Universidade de Aveiro Departamento deElectrónica, Telecomunicações e Informática, 2011
Nuno Filipe
Vieira dos Santos
Armazenamento de Contexto com NoSQL
Context Storage Using NoSQL
Universidade de Aveiro Departamento deElectrónica, Telecomunicações e Informática, 2011
Nuno Filipe
Vieira dos Santos
Armazenamento de Contexto com NoSQL
Context Storage Using NoSQL
dissertação apresentada à Universidade de Aveiro para cumprimento dos req-uisitos necessários à obtenção do grau de Mestre em Engenharia de Com-putadores e Telemática, realizada sob a orientação científica do Dr. Diogo Nuno Pereira Gomes, Assistente Convidado do Departamento de Electrónica, Telecomunicações e Informática da Universidade de Aveiro, e do Mestre Ós-car Narciso Mortágua Pereira, Assistente Convidado do Departamento de Electrónica, Telecomunicações e Informática da Universidade de Aveiro
o júri / the jury
presidente / president Prof. Dr. Rui Luis Andrade Aguiar
Professor Associado da Universidade de Aveiro
vogais / examiners committee Prof. Dra. Maribel Yasmina Campos Alves Santos
Professora Auxiliar do Dep. de Sistemas de Informação da
Escola de Engenharia da Universidade do Minho (Arguente Principal)
Dr. Diogo Nuno Pereira Gomes
Assistente Convidado da Universidade de Aveiro (Orientador)
Mestre Óscar Narciso Mortágua Pereira
palavras-chave contexto, xmpp, bases de dados, nosql, couchdb
resumo O presente trabalho propõe o uso de uma nova geração de bases de dados, denominadas NoSQL, para o armazenamento e gestão de in-formação de contexto, assente numa arquitectura de gestão contexto baseada em XCoA (XMPP-based Context Architecture). Nesta ar-quitectura de gestão de contexto toda a informação de contexto é publicada num componente central, denominado Context Broker, e ar-mazenada para posterior requisição, processamento e análise. Dado o elevado volume de informação de contexto publicada, as bases de dados tradicionais rapidamente apresentam limitações de desempenho, que por sua vez poem em causa a eficiência do funcionamento do pro-tocolo XMPP; pelo contrário, as bases de dados NoSQL apresentam serias melhorias de desempenho na gestão de bases de dados de grande dimensão. Este trabalho estuda várias soluções NoSQL existentes, e apresenta as vantagens e desvantagens do uso de uma solução especí-fica neste tipo de problema.
keywords context, xmpp, databases, nosql, couchdb
abstract This thesis proposes the usage of an upcoming new breed of databases, called NoSQL, for the storage and management of context information, in a context management architecture based on XCoA (XMPP-based Context Architecture). In this context management architecture all context information is published on a central component called Con-text Broker, and stored for further requisition, processing and analysis. Due to the high number of published context data, traditional data-bases quickly develop serious performance limitations, which in turn may jeopardize the XMPP protocol’s efficiency; alternatively, NoSQL databases show serious performance improvements in the storage and management of large-scale data sets. This thesis presents a study of the several available NoSQL solutions, and presents the advantages and disadvantages of the usage of a specific solution in this type of problem.
Contents
Contents i
List of Figures v
List of Tables vii
List of Acronyms ix
1 Introduction 1
2 State of the Art 3
2.1 Context . . . 3
2.2 Context Management Platforms . . . 4
2.2.1 MobiLife . . . 4
2.2.2 C-Cast . . . 5
2.2.3 XCoA: XMPP-based Context Architecture . . . 7
2.3 Large-Scale Data Management Systems . . . 9
2.3.1 Relational Database Management Systems (RDBMS) . . . 10
2.3.1.1 Replication . . . 11 2.3.1.1.1 Master-Slave Replication . . . 11 2.3.1.1.2 Multi-Master Replication . . . 11 2.3.1.2 Sharding . . . 12 2.3.1.3 ACID Properties . . . 12 2.3.1.4 Strong Consistency . . . 13 2.3.2 NoSQL . . . 13
2.3.2.1 Replication and Sharding . . . 15
2.3.2.2 Eventual Consistency . . . 16
2.3.2.3 Multiversion Concurrency Control . . . 16
2.3.2.4 ACID Properties . . . 18
2.3.2.5 Map/Reduce . . . 18
2.3.2.6 Key-Value Store Storage Systems . . . 18
2.3.2.6.1 Amazon Dynamo . . . 19
2.3.2.6.2 Riak . . . 20
2.3.2.7 Wide Column Store / Column Oriented Storage Systems 21 2.3.2.7.1 Cassandra . . . 22
2.3.2.7.2 Apache HBase . . . 23
2.3.2.8 Document-Oriented Storage Systems . . . 24
2.3.2.8.1 MongoDB . . . 25
2.3.2.8.2 CouchDB . . . 26
2.3.2.8.3 MongoDB / CouchDB Comparison . . . 30
3 Context Management and Storage 33 3.1 Why NoSQL? . . . 34
3.2 Why CouchDB? . . . 35
3.3 Full-Text Searching . . . 36
3.4 Architecture . . . 38
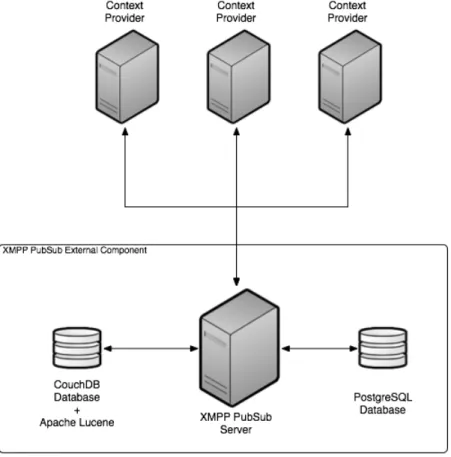
3.4.1 Architecture 1: Single PubSub + CouchDB + Lucene node . . . . 39
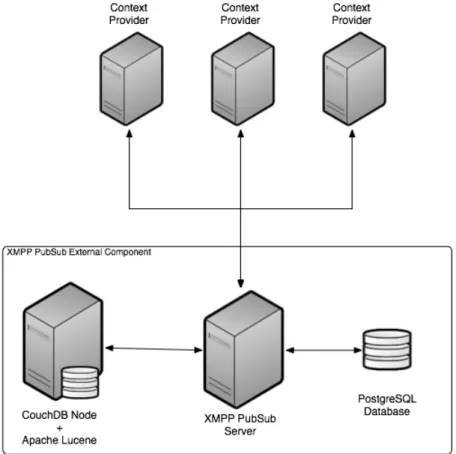
3.4.2 Architecture 2: Separate CouchDB + Lucene node . . . 40
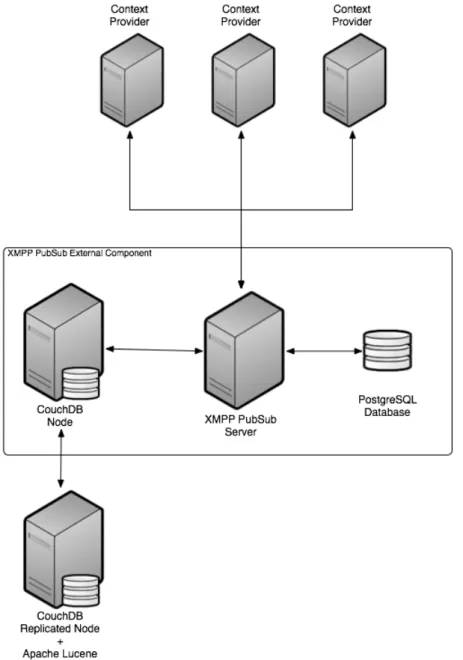
3.4.3 Architecture 3: Single replicated CouchDB + Lucene node . . . . 41
3.4.4 Architecture 4: CouchDB cluster with a Load-Balancer . . . 43
3.4.5 Architecture 5: CouchDB sharded cluster . . . 45
4 Prototype 47 4.1 Prototype considerations and objectives . . . 47
4.2 Libraries and Frameworks . . . 48
4.2.1 Twisted Networking Framework . . . 48
4.2.2 Wokkel . . . 48
4.3 Idavoll . . . 49
4.4 Iteration 1: Pure NoSQL Solution . . . 50
4.5 Iteration 2: NoSQL Items-only with JSON context data . . . 58
4.6 Iteration 3: NoSQL Items-only with XML document attachments . . . . 60
4.7 Iteration 4: NoSQL Items-only with XML document string . . . 62
4.8 Implemented Features . . . 67
4.8.1 CouchDB Storage-Engine . . . 67
4.8.2 PostgreSQL / CouchDB Hybrid Storage-Engine . . . 68
4.8.3 XMPP PubSub Collection Nodes (XEP-0248) . . . 69
4.8.3.1 Collection Nodes: PostgreSQL . . . 70
4.8.3.1.1 Adjacency List . . . 70
4.8.3.1.2 Nested Sets . . . 71
4.8.3.1.3 Selected Model . . . 72
4.8.3.2 Collection Nodes: CouchDB . . . 72
4.8.4 XMPP Service Discovery (XEP-0030) . . . 73
4.8.5 XMPP Publish-Susbcribe (XEP-0060): New Use Cases . . . 74
4.8.5.1 Configure Node . . . 74
4.8.5.2 Retrieve Subscriptions . . . 74
4.8.5.3 Modify Affiliation . . . 74
4.8.5.4 Retrieve Affiliations List . . . 74
4.9 Idavoll Web Interface . . . 75
5 Results 79 5.1 Performance Tests . . . 79
5.1.1 PostgreSQL: Nested Sets vs Adjacency List Model . . . 79
5.1.1.1 Nodes Database Structure . . . 79
5.1.1.2 Test Environment . . . 80
5.1.1.3 Dataset . . . 80
5.1.1.4 Tests . . . 81
5.1.1.4.1 Retrieving Direct Descendants . . . 81
5.1.1.4.2 Retrieving All Ancestors . . . 84
5.1.1.5 Nested Sets vs Adjacency List: Conclusions . . . 88
5.1.2 PostgreSQL vs CouchDB: Item Insertion (Publishing) . . . 88
5.1.2.1 Items Database Structure . . . 88
5.1.2.2 Test Environment . . . 89 5.1.2.3 Dataset . . . 89 5.1.2.4 Tests . . . 90 5.1.2.4.1 Sequential Inserts . . . 90 5.1.2.4.2 Batch Inserts . . . 92 5.1.2.5 Conclusions . . . 93
