistema FACS, como representado na ilustração 7.
É aplicado o algoritmo PCA a esses parâmetros a fim de reduzir a dimensionalidade para 2, o que se traduz numa simplificação do processo de reconhecimento. A PCA é um método que permite reduzir a dimensionalidade de um conjunto de dados através da análise de covariância entre factores.
Assim sendo, o algoritmo que implementa a PCA extrai a direcção de maior extensão de uma nuvem de valores em espaço multi-dimensional. Esta direcção é o componente principal. A direcção ortogonal a esta será encontrada de seguida, como ilustrado na ilustração 8, reduzindo-se a nuvem a um espaço bi-dimensional.
Ilustração 7: Parâmetros de acção sugeridos por Huang e outros Fonte: Huang e Huang [2]
Reconhecimento de expressões faciais 21 O processo de reconhecimento é realizado em duas etapas: a primeira reconhece a expressão através do uso dos APs existentes no conjunto de treino e a segunda consiste na utilização do perfil dos APs de uma dada expressão desconhecida para identificação. É usada uma função de avaliação para determinar o grau de semelhança entre uma expressão desconhecida e uma das seis expressões básicas. Este sistema tem uma taxa de sucesso de cerca de 84,5% nos casos estudados.
No entanto, não pode prever-se o seu desempenho na análise de expressões de indivíduos não conhecidos pelo sistema.
O estudo proposto por Lyons e outros [26] utiliza uma grelha que consiste em 34 nós posicionados manualmente sobre uma imagem facial, como ilustrado na ilustração 9.
É posteriormente calculada a transformada de Gabor para cada um desses nós e combinados os dados num vector. Os vectores deste tipo são submetidos a um algoritmo PCA, sendo posteriormente analisados através de Linear Discriminant Analysis (LDA) e agrupados segundo os atributos faciais. A LDA é um método estatístico que procura a combinação linear das características que melhor classificam uma dada imagem, reduzindo a dimensionalidade do problema. Uma imagem que não seja classificada positivamente em nenhuma das categorias é
Reconhecimento de expressões faciais 22 considerada neutra. Este método foi testado, tendo-se obtido um desempenho de 92% em termos de classificação correcta das expressões faciais para utilizadores conhecidos, enquanto que para novos indivíduos o sucesso é de cerca de 75%.
Mais recentemente, Lu e outros [38] adoptam Support Vector Machines (SVMs) para a classificação de expressões faciais. As SVMs consistem num método para treino de amostras que se baseia num princípio de minimização do risco estrutural, que minimiza, assim, o erro de generalização. Sendo que os dados podem ser vistos como dois conjuntos de vectores num espaço de dimensão N, o SVM divide esse espaço através de um hiperplano que maximiza a margem entre os dois conjuntos de dados, como ilustrado ilustração 10, sendo consequentemente denominado classificador de margem máxima.
Com efeito, uma larga margem entre os valores correspondentes aos vectores dos dois sub-conjuntos de dados implica um risco de generalização minimizado do classificador.
Reconhecimento de expressões faciais 23 Método baseado em redes neuronais
Uma rede neuronal, como representado na figura 11, é representada por ligações entre elementos de processamento a que se atribuem pesos, que consistem nos parâmetros que definem a função não-linear efectuada pela rede neuronal. A determinação destes parâmetros é denominada de treino (training) ou aprendizagem (learning), sendo as redes neuronais adaptativas.
No estudo realizado por Kobayashi e Hara [5], é aplicada uma rede neuronal de propagação inversa (Back-Propagation Neural Network). Este é o tipo mais comum de redes neuronais e caracteriza-se pela existência de camadas de entrada e de saída e ainda de uma camada "escondida", que torna possível o mapeamento de relações de entrada na saída do modelo. Antes de qualquer informação ter passado pela rede, os valores dos nós são aleatórios. São chamadas de Back-Propagation Neural Networks uma vez que, ao serem treinadas, quando uma
Reconhecimento de expressões faciais 24 classificação é atribuída, esta é comparada com a classificação actual dos nós. O valor da classificação é propagado de novo na rede, o que faz com que os nós da camadas escondida e da camada de saída ajustem os seus valores em resposta a um eventual erro de classificação. A entrada da rede neuronal consiste nos dados relacionados com a distribuição de brilho extraídos de uma dada imagem facial. O resultado corresponde a uma categoria de emoção. Usou-se uma amostra de treino da mesma dimensão da amostra de teste, tendo-se obtido resultados na ordem dos 85% de taxa de sucesso.
