ABSTRACTION FOCUSED SYSTEM
FOR USER FRIENDLY INFORMATION
HANDLING OVER WWW
Dr. Pushpa R. Suri
Department of Computer Science and Applications, Kurukshetra University Kurukshetra- 136119, Haryana, India. pushpa.suri@yahoo.com
HARMUNISH TANEJA*
Department of Information Technology, Maharishi Markandeshwar University, Mullana, Haryana- 133203, India. harmunish.taneja@gmail.com
Abstract:
The World Wide Web has become the medium of preference for the circulation of information by common man, teams, organizations, and social communities. Information computing is the fundamental mean by which web information is retrieved and distributed. Conventional information computing approaches continues to be the most common to search documents of potential relevance. But unfortunately these offer only an imperfect solution as many relevant documents may be missed in the crude search process. The search process is sharply query specific and the results blindly follow the terms entered. The proposed Abstraction Focused framework for improved information computing over web attempts to resolve this basic problem that stamps from the information needs of the diverse users from the web. It implements abstraction by defining different indicators for directing the user search interests. Results from experiments with Abstraction Focused System approve the success particularly in cases where different users have a defined boundary of the search over WWW.
Keywords: Abstraction, Search Indicators, Abstraction Focused System (AFS), World Wide Web (WWW), Search Engine (SE).
1. Introduction
Web users and applications are escalating exponentially highlighting the incompetence of the traditional information computing approaches over WWW. With the growing advent of internet use, the range of users may be even poles apart. Distinguishing between different users may helps establish the trajectory of desired search thereby hiding rest of the complexities from the user [1]. Conventional web information retrieval is tagged of being inflexible and under–inclusive. Surely it runs the risk of mismanaging the diverse expectations from ever growing web leading to grave detriment of the users. It is convenient to place information on the Web and on the other hand, incredibly complicated for others to find it with expected level of efficiency therefore abstraction is desired. Also WWW is a unique mixture of the momentary and the permanent. This poses serious challenge to the adaptation of traditional approaches to social research. There are several Search Engines (SEs) on the Web that uses different kind of indexes thus giving different results for the similar query [2]. Due to the dynamic nature of the web, there is high probability of the change of information or links indexed. Some pages get deleted and lead towards wrong results. High cost is needed for keeping the index current. If there is no index entry of value for the user search, the SEs cannot find it. It is not possible to index every possible search expression.
WWW has evolved as a tool for business, learning, communication, leisure, and a whole host of anticipated and unanticipated activities across a diverse range of the population. WWW usage, has led to a mammoth explosion of information available to both the public and private sectors. Information on the WWW means dissimilar things to diverse people, relevant to some and may be completely irrelevant to others and valuable to some, but not all. One critical aspect of whether information retrieved provides a benefit is judged by the ease for its availability and usage, and in particular, by complexity level of the information handling [3]. The higher the complexity, the less likely that relevant information can be obtained from WWW. One solution to complexity is abstraction, also known as information hiding. Information computing must support the user to
view the abstracted view of the web page. Conventional SEs can locate information that is in their search index and users can’t have much preference in limiting or expanding the search parameters. In this paper object oriented information handling highlights the strengths of abstraction that focuses attention on limited view associated with the field of Web studies.
Conventional search strategies are more like open ended questions and the whole burden is on the user ranging from selecting the most appropriate keywords for the query to analysis of the search results of relevance. The proposed system (AFS) suggests concepts like closed ended questions thereby rising the comfort level of usage. While conventional information computing over WWW is not completely discredited, new computing technologies particularly proposed framework embedded with object oriented concepts is promising. It elaborates that using the abstract view; user can use its own search indicators to have more optimized result similar to domain specific to an extent over the web. Abstraction controls the search path and presents a restricted analysis for the user. User’s contribution is always beneficial if users have an idea of the searching contents [4][5]. But generally, users do not have the option of choosing search indicators like URL, price, rank, validity, brand, title, and others that promises optimized search result in terms of time and usage ease. The rest of the paper is organized as follows. Section 2 discusses the issues of web information handling based on traditional information retrieval techniques and provides extensive insight to modern information computing technologies. Section 3 presents the proposed Abstraction Focused System that accommodates the object oriented concepts for information computing. Section 4 demonstrates a prototyped information handling environment constructed under the architecture. Finally, section 5 provides a concluding remark.
