II
Leonardo Augusto Casillo
Metodologia para adaptação de microarquiteturas
microprogramadas soft-core à uma ISA padrão:
Estudo do Impacto sobre a complexidade de hardware
para o padrão MIPS
Natal, RN, julho de 2013
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE- UFRN
CENTRO DE TECNOLOGIA
–
CT
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA
E DE COMPUTAÇÃO
Metodologia para adaptação de microarquiteturas
microprogramadas soft-core à uma ISA padrão:
Estudo do Impacto sobre a complexidade de hardware
para o padrão MIPS
Leonardo Augusto Casillo
Orientador: Prof. Dr. Ivan Saraiva Silva
III UFRN / Biblioteca Central Zila Mamede.
Catalogação da Publicação na Fonte.
Casillo, Leonardo Augusto.
Metodologia para adaptação de microarquiteturas microprogramadas
soft-core à uma ISA padrão: estudo do impacto sobre a complexidade de hardware para o padrão MIPS. / Leonardo Augusto Casillo. – Natal, RN, 2013.
122 f.: il.
Orientador: Prof. Dr. Ivan Saraiva Silva.
Tese (Doutorado) – Universidade Federal do Rio Grande do Norte. Centro de Tecnologia. Programa de Pós-Graduação em Engenharia Elétrica e de Computação.
1. RISP - Processadores - Tese. 2. MIPS - Tese. 3. ISA - Tese. 4. Engenharia Elétrica e de Computação - Tese. I. Silva, Ivan Saraiva. II. Universidade Federal do Rio Grande do Norte. III. Título.
V
Agradecimentos
Este não é apenas o texto final após um doutorado de 5 anos, mas um capítulo que se encerra de um sonho e parte de um projeto de vida que se iniciou em 1998, após a primeira aula do curso de engenharia de computação e ao final do discurso de motivação do saudoso coordenador Prof. Marcelo Mariano, quando tive a certeza de que queria seguir a vida acadêmica. Sou grato a todos os que me ajudaram, incentivaram e torceram por mim, e a todos os professores e profissionais que contribuíram com minha educação desde o ensino fundamental no Colégio Maristela, ensino médio no Inst. Maria Auxiliadora, graduação na UnP-Natal, mestrado e doutorado na UFRN. Não poderei listar aqui o nome de todos, mas de igual modo não posso deixar de manter impresso os meus profundos agradecimentos a algumas pessoas especiais que contribuíram diretamente para que este momento fosse possível.
Agradeço a Deus pelo dom da vida, por ter me dado força, paciência, saúde e motivação quando foi necessário. Por mais que tenha tido algumas faltas, a religião e religiosidade foram extremamente importantes nesta caminhada. Um agradecimento especial ao Padre Lucas, que me acompanha desde minha primeira comunhão.
Imagino que o sonho de quase todo pai era ter um filho doutor. Esta até era uma meta, mas a descoberta de não suportar ver sangue me fez procurar outros caminhos. Mas, desculpem a sinceridade, doutor é quem tem doutorado. Então, a meus pais Francisco e Cristina Casillo, que dedicaram sua vida para me dar a melhor saúde e educação possível, ofereço este título, todo o meu amor, carinho e gratidão, embora palavras não sejam suficientes para agradecer por tudo.
VI Estudei muito na minha graduação, me esforcei ao máximo, mas sempre exigi que esta dedicação fosse uma via de mão dupla. Admito também que não a pessoa mais fácil para se conviver. Talvez por isso tenha discutido com quase todos os meus professores. Minhas desculpas e agradecimentos aos professores Aarão, Alan, Antônio, Oscar e demais por todos os ensinamentos e conselhos durante minha jornada acadêmica. E foi em uma destas brigas que ganhei uma orientadora e amiga. Professora Nádja Santiago, muito deste título eu devo a você. Muito obrigado por tudo.
Nádja também me apresentou a seu orientador após o término de meu TCC. E sem nunca ter me visto anteriormente, me aceitou como aluno de mestrado. E mesmo após algumas dificuldades e tribulações, novamente me aceitou como aluno de doutorado. Novas dificuldades, afastamento de ambos para cidades diferentes, mas ainda assim assumiu os riscos de continuar sendo meu orientador. Portanto, divido esta conquista e agradeço ao Prof. Ivan Saraiva por confiar em mim e por permitir e me ajudar na concretização deste objetivo.
Agradeço também a todos os coordenadores e colegas das instituições de ensino em que estive como professor: UFRN, FAL, FATERN e UERN, onde a troca de experiências e convivência profissional reforçou ainda mais minha paixão pela sala de aula. Em 2009 ingressei como professor efetivo da UFERSA / Mossoró, e encarei o desafio de conciliar as pesquisas com atividades de ensino. Agradeço aos coordenadores do curso durante este período, professores Judson e Danniel, e ao corpo docente que compreendeu minha situação, dando suporte e apoio para concluir meu trabalho.
Neste período tive muitos alunos. Pela carga de trabalho pesada, nem sempre pude corresponder em sala de aula às expectativas dos alunos e ministrar as disciplinas da melhor maneira possível. O meu agradecimento especial aos meus orientandos de TCC e iniciação científica Álamo, Dênis, Julyana, Cadu, Wilka e Valter. O lado gratificante é constatar que alunos podem se tornar amigos.
VII
Resumo
No meio acadêmico, é comum a criação de processadores denominados didáticos, voltados para práticas de disciplinas de hardware na área de Computação e que podem ser utilizados como plataformas em disciplinas de softwares, sistemas operacionais e compiladores. Muitas vezes, tais processadores são descritos sem uma ISA padrão, o que exige a criação de compiladores e outros softwares básicos para prover a interface hardware/software dificultando sua integração com outros processadores e demais dispositivos. Utilizar dispositivos reconfiguráveis descritos em uma linguagem do tipo HDL permitem a criação ou modificação de qualquer componente da microarquitetura, ocasionando a alteração das unidades funcionais do caminho de dados que representa a parte operativa de um processador, bem como da máquina de estados que implementa a unidade de controle do mesmo conforme surgem novas necessidades.
Em particular, os processadores RISP possibilitam a alteração das instruções da máquina, permitindo inserir ou modificar instruções, podendo até mesmo se adaptar a uma nova arquitetura. Este trabalho aborda como objeto de estudo dois processadores didáticos soft-core descritos em VHDL com diferentes níveis de complexidade de hardware adaptados a uma ISA padrão a partir de uma metodologia proposta sem provocar aumento no nível de complexidade do hardware, ou seja, sem o acréscimo significativo da área em chip, ao mesmo tempo em que o seu nível de desempenho na execução de aplicações permanece inalterado ou é aprimorado. As modificações também permitem afirmar que, além de ser possível substituir a arquitetura de um processador sem alterar sua organização, um processador RISP pode alternar entre diferentes conjuntos de instrução, o que pode ser expandido para alternância entre diferentes ISAs, permitindo a um mesmo processador se tornar uma arquitetura híbrida adaptativa, passível de ser utilizada em sistemas embarcados e ambientes multiprocessados heterogêneos.
VIII
Abstract
In academia, it is common to create didactic processors, facing practical disciplines in the area of Hardware Computer and can be used as subjects in software platforms, operating systems and compilers. Often, these processors are described without ISA standard, which requires the creation of compilers and other basic software to provide the hardware / software interface and hinder their integration with other processors and devices. Using reconfigurable devices described in a HDL language allows the creation or modification of any microarchitecture component, leading to alteration of the functional units of data path processor as well as the state machine that implements the control unit even as new needs arise.
In particular, processors RISP enable modification of machine instructions, allowing entering or modifying instructions, and may even adapt to a new architecture. This work, as the object of study addressing educational soft-core processors described in VHDL, from a proposed methodology and its application on two processors with different complexity levels, shows that it’s possible to tailor processors for a standard ISA without causing an increase in the level hardware complexity, ie without significant increase in chip area, while its level of performance in the application execution remains unchanged or is enhanced. The implementations also allow us to say that besides being possible to replace the architecture of a processor without changing its organization, RISP processor can switch between different instruction sets, which can be expanded to toggle between different ISAs, allowing a single processor become adaptive hybrid architecture, which can be used in embedded systems and heterogeneous multiprocessor environments.
