F
ACULDADE DEE
NGENHARIA DAU
NIVERSIDADE DOP
ORTOAutonomic Computing: Processamento
de Eventos
Hélder Filipe Martins Branco
Mestrado Integrado em Engenharia Informática e Computação
Orientador: Rui Filipe Lima Maranhão de Abreu (Professor Auxiliar Convidado)
Autonomic Computing: Processamento de Eventos
Hélder Filipe Martins Branco
Mestrado Integrado em Engenharia Informática e Computação
Aprovado em provas públicas pelo júri:
Presidente: José Manuel Magalhães Cruz (Professor Auxiliar)
Vogal Externo: Ricardo Jorge Fernandes Chaves (Professor Auxiliar)
Orientador: Rui Filipe Lima Maranhão de Abreu (Professor Auxiliar Convidado)
Resumo
No mundo de hoje, os sistemas informáticos encontram-se profundamente enraizados na nossa vida quotidiana. Cada vez mais estes são fulcrais ao bem-estar e funcionamento da nossa civilização. Contudo este facto traduz-se em sistemas cada vez mais complexos e numa maior necessidade do contínuo funcionamento por parte destes. Garantir a con-ciliação de complexidade e funcionamento contínuo é uma tarefa árdua para as equipas de manutenção dos sistemas que desperdiçam demasiado tempo na sua manutenção e traduzindo-se num aumento de custos. O Autonomic Computing pretende ser a resposta a este problema crescente. Construindo sistemas autónomos capazes de se auto-corrigirem e de se adaptarem ao meio envolvente seria a resolução que permitiria “libertar” os técni-cos de TI e reduzir custos de manutenção.
Atenta a esta realidade a empresa I2S iniciou um projecto denominado I2S Log Audit and Problem Determination (I2S.LAP) com o objectivo de proporcionar às suas equipas de TI um sistema capaz de monitorizar, detectar problemas e corrigir automaticamente se possível. Este projecto encontra-se dividido em três subprojectos dos quais o projecto em causa nesta dissertação denomina-se I2S.LAP Services. Este consiste num servidor que recebe os eventos provenientes dos sistemas monitorizados filtrando-os e relacionando-os em transacções de negócio de critérios configuráveis permitindo depois que estes sejam analisados procurando encontrar sintomas de problemas nos sistemas.
O I2S.LAP Services foi implementado de forma configurável de modo a que possa ser adaptado a diferentes necessidades dos sistemas monitorizados contribuindo para uma maior capacidade de resposta das equipas de IT da I2S no diagnóstico e resolução de problemas nos seus sistemas.
O carácter inovador deste tipo de soluções e a possibilidade de contacto com o mundo empresarial foram importantes factores motivadores.
Abstract
Nowadays, computer systems are deeply rooted in our everyday lives. Increasingly these are central to the welfare and functioning of our civilization. Yet this fact is reflected in increasingly complex systems and a greater need of a continued operation by them. Conciliate complexity and continuous operation is a tough task for the teams responsible for maintaining the systems losing too much time in that task causing higher costs. The Autonomic Computing is intended to be a response to this growing problem. Building autonomous systems able to healing themselves and adapt to the surrounding environment would be the resolution that would "free"IT technicians and reduce maintenance costs.
Given this reality, the company I2S initiated a project called I2S Audit Log and Prob-lem Determination (I2S.LAP) in order to provide their IT teams with a system that can monitor other systems, detect problems and automatically correct them if possible. This project is divided into three sub-projects where the project in question in this dissertation is called I2S.LAP Services. This consist in a server that receives events from the mon-itored systems, filtering them and relating them in business transactions of configurable criteria allowing them to be analyzed searching symptoms of problems in the systems.
The I2S.LAP Services was implemented in a configurable way so that it can be adapted to different needs of the monitored systems contributing to greater responsiveness of the I2S IT teams in diagnosing and solving problems in their systems.
The innovative character of such solutions and the ability to contact the business world were important motivating factors.
Agradecimentos
Durante o decorrer desta dissertação várias pessoas contribuíram directa ou indirecta-mente para a sua realização. Por este motivo gostaria de agradecer:
Ao orientador desta dissertação o professor Rui Maranhão pela sua disponibilidade e dedicação demonstradas, factor determinante no desenrolar deste projecto.
A todos os colaboradores da empresa I2S em especial ao sector de Concepção Ino-vação e Desenvolvimento pela disponibilidade e apoio prestados e por me receberem de braços abertos no seio desta empresa.
À minha família pelo apoio incansável nos bons e maus momentos. A todos o meu muito obrigado.
Conteúdo
1 Introdução 1 1.1 Contexto . . . 1 1.1.1 Empresa . . . 2 1.2 Projecto . . . 3 1.3 Motivação e Objectivos . . . 4 1.4 Estrutura da Dissertação . . . 4 2 Revisão Bibliográfica 5 2.1 Autonomic Computing . . . 5 2.1.1 Arquitectura de referência . . . 62.1.2 Common Base Event . . . 8
2.1.3 Vantagens/Desvantagens . . . 9
2.2 Recovery Oriented Computing . . . 9
2.2.1 Principais áreas ROC . . . 10
2.2.2 Vantagens/Desvantagens . . . 11
2.3 Arquitectura Event-Driven (EDA) . . . 11
2.3.1 Estrutura de um evento . . . 12
2.3.2 Processamento de Eventos . . . 12
2.3.3 Vantagens/Desvantagens . . . 13
2.4 Aspectos Tecnológicos . . . 13
2.4.1 Java Enterprise Edition (J2EE) . . . 13
2.4.2 Enterprise Java Beans (EJBs) . . . 13
2.4.3 Websphere Application Server (WAS) . . . 14
2.4.4 Rational Application Developer (RAD) . . . 15
2.4.5 Spring Framework . . . 15
2.5 Sumário . . . 16
3 Proposta de Solução 17 3.1 Representação dos eventos . . . 17
3.2 Agrupamento de Eventos . . . 18
3.2.1 Algoritmo base de agrupamento . . . 20
3.3 Sistema de persistência . . . 22
3.3.1 Descrição das tabelas . . . 22
CONTEÚDO
4 Implementação 25
4.1 Arquitectura geral do I2S.LAP Services . . . 25
4.1.1 LAPSrvEventMgr . . . 25
4.1.2 LAPSrvPersistenceMgr . . . 26
4.1.3 LAPSrvEventDelegatorBean . . . 27
4.1.4 MainLAPWorkManager . . . 27
4.1.5 LAPWorkManager . . . 29
4.1.6 LAPEngines - Motores de Agrupamento . . . 30
4.2 Análise de Sintomas . . . 30
4.3 I2SLAPSrvCommandLine . . . 31
4.4 Sumário . . . 31
5 Análise e Resultados 33 5.1 Registo de eventos . . . 33
5.2 Agrupamento de eventos em transacções . . . 34
5.3 Sumário . . . 35
6 Conclusões e Trabalho Futuro 37 6.1 Satisfação dos Objectivos . . . 37
6.2 Trabalho Futuro . . . 38
Referências 39 A Modelo Relacional 43 B Diagrama de Arquitectura 45 C Roadmap projecto LAP 47 D Exemplo de um Common Base Event 49 E Exemplos de comandos I2SLAPCommandLine 51 E.1 Exemplo de um comando register . . . 51
Lista de Figuras
1.1 Composição do GIS . . . 2
2.1 Capacidades principais de auto-gestão de um sistema Autonomic Com-puting . . . 5
2.2 Ciclo de controlo de um sistema autonomic computing . . . 7
2.3 Estrutura de um Common Base Event . . . 8
2.4 Mecanismo de publicação/subscrição de um evento EDA . . . 12
2.5 As quatro camadas do processamento de um evento . . . 12
3.1 Exemplo de um fragmento XML de configuração de um motor . . . 18
3.2 XML Schema do XML de configuração dos motores de agrupamento . . 19
4.1 Diagrama de actividade do processo de registo de um evento . . . 26
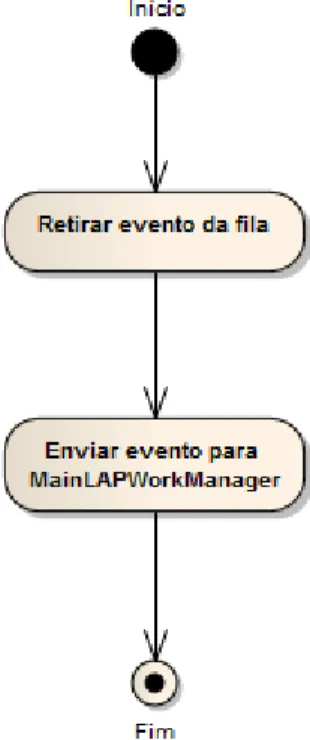
4.2 Diagrama de actividade do LAPSrvEventDelegatorBean . . . 27
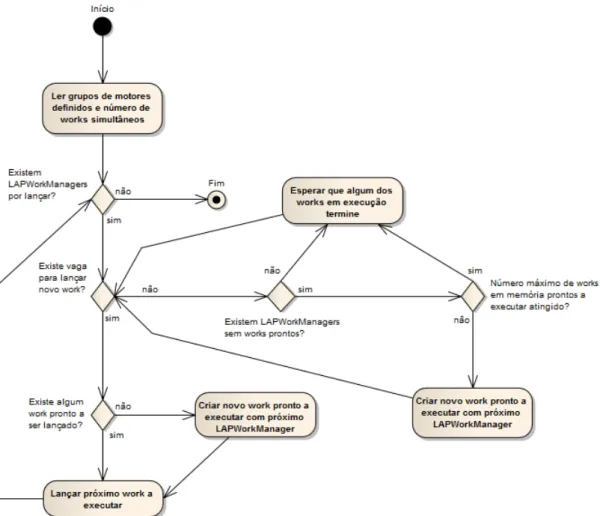
4.3 Diagrama de actividade do MainLAPWorkManager . . . 28
4.4 Diagrama de actividade do LAPWorkManager . . . 29
4.5 Subdiagrama de actividade da actividade Criar novo Work pronto a exe-cutar com próximo motor . . . 30
Lista de Tabelas
5.1 Testes de performance ao processo de registo de eventos . . . 33
Abreviaturas e Símbolos
LAP Log Audit and Problem Determination TI Tecnologias de InformaçãoAC Autonomic Computing
ROC Recovery Oriented Computing EDA Event-driven Architecture CBE Common Base Event J2EE Java Enterprise Edition
WAS Websphere Application Server EJB Enterprise Java Bean
RAD Rational Application Developer IDE Integrated Development Environment JMS Java Message Service
XML Extensible Markup Language IBM International Business Machines
Capítulo 1
Introdução
Nos últimos anos temos assistido a um crescimento exponencial da proliferação e inte-gração de dispositivos computacionais na vida quotidiana, assim como do seu poder com-putacional. Este facto conduziu a uma complexidade nunca antes vista na manutenção e gestão dos sistemas computacionais.
