UNIVERSIDADE FEDERAL DE OURO PRETO
▼❡t❛❤❡✉ríst✐❝❛s ❞❡ ❇✉s❝❛ ▲♦❝❛❧ ♣❛r❛ ♦
Pr♦❜❧❡♠❛ ❞❡ ❙❡q✉❡♥❝✐❛♠❡♥t♦ ❞❡
❚❛r❡❢❛s ❡♠ ▼áq✉✐♥❛s P❛r❛❧❡❧❛s ◆ã♦
❘❡❧❛❝✐♦♥❛❞❛s ❝♦♠ ❚❡♠♣♦ ❞❡
Pr❡♣❛r❛çã♦ ❉❡♣❡♥❞❡♥t❡ ❞❛ ❙❡q✉ê♥❝✐❛
Cristiano Lu´ıs Turbino de Fran¸
ca e Silva
Orientador: Prof. Dr. Haroldo Gambini Santos
Coorientador: Prof. Me. T´
ulio Angelo Machado Toffolo
Cristiano Lu´ıs Turbino de Fran¸
ca e Silva
[email protected]
▼❡t❛❤❡✉ríst✐❝❛s ❞❡ ❇✉s❝❛ ▲♦❝❛❧ ♣❛r❛ ♦
Pr♦❜❧❡♠❛ ❞❡ ❙❡q✉❡♥❝✐❛♠❡♥t♦ ❞❡
❚❛r❡❢❛s ❡♠ ▼áq✉✐♥❛s P❛r❛❧❡❧❛s ◆ã♦
❘❡❧❛❝✐♦♥❛❞❛s ❝♦♠ ❚❡♠♣♦ ❞❡
Pr❡♣❛r❛çã♦ ❉❡♣❡♥❞❡♥t❡ ❞❛ ❙❡q✉ê♥❝✐❛
Disserta¸c˜ao submetida ao Instituto de Ciˆencias Exatas e Biol´ogicas da Universidade Federal de Ouro Preto para obten¸c˜ao do t´ıtulo de Mestre em Ciˆencia da Computa¸c˜ao
Orientador: Prof. Dr. Haroldo Gambini Santos
Coorientador: Prof. Me. T´
ulio Angelo Machado Toffolo
S586m Silva, Cristiano Lu´ıs Turbino de Fran¸ca e.
Metaheur´ısticas de busca local para o problema de sequenciamento de tarefas em m´aquinas paralelas n˜ao relacionadas com tempo de prepara¸c˜ao dependente da sequˆencia [manuscrito] / Cristiano Lu´ıs Turbino de Fran¸ca e Silva. – 2014.
61f.: il. color.; grafs.; tabs.
Orientador: Prof. Dr. Haroldo Gambini Santos.
Disserta¸c˜ao (Mestrado) – Universidade Federal de Ouro Preto. Instituto de Ciˆencias Exatas e Biol´ogicas. Departamento de Computa¸c˜ao. Programa de P´os-gradua¸c˜ao em Ciˆencia da Computa¸c˜ao.
´
Area de concentra¸c˜ao: Ciˆencia da Computa¸c˜ao
1. Otimiza¸c˜ao combinat´oria – Teses. 2. Simulated Annealing (Matem´atica) – Teses. 3. Processo seq¨uencial (Computa¸c˜ao) – Teses. 4. Programa¸c˜ao paralela (Computa¸c˜ao) – Teses. I. Santos, Haroldo Gambini. II. Universidade Federal de Ouro Preto. III. T´ıtulo.
CDU: 004.42
Agradecimentos
Agrade¸co `a Deus.
Aos meus pais pelo amor em todos os momentos da minha vida e por incentivarem constante meus estudos.
`
A minha esposa Alba, pelo amor, paciˆencia e por estar comigo em todos os momentos. Ao meu irm˜ao e melhor amigo Thiago, e `a sua namorada Carol.
Ao meu orientador Prof. Dr. Haroldo Gambini Santos, pelos ensinamentos, pelo apoio e principalmente pela amizade que constru´ımos.
Ao coorientador T´ulio e ao colega Lucas.
Aos membros da banca por disponibilizarem seus tempos preciosos para avaliarem meu trabalho.
Ao amigo Danny pelo aux´ılio. Ao amigo Helton.
A todos meus colegas de trabalho. Meus av´os, tios, tias, primos e primas.
`
A minha sogra, sogro e cunhada, assim como todos da “nova” fam´ılia. Aos professores do Departamento de Computa¸c˜ao da UFOP.
“Procurai suportar com ˆanimo tudo aquilo que precisa ser feito.”
“Digo que me encontro no conhecimento de uma ´unica ciˆencia: a do amor.”
Declara¸
c˜
ao
Esta disserta¸c˜ao ´e resultado de meu pr´oprio trabalho, exceto onde referˆencia expl´ıcita ´e feita ao trabalho de outros, e n˜ao foi submetida para outra qualifica¸c˜ao nesta nem em outra universidade.
Resumo
Este trabalho apresenta uma proposta e a avalia¸c˜ao computacional de quatro m´eto-dos de busca local estoc´astica para o problema de sequenciamento de tarefas em m´aquinas paralelas n˜ao relacionadas com tempo de prepara¸c˜ao dependente da se-quˆencia (UPMSP - unrelated parallel machine scheduling problem with sequence de-pendent setup times). As quatro abordagens metaheur´ısticas que s˜ao analisadas para o UPMSP baseam-se em: Simulated Annealing (SA), Iterated Local Search (ILS),
Late Acceptance Hill Climbing (LAHC) e Step Counting Hill Climbing (SCHC). A estrutura das vizinhan¸cas, bem como os parˆametros dos algoritmos, foram ampla-mente testados e analisados, sendo poss´ıvel verificar como os parˆametros afetam o comportamento de cada algoritmo implementado e pesquisar os melhores parˆame-tros. As compara¸c˜oes dos resultados obtidos foram realizadas com os resultados apresentados por Vallada e Ruiz (2011), proponentes do conjunto de 50 instˆancias consideradas e, mais recentemente, por Haddad (2012). O m´etodo que obteve o me-lhor resultado nessas 50 instˆancias foi testado para todas as 1.000 instˆancias grandes, apresentadas por Vallada e Ruiz (2011), melhorando em 96,6% (966 instˆancias) a melhor solu¸c˜ao conhecida encontrada por esses ´ultimos autores.
Abstract
This paper presents a proposal and a computational review of four methods of stochastic local search to the unrelated parallel machine scheduling problem with sequence dependent setup times (UPMSP). The four metaheuristics approaches that are analyzed for the UPMSP are based in: Simulated Annealing (SA), Iterated Lo-cal Search (ILS), Late Acceptance Hill Climbing (LAHC) and Step Counting Hill Climbing (SCHC). The structure of neighborhoods, as well as the parameters of the algorithms, were widely tested and analyzed, being possible verify how the pa-rameters affect the behavior of each algorithm implemented and search the best parameters. The comparisons of the results were accomplished with the results pre-sented by Vallada and Ruiz (2011), who proposed the set of 50 instances considered, and, more recently, by Haddad (2012). The method that got the best result in these 50 instances was tested for every 1.000 large instances, presented by Vallada and Ruiz (2011), improving in 96.6% (966 instances) the best known solution found by this last authors.
Lista de abreviaturas e siglas
GOAL Grupo de Otimiza¸c˜ao e Algoritmos
ILS Iterated Local Search
LAHC Late Acceptance Hill Climbing
Mi Mixed Strategy (estrat´egia mista)
Mk Makespan Based Machine Selection Strategy (estrat´egia baseada na se-le¸c˜ao da m´aquina makespan que cont´em o tempo makespan)
MRP Manufacturing Resource Planning (planejamento dos recursos de ma-nufatura)
R Random Machine Selection Strategy (estrat´egia baseada na sele¸c˜ao ale-at´oria)
RNA Randomized Non-Ascendent
SA Simulated Annealing
SCHC Step Counting Hill Climbing
SLS Stochastic Local Search
Lista de ilustra¸
c˜
oes
Figura 1 Solu¸c˜oes para o problema P . . . 19
Figura 2 Exemplo de um movimento utilizando a vizinhan¸ca task move . . . 31
Figura 3 Exemplo de um movimento utilizando a vizinhan¸ca shift . . . 31
Figura 4 Exemplo de um movimento utilizando a vizinhan¸ca switch . . . 31
Figura 5 Exemplo de um movimento utilizando a vizinhan¸ca swap . . . 32
Figura 6 Exemplo de um movimento utilizando a vizinhan¸ca 2-realloc . . . 32
Figura 7 LAHC usando a estrat´egia de vizinhan¸ca R . . . 37
Figura 8 LAHC usando a estrat´egia de vizinhan¸ca Mk . . . 37
Figura 9 LAHC usando a estrat´egia de vizinhan¸ca Mi . . . 38
Figura 10 Melhores do LAHC . . . 39
Figura 11 SCHC usando a estrat´egia de vizinhan¸ca R . . . 40
Figura 12 SCHC usando a estrat´egia de vizinhan¸ca Mk . . . 41
Figura 13 SCHC usando a estrat´egia de vizinhan¸ca Mi . . . 42
Figura 14 Melhores do SCHC . . . 42
Figura 15 ILS usando a estrat´egia de vizinhan¸ca R . . . 44
Figura 16 ILS usando a estrat´egia de vizinhan¸ca Mk . . . 44
Figura 17 ILS usando a estrat´egia de vizinhan¸ca Mi . . . 45
Figura 18 Melhores do ILS . . . 45
Figura 19 SA usando a estrat´egia de vizinhan¸ca R . . . 48
Figura 20 SA usando a estrat´egia de vizinhan¸ca Mk . . . 49
Figura 21 SA usando a estrat´egia de vizinhan¸ca Mi . . . 50
Figura 22 Melhores do SA . . . 51
Figura 23 Melhores resultados - vizinhan¸ca Mi . . . 51
Figura 24 Evolu¸c˜ao dos melhores resultados - vizinhan¸ca Mi. . . 52
Figura 25 Resultados para as 1.000 instˆancias com o m´etodo SA-Mi . . . 56
Lista de tabelas
Tabela 1 Tempo de processamento das tarefas em uma m´aquina do problema P 18 Tabela 2 Tempo de setup entre duas tarefas para cada m´aquina do problema P 19
Tabela 3 Varia¸c˜ao do parˆametro l nos experimentos do LAHC . . . 36
