Escola de Educação, Tecnologia e Comunicação
Programa de Pós-Graduação Stricto Sensu em Gestão do
Conhecimento e da Tecnologia da Informação
BIG DATA:
DIRETRIZES E TÉCNICAS PARA PRESERVAÇÃO DA
PRIVACIDADE
Autor: Rogério Augusto de Souza Licks
Orientador: Prof. Dr. Renato da Veiga Guadagnin
ROGÉRIO AUGUSTO DE SOUZA LICKS
BIG DATA: DIRETRIZES E TÉCNICAS PARA A PRESERVAÇÃO DA
PRIVACIDADE
Dissertação apresentada ao Programa de Pós-Graduação Stricto Sensu em Gestão do Conhecimento e da Tecnologia da Informação da Universidade Católica de Brasília, como requisito parcial para obtenção do Título de Mestre em Gestão do Conhecimento e da Tecnologia da Informação.
Orientador: Professor Doutor Renato da Veiga Guadagnin
Ficha elaborada pela Biblioteca Pós-Graduação da UCB
L711b Licks, Rogério Augusto de Souza.
Big Data: diretrizes e técnicas para preservação da privacidade. / Rogério Augusto de Souza Licks 2016.
159 f.; il.: 30 cm
Dissertação (Mestrado) Universidade Católica de Brasília, 2016. Orientação: Prof. Dr. Renato da Veiga Guadagnin.
1. Tecnologia da informação. 2. Big Data. 3. Privacidade. 4. Diretrizes. 5. Técnicas. I. Guadagnin, Renato da Veiga, orient. II. Título.
AGRADECIMENTOS
Agradeço a Deus pelo equilíbrio, saúde, perseverança, clareza de discernimento, em cada momento de aprendizado e de experiência que a vida tem me apresentado.
À minha família, em especial minha esposa e filhos amados, que em todos os momentos dessa jornada me apoiaram com ajuda, incentivos e compreensão pelas ausências durante essa trajetória.
À minha mãe e ao meu pai, pelo amor incondicional, pelos ensinamentos de vida e incentivo à educação.
Ao Banco do Brasil S.A., empresa que apoio e investe no conhecimento, e às valorosas pessoas que compõem essa organização, que me apoiaram e me incentivaram nessa caminhada. Aos professores da Universidade Católica de Brasília, pessoas as quais orgulho-me de ter convivido durante o período do curso, por conta do conhecimento compartilhado e com quem tive a oportunidade de ampliar a compreensão do universo acadêmico.
RESUMO
Referência: LICKS, Rogério Augusto de Souza. Big Data: Diretrizes e Técnicas para Preservação da Privacidade. 2016. 159 p. Dissertação Mestrado em Gestão do Conhecimento e da Tecnologia da Informação. Universidade Católica de Brasília. Brasília DF. 2016.
O êxito no universo empresarial passa pela compreensão e aplicação de soluções estratégicas e negociais inovadoras voltadas ao cliente, com a utilização das inteligências competitiva e estratégica, por meio da produção de informação e conhecimento para suporte adequado e ágil à decisão e apoio aos negócios. O Big Data tem sido apontado como poderoso instrumento para o alcance desses objetivos. O valor proporcionado por essa abordagem considera o aperfeiçoamento de produtos e serviços, eficiência operacional, aumento da produção, superação da concorrência, redundando na oferta de soluções mais adequadas aos clientes de maneira satisfatória e diferenciada. Este trabalho tem o objetivo de levantar diretrizes e técnicas atinentes à preservação da privacidade no uso do Big Data. O sucesso empresarial depende de como as organizações lidam com políticas associadas à reserva de informações pessoais de seus clientes, na busca do equilíbrio entre a obtenção de valor e o respeito do direito dos consumidores quanto ao controle da exposição e a disponibilidade de dados acerca de si. Como método de pesquisa foi utilizada abordagem qualitativa e bibliográfica, por meio da revisão da literatura dos temas Big Data e privacidade. Conclui-se pela existência de diretrizes representadas por leis e regulamentos aplicadas na Europa, Estados Unidos, Ásia, além de técnicas para a preservação da privacidade como a anonimização de dados e privacidade diferencial, inclusive com aplicação ao Big Data. Como trabalho futuro recomenda-se, no tocante à definição de direitos de propriedade e privacidade, o aprofundamento de estudos dos modelos de negócio que envolvem a Internet das Coisas, dentre outros.
ABSTRACT
Success in business requires understanding and application of innovative strategic and business solutions geared to the customer with the use of competitive and strategic intelligence, based on information and knowledge for adequate and agile decision support. Big Data is a powerful tool to achieve these goals. The value provided by this approach considers the improvement of products and services, operational efficiency, increased production, overcoming the competition, resulting in offering best solutions for customers issues in a satisfactory and differentiated way. This work intends to present guidelines and techniques concerning privacy preserving in the use of Big Data. Business success strongly depends on how organizations deal with policies linked to storing personal data from its customers, and how they keep a balance between getting value and assuring the citizens right to control exposure and availability of their own data. A qualitative and bibliographic approach was used as a research method through literature review of issues Big Data and privacy. The results confirmed the existence of guidelines represented by laws and regulations applied in Europe, USA, Asia, as well as techniques for preserving privacy, such as the anonymisation of data and differential privacy, including application to Big Data. As future study concerning the definition of property rights and privacy, new approaches on business models that involve Internet of Things can be developed.
LISTA DE FIGURAS
FIGURA 1 TRANSFORMANDO DADOS EM INSIGHTS ...26
FIGURA 2 SIMILARIDADES E DIFERENÇAS ENTRE AS ÁREAS DE COMPETÊN-CIA EM BI E BIG DATA ...28
FIGURA 3 QUANTIDADE DE DADOS ARMAZENADOS EM 2010 NO MUNDO (EM PETABYTES - PB) ...29
FIGURA 4 COMPORTAMENTO OBSERVADO E ESPERADO DA GERAÇÃO DE DADOS ESTRUTURADOS E NÃO ESTRUTURADOS ...30
FIGURA 5 BIG DATA E OS 3 VS ...32
FIGURA 6 EVOLUÇÃO DA TOMADA DE DECISÃO ORIENTADA POR DADOS ....34
FIGURA 7 INCREMENTO DO FLUXO DE DADOS 2005-2017 ...35
FIGURA 8 COLETA DE DADOS DE EQUIPAMENTOS NA IOT ...40
FIGURA 9 CATEGORIZAÇÃO DE TÓPICOS E TECNOLOGIAS NA IOT ...41
FIGURA 10 POTENCIAL DO BIG DATA ...45
FIGURA 11 CICLO DE VIDA DO BIG DATA ...49
FIGURA 12 SERVIÇOS E APLICAÇÕES MÓVEIS COM BASE EM LOCALIZAÇÃO .54 FIGURA 13 RASTREAMENTO DE LOCALIZAÇÃO DE USUÁRIO - GOOGLE NOW .71 FIGURA 14 RASTREAMENTO DE LOCALIZAÇÃO ...72
FIGURA 15 GRAU DE MATURIDADE DA REGULAMENTAÇÃO SOBRE PROTEÇÃO DE DADOS NO MUNDO ...87
FIGURA 16 NOVAS PERSPECTIVAS DO USO DE DADOS PESSOAIS ...110
FIGURA 17 DESCOBERTA DE CONHECIMENTO E MINERAÇÃO DE DADOS ...119
FIGURA 18 PROCESSO DE DESCOBERTA DE CONHECIMENTO NA MINERAÇÃO DE DADOS ...121
FIGURA 19 ESTRUTURA DE PRESERVAÇÃO DA PRIVACIDADE ...123
FIGURA 21 AGENTES NA COLETA DE DADOS E PUBLICAÇÃO ...130
LISTA DE QUADROS
QUADRO 1 EXEMPLOS DE INICIATIVAS NO BIG DATA ...38 QUADRO 2 EVOLUÇÃO DA PRIVACIDADE EM RELAÇÃO À TI ...60
QUADRO 3 FORMAS DE COLETA E USOS DE DADOS PESSOAIS ...68
LISTA DE GRÁFICOS
LISTA DE SIGLAS
APEC Asia-Pacific Economic Cooperation ou Cooperação Econômica Ásia-Pacífico CAPES Coordenação de Aperfeiçoamento de Pessoal de Nível Superior
CRM Customer Relationship Management
EB Exabyte
EC European Commission FTC Federal Trade Commission
GPS Global Positioning System
IDC Internacional Data Corporation
