CENTRO DE CIÊNCIAS
DEPARTAMENTO DE COMPUTAÇÃO
MESTRADO E DOUTORADO EM CIÊNCIA DA COMPUTAÇÃO
ÍTALO LINHARES DE ARAÚJO
EVOLUINDO O MÉTODO CHAPTER EM DIREÇÃO À GERAÇÃO DE CASOS DE TESTE
EVOLUINDO O MÉTODO CHAPTER EM DIREÇÃO À GERAÇÃO DE CASOS DE TESTE
Dissertação apresentada ao Curso de do Mes-trado e Doutorado em Ciência da Computação do Centro de Ciências da Universidade Federal do Ceará, como requisito parcial à obtenção do título de mestre em Ciência da Computação. Área de Concentração: Engenharia de Software
Orientadora: Profa. Dra. Rossana Maria de Castro Andrade
Co-Orientador: Prof. Dr. Pedro de Alcântara dos Santos Neto
Gerada automaticamente pelo módulo Catalog, mediante os dados fornecidos pelo(a) autor(a)
A692e Araújo, Ítalo Linhares de.
Evoluindo o método ChAPTER em direção à geração de casos de teste / Ítalo Linhares de Araújo. – 2014.
106 f. : il. color.
Dissertação (mestrado) – Universidade Federal do Ceará, Centro de Ciências, Programa de Pós-Graduação em Ciência da Computação, Fortaleza, 2014.
Orientação: Profa. Dra. Rossana Maria de Castro Andrade. Coorientação: Prof. Dr. Pedro de Alcântara dos Santos Neto.
1. Teste de Software. 2. Linha de produtos de software. 3. Aplicações sensíveis ao contexto. 4. Linha de produtos de software sensíveis ao contexto. 5. Caso de uso textual. I. Título.
EVOLUINDO O MÉTODO CHAPTER EM DIREÇÃO À GERAÇÃO DE CASOS DE TESTE
Dissertação apresentada ao Curso de do Mes-trado e Doutorado em Ciência da Computação do Centro de Ciências da Universidade Federal do Ceará, como requisito parcial à obtenção do título de mestre em Ciência da Computação. Área de Concentração: Engenharia de Software
Aprovada em: 07 de março de 2014
BANCA EXAMINADORA
Profa. Dra. Rossana Maria de Castro Andrade (Orientadora)
Universidade Federal do Ceará (UFC)
Prof. Dr. Pedro de Alcântara dos Santos Neto (Co-Orientador)
Universidade Federal do Piauí (UFPI)
Prof. Dr. Pedro Porfírio Muniz Farias Universidade de Fortaleza (Unifor)
Prof. Dr. Reinaldo Bezerra Braga Universidade Federal do Ceará (UFC)
Agradeço primeiramente ao Pai, Inteligência Suprema e Causa primeira de todas as coisas, pela oportunidade de estar terminando mais uma etapa na minha vida. Agradeço, também, por ter colocado pessoas maravilhosas que acompanharam minha caminhada e que contribuíram de alguma forma para que essa etapa fosse concluída. Assim, peço a Ti que converta em bençãos todo auxílio e aprendizado proporcionado por essas pessoas:
Minha amada mãe, pela oportunidade preciosa da vida e por, desde esse momento, batalhou para que eu chegasse até aqui. Ela que é meu exemplo de dedicação, amor, cuidado, zelo pelos filhos. À ela, Senhor, todo o Amor que houver nesse mundo.
Meu adorado pai, que apesar da distância, sempre se fez presente na minha vida. Ele que sempre apoiou minhas decisões e que também contribuiu para que essa etapa fosse concluída.
Meu dedicado irmão, que um dia disse que queria ter uma vida semelhante a minha e hoje possui exatamente o que ele desejou, só tenho a agradecer a palavra amiga, o conforto nas horas difíceis, as mensagens edificantes e o amor dedicado nesses dois anos em que me encontro fisicamente distante dele.
Minha cunhada e irmã, Kalina, que junto com meu irmão dedicou momentos para me auxiliar e me dar conforto durante esses anos em que me encontro aqui em Fortaleza.
Meus tios e padrinhos, Armando e Claudia, que com muito amor me receberam no seu lar e cuidam de mim como um filho. Meus primos, Armando Filho e Amanda, por ter me recebido da maneira como sempre nos tratamos: como irmãos. A Érica que com zelo cuida de mim, e o Armando Neto, pela alegria que ele traz a todos nós.
Aos demais familiares, tios, primos, avós, incluindo os meus avós paternos que se encontram em um local ao teu lado Senhor, que apoiaram minha decisão e que confiaram em mim.
Minha orientadora Rossana, pela experiência que me proporcionou ao confiar em mim e que me ensinará muito mais durante os próximos 4 anos.
Meu co-orientador Pedro, que desde a gradução acompanha meus passos na área acadêmica, e que desde essa época me ensina a ser dedicado ao trabalho e a como ser um bom profissional.
Meus amigos que caminharam diariamente comigo nesses dois anos, Andressa, Candré, Christiano, Nayane, Paulo Artur, Rafael, Rainara, Thalisson, Zezim, pois a cada momento ao lado deles eu ganhava força para continuar essa etapa. Meus amigos de Teresina, que apesar da distância sempre me apoiaram para continuar essa etapa.
Meus amigos da Federação Espírita Piauiense, Gracelcia, Hinália, Lísnia, Rosário, Pablo, Antônio Carlos, Francisco, Irismar e os demais que me deram apoio, coragem, palavras amigas e fortalecedoras nos momentos que precisei.
Todos do MDCC, do GREat e da CTQS e que de alguma forma contribuíram para que esse momento chegasse.
amar.”
