Automatização da integração de informação distribuída e heterogénea
Ricardo Rodrigues 1, André Sampaio 2, Pedro Sousa 31) Instituto Superior Técnico, Lisboa, Portugal [email protected]
2) Link Consulting, Lisboa, Portugal [email protected]
3) Link Consulting, Lisboa, Portugal [email protected]
Resumo
A existência e manutenção de um repositório arquitectural num estado consistente e actualizado são fundamentais para suportar o funcionamento de uma organização, apoiando a sua sobrevivência e competitividade no turbulento panorama empresarial. O elevado volume de informação disponível numa organização bem como a sua distribuição por fontes distribuídas e heterogéneas dificultam no entanto esta tarefa. O foco deste trabalho diz então respeito à integração de informação, estruturada e semi-estruturada, como meio para garantir a manutenção de um repositório arquitectural actualizado. Dados os objectivos de lidar com a actualização e heterogeneidade da informação, foi proposta uma solução baseada na virtualização do repositório, sendo que a informação será sempre consultada directamente da sua fonte original. A validação da solução proposta será feita com recurso ao desenvolvimento de um protótipo que a implementará, e a aplicar a um caso do mundo real.
Palavras chave: integração de informação, repositório arquitectural, virtualização
1. Introdução
No decorrer das últimas décadas tem surgido um crescente interessa na disciplina de Arquitecturas Empresariais. As Organizações num esforço para controlar a funcionalidade e complexidade [Op't Land, et al. 2008] recorrem a esta disciplina como um instrumento que as dote de capacidades para enfrentar as adversidades, tornando-as mais competitivas e consequentemente com maiores hipóteses de sobreviver no turbulento panorama empresarial. Um importante passo na definição de uma arquitectura empresarial é a escolha de uma ferramenta de suporte, uma ferramenta de arquitectura empresarial, sendo que um dos principais requisitos para qualquer ferramenta de AE é a existência de um repositório que consiga persistir a informação e suportar um meta-modelo que estabeleça as regras de estruturação dessa mesma informação em termos de entidades e do modo como se relacionam.
Many enterprises start off using diagramming tools and spreadsheets to document their architectures. Although this can be useful initially, ensuring consistency of these documents becomes extremely difficult once artifacts appear in multiple places. For example, an application might appear on a diagram depicting a server, a diagram depicting a business process and a diagram depicting the application’s interfaces. Changes to the application might require opportunities for inconsistency and inaccuracy. [James e Handler 2008]
A escolha de instrumentos inadequados leva a uma dificuldade acrescida para o atingimento de sucesso de qualquer tipo de iniciativa arquitectural [Sampaio 2010] [Schekkerman 2011] [James e Handler 2008].
A manutenção de um repositório num estado consistente e actualizado é no entanto um desafio a enfrentar, sendo que o elevado volume e descentralização da informação numa organização limitam a facilidade de execução desta tarefa.
A integração de informação tem diversas implicações, sendo que uma das principais é a sua distribuição, ou seja, as organizações têm a totalidade da sua informação distribuída por diversas fontes, autónomas e heterogéneas. Cada fonte disponibiliza informação especializada, cada uma com seu método de acesso distinto, sendo que algumas são até sistemas legados. A heterogeneidade aumenta ainda mais se pensarmos que a informação de uma organização não se encontra apenas situada em sistemas de informação, que são fontes de informação estruturada. De facto, 80% da informação numa organização típica é não estruturada ou semi-estruturada, encontrando-se situada no corpo de mensagens de correio electrónico, em documentos office, ou mesmo não digitalizada, encontrando-se em formato físico [Knox, Andrew e Eid 2005]. A agravar surge o facto do crescimento anual deste tipo de informação numa organização superar em muito aquele da informação estruturada. A IDC1 estima um crescimento anual de 21.8% de informação estruturada contra um crescimento de 61.7% de informação não estruturada ou semi-estruturada [IDC 2008].
