Universidade do Minho
Escola de Engenharia
João Nuno Félix Abrunhosa de Brito
Migração de uma aplicação desktop para a
cloud: geração automática de um web service
Dissertação de Mestrado
Mestrado Integrado em Engenharia e Gestão de Sistemas
de Informação
Trabalho realizado sob a orientação de:
Prof. Doutor José Luís Mota Pereira
Dr. José Miguel Pimenta Marques
Declaração para o RepositoriUM: Dissertação de Mestrado
Nome: João Nuno Félix Abrunhosa de Brito N.º Cartão Cidadão: 14907573
Telemóvel: 913964866
Correio eletrónico: [email protected]
Curso: Mestrado Integrado em Engenharia e Gestão de Sistemas de Informação Ano de conclusão da dissertação: 2018
Título em PT: Migração de uma aplicação desktop para a cloud: geração automática de um web service Título em EN: The migration of a desktop application to the cloud: automatic generation of a web service Orientador: Prof. Dr. José Luís Mota Pereira
Coorientador: Dr. José Miguel Pimenta Marques
Declaro que concedo à Universidade do Minho e aos seus agentes uma licença não-exclusiva para arquivar e tornar acessível, nomeadamente através do seu repositório institucional, nas condições abaixo indicadas, a minha dissertação, em suporte digital.
Concordo que a minha dissertação seja colocada no repositório da Universidade do Minho com o seguinte estatuto:
1. Disponibilização imediata do trabalho para acesso universal;
2. Disponibilização do trabalho para acesso exclusivo na Universidade do Minho durante o período de 1 ano, 2 anos ou 3 anos, sendo que após o tempo assinalado autorizo o acesso universal.
3. Disponibilização do trabalho de acordo com o Despacho RT-98/2010 c) (embargo______ anos)
Guimarães, _____ /_____ /_______
iii
Agradecimentos
Gostaria primeiramente de agradecer aos meus orientadores todo o apoio que me deram durante o decorrer deste grande projeto, e por me terem incentivado a fazer o meu melhor.
Queria agradecer também à minha família, que me apoiou emocionalmente, proporcionando o melhor ambiente possível para conseguir atingir os meus objetivos.
Por fim, gostaria de agradecer aos meus amigos, pelo apoio e ânimo que me transmitiram.
v
Resumo
O mundo reconhece hoje, cada vez mais, a importância de aplicações híbridas que consigam conjugar um ambiente desktop, com a Web e dispositivos móveis. Neste documento é descrita a criação de um serviço Web que vem adicionar valor a um produto já existente, ao permitir disponibilizar as funcionalidades desse produto através da Internet. Devido à complexidade e tamanho da aplicação em questão, será necessária a geração automática da maior parte do código da interface possível, que será feita através de uma ferramenta desenvolvida especificamente para o efeito, já que a criação e manutenção manual do código da interface, seria muito dispendiosa.
Para que a aplicação desktop suporte a nova interface, a sua arquitetura terá de ser estudada e alterada de modo a suportar uma componente extra que permita fazer a ligação da Web com a mesma, respeitando as suas regras de negócio.
Foi também discutida a utilização de uma metodologia ágil adaptada ao desenvolvimento individual de projetos. O documento encerra com uma discussão detalhada dos resultados alcançados, onde é também descrita a utilização da metodologia de desenvolvimento e as diversas validações feitas ao serviço Web.
Atualmente existem duas grandes abordagens para o desenvolvimento de serviços Web: uma baseada em Simple Object Access Protocol (SOAP) e outra em Representational State Transfer (REST). Ambas serão consideradas e avaliadas e a mais indicada será escolhida como abordagem de desenvolvimento do serviço Web.
vii
Abstract
Nowadays, hybrid applications that can manage the interactions between a desktop environment with Web functionalities and mobile devices are steadily gaining more and more importance. The purpose of this dissertation is to investigate, develop and implement an interface between the client’s desktop application and the Web. Due to the desktop application complexity and size, there is a need to generate as much code as possible automatically, thus saving a great amount of resources, instead of the manual creation and maintenance of the interface’s code.
In order for the application to support the new interface, a study must be done to its original architecture to evaluate the best way to re-model it, so that the connection between the Web and the desktop application is done properly, and all the architecture’s business rules are respected.
The usage of an agile development methodology for solo developers was also discussed. The document ends with a thorough discussion of the achieved results, where it is also described the usage of said methodology and the validations made to the Web service.
Currently, two big approaches exist for developing Web services, specifically Simple Object Access Protocol (SOAP) and Representational state transfer (REST). In this document, besides doing the state of the art and planning the work throughout the dissertation, the advantages and disadvantages of each architecture are discussed, considering the type of application and the its scope. This study lead to conclusions as to which Web service is the best to used, developed and implemented during the following work of the dissertation.
ix
Índice
Agradecimentos ... iii Resumo ...v Abstract ... vii Lista de figuras ... xiLista de tabelas ... xii
Lista de Abreviaturas, Siglas e Acrónimos ... xiii
1. Introdução ... 1
1.1. Enquadramento ... 1
1.2. Problema e motivação ... 1
1.3. Objetivos e resultados esperados ... 2
1.4. Estrutura do documento ... 3
2. Revisão de literatura ... 5
2.1. Serviços Web SOAP ... 7
2.2. Serviços Web REST ... 8
2.3. REST versus SOAP ... 10
3. Abordagem metodológica ... 14
3.1. Scrum solo ... 14
4. Arquitetura do ERP da PrimaveraBSS ... 19
5. Web API ... 20
5.1. Arquitetura... 21
5.2. Funcionalidades ... 22
5.3. Utilização da Web API ... 33
5.4. Contratempos no desenvolvimento ... 34
5.5. Documentação ... 35
x
7. Aplicação de Scrum solo ... 40
8. Discussão de resultados ... 44
8.1. Utilização do Scrum solo ... 44
8.2. Validações do projeto ... 44
9. Conclusões... 49
Referências bibliográficas ... 51
Anexo 1 - Scope ... 53
Anexo 2 – Product backlog ... 54
xi
Lista de figuras
Figura 1- Tempo de resposta REST e SOAP (Tihomirovs & Grabis, 2016) ... 13
Figura 2- Fluxo do processo Scrum Solo. Adaptada de (Pagotto et al., 2016) ... 15
Figura 3- Definição de requisitos (Adaptado de Pagotto, Fabri, Lerario & Gonçalves, 2016) ... 15
Figura 4- Sprint (Adaptado de Pagotto, Fabri, Lerario, & Gonçalves, 2016) ... 16
Figura 5- Gestão do projeto (Adaptado de Pagotto, Fabri, Lerario, & Gonçalves, 2016) ... 16
Figura 6- Deployment (Adaptado de Pagotto, Fabri, Lerario, & Gonçalves, 2016) ... 17
Figura 7-Arquitetura e organização da aplicação com a Web API ... 19
Figura 8- Exemplo de uma chamada ao ERP... 21
Figura 9 - Implementação da cache com o namespace "System.Runtime.Caching" ... 23
Figura 10- Exemplo da implementação de cache com “Strahweb.CacheOutput” ... 24
Figura 11- Exemplo da invalidação de cache ... 24
Figura 12- Inserção e extração de um objeto em cache ... 25
Figura 13 - Fluxo do processo SAML ... 25
Figura 14- Fluxo do processo OAuth, OAuth2 e JWT ... 26
Figura 15- Versão simplificada do código do override do método do AuthServerProvider ... 28
Figura 16- Chamada da framework Oauth2.0 ... 29
Figura 17- Teste ao serviço de geração de tokens com Postman ... 30
Figura 18- Utilização de um token para aceder a um recurso ... 30
Figura 19 - Diagrama de utilização de refresh tokens e access tokens ... 31
Figura 20 - Diagrama de sequência da utilização da Web API ... 33
Figura 21- Página inicial da documentação ... 35
Figura 22- Exemplo da documentação de um método GET ... 36
Figura 23 - Exemplo da documentação de um método POST ... 36
Figura 24- Protótipo do UI do gerador de código ... 37
Figura 25- Exemplo de um método gerado... 38
Figura 26- Diagrama de atividades da execução do gerador de código ... 39
Figura 27- Calendário de sprints ... 41
Figura 28 - Exemplo de um sprint backlog (página à direita) ... 42
Figura 29- UI da aplicação para autorização de documentos de venda ... 45
Figura 30- UI do website para criação de documentos de compra ... 46
xii Figura 32- Interface de visualização de vendas pendentes ... 47 Figura 33- Exemplo de um Web test ... 48
Lista de tabelas
Tabela 1- Características de REST e SOAP (Adaptado de Muehlen, Nickerson, & Swenson (2005)) .... 11 Tabela 2- Comparação de SOAP vs REST (Adaptado de Wagh e Thool (2012)) ... 12 Tabela 3- Tabela de comparação de tokens opacos e JWT ... 26
xiii
Lista de Abreviaturas, Siglas e Acrónimos
• API - Application Programming Interface; • DLL – Dynamic-link library;
• ERP - Enterprise Resource Planning; • GPB - Google Protocol Buffers;
• HATEOAS - Hypermedia as the Engine of Application State; • HTTP - Hypertext Transfer Protocol;
• IETF - Internet Engineering Task Force; • JMS - Java Message Service;
• JSON - JavaScript Object Notation; • JWT – JSON Web Token;
• PSP - Personal Software Process; • REST - REpresentational State Transfer; • RPC - Remote Procedure Call;
• SI - Sistemas de Informação;
• SMTP - Simple Mail Transfer Protocol; • SOAP - Simple Object Access Protocol; • TI - Tecnologias de Informação;
• UDDI - Universal Description Discovery and Integration; • URI - Uniform Resource Identifier;
• URL - Uniform Resource Locator;
• WSDL - Web Services Description Language; • XML- Extensible Markup Language.