5.1.3 PostgreSQL vs CouchDB: Item Retrieval . . . 94
5.1.3.1 Items Database Structure . . . 94
5.1.3.2 Test Environment . . . 95
5.1.3.3 Dataset . . . 95
5.1.3.4 Tests . . . 95
5.1.3.5 Conclusions . . . 97
5.1.4 PostgreSQL vs CouchDB: Item Search . . . 97
5.1.4.1 Items Database Structure . . . 97
5.1.4.2 Test Environment . . . 98 5.1.4.3 Dataset . . . 99 5.1.4.4 Tests . . . 99 5.1.4.5 Conclusions . . . 101 5.2 Final Notes . . . 101 6 Conclusion 103 6.1 Scalability, Availability and Reliability . . . 103
6.2 Searching . . . 104
6.3 Performance . . . 104
6.4 Common Pitfalls . . . 105
6.5 NoSQL Ecosystem and Future Direction . . . 106
List of Figures
2.1 KeyFunctions of the Context Management Framework . . . 5
2.2 C-Cast Context Management Architecture & Functional Entities . . . 6
2.3 XCoA Architecture . . . 8
2.4 Creation of a conflict in a database with MVCC . . . 17
2.5 Riak Cluster Architecture . . . 20
2.6 Twitter’s data model: User_URLs . . . 23
2.7 HBase Conceptual View . . . 23
2.8 MongoDB Schema Example . . . 25
3.1 Architecture 1 – Single XMPP PubSub + CouchDB + Lucene node archi-tecture . . . 39
3.2 Architecture 2 – Single CouchDB + Lucene node architecture . . . 40
3.3 Architecture 3 – separate CouchDB replicated node with Lucene . . . 41
3.4 Architecture 4 – CouchDB replicated cluster . . . 43
3.5 Architecture 5 – CouchDB sharded cluster . . . 45
4.1 XMPP Publish-Susbcribe Data Model Relations, as implemented in Idavoll 50 4.2 Pure NoSQL: JSON Node . . . 51
4.3 Pure NoSQL: JSON Entity . . . 51
4.4 Pure NoSQL: JSON Affiliation . . . 51
4.5 Pure NoSQL: JSON Subscription . . . 51
4.6 Pure NoSQL: JSON Item . . . 52
4.7 Pure NoSQL: JSON Collection Node Tree . . . 52
4.8 Pure NoSQL: Example of a node collection tree . . . 53
4.9 XML for GPS context information . . . 53
4.10 Possible JSON for GPS context information . . . 54
4.11 JSON for GPS context information, without losing attributes . . . 55
4.12 SQL+NoSQL Hybrid: JSON Item with Attachment . . . 62
4.13 JSON document with context data as an XML string . . . 64
4.14 couchdb-lucene indexing javascript function . . . 65
4.15 couchdb-lucene query result . . . 66
4.16 couchdb-lucene query result row . . . 66
4.17 "Joe Celko’s Trees and hierarchies in SQL for smarties": Adjacency List 70 4.18 "Joe Celko’s Trees and hierarchies in SQL for smarties": Nested Sets . . 71
4.19 Example of a node collection tree in JSON . . . 73
4.20 Idavoll Web Interface: Start Page . . . 76
4.21 Idavoll Web Interface: Item Search (using Apache Lucene) . . . 77
4.22 Idavoll Web Interface: Item Details . . . 78
4.23 Idavoll Web Interface: Subscriptions, filtered by Entity . . . 78
5.1 Retrieving direct descendants using an adjacency list . . . 82
5.2 Retrieving direct descendants using nested sets . . . 83
5.3 Retrieving direct descendants using nested sets: complexity . . . 84
5.4 Retrieving all ancestors using an adjacency list . . . 86
5.5 Retrieving all ancestors using nested sets . . . 87
5.6 PostgreSQL vs CouchDB Item Insertion: CouchDB Item document structure 89 5.7 Sequential Inserts: Average Insertion Time, PostgreSQL . . . 91
5.8 Sequential Inserts: Average Insertion Time, CouchDB . . . 91
5.9 PostgreSQL vs CouchDB: Average Batch Insertion Speeds . . . 93
5.10 PostgreSQL vs CouchDB Item Retrieval: CouchDB Item document structure 94 5.11 PostgreSQL vs CouchDB Item Retrieval: Average Access Times . . . 96
5.12 PostgreSQL vs CouchDB Item Search: CouchDB Item document structure 98 5.13 PostgreSQL vs CouchDB Item Search: Apache Lucene indexing function 98 5.14 PostgreSQL vs CouchDB Item Search: Average Searching Times (indexed, unindexed PostgreSQL and CouchDB / Lucene) . . . 100
5.15 PostgreSQL vs CouchDB Item Search: Average Searching Times (indexed PostgreSQL and CouchDB / Lucene) . . . 101
List of Tables
2.1 List of distributable and not-distributable NoSQL databases . . . 15
4.1 XMPP Publish-Subscribe Data Model, as implemented in Idavoll . . . . 50
4.2 Example of a deployed Idavoll data structure . . . 58
5.1 PostgreSQL Nested Sets vs Adjacency List: Nodes Data Structure . . . . 80
5.2 PostgreSQL Nested Sets vs Adjacency List: Test Environment . . . 80
5.3 PostgreSQL Nested Sets vs Adjacency List: Test Results . . . 88
5.4 PostgreSQL vs CouchDB Item Insertion: Items Data Structure . . . 89
5.5 PostgreSQL vs CouchDB Item Insertion: Test Environment . . . 89
5.6 PostgreSQL vs CouchDB: Sequential Insertion Throughput . . . 90
5.7 PostgreSQL vs CouchDB: Batch Insertion Throughput . . . 92
5.8 PostgreSQL vs CouchDB Item Retrieval: Items Data Structure . . . 94
5.9 PostgreSQL vs CouchDB Item Retrieval: Test Environment . . . 95
5.10 PostgreSQL vs CouchDB Item Retrieval: Dataset . . . 95
5.11 PostgreSQL vs CouchDB Item Retrieval: Test Results . . . 96
5.12 PostgreSQL vs CouchDB Item Search: Items Table Structure . . . 97
5.13 PostgreSQL vs CouchDB Item Search: Test Environment . . . 98
List of Acronyms
ACID Atomicity, Consistency, Isolation, Durability API Application Programming Interface
BSON Binary Javascript Object Notation CB Context Broker
CC Context Consumer CP Context Provider
CPU Central Processing Unit DB Database
DNS Domain Name System GPL GNU General Public License GPS Global Positioning System HTTP Hypertext Transfer Protocol IBM International Business Machines JID Jabber ID
JSON Javascript Object Notation LZW Lempel–Ziv–Welch
MVCC Multiversion Concurrency Control OTP Open Telecom Platform
POSIX Portable Operating System Interface for Unix RDBMS Relational Database Management System REST Representational State Transfer
SQL Structured Query Language URI Uniform Resource Identifier URL Uniform Resource Locator
XCoA XMPP-based Context Architecture XEP XMPP Extension Protocol
Chapter 1
Introduction
With the ubiquity and pervasiveness of mobile computing, together with the increasing number of social networks, end-users have learned to live and share all kinds of information about themselves. For example, Facebook reports that it has currently 500 million active users, 200 million of which access its services on mobile systems; moreover, users that access Facebook through mobile applications are twice as active as non-mobile users, and it is used by 200 mobile operators in 60 countries [1]. More specific mobile platforms such as Foursquare, which unlike Facebook only collects location information, reports 6.5 million users worldwide, and also has a mobile presence (both with a web application and iPhone / Android applications) [2]. Context-aware architectures intend to explore this increasing number of context information sources and provide richer, targeted services to end-users, while also taking into account arising privacy issues.
