Availability and confidentiality in storage clouds
114
0
0
Texto
(2) UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS DEPARTAMENTO DE INFORMÁTICA. AVAILABILITY AND CONFIDENTIALITY IN STORAGE CLOUDS. Fernando Martins André. MESTRADO EM SEGURANÇA INFORMÁTICA. January 2011.
(3) UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS DEPARTAMENTO DE INFORMÁTICA. AVAILABILITY AND CONFIDENTIALITY IN STORAGE CLOUDS. Fernando Martins André. Orientador Alysson Neves Bessani. MESTRADO EM SEGURANÇA INFORMÁTICA. January 2011.
(4) Resumo Cloud Computing (computação na nuvem) e Cloud Storage (armazenamento na nuvem) em particular, estão a transformar rapidamente a natureza de como o mundo empresarial e o negócio usa as tecnologias de informação, baseado num modelo de software-como-um-serviço. O principal aspecto desta mudança de paradigma é o facto dos dados estarem a deixar os datacenters (centros de dados) das organizações e serem alvo de outsourcing para fornecedores de infra-estruturas de nuvem. No caso do Cloud Storage em concreto, existem diversas vantagens no uso deste novo modelo, tais como a oportunidade de utilizar um serviço de armazenamento completamente flexível e escalável na Internet, e disponível a partir de qualquer ponto do mundo, com uma ligação à mesma. Contudo, do ponto de vista de uma perspectiva de segurança, este avanço representa também novas e graves ameaças à segurança. Questões como a perda de dados, disponibilidade, confidencialidade, integridade e insiders maliciosos estão entre as maiores preocupações dos que decididem mover dados para a nuvem. O sistema DepSky já endereça algumas destas preocupações. Desta forma, os objetivos deste trabalho estão divididos em duas fases principais. Primeiro, o sistema DepSky foi objecto de aperfeiçoamento, tendo sido alvo da adição de um novo mecanismo de nome Erasure Codes, sob a forma de uma biblioteca, e somente após uma análise de algumas das bibliotecas de Erasure Codes disponíveis na Internet. Em segundo lugar, a disponibilidade de 4 (quatro) fornecedores comerciais de armazenamento na nuvem foi estudada ussando a aplicação logger do DepSky. Para alcançar um cenário realista, estas aplicações foram configuradas e iniciadas em vários pontos do mundo, dispersos por diversas zonas geográficas. De seguida, foi realizada uma cuidadosa análise aos registos resultantes, com o objectivo de avaliar e correlacionar vários aspectos do armazenamento na nuvem, tais como a latência (disponibilidade aparente), o custo e as diferenças nos atrasos consoante várias regiões geográficas. Esta análise e os seus resultados são a maior contribuição deste trabalho. Palavras-chave: armazenamento na nuvem, disponibilidade, confidencialidade, erasure codes, secret sharing, depsky. i.
(5) Abstract Cloud Computing and Cloud Storage in particular are rapidly transforming the nature of how business use information technology based on a software-as-a-service model. The main aspect of this paradigm changing is the fact that data is leaving organizations data centers and is being outsourced to cloud providers infrastructures. For Cloud Storage in concrete, there are many appealing advantages on using this new approach such as the opportunity to use a completely flexible web-scale storage service, available from any point in the world with an Internet connection. However, from a security perspective, this advance also poses new and critical security threats. Issues like data loss or leakage, availability, confidentiality, integrity and malicious insiders are amongst the most referenced concerns when deciding to move data to the cloud. The DepSky system already addresses some of these concerns. Therefore the aim of this work is divided in two main phases. First the DepSky system was object of improvement, by adding a new mechanism called Erasure Codes in the form of a library, and only after an analysis of some of the available Erasure Codes libraries in the Internet. Secondly, the availability of 4 (four) commercial cloud storage providers was studied using the logger application of DepSky. To achieve a realistic scenario, several loggers were deployed dispersed around the world in different geographical regions. Afterwards, a careful analysis of the resultant logs was made in order to assess and correlate several aspects such as latency (perceived availability), cost and differences in geographical regions. Therefore, this analysis and its results are the major contribution of this work. Keywords: cloud storage, availability, confidentiality, erasure codes, secret sharing, depsky.. ii.
(6) Acknowledgments. This thesis represented a lot of time and work. However, my effort would be useless if not supported by some people who helped me overcome all obstacles. First, I would like to thank my advisor, Prof. Alysson Bessani, for this orientation, inspiration, support, dedication, and for always showing availability to hear his students. A word of appreciation goes also to Carnegie Mellon University, Information Networking Institute, and for Faculdade de Ciências, Universidade de Lisboa, for the opportunity to attend this superb master program, which have corresponded to the expectations I had. I would also like to thank Bruno Quaresma for his patience, guidance and priceless help with the integration work with DepSky. Another word of thanks goes to my mother and to my father. It’s not too much to say that without their personal sacrifice over the years to provide me better conditions, I could never dream to reach this far. Last, but not least (this sentence never gets old, does it?), the biggest Thank You goes to Cátia Pinto. My girlfriend, but above all my friend, you have always helped and supported me during the course of this endeavour, even when I was absent with work. Most of all, Thank You for showing me that the light at the end of the tunnel is not the train coming towards me. You make me fly higher and I am deeply grateful for your help and patience.. January 2011. iii.
(7) Dedicated to my mother... ...and to my father. iv.
(8) Contents 1. 2. 3. Introduction. 1. 1.1. Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1. 1.2. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 2. 1.3. Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 3. 1.4. Document Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 3. Storage Clouds. 4. 2.1. Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 4. 2.2. What is Cloud Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5. 2.2.1. Essential Characteristics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 2.2.2. Service Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 7. 2.2.3. Deployment Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 2.3. Cloud Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 2.4. Cloud Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 10. 2.4.1. Generic Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 10. 2.4.2. Academic Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 12. 2.4.2.1. Stout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 12. 2.4.2.2. Cumulus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 12. 2.4.2.3. SPORC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 13. 2.4.2.4. Other works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 13. Storage Efficiency on a Cloud-of-Clouds. 14. 3.1. DepSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 14. 3.1.1. DepSky Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 15. 3.1.2. Data model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 16. v.
(9) 3.2. 3.3 4. 3.1.3. System model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 17. 3.1.4. Protocols Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 17. 3.1.5. Basic Functioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 18. DepSky-CA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 19. 3.2.1. Byzantine Quorum Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 19. 3.2.2. Secret Sharing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 21. 3.2.3. Erasure Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 22. DepSky and Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 24. Storage Clouds Evaluation. 26. 4.1. PlanetLab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 26. 4.2. Environment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 27. 4.3. Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 29. 4.4. Cloud Monetary Costs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 30. 4.5. Cloud Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 34. 4.5.1. By Location . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 35. 4.5.1.1. Data size – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 35. 4.5.1.2. Data size – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 39. 4.5.1.3. Data size – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 43. 4.5.1.4. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 47. By Cloud Provider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 47. 4.5.2.1. Data size – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 48. 4.5.2.2. Data size – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 52. 4.5.2.3. Data size – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 56. 4.5.2.4. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 60. By Region . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 60. 4.5.3.1. Providers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 61. 4.5.3.2. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 65. 4.6. Comparison to CloudHarmony . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 66. 4.7. Cloud Availability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 68. 4.7.1. Occurrence of Errors and Mean Latency Correlation . . . . . . . . . . . . . . . . .. 68. 4.7.1.1. 69. 4.5.2. 4.5.3. Locations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi.
