Ciências
Modelo de Regressão Linear e suas Aplicações
Sandra Cristina Antunes Rodrigues
Relatório de Estágio para obtenção do Grau de Mestre emEnsino de Matemática no 3º Ciclo do Ensino Básico
e no Ensino Secundário
(2º ciclo de estudos)Orientadora: Professora Doutora Célia Maria Pinto Nunes
Em primeiro lugar, quero agradecer a todos os que contribuíram para que fosse possível realizar este trabalho.
À minha orientadora, Professora Doutora Célia Maria Pinto Nunes, pela força e motivação, pelas suas orientações e apoio, e sobretudo pela sua amizade.
Um agradecimento especial à colega Sónia Ladeira pelas suas ideias e sugestões e à querida amiga Sílvia Melchior pela sua ajuda no Inglês.
À minha cunhada, Dra. Catarina Reis, que gentilmente me cedeu uma base de dados para uso nas aplicações.
À minha querida irmã, pela sua paciência infindável e carinho imensurável.
À minha família que sempre me apoiou e incentivou, em especial aos meus filhos, pelo tempo que não lhes dediquei, aos meus pais, pilares da minha vida, pelo permanente incentivo e pela formação que me permitiram adquirir, aos meus sogros pela ajuda incondicional.
Ao meu marido, quem mais sofreu com as minhas indisponibilidades e impaciências, pelo seu carinho, companheirismo e compreensão…
A todos, o meu Bem-Haja!
O presente trabalho teve como principal objectivo apresentar os resultados mais importantes sobre os modelos de regressão linear, ilustrando a sua aplicabilidade através de estudos que foram elaborados com base em dados reais.
Como tal abordámos a análise de regressão linear simples e descrevemos sumariamente a regressão linear múltipla, que se distingue da anterior quando incorporadas mais do que uma variável independente no modelo de regressão.
Enquadrado na temática anterior, dedicámos um capítulo a Análise de resíduos.
Por último, e como complemento da investigação realizada ao longo deste trabalho, realizámos alguns estudos aplicados a dados reais, que dizem respeito à Variabilidade da Frequência Cardíaca.
Palavras-chave
Regressão Linear Simples, Regressão Linear Múltipla, Estimação dos Parâmetros, Aplicações a Dados Reais.
This study's main objective was to present the most important results about the linear regression models, illustrating its applicability through studies that wereprepared based on real data.
Therefore we touched the simple linear regression analysis and briefly describe the multiple linear regression, distinct from the previous embedded when more than one independent variable in the regress.
Framed in the previous issue, we devoted a chapter to Waste Analysis ion model.
Finally, and as a complement of research carried throughout this work we held some studies applied to real data, which concern the Heart Rate Variability.
Keywords
Simple Linear Regression, Multiple Linear Regression, Parameter Estimation, Applications to Real Data.
1. Introdução ... 1
2. Análise de Regressão simples ... 5
2.1. Modelo teórico... 5
2.2. Pressupostos do modelo... 6
2.3. Estimação dos parâmetros do Modelo ... 7
2.3.1. Método dos mínimos quadrados ... 7
2.3.2. Propriedades dos Estimadores ... 11
2.4. Estimador de ... 17
2.5. Testes e intervalos de confiança para os parâmetros do modelo ... 19
2.5.1. Testes e intervalos de confiança para ... 20
2.5.2. Testes e intervalos de confiança para ... 21
3. Breve abordagem à regressão linear múltipla ... 23
3.1. Modelo teórico e seus pressupostos ... 23
3.1.1. Interações ... 24
3.1.2. Pressupostos do modelo ... 25
3.1.3. Representação matricial do método de regressão linear múltipla ... 25
3.2. Estimação do parâmetro do modelo ... 26
3.2.1. Propriedades dos estimadores ... 27
3.3. Estimador de ... 28
4.1. Diagnóstico de normalidade ... 33
4.2. Diagnóstico de Homoscedasticidade (variância constante) ... 35
4.3. Diagnóstico de Independência ... 36
4.4. Diagnóstico de Outliers e observações influentes ... 37
4.4.1. Observações Influentes ... 38
4.5. Colinearidade e Multicolinearidade ... 39
5. Aplicações ... 43
5.1. Estudo 1 – Modelo de regressão Linear Simples ... 43
5.1.1. Verificação dos pressupostos do modelo ... 46
5.2. Estudo 2 – Modelo de Regressão linear Múltipla ... 49
5.2.1. Verificação dos pressupostos do modelo ... 51
6. Conclusões ... 57
Bibliografia ... 59
Figura 1.1- Classificação da correlação através do diagrama de dispersão, disponível em
Santos (2007). ... 3
Figura 2.1- Interpretação geométrica dos parâmetros ... 6
Figura 2.2- Representação gráfica dos resíduos ... 8
Figura 3.1- Hiperplano p-dimensional referente às variáveis explicativas. ... 24
Figura 4.1– Normal p-p plot de resíduos ... 34
Figura 4.2- Confirmação da homoscedasticidade dos resíduos (disponível em PortalAction). . 36
Figura 5.1– Diagrama de dispersão ... 44
Figura 5.2– Normal p-p plot ... 46
Figura 5.3– Gráfico dos resíduos estandardizados ... 47
Figura 5.4 – Gráfico resíduos press... 47
Figura 5.5– Gráfico dos Standardized DFFIT ... 48
Figura 5.6– Normal p-p plot da regressão dos resíduos estandardizados ... 52
Figura 5.7- Gráfico dos resíduos estandardizados ... 53
Figura 5.8– Gráfico resíduos press ... 54
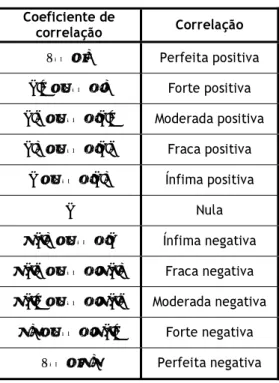
Tabela 1.1- Interpretação do coeficiente de correlação de Pearson. ... 2
Tabela 3.1- Tabela da análise de variância (ANOVA) ... 31
Tabela 4.1- Tabela de decisão em função de e ... 37
Tabela 5.1- Estatística descritiva ... 43
Tabela 5.2– Sumário do Modelo ... 44
Tabela 5.3– Tabela da ANOVA ... 45
Tabela 5.4- Coeficientes ... 45
Tabela 5.5- Teste K-S ... 46
Tabela 5.6- Estatística dos resíduos ... 48
Tabela 5.7- Estatística descritiva ... 49
Tabela 5.8– Tabela de variáveis inseridas/removidas ... 49
Tabela 5.9- Sumário do Modelo ... 50
Tabela 5.10– Tabela da ANOVA ... 50
Tabela 5.11- Coeficientes ... 50
Tabela 5.12– Variáveis excluídas ... 51
Tabela 5.13– Teste K-S ... 52
Tabela 5.14- Diagnóstico da colinearidade ... 53
1.
I
NTRODUÇÃO
“O termo ‘regressão’ foi proposto pela primeira vez por Sir Francis Galton em 1885 num estudo onde demonstrou que a altura dos filhos não tende a reflectir a altura dos pais, mas tende sim a regredir para a média da população. Actualmente, o termo “Análise de Regressão” define um conjunto vasto de técnicas estatísticas usadas para modelar relações entre variáveis e predizer o valor de uma ou mais variáveis dependentes (ou de resposta) a partir de um conjunto de variáveis independentes (ou predictoras).” (Maroco, 2003)
A temática deste trabalho será a análise de regressão linear, no entanto, faremos de seguida uma pequena abordagem ao coeficiente de correlação e consequentemente ao coeficiente de determinação.
A análise de correlação tem como objectivo a avaliação do grau de associação entre duas variáveis, e , ou seja, mede a “força” de relacionamento linear entre as variáveis e .
Para quantificar a relação entre duas variáveis quantitativas utiliza-se o coeficiente de correlação linear de Pearson.
O coeficiente de correlação linear de Pearson entre duas variáveis quantitativas, e , é dado por: ∑ 1 ∑ 2 1 ∑ 2 1 , onde n n i 1 n n i 1 ,
ou seja, é o quociente entre a covariância entre e e o produto de desvios padrão de e .
A partir de podemos tirar conclusões sobre a direcção e intensidade da relação existente entre as variáveis e . Não existe uma “classificação” unânime da correlação. Nós optámos por seguir a considerada por Santos (2007) que é a apresentada na Tabela 1.1.