No entanto, a grande maioria das soluções empresariais existentes focam-se somente em informação estruturada, tal como a existente em bases de dados, sendo que os meios de integração automatizada de outros tipos de informação são limitados ou inexistentes. Assim sendo, é necessária a introdução manual da informação, contida em diversos documentos da organização, em bases de dados, para que posteriormente possa ser integrada [Knox, Andrew e Eid 2005].
Estas implicações fazem com que o custo associado à integração de informação seja bastante elevado. Este processo é frequentemente considerado como o maior e mais dispendioso desafio a que as organizações têm que responder. A Gartner estima que cerca de 40% do orçamento de programação típico numa organização seja dedicado a tarefas de extracção de informação de fontes diversas e sua consolidação numa fonte comum [Gartner 2002].
Além das dificuldades monetárias e temporais associadas a este processo de integração, surgem outros entraves à possibilidade de, através de um único ponto de acesso, poder aceder aos diversos artefactos da organização, no seu estado mais actualizado e correcto, complicando a manutenção de um repositório arquitectural actualizado. A isto deve-se a existência de sistemas que são a autoridade da informação que contêm, como o exemplo de um catálogo aplicacional, que é especializado em lidar com informação de aplicações. Caso seja desejado obter a informação mais recente sobre uma aplicação é essencial que a consulta seja feita directamente à fonte original e não a um duplicado.
1
Assim sendo, de modo a se poder obter uma visão transversal da organização, surge a necessidade de cruzar a informação que estas detêm, sendo necessário um acesso directo a estas fontes para o conseguir. Tendo acesso directo à fonte, e a um meta-modelo que dite os relacionamentos possíveis entre os vários tipos de artefactos, será então possível manter um repositório arquitectural actualizado.
Este artigo visa então expor as dificuldades associadas à integração de informação de diversas fontes, distribuídas e heterogéneas, com a finalidade de manter um repositório arquitectural actualizado. Num contexto em que a localização de cada tipo de artefacto, bem como as relações possíveis entre estes, é conhecida, recorrendo a um meta-modelo para este efeito, será então proposta uma solução que lide com a automatização da integração de informação, estruturada e semi-estruturada, necessária para atingir o propósito enunciado.
2. Estruturação da Informação
A informação reside em diferentes formas, desde informação não-estruturada, que pode ser encontrada num qualquer ficheiro de um sistema de ficheiros, até informação altamente estruturada, tal como a que pode ser encontrada numa base de dados relacional.
No que diz respeito à forma como a informação é reside no seu meio digital, esta será de agora em diante categorizada em (1) Informação Estruturada, (2) Informação não Estruturada e (3) Informação semi-estruturada.
2.1. Informação não estruturada
A informação é considerada como não estruturada quando nenhum tipo de modelo que lhe permita atribuir significado, por meios digitais, se encontra presente. A informação encontrada no corpo de uma mensagem de correio electrónico ou em ficheiros de imagem, vídeo ou som, são exemplos de informação não estruturada.
2.2. Informação estruturada
Contrariamente à informação não estruturada, esta caracteriza-se por ser altamente provida de significado. Maioritariamente encontrada em bases de dados relacionais, este tipo de informação tem um esquema bem definido sendo possível identificar univocamente o seu significado e a sua relação com outra informação pertencente ao mesmo esquema.
2.3. Informação semi-estruturada
Enquanto os dois tipos de informação anteriores têm definições claras, a definição de informação semi-estruturada é mais susceptível a interpretações distintas. É facilmente reconhecido que existe informação que não se enquadra facilmente em nenhumas das categorias anteriores, sendo que se encontra situada entre as duas. Isto deve-se ao facto de a informação semi-estruturada se caracterizar por, embora não possuir um esquema rico que lhe forneça significado univocamente, ser munida de elementos que permitem a dedução de significados, sendo frequentemente designada como auto-descritiva [Buneman 1997].