Actualmente, o número de profissionais de Tecnologias de informação (TI) qualifica-dos começa a ser insuficiente para satisfazer as necessidades de manutenção e gestão qualifica-dos sistemas. Esta escassez de profissionais TI qualificados aliado ao aumento da complexi-dade dos sistemas leva a um maior risco de falhas e perda de informação por parte desses sistemas que poderão ser catastróficas. [IBM10a]
Atenta a este problema, a IBM propôs uma solução, em 2001, denominada Autonomic Computing. O desenvolvimento desta solução baseou-se no sistema nervoso autónomo humano. Este é a parte do sistema nervoso responsável pelo controlo de funções vitais como a respiração, batimento cardíaco e regulação da temperatura corporal. Funções estas que estão em constante funcionamento sem a necessidade do nosso consciente en-volvimento ou esforço.
Com este novo paradigma, a IBM pretende que os sistemas computacionais possuam capacidades de auto-manutenção, ou seja, que sejam capazes de se corrigirem, con-figurarem e optimizarem a eles próprios e se adaptarem às necessidades dos seus uti-lizadores. [IBM10b]
1.1
Contexto
O mundo empresarial actual necessita de uma continuidade dos seus negócios 24 ho-ras por dia, 7 dias por semana, obrigando os sistemas de informação que os suportam
Introdução
a manterem um nível de fiabilidade elevado. Um qualquer problema que surja no sis-tema deve ser rapidamente descoberto e resolvido caso contrário poderá causar prejuízos significativos na organização em causa.
Dentro deste contexto a empresa I2S pretende criar uma solução baseada no paradigma de Autonomic Computing para o suporte dos seus sistemas de informação. O sistema deverá monitorizar, detectar e corrigir automaticamente possíveis problemas nos sistemas de informação. Estes problemas podem ser eventos técnicos (erros de software) ou de negócio (ex: atendimento do cliente está a demorar mais que o esperado).
1.1.1 Empresa
A Informática - Sistemas e Serviços, SA (I2S) é uma empresa fundada em 1984 e sedeada no porto. Esta possui ainda uma delegação em Lisboa e uma associada no Brasil (I2S Brasil). A I2S especializou-se no mercado global de seguros com o objectivo de concepção, desenvolvimento e implementação de soluções informáticas de elevado nível de integração e flexibilidade para esse mercado. A I2S encontra-se neste momento certi-ficada com a norma ISO 9001:2000.
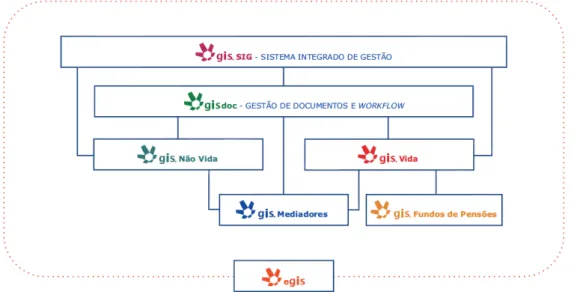
A solução mais importante disponibilizada pelo I2S para o mercado de seguros denomina-se GIS – Gestão Integrada de Seguros.
Figura 1.1: Composição do GIS
Serviços • Consultoria • Formação
Introdução
• Gestão de projectos • Administração de sistemas • Actuariado
• Outsourcing
A I2S é ainda parceira de empresas tão conceituadas como a IBM e a Microsoft
1.2
Projecto
Pretende-se um sistema de monitorização dos sistemas de informação da I2S que apoie as equipas de TI. Este deve ser capaz de determinar, resolver ou antecipar problemas.
O sistema pretendido, denominado I2S.LAP (Log, Auditing and Profile) será com-posto por três subsistemas distribuídos:
• I2S.LAP Agents • I2S.LAP Services
• I2S.PDA – Problem Determination and Advisor for IT
Todo o sistema LAP será desenvolvido em quatro fases, sendo que esta dissertação corresponde à segunda fase de desenvolvimento do subsistema I2S.LAP Services. O I2S.LAP Services consiste num servidor que registará os eventos despoletados pelos sitemas monitorizados através dos vários I2S.LAP Agents instalados nas máquinas onde correm os sistemas. Posteriormente esses eventos serão relacionados e agrupados em transacções de negócio de acordo com critérios configuráveis. Após o seu agrupamento os eventos serão analisádos pelo I2S.LAP PDA procurando sintomas de anomalias e dis-poletando as acções necessárias à correcção das anomalias detectadas. Parte do módulo de análise de sintomas será mais tarde integrado no I2S.LAP Services. Pretende-se que nesta fase o I2S.LAP Services seja capaz de:
• Recepção, registo, validação e triagem inicial dos eventos fornecidos pelos vários agentes do I2S.LAP
• Processamento, em quase tempo real, dos eventos recebidos, agrupando-os em vários tipos de transacções de negócio com critérios configuráveis.
Introdução
1.3
Motivação e Objectivos
A I2S é uma empresa com uma excelente imagem nacional tendo como clientes in-stituições tão importantes como o BES. Para além disso já se encontra fora do mercado nacional, tendo inclusive uma associada no Brasil (I2S Brasil). A possibilidade de estagiar numa empresa desta importância e o contacto com o ambiente empresarial foram impor-tantes factores motivadores. Outro factor motivante foi o carácter inovador envolvido no projecto pois sistemas de detecção e correcção automática de problemas são ainda muito recentes e as metodologias encontram-se ainda em desenvolvimento.
O projecto LAP tem como principal objectivo o desenvolvimento de um sistema que apoie as equipas de TI na determinação e correcção de problemas nos sistemas de infor-mação da I2S.
1.4
Estrutura da Dissertação
Para além da introdução, esta dissertação contém mais 4 capítulos. No capítulo 2, é descrito o estado da arte e são apresentadas as principais tecnologias utilizadas. No capítulo 3, é apresentada uma proposta de solução para o problema proposto. No capí-tulo4é descrita a implementação da proposta de solução. Por ultimo, no capítulo 6são apresentadas as conclusões finais do trabalho elaborado e perspectivas de trabalho futuro.
Capítulo 2
Revisão Bibliográfica
2.1
Autonomic Computing
O conceito Autonomic Computing visa o uso de tecnologia para gerir tecnologia [IBM06a]. Um sistema autónomo deve ser capaz de se gerir a si próprio de acordo com políticas definidas pelo seu administrador [IBM01].
Revisão Bibliográfica
O conceito de auto-gestão neste tipo de sistemas pode ser dividido em quatro áreas principais como é apresentado na figura2.1e descritas seguidamente:
• Auto-configuração — Os ambientes dos mercados actuais encontram-se em con-stante mutação pelo que é fulcral ao sucesso de uma empresa a rápida adaptação dos seus sistemas de informação. Este processo é bastante complexo e demor-ado por parte dos administrdemor-adores do sistema e envolve um risco considerável de introduzir erros. Um sistema auto-configurável permitiria uma resposta extrema-mente rápida às variações imprevisíveis do ambiente e de uma forma mais se-gura [IBM01,KC03,Akb09].