2. Related Work
Conventional web SEs have wide background on implementing index based searching strategies that are handicapped to retrieve the same results by same query next time. SE maintains and catalogs the content of Web pages in order to make them easier to find and browse [6]. SE database may vary from each other, and none provides the best complete index for all the subjects. The design of a parallel indexer for web documents [7] is responsible to carry-out the indexing process. Caching system aimed to reduce the response time of a SE [8]. But incompetence still remained, as far as the performance issues in ever expanding WWW scenario are concerned not only in terms of diversity of information uploaded but also in terms of diversity of its users. Meta-search engines use the indexes of other SEs instead of maintaining a local database and give users a single interface to and from the search results [9]. Although Meta-search is a valuable web search tool, it still leaves problems like good search strategy and technique to handle an overload of results. Webnaut [10]is a prototype agent system for collecting information from the Internet and filtering it according to a profile of user interests. But genetic algorithm included in it requires extensive feedback to evolve with the user’s interests and adaptation to ever changing user interests over WWW is tricky.
attributes has been well studied in existing structured document retrieval work [23][24] and can be directly used in search indicator selection of proposed AFS for web object retrieval scenario.
Most of the past work on information computing over WWW suggests that the inefficient search results stems down from the name disambiguation that is usually based on the string similarity of the attribute values [25][26][27][28]. These approaches are not sufficient for state of affairs with few attribute values available for disambiguation. Recently, the relationship information among different types of objects in a local dataset has started to be exploited for name disambiguation [29][30]. The limitation of these approaches is that they rely too much on the completeness of relationship information.
3. Abstraction Focused System (AFS)
WWW has witnessed many deficiencies in conventional search methodologies [9]. The keyword based search approach for information handling over the web accounts to some strong value as far as speed associated with keyword indexing is concerned. The greatest limitation of this conventional approach is non identification of the actual needs of the users. The naive users lack assistance for efficient search results in terms of appropriate keywords that may yield desired information. User is left with heaps of unrelated data most of the time that need intensive analysis. This approach vacuums up a lot of irrelevant information whose review reduces the computing efficiency. Proposed AFS attempts to overcome the inadequacies of traditional search practices by allowing users to observe the abstracted view to control search area and methods. Abstraction is simply the removal of unnecessary details from the point of view of the user [3]. The idea behind AFS is to design a prototype for information computing on a complex web. Part of information and also the details that user must know has to be identified in order to design the interface, and also the details that need to be hidden has to be settled. The interface supported by AFS creates a contract between the user and the developer and comes with a bunch of user friendly features. The user knows the interface but should not have to know methodology behind it. Also the interface protects the developer from incorrect use of the information by the user. AFS interface not only creates an abstraction barrier that protects the implementation but also encapsulates the implementation details. It also supports flexibility for implementation changes, as long as the user is only retrieving information from web through the defined search indicators, and those operations are still provided by the new implementation. This flexibility results in making AFS a loosely coupled system applicable to various scenarios reflecting diverse user search needs. Also, abstraction overcomes the index related constraints as search indicators partition the searching space efficiently. The grammar used in AFS is quite analogous to WebSQL [31]. The simplified grammar for the query language for AFS is given in Figure 1.