Tabela 1.1- Interpretação do coeficiente de correlação de Pearson. Coeficiente de correlação Correlação 1 Perfeita positiva 0,8 1 Forte positiva 0,5 0,8 Moderada positiva 0,1 0,5 Fraca positiva 0 0,1 Ínfima positiva 0 Nula 0,1 0 Ínfima negativa 0,5 0,1 Fraca negativa 0,8 0,5 Moderada negativa 1 0,8 Forte negativa 1 Perfeita negativa
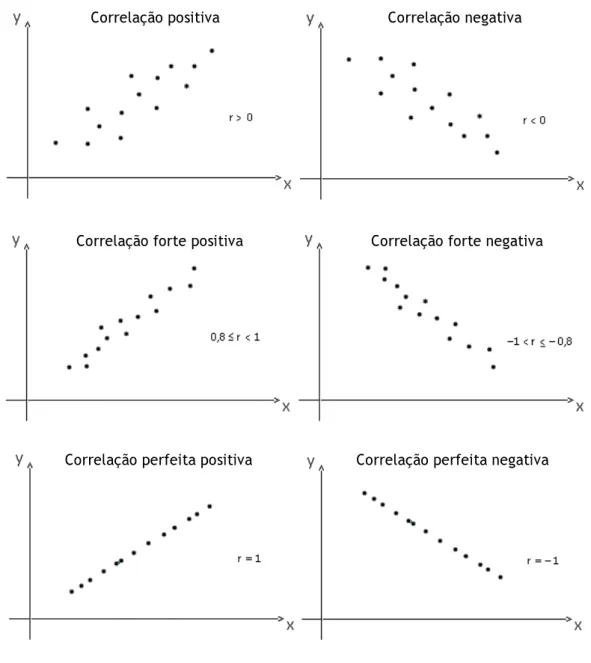
Para investigar a relação entre duas variáveis, e , podemos representar os valores das variáveis num gráfico de dispersão. Afirma-se que existe uma relação linear entre as variáveis se os dados se aproximarem de uma linha recta.
A partir da observação do diagrama de dispersão verificamos se a correlação entre as duas variáveis é mais ou menos forte, de acordo com a proximidade dos pontos em relação a uma recta. Na Figura 1.1, podemos observar alguns exemplos de gráficos de dispersão e a respectiva “classificação” da correlação.
Dependendo da relação entre as variáveis e da intensidade com que se relacionam, a recta obtida será um melhor ou pior modelo para traduzir a relação entre elas.
De seguida iremos definir o coeficiente de determinação, que é igual ao quadrado do coeficiente de correlação de Pearson.
Como vimos, o coeficiente de correlação linear de Pearson entre duas variáveis serve para medir a intensidade da relação linear entre elas. O coeficiente de determinação é mais indicado para medir a explicação da recta de regressão. Assim, quanto mais próximo de 1 estiver o valor do coeficiente de determinação, maior a percentagem da variação de explicada pela recta estimada, e por conseguinte, maior a qualidade do ajustamento.
Figura 1.1- Classificação da correlação através do diagrama de dispersão, disponível em Santos (2007).
O coeficiente de determinação é dado por
∑ 2
∑ ∑ .
O toma valores entre zero e um. A qualidade do ajuste será tanto maior quanto mais se aproximar de 1.
Em resumo, a presença ou ausência de relação linear pode ser averiguada a partir de dois pontos distintos:
a) quantificando a força dessa relação, e para isso usamos a análise de correlação; b) ou explicitando a forma dessa relação, fazendo uso da análise de regressão.
Correlação positiva Correlação negativa
Correlação forte positiva Correlação forte negativa
Correlação perfeita negativa Correlação perfeita positiva
Ambas as técnicas, apesar de intimamente ligadas, diferem, pois na correlação todas as variáveis são aleatórias e desempenham o mesmo papel, não havendo nenhuma dependência, enquanto na regressão isso não acontece.
Assim, a análise de regressão estuda o relacionamento entre uma variável denominada de dependente, , e uma ou várias variáveis independentes, , , , … , . Caso se considere apenas uma variável independente apelidamos de análise de regressão simples, caso usemos duas ou mais variáveis, de análise de regressão múltipla.
A importância do estudo da análise de regressão advém da necessidade do estudo de determinados fenómenos nas Ciências da Natureza (Física, Biologia, Química, …), nas Ciências Sociais, nas Ciências da Saúde, …
Ainda que operacionalmente simples, existem certos aspectos do uso da regressão linear que merecem uma discussão adicional e sobre os quais nos debruçaremos neste trabalho.
Assim, no capítulo 2 debruçamo-nos sobre a regressão linear simples e apresentamos o modelo teórico. São discutidos temas como os parâmetros do modelo, as propriedades dos estimadores e inferência dos parâmetros.
É feita uma breve abordagem sobre a análise de regressão linear múltipla no capítulo 3. Neste capítulo, é apresentado o modelo teórico e os seus pressupostos. É ainda feita referência à análise de variância, de extrema importância para a regressão linear múltipla.
No capítulo 4 é feita a análise de resíduos, onde são apresentados alguns dos métodos existentes para verificação dos pressupostos.
No capítulo 5 são apresentadas algumas aplicações a dados reais recorrendo ao uso do SPSS (Statistical Package for the Social Sciences, versão 19), exemplificando algumas técnicas descritas no trabalho.
2.
A
NÁLISE DE
R
EGRESSÃO SIMPLES
A análise de regressão linear estuda a relação entre a variável dependente ou variável resposta e uma ou várias variáveis independentes ou regressoras , … , .
Esta relação representa-se por meio de um modelo matemático, ou seja, por uma equação que associa a variável dependente com as variáveis independentes , … , .
O Modelo de Regressão Linear Simples define-se como a relação linear entre a variável dependente e uma variável independente .
Enquanto que o Modelo de Regressão Linear Múltiplo define-se como a relação linear entre a variável dependente e várias variáveis independentes , … , .
Neste capítulo vamos apenas debruçar-nos sobre o modelo de regressão linear simples. Será apresentado o modelo teórico e os seus pressupostos, assim como a estimação dos parâmetros do modelo pelo método dos mínimos quadrados. Serão ainda construídos testes e intervalos de confiança para os parâmetros do modelo.
2.1. MODELO TEÓRICO
A equação representativa do modelo de regressão linear simples é dado por:
, 1, … , 2.1
onde:
. representa o valor da variável resposta ou dependente, , na observação , 1, … , (aleatória);
. representa o valor da variável independente, , na observação , 1, … , (não aleatória);
. , 1, … , são variáveis aleatórias que correspondem ao erro (variável que permite explicar a variabilidade existente em e que não é explicada por );
. e correspondem aos parâmetros do modelo.
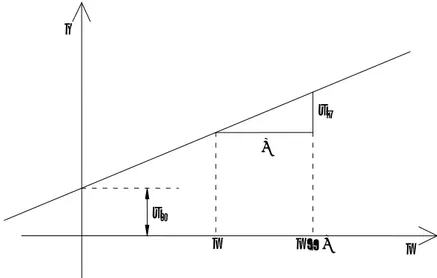
O parâmetro representa o ponto em que a recta regressora corta o eixo dos quando 0 e é chamado de intercepto ou coeficiente linear.
O parâmetro representa a inclinação da recta regressora, expressando a taxa de mudança em , ou seja, indica a mudança na média da distribuição de probabilidade de para um aumento de uma unidade na variável .
Na Figura 2.1 podemos observar a interpretação geométrica dos parâmetros e .
Figura 2.1- Interpretação geométrica dos parâmetros
2.2. PRESSUPOSTOS DO MODELO
Ao definir o modelo 2.1 estamos a pressupor que:
a) A relação existente entre e é linear. b) Os erros são independentes com média nula.
Pressupondo então que 0, tem-se:
. 2.2
Por outro lado, podemos afirmar que o erro de uma observação é independente do erro de outra observação, o que significa que:
, 0, para , , 1, … , .
c) A variância do erro é constante, isto é , 1, … , . 1
Tem-se então
,
e consequentemente
.
d) Os erros, , 1, … , , são normalmente distribuídos.
Concluímos portanto, de b) e c), que
~ 0, , 1, … ,
e portanto que
~ , , 1, … , .
2.3. ESTIMAÇÃO DOS PARÂMETROS DO MODELO
Supondo que existe efectivamente uma relação linear entre e , coloca-se a questão de como estimar os parâmetros e .
