Processo de Descoberta de Conhecimento em Dados Não-Estruturados:
Estudo de Caso para a Inteligência Competitiva
José Marcelo Pereira de Araujo
Orientador: Prof. Dr. Rogério Alvarenga
Brasília
UNIVERSIDADE CATÓLICA DE BRASÍLIA – UCB
PRÓ-REITORIA DE PÓS-GRADUAÇÃO E PESQUISA – PRPGP
PROGRAMA DE PÓS-GRADUÇÃO STRICTO SENSU EM GESTÃO
José Marcelo Pereira de Araujo
Processo de Descoberta de Conhecimento em Dados Não-Estruturados:
Estudo de Caso para a Inteligência Competitiva
Dissertação apresentada ao Programa de Pós-Graduação Strictu Senso em Gestão do Conhecimento e da Tecnologia da Informação da Universidade Católica de Brasília, como requisito parcial para a obtenção do grau de Mestre em Informática.
Orientador: Prof. Dr. Rogério Alvarenga
Brasília
AGRADECIMENTO
A Deus por me fortalecer, por me aconselhar nos momentos de decisão e por ter me
dado a oportunidade de estar desenvolvendo este trabalho.
A todos os meus familiares pela compreensão e suporte para a realização deste
projeto.
A todos os professores que me conduziram para a concretização do sonho de possuir
SUMÁRIO
RESUMO ... 9
ABSTRACT ... 10
1.2 Revisão da Literatura ... 13
1.3 Justificativa ... 20
1.4 Formulação do Problema ... 22
1.5 Objetivos ... 22
1.5.1 Geral ... 22
1.5.2 Específicos ... 23
1.6 Classificação Metodologia ... 23
1.7 Apresentação do Trabalho ... 25
2 REFERENCIAL TEÓRICO ... 26
2.1 Inteligência Competitiva ... 26
2.1.1 Suporte Computacional para Inteligência Competitiva ... 26
2.1.2. Contextualização ... 34
2.1.3 Necessidades da Inteligência Competitiva ... 37
2.1.4 A Importância da Informação para Inteligência Competitiva ... 41
2.1.5 O Papel da Recuperação de Informações para Inteligência Competitiva ... 44
2.1.6 Técnica de Análise Estratégica de Informações SWOT ... 46
2.2 Agentes Móveis ... 50
2.2.1 Contextualização ... 50
2.2.2 Aplicações dos Agentes Móveis ... 51
2.2.3 O papel do Agente Móvel na Recuperação de Informação ... 51
2.3 Descoberta de Conhecimento em Base de Dados ... 53
2.3.1 Descoberta de Conhecimento em Dados Não Estruturados ... 53
2.3.2 Mineração de Dados – Data Mining ... 55
2.3.3 Mineração de Dados – Text Mining ... 60
2.3.4 Agrupamentos (Clustering) ... 62
2.3.5. Aplicações de Text Mining ... 65
2.4 Redes Neurais Artificiais ... 66
2.4.1 Definições ... 66
2.4.2 Modelos não supervisionados ... 67
3. DESCRIÇÃO DAS FASES DO PROCESSO DE DESCOBERTA DO CONHECIMENTO ... 78
3.1 Requisitos de Modelo Conceitual ... 78
3.2 Coleta e Formatação de Textos ... 80
3.3 Transformação e Limpeza de Textos - Processo Text Mining ... 81
3.3.2 Stemming ... 83
3.3.3 Thesauros ... 84
3.4 Vetorização ... 86
3.5 Agrupamento de Textos – Rede Neural ART1 ... 87
4. ESTUDO DE CASO – Classificação de textos públicos não estruturados em quadrantes da Matriz SWOT (Oportunidades, Ameaças, Potencialidades e Fragilidades) de uma organização bancária ... 90
4.1 Apresentação do Estudo de Caso ... 90
4.2 Critérios de Classificação ... 90
4.3 Entendimento dos Dados ... 91
4.4 Preparo dos Dados ... 92
4.5 Modelagem do Conhecimento ... 93
4.6 Modelagem da Aplicação ... 96
4.6.1 Aplicação do modelo do Processo de Descoberta do Conhecimento em Textos não Estruturados. ... 96
5 ANÁLISE DOS RESULTADOS ... 100
5.1 Resultados da Preparação dos Textos não Estruturados ... 100
5.2 Resultados quanto ao Agrupamento dos Textos ... 105
5.3 Resultados relacionados à Inteligência Competitiva ... 113
6 CONCLUSÃO ... 118
ANEXO 1 – Textos sem formatação...137
ANEXO 2 – Textos formatados no padrão XML...147
ANEXO 3 – Textos após a retirada de Stopwords ...158
ANEXO 4 – Textos após a retirada de Stemmings ...161
ANEXO 5 – Textos após a sinonimização por meio do Thesauros ...164
ANEXO 6 – Lista de Stopwords ...167
ANEXO 7 – Lista de Stemmings ...172
ANEXO 8 – Thesauros ...173
ANEXO 9 – Tela inicial do programas em linguagem Java ...177
ANEXO 10 – Tela com os textos após a retirada das stopwords ...178
ANEXO 11 – Tela com os textos após a retirada dos stemmings ...179
LISTA DE FIGURAS
FIGURA 1 - Ciclo e Inteligência Competitiva...39
FIGURA 2 - Matriz SWOT...48
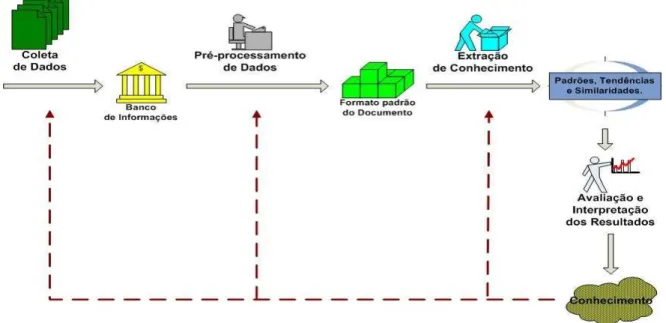
FIGURA 3 - Processo de Data Mining...57
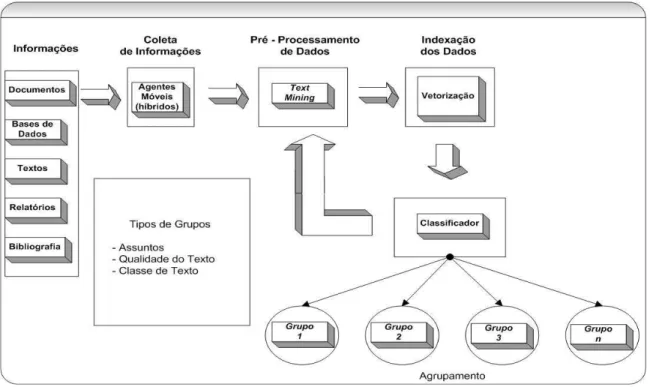
FIGURA 4 - Processo de Text Mining...62
FIGURA 5 - Exemplo do K-Means...70
FIGURA 6 - Exemplo de Rede Neural SOM (Mapa de Kohonen)...72
FIGURA 7 - Arquitetura ART simplificada...76
FIGURA 8 - Processo de Descoberta do Conhecimento...78
FIGURA 9 - Fase 1 Coleta e Formatação de Informações...81
FIGURA 10 - Fase 2 Text Mining Retirada Stopwords...82
FIGURA 11 - Fase 2 Text Mining Identificação de Stemming...84
FIGURA 12 - Fase 2 Text Mining Thesauros...85
FIGURA 13 - Exemplo da Matriz vetor de textos...86
FIGURA 14 - Tela Inicial Ferramenta ARARA...89
FIGURA 15 - Matriz SWOT formato final ...99
FIGURA 16 - Textos no formato TXT...101
FIGURA 17 - Textos no formato XML...102
FIGURA 18 - Textos sem Stopwords, Stemmings e com análise do Thesauros...103
FIGURA 19 - Matriz vetor de textos...104
FIGURA 20 - Agrupamento ART1 com Vigilante a 0.90...107
FIGURA 21 - Agrupamento ART1 ajustado com Vigilante a 0.90 ...112
LISTA DE QUADROS
QUADRO 1 - Pesquisa de revisão de literatura quanto à construção do tema...13
QUADRO 2 - Pesquisa de revisão de literatura quanto à construção do tema...18
QUADRO 3 - Softwares para Inteligência Competitiva...31
QUADRO 4 - Diretrizes para desenvolvimento de Software para IC ...32
QUADRO 5 - Comparativo entre Ferramentas ...33
LISTA DE SIGLAS
‘ PUC - Pontifícia Universidade Católica
ABRAIC - Associação Brasileira dos Analistas de Inteligência Competitiva ARARA - Aprendizagem Automática e Análise de Dados
ART - Teoria da Ressonância Adaptativa
CSV - Comma-separated values
DM - Data Mining
DOC - Documento
ETO - Electronic Trading Opportunities
HTML - Hyper Text Markup Language
IC - Inteligência Competitiva
IEEE - Institute of Electrical and Electronics Engineers
KDD - Knowledge Discovery on Data Bases
KDT - Knowledge Discovery Text
PDC - Processo de Discoberta do Conhecimento
PDF - Portable Document Format
RDF - Resource Descripton Framework
RI - Recuperação de Informação RNA - Rede Neural Artificial
SAR - Synthetic Aperture Radar
SCIP - Society of Competitive Intelligence Professionals
SGML - Standard Generalized Markup Language
SOM - Seft Organizing Map
SWOT - Strengths, Weaknesses, Opportunities e Tthreats
TM - Text Mining
TXT - Texto
UnB - Universidade de Brasília USP - Universidade de São Paulo
WEB - World Wide Web
RESUMO
Processos de descoberta de conhecimentos em dados não estruturados, obtidos em
livros, documentos e relatórios eletrônicos, podem proporcionar a aquisição de
informações, para subsidiar processos de decisão e ações de Inteligência Competitiva. Para
descobrir conhecimento em dados não estruturados, é necessário obter os conceitos
dominantes das informações, ou seja, suas idéias centrais, para, então, classificá-las em