(10) 4.7.1.2. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 70. Number of Errors and Latency Correlation . . . . . . . . . . . . . . . . . . . . . .. 70. 4.7.2.1. Locations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 71. 4.7.2.2. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 71. ANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 71. 4.7.3.1. Cloud Providers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 72. 4.7.3.2. Countries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 73. 4.7.3.3. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 75. Cost Latency Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 75. 4.8.1. Locations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 76. 4.8.2. Final Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 78. Results Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 78. 4.9.1. By Location . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 78. 4.9.2. By Cloud Provider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 79. 4.9.3. By Region . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 79. 4.9.4. Occurrence of Errors and Mean Latency . . . . . . . . . . . . . . . . . . . . . . . .. 80. 4.9.5. Number of Errors and Latency . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 80. 4.9.6. ANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 80. 4.9.7. Cost Latency Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 81. 4.7.2. 4.7.3. 4.8. 4.9. 5. Clonclusion and Future Work. 82. 5.1. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 82. 5.2. Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 83. Bibliography. 85. Appendix A. 92. Appendix B. 95. vii.
(11) List of Figures 2.1. Cloud computing composition options . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 2.2. Cloud computing service models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 2.3. Evolution of cloud storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 10. 3.1. DepSky architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 16. 3.2. DepSky data model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 16. 3.3. DepSky system interactions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 19. 3.4. Quorum systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 20. 3.5. Secret Sharing scheme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 21. 3.6. Erasure Code scheme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 23. 3.7. Erasure Code functioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 24. 4.1. Map with geographical distribution of machines running loggers . . . . . . . . . . . . . . .. 28. 4.2. Sample of collected log . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 30. 4.3. Costs of the 4 cloud providers plus DepSky-A and DepSky-CA with version number . . . .. 34. 4.4. Performance by location/country – S3 provider – 100KB data size . . . . . . . . . . . . . .. 36. 4.5. Performance by location/country – Rackspace provider – 100KB data size . . . . . . . . . .. 37. 4.6. Performance by location/country – Azure provider – 100KB data size . . . . . . . . . . . .. 38. 4.7. Performance by location/country – Nirvanix provider – 100KB data size . . . . . . . . . . .. 39. 4.8. Performance by location/country – S3 provider – 1MB data size . . . . . . . . . . . . . . .. 40. 4.9. Performance by location/country – Rackspace provider – 1MB data size . . . . . . . . . . .. 41. 4.10 Performance by location/country – Azure provider – 1MB data size . . . . . . . . . . . . .. 42. 4.11 Performance by location/country – Nirvanix provider – 1MB data size . . . . . . . . . . . .. 43. 4.12 Performance by location/country – S3 provider – 10MB data size . . . . . . . . . . . . . . .. 44. 4.13 Performance by location/country – Rackspace provider – 10MB data size . . . . . . . . . .. 45. viii.
(12) 4.14 Performance by location/country – Azure provider – 10MB data size . . . . . . . . . . . . .. 46. 4.15 Performance by location/country – Nirvanix provider – 10MB data size . . . . . . . . . . .. 47. 4.16 Performance by provider – Brazil – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . .. 48. 4.17 Performance by provider – China – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . .. 49. 4.18 Performance by provider – CMU – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 49. 4.19 Performance by provider – Japan – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 50. 4.20 Performance by provider – New Zealand – 100KB . . . . . . . . . . . . . . . . . . . . . .. 50. 4.21 Performance by provider – Spain – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 51. 4.22 Performance by provider – UCLA – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . .. 51. 4.23 Performance by provider – UK – 100KB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 52. 4.24 Performance by provider – Brazil – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 52. 4.25 Performance by provider – China – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 53. 4.26 Performance by provider – CMU – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 53. 4.27 Performance by provider – Japan – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 54. 4.28 Performance by provider – New Zealand – 1MB . . . . . . . . . . . . . . . . . . . . . . . .. 54. 4.29 Performance by provider – Spain – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 55. 4.30 Performance by provider – UCLA – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 55. 4.31 Performance by provider – UK – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 56. 4.32 Performance by provider – Brazil – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 56. 4.33 Performance by provider – China – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 57. 4.34 Performance by provider – CMU – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 57. 4.35 Performance by provider – Japan – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 58. 4.36 Performance by provider – New Zealand – 10MB . . . . . . . . . . . . . . . . . . . . . . .. 58. 4.37 Performance by provider – Spain – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . .. 59. 4.38 Performance by provider – UCLA – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . .. 59. 4.39 Performance by provider – UK – 10MB . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 60. 4.40 Performance by region – S3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 62. 4.41 Performance by region – Rackspace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 63. 4.42 Performance by region – Azure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 64. 4.43 Performance by region – Nirvanix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 65. 4.44 CloudHarmony printscreen – available tests . . . . . . . . . . . . . . . . . . . . . . . . . .. 67. 4.45 CloudHarmony printscreen – test results . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 67. ix.
(13) 4.46 Log data separation and read latency and average charts . . . . . . . . . . . . . . . . . . . .. 69. 4.47 Number of errors and latency correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 71. 4.48 Cost and Latency correlation charts for Brazil – China – CMU – Japan – 1MB . . . . . . . .. 77. 4.49 Cost and Latency correlation charts for New Zealand – Spain – UCLA – UK – 1MB . . . .. 77. 1. Cost and Latency correlation charts for Brazil – China – CMU – Japan – 100KB . . . . . . .. 93. 2. Cost and Latency correlation charts for New Zealand – Spain – UCLA – UK – 100KB . . .. 93. 3. Cost and Latency correlation charts for Brazil – China – CMU – Japan – 10MB . . . . . . .. 94. 4. Cost and Latency correlation charts for New Zealand – Spain – UCLA – UK – 10MB . . . .. 94. x.