IX
Sumário
Capítulo 1 – Introdução ... 1
1.1. Motivação ... 3
1.2. Objetivos ... 6
1.3. Estrutura do documento ... 7
Capítulo 2 – Fundamentação Teórica ... 8
2.1. Processadores Acadêmicos ... 8
2.2. Processadores Reconfiguráveis ... 13
2.3. Processadores RISP ... 17
2.4. Processadores soft-core ... 18
2.5. Processadores microprogramados ... 19
2.6. Arquitetura MIPS ... 20
2.7. Processadores MIPS ... 27
2.8. Considerações ... 30
Capítulo 3 – Estado da arte ... 32
3.1. Tradução Binária ... 33
3.2. Considerações ... 39
Capítulo 4 – Microarquiteturas microprogramadaspropostas ... 40
4.1 Processador CABARE ... 40
4.1.1. Reconfiguração de instruções ... 45
4.1.2. Exemplo de funcionamento ... 49
4.2. Processador CRASIS ... 51
4.2.1. Modos de funcionamento ... 54
4.2.2. Exemplo de funcionamento ... 58
4.2.3. Unidade de Reconfiguração ... 61
4.2.4. Exemplo de reconfiguração ... 63
4.3. Interface com a placa DE2 ... 63
Capítulo 5 – Metodologia para adaptação a uma ISA padrão ... 65
5.1. Registradores ... 67
5.2. Unidade Lógica e Aritmética ... 68
X
5.4. Comunicação com a memória ... 72
5.5. Instruções load/store ... 73
5.6. Considerações ... 73
Capítulo 6 – Aplicações e Resultados ... 74
6.1. Adaptação 1: Processador DIMBA ... 74
6.1.1. Registradores ... 75
6.1.2. ULA ... 75
6.1.3. Instruções de Branch ... 76
6.1.4. Comunicação com a memória ... 77
6.1.5. Instruções de Load/Store ... 77
6.1.6. Reconfiguração ... 78
6.1.7. Análise Comparativa ... 83
6.2. Adaptação 2: Processador CRASIS II ... 85
6.2.1. Registradores ... 85
6.2.2. ULA ... 86
6.2.3. Instruções de Branch ... 86
6.2.4. Comunicação com a memória ... 87
6.2.5. Instruções de Load/Store ... 87
6.2.6. Reconfiguração ... 87
6.2.7. Análise Comparativa ... 89
6.3. Exemplo de uma aplicação ... 92
6.4. Considerações ... 95
Capítulo 7 – Conclusões e Perspectivas ... 97
7.1. Trabalhos Futuros ... 99
Referências Bibliográficas ... 101
Apêndice A - Codificação dos formatos de Instruções no MIPS-I ... 105
XI
Lista de Figuras
Figura 2.1 – Modelo de máquinas multinível ... 9
Figura 2.2 – Arquitetura MIC-1 ... 11
Figura 2.3 – Configuração básica de um FPGA ... 14
Figura 2.4 – Exemplo de um modelo de arquitetura RISP ... 17
Figura 2.5 – processador PLASMA ... 19
Figura 2.6 – Diagrama de blocos de um pipeline MIPS ... 27
Figura 2.7 –MIPS monociclo ... 27
Figura 2.8 –MIPS multiciclo ... 28
Figura 2.9 –MIPS pipeline... 29
Figura 3.1 – Mecanismo de tradução binária em dois níve ... 34
Figura 3.2 – Unidades do mecanismo de tradução binária ... 35
Figura 3.3 – Configuração de uma unidade reconfigurável da arquitetura DIM ... 38
Figura 4.1 - Arquitetura do processador CABARE ... 41
Figura 4.2 – Distribuição de memória no CABARE ... 46
Figura 4.3 – Sequência de execução de instruções reconfiguradas no CABARE ... 48
Figura 4.4 – Diagrama de blocos do processador CRASIS ... 51
Figura 4.5 – Formatos de instrução do CRASIS ... 52
Figura 4.6 – Arquitetura do processador CRASIS ... 53
Figura 4.7 – Diagrama de estados simplificado do CRASIS ... 54
Figura 4.8 – Diagrama de estados de um super-estado ... 56
Figura 4.9 – Exemplo de execução de instrução no CRASIS ... 58
Figura 4.10 – Unidade de Reconfiguração do CRASIS ... 61
Figura 4.11 – diagrama de estados de reconfiguração no CRASIS... 62
Figura 5.1 - Fluxograma de multiplicação por algoritmo de Booth ... 69
Figura 5.2 – Fluxograma de uma divisão por algoritmo de Booth ... 70
Figura 6.1 – Visão geral do processador DIMBA ... 74
Figura 6.2 – Áreas de memória do processador DIMBA ... 79
XII
Figura 6.4 – Codificação da instrução ADD ... 82
Figura 6.5 – Comparação do caminho de dados (a) CABARE x (b) DIMBA ... 83
Figura 6.6 – Visão geral do CRASIS II ... 85
Figura 6.7 – Comparação do caminho de dados (a) CRASIS I x (b) CRASIS II... 90
Figura 6.8 – Processo de simulação de um algoritmo no CABARE ... 94
XIII
Lista de Tabelas
Tabela 2.1 Formato de instruções MIPS ... 22
Tabela 2.2 Descrição das convenções de uso dos registradores do MIPS ... 24
Tabela 2.3 Conjunto de instruções MIPS-1 ... 26
Tabela 4.1 – Registradores de uso geral no CABARE ... 42
Tabela 4.2 – Operações da ULA do CABARE ... 42
Tabela 4.3 – Operações realizadas pelo processador CABARE ... 43
Tabela 4.4 – Sinais do controle do CABARE em cada instrução/tempo ... 44
Tabela 4.5 - Configuração de uma microinstrução no CABARE ... 47
Tabela 4.6 – Formatos de microinstruções do CABARE ... 48
Tabela 4.7 – Código objeto para o exemplo 1 ... 50
Tabela 4.8 – Operações realizadas pelo processador CRASIS ... 55
Tabela 4.9 – Palavra de uma microinstrução no CRASIS ... 59
Tabela 4.10 – Bits de controle do CRASIS ... 59
Tabela 4.11 – Chaves para seleção dos displays de 7 segmentos na DE2 ... 64
Tabela 6.1 – Operações da ULA do DIMBA ... 75
Tabela 6.2 – Formatos de microinstruções do DIMBA... 79
Tabela 6.3 – Formato de uma microinstrução no DIMBA ... 80
Tabela 6.4 – Síntese dos processadores CABARE e DIMBA ... 84
Tabela 6.5 – Palavra de uma microinstrução no CRASIS II ... 88
XIV
Lista de Abreviaturas
ALU – Arithmetic Logic Unit
ASIC – Application Specific Integrated Circuit ASIP – Application Specific Instruction set Processor
CABARE – Computador Acadêmico Básico com Reconfiguração CISC – Complex Instruction Set Computer
CLB – Configurable Logic Blocks CodOp – Código da Instrução
CRASIS – Computer with Reconfigurable And Selectable Instruction Set CRIS – Computer with Reconfigurable Instruction Set
CRISP – Configurable and Reconfigurable Instruction Set Processor DCM - Digital Clock Manager
DIMBA – Didactic MIPS Basic Architecture
EEPROM –Electrically-Erasable Programmable Read-Only Memory
FFUs – Fixed Functional Units
FPGAS – Field Programmable Gate Arrays FSM – Finite State Machine
HDL – Linguagens de Descrição de Hardware IOB – Input/Output Blocks
IP – Propriedade Intelectual
ISA – Instruction Set Architectures IJVM - Integer Java Virtual Machine JTAG - Joint Test Action Group
LPM_RAM – Library of Parameterized Modules RAM LUI – Load Upper Immediate
MAC – Multiplicador e Acumulador
XV MIF – Memory Initialization File
MIPS (ISA) – Microprocessor without Interlocked Pipeline Stages MIPS (Métrica) – Milhões de Instruções Por Segundo
MPSoC – Multiprocessor System On Chip MSB – Most Significative Bit
OCP – Open Core Protocol PBL – Problem-Based Learning PC – Personal Computer
PRISC – PRogrammable Instruction Set Computer
PRISM – Processor Reconfigurable through Instruction-Set Metamorphosis RFU – Reconfigurable Functional Unit
RISC – Reduced Instruction Set Computer RISP – Reconfigurable Instruction Set Processor RTL – Register Transfer Level
SoC – System on Chip SP – Stack Pointer
SPARC - Scalable Processor ARChitectures SRC – Shift Right with Carry
TIPI – Tiny Instruction Processors and Interconnect ULA – Unidade Lógica e Aritmética
US – Microssegundos (unidade)
1
Capítulo 1
–
Introdução
Desde a década de 2000 até os dias atuais, a tecnologia aplicada aos processadores está relacionada à era dos multicores [Knight, 2005]. De fato, nos últimos anos a justificativa para se adquirir um novo computador pessoal era o aumento da sua frequência de operação ou uma nova placa-mãe que suportasse maiores quantidades de memória. Com o limite de velocidade de operações praticamente estagnado em virtude das limitações físicas dos equipamentos, por exemplo, quanto à sua dissipação de calor, buscou-se a inserção de diversos núcleos para continuar com o progresso em relação ao desempenho e também continuar a movimentar o mercado financeiro quanto à venda de computadores.
