12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 7 de setembro de 2012, Guimarães, Portugal
ISSN 2183-489X
DOI http://dx.doi.org/10.18803/capsi.v12.186-199
186
Tiago V. Caetano, PT-Sistemas de Informação, Portugal, Tiago-v-caetano@telecom.pt Carlos J. Costa, ISCTE-IUL, ADETTI-IUL, Portugal, Carlos.costa@iscte.pt
Resumo
É certo que hoje em dia nas empresas o Business Intelligence e o Data Warehousing são usados para facilitar aos decisores os dados mais atuais e com a melhor qualidade possível. Mas o data warehouse pode ser também usado noutro contexto, o de sistemas integrados, onde o ator que vai usar os dados não é um decisor mas uma aplicação que os utilizará para integrar com outros sistemas. Com recurso ao Portal SFA da Portugal Telecom, iremos mostrar como esta abordagem traz vantagens quando comparada com a que está atualmente em uso nessa aplicação.
Palavras-chave: Data Warehouse, Business Intelligence, Sistemas integrados, Portais Web, Sales Force Automation
1. I
NTRODUÇÃONormalmente Data Warehousing é usado no âmbito de Business Intelligence, como ferramenta de apoio à decisão, mas e se a utilidade fosse estendida a sistemas integrados? Se em vez de um ator com capacidades de decisão for um sistema a necessitar desses dados, guardados num repositório central e extraídos com o devido tratamento para uma base de dados local, de mais fácil e rápido acesso via código, será que ainda estamos a referir-nos a Data Warehouse?
O objetivo deste artigo é mostrar que, apesar dos atores serem outros, o conceito de Data Warehouse se mantém presente e muito do que é feito para apoio do decisor é também feito na integração de sistemas.
Propomos que ferramentas de Sales Force Automation, que integram com múltiplos sistemas e com quem partilham informação, possam usar o BI, mais concretamente a componente de Data Warehousing. Neste caso o BI será utilizado não para analisar métricas ou decidir estratégias, mas para comunicar com outros sistemas, sendo facilitada a partilha de informação entre todos os sistemas intervenientes no fluxo.
Como caso de estudo será focado o Portal SFA, uma aplicação core da PT Comunicações que, para o funcionamento normal, necessita de dados de diversos sistemas guardados num repositório central.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 187
2. B
USINESSI
NTELLIGENCESegundo Power os Sistemas de Apoio à Decisão, onde o Business Intelligence (BI) se enquadra, existem há mais de 45 anos. BI é apenas o mais recente processo dentro destes sistemas, remontando os primeiros desenvolvimentos a 1985. O termo BI tornou-se popular em 1989 (Power 2003). Atualmente BI é uma prioridade na estratégia das empresas e considerado pelos líderes das empresas como uma ferramenta que promove a efetividade e inovação. Este facto pode ser observado pela crescente procura por ferramentas de BI quando comparado com outras ferramentas de tecnologias de informação (Negash 2004).
Segundo um questionário efetuado a 1400 CIO em 2007 pela Gartner, os projetos de BI estavam no topo da lista de prioridades (Watson e Wixom 2007).
BI pode ser considerado tanto um processo com um produto (Jourdan et al. 2008). Um processo por ser composto por metodologias usadas pela empresa para melhorar o tratamento dos dados, da informação que dispõe, permitindo-lhe tomar melhores decisões e criar vantagens competitivas face à concorrência. O produto é o resultado obtido pelo processo, ou seja, a informação tratada que será disponibilizada aos decisores.
Esta informação deve ser disponibilizada num período de tempo que mantenha os dados úteis para o decisor no momento da tomada de decisão. O BI é, deste ponto de vista, considerado proativo. O BI proativo tem diversos componentes (Negash 2004), entre eles:
• Data warehousing em tempo real; • Data mining;
• Deteção automática de exceções e anomalias;
• Alerta proativo com determinação automática de destinatários; • Acompanhamento contínuo da execução;
• Aprendizagem e melhoria automática; • Sistemas de informação geográfica; • Visualização dos dados.
A figura 1 mostra-nos como o BI engloba as tarefas de recolha dos dados das diversas fontes, a sua transformação para o Data Warehouse e as tarefas do seu envio para as ferramentas que permitem a análise dos dados transformados.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 188
Figura 1 - Framework de Business Intelligence (Watson e Wixom 2007)
3. D
ATA-W
AREHOUSEUm Data Warehouse (DW) é um repositório central que agrega dados das bases de dados operacionais, para permitir a análise e data mining desses dados (Cui e Widom 2003). William Inmon definia um Data Warehouse como um conjunto de dados não voláteis, integrados e orientados ao objeto, que variam com o tempo, para apoio à decisão (Inmon 1992).
