Observatório de publicações científicas de
CSCW
Dissertação de Mestrado apresentada por
Jorge Miguel Guerra dos Santos
Sob orientação dos Professores Doutores Benjamim Fonseca e Hugo Paredes
Universidade de Trás-os-Montes e Alto Douro
Escola de Ciências e Tecnologia
Departamento de Engenharias
Dissertação apresentada à Universidade de Trás-os-Montes e Alto Douro para cumprimento dos requisitos necessários à obtenção do grau de Mestre em Engenharia Informática, sob a orientação dos Professores Doutores Benjamim Fonseca e Hugo Paredes.
V
Agradecimentos
No término de mais uma etapa do meu percurso académico, seria uma lacuna, deixar de expressar os meus sinceros agradecimentos, a todos quantos de alguma forma, contribuíram intervindo nesse processo, não querendo ser injusto por qualquer omissão.
Aos meus colegas de laboratório pelo bom ambiente criado, pois só de trabalho não vive o homem, a eles um muito obrigado.
Aos meus colegas de mestrado que de uma forma ou de outra sempre contribuíram para o meu percurso letivo. Aqui, deixo ênfase ao meu também amigo Henrique, pelos trabalhos que fizemos juntos, e pelo incentivo e boa disposição que sempre me transmitiu.
Não deixando por omissão, quero também agradecer a um professor em particular, o Professor João Varajão, cuja temática dada durante e após o mestrado bem como a abertura sempre demonstrada no ensinamento de novas temáticas que foram de um enriquecimento elevado.
Aos Professores Doutores Benjamim Fonseca e Hugo Paredes, que quer como meus professores quer como orientadores nunca me deixaram “deitar a toalha ao chão”, incentivando sempre abertura a novos conceitos. A paciência e determinação com que sempre me incentivaram deram um contributo fulcral para que eu tenha passado a linha entre o não fazer e o fazer.
Aos meus amigos André Pinheiro e Filipe Fernandes pela grande amizade que sempre foi característica entre nós. Para eles uma frase “Verae amicitiae sempiternae sunt”.
Ao meu amigo “Tozé” pela grande paciência com que sempre me ajudou e ouviu, pois quando eu não acreditava sempre me ensinou que “Labor improbus omnia vincit”. O agradecimento a ti será eterno.
À minha família, aos meus pais, a eles, que quando tudo corria menos bem, sempre me diziam que “tudo é impossível ate à hora de ser feito”, agradeço por ter uns pais como eles pois imagino que melhores não haverá. A Paciência deles ao longo destes anos de vida sempre foram de um tremendo valor, a eles deve-lhes tudo o que sou hoje; aos meus dois irmãos, que agradeço por serem irmãos fantásticos.
VII
Resumo
Num contexto em que a tecnologia é desenvolvida a um ritmo elevado e onde são necessárias soluções robustas para colmatar lacunas e requisitos sociais em constante evolução, o aumento da informação científica apresenta-se como um desafio eminente para instituições, investigadores, equipas de investigação, laboratórios associados, e público em geral. O acentuado volume de publicações apresentado anualmente em atas de conferência, revistas especializadas, e outros meios de disseminação de dados científicos tem levado os investigadores a despender menos tempo com cada artigo e a excluir fontes de informação relevantes de encontro a necessidades específicas. Neste sentido, esta dissertação assenta na implementação de uma infraestrutura tecnológica de suporte a um sistema de informação bibliográfico com a capacidade de armazenar meta-informação de publicações científicas classificadas por múltiplos utilizadores com o intuito de enriquecer os motores de busca e os sistemas de indexação atuais através de uma base aberta de conhecimento com enfoque em dados científicos extraídos a partir de textos não-estruturados e outras formas de produção intelectual. Inicialmente, o sistema visa suportar o campo de Trabalho Cooperativo Suportado por Computador dada a sua natureza multidisciplinar e os desafios que lhe estão associados a nível social e tecnológico. Os processos de análise de requisitos básicos e especificação das funcionalidades mediante os requisitos funcionais, suportam o desenvolvimento de um protótipo que assenta na mediação ao processo de anotação de informação bibliográfica, gestão de níveis e permissões de utilização, e manipulação e visualização de dados sob diferentes perspetivas. Complementarmente, são feitos testes de robustez para verificar o desempenho do sistema.
Palavras-chave
Computação Humana, Crowdsourcing, Groupware, Inteligência Coletiva, Sistemas de Informação Bibliográficos e Trabalho Cooperativo Suportado por Computador.
IX
Abstract
In a context in which the technology is developed at an increasing pace and where robust solutions are needed to fill social gaps and requirements continuosly evolving, the increasing number of scientific data can be considered an eminent challenge for institutions, researchers, research teams, associated labs, and general public. The remarkable volume of publications presented annually in conference proceedings, journals, and other dissemination channels of scientific data has led researchers to expend less time with each paper and excluding relevant information sources to cope with specific needs. In this sense, this master thesis is established on the implementation of a technological infra-structure to support a bibliographic information system able to store publication metadata classified by a crowd of users with the aim of enriching the current search engines and indexing mechanisms with an open semantic knowledge base of scientific data mined from unstructured texts and other intellectual assets. Initially, the system will support the field of Computer Supported Cooperative Work due to its multidisciplinary nature and its associated challenges at a social and technological level. The processes related with the analysis of basic requirements and functionalities’ specification according to functional requirements support the development of a prototype based on the mediation of the processes of bibliographic information annotation, management of use levels and permissions, and data handling and visualization under different perspectives. Complementarily, a set of robustness tests are performed to verify the system performance.
Keywords
Human Computation, Crowdsourcing, Groupware, Collective Intelligence, Bibliographic Information Systems and Computer Supported Cooperative Work.
XI
Índice
Índice de figuras ... XIII Índice de tabelas ... XV Glossário, acrónimos e abreviaturas ... XVI
Capítulo 1 : Introdução ... 1
1.1. Motivação ... 3
1.2. Objetivos ... 4
1.3. Estrutura da dissertação ... 5
Capítulo 2 : Revisão bibliográfica ... 7
2.1. Enquadramento ... 8
2.1.1. Trabalho cooperativo suportado por computador e sistemas colaborativos ... 9
2.1.2. Colaboração científica, cienciometria, modelos de classificação, e análise semântica ... 9
2.1.3. Inteligência coletiva, crowdsourcing e computação humana ... 10
2.2. Definições de sistemas de informação existentes ... 12
2.2.1. Definição de repositório ... 12
2.2.2. Definição de biblioteca digital ... 12
2.2.3. Sistemas de informação bibliográfica ... 13
2.2.4. Colaboratórios científicos ... 13
2.2.5. Ciência de acesso aberto ... 14
2.3. Comparação e características de sistemas ... 14
Capítulo 3 : Especificação do sistema ...17
3.1. Análise de requisitos ... 18 3.1.1. Requisitos funcionais ... 18 3.1.2. Qualidade ... 19 3.1.3. Interfaces ... 19 3.1.4. Restrições... 19 3.2. Modelo do sistema ... 20 3.2.1. Especificação do sistema ... 21
3.3. Modelo de protótipo proposto ... 25
Capítulo 4 : Implementação do sistema ...29
4.1. Opções tecnológicas ... 30
4.1.1. Servidor Web ... 30
XII
4.1.3. Base de dados ... 32
4.2. Detalhes da implementação ... 34
4.2.1. Criação de classes de autenticação ... 34
4.2.2. Criação de classes do núcleo ... 36
4.2.3. Criação da base de dados ... 37
4.3. Instalação e funcionamento da plataforma ... 38
4.3.1. Especificações técnicas da instalação ... 38
4.3.2. Instalação do sistema ... 39
4.3.3. O sistema - Observatório... 39
4.4. Testes de sistema ... 44
4.4.1. Resultados ... 45
Capítulo 5 : Conclusão e trabalho futuro ...49
XIII
Índice de figuras
Figura 1 - Modelo de colaboração em grande escala para a análise de bibliografia científica
(Correia et. al., 2013) ... 15
Figura 2 - Arquitetura do Observatório (Correia et. al., 2013) ... 20
Figura 3 - Caso de uso da inserção de uma publicação ... 22
Figura 4 - Casos de uso de registo de utilizador ... 23
Figura 5 - Diagrama ER da base de dados ... 24
Figura 6 - Autenticação no sistema ... 25
Figura 7 - Página inicial de um utilizador ... 26
Figura 8 - Visualização de uma publicação ... 26
Figura 10 - Inserção de uma publicação ... 27
Figura 11 - Classes de autenticação ... 35
Figura 12 - Exemplo de revogação de permissões ... 35
Figura 13 - Implementação do núcleo do observatório ... 36
Figura 14 - Esquema da base de dados de autenticação ... 37
Figura 15 - Base de dados do núcleo ... 38
Figura 16 - Cronologia de instalação e configuração ... 39
Figura 17 - Listagem de publicações sem permissões especiais ... 40
Figura 18 - Listagem de publicações com permissões especiais ... 40
Figura 19 - Detalhes da Publicação sem permissão ... 40
Figura 20 - Detalhes da Publicação com permissão ... 41
Figura 22 - Painel de administração ... 42
Figura 23 - Vista parcial da listagem de uma publicação em ambiente de administração ... 42
Figura 24 - Painel de criação de uma publicação ... 43
Figura 25 - Listagem de utilizadores ... 44
Figura 26 - Criação de um utilizador ... 44
Figura 27 - Recolha dos resultados ... 46
Figura 28 - Teste de consulta simples ... 46
XV
Índice de tabelas
Tabela 1 - Comparação entre CONTENTdm, DSpace, e DBLP (adaptado de (Hull et al.,
2008) e (Santos et al.) ... 16
Tabela 2 - Tabela de equivalência de requisitos - funcionalidades ... 18
Tabela 3 - Inserção de publicações ... 22
Tabela 4 - Registo de utilizadores ... 23
Tabela 5 - Comparação entre Apache e IIS ... 30
Tabela 6 - Comparação entre Zend e Synfony2 ... 31
Tabela 7 - Comparação dos sistemas de base de dados ... 32
Tabela 8 - Especificações da plataforma ... 39
XVI
Glossário, acrónimos e abreviaturas
ASC - Augmented Social Cognition
DBLP - Digital Bibliography & Library Project CMC - Computer-Mediated Communications
CSCL - Computer-Supported Collaborative Learning CSCW - Computer- Supported Cooperative Work CVE - Collaborative Virtual Environments
C-C - Collaborative Commerce
HCI - Human-Computer Interaction
HPU - Human Processing Units
HTML - Hypertext Markup Language HTTP - Hypertext Transfer Protocol
IIS - Internet Information Services
MVC - Model-view-controller
AO - Office Automation
PDF - Portable Document Format
PHP - Hypertext Pre-processor
Q&A - Question & Answering
SQL - Structured Query Language
TIC - Information and communications technology
UML - Unified Modelling Language
1
1
Capítulo 1: Introdução
“Ajuda o teu semelhante a levantar a sua carga, porém, não a carregá-la.”