Atualmente, é notório que os computadores pessoais do tipo PC (Personal
Computer) estão sendo substituídos por versões portáteis como netbooks, ultrabooks,
tablets, smartphones e demais dispositivos móveis, que suprem as necessidades de
pessoas que querem utilizar recursos simples como aplicativos para escritório e redes sociais, restando aos PCs e notebooks multicores para o nicho de mercado composto por engenheiros, cientistas e demais profissionais que requerem aplicativos que demandem maior desempenho computacional como ferramentas de desenho técnico, computação gráfica e programação.
Entretanto, os computadores não são utilizados apenas nos meios industriais e comerciais. A área acadêmica é fundamental para a pesquisa por novas formas de tecnologias e estudos para aprimoramento dos hardwares e softwares necessários para sua utilização. Em cursos como Ciência e Engenharia da Computação ou demais cursos em áreas afins de tecnologia, é fundamental que professores e estudantes conheçam o funcionamento de cada componente eletrônico que compõe a arquitetura de um computador, suas linguagens de programação em vários níveis de abstração e os
softwares básicos que proveem sua utilização, tais como compiladores e sistemas
2 para a realização de testes quanto à sua funcionalidade. Nesse sentido, muitas universidades estão propondo a seus alunos a criação de arquiteturas próprias, denominadas arquiteturas didáticas ou processadores acadêmicos.
Tais processadores são, em sua maioria, do tipo RISC (Reduced Instruction Set
Computer), e são úteis para algumas disciplinas nos cursos de graduação da área de
computação, como sistemas digitais, arquitetura de computadores, sistemas operacionais, softwares básicos, compiladores, entre outras disciplinas de hardware e
software que envolvam o projeto e construção de circuitos digitais e o suporte para o
desenvolvimento de suas aplicações.
Atualmente, estas arquiteturas podem ser facilmente descritas devido ao uso de dispositivos reconfiguráveis como FPGAS (Field Programmable Gate Arrays), que surgiram na década de 1980 [Carter et al., 1986] e hoje já está consolidada no meio acadêmico. Tais dispositivos, entre outras vantagens, permitem a descrição, simulação e síntese de circuitos digitais de qualquer nível de complexidade de hardware – desde que respeitando os limites físicos de cada dispositivo – em campo, podendo ser modificado a qualquer momento, sem a necessidade da fabricação do chip como um processador de uso geral ou um processador ASIC (Application Specific Integrated Circuit) [Compton & Hauck, 2002].
Explorar as capacidades de dispositivos reconfiguráveis impulsiona o uso de processadores implementados apenas por meio de Linguagens de Descrição de Hardware (HDL), geralmente chamados de Soft-core. Este modelo permite a projetistas e estudantes criarem novas unidades funcionais e alterar arquiteturas anteriormente criadas [Tong et al., 2006].
3 para permitir a tradução de programas desenvolvidos em linguagens de alto nível como C ou Java para a linguagem assembly adotada por cada microarquitetura e simuladores para verificar o correto funcionamento da execução de suas instruções.
Estes problemas de compatibilidade podem ser resolvidos utilizando padrões conhecidos de Arquiteturas de Conjunto de Instruções (ISA – Instruction Set
Architectures). Com a adoção de uma ISA, é possível utilizar compiladores já
desenvolvidos e inserir o processador em um ambiente MPSoC (Multiprocessor System
On Chip) [Kumar, 2005] heterogêneo de ISA única. As modificações para um
processador se adaptar ao padrão de uma ISA estão relacionadas à utilização de um conjunto de instruções específico e algumas restrições em seu caminho de dados, como a quantidade mínima de registradores e do tamanho da palavra de dados.
1.1.
Motivação
No meio acadêmico, processadores sem uma ISA padrão dificultam a sua utilização em aulas práticas, exigindo a criação de compiladores e outros softwares básicos como assemblers, loaders e linkers para prover a interface hardware/software, sendo necessária também a disseminação de tais programas para permitir a outros usuários a utilização da arquitetura. Caso contrário, será necessário escrever programas para tais arquiteturas utilizando a linguagem assembly, com os formatos e instruções específicas criadas para esta arquitetura, sem a opção de reutilização de código em outros processadores. A Computação Reconfigurável, ao propiciar a criação ou modificação de qualquer processador descrito em uma linguagem do tipo HDL, permite que o caminho de dados ou a máquina de estados que implementa a unidade de controle possam ser reescritos e alterados conforme surgem novas necessidades.
A Computação Reconfigurável é um paradigma de computação que combina a flexibilidade do software com o alto desempenho do hardware [Compton, 2002]. Por causa de suas duas principais características (desempenho e flexibilidade), dispositivos reconfiguráveis são utilizados para projetar desde um simples circuito lógico contendo apenas alguns elementos lógicos até sistemas complexos como arquiteturas SoC (System on Chip), processadores ASIC, Sistemas Embarcados ou demais arquiteturas adaptativas, não convencionais e acadêmicas.
4 [Ferlin & Pilla, 2006]. Além destas, o uso de FPGAs está em crescimento no suporte às ferramentas de ensino em disciplinas de graduação em Computação. A possibilidade de explorar o desenvolvimento de sistemas digitais em diferentes níveis de complexidade, da especificação à prototipagem, permite aos alunos uma melhor compreensão de requisitos de hardware e software.
O processo de criação de uma nova microarquitetura não precisa seguir uma metodologia específica ou conter uma ISA padrão. No entanto, embora permita uma maior liberdade de criação ao projetista de hardware, possibilitando o desenvolvimento de novos circuitos digitais ou mesmo arquiteturas não convencionais, isto dificulta a utilização destes sistemas digitais em MPSoCs ou sistemas embarcados, devido a limitações da sua compatibilidade com outros sistemas de arquiteturas.
Já em relação ao meio acadêmico, experimentos genéricos de microarquiteturas sem um padrão de instruções torna o processador um modelo isolado, necessitando de diversas adaptações de hardware e software para que tal modelo possa se comunicar com outros processadores, co-processadores ou demais componentes físicos e executar programas, além de restringir o uso de compiladores e simuladores disponíveis para arquiteturas já fundamentadas como MIPS, SPARC, ARM e x86. Dependendo da quantidade de alterações em seu caminho de dados, este pode se tornar até mesmo um novo processador e perder suas características próprias.
Duas técnicas podem ser utilizadas para minimizar este problema. A primeira é a utilização de microprogramas para a descrição de um processador Soft-Core. As arquiteturas microprogramadas fazem com que todo o ciclo de funcionamento de um processador esteja descrito em VHDL como se fosse a sequência de um programa descrito de forma estrutural. Com isso, todas as etapas de busca, decodificação, execução, salvamento e interrupção estão presentes dentro da unidade de controle do processador, que por um lado aumenta sua complexidade em hardware, mas por outro lado torna o caminho de dados do processador - unidade operativa ou Datapath - com sua estrutura preservada ou com poucas modificações caso sejam necessários incluir, remover ou alterar suas funcionalidades.
5
Set Processor). Processadores RISP podem criar ou combinar novas instruções em
tempo de execução para serem utilizadas juntamente com o conjunto de instruções de uma ISA padrão [Barat & Lauwereins, 2000]. Uma vez que os processadores didáticos foram descritos utilizando-se HDL’s, tais modificações em sua estrutura física podem ser realizadas a partir do reuso de componentes e estruturas previamente implementadas.
Este estudo propõe uma metodologia para adaptação de arquiteturas microprogramadas Soft-Core descritas em VHDL sem um padrão para uma determinada ISA, na qual são identificadas quais as alterações necessárias em suas unidades operativas para que seja possível executar as instruções pertencentes ao seu novo conjunto de instruções, sem perder suas características originais ou aumentar seu nível de complexidade de hardware. Para aplicação desta metodologia, foram utilizadas duas microarquiteturas microprogramadas descritas na linguagem VHDL, com diferentes caminhos de dados, sendo ambas adaptadas à arquitetura MIPS (Microprocessor without Interlocked Pipeline Stages) [MIPS, 2008], e utilizando o conjunto de instruções MIPS-I.
