ISSN 1450-216X Vol.21 No.4 (2008), pp.662-686 © EuroJournals Publishing, Inc. 2008
http://www.eurojournals.com/ejsr.htm
On Scalable Interactive Video-On-Demand Services
Carlo Kleber da Silva Rodrigues
Center of System Development – Department of Science and Technology – Brazilian Army QGEx – Block C – North Side – Brasilia – DF – 70630-901 – Brazil
E-mail: [email protected]
Tel: +55-61-3415-6800; Fax: +55-61-3415-6848 Luiz J. Hoffmann Filho
Federal University of Rio de Janeiro, COPPE/PESC CxP 68511 – Rio de Janeiro – RJ – 21941-972 – Brazil
E-mail: [email protected]
Tel: +55-21-2562-8664; Fax: +55-21-2562-8676 Rosa Maria Meri Leão
Federal University of Rio de Janeiro, COPPE/PESC CxP 68511 – Rio de Janeiro – RJ – 21941-972 – Brazil
E-mail: [email protected]
Tel: +55-21-2562-8664; Fax: +55-21-2562-8676
Abstract
The deployment of a high-quality VoD service at low-bandwidth cost is still far from widespread. Moreover, DVD-like operations have recently become essential for applications using this type of service. Focusing on interactive access, this paper proposes the Efficient Interactive Patching (EIP) and Interactive Merge (IM) schemes. The former is an optimization of the original Patching streaming protocol, and the latter is an optimization of the original Closest Target streaming protocol. Additionally, two new policies for exploiting the client's buffering capability are proposed: Unique Buffer (UB) and Precise Buffer (PB). Throughout trace-driven simulations, using workloads generated from real multimedia servers, we validate our proposals and carry out detailed competitive analyses with other proposals in the literature. Our results show that combining the optimizations with the buffer policies makes it possible to achieve quite significant overall reductions at average bandwidth, peak bandwidth and system complexity.
Keywords: Stream Sharing, Scalability, Interactivity, Multicast, Video on Demand
1. Introduction
then been developed to reduce bandwidth consumption and still support clients' interactive behavior, making the VoD systems scalable and possibly more widely disseminated.
For example, the authors of [1] introduced tuning in staggered VoD which broadcasts multiple copies of the same video at staggered times. Intelligently tuning to different broadcast channels is used to perform user interaction. However, not all types of interactions can be achieved by jumping to different stream channels. Moreover, even if the system can emulate some interactions, it cannot guarantee the exact effect the user wants. Other solutions to DVD-like interactivity are proposed in [2], especially for handling a pause/resume request. Support for continuous service of pause operations was simulated, but stream merge operations [2] were either ignored or did not guarantee continuity in video playout.
The Split and Merge (SAM) technique [3] is the first to formally discuss the merge of ongoing system streams. It opens an exclusive I-channel when the client performs an interaction and makes use of a buffer located at the access node of the network to merge streams. All types of interactive actions are allowed. One drawback is the large number of required I-channels and no service admission is considered. In [4] there was the proposal of the Single-Rate Multicast Double-Rate Unicast (SMRDU) protocol. Clients are served by I-channels as soon as their requests are received by the system. This protocol doubles the transmission rate of unicast streams so that clients may catch up with multicast streams as soon as possible.
The authors of [5] proposed the Best-Effort Patching (BEP) which is based on the original Patching protocol [6], designed for sequential access. BEP aims to offer continuous service for both request admission and DVD-like interaction. This protocol uses a rather complex technique to merge ongoing streams with regular multicast streams. The idea is to let a client listen to (i) a new open stream that delivers his own missing units, to (ii) an ongoing stream that delivers another client's missing units and, eventually, to (iii) a regular multicast stream, thus generating a merging structure of up to three levels. In the original Patching protocol, a client may listen to (i) a new stream that delivers his missing units and to (ii) a multicast stream, thus generating a merging structure of up to two levels only. Other proposals modifying the original Patching protocol to allow merging structures of more than two levels have come in the works of [7, 8, 9]. The main drawback of these schemes is the need of online computation of various time thresholds, thus making the complexity to generate and manage the merging structures possibly too high for real system implementation.
The efficient Hierarchical Stream Merging (HSM) algorithms [10, 11, 12, 13], with their intrinsic unlimited-level merging structures, may in general be adapted for scenarios with interactivity. For example, in the works of [14, 15] it is shown that significant bandwidth savings with respect to unicast streaming may be obtained using HSM schemes for a non-sequential access. One drawback of these techniques may be the high server load due to the intrinsic merging mechanism which makes clients join and leave multicast streams quite frequently, thus leading to a large number of server operations. All these proposals were mainly evaluated using a model that can be far from a real scenario. To the best of our knowledge, there is only one evaluation of the HSM and Patching schemes based on workloads generated from real servers [17]. Among the existing HSM proposals, the Closest Target (CT) protocol [11] deserves special attention because of its noticeable efficiency and practicability for merge decisions.
More elaborated buffer policies have come along the time and mainly follow these design concepts [17]: (i) Locality (LOC) - the client stores all data units played by him. It aims to benefit from an eventual high fraction of jump-backwards actions; (ii) Silent Prefetch (SP) - the client stores data units delivered to other clients while he is paused or playing from his local buffer. During such periods, the client may for instance listen to the active server stream that is the closest to the unit that was most recently played by him; (iii) Keep Merge Buffer (KMB) - the client stores in the buffer data units that would otherwise be discarded during unsuccessful merge attempts; (iv) Preserve Merging Tree (PMT) - the client stores data units streams which are not needed anymore at the present time. Concepts (i), (ii) and (iii) provide significant bandwidth savings, each for different ranges of request rates, while concept (iv) usually does not show to be cost-effective. Still combining different concepts in a single unified solution, such as concepts (i) and (iii) or (i), (ii) and (iii), may be amazingly cost-effective.
This work proposes optimizations to Patching [6, 19, 20, 21] and Closest Target [10, 11], two efficient streaming sequential-access protocols. The first optimization is Efficient Interactive Patching (EIP). It mainly introduces new time thresholds to increase the number of stream merges. The second optimization is Interactive Merge (IM) and is based on the idea of keeping clients, coming out from recent merge operations, in distinct groups. This may then allow merge decisions to be done more efficiently. Both optimizations are designed for client interactive access. Furthermore, we exploit clients' buffering capability by proposing two buffer policies: Unique Buffer (UB) and Precise Buffer (PB). The former deploys a single buffer located at the network access node to serve the clients' requests, and the latter makes the client quantify the available data in the local buffer before soliciting any data from the server. Throughout trace-driven simulations, using workloads generated from real servers and a number of distinct performance metrics, we validate our proposals and carry out a thorough competitive analysis. Combining our optimizations with buffer policies makes it possible to achieve significant reductions at average bandwidth, peak bandwidth and system complexity.
The remainder of this paper is organized as follows. Section 2 introduces several basic concepts and terminology as well as presents the scenario setting for the overall exposition. Section 3 explains the new optimizations and Section 4 discusses the new buffering policies. The performance evaluation comes in Section 5. Lastly, conclusions and ongoing work are included in Section 6.