Tabela 4 Varia¸c˜ao do parˆametro cnos experimentos do SCHC . . . 40
Tabela 5 Varia¸c˜ao dos parˆametros nos experimentos do ILS . . . 43
Tabela 6 Varia¸c˜ao dos parˆametros nos experimentos do SA . . . 46
Tabela 7 Resultados das metaheur´ısticas, cada um com o melhor ajuste de pa-rˆametro encontrado, dentro de um tempo limite de 60 segundos, com duas exeu¸c˜oes por instˆancia. . . 54
Tabela 8 Melhores solu¸c˜oes encontradas em cada m´etodo proposto e melhor solu¸c˜ao apresentada por Vallada e Ruiz (2011), em SOA-ITI. . . 55
Lista de Algoritmos
Algoritmo 1 Simulated Annealing . . . 26
Algoritmo 2 Iterated Local Search . . . 28
Algoritmo 3 Late Acceptance Hill Climbing . . . 29
Sum´
ario
✶ ■♥tr♦❞✉çã♦ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✶✺
1.1 Motiva¸c˜ao . . . 15
1.2 Objetivo . . . 15
1.2.1 Objetivo geral . . . 15
1.2.2 Objetivos espec´ıficos . . . 16
1.3 Organiza¸c˜ao da Disserta¸c˜ao . . . 16
✷ ❋✉♥❞❛♠❡♥t❛çã♦ t❡ór✐❝❛ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✶✼ 2.1 Descri¸c˜ao do Problema . . . 17
2.1.1 O problema UPMSP . . . 17
2.1.2 Formula¸c˜ao matem´atica . . . 19
2.2 Algumas abordagens encontradas na literatura . . . 21
2.3 Metaheur´ısticas . . . 22
2.3.1 Simulated Annealing . . . 22
2.3.2 Iterated Local Search . . . 23
2.3.3 Late Acceptance Hill Climbing . . . 23
2.3.4 Step Counting Hill Climbing . . . 24
✸ ❚é❝♥✐❝❛s ❞❡ ❜✉s❝❛ ❧♦❝❛❧ ♣❛r❛ ♦ ❯P▼❙P ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✷✺ 3.1 Algoritmos . . . 25
3.1.1 Simulated Annealing . . . 25
3.1.2 Iterated Local Search . . . 26
3.1.3 Late Acceptance Hill Climbing . . . 28
3.1.4 Step Counting Hill Climbing . . . 29
3.2 M´etodo construtivo . . . 30
3.3 Estruturas de vizinhan¸ca . . . 31
3.4 Sele¸c˜ao das trocas . . . 33
✹ ❘❡s✉❧t❛❞♦s ❖❜t✐❞♦s ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✸✹ 4.1 Sele¸c˜ao de parˆametros . . . 35
4.2 Resultados e discuss˜oes . . . 36
4.2.1 LAHC . . . 36
4.2.2 SCHC . . . 39
4.2.3 ILS . . . 43
4.2.4 SA . . . 45
✺ ❈♦♥s✐❞❡r❛çõ❡s ❋✐♥❛✐s ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✳ ✺✼
5.1 Conclus˜oes . . . 57 5.2 Trabalhos Futuros . . . 58
15
Cap´ıtulo 1
Introdu¸
c˜
ao
Este trabalho apresenta quatro metaheur´ısticas de busca local eficientes para o pro-blema de sequenciamento de tarefas em m´aquinas paralelas n˜ao relacionadas com tempo de prepara¸c˜ao dependente da sequˆencia (UPMSP -Unrelated Parallel Machine Scheduling Problem With Sequence Dependent Setup Times). As quatro abordagens metaheur´ısticas que s˜ao analisadas para o UPMSP s˜ao: Simulated Annealing (SA), Iterated Local Search
(ILS), Late Acceptance Hill Climbing (LAHC) e oStep Counting Hill Climbing (SCHC).
✶✳✶ ▼♦t✐✈❛çã♦
O estudo do UPMSP ´e relevante, do ponto de vista pr´atico, pois ´e poss´ıvel encontrar v´arios exemplos de sua utiliza¸c˜ao no mundo real. Um exemplo ´e a ind´ustria tˆextil, a qual envolve a produ¸c˜ao de tecidos de cores diferentes, em m´aquinas paralelas n˜ao rela-cionadas (o gargalo de produ¸c˜ao), com tempos de prepara¸c˜ao de longa dura¸c˜ao (LOPES; CARVALHO, 2007). ´E poss´ıvel verificar que esse problema est´a relacionado com o plane-jamento de recurso de fabrica¸c˜ao (MRP - Manufacturing Resource Planning).
Outro fator importante ´e que o UPMSP pertence `a classeN P-dif´ıcil (GLASS; POTTS; STRUSEVICH, 2001), apresentando grande importˆancia, tamb´em, do ponto de vista te´orico, para a Ciˆencia da Computa¸c˜ao.
✶✳✷ ❖❜❥❡t✐✈♦
✶✳✷✳✶ ❖❜❥❡t✐✈♦ ❣❡r❛❧
Cap´ıtulo 1. Introdu¸c˜ao 16
✶✳✷✳✷ ❖❜❥❡t✐✈♦s ❡s♣❡❝í✜❝♦s
• implementar metaheur´ısticas baseadas em SA, ILS, LAHC e SCHC para o UPMSP;
• implementar e avaliar, computacionalmente, m´etodos estoc´asticos de busca em m´ ulti-plas vizinhan¸cas;
• investigar as contribui¸c˜oes dos operadores de busca na vizinhan¸ca;
• compreender como os parˆametros afetam o comportamento das metaheur´ısticas im-plementadas;
• pesquisar os melhores parˆametros para cada m´etodo implementado;
• realizar compara¸c˜oes entre os resultados obtidos e alguns resultados recentes, apre-sentados por Haddad (2012) e Vallada e Ruiz (2011).
✶✳✸ ❖r❣❛♥✐③❛çã♦ ❞❛ ❉✐ss❡rt❛çã♦
Os pr´oximos cap´ıtulos do trabalho est˜ao organizados da seguinte maneira:
• Cap´ıtulo 2: apresenta¸c˜ao da fundamenta¸c˜ao te´orica ao estudo. S˜ao referenciados: descri¸c˜ao do UPMSP, juntamente com a formula¸c˜ao matem´atica do mesmo; abor-dagens encontradas na literatura desse problema; os m´etodos heur´ısticos SA, ILS, LAHC e SCHC.
• Cap´ıtulo 3: descri¸c˜ao das t´ecnicas que foram desenvolvidas para o UPMSP.
• Cap´ıtulo 4: apresenta¸c˜ao dos resultados obtidos, focando a sele¸c˜ao de parˆametros e as compara¸c˜oes dos dados;
17
Cap´ıtulo 2
Fundamenta¸
c˜
ao te´
orica
Este cap´ıtulo apresenta, na Se¸c˜ao 2.1, a descri¸c˜ao do UPMSP, juntamente com a formula¸c˜ao matem´atica; na Se¸c˜ao 2.2, algumas abordagens encontradas na literatura para esse problema e na Se¸c˜ao 2.3, os quatro algoritmos metaheur´ısticos utilizados.
✷✳✶ ❉❡s❝r✐çã♦ ❞♦ Pr♦❜❧❡♠❛
✷✳✶✳✶ ❖ ♣r♦❜❧❡♠❛ ❯P▼❙P
No problema UPMSP existe um conjunto de tarefas que devem ser processadas em um conjunto de m´aquinas, sendo que cada tarefa deve ser processada somente em uma m´aquina. O tempo de execu¸c˜ao de cada tarefa est´a associado a cada m´aquina. Esse tempo pode variar dependendo do equipamento escolhido. Entre duas tarefas h´a, tamb´em, um tempo de prepara¸c˜ao, o qual depende da sequˆencia dessas tarefas e da m´aquina associada. Essas m´aquinas s˜ao paralelas, ou seja, trabalham de forma independente umas das outras. O objetivo ´e minimizar o tempo de conclus˜ao de todas essas tarefas, conhecido como
makespan.
Seja N = {j1, ..., jn} o conjunto de n tarefas e M = {i1, ..., im} o conjunto de m
m´aquinas, de tal forma que:
• cada tarefa j deve ser executada apenas uma vez e por apenas uma m´aquinai;
• cada tarefaj tem um tempo de processamentopij, se for executado pela m´aquina i;
• existe um tempo de prepara¸c˜ao Sijk, tamb´em conhecido como tempo de setup, que
prepara a m´aquina i para executar a tarefa k, logo ap´os a execu¸c˜ao da tarefa j. Para a tarefa inicial, o tempo de prepara¸c˜ao ´e zero.
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 18
Allahverdi et al. (2008) realizam um levantamento dos problemas de programa¸c˜ao com tempos desetup, apresentando as principais diferen¸cas e uma s´erie de algoritmos para essa classe de problemas. O problema UPMSP ´e estudado, tamb´em, por Rabadi, Moraga e Al-Salem (2006), Urlings, Ruiz e Serifoglu (2010) e Vallada e Ruiz (2011).
Rabadi, Moraga e Al-Salem (2006) implementaram um algoritmo de “busca gulosa randˆomica adaptativa” (Greedy Randomized Adaptative Search), apresentado por Feo e Resende (1995), e tamb´em propuseram algumas instˆancias. Mais tarde, Vallada e Ruiz (2011) criaram um conjunto de 1.640 instˆancias desafiadoras para esse problema, dispon´ıveis em SOA-ITI (2013). Essas instˆancias est˜ao divididas em dois grupos: o primeiro, composto por 640 instˆancias pequenas, e o segundo, por 1.000 instˆancias grandes. Nesse primeiro grupo, existem as seguintes combina¸c˜oes de n´umeros de tarefas (n) e m´aquinas (m): n={6, 8, 10, 12} e m={2, 3, 4, 5}. No segundo, as combina¸c˜oes s˜ao:
n={50, 100, 150, 200, 250} e m={10, 15, 20, 25, 30}. Vallada e Ruiz (2011) implemen-taram um algoritmo gen´etico e conclu´ıram que esse algoritmo era capaz de alcan¸car bons resultados em pouco tempo.
Segue um exemplo do problema, que ser´a denominado pela letra P. Na Tabela 1 mostra-se os tempos de processamento de seis tarefas em cada uma das duas m´aquinas dispon´ıveis para o problema P. As linhas representam as m´aquinas (i1, i2) e as colunas
representam as tarefas (j1, j2, j3, j4, j5, j6).