• Auto-correcção — Em sistemas cada vez mais complexos, a tarefa de detectar a causa de um erro é muitas vezes extremamente difícil. Um sistema autónomo de-verá, portanto, ser capaz de detectar problemas (e mesmo potenciais problemas), isolar o componente em causa, corrigi-lo (se necessário com ajuda humana) e por fim reintegra-lo. Deverá ao mesmo tempo reconfigurar-se de forma a manter o seu normal funcionamento [IBM01,KC03,Akb09].
• Auto-optimização — Um sistema autónomo procura formas de se optimizar para garantir o melhor desempenho possível. Tenta optimizar a alocação dos recursos disponíveis e procura formas de melhorar as suas funções e parâmetros associa-dos [IBM01,KC03,Akb09].
• Auto-protecção — Um sistema de informação encontra-se sempre ameaçado por vários perigos existentes no seu meio envolvente (por exemplo: ataques maliciosos de hackers ou vírus pela internet). Um sistema autónomo deve ser capaz de se de-fender de tais perigos. Este deve manter-se em constante alerta, detectar as potenci-ais ameaças e adoptar as medidas necessárias para evitar ou reduzir danos [IBM01,
KC03,Akb09].
2.1.1 Arquitectura de referência
Para que um sistema autonomic computing se possa auto gerir, este necessita de se monitorizar constantemente a si próprio. A implementação de um ciclo de controlo in-teligente que recolha informação, tome decisões e faça ajustes no sistema será necessário (ver figura2.2) [IBM05,Cha04].
Revisão Bibliográfica
Figura 2.2: Ciclo de controlo de um sistema autonomic computing
Autonomic Manager
Componente responsável pela implementação do ciclo de controlo e pela automação da gestão do sistema.
Este ciclo é dividido nas seguintes partes:
• Monitorização — Mecanismos de recolha e filtragem de eventos que ocorram no sistema.
• Análise — Os eventos reportados são sujeitos a uma análise com o objectivo de descobrir o que fazer com eles. Esta análise ajudará o Autonomic Manager a prever situações futuras.
• Planificação — Nesta fase são definidas as acções necessárias a serem executadas para lidar com o evento reportado.
• Execução — O plano elaborado anteriormente é executado.
Durante estas quatro fases do ciclo de controlo é gerado novo conhecimento que é guardado num base de conhecimento permitindo ao Autonomic Manager aprender mais sobre as características dos componentes envolvidos. Assim este poderá optimizar as fu-turas decisões tomadas durante o ciclo [IBM05,Cha04].
Managed resource
Componente do sistema a ser monitorizado. Pode ser apenas um ou um conjunto de componentes ao mesmo tempo [IBM05,Cha04].
Revisão Bibliográfica
Managed resource touchpoint
Interface de comunicação entre o Autonomic Manager e o Managed resource. Esta interface disponibiliza dois tipos de operações, sensor e actuador. As operações de sensor são usadas para transmitir eventos do Managed resource para o Autonomic Manager, enquanto que as operações de actuador são usadas para efectuar alterações no Managed Resource [IBM05,Cha04].
2.1.2 Common Base Event
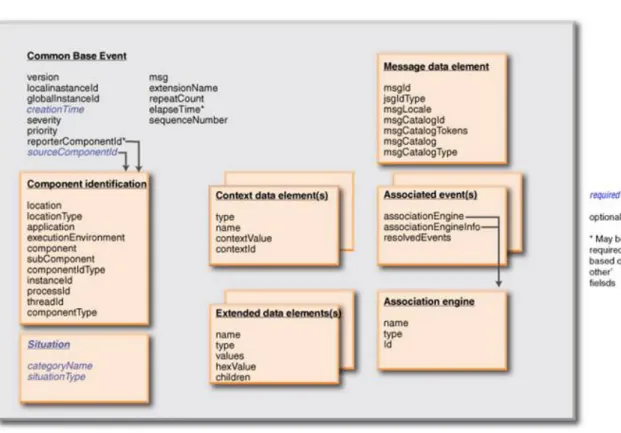
Figura 2.3: Estrutura de um Common Base Event
O Common Base Event é um formato XML standard desenvolvido pela IBM para a comunicação de eventos que ocorram num sistema computacional. Este formato é um elemento fundamental na arquitectura de Autonomic Computing proposta pela IBM pois toda a informação encontra-se num formato comum e facilita a comunicação dos eventos entre as várias camadas do sistema autónomo.
O uso de um standard para a representação de eventos de um sistema é de extrema importância num sistema autónomo pois existe a necessidade de correlacionar os vários eventos entre si e para tal é necessário que a informação contida nos eventos e o seu for-mato seja consistente. A não utilização de um standard levaria a uma maior dificuldade
Revisão Bibliográfica
neste processe de correlação, principalmente em sistemas compostos por vários compo-nentes diferentes e consequentemente, levaria a acções de resposta automáticas menos eficazes. [IBM06b,IBM04]
O formato Common Base Event possui na sua estrutura elementos para informação sobre (ver Figura2.3):
• Identificação do componente que reporta o evento.
• Identificação do componente onde o evento ocorreu (poderá ser o mesmo que o componente que reporta).
• Descrição da situação.
2.1.3 Vantagens/Desvantagens
As vantagens inerentes a um sistema autónomo são:
• Maior adaptabilidade do sistema ao seu meio envolvente.
• Redução de custos relacionados com a manutenção do sistema e libertação dos profissionais responsáveis pela tarefa de manutenção para outras tarefas mais im-portantes.
• Maior tolerância a falhas.
• Mais rápida e maior taxa de resolução de erros.
No então, como tudo tem desvantagens. As principais desvantagens de Autonomic computingprendem-se pelo facto de ser ainda uma área muito recente e que se encontra ainda em desenvolvimento e torna o processo de criação do sistema mais complexo – “Paradoxically, to solve the problem – make things simpler for administrators and users of I/ T – we need to create more complex systems.” [IBM01].
2.2
Recovery Oriented Computing
Recovery Oriented Computing(ROC) é um projecto de investigação conjunto entre as Universidades de Berkeley e Stanford direccionado a serviços altamente dependentes da Internet. O ROC assenta no princípio de que qualquer sistema, mesmo os mais robustos, terá, mais cedo ou mais tarde, falhas devido ao factor erro humano, falhas de hardware ou anomalias de software. Este princípio é a razão da principal diferença do ROC em relação a outras abordagens de tolerância a falhas. O ROC foca-se na recuperação de falhas em vez da prevenção das mesmas [ROC04]. O ROC tem três princípios base:
Revisão Bibliográfica
• As taxas de falhas de software e de hardware não são desprezáveis e estão a aumen-tar
• Os Sistemas não podem ser completamente modelados para análises de fiabilidade e, consequentemente, as suas falhas não podem ser previstas antecipadamente. • Uma das grandes fontes de falhas do sistema são os erros introduzidos pelos
oper-adores do sistema e pelas operações de manutenção do mesmo.
2.2.1 Principais áreas ROC Isolamento e redundância
Neste tipo de sistemas se um componente falhar, este deve ser isolado e substituído por outro redundante. Desta forma o sistema poderá manter o seu normal funcionamento. O isolamento pode ser, tanto de falhas de software como de hardware [ROC04].
Suporte a retrocesso no sistema
Em muitos sistemas de informação é disponibilizada uma ferramenta de retrocesso com o objectivo de permitir recuperar o sistema de erros introduzidos pelos seus uti-lizadores. No entanto esta função não é disponibilizada para o processo de manutenção. Este processo é, normalmente, muito complexo e tem um impacto significativo no sis-tema, pelo que algum problema neste processo poderá revelar-se desastroso. A opção de retroceder o sistema para um estado correcto poderia corrigir estas situações num “abrir e fechar de olhos”. Poderia, também, ser utilizada como ferramenta de diagnóstico pelo método de tentativa-erro. Portanto um sistema ROC deve disponibilizar uma opção de retrocesso que cubra todos os aspectos do mesmo, desde software a hardware [ROC04].
Suporte integrado de diagnóstico
O sistema deve ser capaz de identificar rapidamente a presença de falhas e a sua raiz. Assim que, detectadas, o sistema deve corrigi-las ou pelo menos conte-las de modo a evi-tar uma, potencialmente catastrófica, reacção em cadeia de falhas. Todos os componentes do sistema devem possuir a capacidade de se auto-testarem e de testar todos os módulos pelos quais têm dependências. Estes devem, também, cooperar entre si na obtenção de informação sobre as suas dependências, recursos e pedidos do utilizador pois são infor-mações muito importantes ao diagnóstico [ROC04].
Verificação online de mecanismos de recuperação
Os mecanismos de recuperação são de uma elevada importância num sistema ROC, pelo que devem ser eficazes, eficientes e fiáveis. Para garantir estas qualidades nos seus mecanismos de recuperação, estes devem ser constantemente testados durante o fun-cionamento do sistema. Os testes efectuados podem ser de dois tipos: pré-definidos e
Revisão Bibliográfica
aleatórios. Durante os testes, os mecanismos devem ser testados com falhas de sistema realistas [ROC04].