2. Basic terminology and scenario setting
Consider a server and a group of clients receiving a multimedia object (e.g., a film, a video clip, etc.) from this server. The object is divided into data units u of a same fixed size and each may be played at a time unit. The paths from the server to the clients are multicast enabled. Clients have a non-sequential (interactive) access and always receive immediate service. Each client buffer is large enough to store a portion or the entire multimedia object. The client bandwidth is twice the object play rate. At last, all system streams (unicast and multicast) deliver data at the same object play rate. These are overall assumptions that we implicitly assume in the remainder of this work [3, 17, 22, 23].
Multicast service is not currently deployed over the global Internet. However, this can be alleviated through the use of proxies which can bridge unicast and multicast networks. One of the most common proposed architectures consists of a unicast channel from the server to the proxy and multicast channels from the proxy to the clients. Since the proxy and the clients are usually in the same local area network, multicast service can be easily implemented. Solutions using application level multicast protocols have also been used over the public Internet [24, 25, 26, 27, 28, 30].
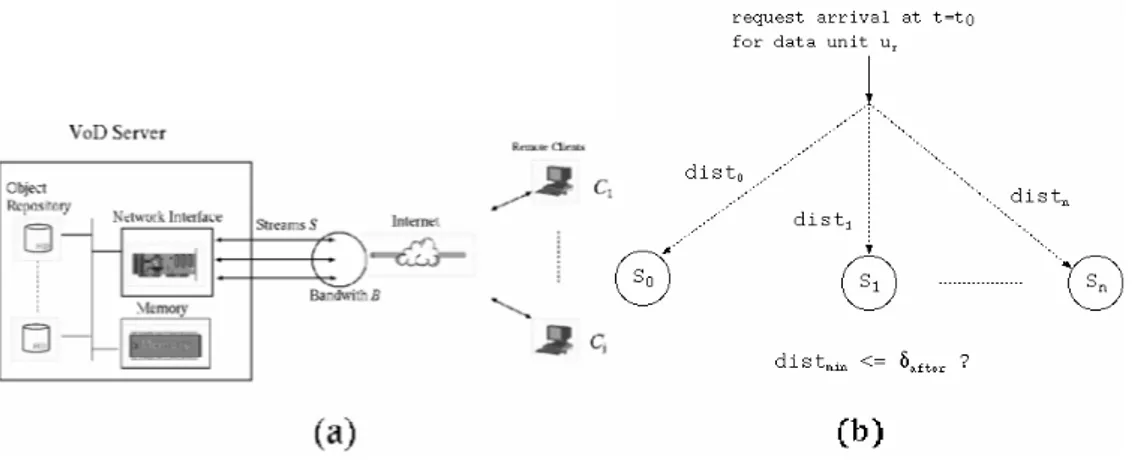
The basic components of an elementary VoD system are shown in Figure 1(a): the server, the object repository and the remote clients. The overall scenario for a data unit request that takes place at time t = t0 is depicted in Figure 1(b). The data unit is ur and it belongs to a repository object. There are
n multicast ongoing streams: S1, S2,…, Sn. Without loss of generality, the streams deliver future data
ur and the unit ui being delivered by stream S ii,
i,...,n
. This distance is measured in number of dataunits.
The server selects the multicast stream owning the minimum value of dist to service the request for ur. Let Smin be this stream and distmin the corresponding distance to ur. If the missing units (related
to distmin) are not delivered to the client, the service is said to be discontinuous since the client does not
receive what he has exactly solicited. For a continuous service, the value distmin is evaluated: (1) if it is
within a given time threshold, denoted as δafter, the request is serviced by Smin and the missing units are
delivered over a new unicast data stream, denoted as patch; (2) otherwise, a new multicast stream Snew is opened to service the request [30, 31]. Although the analytical determination of δafter is still an
open issue in the literature, several researches estimate it in function of the client buffer size [3, 23]. Figure 1: (a) Scenario of a common multimedia system; (b) Servicing requests for an object.
To avoid opening a new stream Snew to service the request for ur, the server may alternatively
select a multicast ongoing stream that delivers a past unit with respect to ur (that is, ur-1, ur-2,…) and
within a time threshold δbefore. Let Sbefore be this stream. If the client is serviced by this stream, he
receives an extra portion of the object which has not been requested. The service then suffers from discontinuity since the delivered data is not actually what the client has solicited. There is though no data loss.
3. Interactivity protocols
In this section we introduce the EIP and IM optimizations. We recall that the former is related to the Patching protocol, and the latter to the CT protocol. We present the complete algorithms as well as discuss over the main differences between the optimizations and the original protocols so as to clarify the innovative aspects.
3.1. The Efficient Interactive Patching Optimization
Event:A client C request a data unit ur.
The server seeks a stream that delivers a past unit within the threshold δbefore. Let Sbefore be
this stream. Case 1 in Figure 2 depicts this situation by showing the wanted play point of client C and the δ past units received in excess from Sbefore.
If there is no stream Sbefore, the server seeks a stream that delivers a future unit within the
threshold δafter. Let Safter be this stream. If Safter exists, the client simultaneously listens to
Safter and to a unicast stream (i.e., a patch) that is opened to deliver the missing units. Case 2
of Figure 2 illustrates this situation.
If Safter does not exist, a new multicast stream Snew is opened to service the request. The
server also seeks a stream, denoted as Smerge, which may merge with Snew. Stream Smerge
delivers a past unit within the time threshold δafter and there are no clients listening to it over
patches. Stream Snew is said to be a target for stream Smerge since the clients of Smerge listen to
both Smerge (for instantaneous viewing) and Snew (for future viewing). After the merge of
Smerge and Snew takes place, Smerge is terminated and the original clients of Smerge start
receiving data units exclusively from Snew. Case 3 of Figure 2 depicts the overall situation.
Determining optimal values for δafter is intricate due to clients' interactive behavior. So we
alternatively deploy opt
2
T L
1 1
T
as an approximation for δafter, where the clientrequest process is assumed to be Poisson with rate β, parameter T is the object length, and each request is for a media segment of average size L. Details are in Appendix A.
The original Patching protocol was designed for sequential access and, consequently, its performance for clients' interactive behaviour is unsatisfactory. This is because every time a client executes a DVD-like operation and requests a data unit different from the object starting unit, a new multicast stream is opened to service the request. The performance then deteriorates since no bandwidth sharing is achieved. Now comparing EIP to the BEP protocol, which is the most recent proposal based on the Patching paradigm, we have that BEP has a more complex strategy than EIP. The BEP protocol allows merging structures of up to three levels, demanding an online computation of at least two interrelated time thresholds to achieve optimality.
3.2. The Interactive Merge Optimization
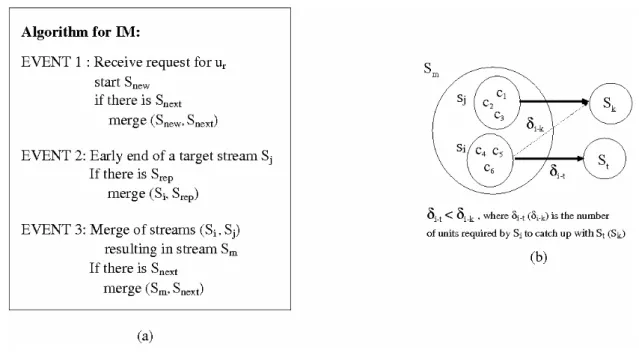
The IM scheme belongs to the HSM paradigm and is an optimization for the Closest Target protocol. Its algorithm is presented in Figure 3(a). Three events may cause the merge of streams as explained in the following.