Tabela 1 – Tempo de processamento das tarefas em uma m´aquina do problemaP
j1 j2 j3 j4 j5 j6
i1 8 42 72 45 4 25
i2 77 4 52 73 10 53
Na Tabela 2 mostra-se os tempos de setup entre duas tarefas em cada uma das m´aquinas para essas seis tarefas, que s˜ao representados por sijk. Cada valor dessa tabela
significa o tempo de setup quando a tarefa j precede, imediatamente, a tarefa k, na m´aquina i, para todo j diferente de k. Nesta tabela, a interse¸c˜ao da linha 2 (j2) com a
coluna 1 (k1) da m´aquina 1 (i1) possui o valor 23, que significa o tempo desetup quando
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 19
Tabela 2 – Tempo desetupentre duas tarefas para cada m´aquina do problemaP
i1 k1 k2 k3 k4 k5 k6 i2 k1 k2 k3 k4 k5 k6
j1 0 40 31 13 41 24 j1 0 23 19 9 44 24
j2 23 0 3 33 33 21 j2 7 0 46 31 29 5
j3 12 29 0 18 5 42 j3 22 2 0 35 7 10
j4 29 42 2 0 33 33 j4 5 18 31 0 22 29
j5 42 18 41 40 0 46 j5 15 35 21 5 0 35
j6 4 13 26 37 39 0 j6 48 11 40 21 35 0
A Figura 1(a) ilustra uma solu¸c˜ao vi´avel qualquer para o problema P. Nesta solu¸c˜ao, as tarefas 2, 1 e 4 s˜ao processadas, nessa ordem, pela m´aquina 1, enquanto as tarefas 5, 3 e 6 s˜ao processadas, tamb´em nessa ordem, pela m´aquina 2. As caixas brancas representam o tempo de processamento de uma tarefa e as caixas em cinza representam os tempos de
setup entre as duas tarefas consecutivas.
A Figura 1(b) ilustra a solu¸c˜ao ´otima para o problema P. ´E poss´ıvel observar que a solu¸c˜ao ´otima reduz omakespande 146 para 95 unidades de tempo, melhorando a solu¸c˜ao em 51 unidades de tempo.
0 10 20 30 40 50 60 70 80 90 100 110 120 131 146
Unidades de tempo
i1 j2 j1 j4
i2 j5 j3 j6
(a) Solu¸c˜ao qualquer.
0 10 20 30 40 50 60 70 80 89 95 110 120 130 140 150
Unidades de tempo
i1 j6 j1 j4
i2 j5 j3 j2
(b) Solu¸c˜ao ´otima.
Figura 1 – Solu¸c˜oes para o problemaP
✷✳✶✳✷ ❋♦r♠✉❧❛çã♦ ♠❛t❡♠át✐❝❛
Para modelar o problema UPMSP, foi utilizada uma formula¸c˜ao matem´atica proposta por Vallada e Ruiz (2011), que tem o objetivo de minimizar o makespan.
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 20
N : conjunto de tarefas que ser˜ao processadas;
M : conjunto de m´aquinas paralelas n˜ao relacionadas;
pij : parˆametro que armazena o tempo de processamento da tarefa j na m´aquina i;
sijk : parˆametro que armazena o tempo de prepara¸c˜ao quando a tarefa j precede,
imediatamente, a tarefa k na m´aquina i;
xijk : vari´avel bin´aria que assume o valor 1 se a tarefa j preceder, imediatamente, a
tarefa k, na m´aquina i, ou o valor 0, caso contr´ario;
cij : vari´avel que armazena o tempo de conclus˜ao da tarefa j na m´aquina i;
cmax : vari´avel que armazena o tempo total de processamento de todas as tarefas,
ou seja, o valor do makespan. Pode ser interpretado, tamb´em, como o maior tempo de conclus˜ao das m´aquinas que processam as tarefas programadas.
A fun¸c˜ao objetivo ´e dada pela equa¸c˜ao (2.1):
mincmax. (2.1)
Nesse modelo, ´e inclu´ıda uma tarefa T0, significando uma tarefa fict´ıcia, com tempo
de conclus˜ao e tempo de prepara¸c˜ao igual a zero. Essa tarefa ´e utilizada para vir antes da primeira, ou seja, no in´ıcio da programa¸c˜ao, conforme as equa¸c˜oes (2.2), (2.3) e (2.4):
xijk ∈ {0,1},∀j ∈ {0} ∪ {N},∀k ∈N, j 6=k,∀i∈M. (2.2)
A equa¸c˜ao (2.3) determina o tempo de prepara¸c˜ao, sendo zero para todas as tarefas fict´ıcias:
si0k = 0,∀i∈M,∀k ∈N. (2.3)
A equa¸c˜ao (2.4) faz com que o tempo de conclus˜ao seja 0 para as tarefas fict´ıcias:
ci0 = 0,∀i∈M. (2.4)
As restri¸c˜oes representadas pela equa¸c˜ao (2.5) fazem com que cada tarefa fique asso-ciada a somente uma m´aquina e possua exatamente uma predecessora:
X
i∈M X
j∈{0}∪{N}
j6=k
xijk = 1,∀k ∈N. (2.5)
As restri¸c˜oes representadas pela equa¸c˜ao (2.6) determinam que o n´umero m´aximo de sucessoras, para cada tarefa, deve ser 1. As ´ultimas tarefas n˜ao possuem sucessoras, portanto, ficam com valor igual a 0:
X
i∈M X
k∈N
j6=k
xijk ≤1,∀j ∈N. (2.6)
As restri¸c˜oes representadas pela equa¸c˜ao (2.7) definem que o n´umero m´aximo de suces-soras das tarefas fict´ıcias deve ser igual a 1 em cada m´aquina:
X
k∈N
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 21
As restri¸c˜oes representadas pela equa¸c˜ao (2.8) verificam se a tarefa j ´e processada na m´aquina i. Em caso afirmativo, existe a predecessora h, nessa mesma m´aquina i:
X
h∈{0}∪{N}
h6=k,h6=j
xihj ≥xijk,∀j, k ∈N, j 6=k,∀i∈M. (2.8)
As restri¸c˜oes representadas pela equa¸c˜ao (2.9) determinam que se xijk = 1, o tempo
para completar a tarefa k (cik) deve ser maior ou igual ao tempo para completar a tarefa
j (cij), adicionado ao tempo desetup sijk e ao tempo de processamento da tarefa k (pik).
Por outro lado, se xijk = 0, a constante V (uma constante com valor grande) torna a
restri¸c˜ao redundante:
cik ≥cij +sijk+pik−V(1−xijk),∀j ∈ {0} ∪ {N},∀k ∈N, j 6=k,∀i∈M. (2.9)
As restri¸c˜oes representadas pela equa¸c˜ao (2.10) determinam que o tempo de conclus˜ao das tarefas regulares (tarefas n˜ao fict´ıcias) deve ser n˜ao-negativo:
cij ≥0,∀i∈M,∀j ∈N. (2.10)
As restri¸c˜oes representadas pela equa¸c˜ao (2.11) definem o tempo de conclus˜ao m´aximo:
cmax ≥cij,∀i∈M,∀j ∈N. (2.11)
Com a formula¸c˜ao matem´atica apresentada, ´e poss´ıvel uma melhor compreens˜ao do problema abordado.
✷✳✷ ❆❧❣✉♠❛s ❛❜♦r❞❛❣❡♥s ❡♥❝♦♥tr❛❞❛s ♥❛ ❧✐t❡r❛t✉r❛
Alguns trabalhos com referˆencias mais recentes, que abordam o UPMSP, s˜ao apresen-tadas a seguir.
Arnaout, Rabadi e Musa (2010) propuseram o algoritmo Ant Colony Optimization
ACO. Seu desempenho ´e avaliado por meio da compara¸c˜ao de suas solu¸c˜oes com as solu¸c˜oes obtidas usando Busca Tabu. Os resultados mostram que ACO superou o m´etodo que utilizou Busca Tabu.
Chang e Chen (2011) introduzem uma nova metaheur´ıstica, atrav´es da integra¸c˜ao das propriedades de dominˆancia com algoritmo gen´etico. O desempenho desta metaheur´ıstica ´e avaliada usando problemas de referˆencia da literatura. Os resultados experimentais intensivos mostram que foi poss´ıvel encontrar todas as solu¸c˜oes ideais para os problemas pequenos e superou as solu¸c˜oes obtidas pelas heur´ısticas para problemas maiores.
Fleszar, Charalambous e Hindi (2011) apresentam um algoritmo que inicia com o
Multistart e o Variable Neighourhood Descent. Em seguida, um modelo de programa¸c˜ao
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 22
Vallada e Ruiz (2011) implementaram dois Algoritmos Gen´eticos que diferem entre si pelos parˆametros adotados. Esses autores geram os conjuntos de instˆancias que s˜ao utilizados neste trabalho, conforme explicado na Subse¸c˜ao 2.1.1.
Ying, Lee e Lin (2012) desenvolveram um algoritmo restricted simulated annealing
(RSA), que incorpora uma estrat´egia de pesquisa restrita. O algoritmo RSA proposto reduz o esfor¸co de pesquisa necess´ario para encontrar a melhor solu¸c˜ao, eliminando movi-mentos ineficazes. A efic´acia do algoritmo RSA proposto ´e comparado com o simulated annealing b´asico. Resultados computacionais indicam que o algoritmo RSA proposto supera, significativamente, o algoritmo de simulated annealing b´asico.
Haddad (2012) desenvolveu trˆes algoritmos heur´ısticos h´ıbridos. O primeiro combina os procedimentos heur´ısticos Iterated Local Search,Variable Neighborhood Descent ePath Relinking; o segundo difere do primeiro pelo fato de gerar a solu¸c˜ao inicial pela fase de
constru¸c˜ao Greedy Randomized Adaptive Search Procedure, e n˜ao por um m´etodo guloso; o terceiro difere dos outros dois na fase Path Relinking, nas vizinhan¸cas que formam o Variable Neighborhood Descent e, no Greedy Randomized Adaptive Search Procedure, inclui um m´odulo de busca local feita por um resolvedor de programa¸c˜ao matem´atica. Esse autor utilizou em seus experimentos as instˆancias criadas por Vallada e Ruiz (2011).
✷✳✸ ▼❡t❛❤❡✉ríst✐❝❛s
Desde o desenvolvimento de computadores digitais, muitos pesquisadores tˆem estudado o problema de otimizar uma fun¸c˜ao objetivo. Uma abordagem ´e a otimiza¸c˜ao estoc´astica, que busca a solu¸c˜ao ideal, utilizando a aleatoriedade (FOUSKAKIS; DRAPER, 2002).