grupos. Essa classificação deriva da ocorrência dos vocábulos contidos nas informações. O
processo de descoberta de conhecimento em dados, em conjunto com um classificador
semântico inteligente, pode servir como facilitador na estruturação, análise, agrupamento e
classificação automática de informações constituídas em textos. A Inteligência Competitiva
se caracteriza como potencial usuário deste tipo de tecnologia, em razão do volume de
textos produzidos e veiculados em diversas mídias digitais, já que necessita de rapidez e
precisão na análise semântica da documentação produzida. Esta dissertação propõe um
processo de descoberta do conhecimento em dados não estruturados, utilizando a rede
neural artificial ART1 como classificador semântico. O intuito é o de potencializar a área
de Inteligência Competitiva com a classificação de textos, segundo o modelo de matriz
SWOT, caracterizando-se pela classificação dos textos nos quadrantes SWOT, que
envolvem fraquezas, fortalezas, vantagens e desvantagens sobre uma instituição. Além
disso, os resultados esperados envolvem uma metodologia processual adequada ao
desenvolvimento de um processo de descoberta do conhecimento, que esteja apoiada na
identificação e sabedoria de teorias e, bases de suporte aos processos de mineração de
dados. Desde modo, são esperados resultados que possam justificar os principais objetivos
desta pesquisa.
ABSTRACT
Processes of knowledge discovery in data not structured obtained from books, documents and electronic reports can provide the acquisition of information to subside processes of decisions and actions of Competitive Intelligence. To discover knowledge in data not structured, it is necessary to obtain the dominant concepts of information, that is, their main ideas to classify them in groups. This classification derives from the occurrence of vocabularies contained in information. The discovery process of knowledge in data together with a semantics intelligence classifier can serve as a facilitator in the structuration, analysis, grouping and automatic classification of information constituted in texts. The Competitive Intelligence characterizes as a potential kind of user of such technology, by reason of the bulk of produced texts and transmitted in several digital media since it demands velocity and accuracy in the semantics analysis of the produced documentation. This dissertation proposes a discovery process of the knowledge in data not structured, using the neural artificial Web ART 1 as a semantics classifier. The aim is to raise to a power the area of Competitive Intelligence with a classification of texts according to the source sample SWOT, characterizing by the classification of texts in the quadrants SWOT that involve weakness, fortress, advantages and disadvantages about an institution. Besides, the waited outcomes involve a processual methodology appropriate to the development of a discovery a process of knowledge that is supported process in the identification of wisdom theories and bases of support to the processes of data mining. Thus, results are waited in order to justify the main objectives of this research.
1. INTRODUÇÃO
1.1 Apresentação
O compartilhamento da informação, por meio de ambientes de troca de informação,
como WEB e alguns meios de comunicação, aproxima países, contribuindo para o aumento de negócios e a troca de informações. Este compartilhamento de informações volta à
atenção das empresas competitivas para as gestões estratégicas de mercado, da informação
e do conhecimento, tornando a informação aliada na redução e antecipação de riscos e
crises e no aumento da vantagem competitiva sustentável. A valorização da informação e
de seus conhecimentos pode subsidiar a crescente importância do processo de extração de
conhecimento em documentos não estruturados, dada a quantidade exponencial de
informações que trafegam em redes, como Internet e Intranet, circulando nos meios de comunicação, gabinetes, setores de empresas privadas e públicas. Descobrir conhecimento
útil e inovador pode representar o diferencial entre os que obterão sucesso, já que este
sucesso depende de vários fatores, entre os quais as formas de coletar, processar e aplicar
informações.
Neste contexto, descobrir conhecimentos em dados não estruturados obtidos em
livros, documentos e relatórios eletrônicos pode proporcionar a aquisição de informações
relevantes para subsidiar processos de decisão e ações de Inteligência Competitiva. Para
que textos não estruturados possam ser classificados como relevantes, é necessário
descobrir seus conceitos dominantes (idéia central), para poder classificá-los em grupos,
observando suas similaridades de idéias e conteúdos, com base nas ocorrências de seus
vocábulos.
No que se refere à análise, classificação e tratamento de dados não estruturados
descoberta de conhecimento em textos (Text Mining) com um classificador semântico inteligente. A junção destas duas técnicas pode gerar um processo capaz de analisar,
selecionar e identificar a relevância de uma informação, independentemente da variedade
de formatos (XML, SGML, HTML, DOC e PDF), da quantidade, do tamanho e origem da
informação.
A Inteligência Competitiva se caracteriza como potencial usuário deste tipo de
tecnologia, em razão do volume de textos produzidos e veiculados em diversas mídias
digitais, já que necessita analisar semanticamente a documentação produzida, com rapidez
e precisão, para que seja possível gerar conhecimento por meio da informação filtrada e
depurada. A análise de informações coloca a informação em um formato adequado para as
decisões táticas e estratégicas. É, ainda, a análise que dá um caráter exclusivo à informação,
pois a interpretação do que se faz está correlacionada às estratégias da empresa. Assim, a
leitura de uma informação é feita sob o prospecto de cada empresa, de suas necessidade, de
seus planos e metas estratégicas. Neste sentido, gerentes buscam informações sobre seus
negócios, visando à obtenção de vantagens competitivas, favorecendo a empresa em que
trabalham.
Esta dissertação propõe um processo de descoberta do conhecimento em texto (não
estruturado), baseado em processos de coleta e processamento de textos, utilizando a rede
neural artificial “ART1” como classificador semântico, com intuito de potencializar a área
de Inteligência Competitiva com a classificação de textos, segundo o modelo de
classificação da matriz SWOT, a qual se caracteriza como uma técnica de análise de
ambientes para o posicionamento de uma organização no mercado, além de verificar a sua
capacidade de competição, proporcionando ainda uma avaliação do ambiente de mercado
interno e dos impactos do ambiente de mercado externo sobre uma empresa, fornecendo
conclusão da análise SWOT deve levar a organização a concentrar-se nos seus pontos
fortes, reconhecer seus pontos fracos, aproveitar as oportunidades e proteger-se contra as
ameaças do ambiente externo.