Uma Linha de Produtos de Software (LPS) facilita o desenvolvimento de aplicações de um mesmo domínio, pois permite a reutilização de artefatos. Uma LPS Sensível ao Contexto (LPSSC), por sua vez, tem como objetivo desenvolver aplicações que mudam o seu comportamento dinamicamente com base em informações de contexto. Um dos problemas associado à LPSSC é a garantia da qualidade, pois a complexidade é maior do que em uma aplicação tradicional, uma vez que uma LPSSC agrega os desafios inerentes tanto à linha de produtos quanto às aplicações sensíveis ao contexto. O teste de software é uma das formas de garantir a qualidade e para reduzir os custos envolvidos na etapa dos testes, a geração automática de casos de testes é uma solução utilizada na literatura. Essa geração pode ser feita com o uso de um Caso de Uso Textual (CUT). Entretanto, há desafios, pois um CUT é descrito em linguagem natural (LN), o que pode levar a ambiguidade e imprecisão na sua descrição, dificultando a geração dos casos de testes. Para resolver o problema do uso de uma LN para descrever um CUT, o vocabulário e a gramática de uma linguagem natural podem ser restringidos, levando à utilização de uma Linguagem Natural Controlada (LNC). Na literatura foi encontrada apenas uma proposta para automatizar os testes para LPSSC a partir de casos de uso, o método ChAPTER, o qual utiliza linguagem natural para descrever um CUT. Diante dos problemas citados ao utilizar um CUT descrito em LN, este trabalho primeiro propõe uma LNC, denominada CARNAUbA, para auxiliar na descrição e na identificação de informações de um CUT a serem utilizadas nos testes. Em seguida, este trabalho estende o método ChAPTER e a ferramenta que o implementa de modo a permitir o uso da CARNAUbA para gerar a estrutura necessária dos testes para LPSSC em direção à execução deles. Para verificar a viabilidade da extensão proposta no método e implementada na ferramenta, duas linhas de produtos de software são utilizadas como estudos de caso e é verificado se os testes gerados se encontram condizentes com os casos de uso utilizados.
A Software Product Line (SPL) facilitates the development of applications within the same domain as it enables the reuse of artifacts. A Context-Aware Software Product Line (CASPL), in turn, aims to develop applications that change their behavior dynamically based on context information. One of the problems associated with CASPL is the quality assurance, because its complexity is greater than a traditional application since a CASPL adds the challenges inherent to both the software product line and the context-aware applications. Software testing is one of the ways to ensure quality and to reduce the costs involved in the testing phase, the automatic generation of test cases is a solution found in the literature. This generation can be done using a Textual Use Case (TUC). However, there are challenges involved, because a CUT is described in natural language (NL), which can lead to ambiguity and imprecision in its description, making it difficult to generate test cases. To solve the problem of using an NL to describe a TUC, the vocabulary and the grammar of a natural language can be restricted, leading to the use of a Controlled Natural Language (CNL). In the literature, only one proposal was found to automate the tests for LPSSC from use cases, the ChAPTER method, which uses natural language to describe a TUC. Given the problems mentioned before when using a CUT described in NL, this work first proposes a CNL, called CARNAUbA, to help in the description and identification of the TUC information to be used in the tests. This work then extends the ChAPTER method and the tool that implements it to allow the use of CARNAUbA to generate the necessary structure of the tests for LPSSC to execute them. To verify the feasibility of the proposed extension in the method and implemented in the tool, two software products lines are used as case studies, and it is checked if the tests generated are in accordance with the use cases.
Figura 1 – Arquitetura de referência para uma aplicação sensível ao contexto . . . 23
Figura 2 – Ciclo de desenvolvimento de uma LPS . . . 26
Figura 3 – Exemplo de features obrigatórias e opcionais da linha Mobiline . . . 28
Figura 4 – Exemplos de features alternativas da linha Mobiline . . . 29
Figura 5 – Exemplo de cenário de teste para o GREat Tour . . . 33
Figura 6 – Exemplo de caso de teste para o GREat Tour . . . 33
Figura 7 – Exemplo de procedimento de teste para o GREat Tour . . . 34
Figura 8 – Caso de Uso “Autenticação” baseado no template de (SANTOS, 2013) . . . 40
Figura 9 – Funcionamento da proposta de [Nebut et al. 2006] . . . 43
Figura 10 – Exemplo de elementos do trabalho de (GOISet al., 2010) . . . 44
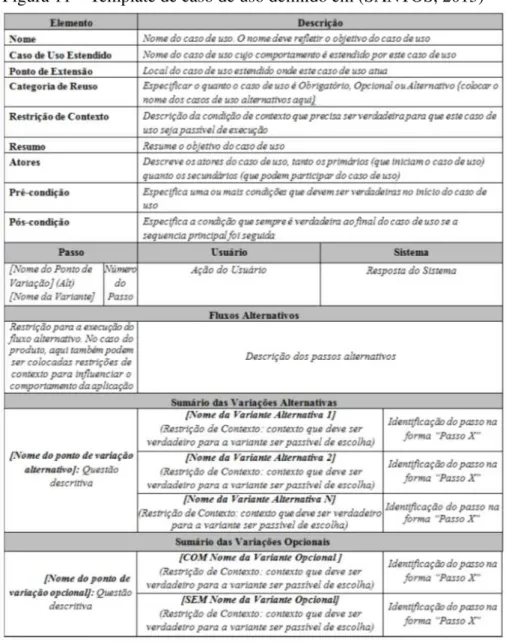
Figura 11 – Template de caso de uso definido em (SANTOS, 2013) . . . 48