O padrão MIPS foi escolhido em virtude de sua vasta utilização acadêmica, sendo sua arquitetura RISC e suas alternativas de implementação com modos monociclo, multiciclo e pipeline utilizadas adotadas como plataformas de ensino em livros de arquitetura de computadores, como em [Patterson, 2008], que permitem transmitir as noções básicas de como um processador é projetado e implementado. Sua arquitetura possui vários níveis ascendentes de conjuntos de instruções, de acordo com o aumento de sua complexidade de hardware, incluindo as versões MIPS I a MIPS V, com versões em 32 e 64 bits [Sweetman, 2006]. Além de sua simplicidade e clareza, a arquitetura base para construção de vários simuladores, como ProcSIM [ProcSIM, 2013], MARS [MARS, 2013], WebSimple [WebSimple, 2013], SPIM [Larus, 2013], entre outros, e influenciou outras ISAs como a SPARC (Scalable Processor
ARChitectures), desenvolvida pela Sun Microsystems® [Oracle, 2013].
6 ao incluir novas unidades de execução como comparadores, multiplicadores ou operações na ULA (Unidade Lógica e Aritmética), são necessárias poucas adaptações no código de descrição de suas unidades de controle, como a inclusão de novos sinais de controle ou a criação de microprogramas que proveem o funcionamento de novas instruções com base nas unidades funcionais anexadas ou a partir da lógica de reconfiguração incorporada ao processador.
É importante ressaltar que a metodologia proposta neste trabalho não busca substituir a metodologia de ensino de arquitetura de computadores ou disciplinas correlatas, mas sim apresentar uma forma de adaptar processadores pré-existentes com estrutura genérica ou com uma determinada arquitetura a um novo padrão, preservando as características físicas originais da microarquitetura, propiciando a estudantes e pesquisadores uma nova ferramenta de auxílio durante suas práticas de ensino, além de aumentar a gama de aplicações e exploração de projetos em seus experimentos arquiteturais acadêmicos. Até o momento da finalização deste documento, não foram encontrados na literatura outros trabalhos que tenham por objetivo a adaptação de arquiteturas ou de conjuntos de instruções a uma ISA padrão utilizando dispositivos reconfiguráveis microprogramados.
1.2.
Objetivos
Esta tese consiste em apresentar uma metodologia para adaptação de processadores microprogramados para o padrão MIPS. Para tanto, foram utilizados dois processadores acadêmicos RISC genéricos microprogramados como estudos de caso para a aplicação dos passos necessários, a fim de que o novo padrão de arquitetura e o conjunto de instruções MIPS-I possam ser executados nas novas versões de suas microarquiteturas. A obtenção de tal objetivo decorre das seguintes etapas:
A partir do processador CABARE (Computador Acadêmico Básico com Reconfiguração), criar o processador DIMBA (Didactic MIPS Basic
Architecture);
A partir do processador CRASIS (Computer with Reconfigurable And
Selectable Instruction Set), criar o processador CRASIS II;
7 execução de uma aplicação sequencial com relação a quantidade de ciclos de relógio;
Mostrar como os processadores DIMBA e CRASIS II podem incorporar e executar instruções MIPS além das que foram previamente inseridas no conjunto de instruções de suas arquiteturas.
1.3.
Estrutura do documento
Os capítulos foram dispostos da seguinte forma:
Capítulo 1: este primeiro capítulo introduziu o assunto, abordou a motivação
para a realização do presente trabalho bem como os objetivos deste estudo e apresentou a organização do texto.
Capítulo 2: neste capítulo é realizada uma fundamentação teórica abordando
conceitos gerais sobre processadores reconfiguráveis, em especial processadores RISP, o que são arquiteturas microprogramadas e uma abordagem sobre o padrão MIPS e o conjunto de instruções MIPS-I.
Capítulo 3: será descrito o estado da arte sobre adaptação, conversão ou tradução entre diferentes ISA’s em hardware e software.
Capítulo 4: serão apresentadas as características básicas de dois processadores
soft-core, RISP sem uma ISA padrão.
Capítulo 5: será apresentada a metodologia utilizada para adaptar os
processadores anteriormente descritos para uma Arquitetura de Conjunto de Instruções padrão, utilizando como base a arquitetura MIPS.
Capítulo 6: apresenta os estudos de caso após as modificações propostas,
detalhando o funcionamento das novas arquiteturas e comparando as versões adaptadas com as versões originais.
Capítulo 7: são expostas as conclusões e perspectivas futuras sobre as
8
Capítulo 2
–
Fundamentação Teórica
2.
Neste capítulo são descritos alguns conceitos acerca de processadores reconfiguráveis, soft-core, microprogramados e RISP, além de abordar com mais detalhes o padrão de arquitetura MIPS e seu conjunto de instruções MIPS-I.
2.1.
Processadores Acadêmicos
Os processadores acadêmicos, também denominados processadores didáticos, são comumente desenvolvidos por alunos e professores da área de hardware de cursos de ciências e engenharia de computação, como exercícios práticos envolvendo os aspectos de arquitetura e organização de computadores ou plataformas de ensino para a execução de programas em linguagens de baixo nível e desenvolvimento de softwares básicos e simuladores. A popularização e redução dos custos de kits de desenvolvimentos em FPGAs propiciam um maior estímulo de estudantes e pesquisadores no projeto e implementação destes experimentos microarquiteturais, por meio da descrição de módulos dos processadores utilizando alguma linguagem de descrição de hardware e simulação e síntese de tais arquivos em dispositivos reconfiguráveis por meio de softwares específicos de acordo com seu fabricante, como por exemplo, o Quartus II da Altera® [Altera, 2013].
9 interna do processador, barramentos internos, sinais de controle disponíveis, tecnologias de memória e interface com o sistema de E/S. Portanto, arquiteturas de uma mesma família, como Intel® ou IBM® podem conter diferentes recursos de organização, mas manter uma compatibilidade no que tange aos conjuntos de instruções das máquinas.
Na literatura, duas abordagens se destacam quanto ao desenvolvimento de uma microarquitetura. A primeira é apresentada por [Tanenbaum, 2007], na qual um modelo de abstração em camadas ou níveis é definido para o projeto e implementação de arquiteturas de computadores. Em cada uma destes níveis, o computador pode ser programado utilizando os recursos desse nível, que pode ser compreendido como uma máquina virtual para execução de programas descritos no seu nível superior. A Figura 2.1 apresenta um modelo de máquinas multinível proposto pelo autor composto por seis níveis.
Figura 2.1 – Modelo de máquinas multinível
10 Cada nível é responsável por interpretar as instruções do nível imediatamente superior. O nível 0 é composto por circuitos lógicos que executam os programas em linguagem de máquina por meio da execução de funções lógicas simples (AND, OR, XOR, NOT, etc). No nível 1, os circuitos lógicos são agrupados a fim de formar elementos mais complexos, como a Unidade Lógica e Aritmética (ULA) e registradores, que formam uma memória local. Estes elementos são conectados formando o caminho de dados do processador (data path).
As operações podem ser controladas por um microprograma ou diretamente por
hardware, sendo o microprograma um interpretador para as instruções do nível 2, de
modo que o microprograma busca, decodifica e executa as instruções provenientes do nível 2 utilizando o caminho de dados como estrutura para realização desta tarefa. Caso seja utilizado um controle via hardware, o ciclo de funcionamento de uma instrução é realizado sem a necessidade de um programa armazenado para interpretar as funções.
O nível 2 define a interface entre o hardware e o software. Cada fabricante define uma linguagem própria, conhecida como linguagem Assembly ou linguagem de montagem, para sua estrutura de hardware construída. Esta linguagem determina o conjunto de instruções da máquina executáveis pelo processador, que deve ser documentado em manuais específicos pelo fabricante. Além dos formatos e tipos de instruções, também são definidos os tipos de dados, modelos de memória e tipos de endereçamento. Portanto, este nível define a Arquitetura do Conjunto de Instruções (ISA – Instruction Set Architecture).