(14) List of Tables 4.1. Cloud providers features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 28. 4.2. Costs charged by the 4 cloud storage providers . . . . . . . . . . . . . . . . . . . . . . . .. 32. 4.3. Estimated costs for 10K read/write operations . . . . . . . . . . . . . . . . . . . . . . . . .. 32. 4.4. Calculations of costs for 1MB of data using DepSky-CA protocol . . . . . . . . . . . . . .. 32. 4.5. Summary results by location/country for 100KB data size . . . . . . . . . . . . . . . . . . .. 35. 4.6. Summary results by location/country for 1MB data size . . . . . . . . . . . . . . . . . . . .. 39. 4.7. Summary results by location/country for 10MB data size . . . . . . . . . . . . . . . . . . .. 43. 4.8. Results of t-Student test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 69. 4.9. ANOVA test – S3 – Rackspace – Azure – Nirvanix . . . . . . . . . . . . . . . . . . . . . .. 73. 4.10 ANOVA test – Brazil – China – CMU – Japan . . . . . . . . . . . . . . . . . . . . . . . . .. 74. 4.11 ANOVA test – New Zealand – Spain – UCLA – UK . . . . . . . . . . . . . . . . . . . . . .. 74. 4.12 Cost and Latency correlation results – 1MB . . . . . . . . . . . . . . . . . . . . . . . . . .. 75. 1. Cost and Latency correlation results – 100KB . . . . . . . . . . . . . . . . . . . . . . . . .. 92. 2. Cost and Latency correlation results – 10MB . . . . . . . . . . . . . . . . . . . . . . . . .. 92. xi.
(15) Chapter 1. Introduction 1.1. Overview. Cloud Computing has brought up large advancements to the IT (information technology) industry and changes in the way of thinking and used paradigms. Building on the predecessors grid [1, 2] and utility [3] computing, it has been envisioned as the next generation architecture of IT enterprise, due to its appealing advantages. These same advantages are at the same time conducting this evolutionary model to a rapid growth and proliferation. Often considered as a disruptive technology with profound implications, Cloud Computing is rapidly transforming the nature of how business use information technology. The main facet of this paradigm shifting is the fact that data is leaving organizations data centers and being outsourced into the Cloud. The reason for this shift comes largely due to what IT always need in any organization: a way to increase capacity or add capabilities on the fly without investing in new infrastructures, training new personnel, or licensing new software. Cloud Computing employs a subscription-based or pay-per-use service that, almost in real time and over the Internet, extends IT existing capabilities, and all this with reduced costs. Moreover, the model of software as a service (SaaS) allied with the cheaper and more powerful processors; together with an increasing network bandwidth allows users and organizations to subscribe more and high quality services from data and software that reside solely on remote data centers. Furthermore, details of the infrastructure are abstracted from the users, who no longer have the need for expertise in, or control over, the technology infrastructure “in the cloud” that supports them. Also, for the cloud success partly contributes the ease of use and access, e.g., the overall act of storing and accessing of applications and data often occur through a Web browser rather than running installed software on personal computer or office servers. With Cloud Computing, a wide variety of cloud services/models are emerging. Particularly, one these offers is the Cloud Storage model, which is a model of networked computer data storage, where data is stored on multiple virtual servers, according to the requirements of the customers. This is becoming one of the most successful models since it’s exploited as a flexible web-scale storage, used to store and retrieve any amount of data, at any time, from anywhere in the world through the Internet. More generally, Cloud Computing and its models are emerging as models in support of “everything-as-a-service”. Nevertheless, as a move toward more and more services in the cloud seems inevitable, from the perspective of 1.
(16) data security, cloud computing poses new and critical security threats. Providers are mainly focused on some aspects as redundancy but other key challenges are yet open problems. For example, strong privacy measures should be carefully implemented to protect cloud customers. Moreover, concerns as availability, reliability, integrity, confidentiality and others, all elements of dependability [4, 5], should be carefully accounted for, existing several reasons to do so. First, many cloud providers sometimes claim they are not responsible for the data stored on their service, and in fact, exists ambiguity in agreements between vendors and customers [6]. Therefore the question that automatically rises is how to ensure reliability and availability? Second, if some catastrophic event occurs on the provider data center, how is safety guaranteed? Third, due to the use of virtualization in cloud environments, data leaks can occur [7]. And this is particular important since organizations are moving their files to the clouds which are likely to become tempting targets for cybercriminals [8]. Can confidentiality, with simple encryption of data, be achieved in a simple and scalable manner? In addition to all these technical issues, another one that is the basis of the outsourcing process of data to cloud providers emerges, and is the cost relation versus the quality of service. Generally it’s important to any organization understand if the latency (delay) of fetching its data located at the cloud provider data center, is high or low. Higher delays (low availability) in accessing data can compromise the organization normal functioning and operation, causing losses besides other problems such as the organization image with customers. Afterwards it’s also crucial to understand and evaluate the costs this new approach implies, and if it counterbalances the expected delay in accessing data. The costs and ultimately the return of investment, associated with the benefits of cloud storage (and cloud computing), are essential concerns that are under close attention and need to be carefully researched.. 1.2. Motivation. This thesis presents a study focused on the availability and confidentiality on some of the current commercial cloud storage providers existing in the market. For this study the DepSky system [9, 10] was used subsequently to the introduction of one improvement, the Erasure Codes technique, described later. The aim of this work centers on two main axes. The first is the study of 4 (four) commercial cloud providers, by making a correlation of data obtained by the performed tests. These tests measured the availability of clouds (through measuring the latency on access times of data), number of failures, and the costs charged by each cloud provider. This study tries to understand if the service offered by the 4 cloud storage providers is differentiated among each other, considering not only the costs, but also the geographical location of access, and the associated delay. In resume, it makes an effort to understand some important variables, such as availability, feasibility of inserting confidentiality on data before transfer it to the cloud, and the overall costs of information dispersion and storage. The second fundamental axis is aimed at understanding if the enhancement made with the insertion of Erasure Codes to this system, impacted the results in terms of costs and availability. Like mentioned previously, DepSky is a dependable and secure storage service in a cloud-of-clouds, with a paper [9] accepted in conference EUROSYS2011 [11]. It focus on security problems as the ones described on the previous section, proposing a system that improves the availability, integrity and confidentiality of information stored in the cloud through several mechanisms and techniques that were combined with these concerns in mind. On this work it was used in a worldwide study, using the PlanetLab platform [12], and involving 4 well known commercial cloud storage providers. 2.
(17) 1.3. Contribution. The work presented in this thesis establishes the following main contributions to the evolution of information security and cloud storage research: • Promotes a better understanding and risk awareness of the security concerns associated with the moving. trend of data from organizations own infrastructures to the cloud, with a particular focus on availability and performance. • Studies in detail, with worldwide conducted tests, the availability of storage clouds, crossing the la-. tency/availability results with the costs charged by each evaluated cloud provider. • Introduces an enhancement on DepSky, which is a novel system to achieve a dependable and secure. storage in a cloud of clouds. The improvement completed, consisted in the introduction of an Erasure Code technique to improve storage efficiency, and ultimately to reduce costs associated with replication. The generic objectives of this thesis aimed, on one hand at studying the availability of commercial storage clouds and correlating that dependability attribute with the charged costs; and on the other hand to enhance the DepSky system with a more efficient technique.. 1.4. Document Structure. The remaining chapters of this thesis are structured in the following way: Chapter 2 – Literature review of Cloud Computing and Cloud Storage basic underlying concepts, and related work. Chapter 3 – Description of the DepSky system upon which the present work intends to integrate an Erasure Code technique and later use one of its components, the logger, to conduct the experiments described and analyze the information presented on the subsequent chapter. Chapter 4 – Presents the environment and methodology used in the conducted experiments, as well as the results of the data analysis performed with focus on cloud performance and cloud availability components. Chapter 5 – Concluding remarks and notes on future work.. 3.