While multiple context management platform architectures have been devised [3], this thesis focuses primarily on Context-Broker-based architectures, such as the ones proposed in the EU-funded projects Mobilife [4] and C-Cast [5]. More specifically, it focuses on the context management platform XCoA [6]. This platform uses XMPP as its main communication protocol, and publishes context information in a Context Broker. This context information is provided by Context-Agents, such as mobile terminals and social networks. Due to the nature of the XMPP protocol, the context information is provided in XML form.
This thesis proposes the usage of a NoSQL storage system in an XMPP broker-based context platform such as XCoA, together with a full-text searching engine. The usage of a NoSQL storage systems allows for better performance, availability and reliability. Moreover, integration with a full-text searching engine would allow extensive searching and data processing on the context information.
Chapter 2
State of the Art
2.1
Context
Before describing existing Context Management Platforms, we should define exactly what is "Context".
One of the first (if not the first) definition of Context-Aware applications was given by Schilit and Theimer [7] as being the ability of a mobile user’s applications to discover and adapt to the environment it is situated in. Hull [8] also describes context-awareness (or situation-awareness) as the ability of computing devices to detect, adapt and respond to changes in the user’s local environment, in a setting of wearable devices.
Perhaps a more generic definition would be the one given by Dey and Abowd [9]: any information that can be used to characterize the situation of an entity (a person, place, or object) that is considered relevant to the interaction between a user and an application, including the user and applications themselves.
There can be several types of context. For example, a user’s present location can be considered Location Context, while a user’s Facebook friends can be considered Social Context.
Some types of context have an associated timeframe. If we have an information about a user’s Location Context that is one day old, we can assume it may already be outdated and incorrect; meanwhile, the user’s Social Context may have not been changed, and can be assumed to be correct.
Why is context information important? Context-aware social networks are becoming increasingly more important. Facebook, Gowalla and Foursquare, which collect social preferences and location context information, have proved end-users are willing to share information. Moreover, context-aware information has the potential to enable targeted services to be delivered, according to the user’s context, provided such information is properly collected and stored, while taking into account privacy issues arising from such scenarios.
The concept of Internet-of-Things, or IoT, also refers to the importance of context information, although with different names and different approaches. In the IoT concept, every-day objects have a virtual representation, and are addressable, using for example RFID tags. These objects collect context information, can communicate with each other
and provide reasoning on the collected context information. The IoT concept focuses more on every-day objects and real-world scenarios, unlike the Context Management Platforms discussed in this dissertation, which although also deal with sensors, focus more on web context sources such as social networks. However, the IoT presents to a much larger scale, possibly city-wide or country-wide scale. At this scale, scalability becomes a much greater concern, and scalability approaches discussed in this dissertation also apply to it. In Context Management Platforms it becomes, then, essential the existence of a cen-tralized and heterogenous platform that enables the collection of context information, the storage of that same context information, and provide mechanisms to allow the proper reasoning and interpretation of context information, providing users with richer services. This heterogeneity refers to the multitude of existing context sources, all with their par-ticular data access models, all of which must coexist in the same repository. As this information will be accessed by actuators, which will use it to provide better services to users, the centralization of the information brings obvious benefits to these actuators, as all context information is accessed in a central location.
The following section presents a brief state-of-the-art in Context Management Plat-forms, as well as large-scale storage systems, required to handle and store large volumes of context information.
2.2
Context Management Platforms
This thesis is based on the XCoA, or XMPP-based Context Architecture, an XMPP broker-based context platform, first devised by D. Gomes et al. [6]. This platform represents an iterative evolution from previous broker-based architectures, trying to better understand their limitations and solve some of the problems found. The following two European Projects implemented such broker-based architectures, first MobiLife, with a "no-persistent-context" approach, then followed by C-Cast. Finally the XCoA platform tries to build upon these approaches and evolve them to a more efficient solution.
2.2.1
MobiLife
The MobiLife project aimed to "bring advances in mobile applications and services within the reach of users in their everyday life" [4], providing context-aware services. It devised a new Context Management Framework to handle the context information, and allow context acquisition and reasoning. This Context Management Platform or Frame-work is broker-based, and based on the producer-consumer principle. The architecture is shown in figure 2.1.
In MobiLife the Context Provider is the main component; it is responsible for produc-ing context information, either from internal or external context sources. It exposes inter-faces for communication with the Context Consumers, and to other Context Providers. The Providers also publish the context information in a Context Broker, which the Con-sumers can then inspect.
The Context Broker is the component responsible for publishing the location and interfaces of all Context Providers, which the Consumers can then use to interact with the desired Providers. This Broker is not responsible for mediating access between the
Figure 2.1: KeyFunctions of the Context Management Framework [4, p. 2]
Providers and the Consumers; instead, it publishes the Context Providers’ location and interface information, which the Consumers then use to communicate directly with the Providers. MobiLife’s architecture allows only for synchronous request / response context queries, not supporting asynchronous request models.