1
1. Introdução
Este capítulo tem como objetivo fazer o enquadramento do projeto, explicar o problema e a sua motivação, os objetivos e resultados esperados e, por fim, explicar o modo como o documento se encontra estruturado.
1.1. Enquadramento
O mundo reconhece, hoje cada vez mais, a importância de aplicações híbridas que consigam conjugar um ambiente desktop com partes de funcionalidades na Web e dispositivos móveis.
Originalmente, a Web era um conjunto de páginas estáticas, porém, está a sofrer uma transformação, apresentando-se cada vez mais como um conjunto de serviços que interagem pela Internet (Paolucci, Kawamura, Payne, & Sycara, 2002). Hoje em dia, esta transformação que estava a decorrer, passou a uma realidade.
A utilização de serviços Web tem aumentado e, consequentemente, é importante que o tipo do serviço Web seja corretamente escolhido na fase de design do projeto. As implementações mais comuns são baseadas em SOAP (Simple Object Access Protocol) e REST (REpresentational State Transfer protocol) (Tihomirovs & Grabis, 2016).
Este tema foi proposto pela PrimaveraBSS, sendo que, o desenvolvimento será feito nas instalações da empresa, e serão disponibilizados recursos, para que o desenvolvimento da solução seja o mais agilizado possível.
1.2. Problema e motivação
Os processos de negócio são o núcleo do mundo empresarial. Embora o número de serviços Web esteja a crescer rapidamente, serviços Web básicos com funcionalidades limitadas não estão a satisfazer os processos de negócio complexos. Para tal, é necessário um conjunto diversificado de participantes para a composição de serviços Web que descrevam estes processos de negócio complexos. Para o desenvolvimento de um serviço Web complexo, seria necessário codificar um cliente ou páginas da Web para cada um dos processos, algo que iria requerer um grande acréscimo de trabalho e que teria pouca flexibilidade (Ge & Wang, 2010).
2 No entanto, existem cada vez mais alternativas para o desenvolvimento de Web services, não baseadas em codificação, que visam facilitar o processo complexo de desenvolver um serviço Web de grande dimensão.
Foi então considerada a geração automática deste código, para minimizar de maneira significante a carga de trabalho necessária.
No contexto específico do cliente, as principais motivações deste projeto foram:
• Dar aos seus clientes a possibilidade de aceder ao seu ERP (aplicação) através de qualquer dispositivo móvel, sem ter de o fazer a partir de uma máquina fixa, previamente preparada. • Permitir rapidamente criar interfaces com a Web automaticamente, de modo a que, mudanças
futuras na aplicação possam ser refletidas facilmente na interface; • Manter-se a par com os seus concorrentes.
1.3. Objetivos e resultados esperados
Neste capítulo são descritos os objetivos e resultados esperados do trabalho que irá ser efetuado na dissertação.
Os objetivos principais deste documento são:
• Garantir a existência de uma camada que permita fazer a ligação entre a Web e a aplicação desktop (ERP da PrimaveraBSS), que esteja dotada de um conjunto de atributos que permitam esta ligação:
o Ter um nível elevado de segurança (através da utilização de meios de autenticação e autorização);
o Não ter estado (stateless), ou seja, cada pedido tem de conter, por si só, toda a informação necessária para que o servidor consiga processar o pedido e fornecer uma resposta;
o Não aceder a ficheiros físicos e registos do Windows (Windows registry);
o Ser capaz de responder a pedidos concorrentes com um elevado nível de desempenho; • Disponibilizar uma ferramenta de geração de código, capaz de interpretar o código do ERP existente, e gerar automaticamente o serviço que irá disponibilizar as funcionalidades do ERP para a Web. Para este trabalho é necessário um estudo sobre a forma de gerar interfaces de forma automática a partir de modelos já existentes (utilizando Winforms e c#);
3 • Implementar com sucesso a ligação entre a aplicação desktop e a Web, que terá um grande impacto positivo no produto, adicionando flexibilidade e mobilidade na sua utilização e validar o produto desenvolvido através da criação de aplicações diversas que façam uso do mesmo. 1.4. Estrutura do documento
A estrutura do presente documento é descrita nesta secção, de maneira sintetizada, oferecendo uma maior compreensão dos pontos essenciais referidos após o capítulo de introdução.
No segundo capítulo, revisão de literatura, é feito um levantamento de informação relevante ao tema abordado, indicando os métodos e recursos utilizados para cumprir esse objetivo.
No terceiro capítulo apresenta-se a abordagem metodológica que tem como objetivo descrever a framework de desenvolvimento utilizada na parte prática do projeto.
O quarto capítulo contém a arquitetura do ERP da PrimaveraBSS, uma breve introdução à aplicação, para contextualizar e ajudar a compreender onde o trabalho realizado se irá enquadrar.
No quinto capítulo está descrita a Web API criada. Este capítulo está dividido nos seguintes subcapítulos: • Arquitetura – descrição da organização da solução e explicação de cada componente chave e
sua função;
• Funcionalidades – descrição das funcionalidades presentes na solução apresentada;
• Utilização da Web API – descrição de um caso de uso genérico, expondo as entidades e o seu papel;
• Contratempos no desenvolvimento – descrição de alguns problemas encontrados no decorrer do projeto;
• Documentação – descrição da documentação gerada de suporte à solução.
No sexto capítulo é descrita a solução desenvolvida para a geração de código, os seus componentes, e o seu fluxo de funcionamento.
No sétimo capítulo é feita a descrição da utilização da framework escolhida para gerir o desenvolvimento do projeto.
No oitavo capítulo é feita a discussão de resultados obtidos da utilização de Scrum solo, dos testes feitos à solução, e das vantagens que trouxe à empresa.
4 Por último, no nono capítulo, são apontadas as conclusões acerca do trabalho efetuado e descrito neste documento.
5
2. Revisão de literatura
Para que exista uma compreensão do tema foi necessária uma revisão de literatura, a partir da pesquisa de palavras chave “Web API”, “Web services”, “REST”, “SOAP” e “REST vs SOAP”, na sua maior parte, feita no motor de busca Google Scholar e no IEEE Explorer.
Foram utilizados dois ciclos principais para a seleção de documentos relevantes ao tema. No primeiro foi feita uma leitura do resumo/abstract, e introdução do documento e, caso fosse relevante, seria então guardado numa pasta devidamente identificada. No segundo ciclo, foi feita a leitura das conclusões e do índice e, mais uma vez, os documentos foram separados para outra pasta. Finalmente, foram ainda lidos, caso necessário, partes do documento (ou mesmo a totalidade do documento) para fazer esta seleção.
Serviços Web foram reconhecidos como o novo padrão para computação distribuída e são considerados por alguns, uma maneira poderosa e viável para atingir um estado de interoperabilidade universal (Zhao & Cheng, 2005).
Na indústria de software é comum que as empresas tentem ganhar clientes através de plataformas e tecnologias proprietárias. Serviços Web são um novo paradigma de programação que, pela primeira vez, está a ser suportado por grandes software developers tais como a IBM, Sun e Microsoft, que tradicionalmente competiriam com as suas próprias tecnologias (Tang & Cheng, 2005).
Serviços Web são aplicações independentes, publicadas na Web, de tal maneira que outras aplicações da Web as possam procurar e usar. Isto permite componentes de software descobrir outros componentes de software e realizar operações de negócio. Exemplos de serviços Web incluem serviços de cartões de crédito que processam as transações para um determinado número de conta (Roy & Ramanujan, 2001).
