Agradecimentos
Quero aqui deixar expressos os meus agradecimentos a todos aqueles que de alguma forma me auxiliaram na realização desta dissertação, nomeadamente:Ao meu orientador, Doutor Manuel Filipe Santos, pelo constante apoio e pelos conselhos prestados.
À Universidade do Minho, sobretudo ao pessoal docente e não-docente do Departamento de Sistemas de Informação.
Ao Tribunal de Contas, pelas condições proporcionadas, no que diz respeito às fontes de informação trabalhadas e ao acesso a alguns dos meios técnicos essenciais para o processamento dessa informação.
Ao Dr. João Carlos Pereira Cardoso, director do Departamento de Sistemas e Tecnologias de Informação da Direcção-Geral do Tribunal de Contas, pelo apoio e facilidades concedidas. Este agradecimento estende-se ao restante pessoal do mesmo serviço, que sempre manifestou o seu apoio.
À minha família, pelo apoio e compreensão demonstrados (e pelo cuidado em me mandarem escrever quando era preciso).
Ao meu filho, João Francisco, pela ajuda prestada no relembrar dos pormenores mais finos (e traiçoeiros) da gramática da língua portuguesa, e pela paciência demonstrada pelo tempo que um trabalho destes forçosamente ocupa.
À Maria do Castelo, por ser a pessoa que melhor me compreende e que apesar de estar a fazer a sua própria dissertação, sempre teve tempo para me apoiar, criticar, comentar e apontar outros caminhos.
Caracterização dos utilizadores de web sites institucionais
via web log mining – O caso do Tribunal de Contas
Resumo
É difícil encontrar outro meio de comunicação que tenha crescido tão rapidamente e num volume tão grande como a World Wide Web. Ao mesmo tempo, é díficil encontrar um que encerre em si próprio, de maneira tão abundante, a meta-informação necessária para o seu estudo aprofundado.Ver a WWW como um simples depósito de informação, constitui um ponto de vista redutor. Muito embora, num sentido restrito, seja possível encarar tudo o que ela oferece como sendo informação à nossa disposição, a verdade é que uma das suas grandes virtudes, é o facto de fornecer cada vez mais maneiras de levar os utilizadores a interagir com essa informação – para a manipular (ajax), para a alterar (wikis), para a aumentar (blogs), para a transformar e ampliar (mashups), entre outros exemplos e abordagens.
Os registos de acesso aos web sites (logs) constituem a principal fonte de informação quanto à forma como a WWW é, de facto, utilizada. Mais do que se basear na análise de factores externos (como qualquer canal de televisão, que tem que perguntar aos tele-espectadores se o viram), qualquer web site pode registar automaticamente todas as consultas que lhe são feitas. Da análise destes acessos depende a correcta compreensão do lugar e funções desempenhadas pelo web site, ao longo da sua vida.
Nesta dissertação procuramos reunir os dois mundos. Pretendemos caracterizar a informação disponibilizada num web site (o do Tribunal de Contas), pedindo “emprestados” alguns conceitos à biologia – para traçar uma espécie de “ADN” de cada documento. Pretendemos também, recorrendo aos logs de acesso, traçar outro ADN, o dos utilizadores do web site, com base nos seus padrões de uso. Os resultados de um trabalho desta natureza poderão auxiliar abordagens futuras a este e outros web sites, no sentido de facilitar um tipo de classificação automática de documentos e de permitir a criação e manutenção no tempo de perfis de utilização, numa tentativa de fazer adequar com maior precisão a informação que é disponibilizada, com as necessidades dos utilizadores.
Institutional web site usage profiling via web log mining.
The Portuguese Court of Auditors as an example.
Abstract
It's hard to find any kind of media with a growth-rate as high as the World Wide Web. At the same time, it's hard to find one that stores within itself such an amount of metadata, useful for an indepth study.It is wrong to look at the WWW simply as a kind of information store. Although all its contents are information one way or the other, truth is there are quite a few ways of letting the users interact with that information, either to manipulate it (via ajax-based applications), to alter it (through the use of wikis), to add to it (via blogs and web sites themselves) or to transform and amplify its meanings (through mashups). These are only a few examples on what can be done today.
Web site access logs are the main information source on how the WWW is used. Rather than asking the users if they viewed the pages (such as a TV station might do), any web site has the means to keep a permanent record about its visitors. By analyzing these logs, we are able to get a better understanding of the roles played by the web site.
In this document we borrow a few concepts from biology, in order to establish a kind of 'DNA' for each document on the web site of the Portuguese Court of Auditors (Tribunal de Contas). We do this by looking at the WWW as an information source and by processing what we find. At the same time, we try do extend the same approach to the users who looked for those documents, by processing the web access logs. The results of such an approach might enable future uses of automatic document classification, as well as an effective personalization of information delivery.
Chractérisation des utilisateurs des web sites institutionelles
à travers des téchniques de minération de web logs.
L’éxample du Cour de Comptes Portugais
Résumé
Il est très difficile de trouver quelque sorte de média avec une croissance si grande que le World Wide Web. En même façon, il est difficile de trouver un moyen intéractif d'information qui préserve une si grande quantité de métadonnées dans son intérieur, et qui puisse les utiliser por des études en profondeur.Le Web n'est seulement un depôt d'information. On peut bien regarder tout ce qu'il présent comme s'il était de l'information toute simple. Pourtant, aujour'dui il'y a plusieurs moyens à la disposition des utilisateurs pour accomplir une intéraction riche avec les contenus présentés: pour faire sa manipulation (à travers les applications Ajax), pour faire des modifications (à travers les wikis), pour participier dans sa croissance (à travers les blogs et les web sites, êux-mêmes) ou pour faire des transformations (à travers les mashups). Ce ne sont que des examples sur les possibilités d'utilisation offertes.
Le logging des pages Web consultées est la première source d'information sur l'utilisation du WWW. Par example, quand on parle d'une châine de télévision, le seul moyen qu'elle a pour connaître les charactéristiques de ses téléspectateurs, est de les demander directement. Par contraire, un web site peut enregistrer automatiquement toutes les visites à ses pages. Quand on analyse ces logs, on peut comprendre parfaitement l'évolution du site et les modes d'intéraction utilisés.
Dans ce travail, nous cherchons une façon d'unifier ces deux réalités. D'un coté nous avons l'information disponible dans le web site do Cour des Comptes Portugais (Tribunal de Contas) laquelle sera procéssé pour créer une espéce d'ADN pour chaque document. De l'autre coté, nous avons les web logs, qui nous permetront identifier des utilisateurs, et établir aussi son ADN (on parle d'ADN d'une façon symbolique, puisque nous créons des séquences d'identification numériques pour chaque document/utilisateur). Les résultats peuvent pêut-être nos approcher d'une classification automatique des documents, et aussi d'une création de profils d'utilisateurs.