1.2 Revisão da Literatura
Entre setembro de 2006 e março de 2007, foram usadas as fontes a seguir:
• Scirus (Science Direct)1;
• ISI WEB of Knowledge2 e
• Proquest.3
Nas pesquisas, foram utilizadas palavras-chave relacionadas ao tema proposto e
combinações entre as mesmas. Os resultados obtidos são apresentados no Quadro 1.
Quadro 1: Pesquisa de revisão de literatura quanto à construção do tema
PALAVRAS-CHAVE SCIRUS ISI WEB
KNOWLEDGE
PROQUEST
Knowledge Discovery
Text
46.067 146 431
Knowledge Discovery
Text
Competitive
Intelligence 2.763 5 9
Knowledge Discovery
Text
Competitive Intelligence
SWOT
Matrix 42 0 0
Knowledge Discovery
Text
Competitive Intelligence
SWOT Matrix
Neural Network
ART1
0 0 0
Inicialmente, os resultados das pesquisas mostraram uma considerável quantidade
No entanto, conforme a utilização de novas combinações entre as palavras-chave, os
resultados sofreram importante redução em seu montante.
Na fonte de pesquisa ISI WEB, por exemplo, a contagem dos resultados mostrou-se pequena, os documentos encontrados estavam direcionados à Descoberta do Conhecimento
em bases de dados estruturados, ao Processamento da Linguagem Natural e não a textos
não estruturados, foco do presente trabalho. Além disso, os respectivos autores não
repercutiam entre os entendidos sobre a Descoberta de Conhecimento em Textos.
Nas outras fontes de pesquisa (Scirus e Proquest), os documentos encontrados com maior semelhança ao tema proposto neste trabalho referenciavam membros da IEEE
Computer Society’s (Transactions on knowledge and Data Engineering), além dos trabalhos relacionados à Association for Computing Machinery e de documentos retirados da EACL-2006 (11° Conferece of the European Chapter of the Association for Computational Linguistics). Dentre os trabalhos pesquisados destacam-se: Courseault (2004) que propõe uma metodologia para descobrir conhecimento em textos e bases de
dados direcionados à Inteligência Competitiva, utilizando técnicas de Text Mining e Análise de Informação para subsistir os processos decisórios de empresas. Esta metodologia é
realizada em seis fases: a primeira determina a técnica de monitoramento de informações; a
segunda, o tipo de informação desejado pelos gerentes; a terceira prevê a utilização de
algoritmo para identificar conceitos sinônimos nos textos; a quarta retrata o agrupamento de
textos; a quinta aborda uma análise estatística dos textos; a sexta e última apresenta os
resultados obtidos com as fases anteriores. Apesar da relevância deste trabalho, o mesmo
não analisa semanticamente os textos, abrindo uma lacuna quanto a relações semânticas
entre palavras chave de textos, fato abordado no presente trabalho; Por outro lado,
competitivos que surgem durante a análise estratégica, que formula a estratégia competitiva
de uma empresa. Além disso, o trabalho também procura esclarecer o relacionamento
existente entre o gerenciamento estratégico e o melhoramento competitivo.
Em complemento às pesquisas, foram consultados outros trabalhos acadêmicos,
como referencial de processos de descoberta do conhecimento em dados não estruturados.
Nesse sentido, Abutridy, Mellish & Aitken (2003) propõem um método para descobrir
conhecimento em textos baseados em algoritmos genéticos, Data Mining e Text Mining. O referido método é realizado em duas fases: na primeira, o algoritmo genético é treinado a
partir da informação inicial; a segunda diz respeito à utilização do processo de Text Mining
propriamente dito, onde é aplicada a técnica de sumarização no intuito de identificar
conhecimento nos textos. Apesar de sua relevância, este trabalho deixa uma lacuna quanto
à utilização de análises semânticas nos textos.
Outro trabalho proposto por Karanikas e Theodoulidis (2002) realiza uma
comparação entre os principais softwares e metodologias vinculadas à área Text Mining, identificando a função de cada técnica aplicada em um processo de descoberta em textos. O
trabalho, apesar de sua relevância, não deixa claro a composição de ideal de um processo
de descoberta do conhecimento, abrindo uma lacuna quanto à integração de técnicas de
Text Mining capazes de compor um processo de descoberta do conhecimento.
Jiang, Tan & Wang (2007) propõem duas técnicas para obtenção de conhecimento
em textos; a primeira chamada de Resource Descripton Framework – RDF visa à extração de relações semânticas entre palavras importantes de um texto, por meio do processamento
o qual é experimentado por meio de estudos empíricos em bases de dados e tem por
objetivo identificar relações semânticas entre palavras dos textos.
Tan (2002) descreve, em seu trabalho, o sistema Flexible Organizer for Competitive Intelligence, transformndo os resultados de consultas na Internet em portifólios de informações. O intuito deste sistema é classificar os portifólios em grupos por assuntos
pesquisados, utilizando o método User-Configurable Clustering. Isto viabilizaria a obtenção de novas informações com a re-estruturação dos portifólios. Esta pesquisa só
utiliza textos da WEB, abrindo lacuna quanto à utilização de textos armazenados em bases de dados ou nas estações de trabalho.
Chen et al (2002) desenvolveram o sistema Competitive Intelligence Spider no intuito de coletar e agrupar coleções de textos advindos da WEB em grupos por assuntos ligados à IC. O sistema ainda é comparado com outros dois métodos de obtenção de
informações da WEB; o Lycos e o Within-site Browsing. Segundo os autores, o CI Spider
tem melhor desempenho e eficácia que os outros dois métodos. Neste trabalho, tanto quanto
no de Tan (2002), existe somente a utilização de textos da WEB, abrindo possibilidades de exploração de textos em estações trabalho.
Oliveira et al (2004) apresentam um conjunto de técnicas de Text Mining como suporte na análise de informações negociais permutadas pelo sistema Electronic Trading Opportunities – ETO. O objetivo do trabalho é identificar conceitos nas informações geradas pelo ETO, o que levaria, em um segundo momento, a identificar padrões nos
respectivos conceitos e assim gerar informações estratégicas para a IC de uma empresa. A
relevância deste trabalho é absoluta. No entanto, expande-se uma lacuna quanto à análise
O trabalho proposto por Kongthon (2004) também é um bom exemplo da aplicação
de técnicas de Text Mining no âmbito da IC, consistindo no desenvolvimento do sistema
VantagePoint, o qual tem por objetivo extrair informações estratégicas de textos advindos da WEB que suportem tomadas de decisão. O sistema desenvolvido tem por base dois algoritmos para extração de informações; o primeiro para identificar relações entre termos
do texto e o segundo para compor um thesauros, utilizado no pré-processamento dos referidos textos.
Pesquisas complementares também foram realizadas em sites brasileiros, na tentativa de encontrar trabalhos relacionados a processos de descoberta do conhecimento
em textos, direcionados à IC. Neste sentido, as pesquisas foram realizadas nos sites:
• Universidade Pontifícia Católica – PUC Rio de Janeiro4;
• Universidade de São Paulo – USP5;
• Universidade de Brasília – UNB6 e
• Universidade Católica de Brasília – UCB7.
Nas pesquisas, foram utilizadas palavras-chave relacionadas ao tema proposto e
combinações entre as mesmas. Os resultados obtidos são apresentados no Quadro 2.