Serviços Web permitem a existência de atividades de e-commerce baseadas num padrão XML (eXtensible Markup Language), tal como SOAP, UDDI (Universal Description Discovery and Integration) e WSDL (Web Services Description Language). Alguns dos benefícios dos serviços Web para as atividades de e-commerce incluem a redução do tempo de produção, a convergência de funcionalidades que estariam, de outra maneira, separadas, e a possibilidade de facilmente disponibilizar uma aplicação de negócio para os parceiros (Chiu, Cheung, Hung, Chiu, & Chung, 2005).
6 Um serviço Web consiste num serviço e descrição do mesmo onde o serviço é um módulo de software fornecido por um prestador de serviços, disponível através da Web. A descrição do serviço contém detalhes acerca da interface do serviço e implementações, incluindo tipos de dados, metadados, informação acerca da categorização e a localização de onde o serviço está exposto (Tihomirovs & Grabis, 2016).
Segundo Gonçalves (2009), os serviços Web requerem várias tecnologias e protocolos para transportar e transformar dados de um consumidor para um serviço numa maneira padrão. As mais aparentes são as seguintes:
• Universal Description Discovery and Integration (UDDI) é um mecanismo de registo e descoberta, semelhante às páginas amarelas, usado para armazenar e categorizar interfaces de serviços Web.
• Web Services Description Language (WSDL) define interfaces com o serviço Web, dados e tipos de mensagem, interações e protocolos.
• Simple Object Access Protocol (SOAP) é um protocolo de cifra de mensagens baseadas em XML, definindo uma espécie de envelope para a comunicação de serviços Web.
• Mensagens são trocadas utilizando um protocolo de transporte. Embora Hypertext Transfer Protocol (HTTP) seja o protocolo de transporte mais adotado, outros, tais como Simple Mail Transfer Protocol (SMTP) ou Java Message Service (JMS) podem também ser usados.
• Extensible Markup Language (XML) é a fundação básica na qual os serviços Web estão construídos e definidos.
As características de dispositivos móveis e plataformas desktop podem ser muito diversificadas. Devido a este aspeto, a interface do utilizador com o serviço Web precisa ter flexibilidade e adaptabilidade para suportar as interações do utilizador (He & Yen, 2007).
Nos próximos subcapítulos encontram-se os três temas principais que vão ser abordados na revisão de literatura:
• Serviços Web SOAP; • Serviços Web REST; • SOAP versus REST.
7 2.1. Serviços Web SOAP
Enquanto que existam dois computadores, existe uma dificuldade em fazer a comunicação entre si. Dezenas, possivelmente centenas, de estratégias emergiram, cada uma com as suas vantagens e desvantagens. No final de contas, o resultado é a continuação da existência de dificuldades no acordo entre computadores, para uma estratégia de comunicação universal. Consequentemente, existem “Communication wars”, “CORBA vs. DCOM”, “DCOM vs. RMI”, “messaging vs. RPC”, etc... Para responder a esta confusão de estratégias de comunicação foi criado o SOAP. Este protocolo não tem como objetivo resolver todos os problemas de comunicação, apenas define um formato simples, baseado em XML. Contudo, com este simples objetivo, e um poderoso mecanismo de extensibilidade, SOAP consegue superar problemas de protocolo de comunicação, de sistemas operativos, ou de linguagem de programação. Enquanto que o computador, sistema operativo, ou linguagem de programação pudesse gerar e processar XML, pode fazer uso de SOAP (Seely & Sharkey, 2001).
Serviços Web baseados em SOAP são desenhados com um protocolo baseado em XML. O objetivo é disponibilizar documentos legíveis à máquina com o intuito de passarem por qualquer tipo e vários protocolos de conexão para criar um sistema distribuído descentralizado (Suda, 2003).
Devido à natureza heterogénea dos serviços Web, que é originada da definição de vários “XML-based standards” para superar a sua dependência de plataforma e linguagem, os serviços Web tornaram-se numa tecnologia emergente e promissora para o design e construção de aplicações complexas de negócios, com origem em componentes únicos de software com base na Web (Dustdar & Schreiner, 2005).
SOAP é fundamentalmente um paradigma de troca unilateral de mensagens stateless (sem estado), mas certas aplicações podem criar padrões de interação mais complexos (como, por exemplo: request/response, request/multiple responses, etc.) combinando estas trocas de mensagens com características providenciadas por certos protocolos e/ou informação específica de aplicações (Mitra & Lafon, 2007).
SOAP é um protocolo independente de plataforma, de transporte e de sistema operativo, tudo devido a ser construído utilizando sistemas de teste temporais tais como o protocolo HTTP e “text mark-up” em XML. (Suda, 2003)
Segundo Ferris e Farrel (2003), existem vantagens e desvantagens relacionadas com a utilização dos serviços Web.
8 • Vantagens:
o Os serviços Web tornam possível aos prestadores de serviços e fornecedores a venda de serviços através da publicação da sua disponibilidade através da World Wide Web. o A dissociação (“decoupling”) de interfaces de serviços de implementações e plataforma,
a possibilidade de executar “dynamic service binding” e um passo para interoperabilidade de “cross-platform” e “cross-language”. Estes benefícios são originados pela interface standard XML e acesso a descrições dadas pela WSDL. o Os serviços Web podem servir de ponte para aplicações que estão a ser executadas em
plataformas diferentes, disponibilizar troca de informação de bases de dados e permitem a distribuição de aplicações que foram desenhadas inicialmente para uso interno. Serviços Web também encontraram um bom mercado quando são desenvolvidos como utilidades ou como componentes de programas “pay-per-use”. • Desvantagens:
o A framework dos serviços Web estão dependentes das agências que anunciam a sua presença. Uma fraca implementação do mecanismo de descoberta pode resultar num enorme retrocesso no alcance dos clientes e mercados.
o As especificações de interoperabilidade ainda não foram preparadas completamente. É necessário que um organismo de interoperabilidade de serviços Web produza padrões para a interoperabilidade relativamente rápido. Estes ainda se encontram em desenvolvimento e precisam de ser completos e lançados para que outras camadas e componentes possam ir construindo a sua framework em cima deles.
2.2. Serviços Web REST
Uma das diversas maneiras de criar um serviço Web é a abordagem REST. REST é uma abordagem nova (comparativamente a SOAP), que se apoia no protocolo HTTP para transmitir dados, em diferentes formatos, tais como XML, JSON, etc. (Serrano, Hernantes, & Gallardo, 2014). Esta abordagem tem características de implementação que, se seguidas, irão resultar num serviço Web focado nos recursos do sistema, incluindo como os estados desses mesmos recursos são manuseados e transferidos através do protocolo HTTP, por uma panóplia de clientes (Rodriguez, 2008).
REST é de diversas formas uma abstração retrospetiva dos princípios que fazem a “World Wide Web” escalável (Muehlen, Nickerson, & Swenson, 2005).
9 REST disponibiliza os seus serviços por meio de uma URL (Uniform Resource Location) inicial, a partir da qual a navegação é guiada conforme a lógica de negócios proposta, dotando orientações dinâmicas quanto à forma de construção e endereçamento dos requisitos, adotando um formato de comunicação maximizado que atenda às necessidades de cada aplicação (Ribeiro & Francisco, 2016).
Segundo Fielding (2000), para que um serviço Web seja considerado REST são necessárias várias condições (arquitetura cliente-servidor, “Stateless” (sem estado), “cache”, interface uniforme, sistema de camadas, código “on-demand” (a pedido)):
• Arquitetura cliente-servidor: esta é a mais comum quando se trata de comunicação de dados em rede hoje em dia, e a sua popularidade pode ser percecionada através do fenómeno que é a expansão da World Wide Web. Uma definição de dicionário para cliente é um sistema ou programa que faz pedidos a outros sistemas ou programas, chamados servidores para executar certas tarefas; um servidor é um sistema ou programa que recebe um pedido por parte do cliente e consequentemente desempenha uma tarefa para suportar o cliente nas suas tarefas. (Hanson, 2000)
• “Stateless” (sem estado): é uma restrição à arquitetura cliente-servidor. Para que a comunicação entre as duas partes seja “stateless”, é necessário que cada pedido do cliente ao servidor contenha toda a informação necessária para que o servidor consiga entender e processar o pedido, não tirando partido de qualquer tipo de contexto armazenado no servidor. Desse modo o estado da sessão estará sempre guardado do lado do cliente (Fielding, 2000). • Cache: é uma restrição de adoção facultativa, que tem como objetivo melhorar a eficiência da
comunicação em rede. Ao adicionar a cache a um serviço Web passa a existir a possibilidade da reutilização de dados guardados na cache do cliente. Caso o cliente faça um pedido e os dados já estejam armazenados em cache, não é perdido tempo com o reenvio dos mesmos pelo servidor. Existe, porém, uma desvantagem na utilização da cache, a redução da confiabilidade dos dados, já que os dados armazenados em cache, por vezes podem não corresponder aos dados existentes do lado do servidor.