Índice de capítulos
Agradecimentos ... iii
Resumo... iv
Abstract ... v
Résumé ... vi
Índice de capítulos ... vii
Índice de imagens ... ix
Índice de tabelas ... xi
Índice de gráficos ... xii
Introdução ... 1 Objectivos ... 3 Contextualização ... 4 Motivação ... 5 Relevância ... 6 Fontes primárias ... 7
Hardware e software utilizados ... 7
Organização da dissertação ... 8
Definição de conceitos ... 9
A teoria (e prática) subjacente à utilização de logs de acesso a web sites ... 10
O software existente ... 28
O Tribunal de Contas ... 34
Enquadramento normativo do Tribunal de Contas ... 35
Organograma do Tribunal de Contas ... 36
Os Actos do Tribunal de Contas - disponibilização externa e interna ... 37
Classificação e recuperação - considerações finais ... 42
O web site do Tribunal de Contas ... 44
Caracterização técnica do web site do TC ... 48
Escolhas técnicas que foram feitas no processo de desenho do web site ... 50
Os logs de acesso ao web site do TC ... 52
Estabelecer um ADN para os documentos do web site do TC ... 56
Operações de text mining ... 63
Conclusões ... 68
Referências: Livros e Artigos ... 71
Referências: Literatura cinzenta ... 80
Referências: Normas e standards ... 82
Referências: Web sites ... 83
Apêndice 1: Hardware e software utilizados ... 86
Apêndice 2: O anúncio do primeiro programa de processamento de ficheiros de log de servidores web ... 88
Apêndice 3: Evolução da estrutura informática do web site do Tribunal de Contas ... 89
Apêndice 4: Listagens em Basic ... 91
Apêndice 5: Macro-comandos de Word ... 95
Índice de imagens
Imagem 1: Sumário da contagem de acessos ao web site BoingBoing ... 19 Imagem 2: Configuração de definições para acesso à Internetno browser Microsoft Internet Explorer ... 21 Imagem 3: Caixa de diálogo de definições de cache
de páginas web no browser Microsoft Internet Explorer ... 22 Imagem 4: Uma minúscula amostra de estilos aplicáveis
a contadores de acessos a páginas web ... 23 Imagem 5: Página de uma pequena empresa
com um contador localizado no canto inferior esquerdo ... 24 Imagem 6: O mesmo contador, ampliado ... 25 Imagem 7: Lista de cookies entregues ao browser Microsoft Internet Explorer .... 26 Imagem 8: Organograma do Tribunal de Contas, incluindo a Direcção-Geral
e as Secções Regionais da Madeira e Açores ... 36 Imagem 9: Página de acesso aos Actos do Tribunal de Contas na Intranet
institucional, tal como estava visível em 17 de Julho de 2006 ... 38 Imagem 10: Formulário de pesquisa do sistema TCJure,
tal como é disponibilizado através da intranet do Tribunal de Contas ... 38 Imagem 11: Página de acesso aos Actos do Tribunal de Contas,
disponível no web site institucional ... 39 Imagem 12: Formulário de pesquisa de Acórdão e Sentenças
no web site do Tribunal de Contas, ... 40 Imagem 13: Estrutura de dados do sistema TCJure,
em uso interno no Tribunal de Contas ... 41 Imagem 14: Aspecto da primeira versão do web site do Tribunal de Contas ... 44
Imagem 15: Aspecto da segunda versão do web site,
tal como foi disponibilizada em 14 de Março de 2001 ... 45 Imagem 16: Página inicial do web site do Tribunal de Contas
em 4 de Fevereiro de 2004 ... 46 Imagem 17: Aspecto da página inicial da terceira versão do web site do TC,
que deverá ser activada no início do mês de Maio de 2007 ... 48 Imagem 18: Como se articulam entre si os grandes componentes
tecnológicos da actual versão do web site do TC ... 49 Imagem 19: Página web com informação relativa
aos acessos ao web site do Tribunal de Contas ... 53 Imagem 20: Vista parcial do relatório Executivo, disponibilizado
pelo serviço Google Analytics, relativo aos acessos feitos à página inicial do web site do Tribunal de Contas,
para o período compreendido entre 2006-07-07 e 2006-07-28 ... 54 Imagem 21: Representação numérica de um ADN baseado
nas classes do TCJure, para os 742 documentos em processamento ... 62 Imagem 22: Representação grafica da mesma informação numérica
Índice de tabelas
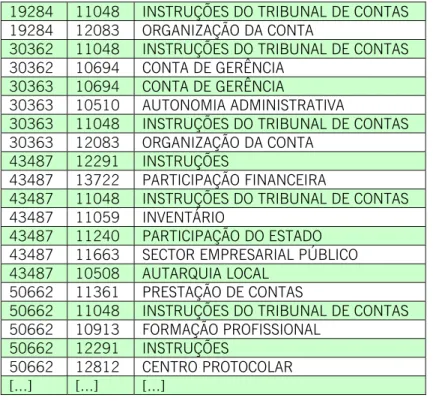
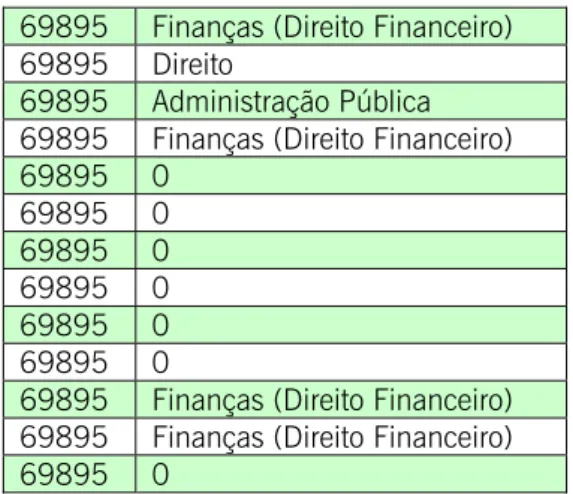
Tabela 1: Excerto da listagem dos descritoresatribuídos a documentos constantes do web site do TC ... 57 Tabela 2: Top Terms identificados para os descritores
atribuídos ao documento com o código 69895 do sistema TCJure ... 59 Tabela 3: Top Terms identificados para os descritores
atribuídos ao documento com o código 70168 do sistema TCJure ... 59 Tabela 4: Top Terms identificados para os descritores
atribuídos ao documento com o código 69776 do sistema TCJure ... 59 Tabela 5: Distribuição de documentos pelas várias classes
de topo identificadas no thesaurus associado ao sistema TCJure ... 60 Tabela 6: Atribuição de números aleatórios a cada um dos 756 documentos
Índice de gráficos
Gráfico 1: Evolução da quantidade de page viewsno web site do TC, para o perído compreendido
entre Março de 2001 e Março de 2007 ... 47 Gráfico 2: Quantidade de documentos por formato,
no web site do Tribunal de Contas ... 50 Gráfico 3: Distribuição dos documentos disponibilizados
no web site do TC e registados no sistema TCJure, pelas classes
deste sistema de gestão de informação ... 60
Introdução
A expressão que mais facilmente caracteriza o ambiente no qual todos os web sites se inserem, a World Wide Web ou WWW, é formada por uma só palavra: “variedade”. Esta variedade nota-se a vários níveis. Por exemplo: Na quantidade potencial de utilizadores que podem aceder ao universo representado pela totalidade dos web sites existentes (cerca de 487 milhões de utilizadores em Janeiro de 20071, para uma quantidade eventual de cerca de 110 milhões de web sites2 em Março do mesmo ano, dos quais apenas cerca de metade se encontram de facto activos).
Na quantidade efectiva de utilizadores que, de facto, acedem a um web site (entre as poucas dezenas e os milhões, consoante o conteúdo, a utilidade e o interesse que desperta).
Na quantidade de sistemas operativos diferentes e de browsers que os utilizadores da WWW podem utilizar (vejam-se as cerca de 250 versões principais de sistemas operativos listadas em
http://en.wikipedia.org/wiki/List_of_operating_systems, sem contar com múltiplas variantes, ou os cerca de 70 browsers listados em
http://en.wikipedia.org/wiki/List_of_browsers, também com múltiplas variantes)3.
Num outro nível, a variedade torna-se ainda mais notável. Ao falar da WWW, estamos a falar de um universo informativo onde existe um número não contabilizado (e não contabilizável) de documentos, que pode variar entre os 15.000 e os 30.000 milhões de páginas web, segundo uma das últimas estimativas4. Todos os dias vastos milhares destes documentos desaparecem ou são modificados. Outros tantos são adicionados ao conjunto. Não há um índice integral
1 Fonte: Nielsen//NetRatings, acedido em 2007-03-17 a partir do endereço
http://www.nielsen-netratings.com/press.jsp?section=pr_netv&nav=3.
2 Fonte: March 2007 Web Server Survey, acedido em 2007-03-17 a partir do enderço
http://news.netcraft.com/archives/web_server_survey.html.
3 Estamos conscientes quanto à polémica em torno do uso da Wikipedia como fonte de informação para o discurso
científico. As opiniões variam entre o cepticismo puro quanto à sua utilidade [Denning, et. al., 2005], o aconselhamento de cautela no seu uso [Read, 2007] e o reconhecimento do seu valor em comparação com outras fontes de conhecimento idênticas [Bernstein, 2006; Stvilia, et. al., 2005]. Quanto a nós, recorremos a ela pontualmente e apenas como ponto de partida para abordar certas questões – neste caso contagens de produtos informáticos.