Quadro 2: Pesquisa de revisão de literatura quanto à construção do tema
PALAVRAS-CHAVE PUC-RIO USP UNB UCB
Descoberta Conhecimento
Textos
19 29 9 83
Descoberta Conhecimento
Textos
Inteligência
Competitiva 0 0 0 5
Descoberta Conhecimento
Textos
Inteligência
Competitiva Matriz SWOT 0 0 0 0
Descoberta Conhecimento
Textos
Inteligência
Competitiva Matriz SWOT
Rede Neural
ART1 0 0 0 0
Os resultados das pesquisas não mostraram uma considerável quantidade de textos
sobre a Descoberta de Conhecimento em Textos e, conforme a utilização de novas
combinações entre as palavras-chave, não foram encontrados documentos relativos aos
assuntos abordados neste trabalho.
Na fonte de pesquisa PUC - Rio, por exemplo, a contagem dos resultados
mostrou-se pequena, os documentos encontrados estavam direcionados à Descoberta do
Conhecimento em bases de dados estruturados, em pesquisas médicas, também utilizando o
processamento de linguagem natural na identificação de relações semântica em textos e
rede neurais para o agrupamento de textos. No entanto, resultados quanto a documentos
relacionados à área de IC, os quais utilizassem processo de descoberta do conhecimento
não foram encontrados.
Na fonte UCB, os trabalhos pesquisados retratavam em sua maioria, temas como o
gerenciamento do conhecimento, gestão do conhecimento e trabalhos pertecentes a área de
Inteligência Competitiva, neste caso, os trabalho não abordavam a matriz SWOT como um
Nas outras fontes de pesquisa (USP e UNB), quanto aos documentos encontrados
com maior semelhança ao tema deste trabalho, destacam-se os trabalhos produzidos por
Loh (2001), onde a técnica de descoberta do conhecimento em textos, baseada em
conceitos, com o propósito de identificar características de alto nível em textos na forma de
conceitos, para depois realizar a mineração de padrões sobre estes conceitos. Embora este
comente outras estratégias de descoberta do conhecimento em textos, uma lacuna pode ser
observada quanto à utilização de uma rede neural na categorização de grupos dos padrões,
gerando conceitos identificados nos textos, os quais são direcionados à Inteligência
Competitiva.
Outro trabalho escrito Schiessl (2007) visa à aplicação de técnicas de Text Mining
na análise de dados, provenientes de textos relativos à qualidade no atendimento ao
consumidor realizado por uma instituição financeira. O trabalho aplica a descoberta do
conhecimento em textos, para criar agrupamentos automáticos de documentos, para que
posteriormente seja possível avaliar o grau de satisfação do cliente em relação aos produtos
e serviços oferecidos pela instituição financeira.
Já Wives (2002) apresenta um conjunto de técnicas, métodos e softwares
provenientes das áreas de recuperação de informação, IC e descoberta do conhecimento, no
intuito de coletar e analisar informações sobre o ambiente interno e externo de uma
empresa, para que a vantagem competitiva seja obtida por meio de produtos diferenciados.
Caputo (2006) desenvolveu um sistema computacional, baseado em métodos de
mineração de textos para análise de patentes industriais brasileiras, tendo por objetivo
analisar resumos de patentes, no intuito de descobrir novas tecnologias que ofereçam
vantagens competitivas, enfatizando o auxílio à tomada de decisão e antecipação de
Furtado (2004) também desenvolveu sistema computacional estruturado em
metodologias de mineração de textos. O foco do trabalho concentra-se em processar textos
de sites de instituições educacionais do ensino superior do Rio de Janeiro. Para isso, são aplicadas técnicas pertinentes à área da Descoberta de Conhecimento em Textos, visando à
obtenção de informações que proporcionem vantagens competitivas, auxiliando a tomada
de decisão no que se refere à concorrência.
Finalizando o trabalho, realizado por Gonçalves e Rezende (2001), faz-se uma
avaliação empírica dos principais algoritmos para extração do conhecimento: Nearest Neighbor; Naive Bayes; Decision Tree; Decision Rule; Decision Table and Support Vector Machines.
Para a análise dos citados algoritmos, o trabalho utilizou-se das fases do processo de
Text Mining, idealizado por Fayyad et al (1996).
1.3 Justificativa
A definição sobre IC, proposta por Coelho (1997), enfatiza a importância das
informações para as empresas, ressaltando a transparência das fontes de informação em
meios como Internet, Intranet, documentos, textos que transitam diariamente por e-mails,
etc. Neste sentido, descobrir conhecimento útil e estratégico nestas fontes de informação
faz parte da gestão estratégica da empresa. Brasiliano (2005) considera a informação como
inteligência útil e com valor similar ao capital. E como tal, tem valor produtivo, gerencial e
competitivo, possuindo custos quanto à sua coleta, armazenamento e disseminação. Além
de ser controlada na forma gerencial ou com o auxílio de computadores.
A importância da informação é evidenciada pelo seu papel na produção do
acumuladas, criados por um fluxo de informações, servindo como base para a tomada de
decisão e planejamento estratégico de negócio. No processo de IC, grande parte das
informações é obtida em fontes externas à empresa, que oferecem, na maioria dos casos,
informações dispostas em um formato sem estrutura ou semi-estruturado (informações
textuais) (FELDENS, 1998).
Esse tipo de informação textual não é tratado pelas ferramentas tradicionais de
descoberta de conhecimento, com características que tornam sua análise complexa (ZAN,
1998). Para que as etapas do processo de IC sejam aplicadas, são necessárias técnicas e
ferramentas computacionais desenvolvidas especificamente para tratar informações textuais
não estruturadas (GOEBEL; GRUENWALD, 1999).
Segundo Nonaka e Takeuchi (1997, apud LOH, 2000), um processo de descoberta do conhecimento é composto de fases: coleta, armazenamento, processamento, análise
semântica e classificação das informações. Adequar cada fase do processo de descoberta do
conhecimento à extração do conhecimento em informações textuais pode ser de grande
valia, já que informações deste tipo são facilmente coletadas e armazenadas, em função de
sua não estruturação e dos diversos formatos. Estatisticamente, 80% das informações de
uma organização estão disponíveis de forma textual não estruturada (TAN, 1999).
Existem várias técnicas que auxiliam a coleta, o processamento e a descoberta de
conhecimento em textos (LOH; WIVES, 2000). Entretanto, por ser ainda uma área recente,
as poucas ferramentas disponíveis são Softwares proprietários que não disponibilizam o processo de descoberta do conhecimento. Na maioria dos casos, as ferramentas apenas
encontram textos que podem conter informações relevantes (ferramentas de recuperação de
informação), deixando para os usuários a difícil tarefa de encontrar o conhecimento
1.4 Formulação do Problema
Como desenvolver um processo de descoberta de conhecimento útil e gerador de
vantagens competitivas em fontes de informação não estruturadas, capaz de servir como
opção ao suprimento das necessidades de processos decisórios vinculados à IC?
A prática da Inteligência Competitiva possibilita aos empresários o acesso a
informações que reduzem riscos, antecipam crises e melhoram seus produtos. Entretanto,
para se obter informações que subsidiam a tomada de decisão e posicionamento estratégico
de uma empresa, existem dificuldades quanto à grande quantidade de informações textuais
disponíveis no mercado, dificuldades de tratamento, análise e veracidade da informação.
As análises das informações do contexto mercadológico de uma organização são
referenciadas pelos estudiosos, como fatores de sobrevivência e competitividade em função
das informações angariadas no ato da execução destas análises, das constantes mudanças no
contexto competitivo e das potencialidades dos concorrentes.
A monitoração do fluxo de informações de negócios implica na análise do ambiente
externo e interno das organizações e, conseqüentemente, na interação de todos os atores e
variáveis que afetam o negócio da organização. O conhecimento sobre esse ambiente
competitivo suporta o processo estratégico de uma empresa, o qual necessita de
informações capazes de gerar vantagens competitivas e servir como subsídio à tomada de
decisão.