• Interface uniforme: é, de todas as condições, a que mais distingue a arquitetura REST de outras. Através da aplicação do princípio da generalização de engenharia de software ao componente da interface, a arquitetura do sistema é simplificada e a visibilidade das interações disponíveis é melhorada. Este aspeto tem vantagens e desvantagens, dependendo do caso, estando
10 otimizado para casos genéricos, no entanto, em casos específicos, torna-se eficiente. Para atingir uma interface uniforme são necessárias 4 condições:
o Identificação de recursos - cada recurso possui o seu único URI que serve como identificador;
o Manipulação de recursos através de representações – As operações são feitas utilizando HTTP, significando que, um pedido do tipo “GET” a um URI significa que se pretende obter informação de um certo recurso;
o Mensagens que se descrevam a si próprias - Cada pedido de um cliente ou resposta de um servidor é uma mensagem que se descreve a si própria, ou seja, contém toda a informação necessária para completar a tarefa por si só;
o “Hypermedia as the Engine of Application State” (HATEOAS) – Um Website orientado por hypermedia é capaz de fornecer informação dinâmica acerca da navegação das interfaces do website, anexando hypermedia links nas respostas. Esta particularidade contribui para o desacoplamento do cliente e servidor, permitindo o servidor evoluir independentemente do cliente.
• Sistema em camadas: para obter melhorias operacionais, Fielding (2000) propôs a divisão do sistema em camadas, possibilitando a existência de uma hierarquia, restringindo o acesso a camadas não adjacentes. Este aspeto vem melhorar a segurança, organização e escalabilidade do serviço Web.
• Código “on-demand” (a pedido): Segundo Moro, Dorneles & Rebonatto (2009), esta característica opcional consiste em permitir que os clientes possam fazer o download e executar código do lado do cliente. Desta maneira, a extensibilidade do produto é aumentada, ou seja, algumas funcionalidades podem não ser implementadas à partida, já que o cliente as pode obter mais tarde. Esta característica é opcional devido à desvantagem de reduzir a visibilidade do seu conteúdo.
2.3. REST versus SOAP
As abordagens SOAP e REST lidam com interações de serviços de maneiras bastante diferentes. SOAP é um protocol padrão para a construção e processamento de mensagens independente das capacidades tecnológicas do recipiente e pode funcionar sobre uma vasta variedade de camadas de protocolos de aplicações tais como RPC (Remote Procedure Call), HTTP (Hypertext Transfer Protocol) ou SMTP (Simple
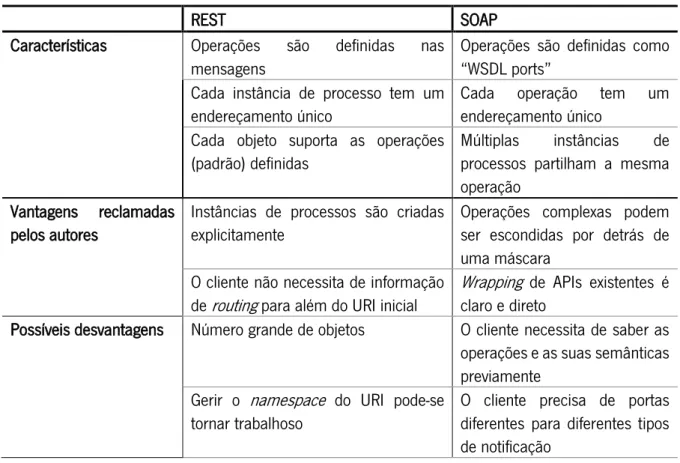
11 Mail Transfer Protocol), enquanto que REST é um conjunto de princípios para o design de aplicações Web (usando HTTP como protocolo de comunicação) (Potti, Ahuja, Umapathy, & Prodanoff, 2012). Segundo Muehlen, Nickerson e Swenson (2005), as vantagens e desvantagens de abordagens baseadas em REST ou SOAP podem ser sumarizadas na seguinte tabela:
Tabela 1- Características de REST e SOAP (Adaptado de Muehlen, Nickerson, & Swenson (2005))
REST SOAP
Características Operações são definidas nas mensagens
Operações são definidas como “WSDL ports”
Cada instância de processo tem um endereçamento único
Cada operação tem um endereçamento único
Cada objeto suporta as operações (padrão) definidas
Múltiplas instâncias de processos partilham a mesma operação
Vantagens reclamadas pelos autores
Instâncias de processos são criadas explicitamente
Operações complexas podem ser escondidas por detrás de uma máscara
O cliente não necessita de informação
de routing para além do URI inicial Wrapping de APIs existentes é claro e direto Possíveis desvantagens Número grande de objetos O cliente necessita de saber as operações e as suas semânticas previamente
Gerir o namespace do URI pode-se tornar trabalhoso
O cliente precisa de portas diferentes para diferentes tipos de notificação
12 Outra tabela proposta por Wagh e Thool (2012) está a seguir representada. Tem como objetivo fazer a comparação geral entre REST e SOAP.
Tabela 2- Comparação de SOAP vs REST (Adaptado de Wagh e Thool (2012))
SOAP REST
É uma tecnologia tradicional bem conhecida. É uma tecnologia nova, comparando a SOAP. No contexto empresarial e B2B (Business to
Business), SOAP continua a ser bastante atrativo.
Embora SOAP talve seja o mais indicado na maior parte dos casos, existem implementações de sucesso em contextos bancários de REST.
No caso de implementação, SOAP tem a vantagem da existência de kits de desenvolvimento.
Mas os desenvolvedores de REST argumentam que esses kits levam a uma inflexibilidade de interface.
Mudar serviços frequentemente numa mudança de código complicada no lado do cliente.
Mudar serviços não requer qualquer mudança do lado do cliente (caso “code on demand” esteja implementado).
SOAP tem uma carga mais pesada comparado com REST.
REST é definitivamente leve na transferência de dados.
SOAP não favorece uma infraestrutura wireless. REST favorece uma infraestrutura wireless Serviços Web SOAP retornam sempre XML. Serviços Web REST são mais flexíveis no que
toca a devolução de dados (e.g. XML, JSON, GPB).
Consome mais largura de banda. Consome menos largura de banda devido à sua natureza leve.
Pedidos SOAP usam POST e necessitam um pedido complexo XML para ser criado, o que leva a uma difícil captura de respostas.
APIs RESTful podem ser consumidas usando um simples pedido GET, servidores intermédios de proxy podem facilmente colocar as suas respostas em cache.
Concebido para lidar com ambientes de computação distribuída.
Concebido para o modelo de comunicação ponto-a-ponto.
Existe um pressuposto falso: SOAP é mais seguro. SOAP utiliza WSS (Web Services Security). WSS foi desenvolvido para suportar a independência de transporte de SOAP, garantindo a segurança na camada de transporte.
REST assume que o transporte será feito em HTTPS e que os mecanismos de segurança que estão embebidos no protocolo estarão disponíveis.
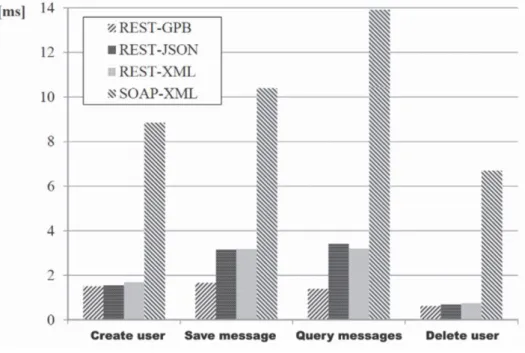
Segundo Tihomirovs e Grabis (Tihomirovs & Grabis, 2016), REST é mais aconselhado se o projeto necessitar de grande escalabilidade, compatibilidade e desempenho. A complexidade de implementação, velocidade de execução, memória consumida e desempenho são melhores que o protocolo SOAP. Conclui-se assim que, para um projeto de integração simples, de ponto a ponto (arquitetura cliente-servidor), ou de boa disponibilidade em grande escala, REST é a escolha mais
13 adequada. No entanto, SOAP é uma escolha melhor, para casos de ambientes de computação distribuida. Para além disso, vários projetos de integração de sistemas de negócio necessitam pedidos de processamento de dados assíncronos, a vantagem de SOAP. Em conclusão, SOAP é mais adequado para integrações de sistemas com grandes quantidades de informação, tal como projetos de integração de sistemas de informação no ambiente bancário. Adicionalmente foram efetuados testes ao tempo de resposta de ambos SOAP e REST nas quatro mais relevantes funcionalidades de um serviço Web, apresentados na figura 1.