The Broker in this architecture assumes, then, more of a passive role, being mainly a registration and lookup service. This is unlike other architectures, where the Broker assumes an active, central role.
Context representation is achieved through the usage of the XML format, as it allows for easy human inspection, extension, validation and integration with existing develop-ment facilities and tools.
One important characteristic of this architecture, is that it does not persistently store all context information, with the rationale that "that would be almost the same as caching all the data that is routed over a server in the Internet" [10]. Some data may be stored or cached, but only in the Context Providers, as decided by them, but never stored in the Context Broker.
2.2.2
C-Cast
C-Cast was an European Project, whose main objective was to "evolve mobile multi-casting to exploit the increasing integration of mobile devices with out everyday physical world and environment" [11]. It was based on two main competence areas: development of context awareness and multicasting technologies.
It devised a possibly-distributed broker-based architecture, based on the producer-consumer model. The architecture is shown in figure 2.2.
Figure 2.2: C-Cast Context Management Architecture & Functional Entities [5, p. 3]
(CP) , and Context Consumers (CC) [12, p. 13].
The central piece of this architecture is the Context Broker, which is responsible for managing the relationship between the Providers and the Consumers. It is the main han-dler of context information, and performs context information lookup and discoverability operations, keeps a persistent log of context information, which is basically a log of all context information exchanged between the Broker and the Providers, and a persistent context Cache, with the most up-to-date context information. This is unlike MobiLife’s approach, which stored no context information (although some information might be cached in the Providers, at its discretion).
The Context Providers are the components responsible for collecting context infor-mation from the various context sources. They may also provide data aggregation and inference, based on their internal logic. They also provide methods for on-demand query-ing and subscription mechanisms, to allow for subscription-based notifications. Context reasoning and interpretation is also embedded in the Providers, deriving high-level con-text information abstractions, which requires inter-CP interaction.
Context Consumers are, as the name implies, the consumers of the context informa-tion, as provided and aggregated by the CPs. They are also the actuators, which interpret the context information and perform actions according to this information. The context information can be retrieved on an event-base (with subscriptions), or on an as-needed query base, with request / response messages. Some architecture components, such as Providers or Service Enablers, can also assume the role of Context Consumers.
This architecture developed a new document format for representing context: Con-textML. ContextML is based on the XML format, and allows the representation of the type, scope, metadata and validity of the context information.
Persistent storage of context information was achieved with an Oracle relational data-base, with the translation of the context structures to the relational model, where every new context type would generate a new database table. This made the creation of new context types difficult, as they required a change (a new table) in the data model.
2.2.3
XCoA: XMPP-based Context Architecture
XCoA, or XMPP-based Context Architecture, builds upon the previous successes (and overcoming some deficiencies) of previous broker-based context architectures, such as the ones implemented in the MobiLife 2.2.1 and C-Cast 2.2.2 European Projects. Because of this they share some similarities, but XCoA tries to iteratively build a better solution than the previous attempts.
XMPP, or eXtensible Messaging and Presence Protocol, is an application-layer open-standard communication protocol, based on XML [13]. It was originally designed for near-real-time instant messaging, and presence information. It is used by Facebook for its chat feature [14], and by Google for its Google Talk instant messaging service [15]. However, due to its open-standard and extensible nature, several extensions were de-veloped, which extended the use of XMPP for areas other than instant messaging and presence information. One of these extensions is the XMPP Publish-Subscribe Extension [16]. This extensions implements a simple Publish-Subscribe service on top of the XMPP communications protocol, using XML as its format. The XMPP Publish-Subscribe exten-sions allows entities (subscribers) to subscribe to specific types of information (through the subscription of specific XMPP PubSub Nodes); other entities called publishers are allowed to publish information on specific Nodes, which will then generate notifications to all subscribers of that particular Node.
XCoa is a broker-based context architecture which uses XMPP and XMPP Publish-Subscribe capabilities as its main communication protocol. It was first devised by D. Gomes, et al. in "XMPP based Context Management Architecture" [6]. The XMPP Extension XEP-0060 "Publish-Subscribe", or PubSub [16], and XEP-0248 "PubSub Col-lection Nodes" [17], are central building blocks of this architecture. The XMPP PubSub framework makes it possible to receive context information in near-real-time, without polling the server for changes. PubSub Collection Nodes allows PubSub nodes to be organized as a tree, where collection nodes are nodes which can only contain other col-lection nodes or leaf nodes, but no items can be published to it, and leaf nodes are nodes contained either inside collection nodes or as root nodes, and items are published to them. The XMPP PubSub component can be contained in an XMPP Server, or can be implemented in an external XMPP PubSub component, and then integrated in an XMPP server. The XMPP PubSub component is responsible for managing entities (or publishers), nodes, subscribers and items published.
In XCoA there are 4 main components: • Context Agents
• Context Broker • Context Consumers
Figure 2.3: XCoA Architecture [6]
As we can see from figure 2.3, Context Agents collect information from context sources. For example, a mobile terminal can provide a multitude of context data, such as Location data, GPS coordinates, etc. Social Networks are also another source of context data; they can provide a list of contacts, a user’s profile, etc. Finally, Wireless Sensor Networks are also good context sources, as they can provide detailed location information. There is no enforced communications protocol for transmitting this context data to Providers, and any Context Agent can provide the information as they see fit.
This context information is then sent and validated by Context Providers. Context Providers are specific entities, which usually only accept one type of context data, be it Location, Social, etc. They are in charge of receiving the context data from Context Agents, parsing and validating it, and then publishing it in the Context Broker. Each Provider is associated to one or more XMPP PubSub nodes, typically one node for each type of context, although more nodes can exist. Moreover, nodes can be arranged as a tree, so nodes can contain any number of nodes themselves, and a Provider can be responsible for one node and all their child nodes. The Provider, after receiving context data from Agents, publishes the context data, already properly parsed and validated, in the Context Broker, using the XMPP PubSub protocol. The context data is published inside an XMPP PubSub Item, in XML form.
Context Consumers can be subscribed to XMPP PubSub nodes. They can be sub-scribed to specific leaf nodes (on which context data will be published), or to collection nodes. When items are published to PubSub leaf nodes, all subscribers of that node will receive notifications with the contents of the data published. Subscribers of collection nodes receive notifications when items are published to any of its descendent leaf nodes. Polling operations, although limited, are also possible. Context Consumers can request context data by requesting data published on specific nodes. It is possible, for example, to ask for the last 10 items published on node X. This should be seen as an extra operation,
and not the main focus of the XCoA architecture, where publish-subscribe plays a much bigger part.
The Context Broker, the central part of the architecture, is the XMPP PubSub com-ponent (either a XMPP Server, or an external comcom-ponent, deployed in an XMPP Server). It handles all the subscription and node management, and is in charge of notifying sub-scribers on each item published (if any). It is also responsible for storing the context information in a persistent way. The implementation described in D. Gomes’ paper [6] uses Openfire, which can store item publications in an relational database such as MySQL or PostgreSQL. In this case, item contents (in XML form) are published in a single table column, as an XML string.
Although this architecture is similar to the ones already described before, such as C-Cast’s (2.2.2) and MobiLife’s (2.2.1), there are differences.
In MobiLife context is exchanged directly between Providers and Consumers, with the Broker being in charge of only publishing the Providers’ location and interfaces; in XCoA, however, the Broker assumes a more active approach, and all interactions are mediated by the Broker, both in synchronous and asynchronous modes of operation, through XMPP PubSub protocol functionalities. Mobilife also does not store all context information; instead, a small cache of the most recent context information is stored. This cache is however present in the Context Providers, and not in the Context Broker.