1.5 Objetivos
1.5.1 Geral
Propor um processo para descoberta do conhecimento em dados não estruturados,
visando potencializar a área de Inteligência Competitiva de acordo com classificações nos
quadrantes da matriz SWOT.
1.5.2 Específicos
• Identificar as ferramentas capazes de auxiliar no processo de Inteligência
Competitiva;
• Desenvolver programas em linguagem JAVA, capazes de realizar tarefas pertinentes
à área de Text Mining;
• Analisar o potencial do classificador;
• Observar os resultados obtidos como a realização do processo, indicando os pontos
fortes, fracos e os trabalhos futuros para o melhoramento do processo de descoberta
de conhecimento em Base de Dados e em textos não estruturados;
• Verificar o processo de descoberta do conhecimento em textos não estruturados na
área da IC;
• Conhecer e classificar semanticamente os significados dos quadrantes da matriz
SWOT;
• Criar as bases de dados de suporte aos processos de mineração de dados (Stopwords, Stemming e Thesauros) adequadas à classificação temática (Financeira – Bancária).
1.6 Classificação Metodologia
A pesquisa está classificada da seguinte forma:
• Quanto à natureza: Aplicada, pois objetiva gerar conhecimento para a aplicação
• Quanto à forma de abordagem do problema: Qualitativa, pois serão coletados
documentos em fontes de informações com respaldo de empresas vinculadas ao meio
financeiro em específico à rede bancária, as quais serão aplicadas nas fases do
processo desenvolvido neste trabalho;
• Quanto aos fins: Experimental, pois visa à construção de processo, método para
manipulação de uma realidade;
• Quanto aos meios: Bibliográfica e de Laboratório, pois será desenvolvido um
processo para a descoberta de conhecimento em base de dados e em textos não
estruturados, vislumbrando a possibilidade de obtenção de conhecimento útil e
aplicável ao âmbito da Inteligência Competitiva.
O presente estudo não pretende gerar ou agregar novos conceitos às teorias citadas
no item 2 deste trabalho (Referencial Teórico), as quais servem de base para o
desenvolvimento do processo descrito neste documento. Ainda no âmbito das limitações,
este estudo não pretende desenvolver o Agente Móvel para a coleta de informações e a rede
neural ART1 para a classificação de informações.
Esta análise visa à obtenção de coleções de informações, servindo de base para o
processo descrito aqui, por meio de um agente móvel capaz de trafegar em redes como
Internet, Intranet e redes internas de empresas. A coleção de informações pode ser formada de documentos, textos, livros e relatórios eletrônicos. O passo seguinte é envolver um
processo de Text Mining, uma vetorização dos textos e a classificação automática dos mesmos por meio da rede neural ART1.
O recurso tecnológico para o desenvolvimento deste trabalho contará com itens
pré-processamentos de textos não estruturados e tecnologias capazes de gerar e compilar
códigos da linguagem Java.
1.7 Apresentação do Trabalho
Este está estruturado em cinco capítulos. Inicialmente, trata-se, no capítulo 1, da
introdução com estudos referentes ao suporte computacional para IC, a descoberta de
conhecimento em textos, as limitações do trabalho, a contextualização do problema foco
deste trabalho, além dos resultados esperados, descrevendo também as principais
ferramentas que executam operações relacionadas à área de Text Mining que estejam associadas à área de IC. No capítulo 2, o referencial teórico esclarece as teorias como
Redes Neurais, Agentes Móveis, Text Mining, Inteligência Competitiva, evidenciando a relação entre as teorias citadas anteriormente com a área de IC; além de fomentar a presente
análise. No capítulo 3, na Metodologia do trabalho, detalha-se uma proposta para um
processo de descoberta do conhecimento em textos não estruturado, descrevendo as etapas
com suas respectivas atividades. São descritos também exemplos dos procedimentos
executados nas referidas fases, além de esclarecer os subsídios de entradas e saída de cada
fase do processo. Já no capítulo 4, são analisados os resultados obtidos com a realização da
validação do processo de descoberta do conhecimento. Estes resultados são mostrados por
meio de quadros que demonstram as fases do processamento dos textos não estruturados,
além da análise dos resultados obtidos com o agrupamento gerado pelas redes neurais
utilizadas aqui. No capítulo 5, são descritas as considerações finais sobre o trabalho,
indicando a possibilidade de realização dos objetivos iniciais deste trabalho, além da
2 REFERENCIAL TEÓRICO
2.1 Inteligência Competitiva
2.1.1 Suporte Computacional para Inteligência Competitiva
Atualmente, as empresas, em sua maioria, estão se virtualizando, ou seja, acessando
uma imensa quantidade de informações na WEB. Neste sentido, pode ser vantajoso para as empresas nos termos da Inteligência Competitiva – IC – o modo de coletar, analisar e
disseminar informações relevantes que permeiam o mercado. Segundo Wives (2002), a
coleta e análise de informações tem que ser cada vez mais rápida para que as decisões e
ações sejam tomadas antes da concorrência, sendo necessária a utilização de técnicas,
metodologias, ferramentas e Softwares que auxiliem esse processo.
Miller (2002) diz que a informação é essencial para Inteligência Competitiva,
baseando-se no conhecimento do negócio que um gerente deve ter de maneira formal e
sistemática. A IC é informação filtrada, depurada onde gerentes buscam a todo custo informações acerca de seus negócios, visando à aquisição de vantagens competitivas,
favorecendo a empresa em que trabalham. Desde modo, é necessário desenvolver processos
que facilitem a filtragem e depuração da informação.
Para a Society of Competitive Intelligence Professionals www.scip.org (SCIP), a IC é o processo da coleta, análise e disseminação ética de inteligência acurada, relevante,
específica, atualizada, visionária e viável em relação às implicações do ambiente dos
negócios, dos concorrentes e da organização em si.
NIC/UNB (1999) define IC como um processo sistemático de coleta e análise de
social, tecnológico, científico, mercadológico e regulatório, para ajudar na conquista dos
objetivos institucionais na empresa pública ou privada.
Um processo de IC pode ser beneficiado de Softwares e ferramentas que auxiliem o mesmo. No intuito de esclarecimento, a seguir são citados alguns dos Softwares mais conhecidos, os quais podem ser destinados à área de IC:
• PUZZLE: Este Software baseia-se em uma metodologia para IC, a qual está ligada ao processamento de informações antecipativas, qualitativas, incertas e
fragmentadas. O Software reagrupa todas as informações da vigília estratégica que foram coletadas pelos captadores. A partir disso, permite os recortes (ou
composições) e a validação progressiva das informações derivadas ou
subjetivamente elaboradas, aceitando informações nas diversas formas: texto,
imagem, voz e isto sem imposição de particularidades quanto à formatação
(VEGARA et al, 2005).
• GRAPEVINE SaaS: Software comercial. É utilizado para o processamento automático de dados destinado a aplicações financeiras, permitindo ainda a
distribuição inteligente de informações, as quais foram obtidas por meio de textos
retirados da WEB. Voltado também para fornecer representações significativas de informações e do processo de escuta do ambiente, o qual permite acesso a
informações inacessíveis. O Software foi desenvolvido pela Grapevine Technologies
(Austrália) (KILMURRAY, 2005).
• WINCITE: É um portal colaborativo, o qual permite o gerenciamento de bases de dados corporativas por meio da Intranet da empresa. Fornece segurança ao acesso à base de dados, além da possibilidade de acesso a outras ferramentas voltadas à área
desenvolvida pela Wincite Systems,Braun Technologies (POZZEBON; FREITAS, 2004).
• SEE-K: Este Software permite validar as competências essenciais de concorrentes, por meio da visualização dos portifólios dos mesmos. Esta visualização resulta em
resposta às seguintes perguntas: Qual a companhia de maior presença no mercado;
Quais as companhias mais flexíveis em questões de acordos; Quais as oportunidades
ainda não exploradas por minha companhia; e quais as categorias de produtos ainda
não exploradas. As respostas são retiradas de textos não estruturados, coletados em
Portais residentes na Internet. O Software analisa os textos, utilizando técnicas ligadas à área de Text Mining. Como resultado, o Software fornece uma árvore de conhecimento, onde são relatadas informações sobre competidores, steckholders e demais assuntos ligados à análise dos concorrentes (MARCHI, 2005).
