Adaptive Hypertext.
The shattered document approach
Departamento de Ciˆ
encia de Computadores da
Faculdade de Ciˆ
encias da Universidade do Porto
Adaptive Hypertext.
The shattered document approach
Tese submetida `a Faculdade de Ciˆencias da Universidade do Porto para obten¸c˜ao do grau de
Doutor em Ciˆencia de Computadores
Departamento de Ciˆencia de Computadores da Faculdade de Ciˆencias da Universidade do Porto
We study how adaptive hypertext may improve the utilization of large online docu-ments. We put forth the inter-related concepts of shattered documents, and renoding: splitting a document into components smaller than the page, called noogramicles, and creating each page as a new assemblage of noogramicles each time it is accessed. The adaptation comes from learning the navigation patterns of the usors (authors and readers), and is manifested in the assemblage of pages. Another essential trait of our work is the utilization of user simulation for testing our hypotheses. We have created software simulators and conducted experiments with them to compare several adaptive and non-adaptive configurations. Yet another important aspect of our work was the study and adoption of the technique of spreading activation to explore the network database of the learnt model of travels. We have realised a quantitative evaluation based on utilization quality measures adapted to the problem: session size, session cost.
Estudamos como o hipertexto adaptativo pode melhorar a utiliza¸c˜ao de documen-tos em-linha de grande dimens˜ao. Apresentamos os conceitos interrelacionados de document fragmentado e rela¸cagem (recria¸c˜ao de n´os): separa¸c˜ao do documento em componentes de dimens˜ao inferior `a p´agina, chamados noogram´ıculos, e cria¸c˜ao de cada p´agina como uma nova montagem de noogram´ıculos de cada vez que ´e acedida, deste modo criando novos n´os na rede hipertextual, `a medida que a utiliza¸c˜ao progride. A adapta¸c˜ao prov´em de aprender os padr˜oes de navega¸c˜ao dos utilizadores (autores e leitores) e manifesta-se na montagem das p´aginas. Outro tra¸co essencial do nosso trabalho ´e o recurso `a simula¸c˜ao para testar as nossas hip´oteses. Cri´amos simuladores em software e realiz´amos experiˆencias com eles para comparar v´arias configura¸c˜oes adaptativas e n˜ao-adaptativas. Ainda outro aspeto importante deste trabalho ´e o estudo e ado¸c˜ao da t´ecnica de propaga¸c˜ao da ativa¸c˜ao para explorar a base-de-dados reticular do modelo de viagens aprendidas. Realiz´amos uma avalia¸c˜ao quantitativa baseada em medidas de qualidade da utiliza¸c˜ao adaptadas ao problema: tamanho da sess˜ao, custo da sess˜ao.
On ´etudie comme l’hypertexte adaptatif peut am´eliorer l’utilisation de documents en-ligne de grande dimension. On pr´esente les concepts, en rapport entre eux-m`emes, du document fragment´e et le rela¸cage (recr´eation de noeuds): la s´eparation du document en des composants de dimension inf´erieure `a celle de la page, nom´es les noogramicules, et la cr´eation de chaque page comme un nouvel assemblage de noogramicules `a chaque fois qu’on l’acc`ede, cr´eant ainsi de nouveaux noeuds sur le r´eseau hypertextuel, au fur et `a mesure du progr`es de l’utilisation. L’adaptation vient de l’apprentissage des mod`eles de navigation des utilisateurs (auteurs et lecteurs) et elle se r´ev`ele `a travers l’assemblage des pages. Un autre trais essentiel de notre travail, c’est le recours `a la simulation afin de tester nos hypoth`eses. On cr´ea des simulateurs logiciels et on r´ealisa des exp´eriences avec eux pour comparer plusieurs configurations adaptatives et non adaptatives. Un autre aspect important de ce travail c’est l’´etude et l’adoption de la technique de propagation de l’activation pour exploiter la base de donn´es r´eseau du mod`ele de voyages appris. On r´ealiza une ´evaluation quantitative support´ee par des mesures de qualit´e d’utilisation, adapt´ees au probl`eme: taille de s´ession, coˆut de s´ession.
I love deadlines. I like the whooshing sound they make as they fly by.
Douglas Adams
I am extremely indebted to my advisor Doctor Al´ıpio Jorge and co-advisor Doctor Z´e Paulo Leal.
Al´ıpio is the most wise person I know. Each of his numerous advice was always entirely pertinent and convenient. Had I followed them all and this thesis would have been a work of absolute perfection. Al´ıpio’s support of my work stood unabated through the unending stream of deadline missing after deadline missing from my part. I was as surprised as I was thankful for this continued support. I was surprised because Al´ıpio is the most wise person I know, and I would expect even a mildly clever person to spot a clear lost case and hastily detach themselves from the dead weight. Paradoxically, the fact that you are now reading these lines on an acceptable if imperfect thesis is a result of Al´ıpio being the most wise person I know.
I am indebted to Professor Pavel Brazdil for being the excellent leader of LIAAD -INESC Porto (formerly NIAAD - LIAAC), the laboratory where this whole business started.
I am indebted to Rodolfo Matos, the prolific sysadmin of LIAAD, for his prompt support and enduring friendship.
I am grateful to all NIAAD and DCC members for their support and comradeship. I am indebted to the Funda¸c˜ao para a Ciˆencia e Tecnologia for supporting four years of doctoral research.
I am indebted to Ada Europe, APPIA, Prolearn, and Universidade Aberta, for conference-xiii
I am grateful to Cec´ılia. With the grace of God.
Abstract vii
Resumo ix
R´esum´e xi
Acknowledgements xiii
List of Tables xxiii
List of Figures xxvii
1 Introduction 1
1.1 Context . . . 1
1.1.1 Rationale for hypertextualization . . . 2
1.1.2 Limitations of hypertext . . . 3
1.2 Solutions . . . 4
1.2.1 Our solution . . . 6
1.2.2 Hypotheses of this work . . . 6
1.3 Main contributions . . . 7
1.4 Structure of the text . . . 8
1.4.1 Notation . . . 9 xv
2.1 Definition . . . 11
2.2 Terminology . . . 12
2.3 Forms of hypertext . . . 13
2.3.1 The words used . . . 19
2.3.2 Items vs. connections . . . 20
2.3.3 The Monographic Principle . . . 22
2.3.4 Summary of hypertext history . . . 24
2.3.5 The document dogma . . . 24
2.3.6 Information search—the impossible that is done . . . 25
2.3.7 Aporias of adaptation . . . 26
2.3.8 Minor issues . . . 27
2.4 Structure of documents . . . 36
2.4.1 Traditional document structure . . . 36
2.4.2 Standard hypertextualization . . . 37
2.5 Learning systems . . . 40
2.5.1 Adaptive hypertext techniques . . . 41
2.5.2 Learning Systems highlights . . . 44
2.6 Summary . . . 46
3 A new model for adaptive hypertext 49 3.1 Motivation . . . 49
3.1.1 Information, not documents . . . 49
3.1.2 Guidelines for adaptive hypertext . . . 50
3.2 Model design . . . 54
3.2.1 The Shattered Documents model . . . 54 xvi
3.2.3 Interface design . . . 57
3.2.4 Detailed design with a network data model . . . 60
3.3 Techniques and tools reused . . . 60
3.3.1 A unified model of spreading activation . . . 63
3.3.2 A didactical example . . . 63
3.3.3 Benefits of spreading activation for information retrieval . . . . 66
3.3.4 The generic model . . . 67
3.3.5 About the implementation . . . 70
3.3.6 Leaky Capacitor Model (LCM) . . . 71
3.3.7 Reverberative Circles (RC) . . . 73
3.3.8 Waterline . . . 74
3.4 Algorithms . . . 74
3.4.1 Overview . . . 75
3.4.2 Formalization . . . 76
3.4.3 Start page algorithms . . . 76
3.4.4 Recentring algorithms . . . 77 3.4.5 Learning algorithms . . . 79 3.5 Summary . . . 80 4 Experimental methodology 81 4.1 Simulation . . . 82 4.1.1 Formalization . . . 83 4.2 Experiments . . . 84 4.3 Parameter settings . . . 85 4.3.1 The document . . . 88 xvii