O nível 3 suporta novas instruções e fornece serviços básicos para as camadas superiores, como escalonamento de processos, gerenciamento de memória, acionamento de dispositivos de E/S, interface com o usuário, etc. A partir deste nível, as camadas superiores são destinadas a programadores de sistema, enquanto as camadas inferiores destinadas a programadores de aplicação. O nível 4 tem o intuito de fornecer uma ferramenta para programadores de aplicativos de uso geral, e os programas desenvolvidos neste nível recebem o nome de montadores ou Assemblers.
11 e/ou 4 por meio de um tradutor denominado compilador ou por algum interpretador como no caso de linguagens como Java ou Python.
Os níveis 0 a 2 são os níveis mais abordados durante a disciplina de arquitetura e organização de computadores, sendo que o nível 0, por ser formado por circuitos lógicos, é visto com mais detalhes em disciplinas de circuitos lógicos / lógica digital. O nível 3 pode ser melhor abordado em disciplinas específicas de Sistemas Operacionais, enquanto que os níveis 4 e 5 são discutidos em disciplinas de Software Básico e Compiladores. Dependendo do projeto de arquitetura, a quantidade e os níveis podem variar, assim como podem ser realizadas outras abordagens para o desenvolvimento de um computador.
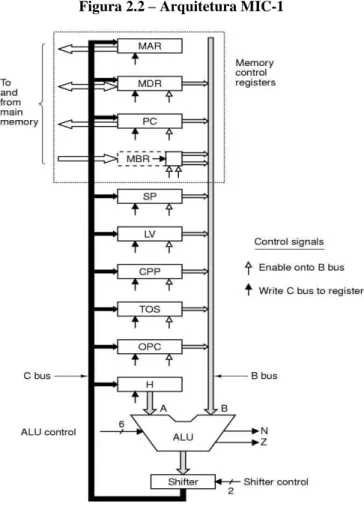
Para exemplificar sua abordagem, Tanenbaum utilizou uma máquina fictícia chamada MAC para ilustrar o conceito de microprogramação e criou a arquitetura didática multiciclo MIC, implementada em quatro versões (MIC-1, MIC-2, MIC-3 e MIC-4), dedicada a executar um subconjunto das instruções da Máquina Virtual Java chamado IJVM (Integer Java Virtual Machine). A arquitetura MIC-1 pode ser visualizada na Figura 2.2
Figura 2.2 – Arquitetura MIC-1
12 A metodologia aplicada por [Patterson, 2008] constrói um computador a partir do seu conjunto de instruções. O autor cita que a arquitetura de um computador é formado pela junção dos aspectos de organização de computadores e arquitetura do conjunto de instruções (ISA). Segundo o autor, a ISA de um computador é um nível de abstração que oferece a interface entre o nível de hardware e o software de baixo nível, responsável pela padronização dos tipos e formatos de instrução, quantidade e disposição dos bits que compõem uma instrução, tipos de operandos, quantidade de registradores necessários, modos de endereçamento e de acesso às palavras ou bytes, organização da memória, etc. O conjunto de instruções da arquitetura forma a linguagem de máquina do computador, que é a base para a construção das unidades operativa e de controle do processador.
Inicialmente são definidas quais as instruções aritméticas, lógicas, de desvio, transferência de dados, controle e de Entrada/Saída que serão utilizadas pelo computador. Adicionalmente, podem ser inseridas instruções de gerenciamento de memória, ponto flutuante e outras especiais. Após a escolha da quantidade e tipos de instruções, os componentes físicos necessários para a execução das instruções são projetados, inseridos e conectados, como por exemplo, desenvolver uma Unidade Lógica e Aritmética (ULA) para prover as instruções aritméticas presentes no seu conjunto de instruções.
Patterson utiliza como base para os conceitos de arquitetura e organização a arquitetura MIPS e o conjunto de instruções MIPS-I. Essa forma de abordagem visa explorar a interface hardware-software de modo a unir os conceitos de programação e circuitos digitais. A metodologia de Patterson sugere que, de acordo com a arquitetura do conjunto de instruções, deva ser definida uma estrutura organizacional macro, composta pelo número de unidades funcionais, sendo esta estrutura refinada para definir os componentes do caminho de dados, sua interconexão e sua unidade de controle. A arquitetura MIPS é apresentada sob três variações: monociclo, multiciclo e pipeline, que serão detalhadas adiante.
Existem outras abordagens na literatura, como por exemplo, a metodologia proposta por [Stallings, 2010], a qual utiliza estudos de caso com arquiteturas reais, como Pentium e PowerPC, para tratar os aspectos de arquitetura e organização de computadores, fazendo uma distinção entre estes.
13 baseada em problemas (PBL – Problem-Based Learning) [Martinez-Mones et al, 2005], [Dos Santos, 2007]. Na fase inicial desta abordagem, denominada etapa de situação, o aluno é apresentado a um determinado problema real, e apresentando fenômenos e objetos que o motive a adquirir novos conhecimentos técnicos para a resolução do problema. Na segunda etapa, ocorre a fundamentação teórica necessária para a resolução do problema identificado na etapa de situação, iniciando uma reflexão crítica sobre o problema aplicado. Na fase final deste ciclo, denominada etapa de realização, o aluno deve utilizar os conceitos teóricos estudados para a produção de um produto final, aproximando a teoria aprendida com a prática, e permitindo ao aluno a compreensão da realidade apresentada.
2.2.
Processadores Reconfiguráveis
Apesar desta metodologia de adaptação não necessitar de nenhuma reconfiguração no hardware do dispositivo, as microarquiteturas utilizadas neste trabalho são processadores RISP, descritos na linguagem VHDL e sintetizados em dispositivos reconfiguráveis FPGAs (Field Programmable Gate Arrays), fato este que justifica uma breve explanação sobre os conceitos e características gerais de tais processadores.
Um FPGA é um dispositivo semicondutor utilizado para o processamento de informações digitais. Foi criado pela Xilinx Inc.® [Xilinx, 2013] em 1985 como um dispositivo que programado de acordo com as aplicações de um usuário programador. Um FPGA é composto basicamente por três tipos de componentes de lógica programável: blocos de entrada e saída (IOB – Input/Output Blocks), blocos lógicos configuráveis (CLB – Configurable Logic Blocks) e chaves de interconexão (Switch
Matrix) [Brown, 1992]. Os blocos lógicos são dispostos de forma bidimensional, e as
14
Figura 2.3 – Configuração básica de um FPGA
Fonte: [Brown, 1992]
Para configurar uma FPGA deve ser especificado um diagrama esquemático do circuito ou um código-fonte em uma linguagem HDL (Hardware Description
Language) que descreve a lógica com que o dispositivo irá funcionar. Para converter
diagramas/HDL para configurações físicas em um FPGA, é necessário enviar o código-fonte por um software disponibilizado pelo fabricante. Este arquivo é transferido para o FPGA por uma interface serial JTAG (Joint Test Action Group) ou para memória externa como uma EEPROM.
Além dos recursos padrões (slices), um FPGA pode disponibilizar em seu arranjo bidimensional recursos adicionais como multiplicadores dedicados, MACs (Multiplicador e Acumulador) programáveis, blocos de memória, DCM (Digital Clock
Manager), utilizados para multiplicar ou dividir a frequência de um sinal de relógio,
microcontroladores (IBM PowerPC), e outras bibliotecas. A utilização de tais recursos embarcados possibilita otimizar a área do dispositivo e desenvolver projetos mais complexos e eficientes [Anderson, 2006]
15 diferença entre processadores reconfiguráveis é dada por características como: grau de acoplamento entre o processador e a lógica reconfigurável, tipo de instruções a serem executadas pela lógica reconfigurável, formato de codificação e passagem de parâmetros das instruções reconfiguráveis, acesso à memória por parte da lógica reconfigurável entre outras características relevantes para o desempenho de processadores reconfiguráveis [Mooler et al., 2005].
Os processadores reconfiguráveis estendem a capacidade de um processador, otimizando seu conjunto de instruções para uma tarefa específica. Com isto é obtido um aumento de desempenho e flexibilidade, ao mesmo tempo em que a área do núcleo do processador permanece inalterada [Mooler et Al., 2005]. Para fazer uma avaliação a respeito de processadores reconfiguráveis, algumas medidas básicas de avaliação são necessárias, tais como desempenho, custo e tamanho.
A medida de desempenho geralmente é associada à velocidade de execução das instruções básicas (MIPS – Milhões de Instruções Por Segundo) ou o tempo gasto em ciclos de relógio para a execução de aplicações como, por exemplo, benchmarks. O custo é geralmente analisado em termos de parâmetros como: número de pinos, área em chip, número de chips por sistema, entre outros. Com relação ao tamanho de programas e dados, este pode ser expresso através da capacidade máxima e a eficiência de ocupação do código gerado. Outras restrições como, peso, volume e consumo de potência podem ser consideradas de acordo com a aplicação.