• TEXT MINING SUÍTE: é um conjunto de ferramentas para Text Mining (mineração de textos), ou seja, para descoberta de conhecimento em informações textuais. O
Software permite a análise qualitativa dos textos, além da análise quantitativa (quantidade de textos em que a proporção referencia cada tema, além de descobrir
associações entre temas) (KLEIN, 2005).
• CONQUEST: Fornece um enfoque integrado para o manuseio e recuperação de informações de texto. Possui capacidade de busca do tipo lógica Booleana,
proximidade, relevância, questionamento, etc., funcionando em uma grande
variedade de tipos de equipamentos. Fornece ainda bases de dados repositórias de
informações extraídas de seus programas de análise. A ferramenta é utilizada para
manusear as informações de texto de toda a organização. Usualmente é integrado ao
• SPHINIX LÉXICA: Realiza a análise lexical para produção automática e gestão do léxico do texto. Aborda a navegação no texto a partir de elementos de léxico ou de
variáveis de contexto, extração de elementos do texto em função de seu conteúdo
lexical, busca de contexto, produção de verbatim (extratos de texto, segundo certo critério). Revisa e anota ascorreções e marcações do texto, agrupamento de palavras
ou expressões, exportação de textos extraídos do texto base. Produz Análise
sintática, busca da classe gramatical das palavras, lematização (mudança nas formas
derivadas – como plural – para a forma original – singular). Tem a disponibilidade
de executar funções estatísticas, contagem e desdobramento das ocorrências,
construção de tabelas lexicais, cálculo de indicadores lexicais e de especificidades.
Produz ainda a análise de dados textuais, produção de variáveis textuais, análise
fatorial, classificação e tratamento integrado de dados textuais e outros. Por fim,
gerencia base de dados, modificação automática dos níveis de análise (texto,
parágrafo, frase) e restrição das variáveis de contexto em função da seleção
(SPHINIX, 2006).
O presente trabalho buscou identificar nas ferramentas características de busca de
conhecimento para IC em textos não estruturados ou base de dados. Estas características
devem estar alinhadas ao ciclo de IC e às principais atividades de sistema de informações,
propostos Prescott & Miller (2002). Neste sentido, foram criados dois quadros: o primeiro
(Quadro 3), identificando as fontes de dados e os resultados apresentados pelas ferramentas,
e o segundo (Quadro 4) com perguntas, baseadas nas diretrizes propostas por Miller (2002),
no que se refere ao desenvolvimento de ferramentas para IC.
O quadro 4 mostra, de forma sucinta, a co-relação entre os principais Softwares
Softwares analisados atendeu às diretrizes. No entanto, quando o foco são as atividades para um sistema de IC, as ferramentas avaliadas, em sua maioria, não atenderam
(PRESCOTT; MILLER, 2002). Isto leva a perceber que a maioria dos Softwares não se preocupou em diagnosticar os pontos fortes e fracos dos concorrentes, em sugerir novas
oportunidades de mercado, em interagir com outros Softwares de IC já existentes na empresa ou até mesmo com diretrizes administrativas que facilitem a gerência da empresa.
Isto abre uma lacuna quanto a novas ferramentas destinadas à IC, as quais trabalhem sob
perspectiva de melhorar a análise sobre o mercado e concorrentes.
A pesquisa sobre ferramentas direcionadas a área de Text Mining, além do desenvolvimento de programas em linguagem JAVA para a execução das atividades de
Text Mining propostas neste trabalho, possibilitou realização de comparativo entre as funcionalidades das ferramentas para IC que realizam operações de Text Mining e os programas em JAVA aqui desenvolvidos. O Quadro 5 mostra o co-relacionamento entre as
principais atividades realizadas pelas referidas ferramentas e programas.
O quadro 5 faz perceber que algumas das ferramentas disponíveis no mercado, estão
mais focadas a área de IC, o que restringe a aplicabilidade na área de Text Mining, no entanto, ferramentas como Sphinix Léxica e Text Mining condicionam suas atividades
mais a área de Text Mining, realizam inclusive analise léxicas de textos, os programas em JAVA não realizam.
Por outro lado algumas das atividades realizadas pelos programas em JAVA, não
são encontradas nos portifólios de atividade da maioria das ferramentas, exemplo disto,
Quadro 3. Softwares para Inteligência Competitiva
Software Área Atuação Dados de
Entrada
Resultados apresentados pelo Software Origem
Informação PUZZLE - Inteligência
Competitiva - Text Mining
- Texto - voz - Imagem
- Reagrupamento de Informações; - Validação progressiva de Informações; - Permite múltiplos agenciamentos ou arranjos de informações;
- Verifica a coerência das informações reunidas;
- Acesso fácil e rápido às informações derivadas dos arranjos realizados pela ferramenta.
(VEGARA et al, 2005)
GRAPEVINE SaaS
- Inteligência Competitiva - Text Mining - Data Mining
- Texto - Sites - Base de Dados estruturadas
-Processamento automático de dados - Análise de Informações,
-Gerenciamento de integrado de documentos -Gerenciamento de conteúdo oriundo da WEB -Distribuição de informações
(KILMURRAY, 2005).
WINCITE - Inteligência Competitiva - Data Mining - Text Mining
- Documentos - Arquivos - Textos - Base de Dados estruturadas
- Integração de Informações - Integração de grupos de trabalho - Análise de informações
- Gerenciamento de Bases de dados estruturadas
- Emite relatórios de feedback
- Gerenciamento da Segurança da base de dados
(POZZEBON; FREITAS, 2004).
SEE-K - Inteligência Competitiva - Text Mining
- Sites - Textos
- Análise de Competências; - Análise de Concorrentes - Análise de Textos
-Análise de diferentes Portifólios -Análise Estratégica de Alianças com concorrentes (MARCHI, 2005) TEXT MINING SUÍTE - Inteligência Competitiva - Text Mining
- Textos - Documentos - Relatórios
- Análise qualitativa e quantitativa de textos - Monitoração de sites para IC
- Atividades de Text Mining - Análise de Conteúdo - Gerenciamento de Dados
(KLEIN, 2005)
CONQUEST Text Mining - Textos - e-mail
-Base repositória de dados -Gerenciamento informações
-Executa o processo de Recuperação de Informação
-Executa busca de informação do tipo; booleana, lógica, proximidade, relevância.
(CASTRO, 2000)
SPHINIX LÉXICA
Data Mining e Text Mining
- e-mail - Textos - Documentos - WEBsites - Base de dados
- Análise de discurso, mapas cognitivos, redes semânticas;
- Realiza análises avançadas e explorar dados textuais provenientes de todas as origens; - Análise de conteúdo, explorar o texto, codificar;
Quadro 4. Verificação dos Softwares para Inteligência Competitiva
Diretrizes
Softwares
Puzzle Grapevine
saas Wincite See-k
Text
min-ing suíte Conquest
Sphinix léxica
O Software produz
informação Qualificada? X X X X X X X
Destina-se aos tomadores de decisões e demais
participantes do processo de IC?
X X X X X X X
Coleta e disseminação informações quando solicitado pelo usuário?
X X X X X X X
Produz relatórios, gráficos com informações acerca dos resultados obtidos com a utilização da IC?
X X X X
A ferramenta produz dados
confiáveis? X X X X X X X
Contou com uma equipe da área de Inteligência, durante o desenvolvimento?
X X X X
Coleta, localiza e exibe documentos com variedades de formatos?
X X X X X X X
Consolida informações obtidas por meio da Internet, Intranet ou redes de comunicação externa?
X X X X X X X
Fornece acesso a outros Softwares da área de Inteligência da empresa?
X
Procura evoluir em paralelo às novas tendências da área de IC?