Karl Gauss entre 1777 e 1855 propôs estimar os parâmetros e visando minimizar a soma dos quadrados dos desvios, , 1, … , , chamando este processo de método dos mínimos quadrados. Este método será descrito de seguida. (Maroco, 2003)
2.3.1. Método dos mínimos quadrados
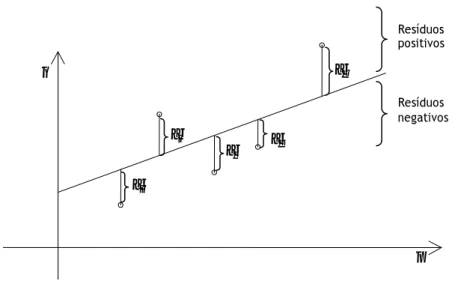
O método dos mínimos quadrados consiste na obtenção dos estimadores dos coeficientes de regressão e , minimizando os resíduos do modelo de regressão linear, calculados como a diferença entre os valores observados, , e os valores estimados, , isto é
, 1, … , .
Em termos gráficos, os resíduos são representados pelas distâncias verticais entre os valores observados e os valores ajustados, como mostra a Figura 2.2.
0
termo constante 0
Figura 2.2- Representação gráfica dos resíduos
O método dos mínimos quadrados propõe então encontrar os valores de e para os quais a soma dos quadrados dos resíduos (SQE) é mínima. Tem-se então:
2.3
,
com ∑ 0 (daí o facto de ser considerado o quadrado de , 1, … , ).
Precisamos agora de calcular as derivadas parciais de em ordem a e , obtendo-se:
2
2
.
Igualando estas derivadas a zero e substituindo e por e , por forma a indicar valores concretos destes parâmetros, tem-se
2 y β β x 0 2 y β β x x 0 Resíduos negativos Resíduos positivos
nβ y β x β x β x x y 0 2.4 ∑ ∑ _____ _____ , 2.5
em que ∑ e ∑ , representam as médias de e , respectivamente.
Vamos agora pegar na 2ª equação de (2.4) e tentar chegar à expressão de . Ora
. Como , vem ∑ ∑ . 2.6
e , anteriormente determinados em (2.5) e (2.6), são designados como os Estimadores de Mínimos Quadrados de e .
De seguida serão apresentadas algumas propriedades do ajuste dos mínimos quadrados.
Como vimos, os resíduos correspondem à diferença entre os valores observados, , 1, … , , e os correspondentes valores ajustados, , 1, … , , isto é:
,
com
, 1, … , .
a) ∑ 0, o que significa que a soma dos resíduos é sempre nula; b) ∑ é mínima;
c) ∑ ∑ , o que significa que a soma dos valores observados é igual à soma dos valores ajustados ;
d) A recta obtida pelo método dos mínimos quadrados passa sempre pelo ponto , .
Demonstração: Como
,
com
.
,
visto que
.
Assim, no ponto de abcissa , vem
.
2.3.2. Propriedades dos Estimadores
a) Valor esperado e variância de
Valor esperado de
Como vimos, de (2.6), tem-se
∑ ∑ ∑ ∑ , 2.7 com ∑ .
Desta forma, de (2.2), vem
Visto que ∑ ∑ ∑ ∑ ∑ ∑ ∑ 0 e que ∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑ 1 ,
pegando em (2.8) concluímos que
0 1 , 2.9
o que significa que é um estimador centrado de .
Variância de
De (2.7) temos que
.
Como , 1, … , são variáveis independentes, temos que
visto que
∑ .
b) Valor esperado e variância de
Valor esperado de
Da 1ª equação de (2.5) tem-se , e visto que, de (2.9) se tem , obtemos: 1 ∑ . 2.10
Logo é um estimador centrado de .
Variância de β
Tem-se
2 , . 2.11
Ora
∑ ∑ ∑ ∑ . Como ∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑ .
Uma vez que, quando , 0, vem
0 .
Por outro lado, quando ,
.
Como
vem
e consequentemente ∑ ∑ ∑ ∑ 0, visto que 0 .
Podemos então concluir que
, 0 .
Assim, voltando a (2.11),
.
Como , 1, … , , são independentes, temos que:
1 ∑ ∑ 1 ∑ . c) Covariância entre e ,
. Como , vem , 1 1 ∑ 1 ∑ 1 ∑ 1 ∑ ∑ .
uma vez que, como provado anteriormente, 0.
d) Distribuição amostral de e de
Como vimos anteriormente, de (2.7) temos que:
,
com
∑ .
Logo é uma combinação linear dos , 1, … , . Assim como o , definido em (2.5). Concluímos portanto que, uma vez que são normalmente distribuídos, com
~ , , 1, … , .
Assim, considerando o valor esperado e a variância de e que obtivemos em a) e b) temos que:
. A distribuição amostral para será:
~ , 1
∑ ;
. A distribuição amostral para será:
~ ,∑ .
2.4. ESTIMADOR DE
Tal como os parâmetros do modelo e , também é necessário obter um estimador da variância dos erros, isto é, um estimador de .
Como vimos anteriormente
2
∑ 2
2 2 2 2 2
2 2
∑ 2 ∑ ∑
Vamos agora calcular o valor esperado de , isto é,
∑ ∑ 1 ∑ 1 ∑ . 2.12 Calculamos e .
Pegando novamente em (2.12), obtemos
∑ 1 ∑ 1 2 0 1 2 0 1 2
1 ∑ 1 ∑ 1 ∑ 2 ∑ ∑ 2 2 2 2 2 2 2 2.13
Concluímos portanto que 2 , o que implica que o estimador centrado de será
2 ,
em que representa o quadrado médio dos erros.
2.5. TESTES E INTERVALOS DE CONFIANÇA PARA OS PARÂMETROS DO MODELO
Nesta secção construiremos testes de hipóteses e intervalos de confiança para e , considerando os pressupostos anteriormente referidos. Estes pressupostos levaram-nos a concluir que as observações
~ , , 1, … , .
2 2
0
2.5.1. Testes e intervalos de confiança para
Como vimos atrás, o estimador pontual de é dado por
∑ ∑
∑
∑ .
Vimos também que a distribuição amostral de para o modelo de regressão normal também é normal, uma vez que é uma combinação linear dos , com:
;
∑ .
Daí
~ ;
∑ .
Suponhamos que pretendemos testar as hipóteses
:
: ,
o que significa que pretendemos testar se é igual a um determinado valor .
Assim, a estatística de teste será dada por
~ ,
com
∑ ∑ .
tem distribuição t-student com 2 graus de liberdade, (ver por exemplo Maroco, 2003).
Suponhamos agora que pretendemos testar
: 0
: 0 , 2.14
que são as hipóteses que queremos testar no modelo em questão. Neste caso a estatística de teste poderá ser reescrita da seguinte forma
~ . 2.15
Logo, rejeita-se , para um nível de significância , se | | , , onde
representa o valor observado da estatística e , o quantil de ordem 1 2 da
distribuição t com 2 graus de liberdade.
No que diz respeito ao intervalo de confiança, a 1 100%, para esse será dado por
; ; ; .
2.5.2. Testes e intervalos de confiança para
Como vimos, o estimador pontual de β é dado por:
.
Assumindo a normalidade das observações e visto que:
e 1 ∑ tem-se ~ , 1 ∑ . Consideremos as hipóteses: : : ,
a estatística de teste será dada por ~ , com 1 ∑ 1 ∑ .
também segue uma distribuição com 2 graus de liberdade, .
Se por outro lado pretendermos testar as hipóteses:
: 0
: 0 ,
a estatística de teste poderá ser reescrita de seguinte forma
~ .
Assim, rejeita-se , para um nível de significância de , se | | , , onde
representa o valor observado de estatística .
Quanto ao intervalo de confiança para , com 1 100% de confiança, será dado por
3.
B
REVE ABORDAGEM À REGRESSÃO LINEAR
MÚLTIPLA
Neste capítulo faremos uma breve abordagem à regressão linear múltipla.
Como referido anteriormente, a diferença entre a regressão linear múltipla e a regressão linear simples é que na múltipla são consideradas duas ou mais variáveis explicativas (independentes). As variáveis independentes são as ditas variáveis explicativas, uma vez que explicam a variação de .
Na regressão linear múltipla assumimos que existe uma relação linear entre uma variável (variável dependente) e variáveis independentes (preditoras), , , … , .