Documentos escritos na linguagem XML são exemplos de possíveis fontes de informação semi-estruturada, dado que contêm meta-informação (etiquetas) que têm como propósito a atribuição de significado ao texto que encapsulam. No entanto, há que notar que o conceito de significado depende fortemente do ponto de vista de quem analisa a informação. Enquanto que para um browser a meta-informação presente num ficheiro escrito em HTML é utilizada para determinar como apresentar o conteúdo do ficheiro no ecrã, para um simples leitor de texto esta é vista
como qualquer outro conjunto de caracteres e apresentada indiscriminadamente no ecrã. Esta subjectividade está na origem da falta de uma clara definição de informação semi-estruturada, sendo que esta é muitas vezes categorizada como não estruturada.
Desde a adopção do XML como formato padrão para representação de documentos Office, principalmente desde a adopção do padrão Office OpenXML2, a leitura e processamento deste tipo de documentos tornou-se mais facilitada, tornando-os uma potencial fonte de informação, já que uma quantidade elevada de informação numa organização encontra-se sob a forma destes documentos.
3. Abordagens à integração de informação
As abordagens actuais à integração de informação podem ser divididas em dois grupos principais: (1) transformação ou materialização e (2) federação ou virtualização [Haas, Lin e Roth 2002] [Ziegler e Dittrich 2007] [Bernstein e Haas 2008].
3.1. Materialização
Esta abordagem, a mais vulgarmente utilizada, materializa a totalidade da informação integrada num repositório central novo. Uma vez que cada fonte pode ter um esquema distinto, são necessários efectuar esforços de modo a que a informação, após integrada, corresponda a um único esquema comum. É a abordagem utilizada na construção de Data Warehouses sendo esta construção frequentemente auxiliada pelo uso de ferramentas ETL (Extract, Transform, Load). Estas ferramentas são peças de software responsáveis pela extracção de informação de diversas fontes, o seu processamento e carregamento no repositório final, tipicamente uma Data Warehouse [Vassiliadis, Simitsis e Skiadopoulos 2002].
3.2. Virtualização
Enquanto que a abordagem anterior materializa toda a informação integrada num repositório único, na abordagem de virtualização a informação é apenas virtualmente integrada. As ferramentas que utilizam esta abordagem apresentam ao utilizador uma vista virtual da informação integrada, apesar de esta permanecer intacta na sua fonte de origem. Contrariamente à materialização em que, no momento da consulta, a informação já se encontra previamente integrada e no mesmo esquema, nesta abordagem a integração é feita programaticamente no momento da consulta, de modo a apresentar os resultados ao utilizador. Projectos como o TSIMMIS [Garcia-Molina, et al. 1995], HERMES [Adali, et al. 1996] e [Hohenstein e Plesser 1997] foram pioneiros na utilização desta abordagem.
4. Proposta de Solução
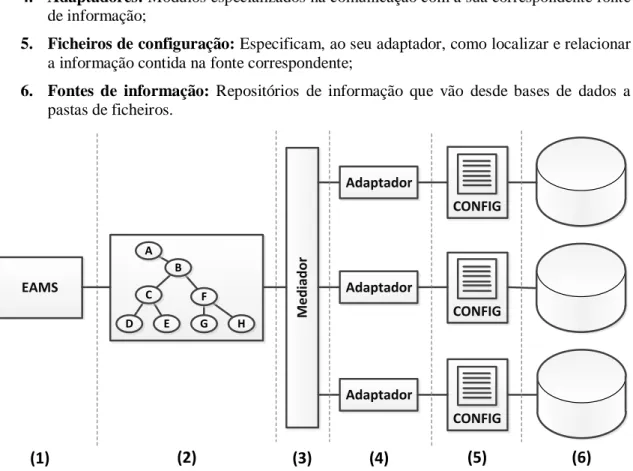
Nesta secção é então apresentada a arquitectura da solução proposta, que pretende responder ao problema previamente apresentado. Esta solução caracteriza-se por manter inalterada a localização original da informação, e por lidar com a heterogeneidade das diversas fontes de informação. A descentralização da solução é requerida já que é essencial a visualização da informação no seu estado mais actual, sendo então necessário aceder à fonte apenas no momento da consulta, garantido que será sempre obtida a informação mais recente. Isto é conseguido ao seguir uma abordagem de federação das fontes de informação, ou seja, através da utilização de um elemento mediador, o cliente consulta a informação directamente da fonte que
2
a contém. O mediador auxilia-se de adaptadores especializados para cada fonte, lidando assim com a heterogeneidade das diversas fontes.