Design para alta modularidade, mensurabilidade e reiniciamento
Algumas falhas, como corrupções de memória, são muitas vezes resolvidas mais efi-cazmente pelo reiniciamento dos componentes afectados. Por vezes o seu reiniciamento antes de falhar pode aumentar a disponibilidade global. Os componentes devem, portanto, ser desenvolvidos de forma a permitir o seu reiniciamento sem afectar todo o sistema, pos-sivelmente de forma automática [ROC04].
Medidas de fiabilidade
Medidas imparciais de avaliação da fiabilidade do sistema devem ser empregues. Desta forma poderá ser determinado se o sistema ROC atingiu aumentos de fiabilidade significativos comparativamente aos sistemas normais [ROC04].
2.2.2 Vantagens/Desvantagens
A filosofia empregue nesta metodologia arrecada como principal vantagen o continuo funcionamento correcto do sistema pois se um componente falhar é substituído por outro redundante. Outra vantagem é a possibilidade de retrocesso no sistema para um estado correcto, permitindo a correcção de erros introduzidos e efectuar diagnósticos através do método tentativa erro.
Como pontos negativos, destaca-se o facto de ser orientado apenas à recuperação de erros. Um sistema ROC não tem a capacidade de detectar potenciais problemas que pos-sam acontecer no futuro como o caso do Autonomic Computing.
2.3
Arquitectura Event-Driven (EDA)
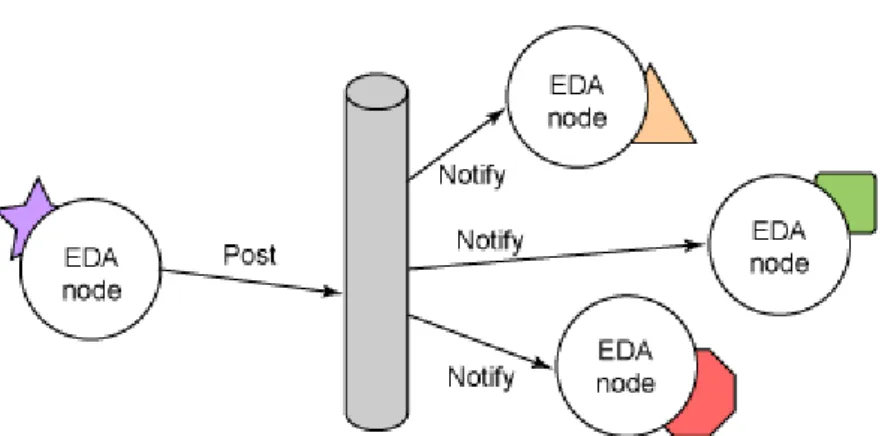
Metodologia para a implementação de aplicações ou sistemas baseados em eventos. Um evento pode ser definido como um acontecimento significativo que se passou dentro ou fora do sistema. Após a detecção de um evento este pode ser e publicado e “consum-ido” pelos componentes ou serviços que subscreveram-se para esse evento (ver figura2.4
) [Mar06,Mic06]. Estes eventos despoletam acções nos componentes que os “consomem” influenciando as operações desempenhadas por estes. Estas acções podem ser por exem-plo, tomar medidas para corrigir um erro detectado no sistema.
Por natureza a arquitectura Event-Driven é altamente distribuída e é principalmente dirigida a comunicações assíncronas. O criador do evento não tem conhecimento das acções que serão despoletadas nem a quem o evento se dirige.
Revisão Bibliográfica
Figura 2.4: Mecanismo de publicação/subscrição de um evento EDA
2.3.1 Estrutura de um evento
Um evento é formado por um cabeçalho e um corpo. O cabeçalho pode conter infor-mações como o seu ID, nome, tipo ou o timestamp. No corpo contem a descrição sobre o que aconteceu realmente. [Mic06]
2.3.2 Processamento de Eventos
Figura 2.5: As quatro camadas do processamento de um evento
O processamento de eventos passa por quatro camadas, desde a sua geração até à reacção ao mesmo. Essas fazes são descritas de seguida [Mic06]:
• Gerador de eventos — Após a detecção de um acontecimento relevante ao sistema este é transformado num evento.
Revisão Bibliográfica
• Canal do evento — Este canal é responsável pela transmissão do evento gerado pelo gerador de eventos até à camada de processamento do evento.
• Processamento de eventos — Nesta camada, o evento é identificado, são escolhidas as acções apropriadas e são executadas através dos meios necessários.
• Actividade de downstream event-driven — Por último, os resultados do evento são apresentados caso seja indicado.
2.3.3 Vantagens/Desvantagens
Uma arquitectura event-driven permite uma melhor construção de aplicações distribuí-das. Um subsistema distribuído pode ser totalmente independente dos outros, não pre-cisando de saber o que outros subsistemas irão fazer com os seus eventos gerados. Um sistema deste tipo terá, também uma maior capacidade de resposta.
No entanto, como ponto negativo, o fluxo destes sistemas torna-se menos óbvio.
2.4
Aspectos Tecnológicos
2.4.1 Java Enterprise Edition (J2EE)Java Enterprise Edition é uma plataforma para a programação de aplicações do tipo servidor na linguagem de programação Java. O J2EE simplifica a criação de aplicações distribuídas e disponibiliza várias tecnologias para tal como por exemplo: para interacção com Bases de Dados, serviços de mensagem, servidores de e-mail, etc. Outra das vanta-gens do J2EE é a grande portabilidade entre sistemas operativos.
A execução de aplicações J2EE necessita de um servidor de aplicações para serem executadas. [Car06,Orac]
2.4.2 Enterprise Java Beans (EJBs)
Enterprise Java Beans é uma tecnologia do tipo servidor pertencente à plataforma J2EE e que encapsula a lógica de negócio de uma aplicação. A lógica de negócio de uma aplicação é o código que implementa os objectivos da aplicação. O uso de EJBs simplifica o desenvolvimento de grandes aplicações distribuídas pois o container EJB trata da gestão de transacções, de segurança e de acesso a Base de Dados. Deste modo permite que o programador se concentre na resolução de problemas de negócio. [SUNc,Orab]
Como os EJBs contêm a lógica de negócio da aplicação, o desenvolvimento de clientes da aplicação concentra-se apenas na sua apresentação resultando em aplicações cliente mais pequenas.
Revisão Bibliográfica
Outras vantagens dos EJBs são a sua grande portabilidade, possibilidade de correr os vários EJBs da aplicação em diferentes máquinas e a possibilidade de construir novas aplicações a partir de EJBs já implementados. [SUNc]
Existem três tipos de EJBs:
• Session Beans — EJB responsável pela execução de pedidos de um cliente. Este pode manter o estado durante uma sessão com o cliente (Statefull) ou não (State-less). [SUNb]
• Entity Beans — Representa um objecto de negócio numa Base de Dados. Tipica-mente um Entity Bean mapeia uma tabela e cada instância deste Bean representa uma linha dessa tabela. A persistência de um Entity Bean pode ser gerida pelo container– container-managed persistence (CMP) – ou pelo próprio Bean – bean-managed persistence(BMP). No modo CMP o Container trata da gestão de acessos à Base de Dados, incluindo SQL. Como no código do Entity Bean não existe SQL este não fica “preso” a um sistema de gestão de Base de Dados específico permitindo a alteração da Base de Dados sem necessitar de recompilar o Entity Bean. No modo BMP essa gestão é feita no código do Entity Bean e programada pelo programador. A vantagem deste modo é um maior controlo nos acessos à Base de Dados. [SUNd] • Message Driven Beans — Este EJB funciona como um listener de uma fila JMS e
processa as suas mensagens de modo assíncrono. [SUNa]
2.4.3 Websphere Application Server (WAS)
O Websphere Application Server é um servidor de aplicações desenvolvido pela IBM e construído sobre a tecnologia Java. O WAS disponibiliza várias tecnologias, entre elas a plataforma J2EE e Web services, para o desenvolvimento de aplicações do tipo servidor e orientadas à Web e para ligações a Base de Dados. Disponibiliza também um ambiente para correr essas aplicações. [Car06]
O WAS é suportado pela maior parte dos sistemas operativos actuais como os sistemas: • Windows
• AIX • Solaris • HP-UX • Linux
Revisão Bibliográfica
• z/OS
Para além da grande portabilidade do WAS, este suporta uma grande variedade de servidores WEB como por exemplo:
• Apache HTTP Server 2.0.54
• IBM HTTP Server for WebSphere Application Server V6.0.2 • IBM HTTP Server for WebSphere Application Server V6.1 • Internet Information Services 5.0
• Internet Information Services 6.0
• Lotus DominoR Enterprise Server 6.5.4 or 7.0R
• Sun JavaTM System Web Server 6.0 SP9
• Sun Java System Web Server 6.1 SP3
O WAS é o servidor de aplicações utilizado pela I2S pelo que a sua utilização é necessária.
2.4.4 Rational Application Developer (RAD)
O RAD é um IDE Java desenvolvido pela IBM e baseado no Eclipse. Este possui ferramentas que facilitam e assistem no desenvolvimento de aplicações Java e de testes unitários a essas aplicações. [IBM]
O RAD é o IDE utilizado na I2S para desenvolvimento de aplicações Java.
