Universidade de Aveiro 2008
Departamento de Matemática
Ângela Marlene Pires
Universidade de Aveiro 2008
Departamento de Matemática
Ângela Marlene Pires
da Cruz
Análise Bayesiana de Séries Temporais
Dissertação apresentada à Universidade de Aveiro para cumprimento dos requisitos necessários à obtenção do grau de Mestre em Matemática, realizada sob a orientação científica da Profª. Doutora Isabel Maria Simões Pereira, Professora Auxiliar do Departamento de Matemática da Universidade de Aveiro
o júri
presidente Prof. Dra. Andreia Oliveira Hall
Professora associada da Universidade de Aveiro
Prof. Dra. Maria Eduarda da Rocha Pinto Augusto da Silva
agradecimentos Á minha orientadora Professora Doutora Isabel Pereira, pela sua disponibilidade, atenção e ajuda em todas as dúvidas que surgiram ao longo do trabalho.
Aos meus pais e irmãos pelo amor e apoio emocional que me deram ao longo da minha vida académica.
palavras-chave Análise Bayesiana, metodologia de Gibbs, WinBUGS, grupos de manchas solares.
resumo O presente trabalho propõe-se analisar a metodologia bayesiana para alguns modelos de séries temporais nomeadamente os autoregressivos, os de médias móveis, os inteiros autoregressivos e os inteiros de médias móveis. É feita uma apresentação dos fundamentos Bayesianos, sua aplicação aos modelos referidos, uma exemplificação para cada modelo utilizando um software adequado e uma aplicação da metodologia a dados de grupos de manchas solares de Palehua.
keywords Bayesian analysis, Gibbs methodology, WinBUGS, groups of sunspots.
abstract This study proposes to examine the Bayesian approach for some models the of time series including the autoregressive, the moving average, the integer autoregressive and the integer of moving averages. Consists in a presentation of the bayesian methodology, its application to the refered models, an exemplification for each model using an appropriate software and an application of the methodology to the sunspots of Palehua data.
Índice
Lista de Figuras v
Lista de Tabelas vii
Glossário de abreviaturas ix
Notação xi
1
Fundamentos da Estatística Bayesiana 3
1.1 Introdução ... 3
1.2 Distribuições a priori ... 5
1.3 Inferência Bayesiana ... 7
1.3.1 Estimação pontual ... 7
1.3.2 Estimação por regiões ... 8
1.3.3 Testes de hipóteses ... 9
1.4 Predição ... 10
1.5 Métodos Computacionais ... 11
2 Análise Bayesiana de alguns modelos lineares de séries temporais 15
2.1 Processos autoregressivos ... 16
2.1.1 Inferência bayesiana para processos AR(1) ... 17
2.1.2 Inferência bayesiana para processos AR(p) ... 23
2.1.3 Previsão ... 27
2.2.1 Inferência bayesiana para processos MA(1) ... 32
2.2.2 Inferência bayesiana para processos MA(q) ... 35
2.2.3 Previsão ... 38
2.2.4 Exemplo de um processo de médias móveis usando o WinBUGS ... 39
3 Análise Bayesiana de alguns modelos de contagem 43
3.1 Operação thinning ... 44
3.2 Processos auto-regressivos de valor inteiro ... 45
3.2.1 Inferência bayesiana para processos INAR (1) de Poisson ... 47
3.2.2 Inferência bayesiana para processos INAR(1) geométrica ... 50
3.2.3 Inferência bayesiana para processos INAR (2) de Poisson ... 52
3.2.4 Inferência bayesiana para processos INAR (2) geométrica ... 55
3.2.5 Previsão ... 57
3.2.6 Exemplo de um processo inteiro autoregressivo de Poisson utilizando WinBUGS………. 59
3.3 Processos de médias móveis de valor inteiro ... 62
3.3.1 Inferência bayesiana para processos INMA(1) de Poisson ... 64
3.3.2 Inferência bayesiana para processos INMA(1) geométrica ... 66
3.3.3 Inferência bayesiana para processos INMA(2) de Poisson ... 68
3.3.4 Inferência bayesiana para processos INMA(2) geométrica ... 70
3.3.5 Previsão ... 72
4 Análise de grupos de manchas solares de Palehua 75
Conclusão e Discussões 81
Anexo A - Dados utilizados ao longo do trabalho 83
Anexo B - Dados das manchas solares 89
Anexo C - Códigos do R e do WinBUGS 91
Lista de Figuras
2.1 Comportamento da série Yt para processo autoregressivo………... 29
2.2 Gráficos das densidades marginais a posteriori dos parâmetros do modelo autoregressivo de primeira ordem da série Yt………. 30
2.3 Comportamento da série Yt para processo de médias móveis………. 39
2.4 Gráficos das densidades marginais a posteriori dos parâmetros do modelo de médias móveis de primeira ordem da série Yt………. 41
3.1 Comportamento da série Yt para processo inteiro autoregressivo………... 60
3.2 Gráficos das densidades marginais a posteriori dos parâmetros do modelo autoregressivo inteiro de primeira ordem da série Yt……….. 61
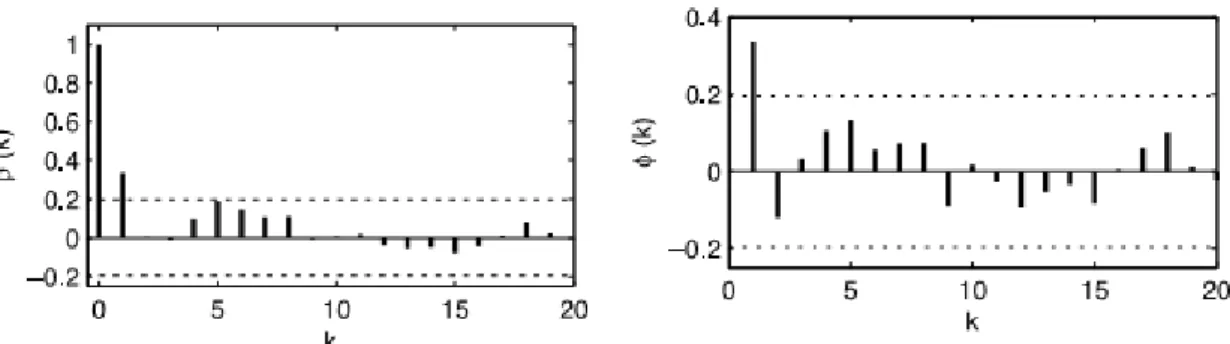
4.1 Número de Grupos de manchas solares semanais entre 1990 e 1991………….. 76 4.2 Funções de autocorrelação e autocorrelação parcial amostrais……… 77 4.3 Gráficos das distribuições marginais a posteriori dos parâmetros do modelo
Lista de Tabelas
2.1 Medidas descritivas da série Yt para o processo autoregressivo………... 28
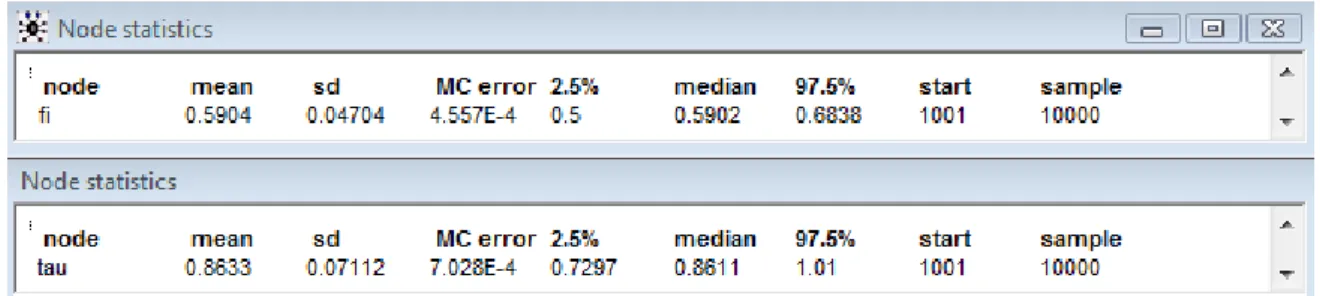
2.2 Output do WinBUGS com as estimativas dos parâmetros do modelo
autoregressivo de primeira ordem da série Yt………...