Pitágoras
Este capítulo tem como finalidade a introdução à dissertação, sendo apresentados a motivação e os objetivos propostos.
Na parte final é apresentada a estrutura da dissertação para que se possa compreender bem a sua evolução.
2 A evolução da sociedade e a consequente diversidade das necessidades sociais provoca uma evolução constante da tecnologia, tornando-se imperativo analisar o crescente volume de informação científica criada e partilhada por investigadores, mas também pelo público em geral, com o intuito de acompanhar avanços alcançados nos mais diversos domínios do conhecimento e diversidade das emergentes necessidades sociais.
Os esforços de trabalho cooperativo entre investigadores têm originado estruturas complexas que exigem uma análise exaustiva ao seu papel e impacto científico, bem como aos modelos mentais nos processos de interpretação, avaliação, criação, aquisição e distribuição de conhecimento (Inzelt et al., 2009). Os processos de recolha e análise de dados compreendem atividades de trabalho intensivo para descobrir padrões e tendências futuras. Os cientistas podem interpretar essas evidências de formas distintas, com ênfase na sua experiência, num desafio recorrente para se manterem a par dos avanços, revelar hipóteses, avaliar os limites disciplinares, campos de investigação, e teorias anteriores às quais não foi dada a devida importância num plano bibliométrico (Evans et al., 2011). Neste contexto, os investigadores e o público em geral despendem muito do seu tempo e esforço cognitivo com a exploração e análise de dinâmicas de colaboração científica usando técnicas ineficientes (Helbing et al., 2011). A forma como esses dados são recolhidos, catalogados, classificados e visualizados difere de campo para campo (Farooq et al., 2009), justificando uma análise aprofundada por parte da comunidade científica.
A extração da semântica a partir dos dados publicados, quanto possível, torna-se uma questão essencial para permitir um retrato desenhado e atualizado da produção científica, um trabalho de investigação que tem vindo a ser realizado manualmente para examinar variações, correlacionar evidências e compilar estatísticas descritivas (Correia et. al., 2013). As métricas e os sistemas de medição existentes são insuficientes para recolher a estrutura intelectual de um campo científico, o que pode ser entendido como uma abstração do conhecimento coletivo dos seus investigadores, bem como para traçar toda uma panóplia de atividades socialmente mediadas de apoio à transmissão científica com contribuições em diferentes disciplinas (Lane, 2010). Nesta perspetiva, a cienciometria precisa ser realizada num contexto social (Correia et. al., 2013) para avaliar o aumento da quantidade e qualidade dos artefactos digitais científicos, tendo em conta os fatores humanos como um campo que necessita de intervenção.
Os sistemas de informação bibliográficos atuais manifestam uma falta de evidências semânticas que podem ser alcançadas a partir do trabalho humano em grande escala usando vários tipos de mecanismos de classificação. Segundo (Quinn et al., 2011), esta abordagem
3 tem sido aplicada na marcação (tagging) de imagens (por exemplo, ESP Game1),
classificação de proteínas (por exemplo, Fold.it2 e RCSB Protein Data Bank3), classificação
de galáxias (mais concretamente, Galaxy Zoo4) e respostas a questões sobre os obstáculos
urbanos (por exemplo, VizWiz5). O crowdsourcing tem-se estabelecido como uma indústria de
desenvolvimento “que emprega mais de 2 milhões de trabalhadores do conhecimento, contribuindo com mais de meio bilião de dólares para a economia digital” (Vukovic et al., 2010). “Multidões” humanas (ou crowds) podem atuar como operadores cognitivos com capacidades diferentes mas complementares para resolver problemas que vão além das permitidas pelas abordagens automatizadas, combinando tarefas de inteligência humana com os sistemas de base de dados em larga escala que coordenam indiretamente esforços conjuntos para analisar grandes volumes de dados. Essa hipótese baseia-se na realização de análises semânticas entre vários colaboradores, enquanto a investigação sobre a possibilidade de escalar a recolha e avaliação manual de dados a um grande conjunto de publicações e trabalhadores do conhecimento continua por explorar em termos científicos (Eysenbach, 2011).
Com base nos problemas de computação humana e avaliação bibliográfica em grande escala apresentados atualmente, é proposto um ambiente de trabalho colaborativo para a classificação de bibliografia, envolvendo investigadores e público em geral em torno de meta-dados e elementos textuais semanticamente anotados. Este sistema tem como objetivo avaliar todos os tipos de artefactos digitais e acervo intelectual produzido, partilhado e mantido por investigadores - por exemplo, artigos de revista, conferências, posters, tutoriais, diapositivos em formato eletrónico, imagens, vídeos, sites, blogues, serviços Web, ferramentas de download, conjuntos de dados e fluxos de trabalho de investigação científica (Tan et al., 2010). Este sistema de informação bibliográfica alimentado pela comunidade científica pode detetar indicadores de inteligência coletiva em grande escala num dado período através de uma arquitetura de participação aberta em que o valor é criado à medida que mais utilizadores cooperam.
1.1. Motivação
A elaboração deste trabalho vem no seguimento de um estudo realizado por Correia (2012), onde foram identificados vários desafios na área da análise semântica de bibliografia científica, incluindo limitações ao nível da capacidade de processamento de informação
1 http://www.gwap.com/gwap/gamesPreview/espgame/ 2 http://fold.it/portal/ 3 http://www.rcsb.org/ 4 http://www.galaxyzoo.org/ 5 http://vizwiz.org/
4 semântica em grande escala, bem como problemas associados à granularidade, generalidade e abstração dos mecanismos de classificação atuais ou semiestruturada em constante crescimento com recurso a uma comunidade de espécies. No entanto, é detetada a inexistência do um sistema capaz de classificar informação não estruturada e catalogada.
É possível ser feita a comparação entre a classificação humana e automática com vista à melhoria dos resultados fornecidos pelos sistemas de indexação e motores de busca atuais. Ao colocar-se esse desafio, fomenta-se a colaboração entre a comunidade e, aplicando esta colaboração é possível fazer com que a classificação esteja ao alcance dos investigadores, tornando-a uma informação mais rápida e precisa face às suas necessidades de pesquisa, informação essa que com o elevado número de publicações existentes pode não ser contemplada no processo de recolha.
1.2. Objetivos
Os dados obtidos no âmbito do projeto elaborado nos anos transatos funcionarão como uma das componentes integrantes da base de dados deste estudo, na medida em que podem ser facilmente atualizados e analisados.