Yoneyama e outros [26], consideram quatro tipos de expressões: tristeza, surpresa, cólera e alegria. No reconhecimento destas expressões, é utilizado um par de bits para representar o valor dos parâmetros e duas redes de Hopfield discretas. Uma rede de Hopfield baseia-se num conjunto de neurónios e um conjunto correspondente de unidades de atraso, formando um sistema de realimentação múltiplo, como pode ver-se na ilustração 12.
Reconhecimento de expressões faciais 25 As redes são treinadas utilizando a regra de aprendizagem de Personnaz [39]. Para cada imagem examinada, o resultado da primeira rede é combinado com os exemplos de treino para esta rede, calculando-se as distâncias Euclideanas e decidindo-se se a categoria da expressão é ou não determinada. Caso não o seja, o resultado da segunda rede de Hopfield é combinado com os exemplos usados para treino desta rede de modo a decidir a categoria da expressão. Neste estudo, a taxa de sucesso é de 92%.
Padgett e Cottrell [22] aplicam também uma rede neuronal de propagação inversa, em que o input consiste na projecção normalizada de blocos de pixéis correspondentes aos principais componentes do espaço próprio de blocos de pixéis da imagem. É aplicada uma função de activação de Sigmoid, que consiste numa função monótona crescente que permite uma transição contínua e diferenciável entre os níveis 0 e 1 da saída. Uma escolha comum para esta função é exemplificada na ilustração 13. O resultado é uma das seis expressões básicas ou, alternativamente, a expressão neutra. Foram treinadas 12 redes neuronais. A taxa de sucesso é de 86%.
Reconhecimento de expressões faciais 26 Zhang e outros [40] utilizam uma rede neuronal para atribuir uma das seis expressões básicas, ou a expressão neutra, a uma dada imagem facial. A rede neuronal recebe a posição geométrica dos principais pontos faciais, para além dos coeficientes de wavelets de Gabor de cada um desses mesmos pontos. A rede reduz a dimensionalidade dos dados de entrada e infere estatisticamente o grupo em que classifica a expressão dada. O resultado consiste numa estimação da probabilidade de a expressão pertencer à categoria em que é inserida. A taxa de sucesso é de cerca de 90,1% para indivíduos conhecidos do sistema, não tendo sido testado noutros casos.
No estudo realizado por Zhao e Kearney [41], é usada uma rede neuronal de propagação inversa para classificação de uma imagem facial numa das seis categorias básicas. Os dados de entrada desta rede neuronal consistem num conjunto de intervalos, que resultam do tratamento estatístico das distâncias normalizadas entre vários pontos da face. O resultado consiste numa das seis expressões faciais básicas. A taxa de sucesso é de 100% para indivíduos conhecidos, enquanto que não se prevê o resultado para indivíduos novos para o sistema.
O estudo proposto por Stathopoulou e Tsihrintzis [42] apresenta um método de extracção de características baseado em aparência, utilizando o vector de elementos faciais como input para uma rede neuronal, que classifica o padrão da janela num de três grandes grupos: surpresa, alegria ou estado neutro. O facto de a rede neuronal não ser aplicada directamente a toda a face mas a pequenas porções do rosto provou ser mais eficiente temporalmente. A taxa de sucesso é de 98,4%.
Feitosa e outros [43] estudam a utilização de duas diferentes redes neuronais no reconhecimento das seis principais expressões faciais. A primeira é uma rede neuronal de propagação inversa, que define um método sistemático de actualizar os pesos de redes
Reconhecimento de expressões faciais 27 multinível. Devido ao facto de o treino destas redes ser bastante demorado, abordaram-se neste estudo as redes neuronais baseadas em Radial Basis Functions (RBF). Estas redes são constituídas por três camadas: a de input, uma camada escondida, que utiliza uma função de activação radialmente simétrica, e a camada de output, com uma função de activação linear. São de treino simples e rápido, uma vez que se baseiam no princípio de que uma função arbitrária pode ser aproximada através da sobreposição de um conjunto de funções básicas localizadas. Os resultados obtidos em termos de taxa de sucesso são de 71,8% através da utilização de uma rede neuronal de propagação inversa e de 73,2% com redes baseadas em RBF.