Figura 12 – Cenário de teste gerado pelo ChAPTER . . . 49
Figura 13 – Processo de análise semântica . . . 63
Figura 14 – Caso de Uso Play Brickles . . . 67
Figura 15 – Visão Geral da extensão do ChAPTER . . . 74
Figura 16 – Tela da ferramenta que exibe informações da CARNAUbA . . . 76
Figura 17 – Inserção de detalhes para as entradas . . . 76
Figura 18 – Diagrama de Pacotes . . . 77
Figura 19 – Lista de Linhas cadastradas . . . 82
Figura 20 – Definição de um passo para o caso de uso Mostra Textos . . . 82
Figura 21 – Extração das informações do passo 1 do caso de uso Mostra Textos . . . 82
Figura 22 – Tela para inserir mais informações para uma entrada . . . 84
Figura 23 – Teste gerado na FitNesse . . . 87
Figura 24 – Fixture gerada para o caso de uso Mostra Textos . . . 89
Figura 25 – Caso de uso “Play Bowling” . . . 90
Figura 26 – Caso de teste na FitNesse para o caso de uso “Play Bowling” . . . 92
Tabela 1 – Comparação entre uma Linguagem Natural e uma LNC . . . 42
Tabela 2 – Comparação entre os métodos de teste . . . 49
Tabela 3 – Definição da sintaxe do elemento “Nome do caso de uso” . . . 52
Tabela 4 – Definição da sintaxe do elemento “Ponto de extensão” . . . 53
Tabela 5 – Definição da sintaxe do elemento “Categoria de Reuso” . . . 54
Tabela 6 – Definição da sintaxe do elemento “Restrição de Contexto” . . . 54
Tabela 7 – Definição da sintaxe do elemento “Atores” . . . 55
Tabela 8 – Definição da sintaxe do elemento “Ponto de Variação e Variante” . . . 57
Tabela 9 – Definição da sintaxe do elemento “Número do Passo” . . . 57
Tabela 10 – Definição da sintaxe de uma “Ação” do elemento “Passo” . . . 59
Tabela 11 – Definição da sintaxe de uma “Ponto de Extensão” do elemento “Passo” . . . 60
Tabela 12 – Definição da sintaxe de uma “Condição” do elemento “Passo” . . . 60
Tabela 13 – Definição da sintaxe de uma “Repetição” do elemento “Passo” . . . 61
Tabela 14 – Caso de uso Mostra Documentos construído . . . 66
Tabela 15 – Caso de uso Play Brickles convertido para a CARNAUbA . . . 69
Tabela 16 – Caso de Uso Mostra Texto . . . 81
Tabela 17 – Cenário de Teste 1 para o caso de uso Mostra Textos . . . 85
Tabela 18 – Cenário de Teste 2 para o caso de uso Mostra Textos . . . 86
CAPLUC Context Aware software Product Line Use Case template
ChAPTER Context Aware software Product line TEsting geneRation method CUT Caso de Uso Textual
GREat Grupo de Redes de Computadores, Engenharia de Software e Sistemas LNC Linguagem Natural Controlada
LPS Linha de Produtos de Software
1 INTRODUÇÃO . . . 16
1.1 Contextualização e Caracterização do Problema . . . 16
1.2 Motivação . . . 18
1.3 Objetivos e Contribuições . . . 19
1.4 Organização da Dissertação . . . 19
2 LINHA DE PRODUTOS DE SOFTWARE SENSÍVEIS AO CONTEXTO 21 2.1 Aplicações Sensíveis ao Contexto . . . 21
2.1.1 Uma arquitetura para Aplicações Sensíveis ao Contexto . . . 22
2.1.2 Aplicações Móveis e Sensíveis ao Contexto . . . 24
2.2 Linhas de Produtos de Software . . . 25
2.2.1 Ciclo de Desenvolvimento de uma LPS . . . 26
2.2.2 Modelo de Características. . . 27
2.2.3 Linha de Produtos de Software Sensível ao Contexto . . . 29
2.3 Conclusão . . . 30
3 GERAÇÃO DE CASOS DE TESTE A PARTIR DE CASOS DE USO . . 31
3.1 Teste de Software . . . 31
3.1.1 Cenário de Teste . . . 32
3.1.2 Caso de Teste . . . 33
3.1.3 Procedimento de Teste. . . 33
3.1.4 Teste em Aplicações Sensíveis ao Contexto. . . 34
3.1.5 Teste em LPS . . . 35
3.1.6 Teste baseado em Requisitos . . . 37
3.2 Caso de Uso . . . 37
3.3 Especificação de Caso de Uso utilizando Linguagem Natural Controlada 39 3.4 Métodos para Geração de Testes . . . 42
3.4.1 Trabalho de Nebut et al. (2006) . . . 42
3.4.2 Trabalho de Gois (2010) . . . 43
3.4.3 Trabalho de Chen e Li (2010). . . 44
3.4.4 Trabalho de Siqueira (2010) . . . 45
. . . 46
3.4.7.1 CAPLUC . . . 47
3.4.7.2 ChAPTER . . . 47
3.4.8 Comparação entre os Métodos para Geração de Teste a partir de Caso de Uso . . . 49
3.5 Conclusão . . . 50
4 CARNAUBA . . . 51
4.1 Visão Geral . . . 51
4.2 Análise Sintática . . . 52
4.2.1 Nome do Caso de Uso . . . 52
4.2.2 Caso de Uso estendido. . . 53
4.2.3 Ponto de Extensão . . . 53
4.2.4 Categoria de Reuso . . . 53
4.2.5 Restrição de Contexto . . . 54
4.2.6 Resumo . . . 55
4.2.7 Atores . . . 55
4.2.8 Pré-condição. . . 56
4.2.9 Pós-condição . . . 56
4.2.10 Passo . . . 56
4.2.10.1 Ponto de Variação e Variante . . . 56
4.2.10.2 Número do Passo. . . 57
4.2.10.3 Ações do Ator e do Sistema . . . 58
4.2.10.3.1 Ação . . . 58
4.2.10.3.2 Ponto de Extensão . . . 59
4.2.10.3.3 Condição . . . 60
4.2.10.3.4 Repetição. . . 61
4.3 Análise Semântica . . . 61
4.4 Exemplo de Uso . . . 63
4.4.1 Caso de Uso: Mostra Documentos . . . 64
4.4.2 Caso de Uso: Play Brickles . . . 66
5 O MÉTODO E A FERRAMENTA PARA ESTENDER O CHAPTER . 71
5.1 Limitações do ChAPTER . . . 71