Souza (2009) explica que as metaheur´ısticas baseadas em busca local exploram o es-pa¸co de solu¸c˜oes atrav´es de movimentos que s˜ao aplicados a cada passo sobre a solu¸c˜ao corrente, gerando outra solu¸c˜ao promissora em sua vizinhan¸ca. ´E importante esclare-cer que uma metaheur´ıstica ´e um procedimento destinado a encontrar uma solu¸c˜ao boa, sendo que essa solu¸c˜ao pode ser ´otima. Dullaert et al. (2007) mostram que a utitliza¸c˜ao de metaheur´ısticas para encontrar solu¸c˜ao de problemas complexos da vida real est˜ao ficando cada vez mais frequentes.
✷✳✸✳✶ ❙✐♠✉❧❛t❡❞ ❆♥♥❡❛❧✐♥❣
Proposto por Kirkpatrick, Gelatt e Vecchi (1983), a metaheur´ıstica SA ´e um m´etodo probabil´ıstico, baseado em uma analogia com a termodinˆamica, simulando o resfriamento de um conjunto de ´atomos aquecidos. Essa t´ecnica come¸ca a busca a partir de uma solu¸c˜ao inicial. O procedimento principal consiste em um la¸co de repeti¸c˜ao que gera, aleatoriamente, em cada itera¸c˜ao, um vizinho s′ da atual solu¸c˜ao s. Seja ∆ a varia¸c˜ao
do valor da fun¸c˜ao objetivo, obtida a partir da mudan¸ca para o vizinho candidato (∆ =
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 23
se ∆ < 0. Por outro lado, se ∆ ≥ 0, o vizinho pode ser aceito com uma probabilidade
e−∆/T
, em que T ´e um parˆametro do m´etodo, chamado de temperatura, o qual regula a probabilidade de aceitar solu¸c˜oes piores que a atual.
A temperatura pode assumir, inicialmente, um elevado valor T0. Depois de um
de-terminado n´umero de itera¸c˜oes SAmax (que representa o n´umero de itera¸c˜oes necess´arias
para que o sistema atinja o equil´ıbrio t´ermico a uma dada temperatura), a temperatura ´e, gradualmente, reduzida por uma taxaαde arrefecimento, de modo queTk ←α Tk−1, para
0< α <1. Com este procedimento, uma maior chance de evitar m´ınimos locais ocorre na itera¸c˜ao inicial e, quando T se aproxima de zero, o algoritmo passa a se comportar como um m´etodo de descida, uma vez que reduz a probabilidade de aceita¸c˜ao de movimentos de piora (GLOVER; KOCHENBERGER, 2003).
✷✳✸✳✷ ■t❡r❛t❡❞ ▲♦❝❛❧ ❙❡❛r❝❤
O m´etodo ILS (LOURENCO; MARTIN; STUTZLE, 2003) ´e baseado na ideia de que um procedimento de busca local pode alcan¸car melhores resultados atrav´es da otimiza¸c˜ao de diferentes solu¸c˜oes, geradas atrav´es de perturba¸c˜oes na solu¸c˜ao do ´otimo local.
O algoritmo ILS come¸ca a partir de uma solu¸c˜ao inicials0 e faz dist´urbios de tamanho
psize sobs0, seguido por um m´etodo de descida. A perturba¸c˜ao ´e a aceita¸c˜ao incondicional
de um vizinho gerado por qualquer um dos movimentos de troca apresentados no Cap´ıtulo 3. A fase de descida usa um m´etodo aleat´orio n˜ao-ascendente, que aceita os vizinhos se o seu valor da fun¸c˜ao objetivo for melhor ou igual ao atual com rna itera¸c˜oes.
A busca local produz uma solu¸c˜ao s′, que ser´a aceita se for melhor do que a melhor
solu¸c˜ao s∗ encontrada. Nesse caso, o tamanho da perturba¸c˜ao p
size volta ao tamanho
inicial p0. Se a itera¸c˜ao Iter atinge um limite de Itermax, o tamanho da perturba¸c˜ao ´e
incrementado. No entanto, se o tamanho da perturba¸c˜ao atinge um limite pmax, ele volta
para o tamanho inicial p0.
✷✳✸✳✸ ▲❛t❡ ❆❝❝❡♣t❛♥❝❡ ❍✐❧❧ ❈❧✐♠❜✐♥❣
A metaheur´ıstica LAHC foi recentemente proposta por Burke e Bykov (2008). Ela consiste em uma adapta¸c˜ao do m´etodo de subida mais cl´assico. Essa metaheur´ıstica baseia-se na compara¸c˜ao de uma nova solu¸c˜ao de candidato com as ´ultimas l solu¸c˜oes consideradas anteriormente, antes de aceitar ou rejeitar o movimento de troca. Nota-se que a solu¸c˜ao candidata pode ser aceita, mesmo que seja pior do que a solu¸c˜ao atual, uma vez que ´e comparada `a solu¸c˜ao da itera¸c˜ao atual.
Cap´ıtulo 2. Fundamenta¸c˜ao te´orica 24
Neste m´etodo, ser´a armazenada uma lista f′
k = {f0, ..., fl−1}, com os custos das
solu¸c˜oes. Inicialmente, esta lista ´e preenchida com o custo da solu¸c˜ao inicial s, ou seja:
f′
k ← f(s) ∀k ∈ {0, ..., l−1}. A cada itera¸c˜ao i, uma solu¸c˜ao candidata s′ ´e gerada.
A solu¸c˜ao candidata ´e aceita se o seu custo ´e menor ou igual ao custo armazenado na posi¸c˜ao i modl da lista f′. Al´em disso, se esta solu¸c˜ao ´e melhor do que a melhor solu¸c˜ao
encontrada, ele ´e atualizado: s∗ ← s′. Depois, a posi¸c˜ao v = i mod l e f′ ´e atualizada:
f′
v ←f(s′). Esse processo se repete at´e que um crit´erio de parada seja atingido.
✷✳✸✳✹ ❙t❡♣ ❈♦✉♥t✐♥❣ ❍✐❧❧ ❈❧✐♠❜✐♥❣
Muito parecido com a metaheur´ıstica LAHC, o m´etodo SCHC (BYKOV; PETROVIC, 2013) foi projetado para realizar uma busca que combina diversifica¸c˜ao e intensifica¸c˜ao das estrat´egias de busca, semelhante ao algoritmo SA.
25
Cap´ıtulo 3
T´
ecnicas de busca local para o
UPMSP
Neste cap´ıtulo, s˜ao apresentadas as quatro metaheur´ısticas implementadas, o m´etodo construtivo utilizado na solu¸c˜ao inicial, as estruturas de vizinhan¸ca e a sele¸c˜ao de trocas.
✸✳✶ ❆❧❣♦r✐t♠♦s
Quatro metaheur´ısticas foram implementadas para resolver o problema UPMSP. A primeira delas ´e o m´etodo SA; a segunda, o ILS; a terceira, o LAHC; e, a ´ultima, o SCHC. Todos esses quatro m´etodos utilizam as estruturas de vizinhan¸ca apresentadas na Se¸c˜ao 3.3 e um filtro, para selecionar essas vizinhan¸cas por m´aquinas, apresentado na Se¸c˜ao 3.4. As metaheur´ısticas implementadas s˜ao detalhadas a seguir.
✸✳✶✳✶ ❙✐♠✉❧❛t❡❞ ❆♥♥❡❛❧✐♥❣
O Algoritmo 1 mostra a implementa¸c˜ao do pseudo-c´odigo para o SA. Nesse algoritmo, o m´etodo selectN eighborhood(.) retorna um dos vizinhos escolhidos aleatoriamente, des-critos na Se¸c˜ao 3.3. Nk(.) ´e a estrutura de vizinhan¸ca k e f(.) ´e a fun¸c˜ao objetivo. O
algoritmo SA apresenta os seguintes parˆametros:
• s: solu¸c˜ao inicial vi´avel;
• T0: temperatura inicial;
• α: taxa de resfriamento;
• SAmax: n´umero de itera¸c˜oes em cada temperatura;
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 26
Algoritmo 1: Simulated Annealing
Input: s, T0, α,SAmax, timeout
Output: Best solution s∗ found.
s∗ ←s; 1
T ←T0;
2
it←0;
3
while elapsedT ime < timeoutdo
4
while it <SAmax do
5
it←it+ 1;
6
k←selectN eighborhood();
7
Generate a random neighbor s′ ∈N
k(s);
8
∆ =f(s′)−f(s); 9
if ∆<0 then
10
s←s′; 11
if f(s′)< f(s∗) then s∗ ←s′; 12
else
13
Takex∈[0,1];
14
if x < e−∆/T then s ←s′; 15
T ←α×T;
16
it←0;
17
if T < ε then
18
T ←T0
19
return s∗; 20
Uma das principais quest˜oes do SA ´e o seu elevado n´umero de parˆametros. O parˆame-troT0´e cr´ıtico, mas uma estimativa razo´avel pode ser feita automaticamente. Ben-Ameur
(2004) mostra algumas formas de calcular a temperatura inicial para obter uma deter-minada propor¸c˜ao de aceita¸c˜ao. Neste trabalho, foi utilizado um m´etodo simples para calcular o valor de T0. Dada uma solu¸c˜ao inicial s, uma amostragem de mti vizinhos
aleat´orios ´e analisada e o pior ∆ obtido ´e armazenado. Esse ∆ ´e, basicamente, um valor de T0, em que todos os mti vizinhos analisados s˜ao aceitos. Em seguida, esse valor de ∆
´e multiplicado por um valor pro, em que pro´e a % de aceita¸c˜ao considerada. O valor de
T0 ´e o pior ∆ encontrado multiplicado por pro.