De acordo com [Adário et al., 1997], uma arquitetura reconfigurável possui como principais metas: acréscimo de velocidade e da capacidade de prototipagem, representado pelo número de portas lógicas equivalentes, proporcionando aumento de desempenho; reconfiguração dinâmica; baixo consumo na reconfiguração; granularidade adequada ao problema, entre outros. A melhoria de desempenho de sistemas é uma das principais utilizações das arquiteturas reconfiguráveis devido a possibilidade da implementação de algoritmos complexos nos atuais processadores diretamente no hardware.
16 O primeiro processador dito reconfigurável foi denominado PRISC (PRogrammable Instruction Set Computer), em 1994 por [Razdan & Smith, 1994]. PRISC foi o primeiro a explorar na pratica a existência de uma RFU (Reconfigurable
Functional Unit) contida em um caminho de dados de um processador MIPS. Neste
processador, assim como para os demais representantes da primeira geração de processadores reconfiguráveis, verificou-se a eficiência da utilização de FPGAs para aplicações específicas, aumentando o desempenho com relação a soluções implementadas em software. O problema principal era o gargalo de comunicação entre o processador e os FPGAs e o alto tempo de reconfiguração. O fato da reconfiguração ser estática impunha a interrupção da execução para que o sistema possa ser reconfigurado.
Com a evolução da tecnologia de integração, surgiu a segunda geração de processadores reconfiguráveis, tornando possível o desenvolvimento de um sistema composto pelo processador, FPGAs e memória em um único chip, resultando no embrião do que hoje se identifica por SoC. Também foi possível o desenvolvimento de processadores utilizando-se reconfiguração dinâmica.
O processador CRISP (Configurable and Reconfigurable Instruction Set
Processor), proposto originalmente por [Barat, 2002] possui a característica de ser
configurável em tempo de desenvolvimento e reconfigurável em tempo de execução. Consiste em um processador VLIW (Very Long Instruction Word), que executa instruções compostas por operações paralelas, executadas em unidades funcionais fixas (FFUs - Fixed Functional Units) e uma unidade funcional reconfigurável.
Em 2003 surgiu a arquitetura VISC (Variable Instruction Set Communications
Architecture), apresentado por [Liu et al., 2003]. A característica que diferencia o
conjunto de instruções deste processador dos demais é a utilização de um dicionário que define o tipo de cada instrução e permite ao compilador configurar o melhor conjunto de instruções para a execução de um determinado programa.
Desde então, diversas versões de FPGAS comerciais e acadêmicos foram e estão sendo desenvolvidos. Alguns destes processadores receberam características específicas, como a possibilidade de modificar ou inserir novas instruções na máquina. Estes processadores são denominados RISP (Reconfigurable Instruction Set Processors
17
2.3.
Processadores RISP
Um processador com conjunto de instruções reconfigurável consiste em um núcleo microprocessado estendido com uma lógica reconfigurável. Este é similar a um ASIP (Application Specific Instruction set Processor), mas em vez de unidades funcionais especializadas, que contém as unidades funcionais reconfiguráveis, esta proporciona a adaptação do processador para a aplicação, enquanto o núcleo do processador fornece programabilidade em software [Barat, 2002].
[Lodi et al., 2003] classificou os Processadores com Conjunto de Instruções Reconfiguráveis RISP como um subconjunto dos processadores reconfiguráveis. Estes processadores não apresentam um custo de hardware para cada nova instrução em
hardware, mas sim um custo pré-definido em área onde a lógica reconfigurável pode ser
programada em tempo de execução [Mooler et al., 2005].
A Figura 2.4 apresenta um modelo hipotético de uma arquitetura RISP. O processador RISP executa instruções, assim como processadores comuns e ASIPs, embora a principal diferença esteja no conjunto de instruções, o qual é implementado em hardware fixo, e um conjunto de instruções reconfiguráveis implementado na lógica reconfigurável e que pode sofrer alterações durante a execução do processador [Barat 2002]. Este conjunto de instrução reconfigurável é equivalente ao conjunto de instrução especializado de um ASIP, mas com a possibilidade de modificação após o processador ter sido projetado.
Figura 2.4 – Exemplo de um modelo de arquitetura RISP
18 O custo de projeto de um microprocessador com núcleo é reduzido devido à reutilização em diversas aplicações. Em ASIPs o custo de cada nova geração vem da remodelação das unidades funcionais especializadas, que podem ser bastante elevados. Técnicas de prototipagem rápidas são essenciais para reduzir o custo e o tempo necessário para a remodelagem [Barat 2002].
2.4.
Processadores soft-core
Um processador soft-core é um microprocessador que pode ser implementado utilizando síntese lógica como, por exemplo, utilizando a linguagem de descrição de hardware VHDL. [Tong, 2006] afirma que tais modelos de processadores possuem diversas vantagens sobre processadores de propósito geral como redução de custos, flexibilidade, plataformas independentes e capacidade de renovação.
Diversos fabricantes de FPGAS disponibilizam seus produtos para uso comercial e acadêmico. Dentre estes, destacam-se os processadores Nios II, MicroBlaze, PicoBlaze e Xtensa, dos fabricantes Altera®, Xilinx® e Tensilica®, respectivamente. Além destas arquiteturas, comunidades científicas costumam disponibilizar processadores Open-Cores [Opencores, 2013], que são componentes IP (Propriedade Intelectual) que podem ser utilizadas livremente pela comunidade, para fins não lucrativos. Destacam-se os processadores OpenSPARC [OpenSPARC, 2013], LEON [Leon, 2013] e Plasma [Rhoads, 2013].
19
Figura 2.5 – processador PLASMA
Fonte: [Opencores, 2013]
O PLASMA, assim como o LEON e as versões do processador MIPS original, por possuírem seu código-fonte aberto, estão disponíveis para a comunidade científica para fins acadêmicos.
2.5.
Processadores microprogramados
Em um processador microprogramado, toda a sua lógica de sua unidade de controle é especificada através de um microprograma. Um microprograma, por sua vez é composto por uma sequência de instruções de uma linguagem de microoperação. A uma sequência de instruções em uma linguagem de microprogramação dá-se o nome de microprograma. [Tanenbaum, 2007].
20 funcional, como a operação da ULA, a codificação da seleção de multiplexadores ou a habilitação de escrita em registradores.
A vantagem de um controle microprogramado sobre uma implementação em
hardware, além da redução da complexidade, é o fato de torná-la mais simples,
compreensível e menos sujeita a erros. Em contrapartida, sua execução é mais lenta e o consumo de potência gerada pelo dispositivo é maior.
O projeto de processadores microprogramados depende da ISA que esta implementada, bem como das metas de custo e desempenho. Das implementações de processadores microprogramados, um trabalho de destaque é o de [Mihal et al., 2006], no qual foi projetado um processador sub-RISC. Este processador é uma classe de um processador ASIP, com arquitetura programável. Além disso, os autores criaram uma ferramenta para gerar um processador sub-RISC de expressões regulares. Para isso foi utilizado um framework denominado TIPI (Tiny Instruction Processors and
Interconnect), que auxilia na criação de um circuito sem a necessidade de programar
em uma linguagem HDL. Através da interpretação de autômatos, o framework gera o código HDL do circuito e o mesmo é carregado em um FPGA.
2.6.
Arquitetura MIPS
A arquitetura MIPS foi desenvolvida inicialmente como um projeto acadêmico na Universidade de Stanford em 1981 por uma equipe de doutorandos e de mestrandos chefiada por John Hennessy [Patterson & Hennessy, 2008]. Este projeto se tornou um dos principais precursores da tecnologia RISC. A arquitetura do conjunto de instruções MIPS-1 é regular, todas as instruções possuem o mesmo tamanho. Conforme [Sweetman, 2006], esta característica permitiu que seus conceitos fossem assimilados mais facilmente se comparado a arquiteturas irregulares.
21
Systems foi adquirida pela Silicon Graphics Computer Systems. Todas as revisões são
retroativamente compatíveis [Kane & Heinrich, 1991].