4 Fonte: The size of the World Wide Web, acedido em 2007-03-17, a partir do endereço
do conteúdo e as capacidades de pesquisa ainda são relativamente rudimentares. Os documentos estão dispersos por toda a superfície do planeta (muito embora até pareça que estão todos juntos no mesmo sítio). A consulta é feita através de computadores, os quais (por questões de configuração e/ou capacidade) podem ter mais ou menos dificuldades no acesso à informação. Não há qualquer garantia que um mesmo documento seja visto da mesma maneira por dois utilizadores diferentes, ao mesmo tempo que é impossível saber de antemão que computadores vão ser utilizados.
Esta variedade tem um grande impacto na forma como um web site deve estar preparado para responder às solicitações a que está sujeito. Tem também impacto na forma como podem (e devem) ser obtidos e processados elementos que permitam caracterizar numericamente a forma como se acede a esse web site: quem, de onde, quando, de que forma, com que meios técnicos, para fazer o quê, durante quanto tempo, com que fidelidade, etc.
É inegável o interesse que desperta a análise dos logs de acesso a um web site. Este procedimento constitui quase sempre a primeira abordagem para caracterizar a “população” que consulta um web site:
Para saber dados técnicos sobre os meios utilizados para aceder à informação (qual o sistema operativo e qual o browser usados para visualizar as páginas do web site). Estes dados podem, de alguma forma, influenciar a estruturação dos conteúdos e a sua própria natureza (maior ou menor conteúdo gráfico, por exemplo).
Para ficar a conhecer quais as apetências do público que consulta o web site – quais as páginas mais consultadas e os conteúdos mais acedidos.
Para recolher informação que permita validar a estrutura do web site. Ao identificar percursos de navegação seguidos pelos utentes, é possível reconhecer gostos e tendências para conteúdos específicos [b052].
A análise dos acessos permite ainda processar e recolher outros tipos de informação. Dependendo da natureza do web site, pode ainda fornecer dados sobre o seu desempenho “económico” (se for um site com funcionalidades de comércio
electrónico, ou que inclua mecanismos de obtenção de receitas baseadas em publicidade), sobre a amplitude do seu reconhecimento geográfico (identificando os países de onde foram feitos os acessos), sobre o grau de incidência de ataques informáticos (pela identificação de “assinaturas” conhecidas de exploits devidamente identificados, ou pela detecção de padrões de acesso considerados suspeitos). A lista é extensa e não se esgota nestes exemplos.
Objectivos
Nesta dissertação propomo-nos abordar um problema que tem vindo a ser alvo de estudo quase desde o início da WWW: de que forma é que, a partir da análise dos logs de acesso a um web site, se torna possível identificar características do universo de utilizadores que faz esse acesso?Para tal, o nosso trabalho vai incidir sobre os logs de acesso ao web site do Tribunal de Contas de Portugal (TC). Tendo em conta as características essenciais do conteúdo deste web site, vamos igualmente procurar definir um conjunto de técnicas que permitam fazer uma classificação dos documentos aí disponibilizados para consulta e download. A correcta aplicação desta técnica deverá depois permitir levar a cabo uma caracterização dos utilizadores do web site, com base na informação por eles consultada.
A analogia utilizada para a técnica de classificação é a da cadeia de ADN – uma cadeia de elementos de informação, individualizados, que no seu conjunto permitam identificar cada documento. Pelas suas características, esses elementos de informação poderão servir para concretizar agrupamentos de documentos (por ser feito através deles um mapeamento de grandes áreas temáticas e/ou intelectuais). Os elementos de informação a utilizar têm a ver com as grandes áreas temáticas pelas quais os documentos existentes neste web site se distribuem. Essas áreas resultam das características da actividade da Instituição (áreas de incidência da sua actividade, por exemplo), ou de questões relacionadas com a sua estrutura enquanto organismo do Estado.
Contextualização
Muito embora esta não seja uma área particularmente nova, em termos do interesse que desperta junto da comunidade académica [b042], é sempre relevante, na medida em que permite reunir informação importante para caracterizar um web site ao longo da sua existência. Ou seja, é uma área que se caracteriza por um intenso dinamismo – conteúdos, universo de utilizadores e ritmos de utilização variam ao longo do tempo, sendo assim bons candidatos para operações de descoberta de conhecimento.A utilidade dos resultados obtidos com este género de operações de processamento, extravasa o simples desejo de classificar o universo de utilizadores. Tais resultados podem ser utilizados em fins tão diversos como:
Optimizar a estrutura do web site, se um dos resultados obtidos for a definição dos caminhos de navegação mais percorridos pelos utilizadores. Essa optimização pode, inclusivé, ser feita de forma automática [b040]. Optimizar a estrutura de bases de dados que sirvam conteúdos dinâmicos,
em função do tipo de consultas que são efectuadas.
Levar a cabo uma avaliação da usabilidade de um web site [b020a].
Averiguar o grau de adequação dos meios técnicos que suportam o web site (acompanhando os percursos de navegação e verificando a ocorrência de falhas e erros de acesso).
Aferir o grau de eficácia dos conteúdos face aos objectivos pretendidos: para um web site de comércio electrónico, é extremamente importante caracterizar o universo dos seus utilizadores [b046].
Resumindo, pretendemos, levar a cabo a classificação básica dos utilizadores de um
web site da Administração Pública portuguesa, em termos do tipo de navegação que
é feita, com o objectivo de recolher informações suficientes que permitam melhorar a resposta proporcionada.
Motivação
A nossa vontade de abordar este tema em dissertação resulta de interesses e práticas de natureza profissional. Propomos levar a cabo a nossa abordagem utilizando dados de acesso ao web site da instituição onde temos vindo a desenvolver a maior parte do nosso percurso profissional, o Tribunal de Contas. Trabalhamos com dados deste web site desde 1998, caindo dentro das nossas competências a análise dos registos (logs) de acesso. No entanto, até à data, todas as análises privilegiaram aspectos puramente quantitativos – por exemplo, quantos acessos foram feitos a partir de um determinado país durante um certo período de tempo.O contacto com estes dados e as análises que até à data efectuámos despertaram o nosso interesse em aprofundar o seu processamento. Os novos conhecimentos proporcionados pelo Mestrado em Sistemas de Informação, no que diz respeito a métodos e técnicas de análise de dados e obtenção de conhecimento, deixaram-nos com a perfeita noção de que estes logs escondem um universo informativo extremamente rico.
Ao mesmo tempo, não podemos deixar de sentir vontade de interligar a nossa prática profissional (neste momento a incidir de forma quase exclusiva sobre a Internet) à nossa formação académica de base (História e Gestão de Documentação). Explorar logs de acesso de um web site é, à sua maneira, um trabalho de historiador – identificar necessidades de informação ao longo do tempo, acompanhar a evolução tecnológica dos meios de acesso, observar a relação entre conteúdo e utilização desse conteúdo e as formas como os dois elementos se influenciaram e influenciam entre si.
Relevância
A abordagem que nos propomos levar a cabo assume um interesse particular no que diz respeito à caracterização dos utilizadores do web site do Tribunal de Contas. Uma vez que, na sua actual versão, não existe qualquer mecanismo de registo de utilizadores, ou referenciação de acessos (via cookies, por exemplo), qualquer esforço de identificação é sempre feito a posteriori, e apenas com base no processamento dos registos desses acessos – processamento dos ficheiros de log do servidor web.Numa primeira análise, este tipo de dados permite descobrir características técnicas relativas a cada acesso (proveniência, software utilizado, sistema operativo de base, etc). Paralelamente, permite também quantificar esses acessos (quantos utilizadores num dado período de tempo, quais as páginas e documentos mais concultados, etc). No entanto, no que diga respeito à análise de parâmetros de acesso mais subjectivos, como os interesses dos utilizadores, quaisquer conclusões têm que passar por um trabalho intenso de contagens, relacionamento de acessos e pré-processamento dos conteúdos que são acedidos.
Por um lado, o resultado final de um trabalho desta natureza é relevante para a instituição em causa, na medida em que providencia um grau de conhecimento quanto à forma como os conteúdos informativos que disponibiliza são aproveitados, que de outra maneira não seria possível obter. Por outro lado, por incluir um conjunto de operações de processamento de informação que se podem revelar bastante demoradas, não é o género de análise que possa ser levada a cabo de forma muito dinâmica – em tempo real, ou com uma periodicidade muito regular. O conhecimento melhorado e aprofundado do universo de utilizadores de uma instituição como o Tribunal de Contas, deverá igualmente contribuir para a melhoria constante da qualidade dos serviços que são prestados ao público.