IOT Internet of The Things
ISACA Information Systems Audit and Control Association NBS China National Bureau of Statistics of China
OECD Organisation for Economic Co-operation and Development PB Petabyte
PCAST President´s Council of Advisors on Science and Technology RFID Radio-Frequency Identification
SNS Social Networking Services
TB terabyte
TI Tecnologia da Informação
TIC Tecnologia da Informação e Comunicações UN United Nations
UNECE United Nations Economic Commission for Europe UNSD United Nations Statistics Division
SUMÁRIO
1 INTRODUÇÃO ... 14
1.1 APRESENTAÇÃO ... 14
1.2 REFERENCIAL TEÓRICO ... 17
1.3 JUSTIFICATIVA ... 19
1.4 FORMULAÇÃO DO PROBLEMA ... 21
1.5 OBJETIVO ... 22
1.6 ESTRUTURA DO TRABALHO ... 22
2 FUNDAMENTAÇÃO TEÓRICA ... 23
2.1 BIG DATA ... 23
2.1.1 Conceito ... 23
2.1.2 Características ... 28
2.1.3 Usos e Aplicações do Big Data ... 35
2.1.4 Big Data e IOT ... 40
2.1.5 Vantagem Competitiva e Inovação no contexto do Big Data ... 43
2.1.6 Ciclo de vida do Big Data ... 49
2.1.7 Desafios ... 53
2.2 PRIVACIDADE ... 58
2.2.1 Conceito ... 58
2.2.2 Tipos e Características de Privacidade ... 60
2.2.3 Privacidade dos dados pessoais ... 63
2.2.4 Distinção entre dados pessoais e dados impessoais ... 64
2.2.5 Eventos de risco à privacidade vinculados à geração e à coleta de dados... 68
2.2.6 Preocupações e Ameaças à Privacidade ... 72
2.3 RESUMO ... 76
3. METODOLOGIA ... 79
3.1 PROPÓSITO DO ESTUDO ... 79
3.2 CLASSIFICAÇÃO DA PESQUISA ... 79
3.3 ETAPAS DA PESQUISA ... 80
4. DIRETRIZES PARA PRESERVAÇÃO DA PRIVACIDADE DE DADOS PESSOAIS ...82
4.1 DISPOSITIVOS LEGAIS E REGULAMENTARES ... 82
4.2.1 Considerações iniciais ... 86
4.2.2 Europa ... 90
4.2.3 Estados Unidos da América (EUA) ... 95
4.2.4 APEC ... 99
4.2.5 OECD ... 101
4.2.6 Brasil ... 104
4.3 CONSIDERAÇÕES FINAIS ... 106
4.4 RESUMO ... 111
5. TÉCNICAS PARA A PRESERVAÇÃO DA PRIVACIDADE NO BIG DATA ... 114
5.1 CONTEXTO GERAL ... 114
5.2 CONSENTIMENTO DO USO DOS DADOS PESSOAIS ... 115
5.3 MODELOS DE PRESERVAÇÃO DA PRIVACIDADE DOS DADOS ... 118
5.4 MECANISMOS ... 125
5.4.1 Anonimização ou desidentificação ... 125
5.4.2 K-anonimização ... 132
5.4.3 Privacidade Diferencial ... 134
5.5 REIDENTIFICAÇÃO DE DADOS ... 135
5.6 RESUMO ... 138
CONCLUSÃO ... 142
TRABALHOS FUTUROS ... 146
REFERÊNCIAS ... 147
ANEXO A Big Data e Inovação para Vantagem Competitiva ... 156
ANEXO B Geração e captura de dados pessoais ... 157
ANEXO C Características do Big Data em relação à privacidade... 158
1 INTRODUÇÃO
1.1 APRESENTAÇÃO
O mundo está em constantes mudanças, tornando-se mais complexo, hiperconectado e fortemente influenciado por ideias prospectadas por meio do Big Data. O ritmo das mudanças, a velocidade e o volume dos dados produzidos não dão sinais de desaceleração.
Em um ambiente de mercado dinâmico, as empresas precisam se adequar a novos contextos rapidamente, inclusive revendo o seu modelo de atuação, de modo a aplicar da melhor forma seus recursos para a geração de resultados que lhe assegurem desempenho sustentável. Assim, o sucesso no mundo empresarial torna-se cada vez mais dependente da inovação e do conhecimento, que provocam a necessidade de mudanças nas formas tradicionais de organizar negócios e processos nas empresas.
Moresi (2000) afirma que a informação terá valor econômico para uma organização se gerar lucros ou for alavancadora de vantagem competitiva. Nessa linha, o conhecimento configura-se como principal ativo organizacional, atuando como alicerce para o desenvolvimento de alavancagem competitiva e na geração de soluções por meio de respostas rápidas aos clientes (DAVENPORT; PRUSAK, 1998).
O conhecimento é recurso fundamental capaz de agregar valor aos produtos e processos organizacionais, permitindo maior velocidade e segurança no processo de tomada de decisão, de modo que habilidades técnicas, inovação e criatividade se tornem elementos intrínsecos no ambiente organizacional para a consecução dos objetivos das empresas e criação de vantagem competitiva sustentável.
Atualmente, as organizações têm muitos dados e pouco conhecimento, fato que indica que é necessário o desenvolvimento de novas formas de exploração desses elementos (DINIZ, 2014). Terá vantagem quem souber a forma de aproveitar os dados que tem em suas mãos. Assim, as empresas poderão inovar, entender como aperfeiçoar um produto, criar uma estratégia de marketing mais eficiente, cortar gastos, aumentar a produção, evitar o desperdício de recursos, superar a concorrência, disponibilizar serviços aos clientes de maneira satisfatória e diferenciada. O Big Data torna-se fonte de vantagem competitiva para muitas companhias, provocando a completa remodelagem da estrutura de algumas indústrias
(MAYER-SCHÖNBERGER; CUKIER, 2013). Nesse contexto, as organizações buscam compreender e
Mcguire, Manyika e Chui (2012) entendem que os dados estão inseridos em cada setor da economia global, ao lado de outros fatores de produção essenciais, como ativos tangíveis e capital humano. Muitas das atividades econômicas modernas simplesmente não existiriam sem os dados e sua exploração. Nessa linha, o uso do Big Data pode se configurar como a base para a competição e crescimento das empresas, incrementando produtividade e criando significante valor para a economia global pela redução do desperdício e aumento da qualidade dos produtos e serviços.
Assim como novas tecnologias da informação, o Big Data pode prover grandes reduções de custos, melhorias substanciais no tempo do processamento de tarefas ou oferta de novos produtos e serviços. Do mesmo modo que os métodos tradicionais de análise, o Big Data
também pode dar suporte a decisões negociais. As tecnologias e conceito por trás do Big Data
permitem que as organizações alcancem uma vasta gama de objetivos. Os objetivos eleitos apresentam implicações não somente para o resultado e benefícios financeiros, mas também para o processo. Usualmente, nas abordagens tradicionais de mineração de dados, o objetivo é dar suporte a decisões negociais internas: O que deveria ser oferecido aos consumidores? Como devem ser precificados os produtos? Qualquer tipo de dado que possa ser utilizado para medir a satisfação do consumidor é valioso, e muitos dados da interação com o consumidor são desestruturados (DAVENPORT; DYCHÉ, 2013).
Assim, as aplicações de Big Data apresentam-se como base para inovação, diferenciação e crescimento nas organizações, além de conhecimento e inteligência, por meio da otimização da oferta e venda cruzada de produtos, entendendo e antecipando as necessidades de seus clientes no nível mais granular e oferecendo ao público-alvo entrega rápida, tempestiva e personalizada de soluções (MANYIKA et al, 2011).
análise de redes sociais e transações para financiamento de possíveis atos terroristas; segurança cibernética, com base em análise de acessos a sistemas; dentre outros (JAGADISH et al, 2014). Dobre e Xhafa (2014) assinalam que todos os dias são gerados 2,5 quintilhões de bytes de dados e mais de 90% dos dados no mundo atualmente foram criados nos últimos dois anos. Esses dados são provenientes de sensores usados para colher informações climáticas, de postagens em sites de redes sociais, fotos digitais e vídeos, transações de compras ou sinais de localização emitidos por telefones celulares, apenas para elencar algumas das fontes.