30
2.3 Medidas descritivas da série Yt para o processo de médias móveis …... 39
2.4 Output do WinBUGS com as estimativas dos parâmetros do modelo de
médias móveis de primeira ordem da série Yt……….. 40
3.1 Medidas descritivas da série Yt para o processo inteiro autoregressivo ….. 59
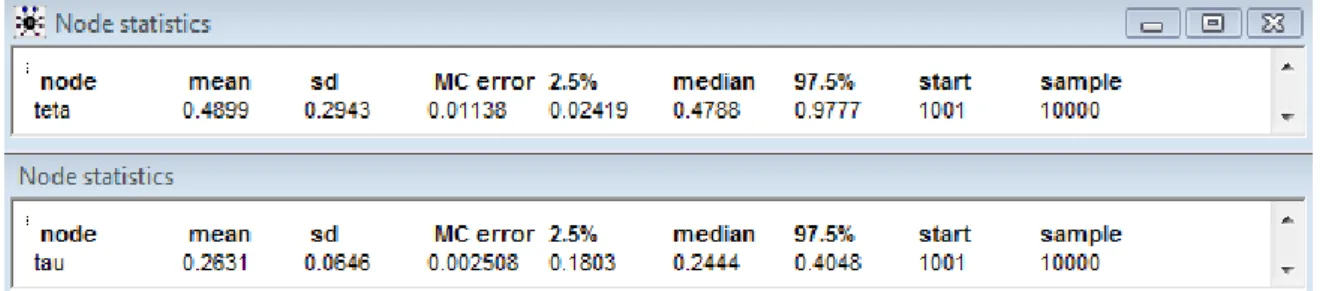
3.2 Output do WinBUGS com as estimativas dos parâmetros do modelo
autoregressivo inteiro de primeira ordem da série Yt………... 61
4.1 Medidas descritivas da série de grupos de manchas solares ……… 77
4.2 Output do WinBUGS com as estimativas dos parâmetros do modelo
INAR (1) para o numero de grupos de manchas solares ………..
78
Glossário de abreviaturas
AR Autoregressivo com suporte em R MA Média móvel com suporte em RARMA Autoregressivo média móvel com suporte em R
CODA Convergence Diagnosis and Output Analysis Software for Gibbs Sampling Output
INAR Autoregressivo com suporte em Z INMA Média móvel com suporte em Z
MCMC Método de Monte Carlo via cadeias de Markov v.a. Variável aleatória
f.g.p. Função geradora de probabilidade
Notação
( )
θ
h Distribuição a priori do parâmetro θ
(
y)
h
θ
| Distribuição a posteriori do parâmetro θ dado y(
yt |yt−1)
Introdução
O estudo de séries temporais é um tema que tem tido grande interesse para matemáticos, economistas e muitos outros profissionais de diversas áreas. Em todas as áreas, um conhecimento prévio da evolução das variáveis em estudo fornece uma maior eficácia na tomada de decisões. A análise destas séries pode ser feita utilizando a metodologia clássica de modelação e previsão mas recentemente há uma outra metodologia que tem tido um crescente interesse: a metodologia bayesiana.
Este trabalho tem portanto como objectivo uma abordagem da metodologia bayesiana na modelação e previsão de alguns modelos séries temporais. Os modelos aqui abordados são modelos autoregressivos (AR), modelos de médias móveis (MA), modelos inteiros autoregressivos (INAR) e modelos inteiros de médias móveis (INMA). A inferência para os parâmetros e as aplicações são feitas com base no Amostrador de Gibbs.
O Capitulo 1 é destinado aos fundamentos utilizados neste trabalho, apresenta-se a inferência bayesiana e os métodos de simulação e controle de convergência. O Capitulo 2 destina-se a análise dos modelos autoregressivos e de médias móveis como definido por Broomeling (1982). No Capitulo 3 descreve-se a metodologia bayesiana para os modelos inteiros autoregressivos e inteiros de médias móveis.
Capítulo 1
Fundamentos da Estatística Bayesiana
1.1
Introdução
A análise Bayesiana de dados é uma alternativa importante aos procedimentos clássicos de modelação, estimação e previsão de dados, que tem tido uma crescente aplicação em problemas de várias áreas. Consiste num procedimento genérico de inferência a partir de dados, utilizando modelos probabilísticos para descrever variabilidade em quantidades observadas ou descrever graus de incertezas em quantidades sobre as quais se quer compreender (geralmente os parâmetros dos modelos ou funções destes parâmetros).
Considera-se o vector aleatório Y =
(
Y1,Y2,KYn)
, uma sua observação(
)
nn R
y y y
y= 1, 2,K ∈ e uma quantidade de interesse desconhecida θ. Se Θ é o espaço de possíveis valores de θ, então pode-se considerar que
{
Fθ :θ
∈Θ}
denota a família(paramétrica) de modelos para Y . A informação de que se dispõe sobre θ pode ser representada probabilisticamente por h
( )
θ
e por h(
y|θ
)
a distribuição amostral de ycondicionada a θ. Observada y e de acordo com um simples resultado da Teoria de Probabilidades (Teorema de Bayes), a função densidade de probabilidade que define a relação entre y e θ, é dada por
e então
(
)
( )
(
)
( )
.(
1.1.2)
| | y h y h h y hθ
=θ
×θ
O denominador h
( )
y representa a distribuição marginal de y e supondo que θ é contínuo obtém-se através do integral( )
y h(
θ, y)
dθ h(
y|θ)
h( )
θ dθ.(
1.1.3)
h =∫
=∫
× Note que em(
1.1.2)
,( )
y h 1, que não depende de θ, funciona como uma constante normalizadora de h
(
θ
|y)
.Para um valor fixo de y , a função h
(
y|θ
)
fornece a informação amostral de cadaum dos possíveis valores de θ enquanto h
( )
θ
é chamada distribuição a priori de θ. Estas duas fontes de informação, a priori e amostral, são combinadas levando a distribuição aposteriori de θ, h
(
θ
|y)
. Assim, pode-se escrever a expressão(
1.1.2)
da seguinte forma(
θ
|y)
h( )
θ
h(
y|θ
)
.(
1.1.4)
h ∝ ×
Isto é tem-se:
distribuição a posteriori ∝ distribuição a priori × distribuição amostral, onde ∝ denota proporcionalidade.