A concretização do objetivo inicial desta dissertação passa pela definição de objetivos parcelares que se concretizarão em várias fases do seu desenvolvimento global. Apresenta-se assim, em Apresenta-seguida, a lista sintetizada de objetivos a concretizar no âmbito desta dissertação:
• Realização de um estudo sobre plataformas existentes;
• Identificação e estudo de possíveis sistemas semelhantes ao observatório proposto; • Recolha e análise de requisitos necessários à conceção de um sistema capaz de
armazenamento de publicações e informações das mesmas;
• Desenvolvimento mediante os requisitos obtidos e testes ao seu desempenho. Colocados os pontos essenciais, e dadas as limitações encontradas nos processos de classificação bibliográfica em grande escala, o objetivo é a criação de um sistema capaz de suportar tarefas que incluam a inserção, alteração e remoção de meta-informação associada às publicações. O sistema a criar deve ser robusto pois o que está a ser criado é uma base para suportar um observatório num processo de desenvolvimento futuro. Além das tarefas básicas é também necessário criar um processo de moderação que contemple a criação de grupos com permissões e de utilizadores agregados a esses grupos.
5
1.3. Estrutura da dissertação
Esta dissertação está dividia em vários capítulos que vão ao encontro dos objetivos propostos. O primeiro capítulo apresenta o enquadramento e a motivação do trabalho, bem como os objetivos que o autor se propõe atingir. No segundo capítulo é feita uma revisão bibliográfica de conceitos relacionados com o tema, bem como os termos necessários à compreensão de toda a envolvente do sistema. No terceiro capítulo definem-se os requisitos necessários para a elaboração do sistema, sendo especificado o modelo a seguir, o sistema e o protótipo proposto. O quarto capítulo consiste numa materialização do capítulo três, onde são abordadas as comparações tecnológicas e especificações das tecnologias usadas, tanto a nível de servidor como a nível de linguagem de programação. É também detalhado o processo de desenvolvimento e apresentam-se a implementação e os testes ao sistema. Na implementação é mostrado todo o processo de instalação e funcionamento do sistema, ao passo que os testes focam-se na capacidade de robustez num teste de carga ao sistema. O quinto e último capítulo reflete sobre o processo de criação do sistema proposto bem como algumas considerações sobre a escolha de algumas tecnologias. Para terminar são referidas algumas melhorias e trabalhos futuros a acrescentar e/ou desenvolver.
7
2
Capítulo 2: Revisão bibliográfica
“A informação é uma semente que tem frutos eternos”
Juliano Kimura
Neste capítulo é feito um levantamento sobre o estado da área relativo ao tema da dissertação. Este estudo tem como objetivo demonstrar o que já foi feito, o que está a ser feito e sobretudo a enunciar todos os conceitos inerentes ao tema. São definidos conceitos necessários e comparações sobre plataformas já existentes onde se possa apresentar o que já está feito e melhorar a compreensão do que se quer fazer.
8
2.1. Enquadramento
O número crescente de dados científicos publicados anualmente em atas de conferência, revistas especializadas e demais meios de disseminação do conhecimento, tem suscitado por si um aumento de informação de tal ordem que começa a ser muito difícil para investigadores, equipas de investigação, instituições e público em geral acompanhar todos os avanços face à tentativa cada vez mais infrutífera de extrair significado de encontro a necessidades específicas, tornando-se premente a criação de alternativas para colmatar essa lacuna. Neste sentido, a informação científica necessita de um maior esforço de técnicas alternativas de catalogação e classificação que englobem mais semântica e diminuam a dispersão verificada na variedade de tópicos, disciplinas e campos científicos. Em geral, as técnicas usadas por investigadores são pouco eficientes levando a perdas de tempo acentuadas e elevado esforço cognitivo nos processos de recolha, catalogação, seleção, análise e classificação de literatura (Correia et al., 2013). Como a extração de informação varia de campo para campo, e sendo esta fragmentada e pouco detalhada, justifica-se uma intervenção com recurso às capacidades preceptivas do ser humano em grande escala.
Atualmente considera-se que os cientistas leem aproximadamente cinquenta por cento mais artigos que na década de 1970, despendendo menos tempo com cada um (Renear et
al., 2009). Apesar destes indicadores, o tamanho das equipas de investigação em esforços
interdisciplinares não está a crescer tão rapidamente, sendo reveladas algumas complexidades relacionadas com a alocação de trabalho pelos seus membros, capacidade de lidar com o risco, especialização, definição de tarefas, estabelecimento de compromissos e falta de recursos como tempo e esforço cognitivo despendido em tarefas de criação e análise de conhecimento em diferentes áreas e subáreas (Rigby, 2009). Complementarmente, é ainda notável que os períodos de publicação desde o processo de pré-produção são manifestamente longos, sendo fundamental apoiar a coordenação, comunicação e cooperação científica em larga escala através de ambientes de investigação multidisciplinares para promover soluções de híbridas, ou seja, soluções de colaboração entre humano e máquina com vista à resolução de problemas no contexto das necessidades científicas, tecnológicas e sociais (Santos et al.), sendo que novos “trabalhadores do conhecimento” distribuídos geograficamente estão a contribuir para superar as barreiras políticas, económicas, culturais e sociais que tornam o trabalho dos cientistas dispendioso a vários níveis.
9
2.1.1. Trabalho cooperativo suportado por computador e sistemas
colaborativos
O Trabalho Cooperativo Suportado por Computador pode ser entendido como um campo de pesquisa científica interdisciplinar que surgiu a partir da fusão das áreas de Comunicação Mediada por Computador e Automação de Escritório, simboliza um movimento intelectual que ganhou proeminência no estudo da dinâmica de trabalho de grupo em vários domínios de aplicação das Tecnologias da Informação e Comunicação (TIC). Alguns desses domínios incluem saúde, aprendizagem, comércio eletrónico, indústria, arquitetura, e, mais recentemente, lazer (Schmidt, 2011), onde a interação é frequente e socialmente organizada (Crabtree et al., 2005). Existem também as preocupações do valor dado aos dados semânticos que resultam de processos de catalogação e classificação dentro do qual os participantes são capazes de adicionar informação e inferir estatisticamente sobre as correlações de informação. Ainda assim, o CSCW não pode ser unicamente entendido como a aplicação de técnicas centrada numa determinada área, estão também presente diversos domínios de investigação que se centram na conceção de trabalho de suporte a grupos.
O CSCW está presente em diversas áreas no universo humano (Correia, 2011): Colaboração móvel (Mobile CSCW), Comércio colaborativo (C-Commerce), Telemedicina, Aprendizagem Colaborativa Assistida por Computador – CSCL, Mundos Virtuais, Ambientes Virtuais Colaborativos - CVE e Jogos Cooperativos.
2.1.2. Colaboração científica, cienciometria, modelos de
classificação, e análise semântica
Investigadores fizeram várias tentativas para compreender o comportamento social e individual em torno da informação, bem como os efeitos do conhecimento em grande escala, analisando os efeitos da chamada “sabedoria das massas” ou wisdom of crowds (Chi, 2009). Contudo, a análise de representações de conhecimento é um processo complexo que requer métricas alternativas e fluxos de trabalho abertos (Brian A Nosek et al., 2012), os quais podem ser instrumentos funcionais através de meta-dados criados por verdadeiros “operadores cognitivos” que avaliam resultados científicos. Tal estrutura permite combinar hipóteses através de perspetivas teóricas distintas, metodologias e unidades de análise num modelo integrado (Correia et. al., 2013). Em relação à dificuldade inerente da manutenção de esforços de colaboração e dinâmicas de análise científica em grande escala, esta abordagem pode expandir a cienciometria clássica para resolver problemas complexos, falhas ou divergências de entendimento, e comunicação de conhecimento tácito (Hennemann et al., 2012).
10 A cienciometria está a atravessar um fase de transição acompanhando a mudança contínua que ocorre em todos os domínios científicos (Kurtz et al., 2010), sendo facto que “as escolhas de parâmetros para observar as tendências são muitas vezes feitas ad hoc” (Tseng
et al., 2009). A cienciometria representa um instrumento valioso para a identificação de
inter-relações entre tópicos de pesquisa, cientistas prolíficos ou grupos de investigação, indicadores de desempenho por país e instituição, padrões de colaboração, e previsão de tendências e desenvolvimentos para o futuro (Vinkler, 2010). A inter-relação e co-evolução entre as comunidades científicas apresenta-se como um objeto de estudo centrado em publicações, disciplinas e temas, os quais podem ser analisados para avaliar o impacto e desenvolver a disciplina que se foca exclusivamente na medição da ciência sustentada nas representações do trabalho intelectual (Priem et al., 2010). Alguns avanços significativos têm sido testemunhados nos campos de webometria, mineração de texto e dados, aprendizagem automática (machine learning), análise semântica, e descoberta de conhecimento (knowledge
discovery) em bases de dados, onde o aumento do uso de ferramentas sofisticadas de
mapeamento e técnicas de visualização constitui-se, provavelmente, como o desenvolvimento mais significativo em bibliometria relacional (Smith, 2012).