Uma grande massa de dados sobre os indivíduos é coletada oriunda de informações demográficas, atividades na Internet, consumo de energia elétrica, padrões de comunicação e interações sociais. Essa atividade é capturada por agências de estatística, organizações de pesquisa, centros médicos e empresas proprietárias de redes sociais. A manipulação e divulgação dos dados capturados pode, por um lado, facilitar o avanço da ciência e das políticas públicas, ajudar os cidadãos a aprender sobre suas sociedades, porém, de outro, pode revelar a identidade de indivíduos ou atributos sensíveis que permitem essa identificação via associação de informações. A falha na preservação da confidencialidade das informações coletadas, tratadas e divulgadas fere princípios éticos e pode causar prejuízos aos indivíduos aos quais as informações estão associadas, também, e para o provedor desses dados (MACHANAVAJJHALA; REITER, 2012).
É necessário assinalar que o valor econômico e social do Big Data não provém apenas da quantidade de informações geradas, mas da qualidade. O potencial de exploração desse valor permeia muitas possibilidades, mas também muitos riscos. A tecnologia e os dados são neutros; o seu uso é que pode gerar grande valor e, também, criar prejuízos significantes, por vezes simultaneamente. Isso requer que as abordagens tradicionais de governança de dados sejam repensadas, particularmente alterando o foco de tentar controlar os dados para o uso deles. Os indivíduos e as instituições de várias sociedades é quem tem a responsabilidade de governar e decidir como extrair o valor econômico e social e garantir a aplicação de mecanismos adequados (WORLD ECONOMIC FORUM, 2013).
alegação de atingir a privacidade individual (INFORMATION SYSTEMS AUDIT AND CONTROL ASSOCIATION, 2013a).
A coleta, armazenamento, manipulação e retenção de grandes quantidades de dados tem provocado importantes debates acerca da privacidade. Nessas discussões há propostas para que a utilização do Big Data seja permitida somente se a privacidade dos indivíduos não for violada. Como exemplo, há situações em que por meio da combinação de dados de uma determinada origem com outros de fonte distinta, mesmo que as informações pessoais sejam removidas, é possível identificar um determinado indivíduo. Esse tipo de situação é potencializado com o uso do Big Data pela combinação de diferentes fontes de informação (NATIONAL SCIENCE FOUNDATION, 2014).
Manyika et al (2011) aduz que o sucesso das empresas vai depender de como elas atendem e lidam com os vários fatores que envolvem o Big Data e os seus impactos, incluindo a privacidade. O grande desafio é assegurar o equilíbrio entre os comandos legislativos e a liberdade para as organizações capturarem o pleno potencial do Big Data, com o compromisso da manutenção da privacidade do público.
É nesse cenário que discutiremos ao longo desse trabalho o valor que o Big Data pode gerar e as questões que visem a correta aplicação das informações obtidas por essa abordagem, como foco na preservação da privacidade dos indivíduos.
1.2 REFERENCIAL TEÓRICO
Este trabalho teve como base a pesquisa realizada em livros, publicações como revistas, jornais e periódicos científicos, artigos e trabalhos científicos, portais eletrônicos da Internet, em especial o do Scopus, por meio da Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (Capes), acessado via Biblioteca da Universidade Católica de Brasília. No Scopus foram realizadas pesquisas considerando várias combinações de palavras-chave, envolvendo termos como Big Data e privacidade no título do artigo, resumo e palavras-chave das publicações.
Entre 2006 e 2016, foram encontradas 634 publicações, conforme Gráfico 1, sendo que entre 2007 e 2010 não houve publicações. Os artigos de 2006 e 2011 não relacionam os termos
Big Data e privacidade de forma direta. A publicação de 2006, apesar de citar o termo Big Data, diz respeito a método de detecção de intrusão de redes.
Gráfico 1 Quantidade de documentos produzidos por ano
Fonte: Elaborado pelo autor
Em 2013, houve um salto na produção acadêmica, de 31 em 2012 para 124 artigos. Já 2014 foi o ano de mais publicações sobre a temática, contando com 244 artigos, com pequeno declínio em 2015, perfazendo 228 documentos.
Quando o foco é a produção de textos, levando em conta os principais países de afiliação dos autores, verifica-se no Gráfico 2 que os Estados Unidos da América (EUA) ganham destaque com 205 documentos, seguidos da China com 100, Austrália 40, Alemanha 39, Reino Unido 37, Índia 32 e demais países completando o total de 634 publicações. Em relação à produção considerando o país de afiliação do autor como Brasil, foi encontrada apenas uma publicação, na língua inglesa, que trata da aplicação do Big Data na biomedicina como oportunidade para o desenvolvimento de programas de medicina personalizada para a melhoria da assistência aos pacientes.
Gráfico 2 Quantidade de documentos produzidos por país
Fonte: Elaborado pelo autor
1.3 JUSTIFICATIVA
A adoção do Big Data está se tornando cada vez mais difundida nas grandes corporações. As empresas precisam estar atentas às melhores formas de extrair o potencial pleno de seus benefícios, porém questões relacionadas à privacidade dos indivíduos exigem atenção e cuidados, pois se utilizado sem ponderação, o Big Data tem a capacidade de criar consequências negativas significativas (INFORMATION SYSTEMS AUDIT AND CONTROL ASSOCIATION, 2013a).
empresas de cartões de crédito, de dados pessoais sobre folha de pagamento, número de telefone e endereço divulgados tantos em listas como na Internet cujo acesso é livre. Com isso, todo tipo de informação particular é divulgada nesses vários locais. Os fundamentos da mineração de dados carecem de reformulação quando lidam com Big Data: o desenvolvimento de um modelo, onde os benefícios trazidos para os negócios têm de ser balanceados com os direitos individuais, com a busca de soluções inovadoras e pesquisa na prevenção da violação da privacidade (CHE, SAFRAN; PENG, 2013).
O Big Data traz grandes expectativas para as empresas no sentido de, por meio da mineração de dados, ajudá-las em novos insights voltados, por exemplo, para a análise de risco, fraude e, especialmente, na captura e entendimento dos hábitos dos consumidores. Entretanto, junto dessas possibilidades surgem grandes desafios inerentes ao uso responsável dos dados utilizados que permitem avaliar o comportamento dos consumidores (JAEGER, 2013).
Como exemplo de impactos positivos, é possível citar a tomada de decisão mais assertiva, rapidez na comercialização de produtos, melhoria nos serviços oferecidos aos clientes e, consequentemente, incremento dos resultados. Em contraponto, as violações de privacidade, por meio da utilização do Big Data, podem acarretar problemas às empresas (INFORMATION SYSTEMS AUDIT AND CONTROL ASSOCIATION, 2013a).
De acordo com Manyika et al (2011), a utilização do Big Data apoiará novas ondas de crescimento da produtividade no universo empresarial e será a base fundamental da concorrência e crescimento para as organizações, considerando o mercado competitivo e o potencial de captura do valor proporcionado. Na maior parte das empresas, os concorrentes estabelecidos e os novos entrantes aplicarão estratégias baseadas na exploração de dados para inovar, competir, obter o valor das informações com profundidade e em tempo real. Assim, a modelagem dessas estratégias de utilização dos dados deve exercer papel fundamental para assegurar que as organizações alcancem o maior potencial do Big Data em áreas chave de talento, pesquisa e desenvolvimento, e infraestrutura, de maneira a fomentar a inovação nessa dinâmica arena.
Com o desenvolvimento da tecnologia da informação, surgiram soluções baseadas na
pegadas e vestígios de muita relevância. Informações de cunho privado pessoal podem ser capturadas por conta da disponibilidade dessas informações publicadas na Internet. Algumas pessoas com intenções maliciosas usam essas informações para fins escusos como fraudes. Essa situação traz muitos problemas e perdas econômicas para a vida pessoal dos indivíduos. Por isso, a questão relacionada à privacidade pessoal tem causado grande preocupação para a indústria e para a academia. No entanto, há poucos trabalhos sobre a preservação da privacidade pessoal no momento (LIU et al, 2015).
Em face da escassa produção acadêmica sobre o tema, quase inexistente no Brasil, a justificativa para a realização do presente trabalho tem como base a relevância e a contribuição para a academia. É importante ressaltar que o foco do estudo não está voltado para questões de segurança, para temas voltados exclusivamente à tecnologia da informação em si ou ainda para discussões sobre dados estruturados de propriedade, sob gestão e armazenados nas empresas em sistemas internos, assuntos para os quais há vasta literatura a respeito. A pesquisa procura alinhar as práticas que podem ser utilizadas no mundo corporativo, com viés estratégico, social e legal, para a preservação da privacidade na exploração de dados tidos como públicos, não estruturados, capturados de fontes externas por meio do Big Data.