Figura 1- Tempo de resposta REST e SOAP (Tihomirovs & Grabis, 2016)
Em conclusão, após a investigação decorrida durante a revisão de literatura, e tendo em consideração os requisitos do serviço Web a desenvolver, a abordagem REST aparenta ser a mais adequada devido maioritariamente à facilidade de escalabilidade (um aspeto imensamente importante tendo em conta o tamanho e complexidade da aplicação em questão), à maior rapidez de resposta (representado na figura 1), por ser mais recente e pela melhoria da experiência do utilizador, já que não tem de fazer alterações caso exista uma mudança do código (algo inevitável no decorrer do ciclo de vida da aplicação).
14
3. Abordagem metodológica
Neste capítulo é feita a descrição da abordagem metodológica adotada para o desenvolvimento do trabalho, tendo em conta a grande componente prática existente.
O cliente deste projeto é a PrimaveraBSS, uma empresa de desenvolvimento de software em que todas as equipas de desenvolvimento de software fazem uso da framework ágil Scrum. À partida, faria sentido a utilização da mesma no decorrer deste projeto, já que o trabalho será feito nas instalações da empresa. No entanto, o Scrum foi desenhado para equipas de duas ou mais pessoas. Face a esta limitação e à existência de uma necessidade, um grupo de quatro autores Brasileiros idealizaram uma framework semelhante, o Scrum solo, a escolhida para desenvolver a parte prática do projeto.
3.1. Scrum solo
Em Portugal, 90% das empresas de desenvolvimento de software são caracterizadas como microempresas (segundo o diretório de empresas do jornal de negócios, consultado em 20/03/2018). No mercado Brasileiro, em 2012, cerca de 60% das empresas de software iniciavam as suas atividades com apenas um developer (Pagotto, Fabrti, Lerario, & Gonçalves, 2016). Esta abordagem foi elaborada com esta diferença em mente, sendo que existia uma necessidade para a organização/orientação do desenvolvimento a solo. O Scrum Solo foi originado como uma personalização do processo Scrum orientado para o desenvolvimento individual de software. (Nunes, 2016).
O Scrum solo é uma adaptação de Scrum e PSP (Personal Software Process) para desenvolvimento de software a solo. Baseado na figura 2, é possível constatar algumas semelhanças entre Scrum e Scrum solo (Pagotto, Fabrti, Lerario, & Gonçalves, 2016).
O objetivo de Scrum é fornecer um processo conveniente para o desenvolvimento de projetos, apresentando uma abordagem empírica, que aplica ideias baseadas na teoria de controlo de processos industriais para o desenvolvimento de software, introduzindo ideias adicionais como a flexibilidade, adaptabilidade e produtividade (Soares, 2007).
Scrum foi desenvolvido para permitir developers normais organizarem-se, e formarem equipas de alto rendimento (Sutherland, Viktorov, Blount, & Puntikov, 2007). Scrum assume que o processo de desenvolvimento de sistemas é complicado e imprevisível, que apenas pode ser descrito como uma progressão geral (Schwaber, 1997).
15 O fluxo de trabalho de Scrum solo começa pela criação de um product backlog, que contém todas as tarefas necessárias para implementar as funcionalidades pretendidas pelo cliente. Deste grupo de tarefas, são selecionadas algumas a ser desenvolvidas durante o sprint (num espaço de tempo de uma semana). Este processo de sprints é iterativo até que a data de conclusão do projeto chegue, ou até que todas as tarefas estejam concluídas. Durante os sprints, é necessária a existência de atividades de gestão, que têm como propósito planear e acompanhar o desenvolvimento do projeto. Após a conclusão das tarefas, é feita a entrega do projeto, que vai ser revisto por um grupo de avalização e, eventualmente, será feita uma reunião de orientação com as pessoas que irão utilizar o produto desenvolvido (figura 2).
Figura 2- Fluxo do processo Scrum Solo. Adaptada de (Pagotto et al., 2016)
Esta abordagem metodológica é dotada de quatro atividades principais: definição de requisitos, sprint, deployment e gestão. A definição de requisitos (figura 3) tem como objetivo definir o âmbito (scope) do produto, o product backlog e, se possível, um protótipo de software. Estes objetivos serão atingidos com a ajuda do input do cliente e orientador que irão auxiliar o developer a atingir a sua meta.
16 Os sprints, representados na figura 4, são a atividade onde ocorre o desenvolvimento de um conjunto de tarefas selecionadas no início do mesmo, provenientes do product backlog. Estas tarefas deverão ser concluídas no espaço de uma semana, originando um sprint backlog, parte do produto, plano de desenvolvimento, e uma ata.
Figura 4- Sprint (Adaptado de Pagotto, Fabri, Lerario, & Gonçalves, 2016)
Durante os sprints é preciso gerir o estado do projeto. A atividade de gestão do projeto (figura 5) tem esse objetivo. Utilizando o product backlog, o developer, o orientador, e o cliente devem discutir o estado do projeto. Dessa reflexão serão gerados a estrutura analítica do projeto (EAP), o cronograma, e a tabela de custos do projeto.
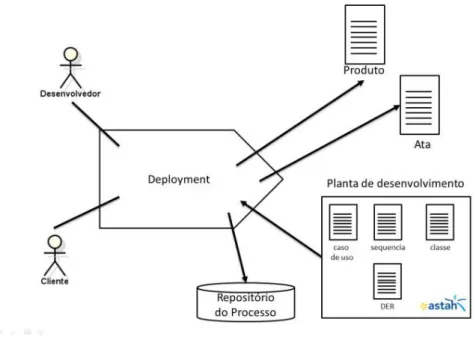
17 Finalmente, como última tarefa, o deployment (figura 6) é a atividade em que o produto é disponibilizado para uso do cliente. É também importante, após a entrega, a existência de uma reunião de orientação para que os envolvidos percebam em maior detalhe o funcionamento do produto.
Figura 6- Deployment (Adaptado de Pagotto, Fabri, Lerario, & Gonçalves, 2016)
Existem diversos atores neste processo, nomeadamente o developer, que é o responsável pelo desenvolvimento do produto e o seguimento da metodologia; o cliente (product owner), que será o proprietário do produto final, pode ser constituído por um ou mais indivíduos que irão interagir com o produto (exemplo: gestores, contabilistas, outros…); o orientador, que tem como responsabilidade ajudar a guiar o developer durante todo o processo, para que os requisitos sejam bem cumpridos; e, finalmente, o grupo de validação, constituído pelos utilizadores finais do produto, que têm como objetivo avaliar o produto e dar feedback.
Os diversos artefactos gerados ao longo de todo o processo são os seguintes (Pagotto, Fabrti, Lerario, & Gonçalves, 2016):
• Scope: serve para caracterizar o âmbito do processo e os aspetos inerentes ao mapeamento dos problemas do product owner, descrevendo o âmbito do produto, o perfil do cliente e os requisitos funcionais.
• Protótipo de software: consiste em imagens da interface do utilizador com o produto. É aconselhada a utilização do formato “.png” e apontar o nome do item do product backlog que representa a imagem.
18 • Product backlog: é uma lista de funcionalidades que devem ser implementadas no software. Cada linha desta lista deve conter um código de funcionalidade, descrição, data de inserção e data de seleção para o sprint backlog.
• Repositório do processo: serve para armazenar todos os documentos relativos a todo o processo de desenvolvimento do produto na cloud. É importante que o developer organize bem as pastas do repositório e siga um conjunto de regras para o efeito.
• Sprint backlog: é uma lista de todas as funcionalidades que devem ser implementadas num determinado sprint. O sprint backlog deve também armazenar o código das funcionalidades. • Produto ou parte em funcionamento: uma versão do produto que dê ao cliente a possibilidade
de obter um retorno pelo investimento previamente feito no momento que pediu o seu desenvolvimento.
• Ata: serve para registar os momentos em que uma funcionalidade é implementada. Utilizada no sprint e na entrega: no sprint, a funcionalidade é validada pelo orientador; na entrega é validada pelo cliente.
• Plano de desenvolvimento: tem como objetivo juntar os artefactos usados na especificação das funcionalidades. O Scrum solo sugere o uso de diagramas de casos de uso, sequência, classes e entidade e relacionamento, existindo sempre a possibilidade de serem usados outros, caso seja necessário para o caso.
• Estrutura analítica do projeto: uma estrutura hierárquica que subdivide o trabalho de um projeto em componentes menores e mais facilmente legíveis.
• Cronograma: tem como objetivo organizar sequencialmente os pacotes de trabalho dentro de um determinado espaço de tempo. Pode-se apontar o responsável pela execução de cada atividade. É sugerido a utilização do cronograma no formato de diagrama de Gantt.
• Tabela de custos: tem como objetivo mapear o custo efetivo gerado durante a execução do projeto para poder ser comparada com o orçamento realizado previamente.