Event 1:Client C request data unit ur.
The server opens a new multicast stream Snew to service the request as well as seeks an ongoing
stream that delivers a future unit with respect to ur. Let Snext be this stream. Note that no time threshold
is used to seek Snext. If Snext exists, the client of Snew also listens to it so that Snew and Snext may be
merged later.
Event 2:Early termination of stream Sj which is the target of another stream si.
The clients of Sm do not have a target stream anymore and their buffer contents are discarded.
The server then seeks an ongoing stream Srep to replace Sj. Stream Srep delivers a future unit with
respect to that of Si. No time threshold is used. If Srep ends before being caught up by Si, the whole
procedure is repeated.
Event 3:The merge of two ongoing streams (Si and its target Sj) takes place.
Let Sm be the resulting stream. The server immediately seeks another ongoing stream that
delivers a future unit with respect to that of Sm. If there is more than one stream that satisfy this
condition, the closest one is chosen. Let St be this stream. The clients of Sm, who originally belong to Si,
listen to St in order to catch up with it later. On the other hand, if the clients of Sm, who originally
belong to Sj, already had another target stream Sk before the merge with Si, they would continue to
listen to it (Sk) with no data discarding.
Figure 3: (a) Algorithm for the IM optimization; (b) Merge scenario.
Suppose that a stream Si merges with its target Sj. Let Sm be the resulting stream from this
merge. Consider that Sj already had a target stream Sk before being caught up by Si. In the CT protocol,
a target stream for Sm is chosen and all data received by the original clients of Sj – while they were
listening to Sk before the merge took place – is simply discarded. If we consider a client sequential
access, this decision does not increase the server bandwidth since the data has to be retransmitted any way to service the original clients of Si, even though it may impact on client bandwidth. On the other
hand, for a non-sequential access, this decision may increase the server bandwidth.
The first situation is: immediately after the merge of Si and Sj, resulting in stream Sm, all clients
who originally belonged to Si decide to jump away from the present play point. In this case, if the
clients who originally belonged to Sj discard the data of the local buffer received from Sk, as it happens
in CT, this same data has to be transmitted again, not because of the original clients of Si, but because
of the clients who originally belonged to Sj. In IM, just the clients of Sm who originally belonged to Si
have a new target stream assigned, and the clients of Sm who originally belonged to Sj are not affected
and, consequently, do not discard any data.
The second situation is: a new stream St is opened before the merge of Si and Sj. The stream St
delivers a future data unit with respect to that of Sj but, at the same time, it is a past data unit with
respect to that of Sk. That is, St is between streams Sj and Sk. After the merge of Si and Sj, resulting in
stream Sm, the adequate decision for the original clients of Si is to have St as the target stream because it
is closer to Si than to Sk, and for the original clients of Sj it is to continue to listen to Sk. Figure 3(b)
shows an example in which several clients listen to Sm and St (original clients of Si) and others to Sm
and Sk (original clients of Sj). In CT protocol, all clients listen to the same stream St and the original
clients of Sj discard any data previously stored in the local buffer; in IM optimization, the original
clients of Si have St as the target stream, and the original clients of Sj continue to listen to Sk and no data
discarding happens.
4. Buffer policies
4.1. Simple Buffer and Complete Buffer Policies
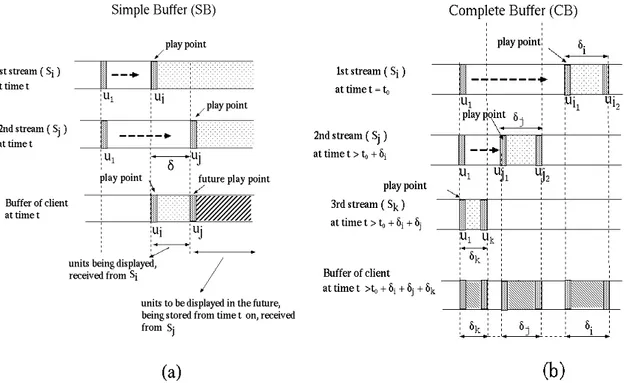
The Simple Buffer (SB) was a pioneering strategy and is still widely deployed. Its main goal is to allow the play synchronization of a multimedia object being delivered by two concurrent streams at a same transmission rate.
The client's local buffer size is determined by the time interval the client may simultaneously listen to the two streams. This interval never needs to be larger than half of the object length [33]. The first stream delivers data which is played by the client immediately, and the second stream delivers data that is stored in client's local buffer for future viewing.
Figure 4: (a) Simple Buffer (SB) policy; (b) Complete Buffer (CB) policy.
When the data unit being delivered by the first stream reaches the first data unit stored in the local buffer, the client stops listening to the first stream and starts retrieving data for immediate viewing directly from the local buffer. The first stream may be then terminated, and the second stream goes on feeding the client's buffer.
Figure 4(a) depicts the overall idea of the SB strategy. The data units of two streams are shown: the data units of stream Si, from ui to (uj- 1), start being played at time t, while the units of Sj, from
data unit uj, start being played at time t + δ. Several variations of the original SB policy have also been
proposed in the literature, mainly those that admit the two concurrent streams with different transmission rates [29, 34].
The Complete Buffer (CB) policy is the combination of LOC and KMB policies. Its overall understanding is: besides providing the play synchronization of the SB policy, all data delivered to the client by the server is stored in the local buffer during the whole client's session, no matter this data is played or not. The buffer size equals the total object length. Every time a client requests a data unit, it verified if this data unit is not already stored in the local buffer. In case the answer is positive, the client then retrieves data directly from the local buffer and, consequently, no server stream is needed. Otherwise, a request to the server is sent.
Figure 4(b) illustrates the buffer of a client who listens to three streams during three time intervals. The CB policy is implemented. The client listens to stream Si (time t = t0), storing from data
unit ui1 to data unit ui2. The client then listens to stream Sj (time t > t0 + δi), storing from unit uj1 to uj2.