Com isso, questões como políticas relacionadas à privacidade e responsabilidades terão de ser discutidas nesse universo de grandes dados. Isso tudo, para permitir o equilíbrio entre a liberdade para as organizações utilizarem os dados em seu pleno potencial e o abrandamento de temores entre o público sobre a manutenção do compromisso relacionado à privacidade individual. Esse balanço requer profundos debates sobre esses pontos, de modo que as políticas sejam modeladas sem se perder de vista os direitos e deveres de cada parte (MANYIKA et al, 2011).
1.4 FORMULAÇÃO DO PROBLEMA
As empresas desejam colher os benefícios do Big Data e seu vasto potencial, porém devem reconhecer sua responsabilidade para a reserva da privacidade dos dados pessoais coletados e analisados pelo Big Data. Mecanismos adequados de manutenção e preservação da privacidade devem ser áreas de foco em toda iniciativa de Big Data.
clientes, levando em conta as diretrizes e técnicas existentes sobre a preservação da privacidade individual, na busca do equilíbrio entre a obtenção de valor e o respeito do direito dos consumidores quanto ao controle da exposição e a disponibilidade de dados acerca de si.
Nessa linha, é necessário buscar resposta para a questão Quais as diretrizes e técnicas que as organizações devem observar em relação à utilização de dados, por meio do uso do Big Data, de forma segura e legal, para a preservação da privacidade dos indivíduos sem se perder de vista os benefícios potenciais que podem ser
1.5 OBJETIVO
O objetivo do trabalho é a identificação de diretrizes consubstanciadas em dispositivos legais e regulamentares, bem como de técnicas para a preservação da privacidade individual e tratamento dos aspectos que afetam a privacidade na utilização do Big Data.
1.6 ESTRUTURA DO TRABALHO
Após este capítulo de Introdução, o segundo capítulo contempla o referencial teórico onde é realizada uma abordagem do tema Big Data, tratando do conceito, características, ciclo de vida, aplicações e usos do Big Data, Big Data e a Internet das Coisas, desafios e vantagem competitiva e inovação. O segundo capítulo abrange ainda o tema Privacidade de modo geral e, também, em relação ao Big Data, passando pelo conceito, tipos e características, estudo sobre dados pessoais, distinção entre dados pessoais e impessoais, eventos de risco e, por fim, preocupações e ameaças relacionadas à privacidade.
O terceiro capítulo trata da metodologia de pesquisa, descrevendo a classificação desse estudo e as etapas do trabalho. No quarto capítulo, são debatidas os dispositivos legais e regulamentares para a preservação da privacidade dos dados pessoais, considerando o contexto geral, modelos e regulamentações pelo mundo, contemplando Europa, Estados Unidos, Ásia, OECD e Brasil, finalizando com considerações adicionais sobre o tema.
2 FUNDAMENTAÇÃO TEÓRICA
2.1 BIG DATA
2.1.1 Conceito
Segundo a Information Systems Audit and Control Association (ISACA) (2013a), Big Data é um termo tanto técnico quanto de marketing, que se refere a informações de recursos de negócios valiosos. Representa uma tendência em tecnologia que abre caminho para um novo método de compreensão do mundo e do processo decisório de negócios. Essas decisões são tomadas com base em quantidades muito grandes de dados estruturados, não estruturados e complexos como, por exemplo, tweets, vídeos, transações comerciais, cujo processamento usando ferramentas básicas é muito difícil. O Big Data refere-se aos conjuntos de dados muito grandes ou com rápidas mudanças para serem analisados com técnicas de banco de dados relacionais tradicionais ou multidimensionais ou ferramentas de software comumente usadas para capturar, gerenciar e processar os dados em um tempo razoável. Fatores como melhoria na tomada de decisão, rapidez na comercialização dos produtos, melhores serviços para o cliente e aumento nos lucros são apenas alguns dos benefícios que contribuíram para a explosão da implementação de Big Data em empresas de todos os tamanhos.
Atualmente, embora a importância do Big Data ter sido reconhecida, há opiniões diferentes sobre sua definição. Em geral, Big Data significa conjuntos de dados, que não podem ser adquiridos, gerenciados e processados pela Tecnologia da Informação (TI) tradicional e ferramentas de software e hardware dentro um tempo tolerável. Por conta de preocupações diversas, cientistas, empresas de TI, pesquisadores acadêmicos, analistas de dados e profissionais técnicos têm definições diferentes sobre o Big Data (CHEN; MAO; LIU, 2014).
centenas de petabytes (PB), o Facebook gera os dados de log de mais de 10 PB por mês, a Baidu, uma empresa chinesa, processa dados de dezenas de PB, e Taobao, uma subsidiária do Alibaba, gera dados de dezenas de terabytes (TB) para o comércio on-line por dia.
Para Fox e Do (2013), em relação ao crescimento de dados digitais, o Big Data é o termo introduzido para descrever o gerenciamento e processamento da informação envolvendo dados em volume crescente, de grande complexidade, variedade e velocidade. Kim, Trimi e Chung (2014) afirmam que o Big Data é um termo genérico para quantidades massivas de dados digitais brutos que podem ser coletados em variadas fontes, não estruturados, cuja análise não pode ser realizada por meio de técnicas convencionais. As abordagens relativas ao Customer Relationship Management (CRM) e os data warehouses, que eram os desafios que existiam há alguns anos atrás, geraram valor limitado em face do investimento realizado nelas (DINIZ, 2014).
De acordo com Miller (2013 apud PARK; LEYDESDORFF Big Data
refere-se a tecnologias analíticas que existiram por anos, mas podem agora ser aplicadas rapidamente em grande escala e serem acessíveis a mais usuários. A esse respeito, a pesquisa sobre Big Data reflete que para se extrair significado de um volume enorme de dados são incorporadas várias técnicas como a mineração de dados e a visualização em diversos campos, incluindo as ciências humanas e sociais.
Segundo Rubinstein (2013), Big Data refere-se a uma nova abordagem pela qual as organizações, incluindo instituições governamentais e privadas, combinam diversos grupos de dados digitais e então usam técnicas estatísticas e outras de mineração de dados para extrair informações ocultas e correlações surpreendentes. Bifet (2013) alinha o entendimento de que Big Data é um novo termo utilizado para identificar o conjunto de dados que, devido ao seu grande volume, não pode ser gerenciado com ferramentas usuais de mineração de dados.
Cuzzocrea, Song e Davis (2011) indicam que o Big Data se refere a enormes quantidades de dados não estruturados produzidos em aplicações de grande performance em uma grande e heterogênea família de cenários de usos científicos de computação a redes sociais, de aplicações governamentais a sistemas de informações médicas, e assim por diante. Dessa massa de dados derivam inteligência e conhecimento utilizável.
identificação de padrões para o atendimento da demanda econômica, social, técnica e legal. Mito, por conta da crença de que grandes bancos de dados podem oferecer uma forma avançada de inteligência e conhecimento que pode gerar insights que até então eram impossíveis, com aura de verdade, objetividade e precisão. O Big Data, segundo os autores, é visto como uma solução para endereçar várias questões relacionadas a problemas sociais, oferecendo o potencial para novos insights em diversas áreas como a pesquisa sobre doenças, terrorismo e mudanças climáticas. Porém, em outra visão o Big Data pode ser reconhecido como mecanismo de invasão de privacidade, redução da liberdade, incremento do poder de controle do estado e de corporações.
Ademais, os autores afirmam que o Big Data possibilita a utilização de ferramentas para a coleta e a análise de dados com grande escala de capacidade e profundidade. Reformula questões-chave sobre a constituição do conhecimento, dos processos de pesquisa, como deveria ser o envolvimento com a informação, a natureza e a categorização da realidade, não simplesmente auxiliando em relação a questões de atividades econômicas, mas também modelando a realidade e demarcando novos terrenos, métodos de conhecimento e definições da vida social. Permite a prática da apofenia, fenômeno cognitivo de percepção de padrões ou conexões em dados aleatórios, encontrando padrões, até então não identificados, simplesmente por conta da enorme quantidade de dados que podem oferecer conexões que irradiam em todas as direções.