É intuitivo que a probabilidade a posteriori de um particular conjunto de valores de
θ será pequena se h
( )
θ
ou h(
y|θ
)
for pequena para este conjunto. Em particular, seatribuirmos probabilidade a priori igual a zero para um conjunto de valores de θ então a probabilidade a posteriori será zero, qualquer que seja a amostra observada.
Suponha-se agora que é pretendida uma actualização da inferência, ou seja, a observação y é obtida em k fases (y1,y2,…,yk). Na primeira fase, a distribuição a
(
θ
|y1)
h( )
θ
h(
y1 |θ
)
.(
1.1.5)
h ∝ ×
Quando se observa y2, segunda fase, a informação a priori de θ é agora p
(
θ
| y1)
, pelo que a distribuição a posteriori é obtida do seguinte modo:(
θ
|y1,y2)
h(
θ
|y1) (
h y2 |θ
)
.(
1.1.6)
h ∝ ×
Substituindo agora h
(
θ
| y1)
pela expressão(
1.1.5)
tem-se:(
θ
|y1,y2)
h( )
θ
h(
y1|θ
) (
h y2 |θ
)
.(
1.1.7)
h ∝ × ×
Procedendo de forma sucessiva, na fase k tem-se:
(
θ |y1,y2,...,yn 1,yn)
h(
θ |y1,y2,...,yn 1)
h(
yn |θ)
.(
1.1.8)
h − ∝ − ×
Pelo que se pode concluir que a ordem em que as observações são processadas pelo teorema de Bayes é irrelevante e permite a actualização da distribuição a posteriori a medida que a informação amostral é disponibilizada.
Esta metodologia apresenta algumas dificuldades nomeadamente na escolha da distribuição a priori e na obtenção da distribuição a posteriori. A propósito destas dificuldades são apresentadas de seguida diferentes formas de especificação da distribuição
a priori.
1.2
Distribuições a priori
A utilização da informação a priori em inferência Bayesiana requer a especificação de uma distribuição a priori para o parâmetro de interesse θ. Esta distribuição deve
representar, probabilisticamente, o conhecimento que se tem sobre θ antes da realização do estudo.
A partir deste conhecimento pode-se definir uma família paramétrica de densidades, isto é, considera-se que a distribuição a priori de θ pertence a uma família de distribuições. Os parâmetros indexadores desta família de distribuições são chamados
Geralmente a abordagem em que se considera uma família de distribuições facilita a análise e o caso mais importante é o das a priori’s conjugadas. Nesta perspectiva, a escolha da distribuição a priori que incorpore a informação sobre θ deve ser feita através da família conjugada1 da distribuição h
(
y|θ
)
pois isso permite que as distribuições apriori e a posteriori pertençam à mesma classe de distribuições. Assim a actualização do
conhecimento que se tem de θ envolve apenas uma mudança nos hiperparâmetros.
Quando não existe informação objectiva sobre θ ou quando se espera que a informação a priori é vaga devem ser utilizadas distribuições a priori não informativas. A primeira ideia apresentada por Bayes e Laplace é de que no caso de não haver informação
a priori suficiente, devem ser considerados todos os possíveis valores de θ como
igualmente prováveis, isto é, utilizar uma distribuição a priori uniforme. Contudo, esta escolha pode originar algumas dificuldades técnicas visto que se o intervalo de variação de
θ for ilimitado então h
( )
θ
=c(constante positiva c) e a distribuição é imprópria:( )
=∞∫
Θhθ
dθ
.Outra dificuldade pode surgir caso
φ
=Ψ( )
θ
seja uma reparametrização não linearmonótona de θ. Pelo teorema de transformação de variáveis h
( )
φ
é não uniforme.Jeffreys (1961) propôs uma classe de a priori’s não informativas invariantes a reparametrizações. Utilizando a medida de informação esperada de Fisher sobre θ, a
priori não informativa de Jeffreys tem função de densidade dada por:
( )
[
( )
]
1/2 θ θ I h ∝ , onde( )
(
)
∂ ∂ = 2 | | ln θ θ θ E θ hY I Y .1 Se F =
{
h(
y|θ)
:θ∈Θ}
é uma classe de distribuições amostrais então uma classe de distribuições P éSe θ for um vector paramétrico então
( )
( )
1/2θ
θ I
h ∝ onde I
( )
θ
é o determinanteda matriz de informação de Fisher I
( )
θ =[
I(
θi,θj)
]
.Em geral esta regra conduz a distribuições impróprias, uma vez que
∫
( )
≠1Θh
θ
dθ
;contudo isto só levanta problemas se a distribuição a posteriori também for imprópria pelo que é necessário certificar que a distribuição a posteriori é própria antes de fazer qualquer inferência.
Uma opção para se obter os parâmetros de modo a que a distribuição seja não informativa é determinar os valores dos hiperparâmetros tais que Var
( )
θ
→+∞.1.3
Inferência Bayesiana
A distribuição a posteriori de um parâmetro θ compreende toda a informação probabilística a respeito deste parâmetro e o gráfico da sua função de densidade2 a
posteriori é a melhor forma de traduzir qualitativamente o comportamento distribucional
(
y)
h
θ
| de descrição do processo de inferência. Todavia, é de grande utilidade resumir a informação da distribuição a posteriori através de medidas de localização, dispersão e forma distribucional. Qualquer medida de localização a posteriori (média, mediana, moda) permitem estimar pontualmente o parâmetro θ.1.3.1
Estimação pontual
A escolha das estimativas na perspectiva bayesiana depende da forma da distribuição a posteriori.