Se as bases de dados operacionais são sistemas transacionais que suportam os processos de negócio diários e armazenam, em tempo real, a informação detalhada de cada transação, um Data Warehouse armazena, normalmente, o histórico completo do negócio, traduzindo-se num gigantesco número de linhas, crescendo a gigabytes, terabytes ou até petabytes (Santos e Bernardino 2009). Para serem obtidos os dados de apoio à decisão, o DW baseia-se na execução de consultas ad-hoc e em ferramentas que efetuam on-line analytical processing (OLAP), ao contrário das bases de dados operacionais que usam on-line transactional processing (OLTP).
Durante o processo de integração, os dados sofrem diversas transformações, que podem variar de simples operações algébricas, agregações ou procedimentos mais complexos de limpeza dos dados para remoção de ruído e dados inconsistentes.
Devido ao tamanho que as tabelas da DW podem atingir e à elevada quantidade de dados a que as consultas de suporte à decisão acedem, a performance é um ponto fulcral na construção de Data Warehouses.
Mas se o BI é considerado para muitos autores um produto e um processo, um DW é um ambiente e não um produto, que agrega vários tipos de tecnologia e módulos que integram dados para suporte efetivo à decisão (Guoling e Ying 2005).
Um DW é composto por um conjunto de Data Marts (Figura 2) que vão representar, cada um deles, uma característica do negócio como vendas, marketing ou clientes. Num Data Mart (DM) independente, os dados podem ser recolhidos diretamente das fontes (Shin 2002).
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 189
Figura 2 – Esquema de Data Warehouse
Basicamente, o esquema de um Data Mart baseia-se em dois tipos de elementos: factos e dimensões (Figura 3). Os factos são usados para guardar as métricas de situações ou eventos. As dimensões são usadas para analisar essas métricas, através de operações de agregação (contagens, somatórios, médias, etc.) (Schneider 2008). Estes elementos são dispostos segundo um esquema, que pode ser em estrela, com a tabela de factos no centro do modelo.
Figura 3 – Exemplo de Data Mart no Esquema em Estrela
4. ETL
–
E
XTRACTT
RANSFORM ANDL
OADUm dos pontos mais importantes no desenho e desenvolvimento de um Data Warehouse é o desenho do fluxo de dados desde as fontes até aos destinos (Skoutas e Simitsis 2006). Este processo ETL é responsável pela extração dos dados das fontes mais diversas, transformação desses dados (conversões, limpeza, etc.) e carregamento dos dados no DW (Figura 4)
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 190
Figura 4 – Exemplo de processo ETL
É ponto assente que o correto desenho, desenvolvimento e manutenção do processo ETL é um fator de sucesso para um projeto de DW (Muñoz et al. 2009). Por este motivo pode-se aferir que se o processo não for bem desenhado, podem ser carregados dados incorretos para o DW, levando a decisões erradas que podem conduzir o projeto de Data Warehouse ao fracasso. Mas o desenho e carregamento do DW através do processo ETL é uma tarefa complexa e demorada tendo assim um elevado custo em termos de recursos humanos, físicos e financeiros (Alkis Simitsis et al. 2008), mesmo que a tarefa seja mal executada e conduza o projeto ao fracasso. Do tempo utilizado no desenho do processo ETL, cerca de 30-50% é usado em análise, para garantir que os sistemas fonte são percebidos e existe alinhamento entre os vários intervenientes (Alkis Simitsis et al. 2008). A complexidade dos DW e o volume de dados aumenta a um ritmo significativo, o que coloca em causa a performance e o correto funcionamento do processo ETL. Para isto é necessário que o mapeamento entre as fontes de dados e os destinos no DW seja correto e o processo ETL deve ser executado na totalidade dentro de um determinado período de tempo para os dados serem viáveis para utilização no apoio à decisão. No entanto, e apesar da importância da performance, os programadores de processos ETL têm adotado outras características de qualidade como fiabilidade, recuperação ou manutenção, entre outros (A. Simitsis et al. 2010).