No contexto científico, considera-se que apenas um esforço de “colaboração em massa” entre os investigadores pode ajudar a delimitar e legitimar a categorização e os protocolos de classificação. No entanto, qualquer processo de avaliação padece de erros, que ocorrem não só devido a possíveis conflitos de interesse, dependendo da homogeneidade e padronização de um campo. As taxonomias são “estruturas cognitivas” que visam fornecer algumas regras de classificação genéricas e robustas através da construção de um conjunto fixo de categorias que abrange a diversidade de conteúdo existente de modo a organizá-lo (Glassey, 2012). As ferramentas e técnicas de classificação e de anotação livre (por exemplo, folksonomias) podem suportar nomenclaturas fornecidas por humanos para qualquer conteúdo usando palavras-chave ou tags que refletem o seu dicionário de sinónimos e conhecimento aprofundado, sem dependência hierárquica a nível semântico. Contudo, a análise manual é trabalhosa e subjetiva (Van Eck et al., 2010), e os sistemas automatizados (por exemplo, RSTTool) são propensos a erros e envolvem uma necessidade eminente de treino especializado.
2.1.3. Inteligência coletiva, crowdsourcing e computação humana
A estrutura intelectual de um campo científico pode ser entendida como uma abstração do conhecimento coletivo dos seus investigadores (Chen et al., 2009), e as diferentes formas de inteligência coletiva podem surgir a partir de aglomerados em contexto de trabalho cooperativo. O estudo da inteligência humana em grande escala constitui-se como um objeto
11 de estudo relativamente recente, e não há nenhuma teoria conhecida e/ou modelo capaz de explicar como isso realmente funciona (Schut, 2010). A inteligência coletiva pode ser concebida como “uma forma universal de inteligência distribuída, que surge a partir da colaboração e competição de muitos indivíduos” (Lévy, 1997) dispersos por grupos e outros ecossistemas de natureza coletiva executando diferentes tarefas como “recolher, formular, modificar e aplicar o conhecimento efetivo” (Atlee et al., 2000). Outra abordagem baseia-se na Cognição Social Aumentada (Chi, 2009), que visa reforçar a capacidade de um grupo para “recordar, pensar e raciocinar”, aumentando a aquisição, produção, comunicação e utilização de conhecimento, evoluindo a inteligência coletiva em ambientes de informação mediados socialmente.
O aproveitamento das “multidões” ou “crowds” para enfrentar problemas que à partida são complexos para um único especialista, grupo, ou algoritmo computacional, tem sido objeto de pesquisa meticulosa. Um estudo psicológico examinou as aptidões cognitivas de uma multidão (N=699 indivíduos, distribuídos por 192 grupos de dois a cinco membros) executando tarefas com base na taxonomia de (McGrath, 1984) (por exemplo, a partilha de anotações num editor compartilhado) para identificar estruturas de grupos genéticos inferindo sobre a inteligência coletiva (Woolley et al., 2010). Alguns estudos têm tentado enfatizar
crowdsourcing em abordagens como a criação automática de taxonomias através de esforços
coletivos fornecidos pela “multidão” através de sistemas de automatização (por exemplo, Cascade (Chilton et al., 2013)), jogos com um propósito científico (Good et al., 2011), manutenção de informações espaciais sobre elementos urbanos (Mashhadi et al., 2013), fluxos de trabalho de suporte à colaboração para procedimentos de crowdsourcing (por exemplo, Turkomatic (Kulkarni et al., 2012)), autoria de trabalhos académicos distribuídos em grande escala (Tomlinson et al., 2012), análise ao comportamento e aos perfis dos utilizadores em plataformas de perguntas e respostas (Question & Answering - Q&A) (por exemplo, Stack Exchange (Furtado et al., 2013)), processamento de perguntas que nem os sistemas de base de dados nem os motores de busca podem razoavelmente responder (mais especificamente, CrowdDB) (Franklin et al., 2011), bem como plataformas de colaboração online para a ciência dos cidadãos (Citizen Science) sem a necessidade de conhecimentos de programação (por exemplo, Pathfinder (Luther et al., 2009)). Assim, verdadeiras Unidades de Processamento Humano (Human Processing Units - HPU) podem atuar como poderosas forças de trabalho cognitivo, devendo ser combinadas com os princípios e as melhores práticas para melhorar o
design das aplicações, dando origem a uma classe avançada de aplicações habilitadas por
12
2.2. Definições de sistemas de informação existentes
Existem vários sistemas de informação existentes com capacidades de partilha de informação. São mostradas definições do que já existe para se perceber a diferença do que é proposta nesta dissertação e do já existente.
2.2.1. Definição de repositório
Um repositório pode ser considerado como uma base de dados de partilha de informação sobre diferentes áreas, sendo muito usado para a produção de artefactos de engenharia ou por uma outra qualquer empresa (Bernstein & Dayal, 1994). Segundo Bernstein (1998), para a criação desses artefactos são necessárias ferramentas de software, o qual defende também que o grande objetivo de um repositório passa pelo armazenamento de modelos e conteúdos de tais artefactos que suportem ferramentas de desenvolvimento e implementação de software, podendo armazenar vários campos, tais como descrição da base de dados, documentos, interfaces, código fonte, texto de ajuda, e execução.
Na visão de Hayes (2005), um “repositório digital é onde estão armazenados conteúdos e ativos”. Estes objetos digitais ficam disponíveis para serem pesquisados e recuperados para uso posterior. Um repositório suporta mecanismos de importação, exportação, identificação, armazenamento e recuperação de objetos digitais.
A colocação de conteúdo digital num repositório permite aos funcionários e instituições geri-los e preservá-los tirando assim o máximo partido do valor correspondente. Os repositórios digitais podem incluir retornos de pesquisas, artigos de revista, teses, objetos de aprendizagem e materiais de ensino ou dados de pesquisa”.
2.2.2. Definição de biblioteca digital
Para Schwartz (2000), as bibliotecas digitais não têm uma definição exata, sendo que a definição genérica é constituída por características que possam servir uma comunidade ou número de comunidades, podem adotar uma entidade não única, cujo suporte é dado por uma estrutura organizacional unificada e lógica, que incorpora aprendizagem e acesso, com um rápido e eficiente acesso com múltiplos tipos de acesso, de livre acesso (para comunidades específicas e controlo de recursos.
Uma outra definição refere que as bibliotecas digitais são uma coleção de informação digital (digitalizada) e fortemente organizada. Este tipo de instrumento é pesquisável pela sua capacidade de obter palavras-chave, sendo acessível em qualquer parte do mundo, tendo também como base o não desgaste pois pode ser copiado sem erros, não tendo limite de folheio ao contrário das bibliotecas tradicionais (documentos em formato de papel). A nível de
13 espaço, tem uma ocupação não tão comparável às bibliotecas tradicionais, pois ocupam o espaço reduzido, ficando o mesmo cingido ao hardware. Adicionalmente, não se pode esquecer que os serviços são fortemente orientados ao utilizador, tendo como foco principal o tempo e a localização dos mesmos.
Segundo Farooq (Farooq et al., 2009), as bibliotecas digitais, entendidas como repositórios online que permitem a descoberta científica (através de pesquisa e reaquisição de recursos intelectuais), carecem de capacidades de colaboração científica. A premissa baseia-se numa colaboração direta entre os pares de uma comunidade científica em torno de artefactos digitais, esforços significativos de longo prazo, e os resultados científicos.
2.2.3. Sistemas de informação bibliográfica
A criação e aperfeiçoamento de sistemas de informação bibliográficos de suporte à colaboração em grande escala são necessários para produzir, partilhar, filtrar, combinar e apresentar descobertas científicas. Uma forma eficaz de criar sistemas de informação tem sido abordada a partir de uma perspetiva de Design Science (Wieringa, 2009) considerando o propósito de atividades coletivas, rotinas e recursos para produzir um processo linguístico, esquema organizacional, ou artefacto técnico representativo de uma prática social (Rohde et al., 2009). As ferramentas da Web 2.0 e as bibliotecas digitais podem ser integradas para projetar sistemas personalizados de informação bibliográfica e apoiar a convergência científica por meio da interação social mediada em torno de elementos semanticamente anotados.
2.2.4. Colaboratórios científicos
Os colaboratórios, sistemas cuja finalidade é fazer com que pessoas interagem e possam colaborar entre si, apoiam os cientistas distribuídos espacialmente facilitando o trabalho conjunto com recursos disponibilizados para aceder, visualizar, manipular e discutir artefactos intelectuais (Finholt et al., 1997), criando um vasto conjunto de possibilidades de pesquisa (por exemplo, o significado partilhado) através do apoio de uma infraestrutura cibernética. Os sistemas de informação orientados a uma comunidade (por exemplo, RCSB Protein Data Bank) suportam recursos de informação de apoio que são criados e manipulados por um organismo ou grupo de colaboradores geograficamente distribuído (Bos et al., 2007). Algumas tentativas têm sido feitas sugerindo métodos para classificar o conteúdo do texto completo das publicações científicas (Bertin et al., 2012) através do enriquecimento de metadados bibliográficos com base no protocolo Open Archives Initiative.