(18) Chapter 2. Storage Clouds This chapter provides a summary of the field in which this thesis is inserted and provides some context of the work already developed on this area. Therefore, it’s discussed here the basis, the environment and the paradigms related to the work developed for this thesis. Moreover, it’s given an overview for the needs and concerns that organizations and users seek and try to overcome when using cloud-based services, with an emphasis on cloud-based storage services.. 2.1. Context. Currently, and all around the world, companies of all sizes have come to rely on digital contents and applications to conduct or assist their business. From the simple email and websites (for personal and organizational use), passing on financial applications and collaboration platforms, finishing on large organization databases, all are common standards, even at smaller enterprises. With such dependence on electronic communications, commerce and collaboration, downtime tolerance is low. In fact a great majority of companies can tolerate a small downtime before experiencing significant revenue loss or other adverse business impact [13]. Cloud computing and cloud storage represent the promise of outsourcing as applied to computation and storage, and a way to reduce both costs at the same time it can increase availability and recovery, conducted by the cost reduction argument. Cloud computing is becoming another key resource for IT deployments, and with an increasing number of success stories. However, there is still fear of securing applications and data in the cloud [14]. Services such as Microsoft’s Windows Azure and Amazon EC2 [15, 16], are just two examples, that allow users to instantiate virtual machines (VMs) on demand, and thus purchase precisely the capacity required and on-demand, in a completely scalable manner. If on the other hand, the needs are related to storage and not computation, similar services are provided, with identical advantages. While organizations certainly see a business benefit on a pay-per-use model for computing resources, security concerns seem to always appear at the top of concerns regarding cloud computing and storage. Among several others, these concerns include authentication, authorization, and accounting (AAA) services; encryption; storage quality; security breaches; regulatory compliance; location of data and users; and other risks associated with isolating sensitive corporate data. Adding to this set of concerns the potential loss of control over 4.
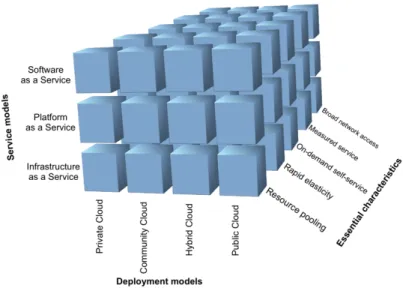
(19) data, and the cloud model starts to become a little scary for any organization. At the end, no matter where applications live in the cloud, where their being stored or how they are being served, one issue is always present: organizations (and persons/users in general) are hosting and delivering critical data at a third-party location, not within the traditional four walls of private data centers. Furthermore, the Cloud Security Alliance has published the top threats to Cloud Computing in [17]. Between these are malicious insiders, data loss or leakage and account or service hijacking. Therefore and in conclusion keeping that data safe is a top priority. Consequently, the proceeding into the cloud must be done with caution. Among the cloud models, the cloud storage is one of the most successful ones, due to the possibility of being explored as a flexible web-scale storage completely scalable on demand and that can be used to store and retrieve any amount of data, at any time, from anywhere on the web. This presents advantages for a full set of businesses and situations. Roughly, every organization spread over a geographic region can make use and withdraw benefits from this technology and its advantages. This model in particular is the central point of this thesis that focus on such issues as the availability and confidentiality of sensitive data being transferred to the cloud.. 2.2. What is Cloud Computing. Defining Cloud Computing is not an easy task because this is still an evolving paradigm. However, Cloud Computing can be perceived as an Internet-based development and use of computer technology and resources. In addition to the plethora [18, 19, 20, 21] of technical approaches associated with the term, Cloud Computing is often referred to as a new business model in which core computing, software capabilities and storage resources are outsourced on demand to shared third-party infrastructures. Given this high level overview, its definitions, underlying technologies, issues, risks and benefits will be refined with time by public and private sectors, since this industry represents a large ecosystem of many models, vendors and market niches. Nevertheless, and even not having a completely agreement on the meaning of Cloud Computing, a general refined and wide accepted definition in the literature, from the perspective of a client outside the cloud, is the following: Cloud computing is Internet-based computing (computer technology), whereby dynamically scalable and often virtualized resources, software and information are provided to computers and other devices on demand [22]. According to the National Institute of Standards and Technology (NIST) in the United States, Cloud Computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This cloud model promotes availability and is composed of five essential characteristics, four service models, and four deployment models [23]. Figure 2.1 retrieved from [20] gives a more comprehensive view of this composition of options, which are detailed below.. 5.
(20) Figure 2.1: Cloud computing composition options Generally, the common cloud computing characteristics often leverages: massive scale, homogeneity, virtualization, resilient computing, low cost software, and geographic distribution.. 2.2.1. Essential Characteristics. There is a set of properties that characterize essential aspects of cloud computer platforms. They typically are divided as follows: On-demand self-service – A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service’s provider. Broad network access – Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, laptops, and PDAs). Resource pooling – The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or data center). Examples of resources include storage, processing, memory, network bandwidth, and virtual machines. Rapid Elasticity – Capabilities can be rapidly and elastically provisioned, in some cases automatically, to quickly scale out and rapidly released to quickly scale in. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be purchased in any quantity at any time. Measured Service – Cloud systems automatically control and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth, and active user accounts). Resource usage can be monitored, controlled, and reported providing transparency for both the provider and consumer of the utilized service. 6.
(21) 2.2.2. Service Models. Cloud services aspects are commonly divided in 4 main models, usually divided in the following categories as depicted in Figure 2.2: Cloud Software as a Service (SaaS) – The capability provided to the consumer is to use the provider’s applications running on a cloud infrastructure. The applications are accessible from various client devices through a thin client interface such as a web browser (e.g., web-based email). The consumer does not manage or control the underlying cloud infrastructure including network, servers, operating systems, storage, or even individual application capabilities, with the possible exception of limited user-specific application configuration settings. Examples of this model are for example Google Email - Gmail [24], or Google Apps [25]. Cloud Platform as a Service (PaaS) – The capability provided to the consumer is to deploy onto the cloud infrastructure consumer-created or acquired applications created using programming languages and tools supported by the provider. The consumer does not manage or control the underlying cloud infrastructure including network, servers, operating systems, or storage, but has control over the deployed applications and possibly application hosting environment configurations. One good example of this model is provided by Google App Engine, which allows running web applications on Google’s infrastructure [26]. Cloud Infrastructure as a Service (IaaS) – The capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. The consumer does not manage or control the underlying cloud infrastructure but has control over operating systems; storage, deployed applications, and possibly limited control of select networking components (e.g., host firewalls). One of the pioneers of this service model on a large scale is Amazon EC2 (Elastic Compute Cloud) [27]. EC2 is a web service that provides resizable compute capacity in the cloud. Cloud Storage as a Service (StaaS) – It’s a subset of IaaS. It facilitates cloud applications to scale beyond their limited servers. StaaS allows consumers to store their data at remote disks and access them anytime from any place. Cloud storage systems are expected to meet several rigorous requirements for maintaining consumers and data information, including high availability, reliability, performance, replication and data consistency. Again, the consumer does not manage or control the underlying cloud storage infrastructure but has control over storage and its contents. An example for this service model comes also from Amazon Web Services, which provide Amazon S3 (Simple Storage Service) [16]. S3 is service of storage for the Internet, and designed to be scalable and accessed from anywhere, at any time.. 7.