5.2 Funcionamento da extensão proposta . . . 71
5.3 Ferramenta de Apoio ao Método . . . 75
5.4 Arquitetura da Ferramenta . . . 75
5.4.1 Diagrama de Pacotes . . . 75
5.5 Limitações . . . 77
5.6 Conclusão . . . 78
6 APLICAÇÃO DA EXTENSÃO PROPOSTA . . . 79
6.1 Mobiline e Arcade Game Maker . . . 79
6.2 Aplicação da Extensão na LPSSC Mobiline . . . 80
6.3 Aplicação da Extensão na LPS Arcade Game Maker . . . 89
6.4 Conclusão . . . 94
7 CONCLUSÃO . . . 96
7.1 Resultados Alcançados . . . 96
7.2 Trabalhos Futuros . . . 98
REFERÊNCIAS . . . 99
1 INTRODUÇÃO
Esta dissertação apresenta uma extensão do métodoContext Aware software Product
line TEsting geneRation method (ChAPTER) (Context Aware software Product line TEsting geneRation method) em direção a geração automática da estrutura para execução de testes em Linhas de Produtos de Software Sensíveis ao Contexto. Para isso, é definida uma linguagem natural controlada que permite essa geração.
Este capítulo está estruturado da seguinte maneira: a Seção 1.1 trata da contextuali-zação e da caractericontextuali-zação do problema; a Seção 1.2 apresenta a motivação para este trabalho; a Seção 1.3 aborda os objetivos e as principais contribuições deste trabalho; e a Seção 1.4 apresenta a organização desta dissertação.
1.1 Contextualização e Caracterização do Problema
Uma Linha de Produtos de Software (Linha de Produtos de Software (LPS)) pode ser definida como “um conjunto de sistemas de software que compartilham um conjunto de recursos comuns que satisfazem as necessidades específicas de um segmento particular do mercado e que é desenvolvido a partir de artefatos comuns de forma sistemática” (NORTHROP, 2002). O conceito de LPS é utilizado para explorar similaridades entre os produtos desenvolvidos (NORTHROP, 2002), e assim, uma LPS apresenta várias possíveis configurações de um dado domínio (ENSANet al., 2011).
LPS é um paradigma de desenvolvimento de software bastante utilizado quando se deseja obter redução nos custos e no tempo necessário para desenvolver aplicações que pertençam a um mesmo domínio (NORTHROP, 2002). Essa redução no tempo e nos custos acontece devido à reutilização de artefatos. Por isso, esse paradigma é uma das principais abordagens do desenvolvimento baseado em reuso (SELBY, 2005).
Tanto em uma Linha de Produtos de Software Sensível ao Contexto (LPSSC) quanto em uma aplicação tradicional é preciso garantir que as aplicações tenham mais qualidade, evitando que a aplicação chegue até o usuário final com problemas. E uma das formas de se assegurar a qualidade de um software é através do teste de software (LIU et al., 2005) que se torna mais complexo à medida que a complexidade e a criticidade das aplicações aumenta (LOKE, 2006). Sendo assim, pode-se afirmar que os testes executados em linhas de produtos e aplicações sensíveis ao contexto são mais complexos do que os testes executados em aplicações tradicionais. No caso de uma LPS, por exemplo, uma das dificuldades de se testá-la vem da definição, por exemplo, do momento correto dos testes serem gerados. Isso porque existem dois momentos para se executar tal atividade (POHL et al., 2010). Em um desses momentos, os artefatos reutilizáveis de uma LPS podem ser verificados e, no outro, os produtos desenvolvidos a partir de uma LPS podem ser testados (POHLet al., 2010). Em se tratando de aplicações sensíveis ao contexto, por sua vez, devem ser consideradas questões como a volatilidade do contexto (LU, 2009), que trata da rapidez da mudança do contexto e como a aplicação se adapta a essas mudanças.
No caso dos testes realizados em uma LPSSC, que une os conceitos de LPS e de aplicações sensíveis ao contexto, a complexidade é maior neles, visto que as dificuldades das duas áreas que a compõem são agregadas.
Para reduzir a complexidade da criação dos testes, eles podem ser automatizados a partir de informações contidas nos artefatos da especificação. Essa técnica é conhecida como testes baseados em especificação e permite uma abordagem efetiva para testar a corretude de software (MILUZZO et al., 2008). Como exemplo, os testes podem ser gerados a partir de casos de uso, os quais descrevem o comportamento do sistema sem revelar a estrutura do comportamento interno (SOMÉ, 2006).
O uso dessa abordagem é útil, pois os testes podem ser gerados antes do código estar completo e até mesmo antes deles serem iniciados, por exemplo, com o uso da técnica Desenvolvimento Dirigido por Testes (TDD – Test Driven Development) (BECK, 2003) ou da técnica Desenvolvimento Dirigido por Testes de Aceitação (ATDD – Acceptance Test Driven Development) (KOSKELA, 2008).
(SCHNELTE, 2009), o que dificulta a geração automática de testes. Uma solução para esse problema é o uso de uma Linguagem Natural Controlada (LNC), a qual permite restringir definições de gramática e vocabulário de uma linguagem natural (SCHNELTE, 2009).
