Planning and Verification of Multipath Routing Protocols
Texto
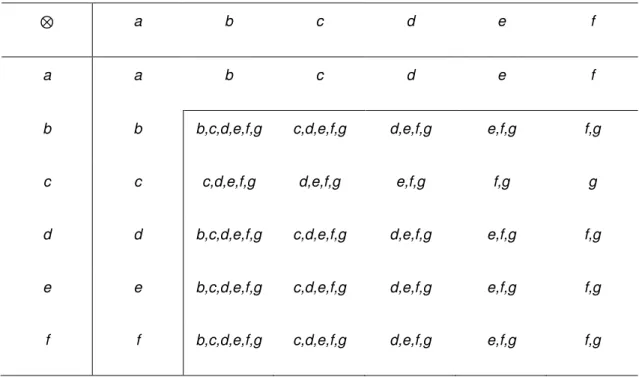
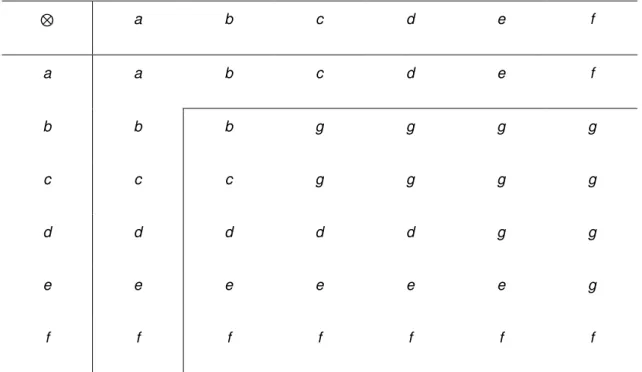
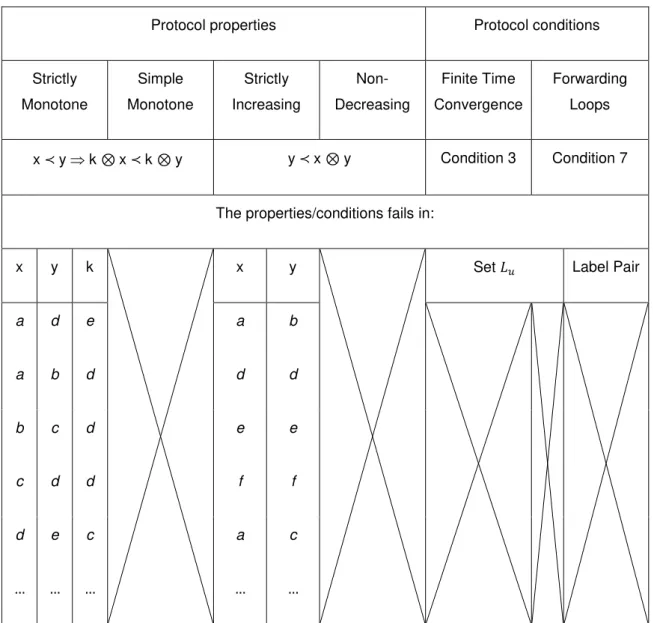
Imagem

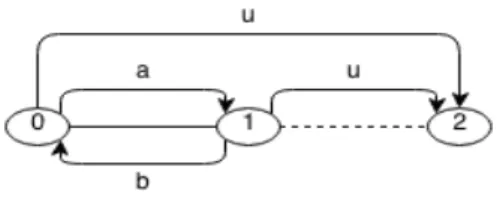
![Figure 2.2: Free cycle illustration [1].](https://thumb-eu.123doks.com/thumbv2/123dok_br/16576682.738303/49.892.313.581.313.605/figure-free-cycle-illustration.webp)

Documentos relacionados
We demonstrated this by proposing a simulation based framework for on-demand source routing protocols that allows us to give a precise definition of routing security, to model the
In reactive routing protocols the routes are created only when source wants to send data to destination whereas proactive routing protocols are table driven.. Being a
The Energy consumption network is used to measure the amount of energy consumed by each node in a network using the different location aware routing protocols (SVR, LAR-1, LAR-2,
Then the routing paths are selected by connecting all the cluster head nodes using the minimum spanning tree with degree constraint that minimizes the energy consumption for
These approaches vary from source routing approaches, where the entire path towards the destination is pre-computed by the data source, to the dynamic routing
The results are verified for the reactive routing protocols such as Dynamic Source Routing protocol (DSR) and Adhoc on demand distance vector routing protocol (AODV) and they
In Case 1, i,e., for high level of security ( sec_ level = 1), during routing process, the source and destination nodes separately verify the authenticity of all other nodes in
Earlier on-demand routing protocols[3,4,5,6,7] were based on flooding the routing packets in all directions irrespective of the location of the destination node, resulting