(22) Figure 2.2: Cloud computing service models. 2.2.3. Deployment Models. The deployment models that characterize essential aspects of installing and deploying cloud computing services are typically separated in the subsequent 4 categories: Private cloud – The cloud infrastructure is operated solely for an organization. It may be managed by the organization or a third party and may exist on premise or off premise. Community cloud – The cloud infrastructure is shared by several organizations and supports a specific community that has shared concerns (e.g., mission, security requirements, policy, and compliance considerations). It may be managed by the organizations or a third party and may exist on premise or off premise. Public cloud – The cloud infrastructure is made available to the general public or a large industry group and is owned by an organization selling cloud services. Hybrid cloud – The cloud infrastructure is a composition of two or more clouds (private, community, or public) that remain unique entities but are bound together by standardized or proprietary technology that enables data and application portability (e.g., cloud bursting for load-balancing between clouds).. 2.3. Cloud Storage. Cloud storage is a model of networked online storage where data is stored on multiple virtual servers, generally hosted by third parties, rather than being hosted on dedicated servers at organizations own data centers. In generic terms, hosting companies operate large data centers, and people or organizations that require their data to be hosted, buy or lease storage capacity from them and use it for their storage needs. Typically, the data center operators, in the background, virtualize the resources according to the requirements of the customers and expose them as storage pools, which the customers can themselves use to store files or data objects. Physically, the resource may span across multiple servers. Among the advantages of cloud storage the ones that stand out are: i) organizations need only to pay for the storage they actually use; ii) completely 8.
(23) flexible and scalable service; iii) organizations do not need to install physical storage devices in their own infrastructure (data center or offices), which reduces IT costs, and; iv) storage maintenance tasks, such as backup, data replication, and purchasing additional storage devices are offloaded to the responsibility of a serviced provider, allowing organizations to focus on their core business, that many times, is not even related to the IT industry [28, 29]. The increasing popularity of this model has lead to the appearance of new providers on the market, that offer several and differentiated storage services, as for example backups and disaster recovery services, or simply data file-systems. Nonetheless, organizations considering such service, like cloud backup for example, face among others these security concerns: • Could an unauthorized individual gain access to backed-up data stored in a cloud provider infrastruc-. ture? - Could backed-up data to the cloud be altered? • Will necessary data stored in the cloud be available when needed? • Will performance of cloud storage be significantly lower than local storage? • Is data safe from catastrophes (e.g., fire, floods and human error)? • Is the integrity and authenticity of (sensitive) data in transit being accounted for?. Another important subject that can become an issue is the fact that today cloud storage is amorphous, with neither a clearly defined set of capabilities nor any single architecture [30]. Choices differ from many traditional hosted or managed service providers, offering block or file storage, usually alongside with conventional remote access protocols, or virtual or physical server hosting. Moreover, current available APIs are heterogeneous, which raises difficulties when using more than one service. However, there are already some standardization efforts [31] despite the controversy such standardization may cause [32]. Proponents of drafting a standard argue it will boost customer adoption to the cloud, while opponents say that attempts to standardize the cloud in an early stage, might stifle innovation. Storage in the cloud encompasses common hosted storage, including offerings accessed by FTP, HTTP, NFS, or block protocols either remotely or from within a hosted environment. Cloud storage is an evolution of this hosted storage technology that wraps more sophisticated APIs, namespaces, file or data location virtualization, and management tools, around storage. Figure 2.3 shows the evolution of cloud storage based on traditional network storage and hosted storage. Presently, there are hundreds of different cloud-based storage systems, such as Amazon S3 [16], Windows Azure [15], Google storage [33], Nirvanix [34], Rackspace [35], Nasuni [36] and GoGrid [37] just to name a few. All of them with services directed to satisfy both organizations needs and personal use. Other providers such as Dropbox [38] and Drop.io [39] are more oriented to modest and personal needs. Nevertheless, these smaller market providers and startups commonly know different paths. While Dropbox service is consistently growing in number of users [40], Drop.io due to its notorious success, was acquired by Facebook [41, 42]. In any case, cloud computing and cloud-based storage is becoming more and more a certainty in every person’s life, either trough company use, personal use or both [43].. 9.
(24) Figure 2.3: Evolution of cloud storage. 2.4. Cloud Evaluation. 2.4.1. Generic Evaluation. The emerging cloud computing model is gaining serious interest from both industry and academia in the area of large-scale distributed computing. Mainly because it provides a new interesting paradigm for managing computing resources: instead of buying and managing hardware, users and organizations rent virtual machines and storage space, being the later, the focus of this thesis. At first sight, and mainly for organizations, the cost reduction in using cloud-based storage seems to have a preponderant role in the migration of data to the cloud [44]. However, other less noticeable advantages/arguments are persuading organization leaders to this shift. Among others, there are: • Shifting public data to an external cloud reduces the exposure of the internal sensitive data. The concern. of organization internal attacks might be reduced by shifting data to a different geographical data center, and not controlled by the organization itself. • Cloud homogeneity makes security auditing and testing simpler. For the organizations interested in. complying with standards or just requiring periodic auditings, may find this approach simpler and more effective due to the homogeneity of the service, that cloud storage provider might offer. • Clouds enable automated security management. For any organization willing to outsource its data to. the cloud, will find that it’s not necessary to also invest in management systems, since cloud providers in many cases already deploy this feature. Therefore, there is a cost reduction in this point, both in terms of investing in applications and on trained staff to work with them. • Redundancy and Disaster Recovery is also a key advantage publicized by cloud providers. In fact, in. case of some catastrophe at one organization headquarters, if data backups are stored at a remotely 10.