X X X X X X X
Alerta com a devida antecipação o surgimento de oportunidades e ameaças à empresa?
X X X X
Subsidia o processo de tomada de decisão estratégica da empresa?
X X X X X X X
Subsidia decisões táticas e
operações de negócios? X X X X
Avalia e monitora concorrentes, setores de negócios e tendências sociológicas e políticas?
Quadro 5. Comparativo entre Ferramentas.
Software Atividades de Text Mining Realizadas pelos Softwares
Atividades Realizadas pelos programas JAVA
Atividades não Realizadas pelos programas JAVA
Atividades não Realizadas pelos Softwares
Puzzle -Reagrupamento de Informações; -Verifica a coerência das informações reunidas.
- Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
-Verifica a coerência das informações reunidas.
- Processamento de textos em XML;
-Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Vetorização de textos.
Grapevine SaaS
-Processamento automático de dados;
- Analise de Informações.
- Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Vetorização de textos.
Wincite - Análise de informações. - Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
- Integração de Informações. - Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos. SEE-K - Análise de Textos. - Processamento de textos em
XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
Text Mining - Análise qualitativa e quantitativa de textos;
- Atividades de Text Mining; - Análise de Conteúdo;
- Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos. Conquest -Executa o processo de
Recuperação de Informação; -Executa busca de informação do tipo; booleana, lógica, proximidade, relevância.
- Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
- Executa busca de informação do tipo; booleana, lógica, proximidade, relevância.
-Executa busca de informação do tipo; booleana, lógica, proximidade, relevância.
- Vetorização de textos.
Sphinix Léxica -Análise de discurso, mapas cognitivos, redes semânticas; -Realiza análises avançadas e explorar dados textuais provenientes de todas as origens; -Análise de conteúdo, explorar o texto, codificar;
-Aproximação lexical, -Lexicometria e análise dados textuais.
- Processamento de textos em XML;
- Retirada de Stopwords dos textos; - Verificação de Stemmings nos textos;
- Sinonimização de Palavras; - Vetorização de textos.
-Análise de discurso, mapas cognitivos, redes semânticas; -Realiza análises avançadas e explorar dados textuais provenientes de todas as origens; -Aproximação lexical; -Lexicometria.
processo de descoberta do conhecimento desenvolvimento. No entanto, ao que se refere as
ferramentas analisadas, suas respectivas aplicabilidades envolvem não somente a área Text Mining, mas também, a área de IC, o que faz com as mesmas não se tornem software específicos a área de Text Mining.
2.1.2. Contextualização
O avanço nos ambientes de troca de informações caracterizados principalmente pela
Internet e Intranet, além da globalização, minimizam as fronteiras entre países e serve como estopim para o aumento dos negócios e da quantidade de informações ao alcance de
todos (FURTADO, 2004). No entanto, segundo Junior (2003), a sobrevivência em
ambientes com elevados níveis de negócios e grandes quantidades de informação depende
da construção e aplicação de uma boa estratégia competitiva apoiada em inovações e
criatividade, o que exige da organização conhecer e antever o que representa ameaça ou
oportunidade a seu negócio.
A visão a respeito da sobrevivência empresarial é avaliada e enfatizada por Prescott
e Miller (2002), onde cada vez mais os estrategistas da gestão empresarial estão se apoiando na Inteligência Competitiva. Os profissionais de IC coletam, analisam e aplicam,
de forma legal e ética, informações relativas sobre as capacidades, deficiências e intenções
de seus concorrentes. Monitoram também os acontecimentos do ambiente competitivo
(como novos concorrentes ou novas tecnologias que podem alterar tudo). O seu objetivo é
obter informações que subsidiem o processo de tomada de decisões estratégicas e que
possam ser utilizadas para aumentar a competitividade da organização.
Em se tratando de IC, várias são as suas definições. Na visão de Kahaner (1996), é
atividades da concorrência e as tendências do setor específico e do mercado em geral, com
o propósito de levar a organização a atingir seus objetivos e metas.
A IC também é definida como um processo sistemático de coleta, tratamento,
análise e disseminação da informação sobre atividades dos concorrentes, tecnologias e
tendências gerais dos negócios, visando à subsidiação da tomada de decisão e atingir as
metas estratégicas da empresa (COELHO, 1999).
Já para NIC/UNB (1999), é um processo sistemático de coleta e análise de
informações sobre a atividade dos concorrentes e tendências gerais do ambiente econômico,
social, tecnológico, científico, mercadológico e regulatório, para ajudar na conquista dos
objetivos institucionais na empresa pública ou privada.
Segundo a ABRAIC (2001), é um processo informacional proativo que conduz para
melhor tomada de decisões, seja estratégica ou operacional. É um processo sistemático, que
visa à descoberta das forças que regem os negócios, reduz risco e conduzir o tomador de
decisão a agir antecipadamente, bem como proteger o conhecimento gerado.
Conforme Miller (2002), IC baseia-se no conhecimento do negócio que um gerente
deve ter de maneira formal e sistemática. É a informação filtrada, depurada, visando à obtenção de vantagens competitivas que favoreçam a empresa. Neste sentido, há
necessidade extrema de estabelecer processos que facilitem a filtragem e a depuração da
informação.
Tyson (1998) define a Inteligência Competitiva no contexto empresarial como um
processo sistemático, que transforma dados e informações aleatórias em conhecimento
estratégico. É o conhecimento da posição competitiva atual e dos planos futuros dos
como as influências econômicas, políticas e demográficas que tenham um impacto no
mercado.
Tarapanoff (2001) descreve a IC como uma metodologia que permite a tomada de
decisão e o monitoramento informacional do ambiente depois de sistematizado e analisado.
É um processo sistemático que transforma dados em conhecimento estratégico, utiliza
informações sobre tecnologia, meio ambiente, usuários, competidores, mercados, produtos,
Inclui também o monitoramento de informações externas que afetam o mercado da
organização.
Para Vaitsman (2001), a inteligência competitiva é um sistema constituído por
pessoas, equipamentos e procedimentos para reunir, selecionar, avaliar e distribuir
informações periódicas e necessárias, atuais e precisas para que a gerência de alto nível da
empresa possa tomar as suas decisões.
Neste trabalho, o conceito referência sobre IC foi definido por Gomes & Braga
(2004), que consiste no resultado da análise de dados e informações coletados do ambiente
competitivo da organização, os quais geram recomendações que consideram eventos
futuros e não somente relatórios para justificar decisões passadas. A IC tem o propósito de
identificar tendências mercadológicas, vantagens e desvantagens de concorrentes, além de
subsistir as tomadas de decisões.
Em um mundo globalizado, as empresas estão se virtualizando, ou seja, têm acesso
ao mesmo número infindável de informações. Neste sentido, o que pode levar as empresas
à vantagem competitiva é modo de coletar, analisar e disseminar informações relevantes
que permeiam as empresas. Segundo Leandro Wives (2002), a coleta e análise de
informações (em sua maioria textual) têm que ser rápida para que as decisões e ações sejam
ferramentas e Softwares que auxiliem esse processo. Os processos que auxiliam a descoberta de conhecimento em informações textuais estão vinculados a uma área
denominada Descoberta de Conhecimento em Textos – KDT – ou Text Mining.
Apesar do forte vínculo da IC com a descoberta de conhecimento em contextos
competitivos, é de suma importância frisar, segundo Miller (2002), que a IC de uma
empresa está alicerçada em um processo de inteligência. Os dados, quando organizados,
tornam-se informação; as informações, quando analisadas, transformam-se em inteligência.
A partir deste modelo, os profissionais da inteligência normalmente executam um processo,
ou ciclo, de quatro fases: 1) identificam as necessidades de inteligência dos principais
responsáveis pelas decisões em toda a empresa; 2) colhem informações sobre fatos relativos
ao ambiente externo de uma empresa em fontes impressas, eletrônicas e orais; 3) analisam e
sintetizam as informações; 4) disseminam a inteligência resultante entre os responsáveis
pelas decisões.