4.4 Evaluation methodology and measures . . . 91
4.4.1 Session size . . . 91
4.4.2 Session cost . . . 91
4.5 Statistics . . . 92
4.5.1 Common and bottom line statistics . . . 94
4.5.2 Statistics in the Outcomes tables . . . 95
4.5.3 Statistics in the Results tables . . . 96
4.5.4 Statistics in the Evolution tables . . . 96
4.5.5 Alternate terms . . . 97
4.6 Summary . . . 97
5 Results 99 5.1 Main results . . . 100
5.1.1 Session size and success rate . . . 101
5.1.2 Evolution . . . 102
5.2 Testing link types . . . 103
5.3 Testing adaptative techniques . . . 105
5.4 Summary . . . 105
6 Conclusions 107 6.1 Main conclusion . . . 107
6.2 The pros and cons of simulating . . . 107
6.3 Paths not taken . . . 108
6.4 Future work . . . 109
A Electronic archive 127
B.1 Package Arm05 Model (spec) . . . 129
B.2 Package Arm05 Model (body) . . . 131
B.3 Procedure Arm05 Model.Get Info (body only) . . . 134
B.4 Package Kasim2 (spec) . . . 137
B.5 Package Kasim2 (body) . . . 143
B.6 Package Kasim2.Activation (spec) . . . 151
B.7 Package Kasim2.Activation (body) . . . 152
B.8 Package Kasim2.Comparate (spec) . . . 160
B.9 Package Kasim2.Comparate (body) . . . 161
B.10 Procedure Kasim2.Comparate.Experiment (body only) . . . 186
B.11 Package Kasim2.Markov (spec) . . . 187
B.12 Package Kasim2.Markov (body) . . . 187
B.13 Package Kasim2.Markov With Heuristics (body) . . . 190
B.14 Package Kasim2.Markov With Heuristics (body) . . . 193
B.15 Package Kasim2.Structural (spec) . . . 197
B.16 Package Kasim2.Structural (body) . . . 197
C Supplemental Items 201 C.1 Software requirements for the Knowledge Atoms design . . . 201
C.2 Kasim 1. First cycle of experiments . . . 202
C.2.1 Second round: 60 atoms, 10 oracles . . . 205
C.2.2 Conclusion of cycle one . . . 207
C.3 Notes on Network Data Models . . . 207
C.3.1 Primary concepts of network data structures . . . 208
C.3.2 The untyped network hypothesis . . . 209 xix
C.3.4 A network calculus . . . 215
C.3.5 Fundamental entities, definitions . . . 215
C.3.6 Useful theorems . . . 216
C.3.7 Proofs, lemmas, axioms . . . 217
D Detailed results of experiments 219 D.0.8 Common and bottom line statistics . . . 221
D.0.9 Statistics in the Outcomes tables . . . 222
D.0.10 Statistics in the Results tables . . . 223
D.0.11 Statistics in the Evolution tables . . . 223
D.0.12 Alternate terms . . . 224
D.1 Complete results of configuration Shattered Document . . . 225
D.2 Complete results of configuration Shattered Document with Random Clicks . . . 233
D.3 Complete results of configuration Shattered Document with Random Pages . . . 241
D.4 Complete results of configuration Shattered Document with Random Learning . . . 249
D.5 Complete results of configuration Shattered Document with Random Pages and Random Learning . . . 257
D.6 Complete results of configuration Shattered Document with Random Document (fixed) . . . 265
D.7 Complete results of configuration Structural . . . 273
D.8 Complete results of configuration Shattered Document with high max-imum cost . . . 281 D.9 Complete results of configuration Structural with high maximum cost . 289
D.11 Complete results of configuration Shattered Document, no Next links, weak Residual . . . 305 D.12 Complete results of configuration Shattered Document, weak Next links 313 D.13 Complete results of configuration Shattered Document with Strong
Legacy . . . 321 D.14 Complete results of configuration Shattered Document, dense start . . 329 D.15 Complete results of configuration Shattered Document with Markov
Chains . . . 337 D.16 Complete results of configuration Shattered Document with Markov
Chains with heuristics . . . 345 D.17 Complete results of configuration Shattered Document, Trimmed Tree . 353 D.18 Complete results of configuration Structural, Trimmed Tree . . . 361 D.19 Complete results of configuration Shattered Document with Markov
Chains, Trimmed Tree . . . 369 D.20 Complete results of configuration Shattered Document with Markov
Chains with heuristics, Trimmed Tree . . . 377
2.1 Summary of hypertext history . . . 24
4.1 Some scalar parameters of the simulator . . . 87 4.2 Distribution of nodes per level in the ARM . . . 88 4.3 Random sample of sections . . . 90 4.4 Distribution of nodes per level in the Cut ARM . . . 90 4.5 Distribution of nodes per level in the TrimmedARM . . . 91
5.1 Main results. . . 100 5.2 P-values for the main results. . . 101 5.3 Results for maximum cost = 6. . . 102 5.4 Varying the link weights . . . 104 5.5 Markov chain results . . . 105
1.1 Adaptive hypertext process. . . 2 1.2 Example of online shop recommendations. . . 5
2.1 Screenshot of a Xanadu prototype on Nelson 2007a. . . 15 2.2 Illustration of an advanced form of hypertext on Nelson 2007b. . . 16 2.3 SWI-Prolog help panel. . . 17 2.4 SWI-Prolog help panel for consult/1 . . . 18 2.5 Dictionary. . . 19 2.6 SWI-Prolog help for catch/3. . . 28 2.7 Alternative to the design in figure 2.6 . . . 28 2.8 The web interface of the network router Linksys WRT54G. . . 29 2.9 How compound terms are (mis)treated inDictionary. . . 30 2.10 The Back button aporia. In certain contexts the user expects a
chrono-logical behaviour. 33
2.11 The Back button aporia. Why the Back button should not behave chronologically.
33
2.12 Standard hypertextualization of the sequential structure. . . 39 2.13 Real look of the first page in figure 2.12. . . 39 2.14 The Knowledge Sea interface (KnowledgeSea). . . 46
3.1 Model of the same document in figure 2.12 but with the shattered document approach and the two types of connection Next (N) and Child (C). . . 55 3.2 Page made up of document fragments. . . 55 3.3 Example design of our own adaptation model. . . 59 3.4 Relating the web page as seen and the graph model underneath. . . 61 3.5 Travelling . . . 62 3.6 Toy network, for a general understanding of spreading activation . . . . 64 3.7 Instances of spreading activation over the toy network (transcripts of
sessions with the Minibrain program). . . 65 3.8 Step algorithm. . . 70 3.9 Minibrain usage. . . 70 3.10 Super Page algorithm . . . 76 3.11 Main recentring algorithm . . . 77 3.12 Pure Markov chains recentring algorithm . . . 78 3.13 Heuristical Markov chains recentring algorithm . . . 78
4.1 Choose algorithm . . . 84 4.2 Evolution of session size in an exploratory experiment . . . 85 4.3 Top level models and respective components of the experimental setup. 86 4.4 Partial configuration map of the simulator. . . 87 4.5 Hierarchical structure of the ARM(excluding annexes). . . 89
5.1 Session cost evolution for the shattered document D.9 . . . 103 5.2 Session costs and sizes for the original structure D.8 . . . 103
C.2 Complete structure of document X3 . . . 204 C.3 Evolution of session size for each oracle . . . 205 C.4 Hierarchical structure of document X4 (CHILD links) . . . 206 C.5 Evolution of session size . . . 207 C.6 A subset of XQuery use case 1.1.2 (Chamberlinet al.2005) represented
in (a) the original XML format, (b) a typed network a la RDF. This example illustrates various issues discussed in the text. . . 209 C.7 The direct attribute structure equates a connection. . . 211 C.8 Untyped base structure to represent an explicit, extensively defined set
X = {x1, . . . , xm}. . . 212
C.9 The road intersection pattern (a), for representing an (abstract) typed connection (b), in the untyped network base. . . 212 C.10 A subset of XQuery use case 1.1.2 (Chamberlinet al.2005) represented
in: (a) the original XML format; (b) a typed network; (c) the untyped network base. This example illustrates various issues discussed in the text. . . 213
Introduction
Traveller, there are no paths. Paths are made by walking.