1.2 Motivação
Na literatura são encontrados trabalhos que tratam da geração de testes para aplica-ções tradicionais e para LPS (BERTOLINO; GNESI, ; CHEN; LI, 2010; NEBUTet al., 2006; GOISet al., 2010; NETO, 2011; SIQUEIRA, 2010), para LPSSC (SANTOS, 2013) e trabalhos que definem LNC (SCHNELTE, 2009; BARROSet al., 2011) para a geração de testes.
Entretanto, apenas o trabalho de (SANTOS, 2013) tem como objetivo a geração de testes para LPSSC. Para realizar a automação da geração dos testes, o autor define um template de caso de uso, denominadoContext Aware software Product Line Use Case template (CAPLUC) (Context Aware software Product Line Use Case template), que permite a inserção de informações associadas a LPS e a sensibilidade ao contexto, como é detalhado no Capítulo 2. O autor também define um método, chamado de ChAPTER (Context Aware software Product line TEsting geneRation method), para gerar automaticamente cenários de teste, os quais são uma representação abstrata do teste (SOMÉ; CHENG, 2008), para uma LPSSC, a partir de casos de uso baseados no CAPLUC. Assim, em (SANTOS, 2013), há a lacuna em relação a estudos para automatizar a criação de testes que estejam mais próximos da execução, para reduzir os custos e o tempo envolvidos na geração dos testes.
Conforme mencionado anteriormente, uma forma de permitir a automação da ge-ração dos testes pode ser por meio de uma LNC para descrever casos de uso. O trabalho de (SCHNELTE, 2009) define uma LNC para gerar testes para LPS de uma indústria automotiva, entretanto, a LNC não foi definida para descrever casos de uso. (BARROSet al., 2011), por sua vez, definem uma LNC para descrever casos de uso para aplicações convencionais com o objetivo de gerar testes a partir dos casos de uso. Porém, os autores ainda não contemplam as restrições em uma linguagem natural controlada para descrever a variabilidade de uma LPS ou informações contextuais.
1.3 Objetivos e Contribuições
Este trabalho possui como objetivo propor uma evolução do trabalho desenvolvido por (SANTOS, 2013) em direção a geração automática de testes para Linhas de Produtos de Software Sensíveis ao Contexto. Essa evolução consiste da geração de uma estrutura para a execução dos testes a partir de casos de uso descritos textualmente usando uma Linguagem Natural Controlada.
Para alcançar esse objetivo, é necessário atingir as seguintes metas:
• Definir uma Linguagem Natural Controlada que permita descrever casos de uso que possuam informações de uma LPS e também informações contextuais;
• Propor uma evolução para o método ChAPTER de maneira que seja possível gerar auto-maticamente testes para LPSSC a partir de casos de uso descritos com a LNC definida neste trabalho;
• Implementar a evolução do método ChAPTER na ferramenta desenvolvida por Santos (2013); e
• Avaliação do método proposto com uma prova de conceito.
Como principais contribuições desta dissertação, espera-se: a) uma Linguagem Natural Controlada para descrever o CAPLUC; b) uma evolução do método ChAPTER para permitir a geração de testes a partir de casos de uso; e c) uma ferramenta de apoio ao uso da LNC e do método.
1.4 Organização da Dissertação
Este capítulo fez uma breve introdução sobre os temas abordados neste trabalho, bem como a motivação, os objetivos a serem alcançados e das principais contribuições. O restante da dissertação está dividida nos seguintes capítulos.
Capítulo 2 – Linhas de Produtos de Software Sensíveis ao Contexto: Este capí-tulo trata dos conceitos básicos de aplicações sensíveis ao contexto e de Linhas de Produtos de Software, bem como de LPSSC.
Capítulo 4 – CARNAUbA:Este capítulo trata da descrição da linguagem natural controlada definida nesta pesquisa.
Capítulo 5 – O Método e a Ferramenta para Estender o ChAPTER:Este capí-tulo aborda o método definido durante esta pesquisa e que estende o método ChAPTER.
Capítulo 6 – Aplicação da Extensão Proposta: Este capítulo apresenta uma apli-cação do método proposto que estende o ChAPTER em dois estudos de caso.
2 LINHA DE PRODUTOS DE SOFTWARE SENSÍVEIS AO CONTEXTO
Este capítulo aborda os conceitos associados à Linha de Produtos de Software Sensíveis ao Contexto, que são a base para a compreensão desta pesquisa. Ele está dividido da seguinte maneira: na Seção 2.1 são apresentados os conceitos associados à aplicações sensíveis ao contexto e sensibilidade ao contexto; e a Seção 2.2 aborda o conceito de linha de produtos de software, bem como dos conceitos necessários para a compreensão de LPSSC.
2.1 Aplicações Sensíveis ao Contexto
Conforme apresentado na Introdução, uma aplicação sensível ao contexto é aquela que se adapta com base nas informações contextuais atuais do usuário (DU; WANG, 2008) ou que fornece um serviço com maior qualidade ou de maneira mais adequada. Porém, para uma melhor compreensão desse conceito é necessário compreender o que é contexto. (DEY, 2001) definiu contexto como sendo qualquer informação que pode ser usada para caracterizar a situação de qualquer entidade, que pode ser uma pessoa, lugar ou objeto relevante para a interação entre o usuário e a aplicação, incluindo o próprio usuário e a aplicação.