14
2.2.5. Ciência de acesso aberto
As plataformas de conhecimento de acesso livre (open access) tendem a fomentar o estabelecimento de modelos avançados de colaboração entre os investigadores. Várias comunidades têm adotado plataformas de desenvolvimento como o HUBzero para construir plataformas com capacidade de partilhar ideias, publicações, modelos e dados. O Pegasus Workflow Management System tem sido aplicado para gerir análises complexas em campus e infraestruturas cibernéticas de grande escala (por exemplo, Open Science Grid) (Deelman
et al., 2012 ). Por sua vez, o Talkoot é um kit de ferramentas de software e um ambiente de
gestão do conhecimento projetado para colaboração em Ciências da Terra que “permite aos investigadores reunir sistematicamente, anotar e partilhar os seus dados, analisar fluxos de trabalho e notas de pesquisa” dentro de uma comunidade virtual (Ramachandran et al., 2012). Relativamente aos dados bibliográficos, o DeaiExplorer (Konomi, 2011) foi apresentado como uma “ferramenta de mapeamento centrada em dados produzidos por uma comunidade, que extrai e visualiza centenas de comunidades de pesquisa em Ciências da Computação, assente na base de dados de publicação DBLP”. O Figshare oferece um repositório de dados, materiais e métodos para a partilha de arquivos públicos ou privados, enquanto o Open Science é um instrumento de gestão de projetos baseado na Web que permite documentar e arquivar os materiais de pesquisa e análise de scripts, dotando os utilizadores para manter materiais de forma pública ou privada (Brian A. Nosek et al., 2012). O WikiDashboard (Chi, 2009) foi apresentado como uma ferramenta de análise dinâmica social para a Wikipedia, enquanto o Alpha (Abercrombie et al., 2012) é construído em torno de um vasto repositório de dados de curadores.
2.3. Comparação e características de sistemas
Várias limitações foram discutidas exaustivamente na literatura a respeito do valor das bases de dados científicas (por exemplo, ACM Digital Library, IEEE Xplore, DBLP, PubMed, Web of Knowledge, Scopus, CiteSeer, Google Scholar, e arXiv (Hull et al., 2008)). Os gestores de referências com base na Web (tais como o Mendeley) permitem que os utilizadores guardem arquivos PDF na sua aplicação desktop, extrair automaticamente informações bibliográficas, e partilhar dados com outros colaboradores (Li et al., 2012). Alguns mecanismos de sensibilização têm sido estudados com aplicação no CiteSeer (Farooq et al., 2009), uma biblioteca digital académica que fornece aos utilizadores um conjunto de mecanismos de notificação para eventos e publicações usando feeds. Complementarmente, os sistemas de bookmarking e partilha de publicações num plano social (como o Bibsonomy)
15 fornecem aos utilizadores a capacidade de armazenar e organizar os seus favoritos e as entradas de novas publicações, bem como o apoio à comunidade e/ou grupo através da criação de uma plataforma social para a partilha de literatura.
Figura 1 - Modelo de colaboração em grande escala para a análise de bibliografia científica (Correia
et. al., 2013)
Em termos comparativos, o DBLP é um repositório atualizado automaticamente mas é demasiado estático para o enriquecimento de meta-dados, uma vez que é mantido pela equipa de desenvolvimento, negando o acesso de um utilizador comum. Os sistemas DSpace e DBLP apresentam algumas semelhanças, mas o primeiro fornece a personalização da infraestrutura que permite às instituições construir ou modificar um repositório personalizado sem custos adicionais. O CONTENTdm é um sistema proprietário que contém vários recursos e ferramentas da Web 2.0, tendo um modelo aberto de participação para utilizadores registados. No entanto, os sistemas existentes não têm os recursos necessários para um ambiente de classificação semântica em larga escala focado em indicadores ciênciométricos (por exemplo, os dados de co-autoria), e análises semânticas através de abordagens de classificação distintas.
A análise apresentada na Tabela 1 é demonstra estudos comparativos anteriores (Hull et
al., 2008), o que representa uma tentativa de identificar um conjunto de requisitos para um
ambiente de trabalho colaborativo apoiado por um modelo aberto e participativo (Figura 1) que atravessa vários recursos de colaboração da Web 2.0 com visualizações de meta-dados (Correia et. al., 2013).
16 Tabela 1 - Comparação entre CONTENTdm, DSpace, e DBLP (adaptado de (Hull et al., 2008) e (Santos et al.)
CONTENTdm DSpace DBLP
Licença Proprietário Livre ODC-BY 1.0
Tipo de produto Software Software Host
Tipos suportados
JPEG, GIF, ou imagens TIFF; WAV ou MP3 ficheiros audio; AVI ou MPEG video ficheiros; Ficheiros PDF; EAD Finding Aids and URLs
(PDF, JPEG, MPEG, TIFF). DSpace aceitará ficheiros de qualquer tipo de formato
-
Formato metadados
Unicode; Z39.50; Qualified Dublin Core; METS; VRA; XML; JPEG2000; OAI-PMH; e METS/ALTO
Qualified Dublin Core, MARC/MODS
-
Conversão de Formatos
PDF files; PDF compound objects; and XML
BibTex, RIS, TSV, CSV XML, BibTex, Google Scholar, CiteSeerX, pubzone.org e Electronic Edition
Mecanismo de busca
Procura avançada; todas as palavras; frases completas; qualquer palavra; nenhuma daquelas palavras; procura por título, assunto, descrição, criador, cobertura, formato e publicador.
Keyword, Autor, Título, Assunto, Resumo, Series, Patrocinador, Identificador
Procura por conferências, journals e series - Procura por autor, tipo, ano, Coautor Index – Procura completa, Procura Faceted Search @ L3S, Procura Livre @ isearch
Especificações Web 2.0
Partilha (via e-mail, Facebook, Twitter, Flickr); tagging; Comentário e classificação - - Relatório de estatísticas Downloads e visualização de item; visualização de sumário, top de procuras, sumário mensal, sumário diário e sumário por hora.
Total de visitas de página corrente da comunidade; visita da comunidade temporal dos 7 últimos meses; top dos 10 países de onde as visitas são; top das 10 cidades.
Distribuição da publicação, tipos, publicação por ano, número de autores ppor publicação, números de publicação por autor, número de coautores por autor, registos no DBLP (agrupados por ano), registos no DBLP
(agrupados por data e última modificação), número de edições por publicações. Novos registos por ano e mês e pelos anos 2012, 2011, 2010, 2009, 2008, 2007, 2006, 2005, 2004, 2003, 2002
17
3
Capítulo 3: Especificação do sistema
“Andar sobre as águas e fazer software a partir de uma especificação é simples se ambas estiverem congeladas.”
Edward V Berard
Neste capítulo é feito o levantamento dos requisitos necessários para o desenvolvimento da plataforma, depois desses mesmos serem definidos, é elaborado um processo de especificação de como o sistema deve se comportar. Neste último processo é apresentado um diagrama de classe, um modelo de arquitetura, principais casos de uso e um protótipo de baixa resolução.
18
3.1. Análise de requisitos
Os requisitos fundamentais estão assentes na necessidade de criar um sistema base de suporte a um observatório. Os mesmos serão fundamentais para que a base seja fiável e de suporte para novos desenvolvimentos. A análise de requisitos foi efetuada partindo de um estudo exaustivo que é apresentado e analisado nos subcapítulos seguintes.
3.1.1. Requisitos funcionais
Os requisitos podem ser classificados de diversas formas no que toca ao entendimento do comportamento dos objetivos, funções e tarefas. Neste modo existem os requisitos funcionais onde são declaradas funções que regem o comportamento do sistema sob determinadas situações sendo especificação de cada uma detalhada e consistente. É uma interação entre o sistema e o ambiente.
Autenticação: é necessário um mecanismo de autenticação que identifique inequivocamente o papel de cada utilizador no sistema. Está também previsto o papel de convidado para utilizadores não autenticados;
Moderação: a moderação tem como principal objetivo evitar abusos e erros. A moderação é concretizada através da visualização de todas as operações realizadas pelos utilizadores;
Controlo: é obrigatório a existência de um mecanismo de controlo capaz de retirar ou adicionar permissões da respetiva interação. Estas permissões são colocados por grupos e revogadas individualmente;
Interação: é imperativo um mecanismo de interação entre os utilizadores, por exemplo, um mecanismo que permita que os utilizadores possam ter um meio de anotações colocando assim o seu ponto de vista sobre determinado artigo;
Visualização: um mecanismo básico mas ao mesmo tempo essencial, o campo da visualização de todos os elementos presentes, sejam eles publicações, utilizadores, detalhes de autores, etc.;
Segurança: o mecanismo de segurança garante que nada é acedido sem autorização.