✸✳✶✳✷ ■t❡r❛t❡❞ ▲♦❝❛❧ ❙❡❛r❝❤
O Algoritmo 2 apresenta o pseudo-c´odigo dos ILS implementado. Nesse algoritmo,f(.) ´e a fun¸c˜ao objetivo,Nk(.) a estrutura de vizinhan¸cak,selectNeighborhood(.) ´e um m´etodo
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 27
representa a fase de descida. Nessa fase, os vizinhos s˜ao gerados em movimentos aleat´orios e apenas os que pioram a solu¸c˜ao atual n˜ao s˜ao aceitos. O algoritmo ILS apresenta os seguintes parˆametros:
• s: solu¸c˜ao inicial vi´avel;
• p0: n´umero de movimentos realizados na fase de perturba¸c˜ao inicial;
• pmax: n´umero m´aximo de movimentos feitos em uma perturba¸c˜ao;
• ILSmax: n´umero de itera¸c˜oes;
• rna: n´umero de itera¸c˜oes na fase de decida;
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 28
Algoritmo 2: Iterated Local Search
Input: s, ILSmax, p0, pmax, timeout
Output: Best solution s∗ found.
s←descentP hase(s, rna);
1
s∗ ←s; 2
psize ←p0;
3
it←0;
4
while elapsedT ime < timeoutdo
5
for j ←0 to psize do
6
k←selectN eighborhood();
7
Generate a random neighbor s′ ∈N
k(s);
8
s←s′; 9
s′ ←descentP hase(s, rna); 10
if f(s′)< f(s∗)) then 11
s←s′; 12
s∗ ←s′; 13
it←0;
14
psize ←p0;
15
else
16
s←s∗; 17
it←it+ 1;
18
if it≥ILSmax then
19
it←0;
20
psize ←psize +p0;
21
if psize ≥pmax then psize ←p0;
22
return s∗; 23
✸✳✶✳✸ ▲❛t❡ ❆❝❝❡♣t❛♥❝❡ ❍✐❧❧ ❈❧✐♠❜✐♥❣
O Algoritmo 3 apresenta a implementa¸c˜ao do LAHC. Esse algoritmo apresenta os seguintes parˆametros:
• l: tamanho da lista;
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 29
Algoritmo 3: Late Acceptance Hill Climbing
Input: s,l
Output: Best solution s∗ found.
f′
k ←f(s)∀k ∈ {0, ..., l - 1};
1
s∗ ←s; 2
i←0;
3
while elapsedT ime < timeoutdo
4
k←selectN eighborhood();
5
Generate a random neighbor s′ ∈N
k(s);
6
v ←i modl;
7
if f(s′)≤f′
v then
8
s←s′; 9
if f(s)< f(s∗) then 10
s∗ ←s; 11
f′
v ←f(s);
12
i←i+ 1;
13
return s∗; 14
Al´em da implementa¸c˜ao do LAHC ser simples, o ajuste do parˆametro tamb´em ´e sim-ples, pois existe um ´unico parˆametro, ou seja, o tamanho da listal. Apesar dessa simpli-cidade, os resultados alcan¸cados por tal implementa¸c˜ao s˜ao competitivos, em compara¸c˜ao com os m´etodos que foram propostos.
✸✳✶✳✹ ❙t❡♣ ❈♦✉♥t✐♥❣ ❍✐❧❧ ❈❧✐♠❜✐♥❣
A implementa¸c˜ao do SCHC ´e representada no Algoritmo 4. Esse algoritmo apresenta os seguintes parˆametros:
• c: contador limite;
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 30
Algoritmo 4: Step Counting Hill Climbing
Input: s,c
Output: Best solution s∗ found.
i←0;
1
b←f(s);
2
s∗ ←s; 3
while elapsedT ime < timeoutdo
4
i←i+ 1;
5
k←selectN eighborhood();
6
Generate a random neighbor s′ ∈N
k(s);
7
if f(s′)< b or f(s)≤f(s′) then 8
if f(s′)≤f(s∗)then 9
s∗ ←s′ 10
if i≥cthen
11
b←f(s∗); 12
i←0;
13
s←s′ 14
return s∗; 15
Assim como ocorre com o algoritmo LAHC, a implementa¸c˜ao e o ajuste de parˆametro do SCHC tamb´em s˜ao simples. O ´unico parˆametro que possui ´e o contador limite c. Ainda assim, o SCHC alcan¸ca resultados competitivos, em compara¸c˜ao com os m´etodos que foram propostos.
✸✳✷ ▼ét♦❞♦ ❝♦♥str✉t✐✈♦
Tendo em vista que o objetivo deste trabalho ´e avaliar a robustez de metaheur´ısticas de busca local, que devem funcionar bem, independentemente da qualidade da solu¸c˜ao inicial, um algoritmo construtivo r´apido e simples foi desenvolvido. Como esses algoritmos ser˜ao comparados para verificar o desempenho de cada m´etodo, ´e interessante que todos come-cem na mesma solu¸c˜ao inicial. Neste m´etodo construtivo, as tarefas s˜ao, sequencialmente, alocadas para as m´aquinas e cada m´aquina i recebe j/i tarefas.
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 31
✸✳✸ ❊str✉t✉r❛s ❞❡ ✈✐③✐♥❤❛♥ç❛
Existem metaheur´ısticas cujo objetivo ´e escapar de ´otimos locais, a fim de prosseguirem na explora¸c˜ao do espa¸co de busca, para encontrarem valores melhores. Essas metaheur´ıs-ticas podem trabalhar com v´arias estruturas de vizinhan¸ca, para explorar o espa¸co de busca (BLUM; ROLI, 2003).
Para explorar o espa¸co de busca de solu¸c˜oes diferentes, foram desenvolvidas cinco estruturas de vizinhan¸ca. Tais vizinhan¸cas s˜ao utilizadas nas rotinas das metaheur´ısticas implementadas durante a fase de busca local e s˜ao apresentadas a seguir.
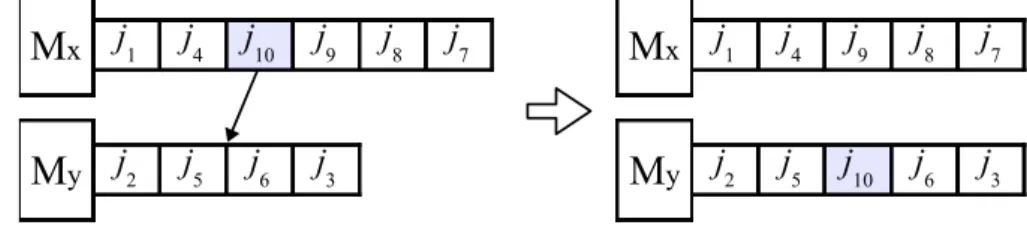
• Task move: gera um vizinho retirando uma tarefa de uma m´aquina Mx e alocando
essa tarefa em outra m´aquina My. As posi¸c˜oes de retirada e inser¸c˜ao da tarefa s˜ao
aleat´orias. A Figura 2 ilustra um exemplo da gera¸c˜ao de um vizinho a partir desse movimento:
M
x j1 j4 j10 j9 j8 j7M
x j1 j4 j9 j8 j7M
y j2 j5 j6 j3M
y j2 j5 j10 j6 j3Figura 2 – Exemplo de um movimento utilizando a vizinhan¸catask move
• Shift: gera um vizinho pela troca da posi¸c˜ao de uma tarefa em uma m´aquina Mx.
As posi¸c˜oes de retirada e inser¸c˜ao da tarefa s˜ao aleat´orias. A Figura 3 ilustra um exemplo da gera¸c˜ao de um vizinho a partir desse movimento:
M
x j1 j4 j10 j9 j8 j7M
x j1 j10 j9 j8 j4 j7Figura 3 – Exemplo de um movimento utilizando a vizinhan¸cashift
• Switch: gera um vizinho atrav´es da troca entre duas tarefas em uma m´aquina Mx.
A Figura 4 ilustra um exemplo da gera¸c˜ao de um vizinho a partir desse movimento:
M
x j1 j4 j10 j9 j8 j7M
x j1 j8 j10 j9 j4 j7Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 32
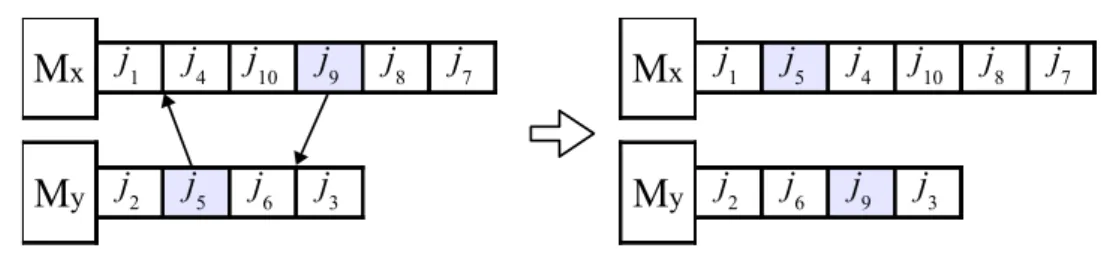
• Swap: gera um vizinho realizando a troca de duas tarefas entre duas m´aquinas, uma tarefa na m´aquina Mx e outra na m´aquinaMy. A tarefa retirada da m´aquinaMx ´e
alocada na m´aquina My e a tarefa retirada da m´aquina My ´e alocada na m´aquina
Mx. As posi¸c˜oes de retirada e inser¸c˜ao das tarefas s˜ao aleat´orias. ´E importante
notar que as tarefas trocadas podem ser colocadas em qualquer posi¸c˜ao. A Figura 5 ilustra um exemplo da gera¸c˜ao de um vizinho a partir desse movimento:
M
x j1 j4 j10 j9 j8 j7M
x j1 j5 j4 j10 j8 j7M
y j2 j5 j6 j3M
y j2 j6 j9 j3Figura 5 – Exemplo de um movimento utilizando a vizinhan¸caswap
• 2-realloc: gera um vizinho pela mudan¸ca da posi¸c˜ao de duas tarefas em uma m´aquina
Mx. Essa mudan¸ca ´e realizada em posi¸c˜oes aleat´orias. A Figura 6 ilustra um
exemplo da gera¸c˜ao de um vizinho a partir desse movimento:
M
x j1 j4 j10 j9 j8 j7M
x j4 j7 j10 j9 j1 j8Figura 6 – Exemplo de um movimento utilizando a vizinhan¸ca2-realloc
Essas vizinhan¸cas apresentadas realizam movimentos para escapar de ´otimos locais. S˜ao realizados movimentos envolvendo diferentes m´aquinas e outros que mudam a se-quˆencia de processamento em uma mesma m´aquina. Para selecionar uma vizinhan¸ca de troca, ´e utilizada uma abordagem de busca local estoc´astica (SLS - Stochastic Local Search). Hoos e St¨utzle (2004) mostram que, nos algoritmos SLS, as decis˜oes de percorrer
as vizinhan¸cas s˜ao randomizadas.
