Indexação automática e ontologias: identificação dos contributos convergentes na ciência da informação
17
0
0
Texto
Imagem

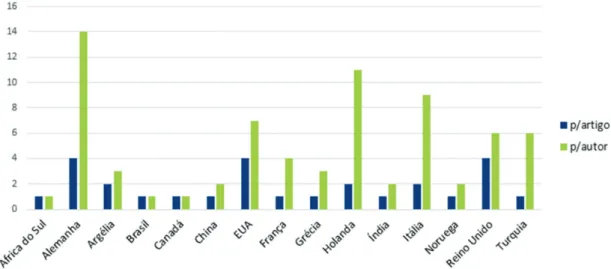
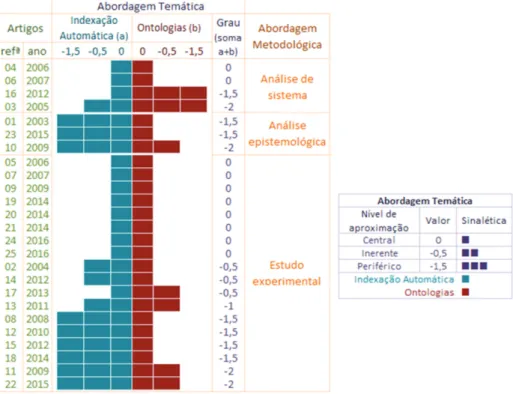
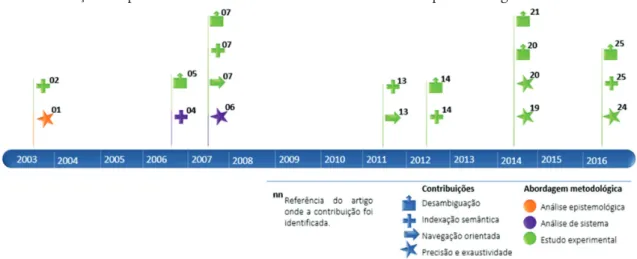
Documentos relacionados