3.1. MODELO TEÓRICO E SEUS PRESSUPOSTOS
O modelo de regressão linear múltipla com variáveis explicativas é definido da seguinte forma:
, 1, … , , 3.1
em que
. representa o valor de vaiável resposta na observação , 1, … , ;
. , … , 1, … , são os valores da -ésima observação das variáveis explicativas, (constantes conhecidas);
. , , , … , são os parâmetros ou coeficientes de regressão;
. , 1, … , correspondem aos erros aleatórios.
Este modelo descreve um hiperplano p-dimensional referente às variáveis explicativas como mostra a Figura 3.1.
Figura 3.1- Hiperplano p-dimensional referente às variáveis explicativas.
Os parâmetros , 1, … , , representam a média esperada na variável resposta, , quando a variável , 1, … , sofre um acréscimo unitário, enquanto todas as outras variáveis
, são mantidas constantes.
Por esse motivo os , 1, … , são chamados de coeficientes parciais.
O parâmetro corresponde ao intercepto do plano de regressão. Se a abrangência do modelo incluir 0, 1, … , , então será a média de nesse ponto. Caso contrário não existe interpretação prática para .
3.1.1. Interações
Vamos considerar o caso particular do modelo de regressão linear múltipla com duas variáveis explicativas e . Assim, o modelo será definido por
. 3.2
Se considerarmos um modelo mais complexo, em que existe interacção entre as variáveis explicativas, obtemos
. 3.3
Neste caso, representa a interacção existente entre as variáveis e . Se a interação existir e for significativa, o efeito de na resposta média depende do nível e vice-versa.
3.1.2. Pressupostos do modelo
Os pressupostos para o modelo de regressão linear múltipla são análogos ao do modelo de regressão linear simples. Assim tem-se:
a) 0 , 1, … , ;
b) Os erros são independentes;
c) , 1, … , (variâncias constantes); d) Os erros têm distribuição normal.
Destes pressupostos, concluímos que ~ 0, , 1, … , e consequentemente que tem distribuição normal com varância e, para o caso de modelo definido em (3.1),
.
3.1.3. Representação matricial do método de regressão linear múltipla
Como vimos em (3.1), a expressão geral de i-ésima observação no modelo de regressão linear (sem interacção) é dada por:
, 1, … , .
Este modelo pode ser reescrito em notação matricial da seguinte forma:
, 3.4 onde 1 … , 1 … , 1 … , 1 .
Concluímos então que:
. é um vector de dimensão 1 cujas componentes são os erros aleatórios, , 1, … , ;
. é uma matriz de dimensão 1 denominada matriz do modelo, cujas colunas são constituídas pelos vectores 1 1, … ,1 e , , … , , , 1, … , . A notação
representa a transposta da matriz .
. é um vector coluna 1 1 cujos elementos são os coeficientes de regressão, , , … , .
Uma vez que é normalmente distribuído, tendo-se ~ 0, , com 0 o vector nulo e a matriz identidade de ordem , será normalmente distribuído com e matriz de variâncias-covariâncias , isto é
~ , .
3.2. ESTIMAÇÃO DO PARÂMETRO DO MODELO
De modo análogo à regressão simples, usando o método dos mínimos quadrados, pretendemos encontrar o vector de estimadores , com componentes , , … , , que minimiza
2 ,
uma vez que se tem , pois este produto é igual a um escalar.
Derivando obtemos
2 2 .
Igualando a derivada a zero e substituindo por , obtemos
2 2 0
onde, representa a matriz inversa de . De (3.4), concluimos que o modelo de regressão linear ajustado é
e o vector dos resíduos
.
3.2.1. Propriedades dos estimadores
a) Valor esperado de :
,
visto que 0 e .
b) Matriz de covariâncias de :
Sendo um vector das variáveis aleatórias , … , , então a matriz de covariâncias de é dada por
,
que na forma matricial é escrita como
, , … ,
, , … ,
, , … ,
, , , …
.
Como vimos anteriormente e , logo
,
visto que .
3.3. ESTIMADOR DE
Consideremos a soma do quadrado dos resíduos, que como vimos anteriormente, é definido por:
2 .
2
.
Pelo que
.
Se ~ ; Σ então, segue uma distribuição qui-quadrado não central com graus de liberdade e parâmetro de não centralidade de , ~ , , (ver, por exemplo,
Mexia, 1995) e corresponde à característica de matriz , .
Como assumimos que o vector dos erros ~ 0; , segue que ~ ; .
Desta forma, obtemos que
~ ;
com . Neste caso
1
2 0
e
1 ,
então segue uma distribuição qui-quadrado central com 1 graus de liberdade,
~ .
Portanto, um estimador não viciado para é dado por:
3.4. ANÁLISE DA VARIÂNCIA
A análise de variância é importante para a análise de regressão linear múltipla. Este tema não foi abordado na análise de regressão linear simples, uma vez que não traz novidades em termos de aplicação dos testes, já que o teste e o teste darão os mesmos resultados. Basta-nos observar que o teste é o quadrado do teste .
Na análise de regressão múltipla, o teste produz um teste mais geral. Através da sua utilização determina-se se qualquer das variáveis independentes no modelo possui poder de explicação. Cada variável pode então ser testada individualmente com o teste para determinar se é uma das variáveis significativas.
A análise de variância, baseia-se na decomposição da soma dos quadrados total, SQT, (que corresponde à variação da variável resposta), na soma dos quadrados explicada, SQR, (que corresponde à variação da variável resposta que é explicada pelo modelo) e na soma dos quadrados dos resíduos, SQE, (que corresponde à variação da variável resposta que não é explicada pelo modelo).
Desta forma, podemos escrever,
Assim, no conceito de regressão linear múltipla, as hipóteses a testar serão
: 0
: : 0, 1, … , .
Para testar a hipótese , utiliza-se a estatística de teste
1
~ , ,
com ~ , ~ e e independentes. Assim, sob , a estatística de segue uma distribuição central com e 1 graus de liberdade, , .
Portanto, se ; , rejeita-se a hipótese , com o valor observado de estatística e , , o quartil 1 de distribuição central com e 1 graus
de liberdade. Ao rejeitarmos concluimos que pelo menos uma das variáveis explicativas contribui significativamente para o modelo.
Estas somas de quadrados podem ser apresentadas numa tabela como a que apresentamos de seguida.
Tabela 3.1- Tabela da análise de variância (ANOVA)
Causas de
Variação Quadrados Soma Liberdade Graus Quadrados Médios F Regressão
Erro
(resíduo) 1 1
Total 1
Como vimos anteriormente o coeficiente de determinação é igual ao quadrado do coeficiente de correlação de Pearson, que agora poderá ser reescrito da seguinte forma
çã çã
1 .
Este coeficiente é usado para quantificar a capacidade explicativa do modelo, ou seja, segundo Esteves and Sousa (2007), é uma medida da proporção da variação da variável resposta que é explicada pela equação de regressão quando estão envolvidas as variáveis independentes , , … , .
Como já foi referido anteriormente,
0 1 .
Temos no entanto de ter atenção ao facto de que 1 não significa que o modelo de regressão providencia um bom ajustamento aos dados, dado que a adição de uma variável aumenta sempre o valor deste coeficiente (mesmo que tenha muito pouco poder explicativo sobre a variável resposta).
Desta forma, quando é elevado em determinados modelos, leva-nos a interpretações erradas de novas observações ou estimativas pouco fiáveis do valor esperado de . Por isso, concluímos que poderá não ser um bom indicador do grau de ajustamento do modelo.
Assim sendo, é preferível utilizar o coeficiente de determinação ajustado, que é uma medida ajustada do coeficiente de determinação e que é “penalizada” quando são adicionadas variáveis pouco explicativas.
O coeficiente de determinação ajustado é definido por:
1 1
1 1 .
Note-se que a inclusão de mais variáveis diminui o valor de , pois aumenta , e não traz muito “incremento” a .
Ou seja, ao contrário do coeficiente de determinação , o coeficiente de determinação ajustado, , não aumenta sempre quando adicionamos uma nova variável. Aliás, se adicionarmos variáveis com pouco poder explicativo este tende a decrescer. Pelo que, quando existe uma diferença significativa entre e , estamos perante uma situação em que provavelmente tenham sido incluidas no modelo variáveis estatisticamente não significativas.
4.
A
NÁLISE DE
R
ESÍDUOS
Como vimos nos capítulos anteriores os resíduos são dados pela diferença entre os valores da variável resposta observada e a variável resposta estimada, isto é,
, 1, … , .