Bertot e Choi (2013) definem Big Data como um conjunto de dados que não pode ser analisado por meio de ferramentas analíticas convencionais. O fenômeno é medido em
terabytes (TB) que são criados por meio de esforços colaborativos e requerem crescente poder de processamento e novos instrumentos analíticos. Envolve uma grande gama de tipos de dados como textual, numérico, imagem, vídeo; pode cruzar múltiplas plataformas de dados como os de mídias de redes sociais, como arquivos de log da Internet, sensores, dados de localização de
smartphones, documentos digitalizados, fotografias, arquivos de vídeos.
Dumbill (2012) afirma que o Big Data são dados que excedem a capacidade de processamento de sistemas de banco de dados convencionais. O fenômeno está intimamente ligado ao surgimento da ciência de dados, uma disciplina que combina matemática, programação e instinto científico. Essa abordagem pode se caracterizar como a aplicação de técnicas analíticas para buscar, agregar e cruzar grandes conjuntos de dados. Estes grandes conjuntos de dados podem ser obtidos de dados publicamente disponíveis a conjuntos de dados internos sobre consumidores de uma companhia em particular. Cada vez mais, o Big Data inclui não apenas informação aberta, mas se estende para a coleta de informação em setores privados (PRIVACY INTERNATIONAL, 2015b).
Nunan e Di Domenico (2013) apontam que o conceito de Big Data pode ser concebido em três perspectivas. A primeira é a resposta os problemas tecnológicos associados com armazenamento, segurança e análise do sempre crescente volume de dados que está sendo coletado pelas organizações. Isto inclui a gama de inovações técnicas, tais como novos tipos de bancos de dados e armazenamento em nuvem. A segunda perspectiva tem foco no valor comercial que pode ser adicionado às organizações por meio da geração mais efetiva de insights
a partir dos dados. Esse valor tem emergido através da combinação de melhores tecnologias e grande disposição dos consumidores em compartilhar informações pessoais por meio dos serviços da Web. Por fim, a terceira perspectiva considera o vasto impacto social do Big Data, particularmente as implicações para a privacidade individual e o efeito na regulamentação e diretrizes para o uso ético desses dados.
Por conta do disseminado e constante uso de telecomunicações e outros dispositivos direcionados por inovações na tecnologia, a informação digital é constantemente gerada a partir de aparelhos de GPS, caixas automáticos, digitalizadores, sensores, celulares, satélites e mídias sociais. Esses dados comumente referidos como Big Data são potencialmente úteis e requerem novas ferramentas e métodos de captura, gestão e processamento de modo eficiente, para a geração de iniciativas inovadoras. Assim, inovações tecnológicas, vasto uso de dispositivos eletrônicos e toda a geração de informações digital trazem mudanças fundamentais na disponibilização de informações em tempo real (UNITED NATIONS STATISTICS DIVISION
otimização de processos. Esses dados requerem a aplicação de técnicas emergentes de estatística, processamento e análise para o propósito de avanço empresarial e para derivar conclusões que são benéficas ao negócio. O termo Big Data também descreve grandes volumes de alta velocidade, complexidade e variabilidade de dados que requerem técnicas e tecnologias avançadas para permitir a captura, armazenamento, distribuição, gerenciamento e análise da informação (NAVETTA; 2014).
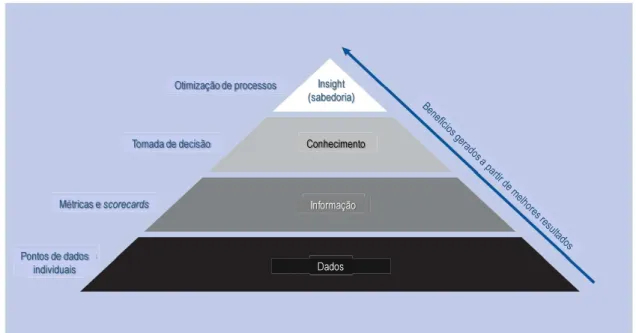
Nessa linha que permeia a melhoria na tomada de decisão e insights, Pepper e Garrity (2014) indicam que os dados isoladamente não são úteis; quando esses elementos podem ser utilizados para modificar processos, tem impacto positivo direto na vida das pessoas e organizações. Na hierarquia exposta na Figura 1, os dados agregados tornam-se informação que, quando analisadas, produzem conhecimento que apoia a tomada de decisão, levando a
insights e ao nível mais alto que é a sabedoria.
Figura 1 - Transformando dados em insights
Fonte: Ackoff (1989 apud PEPPER; GARRITY, 2014).
Também é importante criar um ambiente de confiança no uso do Big Data para que se garanta a preservação da privacidade e da confidencialidade da informação pessoal (UNITED NATIONS ECONOMIC AND SOCIAL COUNCIL, 2014).
2.1.2 Características
Em 1992, Frawley, Piantesky-Shapiro e Matheus (1992) indicavam que o volume estimado de informações no mundo dobrava em 20 meses. A automação das atividades empresariais produziria um crescente fluxo de dados por conta de simples transações como chamadas telefônicas, uso de cartão de crédito ou testes médicos que são usualmente registrados em computadores. Os bancos de dados científicos e governamentais cresciam rapidamente. A NASA (National Aeronautics and Space Administration) tinha mais dados do que ela poderia analisar. A previsão era que a observação por satélites, planejada para 1990, gerava a expectativa de 1 terabyte de dados todos os dias. Como resultado, havia um crescente gap entre a geração e o entendimento dos dados. Ao mesmo tempo, havia grande expectativa de que os dados, inteligentemente analisados e apresentados, seriam uma fonte valorosa que poderia ser utilizada para vantagem competitiva.
Debortoli, Müller e Vom Brocke (2014) indicam que, no fim da década de 90, o termo
Big Data começou a aparecer na literatura científica, referindo-se a banco de dados que fossem tão grandes para ser suportados pela memória ou mesmo discos locais. As primeiras publicações sobre Big Data foram originadas do campo da computação científica, mas em 2001 Doug Laney
e variedade, que rapidamente tornaram-se as dimensões que constituem o Big Data. Em meados da década de 2000, a área empresarial voltou os seus interesses para o fenômeno e mudou o foco de questões técnicas como armazenamento para a sua análise. Empresas cujo negócio se baseia na Internet como Google, Amazon e Facebook estiveram entre as primeiras a explorar as sofisticadas aplicações de mineração de dados e técnicas de aprendizado de máquina. O que diferencia as aplicações atuais de análise de Big Data das tradicionais aplicações de inteligência empresarial como business intelligence ou BI não é somente a amplitude e profundidade dos dados processados, mas também os tipos das questões que eles respondem.
Figura 2 - Similaridades e diferenças entre as áreas de competência em BI e Big Data
Fonte: Debortoli, Müller e Vom Brocke (2014)
Nesse sentido, identifica-se um número de similaridades entre os campos da BI e do Big Data. Especialmente nos conceitos genéricos de TI e métodos e habilidades negociais, observa-se uma considerável sobreposição entre BI e Big Data. Por exemplo, trabalhar em ambos campos requer conhecimentos em engenharia de software e bancos de dados. Habilidades desenvolvidas em vendas e negócios para o gerenciamento das soluções de BI e do Big Data, também se sobrepõem. Finalmente, a sobreposição no domínio do conhecimento e pesquisa sobre marketing digital e ciências médicas, domínios sabidos que são especialmente guiados por dados (DEBORTOLI; MÜLLER; VOM BROCKE, 2014).
Zikopoulos et al (2012) indicam que o volume de dados armazenados atualmente aumenta expressivamente. No ano de 2000, 800.000 petabytes (PB) de dados foram armazenados no mundo, porém, naturalmente, muitos dados são criados, mas não são analisados. A expectativa é que o número alcance 35 zettabytes (ZB) em 2020. O Twitter sozinho gera mais do que 7 terabytes (TB) por dia, Facebook 10 TB e algumas empresas geram
Figura 3 - Quantidade de dados armazenados em 2010 no mundo (em petabytes - PB)
Fonte: Manyika et al (2011)
No entendimento dos autores, assim como o volume, a variedade associada ao fenômeno
Big Data traz novos desafios que devem ser tratados. Com o aumento expressivo da quantidade de sensores e dispositivos inteligentes, assim como as tecnologias colaborativas sociais, os dados nas empresas têm se tornado complexos. Além dos tradicionais dados relacionais, são considerados dados brutos, semiestruturados e os não estruturados provenientes de páginas na
Web, buscas indexadas, mídias sociais, e-mails, documentos, sensores que capturam dados de sistemas ativos e passivos e assim por diante. Os sistemas tradicionais podem ter dificuldades para o armazenamento e a performance requerida na análise para a extração do conhecimento desses conteúdos em face de que muitas dessas informações que estão sendo geradas não se prestam ou não se encaixam nas tecnologias tradicionais de bancos de dados.