(25) and secure geographical location, the probability of recovering the services and the business faster, increases considerably if a business continuity plan exists. The redundancy of data is a key factor for this. • Ease of management is another persuading argument. Since the infrastructure is managed by another. party, the organization doesn’t need to be concerned with low level details of hardware, or more high level details of configurations. The few concerns inherent are the management of the requested storage and configurations of access control to it, if necessary. • Cost effectiveness is one of the major arguments impelling cloud storage, since if follows the pay-. per-use model. Therefore no misuse or wasted investments on own underutilized infrastructures are made. • Simplified planning is closely related to the previous point. The planning required focus on the migra-. tion and/or backup of data, instead of focusing on the details of entire projects that involve the planning of the infrastructure, acquiring equipments, deploying them, configurations and other details. Given such appealing strong points, it’s necessary to look at the other end of the scale, and analyze possible problems and challenges that might rise from using these cloud-based storage services. For both parties, academia and industry, the array of major concerns and key issues to overcome include the following: Availability, Confidentiality, Performance, Cost, Scalability, Integration, Trust (on vendors’ security model), Loss of physical control, Accountability and Compliance. Moreover, by having data on the clouds means that also value is on the clouds, which serves as stimulus for hackers to undertake malicious actions. Therefore it’s easy to perceive that many open problems need to be properly researched and tested. Some studies [45] already describe some of these challenges and the Cloud Security Alliance has published the top threats to Cloud Computing in [17]. Among others are described malicious insiders, account or service hijacking and data loss or leakage. The later for example, becomes especially important if we consider the kind of data that can be put on the cloud, like for example Healthcare records. On [46] it’s foreseen at United Kingdom a trend where “hospitals and medical centers will not buy computer servers or software anymore, but instead buy services from the web”. On the other side of the Atlantic, the fast grow of cloud business is already impelling administrations to adopt electronic medical records [47]. And studies involving big market player companies, plus huge investments are already ongoing by Intel [48] and EMC [49]. Other representatives of sensitive data can be easily obtained, being financial data and telecommunication data other examples. And even when not addressing sensitive data, diverse examples of data migration to cloud can be found. One important reference is the United States Library of Congress, which is using cloud technologies to test perpetual access to digital content [50]. At a high level, the interest of organizations and public in general is associated with the concerns already mentioned, plus QoS (Quality of Services) guarantees. With a long history in computer hardware and software, benchmark studies can be one way to evaluate cloud performance. However, benchmarking presupposes standardized tests and platforms, which are not yet a reality. There are already players (providers) with this interest in mind, of standardizing platforms and offer data integration [51]. Nonetheless, the benchmarking model isn’t really a good match for clouds, where the service model is designed to be dynamic, distributed and robust. One of the key selling points for cloud infrastructure is precisely that, it can be scalable. Even so, there are some clouds benchmarking efforts. Cloudstone [52] and CloudHarmony [53] are two good. 11.
(26) examples. The former is a benchmark out of Berkeley, designed to measure the performance of clouds planned to run Web 2.0 applications. The latter is the result of a startup effort, that recognized the need for better benchmarks and performance data to measure and compare cloud providers in an independent and unbiased way. They already make available several studies and an online cloud speed test [54] that encompasses four services: Content Delivery Networks (CDN), Cloud Servers, Cloud Storage and Cloud Platforms. All with parameterized variables. Some of this thesis work fits exactly on the category of testing cloud storage providers measuring variables as latency and access failures to understand, among others, the availability of some of the current commercial providers. One work that has some shared points with this thesis and DepSky is [55], where a performance evaluation of cloud computing offerings is presented at some detail. The authors used several benchmark tools but focus primarily in cloud computing configurations. Despite the work having a granular approach to particular services types, it misses the storage component aside. Other benchmarks and useful pointers about this problematic can be found in [56, 57, 58].. 2.4.2. Academic Works. On a more low level, and more related to academia, some interesting works have recently been published on this field. Two of those works, more closely related to this thesis line of work are the HAIL [59] and RACS [60] systems, which are described more carefully in Section 3.3. Other newsworthy researches often deal with the complexity of implementing a storage within the infrastructure of a cloud provider [61], or in using cloud storage to implement a service with better QoS, e.g., for backups [62] or even to use in group collaboration [63]. 2.4.2.1. Stout. In [61], was developed a system - Stout - that helps applications, that offer scalable and multi-tier services (many times software-as-a-service model), to adapt to variations in storage-layer performance, by treating scalable key-value storage as a shared resource requiring congestion controls. Overall this research presents optimizations in latency for light workloads. A typical example of applications of this work would be online applications like Google Docs [64] or similar ones. However this work is application specific and lacks the reach scope of other works such as DepSky system which embrace a larger variety of situations/scenarios (see Section 3.1). Moreover, this thesis goes one step further by using DepSky to measure latency and correlate data like number of access failures to clouds providers, among others (see Section 4). 2.4.2.2. Cumulus. On [62] is described Cumulus. A system for efficiently implement filesystem backups over the Internet, and designed merely under a thin cloud assumption, i.e., that the remote data center storing the backups does not provide any special backup services, but only a least-common-denominator storage interface. One of the advantages of this system is its capability of virtually being used with any storage service, which makes it useful for a wide range of utilization scenarios by any organization. In fact the corresponding paper shows one approach. However, the backup operation is the only application considered, and the concept of filesystem for daily use is not deepened. 12.
(27) 2.4.2.3. SPORC. Whit a different approach, SPORC [63] is a generic framework for building a wide variety of collaborative applications with untrusted servers, i.e., the cloud providers servers and storage. The heart behind SPORC is that a server observes only encrypted data and cannot deviate from correct execution without being detected. Moreover, SPORC allows concurrent, low-latency editing of shared state, permits disconnected operation and supports dynamic access control even in the presence of concurrency. However, one of the less successful points is the fact that this system requires membership management based on public key cryptography. What is more, SPORC is focus only in group collaboration application/data and not with concerns as reliability and security of data, which DepSky provide. Another common denominator to the above works is that they do not provide guarantees like confidentiality, and do not consider a cloud-of-clouds, like DepSky does. Furthermore, this thesis deepens the work of DepSky by adding new components and by performing a profound study of data availability and confidentiality.. 2.4.2.4. Other works. Besides the research works presented above, other interesting works exist on the domain of cloud storage services. On [65] is presented a scheme where is possible to introduce hierarchy in distributed cloud data access. This scheme enables a high level user (with higher administration rights) to efficiently share data and application services with all or some users at lower levels (lower administration rights). The main paradigm used is to join the common “one-to-many” encryption model to a hierarchical model. This can be extremely interesting to apply in any organization willing in migrate data to the cloud, and still maintain the ability to the collaborators to access, modify and share that data. Nevertheless, this work focus only in the confidentiality attribute and access control of information, and doesn’t address the availability of clouds, which is the scope of this thesis To end with, another relevant work to this topic is described on [66] which addresses the differentiated data availability guarantees in data clouds, and the associated costs. Nonetheless, this paper clearly takes a more economical approach to the subject in a very superficial study.. 13.