Métodos baseados em regras
Pantic e Rothkrantz [3] dividem o reconhecimento facial em várias etapas. Depois de calculados os pontos principais da face, as características-modelo são extraídas e é calculada a diferença entre estas e as mesmas características-modelo da face neutra do mesmo indivíduo, como se pode ver na ilustração 14 em relação aos olhos.
A deformação do modelo, conjuntamente com o FACS, permitem a classificação da expressão na classe correspondente. A taxa de sucesso é de 92% para a metade superior da face e de 86% para a metade inferior.
Reconhecimento de expressões faciais 28 O estudo recente de Khanam e outros [44] apresenta um sistema fuzzy Mamdani-type, baseado em regras, para reconhecimento de expressões faciais. Esta implementação utiliza uma base de conhecimento dividida em dois componentes principais: base de dados e base de regras. A primeira é composta pelo input do sistema, que consiste em vários estados das diversas características faciais, e expressão de output, que corresponde a uma das sete expressões básicas. A base de regras é constituída por regras fuzzy, sendo estas maiores ou menores. As primeiras são as que classificam as expressões faciais básicas do rosto, representando o estado típico de cada emoção. As segundas permitem uma ligeira sobreposição entre expressões (como, por exemplo, alegria-surpresa, que comummente se verifica), possibilitando uma transição suave entre as expressões básicas e tendo, logicamente, um menor peso na classificação. A taxa de sucesso varia dos 70% aos 100%, sendo o valor médio de 87,5%.
Sequência de imagens
Métodos baseados em Modelos
Cohn e outros [28] aplicam classificadores distintos nas diversas partes do rosto. Os preditores são os deslocamentos dos pontos faciais ao longo de uma sequência de imagens. Como pode observar-se na ilustração 14, uma dada expressão é determinada pela sequência de imagens desde o estado neutro até à sua amplitude máxima.
Reconhecimento de expressões faciais 29 A classificação baseou-se em matrizes de variância-covariância. Este sistema tem algumas restrições, principalmente no que diz respeito à iluminação (pelo que o ambiente deve ser de luminosidade constante), bem como à não existência de óculos ou pêlos faciais por parte do indivíduo a analisar. A melhor classificação, na zona das sobrancelhas, é de 92%, enquanto que nas regiões dos olhos e do nariz e boca as taxas de sucesso são de 88% e 83%, respectivamente.
O estudo realizado por Essa e Pentland [30] extrai a energia relacionada com o movimento no plano espacio-temporal da sequência recebida, relacionando os valores obtidos com os modelos de energia bi-dimensionais do plano espacio-temporal para as expressões-padrão, como mostrado na ilustração 16. É calculada a norma Euclideana da diferença entre ambas, sendo esta usada como classificador para a semelhança com uma dada expressão básica. A taxa de sucesso deste método ronda os 98%.
Reconhecimento de expressões faciais 30 Kimura e Yachida [31] estudam a adequação de uma rede de potencial a cada quadro da sequência. O padrão da rede deformada é comparado com o padrão extraído de uma face que apresenta a expressão neutra, sendo a variação da posição dos nós da rede usada para processamento posterior. Este estudo não teve sucesso em indivíduos desconhecidos.
Eisert e Girod [45] propõem um algoritmo baseado num modelo tridimensional que especifica a forma e a textura da cabeça de uma pessoa, cuja superfície é modelada por B-Splines. Partindo do princípio de que uma expressão facial resulta da combinação de movimentos locais, como definido no sistema FACS, são localizadas as deformações do modelo, classificando uma dada expressão na classe correspondente. O movimento é obtido através de um método hierárquico baseado na análise
de fluxo óptico. Não é conhecido o tempo necessário ao processo. A taxa de sucesso é classificada qualitativamente como sendo bastante satisfatória mas não se conhecem métricas quantitativas.
Otsuka e Ohya [46] usam um Hidden Markov Model (HMM) que modela a expressão, desde o estado neutro inicial até ao estado neutro final. Para tal, recorrem à estimação do movimento na área que circunda o olho direito e a boca através de algoritmos de fluxo (como ilustrado na ilustração 17), após o que procedem à extracção de características e fazem corresponder a sequência temporal do vector de características aos modelos que representam cada expressão facial.