Ao realizarmos uma análise de resíduos pretendemos verificar se o modelo de regressão que está a ser utilizado é adequado. Para tal os resíduos devem verificar os pressupostos anteriormente impostos ao erro do modelo. Tais pressupostos são, considerando o modelo
,
com
, … , , a matriz do modelo, , … , e , … , ,
a) , 1, … , são normalmente distribuídos;
b) , 1, … , , têm variância constante (homoscedasticidade); c) e , , são independentes;
d) não existem Outliers influentes.
No caso da regressão linear múltipla, para além destes pressupostos, é preciso ainda verificar se existe colinearidade ou multicolinearidade entre as variáveis explicativas.
De seguida apresentamos algumas “técnicas” por forma a verificar estes pressupostos.
4.1. DIAGNÓSTICO DE NORMALIDADE
A normalidade dos resíduos pode ser analisada quer através de gráficos, quer usando alguns testes, nomeadamente através do
i. gráfico P-P plot dos resíduos;
ii. histograma dos resíduos estandardizados; iii. teste de Kolmogorov-Smirnov;
Vejamos:
i. Gráfico P-P plot dos resíduos;
Neste gráfico, vamos visualizar a distribuição de probabilidades dos valores observados com os valores esperados, representada por uma diagonal, segundo uma distribuição normal.
Caso a normalidade se verifique, as observações registadas aproximam-se dessa diagonal, sem nenhum afastamento significativo.
A Figura 4.1 mostra o gráfico p-p plot de resíduos. Nesta situação a normalidade é verificada já que os pontos se aproximam da recta.
Figura 4.1– Normal p-p plot de resíduos
ii. Histograma dos resíduos estandardizados
Também se pode fazer um histograma dos resíduos no qual se procuram afastamentos evidentes em relação à forma simétrica e unimodal da distribuição normal. Este gráfico apenas deverá ser utilizado em amostras de dimensão elevada, já que quando se trabalha com amostras de dimensão reduzida o histograma não é muito conclusivo.
iii. Teste de Kolmogorov-Smirnov (K-S)
Neste caso o teste de K-S é utilizado para testar as hipóteses:
: A distribuição é normal :A distribuição não é normal .
A estatística de teste, é dada por, ver Maroco (2003),
em que representa a diferença entre a frequência acumulada de cada uma das observações e a frequência acumulada que essa observação teria, sendo a sua distribuição normal.
Este teste observa a máxima diferença absoluta entre a função de distribuição acumulada assumida pelos dados, neste caso da distribuição normal, e a função de distribuição empírica dos dados.
iv. Teste de Shapiro-Wilk (S-W)
Este teste sugere-nos preferência em relação ao teste de K-S para amostras de pequenas dimensões 30 . Neste caso, as hipóteses a serem testadas são as definidas anteriormente para o teste de K-S.
A estatística de teste é definida da seguinte forma:
∑
∑ ,
onde:
. são constantes geradas a partir da média, variância e covariância de ordens, ver Maroco (2003).
4.2. DIAGNÓSTICO DE HOMOSCEDASTICIDADE (VARIÂNCIA CONSTANTE)
Um dos pressupostos do modelo de regressão linear é a de que os erros devem ter variância constante. Esta condição é designada por homoscedasticidade.
A variância ser constante equivale a supor que não existem observações incluídas na variável residual cuja influência seja mais intensa na variável dependente.
Uma das técnicas usadas para verificar a suposição de que os resíduos são homoscedásticos, é a análise do gráfico dos resíduos versus valores ajustados. Este gráfico deve apresentar pontos dispostos aleatoriamente sem nenhum padrão definido, como se pode ver, por exemplo na Figura 4.2.
Figura 4.2- Confirmação da homoscedasticidade dos resíduos (disponível em PortalAction).
Por isso, se os pontos estão aleatoriamente distribuídos em torno da recta 0, sem nenhum comportamento ou tendência, temos indícios de que a variância dos resíduos é constante. Já a presença, por exemplo, de “funil” é um indicativo da presença de heteroscedasticidade.
4.3. DIAGNÓSTICO DE INDEPENDÊNCIA
Para testar o pressuposto da independência dos resíduos, ou a presença de autocorrelação entre eles, pode utilizar-se o teste de Durbin-Watson (DW).
O teste de Durbin-Watson testa as hipóteses:
: ã çã í
: çã í .
A estatística de teste é dada por:
∑
∑
e toma valores entre zero e quatro, 0 4.
Esta estatística mede a correlação entre cada resíduo e o resíduo correspondente à observação imediatamente anterior.
Podemos tomar a decisão comparando o valor de com os valores críticos e da tabela de Durbin-Watson disponível no Anexo 1.
Tabela 4.1- Tabela de decisão em função de e
Zona de Rejeição e de não-rejeição de
0; ; ; 4 4 ; 4 4 ; 4
Decisão Rejeitar Nada se pode concluir
Não rejeitar Nada se pode
concluir Rejeitar Auto-correlação
positiva Os resíduos são independentes Auto-correlação negativa
4.4. DIAGNÓSTICO DE
O
UTLIERS E OBSERVAÇÕES INFLUENTESDe acordo com Pires e Branco (2007), Outliers são observações extremas que se encontram de tal forma afastadas da maioria dos dados que surgem dúvidas sobre se elas poderão ou não ter sido geradas pelo modelo proposto para explicar essa maioria dos dados.
Os Outliers podem ser classificados em severos ou moderados consoante o seu afastamento em relação às restantes observações. Os Outliers moderados encontram-se fora do intervalo 1,5 ; 1,5 e os Outliers severos encontram-se fora do intervalo 3 ; 3 , em que representa o 1º quartil dos dados e a amplitude interquartil, isto é, é a diferença entre o 3º e o 1º quartil, .
Se um Outlier for influente vai interferir sobre a função de regressão ajustada o que significa que a inclusão ou não desse ponto modifica substancialmente os valores ajustados. Assim, um ponto é influente se a sua exclusão na regressão ajustada provoca uma mudança substancial nos valores ajustados.
Uma medida que serve para diagnosticar Outliers é Leverage (LEV). Para uma dada observação, um Leverage elevado indica que essa observação se distancia do centro das observações exercendo influência sobre o valor previsto. O Leverage varia entre 0 e 1.
Acontece que um elevado Leverage indica apenas que a observação poderá ser influente.
Considera-se um Leverage elevado quando, ver Pestana e Gageiro, 2005a,
3 1
, ã
2 1
,
onde é a dimensão da mostra e o número de variáveis independentes.
Segundo Pires e Branco, (2007), para se perceber os problemas que a presença de Outliers podem causar à estimação dos mínimos quadrados é conveniente distinguir vários tipos de
a) Outlier de regressão:
Trata-se de um ponto que se afasta significativamente da estrutura linear descrita pelos dados e que influencia a estimação, conduzindo a modelos ajustados impróprios.
b) Outlier em x (ponto de Leverage ou alavanca)
É um ponto que é um Outlier em relação à coordenada , isto é, a coordenada está demasiado afastada das restantes. É um potencial Outlier de regressão.
c) Outlier em
É um ponto que é Outlier em relação à coordenada . Pode ou não ser um Outlier de regressão.
d) Outlier em ,
Um ponto que é Outlier nas duas coordenadas. Este pode ou não ser um Outlier de regressão.”
Uma vez que uma observação pode ser considerada um Outlier e pode ou não ser uma observação influente é importante identificar quais as observações influentes. De seguida serão apresentadas algumas “técnicas” que permitem essa identificação.
4.4.1. Observações Influentes
As observações influentes são aquelas que individualmente ou em conjunto com as outras observações demonstram ter mais impacto do que as restantes no cálculo dos estimadores.
Nesta subsecção, apresentamos várias medidas que são utilizadas para identificar as observações influentes.
1) SDFFIT
É uma das medidas de utilização mais frequente para medir a influência de cada observação. SDFFIT trata-se de uma medida estandardizada que mede a influência que a observação tem sobre o seu valor ajustado.
Considera-se que uma observação é influente se, ver Pestana e Gageiro, 2005a,
| | 2 1
2) SDFBETA
A influência que uma observação tem sobre a estimação de cada um dos coeficientes de regressão pode ser calculada pelo SDFBETA. Trata-se de uma medida
estandardizada que corresponde à alteração nos coeficientes estimados, , 0, … , , quando se exclui essa observação.
Neste caso, a observação é influente quando,
| | 1,96, ã
| | 2
√ ,
3) Para verificar se uma observação é influente também podemos usar a distância de Cook que mede a influência da i-ésima observação sobre todos os valores ajustados
, 1, … , .