(28) Chapter 3. Storage Efficiency on a Cloud-of-Clouds This chapter addresses a storage efficient solution to form a cloud-of-clouds, which is the DepSky system. The focus behind DepSky has two main reasons. The first because the logger tool of this system was used to conduct the availability testes for this thesis. The second is related with the characteristics of DepSky, which was enhanced with one extra feature – Erasure Codes – also as part of the work for this thesis. Therefore it’s important to understand the essence of DepSky, with its system model, architecture and how the improvement made fits the whole frame. Thus, this chapter contains all the information related to storage efficiency and to DepSky.. 3.1. DepSky. DepSky is a dependable and secure storage system that leverages the benefits of cloud computing by using a combination of diverse commercial clouds to build a cloud-of-clouds. Although the scope of this thesis is not focused on DepSky, the latter was the main tool used to conduct the experiments after improvements being introduced. Therefore this section provides a brief overview of DepSky [9] and its advantages and accomplishments to put the reader in context. In general, the DepSky improves the availability, integrity and confidentiality of information stored in the cloud through the encryption, encoding and replication of the data. This allows mitigating the limitations of individual clouds using several dependability and security techniques. Specifically, DepSky addresses four important limitations of cloud computing for data storage; in particular: Loss of availability – temporary partial unavailability of the Internet is a well-known phenomenon [67]. When data is moved from inside of the organization network to an external data center, it is inevitable that service unavailability will be experienced. The same problem can be caused by DoS (Denial of Service attacks). DepSky deals with this problem by exploiting replication and diversity to store the data on several clouds, thus allowing access to the data as long as a subset of them is reachable. Loss and corruption of data – there are several cases of clouds services losing or corrupting customer data [68, 69]. DepSky addresses this problem using Byzantine fault-tolerant replication to store data on several cloud services, allowing data to be retrieved correctly even if some of the clouds corrupt or lose data (see Section 3.2.1). 14.
(29) Loss of privacy – the cloud provider has access to both the data stored in the cloud and metadata like access patterns. The provider might even be trustworthy, but malicious insiders are a wide-spread security problem. This is a special concern in applications that involve keeping private data like health records or financial information. An obvious solution is the customer encrypting the data before storing it, but if the data is accessed by distributed applications this involves running protocols for key distribution (processes in different machines need access to the cryptographic keys). DepSky employs a cryptographic secret sharing scheme (see Section 3.2.2) and erasure codes (see Section 3.2.3) to avoid storing clear data in the clouds and to improve the storage efficiency, amortizing the replication factor on the cost of the solution. Vendor Lock in (not security) – currently there is some concern about the vendor lock-in issue [60]. This problematic occurs in situations when a client of a cloud storage provider wants to move his data to another provider, but the costs of such operation become too expensive. Typically, moving from one provider to another one has a cost component proportional to the amount of data that is read and written, plus the storage itself. Moreover, the fear of a few cloud providers become dominant on the market is real, in particular in Europe, as the most conspicuous providers are not in the region. DepSky addresses this issue in two ways. First it does not depend on a single cloud provider, but on a few, so data access can be balanced among the providers considering their practices (e.g., cost). Second, DepSky uses erasure codes to store only a fraction (usually half) of the total amount of data in each cloud. In case of exchanging one provider by another arises, the migration cost of the data will be only a fraction of what it would be otherwise. The key insight of DepSky is that these limitations of individual clouds can be overcome by using a cloudof-clouds in which operations (read, write, etc.) are implemented using a set of Byzantine quorum systems protocols. These protocols require diversity of location, administration, design and implementation, which in this case comes directly from the use of different commercial clouds.. 3.1.1. DepSky Architecture. The architecture of DepSky is presented in Figure 3.1. As mentioned before, the clouds are storage clouds providers without the capacity of executing users’ code, so they are accessed using their standard interface without modifications. The DepSky algorithms are implemented as a software library in the clients. This library simply reads and writes data in the original clouds.. 15.
(30) Figure 3.1: DepSky architecture. 3.1.2. Data model. In order to achieve diversity and building a cloud-of-clouds, the DepSky library has to deal with the heterogeneity of the interfaces of each of the clouds. An aspect that is specifically important is the format of the data accepted by each cloud. The data model used by DepSky allowed abstracting these details and using all cloud providers uniformly. Figure 3.2 presents the data model of DepSky in three distinct levels. On the first one, a conceptual level of metadata, there are blocks represented by data units, which contain besides their value, a version number and verification information, to make the data self-verifiable. Generically, a data unit of DepSky contains: i) metadata with version number, verification data and a data pointer; ii) the actual data with the more recently stored value. Both these two components are always inside a container. Each data unit has its unique name which is its identifier. This is used to obtain references to the container and metadata of those units, on the defined protocols.. Figure 3.2: DepSky data model. 16.
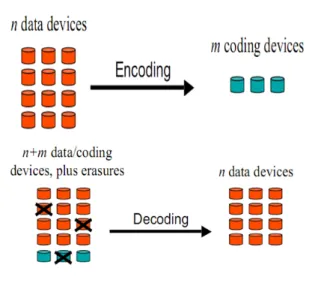
(31) The metadata files, as mentioned, are composed of version number, a reference for the file with this version number (data pointer) and verification information, which includes a cryptographic checksum of the data value to integrity verification. It’s also important to mention that to perform a write or read operation of a data unit, it’s always necessary to first make download of associated the metadata file. For that reason, there are two accesses to each cloud provider, i.e., two round trips. One for fetching the metadata file, and afterwards another one for obtaining the data itself.. 3.1.3. System model. DepSky considers an asynchronous distributed system composed by three types of parties: writers, readers and cloud storage providers. The latter are the clouds in Figure 3.1, while writers and readers are the roles of the clients. For the readers, DepSky considers that they can fail arbitrarily [70], i.e., they can crash, fail intermittently and present any behavior, either correct or not. On the other hand, writers are assumed to fail only by crashing. This decision is based on two arguments. First the protocols that tolerate malicious writers are quite complex. In second, arbitrary failures were not considered because even if the protocol tolerated inconsistent writes in the replicas, faulty writers would still be able to write wrong values, and effectively corrupting the state of the data. On the cloud storage providers’ side, DepSky assumes that clouds can fail in a Byzantine way, i.e., the data stored can be removed, corrupted, created or leaked to unauthorized parties. This is the most general fault model and encompasses both malicious attacks and intrusions on a cloud provider, and also arbitrary data corruption. Consequently, the protocols of DepSky require a set of n = 3f + 1 storage clouds with at most f of which can be faulty. The rationale for this assumption is to better represent the intrusion tolerance capabilities developed in DepSky.. 3.1.4. Protocols Overview. DepSky has two main protocols DepSky-A (Available DepSky) and DepSky-CA (Confidential and Available DepSky). The first protocol aims at improving the availability of cloud-stored data by replicating it on several providers using quorum techniques. However, his protocol has two main limitations. At one hand, a data unit of size S consumes n x S storage capacity of the system and costs on average n times more than if it was stored in a single cloud. On the other hand, it stores the data in clear-text, so it does not give confidentiality guarantees. To cope with this limitations, the second protocol, DepSky-CA employs an information-efficient secret sharing scheme [71] that combines symmetric encryption with a classical secret sharing scheme and optimal erasure code [72] to partition the data in a set of blocks in such a way that: i) f + 1 blocks are necessary to recover the original data and; ii) f or less blocks do not give any information about the stored data. Nevertheless, it is important to mention that erasure codes alone cannot satisfy any confidentiality guarantee. Furthermore, the work developed during this thesis involved precisely the integration of an Erasure Codes library with DepSky. Additionally, since the effort of this thesis focused on DepSky-CA protocol, only this will be further described, leaving aside DepSky-A. The rationale behind DepSky-CA protocol consists on the following three pillars. First, it uses Quorum protocols to serve as backbone of highly available storage systems. One key difference implemented in 17.