Reconhecimento de expressões faciais 31 Este sistema permite o reconhecimento de múltiplas sequências de imagens. É usado o algoritmo de Baum-Welch para calcular a probabilidade de transição entre estados. Não se conhece uma taxa de sucesso quantitativa deste método.
Wang e Yachida [47] exploram grafos com arestas com um determinado peso para representar a face, em que algumas destas são representadas para reconhecer expressões. Para cada uma de três categorias de emoções – cólera, alegria e surpresa – é associada uma curva B-spline que descreve a relação entre a alteração de expressão e o deslocamento da aresta correspondente. Existem restrições à existência de óculos ou pêlos faciais e a iluminação deve ser constante para a aplicação deste método. A taxa de sucesso ronda os 95%.
Hulsken e outros [48] utilizam uma evolução de HMM para processar eficientemente sequências de imagens, que consiste em modelos HMM Pseudo-tridimensionais (P3DHMM), gerados a partir da encapsulação dos super-estados correspondentes a HMM bidimensionais. Para melhorar o desempenho, os super-estados são partidos em quatro HMM dimensionais, reduzindo-se assim a complexidade temporal. Nesta aproximação usa-se o algoritmo de Baum-Welch para treinar as amostras e o algoritmo de Viterbi na classificação. Conseguiram-se taxas de sucesso na ordem dos 90% para reconhecimento independente da pessoa a ser analisada. Não é referido quantitativamente o tempo inerente a este processo.
Outra evolução, mais recente, dos modelos baseados em HMM é o trabalho de Cao e Tong [14], que estuda a utilização de Embedded Hidden Markov Model (EHMM). Estes modelos baseiam-se na expansão de cada estado do HMM principal para um novo HMM, obtendo-baseiam-se assim um super-estado, correspondente ao modelo exterior, e um estado embebido, correspondente ao estado do modelo interior.
Tem-se, assim, um super-estado por característica, sendo que um estado embebido não pode ser transferido de um super-estado para outro.
Reconhecimento de expressões faciais 32 O estudo de Cohen e outros [49] visa construir um sistema em tempo-real que classifique imagens faciais a partir de dados de vídeo. Baseia-se no tracker desenvolvido por Tao e Huang [50] denominado Piecewise Bézier Volume Deformation (PBVD), que se serve de um modelo tridimensional da imagem facial, ajustado ao rosto a analisar, para acompanhar os movimentos dos principais elementos faciais (ilustração 18).
Os movimentos são definidos em termos de parâmetros de controlo de volume de Bézier e são denominados de Motion Unit (MU). Utilizam-se classificadores de redes Bayesianas, aplicando estimações de máxima verosililhança para aprender os parâmetros da rede. O algoritmo Expectation Maximization (EM) é utilizado para maximizar a função de verosimilhança quando os dados estão incompletos. Neste estudo é explorado o uso dos classificadores Naive Bayes (NB) e Tree-Augmented
Naive Bayes (TAN). O primeiro assume os elementos como independentes dado o rótulo da classe. O seu desempenho é aceitável muitas vezes devido à necessidade de aprendizagem de poucos parâmetros. O segundo constrói uma árvore através da organização hierárquica dos elementos faciais. Estes classificadores permitem obter bons resultados, sendo de 77,70% no
Reconhecimento de expressões faciais 33 melhor caso para o NB e 80,40% para o classificador TAN. É ainda explorado o classificador Classification Driven Stochastic Structure Search (CDSSS), que permite obter resultados melhores que os anteriores, com uma taxa de sucesso máxima de 83,62%. De notar que este sistema opera em tempo real.
Bartlett e outros [51] exploram um sistema que lida com rotação facial associada a acções faciais espontâneas. Esta aproximação ajusta um modelo tridimensional da face e normaliza a mesma, colocando-a numa vista frontal. Este processo, contudo, não é totalmente automático, uma vez que os pontos-chave da face são marcados manualmente de modo a aplicar o modelo tridimensional. O desempenho do classificador atingiu um sucesso de 98%.