The C-Cast architecture is very similar to this XCoA architecture, where a full con-text history exists, along with a concon-text cache; subscription-based notifications are also al-lowed, and context is represented in XML format. XCoA improves upon this architecture by using XMPP Publish-Subscribe to allow for easier subscription-based notifications, as well as synchronous queries.
Moreover, in XCoA the context information does not require prior data modeling in the database for storage, as was the case in C-Cast, where each context type required a new data table to be created, and a conversion from the internal context representation to a database table; instead, context information is stored as an XML string in a single table field, meaning that new context types do not require a change in the data model, or the creation of a new database table.
2.3
Large-Scale Data Management Systems
With a context platform’s ability to persist context information comes the question of how and where to store it. Context platforms handle very large numbers of context data, and it becomes necessary to evaluate what solutions exist, what are the most efficient ones and what features are needed for this particular type of problem. Existing solutions fall into two broad categories: Relational Databases, traditional SQL-based storage systems based on the relational model, usually grouped by rows of data into tables; and the upcoming NoSQL storage systems, specifically designed to efficiently handle large amounts of data, at the expense of richer features offered by relational databases.
2.3.1
Relational Database Management Systems (RDBMS)
Relational databases are the most common solution for persistently storing structured data. They are based on the relational model, first introduced by E. F. Codd in the paper "A Relational Model of Data for Large Shared Data Banks" [18]. The relational model allows data to be modeled with its natural representation only (with properties and relationships between them), without imposing any additional structure for machine representation purposes, unlike other models such as the hierarchical and the network model. This provides a basis for a high-level data language representation, protecting it from disruptive changes on its underlying low-level representation.
These relational databases keep and manage data as a set of relations. In the relational model, a relation is a data structure composed of tuples, all of which share the same type. In the context of relational databases, these relations are usually a table: a set of columns and rows. Each column has an associated data type, and different rows of a column may have different values, but the same data type. These systems must also provide relational operators to manipulate data, such as operators to combine and filter data, according to rules defined by the users.
Most relational databases use SQL (Structured Query Language) as its high-level language querying format. Although it does not adhere 100% to Codd’s relational data model, it became the most widely used database language, being deployed in virtually all relational database management systems.
Relational databases have a fixed structure (or schema), requiring prior database modeling. This modeling consists in identifying and creating the database relations (or tables), and their respective composition in terms of columns, data types and constraints. This modeling is then enforced throughout the database usage, and every data item must obey to its schema. Although fixed, this model can be altered after the table’s creation, taking into account the table’s restrictions.
One important advantage of these solutions is the possibility of organizing data to minimize redundancy, also known as normalization. Normalization allows tables to be decomposed in order to produce better, smaller, well-structured relations. This isolates redundant data in separate tables, allowing it to be altered and changed without changing other related data.
These features all contribute to make relational databases a very structured and dis-ciplined data model, allowing for several features such as enforcing data integrity and consistency, all described in sections 2.3.1.1 through 2.3.1.4. A list of the most popular Relational Database Management Systems (RDBMS), both open-source and commercial ones, is listed bellow:
• Microsoft SQL Server • Oracle
• MySQL • PostgreSQL • SQLite
• IBM DB2
Following is a list of common features offered by traditional relational databases, some of whom important for efficient context information handling in context platforms, and some of them less important, and may even be abandoned and traded for other more important features.
2.3.1.1 Replication
Replication (or as V. Gupta [19] refers to it, "scaling by duplication"), in a database context, means duplicating data through more than one database node, increasing read performance, as it distributes all read operations among all nodes that contain the needed data. It also has the additional benefit of providing higher availability, as data is dis-tributed among several nodes, and one node failure will not result in database downtime, as other nodes will service the request. However, write operations become complex, as all operations must be synchronized between all nodes. This leads to multiple models of replication, such as Master-Slave and Multi-Master replication. [19] [20]
Replication may play an important role in scaling a context storage management system, if it means the distribution of load between different machines (horizontal scala-bility).
2.3.1.1.1 Master-Slave Replication Master-Slave database replication is the sim-plest form of replication. In this configuration there is only one master, and one or more slaves. The master is regarded as the owner of the objects, where all changes are first sent to. The Master is the only node allowed to change the database data. It logs the updates, and then propagates them to all the slaves, who confirm the success of the operation back to the Master, allowing it to re-send the failed updates to the slaves as needed. This always requires a connection between the Slave and the Master, making it less scalable but also less prone to failures [20, p.178].
This type of replication is useless to horizontal scalability and reliability, as it only guarantees the existence of backup copies of the data, but in case the Master fails all the databases become inaccessible, and it is impossible to continue normal operations until the Master comes back online.
2.3.1.1.2 Multi-Master Replication In Multi-Master replication, any node can be responsible for updating the data, and propagating the changes further to all the other nodes. It is also able to resolve conflicts arising from updating the same data in different nodes. Transactions can be propagated synchronously, or asynchronously. In the syn-chronous mode of operation, transactions are propagated immediately; in asynsyn-chronous mode, the changes are buffered temporarily, and only propagated periodically. This has the advantage of requiring less bandwidth and providing better performance. It also pro-vides higher availability, so if any node in the set becomes unavailable, all the changes will be buffered for that node, while all other nodes receive the changes as if no node had failed; when the failing node gets back online, the buffered changes will be propagated to it. With synchronous replication, if one node becomes unavailable, no changes will be propagated to any node until all nodes are available.
Although Multi-Master replication makes the node set more error prone, as the failing of one database node does not compromise the availability of the data, it also has some drawbacks. Due to the buffer-and-send nature of asynchronous Multi-Master replication, the possibility of conflicts between buffered changes arises, requiring a complex conflict-detection strategy. [21]
Multi-Master replication in relational databases is a means to achieve better avail-ability and prevent downtime, not as a scaling mechanism. Most relational databases provide very few or even none clustering capabilities, which is a central feature to achieve horizontal scalability, although some third-party solutions exist [22].
2.3.1.2 Sharding
Sharding means distributing the contents of a database between a number of nodes; this can be done by applying a hash function to a field of the data, to determine the right shard node. This means that a database table is not stored only on a single machine, but on a cluster of nodes. This has some advantages and disadvantages.
Partitioning the data through several nodes has the advantage of requiring less storage space requirements, while also distributing the load through all the nodes. How even this distribution of load is depends on how even the data is distributed through the cluster. Besides balancing data operations through the cluster, availability is also increased, as the failure of a single node does not compromise the whole database, but only the single data partition which was assigned to it.
However, sharding makes access operations much more complex; most sharded data-bases do not support join operations, even though these are one of the most important operations in relational databases. Join operations are used to produce data from two different sets of data, a left and a right one, connecting them by a pair of attributes. This means retrieving all data items from the right set associated with each item in the left set. In a sharded database, this would mean requests to all nodes that contain data from the two data sets, which would be impractical. Sharding can be done by using a consistent hash function, applied to primary keys of data items, to determine the correct associated shard node [23].
2.3.1.3 ACID Properties
ACID (Atomicity, Consistency, Isolation, Durability) are a set of properties designed to ensure the reliable process of database transactions. The term was coined in 1983 by Andreas Reuter and Theo Haerder, in "Principles of transaction-oriented database recovery" [24].
Transaction, in a database context, consists in a set of operations that are treated as a single unit of work, and are treated independently of other transactions. The transaction can either be committed to the database, or aborted.
Atomicity means that all operations associated with a transaction are either success-fully executed, or the whole transaction is aborted. In this case, the database is left in the same state it was before the transaction was attempted;
Consistency means that all operations of a transaction must leave the database in a consistent state; if any of the operations in a transaction violate the database consistency,
the whole transaction must be aborted, and any changes rollbacked;
Isolation means any uncommitted changes are invisible to the database, making trans-actions unaware of other currently running transtrans-actions;
Durability guarantees that committed transactions are never lost, such that in case of a system failure, the data is available in a correct state. This is usually achieved in RDBMSs by using a write-ahead log file. This log file allows a database to redo transactions that were committed but never applied to the database.