Fontes primárias
As operações de processamento de informação que desenvolvemos para levar a cabo este trabalho utilizaram duas fontes primárias distintas:Ficheiros relativos aos logs de acesso ao web site do TC, abrangendo um período de seis anos, entre 14 de Março de 2001 e 14 de Março de 2007. Isto corresponde a um total de 2.163 ficheiros, com 18.153.325 linhas de registos (já depois das etapas de pré-processamento, documentadas mais adiante). Não há uma correspondência 100% exacta entre a quantidade de dias decorridos e a quantidade de ficheiros de log, dado terem ocorrido algumas junções de dias e poderem assim aparecer dois ou três dias juntos no mesmo ficheiro.
Ficheiros relativos aos documentos disponibilizados no web site do TC. Estes documentos foram utilizados em operações de text mining, com o objectivo de proceder à extracção de palavras-chave. O seu formato nativo é o PDF, tendo sido convertidos para formato textual simples, para facilitar não só as as operações de text mining5, como também para permitir posteriores
operações de manipulação de texto.
Hardware e software utilizados
No Apêndice 1 descrevemos todas as configurações de hardware e software utilizadas na realização desta dissertação, com indicação de constrangimentos e soluções adoptadas.
5 Muito embora o software de text mining utilizado, SAS 9.1, possa trabalhar directamente sobre ficheiros em formato PDF,
algumas das operações que efectuámos com esse formato não obtiveram bons resultados, do ponto de vista da legibilidade dos conteúdos. A isso não será estranho o facto de os ficheiros PDF utilizados terem sido criados com vários tipos diferentes de software: Adobe Acrobat versões 5, 6, 7 e 8, bem como utilitários de conversão directa do formato DOC para o formato PDF. A conversão prévia para formato TXT revelou-se como a abordagem mais acertada.
Organização da dissertação
Esta dissertação vai-se organizar de acordo com a seguinte estrutura:Introdução, cobrindo a abordagem inicial ao tema, os objectivos a que nos propomos, a contextualização do tema, a nossa motivação para levar a cabo este trabalho e a sua relevância.
Definição de conceitos, capítulo no qual apresentamos definições para o conjunto de conceitos que estão na base do desenvolvimento do nosso trabalho.
Fundamentação teórica, capítulo no qual abordamos os fundamentos das tecnologias sobre as quais o nosso trabalho incide e onde fazemos a definição dos conceitos fundamentais que utilizamos.
Estado da arte, capítulo no qual abordamos trabalhos levados a cabo nesta área, com apreciação dos seus resultados, em função dos objectivos que pretendemos alcançar.
O Tribunal de Contas, capítulo no qual fazemos uma descrição da instituição em estudo e das características essenciais da sua produção documental. O web site do Tribunal de Contas, capítulo no qual caracterizamos esta
estrutura de informação.
Estabelecer o DNA dos documentos do web site do TC, capítulo no qual descrevemos a nossa abordagem ao processamento de documentos do web
site.
Estabelecer o DNA dos utilizadores do web site do TC, capítulo no qual levamos a cabo a caracterização dos utilizadores.
Análise dos resultados, capítulo no qual procuramos fazer uma avaliação crítica dos resultados obtidos.
Conclusão, momento em que avaliamos o grau de concretização dos objectivos, bem como identificamos pistas para trabalhos futuros.
Definição de conceitos
Do ponto de vista da história da tecnologia, a área sobre a qual incide esta dissertação é relativamente recente. Ao mesmo tempo, é uma área que se caracteriza por um intenso dinamismo – não apenas em termos de mudanças nas características básicas das tecnologias envolvidas, como também nos usos que lhes são dados.Este dinamismo, benéfico para a utilização e aproveitamento da WWW em geral, acaba por ter o efeito algo perverso de provocar uma variedade de interpretações do significado de alguns dos conceitos utilizados. Vamos apresentar neste capítulo as definições que tomámos por base para o nosso trabalho.
ADN-ÁCIDO DESOXIRRIBONUCLEICO
O ADN é uma molécula orgânica, responsável pela reprodução do código genético. Os progenitores transmitem partes copiadas do seu ADN para os seus descendentes durante o processo de reprodução, provocando assim a propagação das suas características.
A informação no ADN é armazenada como um código, composto por quatro bases azotadas: Adenina (A), Guanina (G), Citosina (C) e Timina (T). Estas bases juntam-se em pares, A-T e C-G, para formar os chamados pares-bajuntam-se. Cada bajuntam-se também se liga a uma molécula de açúcar e uma molécula de fosfato. Este conjunto - base, açúcar e fosfato - forma um nucleótido.
O ADN é composto por um par de cadeias destes nucleótidos, entrelaçados numa dupla-hélice. A estrutura assemelha-se a uma escada, na medida em que os pares-base formam os degraus, estando ligados uns aos outros pelas moléculas de açúcar e fosfato.
A funcionalidade de indentificação associada ao ADN (no que ele tem de unívoco para estabelecer as características de um determinado ser vivo), auxiliou a sua adopção, do ponto de vista conceptual, como metáfora para a identificação de segmentos de informação. É assim que surge a expressão "ADN de um documento"
(b020a), como maneira de designar um conjunto de atributos que identifiquem de forma absoluta um documento perante outros.
ADN DE UM DOCUMENTO
No âmbito em que estamos a trabalhar, a aplicação de uma metáfora baseada na biologia, não é levada às últimas consequências. Não vamos procurar a definição de cadeias de identificação únicas para cada documento. Quando falamos em ADN de um documento, no contexto deste trabalho, referimo-nos a uma cadeia de valores numéricos, entre 0 e 9, os quais ocupam um determinado número de posições numa cadeia de caracteres, a qual irá servir para posicionar o documento no contexto temático de um web site. Assim sendo, ao contrário de um ADN biológico, este ADN documental pode-se repetir - vários documentos podem partilhar o mesmo âmbito temático, com um elevado grau de precisão.
ADN DE UM UTILIZADOR
O contraponto ao ADN dos documentos é o ADN dos utilizadores que os tiverem consultado. Com esta expressão designamos uma cadeia de valores numéricos, entre 0 e 9, os quais ocupam um determinado número de posições numa cadeia de caracteres, e que é utilizada para expressar as preferências de cada utilizador em função dos documentos que consulta. Tal como acontece para o ADN dos documentos, também este se pode repetir - vários utilizadores podem ter o mesmo perfil de consulta.
BROWSER
Programa utilizado para localizar e visualizar PÁGINAS WEB. Tendo começado como
simples visualizadores de conteúdos de natureza textual, não suportando sequer a inclusão de imagens nas páginas [b035, pp. 244-245], surgem hoje como produtos multifuncionais. Para isto contribuiu a própria evolução da WWW, que tem uma grande tendência aglutinadora, possibilitando a reunião, sob um mesmo
interface, de um vasto conjunto de funcionalidades: consulta de páginas web, download de ficheiros, acesso a correio electrónico, participação em fóruns de
discussão, consulta de documentos nos formatos mais variados, acesso a dados multimédia... a lista de funcionalidades é grande e não pára de aumentar.
CIBERESPAÇO
Este termo apela, antes do mais, a uma certa visão “poética” ou literária de algo que não é inteiramente real6. Foi criado pelo autor de ficção científica William Gibson, que o utilizou pela primeira vez na história Burning Chrome, em 19827. O ciberespaço será assim um “espaço” formado pela totalidade da “realidade electrónica” existente no mundo (termo que inclui todos os dados armazenados e comunicados electronicamente). O ciberespaço é formado não só pelo universo comunicacional propiciado pela Internet, mas também por realidades mais antigas, como o conjunto de meios de comunicação formados pelas redes telefónicas, de televisão, etc. [b003a]
CLASSIFICAÇÃO DE DOCUMENTOS
Nome dado à tarefa de classificar um documento de natureza textual numa quantidade de categorias temáticas, relevantes para o seu conteúdo [b050a]. De acordo com o contexto de criação e utilização, essa classificação pode ser manual (recorrendo directamente ao conteúdo, ou recorrendo a classificadores externos [b034a], como listas de descritores ou a thesauri), ou pode ser automática.