A moda a posteriori é dada por:
( )
ˆ| max(
|)
.(
1.3.1.1)
:
ˆ h
θ
y hθ
yNão é necessário o cálculo do integral dado em
(
1.1.3)
pois é suficiente conhecer a distribuição a posteriori a menos de uma constante de proporcionalidade para determinar a moda e isso facilita a sua utilização como medida de localização.A medida mais utilizada é a média a posteriori que é θˆ=E
[
θ |y]
, onde[
]
∫
(
)
Θ = | , | θ θ θ θ y h y d E i i i=1,2,...k.(
1.3.1.2)
A mediana a posteriori é
θ
ˆ=(
θ
ˆ1,θ
ˆ2,...,θ
ˆk)
definida por(
)
(
)
, 1,2,..., .(
1.3.1.3)
2 1 | ˆ 2 1 | ˆ k i y P y P i i i i = ≤ ≥ ≥ ≥ θ θ θ θA escolha da melhor estimativa baseia-se na relevância de cada uma destas quantidades para o problema e nas facilidades de cálculo.
1.3.2
Estimação por regiões
A principal restrição da estimação pontual é que, quando se estima um parâmetro através de um único valor numérico toda a informação presente na distribuição a posteriori é resumida através desse número. É importante também associar alguma informação sobre a precisão da especificação dessa quantidade numérica. Para tal é importante a estimação por regiões que contenham a maior parte da informação probabilística a posteriori.
Diz-se que R( y) é uma região de credibilidade para θ de grau γ se e só se
( )
(
)
(
)
( )(
1.3.2.1)
. | | θ θ γ θ∈ =∫
≥ y R d y h y y R PQualquer região de credibilidade é definida numericamente e admite uma interpretação probabilística e directa.
Visto que existe uma infinidade de regiões de credibilidade com o mesmo grau de credibilidade γ interessa considerar a região que compreenda todos os valores de γ mais credíveis a posteriori, ou seja,
(
1| y)
h(
2 |y)
, 1 R(y), 2 R(y).(
1.3.2.3)
h
θ
≥θ
∀θ
∈θ
∉Define-se, então, R( y) como a região de credibilidade γ com densidade a
posteriori máxima (abreviadamente região HPD – Highest Posterior Density) se
(
)
{
: |}
,(
1.3.2.4)
)
(y θ hθ y cγ
R = ∈Θ ≥
onde cγ é a maior constante tal que
( )
(
θ
∈R y | y)
≥γ
.(
1.3.2.5)
P
1.3.3
Testes de hipóteses
Considera-se o teste de hipóteses H0 :θ∈Θ0 versus H1:
θ
∈Θ1, onde0 1 =Θ−Θ
Θ . A razão das vantagens a favor de H0 é dada por:
(
)
(
)
(
|)
.(
1.3.3.1)
| | , 1 0 1 0 y P y P y H H O Θ ∈ Θ ∈ =θ
θ
Rejeita-se a hipótese nula se P
(
H0 | y)
>P(
H1| y)
⇒O(
H0,H1| y)
<1.Para analisar a influência dos dados y na alteração da credibilidade relativa de H0 e H1
compara-se a razão a posteriori
(
)
(
)
(
H y)
P y H P y H H O | | | , 1 0 10 = com a razão a priori
(
)
(
)
( )
1 0 1 0, H P H P H HO = . Tomando a razão destes quocientes, tem-se o que se designa por Factor de Bayes a favor de H0 :
( )
(
)
(
,)
.(
1.3.3.1)
| , 1 0 1 0 H H O y H H O y B =Este factor representa o peso relativo da evidência contida nos dados a favor de uma das hipóteses em causa. Se B
( )
y for muito grande ou muito pequeno relativamente àunidade tem-se evidência estatística muito forte nos dados a favor de H0 ou H1
A própria consideração de um problema de testes de hipóteses, é já uma indicação de algum tipo de informação a priori, provavelmente vaga, e isso não pode deixar de originar restrições ao uso de distribuições não informativas. A inconveniência destas acentua-se quando correspondem a distribuições impróprias visto que a indeterminação na sua definição se estende ao factor de Bayes.
Para tornear esta dificuldade decorrente do uso de distribuições impróprias, Key e
al (1999) sugerem uma série de medidas ajustadas do factor de Bayes, nomeadamente o
uso de factor de Bayes parciais, factor de Bayes intrínsecas, factor de Bayes fraccionais, entre outros.
1.4
Predição
Assim como na estatística clássica, também na estatística bayesiana por vezes a inferência sobre os parâmetros do modelo escolhido não é a última finalidade, mas um meio que possibilita a predição de observações futuras.
Dadas observações de um vector aleatório Y com distribuição h
(
y|θ
)
, pretende-sepredizer um vector aleatório Y~ com distribuição amostral dependente de θ. Então a distribuição preditiva a posteriori é dada por:
(
|)
.(
1.4.1)
, | | ~ ~ θ θ θ h y d y y h y y h∫
= Caso se verifique a independência entre y e y~ condicionado em θ, é possível reescrever a equação anterior como:
(
|)
.(
1.4.2)
| | ~ ~ θ θ θ h y d y h y y h∫
= Portanto, h
(
θ
|y)
é a distribuição a posteriori de θ em relação a y (que já foi observado) mas é a priori de θ em relação a ~y (que ainda não foi observado).1.5
Métodos Computacionais
Como foi visto anteriormente, a inferência sobre o parâmetro θ, é feita através da distribuição a posteriori com base no cálculo de probabilidades e igualmente em esperanças.
Muitas quantidades de interesse passam pela necessidade do cálculo de integrais do tipo:
( ) (
|)
.(
1.5.1)
∫
Θ θ θ θ h y d gEm geral só é conhecida h
(
θ
|y)
a menos de uma constante de proporcionalidade e então estes cálculos representam uma dificuldade, uma vez que nem sempre se consegue obter expressões explícitas para os integrais em causa. Existem alguns métodos baseados em aproximações numéricas e analíticas que podem aproximar estes integrais. Nos métodos analíticos destacam-se a aproximação da distribuição a posteriori a uma Normal multivariada (Walker, 1986 ou 1969) e o método de Laplace (Tierney e Kadane, 1986). Nos métodos de integração numérica evidencia-se a quadratura iterativa (Naylor e Smith, 1982). Outra alternativa é a utilização de métodos aproximados baseados em simulações para obtenção destes integrais, nomeadamente os métodos de Monte Carlo. Neste trabalho somente se tratam os métodos de Monte Carlo.1.5.1
Método de Monte Carlo Ordinário
Este método permite obter uma aproximação do integral:
( )
[
|]
∫
( ) (
|)
.(
1.5.1.1)
Θ = θ θ θ θ y g h y d g EO método consiste em simular uma amostra aleatória de dimensão N, θ1,θ2,...,θN
da distribuição h
(
θ
|y)
, calcular g( ) ( )
θ1 , gθ2 ,...,g( )
θN e usar a média amostral como umaaproximação do valor esperado de
(
1.5.1.1)
, isto é,∑
Nque tem uma convergência quase certa pela lei dos grandes números3. Alem disso, a precisão desta aproximação pode ser medida pelo erro padrão de Monte Carlo
(
)
( )
( )
.(
1.5.1.3)
1 1 1 2 1 2 1 1 − −∑
=∑
= N i N i i i g N g N Nθ
θ
1.5.2
Método de Monte Carlo via cadeias de Markov
Um método com muita relevância para o cálculo das estimativas bayesianas é o método de Monte Carlo via cadeias de Markov (MCMC). A ideia ainda é obter uma amostra da distribuição a posteriori e calcular estimativas amostrais de características desta distribuição. A diferença é a construção de um processo estocástico que seja fácil de simular e cuja distribuição estacionária convirja para a distribuição de interesse no problema. O processo estocástico utilizado é a cadeia de Markov cuja distribuição de equilíbrio é a que se pretende simular.