Uma distância de Cook elevada significa que o resíduo é elevado, ou a Leverage para essa observação é elevada, ou ambas as situações.
De tal forma que, uma observação é influente quando, ver Pestana e Gageiro, 2005a,
4 1 ,
em que é a dimensão da amostra e o o número de variáveis independentes. Considera-se que observações com Distância de Cook superior a 1 são excessivamente influentes.
4.5. COLINEARIDADE E MULTICOLINEARIDADE
Como foi referido atrás, na regressão linear múltipla é importante efectuar uma análise de colinearidade e multicolinearidade.
O termo colinearidade é utilizado para expressar a existência de correlação elevada entre duas variáveis independentes, enquanto o termo multicolinearidade é utilizado quando se trata de mais do que duas variáveis independentes fortemente correlacionadas. No entanto, existem autores que definem colinearidade como a existência de relação linear entre duas variáveis independentes e multicolinearidade como a existência de relação linear entre uma das variáveis independentes e as restantes.
Se considerarmos duas quaisquer variáveis independentes, e , entre as quais existe uma elevada correlação, a proporção da variação total da variável dependente, explicada por é idêntica à proporção da variação total da variável dependente, explicada por .
Quando uma das variáveis independentes já se encontra no modelo de regressão, a inclusão de outra variável independente, não implica, uma explicação adicional significativa da variação total da variável dependente.
A colinearidade poderá ser diagnosticada:
. verificando se a matriz de correlações das variáveis independentes demonstra correlações elevadas. Caso a correlação de duas variáveis seja muito próxima de 1, indica de facto um problema;
. Verificando se, ao se realizar a regressão de em função das outras variáveis independentes, o valor de 1.
Um indicador usado com frequência para detectar a multicolinearidade é o Variance Inflation Factor (VIF).
A variância de cada um dos coeficientes de regressão associados às variáveis independentes é dada por, ver Maroco (2003):
1 1
1
∑ ,
em que é o de regressão de sobre as restantes variáveis explicativas.
Esta variância é tanto maior quanto maior for a correlação múltipla entre e as variáveis independentes.
O termo designa-se, em concreto, por VIF para o coeficiente de regressão associado à variável .
Segundo Maroco (2003), caso se obtenham valores de 5 conclui-se que estamos perante problemas com a estimação de devido à presença de multicolinearidade nas variáveis independentes.
Suponhamos que temos a equação de regressão
,
em que e são altamente correlacionadas.
Existem vários métodos que permitem, na egressão linear múltipla, fazer uma selecção das variáveis independentes que melhor explicam a variável resposta, nomeadamente:
. FORWARD – o método começa apenas com a constante e adiciona uma variável independente
de cada vez. A primeira variável selecionada é a que apresenta maior correlação com a variável resposta (maior score statistic)
. BACKWARD – o método faz o “contrário” do método Forward. Neste caso todas as variáveis
independentes são incorporadas no modelo. Depois, por etapas, cada uma pode ser ou não eliminada.
. STEPWISE -o método Stepwise é uma “modificação” do método Forward que permite resolver problemas de multicolinearidade. Consiste no seguinte: fazemos entrar no modelo a variável explicativa que apresenta maior coeficiente de correlação com a variável dependente. Em seguida, calculam-se os coeficientes de correlação parcial para todas as variáveis que não fazem parte da primeira equação de regressão, para que, a próxima variável a entrar, seja a que apresenta maior coeficiente de correlação parcial.
Estima-se a nova equação de regressão e analisa-se se uma das duas variáveis independentes deve ser excluída do modelo.
No final, se ambas as variáveis apresentarem valores significativos, novos coeficientes de correlação parcial são calculados para as variáveis que não entraram.
Este processo finda, assim que se chegue à situação em que nenhuma variável deva ser acrescentada à equação.
5.
A
PLICAÇÕES
Os dados que usamos neste capítulo foram cedidos pela Doutora Catarina Reis Santos, Nefrologista na Unidade Local de Saúde de Castelo Branco. A amostra é constituída por 35 utentes da Consulta de Hipertensão e Dislipidémia, no Hospital de Sta. Marta, Lisboa, em 2010, e os dados foram recolhidos através de documento próprio, Avaliação da Variabilidade da Frequência Cardíaca, disponível no anexo 2. Estes dados foram recolhidos com o intuito de avaliar a existência de diferenças da variabilidade da frequência cardíaca, entre utentes diabéticos e não diabéticos.
O nosso estudo vai-se concentrar nas seguintes variáveis: peso, colesterol total (CT), triglicéridos e high density lipoprotein (HDL).
Estes dados foram tratados recorrendo ao software SPSS, versão 19, de onde provêm as tabelas e figuras que apresentamos neste capítulo.
Serão apresentados dois estudos. No primeiro estudo foi utilizado o Modelo de Regressão Linear Simples, enquanto que no segundo considerámos o Modelo de Regressão Linear Múltipla, com três variáveis explicativas.
5.1. ESTUDO 1 – MODELO DE REGRESSÃO LINEAR SIMPLES
Com vista a perceber se o nível de HDL no sangue, (mg/dl), influencia o nível de CT no sangue (mg/dl), foi realizada uma análise de regressão linear simples.
O modelo de regressão linear simples que representa a relação entre a variável dependente, CT, e a variável independente, HDL, é dado pela seguinte equação:
5.1
Tabela 5.1- Estatística descritiva
Mean Std. Deviation N CT 154,8857 103,45467 35 HDL 33,6000 19,72040 35
A Tabela 5.1- Estatística descritiva mostra o valor médio e o desvio padrão de CT e HDL. Concluimos que, nesta amostra, o nível de concentração de CT no sangue é em média 154,8857 (mg/dl), enquanto que de HDL é 33,6.
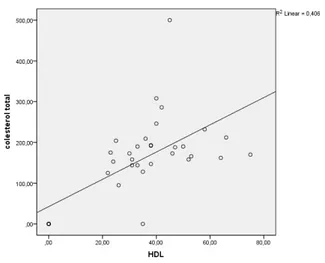
Figura 5.1– Diagrama de dispersão
Elaborámos um diagrama de dispersão com o intuito de perceber se a relação existente entre as duas variáveis é de facto linear.
De acordo com a observação do diagrama de dispersão (Figura 5.1) somos tentados a concluir que existe uma relação linear entre o CT e o HDL e que as duas variáveis tendem a variar no mesmo sentido, o que significa que o aumento da variável independente, HDL, provoca um aumento da variável dependente, CT.
Analisando a Tabela 5.2 podemos afirmar que a correlação existente entre as variáveis é positiva moderada ( 0,637 .
Tabela 5.2– Sumário do Modelo
Model R R Square Adjusted R Square Std. Error of the Estimate Durbin-Watson 1 ,637a ,406 ,388 80,91691 1,739
a. Predictors: (Constant), HDL
b. Dependent Variable: colesterol total
Continuando a análise à Tabela 5.2 concluímos que o valor de 0,406 e de 0,388 não são muito diferentes.
Como foi dito no capítulo 3, a nossa preferência recai sobre o valor do coeficiente de correlação ajustado que, neste caso, nos leva a afirmar que 38,8% da variabilidade da variável dependente CT é explicada pela variável independente HDL, sendo a restante variabilidade explicada por factores não incluídos no modelo.
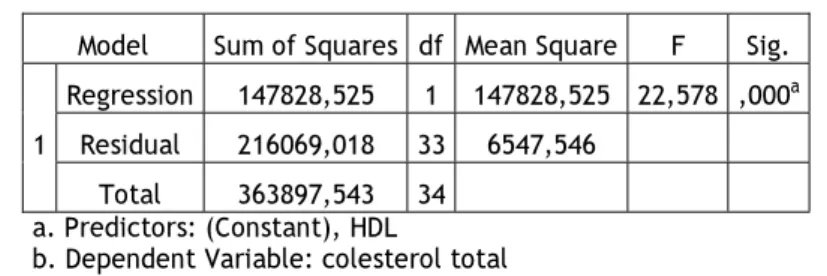
Tabela 5.3– Tabela da ANOVA
Model Sum of Squares df Mean Square F Sig. 1
Regression 147828,525 1 147828,525 22,578 ,000a
Residual 216069,018 33 6547,546 Total 363897,543 34
a. Predictors: (Constant), HDL
b. Dependent Variable: colesterol total
Para efectuar a análise de variância do modelo recorreu-se ao teste de que tem associado o seguinte de 0,000. De acordo com o seu valor, rejeitamos : 0, pelo que podemos dizer que o modelo é significativo.