No caso do presente trabalho, em que se busca a minimiza¸c˜ao, ser˜ao aceitos movimen-tos que reduzem o valor corrente domakespan ou movimentos que n˜ao alteram esse valor. Tais tipos de movimentos se enquadram no m´etodo randˆomico n˜aoascendente (RNA
Cap´ıtulo 3. T´ecnicas de busca local para o UPMSP 33
✸✳✹ ❙❡❧❡çã♦ ❞❛s tr♦❝❛s
A sele¸c˜ao dessas trocas, apresentadas na Se¸c˜ao 3.3, s˜ao realizadas segundo um crit´erio que envolve a m´aquina que cont´em o valor do makespan. Esse crit´erio ser´a denominado “filtro das vizinhan¸cas por m´aquina”, conforme descrito a seguir:
• trocas realizadas envolvendo todas as m´aquinas, com igual probabilidade de serem sorteadas de forma aleat´oria. Permite chances iguais de um movimento ocorrer em qualquer m´aquina e ser´a denotada por Estrat´egia de Sele¸c˜ao de M´aquina Aleat´orio (R - Random Machine Selection Strategy);
• trocas realizadas somente envolvendo a m´aquina que cont´em o valor do makespan. Seleciona movimentos somente que envolvam a m´aquina que determina o valor do
makespan e ser´a denotada por Estrat´egia de Sele¸c˜ao Baseada na M´aquina Makespan (Mk - Makespan Based Machine Selection Strategy);
• trocas realizadas envolvendo todas as m´aquinas, dando mais chance para sortear a m´aquina que cont´em o valor domakespan. Uma Estrat´egia Mista (Mi -Mixed Strat-egy) considera todas as m´aquinas a serem selecionados na gera¸c˜ao de movimentos, mas a m´aquina que determina o valor do makespan tem mais chance de se envolver no movimento gerado. No caso da estrat´egia Mi, a cada itera¸c˜ao, ´e selecionada aleatoriamente, a estrat´egia R ou Mk.
34
Cap´ıtulo 4
Resultados Obtidos
Nesta se¸c˜ao, os experimentos computacionais s˜ao detalhados. As instˆancias de Vallada e Ruiz (2011) foram utilizados para avaliar os algoritmos implementados. Esse mesmo autor propˆos um total de 1.640 instˆancias, sendo 640 pequenas e 1.000 grandes. Al´em de gerar instˆancias com tamanhos diferentes, gerou, tamb´em, instˆancias com diferentes faixas de processamento e tempos de prepara¸c˜ao. Durante os testes, observou-se que essas diferentes faixas de processamento e tempos de prepara¸c˜ao n˜ao afetam a dificuldade do problema. Assim, os casos com faixas intermedi´arias para os tempos de processamento foram eliminados e apenas casos com faixa mais restrita (9) e mais extensa (124) foram mantidos nos testes. Como pode ser visto a seguir, resultados muito semelhantes foram obtidos para esse conjunto de faixas.
O conjunto resultante para testes consiste em 50 instˆancias grandes, com v´arios valores diferentes para o n´umero de tarefas n = {50,100,150,200,250}, n´umero de m´aquinas
m ={10,15,20,25,30}, faixa restrita r ={1,124} e sempre a primeira instˆancia, das 10 que s˜ao apresentadas por Vallada e Ruiz (2011), para cada uma dessas combina¸c˜oes. Os testes para as instˆancias menores produziram a melhor solu¸c˜ao conhecida. As solu¸c˜oes geradas para todas as 1.000 instˆancias grandes, bem como os relat´orios e os softwares desenvolvidos, est˜ao dispon´ıveis em GOAL-UFOP (2013).
Os algoritmos foram codificados na linguagem de programa¸c˜ao C, em conformidade com o ANSI 99 C standard. A implementa¸c˜ao computacional dos algoritmos foi elaborada com cuidado, para que as opera¸c˜oes dos m´etodos de busca local fossem realizadas de modo eficiente, evitando rec´alculos desnecess´arios. O c´odigo foi compilado com o GNU Compiler Collection, vers˜ao 4.6.3, com a op¸c˜ao de otimiza¸c˜ao-O3. Os experimentos foram realizados em um computador com processador IntelR Core i7-3770 3.4Ghz e 24 Gb de mem´oria
RAM, rodando o sistema operacional linux openSUSE 12.1.
Cap´ıtulo 4. Resultados Obtidos 35
✹✳✶ ❙❡❧❡çã♦ ❞❡ ♣❛râ♠❡tr♦s
Grande parte do trabalho de constru¸c˜ao de modelos estat´ısticos envolve a estima-tiva dos parˆametros do modelo e valida¸c˜ao desses modelos (CHATTERJEE; LAUDATO; LYNCH, 1996). Um grande conjunto de experimentos foi realizado, a fim de tentar encon-trar a melhor configura¸c˜ao poss´ıvel de parˆametros e entender o impacto desses parˆametros no desempenho de cada m´etodo em todas as instˆancias selecionadas.
Inicialmente, um conjunto de valores foi escolhido, manualmente, para cada parˆame-tro. Em seguida, foi realizada uma avalia¸c˜ao do comportamento de cada algoritmo para esses valores, e novos valores foram considerados, realizando combina¸c˜oes com outros parˆametros. Esse processo se repetiu at´e chegar aos resultados finais. Nesta fase, o obje-tivo foi compreender as poss´ıveis correla¸c˜oes entre os parˆametros e, tamb´em, verificar a sensibilidade de cada algoritmo, em rela¸c˜ao `as diferentes configura¸c˜oes desses parˆametros. Na gera¸c˜ao de vizinhos, foram consideradas trˆes estrat´egias que intensificam ou n˜ao a explora¸c˜ao de movimentos na m´aquina que determina o valor do makespan. A primeira estrat´egia ´e a R, a segunda Mk e a terceira Mi, coforme apresentadas na subse¸c˜ao 3.4. Es-tas trˆes estrat´egias (R, Mk e Mi) foram avaliadas manualmente, ou seja, a escolha de qual estrat´egia adotar representa um parˆametro de entrada de cada algoritmo desenvolvido.
A avalia¸c˜ao de cada parˆametro selecionado foi realizada utilizando uma m´etrica que n˜ao ´e sens´ıvel `as escalas: o Desvio de Porcentagem Relativa (RPD - Relative Percentual Deviation) (VALLADA; RUIZ, 2011), conforme se verifica na equa¸c˜ao (4.1). Nessa
equa¸c˜ao,Algoritmosol´e o valor da fun¸c˜ao objetivo (makespan), obtido por um dos
algorit-mos que foram implementados, eM elhorsol´e o valor da fun¸c˜ao objetivo da melhor solu¸c˜ao
apresentada em SOA-ITI. ´E importante lembrar que M elhorsol sempre ser´a diferente de
zero. O valor do RPD para um determinado m´etodo define a qualidade da solu¸c˜ao, sendo que, quanto menor for esse valor, melhor ser´a a qualidade desse m´etodo.
RP D= 100× Algoritmosol−M elhorsol
M elhorsol
, M elhorsol 6= 0 (4.1)
A partir da Equa¸c˜ao 4.1, ´e poss´ıvel concluir que os valores negativos para RPD indicam que a abordagem proposta superou a melhor solu¸c˜ao apresentada em SOA-ITI, j´a que os menores valores do makespan s˜ao melhores. Os valores positivos indicam o oposto. Os valores da M elhorsol foram obtidos de Vallada e Ruiz (2011), em SOA-ITI, e s˜ao
apresentados na Tabela 8 (coluna SOA Melhor). Nessa tabela, s˜ao apresentadas, tamb´em, as melhores solu¸c˜oes produzidas com cada um dos m´etodos propostos.
Para compara¸c˜ao dos dados, ser´a utilizado o modelo de gr´afico conhecido como dia-grama de caixa, ou boxplot. Mason, Gunst e Hess (2003) explicam que o boxplot destaca, visualmente, a localiza¸c˜ao e dissemina¸c˜ao de um conjunto de dados e, muitas vezes, ´e al-tamente sugestiva para comparar dados. Bussab e Moretin (2002) enfatizam que oboxplot
Cap´ıtulo 4. Resultados Obtidos 36
´
util para revelar o centro, a dispers˜ao e a distribui¸c˜ao dos dados, al´em da presen¸ca de
outlliers. Todos os gr´aficos foram gerados no software livre“R”.
✹✳✷ ❘❡s✉❧t❛❞♦s ❡ ❞✐s❝✉ssõ❡s
As figuras apresentadas nas subse¸c˜oes a seguir ilustram os resultados de diferentes ajustes de parˆametros para cada metaheur´ısitica. Foram realizados trˆes testes em cada parˆametro e obtido o RPD m´edio. Para todos os casos, considera-se o RPD m´edio e um tempo limite de 60 segundos por execu¸c˜ao. Os ajustes dos parˆametros foram realizados manualmente. Para cada parˆametro, s˜ao verificadas as trˆes estrat´egias de vizinhan¸ca: R, Mk e Mi.
✹✳✷✳✶ ▲❆❍❈
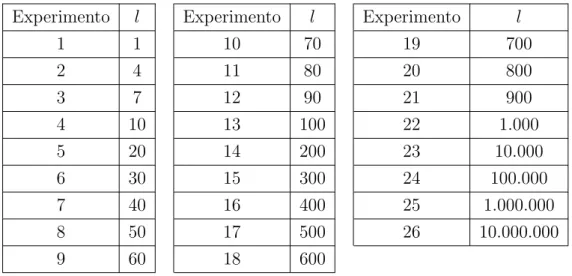
O ajuste de parˆametros da metaheur´ıstica LAHC ´e simples, pois essa metaheur´ıstica possui apenas um parˆametro. O parˆametro utilizado para esse ajuste ´e o tamanho da lista, chamado de l. Na Tabela 3, est˜ao representados os n´umeros dos experimentos com os respectivos valores do parˆametro l.