+ δi + δj + δk, the client has in his local buffer a total of δi + δj + δk data units stored into three
separated segments. These data units may be used to service the client's own later requests. 4.2. The Unique Buffer Policy
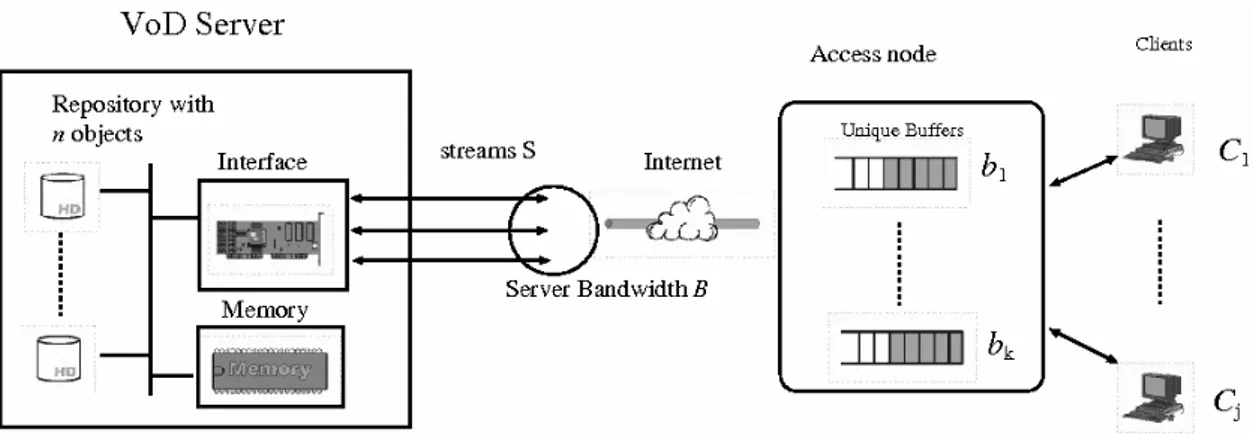
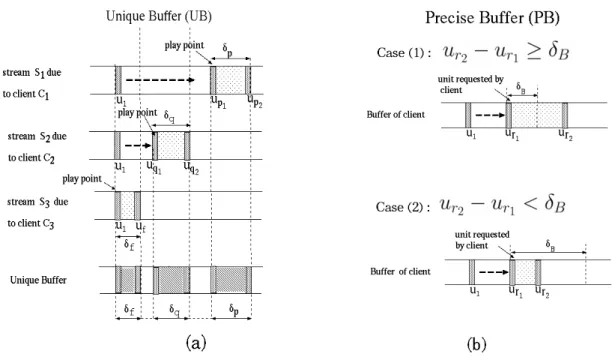
The Unique Buffer (UB) proposal attempts to profit from the aggregate requests for a same multimedia object stored in the server. These requests come from clients who are in a same local network (or region) and share a single buffer located on the access node [3]. Thus we have that: (i) the client profits from his own past requests, preserving the very same features of the CB scheme, and (ii) the client profits from past requests made by other system clients who are in the same local network.
An elementary VoD system implemented with the UB policy is shown in Figure 5. The server stores n objects and there are j clients located in a remote network: C1,…,Cj. These clients are
connected to Internet through an access node. There is a set of k buffers in the access node: b1, …, bk.
In general, we have that j ≥ n ≥ k, where n and j come from the real system design and k must be notably cost-effective.
Figure 5: Multimedia system operating with the UB policy.
The parameter k may be computed as the number of the most frequently accessed objects. It may estimated from the Zipf distribution [30] which states that the probability of choosing an object or rank β is equal to
1 1
1 1
1
n x x
, where α is the skew factor of the distribution. The k buffers are dynamically allocated according to the client requests. When all k buffers are being used, the requests for the remaining n – k objects are served through conventional buffers located on the client side.Figure 6(a) illustrates the data segments stored in one of the k buffers due to the listening of three distinct streams by three distinct clients who view the same object simultaneously. Stream S1
refers to client C1, stream S2 to client C2, and stream S3 to client C3. The data units stored in the buffer
may be simultaneously accessed by any of the j system clients.
The sharing of a same single buffer by all clients of a local network accessing the same object is of non-trivial implementation. It urges specific access methods since more than one client is most willing to read/write in the buffer simultaneously. We may model this as the Producer/Consumer Problem [35]. In principle, there are two basic approaches. The first lies on Software Transactional Memory [36, 37], which is based on concepts in the field of data base, invoking atomicity, consistency and transaction isolation theories. The second is simpler and deploys semaphores and locks [38] to provide secure read/write simultaneous operations.
and the number of units of the object that should be stored in the proxy cannot dynamically adapt to the clients' demands as in the UB strategy [28, 39, 40, 41].
4.3. The Precise Buffer Policy
The main motivation for the Precise Buffer (PB) strategy is to prevent data fragmentation in the client side from impairing system scalability. The fragmentation is observed when the data stored in the client side shows to be divided into small spaced segments over the entire local buffer. Most frequently, the client is not satisfied by only one of these small segments and then needs to enter a read-alternating cycle: from local buffer to server streams and vice-versa. This makes stream sharing more difficult since stream lengths tend to be shorter. Once we reduce the number of read-alternating cycles, we may also expect for a lower variability of bandwidth requirements, implying a larger traffic smoothing [28] and a lower server overhead [33].
Figure 6: Unique Buffer (UB) policy; (b) Precise Buffer (PB) policy.
The PB strategy operates as follows: upon receiving a request, the segment size stored in the local buffer is evaluated, counting from the requested data unit as far as the last stored unit. It is then verified if this size suffices to avoid the read-alternating cycle just described. Figure 6(b) illustrates a scenario in which a client requests the data unit
2 r
u , where the variable δB designates the minimum
segment size in order to avoid the read-alternating cycle. The client has already stored in his buffer from data unit
1 r
u to data unit 2 r u . If
2 r
u –
1 r
u ≥ δB, then the buffer content is used to service the client;
otherwise, the buffer content is ignored and the client must listen to server data streams. Note that when δB → 0, the PB policy becomes equivalent to the CB policy, and when δB → ∞, the PB policy
becomes equivalent to the SB policy.
5. Performance Evaluation
5.1. Competitive Metrics[21]. These three metrics are herein measured in number of server concurrent streams being used to service the clients' requests arriving in the system.
The server work is used to evaluate the system complexity. It is a function of the average number of messages and the operations executed to manage them. The most costly operation is the search for a multicast stream. We consider the worst case analysis and admit each search may be done in time O(n), where n stands for the number of ongoing multicast streams.
The server may receive four types of messages: request for data units, request for merge process termination, request for patch termination, and request for data-delivery termination. For this last type of message, the client may be either in (i) Pause state, (ii) reading from his local buffer, or (iii) terminating the session. Parameters RD, RM, RP and RT, defined in Table 1, respectively denote the average number of each type of message and, similarly to n, are all obtained from the simulation model. Table 2(a) summarizes the time complexities due to each type of message, where O(C) denotes a constant-time complexity. Table 2(b) presents the final formulations for the server average work. Table 1: Average Number of Messages.
Symbol Definition
RD average number of messages requesting data unit
RM average number of messages requesting merge process termination
RP average number of messages requesting patch termination
RT & average number of messages requesting data-delivery termination
Table 2: Time Complexities and Server Work.
(a) Time complexities (b) Server work
Technique RD RM RP RT Technique Formulas
Patching O(n) - O(C) O(C) Patching RD * n + RP + RT
IP O(n) O(C) O(C) O(C) EIP RD * n + RM + RP + RT
IM O(2n) O(n) - O(n) IM RD * 2n + (RM + RT) * n
CT O(2n) O(n) - O(n) CT RD * 2n + (RM + RT) * n
5.2. Synthetic Workloads
We consider seven synthetic workloads. Each represents a distinct evaluation scenario in which a multimedia object is being delivered. Four of these workloads are obtained by means of a workload generator [17] and refer to the multimedia servers eTeach, MANIC and Universo Online (UOL) [15, 42]. The remaining three workloads are CEDERJ-1, CEDERJ-2 and CEDERJ-3 and are generated from the distributed multimedia system RIO (Random I/O System), deployed at the distance-learning project CEDERJ (Distance Education Center of Rio de Janeiro State, Brazil) [43].