<QUERY> ->
SELECT <attribute> [, <attribute>]*
FROM [+<USI>] <URL>[,[+<USI>]<URL>]* WHERE [!] (<PDS>) [(and|or) [!](<PDS>)]* [ (and|or) [(+|=)] USI>] <phrase> TIME <USI>;
<attribute> -> Prod1 | Prod2 | Prod3 | ...| Prod n <USI> -> (0 | 1 | .. | 9)+
<PDS> -> <pC> | <dC> | <sC>
<p> -> (Prod1 | Prod2 | Prod3 | ...| Prod n ) <d> -> <relop> <date>
<s> -> <relop> <UnsignedInt> <relop> -> < | <= | = | > | >= | != <date> -> <USI>
Abbreviations Used
USI : UnsignedInt
pC : phraseCond
dC : dateCond
sC : sizeCond
Prod : Product
! : not
Figure 1: Grammar Used in AFS
integer in the FROM clause. For the above query, AFS assigns maximum priority to each URLs in the FROM clause, and put them in a heap. They get the maximum priority because user wants to make sure that all URLs introduced primarily by the user get processed as long as the time is sufficient. Subsequently, the threads are created that work on the query. The threads work in parallel and straightforwardly communicate results back to the users [5]. Each thread gets the recent high ranking search pages based on the search indicators in the heap and processes it. Removed indicators from the heap are swapped with the last outcome in the heap if existing, before a filter down is applied from the URL to preserve the order property. One heap is employed, and all threads interact with this heap. Insertions and deletion of search results from the heap is synchronized so only one thread can be in that section at any time. This is necessary because if one thread is reading from the heap and another thread is writing to it, the heap may become inconsistent. The use of threads is necessary because sometimes hosts are very slow in replying to a server program with web page information, especially when the demanded page is not available. When threads are used, this slowness of hosts is not as damaging because when one thread block waiting for the reply from host, meanwhile other threads may have a chance of continuing and sending something back to the user. The result of the query is presented in the list, and users may click on the desired search indicators for the result. Abstracted information computing involves retrieving the web page contents related to the URL indicated by the user, relevant search indicators to be asked from the user and then searching it in the given domain. The help button provides the list of search indicators the user will be allowed to select only the given search indicators as present in the graphical interface. The searching of a page requires matching the content with WHERE clause of the query as well as extracting other URLs enclosed in it. URLs extracted from processed search results are assigned priorities based on how well their address text [32] and the page they are contained in matches the query’s WHERE clause. AFS emphasizes the matched search indicators as most vital. In the earlier real time web searching techniques there was no remedy for occasional hang-up aroused during sending back the selected attributes to the users. AFS Pseudo code shown in figure 2 overcomes this disability of the former technique by handling the exception for the same.
Input the query
Syntactic analysis and parsing of query is done While (values not matched exactly with Where Clause) {
Put starting URLs into heap
for (time=Init_time; time<=end_time; time_increment_by_1) {
if (heap is empty) {
repeat threads // threads may add new nodes update CurrentTime
continue; }
try
{ Connect to web page and Read web page through this connection }
catch {
Handle the exception }
-Match taken URLs from web page with contents of WHERE clause -Rank Web page based on matching of its values with WHERE clause try
{
send selected Search Indicators to user }
catch {
Handle the exception }
-send back “SELECT” Search Indicators to user after matching successful, -put into heap, the extracted links
-update current Time }
}
4. Results
Command line interface of the AFS is as shown in the Figure 3 and Figure 5. A graphical interface is developed using NetBeans on the front-end and Oracle at the backend. Based on the abstraction focused architecture, the prototype of AFS is implemented to demonstrate its practicability. AFS generates the graphical interface automatically as the user enters the search choices as shown in Figure 4 and Figure 6. The execution scenario and input data are recorded by AFS after pressing the button Run and Output button displays the searched results as desired by the users.
Query 1.
SELECT link, price, rank, offer, validity
FROM +3www.amazon.com, +5www.dealstobuy.com WHERE body contains “laptop”
TIME 60;
Figure 3: Command line AFS for Electronic Gazettes
The example query exhibited in Figure 3 will display ‘link’, ‘price’, ‘rank’, ‘offer’, ‘validity’ for the electronic product ‘laptop’ originating from www.amazon.com and www.dealstobuy.com. The maximum depth of the links searched in the www.amazon.com part is three and the depth for www.dealstobuy.com is five and search concludes in 60 seconds.
Figure 4: Search Results of AFS for Electronics Gazettes
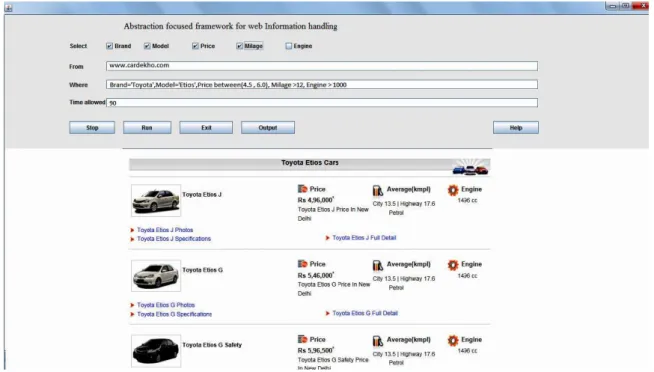
The output result for the query in Figure 3 is shown in Figure 4 where user gets the list of various laptops with the desired set of search indicators i.e. link, price, rank, offer, validity. Another query reflecting the need of a different user in search for cars features is exhibited in Figure 5 will display ‘brand’, ‘model, ‘price’, ‘mileage’ and ‘engine’ for the cars originating from www.cardekho.com. Figure 5 displays the brand of Toyota cars originating from www.cardekho.com that contains an image title containing “Etios”, price ranging between 4.5 lacs to 6.5 lacs and ends in 90 seconds.