2.4.5 Spring Framework
O Spring é uma framework Java/J2EE que disponibiliza vários módulos para o de-senvolvimento e simplificação de aplicações J2EE. Os vários módulos do Spring foram projectados para diferentes necessidades e tipos de aplicações a desenvolver (WEB, Base de Dados, Aspect-oriented programming, etc). A arquitectura por camadas do Spring confere uma grande flexibilidade a esta Framework.
Um dos módulos do Spring é o Inversion of Control. Este possui um container re-sponsável pela instanciação dos objectos do sistema bem como das suas dependências que se encontram configuradas em ficheiros XML (Dependency injection) substituindo o tradicional new. Através deste método de instanciação é possível alterar os atributos dos objectos a instanciar ou mesmo que objectos instanciar sem necessidade de alterar código ou de o recompilar. A configuração de cada objecto nos ficheiros XMl usados denomina-se bean e possui um id único através do qual denomina-se pode obter uma instância do objecto no código da aplicação. [Spra,Sprb]
Revisão Bibliográfica
2.5
Sumário
A introdução destes novos paradigmas para sistemas de informação poderá traduzir-se num avanço muito significativo na área das tecnologias de Informação. Sistemas que se auto-gerem permitirão uma redução significativa de custos com as suas manutenções, bem como a maior disponibilidade dos técnicos de TI para outras tarefas mais importantes.
Tendo em conta que, nos sistemas de informação disponibilizados pela I2S aos seus clientes é extremamente importante o seu contínuo funcionamento correcto, o método Recovery Oriented Computing apresenta neste contexto uma limitação importante. Um sistema ROC foca-se apenas na recuperação de falhas ignorando a sua prevenção.
Quanto aos aspectos tecnológicos, o uso de tecnologias Java acarreta as suas grandes vantagens para o sistema desenvolvido como a grande portabilidade e robustez.
Capítulo 3
Proposta de Solução
A gestão e o diagnóstico dos sistemas geridos pela I2S é, actualmente, uma tarefa dispendiosa pois exige a análise de enormes registos de logs dos sistemas. Logs esses que não se encontram obrigatoriamente organizados, isto é, logs de uma mesma transacção de negócio podem encontrar-se “espalhados” pelos registos de logs.
Com o subsistema I2S.LAP Services pretende-se facilitar esta tarefa e em alguns casos substitui-la por completo. Este deverá receber logs (eventos) provenientes de vários sis-temas (através dos vários I2S.LAP Agents) ou directamente de ficheiros de log, agrupa-los por transacções de acordo com vários critérios configuráveis e posteriormente analisa-los, recorrendo ao módulo de análise de sintomas do I2S.LAP Problem Determination, procu-rando identificar qualquer sintoma de alguma anomalia. Após a identificação de anoma-lias, o sistema deverá definir quais as melhores estratégias para a resolução do problema detectado e aplicar as medidas dai resultantes.
3.1
Representação dos eventos
Para que o processamento e análise de eventos log seja possível é necessário que estes se encontrem num formato standard. Sem um formato standard, o processamento automático dos eventos torna-se muito complicado, principalmente quando o sistema é composto por vários componentes diferentes. Para além de uma maior complexidade, o sistema de processamento de eventos seria menos genérico e a determinação de acções de resposta aos eventos seria menos eficaz.
Estes devem, também, incluir informação sobre o seu contexto, ou seja, informação sobre a situação que ocorreu no sistema bem como informação sobre o componente onde essa situação ocorreu e ainda se o componente que o reporta é o mesmo onde este ocorreu.
Proposta de Solução
Sem estas informações de contexto a interpretação, relacionamento e análise programática dos eventos é impraticável.
O uso do standard Common Base Event é a escolha óbvia para representar os eventos pois é um standard desenvolvido a pensar em sistemas autónomos e é um formato inte-grado no sistema de logs do Websphere, servidor de aplicações que suporta os sistemas da I2S. Um exemplo de um Common Base Event pode ser consultado no AnexoD.
3.2
Agrupamento de Eventos
A análise individual de cada evento por si só não permite um diagnóstico eficaz e o mais correcto possível das anomalias que possam surgir nos sistemas monitorizados. É necessário relaciona-los entre si, isto é, agrupa-los por transacções de negócio tornando possível a obtenção de informações de contexto e a detecção de padrões de eventos que serão extremamente importantes na determinação dos problemas e das causas dos mes-mos.
A execução deste processo será realizada por vários motores de agrupamento config-uráveis. Cada motor é configurado a partir de um fragmento XML que indica o como identificar o início e o fim de uma transacção e as regras para a determinação de quais os eventos que pertencem a uma mesma transacção.
A figura 3.1 apresenta um exemplo de um fragmento XML de configuração de um motor.
Figura 3.1: Exemplo de um fragmento XML de configuração de um motor
No Elemento EngineClass é especificado, no atributo name, qual o objecto imple-mentação do motor a ser usado. Desta forma permite-se facilmente alterar a implemen-tação dos motores usados pelo I2S.LAP Services.
No elemento Rules especificam-se as regras para o processo de agrupar eventos em transacções. Dentro deste elemento existem três subelementos: Start, End e Group. Nos subelementos Start e End é indicado ao motor como identificar se um evento é
Proposta de Solução
início ou fim de uma transacção respectivamente. Estes são constituídos pelos atributos expression e xpath. Para que um evento verifique uma destas regras é necessário que o texto no atributo expression se encontre no resultado da expressão xpath, indicada pelo atributo com o mesmo nome, aplicada sobre o evento. Por exemplo, a primeira regra Start indicada na figura3.1 será verificada se no atributo Msg do Common Base Event representante do evento a ser processado incluir a palavra “Início”. Quanto às regras Group, estas indicam ao motor através das expressões xpath definidas, quais os critérios para agrupar eventos. No exemplo apresentado na figura3.1 , os eventos pertencerão a uma mesma transacção se foram gerados na mesma máquina, no mesmo processo, na mesma thread e data de criação entre as datas dos eventos identificados como início e fim de transacção. O critério da data de criação é um critério implícito nos motores de agrupamento.
Este XML de configuração segue o XML Schema apresentado na figura3.2.
Proposta de Solução
3.2.1 Algoritmo base de agrupamento
Para agrupar os eventos em transacções de negócio propomos o seguinte algoritmo base:
1. Se evento é início de transacção (a) Registar início de uma transacção
(b) Se já foi identificado fim da mesma transacção
i. Preencher transacção com todos os eventos que verifiquem todos os critérios de agrupamento configurados e o tempo de criação se encontrar entre os tempos de criação do início e fim
ii. Fechar transacção identificada e lançar um evento a informar que uma transacção foi identificada
2. Senão se evento é fim de transacção (a) Registar fim de uma transacção
(b) Se já foi identificado início da mesma transacção
i. Preencher transacção com todos os eventos que verifiquem todos os critérios de agrupamento configurados e o tempo de criação se encontrar entre os tempos de criação do início e fim
ii. Fechar transacção identificada e lançar um evento a informar que uma transacção foi identificada
3. Senão
(a) Se evento pertencer a uma transacção já fechada i. Reabrir transacção fechada
ii. Acrescentar evento na transacção
iii. Passo assíncrono Após N tempo fechar transacção reaberta e lançar evento a informar transacção fechada
Esta informação reunida pelos motores é importante para a análise e determinação de problemas nos sistemas monitorizados. O formato Common Base Event possui na sua estrutura elementos onde esta informação pode ser armazenada – contextDataElements e associatedEvents.
O princípio base de um contextDataElements é providenciar informação para cor-relacionar eventos, sendo portanto o elemento ideal para conter a informação sobre as transacções a que um evento pertence. Um contextDataElements é composto pelas seguintes propriedades:
• type — Identificador do formato do contextDataElements (específico das aplicações). • name — Nome da aplicação que criou o contextDataElements.
Proposta de Solução
• contextValue — Valor do elemento contextDataElements (por exemplo id da transac-ção).
• contextId — Referência para o elemento que é o valor do contextDataElements.
O contexValue e o contextId são mutuamente exclusivos logo apenas um deles pode ser especificado.
Um contextDataElements adicionado pelos motores de agrupamento aos eventos pro-cessados teria a seguinte forma:
< c o n t e x t D a t a E l e m e n t s t y p e =" T r a n s a c t i o n " name =" nome c o m p l e t o do m o t o r " >
< c o n t e x t V a l u e >ID da t r a n s a c c a o < / c o n t e x t V a l u e > </ c o n t e x t D a t a E l e m e n t s >
Quanto ao associatedEvents, este é utilizado para indicar que outros eventos estão associados ao evento. A estrutura de um associatedEvents é a seguinte:
• resolvedEvents — Array de globalInstanceIds dos eventos associados. O globalIn-stanceId é um atributo de um Common Base Event cujo valor é um identificador único de um evento.
• associationEngine — Nome da aplicação que criou a associação de eventos. • associationEngineInfo — Referencia para o elemento AssociationEngine que
iden-tifica a aplicação que criou a associação. Este elemento AssociationEngine é difer-ente do atributo associationEngine descrito anteriormdifer-ente. Possui três atributos:
– name — Nome da aplicação que criou a associação de eventos.