The synthetic workload generator [17] uses, as inputs, a real trace of sessions to a media object and a target session arrival rate, and produces an output session trace with interactive patterns similar to the input trace. The generator first builds a state-transition model, where each state represents a fixed-sized segment of the media object. The probabilities of starting a session at each segment state as well as the transition probabilities between pairs of states are computed from the real input trace. A synthetic output session trace is then generated assuming session arrival process to be Poisson [15, 42], and user behavior within each session is extracted from the real workload profile. More details may be obtained in [17].
Each workload has a total of 500 sessions and the client may execute the following DVD-like operations: Play, Stop, Pause/Resume, Jump Forwards and Jump Backwards. The main symbols used to denote the synthetic workloads' statistics are in Table 3, and their corresponding values appear in Table 4. The workloads are statistically different from each other in order to guarantee a wide spectrum of analysis.
Table 3: Statistics
Symbol Definition
T object length, measured in data units
P object popularity, measured as the average number of requests during T
I object interactivity, measured as the average number of requests per session
Du data unit length, measured is seconds
L average segment length, measured in data units
Std(L) standard deviation of L, measured in data units
Coef(L) coefficient of variation of L
X random variable for segment starting unit X
No(X) no. of different values of variable X
Table 4: Synthetic Workloads.
Statistic eTeach MANIC-1 MANIC-2 UOL CEDERJ-1 CEDERJ-2 CEDERJ-3
T 2199 4175 4126 226 4499 4499 4499
Du 1 1 1 1 1 1 1
P 98 99 100 97 100 100 100
No. Request 5146 677 2366 1114 2317 7248 17147
I 10.29 1.35 4.73 2.23 4.63 14.50 34.30
L 118 1190 496 134 383 93 47
Std(L) 143 1184 473 91 534 74 23
Coef(L) 1.21 1.00 0.95 0.68 1.40 0.80 0.52
No(X) 2199 24 98 24 1159 2304 3330
5.3. Results
The simulation results are obtained using Tangram-II [16]. It is an environment for computer and communication system modelling and experimentation developed at Federal University of Rio de Janeiro (UFRJ), with participation of UCLA/USA, devoted to research and educational purposes. This environment combines a sophisticated user interface based on an object oriented paradigm and new solution techniques for performance and availability analysis. The user specifies a model in terms of objects that interact via a message exchange mechanism. Once the model is compiled, it can be either solved analytically, if it is Markovian or belongs to a class of non-Markovian models, or solved via simulation. There are several solvers available to the user, both for steady state and transient analysis.
Our experiments and results are organized as follows. In Subsection 5.3.1 we discuss over the time thresholds δ of the EIP-SB optimization. The goal is to conclude about near-optimal values for each of the workloads, quantify their influence on bandwidth optimization and verify the accuracy of the approximation δopt proposed in this work. The reason to consider the simplest buffer policy (i.e., SB
- Simple Buffer) is to estimate the benefits due only to the deployment of time thresholds. Subsection 5.3.2 presents a competitive analysis between EIP-SB and IM-SB. We aim to know the best-performance scheme. The reason to consider the simplest buffer management policy (i.e., SB - Simple Buffer) is to evaluate the optimizations due to the scheme itself and not due to the buffer management policies.
considering Patching and CT protocols in addition to the optimizations EIP and IM. The goal is to examine the benefits in performance introduced by the optimizations with respect to the main past proposals in the literature.
5.3.1. Time Threshold Analysis
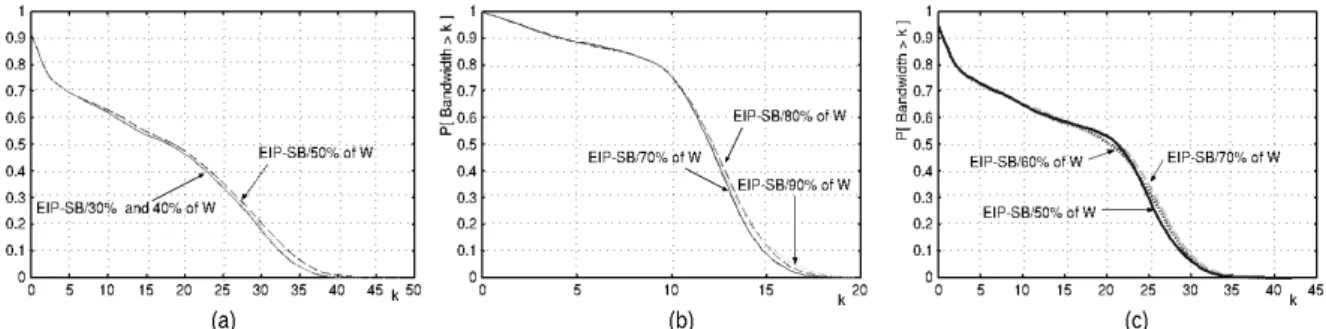
For δbefore set to 10s and considering several distinct values of δafter, we look into the complementary
cumulative distribution functions (CCDF) of the EIP-SB optimization. The results indicate that δopt
may be an acceptable approximation for δafter when the interactivity level (I) is greater than 2.3 (two
dot three). This is because the more interactive the scenario is, the more realistic the assumptions to derive δopt tend to be. For example, the distribution of X is assumed to be uniform and this is mainly
observed for more interactive workloads.
For lower-interactive scenarios we could alternatively deploy either the average segment size L
or the Patching window W (computed in [6]) as an initial estimate and then determine an ideal value for δafter through a dynamic procedure based on that of [8]. Several of these results (CCDFs) are
illustrated in Figure 7. The percentage that appears in the label of each curve indicates the size of δafter
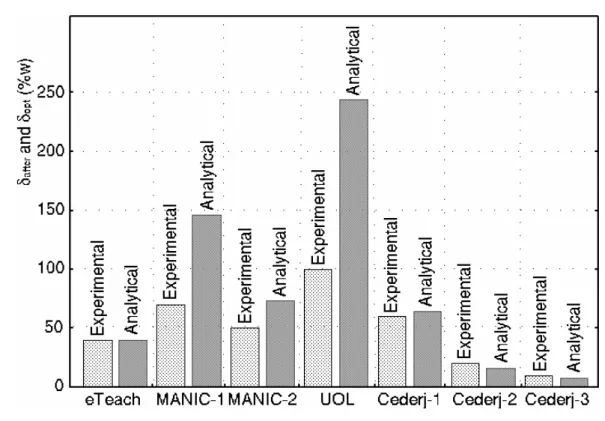
in function of the Patching window W. Lastly, in Figure 8 there is a graphical comparison between δafter
and δopt.
Figure 7: Experimental analysis of the threshold δafter in three distinct scenarios:
(a) eTeach workload; (b) MANIC-1 workload and (c) MANIC-2 workload.
The experiments also show that the larger the δbefore is, the more savings at average bandwidth,
peak bandwidth and server work we tend to achieve. Figure 9(a) illustrates several results for δbefore
within a 10 – 60s time interval. Figure 10 shows the reductions obtained when δbefore is equal to 10s or
60s compared to δbefore = 0s.
Larger values of δbefore imply larger discontinuities. How tolerant to discontinuities a client is
Figure 8: Thresholds δafter (experimental) and δopt (analytical), measured in function of the Patching window W (%).