Tabela 3 – Varia¸c˜ao do parˆametrol nos experimentos do LAHC
Experimento l Experimento l Experimento l
1 1 10 70 19 700
2 4 11 80 20 800
3 7 12 90 21 900
4 10 13 100 22 1.000
5 20 14 200 23 10.000
6 30 15 300 24 100.000
7 40 16 400 25 1.000.000
8 50 17 500 26 10.000.000
9 60 18 600
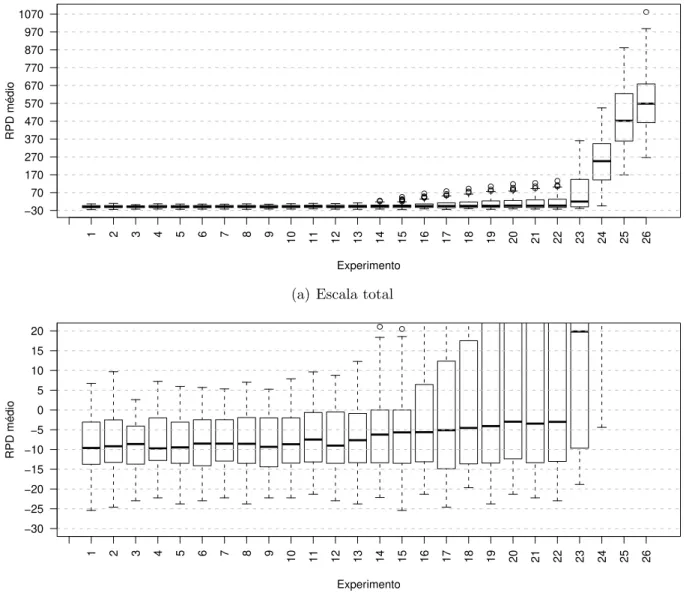
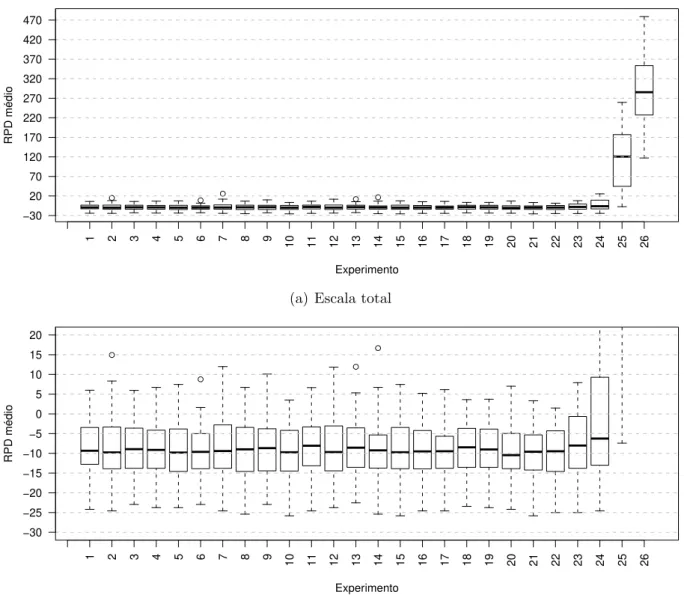
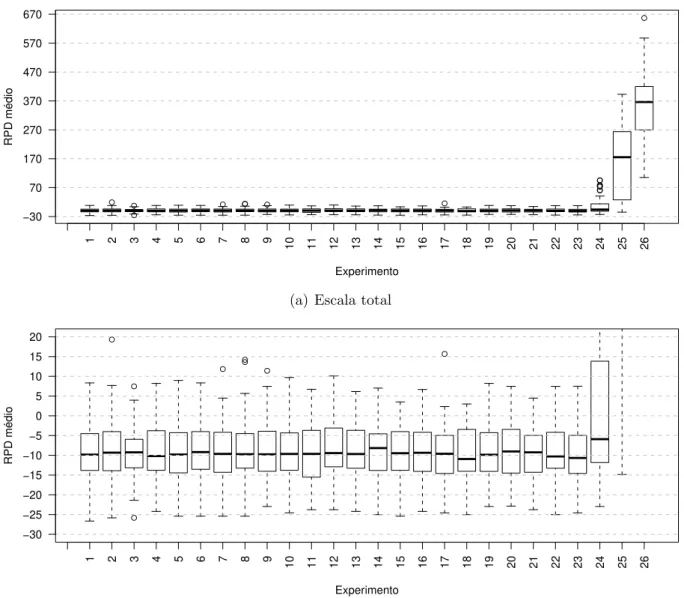
Na Figura 7(a), ´e poss´ıvel observar que valores menores de lista geram resultados melhores para a vizinhan¸ca R. Na Figura 7(b), a escala do eixo RPD m´edio ´e ampliada, para verificar um valor da lista l que fornece um melhor resultado. Ser´a considerado melhor resultado, arbitrariamente, o experimento 3, com tamanho de lista igual a 7.
Cap´ıtulo 4. Resultados Obtidos 37 ● ● ●●●●●● ●●●●● ●●●● ●●● ●● ● ●●●● ●●● ●●● ● Experimento RPD médio −30 70 170 270 370 470 570 670 770 870 970 1070
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(a) Escala total
● ● Experimento RPD médio −30 −25 −20 −15 −10 −5 0 5 10 15 20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(b) Escala ampliada
Figura 7 – LAHC usando a estrat´egia de vizinhan¸ca R
● ● ● ● ● ● ● ● ● ● Experimento RPD médio 0 30 60 90 120 150 180 210 240 270 300
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
Cap´ıtulo 4. Resultados Obtidos 38
Na Figura 9(a), percebe-se um comportamento semelhante ao da Figura 7(a), ou seja, valores menores de lista geram resultados melhores para a vizinhan¸ca Mi. Na Figura 9(b), a escala do eixo RPD m´edio ´e ampliada para verificar um valor da listal que fornece um melhor resultado. Ser´a considerado melhor resultado, arbitrariamente, o experimento 22, com tamanho de lista igual a 1.000.
A Figura 10 ilustra o resultado dos melhores experimentos do LAHC para as vizinhan-¸cas R, Mk e Mi. ´E poss´ıvel observar que as vizinhan¸cas R e Mi obtiveram resultados bem pr´oximos, sendo a Mi um pouco melhor. Fica claro que selecionar sempre a m´aquina que determina o valor do makespan ´e a pior op¸c˜ao. A sele¸c˜ao de vizinhos envolvendo todas as m´aquinas ´e extremamente importante para produzir melhores resultados.
● ● ● ● ●
Experimento
RPD médio
−30 20 70 120 170 220 270 320 370 420 470
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(a) Escala total
●
●
● ●
Experimento
RPD médio
−30 −25 −20 −15 −10 −5 0 5 10 15 20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(b) Escala ampliada
Cap´ıtulo 4. Resultados Obtidos 39
Experimento
RPD médio
−30 −25 −20 −15 −10 −5 0 5 10 15 20
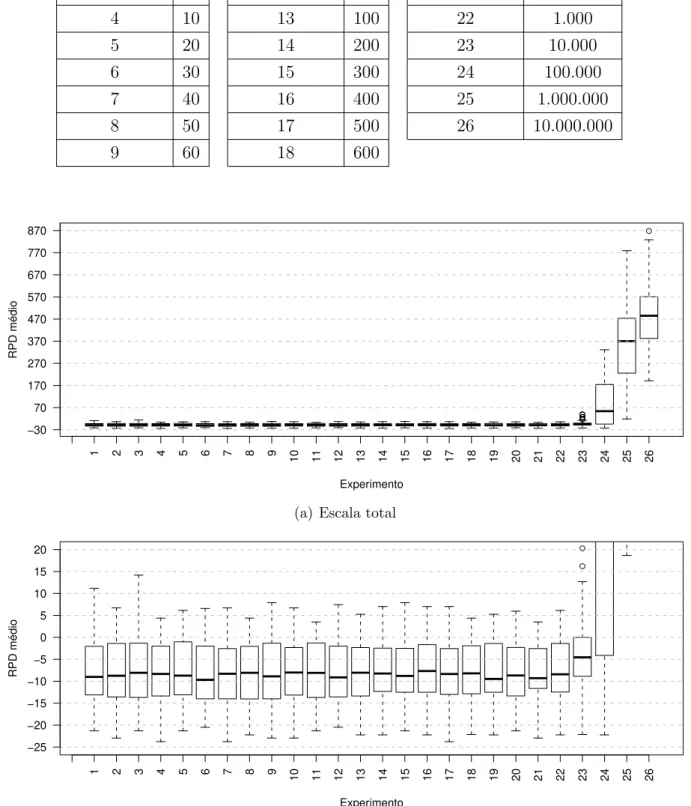
24−Mk 3−R 22−Mi
Figura 10 – Melhores do LAHC
De forma geral, considerando-se o parˆametro “tamanho da lista l”, os resultados s˜ao piores para valores maiores. Dependendo da estrat´egia de sele¸c˜ao de m´aquina, diferentes valores de l s˜ao melhores. Em particular, quando se utiliza a estrat´egia de sele¸c˜ao Mk, ´e melhor ter valores maiores de l(at´e 100.000), o que ´e explicado pelo fato das modifica¸c˜oes mais profundas na solu¸c˜ao exigirem movimentos de piora. De qualquer forma, os melhores resultados foram obtidos usando a estrat´egia Mi, com pequenos valores de l. ´E poss´ıvel observar, na Figura 10, que o experimento 22, da vizinhan¸ca Mi, com tamanho de lista igual a 1.000, ´e o melhor do m´etodo LAHC.
✹✳✷✳✷ ❙❈❍❈
O ajuste de parˆametros da metaheur´ıstica SCHC ´e simples, pois essa metaheur´ıstica, assim como a LAHC, possui apenas um parˆametro. O parˆametro utilizado para esse ajuste ´e o c. Na Tabela 4, est´a representado o n´umero do experimento com o respectivo valor do parˆametro c.
Cap´ıtulo 4. Resultados Obtidos 40
Tabela 4 – Varia¸c˜ao do parˆametroc nos experimentos do SCHC
Experimento c Experimento c Experimento c
1 1 10 70 19 700
2 4 11 80 20 800
3 7 12 90 21 900
4 10 13 100 22 1.000
5 20 14 200 23 10.000
6 30 15 300 24 100.000
7 40 16 400 25 1.000.000
8 50 17 500 26 10.000.000
9 60 18 600
● ● ● ● ● ●
●
Experimento
RPD médio
−30 70 170 270 370 470 570 670 770 870
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(a) Escala total
● ●
Experimento
RPD médio
−25 −20 −15 −10 −5 0 5 10 15 20
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(b) Escala ampliada
Cap´ıtulo 4. Resultados Obtidos 41
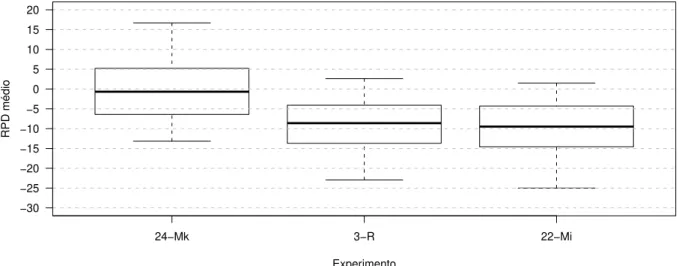
Na Figura 12, observa-se um comportamento diferente da Figura 11(a). Para a vizi-nhan¸ca Mk, o experimento 23 obt´em o melhor resultado, com um valor para o parˆametroc
igual a 10.000. Valores decmenores ou maiores, dentro do intervalo que foram realizados os testes, geram resultados piores.