Tipicamente, o processo ETL pode ser visto de forma simples na figura 5. À esquerda, as fontes de dados (bases de dados relacionais, ficheiros, etc.). Além destas fontes de dados, o processo de ETL pode recorrer ainda a outras fontes como cookies, bases de dados de anúncios, bases de dados de registo, logs web, base de dados aplicacionais, etc., obrigando a que o desenho do processo ETL tenha em conta a análise dos cookies ou de ataques ao sistema, por exemplo, gerindo os dados de
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 191 acordo com os diferentes tipos de acesso, analisando ainda a relação dos logs dos diferentes servidores Web (Guoling e Ying 2005).
Os dados são extraídos dessas fontes através de rotinas que trazem a totalidade dos dados ou apenas a diferença entre a fonte e o destino. Depois, estes dados são levados para uma Data Staging Area (DSA) onde são transformados e limpos antes de serem carregados na DW. O Data Warehouse está representado à direita da ilustração com as tabelas de destino, ou seja, as tabelas de factos e dimensões. Em algumas situações o carregamento dos dados pode ser feito sem ocorrer qualquer transformação dos mesmos.
Figura 5 – Framework do processo ETL (Panos et al. 2002) Resumidamente, as etapas do processo ETL são as seguintes:
• Identificação dos dados relevantes nas fontes de dados; • Extração desses dados;
• Transformação e integração dos dados vindos de múltiplas fontes num formato comum; • Limpeza do conjunto de dados resultante da transformação, com base em regras da base de
dados e do negócio;
• Propagação dos dados para o DW e/ou para os DM.
5. C
ASO DEE
STUDOPara uma empresa com centenas de lojas e agentes espalhados pelo país, não ter uma ferramenta única e integrada para vendas e configuração é uma limitação que pode tornar os processos ainda mais complexos. Num cenário como este, ferramentas de Sales Force Automation (SFA) associadas a outras de Customer Relationship Management (CRM) ou mesmo ferramentas que integrem as duas funcionalidades, são essenciais para maximizar o desempenho dos vendedores, automatizando atividades das vendas e o processamento dos pedidos, melhorar o relacionamento com o cliente,
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 192 permitir a integração das vendas para outros sistemas legados, análise e previsão de vendas pelos decisores da organização (Barker et al. 2009).
A utilização destas ferramentas é tão relevante em aspetos como a eficiência que, em estudos efetuados, os utilizadores de aplicações SFA referiram que com o uso da aplicação, havia uma redução do tempo despendido em atividades relacionadas com vendas de cerca de 85% (Buehrer et al. 2005). Para a Portugal Telecom, a aplicação Portal SFA é um sistema crítico para o negócio através do qual atualmente é realizada uma elevada percentagem do volume das vendas.
5.1. O Portal SFA
O Portal SFA é um portal web (Figura 6) que agrega inúmeras funcionalidades comuns a sistemas de Sales Force Automation, e cujo objetivo essencial é a automatização máxima dos processos relacionados com a comercialização de produtos PT, através da integração de processos críticos numa única solução. Esta unificação de processos e dados permite também a análise estratégica por parte de decisores como Gestores de Agentes ou Gestores de Produto.
A principal função do Portal SFA é a possibilidade de registo de vendas. Alguns objetivos importantes do Portal SFA são:
• Maximizar as vendas e minimizar os custos; • Criação e configuração de produtos;
• Agregar um conjunto de serviços disponibilizados aos parceiros da PT Comunicações; • Criar um repositório único de vendas;
• Ferramenta de Order Entry para os canais de venda;
• Facilitar a interação da PT Comunicações e respetivos Parceiros com o Cliente final.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 193 Como o negócio da PT não é estático, o Portal SFA necessita estar atualizado estando em constante evolução, seja com novas funcionalidades, novos processos de negócio ou com novos portfolios de produtos e serviços.
Uma grande parte destes produtos e serviços é comum aos diversos sistemas com que o Portal SFA se relaciona e é gerido pelo Negócio, existindo depois, dentro de cada sistema, um mecanismo de recolha e tratamento desses dados. O Portal SFA não é exceção, e conta com um sistema ETL desenvolvido em Microsoft SQL Server 2000 Data Transformation Service para esse efeito. No entanto, o método atual de ETL, pensado para um número baixo de tabelas de origem, continuou a crescer e tornou-se inviável devido ao elevado número de sistemas legados dos quais o Portal SFA recebe dados de negócio, a quantidade de dados que são recebidos e a frequência com que são adicionadas novas coleções de dados de negócio. Também a morosidade no processo ETL como a forma de recolha dos dados da mainframe (repositório dos dados de negócio), através de openquerys, que induz erros no tipo dos dados, variando de ambiente para ambiente não permitindo a correção atempadamente, tornam o método inviável.