Esta arquitectura é composta por seis componentes distintos (ver Figura 1):
1. EAMS3: Esta aplicação (Enterprise Architecture Management System), desenvolvida
pela Link Consulting, é uma solução tecnológica para Arquitecturas Empresariais;
2. Meta-modelo: Responsável por ditar quais os conceitos existentes e quais os
relacionamentos entre estes;
3. Mediador: Camada responsável por mediar a comunicação entre as diversas fontes de
informação e o núcleo da aplicação (EAMS);
4. Adaptadores: Módulos especializados na comunicação com a sua correspondente fonte
de informação;
5. Ficheiros de configuração: Especificam, ao seu adaptador, como localizar e relacionar
a informação contida na fonte correspondente;
6. Fontes de informação: Repositórios de informação que vão desde bases de dados a
pastas de ficheiros. (1) (2) (3) (4) (5) (6) EAMS A B C F E G D H M e d ia d o r Adaptador Adaptador Adaptador CONFIG CONFIG CONFIG
Figura 1 - Arquitectura da solução proposta
Os próximos tópicos dedicam-se a oferecer uma explicação mais detalhada dos diversos elementos que constituem a arquitectura desta solução.
4.1. EAMS
O EAMS é uma solução tecnológica para Arquitectura Empresarial, desenvolvida pela Link Consulting. Esta solução automatiza a geração e manutenção de diagramas ou modelos de arquitectura (blueprints). Na solução, esta aplicação terá o papel de cliente que irá consultar a informação após integrada.
3
4.2. Meta-modelo
Um meta-modelo pode ser usado numa tarefa de integração para descrever a semântica das várias fontes e da informação que estas contêm e tornar o conteúdo explícito [Wache, et al. 2001], ou seja, o meta-modelo surge nesta arquitectura como o elemento responsável por garantir a coerência entre os vários conceitos existentes nas diversas fontes.
Uma das responsabilidades do meta-modelo é especificar quais os conceitos existentes e qual a sua localização, ou seja, qual a fonte que deverá ser utilizada para a sua consulta. Além de especificar quais os conceitos existentes, o meta-modelo é responsável por ditar como estes se relacionam entre si, identificando e associando os conceitos semanticamente correspondentes.
4.3. Mediador
Um mediador é um módulo que tem o conhecimento necessário sobre vários conjuntos ou subconjuntos de informação de modo a consolida-los e transmitir a informação resultante para camadas mais elevadas da aplicação [Wiederhold 1992].
O papel do mediador pode ser visto como um tradutor entre o cliente (o EAMS neste caso) e os diversos adaptadores, partilhando uma interface com o cliente e outra com os diversos adaptadores. O mediador recebe pedidos de consulta de informação e, recorrendo ao meta-modelo para determinar qual a fonte correspondente, redirecciona o pedido para o adaptador adequado, realizando obviamente o processo inverso, após recebida a resposta do adaptador [Garcia-Molina, et al. 1995] [Adali, et al. 1996].
4.4. Adaptadores
Os adaptadores, também designados de tradutores ou wrappers [Garcia-Molina, et al. 1995] são componentes especializados na comunicação com a fonte de informação para a qual foram desenhados. Dado que cada adaptador é único para uma fonte, entre si, são apenas semelhantes no facto em que partilham uma interface com o mediador, ao qual respondem. A sua implementação em si é variada dada a heterogeneidade das fontes, podendo comunicar com estas através de consultas SQL, web-services, ou mesmo processando directamente o ficheiro (parsing), no caso de a fonte corresponder a ficheiros com informação semi-estruturada, como é o caso de documentos office. Uma vez que todos os adaptadores partilham uma interface com o mediador, torna-se possível a introdução de novos adaptadores previamente não planeados, com um esforço reduzido, tornando assim a solução escalável.