Além do volume e da variedade dos dados coletados e armazenados, os autores assinalam que a velocidade em que os dados são gerados também carece de tratamento. O conhecimento convencional de velocidade, tipicamente, considera o quão rápido os dados chegam e são armazenados e ao seu respectivo ritmo de recuperação. Para tratar da velocidade, um novo modo de encarar o problema deve começar pela origem da geração dos dados e considerar a rapidez com que esses dados fluem, levando em conta que atualmente as empresas
América
do Norte Europa China
Japão
Ásia-Pacífico (demais) Índia
América Latina
lidam com petabytes (PB) de dados em vez de terabytes (TB) e o aumento considerável de sensores produzindo dados e outros fluxos de informação tem levado a um patamar em que os sistemas tradicionais não podem mais dar cabo.
No que tange ao volume e à variedade, observa-se na Figura 4 o comportamento da geração de volumes relativos a dados estruturados e não estruturados gerados e esperados de 2008 a 2015 no mundo, projetando uma diferença de mais de 200 petabytes em 2015 comparada à diferença de mais de 50 PB em 2012 em relação a 2008. Análises, incluindo a combinação dos dois tipos de dados, requerem integração, interpretação e o sentido de que cada vez esses dados são oriundos de ferramentas da ciência da computação, linguística, econometria, sociologia e outras disciplinas (DHAR, 2013).
Figura 4 Comportamento observado e esperado da geração de dados estruturados e não estruturados
Fonte: DHAR (2013)
em nuvem proporciona uma promissora plataforma para armazenamento e processamento do
Big Data.
Na visão de Navetta (2014), as características do Big Data podem ser resumidas da seguinte forma: a) Volume: grande quantidade de dados gerados ou da intensidade de dados que deve ser absorvida, analisada e gerenciada para a tomada de decisões com base na completa análise dos dados; b) Velocidade: forma como os dados são produzidos e alterados e a rapidez com que os dados são recebidos, entendidos e processados; e c) Variedade: o surgimento da informação vem de novas fontes ambas dentro e fora das paredes das empresas ou organizações criam integração, gerenciamento, governança e pressões na arquitetura da TI.
Naturalmente, o maior desafio está no tratamento do grande volume de dados e este é o obstáculo mais simples de se identificar, assim como apontado por outros autores. Entretanto, além do volume, há outros problemas a serem ajustados como a variedade e a velocidades dos dados. Enquanto a variedade se refere à heterogeneidade dos tipos de dados, representação e interpretação semântica, a velocidade denota a taxa pela qual os dados são gerados e também pela qual devem ser tratados (JAGADISH et al, 2014).
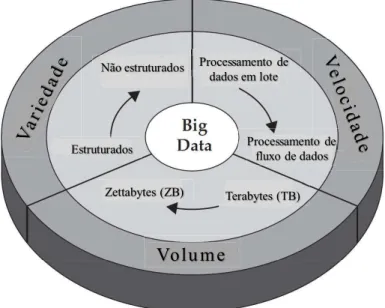
De acordo com Kowalczyk e Buxmann (2014) Big Data refere-se ao vasto crescimento dos dados que as organizações atualmente estão experimentando. Uma definição de Big Data
que tem se tornado relativamente estabelecida se baseia no modelo de 3 Vs, conforme ilustra a Figura 5. Os 3 Vs consideram três dimensões de desafios para o crescimento dos dados: volume, velocidade e variedade. Volume: refere-se ao crescimento da quantidade dos dados, volumes que usualmente são considerados para serem grandes giram em torno de vários terabytes e mais. Velocidade: descreve a velocidade da criação de novos dados, assim como o quanto esses dados são acessados para processamento e análise adicional. A velocidade do acesso em tempo real é geralmente mencionada em conexão com rapidez, entretanto a utilidade dessas dimensões é considerada altamente dependente do cenário de uso. Variedade: descreve a gama de fontes diferentes de dados e tipos, que podem ser mais ou menos estruturados.
acesso dos dados armazenados de forma rápida o bastante para torna-los utilizáveis, pois os dados necessitam de estar acessíveis em algo próximo ao tempo real. A variedade refere-se ao tipo de informação a ser armazenada. Tradicionalmente, os dados armazenados tendem a ser altamente estruturados, porém, os tipos de dados que tendem a dominar os armazenamentos modernos são não estruturados, como fluxos de dados colhidos de sites de mídias sociais, áudio, vídeo, documentos internos, e-mails, páginas da Web de organizações e comentários de consumidores.
Figura 5 - Big Data e os 3 Vs
Fonte: Zikopoulos et al (2012)
A propósito dos métodos tradicionais de armazenamento de dados, Naveenkumar e Naveenkumar (2014) explicam que o data warehouse é usualmente utilizado para o armazenamento de grandes quantidades de dados estruturados. Nesse processo, os dados são carregados pelo uso de ETL (extract, transform and load), ferramenta utilizada para a extração de dados de fontes externas, transformados de acordo com as necessidades operacionais e carregados em um banco de dados ou data warehouse.
Muitas definições comuns de Big Data, segundo Andrade et al (2014), geralmente se concentram não em tamanho, mas em vez disso, várias características, incluindo a frequência de produção, velocidade, volume, variedade e a capacidade necessária para gerenciar e processar informações. As principais características, quantidade, velocidade, variedade, são propriedades técnicas que não dependem de os dados em si, mas sim sobre a evolução das
Volume
Não estruturadosTerabytes (TB) Zettabytes (ZB)
Processamento de dados em lote
tecnologias de computação, armazenamento e processamento. Outro ponto é que o que pode parecer grande hoje provavelmente não vai ser tão "grande" em um futuro próximo.
Gupta (2014) sinaliza que o Big Data é frequentemente caracterizado por 3 Vs: o seu tremendo volume, a velocidade a que ele precisa a ser processado e a variedade de tipos de dados que ele abrange. As duas primeiras características são bastante óbvias: a tecnologia tornou possível a captura cada vez mais grandes quantidades de informação e torná-la disponível para análise em tempo real. A extração de valor do Big Data é tarefa complexa pois exige análise simultânea de vários tipos de informações como transações, e-mails, interações de mídia social, dados gerados por máquinas, dados geoespaciais, vídeo e áudio, para citar alguns dos tipos de dados não estruturados. Tradicionalmente os dados relacionados aos negócios estavam disponíveis em um formato estruturado e poderiam ser automaticamente analisados como, por exemplo, uma planilha para quantificar as devoluções de produtos diferentes em diferentes lojas ao longo do tempo. No entanto, a maior parte do valor no Big Data está nas informações não estruturadas, como a transcrição de uma sessão de bate-papo entre um cliente de varejo e com uma central de atendimento. Sintetizar os dados não estruturados de numerosas fontes e extrair informações relevantes pode ser considerado mais arte do que ciência.
Para El-Darwiche et al (2014), o Big Data representa a versão mais recente e mais abrangente de aspiração a longo prazo das organizações para estabelecer e melhorar sua tomada de decisão orientada por dados, conforme é possível visualizar na Figura 6. Caracteriza-se pelo que são conhecidos como os " três Vs": grandes volumes de dados, a partir de uma variedade de fontes, gerados a alta velocidade, ou seja, a captura de dados em tempo real, armazenamento e análise. Além de dados estruturados, como registros de clientes ou financeiros, que são tipicamente mantidos em bancos de dados tradicionais nas organizações, o Big Data baseia-se em dados não estruturados a partir de fontes tais como mensagens de mídia social, texto, vídeo e sensores técnicos, tais como o sistema de posicionamento global, dispositivos originários, muitas vezes, de fora da própria organização. A magnitude e complexidade dos dados que são produzidos excedem em muito as capacidades dos bancos de dados tradicionais para fins de armazenamento, processamento, análise e derivação de insights.
De acordo com a International Data Corporation (IDC) (2013), o termo Big Data
que integra, organiza, gerencia, analisa e apresenta dados que são caracterizados por 4 Vs: i) Volume: volume massivo de dados; ii) Variedade: amplitude dos formatos e fontes de dados; iii) Velocidade: rapidez com que a informação chega, é analisada e entregue; iv) Valor: refere-se aos custos de tecnologia e ao valor entregue a partir do refere-seu uso.