Segundo (WANGet al., 2007), uma aplicação sensível ao contexto é uma aplicação que adapta seu comportamento baseado em dados situacionais para prover serviços ricos e gerenciar recursos escassos. Esses dados situacionais, ou contexto, são informações relevantes para aplicação e podem estar associados a localização do usuário, nível da bateria, hora do dia, dados ambientais (temperatura, umidade) ou preferências do usuário, entre outros. Exemplos de uso de algumas dessas características são descritos a seguir:
• Localização do Usuário: a aplicação pode apresentar informações como dados climáticos ou pessoas presentes no ambiente em que o usuário se encontra;
• Nível da bateria: o sistema deixa de apresentar determinadas funcionalidades, como a exibição de um vídeo, quando a bateria de um dispositivo móvel estiver em um nível crítico; e
• Preferências do usuário: a aplicação pode mudar o idioma de exibição de acordo com o idioma definido no sistema.
mudança no contexto ocorreu e é dita proativa quando tenta prever os momentos em que alterações no contexto podem ocorrer (SALEHIE; TAHVILDARI, 2009).
Um exemplo de aplicação sensível ao contexto é o GREat Tour (LIMAet al., 2013) desenvolvida pelo Grupo de Redes de Computadores, Engenharia de Software e Sistemas – Grupo de Redes de Computadores, Engenharia de Software e Sistemas (GREat)1. O objetivo dessa aplicação é guiar os visitantes dentro do laboratório, exibindo, quando solicitado pelos mesmos, informações associadas a cada ambiente. Essas informações podem ser textos, imagens, vídeos e pessoas que trabalham nesses ambientes. Ela foi implementada a partir de uma Linha de Produtos de Software Sensíveis ao Contexto, a Mobiline (MOBILINE, 2013), que será descrita na seção 2.2.3.
2.1.1 Uma arquitetura para Aplicações Sensíveis ao Contexto
A complexidade das informações de contexto torna o processo de desenvolvimento de software sensível ao contexto mais complexo devido a necessidade de uso de técnicas específicas para desenvolvê-las. Muitas vezes é necessário utilizar middlewares, por exemplo (WANGet al., 2007). Assim, para desenvolver uma aplicação sensível ao contexto, é importante que a mesma possua componentes que permitam desde a captura de informações contextuais até a adaptação do comportamento da aplicação. Dessa forma, é importante que durante o desenvolvimento de aplicativos sensíveis ao contexto sejam seguidas recomendações para a arquitetura.
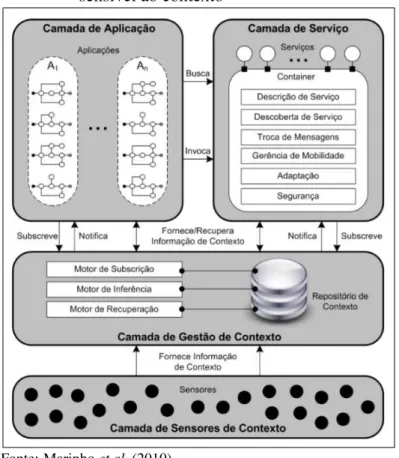
(MARINHOet al., 2010), por exemplo, propuseram uma arquitetura de referência com o intuito de tentar facilitar o desenvolvimento de aplicações sensíveis ao contexto. Essa arquitetura, que é apresentada na Figura 1, é composta por 4 camadas: (i) camada de aplicação, (ii) camada de serviço, (iii) camada de gestão de contexto e (iv) camada de sensores de contexto. A camada de sensores de contexto é a camada mais inferior dessa arquitetura e tem como papel a captura das informações contextuais do meio em que a aplicação está executando. Tais informações devem ser enviadas para as camadas superiores para serem tratadas e as adaptações de conteúdo ou de serviços sejam realizadas de maneira mais adequada.
A camada de gestão de contexto interage com as outras três camadas e o seu objetivo é armazenar as informações de contexto recebidas das outras três camadas no Repositório de Contexto. Dentro dessa camada existem motores responsáveis para prover informações de contexto para as outras camadas. O primeiro desses motores é o Motor de Recuperação cuja
atividade é permitir que as aplicações realizem consultas no Repositório de Contexto a fim de obter as informações de contexto desejadas. O Motor de Inferência, por sua vez, deriva novas informações com base nas informações já existentes e o Motor de Subscrição comunica, de forma assíncrona, às camadas de Aplicação e de Serviço, sobre as informações contextuais no momento em que as mesmas forem necessárias.
Figura 1 – Arquitetura de referência para uma aplicação sensível ao contexto
Fonte: Marinhoet al.(2010).
A camada de serviço contém os serviços providos pelo software. (MARINHOet al., 2010) definiram que um serviço é “uma unidade modular de software passível de composição e que provê uma funcionalidade específica podendo ser implantado de maneira independente”. Assim, um serviço possui um Container, cuja responsabilidade é gerenciar o ciclo de vida do serviço fornecido e que possibilita a comunicação com outros serviços e aplicações. Cada Container é composto por 6 módulos:
• Descrição de Serviços: módulo responsável pela descrição do serviço, contendo dados que o representem, podendo ser essa descrição feita por descrição sintática (palavras-chave) ou por descrição semântica (lógicas descritivas);
para uma requisição da camada de aplicação;
• Adaptação: módulo responsável pela coordenação da adaptação dos serviços com base nas informações de contexto coletadas;
• Segurança: módulo responsável pela mudança do ponto de conexão que o usuário está conectado e pela garantia da manutenção da sessão do usuário;
• Gerência de Mobilidade: módulo responsável pela gerência do código e do estado de execução de um serviço, além de gerenciar os dados acessados pelo serviço; e
• Troca de Mensagens: módulo responsável pela gerência da interoperabilidade entre as diferentes tecnologias de redes de computadores.
A última camada é formada pelas próprias aplicações que, por sua vez, são compostas de serviços providos aos usuários das mesmas. E, conforme apresentado anteriormente, tais serviços são selecionados e adaptados baseados nas informações contextuais coletadas e tratadas pelas demais camadas.