Foi feita também uma pesquisa por “Scrum solo” através da plataforma Google académico, no entanto, o estado de arte ainda se encontra pouco desenvolvido. Fonseca (2016) apenas descreve genericamente o que é o Scrum solo como uma “metodologia para gestão dinâmica do projeto que permite também o desenvolvimento de software de maneira ágil”. Similarmente, Kleim (2016) descreve que Scrum solo foi desenvolvido com o âmbito de ajudar no que toca à organização do desenvolvimento de software por indivíduos, baseando-se nas boas práticas descritas pelo PSP e Scrum.
19
4. Arquitetura do ERP da PrimaveraBSS
Neste capítulo é feita uma breve introdução à a arquitetura do ERP, para que haja uma contextualização e para que seja mais fácil a compreensão das interações da Web API com a aplicação. Um dos diversos produtos da PrimaveraBSS é o seu ERP. Esta aplicação tem como objetivo auxiliar a gestão de médias e grandes empresas, disponibilizando vários módulos conforme as necessidades do cliente.
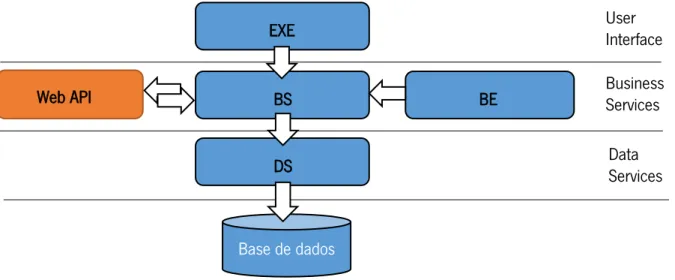
Na base do ERP está uma plataforma que tem motores para fazer o acesso aos dados. Este produto está estruturado em 3 camadas principais. Este aspeto permite o tratamento de cada camada independentemente das outras, promove a escalabilidade, e adiciona uma facilidade de manutenção de código. Esta arquitetura distribuída possibilita também a substituição individual de componentes, sem haver necessidade da reinstalação completa da aplicação.
Na figura 7, está representada a nova arquitetura proposta, composta pela camada de interface com o utilizador (composta por um executável, EXE); a camada de serviços de dados (composta por serviços de dados, DS); e a camada de serviços de negócios (composta originalmente por os serviços de negócios, BS, e entidades de negócio, BE) que terá adicionalmente uma componente da Web API, ligada à componente dos serviços de negócios (BS), permitindo o acesso a todos os serviços, respeitando todas as regras de negócio impostas.
Figura 7-Arquitetura e organização da aplicação com a Web API
A aplicação é dotada de diversos módulos, tais como, vendas, contabilidade, inventários, tesouraria, etc… Todo o código que representa estes módulos do lado da Web API serão gerados
automáticamente, no entanto, existe um módulo a destacar, a plataforma. Este módulo está
encarregue de, entre outros, abrir o motor da aplicação e fazer chamadas aos módulos. Por isto, a sua implementação foi feita manualmente, já que o contexto Web e Desktop são tão diferentes.
User Interface Business Services Data Services EXE BS BE DS Base de dados Web API
20
5. Web API
Neste capítulo é feita a descrição da Web API, destacado o porquê da escolha da abordagem REST face a SOAP, da arquitetura da Web API desenvolvida, das suas funcionalidades, de alguns dos contratempos e limitações que ocorreram e da documentação gerada.
Depois de toda a investigação feita em torno de REST e SOAP, foi concluído que a abordagem REST seria a mais indicada para resolver o problema em questão. Esta conclusão foi maioritariamente suportada pelas seguintes características:
• REST promove a escalabilidade – tendo em conta a complexidade e o tamanho do ERP da PrimaveraBSS, a escalabilidade é um aspeto essencial a ter em consideração na escolha entre REST e SOAP;
• REST tem uma velocidade de resposta melhor – tal como demonstrado na figura 1, existe uma grande diferença no tempo de resposta entre SOAP e REST;
• Há maior facilidade na mudança do código do lado do cliente seguindo a abordagem REST – ao contrário de SOAP, se um serviço Web do tipo REST não vier com todas as funcionalidades para o cliente, a user experience não será tão prejudicada, já que, para obter novas funcionalidades, o cliente terá apenas de fazer a aquisição da nova versão. Visto que a aplicação está em constante desenvolvimento, faz sentido a adoção da abordagem REST.
O trabalho realizado tem como finalidade aceder à camada de serviços de negócios (Business Services) do ERP, e fazer chamadas aos métodos do ERP de maneira segura, e com o maior nível de desempenho possível. Para garantir a segurança, são utilizados tokens de acesso para validar o utilizador (descritos posteriormente no capítulo “5.2.2 – Autenticação”) e é estritamente utilizado o protocolo HTTPS para que os dados transmitidos, do cliente para o servidor e vice-versa, sejam transportados de uma maneira segura. Para obter o melhor desempenho possível, foram executados testes de desempenho (descrito posteriormente no capítulo “8.2 – Validações do projeto”) e foi implementado um sistema de cache (descrito posteriormente no capítulo “5.2.1 – Cache”) que reduz de maneira significante o tempo de resposta das respostas e pedidos.
21 5.1. Arquitetura
Esta Web API foi desenvolvida fazendo uso da ferramenta “Visual Studio 2017”. Foi criada uma solução constituída pelo projeto principal, denominado “WebAPI”, juntamente com outros projetos do tipo “.NET Framework Class Library” que tem como objetivo adicionar funcionalidade ao projeto principal, contendo as classes geradas dos módulos do ERP e algumas classes adicionais auxiliares.
“WebAPI” é o projeto principal da solução, do tipo “ASP.NET Web Application – Web API”. Sendo o projeto principal, tem como papel a desempenhar integrar todos os outros projetos, que estão referenciados nesta solução.
Os restantes projetos consistem em módulos do ERP e, em certos casos, possuem projetos auxiliares. A nomenclatura escolhida para identificar os módulos foi “Primavera.<módulo>.Services”. Esta normalização permite distinguir facilmente os diferentes módulos do ERP dos outros projetos.
Embora tenham a mesma nomenclatura, o módulo “plataforma” distingue-se dos outros, sendo o único que não foi gerado automaticamente devido à sua funcionalidade: gerir a autenticação dos utilizadores, e abrir a plataforma. Algo que é feito de maneira distinta do ERP, requerendo, portanto, uma implementação adaptada ao problema em questão.
Para fazer chamadas ao ERP, são utilizadas as classes geradas pelo gerador de código. Estas não contêm o código dos métodos presentes no ERP, mas sim, uma chamada à camada dos serviços de negócio do ERP. Tipicamente (como ilustrado na figura 8), no cabeçalho estão presentes a cache, a verificação da autorização do pedido, a route e o tipo de chamada (GET ou POST). Já dentro do método, é aberta uma ligação à plataforma do ERP é executado o método, e o resultado é enviado em formato JSON para o cliente.
22 5.2. Funcionalidades
Seguidamente são apresentadas as funcionalidades da Web API, cada uma dotada de uma breve explicação, do processo da sua implementação e, se pertinente, uma explicação da sua utilização face a outras opções existentes.
Segundo Fielding (2000), para que a implementação de um serviço Web seja considerada REST, são necessários os seguintes requisitos:
• Arquitetura cliente-servidor; • “Stateless” (sem estado); • Cache;
• Interface uniforme; • Sistema em camadas;
• Código “on-demand” (a pedido).
Embora alguns sejam opcionais, foi entendido que a sua inclusão na solução final seria benéfica para o projeto, nomeadamente a cache para a melhoria do desempenho e escalabilidade, e o código “on-demand” que visa a possibilidade de implementar versões futuras mais facilmente.
5.2.1. Cache
A cache pode ser utilizada de ambos os lados do cliente e do servidor. Ao adicionar a cache a um serviço Web, passa a existir a possibilidade da reutilização de dados guardados na cache do cliente ou do servidor.
Quando ocorre um pedido e o cliente já tem os dados armazenados em cache do seu lado, não é perdido tempo com o reenvio dos mesmos pelo servidor. Foi também utilizada a cache para guardar o objeto plataforma do lado do servidor, para mitigar o tempo de espera da sua abertura.
Existe, porém, uma desvantagem na utilização da cache, a redução da confiabilidade dos dados, já que os dados armazenados em cache, por vezes podem não corresponder aos dados existentes do lado do servidor, em casos da má implementação da cache.
Foi então feita uma exploração de diferentes implementações de cache, tendo-se ponderado três maneiras diferentes de implementar esta funcionalidade para cliente e duas para servidor:
23 • Cliente:
o Projeto open source “CacheCow”; o Namespace “System.Runtime.Caching”; o Projeto open source “Strathweb.CacheOutput”. • Servidor:
o Combinação de Redis e CacheManager;
o Namespace “System.Web.HttpRuntime.Cache”.
