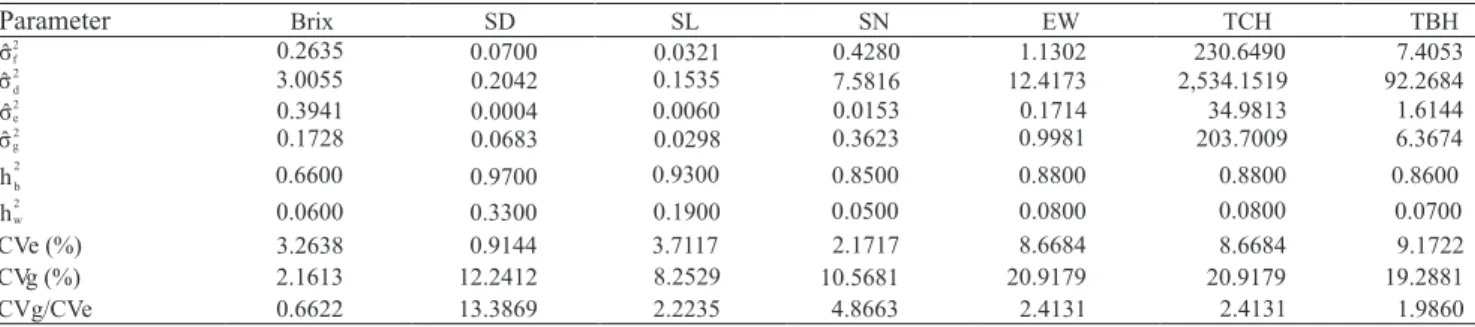
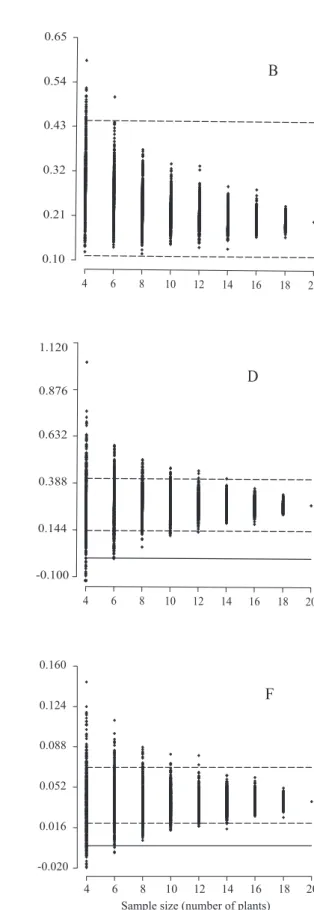
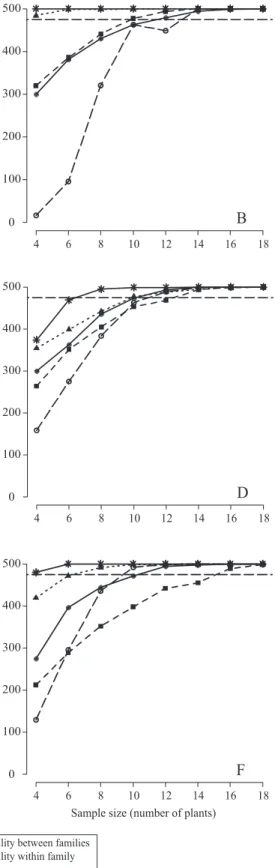
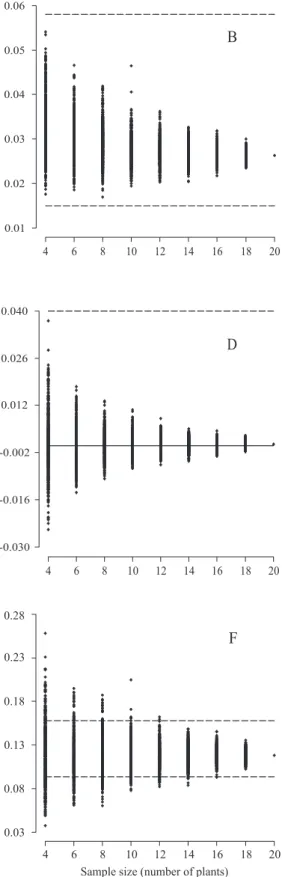
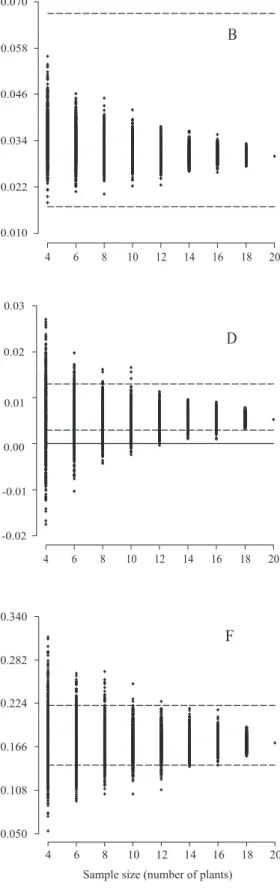
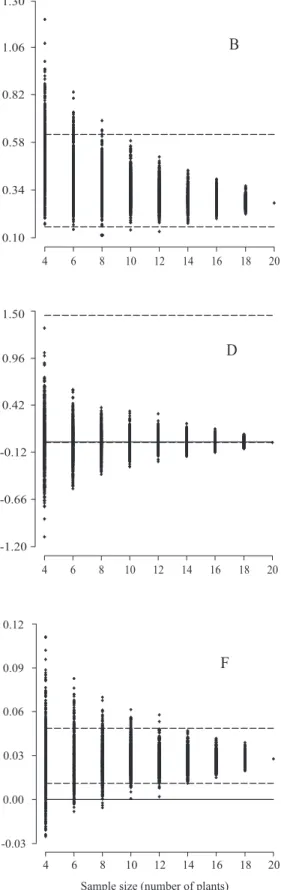
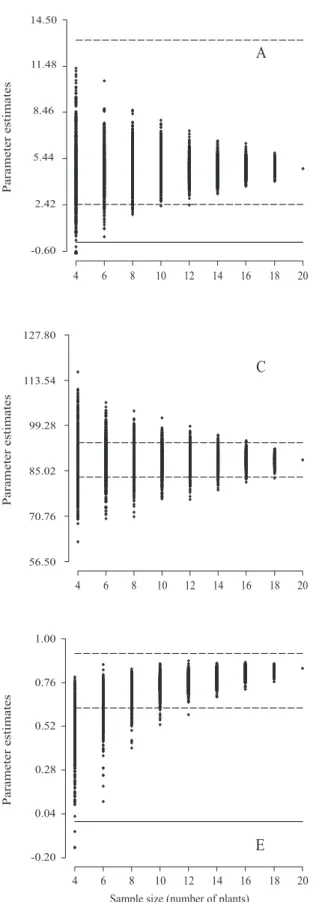
Sample size for full‑sib family evaluation in sugarcane
Texto
Imagem

Documentos relacionados
É importante destacar que as práticas de Gestão do Conhecimento (GC) precisam ser vistas pelos gestores como mecanismos para auxiliá-los a alcançar suas metas
Ao Dr Oliver Duenisch pelos contatos feitos e orientação de língua estrangeira Ao Dr Agenor Maccari pela ajuda na viabilização da área do experimento de campo Ao Dr Rudi Arno
Neste trabalho o objetivo central foi a ampliação e adequação do procedimento e programa computacional baseado no programa comercial MSC.PATRAN, para a geração automática de modelos
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
Assim, comecei a refletir sobre os seguintes pontos: as três festas, Festa do Comércio, Carnaval e Festa Junina, existiram, simultaneamente, entre as décadas de 1960 e 1990, porém,
A infestação da praga foi medida mediante a contagem de castanhas com orificio de saída do adulto, aberto pela larva no final do seu desenvolvimento, na parte distal da castanha,
b) Organizações do setor voluntário – Aplicação de formulário com questões abertas e fechadas, conforme mostra o Apêndice A, a 28 pessoas sendo: uma
Com o intuito de criar dentro da Operação CMIP um processo piloto para a implementação de um BPMS de forma a demonstrar as mais valias da extensão do projeto, para as mais diversas