2.1.2 Aplicações Móveis e Sensíveis ao Contexto
Como apresentado anteriormente, uma aplicação sensível ao contexto reage de acordo com informações relevantes para o comportamento da aplicação. Este tipo de aplicação pode ser mais facilmente encontrado em dispositivos móveis devido aos avanços desses, além da popularização de tais dispositivos. Tais avanços estão associados à conectividade da rede, processamento e armazenamento de recursos (MAIA et al., 2009), sensores presentes nos dispositivos, entre outros fatores. Sendo uma aplicação móvel uma aplicação que executa em um dispositivo móvel (DANTAS, 2009), uma aplicação móvel e sensível ao contexto une os conceitos dos termos que o compõem. Assim, uma aplicação móvel e sensível ao contexto é uma aplicação que executa sobre um dispositivo móvel e que se adapta ou provê um serviço com base em informações contextuais.
Apesar dos avanços nos dispositivos móveis permitindo que sejam desenvolvidas aplicações mais robustas, ainda existem limitações no hardware (e.g., memória e bateria) que agregam desafios ao desenvolvimento de aplicações móveis e sensíveis ao contexto. (BUTH-PITIYA et al., 2012) enumeraram alguns desses desafios presentes no desenvolvimento de aplicações sensíveis ao contexto em um ambiente móvel:
• Número de fontes de informações de contexto: as fontes podem ser de sensores de software ou de hardware. Devido a isso, os dispositivos têm que tratar com diversas fontes de informação de contexto, o que acarreta em um maior processamento e, como mostrado, o mesmo ainda é limitado;
• Informação de contexto “em mãos erradas”: a aplicação tem que tratar a segurança da informação de maneira que não permita que ela “caia em mãos erradas”. Isso se deve ao fato de não se poder garantir a segurança física de sensores ubíquos ou de plataformas de computação móvel; e
• Aplicações estão se tornando bastante complexas: as aplicações estão mais complexas, principalmente em ambientes móveis distribuídos. Outro aspecto que aumenta a complexi-dade é a lógica do comportamento proativo da aplicação que podem ser inteligíveis para o usuário.
Em suma, ao desenvolver aplicações sensíveis ao contexto é de extrema importância tratar os aspectos da limitação de recursos dos dispositivos, bem como da quantidade de fontes de informação de contexto que podem ser utilizadas para prover um serviço com maior qualidade ao usuário. O aumento do número de fontes acarreta em um maior processamento e também numa maior complexidade das aplicações, além de necessidade, por exemplo, de uma memória com maior capacidade para armazenar, mesmo que temporariamente, tais informações, exigindo, assim, um dispositivo com maiores recursos. Além disso, mas não menos importante, tem-se o aspecto da segurança das informações utilizadas pela aplicação de tal modo que não permitam que aplicativos ou usuários sem autorização tenham acesso aos dados dos usuários com fins prejudiciais para os mesmos.
2.2 Linhas de Produtos de Software
2.2.1 Ciclo de Desenvolvimento de uma LPS
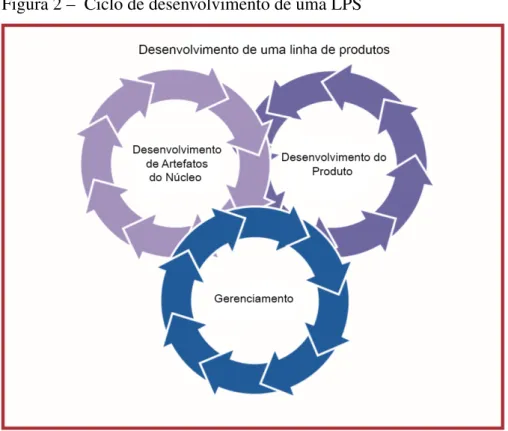
A Figura 2.2 apresenta o ciclo de desenvolvimento de uma LPS definido por (NORTHROP, 2002). Esse ciclo possui dois processos principais, Desenvolvimento dos Arte-fatos do Núcleo e Desenvolvimento do Produto, e outro processo secundário que representa o Gerenciamento das atividades desenvolvidas nos processos principais. Essa figura mostra que o ciclo de desenvolvimento de uma LPS é contínuo.
Figura 2 – Ciclo de desenvolvimento de uma LPS
Fonte: Northrop (2002).
O primeiro processo, denominado de Desenvolvimento dos Artefatos do Núcleo, é responsável por definir o domínio da linha e suas principais características. Tais características devem estar presentes em todos os produtos desenvolvidos a partir da mesma. Segundo (POHL et al., 2010), nessa etapa são definidas as similaridades e variabilidades, que indicam o que todos os produtos devem ter em comum e os que diferenciam para se tornarem novos produtos, além do escopo. Nesse momento, também ocorre a construção de artefatos reutilizáveis.
Desenvol-vimento dos Artefatos do Núcleo são reutilizados e também onde é explorada a variabilidade da linha (POHLet al., 2010). Segundo (POHLet al., 2010) os principais objetivos desse processo são:
• Alcançar um alto grau de reuso ao reutilizar os artefatos do domínio quando definir e desenvolver uma aplicação da LPS;
• Explorar as similaridades e variabilidades da LPS durante o desenvolvimento de uma aplicação;
• Documentar os artefatos da aplicação e relacionar com os artefatos do domínio; e • Vincular as variabilidades de acordo com a necessidade da aplicação.
O último processo, denominado Gerenciamento, tem entre suas responsabilidades a supervisão dos outros dois processos, garantindo que nos mesmos, os artefatos necessários sejam produzidos e que os processos definidos para a linha possam ser seguidos corretamente. É atribuição ainda dessa etapa a gestão de pessoas e alocação de recursos para que os processos possam ser executados com sucesso e dentro dos prazos estimados.