Tabela 2 - Tabela de equivalência de requisitos - funcionalidades
Requisito Funcionalidade
Autenticação Sistema de Autenticação
Moderação Perfil de moderador
Controlo Permissões
Interação Sistema de anotações
Visualização Listagem dos elementos
19
3.1.2. Qualidade
Os requisitos relativos à qualidade do software são os seguintes:
Usabilidade: um dos requisitos básicos é a usabilidade, este campo permite que o utilizador ter uma melhor perceção da página que está a visitar. Neste requisito, é necessário ter atenção ao contraste das cores, à disposição dos menus e à localização do site durante aa navegação. É também neste requisito que se define que atenções são dadas pessoas com necessidades especiais;
Desempenho: como se prevê que o sistema possa englobar vários tipos de publicações bem como um número elevado de informação relativas às mesmas, deve-se garantir dedeve-sempenho adequado em condições de carga elevada;
Suportabilidade: dada a existência de uma ligação a uma base de dados (contendo toda a informação), é necessário que essa ligação não falhe. Caso exista falha nessa ligação, o sistema não deve permitir operações, colocando-se em modo de manutenção.
3.1.3. Interfaces
Na conceção de qualquer projeto de software é sempre necessário ter em atenção aos diversos tipos de interfaces existentes, neste caso temos a interface responsável pela interação humano-máquina.
Interação Humana: esta interface é apresentada pelo sistema através de um navegador de internet. Além desta funcionalidade, deve adaptar-se aos diversos perfis existentes no sistema, pois cada utilizador tem o seu próprio perfil, um administrador não tem o mesmo tipo de perfil e página que um utilizador comum.
3.1.4. Restrições
Todo o processo de desenvolvimento sofre de restrições, que podem ser associadas a diversos fatores, que vão desde a linguagem de programação ao tipo de licença no qual o programa vai funcionar.
Desenvolvimento em PHP;
Suporte a diversos Navegadores Web;
Suporte da comunidade;
20
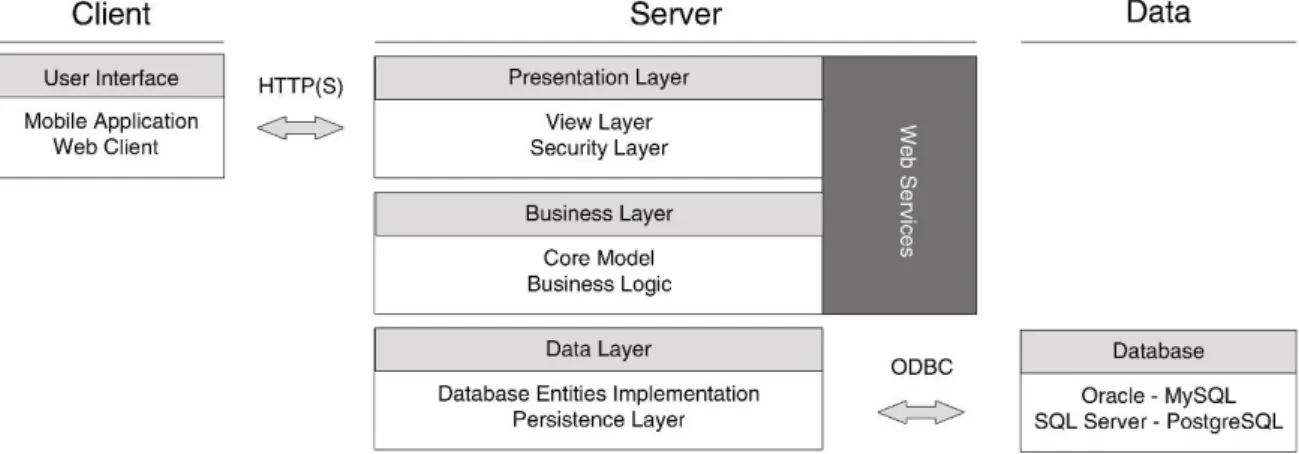
3.2. Modelo do sistema
A arquitetura de três camadas (Figura 2) permite que o sistema seja bem compreendido e bem documentado. Esta topologia define que haja uma separação entre as camadas de código para que uma mudança de implementação de uma camada não afete outra bem como que uma camada trabalhe com diferentes versões de outras camadas (Microsoft, 2009), tendo como vantagens principais escalabilidade, desempenho e disponibilidade. Esta topologia permite que sejam feitas modificações de camadas sem que as outras sejam afetadas. Por exemplo, é possível modificar a camada de apresentação sem termos de modificar as restantes ou, no caso de existirem alterações das demais, não serem alterações de nível crítico.
Figura 2 - Arquitetura do Observatório (Correia et. al., 2013)
Como já referido, a arquitetura (Figura 2) é responsável pelo transporte e manipulação entre as diferentes interfaces (base de dados e o apresentação). É necessário ter em atenção aos futuros processos de desenvolvimento e ter a necessidade de possuir uma arquitetura bem estruturada para que a possível distribuição do código detalhadamente documentado para suporte e apoio da comunidade (Santos et al., 2012). De acordo com as características já referidas, fazem com que as camadas tenham como objetivo o seguinte:
Cliente: pode ser usado um qualquer navegador que suporte código HTML, no entanto, e com os Serviços Web, é deixada uma porta aberta para um cliente de várias plataformas, sejam por dispositivos móveis ou pelas tradicionais aplicações tipo janelas;
Camada de Apresentação: responsável pela transformação do código com os dados vindos da camada de negócio mais o HTML, enviando assim para o navegador do cliente para que o mesmo interprete e mostre o resultado final;
21
Camada de negócio: esta camada faz o processamento da informação entre a camada de apresentação e a camada de dados. É onde existe toda a verificação de informação, segurança, etc. Esta camada, por exemplo, tanto recolhe os dados da BD para enviar para a camada de apresentação como da camada de apresentação para a camada de dados. Nesta camada é também onde se manipula ou cria objetos temporários.
Camada de dados: a camada de dados é a representação da base de dados em códigos. Esta representação tem a vantagem de o programador não precisar de usar tanto o SQL, usando para isso métodos, uma vez que as tabelas da base de dados estão representadas aqui como classes.
Serviços Web: interface que permite a entidades externas aceder aos serviços da plataforma.
Base de dados: esta parte, responsável pelo armazenamento da informação, pode ser usada por um qualquer servidor de base de dados, seja ele Mysql, SQL Server, etc. Isto só é possível, o uso de um qualquer tipo de base de dados, pois existe uma abstração (camada de dados), que liberta o programador da preocupação de como ligar as diferentes base de dados e de escrever o SQL.
3.2.1. Especificação do sistema
Este sistema tem como objetivo ser uma base do observatório cujos requisitos que definem as características mais importantes são apresentados na Tabela 2. A evolução do observatório será gradual e evolutiva pelo que é de todo importante que a base seja robusta para o suporte dessa evolução. É também previsível o surgimento de novas funcionalidades ao longo do tempo.
De forma a compreender melhor quais as formas como deve ser a interação entre o computador e o utilizador, são apresentados diagramas de caso mais importantes. São expostos os mais importantes pois é neles que residem as partes principais desta base: controlo de permissões e inserção de publicações.