5.2. Implementação do processo
No processo atual de ETL são carregados dados de dezenas de tabelas de referência, com poucas transformações ou validações dos dados. Numa primeira instância, é feita a recolha dos dados através de openquery para uma tabela de staging. Se a tabela de staging tiver sido carregada, a tabela de destino é limpa e os dados presentes na tabela de staging são transferidos para a tabela de destino. E se a extração de dados falhar a meio do procedimento? Como os dados estão num servidor central, e são acedidos via openquery, pode ocorrer uma falha de rede ou indisponibilidade do sistema a meio de uma consulta. Nesta situação, a tabela de staging tem dados carregados, mas não a totalidade dos dados existentes na tabela de origem e que podem ser essenciais para um processo de negócio, estes dados vão ser enviados para a tabela de destino, depois de eliminados os antigos, provocando incoerência dos dados.
Tendo em conta o processo atual e as dimensões do mesmo, para este artigo foram extraídas apenas algumas amostras a partir das quais foi implementado o novo procedimento: área geográfica, códigos postais, tipificações de SIEBEL e incompatibilidades.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 194
Figura 7 – Algumas tarefas de ETL para o Portal SFA
Apesar de algumas das tarefas serem relativamente rápidas de executar, tanto pelo tratamento que é feito aos dados como ao volume de dados movimentado, nesta fase inicial foram todas colocadas no mesmo contentor, para permitir serem executadas em simultâneo, o que reduziu o tempo de execução. A partir daqui podemos extrapolar o tempo total do processo completo pela duração da atividade mais lenta.
O processo de transformação dos dados na maior parte das tabelas da amostra, incide sobre a conversão dos dados e a colocação da data atual na inserção dos novos registos. Sempre que o fluxo é executado é feita a comparação dos dados da tabela de origem com a tabela de destino e, apenas os dados que não existirem na tabela de destino são inseridos.
Figura 8 – Fluxo de tipificações
Na interação do Portal SFA com SIEBEL, são transmitidas via Web Service tipificações que necessitam ter o mesmo significado e tipo de resposta nas duas aplicações.
Na tarefa da área geográfica, correm três fluxos também em simultâneo.
Apesar de aparentar ser informação irrelevante, no contexto de processo de vendas de um serviço ADSL, por exemplo, a não existência de uma morada ou má configuração da mesma pode implicar que não se obtenha o tipo de cobertura necessário e, por conseguinte, não seja possível realizar a venda. Esta informação, a par dos códigos postais, permite efetuar a consulta à aplicação que gere viabilidade de cada morada.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 195
Figura 9 – Fluxo da área geográfica
No caso dos códigos postais, optou-se por efetuar a validação dos campos numéricos de tamanho fixo, de forma a garantirmos que só são inseridos na tabela de destino os que cumprem o tamanho definido. Em caso de não passarem nas validações, estes registos são ignorados e não são inseridos na tabela de destino.
Figura 10 – Fluxo de códigos postais
O fluxo de incompatibilidades precisou de algumas operações intermédias, para concatenar os códigos do Serviço de Incompatibilidades, num código que o sistema do SFA possa usar nas suas validações.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 196 No contexto da realização de uma venda, o Serviço de Incompatibilidades permite validar se o cenário da venda é viável para ser integrado nos sistemas seguintes. Recebe todos os dados introduzidos na venda, entre dados do cliente e produtos e serviços recolhidos e, na resposta do Web Service, indica se existe algo que não permita concluir a venda. É na situação de erro que o Portal SFA usa a informação carregada neste fluxo.
Para permitir o envio de mensagens de email no novo modelo, foi adicionada uma tarefa de execução de scripts (Script Task). Podíamos ter usado a tarefa Send Email Task, no entanto esta tarefa necessita de um servidor SMTP sem autenticação, configuração que o servidor SMTP usado não tinha.
Neste script, criou-se, em Linguagem C#, um método para enviar um email, para um endereço parametrizável, com um relatório da execução. Neste modelo, tal email ficou apenas definido para a execução completa do processo.