CLICKSTREAM
Sequência de CLIQUES realizada por um UTILIZADOR ao longo do seu processo de
interacção com as páginas de um [b058a] ou vários [b030] WEB SITES.
CLIQUE
A activação de uma HIPERLIGAÇÃO por um UTILIZADOR válido [b058a].
6 “[...] O ciberespaço. Uma alucinação consensual, vivida diariamente por biliões de operadores legítimos, em todas as
nações, por crianças a quem se estão a ensinar conceitos matemáticos. Uma representação gráfica de dados abstraídos dos bancos de todos os computadores do sistema humano. Uma complexidade impensável. Linhas de luz alinhadas no não espaço da mente; nebulosas e constelações de dados. Como luzes de cidade, retrocedendo”. [b022, pág. 65]
7 “[…] A science fiction writer coined the useful term "cyberspace" in 1982, but the territory in question, the electronic
frontier, is about a hundred and thirty years old. Cyberspace is the "place" where a telephone conversation appears to occur. Not inside your actual phone,the plastic device on your desk. Not inside the other person's phone,in some other city. THE PLACE BETWEEN the phones. The indefinite place OUT THERE, where the two of you, two human beings, actually meet and communicate.” [b046a]
FICHEIRO DE LOG (LOG FILE)
No contexto deste trabalho, este termo designa um ficheiro criado por um SERVIDOR
WEB, contendo o registo de toda a actividade relacionada com o acesso ao conteúdo
do web site (ou web sites) que alberga [b064]. Podem ser utilizados como fonte de informação de natureza quantitativa [b017a, b025], devendo ser alvo de sucessivas operações de processamento e interpretação.
HIPERLIGAÇÃO
Na década de 60 do séc. XX, Theodor “Ted” Nelson criou a expressão “hipertexto”, definindo-a como uma forma de escrita não-sequencial. Denominando a sua abordagem como Projecto Xanadu [b061], definiu a possibilidade de estabelecer ligações - hiperligações - entre segmentos diferentes de informação de natureza hipertextual [b036]. Muito embora este projecto nunca tenha atingido os objectivos pretendidos, a terminologia acabou por se manter e por ser aproveitada noutros contextos - nomeadamente no software HyperCard da companhia Apple Computers [b035] e, obviamente, na própria WWW.
HIT
De uma forma genérica, é considerado como qualquer pedido de ficheiro feito a um SERVIDOR WEB. Um pedido de uma PÁGINA WEB pode dar origem a múltiplos hits, na
medida em que ela pode ser composta por múltiplos ficheiros (com texto, imagem, código...), que são enviados pelo servidor web [b064]. Ou seja, cada acesso a uma página web pode dar origem a múltiplos hits. No entanto, há contextos de utilização em que uma página web pode ser formada por uma quantidade variável de elementos entre cada pedido de página [b041] (web sites de conteúdo dinâmico, de agências noticiosas, por exemplo). Ou seja, a contagem de hits por si só, pode não transmitir uma noção correcta do volume de utilização de um web site.
INTRANET INSTITUCIONAL
Nome pelo qual designamos o sistema interno de disponibilização de documentos utilizado na rede informática do Tribunal de Contas. O seu nome oficial é S3i, ou
Sistema de Informação Integrado na Intranet. A sua composição tecnológica é a seguinte:
Gestão de conteúdos através do software Microsoft Share Point Portal Server 2003;
Software SERVIDOR WEB Microsoft Internet Information Server (IIS) v6.0;
Sistema operativo Microsoft Windows Server 2003 R2 Enterprise Edition.
PAGE VIEW (VISTA DE PÁGINA OU CONSULTA DE PÁGINA)
Nome dado ao pedido de consulta de cada página isolada de um web site [b064]. Resulta de um CLIQUE numa HIPERLIGAÇÃO, ou na indicação explícita de um URL em
software que saiba processar essa informação (quer se trate de um BROWSER, quer
se trate de outro tipo de programas). Uma única page view traduz-se habitualmente numa quantidade variada de HITS.
PÁGINA WEB
Nome dado às unidades individuais de visualização do conteúdo de um WEB SITE. Pode ser formada por conteúdos estáticos (texto e imagens) ou dinâmicos (animações e vídeos). Pode ter características multimédia (misturando vários tipos e proveniências de informação, incluíndo áudio) e pode oferecer pontos de acesso a fontes de dados externas à própria página - por exemplo, interfaces para consulta de bases de dados. Enquanto metáfora de acesso e disponibilização de informação, as páginas web assumem hoje um papel muito importante - boa parte dos interfaces de acesso a todo o tipo de informação têm uma versão web. A sua consulta e visualização é feita a partir de programas próprios - habitualmente os BROWSERS da
web, muito embora seja possível codificar e filtrar conteúdos web de múltiplas
maneiras e utilizar outro tipo de programas (clientes de correio electrónico, leitores de feeds RSS, entre outros).
PEDIDO DE PÁGINA
A oportunidade de uma PÁGINA WEB aparecer na janela de um BROWSER, como
resultado da interacção de um UTILIZADOR com um WEB SITE [b057b].
REFERENCIADOR (REFERRER)
Nome dado a qualquer ponto de origem online (WEB SITE, anúncio, resultado de pesquisa) que leve UTILIZADORES ao web site em análise, gerando VISTAS DE PÁGINA.
Deve ser identificável univocamente, através de um URL específico, que identifique com precisão o ponto de origem do acesso.
SERVIDOR WEB
Este termo assume uma dupla vertente:
Nome dado ao computador onde se encontram alojadas fisicamente as
PÁGINAS WEB (e restante conteúdo) que dão forma a um WEB SITE. Neste
contexto, o termo pode surgir como um “agregador”, na medida em que pode esconder realidades complexas – ambientes de clustering, onde várias dezenas, centenas ou milhares de máquinas individuais respondem como se fossem uma só (veja-se o exemplo extremo do motor de pesquisa Google, onde mais de uma centena de milhar de servidores individuais [b001a] são agrupados em clusters de mais de 15.000 máquinas [b003b], que respondem de forma unificada aos pedidos que são feitos).
Nome dado ao software que corre num computador que aloja páginas web e que é responsável pela recepção e processamento dos pedidos de página.
SESSÃO DE UTILIZADOR (USER SESSION)
Um período de actividade de um UTILIZADOR num WEB SITE. Habitualmente,
considera-se a sessão terminada quando o utilizador estiver inactivo por mais de 30 minutos [b064]. Trata-se de um conceito fortemente idêntico ao de VISITA.
TEXT MINING
Conjunto de técnicas de análise de documentos, com o objectivo de extrair conhecimento "escondido" de dados de natureza textual [b048]. Este conhecimento pode assumir a forma de padrões, modelos, direcções, tendências ou regras, a serem encontrados em texto não estruturado [b034b].
URL
Acrónimo que significa Uniform Resource Locator (traduzível por Localizador Uniforme de um Recurso), endereço unívoco de identificação de um recurso na Internet. A sua composição inclui o protocolo (HTTP, FTP, WML, MMS...), o nome do domínio onde o servidor se encontra (ou o seu endereço IP), nomes de directorias e/ou ficheiros e um formato de dados (HTML e variantes, CGI, PL, PHP, consoante a tecnologia que estiver na base do conteúdo).
UTILIZADOR
Nome dado à entidade, individual ou colectiva, em relação à qual é feita a atribuição de uma VISITA ou USER SESSION. No caso do web site do TC, não é feito
qualquer registo de utilizadores, nem são utilizadas quaisquer tecnologias de rastreio (baseadas em cookies, por exemplo). Por esta razão, a identificação de utilizadores é feita a partir dos endereços IP registados nos FICHEIROS DE LOG. Assim sendo, esses
endereços tanto se podem referir a um utilizador individual (a fazer um acesso doméstico, por exemplo), como a um acesso institucional (onde um único endereço IP pode “esconder” centenas de utilizadores).