Também recentemente, Kotsia e outros [52] utilizam, além de informação geométrica obtida através de informação relacionada com o movimento dos músculos faciais, uma evolução de SVM para a classificação de expressões. O método que estudam sugere a adopção do Candide [53], um modelo facial definido por aproximadamente 100 polígonos (e portanto computacionalmente leve), controlado pelas várias AUs, que é ilustrado na ilustração 18.
Reconhecimento de expressões faciais 34 Este modelo é semi-automaticamente ajustado à face do utilizador no primeiro quadro de vídeo e acompanhada até ao final do mesmo, enquanto a expressão facial vai sofrendo evoluções. No fim, o algoritmo produz a grelha Candide deformada que corresponde à expressão facial com maior intensidade.
O deslocamento geométrico de cada ponto da grelha, definido pela diferença entre a posição inicial e final, é utilizado como input para o sistema SVM. Este sistema evoluiu para incorporar informação estatística acerca das classes a examinar, obtendo um aumento de cerca de 6% relativamente ao SVM convencional. Com efeito, o melhor resultado em termos de desempenho é de 98,2%.
Métodos baseados em regras
Os estudos realizados por Black e Yacoob [54], [55] utilizam modelos de movimento para representar movimentos rígidos da cabeça e movimentos não rígidos na zona facial. Os parâmetros extraídos desses modelos, denominados de regras, são usados para derivar as características que permitem identificar o movimento de dada zona facial. O número de acções faciais identificáveis através deste método é desconhecido. No entanto, para cada uma das seis expressões básicas, é desenvolvido um modelo identificado por um conjunto de regras para detectar o início e o fim de cada expressão facial.
Nos testes realizados pelos autores, a taxa de sucesso é de aproximadamente 88%. Contudo, existe ainda alguma confusão de expressões, provavelmente devido ao facto de as regras usadas para a classificação não estarem suficientemente optimizadas.
Reconhecimento de expressões faciais 35
2.4 Análise Global
A tabela 2 apresenta um resumo dos vários métodos de classificação de expressões faciais, em termos de aspectos significativos num sistema que implementa algum tipo de interface pessoa-máquina.
As características de valor a ser consideradas consiste na capacidade do sistema de responder a tempo real, de suportar sequências de imagens ou imagens estáticas, a sua robustez a variações de luminosidade, pêlos faciais e óculos e rotação facial e a taxa de sucesso de classificação (no melhor caso).
No que diz respeito aos sistemas que suportam imagens estáticas, os baseados em modelos parecem apresentar uma maior robustez a variações de luminosidade e artefactos adicionais, embora alguns destes estudos tenham algumas limitações em termos de desempenho. O mais relevante é o proposto por Lu e outros [15], que apresenta uma taxa de sucesso bastante satisfatória e opera em tempo real, mesmo sob condições variáveis de luminosidade, embora não exista informação relativamente à robustez a rotação e artefactos faciais adicionais. Ainda, o estudo de Zhao e outros [41] destaca-se entre os métodos baseados em redes neuronais, apresentando uma taxa de sucesso de 100% para indivíduos conhecidos, embora não se saiba o resultado para indivíduos novos ao sistema. No entanto, no âmbito desta abordagem, não se dispõe de informação suficiente para averiguar a robustez dos sistemas às condicionantes consideradas. O mesmo acontece no que diz respeito aos métodos baseados em regras, embora estes pareçam ser promissores no que diz respeito ao trabalho de Khanam e outros [44], uma vez que é possível a obtenção de desempenhos de 100%.