– Type — Tipo de associação criada. Escolher um dos valores: Contains, CausedBy, Cleared, MultiPart, Correlated.
– Id — Identificador único deste elemento.
Apenas um dos atributos associationEngine e associationEngineInfo pode ser especi-ficado. O formato utilizado pelos motores de agrupamento é apresentado pelo seguinte exemplo:
< a s s o c i a t e d E v e n t s r e s o l v e d E v e n t s =" E 0 2 1 0 9 i 2 1 d s a 2 1 0 1 9 2 1 , E3232aEW22342531239 " >
< a s s o c i a t i o n E n g i n e >" nome do motor < / a s s o c i a t i o n E n g i n e > </ a s s o c i a t e d E v e n t s >
Num sistema informático pode ocorrer qualquer tipo de anomalia que provoque a in-terrupção inesperada deste. Nestes casos as transacções de negócio que se encontravam
Proposta de Solução
em aberto não são concluídas o que implicaria que o I2S.LAP Services ficaria indefinida-mente à procura de terminar a identificação destas transacções. Para resolver esta situ-ação, propomos a utilização de um sistema de timeouts configurável pelo utilizador que permita aos motores de agrupamento do I2S.LAP Services determinar que uma transacção é incompleta se, expirado o timeout, não tiver sido ainda identificado o início e o fim da transacção. Após o timeout a transacção deve ser guardada pelo I2S.LAP Services como uma transacção incompleta e a sua causa analisada posteriormente pelo módulo de análise de sintomas do I2S.LAP Problem Determination. Quanto à determinação de erros ocor-ridos e eventos faltosos nas transacções identificadas, esta será, também, uma tarefa do módulo de análise de sintomas do I2S.LAP Problem Determination.
3.3
Sistema de persistência
O I2S.LAP Services necessita de um sistema de persistência onde todos os eventos e informação recolhida e gerada possam ser guardados. O modelo relacional apresentado no Anexo A constitui a nossa proposta para uma Base de Dados relacional onde toda a informação relevante do sistema possa ser armazenada. Por questões relacionadas com uma melhor performance do sistema, o modelo proposto não respeita totalmente a terceira forma normal. Existem campos redundantes como por exemplo os campos fstAssociated-StartCBEID e fstAssociatedEndCBEID da tabela TransactionDM cujo objectivo é reduzir o número de operações JOIN em consultas à Base de Dados. No exemplo apresentado, a utilização do campo fstAssociatedStartCBEID e fstAssociatedEndCBEID permite saber que eventos correspondem ao início e ao fim da transacção sem necessitar de fazer JOIN da tabela TransactionDM com a tabela TransactionDMCltCBE.
3.3.1 Descrição das tabelas
LAPDataHdr — Nesta tabela é registado quem registou o evento, em que data e se este já foi processado ou não.
LAPOriginalData — Registo do evento original (evento sem qualquer tipo de processa-mento pelo I2S.LAP Services) em formato XML.
CBE — Registo de toda a informação contida no evento em formato Common Base Event. Esta tabela apenas inclui referências a outras tabelas onde se encontram os ele-mentos constituintes do evento. Inclui ainda uma ligação à tabela LAPDataHdr onde se encontram informações adicionais ao evento.
CBEHead — Elementos do evento que descrevem a situação reportada por este.
CBEMsgCatalogTokens — Registo dos vários elementos MsgCatalogTokens de um evento Common Base Event caso este os possua.
Proposta de Solução
CBEBody — Nesta tabela são registados os elementos do evento que correspondem à descrição detalhada do componente onde o evento foi gerado e do componente que o reportou caso este não seja o mesmo. Na tabela CBE, o campo ID_CBEComponent indica qual o registo da tabela CBEBody que corresponde ao componente onde o evento foi gerado, enquanto que o campo ID_Reporter indica o registo do componente que reportou o evento.
CBEContextDataElements — Um Common Base Event pode possuir vários elementos do tipo ContextDataElement. Nesta tabela são armazenados todos esses elementos.
CBEExtendedDataElement — Registo dos elementos ExtendedDataElement de um evento Common Base Event. Esta tabela possui uma relação consigo própria pois um elemento ExtendedDataElement pode conter outros ExtendedDataElements como filhos.
CBEExtendedDataElementValues — Um elemento ExtendedDataElement pode pos-suir vários subelementos values. Estes são guardados nesta tabela.
CBEAssociatedEvents — Tal como os ContexDataElements e ExtendedDataElements, um evento Common Base Event pode possuir vários elementos AssociatedEvents. É nesta tabela onde estes elementos são guardados.
ActionEngine — Nesta tabela são especificados os vários motores de agrupamento a utilizar pelo I2S.LAP Services. Esta tabela relaciona-se com as tabelas ActionEngine-Groups, ActionEngineConfiguration e ActionEngineObject.
ActionEngineGroups — Especificação de grupos de motores de agrupamento. ActionEngineConfiguration — XML de configuração dos vários motores.
ActionEngineObject — Objectos serializados dos motores com o objectivo de permitir a instanciação mais rápida destes pois já foram configurados.
PendingActions — Tabela onde são registados os eventos que correspondem a inícios e fins de transacções. Este registo é temporário pois quando é detectado o início e o fim de uma transacção esta é movida para a tabela TransactionDM.
TransactionDM — Registo de todas as transacções já identificadas.
TransactionDMCltCBE — Todos os eventos pertencentes às transacções identificadas (TransactionDM).
3.4
Análise de Sintomas
Esta análise de sintomas nos eventos recebidos será, principalmente, da responsabil-idade do I2S.LAP Problem Determination (subprojecto do I2S.LAP não incluído nesta dissertação). No entanto o motor de análise resultante desse projecto será incluído no I2S.LAPServices para que, quando for possível o despoletar de acções automáticas para correcção de problemas, este as possa efectuar sem necessitar de comunicar com o I2S.LAP Problem Determination.
Proposta de Solução
De forma a demonstrar de forma muito simples o funcionamento de sintomas imag-inemos o seguinte exemplo de eventos recebidos:
• Recebido um evento de uma máquina A que indica que não recebeu o retorno de uma chamada a outra máquina B.
• Recebido outro evento de falha de comunicação da máquina A para a máquina B. • Mais um evento a indicar falha de comunicação da máquina A para a máquina B.
Após esta sequência de eventos e se o sistema LAP tiver deixado de receber eventos da máquina B pode-se concluir que é provável que a máquina B tenha ficado offline. No entanto se o sistema LAP continuar a receber eventos da máquina B a falha é provável que seja na ligação da máquina A com a máquina B.
Capítulo 4
Implementação
Na implementação dos vários componentes do I2S.LAP Services foi utilizada uma metodologia denominada Command Pattern. Esta metodologia consiste no desenvolvi-mento de uma classe interface e de uma classe que implementa essa interface. A classe interface é distribuída aos clientes do componente dando-lhes acesso a métodos que po-dem invocar mas abstraindo os clientes de toda a lógica dos métodos. A grande vantagem desta metodologia é a fácil alteração de um componente sem implicar a alteração dos clientes.
É também utilizado o Spring para a instanciação dos componentes. A utilização do Spring em vez do tradicional new permite alterar os atributos a inicializar ou mesmo a classe implementação a utilizar sem necessitar de recompilar novamente o componente.
4.1
Arquitectura geral do I2S.LAP Services
No anexoBencontra-se um diagrama que demonstra a arquitectura geral do I2S.LAP Services.
4.1.1 LAPSrvEventMgr
Este componente do sistema I2S.LAP Services é responsável pela interacção de out-ras aplicações com o I2S.LAP Services. É através do LAPSrvEventMgr que os vários I2S.LAP Agents registam no I2S.LAP Services os vários eventos despoletados pelos sistemas monitorizados pelo LAP. Para além das funcionalidades de registo, este com-ponente disponibiliza funcionalidades de consulta dos eventos registados e dos resul-tados do processamento sobre os mesmos. Estas funcionalidades são utilizadas pelo I2SLAPSrvCommandLine descrito mais à frente neste capítulo.
Implementação
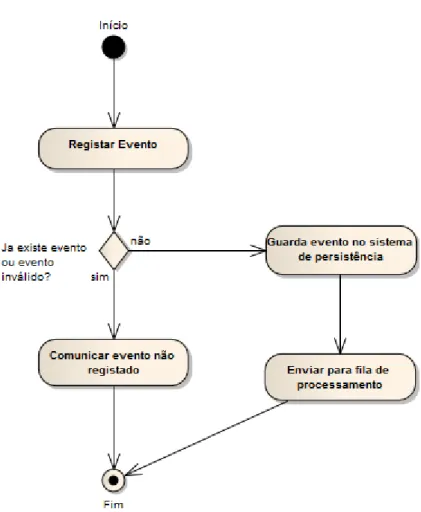
Figura 4.1: Diagrama de actividade do processo de registo de um evento
Na figura4.1 é apresentado um diagrama de actividade que explica os passos efectu-ados pelo processo de registo de um evento no sistema.