Ant´onio Machado
1.1
Context
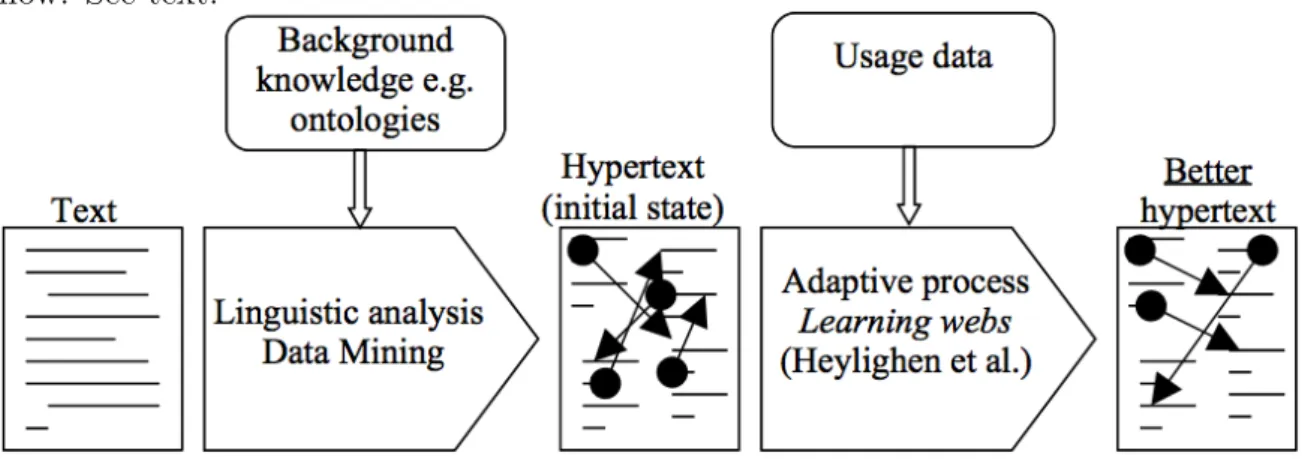
This thesis studies the process of hypertextualization and hypertext adaptation, as a means to improve the utilization of large online documents. Figure 1.1 illustrates this two-phase transformation process from a traditional document, or set of items, to hypertext, and therefrom to a different, adapted, hypertext—hopefully a better one. The diagram depicts the overall process; the techniques named therein are just a few of many possible ones, all addressed later.
We study the different parts of the process. In general, we delve more deeply into the adaptive parts of the process, situated on the right-hand half of the diagram. Our main original contributions are the concept of renoding, or shattered documents, and a simulator of user behaviour, which we use to automate the evaluation of different hypertext systems.
In sum, we study the large online document, and how its utilization might be improved by means of adaptive hypertext features. Large means an extent such that the document cannot be seen all at once. In other words: large = (much) larger than a screenful.
Figure 1.1: Adaptive hypertext process.
The horizontal direction represents transformation. Vertical arrows represent data flow. See text.
1.1.1
Rationale for hypertextualization
It is a fair assumption that large online documents have much to gain from being structured as hypertext. The amount of hypertext present in the Word “Wild” Web, its sheer weight, supports this assumption. (However its relative weight is small, 44% only, against 56% of PDF documents. More on this later.)
The collective mind of Web authors, manifested in the authored Web links, has also been shown a useful resource for exploring the Web space. The current epitome of this approach is the famous PageRank algorithm, which arranges Google results (Pageet al.1999).
Since the Web can be seen as a huge hypertext document, we may transpose these facts to the general concept of large document, and hypothesise that any large online document will gain by taking the form of hypertext and being adapted to—and by—its users and authors, or usors1.
More generally, hypertextualization can be seen as an effect of the desire to augment intelectual power via technology (Bush 1945). This movement is pervasive to all mankind, and clearly justifiable. This rationale of intelect augmentation is adressed lengthly in chapter 2.
1After having arrived at the concept and term of usor, we have found the term wreader being
used for a similar concept, as reported by Weel 2006. We have stayed with usor : its morphology is more regular than that of wreader, and its sound is more distinguishable from user than the sound of wreader from reader.
1.1.2
Limitations of hypertext
The main problem with hypertext is an increased utilization effort relative to normal text. This accrued effort is two-fold: there is an increased effort of authoring, and there is an increased effort of navigation.
1.1.2.1 Hypertext is costly to build
There is an increased authoring effort of creating the pages and the links—accrued relatively to the work of producing normal text (Braet al.1999). The hypertext author has to organize or divide the content into pages, and create links between the pages. The number of possible page partitions and manner of linking is virtually infinite, which puts upon the author the burden of making an innordinate number of decisions that are difficult, violent (Belo 1991)—and therefore very costly.
One might think that normal text has a specific cost of its own too: because of the sequential nature of normal text, special devices of anaphor, narrative, prosody, punctuation, textual cohesion—rhetorical devices in whole—must come into play to make for a good sequential reading. But it has been shown that such factors play their part in hypertext too (Mancini 2004). For one, hypertext is still text. Even if the pages are short, they are still large enough for most rhetorical devices to operate in—and be required to.
1.1.2.2 Hypertext is costly to navigate
There is an increased reading effort of navigating an hypertext—additional to the effort of reading normal text. Essentially, the user is put in charge of constructing their own unique pathway through a variety of options (Lawlesset al.2003, Raskin 2000). This activity incurs the extra cognitive cost of making choices, from a sometimes unwiedy number of options, of links on a page.
A related, often purported limitation of hypertext is the lost in hyperspace syndrome. We discuss this on chapter 2, particularly on section 2.3.8.6.
1.2
Solutions
A number of automatic adaptive techniques have been tried or proposed as a means to alleviate the costs of both authoring and reading hypertext (Braet al.1999). Such techniques are analysed at length on chapter 2, particularly on section 2.5. Most if not all such proposals revolve around the concept of relinking—creating or changing links automatically, with the objective of helping users in their navigation. Those proposals are academic, stemming mostly from the Intelligent Tutoring Systems area, and are still confined to the laboratory. So is our own proposal.
In the real world, there is Google and Amazon. These resources can be seen as large hypertexts too, because they have pages and links. Google results are automatically created links from a search expression to related items on the Web. Amazon recom-mendations are automatically created links to related items on the store. Amazon and similar sites are adaptive hypertexts.
The principal part of Google algorithm is the PageRank algorithm that order the results (Pageet al.1999). PageRank relies entirely on the authoring effort of others, namely of all authors of all the pages on the Web, because it draws results from the analysis of the links between the pages, and such links and pages were created at a cost to the authors, as we have discussed. So PageRank is not really a solution to the hypertextualization cost problem, it just moves the problem out of its sight. Without authored links, there would be no Google.
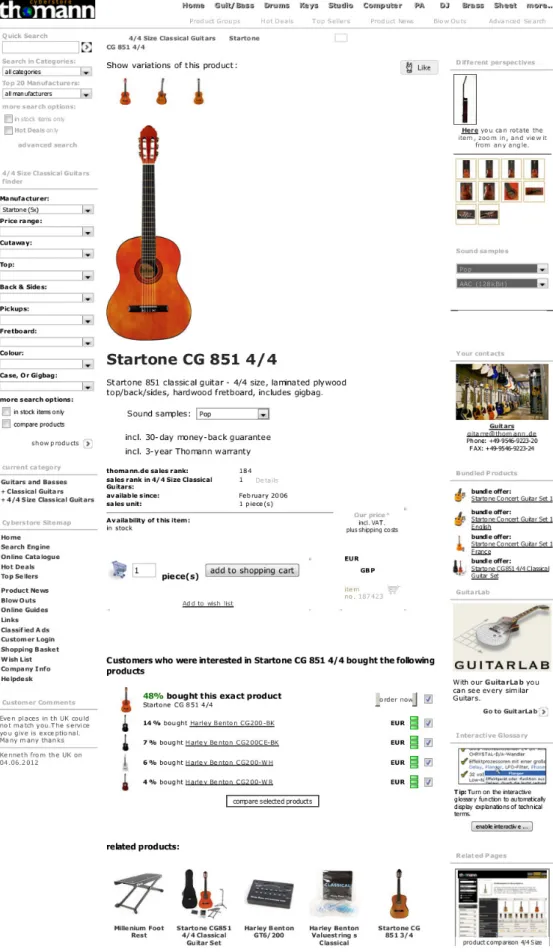
The recommendations at Amazon, or at other similar online shops, are computed based on the recorded navigation data, using a technique called collaborative filtering (Goldberget al.1992). The navigation data includes conversion information: wheather the user has bought the item or not. See figure 1.2 for an example; note the recomenda-tions at the bottom of the large central zone; note the recommendarecomenda-tions clearly marked as derived from the choices made by other users: “Customers who were interested in Startone CG 851 4/4 bought the following products”, and the items recommended by some other means, simply titled “related products”.