4.5. Ficheiros de configuração
Os ficheiros de configuração existem como forma de aumentar o nível de personalização que é possível associar a um adaptador, bem como reduzir a dependência que a solução tem sobre estes. Assim, é possível que um adaptador seja desenhado com o objectivo de ser especializado na comunicação com um determinado tipo de fonte (ex: Base de dados SQL) e não com instâncias (ex: Base de dados SQL ‗clientes‘). A responsabilidade da configuração de cada instância de uma fonte de informação cai então sobre estes elementos, sendo possível que um adaptador esteja associado a vários ficheiros de configuração, cada um com instruções específicas a cada instância da mesma fonte.
A relevância da existência destes elementos torna-se especialmente evidente no caso de um adaptador desenhado para leitura de documentos office: enquanto que existe apenas um adaptador para o efeito, com a existência destes ficheiros é possível configurar individualmente cada subconjunto de documentos (pastas por exemplo) que sigam uma estrutura semelhante.
4.6. Fontes de informação
Os vários repositórios dos quais se pretende consultar informação. Como já referido, a solução permite a heterogeneidade destes elementos, sendo que podem variar desde sistemas de informação que operam sobre bases de dados relacionais até documentos de texto.
5. Resultados
Até à data foram conseguidos resultados positivos na integração de três fontes de informação, sendo que uma contém informação estruturada e as outras duas contêm informação semi-estruturada:
IBM Rational System Architect Documentos XML
Documentos Office OpenXML
5.1. IBM Rational System Architect
A primeira fonte a ser integrada foi o IBM Rational System Architect, sendo esta a fonte de informação estruturada.
Esta ferramenta disponibiliza uma API própria para acesso à informação que gere. São disponibilizados métodos para obtenção dos conceitos, instâncias e propriedades, entre outros. Como tal foi utilizada a API disponibilizada como método de acesso à informação disponibilizada por esta fonte.
5.2. Documentos XML
De seguida, foram escolhidos documentos XML como fonte de informação. Existem várias razões que justificam a existência de informação neste suporte. Com a crescente popularidade deste formato, tem-se registado um aumento significativo na quantidade de informação disponibilizada neste formato, desde documentos isolados a repositórios de documentos XML. São também frequentemente utilizados como elementos intermédios na integração de informação proveniente de sistemas legados [Coyle 2000]. É de notar que esta secção diz respeito a documentos escritos em XML cuja meta-informação explicita directamente o significado da informação contida, contrariamente a documentos escritos nesta linguagem mas cuja meta-informação, embora auxilie, não é suficiente para inferir a semântica da informação (secção 5.3).
Figura 2 – Exemplo de informação contida num documento XML
5.3. Documentos Word
Neste último caso, a fonte de informação consiste numa colectânea de documentos escritos segundo o padrão Office OpenXML. É frequente a utilização destes documentos como forma de especificação de requisitos, interfaces, stakeholders, etc. Contrariamente ao caso anterior, em que a meta-informação especifica directamente o significado da informação contida, neste caso é necessário o auxílio de outros elementos para poder fazê-lo. A meta-informação presente nestes documentos é sobretudo direccionada para leitura por parte de software de edição/visualização. Contém a informação necessária para estruturar correctamente o documento, especificando quais os parágrafos, tipos de letra, estilos de texto, indentações, entre muitos. A Figura 3 representa um exemplo simplificado de um documento escrito neste formato.
Figura 3 – Exemplo simplificado de um documento escrito segundo o padrão Office OpenXML1 @"<?xml version=""1.0"" encoding=""UTF-8"" standalone=""yes""?>
<w:document xmlns:w=""http://schemas.openxmlformats.org/wordprocessingml/2 006/main""> <w:body> <w:p> <w:r> <w:t>Hello world!</w:t> </w:r> </w:p> </w:body> </w:document> <Repository> ...
<DataType Name=”Stakeholder” Uid=”175”> <DataType_Properties>
...