5.3.2. Competitive Analysis: EIP and IM Optimizations
The goal is to competitively evaluate the EIP-SB and IM-SB optimizations. The parameter δbeforeis set
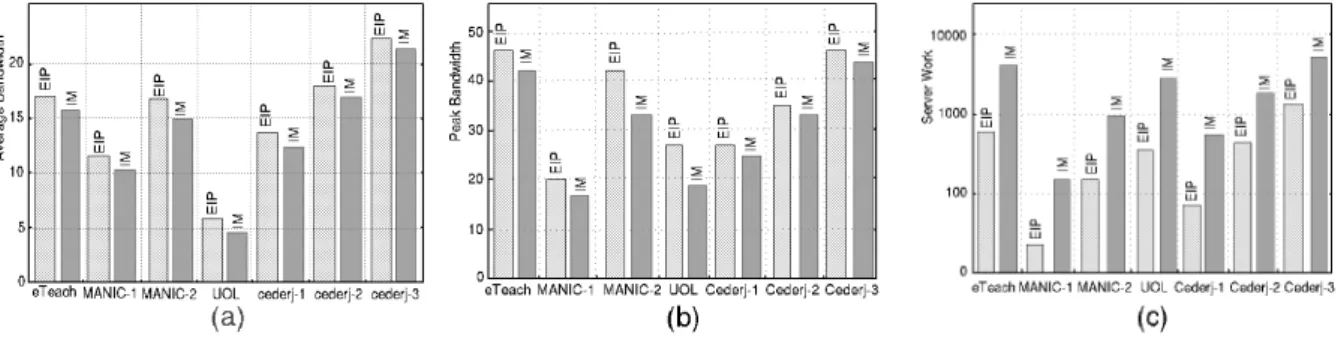
to 10s and δafter to the near-optimal experimental value, according to the scenario. Considering average
bandwidth and peak bandwidth, the results indicate that IM outperforms EIP. More precisely, IM provides reductions with respect to EIP of up to 23% (at average bandwidth) and 29% (at peak bandwidth). For server work, the results are in favor of EIP and usually differ in one order of magnitude. The values computed for each metric are illustrated in Figure 11. The corresponding savings of IM with respect to EIP are included in Figure 12.
Figure 10: Savings (%) due to δbefore=10s and 60s with respect to δbefore = 0s: (a) average bandwidth; (b) peak bandwidth; (c) server work.
Figure 11: Evaluation of competitive metrics in IM and EIP optimizations: (a) average bandwidth; (b) peak bandwidth and (c) server work.
Figure 12: Savings due to IM with respect to EIP optimization: (a) at average bandwidth; (b) at peak bandwidth and (c) at server work.
More bandwidth sharing is achieved by IM at the cost of a larger number of messages exchanged between clients and server. For a fair judgment, a compromise between efficiency and complexity needs to be settled. The EIP optimization benefits from its simplicity, whereas IM shows to be more efficient. The cons for IM refer to the larger system complexity that we evaluate through the metric server work (messages + operations executed by the server). If server work does not play an important role in the system design and operation, we therefore have that IM is the best choice. Otherwise, EIP may still be considered for deployment in practice.
5.3.3. Analysis of Buffer Policies
segment (Table 3). This is because we could observe through simulation that setting δB to other values
than that of L does not show to be efficient, since almost no bandwidth optimization, if any, is achieved.
In Figures 13, 14 and 15, we respectively have the average bandwidth, peak bandwidth and server work for all workloads. Figure 16 and 17 show the savings provided by each policy with respect to the SB policy. Even though PB and CB+SP strategies alternate appreciative performances, the UB policy is the first-best choice followed in general by the CB policy. For UB, the savings to SB are nearly up to: 98% (average bandwidth); 95% (peak bandwidth) and 95% (server work); and for CB, the savings to SB are nearly up to: 40% (average bandwidth); 25% (peak bandwidth) and 24% (server work).
Even though the results are clearly in favor of UB, its implementation in practice is potential more complex than CB due to the need of simultaneous read/write operations, as we discussed before. Thus, CB may be seen as a competitive solution for real server designs.
Figure 13: Computed values for average bandwidth.
Figure 15: Computed values for server work.
Figure 16: Savings at (a) average bandwidth and (b) peak bandwidth with respect to SB policy.
Figure 17: Savings at server work with respect to SB policy.
5.3.4. Competitive Analysis: Paching and HSM paradigms
In the experiments to follow we compare Patching and CT protocols versus the optimizations IM-CB, IM-UB, EIP-CB and EIP-UB. Only CB and UB policies are considered because they have shown to be more efficient than the others. The parameter δbefore is set to 10s (for EIP optimization), δB to L (for PB
The server bandwidth distributions (CCDFs) demonstrate that IM-UB and EIP-UB appear to be the best-performance schemes, followed by IM-CB and EIP-CB at second place. However, as the UB strategy demands a complex implementation, as we commented before, we therefore only consider the other policies in the discussion to follow. For the sake of mere illustration, we plot the distributions (CCDFs) for the workloads UOL, CEDERJ-1 and CEDERJ-2 in Figure 18.
Figure 18: CCDFs for workloads (a) UOL, (b) CEDERJ-1 and (c) CEDERJ-2.
The savings of average bandwidth, peak bandwidth and server work with respect to Patching may be seen in Figures 19, 20 and 21. They are up to nearly: 70% for IM-CB and 60% for EIP-CB (average bandwidth); 70% for IM-CB and 60% for CB (peak); -80% for IM-CB and 50% for EIP-CB (server work). As for this last metric, we may observe that the IM-EIP-CB strategy increases the server work, implying a larger number of messages in the system and so a more complex system operation.
Figure 20: Savings at bandwidth peak with respect to Patching-SB.
Figure 21: Savings at server work with respect to Patching-SB
In spite of the larger server work with respect to the EIP optimization, IM may still be outlined as the best-performance merging scheme for most of real server designs. We believe that the savings at average bandwidth, bandwidth distribution and peak bandwidth due to the deployment of IM are more relevant than the larger server work (≈ one order of magnitude with respect to EIP) that unfortunately comes along. We though stress that the EIP policy is also a competitive solution and may also be the choice for special situations in which the metric server work plays a more important role than the other metrics herein analysed, namely average bandwidth, bandwidth distribution and peak bandwidth.
6. Conclusions and Ongoing Work
In this work we developed efficient optimizations to Patching and Closest Target (CT) streaming protocols. The first optimization was denoted as Efficient Interactive Patching (EIP) and basically introduces extra time thresholds into the original algorithm of Patching. The goal was to increase the number of stream merges during the play of the multimedia object. The second was called Interactive Merge (IM) and mainly modified the CT protocol in the sense that the clients of distinct multicast groups are not necessarily merged, possibly preventing erroneous data discarding.
client firstly checks whether he may not be serviced locally using data stored in his buffer without alternating cycles of local-buffer reading and server-stream reading.
Some of our main observations were:
The EIP and IM optimizations were able to greatly improve the scalability of the popular Patching and CT protocols. Our best performance could provide savings of up to nearly: 70% (at average bandwidth); 70% (at peak bandwidth); 50% (at server work).
The policies UB and PB show to be both efficient. The results for UB were though more expressive, but at the cost of a non-trivial implementation that may be modelled as the Producer/Consumer Problem [35]. On the other hand, PB is simpler and show to be competitive with other proposals of the literature and, consequently, may be seen as a practical solution for real system designs.