Após o registo do evento na Base de Dados este é enviado para uma fila do tipo JMS. Uma fila JMS é assíncrona [Oraa] permitindo desta forma que o sistema continue a reg-istar eventos sem ter que esperar pelo fim do processamento do anterior. Outra vantagem do JMS é o facto de utilizar o disco rígido e não a memória RAM para guardar as men-sagens. Assim se por alguma razão o sistema for interrompido, quando este for novamente iniciado não perde os eventos que estavam em fila para processamento.
4.1.2 LAPSrvPersistenceMgr
O LAPSrvPersistenceMgr consiste no serviço de persistência do I2S.LAP Services. Este é responsável pela interacção com a Base de Dados fornecendo todas as funcionali-dades necessárias aos outros componentes do sistema para inserção, actualização e con-sulta de dados. A interacção com a Base de Dados é realizada através de Entity Beans no modo CMP. Como referido nos aspectos tecnológicos do capítulo 2, a utilização de Entity Beans CMP tem a grande vantagem de se puder alterar a Base de Dados utilizada
Implementação
sem necessidade de modificar os Entity Beans ou recompilar código. Outro motivo para a utilização de Entity Beans é o facto de estes possuírem um sistema de cache próprio permitindo desta forma uma maior performance no acesso aos dados da Base de Dados.
4.1.3 LAPSrvEventDelegatorBean
Message Driven Bean responsável pela leitura dos eventos na fila de processamento e pelo seu reencaminhamento para o MainLAPWorkManager onde será desencadeado todo o processo de agrupamento.
O funcionamento deste componente é demonstrado pela figura4.2.
Figura 4.2: Diagrama de actividade do LAPSrvEventDelegatorBean
4.1.4 MainLAPWorkManager
Durante o agrupamento dos eventos em transacções, podemos pretender que estes sejam agrupados em diferentes níveis de transacções de negócio. Por exemplo, agrupar eventos de uma transacção local, ou seja, da mesma máquina, mesmo processo e mesmo thread. Mas podemos pretender também saber que eventos pertencem a todo o processo de registo de uma apólice de seguros que envolve várias máquinas de um sistema distribuído. Dentro de um mesmo tipo de transacção podemos ter vários motores que apliquem critérios diferentes para identificação do início e do fim de uma transacção permitindo que os vários critérios sejam aplicados paralelamente e não sequencialmente. Atendendo a isto podemos ter no sistema vários grupos de motores por tipo de transacção.
Implementação
A função do MainLAPWorkManager é lançar LAPWorkManagers em paralelo. Cada LAPWorkManager será responsável pela gestão de um grupo de motores de agrupamento. Estes grupos encontram-se especificados nas tabelas ActionEngineGroup e ActionEngine. Para o lançamento de threads é utilizada a Commonj WorkManager API. Esta API permite a execução de múltiplas threads num container J2EE. Para tal é necessária uma classe que implementa a interface Work.
Na instanciação do MainLAPWorkManager é indicado, através da sua especificação no Spring, o número máximo de LAPWorkManagers que este deve manter em execução paralela. O MainLAPWorkManager é, portanto, responsável por manter o número de Works por si lançados dentro desse valor. De forma a optimizar o lançamento de Works, o MainLAPWorkManager não se limita a ficar “quieto” à espera que um Work termine quando o número máximo de Works em simultâneo foi atingido. Enquanto nenhum Work termina, o MainLAPWorkManager vai criando os próximos Works de LAPWorkMan-agers a executar. Desta forma quando houver uma “vaga” para lançar um novo Work não se perde tempo com a criação do novo Work. Na figura4.3 é apresentado o diagrama de actividade do MainLAPWorkManager.
Implementação
4.1.5 LAPWorkManager
Neste componente são executados os motores de agrupamento de um grupo de mo-tores. A gestão de motores em execução simultânea é idêntica à utilizada pelo MainLAP-WorkManager mas com a diferença de o processo ser interrompido no caso de um dos motores identificar o evento como início ou fim de transacção. Isto porque dentro de um mesmo grupo os motores trabalham sobre o mesmo tipo de transacção aplicando critérios diferentes para identificação de inícios e fins de transacção. Se um dos motores identificar o evento, a execução dos outros motores é desnecessária.
Como os motores são configurados a partir de XML, a leitura constante do fragmento XML de configuração sempre que se instancia um motor seria dispendiosa em termos de performance. Para resolver este problema, após a primeira instanciação de um motor é criado um objecto binário do motor que permitirá carrega-lo a partir deste nas suas futuras instanciações. Desta forma elimina-se a necessidade de ler o fragmento XML de configuração em cada instanciação. Estes objectos binários são armazenados na tabela ActionEngineObject.
O diagrama de actividade deste componente é apresentado na figura4.4.
Implementação
Figura 4.5: Subdiagrama de actividade da actividade Criar novo Work pronto a executar com próximo motor
4.1.6 LAPEngines - Motores de Agrupamento
Os motores de agrupamento são um componente essencial do sistema pois são estes que a partir de regras previamente definidas organizam e agrupam os eventos recebidos. Através dessas regras os motores identificam transacções ocorridas nos sistemas moni-torizados permitindo relacionar os eventos entre si. Este relacionamento entre os eventos será extremamente importante na análise de sintomas e problemas nos sistemas monitor-izados.
O algoritmo de agrupamento apresentado no capítulo anterior é implementado por estes motores, porém o sistema foi desenvolvido de forma a permitir a instanciação de qualquer classe implementação de motores desde que implemente a interface LAPEngine e se encontre especificada no Spring. Assim se se pretender utilizar outros algoritmos será fácil a sua integração e não é necessário recompilar o sistema. Na instanciação dos motores é utilizado o bean especificado no Spring indicado no elemento EngineClass do XML de configuração.
Quanto à implementação de timeouts para determinar transacções incompletas, foi uti-lizada a tecnologia Timer Service API dos Enterprise Java Beans que os permite notificar quando uma data específica ou um determinado intervalo de tempo foi atingido. Quando um motor abre uma nova transacção pendente é inicializado um timer, com o tempo de timeout pretendido, no Entity Bean associado ao registo dessa nova transacção pendente. Se a transacção não for fechada antes do timeout se esgotar esta é considerada incompleta. Este timeout é configuravel pelo utilizador.
4.2
Análise de Sintomas
Para esta análise de sintomas foi inicialmente escolhida, pelo responsável do I2S.LAP Problem Determination, uma aplicação já existente denominada Log and Trace Analyzer do projecto Eclipse Test & Performance Tools Platform Project. Esta possui um motor
Implementação
de análise de sintomas e uma API para a criação destes através de expressões xpath. No entanto em finais de Maio de 2010, o suporte a esta aplicação foi terminado pelo que o seu uso no projecto foi posto em causa.
Neste momento o projecto I2S.LAP Problem Determination encontra-se em fase de estudo de alternativas ao LTA. Por este motivo não foi possível a integração de um módulo de análise de sintomas até esta data.
4.3
I2SLAPSrvCommandLine
O I2SLAPSrvCommandLine é uma linha de comandos para interacção com o I2S.LAP Services. Através desta é possível a um utilizador registar no I2S.LAP Services ficheiros de log para serem processados, consultar eventos processados e obter ficheiros com esses eventos.
O utilizador pode utilizar vários critérios para obter os eventos processados como por exemplo entre intervalos de tempo ou por transacção. O utilizador pode ainda escolher o tamanho máximo por ficheiro criado com os eventos consultados dividindo assim os eventos por vários ficheiros dentro desse tamanho.
No anexoEencontram-se exemplos de comandos do I2SLAPSrvCommandLine.
4.4
Sumário
O resultado deste sistema foi um sistema capaz de um elevado processamento e con-figurável em vários aspectos. É possível configurar todo o funcionamento dos motores de agrupamento e inclusivamente a quantidade de processamento paralelo. Desta forma é possível adaptar o sistema à capacidade da máquina em que este executa. Se a máquina possuir mais CPUs pode-se então aumentar o nível de processamento paralelo permitindo ganhos de desempenho. Outro aspecto positivo é a sua arquitectura modular que permite a fácil substituição de componentes e sem necessidade de recompilar o sistema.
O facto de os motores a usar e suas classes implementação serem especificados fora do sistema traz a grande vantagem de se poder adaptar o agrupamento dos eventos consoante as necessidades dos vários sistemas a serem monitorizados.
Capítulo 5
Análise e Resultados
5.1
Registo de eventos
Na tabela5.1 são apresentados os resultados de testes de performance efectuados ao processo de registo de eventos no I2S.LAP Services (componentes LAPSrvEventMgr e LAPSrvPerssistenceMgr). Nestes testes foi utilizada a ferramenta JMeter para simular vários I2S.LAP Agents a comunicar e registar eventos no I2S.LAP Services.
O JMeter é uma ferramenta desenvolvida pela Apache que disponibiliza várias fun-cionalidades para teste de aplicações como, por exemplo, testes de carga num servidor. Disponibiliza ainda ferramentas de análise e estatísticas dos resultados obtidos.
Os resultados apresentados na tabela 5.1 representam o registo de 16 eventos no I2S.LAP Services por 1, 5, 10, 25 e finalmente 50 I2S.LAP Agents em simultâneo.