O algoritmo de Metropolis-Hastings garante a convergência da cadeia de Markov para a distribuição de equilíbrio, que neste caso é a distribuição a posteriori. Uma vertente particular deste algoritmo é o método de amostragem de Gibbs que se baseia num resultado probabilístico em que, se a distribuição a posteriori for positiva em Θ1×...×Θkcom Θ i
suporte da distribuição de θi, =i 1,...,k, então h
(
θ
|y)
é determinada exclusivamente pelo conjunto das suas distribuições condicionais completas h(
θi |θ−i,y)
, i=1,...,k onde(
i i k)
i θ θ θ θ
θ− = 1,..., −1, +1,..., .
Em termos práticos, o algoritmo de Gibbs pode ser especificado pelos seguintes passos,
1. Inicializar o contador de iterações i=0 e especifique um valor inicial
(
(0) (0))
2 ) 0 ( 1 ) 0 ( , ,..., k θ θ θ θ = . 3Seja
{
Y1,...,Yt}
uma sucessão de variáveis aleatórias i.i.d. e defina-se∑
= = Nt N Yt S 1 e N S N N Y = 1 . Então,
2. Para i=1,....l, gerar novos valores θ(i) a partir de ( −i 1) θ e assim sucessivamente gerando os valores: ) ( 1 i θ a partir de h
(
ki x)
i i ,. ,..., , | 2( 1) 3( 1) ( 1) 1 − − − θ θ θ θ ) ( 2 i θ a partir de h(
θ2|θ1(i),θ3(i−1),...,θk(i−1),.x)
M ) (i k θ a partir de h(
θk |θ−(ik),.x)
Quando é obtida a convergência, ou seja, quando se aproxima da condição de equilíbrio, então o vector gerado nessa iteração θ(i) pode ser considerado uma realização
de valores de θ com distribuição h
(
θ
|y)
.Resultados associados as cadeias de Markov (ver Gilks et al, 1996) permite concluir que, quando t→∞, θ(t) =
(
θ1(t),θ2(t),...,θk(t))
tende em distribuição para umvector cuja função de densidade de probabilidade conjunta é h
(
θ
|y)
e o estimador da média dos parâmetros a posteriori é( )
E[
g( )
y]
g t t i i | 1 1 ) ( θ θ →∑
= ,para qualquer função g
( )
• , onde E[
g( )
θ
|y]
representa o valor esperado de g( )
θ
emrelação à distribuição a posteriori h
(
θ
|y)
.Os métodos de MCMC são uma óptima ferramenta para resolução de muitos problemas práticos na análise Bayesiana. Porém, algumas questões relacionadas à convergência nestes métodos ainda merecem bastante pesquisa.
Entretanto, uma questão que pode surgir é “Quantas iterações deve ter o processo de simulação para garantir que a cadeia convirja para o estado de equilíbrio?”. Como a cadeia não é inicializada na distribuição estacionária, uma prática comum é usar um período de aquecimento (Gilks et al., 1996). A cadeia passa por l+m iterações, sendo as primeiras l iterações iniciais descartadas. Espera-se que depois deste período de
de equilíbrio; a amostra resultante de tamanho m, será uma amostra da distribuição de
equilíbrio. Para eliminar uma possível autocorrelação dos valores gerados seleccionam-se a partir do período de aquecimento as observações espaçadas de um valor k (espaçamento de amostragem).
Para avaliar a convergência dos métodos de MCMC usam-se alguns critérios que existem na literatura. As técnicas mais populares são as Geweke (1992) que sugere métodos baseados em séries temporais, Raftery e Lewis (1992) que apresentam fórmulas que relacionam a dimensão da cadeia de Markov a ser construída, o espaçamento e a dimensão da amostra a ser utilizada e Gelman e Rubin (1992) que usa resultados baseados na análise de variância clássica para duas ou mais cadeias simuladas com valores iniciais diferentes. As técnicas de Geweke, Raftery-Lewis, Gelman-Rubin e outras estão implementadas no pacote CODA (Best el al, 1996) executável no freeware R.
Capítulo 2
Análise Bayesiana de alguns modelos lineares
de séries temporais
Uma série temporal, também designada por série cronológica, é uma sucessão de observações feitas sequencialmente ao longo do tempo, onde a ordem de recolha desempenha um papel extremamente importante. Ou, por outras palavras, uma série temporal é uma sequência de dados obtidos em intervalos de tempo, igualmente espaçados, durante um período específico. Em geral denota-se essa dependência do tempo por t e designa-se por Yt a t -ésima observação da série temporal.
A maioria das análises económicas envolve séries temporais. Então é importante ter boas técnicas para a análise de modelos de séries temporais. A importância da metodologia Bayesiana em séries temporais tem aumentado rapidamente ao longo da última década, explicada pela facilidade de implementação computacional. Esta é, sem dúvida, alimentada por uma cada vez maior valorização das vantagens que implica a inferência bayesiana. Além disso, o paradigma bayesiano é particularmente natural para previsão, tendo em conta todos os parâmetros ou mesmo modelo de incerteza.
temporais. Esta abordagem é aplicada aos modelos autoregressivos (AR) e modelos de médias móveis (MA).
2.1
Processos autoregressivos
Seja um processo estocástico
{
Yt : =t 1,2,...}
. Um modelo linear auto-regressivo deordem p , abreviadamente AR
( )
p (do inglês Autoregressive), é aquele cujo valor correntet
y é expresso como uma combinação linear de seus p valores passados yt−1,yt−2,...,yt−p e
de um ruído branco εt. Um modelo autoregressivo pode, então, ser escrito da seguinte
forma: t p t p t t t y y y y =φ1 −1+φ2 −2 +K+φ − +ε , t =1,2,K,n,
(
2.1.1)
onde φ1, φ2 ,K, φp são números reais (com φpdiferente de zero) e εt é um processo ruído
branco, com media µε =0 e variância 2
ε
σ .