The recorded navigation data represent the actions made by users. Using this data is indeed likely to provide a means of alleviating the hypertextualization effort. Actually our own proposal in this thesis can be seen as a variant of this approach, as we shall see. That is, our system can partially be seen as a recommendation system. Among other similarities of our proposal with online shop recommendations, there is the obvious alignment between the concepts of conversion (online shop) and successful session
(our system).
Recommendation systems have yielded good results in online shopping—we have not seen the method applied to documents. The laboratorial, academic adaptive tech-niques (cf. chapter 2, particularly section 2.5), have indeed been aplied to documents, with results that are also, so far, generally positive. However, it is hard to draw convincing comparisons because there is no common methodology, no common mea-sures of hypertext usability used across the different proposals. We wanted to improve on this situation. In particular, we wanted to explore the following observation: all existing systems, laboratorial or real, treat the pages as given, integral wholes.
1.2.1
Our solution
We questioned the presumed atomicity of pages, on the assumption that it might be an obstacle to better adaptation. Our rationale is based greatly on the observation that when we consult a document for reference, we end up selecting a small part of the document to satisfy our precise information need. So perhaps we could split, or shatter, a document into such small parts, or noogramicles, in order to adapt pages made of them towards the (computed) needs of the reader.
So, whereas in all existing systems (laboratorial or real) the pages are given, integral wholes, in our system the pages, or nodes, are an assemblage of small document parts, which we call noogramicles. Some noogramicles are shown contracted and actually constitute links to their fully expanded expression, or view. So a page in our system is actually a set of items of two types: document parts, links to other document parts. Each page is created anew upon each request. So we have called this approach renoding, as a paraphrase of relinking. The constituend noogramicles of each page are selected based on usage, or navigation data, as in recommendation systems. This selection is done using a spreading activation algorithm, described later.
1.2.2
Hypotheses of this work
Naturally we expect our approach to improve upon a non-adaptive document, and so our main hypothesis is expressed thus:
a user in a shattered adaptive hypertext document is reduced with respect to the original hypertext document.
We also hope our spreading activation algorithm to fare better than a standard adaptive technique like Markov chains.
Spreading Activation Hypothesis (supplemental hypothesis). Spreading acti-vation is a better adaptation model for shattered documents than first order Markov chains.
Finally, a part of our method consists in treating all relations, or links, equally. Namely, we propose that, for adaptation purposes, the original document relations between noogramicles, namely the relations of sequence, hierarchy, and cross-reference, equate each other and, more importantly, they equate the relation established by the user when travelling between noogramicles. This amounts to viewing the author simply as the first user, or usor of the document, i.e. we unify the concepts of author and reader.
Usor Hypothesis (supplemental hypothesis). Varying the weights of links ac-cording to their type does not have an influence on results.
1.3
Main contributions
The main contributions of this thesis are concentrated in the new concept of renoding. Renoding is a paraphrase of relinking. Relinking is the adaptive hypertext state-of-the-art item that consists of changing, creating, or deleting hyperlinks (Bollen 2001). A foundational observation of our research is that there is no a priori reason why links should be thus changed and pages not. In particular, we observe that the state-of-the-art tacitly subsumes pages as given, integral items.
Renoding is necessarily achieved by means of shattering the document into small pieces, or noogramicles, for adaptation. It is very important to keep in mind that renoding and shattering are done for the purpose of adaptation only. That is, renoding is strictly an adaptation technique.
Given the extremely networked nature of the data structures involved, we have decided to use spreading activation as a technique to explore these data graphs. The use of
spreading activation for data analysis is still an evolving research issue, therefore our findings in this area are also a contribution of this thesis.
As an experimental test bed, we have built a user simulator. Although potentially imperfect and necessarily simplified with respect to reality, the simulator enables extensive testing with different variants and can be regarded as a contribution per se. It also provides a well defined characterization of the assumptions under which the proposed approaches can operate. The evaluation of selected techniques, as well as the callibration of the simulator, on real user experiments has been left for future work. Using the proposed simulator, we have compared our approach against non-adaptive variants, and also against non-adaptive variants using a standard recommendation algorithm based on Markov Chains. Our approach has indeed fared the best in our main measure of session cost, ultimately verifying all our hypotheses.
1.4
Structure of the text
This thesis is organized into the following main parts.
Chapter 1. Introduction. Main theme and hypotheses briefly presented and mo-tivated.
Chapter 2. Hypertext. Discussion of hypertext in general, its history, including background and related work, and further motivation for the approaches in this thesis.
Chapter 3. A new model for adaptive hypertext. Description of the shattered document approach, including algorithms.
Chapter 4. Experimental methodology. Definition of the experimental setup, in-cluding simulation algorithms.
Chapter 5. Results Presentation of the results of the experiments. Chapter 6. Conclusions Conclusions and future work.
References. Bibliographical descriptions of cited or studied works, websites, software works.
Appendix A. Electronic archive. DVD-ROM or card with the software created in this thesis, or indication of where on the web to obtain it.
Appendix B. Program listings. Listings of the principal source code units cre-ated.
Appendix C. Supplemental writings. A few writings that did not fit on the main body of the thesis, including a description of the first, small scale, exploratory experiments and simulator.
Appendix D. Detailed results of experiments. Complete result data of the large scale experiments reported, in the form of tables and charts.
Physical copies of this thesis are normally divided in volumes (the page numbers and quantities are approximate):
Volume Page numbers Qt. of pages
I. Main text and appendix A i–xxv, 1–125 150
II. Appendices B–D 125–375 250
total = 400
1.4.1
Notation
Forms like Rome 2003 are bibliographical references. Forms like Turbo C, undated, are references to entities of a different type than documents, but still referable, like software works or websites. All references are collected and described on the respective section.
Single word, or expression, quotations take this form. Short, in-text quotations “take this form”. Single word or expression quotations take the same form as emphasis, not to overload the text with too many distinct notations. All short or long quotations are accompanied by the respective bibliographical reference.
“A long quotation takes the form of this paragraph. A long quotation takes the form of this paragraph. A long quotation takes the form of this paragraph.”
Hypertext
Our writing equipment takes part in the forming of our thoughts.
F. Nietzsche
In this chapter we define hypertext, and discuss the aporias, or theoretical difficul-ties, of text, hypertext, and adaptive hypertext. Occasionally, we lay down certain assumptions, which we have found necessary in order to proceed with our work. We also chart the history of hypertext in this chapter.
2.1
Definition
An entirely consensual definition of hypertext does not exist. Below (section 2.3) we shall discuss this issue in detail and arrive at a working definition, which we preview here for convenience:
Hypertext is an interface to interconnected items of textual or pictorial information, which interface lets the user follow any connection, and also records the connections followed and lets the user relive them at will, typically by means of a “back button”.
2.2
Terminology
We use the following non-trivial or specific terms in this thesis. Terms marked with an asterisk have a specific meaning in this thesis i.e. we give the meaning specifically used in this thesis and particulary in the shattered document design.
Atom* See noogramicle.
Codex The current form of the physical book: a set of rectangular leaves of paper bound together along one side.
Context The wider or historical circunstances. Other authors use the term user context instead of user input.
Cybernetics The science that studies the abstract principles of organization in com-plex systems. (Heylighen&Joslyn 2001)
Distal content The page at the other end of the link. (Olson&Chi 2003)
Fan-in The quantity of afferent (incoming) immediate connections from a node in a tree or graph data structure. A.k.a. in-degree.
Fanout The quantity of efferent (outgoing) immediate connections from a node in a tree or graph data structure. A.k.a. out-degree.
Information need The information need of a user of an information repository. Syn-onymous with the term and concept of reference question from library science. The information need triggers, and sustains, a search session.
Noogramicle* The smallest constituent of meaning on a document. A caption, a figure, a formula, a footnote, a heading, a listing, a paragraph, a sentence, a table, a title, etc. Synonyns used at some time in our work include atom, knowledge atom, paragraph, extended paragraph; these forms may surface for historical reasons on software items; please adjust.