A primeira foi um projeto open source, denominado “CacheCow”. No entanto, está mencionado na documentação do projeto a incompatibilidade com “attributed routing” (Exemplo: [Route("TestFunc/{name}")]). Devido a esta incompatibilidade, esta solução foi descartada, já que “attributed routing” é mais flexível que a contraparte, “convention routing”. Esta flexibilidade de “attributed routing” provém do facto dos caminhos (“routes”) estarem definidos a par com os métodos que as vão utilizar, enquanto que “convention routing” as centraliza num só ficheiro, dificultando a sua geração automática e debugging.
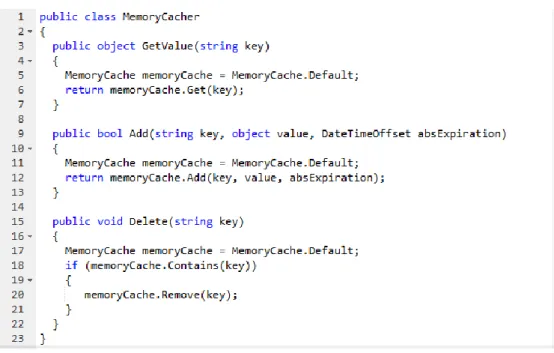
Outra opção foi a implementação de raiz da cache (representado na figura 9), fazendo uso do namespace “System.Runtime.Caching”. No entanto, esta implementação era demasiado simples para a complexidade da solução desejada. É necessária a existência da gestão de confiabilidade de dados, para evitar que os dados recebidos pelos utilizadores estejam sempre atualizados.
24 Finalmente, foi ponderado o projeto open source “Strahweb.CacheOutput”. A sua utilização é simples e facilmente gerida na geração de código, sendo que, caso seja desejado guardar em cache o output de um método, é apenas necessário adicionar uma linha no seu cabeçalho e, ao contrário da última opção, permite a invalidação da cache sempre que uma alteração é feita a nível da classe (figuras 10 e 11). Este projeto enquadrou-se nos requisitos e foi assim escolhido para a gestão da cache do lado do cliente.
Com o intuito de guardar o objeto da plataforma em cache para melhorar o desempenho do servidor, foi inicialmente ponderado uma solução que fizesse uso do programa Redis (“open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker”) e do projeto “Cache Manager”. Esta solução consiste na utilização do projeto Cache Manager para gerir a cache do servidor e do programa Redis para guardar e disponibilizar pares chave-valor, em que a chave seria o token do cliente e o valor seria um objeto serializado. No entanto a serialização do objeto pretendido demonstrou-se impossível, devido à sua complexidade, tornando esta solução inviável.
Face à impossibilidade de serializar o objeto, foi procurada uma nova maneira de armazenar um objeto em cache, do lado do servidor que não envolvesse este processo. O Namespace “System.Web.HttpRuntime.Cache” foi então escolhido pois permite guardar em cache um objeto associado a uma chave. Na figura 12 está representada a inserção do objeto em cache (linha 2), sendo a chave de identificação o token do cliente, e sua obtenção (linhas 4-12), com um método que extrai o token do pedido feito pelo cliente e devolve o objeto associado.
Figura 10- Exemplo da implementação de cache com “Strahweb.CacheOutput”
25 5.2.2. Autenticação
Para fazer a autenticação de um cliente, foram consideradas diversas maneiras de abordar este problema, nomeadamente, OAuth, OAuth2, JWT (JSON Web Token) e SAML (Security Assertions Markup Language).
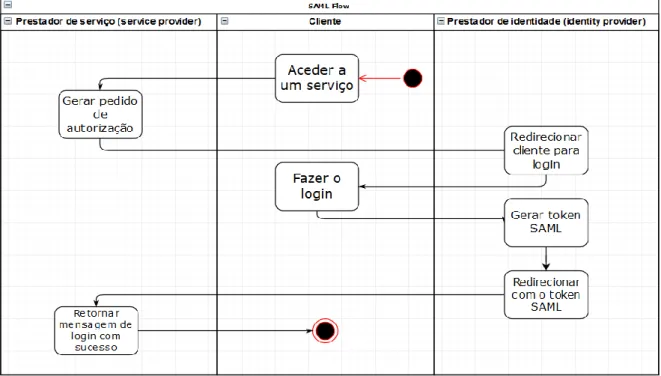
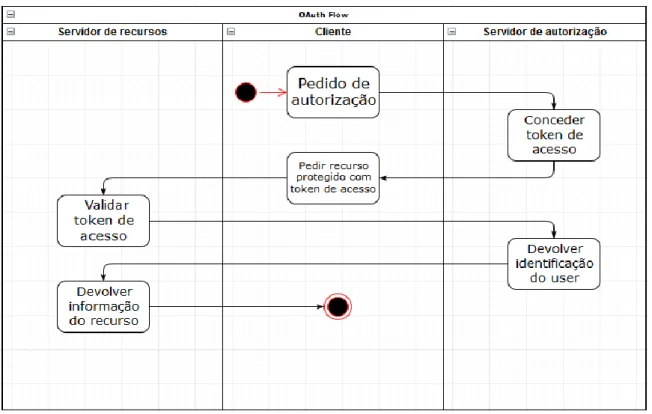
As duas figuras seguintes (figuras 13 e 14) são representações do fluxo do processo de autenticação do processo SAML e dos processos OAuth, Oauth2 e JWT, respetivamente. A grande diferença entre estes dois fluxos é que, no processo SAML, existe apenas um prestador identidade centralizado, ao qual, qualquer prestador de serviços conhecido pode aceder para verificar o cliente. Contudo, no fluxo do processo de OAuth, OAuth2 e JWT, cada servidor de recursos precisa de ter o seu servidor de autorização próprio, para fazer a verificação do cliente.
Figura 13 - Fluxo do processo SAML
26 Visto que a autenticação da Web API apenas será feita num local (plataforma do ERP), a abordagem SAML não será a mais apropriada para o caso.
As frameworks OAuth, OAuth2, e os JWT não se devem comparar diretamente, sendo que as frameworks podem fazer uso dos JWT ou dos seus próprios tokens opacos (conjunto de carateres aleatórios que não têm significado para o seu titular). A diferença reside no facto dos JWT não serem opacos, pelo contrário, contêm informação real, cifrada, resultando em tokens grandes, aproximadamente de 300 bytes ou mais. Qualquer entidade que possua o token é capaz de o abrir, validá-lo e fazer uso das alegações (“claims”) presentes para fazer decisões de autorização, caso tenha a chave para decifrá-lo.
Tabela 3- Tabela de comparação de tokens opacos e JWT
Usar JWT quando: Usar tokens opacos quando: Características comuns: É desejada a existência de
múltiplas entidades capazes de gerar e decifrar tokens. Por exemplo: usar uma entidade para gerar um token e depois usar uma outra entidade para validar o token. Com JWT, é possível que tokens gerados possam ser interpretados e validados por terceiros.
Quem emite o token é quem o valida.
Ambos têm a funcionalidade de ter alegações personalizadas.
Não há necessidade nem intuito do titular do token examinar as alegações contidas no token.
Ambos precisam ser segredos bem protegidos.
27 Não é necessária ligação
assíncrona. Por exemplo: quando o cliente faz o pedido, esse pedido será guardado e processado por outro sistema (que não possui uma ligação síncrona com o cliente) posteriormente.
É desejado revocar tokens por parte do cliente. JWT expiram apenas na data de expiração, definida durante a sua criação.
Ambos podem expirar após um determinado tempo e ser atualizados.
Ambos mecanismos de autenticação proporcionam uma experiência semelhante para o utilizador.
No caso presente, não é necessária a inclusão de terceiros para a criação e/ou validação de tokens. A entidade que emite os tokens é quem os valida, sendo que os JWT não fazem tanto sentido como os tokens opacos presentes em OAuth e OAuth2.
OAuth é um protocolo de segurança, que permite quem o utiliza, facultar acesso dos seus recursos Web (“Web resources”) a terceiros, sem partilhar as suas palavras-passe.
A primeira versão de OAuth foi publicada em Dezembro de 2007 e foi adotada rapidamente como o padrão para suportar a delegação de acessos baseados em Web. Em Abril de 2010, foi publicado como RFC 5849 pela IETF (Internet Engineering Task Force).
OAuth 2.0 é um protocolo completamente novo e não é compatível com as versões anteriores. No entanto, reteve a maior parte da arquitetura e abordagem estabelecida pelas versões anteriores, publicado pela IETF como RFC 6749 e atualizado posteriormente por RFC 8252.