Utilizando o operador atraso tem-se:
(
2)
,(
2.1.2)
2 1 t t p p t B B B y y =φ
+φ
+K+φ
+ε
ou(
)
t t p p B y B Bφ
φ
ε
φ
− − − = − 1 2 2 K 1 , t=1,2,Kn.(
2.1.3)
Designando( )
p p B B B B = −φ
−φ
− −φ
Φ 1 1 2 2 K , que é denominado por polinómio autoregressivo de ordem p, obtém-se
( )
B yt =εt.(
2.1.4)
Φ
Neste contexto um conceito importante é o de estacionariedade. Um processo de séries temporais estacionário é um processo cuja distribuição é estável ao longo do tempo no seguinte sentido: se se fizer uma análise de qualquer colecção de variáveis aleatórias na sequência e deslocar-se essa sequência k períodos de tempo, a distribuição deve permanecer inalterada. Especificamente a média e a variância do processo são constantes ao longo do tempo e a covariância entre yt eyt+k depende somente da distância entre dois
correlação entre yt eyt+k também somente depende de k. Portanto um processo AR
( )
p éestacionário se todas as raízes do polinómio autoregressivo de ordem p, Φp
( )
B, estiverem fora do círculo unitário. Em particular para p=1, temos que Θ( )
B =1−φ
1B=0 implica que1
1
φ
=
B conduzindo a condição de estacionariedade
φ
1 <1.Ao contrário da abordagem clássica, a análise Bayesiana de um modelo AR
( )
p nãoexige a estacionariedade dos processos. Como salientado por Zellner (1971) o pressuposto de estacionariedade de um processo AR
( )
p pode ser considerado como um pressuposto aser avaliado em vez de uma restrição necessária.
2.1.1
Inferência bayesiana para processos
AR(1)Considera-se o processo autoregressivo de primeira ordem AR
( )
1 :t t
t y
y =φ1 −1 +ε , t=1,2,K,n,
(
2.1.1.1)
onde
φ
1 é um número real diferente de zero e εt é um processo ruído branco gaussiano, com media µε =0 e variância 2ε
σ .
Sob estas condições, a função verosimilhança de
φ
1 eσ
com base nas observações é dada por(
)
(
)
,(
2.1.1.2)
2 1 exp 1 | , 2 1 1 1 2 1 − − ∝∑
= − n t t t n y y y lφ
σ
σ
σ
φ
onde y(
y1,y2,...,yn)
'= é a série temporal,
φ
1 eσ
são os parâmetros desconhecidos epressupõe-se que é conhecida a primeira observação, y0.
i) Usando a distribuição a priori não informativa de Jeffreys
No que se refere à informação prévia sobre
φ
1 eσ
, assuma-se que pouco se sabe(
1,)
1,(
2.1.1.3)
σ
σ
φ
∝h
com −∞<
φ
1 <∞ e 0<σ <∞. Então, usando o teorema de Bayes, a distribuição aposteriori para os parâmetros é dada por
(
)
(
)
.(
2.1.1.4)
2 1 exp 1 | , 2 1 1 1 2 1 1 − − ∝∑
= − + n t t t n y y y hφ
σ
σ
σ
φ
Para obter a distribuição marginal a posteriori para
φ
1 é necessário integrar(
3.1.1.4)
em ordem aσ
,(
)
(
)
(
)
.(
2.1.1.5)
2 1 exp 1 | , | 2 1 1 1 2 1 1 1∫
∫
∑
− − = = = − +φ
σ
σ
σ
σ
σ
φ
φ
y h y d y y d h n t t t n É claro que(
)
2 1 1 1∑
= − − n t t t yy
φ
é independente deσ
, pelo que considera-se(
y y)
C n t t t − =∑
= − 1 2 1 1φ
. Desta forma o integral dado em(
3.1.1.5)
pode ser reescrito do seguinte modo(
)
.(
2.1.1.6)
2 1 exp 1 | 1 2 1∫
− = +σ
σ
σ
φ
y C d h nEfectuando uma mudança de variável
2 1 2 2 2 1 = ⇒ = w C w C
σ
σ
e dw w C d 3/2 2 1 2 2 1 − − =σ
, tem-se:(
)
( )
( ( ) ) ( )( )
( 1)2 2 2 1 2 1 2 1 2 1 2 1 2 1 1 2 2 1 exp 2 2 2 1 exp 2 | n n n n n C dw w w C C dw w C C w y h + − + + − +∫
∫
∝ = =φ
. Visto que( )
( )∫
+ dw w w n 2 2 1 exp2 1 2 é uma constante em relação a 1
φ
, tem-se(
|)
(
)
.(
2.1.1.7)
2 1 2 1 1 2 1 n n t t t n y y C y h − = − − − = ∝∑
φ
φ
Mas
(
)
(
)
[
(
) (
)
]
(
)
(
)
(
)(
)
(
) (
)
∑
(
)
∑
∑
∑
∑
∑
∑
∑
∑
= − = − = − = − − − = − = − = − − − = − − − = − − + − = − + − = = − − + − + − = − + − = − + − = − n t t n t t n t t t n t t t t t n t t n t t t n t t t t t n t t t t t n t t t y s n y y y y y y y y y y y y y y y y y y y y 1 2 1 2 1 1 2 1 2 1 2 1 1 1 2 1 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 2 1 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 2 1 1 ˆ ) 1 ( ˆ ˆ 0 ˆ ˆ 2 ˆ ˆ ˆ ˆ ˆ ˆφ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
4 4 4 4 4 3 4 4 4 4 4 2 1 onde∑
(
)
= − − − = n t t t y y n s 1 2 1 1 2 ˆ 1 1 ˆφ
e∑
∑
= − = − = n t t n t t t y y y 1 2 1 1 1 1 ˆφ
estimador deφ
1 pelo método dosmínimos quadrados. Então a expressão dada em
(
2.1.1.7)
é substituída por(
)
(
)
(
)
( ) , ˆ ) 1 ( ˆ ) 1 ( | 2 1 1 1 2 1 2 1 1 2 2 1 2 1 2 1 1 2 2 1 + − − = − − = − − − + − = − + − = ∝∑
∑
n n t t n n t t n y s n y s n C y hφ
φ
φ
φ
φ
(
2.1.1.8)
pelo que se pode verificar que distribuição marginal a posteriori para
φ
1 é uma t-Student univariada com n−1 graus de liberdade.Do mesmo modo a distribuição marginal a posterior para
σ
é pode ser obtida integrando(
2.1.1.4)
em ordem aφ
1,(
)
(
)
(
)
(
)
(
)
= − − − − = = − + − − = = − − = =∫
∑
∑
∫
∑
∫
∑
∫
= − = − + = − + = − + 1 1 2 1 2 1 2 1 1 2 1 2 1 2 2 1 1 1 2 1 2 1 1 2 2 1 1 2 1 1 1 2 1 1 1 , ˆ ˆ 2 exp ) 1 ( 2 1 exp 1 ˆ ) 1 ( 2 1 exp 1 2 1 exp 1 | , | φ σ φ φ φ σ σ σ φ φ φ σ σ φ φ σ σ φ σ φ σ d y N da nucleo y s n d y s n d y y d y h y h n t t n t t n n t t n n t t t n 4 4 4 4 3 4 4 4 4 2 1(