Oracle* The noogramicle, or noogramicles, that constitute the answer to the refer-ence question. We chose this term over the more common target or goal, to facilitate distinction from other meanings of the latter, notably the end point of a link, or the head of a directed connection in a data graph, which are concepts operating in this thesis also.
Page* An assemblage of noogramicles. More precisely, of views of noogramicles. Reference question See information need.
Session A finite episode of utilization of an hypertext system, by a user with a reference question in mind. The session represents the user searching for the answer to the reference question. The session terminates upon finding the answer (successful session) or giving up (unsuccessful session).
Session cost* Cognitive effort associated with the navigation aspect of a session. A rough measure is Session size. Finer measures takes into account other factors like page size, need for scrolling, etc.
Session size Session size = number of pages visited = number of clicks + 1.
View* The view of a noogramicle is the readable representation of the noogramicle. It is either expanded or contracted. The expanded or full view represents the noogramicle entirely. The contracted view, or label, serves as the anchor of a link. For indicative noogramicles like headings and titles normally the full view is used as the label i.e. there is no contraction proper. For propositional noogramicles like paragraphs normally the first few words are used to form the label; for items with a caption like tables and figures normally the caption is used for this purpose.
2.3
Forms of hypertext
The first aporia of hypertext concerns the notion itself. Very different kinds of hypertext have been proposed, some even antagonistic between them. For example, Nelson’s conception is consistently put in dire opposition to Berners-Lee’s, or HTML. This state of affairs makes the use, the denotation, of the word hypertext inaccurate, to say the least.
In the 1960’s Ted Nelson coined the very word hypertext, with the general meaning of
“a body of written or pictorial material interconnected in such complex way that it could not conveniently be presented or represented on paper.” (Nelson 1965)
The word has thriven, as we know. In the course of these four or five decades, it has become an essential part of both popular and scientific culture. Today, ar-guably the most common species of hypertext is that inhabiting the World Wild Web.
N¨urnberget al.1996integrate well from several notable sources (Engelbart&English 1968,
Halasz 1988, Marshallet al.1994), for a definition of such kind of hypertext:
“Information realized in the interface by connected “pages” of text and graphics traversed through a “point-and-click” navigation mechanism.” (N¨urnberget al.1996)1
Surveying an even wider range of sources, Mancini 2004 arrives at a tripartite classifi-cation, of which we will attempt a synthetic formulation2
• page-based hypertext: the common, web-like hypertext
• semantic hypertext, characterized by having typed connections • spatial hypertext: semantic hypertext visualized graphically.
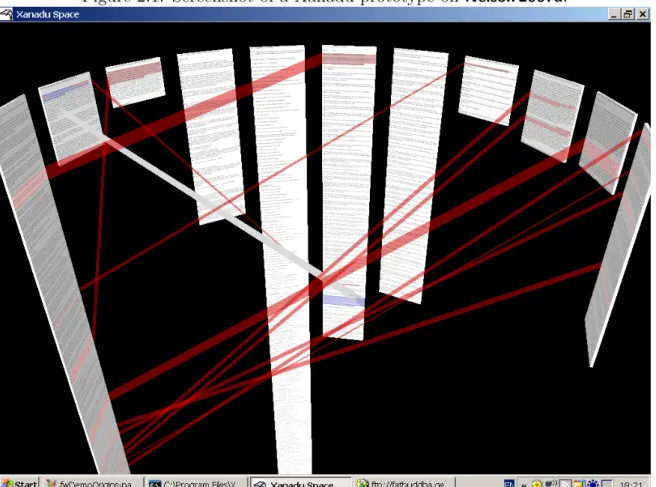
Mancini 2004 stands as one of the best works we have studied on the subject of hyper-text, and one of the very few correctly acknowledging the existence of various kinds of hypertext. Nevertheless, we observe that, strangely, she colocates Ted Nelson’s hypertext alongside web hypertext, in the page-based category. This might be unfair towards Nelson’s original proposal, called Xanadu:
“I believe it was in 1968 that I presented the full 2-way Xanadu3 design to a
university group, and they dismissed it as “raving”; whereupon I dumbed it down to 1-way links and only one visible window. When they asked how the user would navigate, I suggested a backtrackable stack of recently visited addresses. I believe that this dumbdown, through the various pathways of projects imitating one another, became today’s general design, and I am truly sorry for my role in it.” (Nelson 1999)
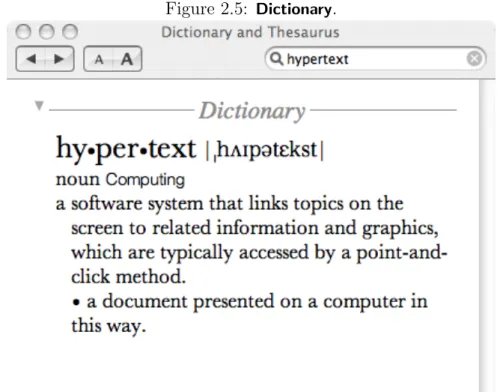
1Not surprisingly, this definition approximates closely that of dicionaries, cf. figure 2.5.
2This formulation is our own very subjective reinterpretation of Mancini 2004, because we were
not able to locate, on this part of Mancini’s text, a clear statement of a sharp, essential distinction between the proposed classes.
Figure 2.1: Screenshot of a Xanadu prototype on Nelson 2007a.
Xanadu presents multiple windows at the same time, and visible connections between them. See also figures 2.1 and 2.2. Clearly, spatial hypertext in Mancini’s classifica-tion, not page-based.
Incidentally, note how Nelson, according to the account above, invented the Back Button right there. Let us take notice that the associated requirement—navigational memory—has been a staple of hypertext since its inception onBush 1945. And many other essential sources, notably Nelson 1963, indicate clearly that users are supposed to be able to backtrack to any past point in their travels.
And indeed the Back Button has proven itself a formidable weapon against the lost in hyperspace syndrom, discussed later (section 2.3.8.6. It accounts for up to 42% of user actions with web browsers (Cockburnet al.2002). If there ever was a silver bullet of interfaces, this was it. So we must make the Back Button—or some other form of access to the navigation history of the user—a strict requirement of our working definition of hypertext.
Figure 2.2: Illustration of an advanced form of hypertext onNelson 2007b. The name is now transliterature, but the concept is essentially the same as Xanadu and Nelson 1965.
Figure 2.3: SWI-Prolog help panel.
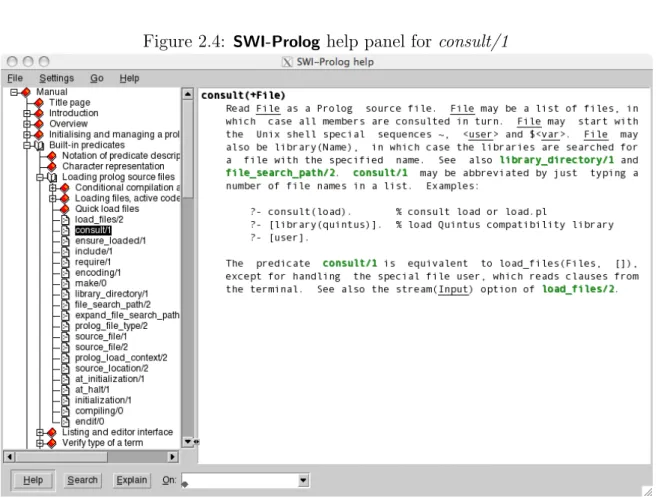
In the help text, the terms set in bold face and coloured green are clickable connections. For example, clicking on consult/1 (under the arrow on the picture) replaces the page with the one on figure 2.4
Above, and on other sources, the Web has been given as an example of page-based hypertext. It must be noted that page-based hypertext is also common in offline programs, for example in help systems, multimedia encyclopedias, etc. Recall pro-gramming in the early 1980’s—before the Web—with the Turbo C compiler and environment. With the cursor upon a keyword or library entity in our program text, a hit of the F1 key would bring up instant documentation about it, and these help panels contained similar linkage to others. For a current, after the Web, example of offline programming help let us refer to the help system of SWI-Prolog, cf. figures 2.3 and 2.4.
We observe that the SWI-Prolog help system, like many such systems, unfortunately, lacks the Back Button, or any other navigational memory.