We have used a set of seven synthetic workloads, generated from four different real servers. These workloads were statistically different from each other, making it possible to cover important and distinct aspects of the real world space such as interactivity and unpredictability. This fact certainly contributes to validate the usefulness of the results achieved.
Ongoing work includes studying the impact of time thresholds on client perception during viewing sessions, especially those of the Patching paradigm, as well as designing new optimizations by aggregating the EIP and IM schemes with peer-assisted (P2P) streaming approaches [44].
A. Approximation for the Time Threshold
δ
afterThe approximation for the time threshold δafter is based on following assumptions: (i) the client request
process is Poisson with rate β; (ii) T is the object length (i.e., the total number of data units of the object) and each request is for a segment (i.e., a number of consecutive data units) of average size L; (iii) X is a random variable that denotes the first data unit (i.e., starting data unit) of the segment. X has uniform distribution, i.e., all object data units have a same access probability; (iv) only requests for segments with the same value of X may share data streams.
Figure A.1: Delivery scenario.
The assumption that all object units have the same access probability is based on the results of Almeida et al. [15, 42]. It is also verified that this tendency becomes more expressive as the object popularity increases. The assumption that all requests are for an object segment of size L lies in the works of Almeida et al. [15], Vernon et al. [14], Jin and Bestavros [51], and Gupta et al. [52]. The authors analyze the access pattern herein adopted in addition to others that may be found in interactivity scenarios. Lastly, the assumption that only requests that have the same starting data unit are allowed to share the stream initially triggered by one of them is pessimistic. The main motivation is the mathematical simplicity it may introduce.
Using the four above assumptions we obtain an analytical approximation for δafter as it follows.
Consider a single object server. Let the request arrival rate be β and admit the object is divided into T
data units, i.e., units u1, …, uT. Since the arrivals follow a Poisson process and the access distribution is
uniform, we then have that the arrival process for each one of the units ui is Poisson with rate
T
. This conclusion comes from the decomposition property of a Poisson process [53].
Now consider a scenario in which there are requests exclusively for a data unit ui. Assume that
the first request takes place at t = t0 and requests a segment of size L. This segment is then sent by the
server over a multicast stream. Let Di be a time threshold. We have that later arrivals within Di may
listen to the same opened multicast stream and receive the missing units over a unicast stream (patch). The next arrival, coming after Di, opens a new multicast data stream and the whole process is restarted.
The optimal value of Di corresponds to the approximation we want to derive for δafter. Since this
computation does not depend on ui, we omit the subscript i and, for notation simplicity, we set
T
. The delivery scenario of the object segment as well as the patches is illustrated in Figure A.1. There are on average 1 + γD arrivals sharing the first multicast stream. Note that γD arrivals are also serviced by unicast streams. Thus the arrival rate for unicast streams is
1
D D
unicast stream has average length 2
D
[54], we may then obtain the average number of unicast stream Nu from Equation A.1 (Little's formula [55]).
1 2 u D D N D
(A.1)
Now since multicast streams (of average size) are triggered at every time interval of duration 1
D
, we then have that the average number of multicast streams Nm is computed from Equation A.2
(Little's formula[55]). 1 m L N D (A.2)
Adding up Equations A.1 and A.2 we have the result presented in Equation A.3. Lastly, minimizing this sum and substituting
T
, we then have an optimal value for D, denoted as δopt
given in Equation A.4. This corresponds to an approximate value for δafter.
2 2 1 u m D L N D (A.3)
2 1 1
opt
L T
T
(A.4)
References
[1] R. O. Banker and et al., “Method of providing video-on-demand with VCR-like functions”, U. S. Patent 5357276, 1994.
[2] K. Dan, D. Sitaram, P. Shahabuddin, D. Towsley, “Channel allocation under batching and {VCR} control in movie-on-demand servers”, Journal of Parallel and Distributed Computing 30 (2) (1995) 168-179.
[3] W. Liao, V. O. K. Li, “The split and merge protocol for interactive video-on-demand”, IEEE Multimedia 4 (4) (1997) 51-62.
[4] W. W. F. Poon, K. T. Lo, “Design of multicast delivery for providing {VCR} functionality in interactive video-on-demand systems”, IEEE Transactions on Broadcasting 45(1) (1999) 141-148.
[5] H. Ma, G. K. Shin, W. Wu, “Best-Effort Patching for Multicast True VoD Service”, Multimedia Tools and Applications 26 (1) (2005) 101-122.
[6] K. A. Hua, Y. Cai, S. Sheu, “Patching: A multicast technique for true video-on-demand services”, in: Proc. 6th ACM Int'l Multimedia Conference (ACM MULTIMEDIA'98), 1998, 191-200.
[7] Y. Cai, K. A. Hua, “An efficient bandwidth-sharing technique for true video on demand systems”, in: Proc. 7th ACM Int'l Multimedia Conference (ACM Multimedia'99), 1999, pp. 211-214.
[8] D. Guan, S. Yu, “A two-level patching scheme for video-on-demand delivery”, IEEE Transactions on Broadcasting 50 (1) (March 2004) 11-15.
[9] Y. W. Wong, J. Y. B. Lee, “Recursive Patching - An efficient technique for multicast video streaming”, in: Proc. 5th International Conference on Enterprise Information Systems (ICEIS) Angers, France, 2003, pp. 23-26.
[10] D. Eager, M. Vernon, J. Zahorjan, “Minimizing bandwidth requirements for on-demand data delivery”, in: Proc. 5th Int'l Workshop on Multimedia Information Systems (MIS'99), 1999, pp. 80-87.
[11] D. Eager, M. Vernon, J. Zahorjan, “Optimal and efficient merging schedules for video-on-demand servers”, in: Proc. 7th ACM Int'l Multimedia Conference (ACM Multimedia'99), 1999, pp. 199-202.
[12] E. Coffinan, P. Jelenkovic, P. Momcilovic, “Provably efficient stream merging”, in: Proc. 6th Int'l Workshop on Web caching and Content Distribution, Boston, MA, 2001.
[13] W. Chan, T. Lam, H. Ting, W. Wong, “On-line stream merging, Max Span, and Min Coverage”, in: Proc. 5th Conference on Algorithms and Complexity (CIAC), 2003, pp. 337-346.
[14] H. Tan, D. Eager, M. Vernon, “Delimiting the range of effectiveness of scalable on-demand streaming”, Performance Evaluation 49 (2002) 387-410.
[15] J. M. Almeida, J. Krueger, D. L. Eager, M. K. Vernon, “Analysis of educational media server workloads”, in: Proc. 11th Int'l Workshop Network and Operating Systems Support for Digital Audio and Video (NOSSDAV'01), 2001, pp. 21-30.
[16] E. de Souza e Silva, R. M. M. Leão, A. P. C. da Silva, A. A. de A. Rocha, F. P. Duarte, F. J. S. Filho, G. D. G. Jaime, R. R. Muntz, “Modeling, Analysis, Measurement and Experimentation with the Tangram-II Integrated”, in: Proc. International Conference on Performance Evaluation Methodologies and Tools, Pisa, Italy, 2006.
[17] M. Rocha, M. Maia, I. Cunha, J. Almeida, S. Campos, “Scalable Media Streaming to Interactive Users”, in: Proc. 13th annual ACM conference on multimedia, Singapore November, 2005.