22 Tabela 3 - Inserção de publicações
Âmbito Inserção de uma publicação
Finalidade Utilizador insere uma nova publicação Pré-condições Estar registado no sistema com permissão Condição de
sucesso
A publicação é criada pelo utilizador Condição de falha A publicação é rejeitada pelo sistema Atores primários Administradores e utilizadores registados Sequência típica dos
eventos
1. O utilizador faz o processo de autenticação
2. O sistema fornece-lhe todas as opções e condições relativas ao perfil 3. O utilizador cria uma nova publicação
4. O sistema apresenta-lhe a publicação criada mas por aprovar 5. O utilizador deixa de estar autenticado
6. Caso termina com sucesso. Sequência
alternativa e extensões
1. Autenticação Inválida
1.1. Se autenticação Inválida:
1.1.1. Apresenta mensagem de erro
1.1.2. Caso de uso retomado ao estado de autenticação
2. Se o utilizador fizer logout em qualquer sequencia típica de eventos, então:
2.1. O sistema pede ao utilizador para confirmar o lougout 2.2. O caso acaba
3. Se o utilizador tentar inserir uma publicação já existente 3.1. É apresentada uma mensagem de duplicação de dados Requisitos especiais Permissões de inserção
Aspetos em aberto Base de dados indisponível
Figura 3 - Caso de uso da inserção de uma publicação uc Publicações Aprovação Publicações Inserir Alterar Remov er Aprov ação Moderador Administrador Utilizador
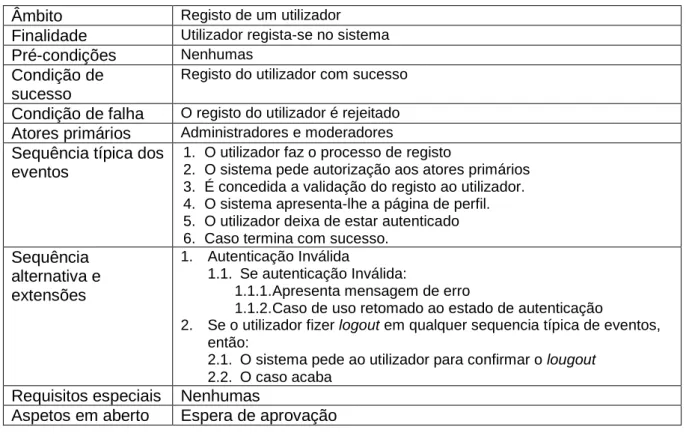
23 Tabela 4 - Registo de utilizadores
Âmbito Registo de um utilizador Finalidade Utilizador regista-se no sistema Pré-condições Nenhumas
Condição de sucesso
Registo do utilizador com sucesso Condição de falha O registo do utilizador é rejeitado Atores primários Administradores e moderadores Sequência típica dos
eventos
1. O utilizador faz o processo de registo
2. O sistema pede autorização aos atores primários 3. É concedida a validação do registo ao utilizador. 4. O sistema apresenta-lhe a página de perfil. 5. O utilizador deixa de estar autenticado 6. Caso termina com sucesso.
Sequência alternativa e extensões
1. Autenticação Inválida
1.1. Se autenticação Inválida:
1.1.1. Apresenta mensagem de erro
1.1.2. Caso de uso retomado ao estado de autenticação
2. Se o utilizador fizer logout em qualquer sequencia típica de eventos, então:
2.1. O sistema pede ao utilizador para confirmar o lougout 2.2. O caso acaba
Requisitos especiais Nenhumas
Aspetos em aberto Espera de aprovação
Figura 4 - Casos de uso de registo de utilizador
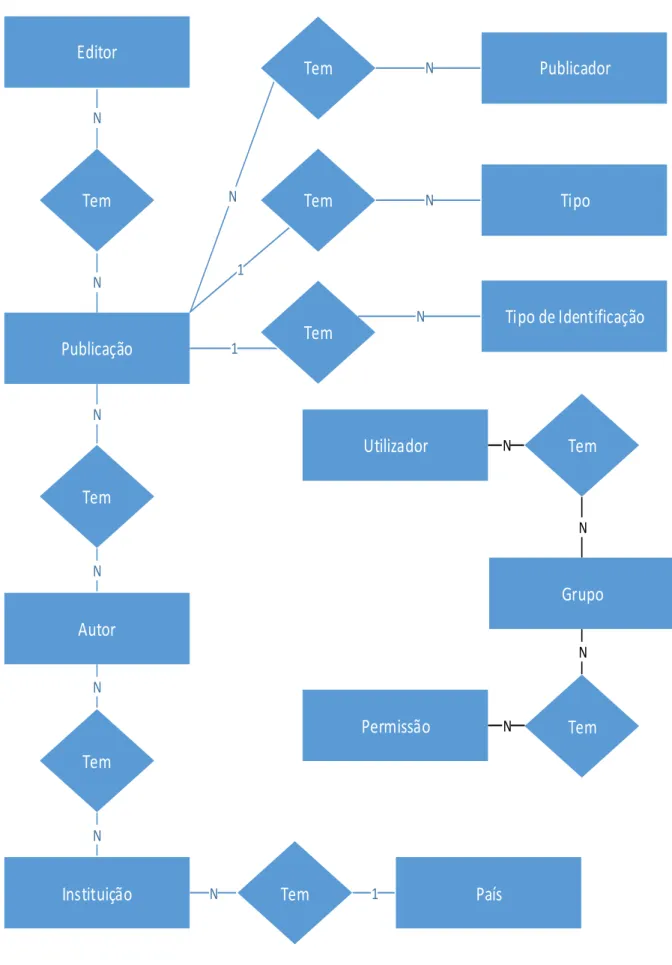
Por último temos o diagrama de entidade relação que permite verificar como a base de dados será criada, sendo proposta a base de dados presente na Figura 5.
uc Registo Utilizador Administrador Registo Registar Alterar Eliminar Aprovação Aprov ação
24
Publicação
NTem
NAutor
NTem
NInstituição
NTem
1País
N
Tem
NEditor
NTem
1Tem
1Tem
NPublicador
NTipo
NTipo de Identificação
Utilizador
Tem
Grupo
N NTem
Permissão
N N25
3.3. Modelo de protótipo proposto
Este subcapítulo tem como objetivo mostrar alguns conceitos de como a interface visual ficará na versão final do sistema. São mostrados vários protótipos principais de baixa resolução com o intuito de explicar o resultado final do layout das funcionalidades em execução. Na parte da implementação é mostrado o funcionamento de tarefas principais.
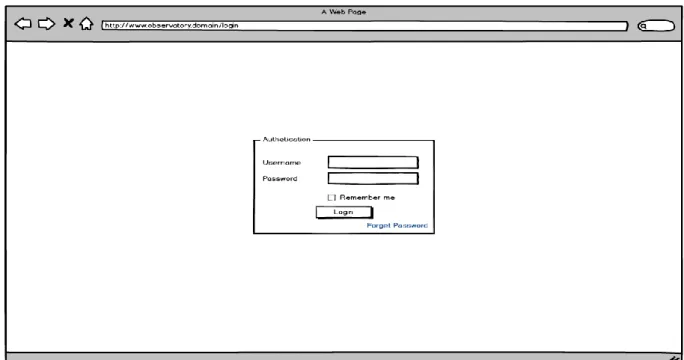
A Figura 6 ilustra o painel de autenticação a ser usado para a entrada do sistema. De referir que para utilizadores sem autenticação (convidados) não aparecerá este tipo de página. Como é habitual, são necessários os campos de utilizador e palavra-passe para a verificação da autenticidade e nível do utilizador. Há também a opção de ficar com a autenticação ativa sempre que o navegador é fechado. Para os utilizadores mais distraídos, para casos de esquecimento ou outro motivo que demonstre perder a palavra-passe, existe a opção de recuperar a palavra-passe, que será enviada para o correio eletrónico de registo.
Figura 6 - Autenticação no sistema
A Figura 7 ilustra como é apresentada a página para utilizadores com ou sem autenticação (convidados), mas sem permissões de alterações de publicações, podendo os mesmos efetuar única e exclusivamente consultas mais detalhadas de cada publicação.
26 Figura 7 - Página inicial de um utilizador
A Figura 8 é o detalhe de cada publicação, mostrando os campos necessários. Esta funcionalidade permite que um utilizador tenho a acesso à informação relevante de cada publicação.
Figura 8 - Visualização de uma publicação
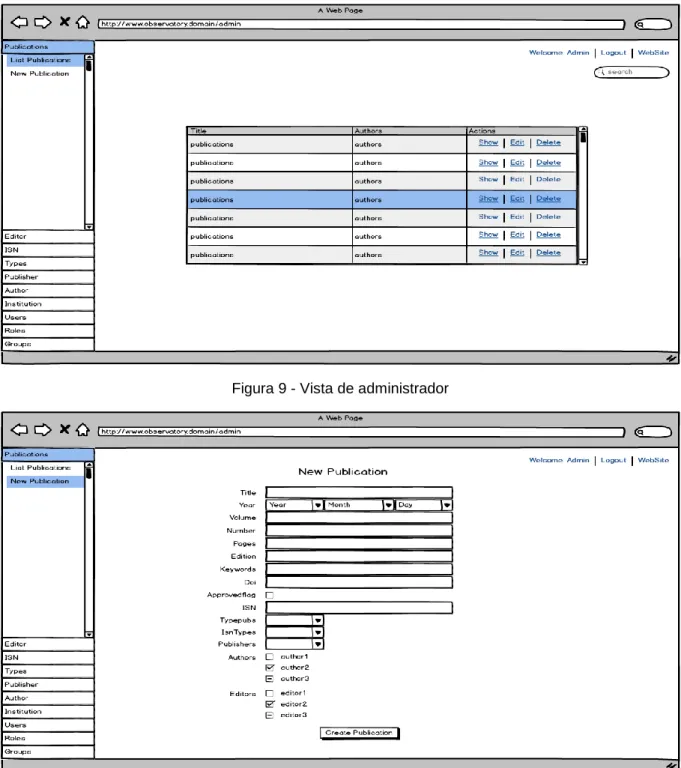
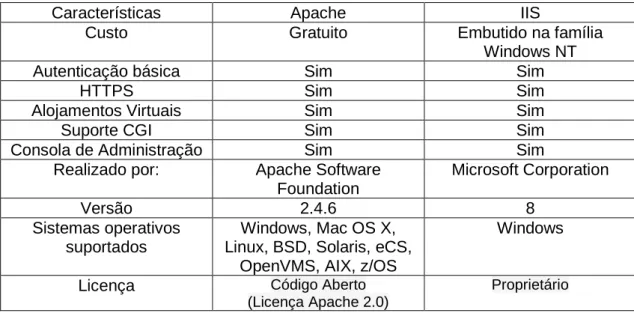
A Figura 9 mostra a listagem de publicações como vista de administrador, diferente da de utilizador (Figura 7), pois já tem operações de manipulação associadas. A Figura 10 mostra a página de inserção de publicações, disponível apenas para os atores com as respetivas permissões.