In RDBMSs, ACID properties are usually achieved through a locking mechanism. This allows transactions to have a lock on the database, perform all operations, and release the lock after all is done. If another transaction wants to access data already locked by another transaction, it has to wait for the locking transaction to finish, and release the lock. While this is generally not a problem with most relational databases, it can present problems and become a bottleneck for distributed databases. [23]
These are all necessary features for a context storage management platform. 2.3.1.4 Strong Consistency
Strong consistency, a particular type of consistency usually used in traditional re-lational databases, consists in ensuring that all entities and processes always see the same version of a database. After a database update operation, every subsequent read operation will always return the same value. [23] [25]
Although this is a useful feature, it may not be strictly necessary in this particular scenario of a context management platform. Context management platforms handle real-time context data from multiple sources, somereal-times with very little real-time intervals and very little change between them. As in a context management platform notifications are not dependent on the stored information and are generated in real-time only with the received information, strong consistency may be abandoned for other more useful features. The only operations that retrieve context information from the database are specific queries for specific types of context, and usually retrieve ranges of context information and not a single item; for this reason, the exclusion of a single context item in a range of 10 is acceptable.
It is sufficient, for example, to think of a case of retrieval of the last 20 locations a user has visited. If a user is publishing location context information at the exact same time the retrieval of the last 20 locations is issued, the exclusion of the item the user is currently publishing can be accepted, as we are more interested in its location history, not necessarily the present location. The notification, however, is completely unaffected, as the notification is issued on-the-fly without ever touching the database (although the context item is eventually persistently stored).
2.3.2
NoSQL
In this section we describe what are NoSQL databases, and what are their main characteristics and advantages, followed by the types of NoSQL databases available, and some examples of each.
"NoSQL" is a name given to databases that share one common characteristic: they are not relational; however, they have different characteristics and follow different approaches
to storing data.
Leavitt [26] refers this:
What they [NoSQL databases] have in common is that they’re not relational. Their primary advantage is that, unlike relational databases, they handle unstructured data such as word-processing files, e-mail, multimedia, and social media efficiently.
This lack of relations makes them automatically unsuited for a large set of applications. Businesses that have large, complex business rules, with multiple tables all related to each other, would find it hard to migrate to a solution with a simpler data-model, limited query support and lack of strong consistency.
Unlike relational databases, these NoSQL databases generally lack any enforced struc-ture, being ideal candidates for storing random unstructured data.
Usually with a relational database, one has to define the structure of the data before-hand, creating the database schema (tables and columns), depending on the structure of the data. This gives them very little flexibility with regards to the data it can store. With a schema-free NoSQL database (some NoSQL databases are not 100% schema-free), any data can be stored. Besides the flexibility gains, this may also give them better storage efficiency, as no empty columns are wasted.
The need for the development of NoSQL databases arose primarily out of scalability concerns issues with relational databases, such as its lack of support for being distributed, which some argue is "key to write scalability" [19]. Relational databases provide a rich set of features (such as strong consistency, ACID properties, rich data query model) that, for some use-cases, can be traded for higher scalability and availability and performance. While not all NoSQL databases are distributable, they all try to address scalability concerns, "by being distributed, by providing a simpler data / query model, by relaxing consistency requirements" [19].
The greatest advantage this type of databases have is, then, the increased performance and scaling capabilities they offer. This performance advantage is obtained thanks to two important factors: the non-relational and schema-free nature of this databases means data models are much simpler, increasing the database (DB) access speeds significantly; Leavitt [26] quotes Kyle Banker, engineer at 10gen, makers of MongoDB, a document-oriented NoSQL solution:
There’s a bit of a trade-off between speed and model complexity, [...] but it’s frequently a tradeoff worth making.
The other factor is the fact that most of NoSQL databases are able to be distributed. V. Gupta [19] notes this "is key to write scalability", and offers a list of Distributed / Not Distributed NoSQL solutions, shown in table 2.1.
A database, whether relational or NoSQL, can be scalable in three essential ways: with the amount of read operations, the number of write operations, and the size of the database. This is usually achieved through Replication and/or Sharding (described in the following section 2.3.2.1) [23].
With the ability to distribute a database through several nodes comes several prob-lems, such as maintaining data consistency. One way to guarantee data consistency in distributed databases is "Multiversion Concurrency Control", described in section 2.3.2.3.
Distributed Not Distributed Amazon Dynamo Redis
Amazon S3 Tokyo Tyrant Scalaris MemcacheDb Voldemort Amazon SimpleDb
CouchDb Riak MongoDb BigTable Cassandra HyperTable HBase
Table 2.1: List of distributable and not-distributable NoSQL databases
Even when NoSQL databases are a good fit for a given problem, it bears mentioning that they are relatively recent and, in some cases, largely untested in real-world scenarios. Leavitt [26] cites Google’s BigTable (2006) [27] and Amazon’s Dynamo (2007) [28] as the forerunners in the development of NoSQL solutions, "which have inspired many of today’s NoSQL applications".
There are essentially three types of NoSQL databases that should be considered for a context management storage system, described in detail in the coming sections:
• Key-Value Store (section 2.3.2.6)
• Wide Column Store / Column Oriented (section 2.3.2.7) • Document Oriented (section 2.3.2.8)
It should be noted that a fourth type of NoSQL databases exist: Graph Databases, such as Neo4j [29], based on graph structures, that use graph nodes, edges and properties to represent information. They were not considered because context information, as well as the XMPP Publish-Subscribe model, do not map to graph structures at all.
First, a list of features usually available in NoSQL solutions is presented bellow, as well as its need and importance in relation to a context management platform.
2.3.2.1 Replication and Sharding
Replication, described in section 2.3.1.1 for RDBMSs, is also used in NoSQL data-bases, perhaps even more so than in traditional relational databases. As scalability in NoSQL databases is addressed by distributing the database through several nodes, repli-cation becomes very important. While in traditional databases replirepli-cation becomes a complex task, due to the complexity of the data models involved, and the need to pro-vide strong consistency, NoSQL solutions usually don’t propro-vide strong consistency, and as such replicating data between nodes no longer require the operation to be atomic, and changes can be propagated to all nodes without disrupting read operations (NoSQL data-bases generally only provide eventual consistency, which is further described in section
2.3.2.2). Replication in NoSQL solutions usually follow more of a peer-to-peer architec-ture, very similar to Master-Master replication, where all nodes are equal and operations can be executed on any replica, with the changes being replicated through all nodes afterwards.
Sharding also shares the same advantages and disadvantages with RDBMSs 2.3.1.2: they provide higher availability and balance the load between all nodes, but also make access operations much more complex.
Replication and sharding are both very important features in a large-scale context management system, essential to achieve horizontal scalability and increase reliability and availability. Ideally both would be present; sharding distributes data evenly across different nodes, allowing greater load-balancing, and replication guarantees the existence of backup data replicas through one or more nodes, providing reliability and availability. In the absence of sharding, replication can also provide some form of horizontal scal-ability, provided a load-balancing application is used to evenly distribute operations through all existing replica nodes. On the other hand, this means that all nodes contain a full snapshot of the database, which may or may not be desired, and may lead to higher storage requirements.