6. D
ISCUSSÃO DER
ESULTADOSA implementação do novo modelo a partir das amostras permitiu-nos ficar com uma noção do tempo necessário para a implementação do modelo completo e da sua performance e eficácia. A performance do modelo nem sempre é diretamente afetada pelo volume de registos a inserir ou apenas a comparar. Estes fatores podem não ser suficientes para alterar o tempo de execução e a memória usada pelo processo.
Quando comparamos o novo modelo com o antigo, ainda em utilização, do qual foi possível apenas obter o tempo de execução e utilização do sistema, observamos que, para as mesmas condições de execução do novo processo, foi superior, em cerca de 25 segundos, o que nos permite inferir que, na execução da totalidade do processo o tempo deva aumentar, continuando superior ao novo processo implementado.
Processo Tempo médio de execução Utilização da CPU Memória usada
Antigo 00:01:59.200s 87% 381 MB
Novo 00:01:35.980s 71% 165 MB
Tabela 1- Comparação dos dois processos
Além do menor tempo de execução, o novo processo exige também menos do sistema, com uma redução de 16% na utilização da CPU e menos 216 MB de memória.
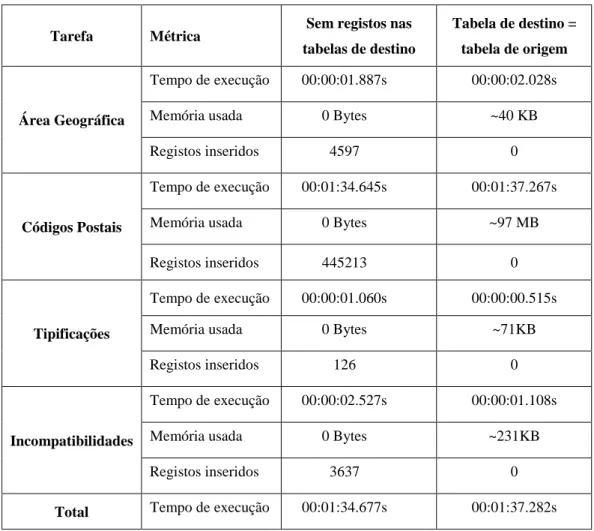
Este ganho de tempo de execução pode ser analisada no novo modelo individualmente, tarefa a tarefa. Comparando as tarefas de área geográfica e tipificações, apesar de haver um volume de dados
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 197 muito superior, o tempo que a primeira demora, mesmo sendo mais elevado, não é proporcional à diferença do volume de dados. A memória usada é inclusive inferior.
Tarefa Métrica Sem registos nas tabelas de destino
Tabela de destino = tabela de origem
Área Geográfica
Tempo de execução 00:00:01.887s 00:00:02.028s Memória usada 0 Bytes ~40 KB
Registos inseridos 4597 0
Códigos Postais
Tempo de execução 00:01:34.645s 00:01:37.267s Memória usada 0 Bytes ~97 MB Registos inseridos 445213 0
Tipificações
Tempo de execução 00:00:01.060s 00:00:00.515s Memória usada 0 Bytes ~71KB
Registos inseridos 126 0
Incompatibilidades
Tempo de execução 00:00:02.527s 00:00:01.108s Memória usada 0 Bytes ~231KB
Registos inseridos 3637 0
Total Tempo de execução 00:01:34.677s 00:01:37.282s
Tabela 2 – Resultados da execução do novo processo
Outra ilação a retirar é quanto ao processamento do lookup – quando a tabela está vazia, o tempo de processamento é muito baixo e não há registo de utilização de memória. Quando é necessário comparar registos entre as tabelas de origem e destino, o tempo de processamento e recursos utilizados é incrementado.
Tarefa Sem registos nas tabelas de destino Tabela de destino = tabela de origem Área Geográfica 0,001s 0,047s Códigos Postais 0,015s 2,761s Tipificações 0,016s 0,031s Incompatibilidades 0,078s 0,405s
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 198
7. C
ONCLUSÃOCom o caso prático podemos observar a utilidade do Data Warehouse fora do Business Intelligence, seja para tratar dados que vão servir para auxiliar o utilizador na sua interação com a aplicação, para validar o fluxo da venda ou para enviar esses dados para outros sistemas. Foi- nos possível assim identificar as vantagens deste modelo face ao anterior: a diminuição do tempo de execução do processo, a adição de validações para deteção de falhas, envio de notificações.