Query 2.
SELECT brand
FROM +3www.cardekho.com
WHERE body contains Toyota and imageTitle contains “Etios” and price between 4.5 lac to 6.5 lacs TIME 90;
Figure 6: Search Results of AFS for Cars
5. Conclusion
In this paper, an enhanced search methodology is presented in the form of proposed object oriented framework (AFS). This is quite helpful on occasions when users have an idea of searching both the domain and the contents. Users contribute in terms of entering the data in the more structured manner facilitated by the abstract view through the frame. In spite of searching the contents from web server’s database, the AFS searches the contents from the domain in real time on the basis of search indicators chosen by the users and displays the results as per user requirements. While extracting the information, the problem faced by the users is that additional web page attributes like title, price, model, brand or images can’t be requested. AFS works well with indexless search in the real time. Earlier SEs can not handle such attributes due to over dependency on indexing. In case of index based search, the search is actually performed on the server, which stores all the data in the index. Many search sites may take a long time for refreshing their index. In contrast, dynamic search actually fetches the data at the time the query is issued. In this paper we proposed an abstraction focused prototype AFS for information handling over WWW with better ease of usage.
References
[1]. Ziv Bar-Yossef ; Andrei Z. Broder; Ravi Kumar; Andrew Tomkins; Sic Transit Gloria Telae (2004): Towards an understanding of the web's decay in Proceedings of the 13th conference on World Wide Web, May 17-20, pp 328-337.
[2]. Lawrence, S.; Giles, C. L.; Bollacker, K.(1999): Digital Libraries and Autonomous Citation Indexing, IEEE Computer, 32(6), pp. 67– 71.
[3]. Gustavo Rossi; Daniel Schwabe; Fernando Lyardet(2000): Abstraction and Reuse Mechanisms in Web Application Models in Proceedings of the Workshops on Conceptual Modeling for E-Business and the Web, Springer-Verlag London, UK, pp. 76 – 88. [4]. Ahmed Patel; Muhammad J. Khan (2007): Evaluation of service management algorithms in a distributed web search system,
Computer Standards & Interfaces, 29(2), pp 152-160.
[5]. Augustine Chidi Ikeji; Farshad Fotouhi (1999): An Adaptive Real-Time Web Search Engine in the proceedings of the 2nd International
workshop on Web information and Data Management, ACM, pp 12-16.
[6]. Junghoo Cho; Hector Garcia; Molina (2003): Effective Page Refresh Policies for Web Crawlers, ACM Transactions on Database Systems, 28(4), pp. 390-425.
[7]. Fabrizio Silvestri (2004): High Performance Issues in Web Search Engines: Algorithms and Techniques, Ph.D. Thesis: TD 5/04, pp 15-67.
[8]. Tiziano Fagni; Salvatore Orlando; Paolo Palmerini; Raffaele Perego; Fabrizio Silvestri (2003): A hybrid strategy for caching web search engine results in Proceedings of the 12th International conference on World Wide Web.
[9]. Zonghuan Wu; Weiyi Meng; Clement Yu; Zhuogang Li (2001): Towards a highly scalable and effective Meta search engine in the Proceedings of the 10th International conference on World Wide Web, pp 379-388.
[10].Zacharis Z. Nick; Panayiotopoulos Themis (2001): Web Search Using a Genetic Algorithm, IEEE Internet Computing, pp. 18-26. [11].Zaiqing Nie; Ji-Rong Wen; Wei-Ying Ma (2007): Object-Level Vertical Search in the Proceedings of CIDR, pp. 235-246.
[13].Zaiqing Nie; Yuanzhi Zhang; Ji-Rong Wen; Wei-Ying Ma (2005): Object-Level Ranking: Bringing Order to Web Objects in the proceedings of WWW, pp. 567-574.
