Portuguese sign language recognition from depth sensing human gesture and motion capture
Texto
Imagem
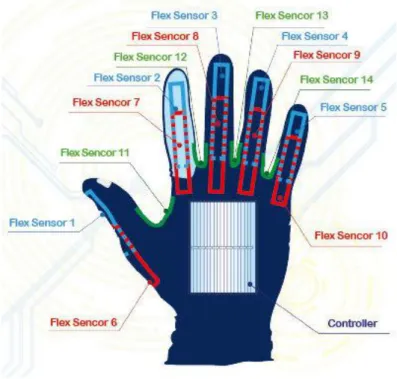



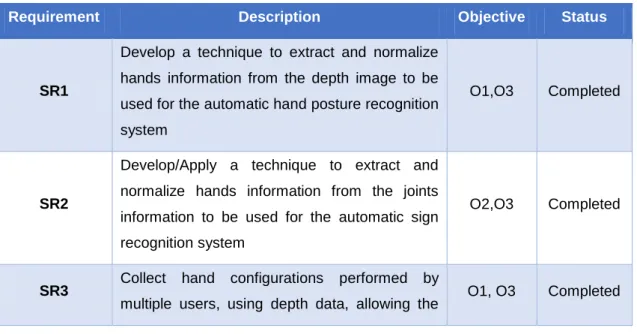
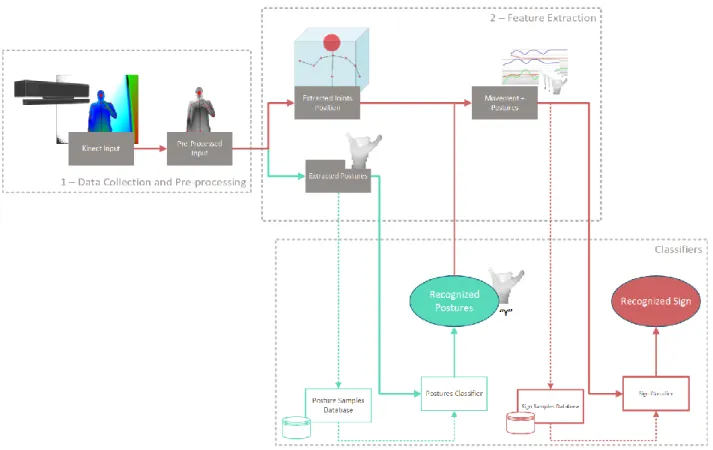
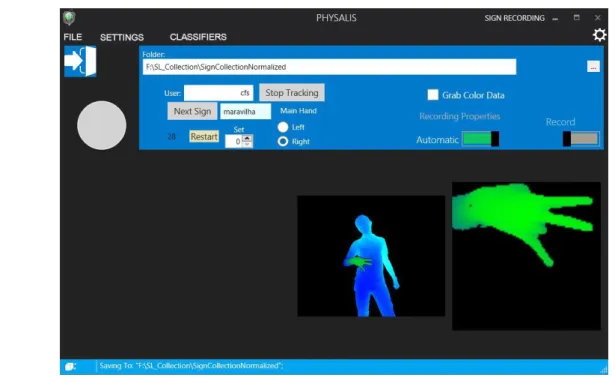


Documentos relacionados
We just target the computation of the ruin probability in in…nite time by approximation, picking up some simple and classical methods, built for the basic or classical
PRÁTICAS EDUCATIVAS DOS PROFESSORES DE CIÊNCIAS DA NATUREZA, MATEMÁTICA E EDUCAÇÃO FÍSICA DA REDE PÚBLICA DE ENSINO DE CATALÃO (GO): análise da dimensão ambiental. 67 o meio
Os problemas de custeio que as empresas enfrentam, nomeadamente a distribuição dos custos indiretos pelos objetos de custo, tiveram origem na mudança da estrutura de
Destas, quatro tipos foram de conhecimento prévio (ativa significado das palavras, ativa conhecimentos prévios relativos aos conteúdos das frases, contrasta informação do texto
Este método do historiador, enfim, levou-nos novamente à História do cerco de Lisboa - o romance de Saramago - justamente por nele encontrar-se textualizada a desconfiança para com
É ainda objetivo (3º) desta dissertação explanar e avaliar a abordagem socioeconómica da Colónia do Sacramento, com vista à compreensão da estrutura demográfica e
International Scale Severity of the International Restless Legs Syndrome study group; SA: Subjective avaliation; PGI: Patient Global Impression; CGI: Clinical Global Impression;
onerosa de aquisição respeitante a bens imóveis, são sujeitas a IMT, segundo o art.º 2º, n.º 5, al. No entanto, o CIMT não prevê especificamente a determinação do seu