A arquitetura MIPS segue os princípios básicos de um projeto de hardware, para que o processador criado seja simples, eficiente, livre de falhas e de baixo custo. A representação de instruções MIPS segue um formato regular de campos, cada um com uma função específica, seguindo o princípio de que “a simplicidade é favorecida pela regularidade”. Cada instrução possui 32 bits, o mesmo tamanho de uma palavra de memória ou uma palavra de dados. Apesar de possuir um tamanho fixo, são utilizados diferentes formatos para tipos distintos de instruções.
Para alcançar o princípio de “quanto menor, mais rápido”, não são utilizadas variáveis em linguagem de montagem, prática presente em linguagens de alto nível. O MIPS utiliza 32 registradores, cada um representando uma palavra da arquitetura. Um número maior de registradores acarreta um aumento na duração do ciclo de relógio, que tornaria o sistema mais lento.
Outro princípio de projeto adotado pelo padrão MIPS é “tornar o caso comum mais rápido”, pois a utilização de operandos imediatos ocorre com tal frequência em linguagens de montagem que é preferível tratá-los como um caso comum ao invés de instruções especiais.
Os conceitos básicos relacionados à arquitetura MIPS podem ser resumidos pelas seguintes características:
execução implementada sobre um pipeline com cinco estágios;
conjunto de instruções regular, onde todas as instruções possuem comprimento fixo (32 bits);
instruções lógicas e aritméticas compostas de três operandos: fonte, alvo e destino;
32 registradores de propósito geral, cada um com 32 bits;
nenhuma instrução complexa, como gerenciamento de pilha ou operações sobre cadeias de caracteres;
22 instruções de acesso à memória exclusivas: load e store, tanto para memória principal como para dispositivos periféricos, o que força o uso do conceito de entrada e saída mapeada em memória;
espaço de endereçamento contínuo de 4GB para acesso à memória, alinhado à palavra de 32 bits, com possibilidade de acesso à palavra (32 bits), meia palavra (16 bits) ou byte (8 bits);
mapeamento de endereços virtuais para endereços reais;
código em linguagem de montagem otimizado pelo compilador, em substituição à intervenção manual ou otimização via hardware;
A estrutura de hardware não verifica dependências de instruções.
O conjunto de registradores da arquitetura MIPS é constituído por três grupos de registradores de 32 bits distintos: 32 para propósito geral, numerados de 0 a 31, dois para operações de multiplicação e divisão (HI e LO) e um contador de programa (PC). Todos os registradores de propósito geral podem ser usados como fonte ou destino de dados para instruções lógico-aritméticas, acesso à memória e controle de fluxo. A única exceção é o registrador 0 (zero), não alterável, que possui seu valor fixado em zero pelo
hardware, e utilizado como constante em operações aritméticas e de transferência de
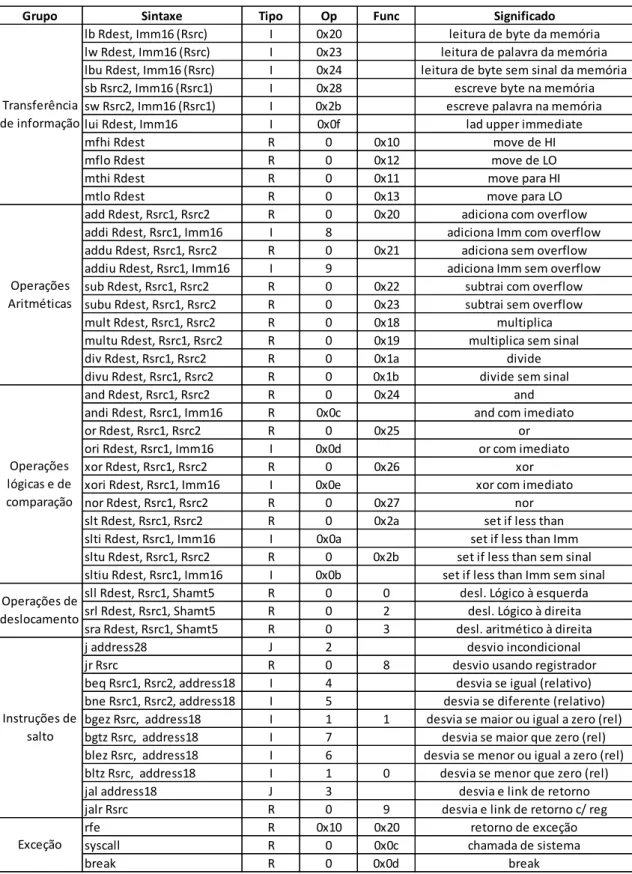
dados. Portanto, operações de leitura deste registrador sempre retornam valor zero e as de escrita são ignoradas, sendo o valor escrito descartado. O conjunto de instruções MIPS-1 divide-se em três formatos básicos, conforme descrito na Tabela 2.1:
Tabela 2.1 Formato de instruções MIPS
em que:
opc: código de operação;
rs: endereço do registrador origem;
rt: endereço do registrador alvo (origem ou destino, conforme instrução
específica);
rd: endereço do registrador destino;
23 funct: função;
imm-16: constante imediata de 16 bits;
addr-26: endereço parcial de 26 bits.
As características de cada formato podem ser resumidas como segue.
Instruções com formato R (register): inclui instruções lógicas e aritméticas com três registradores, inclusive multiplicação e divisão, instruções de deslocamento de bits, desvio baseados em registrador e instruções de exceções syscall e break. O campo funct atua como um campo adicional de 6 bits para identificação da instrução. O campo shamt é usado para indicar a quantidade de bits a ser deslocada em instruções de deslocamento de bits. Os registradores rs e rt são usados como origem de dados e rd como destino do resultado da operação;
Instruções com formato I (immediate): incluem instruções de acesso à memória (alinhado ou não), instruções lógicas e aritméticas que fazem uso de constantes imediatas e instruções de desvio condicional (branches). O registrador rs é usado como origem de dados e o rt como destino do resultado da operação. O campo imm-16 contém um valor imediato de 16
bits usado de uma de duas formas: como valor literal (positivo ou negativo)
em instruções lógicas e aritméticas ou como um inteiro com sinal (entre -32678 a +32467) indicando o deslocamento relativo a um registrador (modo de endereçamento base-deslocamento);
24 Além da classificação das instruções MIPS-I quanto ao formato, também se pode dividir o conjunto de instruções quanto à funcionalidade das instruções. Existem três classes de instruções, conforme este critério:
Classe Padrão (Standard): caracterizada pelas instruções que possuem o campo opc diferente de 0 ou 1 (zero ou um). Nesta classe enquadram-se as instruções de acesso à memória (alinhado ou não), instruções lógicas e aritméticas que fazem uso de constantes (imediatas), instruções de salto que usam modo de endereçamento pseudo-direto e instruções de desvio condicional que usam dois registradores;
Classe Especial (Special): caracterizada pelas instruções que possuem o valor 0 (zero) no campo opc. Inclui instruções lógicas e aritméticas com três registradores inclusive multiplicação e divisão, instruções de deslocamento de bits, instruções de salto baseadas em registrador e as instruções para tratamento de exceções syscall e break. O campo funct atua como campo complementar ao opc, permitindo selecionar a operação desejada;
Classe Registrador-imediato (RegImm): caracterizada pelas instruções que possuem o valor 1 (um) no campo opc. Inclui instruções de desvios condicionais (branches) que comparam valores em relação a 0 (zero), exceto as instruções blez e bgtz. O campo rt define qual o tipo de comparação a ser realizada, portanto é usado em conjunto com o campo opc para decodificar a instrução.
Embora os 32 registradores de propósito geral possam ser usados indistintamente para qualquer objetivo (com exceção de $0), existe uma convenção para o uso destes registradores em programação, com o objetivo de padronizar o desenvolvimento de software básico, como montadores, compiladores e carregadores, conforme a sequência exibida na Tabela 2.2. Estas convenções não implicam a existência de qualquer estrutura no hardware que as dê suporte a elas.