[18] S. Viswanathan, T. Imielinski, “Pyramid broadcasting for video-on-demand service”, in: Proc. SPIE Multimedia Computing and Networking Conference,1995, pp. 66-77.
[20] Y. Cai, K. Hua, K. Vu, “Optimizing Patching Performance”, in: Proc. SPIE/ACM Conference on Multimedia Computing and Networking, 1999, pp. 204-215.
[21] C. K. S. Rodrigues, R. M. M. Leão, “Bandwidth Usage Distribution of Multimedia Servers using Patching”, Computer Networks 51 (3) (February 2007), pp. 569-587.
[22] K. C. Almeroth, M. H. Ammar, “The use of multicast delivery to provide a scalable and interactive video-on-demand service”, IEEE Journal on Selected Areas in Communications 14 (5) (1996), pp. 1110-1122.
[23] H. Ma, K. G. Shin, “A new scheduling scheme for multicast true VoD Service”, Lecture Notes in Computer Science Springer 2195, (2001) pp. 708-715.
[24] F. Wang, Y. Xiong, J. Liu, “mTreebone: A Hybrid Tree/Mesh Overlay for Application-Layer Live Video Multicast”, in: Proc. 27th IEEE International Conference on Distributed Computing Systems, 2007.
[25] C. K. Yeo, B. S. Lee, M. H. Er, “Hybrid Protocol for Application Level Multicast for Live Video Streaming”, in: Proc. IEEE International Conference on Communications, 2007, pp. 1685-1691.
[26] S. Banerjee, B. Bhattacharjee, C. Kommareddy, “Scalable Application Layer Multicast”,in: Proc. ACM SIGCOMM, 2002.
[27] C. K. Yeo, B. S. Lee, M. H. Er, “A Survey of Application Level Multicast Techniques”, Computer Communications 27 (15) (September 2004), pp. 1547-1568.
[28] E. de Souza e Silva, R. M. M. Leão, B. Ribeiro-Neto, S. Campos, “Performance Issues of Multimedia Applications”, Lecture Notes in Computer Science 2459 (July 2002), pp. 374-404. [29] D. Eager, M. Vernon, J. Zahorjan, “Bandwidth skimming: A technique for cost-effective
video-on-demand”, in: Proc. IS&T/SPIE MMCN'00, 2000, pp. 206-215.
[30] Huadong Ma, K. G. Shin, “Multicast video-on-demand services”, ACM SIGCOMM, Computer Communication Review 32 (1) (2002), pp. 31-43.
[31] E. L. Abram-Profeta, K. G. Shin, “Providing unrestricted VCR functions in multicast video-on-demand servers”, in: Proc. IEEE ICMCS, Austin, Texas, 1998, pp. 66-75.
[32] Y. Cai, W. Tavanapong, K. Hua, “Enhancing patching performance through double patching”, in: Proc. Int'l. Conf. on Distributed Multimedia Systems, Miami, FL, USA, 2003 pp. 72-77. [33] A. Bar-Noy, G. Goshi, R. E. Ladner, K. Tam, “Comparison of stream merging algorithms for
media-on-demand, in: Proc. Multimedia Computing and Networking (MMCN'02), San Jose, CA, 2002, pp. 18-25.
[34] L. Golubchick, J. C. S. Lui and R. R. Muntz, “Adaptive piggybacking: a novel technique for data sharing in video-on-demand storage servers”, ACM Multimedia Systems, 4 (3) (1996), pp. 140-155.
[35] I. Yang and W. Moloney, “Concurrent reading and writing with replicated data objects”, in: Proc. ACM 16th annual conference on Computer science, Atlanta, Georgia, US, 1988, pp. 414--417.
[36] V. J. Marathe, M. F. Spear, C. Heriot, A. Acharya, D. Eisenstat, W. N. Scherer III, M. L. Scott, “Lowering the Overhead of Nonblocking Software Transactional Memory”, in: Proc. Workshop on Languages, Compilers, and Hardware Support for Transactional Computing (TRANSACT), Ottawa, Canada, 2006.
[37] T. Harris, S. Marlow, S. Peyton-Jones, M. Herlihy, “Composable memory transactions”, in: Proc. 10th ACM SIGPLAN symposium on Principles and practice of parallel programming, Chicago, IL, USA, 2005, pp. 48-60.
[38] G. Hermannsson, L. Wittie, “Fast Locks in Distributed Shared Memory Systems”, in: Proc. 27th Hawaii Int'l Conf. on System Sciences (HICSS-27), 1994, pp. 574-583.
[40] H. Fahmi, M. Latif, S. Sedigh-Ali, A. Ghafoor, P. Liu and L. Hsu, “Proxy Servers for Scalable Interactive Video Support”, IEEE Computer, 34 (9) (2001), pp. 54-59.
[41] B. Wang, S. Sen, M. Adler, D. Towsley, “Optimal Proxy Cache Allocation for Efficient Streaming Media Distribution”, IEEE Transaction on Multimedia 6 (2) (April 2004), pp. 366-274.
[42] C. Costa, I. Cunha, A. Borges, C. Ramos, M. Rocha, J. M. Almeida, B. Ribeiro-Neto, “Analyzing Client Interactivity in Streaming Media”, in: Proc. 13th ACM Int'l World Wide Web Conference, May, 2004, pp. 534-543.
[43] E. de Souza e Silva, R. M. M. Leão, A. D. Santos, B. C. M. Netto, J. A. Azevedo, “Multimedia Supporting Tools for the CEDERJ Distance Learning Initiative applied to the Computer Systems Courses”, in: Proc. 22nd ICDE World Conference on Distance Education, September, 2006, pp. 01-11.
[44] C. Huang, J. Li and K. W. Ross, “Can Internet Video-on-Demand be Profitable?”, in: Proc. ACM SIGCOMM'07, Kyoto, Japan, 2007, pp. 27-31.
[45] eTeach - http://eteach.engr.wisc.edu/newEteach/home.html.
[46] J. Padhye, J. Kurose, “An empirical study of client interactions with continuous-media courseware server”, in: Proc. IEEE NOSSDAV, Cambridge, U. K., 1998.
[47] J. F. Kurose, H. I. Lee, J. Steinberg, M. Stern, Technical Report, pp. 96-72, Department of Computer Science, University of Massachusetts, 1996.
[48] W. Mendenhall, T. Sincich, “Statistics for Engineering and the Sciences”, 3rd Edition, Macmillan, 1991.
[49] Raj Jain, “The art of Computer Systems Analysis: Techniques for Experimental Design”, Measurement, Simulation and Modeling, John Wiley & Sons, Inc., New York, 1991.
[50] H. J. Larson, “Introduction to Probability Theory and Statistical Inference”, 3rd Edition, John Wiley & Sons, Inc., New York, 1982.
[51] S. Jin, A. Bestravros, “Scalability of Multicast delivery for non-sequential streaming access”, in: Proc. ACM SIGMETRICS, Marina Del Rey, CA, 2002.
[52] L. He, J. Grudin, A. Gupta, “Designing presentations for on-demand viewing”, in: Proc. ACM Conf. On Computer Supported Cooperative Work, 2000, pp. 127-134.
[53] K. S. Trivedi, “Probability and Statistics with Reliability, Queuing and Computer Science Applications”, 2nd Edition, John Wiley & Sons, Inc., New York, 2002.