VISITA
Sequência de interacções entre um UTILIZADOR e um WEB SITE, que termina quando
houver um intervalo de 30 ou mais minutos entre CLIQUES, ou quando o utilizador
abandonar o web site (passando para outro) [b064]. Não há uma razão explícita para ser utilizado o valor de 30 minutos [b041, p. 7], mas é considerado como um valor standard.
VISTA DE PÁGINA (PAGE VIEW)
Momento em que uma PÁGINA WEB é vista por um UTILIZADOR. De acordo com
[b057b], é uma variável não mensurável, sendo preferível falar em apresentação de página - momento em que a página é apresentada no écran do computador do utilizador. Em [b041] esta distinção não é contemplada, sendo a vista de página considerada como a apresentação com sucesso de todo o conteúdo que forma uma página web, independentemente da forma como é apresentada. Esta é a definição em que nos baseamos.
WEB BUG
Nome dado a uma imagem existente numa página web ou numa mensagem de correio electrónico (em formato HTML), que tenha por objectivo monitorizar a consulta da página, ou a leitura da mensagem. Muitas vezes são imagens de reduzidas dimensões e/ou invisíveis (imagens que ocupam um pixel de área, ou imagens transparentes). Permitem recolher informação como:
O endereço IP do computador onde foi activado/apresentado; O endereço da página em que ele se localiza;
A hora e data da visualização;
O ambiente operacional em que foi visualizado (versão de sistema operativo e do browser);
Informação previamente armazenada num cookie. Encontram utilização em áreas como:
a criação de perfis de utilização (de um web site ou de conjuntos específicos de informação);
a recolha de dados para contabilização de acessos a páginas ou web sites; a recolha de dados para caracterização de acessos.
WEB LOG MINING
Aplicação de técnicas de WEB MINING ao conteúdo de FICHEIROS DE LOG, relativos aos
acessos que são feitos a um WEB SITE.
WEB MINING
Conjunto de técnicas de análise e extracção de informação de dados relacionados com a WWW: a partir do conteúdo de PÁGINAS WEB, a partir de estruturas de
hiperligações e a partir de estatísticas de acesso a conteúdos web [b048 e b051b].
WEB SITE
Um web site é uma colecção de PÁGINAS WEB, localizadas num domínio ou sub-domínio específico da Internet, disponibilizadas a partir de um SERVIDOR WEB, através do conjunto de tecnologias que compõem o universo informativo denominado World Wide Web.
WEB SITE EXTERNO DO TC
Nome pelo qual designamos o web site institucional do Tribunal de Contas, disponível em http://www.tcontas.pt, cujo conteúdo informativo e condições de utilização serviram de base à elaboração desta dissertação. A sua composição tecnológica é a seguinte:
Software SERVIDOR WEB Microsoft Internet Information Server (IIS) v6.0; Sistema operativo Microsoft Windows Server 2003 R2 Enterprise Edition. Não é utilizado qualquer sistema de gestão de conteúdos. As páginas são estáticas na sua maioria, sendo apenas utilizadas algumas tecnologias de apoio à compiosição de conteúdos (nomeadamente Server Side Includes). Alguns subsistemas recorrem a bases de dados de estrutura flat-file (pesquisa de Acórdãos e Sentenças em http://www.tcontas.pt/pt/actos/acordaos.shtm, e base de dados bibliográfica do Auditing Standards Comittee da INTOSAI – International
Organization of Supreme Audit Institutions em http://www.tcontas.pt/cgi-bin/asc/db.cgi). Em situações específicas, são disponibilizados interfaces para bases de dados de SQL Server.
A teoria (e prática) subjacente à utilização
de logs de acesso a web sites.
A existência de logs de acesso a web sites não assume uma relevância “externa” ao contexto em que se inserem, na medida em que se trata de um tipo de informação cuja recolha não é essencial ou obrigatória, mas que, quando existe, tem utilidade primariamente para os responsáveis pelo web site8. Quando é bem aproveitada, tem uma enorme importância e reveste-se de extrema utilidade.Desde as suas primeiras versões, os servidores web registam pormenores de operação nos chamados ficheiros de log, ou ficheiros de registo (mantemos a expressão log por comodidade de referências). A isso não será estranho o facto de o desenvolvimento inicial deste software ter sido feito em máquinas com variantes do sistema operativo Unix (workstations NeXT, com um sistema operativo baseado no
kernel Mach), sendo a existência de logs uma das características notórias de
qualquer componente servidor que nele corra.
O uso inicialmente dado a este registo de informação foi o de, muito simplesmente, fornecerem contagens de acessos a páginas de web sites [b041, p. XV e Apêndice 2], operação que se foi tornando cada vez mais complexa à medida que a WWW crescia e se tornava mais rica (cada vez mais páginas por web site, com maior diversidade de conteúdos – imagens, por exemplo). É assim que fomos assistindo a um refinamento progressivo dos conceitos (e metodologias) associados ao processamento de logs:
Inicialmente o parâmetro mais fácil de medir foi o da quantidade de pedidos feitos pelos utilizadores e registados no servidor web, designados como hits. Na altura, tal como hoje, uma página web que apenas contivesse texto traduzia-se num único hit. Se a página contivesse gráficos, ou tivesse o seu conteúdo repartido por frames, daria origem a tantos hits quantos fossem os objectos que a fazer parte da sua composição.
Para acompanhar a crescente complexidade das páginas e a crescente necessidade de obter informações mais precisas e exactas, foram adoptados
8 Há casos em que a informação constante nos logs de acesso a web sites é considerada útil para divulgação pública
outros conceitos, sempre com o intuito de permitir fazer contagens, de forma tão exacta quanto possível. Surge assim a contagem de visionamentos de página (ou page views, em que um visionamento pode agrupar vários pedidos) e a contagem de sessões (em que uma sessão pode agrupar vários visionamentos de página por utilizador).
Na imagem seguinte exemplificamos esta forma de recolher informação:
Imagem 1: Sumário da contagem de acessos ao web site BoingBoing (http://www.boingboing.net) Nas várias colunas podem ser vitas contagens de pedidos (coluna Hits), de páginas (coluna Pages)
e de visitas (colunas Number of Visits e Unique visitors) Fonte: http://www.boingboing.net/stats/
Software utilizado: Advanced Web Statistics 6.4 (http://awstats.sourceforge.net/)
O desenvolvimento da WWW propiciou o aparecimento de novas formas de aceder e disponibilizar informação. Com o passar do tempo, elas começaram a desempenhar um papel cada vez mais importante, no que toca ao impacto sobre as funções de navegação. Entre elas contam-se:
O aparecimento e crescente actividade das “aranhas” de indexação de web
sites (mecanismos automáticos de pesquisa e indexação de conteúdos na web, geralmente associados a motores de pesquisa como o Google, Yahoo,
MSN Live Search, etc.). Qualquer operação feita por uma destas aranhas sobre uma página web provoca entradas de log, como se de uma consulta por um utilizador humano se tratasse. O único factor de diferenciação consiste na utilização de designações que a identifiquem como aranha. Atente-se no seguinte exemplo:
2004-10-28 00:00:36 W3SVC1447415605 MARTE 10.128.0.2 GET /pt/actos/rel_auditoria/2004/rel008-2004-2s.pdf - 80 - 66.249.64.131 HTTP/1.0 Googlebot/2.1+(+http://www.google.com/bot.html) - - www.tcontas.pt 200 0 64 0 222 437 2004-10-28 01:03:59 W3SVC1447415605 MARTE 10.128.0.2 GET /pt/actos/rel_auditoria/2004/rel008-2004-2s.pdf - 80 - 82.155.17.82 HTTP/1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) ) - - www.tcontas.pt 200 0 64 0 222 437
Ambas as linhas foram extraídas do log de acessos ao web site do Tribunal de Contas, relativo ao dia 28 de Outubro de 2004. Ambas dizem respeito a uma operação do protocolo http, o comando GET, relativa ao acesso a um dos documentos constantes desse web site – o Relatório de Auditoria nº 8/2004. Na primeira linha o acesso foi feito pela aranha associada ao Google, denominada Googlebot. Na segunda linha, o acesso foi feito por um operador humano, utilizando o browser Microsoft Internet Explorer 6.0 a correr sobre o sistema operativo Windows XP. A não ser esse detalhe, a informação genérica sobre o acesso é virtualmente idêntica.