)
( )(
ˆ)
. 2 1 exp ) 1 ( 2 1 exp 1 ˆ 2 exp 2 1 2 1 2 1 1 1 2 1 1 2 2 1 2 1 1 2 1 2 1 1 2 1 1 2 1 2 ) 1 ( 2 2 1 1 − − = − − ∝ = − − =∑
∫
∑
∑
∑
= − + − − − = − = − = − − − + n t t t n n n t t n t t n t t s n n y y s n d y y y eφ
σ
σ
σ
σ
φ
φ
φ
σ
π
σ
π
σ
σ
σ 4 4 4 4 4 4 3 4 4 4 4 4 4 2 1Logo a distribuição marginal a posteriori para
σ
2 é uma distribuição gama invertida deparâmetros 1 2− n e
(
)
2 1 1 1 2 1∑
= − − n t t t y yφ
.ii) Usando a distribuição a priori conjugada
Uma outra abordagem é a utilização de distribuições a priori conjugadas e aqui utiliza-se o parâmetro 12
σ
τ
= , que é designado por precisão, em vez do parâmetroσ
2. Esta opção deve-se ao facto de ser mais prático considerar uma distribuição a priori gama para o parâmetroτ
do que uma distribuição gama invertida paraσ
2. Então, a funçãoverosimilhança dada na equação
(
2.1.1.2)
pode ser rescrita da seguinte forma:(
)
(
)
.(
2.1.1.9)
2 exp | , 2 1 1 1 2 1 − − ∝∑
= − n t t t n y y y lφ
τ
τ
τ
φ
Esta verosimilhança sugere uma distribuição a priori normal para
φ
1 condicionado aτ
e uma distribuição a priori gama paraτ
, ou seja,tal que
(
)
[
(
)
]
, | ~(
,)
(
2.1.1.10)
2 exp | 12 1 2 1 1φ
µ
φ
τ
µ
τ
τ
τ
τ
φ
N h − − ∝( )
τ
τ
α 1exp{
βτ
}
,τ
~(
α
,β
)
(
2.1.1.11)
Gama h = − −onde
µ
é a média eτ
a medida de precisão em(
2.1.1.10)
,α
eβ
em(
2.1.1.11)
são conhecidos. Logo a distribuição a priori conjugada é dada por(
φ
1,τ
)
h(
φ
1 |τ
) ( )
hτ
, h =(
)
[
(
)
2]
.(
2.1.1.12)
2 exp , 2 1 2 1 1 + − − ∝τ
−τ
φ
µ
β
τ
φ
α hVisto que se está a trabalhar com a classe das a priori’s conjugadas para os parâmetros, a distribuição a posteriori conjunta dos parâmetros também é normal-gama, e podem-se encontrar os parâmetros a posteriori.
Assim, a distribuição a posteriori conjunta, calculada de acordo com a equação
(
1.1.4)
é dada por(
)
(
)
2(
)
.(
2.1.1.13)
2 exp | , 2 1 1 1 2 1 2 1 2 1 − + + − − ∝∑
= − − + n t t t n y y y hφ
τ
τ
τ
φ
µ
β
φ
αIntegrando
(
2.1.1.13)
em ordem aτ
, a distribuição marginal a posteriori paraφ
1 é dada por(
)
∫
(
)
∫
(
)
∑
(
)
− + + − − = = = − − +τ
φ
β
µ
φ
τ
τ
σ
τ
φ
φ
α d y y d y h y h n t t t n 2 1 1 1 2 1 2 1 2 1 1| , | exp 2 2 . Suponha-se(
)
(
)
− + + − =∑
= − 2 1 1 1 2 1 2 n t t t y yC
φ
µ
β
φ
e como C é uma constante no integral então(
)
.(
2.1.1.14)
2 exp | 2 1 2 1∫
− = − +τ
τ
τ
φ
α d C y h nEfectuando uma mudança de variável
C w w C 2 2 = ⇒
τ
=τ
e dw C dτ
= 2 tem-se:(
)
=∫
( )
(
−)
=∫
( )
(
−)
− + + − + − + − + , exp 2 2 1 2 exp 2 | 2 1 2 1 2 1 2 2 1 2 2 1 2 1 w w dw C dw C w C w y h n n n n α α α αφ
e visto que∫
( )
w + −(
−w)
dw n exp 2 2 2 1 2αpode ser vista como uma constante em relação a
φ
1(
|)
(
)
2(
)
;(
2.1.1.15)
1 2 1 2 2 1 1 1 2 1 1 2 1 2 1 − − + − = − − − + − − + + − = ∝∑
α αφ
β
µ
φ
φ
n n t t t n y y C y hpelo que, após algumas transformações pode-se verificar que a distribuição marginal a
posteriori para
φ
1 é uma t-Student com n+2α graus de liberdade.Ainda, integrando
(
2.1.1.13)
em ordem aφ
1, a distribuição marginal a posterior paraτ
é(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
2.1.1.16)
2 exp exp 2 2 exp | , | 1 2 1 1 1 2 1 2 1 2 1 2 1 1 1 2 1 2 1 2 1 1∫
∑
∫
∑
∫
− + − − − = = − + + − − = = = − − + = − − + φ φ µ φ τ τβ τ φ φ β µ φ τ τ φ τ φ τ α α d y y d y y d y h y h n t t t n n t t t n Para simplificar(
)
(
)
= + + + − + = = + − + + − = − + −∑
∑
∑
∑
∑
∑
∑
= = − = − = − = − = = − n t t n t t n t t n t t n t t n t t n t t t y y y y y y y y 1 2 2 1 1 1 1 2 1 2 1 1 2 1 1 1 1 1 2 2 1 2 1 2 1 1 1 2 1 2 1 2 2µ
µ
φ
φ
φ
µ
µφ
φ
φ
µ
φ
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
= = − = − = − = − = − = − = = − = − = − + + + − + + + + + − + = = + + + + − + = n t t n t t n t t n t t n t t n t t n t t n t t n t t n t t n t t y y y y y y y y y y y 1 2 2 2 1 1 2 1 2 1 1 1 1 1 2 1 1 1 2 1 1 2 1 1 2 2 1 1 2 1 1 1 2 1 1 2 1 1 1 2 1 1 2 1 µ µ µ φ µ φ µ φ µ φ∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
= = − = − = − = − = − = = − = − = − = − + − − + + − + = = + + + − + + − + = n t t n t t n t t n t t n t t n t t n t t n t t n t t n t t n t t y y y y y y y y y y y 1 2 1 2 1 1 1 2 1 2 1 1 1 1 1 2 1 1 2 2 2 1 1 2 1 2 1 1 1 1 1 2 1 2 1 1 1 1 µ µ φ µ µ µ φ Representando∑
∑
∑
= = − = − − + − = n t t n t t n t t y y y V 1 2 1 2 1 1 12
µ
é possível rescrever(
2.1.1.16)
na forma(
)
(
)
(
)
(
2.1.1.17)
2 exp 2 exp exp 2 exp 1 1 exp exp | 2 1 2 2 1 2 1 2 1 2 1 1 1 1 1 2 1 2 1 2 + − = − − = = − + + − + − ∝ − + − + = − = − = − − +∫
∑
∑
∑
V V d V y y y y h n n n t t n t t n t t nβ
τ
τ
τ
τβ
τ
φ
τ
µ
φ
τβ
τ
τ
α α αentão
τ
tem uma densidade gama com parâmetros 2 1 2 + +α
n e 2 V +β
.2.1.2
Inferência bayesiana para processos
AR(p
)
Considerando agora o processo autoregressivo de ordem p dado pela equação
(
2.1.1)
, a sua função verosimilhança é obtida na forma(
)
(
...)