For another example of offline hypertext consider the Dictionaryapplication, depicted in figure 2.5. In Dictionary, every word is clickable, so the designers chose not to use any special typography—wisely, because that would only produce unecessary visual
Figure 2.4: SWI-Prolog help panel for consult/1
clutter. Note also that, unlike SWI-Prologhelp,Dictionaryfeatures Back and Forward buttons, and is therefore an hypertext system by all accounts.
In sum, there are various kinds of hypertext. We can define the invariants as follow:
• hypertext is an interface to interconnected items
• the items are of information, textual or pictorial
• the interface lets the user follow any connection
• the interface records the connections followed, and lets the user relive them at will; in particular, the interface provides a back button
Figure 2.5: Dictionary.
2.3.1
The words used
Nelson 1965 introduces other hyper concepts: hypermedia, hyperfilm. But does not offer a rigourous ontology. The words hypermedia, hypertext are used interchangeably in the research literature i.e. they mean the same. The word hypermedia seems to be preferential in the learning systems4 area, cf.Chen&Ford 1998; it is also often used in commercial marketing, to inform potential costumers of an hypermedia product that it contains multimedia, not just plain text. The word hypertext is used everywhere else—including here.
Let me suggest that the text in hypertext, as used by Nelson and others, already means more than just plain text, more than just letters. It means document, discourse, sign. It includes pictures, graphics, formulae, even sound and films. In a word: content. This, shall we say, semiotic meaning of text is common in the humanities (an habitual Nelson dweling); recall the idiom subtext of a film, etc. Nelson’s own definition supports this approach: hypertext is ... “textual or pictorial ”.5
4Comprising ITS: intelligent tutoring systems.
5Curiously enough, this extension of the meaning of text mirrors the way Otlet, as we shall
see, has extended the meaning of document to include all information objects, further than books, e.g. artifacts, archeological findings, models, didactical toys, works of art, etc. Or as, in semiotics,
2.3.1.1 Literary vs. technical hypertext
Consider the two distinct classes of text, or discourse:
• literary, poetic, artistic discourse: works of fiction, poetry, etc.
• technical, scientific, utilitarian discourse:6 manuals, thesis, articles, etc.
We note that Nelson often uses the term literature for any kind of text. Here we use the terms literary and technical for the two classes purportedly in opposition.
This aporia relates closely to rhetorical categories. Literary hypertext studies seem to proceed in terms of rhetorical categories, cf. Mancini 2004.
Rosenberg 1999 provides an impressive review of the potential structural complexities of hypertext, particularly of the literary kind.
2.3.2
Items vs. connections
Recall our working definition of hypertext (slightly abridged):
• hypertext is an interface to interconnected items • the items are of information, textual or pictorial • the interface lets the user follow any connection
• the interface records the connections followed, and lets the user relive them
Items, connections: cleary the two basic building materials of hypertext. These two materials are—we submit—at a tension, which constitutes a foundational aporia of hypertext.
Theoretically, any large enough item may be transformed—shattered—into, two items plus a connection between them. Conversely, any two items with the proper connection
natural language is often taken as the prototype of language, and, accordingly, linguistics as the mother science of semiotics. We also note that the term media in hypermedia denotes something often also called content —which concept is, in a way, the very opposite of media. Probably semiots are more keen on the sensibleness of their terminology than marketeers—as it should.
between them may coalesce into a single item. Indeed, this observation is at the basis of the Shattered Documents approach of this thesis.
The Nelsonian concept of transclusion also blurrs the distinction between item and connection, cf. Nelson 2007b.
This aporia is perhaps better understood within an historical perspective. The current times are the age of connections. Little or null attention is given to the nature or construction of items. This focus on connections has been a constant sinceBush 1945:
“The process of tying two items together is the important thing.” (Bush 1945)
Incidentally, note that this focus corresponds to the hyper part of the many hyper... words, which would in fact explain their proliferation.
Bush 1945describes the memex, an hypothetical machine for memory extension, based on a network of microfilms and on an user interface equiped with means to explore this network. Indeed, the memex crucial attribute is, in the author’s own words,
“associative indexing, a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of the memex. The process of tying two items together is the important thing.” (Bush 1945)
Bush 1945 is consistently touted in the current literature (e.g. Mancini 2004) as the seed of hypertext thinking. But we have found descriptions of similar conceptions predating Bush 1945.
Earlier in the 20th century, there was a documentalist movement concerned with using the information and communication technology of the day—radio, x-rays, cinema, microfilm—to improve the global access to global knowledge. Otlet 1934, Otlet 1935
envision the convergence of such technology into an Office of Documentation, or Mundaneum, to form “a mechanical, collective brain... an exodermic appendage to the brain... a substratum of memory... an external mechanism and instrument of the mind” (Otlet 1934, Otlet 1935, apudRayward 1999).
Note the obstinated use of brain metaphors. Clearly this line of thinking is already inscribed in a tradition of intelect augmentation7 by artificial means.
7Let us use the term introduced by Engelbart 1963, advantageously more general than the memory
“Intellectual power, like physical power, can be amplified. Let no one say that it cannot be done, for the gene-patterns do it every time they form a brain that grows up to be something better than the gene-pattern could have specified in detail. What is new is that we can now do it synthetically, consciously, deliberately.” (Ashbi 1956)
Returning to Otlet and the 1930’s: he proposes the organization and transmission of knowledge in a global network. The Mundaneum, conceived as the centre of the network, would be replicated at several levels. There would be a Mundaneum in every country, in every city, and, finally, every person could have their own technologically sophisticated office, called Studium Mundaneum, in which they could access the repertoires. Which would clearly impact the professional, personal, familiar and social life of every individual (Santos 2006, p. 97, quoting Rayward 2003, p.7). Clearly, Otlet envisioned no less than the Internet of today.
Also, the documentalists sustained the Monographic Principle as a basis for the Office of Documentation.
2.3.3
The Monographic Principle
The Monographic Principle takes form in the recording of single pieces of information onto standardized cards, with larger chunks of information recorded on separate sheets. These cards could be managed, copied, combined, in order to search, form, present information. (Otlet 1918, apud Rayward 1994). The approximation to the nodes of hypertext, specially in the Shattered Documents approach, is compelling. As
Santos 2006puts it: “Otlet reformats the document by fragmenting it, and reorganizes content, generating new informational wholes. The informational objects created by the Monographic Principle approximate today’s databases and hypertextual objets.” (p. 90).
Nelson would coin the word hypertext. Otlet created none other than the term: documentation! (Otlet 1918)
The monographic units, the fragments, were reorganized on the basis of classification systems e.g. Otlet’s own Universal Decimal Classification. The units were organized in sequences assigned to a certain classification. The UDC and other classificatory systems allow for multiple classification of the same item, so an item could participate in multiple sequences. So, structurally, these sequences are like the trails of the memex
Bush 1945. Conceptually, however, they are a world apart.
The difference is between positivism (documentalists) and deconstructivism (memex). The documentalists assumed the possibility of a man-made, predefined classification system capable of organizing all knowledge, whereas memex hypertext is created, organized at will by the user, with or without resorting to any predefined classifica-tory system. Indeed Bush 1945 discusses the inadequacy of classification systems for hypertext. So, along with the general passing of positivism, eventually classification systems were abandoned as a means of connecting the items, and replaced with free linking by the usors.
Unfortunately, the baby was thrown with the bath water. Since Bush 1945 the focus has shifted towards the connectionist part of hypertext, and little or null thought has been given to the items connected. More often than not, the items are assumed as given, integral parts of the system: the pages. We have already noted in several parts on this thesis how this assumption lacks theoretic foundation, and how the respective design creates interface faults, for example long pages requiring scrolling, which extra cognitive effort distracts the user from their main quest. Pages must be shatterable. So, our approach of Shattered Documents may be seen as a return to the good part of Otlet’s documentalist theory.
In sum, Otlet created the monographic principle, but no hyperlinking. Bush envisioned hyperlinking, but sans monographic principle. And to this day the monographic principle as been dormant to say the least. Whether on a path of Hegelian dialetics or not, on this thesis we do try to make a small contribution to finally unite the two things—free connections, free items—in a long due synthesis.
2.3.3.1 More words: microtext, macrotext
We have seen how the notion of hypertext is often blurred with the notion of global access to global knowledge. In the current Word Wild Web the two aspects seem inextricable.
A certain branch of (modern) hypertext literature uses the terms microtext, macrotext, to refer to the local vs. global range of hypertext (Keepet al.1995). The Web is a macrotext. The memex is a microtext.