A recolha desta informação em logs de acesso é recebida com alguma ambivalência, na medida em que pode ter vários contextos de uso: tanto é considerada válida por si só para acompanhar o comportamento das aranhas de indexação [b034b], como pode pode exigir um processamento separado, tendo em vista não afectar a medição de variáveis de acesso recolhidas na óptica da utilização de um web site por seres humanos [b025]. Situações em que se pretenda obter uma ideia clara dos percursos efectuados pelos utilizadores dentro do web site, podem obrigar a etapas prévias de limpeza dos ficheiros de log, tendo em vista a remoção de referências a aranhas de indexação [b005].
O desenvolvimento de soluções técnicas para o acesso à Internet, que assentam em web proxies e em endereços atribuídos dinamicamente tornaram muito difícil, ou mesmo impossível, fazer corresponder um acesso a
uma página a um utilizador específico, identificável pelo registo deixado no log. Veja-se a seguinte imagem:
Imagem 2: Configuração de definições para acesso à Internet no browser Microsoft Internet Explorer.
A imagem anterior retrata uma realidade típica na maior parte das organizações onde a ligação à Internet seja feita através de uma rede local: o acesso passa por um servidor proxy, computador que controla as ligações de dezenas ou centenas de utilizadores individuais. Quando estes utilizadores acedem a um web site, nos logs de acesso deste fica apenas registado o endereço IP atrás do qual se situa o servidor proxy – para todos os efeitos, as dezenas ou centenas de acessos ficam registadas como se fossem de um único utilizador.
A possibilidade de atribuir endereços de rede de forma dinâmica (através do protocolo de rede DHCP [b052a]) é particularmente atraente para as empresas que fornecem acesso à Internet. Em vez de manter manualmente listas de milhares de endereços fixos, esses endereços passam a ser atribuídos de forma dinâmica, à medida que os utilizadores estabelecem ligações à rede. Isto pode dificultar a identificação fácil da proveniência dos acessos registados em logs, sendo quase sempre necessário realizar etapas de processamento a posteriori, para identificar com precisão gamas de endereços e a sua proveniência.
Ambas as soluções, inteiramente válidas e práticas de um ponto de vista técnico, dificultam o trabalho a quem pretenda conhecer com precisão a forma como se acede ao seu web site. A utilização de proxies torna impossível fazer contagens
precisas de quantas pessoas acedem e a utilização de endereços dinâmicos dificulta a identificação de quem acede (se esse grau de detalhe for necessário, o que varia de acordo com a natureza do web site).
Outro pormenor do funcionamento dos browsers também se veio a revelar algo nefasto para a obtenção de estatísticas válidas. Com efeito, a possibilidade de manter localmente em cache as páginas consultadas facilita o trabalho dos utilizadores, por tornar mais rápidos os acessos consecutivos à mesma página. No entanto, ao recorrer a este artifício, uma sessão de consulta de páginas de um mesmo web site pode ficar insuficientemente registada nos logs deste – só ficam registados em log os acessos a páginas que não estavam na cache do utilizador [b025]. Se bem que isto seja útil para quem navega (por ser mais rápido) e alivie a carga de acessos ao servidor web, impede que os responsáveis pelo web site consigam obter respostas concretas a perguntas como “quais os caminhos de navegação que os utilizadores percorrem no nosso web site?” [b005]. Veja-se a imagem seguinte:
Imagem 3: Caixa de diálogo de definições de cache de páginas web no browser Microsoft Internet Explorer. As opções variam entre utilizar sempre em primeiro lugar a versão da página que estiver em cache
(opção Nunca) e não utilizar a versão em cache (opção Sempre que voltar a página)
Tendo em vista a obtenção de métricas mais exactas, bem como a possibilidade de identificar com precisão os utilizadores individuais que acedem aos web sites, foram desenvolvidas novas soluções. Elas assentaram essencialmente em esforços para conseguir identificar univocamente cada utilizador que acedesse a cada página (proporcionando contagens mais exactas e possibilitando a criação de perfis de
navegação). Este objectivo raramente é conseguido na totalidade, mas isso não impediu a proliferação da tecnologia.
Desta forma, a partir de determinado momento, a obtenção de informação sobre o acesso a web sites não ficou exclusivamente na mão dos logs mantidos pelos servidores. Numa tentativa de obter métricas fiáveis, surgiram soluções em que o esforço de recolha de informação foi deslocado para cada página web, através de métodos mais ou menos engenhosos de apresentar certos conteúdos:
A colocação de contadores de acesso visíveis em certas páginas.
O registo de acessos a páginas feito de maneira “secreta”, sem conhecimento directo por parte do utilizador.
A partir de meados da década de 90 do século XX, muitas páginas começaram a mostrar contadores numéricos, que pretendiam indicar a quantidade de vezes que a página era consultada. De natureza textual, ou de natureza gráfica, podiam servir como uma medida de popularidade da página (quanto maior o número apresentado, mais pessoas teriam acedido à página). Na imagem seguinte mostramos alguns exemplos de estilos gráficos aplicáveis a este género de contadores.
Imagem 4: Uma minúscula amostra de estilos aplicáveis a contadores de acessos a páginas web (Fonte: http://freelogs.com/)
Com o passar do tempo, esta ideia foi tendo cada vez menos aplicação, por se terem tornado óbvias várias limitações:
Os números apresentados por um contador de acessos não são forçosamente exactos. A partir do momento em que compete ao webmaster de um web site a sua preparação inicial, é fácil fazer o contador começar logo por apresentar um número de acessos bastante grande…
Se o contador for mantido com numeração exacta, pode dar-se o caso de o
web site ter muito pouco tráfego e o número apresentado raramente
aumentar. Isto não abona muito a favor do prestígio do web site.
A passagem do tempo fez com se desenvolvessem novas metodologias para o cálculo de acessos. Utilizar os contadores tornou-se num obstáculo e não numa vantagem.
Tal como a tecnologia evolui, também os gostos do público evoluem. Hoje, a utilização de contadores de acesso como elementos integrantes do desenho da página só raramente é utilizada em institucionais, ficando cada vez mais reservada para sites individuais. Veja-se o seguinte exemplo:
Imagem 5: Página de uma pequena empresa com um contador localizado no canto inferior esquerdo (destaque) (Fonte: http://www.4ateapot.co.uk/)
Imagem 6: O mesmo contador, ampliado. Neste caso trata-se de uma aplicação do serviço FastCounter, que permite o processamento da contagem por outro web site que não o que apresenta o contador. Este serviço está integrado no pacote Small Business Server da Microsoft.
Note-se que este tipo de informação tem um valor que apenas é habitualmente associado a funções de marketing – mostrar em que medida o web site agrada aos utilizadores, por exemplo.
O recurso às próprias páginas para recolher informação de acessos, deu origem a outro aproveitamento técnico, este muito mais polémico. Pode ser identificado de várias maneiras, mas a que melhor expressa a forma como acabou por ser encarado é o termo web bug. Um web bug consiste num gráfico, habitualmente transparente (e, como tal, invisível na página), para além de ter dimensões muito reduzidas (ocupando normalmente apenas um pixel do écran). Na prática, esta imagem é colocada na página depois de ter sido executado um programa num web site externo que que está a ser consultado. Veja-se o seguinte exemplo de código HTML, detectado por volta de 1999, no web site do programa Quicken:
<img src="http://ad.doubleclick.net/ad/pixel.quicken/NEW" width=1 height=1 border=0>
A origem da imagem está situada num web site (ad.doubleclick.net) que não era o da página que estava a ser consultada (http://www.quicken.com). A linha de código não se refere directamente a uma imagem: ela faz uma chamada a um programa, que retorna uma imagem, um GIF transparente, que irá ocupar apenas 1 pixel do écran – na prática, fica invisível.
Regra geral, o processamento deste tipo de informação fica a cargo de empresas que se dedicam ao processamento comercial de estatísticas de acesso, ou à recolha de dados com vista à constituição de perfis de potenciais clientes (para fins publicitários ou outros). Ou seja, é feita recolha de informação, sem que o utilizador disso se aperceba, pois apenas é colocado mais um elemento gráfico na página web
que estiver a consultar e não tem que haver nenhum elemento que indique que está a ser fornecida informação a terceiras partes.