Tabela 2.2 Descrição das convenções de uso dos registradores do MIPS
Número Nome Descrição do uso
0 Zero Valor zero
1 At Reservado para uso do montador (assembler temporary) 2-3 v0-v1 Valores retornados por sub-rotinas (returned value)
25
16-23 s0-s7 Valores preservados entre chamadas de sub-rotina, devem ser restaurados após o retorno (saved)
24-25 t8-t9 Uso livre para sub-rotinas (temporaries)
26-27 k0-k1 Reservados para rotina de interrupção, usados pelo sistema operacional (kernel)
28 gp Acesso às variáveis estáticas ou externs (global pointer) 29 SP Ponteiro para área de pilha (stack pointer)
30 Fp Ponteiro para área de frame (frame pointer) 31 Ra Endereço de retorno de sub-rotina (return address)
A arquitetura pipeline de cinco estágios pressuposta como natural para a implementação do hardware de um processador MIPS inclui:
IF – estágio de busca (instruction fetch): busca a próxima instrução a ser executada;
ID – estágio de decodificação (instruction decode): realiza a decodificação da instrução e a leitura dos operandos fonte do banco de registradores; EX – estágio de execução (execution): realiza a execução da instrução ou o
cálculo de endereço quando aplicável;
MEM – estágio de acesso à memória (memory access): realiza o acesso à memória externa;
WB – estágio de escrita do resultado (write back): escrita do resultado no banco de registradores.
26
Tabela 2.3 Conjunto de instruções MIPS-1
A Figura 2.6 apresenta um diagrama esquemático simplificado de um pipeline típico do MIPS, conforme empregado para dispositivos com os MIPS R2000 e R3000.
Grupo Sintaxe Tipo Op Func Significado
lb Rdest, Imm16 (Rsrc) I 0x20 leitura de byte da memória lw Rdest, Imm16 (Rsrc) I 0x23 leitura de palavra da memória lbu Rdest, Imm16 (Rsrc) I 0x24 leitura de byte sem sinal da memória sb Rsrc2, Imm16 (Rsrc1) I 0x28 escreve byte na memória sw Rsrc2, Imm16 (Rsrc1) I 0x2b escreve palavra na memória lui Rdest, Imm16 I 0x0f lad upper immediate
mfhi Rdest R 0 0x10 move de HI
mflo Rdest R 0 0x12 move de LO
mthi Rdest R 0 0x11 move para HI
mtlo Rdest R 0 0x13 move para LO
add Rdest, Rsrc1, Rsrc2 R 0 0x20 adiciona com overflow addi Rdest, Rsrc1, Imm16 I 8 adiciona Imm com overflow addu Rdest, Rsrc1, Rsrc2 R 0 0x21 adiciona sem overflow addiu Rdest, Rsrc1, Imm16 I 9 adiciona Imm sem overflow sub Rdest, Rsrc1, Rsrc2 R 0 0x22 subtrai com overflow subu Rdest, Rsrc1, Rsrc2 R 0 0x23 subtrai sem overflow mult Rdest, Rsrc1, Rsrc2 R 0 0x18 multiplica multu Rdest, Rsrc1, Rsrc2 R 0 0x19 multiplica sem sinal div Rdest, Rsrc1, Rsrc2 R 0 0x1a divide divu Rdest, Rsrc1, Rsrc2 R 0 0x1b divide sem sinal
and Rdest, Rsrc1, Rsrc2 R 0 0x24 and
andi Rdest, Rsrc1, Imm16 R 0x0c and com imediato
or Rdest, Rsrc1, Rsrc2 R 0 0x25 or
ori Rdest, Rsrc1, Imm16 I 0x0d or com imediato
xor Rdest, Rsrc1, Rsrc2 R 0 0x26 xor
xori Rdest, Rsrc1, Imm16 I 0x0e xor com imediato
nor Rdest, Rsrc1, Rsrc2 R 0 0x27 nor
slt Rdest, Rsrc1, Rsrc2 R 0 0x2a set if less than slti Rdest, Rsrc1, Imm16 I 0x0a set if less than Imm sltu Rdest, Rsrc1, Rsrc2 R 0 0x2b set if less than sem sinal sltiu Rdest, Rsrc1, Imm16 I 0x0b set if less than Imm sem sinal sll Rdest, Rsrc1, Shamt5 R 0 0 desl. Lógico à esquerda srl Rdest, Rsrc1, Shamt5 R 0 2 desl. Lógico à direita sra Rdest, Rsrc1, Shamt5 R 0 3 desl. aritmético à direita
j address28 J 2 desvio incondicional
jr Rsrc R 0 8 desvio usando registrador
beq Rsrc1, Rsrc2, address18 I 4 desvia se igual (relativo) bne Rsrc1, Rsrc2, address18 I 5 desvia se diferente (relativo) bgez Rsrc, address18 I 1 1 desvia se maior ou igual a zero (rel) bgtz Rsrc, address18 I 7 desvia se maior que zero (rel) blez Rsrc, address18 I 6 desvia se menor ou igual a zero (rel) bltz Rsrc, address18 I 1 0 desvia se menor que zero (rel)
jal address18 J 3 desvia e link de retorno
jalr Rsrc R 0 9 desvia e link de retorno c/ reg
rfe R 0x10 0x20 retorno de exceção
syscall R 0 0x0c chamada de sistema
break R 0 0x0d break
Transferência de informação
Operações Aritméticas
27
Figura 2.6 – Diagrama de blocos de um pipeline MIPS
Fonte: [Patterson, 2007]
2.7.
Processadores MIPS
MIPS é acrônimo para Microprocessor without Interlocked Pipeline Stages, ou microprocessador sem estágios de pipeline bloqueados. Tipicamente, arquiteturas MIPS-I empregam um pipeline de 5 estágios: busca, decodificação, execução, acesso à memória e escrita no banco de registradores. Nesta implementação de pipeline,se não houver conflitos entre diferentes instruções executando simultaneamente, a cada ciclo de relógio é realizada a execução de uma destas instruções.
Utilizando um conjunto de instruções como ponto de partida, inicialmente é projetada uma implementação simples de caminhos de dados e de controle para prover a execução destas instruções, formando uma arquitetura monociclo, como pode ser visualizado na Figura 2.7.
Figura 2.7 –MIPS monociclo
28 Na implementação monociclo, um ciclo de relógio possui mesmo tamanho para todas as instruções implementadas em seu conjunto. Este ciclo é definido pela instrução de maior duração, no caso MIPS-I pela instrução Load Word. Como cada unidade funcional somente pode ser utilizada uma vez por ciclo de relógio, a duplicação de unidades funcionais acarreta em um maior custo de hardware.
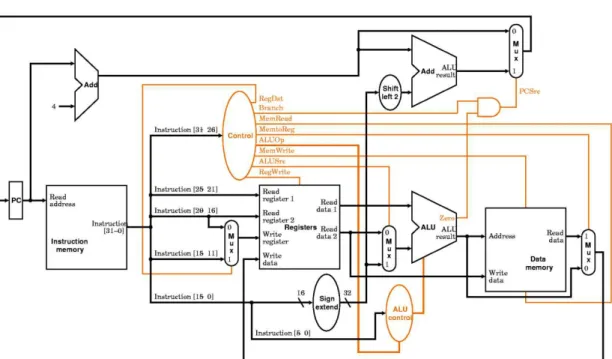
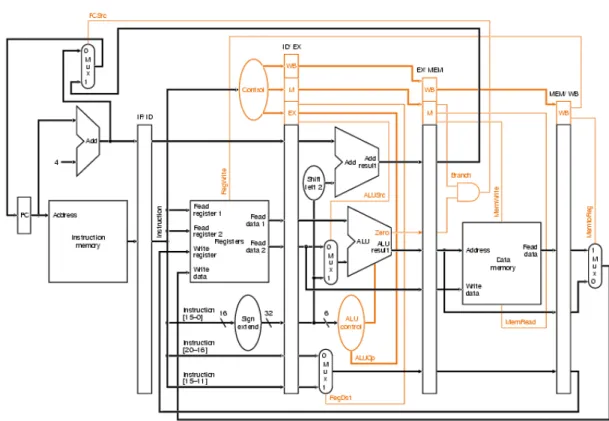
A segunda alternativa de implementação é a versão MIPS multiciclo. A execução de cada instrução é dividida em etapas, sendo que cada etapa necessita de um ciclo de relógio. Assim, cada unidade funcional da arquitetura pode ser utilizada mais de uma vez por instrução. Nesta versão, são inseridos os conceitos de microprogramação e máquinas de estados finitos. A Figura 2.8 apresenta a versão do MIPS multiciclo.
Figura 2.8 –MIPS multiciclo
Fonte: [Patterson, 2007]
As instruções do MIPS são executadas em ate 5 etapas: 1. Busca da instrução na memória;
2. Leitura dos registradores enquanto uma instrução é decodificada, (o formato das instruções do MIPS permite que a leitura e a codificação ocorram simultaneamente);
3. Execução de uma operação ou cálculo de um endereço; 4. Acesso a um operando de memória;