Reconhecimento de expressões faciais 36 Em particular, embora os estudos de Lyons e outros [38], Yoneyama e outros [26], Zhang e outros [40], Stathopoulou e Tsihrintzis [42], e Pantic e Rothkrantz [3] apresentem também taxas de sucesso extremamente satisfatórias (acima dos 90%), não se conhecem as restrições impostas em termos de robustez à existência de pêlos faciais ou óculos, bem como à rotação facial ou, em vários casos, variações de luminosidade. Os sistemas propostos por Hong e outros [17], Huang e Huang [2], Feitosa e outros [43], e Padgett e Cottrell [22] não são particularmente interessantes no presente contexto, uma vez que estão sujeitos às mesmas incertezas em termos de robustez a factores externos e apresentam taxas de sucesso menos favoráveis. Os sistemas que suportam sequências de imagens são maioritariamente baseados em modelos. No entanto, muitos dos estudos não suportam variações de luminosidade, bem como existência de pêlos faciais ou óculos. De facto, os sistemas propostos por Cohn e outros [28], Wang e Yachida [47] e Hulsken e outros [48] apresentam taxas de sucesso bastante elevadas, mas tornam-se pouco interessantes no presente contexto dada a sua baixa robustez a condições aleatórias de interacção. No que diz respeito aos estudos de Eisert e Girod [45], Kimura e Yachida [4] e Otsuka e Ohya [46], existe alguma falta de
informação não só no que diz respeito à robustez dos sistemas em termos de restrições ambientais e contextuais, mas também no que concerne as taxas de desempenho, sendo estas mencionadas como sendo aceitáveis ou bastante positivas, embora não existam métricas quantitativas. Os estudos que satisfazem as restrições impostas para um sistema desejável são os de Cohen e outros [49] e de Cao e Tong [14], uma vez que ambos operam em tempo real. O segundo, embora apresente uma taxa de acerto menos elevada, é robusto a condições variáveis de luminosidade.
Reconhecimento de expressões faciais 37
Metodo Tempo
real
variações de luz Robustez a pelos/óculos robustez a rotacção Taxa máxima de sucesso Imagens Estáticas Modelos Huang e Huang[2] 84.5% Edwards e outros [37] S S 40.6% Hong e outros [17] N S N 89% Lyons e outros [38] 75% Lu e outros [15] S S <98.2% Redes Neuronais Padgett e Cottrell [22] 86% Zhao e outros [41] 100% Kobayashi e Hara [5] S 85% Yoneyama e outros [26] 92% Zhang e outros [40] 90.10% Feitosa e outros [43] 71.8-73.2% Stathopoulou e Tsihrintzis [42] 98.4% Regras Pantic e Rothkratz [3] 86-92% Khanam e outros [44] 70-100% Sequencia de imagens Modelos Eisert e Girod [45] Essa e Pentland [30] 98% Kimura e Yachida [4] Cohn e outros [28] N N 83-92% Otsuka e Ohya [46] Wang e Yachida [47] N N 95% Hulsken e outros [48] N N 90% Bartlett e outros [51] S 98% Cohen e outros [49] S 83.62% Kotsia e outros [52] 98.20% Cao e Tong [14] S S 79.30% Regras Black e Yacoob [55] 88%
Reconhecimento de expressões faciais 38
Capitulo III
3. Trabalho realizado
Baseado nos principais trabalhos de investigação resumidos no capitulo anterior, decidiu-se seguir a norma existente para este tipo de sistemas. Por forma a simplificar a complexidade do problema existente, decidiu-se dividir o problemas em 3 sub- problemas sendo eles
1. Detecção Facial: localização do rosto na imagem e extracção do respectivo rosto do resto da imagem
2. Utilização de PCAs e eigenfaces para detecção da respectiva face 3. Detecção da expressão facial através de uma base de dados Estas etapas estão resumidas na ilustração 20
Reconhecimento de expressões faciais 39 3.1 Espaço de imagens
Para a realização deste estudo foi utilizado um banco de imagens disponibilizado por Markus Weber do Instituto de Tecnologia da California, que consiste num conjunto de 447 imagens, distribuído por 27 pessoas diferentes.
O computador interpretará as imagens do face bank como vectores em uma matriz que as contém, por isso é necessário fazer o processo de vectorização: sendo h o numero de linhas de uma imagem e w o numero de colunas, pode-se dizer que uma imagem é um padrão de h*w características, ou um vector no espaço ((h*w)- dimensional), o qual chamaremos de “espaço de imagens”
Para se trabalhar com a técnica que será demonstrada, é feita a transposição das imagens para o espaço de imagem Tr, de tamanho M*n, sendo M=h*w e n o número de imagens a serem utilizadas durante a fase de treinamento.
Reconhecimento de expressões faciais 40 3.2 Detecção facial
No âmbito do presente estudo, dada se utilizarem imagem seleccionadas e obtidas em razoáveis condições de luminosidade, não era necessário grandes cuidados. Desta forma não haverá necessidade de aperfeiçoar as condições de extracção de imagem nem o seu melhoramento posterior, sendo que também não existem objectos “estranhos” nas imagens.