A polémica levantada em torno desta abordagem, juntamente com uma preocupação crescente com a necessidade de garantir a privacidade por parte de quem consulta páginas web, fez com que, com o passar do tempo, o uso de web
bugs fosse diminuindo. Isto não quer dizer que tenham desaparecido por completo,
nem que ideia subjacente ao seu uso (passar informação a terceiras partes) tenha deixado de interessar. Muito simplesmente, as soluções tecnológicas vão mudando com o tempo.
Da lista dessas soluções também fazem parte os magic cookies de http ou, mais simplesmente, cookies [b052b]. Eles consistem em pequenos pacotes de informação que são enviados por um servidor web para um browser, sendo depois reenviados pelo browser de cada vez que voltar a aceder a esse servidor. Veja-se a imagem seguinte:
Imagem 7: Lista de cookies entregues ao browser Microsoft Internet Explorer. Para cada um é identificado o nome do utilizador, o endereço do servidor web que o enviou e várias datas (o prazo de validade, datas de acesso, etc.)
Um cookie contém informação arbitrariamente estabelecida pelo servidor web, a qual serve para atribuir um determinado estado a uma operação (navegação na
web) que, no seu essencial, é stateless. Desta forma, em vez de cada consulta de
que consultou da última vez que esteve no web site, etc. Por exemplo, o que se segue é o conteúdo do segundo cookie da lista que apresentámos em cima:
PREFID=7a897a06d8729fa4:CR=1:TM=1126273418:LM=1126273418:S=awQvzumMjLpK_wbMgoo gle.com/1024261887833632111634209219924829734212*
Os cookies podem ainda ser utilizados para:
Manter listas de produtos, ao estilo do “carrinho de compras”, solução muito utilizada em web sites de comércio electrónico.
Armazenar informação de autenticação dos utilizadores no primeiro acesso a um web site, tornando mais rápidos os acessos seguintes.
Personalizar o acesso à informação, apresentando informação diferente para cada utilizador, com base em opções seleccionadas com antecedência (por exemplo, numa fase de registo).
Enquanto mecanismo de identificação de utilizadores (se não de um utilizador individual, pelo menos de um ponto de acesso único – um posto de trabalho), os
cookies aparentemente responderam a várias necessidades de obtenção de
métricas. No entanto, uma das suas características essenciais pode dificultar esse uso: o facto de a sua existência poder ser inteiramente controlada pelo utilizador. De facto tal como é possível ver quais os cookies instalados num computador, também é possível apagar todos os que lá estiverem, ou até configurar os browsers para recusarem todos os cookies.
Neste sentido, podemos afirmar que os cookies não constituem uma solução sólida para auxiliar a obtenção de métricas de acesso. Um web site pode estar configurado para exigir a colocação de cookies em todos os browsers que o visitarem, sem o que o seu conteúdo não aparece, ou aparece de forma parcial. Isto é aceitável para muitos utilizadores, mas outros limitar-se-ão a ignorá-lo e a procurar outro que não faça tais exigências. Noutros casos, o mesmo utilizador pode não dar hipóteses a que sejam constituídos perfis de uso das suas actividades de navegação, eliminando
os cookies entre cada visita a um web site, ou recusando pura e simplesmente a sua entrega9.
Tal como os web bugs permitiram a recolha de informação por terceiras partes, também os cookies o acabaram por permitir. Através dos denominados “third-party
cookies”, vários web sites procuraram passar informação sobre o seu uso, de forma
automática, a empresas de recolha de dados. Esta abordagem tornou-se polémica pelas questões que levantou em torno da privacidade – ao consultar um web site, os utilizadores vêem de repente o seu computador ser invadido por pequenos “artefactos” de recolha de informação, plantados lá por uma empresa que muitas vezes desconhecem.
O software existente
A obtenção de métricas de acesso a web sites continua a ser uma tarefa inteiramente válida e, muitas vezes, essencial para avaliar o estado do desempenho de um determinado web site: desde saber muito simplesmente se recebe visitas, até caracterizar em profundidade as visitas que são feitas.A importância desta actividade reflecte-se por um lado na quantidade de software existente, por outro na quantidade da produção teórica que aborda o tema.
A lista seguinte contém alguns dos títulos de software actualmente disponíveis. As suas capacidades são variáveis, tal como são os seus objectivos – uma maior orientação para a contabilização numérica, uma maior orientação para a obtenção de dados úteis para finalidades relacionadas com marketing, a possibilidade de acompanhar o bom funcionamento do web site com detecção de potenciais erros, etc.
9 Sobre este assunto, é muito recente a polémica que envolveu um relatório apresentado pela empresa americana de
medição de audiências online comScore, relativo à eliminação de cookies pelos utilizadores (disponível online em http://www.comscore.com/press/release.asp?press=1389). Outras empresas e grupos de discussão (vejam-se os comentários no grupo webanalytics a partir de http://tech.groups.yahoo.com/group/webanalytics/message/10403) apresentaram rapidamente mais informação a completar ou a contrariar estes pontos de vista. Com ou sem relação com esta questão, o Internet Advertising Bureau [b057a] apresentou uma carta aberta às empresas comScore [b054a] e Nielsen/NetRatings [b059a] (http://www.iab.net/news/pr_2007_04_20.asp), pedindo uma validação por terceiras partes dos seus processos de medição.
Analog
http://www.analog.cx
Software gratuito, instalável no servidor web a analisar, ou em qualquer outra
máquina, desde que tenha acesso aos ficheiros de log. Muito configurável e flexível, está orientado sobretudo para a contagem de elementos relativos aos acessos a páginas.
AWStats
http://awstats.sourceforge.net
Software gratuito, instalável no servidor web a analisar, ou em qualquer outra
máquina, desde que tenha acesso aos ficheiros de log. Está também orientado para a contagem de elementos relativos ao acesso às páginas web, oferecendo mais funcionalidades relacionadas com a geo-localização.
HBX Analytics
http://www.websidestory.com
Software comercial, que faz análise de informação relativa à navegação no web site, ao grau de desempenho de web sites de comércio electrónico, ao
impacto de campanhas específicas (de informação ou de marketing) e a múltiplos aspectos dependentes das características do web site (por sua vez ligados ao tipo de actividade da organização que o controla). É posicionado sobretudo como uma ferramenta de marketing.
Omniture Site Catalyst
http://www.omniture.com
Software comercial, que cobre aspectos relacionados com o desempenho de web sites de comércio electrónico, a análise detalhada da percursos de
navegação, a segmentação de visitantes do web site (em função da navegação que fazem) e a eficácia de campanhas de marketing.
OneStat
http://www.onestat.com
Software comercial que cobre aspectos como a contagem de visitantes,
percursos percorridos, impacto de motores de pesquisa e desempenho de funcionalidades de comércio electrónico. Para web sites pequenos, oferece um serviço gratuito, em regime de outsourcing, baseado na utilização de contadores nas páginas.
Urchin On Demand / Google Analytics
http://www.google.com/analytics/
Começou por ser serviço de web analytics fornecido em regime de
outsourcing – sem instalação de software nos clientes. Cobria aspectos
relacionados com a caracterização dos visitantes do web site, o impacto de campanhas de marketing, o recurso a motores de pesquisa, acompanhamento do desempenho do comércio electrónico, análise de navegação, etc. Em 2005 a empresa foi comprada pela Google, que integrou o serviço e o disponibilizou, gratuitamente, sob o nome Google Analytics. Webalizer
http://www.mrunix.net/webalizer
Software gratuito, instalável no servidor web a analisar, ou em qualquer outra
máquina, desde que tenha acesso aos ficheiros de log. Também orientado para a contagem de elementos relativos aos acessos.
WebTrends
http://www.webtrends.com
Software comercial, instalável no cliente ou fornecido como serviço em
regime de outsourcing. É um dos poucos a fornecer a possibilidade de recolher informação de tracking de utilização através de “first-party cookies” (em oposição aos third-party cookies referidos anteriormente). Também cobre o processamento da segmentação de visitantes, a análise de campanhas de e-mail e a análise de percursos de navegação.