2.3.2.2 Eventual Consistency
Eventual Consistency, as opposed to relational databases’ "strong consistency" (sec-tion 2.3.1.4), means that there are no guarantees given that different processes accessing the database will see the same version of the data. It is a specific form of weak consis-tency, where the storage system simply guarantees that, if no new updates are made to an object, eventually all accesses return the same, last updated version of the object. As updates to an object are made, updates to all replicas are propagated asynchronously. While no guarantees are made as to when all replicas will be updated, usually the maxi-mum size of the inconsistency window can be determined based on known factors, such as number of replicas and communication delays [25].
One of the most popular distributed systems that implements eventual consistency is the Domain Name System, or DNS. Updates to a name are propagated upwards through the hierarchy tree, and eventually all clients will see the update [25].
While eventual consistency is inherently a feature commonly found in NoSQL data-bases (due to its requirements), some modern traditional RDBMSs that provide primary-backup mechanisms implement a form of asynchronous primary-backup techniques, where the backups arrive in a delayed manner, similar to the Eventual Consistency model [25].
As explained previously in Relational Databases’ Strong Consistency (2.3.1.4), even-tual consistency is an acceptable tradeoff to make in exchange for better performance, horizontal scalability and reliability guarantees. Some NoSQL solutions use Multiversion Concurrency Control for ensuring eventual consistency, which is described in the next section.
2.3.2.3 Multiversion Concurrency Control
Multiversion Concurrency Control, or MVCC , was first described in 1978 by D. Reed [30], and is a mechanism that provides concurrent access to databases, mostly distributed
ones.
It implements a system where no data in the database is overwritten; instead, every change to the database creates a new version of the data, marking the old version obsolete. This guarantees that read locking mechanisms don’t interfere with database-writing locks, meaning that no read operations are every delayed by a write operation. Each read operation sees only a snapshot of the data, as it was some time ago, regardless of the current state of the data [31]. However, a read operation can read an outdated version of the document, if a new updated version is being written simultaneously. MVCC is also mention in the P. Bernstein, N. Goodman paper "Concurrency Control in Distributed Database Systems" [32].
Instead of locking access to the database and providing exclusive access to processes that execute write operations, MVCC allows the data to be read in parallel, even if the data is currently being updated. All data items maintain some form of timestamp or version id, to guarantee consistency and detect and resolve conflicts. When a document update occurs, it is first necessary to read the document and get the timestamp or version id of the document. This timestamp is then provided in the document update request. Upon successful update of the document, this timestamp or version id is then incre-mented; however, if the current timestamp of the document (as currently present in the database) is different than the timestamp given in the update request, then it is possible the document has already been changed between the document read and write operations, generating a conflict. This conflict must then be resolved, with different storage systems offering different solutions to these conflicts.
The following diagram 2.4 (from Figure 2.8 in Orend [23, p.14]) shows the creation of a conflict in a database with MVCC. Process A and B are both trying to write a new value to the data item x. Both read at first item x including its current revision number. Process B is the first to write its new version to the database. Process A tries to write a new version of x based on an older version than the current version in the database and thereby generates the conflict.
Figure 2.4: Creation of a conflict in a database with MVCC [23]
This conflict can be generated in two cases: two clients trying to write the same data on the same node, where they both retrieve the same document revision, and try to write the data, when only one update is valid; this conflict is easily detected by the database
during the write operation. In the other case, two clients are trying to write data to different nodes, where one node’s data is not yet in a consistent state. In a distributed, asynchronous database, the conflict can not be detected during the write operation. The node must first be synchronized to a consistent state before the conflict can be handled. [23]
It is also present in some traditional RDBMSs, such as Oracle or PostgreSQL [31], although in a more transparent manner (CouchDB provides explicit document versions). In NoSQL solutions, MVCC enables concurrent database accesses, provides higher per-formance, and ensures weaker forms of data consistency.
2.3.2.4 ACID Properties
ACID properties (Atomicity, Consistency, Isolation, Durability) was already explained in section 2.3.1.3; However, due to its distributed nature and simplistic data model, NoSQL storage systems either use different approaches to achieve the same guarantees, or choose to only offer limited support for ACID. A central locking mechanism, used by most RDBMSs to guarantee ACID properties, is infeasible in distributed databases, as most NoSQL databases are. Instead, most NoSQL storage systems only offer limited support for ACID; for example, consistency may be guaranteed by using Multiversion Concurrency Control (section 2.3.2.3) [23]
Most of these features are required for a context management platform, although they may not necessarily be guaranteed by a single-server configuration. Data durability is essential, as it guarantees that no data loss occurs, but although a storage system in a single-node deployment scenario may not guarantee it, a cluster of multiple nodes can guarantee data durability on the cluster as a whole, but not on a single node.
2.3.2.5 Map/Reduce
Map/Reduce is a concept largely used by distributed storage systems, usually applied on large data sets. It was first develped and patented by Google [33], although it is based on a concept originally found in functional programming languages.
Map/Reduce consists basically in performing two operations on a dataset: applying a Map function, which partitions the data into a smaller dataset, based on filtering criteria; followed by an optional Reduce function, which can combine the resulting partitioned data into an even smaller dataset. These operations’ workload is easily distributable, making its use ideal in distributable storage systems.
Some storage systems such as CouchDB provide internal Map/Reduce facilities, while external Map/Reduce frameworks such as Hadoop [34] provide stand-alone Map/Reduce features. A more detailed description of Map/Reduce is given in subsequent chapters, when describing specific NoSQL solutions.
2.3.2.6 Key-Value Store Storage Systems
Key-Value store databases are very similar to Hash Tables, with low complexity, that allow storing of data indexed by a key. The data stored can be of any type, and can be structured or unstructured; however, they don’t allow the retrieving of data by using
anything other than its key, making them very high performant, but very little flexible. Given these limitations, they are usually used alongside traditional relational data-bases, allowing fast access to a limited set of data, with full (and slower) access to all the data provided by more powerful solutions such as RDBMSs. A good example would be the usage of a data cache alongside a full RDBMS: storing the most frequently accessed data items in a separate NoSQL Key/Value storage system would provide faster access to most accessed data, while also preserving the full data model in the RDBMS, ready to be accessed as needed. MemcacheDB, a persistent version of memcached 1, follows this usage pattern.
A few examples of Key-Value Store databases: • Amazon Dynamo
• MemcacheDB [35] • Amazon SimpleDB [36] • Redis [37]
• Riak [38]
Key-Value Store systems were deemed very high-performant, but very basic, not offer-ing enough features required for a large-scale context management system, such as data retrieval by any field other than its key. Moreover, most are mainly oriented towards in-memory storage deployments. Although they can also persist data items asynchronously to disk as a fallback (in case of a crash), they should be regarded as mainly in-memory storage systems, as the data is read from disk to memory when the database restarts [39]. 2.3.2.6.1 Amazon Dynamo Dynamo is a proprietary, highly-available, distributed key-value storage system developed and used internally at Amazon for its own services. It focuses on high reliability and scalability, reliability being "one of the most impor-tant requirements [at Amazon] because even the slightest outage has significant financial consequences and impacts customer trust" [28].
It was developed in detriment of traditional RDBMSs because most internal Amazon services only need to "store and retrieve data by primary key and do not require the complex querying and management functionality offered by an RDBMS. This excess functionality requires expensive hardware and highly skilled personnel for its operation, making it a very inefficient solution". Further concerns of scalability arose, as "available replication technologies are limited and typically choose consistency over availability" [28].
Amazon Dynamo has a very simple key/value interface, with objects being stored in binary blobs. Queries are executed giving only a key. Multiple-data-item operations are not allowed, and no relational schema is supported. It targets "applications that need to store objects that are relatively small (usually less than 1 MB)" [28]. It only provides Weak Consistency, resulting in very high Availability. It does not provide any isolation guarantees.
It is designed to operate in a network of nodes built from commodity hardware, assuming that any node can fail at any given time. Nodes can be added at any given time, without requiring further data partitioning, and with workload being distributed among all available nodes automatically.