Entretanto, tendo em vista aplicações futuras, como o caso de sistemas em tempo real, foi definido que a solução deveria ter a capacidade de processar imagens independentemente do seu contexto, ou seja, seja capaz de processar imagens em ambientes arbitrários. Nestas circunstâncias nas imagens processadas podem existir mais objectos que a face, sendo necessário a existência de métodos de extracção automática de faces de imagens.
Como visto no capitulo anterior, existem diversos métodos para detecção facial, desde a utilização de blobs de movimento (Pentland e outros[16]) até à utilização de algoritmos de cor e posterior adaptação de modelos (Saber e Tekalp [6]), ao uso de filtros preditivos para estimar a posição da cabeça do individuo (Hong e outros [17]) e redes neuronais (Rowley e outros [9] e Pham e outros [10]).
Uma vez, que uma das aplicações futuras deste sistema, é a aplicação em sistemas em tempo real, optou-se pela criação de um algoritmo de detecção simples, e de rápida resposta.
Yi-chi Liu e outros [56] propuseram um método que se enquadra nas nossas exigências. O método consiste na detecção facial em imagens com fundos complexos através da detecção do tom de pele . Esta tarefa é alcançada através de um conjunto de técnicas que vão ser descritas a seguir.
Reconhecimento de expressões faciais 41 Este método é capaz de funcionar em tempo real, uma vez que utiliza o sistema de cor YCbCr para detecção do tom de pele. O sistema de cor YCbCr funciona um pouco mais rápido que os outros sistemas, permitindo através das outras componentes encontrar zonas de tonalidade da cor de pele na imagem. A luminância também é usada para reforçar o grau de detecção
O método utlizado consiste num conjunto de equações para efectuar a compensação de luz na imagem,
∑
onde Yi,j = 0.3R+ 0.6G+ 0.1B, Yi,j é normalizado (0,255), onde i e j são o índice do pixel. De acordo com o Yavg, pode-se determinar a imagem compensada Ci,j de acordo com as seguintes
equações ( ) ( ) * + onde {
Reconhecimento de expressões faciais 42 A aplicação deste método de detecção foi testado em várias imagens. Um dos resultados obtidos está presente na figura 21
O resultado obtido foi o seguinte,
No caso do algoritmo desenvolvido no âmbito desta dissertação a compensação de luz foi obtida através de uma função existente existente no MatLab, chamada de “imadjust”, que permite ajustar os valores de intensidade da imagem.
A aplicação deste método a uma imagem pode ser visto na figura 22
Ilustração 21: Compensação de Luz

![I lustração 2.2: As seis expressões faciais básicas. Fonte: Ekman e Friesen [33] Ilustração 2: As seis expressões faciais básicas](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/28.892.127.770.678.778/lustração-expressões-faciais-básicas-friesen-ilustração-expressões-básicas.webp)
![Ilustração 3:Ajuste de AAM em três iterações a partir da posição inicial. Fonte: Edwards e outros [37]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/32.892.189.737.726.889/ilustração-ajuste-iterações-partir-posição-inicial-fonte-edwards.webp)
![Ilustração 4: Exemplos típicos de faces utilizadas no estudo de Edwards e outros [37]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/33.892.165.713.245.380/ilustração-exemplos-típicos-faces-utilizadas-estudo-edwards-outros.webp)

![Ilustração 7: Parâmetros de acção sugeridos por Huang e outros Fonte: Huang e Huang [2]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/35.892.308.523.252.520/ilustração-parâmetros-acção-sugeridos-huang-outros-fonte-huang.webp)
![Ilustração 9: Posicionamento de grelha sobre imagem facial. Fonte: Lyons e outros [38]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/36.892.349.508.597.784/ilustração-posicionamento-grelha-imagem-facial-fonte-lyons-outros.webp)
![Ilustração 10: SVM - Margem máxima entre os vectores de dados. Fonte: Lu e outros [29]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/37.892.285.561.517.787/ilustração-margem-máxima-entre-vectores-dados-fonte-outros.webp)
![Ilustração 12: Exemplo de Rede de Hopfield com 4 neurónios. Fonte: Yoneyama e outros [26]](https://thumb-eu.123doks.com/thumbv2/123dok_br/16026578.1104499/39.892.305.603.629.1047/ilustração-exemplo-rede-hopfield-neurónios-fonte-yoneyama-outros.webp)