,(
2.1.2.1)
2 1 exp 1 | , 2 1 1 1 2 − − − − ∝∑
= − − n t p t p t t n y y y y lφ
φ
σ
σ
σ
φ
ou na forma matricial, supondo Y =
φ
Z +ε
t,(
)
(
) (
)
.(
2.1.2.2)
2 1 exp 1 | , ∝ − 2 −φ
' −φ
σ
σ
σ
φ
y y Z y Z l ni) Usando a distribuição a priori não informativa de Jeffreys
Conhecidas as observações y0,y−1,...,y1−p e usando a distribuição a priori não
informativa (Zellner, 1971) dada por
(
2.1.1.3)
com −∞<φ
1,φ
2,...φ
p <∞ e 0<σ <∞, então pelo teorema de Bayes, a distribuição a posteriori para os parâmetros(
φ
φ
φ
p)
φ
= 1, 2,..., eσ
é(
)
(
)
,(
2.1.2.3)
2 1 exp 1 | , 2 1 2 2 1 1 2 1 − − − − − ∝∑
= − − − + n t p t p t t t n y y y y y hφ
φ
φ
σ
σ
σ
φ
K ou(
)
(
) (
)
.(
2.1.2.4)
2 1 exp 1 | , ∝ +1 − 2 −φ
' −φ
σ
σ
σ
φ
y y Z y Z h nIntegrando
(
2.1.2.4)
em ordem aσ
e efectuando alguns cálculos análogos ao caso dos autoregressivos de primeira ordem, a distribuição marginal a posteriori paraφ
é dada por(
|y)
[
(
y Z) (
' y Z)
]
n2 .(
2.1.2.5)
hφ
∝ −φ
−φ
− Mas(
) (
)
(
) (
)
(
)
[
]
[
(
)
]
(
) (
) (
)
(
)
(
ˆ)
(
ˆ)
, ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ' ' 2 ' ' ' ' ' 'φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
− − + = = − − + − − = − − − − − − = = − + − − + − = − − = Z Z vs Z Z Z y Z y Z Z y Z Z y Z Z Z y Z Z Z y Z y Z y S onde(
) (
)
v n p p n Z y Z y s = − − − − = ˆ ˆ , '2
φ
φ
eφ
ˆ é o estimador deφ
pelo método de mínimosquadrados. Então
(
)
[
(
) (
)
]
(
)
(
)
(
)
(
)
(
)
(
)
2 2 ' ' 2 ' ' 2 2 ' ' 2 2 ' ˆ ˆ ˆ ˆ ˆ ˆ | p v p v n n s Z Z v Z Z vs Z Z vs Z y Z y y h + − + − − − − − + ∝ + − − = = + − − ∝ − − ∝φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
φ
Logo a distribuição marginal a posteriori para
φ
é uma t-Student p-variada com v grausde liberdade e parâmetro de localização
φ
ˆ.Ainda, integrando
(
2.1.2.4)
em ordem aφ
, a distribuição marginal a posteriori paraσ
é(
)
(
ˆ) (
ˆ)
,(
2.1.2.6)
2 1 exp 1 | ∝ + − 2 −φ
' −φ
σ
σ
σ
y y Z y Z h v pe logo a distribuição marginal a posterior para
σ
2 é uma distribuição gama invertida deparâmetros 2 2 − + p v e
(
φ
ˆ) (
φ
ˆ)
2 1 ' Z y Z y− − .ii) Usando a distribuição a priori conjugada
Utilizando a abordagem de Broomeling (1982) que utiliza a família de distribuições conjugadas pode-se observar que a forma da função verosimilhança dada na equação
(
2.1.2.1)
sugere uma distribuição a priori normal paraφ
e uma gamaτ
, ou seja,(
φ
,τ
)
h(
φ
|τ
) ( )
hτ
,(
2.1.2.7)
h = tal que(
)
[
(
) (
)
]
, | ~(
,( )
)
(
2.1.2.8)
2 exp | 2 ' −1 − − − = P N P hφ
τ
τ
pτ
φ
µ
φ
µ
φ
τ
µ
τ
( )
τ
τ
α 1exp{
βτ
}
,τ
~(
α
,β
)
(
2.1.2.9)
Gama h = − −onde os hiperparâmetros
µ
, P,α
eβ
são conhecidos, comµ
∈ p,α
>0,β
>0R e P uma
Assim, a distribuição a posteriori conjunta, calculada de acordo com o teorema de Bayes é dada por
(
)
[( ) ][
(
) (
)
]
,(
2.1.2.10)
2 exp | , 2 2 1 1 ' 1 + − − − = + + − − − D C A A C A y hφ
τ
τ
n α pτ
φ
φ
onde A=P+( )
aij , C =Pµ
+( )
cj , D P y C A C n t t 1 ' 1 2 ' 2 − = − + + =β
µ
µ
∑
,( )
aij é matriz(
p×p)
com o ij-ésimo elemento t j n t i t ij y y a − = −∑
= 1e
( )
cj é vector(
p×1)
com o j-ésimoelemento t j n t t j y y c − =
∑
= 1 .Integrando
(
2.1.2.10)
em ordem aτ
, a distribuição marginal a posteriori paraφ
é dada por(
)
(
) (
)
[
]
( ) ,(
2.1.2.11)
1 | 2 2 1 ' 1 n p D C A A C A y h + + − − + − − ∝ αφ
φ
φ
então
φ
tem uma densidade t-Student com n+2α graus de liberdade, localização A−1Ce matriz precisão
(
2)
−1+ AD
n
α
.Ainda, integrando
(
2.1.2.10)
em ordem aφ
, a distribuição marginal a posterior paraτ
é(
)
[( ) ] ,(
2.1.2.12)
2 exp | 2 2 1 − ∝ + − D y hτ
τ
n ατ
então
τ
tem uma densidade gama com parâmetros 2 2α
+ n e 2 D .É de registar que quer admitindo a priori de Jeffreys ou conjugada, as distribuições marginais a posteriori são conhecidas pelo que facilmente se determinam as estimativas bayesianas dos parâmetros.