O foco do processo de decisão geralmente determina os objetivos do processo de
inteligência, concentrando-se nas perspectivas atuais e potenciais quanto a pontos fortes,
fracos, nas atividades organizacionais que tenham produtos ou serviços similares dentro de
um setor da economia.
2.1.3 Necessidades da Inteligência Competitiva
Segundo Prescott & Miller (2002), o ato de definir as reais necessidades de
inteligência de uma organização e fazê-lo de forma que seus resultados levem os executivos
a agir em conseqüência é um dos objetivos mais evasivos da IC. O uso de um processo de
identificação das necessidades gerenciais, sistematizado ou formal é uma maneira
necessária à identificação e à definição das necessidades reais de inteligência para empresa.
O autor ainda revela que a conceituação das verdadeiras necessidades de inteligência de
uma empresa tem início em um processo de IC, proporcionando foco e prioridade
necessários à condução de operações de inteligência eficazes na geração de inteligência
adequada.
Para Porter (1986), é preciso determinar uma metodologia para a decisão dos dados
particularmente cruciais e como podem ser analisados, podendo levar a uma compreensão
mais profunda de uma determinada indústria e de seus concorrentes, exigindo grande
volume de dados, alguns dos quais sutis e de difícil obtenção. A compilação dos dados para
uma análise sofisticada da concorrência requer mais do que trabalho duro: um mecanismo
organizado, algum tipo de sistema de inteligência.
A visão de Swaka (apud PRESCOTT & MILLER, 2002) sobre a necessidade das empresas em obter benefícios permanentes que rendam dividendos para o desenvolvimento
e a execução da estratégia consiste fundamentalmente em uma IC convertida em atividades
sistemáticas, contínuas que residam na organização. O ciclo do processo de IC, apresentado
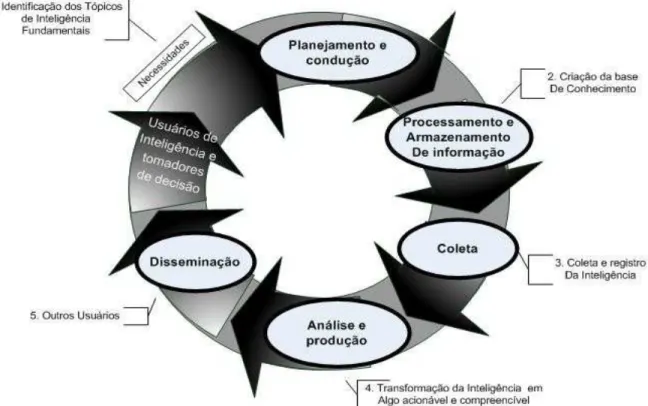
na figura 1, mostra seus principais elementos. Entretanto, o autor deixa transparecer que
nenhuma das fases do processo se sustenta por si só, ou seja, todas são necessárias e
Figura 1. Ciclo de Inteligência Competitiva (PRESCOTT e MILLER, 2002)
As principais características das fases do processo de IC perpassam pela
identificação das necessidades dos responsáveis pelas principais decisões da empresa, pela
obtenção de informações relevantes a partir de fontes de informações (balanços
patrimoniais, relatórios de bancos, publicações internas, jornais, revistas, rumores, Internet
ou fornecedores) na identificação e análise de tendências significativas com base nas
informações previamente colhidas e finalizadas na disseminação do conhecimento obtido
por meio do processo de IC (MILLER, 2002).
A estruturação da IC em ciclos, como mostra a figura 1, deve-se ao aumento da
competição no mercado, o qual demanda uma velocidade enorme na identificação,
obtenção, tratamento, análise e disseminação de informação. Para que esta demanda seja
suportada, são necessárias ferramentas adequadas e com grande poder de contribuição para
Um sistema de IC em organização tem como propósito antecipar mudanças no
ambiente de negócio; descobrir concorrentes e aprender sobre mudanças políticas e
legislativas que possam aferir o negócio. Além disso, as informações, geradas por este
sistema, auxiliam a abertura e definição de um novo negócio e principalmente aumenta a
qualidade das atividades alianças estratégicas (GOMES & BRAGA, 2004).
Visando à eficácia do sistema de IC, as diretrizes para o seu desenvolvimento
assumem as seguintes características (MILLER, 2002):
• Produzir informação qualificada e não simplesmente redistribuir documentos;
• Servir simultaneamente aos usuários finais de inteligência (os responsáveis pelas
decisões) e aos participantes do processo (vendas, marketing, experts, etc.);
• Prover, ao mesmo tempo, resposta para cada caso (solicitação de curto prazo quanto
a uma coleta histórica, estática) e encaminhamento (detalhamento de temas
presentes, escolhendo textos de um fluxo de informações em constante mutação);
• Medir o sucesso com fornecimento de inteligência com foco e detalhada (não apenas
a simples informação);
• Proporcionar fator de confiança (mensuração da validade) a cada unidade
relacionada à fonte das informações;
• Ser acessível por meio dos sistemas primários de Software da organização;
• Contar com uma equipe de apoio de tempo integral, ou na inteligência ou na
tecnologia de informação da organização;
• Buscar, localizar e exibir documentos, contendo uma variedade de formatos e
• Consolidar a informação colhida na Internet, Intranet, redes externas (redes privadas de intercâmbio de informação entre duas ou mais empresas, quase sempre
fornecedores), e-mail, sistemas de informação locais (descentralizados) e próprios (centralizados);
• Evoluir constantemente em paralelo com as exigências representadas pelas
mudanças na inteligência da organização.
2.1.4 A Importância da Informação para Inteligência Competitiva
Hoje, com a globalização e a evolução das telecomunicações, as organizações
podem se comunicar de qualquer lugar ou país e ter acesso a várias culturas e ambientes,
aumentando sua capacidade de se colocar no mercado. O desafio é lidar com a incerteza, a
turbulência e a instabilidade desse mundo. Para isso, antecipar-se às mudanças, enxergar as
oportunidades, observar com olhos críticos o panorama sócio econômico configura-se
como uma boa solução. No entanto, monitorar esse fluxo de informações de negócios
implica analisar o ambiente externo e interno das organizações e, conseqüentemente,
interagir com todos os atores e variáveis que afetam o negócio da organização (GOMES &
BRAGA, 2004).
A necessidade de informação de negócios está mudando rapidamente. Nos últimos
anos, os esforços foram direcionados para melhorar a informação tradicional,
principalmente sobre o que está se passando na empresa. Ainda hoje, mais de 90% das
informações coletadas são sobre dados e eventos internos (DRUCKER, 1997).
A obtenção de informações relevantes se dá por meio de várias fontes, tanto internas
como externas. Os vendedores estão próximos dos clientes no dia a dia e provavelmente
fornecedor que também atende ao concorrente. Esses são apenas alguns exemplos de fontes
de informação internas e informais, ligadas ao conhecimento das pessoas (KAHAMER,
1996).
Outra fonte importante são as informações externas, isto é, aquelas publicadas por
meio de jornais, relatórios anuais, patentes, estatísticas, Internet, etc. Pode-se considerar, de acordo com Montalli & Campello (1997), como informações para negócios:
• Informações jornalísticas;
• Informações de empresa;
• Informações de indústrias ou de mercados;
• Dados de importação e exportação;
• Produtores e preços;
• Informações macroeconômicas;
• Informações de países;
• Legislações;
• Informações de patentes, etc.
Embora a atividade de coleta de informação para IC tenha seu foco inicial em
informações impressas geradas externamente, não deixa de ser extraordinária tudo sobre o
ambiente externo que existe na própria organização. Parte dela está contida nos bancos de
dados internos relacionados à questão cliente-produto, que são, em primeiro lugar, bancos
de dados relacionais estruturados de informações históricas. Esses dados podem ser
colhidos diretamente dos bancos de dados, das fontes, como sistemas de pedidos de