Tabela 5.1: Testes de performance ao processo de registo de eventos Tempo médio por thread (16 eventos) Tempo médio por evento
1 Thread 415 ms 26,0 ms
5 Threads 580 ms 36,3 ms
10 Threads 960 ms 60,0 ms
25 Threads 1695 ms 105,9 ms
50 Threads 3385 ms 211,6 ms
O Processo de registo de um evento no I2S.LAP Services envolve a validação e ar-mazenamento do evento recebido numa Base de Dados e numa fila JMS pelo que pode-mos afirmar que um tempo de 26ms para todo este processo é um resultado muito bom. Contudo o funcionamento regular do sistema I2S.LAP envolverá constantemente vários I2S.LAP Agents em simultâneo. Como tal o resultado mais importante será o tempo mé-dio por evento com 50 threads simultâneos. Aqui o tempo mémé-dio (211,6 ms) é bastante superior ao tempo médio de um thread apenas (26 ms) como seria de esperar. Ainda assim podemos afirmar que, este tempo médio por evento de 211,6 ms para 50 I2S.LAP Agents em simultâneo é um resultado muito positivo e animador pois verifica-se que, apesar de
Análise e Resultados
uma elevada carga simultânea de pedidos de registo, o I2S.LAP Services consegue dar uma resposta rápida a cada pedido.
5.2
Agrupamento de eventos em transacções
Antes do I2S.LAP, quando um técnico de TI da I2S necessitava de analisar os logs de uma aplicação recorria à ferramenta Notepad++. Esta possui várias opções de pesquisa e cópia de texto que permitiam encontrar e juntar num outro ficheiro todos os logs de um único thread da aplicação em cerca de 30 segundos. Contudo isto diz respeito a apenas um único thread dos vários existentes numa aplicação e no mesmo thread podem existir várias transacções de negócio. Para isolar os logs de apenas uma transacção de negócio entre os logs de um thread já isolado demoraria mais uma vez cerca de 30 segundos, segundo a experiência de alguns técnicos de TI da I2S.
De modo a verificar se o I2S.LAP Services proporciona benefícios nesta matéria foram efectuados testes a várias amostras de eventos log gerados por aplicações da I2S onde os resultados de três amostras são apresentados na tabela5.2. Nestes testes foram utilizados cinco motores de agrupamento em simultâneo para cinco tipos de transacções.
Tabela 5.2: Resultados de identificação de transacções em três amostras de eventos Node Eventos Node Transacções detectadas Tempo demorado
2191 68 2m22s
4813 109 5m04s
61251 879 33m24s
Mesmo considerando apenas o tempo que um técnico demora em média a isolar man-ualmente uma transacção de negócio dos logs de um thread já isolado (30 segundos), este demoraria por volta de 34 minutos, 55 minutos e 7 horas 20 minutos a identificar todas as transacções das mesmas amostras de 2191, 4813 e 61251 eventos respectivamente. Desta forma, podemos afirmar que, não só o I2S.LAP Services é muito mais eficaz na iden-tificação de transacções de negócio, mas também permite um benefício total em tempo dispendido por parte dos técnicos de TI pois estes não necessitam de se envolver neste processo.
Estes resultados demonstram que o I2S.LAP Services possibilita, já neste ponto, uma mais rápida determinação de problemas por parte das equipas de TI mesmo que a análise de erros e sintomas de problemas seja feita manualmente por estes e não pelo módulo de análise de sintomas do I2S.LAP Problem Determination.
Análise e Resultados
5.3
Sumário
Analisando os testes efectuados ao I2S.LAP Services podemos afirmar que este apre-senta uma boa capacidade de resposta a uma elevada carga de I2S.LAP Agents a regis-tar eventos em simultâneo. Podemos ainda constaregis-tar que o agrupamento de eventos em transacções de negócio permite obter benefícios visíveis no processo de determinação de problemas nas aplicações monitorizadas mesmo que a análise de sintomas seja efectuada manualmente pelos técnicos de TI e não pelo módulo de análise de sintomas do I2S.LAP Problem Determination.
Capítulo 6
Conclusões e Trabalho Futuro
6.1
Satisfação dos Objectivos
Apesar do contratempo no módulo de análise de sintomas devido ao fim do suporte do projecto Eclipse Test & Performance Tools Platform Project ao Log and Trace An-alyzer em finais de Maio de 2010 e que obrigou ao estudo de alternativas por parte do responsável pelo subsistema I2S.LAP PDA, o resultado do agrupamento de eventos em transacções permite desde já às equipas de TI um melhor tempo de resposta no diagnós-tico manual de problemas. No caso de um problema acontecer, o analista consegue obter através do I2SLAPSrvCommandLine os eventos da máquina onde o problema ocorreu, num intervalo de tempo e ordenados por transacção. Deste modo consegue facilmente chegar ao evento que reportou o problema e analisar todo o histórico dos eventos rela-cionados. Sem esta organização, o diagnóstico seria muito mais complicado e moroso pois em sistemas de grande dimensão e com processamento paralelo não há garantias de um registo sequencial dos eventos do sistema.
A implementação do I2S.LAP Services resultou num sistema altamente configurável e adaptável às necessidades de processamento de eventos provenientes dos mais varia-dos sistemas. Através de XML é possível configurar os motores de agrupamento para critérios diferentes de agrupamento e mesmo para implementações diferentes dos mo-tores consoante as necessidades e os sistemas a monitorizar. Outra possibilidade é o ajustamento do nível de processamento paralelo do I2S.LAP Services para que se tire o melhor proveito da máquina onde este execute. O aspecto modular do sistema é outra vantagem pois permite a fácil substituição de componentes do sistema.
Quanto aos objectivos para esta fase do projecto, podemos dizer que estes foram cumpridos excepto a integração do módulo de análise de sintomas do projecto I2S.LAP PDA devido ao contratempo referido anteriormente (AnexoC).
Conclusões e Trabalho Futuro
O uso de tecnologias por nós desconhecidas no arranque deste projecto (Enterprise Java Beans, Websphere Application Server e Spring) consistiram na principal dificuldade enfrentada durante o desenvolvimento deste projecto, sendo que as primeiras 3 semanas consistiram no estudo e formação nestas tecnologias. A manutenção da integridade dos dados num elevado nível de processamento paralelo foi outra dificuldade a enfrentar.
6.2
Trabalho Futuro
No futuro mais próximo é necessário integrar o módulo de análise de sintomas re-sultante do I2S.LAP PDA. Mais tarde serão implementadas as fases 3 e 4 do projecto (Anexo C ). Nestas fases pretende-se que o I2S.LAP Services consiga pedir aos vários I2S.LAP Agents resultados de auditorias da aplicação monitorizada (exemplo: percent-agem de CPU utilizada) permitindo adicionar mais informação aos eventos quando for necessário de modo a ajudar na posterior análise de sintomas. Pretende-se também que aplique acções automáticas de correcção quando possível. Pretende-se ainda interfaces amigáveis para a configuração dos motores de agrupamento.
Referências
[Akb09] Akb_eee. Autonomic Computing, 2009. disponível em http://www. scribd.com/doc/22599254/Autonomic-Computing, acedido a úl-tima vez em 28 de Janeiro 2010.
[Car06] Carla Sadtler, Fabio Albertoni, Bernardo Fagalde, Thiago Kleinubing, Henrik Sjostrand, Ken Worland, Lars Bek Laursen, Martin Phillips, Martin Smithson, Kwan-Ming Wan. WebSphere Application Server V6.1: System Management and Configuration. pages 27–35, 2006.
[Cha04] Nicholas Chase. An autonomic computing roadmap, 2004. disponível em
http://www.ibm.com/developerworks/library/ac-roadmap/, acedido a última vez em 29 de Janeiro 2010.
[IBM] IBM. IBM RationalR Application Developer for WebSphere Software.R
disponível em http://www-01.ibm.com/software/awdtools/ developer/application/features/index.html?S_CMP=rnav, acedido a última vez em 26 de Junho de 2010.
[IBM01] IBM. Autonomic Computing - IBM’s Perspective on the State of Information Technology, 2001.
[IBM04] IBM. Autonomic Computing Toolkit - Developer’s Guide, 2004. disponível emhttp://www.ibm.com/developerworks/autonomic/ books/fpy0mst.htm#HDRAPPA, acedido a última vez em 15 de Junho de 2010.
[IBM05] IBM. Autonomic Computing Toolkit - User’s Guide. pages 3–5, 2005. [IBM06a] IBM. An architectural blueprint for autonomic computing., 2006.
[IBM06b] IBM. Best Practices for the Common Base Event and Common Event Infrastructure, 2006. disponível em http://download.boulder.ibm. com/ibmdl/pub/software/dw/autonomic/books/cbepractice/ index.htm#_Toc130892522, acedido a última vez em 15 de Junho de 2010.
[IBM10a] IBM. Autonomic computing - the problem, 2010. disponível em http: //www.research.ibm.com/autonomic/overview/problem.html, acedido a última vez em 19 de Janeiro de 2010.