[14].Jun Zhu; Zaiqing Nie; Ji-Rong Wen; Bo Zhang; Wei-Ying Ma (2006): Simultaneous Record Detection and Attribute Labeling in Web Data Extraction in the proceedings of SIGKDD, pp. 494-503.
[15].A. McCallum; K. Nigam; J. Rennie; K. Seymore (1999): A Machine Learning Approach to Building Domain-Specific Search Engines in the proceedings of 16th International Joint Conference on Artificial Intelligence, pp. 662- 667.
[16].W.W. Cohen (1998): A Web-Based Information System that Reasons with Structured Collections of Text in the proceedings of 2nd
international Conference on Autonomous Agents (Agents ’98), pp. 116-123.
[17].M. Craven; D. DiPasquo; D. Freitag; A. McCallum; T. Mitchell; K. Nigam; S. Slattery (1998): Learning to Extract Symbolic Knowledge from the World Wide Web in the proceedings of 15th National Conference on Artificial Intelligence (AAAI-98), pp.
509-516.
[18].O. Etzioni (1996): Moving Up the Information Food Chain: Deploying Softbots on the World Wide Web in the Proceedings of 13th
National Conference on Artificial Intelligence (AAAI-96), pp. 1322-1326.
[19].K. Lerman; L. Getoor; S. Minton; C. A. Knoblock (2004): Using the structure of Web sites for automatic segmentation of tables. In ACM SIGMOD Conference (SIGMOD), pp. 119-130.
[20].J. Wang and F. H. Lochovsky. Data extraction and label assignment for Web databases, in proceedings of World Wide Web conference (WWW), 2003, pp 187-196.
[21].Bing Liu; Robert Grossman; Yanhong Zhai (2003): Mining Data Records in Web Pages in proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD).
[22].Jun Zhu; Zaiqing Nie; Ji-Rong Wen; Bo Zhang; Wei-Ying Ma (2005): 2D Conditional Random Fields for Web Information Extraction, in the proceedings of the 22nd International Conference on Machine Learning (ICML), pp. 1044-1051.
[23].Stephen Robertson: Hugo Zaragoza: Michael Taylor (2004): Simple BM25 Extension to Multiple Weighted Fields. ACM CIKM, pp. 42-49.
[24].Paul Ogilvie; Jamie Callan (2003): Combining Document Representations for known item search in the proceedings of SIGIR, pp. 601-606.
[25].W. E. Winkler (1999): The state of record linkage and current research problems. Technical report, Statistical Research Division, U.S. Bureau of the Census, Washington, DC.
[26].A. Monge; C. Elkan (1997): An efficient domain independent algorithm for detecting approximately duplicate dataset records. In DMKD.
[27].A. McCallum; K. Nigam; L. H. Ungar (2000): Efficient Clustering of High-Dimensional Data Sets with Application to Reference Matching. In Proceedings of SIGKDD, pp. 169-178.
[28].L. Jin; C. Li; S. Mehrotra (2003): Efficient record linkage in large data sets, in the proceedings of DASFAA, pp. 137.
[29].Z. Chen; D.V. Kalashnikov; S. Mehrotra (2005): Exploiting relationships for object consolidation in the proceedings of ACM IQIS, pp. 47-58.
[30].X. Dong; A. Halevy; J. Madhavan (2005): Reference reconciliation in Complex Information Spaces in the proceedings of SIGMOD, pp. 85-96.
[31].A. Mendelson; G. Mihaila; T. Milo (1997): Querying The World Wide Web, Journal of Digital Libraries, 6(1), pp. 68-88.
[32].Vanessa Murdock; Diane Kelly; W. Bruce Croft; Nicholas J. Belkin; Xiaojun Yuan (2007): Identifying and improving retrieval for procedural questions, Information Processing & Management, 43(1), pp. 181-203.
Dr. Pushpa R. Suri received her Ph.D. Degree from Kurukshetra University, Kurukshetra. She is working as Associate Professor in the Department of Computer Science and Applications at Kurukshetra University, Kurukshetra, Haryana, India. She has many publications in International and National Journals and Conferences. Her teaching and research activities include Discrete Mathematical Structure, Data Structures, Information Computing and Database Systems.