Figura 6 - Evolução da tomada de decisão orientada por dados
Fonte: El-Darwiche et al (2014)
A IDC entende que o Big Data é uma nova geração de tecnologias e estruturas, desenvolvidas para extrair economicamente valor de um grande volume de ampla variedade de dados por meio de grande velocidade, descoberta e análise. Essas tecnologias envolvem infraestrutura, como sistemas de armazenamento, servidores e infraestrutura de rede; sistemas analíticos e de descoberta; sistemas de automação e suporte à tomada de decisão; serviços de consultoria empresarial, terceirização de processos de negócios, terceirização de TI e suporte e treinamento de TI relacionados a implementação do Big Data.
2.1.3 Usos e Aplicações do Big Data
sensores químicos e biológicos do ambiente. Além disso, conforme consta da Figura 7, milhões de indivíduos estão gerando fluxos de dados pessoais por meio de seus celulares, computadores, sites e outros dispositivos digitais. Por conta desses fluxos de dados, o Big Data representa muitas oportunidades para o progresso empresarial e da sociedade. Há muitas frentes que podem ser exploradas para acelerar a descoberta e inovação. Pessoas podem usar novas ferramentas para ajudar a melhorar a sua saúde e o bem-estar, os cuidados médicos podem ser mais eficientes e efetivos. O governo também tem uma grande participação no uso de grandes bancos de dados para melhorar a entrega de serviço e monitorar ameaças à segurança nacional. Esses dados também abrem toda sorte de novas oportunidades negociais, ajudando as companhias a entender a dinâmica de certas áreas da vida, como a difusão de doenças, hábitos de consumo, atividade da vida cotidiana, que terão forte repercussão nas atividades empresariais e do governo (BOLLIER, 2010).
Figura 7 - Incremento do fluxo de dados 2005-2017
Fonte: Reimsbach-Kounatze (2015)
A International Data Corporation (IDC) (2013) apresenta uma extensa lista de oportunidades vertentes de negócios e processos em vários segmentos de mercado e governo:
a) serviços financeiros: prevenção e detecção de fraudes bancárias e de seguros; avaliação preditiva de danos na indústria de seguros; análises de reclamações em seguros; integração de dados transacionais a partir de técnicas de Customer Relationship Management (CRM), pagamentos com cartões de crédito, transações em conta e dados não estruturados de redes sociais; avaliação de exposição de portfólio e riscos; perfis de consumo, foco e otimização de ofertas para vendas cruzadas; central de atendimento a consumidores; análises de reputação da marca e de opinião de clientes; correlação de opiniões em mídias sociais com o retorno de ações para apoiar decisões de investimento; modelagem de catástrofes em seguros; gerenciamento do valor do cliente;
b) telecomunicações: otimização de rede; retenção de consumidores baseada em gravações de atendimentos, contatos e atividades de assinantes; redução de evasão de clientes; otimização de ofertas por venda cruzada; prevenção de fraudes; oferta de serviços com base em localização geográfica; alocação de largura de banda baseada em padrões de uso;
c) meios de comunicação: classificação de consumidores, prevenção de fraudes, retenção de clientes, otimização de audiência, alocação de largura de banda baseada no padrão de acesso para vídeo, música e fluxo on-line oriundo de software de jogos; d) serviços/óleo e gás: utilização de padrões em tempo real para a otimização do consumo e definição de preço; análise preditiva; previsão de carga de distribuição e agendamento; modelagem de processos operacionais; gestão de desastres; análise de feedback de consumidores e de gravações telefônicas; pesquisas da exploração na indústria de óleo e gás; processamento de dados sísmicos; otimização e vigilância de perfurações;
f) transporte: otimização de logística; análises baseadas na localização pela utilização de dados de GPS; análise de clientes e fidelidade; manutenção preventiva; otimização de capacidade e preço;
g) varejo e atacado: leiaute e localização de estoque; otimização da cadeia de fornecedores; rastreamento via identificação por rádio-frequência ou radio-frequency identification (RFID); otimização de preços; análise de comportamento de consumidores; insights práticos de consumidores, micro segmentação; análise de fidelidade e promoções; venda cruzada e indução de vendas no ponto de vendas; otimização de descontos com base nos padrões de consumo do cliente; análise de cesta baseada na demografia; otimização de merchandise; prevenção e detecção de fraudes; detecção de fraudes no comércio eletrônico;
h) produção industrial: manutenção preventiva; análise de processos e qualidade; gestão de garantias; automação da produção; automação da detecção de efeitos adversos de drogas na indústria farmacêutica; monitoramento, via sensores, para a manutenção de veículos, construções e máquinas; monitoramento para otimização do consumo de energia; análise baseada em localização pelo uso de dados de GPS; análise de comentários em redes sociais para gestão de qualidade de veículos; previsão de demandas e planejamento de fornecimentos; fábrica digital para enxugamento da manufatura; otimização da distribuição; gerenciamento de qualidade com base em comentários em redes sociais;
i) setor público: aperfeiçoamento de serviços para cidadãos e pacientes; sistemas de armas e contra o terrorismo; análise de impostos; detecção de fraude; segurança cibernética; programas de vigilância e resposta.
Por sua vez o World Economic Forum (WEF) (2012), também aborda alguns exemplos de iniciativas que podem extrair benefícios por meio da utilização do Big Data, de acordo com o Quadro 1.
atividades fraudulentas ou suspeitas, bloqueando transações futuras e minimizando perdas potenciais.
Quadro 1 - Exemplos de iniciativas no Big Data
Segmentos Exemplos de iniciativas
Serviços Financeiros Insights em relação a hábitos de economia e gastos através de setores e regiões.
Históricos de crédito individuais para avaliação dos candidatos a empréstimos e outros serviços financeiros com base em crédito.
Saúde Entendimento da saúde da população. Podem ser utilizados para criar grandes bases de dados com os quais os tratamentos e resultados podem ser comparados de modo eficiente e com eficiência de custos.
Agricultura Previsões sobre a tendência de produção de alimentos e incentivos. Avaliação adequada do armazenamento da colheita, redução de desperdícios e estragos, disponibilização de melhores informações sobre que tipos de serviços financeiros são necessários pelos fazendeiros.
Ajuda os governos e organizações de desenvolvimento identificar regiões em dificuldades e direcionar assistência direta a elas. Ajuda a prevenir que as famílias abandonem as suas terras e a queda da produção agrícola
Fonte: WEF (2012)
falsos que causam recusa de compras, deve haver equilíbrio entre as aprovações, perdas por fraudes e a satisfação do consumidor e acesso em tempo real para a avaliação de indícios de fraude que determine um padrão de normalidade de compras.
No panorama do sistema financeiro, Flood et al (2011) indicam que instituições financeiras coletam informações de centenas de fontes, incluindo prospectos, contratos, arquivos, oferta de aquisição, procurações, relatórios de pesquisa e operações de capital. As informações oriundas desses vetores alimentam bancos de dados fornecendo acesso a preços, taxas, dados descritivos, classificações e informações sobre crédito. Assim, são utilizadas para derivar rendimentos, valoração, variâncias, tendências e correlações. Elas alimentam fluxos de dados brutos e dados derivados em modelos de precificação, motores de cálculo e processos analíticos. Esses dados são ligados à contabilidade, execução de transações, compensação, liquidação, valoração, gestão de portfólios e autoridades de mercado e reguladores.
No contexto das mídias sociais, Twitter ou Facebook, o Big Data é utilizado para classificar padrões de comportamento da população em áreas urbanas por meio da utilização de dados relativos à localização. Assim, os dados sociais podem ser utilizados para definir e identificar áreas pelo padrão de comportamento em comum da população e categorizá-las em diferentes tipos como quartos, escritórios, vida noturna e cidades multifuncionais, por exemplo. Isso leva em consideração preferências pela escolha de pontos de interesse, influências e padrões de mobilidade com base nas localizações de usuários de redes sociais (BENDLER et al, 2014).
2.1.4 Big Data e IOT
O termo Internet das Coisas ou Internet of Things (IOT) descreve um serviço de informação com arquitetura baseada na Internet. O propósito da IOT consiste em facilitar a troca de informações entre objetos, bens em redes globais de cadeias de suprimentos, isto é, a infraestrutura de TI deve prover informações sobre objetos de maneira segura e confiável. A IOT também pode servir para habilitar ambientes inteligentes de modo a reconhecer e identificar objetos e recuperar informações da Internet para facilitar as suas funcionalidades adaptativas (WEBER, 2009).
de dispositivos estarão conectados à Internet, gerando dados para o Big Data na análise e extração de conhecimento.