A single Office of Documentation is local, but Otlet’s envisioned a network of such Offices spanning the World, and each replicating the collection of World’s knowledge.
Clearly a world of Internet caf´es. Macrotext.
Macrotext was the focus of another hypertext visionary—seldom recognized as such, albeit a very famous author: H. G. Wells. Aparently since 1902 (apudRayward 1999), Wells has exposed a vision of a world brain, and a global encyclopedia, created by means of technology—notably the same technology and even the same methods selected by the documentalists (Wells 1938). Aparently Wells and Otlet met in the late 1930’s ou early 1940’s, cf. Rayward 1999.
(At this point, the science fiction connoisseur will probably evoke the Encyclopaedia Galactica or the Hitchhicker’s Guide to The Galaxy. We note in passing that neither of these devices seems to be a macrotext or even a microtext.)
Aparently H. G. Wells has also foretold the screen, or monitor, as we know it today, on his science fiction novels (apud active literature cited above).
2.3.4
Summary of hypertext history
For a summary of hypertext history see table 2.1.
Table 2.1: Summary of hypertext history Early 1900’s Otlet, Wells, envision the cyberfuture
Otlet coins the term documentation 1945 Bush designs the Memex
1960 Nelson designs Xanadu
1965 Nelson coins the term hypertext
Engelbart creates HyperCards (and the mouse)
1980 Berners-Lee creates HTML, a limited form of hypertext 1990 The Web develops within this initial philosophy
1995 The Web grows enourmously—lost in hyperspace 2000 Web 2.0, social networks—lost in MySpace
2.3.5
The document dogma
Circa 56% of the text on the Web is in the form of traditional documents stored in PDF format.
This reflects a mentality, which we may call the document dogma, that the traditional document is the preferred, or somehow best, format to represent information. Either from the reader or the author point of view—the result is the same.
But it has been shown that hypertext—at least a moderate form thereof—is actually better for online reading than the imitation of paper (cf.Nielsen 1997).
However, traditional documents are hard to decompose into the independent units required for full-fledged hypertext, because traditional documents contain elements of—cross-unit—sequentiality or structure that give meaning to each unit involved. Also, in the literature—and in designed or constructed systems—the nodes are always given. The various theories, systems, designs, focus on the links, on different ways of connecting the nodes. They never study, model, much less challenge, the internal construction of nodes. This assumption is probably in line with the document dogma mentality.
2.3.6
Information search—the impossible that is done
A search for information is a theoretical conundrum, because it aims at finding what is unknown; and therefore—theoretically—the search cannot be expressed, stated, in the terms of the sought solution. But as we all very well know, search for information happens all the time. This is so because the need for information is real, and must be solved, even if imperfectly. (The difference between theory and practice is that, in theory, there is no difference, but in practice, there is.) Some encompassing works of library science, documentation, and information retrieval, e.g. Foskett 1996, correctly recognize this effort of finding the unkown as the fundamental problem of information retrieval.
This impossibly perfect concept of information search entails the equally impossibly perfect, fixed concept of information need: “a constantly changing, inaccessible phe-nomena present only in the mind of the searching agent; a combination of ideas such as what the target information might look like, where it might be found, or how one might go about tracking it down—with the words look, where, and how used in a most general sense.” (Campbell 2000)
A single query of (classical) information retrieval subsumes a fixed information need. The real, dynamic, changing information need is often realised as a series of queries, with each subsequent one said to be a refinement of the previous. This dynamics is
also the essence of relevance feedback techniques.
Hypertextual navigation (as well as the ostensive search model of Campbell 2000, which is essentially hypertext), as a form of information search, represents a slight departure from the classical query model. With hypertext, the user is presented, at each time, with predefined paths to follows.
In practice, users of the Web, and of hypertext, alternate between querying and nav-igation, mostly according to the circumstances. The integration of these two distinct search methods in a single interface has been a kind of holy grail for some researchers e.g. Olson&Chi 2003. In this thesis we do not pursue this type of integration. We simply focus on navigation.
2.3.7
Aporias of adaptation
2.3.7.1 Dictatorship of the majority
Of the two main kinds of adaptation—personal, colective—only the latter construes aporias.
Adaptation towards the colective mind brings the problem of dictatorship of the majority.
We assume that the collective brain is nevertheless useful to the individual in a large enough class of situations. There is plenty of (soft) evidence of this fact—the epitome being the very successful ranking of Google results based on PageRank, an algorithm that integrates data from many usors (and therefore is a kind of collective brain).
2.3.7.2 Unwarrant self-reinforcement
The essential design of recommender systems causes the following problem.
In a recommender system, the user is presented with recommendations. It is likely that the user follows the recommendations—or else the recommender system would be useless. But following a recommendation will strengthen the presence of the recommended item itself in the recommendation set. This veritable self reinforcement of the identity of the recommended set, i.e. of its set of items, has the vicious effect of keeping other possibly interesting items out of the set—and hence outside the user’s view.
So far the only patch to this problem is to bypass the recommendation model proper by including random items in the recommendation set. Formally this represents a degradation of the result, and an artificial injection of noise into the system—clearly not a satisfactory situation (and hence an aporia).
(The identification of this problem, as well as the suggested patch, are, to the best of our knowledge, original contributions of this thesis. If I remember correctly, problem and patch were firstly proposed by myself in a meeting of a past European research project (Mladeni´c&Lavraˆc 2003). Albeit discussion has ensued, it has remained un-published. However the problem is so evident, that we cannot but wonder how it has been treated by the myriad recommender systems out there in the commercial Web e.g. amazon.com.)
2.3.8
Minor issues
The aporias in this section seem only distantly related, if at all, to our main hypotheses. But they are too related to hypertext in general, or too culturally widespread, or just too interesting, not to be addressed in this thesis.
2.3.8.1 Anchoring aporias
On commonplace hypertext, links are anchored in the text it self, identified by a different typography. This design poses a number of problems.
When the term under anchoring appears multiple times on the same page, as often is the case, the design decision is not clear of which occurrence of the term to select as anchor. The first? All? Some subset? Which one? For example,SWI-Prologdesigners chose to select all occurrences, cf. figure 2.6.
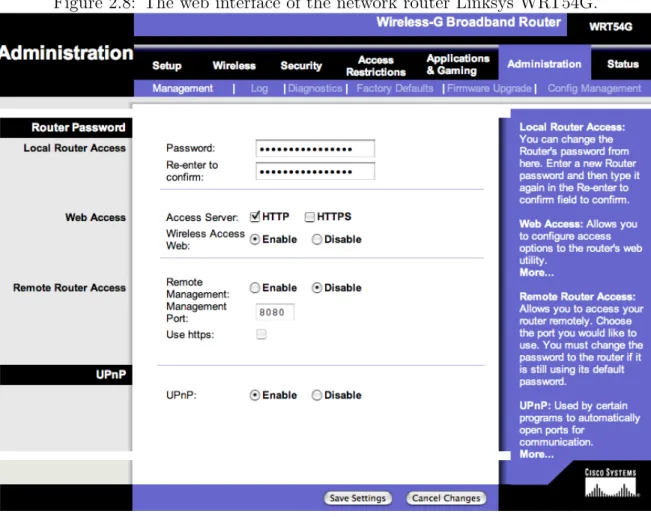
An alternate design, which dissolves this aporia, is to represent the links as separate items from the text, perhaps as buttons situated to the right margin of the page, and ranked by order of appearance on the text, as illustrated on figure 2.7.
As another, independent, example of this alternate design for help text, consider the interface depicted on figure 2.8. Note how the help items are strictly contained in the right panel—and not as hyperlinks anchored on the main text (the remainder panels), which would create visual clutter, and incur in the anchoring problems discussed. Another problem of in-text anchoring is when the anchor is a compound term (i.e.
Figure 2.6: SWI-Prolog help for catch/3.