27 Figura 9 - Vista de administrador
29
4
Capítulo 4: Implementação do sistema
“Medir o progresso de um programa por linhas de código é como medir o processo de montagem de um avião pelo peso.”
Bill Gates
Do seguimento do capítulo anterior, onde são especificados todas as funcionalidades, este apresenta a implementação do modelo proposto, sendo apresentados detalhes técnicos e comparações entre várias tecnologias. Na parte final é apresentado o funcionamento principal da parte do sistema e os resultados a que este foi submetido.
30
4.1. Opções tecnológicas
Neste subcapítulo serão abordadas todas as etapas e comparações das ferramentas usadas, bem como discutidas as opções na seleção de tecnologias.
4.1.1. Servidor Web
Atendendo ao facto de este observatório ter de ficar alojado num servidor web, este tem de possuir as seguintes características: não limitação ao tipo de alojamento (este tem suportar a instalação num maior número de sistemas operativos); possuir um menor custo, preferencialmente gratuito; e por último o de ser de código aberto.
A nível de suporte de linguagens de programação, existe uma semelhança no suporte do necessário, linguagem PHP, podendo ser integradas com outras base de dados, todavia, a escolha recai pelas três características já enunciadas, baixo custo, independência do sistema operativo e licença de código aberto.
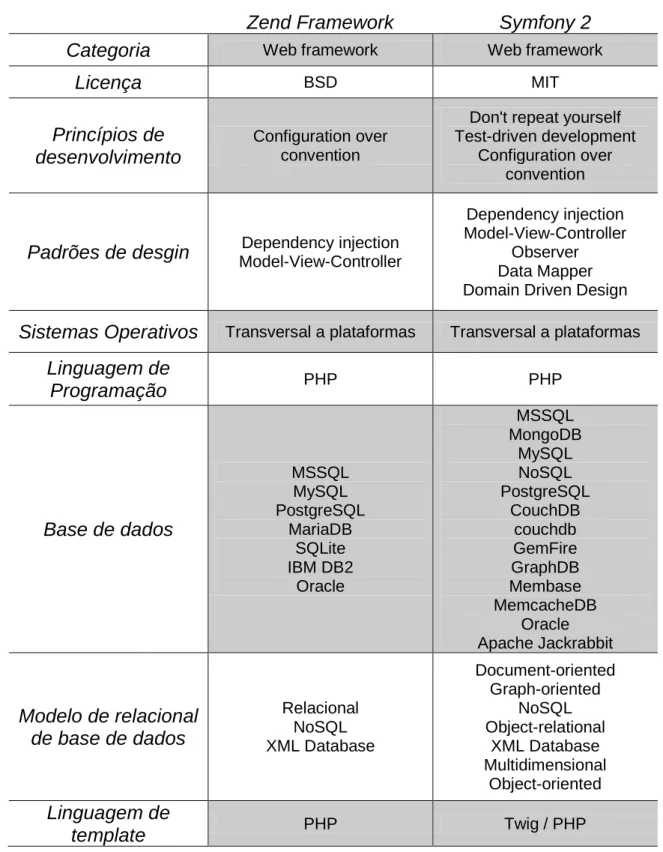
A comparação (Tabela 5) foi realizada e demonstrada com algumas características gerais das diferenças entre ambos dos dois servidores mais populares. Como já referido, a escolha ficou pelo Apache, pelas razões já enunciadas.
Tabela 5 - Comparação entre Apache e IIS
Características Apache IIS
Custo Gratuito Embutido na família
Windows NT
Autenticação básica Sim Sim
HTTPS Sim Sim
Alojamentos Virtuais Sim Sim
Suporte CGI Sim Sim
Consola de Administração Sim Sim
Realizado por: Apache Software Foundation Microsoft Corporation Versão 2.4.6 8 Sistemas operativos suportados Windows, Mac OS X, Linux, BSD, Solaris, eCS,
OpenVMS, AIX, z/OS
Windows
Licença Código Aberto
(Licença Apache 2.0)
Proprietário
4.1.2. Framework
A escolha da linguagem PHP baseou-se no mesmo conceito da escolha dos Servidores Web, é uma linguagem popular, de fácil acesso e usada por muitas empresas, muitas delas bem conhecidas, tais como wikipédia, facebook, wordpress e joomla.
31 Com a evolução da programação, começaram a surgir ferramentas (frameworks) de desenvolvimento de software. Estas ferramentas têm como objetivo simplificar o processo de desenvolvimento e, na maioria dos casos, adotar métodos padrão de desenvolvimento. Nas ferramentas de desenvolvimento web destacam-se duas, Symfony e Zend. A Tabela 6 ilustra a comparação das duas mais usadas.
Tabela 6 - Comparação entre Zend e Synfony2
Zend Framework
Symfony 2
Categoria
Web framework Web frameworkLicença
BSD MITPrincípios de
desenvolvimento
Configuration over convention
Don't repeat yourself Test-driven development
Configuration over convention
Padrões de desgin
Model-View-Controller Dependency injectionDependency injection Model-View-Controller
Observer Data Mapper Domain Driven Design
Sistemas Operativos
Transversal a plataformas Transversal a plataformasLinguagem de
Programação
PHP PHPBase de dados
MSSQL MySQL PostgreSQL MariaDB SQLite IBM DB2 Oracle MSSQL MongoDB MySQL NoSQL PostgreSQL CouchDB couchdb GemFire GraphDB Membase MemcacheDB Oracle Apache JackrabbitModelo de relacional
de base de dados
Relacional NoSQL XML Database Document-oriented Graph-oriented NoSQL Object-relational XML Database Multidimensional Object-orientedLinguagem de
template
PHP Twig / PHP32
Paradigma de
programação
Orientada a objetosOrientada a objetos Orientada a aspetos
Linguagem de script
suportada
JavaScript PHP/ JavaScriptWSDL
Sim SimACL
Sim SimCódigo Livre
Sim SimLDAP
Sim SimA Ferramenta escolhida foi o Symfony2, uma ferramenta já com alguns anos de vida, recentemente surgiu a 2ª versão com alterações significativas. O Symfony2 é uma ferramenta facilmente confundível como modelo MVC, no entanto, alguns defende que é só VC pois permite a injeção direta no controlador. Não é indicada para pequenos projetos, pois é extensa e requer algum tempo de aprendizagem e adaptação, no entanto, para grandes projetos torna-se uma enorme mais-valia face à sua modularização6 e estrutura. Como é esperado que esta
plataforma possa ser de grande acesso e de elevada disponibilidade, é uma escolha adequada.
4.1.3. Base de dados
Mais uma vez, a escolha da base de dados assenta nos pilares de código aberto e de licença gratuita.
Tabela 7 - Comparação dos sistemas de base de dados7
MS SQL Server
MySQL
Oracle
Proprietário
Microsoft Oracle OracleLicença
Proprietária GNU GPL ProprietáriaLinguagem base
C++ C/C++ C/C++Sistema Operativo
WindowsFreeBSD Linux OS X Solaris Windows AIX HP-UX Linux OS X Solaris Windows z/OS
Base de dados
DBMS Relacional DBMS Relacional DBMSRelacional
6http://symfony.com/six-technical-reasons
33
Esquema de
dados
Sim Sim SimTipo de dados
Sim Sim SimIndexação
Secundária
Sim Sim SimSQL
Sim Sim SimAPI
OLE DB TDS ADO .NET JDBC ODBC ADO .NET JDBC ODBC ODP .NET OCI JDBC ODBCLinguagens
Suportadas
.NET Java PHP Python Ruby Visual Basic Ada C C# C++ D Eiffel Erlang Haskell Java Objective-C OCamil Perl PHP Python Ruby Scheme Tcl C C# C++ Cobol Fortran Java Visual BasicTriggers
Sim Sim SimScripts
T-SQL Sim PL/SQLA escolha da base de dados para o armazenamento de informação foi o MySQL, que é já um sistema maduro e bastante robusto, equiparando-se a sistemas de licença proprietária bastante usados. A facilidade de aprendizagem bem como a licença de carácter gratuito ditou a escolha.