</DataType_Properties> <DataInstances>
<DataInstance Name=”Customer” Uid=”517” DataType=”Stakeholder” ...> <DataInstance_Property ... /> <DataInstance_Property ... /> ... <DataInstance> </DataInstances> </DataType> ... </Repository>
A meta-informação nestes documentos é no entanto também útil na perspectiva desta solução de integração. Elementos como os estilos de texto, numerações, tipos e tamanhos de letra, etc, em conjugação com características textuais, permitem a configuração de vários documentos através dos ficheiros de configuração. A Figura 4 representa um excerto de um documento, onde se pode ver a especificação de alguns requisitos.
As possibilidades de configuração deste excerto de modo a integrar a sua informação são diversas. Por exemplo:
Consideram-se instâncias do conceito ―Requisito‖:
Todos os blocos de texto numerados, cujo valor de numeração é descendente de ―3‖; Todos os blocos de texto numerados, que sucedem o bloco de texto com valor
―Requisitos‖
Todos os blocos de texto numerados, que sucedem o bloco de texto numerado, com estilo de texto ―Heading1‖ e com valor ―Requisitos‖
Verifica-se então que as possibilidades de configuração deste adaptador são bastante diversas, sendo possível uma configuração ajustada às necessidades de cada organização, sem que para tal seja necessário modificar o adaptador.
Figura 4 – Excerto de um documento Word
6. Conclusões
A necessidade da existência de um meio que possibilite a manutenção de um repositório arquitectural actualizado, com esforços de integração reduzidos, surge da necessidade, por parte de uma ferramenta de arquitecturas empresárias, em poder utilizar informação o mais correcta e
(…)
3. Requisitos
3.1 Os arquivos de dados permanecerão disponíveis para serem transportados via FTP pela Empresa por um período de tempo específico, conforme determinação da Empresa. A empresa será responsável por retirar os arquivos via FTP do diretório definido pela empresa.
3.2 Com relação aos arquivos de dados, a Empresa será responsável por: (…)
3.3. A Empresa será responsável por disponibilizar o espaço em disco necessário para armazenar os arquivos de interface pelo período de retenção.
3.4 Aumento de espaço em disco se vê necessário para se implementar as interfaces de serviço de terceiros para que não impactem outras funcionalidades do sistema.
3.5 Os arquivos deverão ser disponibilizados nas máquinas de FTP zipados (Gzip). A Empresa será responsável por retirar os arquivos zipados via FTP do diretório.
fiel à realidade da organização, de modo a contribuir para o seu sucesso. Para o conseguir surge então a necessidade em integrar a informação, em tempo real, das várias fontes existentes na organização.
Após realizado o estudo de diversas abordagens que lidam com a integração de informação, foi feita uma análise das características de cada uma que se adequam à resolução do problema aqui apresentado. Entre estas, a necessidade de aceder sempre à informação no seu estado mais actualizado foi fundamental na adopção de uma abordagem de virtualização do repositório. Igualmente relevante foi a adopção de meios que permitissem a configuração dos adaptadores, reduzindo a dependência da implementação, possibilitando assim uma adaptação, com esforços reduzidos, às necessidades específicas de cada fonte.
Os resultados conseguidos até à data são satisfatórios na medida em que foi conseguida a implementação da solução proposta, tendo sido integrada informação de fontes distintas (System Architect, Documentos XML e Documentos Word). A solução correspondeu às espectativas ao ser capaz de lidar simultaneamente com informação estruturada e semi-estruturada, possibilitando a manutenção de um repositório actualizado com informação oriunda de fontes cujo suporte (do ponto de vista da integração) é, até à data, limitado.
De momento encontramo-nos a proceder à criação de uma base de conhecimento constituída por informação retirada de centenas de documentos office com informação referente a diversas empresas reais, sendo que a nossa ambição é conseguir maximizar a automatização da integração destes documentos através do melhoramento das possibilidades de configuração do correspondente adaptador.
Referências
Abiteboul, Serge. "Querying Semi-Structured Data." Database Theory, 1997: 1-18.