(32) DepSky is that metadata and data are written in separate quorum accesses. Moreover, since supporting multiple writers for a register (data unit) can be problematic due to the lack of server code to verify the version number of the data being written, the DepSky overcomes this by implementing a single-writer multireader register, which is sufficient for many common applications. Additionally, it’s important to mention that DepSky protocols requires at most two communication round-trips to read or write the metadata and the data files that are part of the data unit, respectively. The second pillar is concerned in assuring confidentiality of stored data on the clouds, without requiring a key distribution service. Therefore, DepSky employs a secret sharing scheme described in Section 3.2.2. With this scheme, a special party called dealer distributes a secret to n players, but each player gets only a share of this secret. The main properties of this scheme are that at least n ≥ f + 1 different shares of the secret are needed to recover it and that no information about the secret is disclosed with f or less shares. This scheme is integrated on the basic replication protocol in such a way that each cloud receives just a share of the data being written, besides the metadata. By doing this, its ensured that no individual cloud will have access to the data being stored, but on the other hand ensures that clients with authorization to access the data will be granted access to the shares of (at least) f + 1 different clouds, and will be able to rebuild the original data. In conclusion, the use of a secret sharing scheme allows the integration of confidentiality guarantees to the stored data, without requiring other mechanisms. Finally, the third pillar addresses the monetary cost of replication. By just replicating data on n clouds, the monetary cost of storing data, would increase by a factor of n. And this is also true for DepSky. In order to avoid this disadvantageous situation, the secret sharing scheme aforementioned, was composed with an information-optimal erasure code algorithm, reducing to approximately half, the size of each share to be stored. This composition was an active part of this thesis and is described in detail on Section 3.2.3.. 3.1.5. Basic Functioning. The generic approach adopted by DepSky for reading operations is the following. First, it tries to fetch the metadata files from a quorum of clouds, chooses the one with greatest version number and reads the value corresponding to this version number and the cryptographic hash value found in the chosen metadata. After receiving the first reply that satisfies this condition the reader returns the value by fetching the actual data from a quorum of clouds. This functioning is implemented on a logger application, which collects latency measurements for these operations, when tries to read a data unit from clouds in six different setups: the four storage clouds individually and the two DepSky protocols. The logger applications executes periodically a measurement epoch, which comprises: i) read the data unit from each of the clouds individually, one after another; ii) read the data unit using DepSky-A; iii) read the data unit using DepSky-CA; iv) sleep for until the next epoch. The goal is to read the data through different setups within a time period as small as possible in order to minimize Internet performance variations. For this thesis, the focus was made on the analysis of the readings (latency measurements) conducted by the DepSky logger on four cloud providers individually. The analysis of the readings performed by the DepSky-A and DepSky-CA protocols, are not the aim of this work, since those results are already reflected on the corresponding paper [9]. Despite the fact that DepSky also supports write operations, as most storage systems are designed for workloads in which readings are more frequent than writings, this investigation focused only on the latency of reading operations. 18.
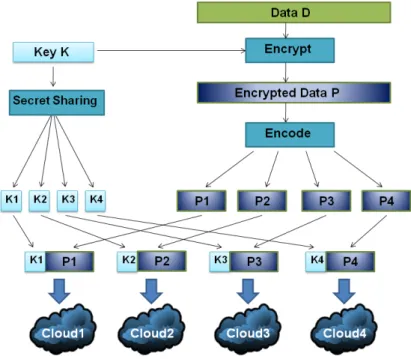
(33) 3.2. DepSky-CA. This Section presents the DepSky-CA protocol in more detail, with an emphasis on the mechanisms employed, and the reasons and advantages behind the inclusion of such mechanisms. The main reason for the use of Byzantine Quorum Systems is the assumption that cloud providers infrastructure can fail in an arbitrary way. On the other hand, the use of Secret Sharing is primarily related with confidentiality concerns of data, that otherwise would travel and be stored at the clouds, in clear-text. Lastly, the introduction of an Erasure Code scheme was made in order to cope with the problematic of increasing costs associated with data replication. Therefore it was a mechanism specifically aimed at making storage on clouds efficient and also to reduce such costs. Each topic is presented in the following subsections.. Figure 3.3: DepSky system interactions. The entire process of creating a cloud-of-clouds by the DepSky system, using for that 4 (four) commercial storage cloud providers, is depicted in Figure 3.3. This figure represents a data block being encrypted (using AES symmetric cryptography) and later encoded using the classic Reed-Solomon Erasure Codes [73]. The key use to encrypt the data is then submitted to a secret sharing (PVSS) scheme [74] in order to split the key on several different pieces, which alone don’t reveal the key itself. The following process consisted in join each piece of the key with a part of the already encoded data, which together were sent to each one of the cloud providers.. 3.2.1. Byzantine Quorum Systems. Fault tolerance, is the property that enables a system to continue operating properly even in the event of the failure (caused by a fault) of some of its components. The objective of Byzantine fault tolerance is to be able 19.
Imagem

+7
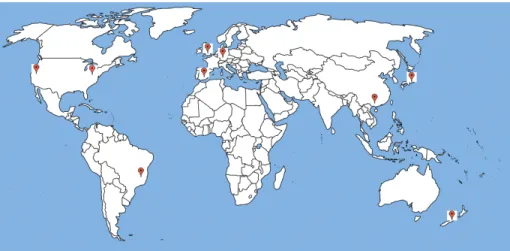




Documentos relacionados
Neste trabalho o objetivo central foi a ampliação e adequação do procedimento e programa computacional baseado no programa comercial MSC.PATRAN, para a geração automática de modelos
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
Mari Lucie da Silva Loreto – Universidade Federal de Pelotas – Pelotas-RS – Área de Arte/ Literatura Comparada/ Filosofia da arte/ Teoria da Arte/ História da
We differentiate between nonlinear physiological-based models, such as the Bal- loon model (Buxton, Wong and Frank, 1998; Friston et al., 2000; Riera et al., 2004), which describes
The probability of attending school four our group of interest in this region increased by 6.5 percentage points after the expansion of the Bolsa Família program in 2007 and
Moreover, the evaluation of the reinforcing steel deformation capacity – which is essential for an accurate calculation of the force-deformation curves, failure modes and, in