It uses partitioning (or sharding) through consistent hashing (see section 2.3.2.1), and replication, to achieve high availability and "incremental stability".
2.3.2.6.2 Riak Riak is a Dynamo-inspired open-source Key-Value store storage sys-tem [38]. Its development was inspired by the Dynamo paper "Dynamo: Amazon’s Highly Available Key-value Store" [28]. It is primarily written in Erlang and C, and used by Mozilla and Comcast [38].
Its local storage is organized in Buckets, and each bucket has Key/Value pairs. Each data entry is then identified by the combination of its Bucket and Key information. It offers an HTTP REST API, making client development easier and language-agnostic.
Riak has a distributed architecture, where all nodes are equal and there is no Master node. It supports sharding, where data is partitioned through multiple nodes, and each data partition can also be replicated to several nodes, increasing data availability and reliability.
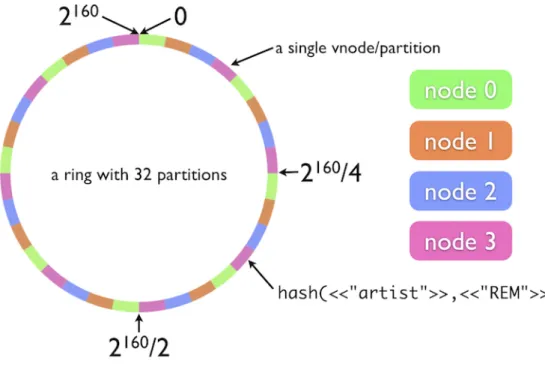
Data is partitioned in a 160-bit keyspace, divided into equal-size partitions. The cluster is composed by physical nodes, and each physical node is further divided into several virtual nodes, called vnodes. Each physical node is responsible for 1/(total number of nodes) of the cluster, and contains an equal number of vnodes. Vnodes are then arranged in a ring, as detailed in the following figure 2.5.
Figure 2.5: Riak Cluster Architecture
HTTP POST to a predefined address. These Map/Reduce functions can be written in either Erlang, or Javascript [40].
2.3.2.7 Wide Column Store / Column Oriented Storage Systems
In a very simplified view, the Column-Store Database concept consists on storing in-formation grouped by columns, instead of the traditional RDBMSs grouping by lines. This allows faster data processing over similar data items, as they are all physically close in disk; it allows also several optimizations, such as compression (the LZW algorithm, for example, benefits the similarity of adjacent data, which translates in efficient compres-sion). Its emphasis are, thus, on performance and disk efficiency.
This architecture has most advantages when dealing with small sets of columns, but large sets of rows; let’s consider the following example relation:
ID Name Salary 1 Alice 30000 2 Bob 40000 3 Claire 45000
A traditional relational database would serialize this data by row; however, a column-store database would serialize this data by column, grouping similar data together. 1;2;3;
Alice;Bob;Claire 30000;40000;45000
When adding or accessing data, if all columns are supplied / required, there would be little advantage of using a column-store database, as this could mean only one disk-write. If, however, only sets of columns are supplied (for example, only the Name column), there would need to be one or more disk seeks to move to the right column on each row, on a traditional database; this would be a case where using a column-store database would be advantageous, as all data would be written adjacently, possibly with only one disk-write.
Some examples of Column-Store databases include: • Cassandra
• Apache HBase [41]
Column-Store storage systems were also deemed unfit for an XMPP-based context management platform. Although they are also distributable, scalable and high perfor-mant, Document-Oriented systems were preferred, as context information is transmitted in document form (XML); moreover, most column-store solutions lack full-text searching capabilities, or any type of integration with a full-text searching engine such as Apache Lucene. A project exists to integrate Cassandra and Solr, named Solandra [42] (Solr is a a document indexer based on Apache Lucene). However, instead of enabling searching on an existing Cassandra dataset, it works the other way around, where it indexes documents by itself but stores its internal index in Cassandra. Cassandra is only used internally by Solr, so the main application of this configuration is then Solr and not Cassandra.
2.3.2.7.1 Cassandra Cassandra is a NoSQL decentralized eventual-consistent Column-Store database, initially developed by Facebook to power their Inbox Search facility [43] [44], promoted to Apache Incubator Project in March 2009 and to Top-Level Project in February 2010. Its main focus are Distribution, Replication and Fault Tolerance, with emphasis on Performance.
Cassandra has a distributed architecture and is decentralized, where every node has an equal role and there is no Master node. It supports sharding, or data partitioning, and data is partition using a consistent hashing function. Two partitioners exist: one which distributes data randomly across the cluster, or an order-preserving partitioner, which preserves the order of the data and allows range scans to be applied later on the data. Moreover, data is replicated to several nodes for fault-tolerance.
Quoting Avinash Lakshman on its Data Model [43]:
Every row is identified by a unique key. The key is a string and there is no limit on its size.
An instance of Cassandra has one table which is made up of one or more column families as defined by the user.
The number of column families and the name of each of the above must be fixed at the time the cluster is started. There is no limitation the number of column families but it is expected that there would be a few of these.
Each column family can contain one of two structures: supercolumns or columns. Both of these are dynamically created and there is no limit on the number of these that can be stored in a column family.
Columns are constructs that have a name, a value and a user-defined times-tamp associated with them. The number of columns that can be contained in a column family is very large. Columns could be of variable number per key. For instance key K1 could have 1024 columns/super columns while key K2 could have 64 columns/super columns.
"Supercolumns" are a construct that have a name, and an infinite number of columns associated with them. The number of "Supercolumns" associated with any column family could be infinite and of a variable number per key. They exhibit the same characteristics as columns.
Figure 2.6: Twitter’s data model: User_URLs [45]
This figure shows a single column family, UserURLs , with a single row identified by the key "98725". This column family has two super columns ("http://techcrunch.com/..." and "http://cnn.com/..."), and each super column has exactly two columns.
2.3.2.7.2 Apache HBase HBase is an open-source, distributed, versioned column-oriented database, modeled after Google’s paper by Chang, et al. "Bigtable : A Dis-tributed Storage System for Structured Data" [27].
HBase’s datamodel is, then, very similar to that of BigTable. The data rows are stored in labeled tables, and each data row has a sortable key and multiple columns. Columns are identified by <family>:<label>, where family and label can be arbitary byte arrays. Column families fixed and set administratively, while labels can be added any time, even during a write operation, without previous configuration. Columns may not have values for all data rows. All column families are stored physically close on disk, so items in the same column family have roughly similar read / write characteristics and access times [41] [46].
The next example, taken from HBase’s Architecture wiki page, shows a typical HBase data row, three column families: "contents", "anchor" and "mime". The "anchor" column family then has two columns: "anchor:cnnsi.com" and "anchor:my.look.ca".
![Figure 2.1: KeyFunctions of the Context Management Framework [4, p. 2]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/25.892.217.663.125.483/figure-keyfunctions-context-management-framework-p.webp)
![Figure 2.2: C-Cast Context Management Architecture & Functional Entities [5, p. 3]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/26.892.145.757.126.556/figure-cast-context-management-architecture-amp-functional-entities.webp)
![Figure 2.3: XCoA Architecture [6]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/28.892.141.754.214.477/figure-xcoa-architecture.webp)
![Figure 2.4: Creation of a conflict in a database with MVCC [23]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/37.892.122.762.753.955/figure-creation-conflict-database-mvcc.webp)
![Figure 2.6: Twitter’s data model: User_URLs [45]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/43.892.130.774.121.367/figure-twitter-s-data-model-user-urls.webp)
![Figure 2.8: MongoDB Schema Example [48]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15967136.1100606/45.892.205.684.470.794/figure-mongodb-schema-example.webp)