Adali, S., Candan, K. S., Papakonstantinou, Y., and Subrahmanian, V. S. "Query caching and optimization in distributed mediator systems." Proceedings of the 1996 ACM SIGMOD international conference on Management of data. New York: ACM, 1996.
Bernstein, Philip A., and Haas, Laura M. "Information Integration in the Enterprise." Commun. ACM [ACM] 51, no. 9 [2008]: 72-79.
Buneman, Peter. "Semistructured data." Proceedings of the sixteenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems. New York: ACM, 1997. Coyle, FP. "Legacy Integration: Changing Perspectives." IEEE Software, 2000: 37-41.
Doan, AnHai, and Halevy, Alon Y. "Semantic Integration Research in the Database Community: A Brief Survey." AI magazine, 2005.
Gantz, John F. The Diverse and Exploding Digital Universe. IDC, 2008.
Garcia-Molina, Hector, Hammer, Joachim, Ireland, Kelly, Papakonstantinou, Yannis, Ullman, Jeffrey, and Widom, Jennifer. "Integrating and Accessing Heterogeneous Information Sources in TSIMMIS." Proceedings of the AAAI Symposium on Information Gathering. Stanford: AAAI Press, 1995. 61-64.
Gartner. Cutting Implementation Costs by Application Integration. Gartner, 2002.
Haas, L. M., Lin, E. T., and Roth, M. A. Data integration through database federation. IBM, 2002.
Hohenstein, Uwe, and Plesser, Volkmar. "A generative approach to database federation." Lecture Notes in Computer Science 1331/1997 [1997]: 422-435.
IDC. Enterprise Disk Storage Consumption Model: Analytics and Content Depots Provide A New Perspective on the Future of Storage Solutions. IDC, 2008.
James, G. A., and Handler, Robert A. Magic Quadrant for Enterprise Architecture Tools. Gartner, 2008.
Jhingran, A. D., et al. "Information integration: A research agenda." IBM Systems Journal [IBM] 41, no. 4 [2002].
Knox, Rita E., Andrew, White, and Eid, Tom. Management Update: Companies Should Align Their Structured and Unstructured Data. Gartner Research, 2005.
Op't Land, Martin, Proper, Erik, Waage, Maarten, Cloo, Jeroen, and Steghuis, Claudia. Enterprise Architecture: Creating Value by Informed Governance. Berlin-Heidelberg: Springer-Verlag, 2008.
Sampaio, André. An Approach for Creating and Managing Enterprise Blueprints. IST UTL, 2010.
Schekkerman, J. Schekkerman. "Enterprise Architecture Tool Selection Guide v6.0." Institute for Enterprise Architecture Developments. 2011. http://www.enterprise-architecture.info/Images/EA%20Tools/Enterprise%20Architecture%20Tool%20Selecti on%20Guide%20v6.0.pdf.
Sukumaran, Sreekumar, and Sureka, Ashish. "Integrating Structured and Unstructured Data Using Text Tagging and Annotation." 2007.
Tapscott, Don, and Elmore, Steve. Managing Enterprise Information: Architecting for Survival and Positioning for Success in Tough Times. nGenera Corporation, 2009.
Vassiliadis, Panos, Simitsis, Alkis, and Skiadopoulos, Spiros. "Conceptual Modeling for ETL Processes." Proceedings of the 5th ACM international workshop on Data Warehousing and OLAP. New York: ACM, 2002.
Wache, H., et al. "Ontology-Based Integration of Information - A Survey of Existing Approaches." Proceedings of IJCAI-01 Workshop: Ontologies and Information Sharing. Seattle, 2001. 108-117.
Wang, Zhiming, et al. "An Evaluation of Multiple Approaches For Database Federation in Life Science." 2008.
Wiederhold, Gio. "Mediators in the architecture of future information systems." Computer, 1992: 38 - 49.
Ziegler, Patrick, and Dittrich, Klaus R. "Data Integration — Problems, Approaches, and Perspectives." 2007.