Chen, Mao e Liu (2014) assinalam que, no modelo de IOT, uma enorme quantidade de sensores em rede é inserida em vários dispositivos e máquinas no mundo real. Tais sensores instalados em diferentes campos podem coletar vários tipos de dados, como dados do ambiente, geográficos, astronômicos e de logística. Equipamentos móveis, meios de transporte e aplicações domésticas poderiam todos servir como equipamentos de coleta de dados na IOT, como consta da Figura 8. Os autores entendem que os dados gerados pela IOT possuem características diferentes se comparadas com os dados em geral por conta dos diferentes tipos de dados colecionados, os quais têm características que incluem heterogeneidade, variedade, aspecto não estruturado, ruído e grande redundância. A IOT tem três aspectos que comportam o paradigma do Big Data: i) abundância de terminais gerando massas de dados; ii) dados gerados pela IOT são usualmente semi e não estruturados; iii) dados da IOT são úteis somente quando analisados. Muitos operadores da IOT reconhecem a importância do Big Data e que o sucesso da IOT está na dependência da integração efetiva com o Big Data e a computação em nuvem. É amplamente reconhecido que essas tecnologias são interdependentes e devem ser desenvolvidas em conjunto: de um lado, a divulgação da implementação da IOT direciona o grande crescimento de dados em quantidade de categoria, então provendo a oportunidade para a aplicação e desenvolvimento do Big Data; de outro lado, a aplicação da tecnologia do Big Data para a IOT também acelera os avanços da pesquisa e modelos de negócio da IOT.
Figura 8 - Coleta de dados de equipamentos na IOT
Mayer (2009) entende que a Internet das Coisas é um amplo campo com diversas tecnologias usadas, categorizadas em tópicos e tecnologias, conforme pode ser observado na Figura 9. A implantação dessas tecnologias não pode falhar no ponto que a Internet não foi capaz de fazer: fornecer mecanismos de privacidade adequadas desde o início. Por isso, é necessário assegurar que a privacidade adequada estejam disponíveis antes de a tecnologia ser implantada e tornar-se parte da vida diária das pessoas.
Figura 9 - Categorização de tópicos e tecnologias na IOT
Fonte: Mayer (2009)
Nessa linha, o autor entende que a IOT pode ser categorizada em oito tópicos:
a) comunicação para permitir a troca de informações entre dispositivos: a pesquisa nos protocolos de comunicação tem surgido com soluções para prover integridade, autenticidade e confidencialidade;
c) atores para performar ações no mundo físico acionados no mundo digital: a integridade, autenticidade e confidencialidade dos dados enviados para um acionador depende da segurança da comunicação;
d) armazenamento para a coleta de dados a partir de sensores, sistemas de identificação e rastreamento: a disponibilidade do armazenamento muitas vezes depende da disponibilidade da infraestrutura da comunicação e mecanismos bem estabelecidos para o armazenamento.
e) dispositivos para interação com humanos no mundo físico: a disponibilidade dos dispositivos depende da integridade, confiabilidade e disponibilidade da comunicação que conecta o dispositivo.
f) processamento para prover mineração de dados e serviços: a integridade do processamento dos dados para serviços e correlações é baseada na integridade da comunicação e do dispositivo;
g) localização e rastreamento para a determinação do local no mundo físico: a integridade da localização e o rastreamento é especialmente baseada na integridade da comunicação. A disponibilidade da localização é importante para assegurar que os sinais de referência para a localização são robustos e não possam ser manipulados;
h) identificação para disponibilizar um único objeto físico de identificação no mundo digital: para a identificação aplicam-se as mesmas premissas para localização e rastreamento. Uma diferença é a alta sensibilidade na integridade.
2.1.5 Vantagem Competitiva e Inovação no contexto do Big Data
De acordo com a Organisation for Economic Co-operation and Development (OECD) (2013b), o fenômeno do Big Data implica na enorme quantidade de dados que podem ser armazenados, vinculados e analisados, trazendo consigo a possibilidade de se encontrar informações, tendências, percepções que não foram previamente determinadas. Isto pode congregar grande valor econômico e social, mas, por outro lado, pode ter implicações em relação à manutenção da privacidade.
criam valor para empresas e consumidores, porém muitas das inovações utilizam múltiplas fontes de dados que envolvem a transferência de dados para terceiros.
A inovação tem sido um foco estratégico central de empresas, e sustentabilidade tornou-se recentemente mais um ponto convergente aos interestornou-ses corporativos, tornou-segundo ensinam Jelinek e Bergey (2013). A inovação em toda a cadeia de valor, na estratégia e nos modelos de negócios é o elemento central de qualquer empreendimento sustentável. As aplicações para a análise do Big Data podem fomentar a criação de inovação para a sustentabilidade a longo prazo na sobrevivência empresa, por meio da geração de resultados rentáveis e ajuste dinâmico com o ambiente sempre em mudança.
Nessa linha, o Big Data representa um direcionador para um amplo espectro de inovações, esquematicamente organizado pela cadeia de valor em torno do diagrama de Venn no centro da figura constante do Anexo A, permitindo que as organizações efetivem uma mudança intencional de suas capacidades gerando impulso ao mercado, em vez do que simplesmente responder a ele. A inovação é alimentada por uma perspectiva que tem base no conhecimento. As empresas devem inovar para sobreviver, pois a inovação é retratada como sobrevivência e sustentabilidade empresarial, transformando a indústria, criando um novo ambiente onde as corporações têm vantagem estratégica duradoura. Assim, olhando além da cadeia de valor, uma perspectiva baseada no conhecimento direciona a busca por significados para transformar os elementos existentes: produção, recursos, modelagem, materiais, distribuição e até a definição fundamental da indústria.
De particular interesse em termos de inovação, estão aquelas menos visíveis. Além de recursos e produtos e, certamente, além dos típicos usos nas finanças e orçamento, as empresas se mantêm pela evolução de melhores meios de manufatura, para fomentar ou assegurar qualidade, para a gestão de riscos, atendimento de clientes ou melhoria da experiência do consumidor. Com a aplicação do Big Data a cada um desses elementos, mais garantias de inovações no futuro. Os modelos de inovação empresariais surgem em novas combinações de produtos, recursos e serviços arrebatando para incomensuráveis grandes áreas para a criação de vantagem competitiva e sua sustentabilidade (JELINEK; BERGEY, 2013).
Al-Aqeeli e Alnifie (2015) afirmam que, em face da revolução das tecnologias digitais recentes e aplicações Web, tais como as redes sociais e outras aplicações, o armazenamento, gerenciamento e análise desses dados pode proporcionar às organizações vantagem competitiva. Para explorar esse potencial, as empresas precisam investir em desenvolvimento de soluções, infraestrutura de hardware e analistas para manipular os dados acumulados coletados, resultado do Big Data. Muitas vezes, tal investimento está além das capacidades da organização, enquanto em outras vezes a aquisição de tais recursos seria considerada como não rentável no longo prazo, uma vez que pode não fazer uso deles para o seu pleno potencial.
parte crucial de infraestruturas informacionais do capitalismo contemporâneo, podem ser utilizados para definição de preços e ofertas de produtos, com o aumento da satisfação e do bem-estar do consumidor, além de propiciar o crescimento da rentabilidade das empresas.
Nesse contexto que evidencia potencial proporcionado pela aplicação do Big Data, conforme ilustra a Figura 10, Mcguire, Manyika e Chui (2012) relatam que o uso do fenômeno está tornando-se um meio fundamental para levar as companhias a superar os seus pares. Na maioria das indústrias, os competidores já estabelecidos e os novos entrantes, igualmente, alavancarão estratégias direcionadas por dados para inovar, competir e capturar valor. Na área de saúde, os precursores no uso de dados estão analisando os resultados de produtos farmacêuticos quando eles são largamente prescritos e descobrindo benefícios e riscos que não eram evidentes durante os limitados testes clínicos. Outras adesões recentes ao uso do Big Data
referem-se à utilização de sensores inseridos em produtos desde brinquedos para crianças até bens industriais, para determinar como esses produtos são, de fato, utilizados no mundo real pelos usuários. Tal conhecimento, então, contribui para a criação de novos serviços e desenvolvimento de futuros produtos.
Figura 10 - Potencial do Big Data