As diferenças chave de OAuth e OAuth2.0 são:
• A adição de fluxos que suportam melhor aplicações não baseadas em browsers. Este era um dos pontos mais criticados da arquitetura OAuth 1.0. A user experience era prejudicada uma vez que aplicações desktop ou móveis tinham de direcionar o utilizador para um browser no seu dispositivo, autenticar-se com um serviço de autenticação, copiar o token retornado pelo serviço e introduzi-lo na aplicação ao qual estavam a tentar aceder. Com OAuth 2.0, existem maneiras novas de uma aplicação obter autorização para os seus utilizadores.
• OAuth 2.0 não requer criptografia do lado do cliente. Com OAuth 2.0, o cliente apenas precisa de fazer o pedido enviando o token por HTTPS, para aceder aos recursos desejados.
• Em OAuth 2.0 os tokens de acesso têm menos longevidade. Envés da existência de um token de grande duração (tipicamente um ano ou mesmo de tempo ilimitado), o servidor pode emitir tokens de menos longevidade e um “refresh token”. Este aspeto permite aos clientes obter
28 novos tokens de acesso quando necessário e manter o número de tokens limitado, melhorando a escalabilidade.
• OAuth 2.0 faz a separação dos papeis do servidor responsável pela gestão dos pedidos de geração de tokens e do servidor responsável pela gestão das autorizações to cliente.
Foi então adotada a framework OAuth 2.0, maioritariamente devido à necessidade da existência de escalabilidade e pela melhoria da “user experience”.
A implementação foi feita em duas partes, a primeira (ilustrada na figura 15) consiste na customização de um dos métodos do fornecedor de serviços de autenticação (“Authorization Server Provider”) para que, quando um cliente faz um pedido de um token, apenas o é permitido caso as suas credenciais sejam verificadas pela plataforma do ERP da PrimaveraBSS. O primeiro passo da customização foi a extração da informação necessária do contexto e o seu armazenamento (“username”, “password”, “company”, “instance”).
29 Seguidamente foi criada uma instância do objeto que representa a sessão de um utilizador (“UserSession”), que será posteriormente utilizado na plataforma do ERP para verificar se as credenciais inseridas pelo cliente estão corretas (“platformFunctions.Open(user, password) e platformFunctions.IsPlatformOpen()”). No caso de as credenciais serem válidas, o utilizador é então validado e a framework irá gerar um token de acesso que será devolvido ao utilizador.
A segunda parte consiste em chamar a framework na inicialização da Web API (figura 16).
Esta chamada da framework permite configurar aspetos tais como o caminho ao qual aceder para obter um token, a duração da validade de um token e permitir a utilização de HTTP inseguro (utilizado na fase de construção e de testes da solução).
Para testar esta funcionalidade, foi feito uso da ferramenta “Postman”. Foi enviado um pedido ao servidor com os dados de um utilizador fictício no corpo do pedido e o servidor devolveu um token de acesso (figura 17) que o cliente poderá utilizar para aceder aos recursos do servidor, colocando o token no cabeçalho de um pedido, como ilustrado na figura 18.
30
Figura 17- Teste ao serviço de geração de tokens com Postman
31 É também importante referir a existência de refresh tokens. Estes são tokens de longa duração, utilizados para obter access tokens de curta duração (figura 19). Caso um atacante consiga obter um token de acesso indevidamente, tem uma pequena janela de oportunidade para o utilizar, já que a sua longevidade é pequena. No entanto, caso obtenha um refresh token, é possível a sua utilização até que seja manualmente revocado.
Embora existam vantagens de criar uma solução com refresh tokens, o caso em questão não é ideal pois não existe a possibilidade de revocar um token na eventualidade de um utilizador ser removido pelo administrador do lado do ERP. Esse utilizador poderia usar o seu refresh token para obter acesso a dados ao qual não deveria ter acesso.
A solução elaborada faz uso de tokens de curta duração, certificando que o utilizador possui as credenciais corretas em curtas janelas de tempo. A sua duração é por defeito 20 minutos, mas pode ser configurada por um administrador para suportar a sua realidade.
5.2.3. Outras funcionalidades
Para além das previamente mencionadas neste capítulo, Fielding (2000) propôs a utilização das seguintes funcionalidades, para que um serviço Web seja considerado REST:
• Comunicação sem estado (“stateless”) - Esta restrição impede que o servidor mantenha o estado de um cliente armazenado, mantendo-o do lado do cliente, que o envia juntamente com
Cliente
Auth
Server
Resource
Server
Refresh Token Access Token Access Token Protected Resource32 cada pedido. Este aspeto tem como objetivo aumentar a escalabilidade de um serviço Web. Cada pedido é tratado independentemente, o serviço Web não mantém registo das interações prévias do cliente.
• Código “on-demand” (a pedido) – Quando chegar a altura de fazer a distribuição da Web API para os clientes, estes poderão ter acesso à Web API da mesma maneira que têm acesso ao ERP. Ou seja, sempre que for lançada uma nova versão da nova versão do ERP, a Web API irá também anexada, possibilitando aos developers, implementar novas funcionalidades no futuro. • Interface uniforme - Através da utilização de padrões de URI (“Uniform Resource Identifier”) é feita a separação do cliente de uma estrutura específica de URI da aplicação. Utilizando o URL “http://exemplo.com/ clientes /1234” como exemplo, é fácil identificar que um pedido feito irá retornar o cliente cujo número identificador é “1234” e um pedido feito a “http://exemplo.com/clientes” irá retornar uma lista de clientes. A adoção desta normalização facilita a escalabilidade da Web API.
• Arquitetura cliente-servidor –De forma geral, um serviço prestado pelo servidor é uma abstração para o cliente, na medida em que o cliente não necessita de se preocupar com nada para além de entender a resposta do servidor. Adicionalmente, qualquer cliente apenas tem acesso de comunicação ao servidor, e não a qualquer outro cliente.
33 5.3. Utilização da Web API
A utilização da Web API é descrita neste subcapítulo. Para auxiliar a compreensão do fluxo de atividades entre as entidades diferentes presentes na utilização da Web API por um utilizador com credenciais válidas, foi elaborada a seguinte diagrama de sequência (figura 20).
Para que um utilizador possa aceder a qualquer recurso do ERP, necessita de um token de acesso. Este token é concedido pelo servidor de autenticação (Auth Server), caso as credenciais enviadas pelo utilizador permitam abrir a plataforma do ERP. Neste caso, o token é guardado internamente no website para ser anexado em todos os pedidos futuros.
Após a autenticação, o utilizador por fazer um pedido para ler um objeto do ERP, para tal, o website anexa o token ao pedido, que é depois processado pela Web API que verifica a validade do token com o servidor de autenticação e, caso seja válido, faz um pedido ao ERP para obter o objeto desejado, que é então retornado ao utilizador.
Depois de obter o objeto desejado, o utilizador pode editá-lo e, tal como para o pedido de leitura do objeto, é feito todo um processo idêntico em que o token é validado, o pedido é feito ao ERP e o utilizador recebe uma resposta de sucesso.
34 5.4. Contratempos no desenvolvimento
Nesta secção são evidenciados alguns dos problemas encontrados no decorrer do desenvolvimento da Web API e a sua solução.
Um dos contratempos mais dispendiosos foi o processo de descoberta de quais das 320 DLL existentes na solução do ERP eram necessárias para a Web API. Utilizando o protótipo inicial da Web API, foram feitas inúmeras compilações e execuções para as identificar. Este processo, embora demoroso, beneficiou a solução, reduzindo ao máximo o tempo de compilação. Após este processo, todas as DLL essenciais encontravam-se associadas à solução.
Houve também um problema pontual de comunicação com um dos orientadores, que originou a procura de uma solução para um problema inexistente. No entanto, o impacto deste contratempo foi mínimo graças à grande disponibilidade de comunicação com o mesmo.
A Web API está diretamente dependente de DLLs do ERP, sendo que, o seu propósito é fazer chamadas a métodos do ERP. Estando o ERP em constante evolução, ocorreram situações em que as mudanças do ERP influenciaram negativamente a Web API, chegando, por vezes, ao ponto de impedir o seu funcionamento completamente.
Um destes casos foi a atualização para DLLs assinadas, em que existia uma variável automaticamente gerada em contexto desktop que não era gerada no contexto da Web API. Este problema foi resolvido através da definição manual da variável no momento em que a Web API chama pela primeira vez a plataforma do ERP.
Outro exemplo foi a mudança da versão da “.NET framework target” do ERP, que incapacitou a solução da Web API de compilar até que todos os projetos fossem atualizados para a mesma versão e todas as dependências fossem atualizadas para versões compatíveis.
Existiram também uma limitação por parte do hardware da máquina no qual o trabalho foi feito. A falta de espaço de disco necessário para o desenvolvimento da solução levou à necessidade da incorporação de um disco adicional na máquina que conseguisse suportar a grande quantidade de dados existentes.