Tabela 5.4- Coeficientes
Model Unstandardized Coefficients Standardized Coefficients t Sig. B Std. Error Beta
1 (Constant) 42,538 27,315 1,557 ,129 HDL 3,344 ,704 ,637 4,752 ,000 a. Dependent Variable: colesterol total
A equação do modelo ajustado de regressão será, segundo a Tabela 5.4
42,538 3,344 . 5.2
O teste ao coeficiente de regressão é dado pelo teste t-student ao qual está associado um valor de significância de 0,129 (>0,05). Concluímos, portanto, que não se deve rejeitar a hipótese : 0, o que significa que a recta ajustada passa pela origem.
Quanto ao teste para é dado pelo teste t-student ao qual está associado um valor de significância de 0,000 (<0,05). Logo rejeita-se a hipótese : 0, o que significa que a variável HDL influencia significativamente o CT.
Fazendo a comparação dos resultados do teste t com o teste F, verificamos que foram obtidos os mesmos resultados como podemos confirmar pelas tabelas Tabela 5.3 e 5.4, tal como era esperado pelo que foi justificado no capítulo 2.
5.1.1. Verificação dos pressupostos do modelo
O modelo definido em (5.2) só será adequado se validados todos os pressupostos. Vamos nesta subsecção fazer uma análise desses pressupostos.
• NORMALIDADE DOS RESÍDUOS
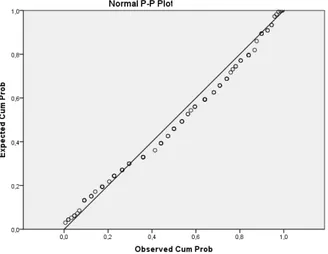
Figura 5.2– Normal p-p plot
A partir da análise da Figura 5.2, podemos concluir que as observações se aproximam da recta sem nenhum afastamento sistemático, pelo que somos levados a concluir que os resíduos são normalmente distribuídos.
Tabela 5.5- Teste K-S
Unstandardized Residual
N 35
Normal Parametersa,b Mean ,0000000
Std. Deviation 75,68119963 Most Extreme Differences
Absolute ,157 Positive ,139 Negative -,157 Kolmogorov-Smirnov Z ,930
Asymp. Sig. (2-tailed) ,353 a. Test distribution is Normal.
b. Calculated from data.
Com o intuito de confirmar a normalidade dos resíduos realizámos o teste K-S apresentado na Tabela 5.5. Pelo valor obtido de significância (0,353) concluímos que não se rejeita , pelo que os resíduos são normalmente distribuídos.
• AUTOCORRELAÇÃO DOS RESÍDUOS
O valor do teste de Durbin-Watson foi de 1,739, como se pode ver na Tabela 5.2. Uma vez que este valor pertence ao intervalo ; 4 (ver Tabela 4.1 e Tabela do Anexo 1) somos levados a concluir que os resíduos são independentes.
• HOMOSCEDASTICIDADE DOS RESÍDUOS
Figura 5.3– Gráfico dos resíduos estandardizados
A partir da análise gráfica da Figura 5.3 concluímos que os resíduos são homoscedásticos uma vez que estes se distribuem de forma aleatória em torno zero (0). (ver Maroco (2003) e Pestana e Gageiro (2005b))
• OUTLIERS E OBSERVAÇÕES INFLUENTES
Figura 5.4 – Gráfico resíduos press
Pela análise gráfica dos resíduos estandardizados (Figura 5.3) e dos resíduos press (Figura 5.4) podemos concluir que existem Outliers, dado que há resíduos que apresentam valores absolutos superiores a 1,96, sendo eles os correspondentes às
Tabela 5.6- Estatística dos resíduos
Minimum Maximum Mean Std. Deviation N Predicted Value 42,5383 293,3138 154,8857 65,93859 35 Std. Predicted Value -1,704 2,099 ,000 1,000 35 Standard Error of Predicted Value 13,684 32,184 18,486 5,776 35 Adjusted Predicted Value 48,0091 316,4877 156,4813 66,73882 35 Residual -159,56686 306,99640 ,00000 79,71807 35 Std. Residual(ZRE_1) -1,972 3,794 ,000 ,985 35 Stud. Residual(SRE_1) -2,001 3,869 -,009 1,013 35 Deleted Residual -164,28506 319,25589 -1,59559 84,28194 35 Stud. Deleted Residual(SDRE_1) -2,102 5,154 ,026 1,177 35 Mahal. Distance ,001 4,407 ,971 1,275 35 Cook's Distance ,000 ,299 ,029 ,065 35 Centered Leverage Value ,000 ,130 ,029 ,038 35 a. Dependent Variable: colesterol total
A confirmação da existência de Outliers pode ser feita, por exemplo, através do valor máximo do student deleted residual que neste caso corresponde ao valor 5,154 > 1,96. E também analizando o valor da Leverage centrada máxima, que é igual a 0,130
0,12, 35, 1. Interessa verificar se Outliers são ou não observações influentes. Olhando ainda para a Tabela 5.6 tudo leva a crer que sim, já que temos como valor máximo da distância de COOK 0,299 0,121.
Vamos usar mais uma técnica para averiguar a existência de Observações Influentes, recorrendo à análise dos SDFFIT. Para isso apresentamos o gráfico dos SDFFIT (Figura 5.5).
Visto que as observações 4, 13 e 26 da Figura 5.5 têm | | 2 0,49, concluímos que se tratam de observações influentes, devendo ser mantidas no estudo como é sugerido, por exemplo, por Pestana e Gageiro (2005a).
Conclusão
Uma vez que todos os pressupostos da regressão linear simples foram validados, podemos concluir que o modelo (5.2) é adequado justificando correctamente os dados.
5.2. ESTUDO 2 – MODELO DE REGRESSÃO LINEAR MÚLTIPLA
Neste estudo passamos a considerar o modelo de regressão linear múltipla, que será “estimado” através do método Stepwise. O que pretendemos averiguar é de que forma o peso, o nível de HDL, e o nível de triglicéridos (mg/dl) influenciam o nível de CT no sangue.
O modelo de regressão linear múltipla que representa a relação entre a variável dependente, CT, e as variáveis independentes, peso, HDL, triglicéridos, é dado pela seguinte equação:
é 5.3
Tabela 5.7- Estatística descritiva
Mean Std. Deviation N CT- Colesterol Total 154,8857 103,45467 35 HDL 33,6000 19,72040 35 Peso 73,8429 21,21624 35 Triglicéridos 160,7429 298,36134 35
O valor médio de CT é aproximadamente 154,8857 mg/dl enquanto que o valor médio de HDL é de 33,6 mg/dl aproximadamente e dos triglicéridos é 160,7429 mg/dl. O peso médio dos indivíduos da amostra é de 73,8 Kg, aproximadamente.
Tabela 5.8– Tabela de variáveis inseridas/removidas Model Variables
Entered
Variables
Removed Method
1 Triglicéridos . Stepwise (Criteria: Probability-of-F-to-enter <= ,050, Probability-of-F-to-remove >= ,100). 2 HDL . Stepwise (Criteria: Probability-of-F-to-enter <= ,050,
Probability-of-F-to-remove >= ,100). a. Dependent Variable: CT- Colesterol Total
A Tabela 5.8 confirma a utilização do método Stepwise. Verificamos que a primeira variável a entrar é triglicéridos, seguindo-se a variável HDL.
Tabela 5.9- Sumário do Modelo
Model R R Square Adjusted R Square Std. Error of the Estimate Durbin-Watson 1 ,682a ,465 ,449 76,81933
2 ,856b ,733 ,716 55,10980 1,716
a. Predictors: (Constant), Triglicéridos b. Predictors: (Constant), Triglicéridos, HDL c. Dependent Variable: CT- Colesterol Total
Observando a Tabela 5.9, concluímos que e tomam valores aproximados, sendo que o maior valor de corresponde ao modelo em que são consideradas as duas variáveis explicativas, HDL e triglicéridos. Concluímos que este modelo será provavelmente o que melhor explica os valores de CT. Este valor permite-nos afirmar que 71,6% ( 0.716 da variabilidade de CT é explicada por este modelo.