Obteve-se uma redução de cerca de 25 segundos na execução das mesmas tarefas, em iguais condições de execução. Esta diferença apesar de parecer irrelevante, neste cenário, em que é usada para uma aplicação com a utilização e um volume de vendas como o Portal SFA, se corresponder a indisponibilidade do sistema podem significar um elevado número de vendas não seja realizado ou não possam evoluir para outros sistemas que, em casos extremos pode obrigar a evolução manual das mesmas.
Com a ferramenta utilizada na implementação deste modelo, é-nos permitido tratar e validar os dados de forma mais fácil e intuitiva, sendo vantajoso não só para a diminuição do tempo de alocação do recurso que irá efetuar a alteração à tarefa, como para garantir que os dados que são recebidos são apenas os novos registos ou os que foram atualizados, mas também cumprem as condições exigidas nas validações. Desta forma, ao executar o processo quando as tabelas já estão preenchidas não há indisponibilidade do sistema, visto que só são inseridos os registos inexistentes no destino, sendo todo o processo de tratamento e comparação de registos efetuado na staging área, quando no modelo anterior era eliminada a totalidade dos registos das tabelas de destino e novamente carregados.
O envio de notificações quando configurado para funcionar no momento de falha de uma atividade, permite reduzir o tempo de indisponibilidade do sistema e a mais fácil e rápida deteção da anomalia.
R
EFERÊNCIASBarker, Robert M., et al. (2009), 'Why is my sales force automation system failing?' Business Horizons, 52 (3), 233-41.
Buehrer, Richard E., Senecal, Sylvain, e Bolman Pullins, Ellen (2005), 'Sales force technology usage - reasons, barriers, and support: An exploratory investigation', Industrial Marketing Management, 34 (4), 389-98.
Cui, Y. e Widom, J. (2003), 'Lineage tracing for general data warehouse transformations', The VLDB Journal, 12 (1), 41-58.
Guoling, Lao e Ying, Tang (2005), 'The application of data warehousing in e-business environment and case study', Proceedings of the 7th international conference on Electronic commerce (Xi'an, China: ACM).
Inmon, William (1992), 'Building the Data Warehouse.' PRISM Tech Topic, Vol. 1 (No. 1).
Jourdan, Zack, Rainer, R. Kelly, e Marshall, Thomas E. (2008), 'Business Intelligence: An Analysis of the Literature', Information Systems Management, 25 (2), 121- 31.
12.ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI’2012) 199
Muñoz, Lilia, Mazón, Jose-Norberto, e Trujillo, Juan (2009), 'Automatic generation of ETL processes from conceptual models', Proceeding of the ACM twelfth international workshop on Data warehousing and OLAP (Hong Kong, China: ACM).
Negash, Solomon (2004), 'Business Intelligence', Communications of the Association for Information Systems, 13, 177-95.
Panos, Vassiliadis, Alkis, Simitsis, e Spiros, Skiadopoulos (2002), 'Conceptual modeling for ETL processes', Proceedings of the 5th ACM international workshop on Data Warehousing and OLAP (McLean, Virginia, USA: ACM).
Power, D. J. (2003), 'A Brief History of Decision Support Systems', (DSSResources.COM, World Wide Web, http://DSSResources.COM/history/dsshistory.html,
version 2.8: DSSResources.COM).
Santos, Ricardo Jorge e Bernardino, Jorge (2009), 'Optimizing data warehouse loading procedures for enabling useful-time data warehousing', Proceedings of the 2009 International Database Engineering & Applications Symposium (Cetraro - Calabria, Italy: ACM).
Schneider, Michel (2008), 'A general model for the design of data warehouses', International Journal of Production Economics, 112 (1), 309-25.
Shin, Bongsik (2002), 'A case of data warehousing project management', Information & Management, 39 (7), 581-92.
Simitsis, A., et al. (2010), 'Optimizing ETL workflows for fault-tolerance', Data Engineering (ICDE), 2010 IEEE 26th International Conference on, 385-96.
Simitsis, Alkis, et al. (2008), 'Natural language reporting for ETL processes', Proceeding of the ACM 11th international workshop on Data warehousing and OLAP (Napa Valley, California, USA: ACM).
Skoutas, Dimitrios e Simitsis, Alkis (2006), 'Designing ETL processes using semantic web technologies', Proceedings of the 9th ACM international workshop on Data warehousing and OLAP (Arlington, Virginia, USA: ACM).
Watson, H. J. e Wixom, B. H. (2007), 'The Current State of Business Intelligence', Computer, 40 (9), 96-99.