Multiple anchors design. (Anchors are set in a green bold face.)
a multiword term) which comprises one or more subterms which are also potential anchors. This occurs extremely often in dictionary or encyclopaedic hypertext e.g. the Wikipedia. In-text anchoring simply cannot solve this problem. Consider, for example, the Dictionary definition of HTML, depicted in the centre of figure 2.9. The definition contains the compound terms Hypertext Markup Language and World Wide Web. These two terms encompass the eight terms entouring the picture, all entries in the Dictionary. However, the in-text anchoring design has made some terms not directly reacheable. The lines connecting the first letter of a word in the definition text represent clickable connections (remember that inDictionaryevery word is clickable); the connections are to the indicated dictionary entries. Note that the entries markup language8 and world are disconnected. Note how the designers chose a special behaviour for the word World, namely selecting it as an anchor for the compound World Wide Web—disconnecting world in the process. And, of course, unsignalled different linking behaviours introduce unpredictability in the interface.
Figure 2.9: How compound terms are (mis)treated in Dictionary.
wide world markup language hypertext web markup language
World Wide Web
Yet another problem, albeit less severe, of in-text, typographical, anchoring is when the anchor is not text at all, but e.g. a picture or an icon. In this case a typographical difference is simply not possible. But this problem only affects the typographical approach to anchoring, and can be solved relatively easily in a number of manners.
8The term markup language is meaning number 3 the entry for markup, requiring scanning, and
normally scrolling, on this entry in order to be found; a direct link would avert this cognitive effort. All other terms are main entries.
2.3.8.2 Data deficit
Invariably the access data, or HTTP log, is not rich or acurate enough for the expectations of the adaptation model.
A typical subproblem is the derivation of a session i.e. the identification of the accesses (clicks) that constitute a session by each user. Normally this can only be acomplished by the 30 minute rule—an heuristic rule based on the assumption that if a user is quiet for 30 minutes then their last request terminated a session.9 This rule yields results of varying degree—depending on the context or information domain—but that can never be 100% right.
Another subproblem is the identification of users, for cross-session derivations, user model construction, and of course personalisation. Only registered users can be rightly identified—but user registration impinges somewhat upon the Null User Effort principle.
Another problem is that the Back button serves distinct, even opposite, purposes:10
(1) The user follows a link that appears to be the oracle11; after going there, the
user realises that it is not; the user pushes the back button simply to retreat from this false oracle, back to a point known to be of greater interest
(2) Same context as above, but Back button pushed simply out of panic. The Back button as a Panic button. The user is lost. They do not press the button to return to a Emknown place. They simply want to get out of there.
(3) The user has followed a link that appears to be part of the oracle—and it is. Then the user uses the Back button simply to continue exploring the web space from a more confortable place, probably a hub.
etc.
Note item pairs (1)–(3) and (2)–(3) are pairs of opposites.
9In an concrete experience this value has been fine-tuned to 28 minutes.
10This problem is distinct from the Back button aporia described in a dedicated section. This
problem is about interpreting Back button hits for adaptive purposes. The aporia is about the user expectations towards the interface.
11On this thesis oracle means roughly what the user is looking for. For the specialized meaning of
Note that access logs typically do not even contain Back button information. They simply stack the accessed pages. For example, for the session in figure 2.10(1), the log would simply record the sequence A-B-C-B-D-E. This is so in part because HTTP12 was designed as a stateless protocol. So, typical access logs, produced by the web server (e.g. Apache), are too low level for an adaptive system relying on user action information. There is a semantic mismatch. An adaptive system should maintain its own user action log. Several designs are proposed on this thesis.
2.3.8.3 Aporias of renoding
The concept of renoding, introduced in this thesis, carries an aporia of its own: if the page as we knew it ceased to exist, what else becomes the nature of links between pages?
In this thesis, and specifically in the shattered documents approach, this aporia is dealt with by introducing the concept of central noogramicle. Each page has a central noogramicle, which acts as representative of the page for linking across pages. The actual links are between noogramicles. This can be reinterpreted as connection between pages when the noogramicles are central.
2.3.8.4 Landmarks
Already well into the course of our investigation we have realized that Raskin 2000 is probably right in his observation that landmarks are a major help in navigation. Users looking for a certain item A, which they have seem before next to a certain item B, might find it easier to relocate A via B, because, for example, B is in sight (and A is not).
Landmarks and adaptive hypertext are irreducible. Landmarks require a stable, fixed territory which to mark and be inscribed upon. Adaptive hypertext is, by definition, a changing territory.
2.3.8.5 The Back button aporia
The Back button concept contains an aporia of its own, namely an unsolvable tension between its expected behaviour being chronological or not, cf. figures 2.10 and 2.11.
Figure 2.10: The Back button aporia. In certain contexts the user expects a chronological behaviour.
user presses Back three times,
B
C A
E D
but A is where he gets: B C A E D (back) to go back to C here user wants (1) (2) (3) B C A E D
expecting to travel thus:
Figure 2.11: The Back button aporia. Why the Back button should not behave chronologically.
(3) B
C A
user presses Back two times, being delivered to where expected
B
C A
pernicious effect would take place if Back button behaved chronologically, now user wants
to get back to A B C A (1) (2)
2.3.8.6 Lost in hyperspace
The phrase lost in hyperspace has been echoed in the literature, with two meanings: (1) lost in the hypertext structure, because of the hypertextual nature
(2) lost in the enourmous sea of information of the Web and modern culture in general We downplay this purported aporia.
We believe that problem (1) has been solved with the Back Button and akin devices e.g. the Site Map. Golovchinsky 2002 provides a discussion of the Back Button, including advanced variants. The Site Map is commonplace in the Web today. Other navigational aids include: the fish eye, prototyped on Campbell 2000; the ZOOM interface, reported on Raskin 2000; the Map View, commonplace in videogames; the page trail, proposed in the current thesis.
Problem (2), in the Web, is partially solved with search engines e.g. Google. A better metaphor would be: drown in hyperspace. Or, with the advent of the so called Web 2.0, and its social networks, problem (2) becomes more like lost in MySpace—which might happen well before one reaches one million “friends”: according to recent results from psycho-social studies, 150 is the approximate number of direct contacts that a single person is able to manage (Dunbar 1993).13
Problem (2) in general equates the well known information overload problem. We shall observe that, contrarily to a common conception, this problem is not specific of our times, say of TV and Web times, but it has emerged, and has been analysed, and fought, since as early as the begining of the 20th century at the least. It is the very problem addressed by Otlet and the documentalists, as already discussed (sections 2.3.2, 2.3.3, Otlet 1934,Otlet 1935, Rayward 1999).
2.3.8.7 Design by tekkies
The design of web hypertext is extremely technology driven. HTML, JavaScript, Flash, whatnot, set the boundaries of what is done.
13MySpace, FaceBook, LinkedIn, Ecademy, HiFive, Plaxo, OpenSocial, SoundClick, Ning, Indaba...
Albeit the social networking phenomenon is here to stay, and it is clearly related to collective adaptiveness in potential, in this thesis we had to stay away from the issue, because it is too large an issue on its own, and clearly the dust has not settled on it yet.
Technologues are not only in charge of designing the underlying technology—much too often they impinge on the area of web design itself, of the use of said technology. Most disastrous designs that plague the web probably stem from this fact.
“The purpose of hypertext was always to make up for the deficiencies of paper. Paper cannot easily show connections, has very limited space, and forces an inflexible rectangular arrangement. Hypertext, the generalization of writing, potentially offers many forms of interconnection and presenta-tion beyond what paper allows. But so far the mechanisms, not the users, have been put in control.” (Nelson&Smith 2007)
Nelson also affirmed that computer interfaces should be designed not by tecnologues— as the Web was—but by filmmakers. He points out a lesson from history that the first films—made by the technologues of the day—were very poor in design or art. Recalling the prototype of first film, La Sortie des usines Lumi`ere (1895), we cannot but agree. See also: Nelson 1999 and references thereof; Nielsen 1997 and other articles by this columnist on usability; Lebedev 2007for design insights (and insightful design).
2.3.8.8 The computer as hypertext
One could argue that any clickable item on the computer constitutes hypertext. Menu items, file icons, window controls... the WIMP14 as hypertext. The general pattern
of the definitions seen so far certainly apply. The only provision necessary is that the nodes (pages) may be also actions, operations of the computer. Even the Back button requirement is met:
• it is right there on certain WIMP interfaces, notably file navigators like Mac OS’s Finder, Windows Explorer...
• in a limited number of contexts, the WIMP has it under other forms, namely the Escape key (to regress from a submenu or window), or the Undo operation (often bound to the Ctrl-Z key combination).
So there a bit of hypertext in the WIMP after all—which is good.
14WIMP = Windows, Icons, Menus, Poiting device (mouse): the interface quartet on most if not