Tabela 5.10– Tabela da ANOVA
Model Sum of Squares df Mean Square F Sig. 1 Regression 169157,648 1 169157,648 28,665 ,000a Residual 194739,895 33 5901,209 Total 363897,543 34 2 Regression 266710,661 2 133355,331 43,909 ,000b Residual 97186,882 32 3037,090 Total 363897,543 34
a. Predictors: (Constant), Triglicéridos b. Predictors: (Constant), Triglicéridos, HDL c. Dependent Variable: CT- Colesterol Total
Pela análise do valor de significância do teste F (0,000) concluímos que o modelo é altamente significativo. Constata-se que o CT é explicado pelas duas variáveis independentes (triglicéridos e HDL). Esta conclusão pode ser confirmada observando a significância do teste t da Tabela 5.11 ( 0,000 . Tabela 5.11- Coeficientes Model Unstandardized Coefficients Standardized Coefficients t Sig. 95,0% Confidence Interval for B Collinearity Statistics B Std. Error Beta Lower Bound Upper
Bound Tolerance VIF 1 (Constant) 116,885 14,798 7,899 ,000 86,778 146,992 Triglicéridos ,236 ,044 ,682 5,354 ,000 ,147 ,326 1,000 1,000 2 (Constant) 29,500 18,720 1,576 ,125 -8,630 67,631 Triglicéridos ,202 ,032 ,582 6,256 ,000 ,136 ,268 ,964 1,037 HDL 2,766 ,488 ,527 5,667 ,000 1,772 3,760 ,964 1,037 a. Dependent Variable: CT- Colesterol Total
Ainda da análise da Tabela 5.11 concluímos que o modelo ajustado tem como equação
29,5 0,202 é 2,766 5.4
Ambas as variáveis explicativas apresentam um coeficiente positivo o que parece fazer sentido, uma vez que, o aumento do nível de triglicéridos e de HDL fazem aumentar o valor de CT.
Tabela 5.12– Variáveis excluídas
Model Beta In t Sig. Partial Correlation Collinearity Statistics Tolerance VIF Minimum Tolerance 1 HDL ,527
a 5,667 ,000 ,708 ,964 1,037 ,964
Peso -,075a -,586 ,562 -,103 1,000 1,000 1,000
2 Peso -,070b -,762 ,452 -,136 ,999 1,001 ,964
a. Predictors in the Model: (Constant), Triglicéridos b. Predictors in the Model: (Constant), Triglicéridos, HDL c. Dependent Variable: CT- Colesterol Total
A Tabela 5.12 dá-nos a informação de quais as variáveis excluídas da análise. A variável excluída é o peso, dado que pelo valor da significância para o teste t (0.452) leva à não rejeição da hipótese nula. Assim, esta variável não influencia significativamente os níveis do CT.
O que vai de encontro à realidade, uma vez que o aumento de peso nos individuos não significa que estes venham a “sofrer” de níveis de CT no sangue superiores ao níveis normais. Pode inclusivamente surgir a situação de que individuos com peso abaixo do peso ideal “sofram” de níveis bastante elevados de CT.
5.2.1. Verificação dos pressupostos do modelo
Com o intuito de verificar se o modelo (5.4) é adequado, de seguida é feita uma análise dos pressupostos da regressão linear múltipla.
• NORMALIDADE DOS RESÍDUOS
Observando a Figura 5.6 parecem existir alguns pontos que se afastam da diagonal principal, não sendo conclusivos quanto à normalidade dos resíduos.
Figura 5.6– Normal p-p plot da regressão dos resíduos estandardizados
Para confirmar a normalidade realizamos o teste K-S apresentado na Tabela 5.13. Mediante o valor de significância obtido (0,123) confirmamos que os resíduos são normalmente distribuídos, devido a não se rejeitar a hipótese nula.
Tabela 5.13– Teste K-S
Unstandardized Residual
N 35
Normal Parametersa,b Mean ,0000000
Std. Deviation 53,46435912 Most Extreme Differences
Absolute ,195 Positive ,095 Negative -,195 Kolmogorov-Smirnov Z 1,152 Asymp. Sig. (2-tailed) ,141
Exact Sig. (2-tailed) ,123 Point Probability ,000 a. Test distribution is Normal.
b. Calculated from data. • AUTOCORRELAÇÃO DOS RESÍDUOS
Considerando o resultado obtido para o teste de Durbin-Watson, apresentado na Tabela 5.9 (1,716) e uma vez que eese valor pertence ao intervalo ; 4 , concluímos que os resíduos são independentes (ver Tabela 4.1 e Tabela do Anexo 1).
• HOMOSCEDASTICIDADE DOS RESÍDUOS
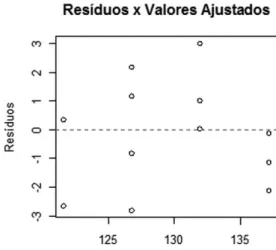
Figura 5.7- Gráfico dos resíduos estandardizados
A partir da análise gráfica dos resíduos estandardizados, Figura 5.7, como os resíduos se distribuem aleatoriamente em torno de zero, concluímos que os resíduos são homoscedásticos. (ver Maroco, (2003) e Pestana e Gageiro, (2005b))
• COLINEARIDADE
Como se trata de uma análise de regressão linear múltipla, um dos pressupostos que terá de ser verificado é se existe colinearidade entre as duas variáveis independentes.
Tabela 5.14- Diagnóstico da colinearidade
Model Dimension Eigenvalue Condition Index Variance Proportions (Constant) Triglicéridos HDL 1 1 1,480 1,000 ,26 ,26 2 ,520 1,686 ,74 ,74 2 1 2,249 1,000 ,04 ,08 ,04 2 ,617 1,909 ,05 ,92 ,04 3 ,134 4,095 ,91 ,00 ,92 a. Dependent Variable: CT- Colesterol Total
Dado que para as duas variáveis independentes os valores de VIF 5, como podemos confirmar pela Tabela 5.11, concluímos que não existem problemas de colinearidade. Esta conclusão pode ser confirmada pelos Condition Index na Tabela 5.14, já que estes valores são inferiores a 15 (ver Maroco, 2003).
• OUTLIERS E OBSERVAÇÕES INFLUENTES
Figura 5.8– Gráfico resíduos press
Pela análise gráfica dos resíduos press, Figura 5.8, temos que, existem Outliers, dado que apresenta resíduos com valores absolutos superiores a 1,96 (ver Pestana e Gageiro, 2005b). São Outliers as observações 4, 24 e 26.
Tabela 5.15- Estatística dos resíduos
Minimum Maximum Mean Std. Deviation N Predicted Value 29,5005 515,2530 154,8857 88,56879 35 Std. Predicted Value -1,416 4,069 ,000 1,000 35 Standard Error of Predicted Value 9,354 52,627 14,193 7,785 35 Adjusted Predicted Value 33,3483 673,1512 160,4467 109,00174 35 Residual -184,03899 115,37788 ,00000 53,46436 35 Std. Residual -3,339 2,094 ,000 ,970 35 Stud. Residual -3,397 2,130 -,028 1,009 35 Deleted Residual -190,46869 119,42819 -5,56101 63,58802 35 Stud. Deleted Residual -4,182 2,263 -,044 1,104 35 Mahal. Distance ,008 30,033 1,943 5,064 35 Cook's Distance ,000 3,001 ,105 ,505 35 Centered Leverage Value ,000 ,883 ,057 ,149 35 a. Dependent Variable: CT- Colesterol Total
A confirmação de existência de Outliers pode ser feita através do valor máximo de
Student Deleted Residual (2,263>1,96) e do Leverage (0,883 0,17). (ver
Maroco, 2003)
Olhando ainda para a Tabela 5.15 concluímos que estes Outliers poderão ser influentes uma vez que o valor máximo da distância de 3,001 0,125.
Para averiguar se as observações são efectivamente influentes, devemos ainda recorrer à análise dos SDFFIT, pelo que apresentamos de seguida o gráfico destes.
Figura 5.9– Gráfico dos Standardized DFFIT
Concluímos então que as observações 4 e 26 são observações influentes, uma vez que | | 2 0,61. No entanto a observação 24 não satisfaz esta condição, o que significa que não é influente.
Conclusão
O que fazer em situações como esta é uma questão ainda nos tempos actuais colocada por muitos autores da área. Podemos tomar a decisão mais fácil, que passa por excluir esta observação da análise e reestimar de novo o modelo. No entanto há quem defenda que se deve manter este tipo de observações, ver por exemplo, Figueira (1995).
À excepção desta questão todos os restantes pressupostos foram validados. Optando pela não exclusão da observação 24, teríamos o modelo (5.4) como o modelo válido, adequado aos dados.