● ●
● ● ● ● ●
●
● ●
● ● ● ●
● ● ●
● ● ●●
Experimento
RPD médio
−30 20 70 120 170 220 270 320 370 420 470 520 570
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
Figura 12 – SCHC usando a estrat´egia de vizinhan¸ca Mk
Na Figura 13(a), percebe-se um comportamento semelhante ao da Figura 11(a), ou seja, valores menores de c geram resultados melhores para a vizinhan¸ca Mi. Na Figura 13(b), a escala do eixo RPD m´edio ´e ampliada, para verificar um melhor valor para o parˆametroc. Para valores decat´e 10.000 (experimento 23), os resultados s˜ao semelhantes e, para valores de c acima de 10.000, os resultados pioram. O experimento 18, com valor de cigual a 600, ser´a, arbitrariamente, considerado o melhor.
Conclus˜oes muito semelhantes ao experimento LAHC, apresentado na subse¸c˜ao 4.2.1, podem ser tiradas para os resultados do SCHC. De forma geral, considerando-se o pa-rˆametro c, os resultados s˜ao piores para valores maiores. Dependendo da estrat´egia de sele¸c˜ao de m´aquinas diferentes, os valores de cs˜ao melhores.
Cap´ıtulo 4. Resultados Obtidos 42 ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● Experimento RPD médio −30 70 170 270 370 470 570 670
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(a) Escala total
● ● ● ● ● ● ● ● Experimento RPD médio −30 −25 −20 −15 −10 −5 0 5 10 15 20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
(b) Escala ampliada
Figura 13 – SCHC usando a estrat´egia de vizinhan¸ca Mi
Experimento RPD médio −25 −20 −15 −10 −5 0 5 10 15 20 25 30 35
23−Mk 21−R 18−Mi
Cap´ıtulo 4. Resultados Obtidos 43
De forma semelhante ao que ocorre no LAHC, quando se utiliza a estrat´egia de sele¸c˜ao Mk no SCHC ´e melhor ter valores maiores dec(at´e 10.000). Os melhores resultados foram obtidos usando a estrat´egia Mi e com pequenos valores de c. Conforme ´e poss´ıvel verificar na Figura 14, o experimento 18, da vizinhan¸ca Mi com parˆametrocigual a 600, ´e o melhor do m´etodo SCHC.
✹✳✷✳✸ ■▲❙
A metaheur´ıstica ILS implementada possui quatro parˆametros para serem ajustados:
rna, p0, ilsmax e pmax. Na Tabela 5, est˜ao representados os n´umeros dos experimentos
com os respectivos valores desses parˆametros.
Tabela 5 – Varia¸c˜ao dos parˆametros nos experimentos do ILS
Experimento rna p0 ilsmax pmax
1 1.000.000 100 5 1.000
2 1.000.000 300 5 1.000
3 1.000.000 500 5 1.000
4 10.000.000 10 10 100
5 10.000.000 30 10 100
6 10.000.000 50 10 100
7 10.000.000 70 10 100
8 10.000.000 100 5 1.000
9 10.000.000 300 20 1.000
10 10.000.000 300 60 1.000
11 10.000.000 300 1.000 1.000
12 10.000.000 300 6.000 1.000
13 10.000.000 300 11.000 1.000
14 100.000.000 100 5 1.000
Na Figura 15, ´e poss´ıvel observar que valores maiores dernageram resultados melhores para a vizinhan¸ca R. Os outros parˆametros (p0,ilsmax e pmax) n˜ao alteram os resultados
Cap´ıtulo 4. Resultados Obtidos 44 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Experimento RPD médio −20 −10 0 10 20 30 40 50 60 70 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Figura 15 – ILS usando a estrat´egia de vizinhan¸ca R
Na Figura 16, pode-se observar que os valores est˜ao pr´oximos para todas varia¸c˜oes de parˆametros que foram realizadas na vizinhan¸ca Mk. Existe uma pequena melhora nos resultados para valores menores de rna e de p0. Os outros parˆametros n˜ao alteram
os resultados de forma significativa. O experimento 4, do ILS com vizinhan¸ca Mk, ´e o melhor. Experimento RPD médio 0 10 20 30 40 50 60 70 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Figura 16 – ILS usando a estrat´egia de vizinhan¸ca Mk
Na Figura 17, ´e poss´ıvel observar que os valores dos parˆametros do ILS, para a vizi-nhan¸ca Mi, est˜ao semelhantes aos valores da vizivizi-nhan¸ca R representados na Figura 15. O experimento 14, do ILS com vizinhan¸ca Mi, ser´a considerado o melhor.
Cap´ıtulo 4. Resultados Obtidos 45
● ●
● ● ●●
● ●● ●●● ●
●
Experimento
RPD médio
−25 −20 −15 −10 −5 0 5 10 15 20
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Figura 17 – ILS usando a estrat´egia de vizinhan¸ca Mi
Experimento
RPD médio
−25 −20 −15 −10 −5 0 5 10 15 20 25 30 35 40 45
4−Mk 14−R 14−Mi
Figura 18 – Melhores do ILS
Os resultados do ILS tamb´em obtiveram melhores resultados utilizando a estrat´egia de vizinhan¸ca Mi. Observou-se que valores pequenos de p0 (p0 = 10) e altos valores de rna
(rna= 107
ou rna= 108
) produziram resultados muito bons. Os outros dois parˆametros que foram considerados, ilsmax e pmax, n˜ao foram muito influentes nos resultados. O
experimento 14, da vizinhan¸ca Mi, ser´a considerado o melhor do m´etodo ILS.
✹✳✷✳✹ ❙❆
A metaheur´ıstica SA implementada possui quatro parˆametros para serem ajustados:
samax, α, pro emti. Na Tabela 6 est˜ao representados os n´umeros dos experimentos com
Cap´ıtulo 4. Resultados Obtidos 46
O valor para a temperatura inicial ´e determinado por simula¸c˜ao da seguinte forma: realizam-semtitrocas aleat´orias na vizinhan¸ca da solu¸c˜ao inicial; o maior valor encontrado da fun¸c˜ao objetivo ´e gravado e multiplicado por pro; esse valor que foi multiplicado por
pro ser´a a temperatura inicial.
Tabela 6 – Varia¸c˜ao dos parˆametros nos experimentos do SA
Experimento samax α pro mti
1 10.000 0,98 0,05 1.000
2 40.000 0,98 0,05 1.000
3 70.000 0,98 0,05 1.000
4 100.000 0,98 0,05 1.000
5 200.000 0,98 0,05 1.000
6 300.000 0,98 0,05 1.000
7 400.000 0,98 0,05 1.000
8 500.000 0,98 0,05 1.000
9 1.000.000 0,98 0,05 1.000
10 2.000.000 0,98 0,05 1.000
11 10.000 0,99 0,05 1.000
12 40.000 0,99 0,05 1.000
13 70.000 0,99 0,05 1.000
14 100.000 0,99 0,05 1.000
15 200.000 0,99 0,05 1.000
16 300.000 0,99 0,05 1.000
17 400.000 0,99 0,05 1.000
18 500.000 0,99 0,05 1.000
19 200.000 0,99 0,05 200
20 200.000 0,99 0,05 400
21 200.000 0,99 0,05 600
22 200.000 0,99 0,05 800
23 200.000 0,99 0,05 1.300
24 200.000 0,99 0,05 1.600
25 200.000 0,99 0,05 1.900
26 200.000 0,99 0,05 2.200
27 200.000 0,99 0,10 1.000
28 200.000 0,99 0,01 1.000
Cap´ıtulo 4. Resultados Obtidos 47
resultados do SA com estrat´egia de vizinhan¸ca R. Na Figura 19(b), a escala do eixoRPD m´edio ´e ampliada para verificar, de forma mais leg´ıvel, as varia¸c˜oes dos parˆametros em cada experimento. Nessas duas ´ultimas figuras citadas, ´e poss´ıvel observar que, para valores de α igual a 0,98, o melhor resultado ´e obtido com o samax em torno de 400.000
(experimento 7). Caso o valor do α seja aumentado de 0,98 para 0,99, percebe-se um melhor resultado para um valor de samax em torno de 200.000 (experimento 15). Nessa
rela¸c˜ao entre αesamax´e bem interessante observar um comportamento de forma inversa,
ou seja, para realizar um aumento no valor de α deve-se reduzir o valor de samax caso
deseje alcan¸car resultados semelhantes.
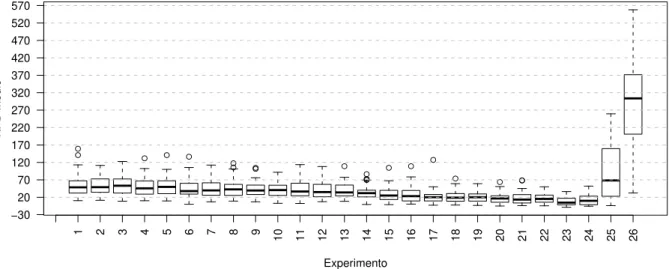
Cap´ıtulo 4. Resultados Obtidos 48 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Experimento RPD médio −30 20 70 120 170 220 270 320 370 420 470 520 570
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
(a) Escala total
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Experimento RPD médio −25 −20 −15 −10 −5 0 5 10 15 20 25 30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
(b) Escala ampliada
Figura 19 – SA usando a estrat´egia de vizinhan¸ca R
Cap´ıtulo 4. Resultados Obtidos 49
● ●
●
Experimento
RPD médio
−20 10 40 70 100 130 160 190 220
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
(a) Escala total
Experimento
RPD médio
−20 −15 −10 −5 0 5 10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
(b) Escala ampliada
Figura 20 – SA usando a estrat´egia de vizinhan¸ca Mk
Na Figura 21(a), ´e poss´ıvel observar como a varia¸c˜ao de parˆametros interfere nos resultados do SA, com estrat´egia de vizinhan¸ca Mi. Na Figura 21(b), a escala do eixoRPD m´edio ´e ampliada para verificar, de forma mais leg´ıvel, as varia¸c˜oes dos parˆametros, em cada experimento. Nessas duas ´ultimas figuras pode-se observar um comportamento bem diferente do SA, com vizinhan¸ca R e Mk, sendo a vizinhan¸ca Mi bem melhor. Em mais de 70% dos diferentes ajustes dos parˆametros testados, os resultados s˜ao sempre melhores ou iguais `as solu¸c˜oes apresentadas por Vallada e Ruiz (2011), em SOA-ITI. Observou-se que os valores de samax, na faixa de 40.000 `a 500.000, com α= 0,98 ou α= 0,99, s˜ao ´otimas