2.2.2 Modelo de Características
Para uma melhor compreensão da representação das similaridades e variabildiades presentes nos produtos desenvolvidos a partir de uma LPS, é importante conhecermos alguns termos bastante utilizados no domínio de LPS. O primeiro desses conceitos é o de features (características). Segundo (KANGet al., 1990),featureé uma característica do sistema visível para o usuário final e pode ser obrigatória, opcional ou alternativa.
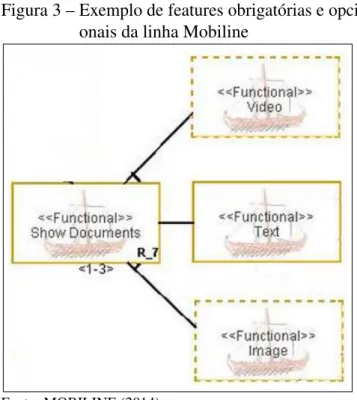
Umafeatureobrigatória representa uma característica que deve estar presente em todas as aplicações da linha. Este tipo defeaturepode ser visualizado na Figura 3, que possui um excerto do modelo de características da LPSSC Mobiline (MOBILINE, 2014), no retângulo com linha cheia com a inscrição “Text” que indica que todos os produtos originados a partir dessa linha devem conter textos como uma das fontes de informação para os usuários.
Umafeaturedita opcional é aquela que pode ou não estar presente em um produto, cabendo a fase de “Desenvolvimento do Produto” definir o que deverá estar presente após o de-senvolvimento. Ainda na Figura 3, é possível observarfeaturesopcionais. Elas são apresentadas em um retângulo com linha tracejada como é o caso dasfeatures“Video” e “Image”.
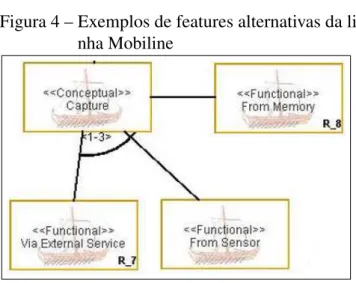
Umafeatureé considerada alternativa quando ela restringe a seleção de uma ou mais
Sensor” (Sensor) e “From Memory” (Memória) referentes a propriedade “Capture” mostradas na Figura 4. Ao desenvolver um produto, uma ou mais das features alternativas podem ser selecionadas. Elas são representadas porfeaturesque possuem uma ligação em comum que seria a mesmafeaturepai. No caso da notação presente na Figura 4, é possível escolher entre 1 ou 3
featuresalternativas devido à existência da notação “<1-3>” logo abaixo dafeature“Capture”. Ainda no modelo de características, podemos definir relacionamentos entre as fe-atures. Esses relacionamentos podem ser “requer” e “mutuamente exclusivo” (KANGet al., 1990). O relacionamento “requer” dene que umafeaturenecessita que outra esteja ativa para que possa também estar presente representado, assim, uma dependência entre as mesmas. O outro relacionamento diz que duasfeaturesnão podem estar presentes no mesmo produto (KANGet al., 1990). Assim, se umafeatureestiver ativa a outrafeature, que possui esse relacionamento com a primeira, deve estar obrigatoriamente inativa.
Figura 3 – Exemplo de features obrigatórias e opci-onais da linha Mobiline
Fonte: MOBILINE (2014).
As notações “R_7” e “R_8”, como podem ser vistas nas Figuras 3 e 4, indicam que as características marcadas fazem parte de uma regra de composição inclusiva. Existem também formas de representar regras de composição exclusivas ou regras de contexto. Mais detalhes sobre essas representações podem ser encontrados em (FERNANDES, 2009).
Figura 4 – Exemplos de features alternativas da li-nha Mobiline
Fonte: MOBILINE (2014).
pode variar entre os diversos produtos de uma linha, que pode ser representada como umafeature pai ou umafeaturealternativa. Um exemplo de ponto de variação é afeature“Capture” mostrada na Figura 4. Uma variante é denida como sendo uma das possíveis variações de uma LPS associadas a um ponto de variação, por exemplo, asfeatures“Via External Service” (via Serviço Externo), “From Sensor” (Sensor) e “From Memory” (Memória) filhas dafeature “Capture” apresentada na Figura 4.
2.2.3 Linha de Produtos de Software Sensível ao Contexto
Uma Linha de Produtos de Software Sensíveis ao Contexto (LPSSC) é uma linha cujo objetivo é desenvolver aplicações sensíveis ao contexto (FERNANDESet al., 2011). As questões associadas ao desenvolvimento de uma aplicação sensível ao contexto são agregadas às questões de uma LPS, aumentando, assim, a dificuldade de implementação dos produtos da linha, além de aumentar a dificuldade relacionada a atividade de testes da linha.
Um aspecto relevante do teste em uma LPS ou LPSSC é o fato que eles podem ser executados durante a definição das características da linha, no processo “Desenvolvimento dos Artefatos do Núcleo”, ou no desenvolvimento do produto. Quando se trata do teste na linha, ele pode ser executado para verificar algum componente que já esteja desenvolvido e que será reutilizado por outros produtos originários a partir da LPS ou LPSSC.
abordados no Capítulo 3.
Um exemplo de LPSSC é a linha Mobiline, como citado anteriormente, que tem como objetivo desenvolver aplicações de guias de visitas móveis e sensíveis ao contexto. Essas aplicações devem ser desenvolvidas para dispositivos móveis e devem guiar os usuários dentro do ambiente fornecendo ao usuário informações específicas dos ambientes em que ele se encontra, além de informações sobre as pessoas que trabalham no ambiente. É possível também melhorar as informações fornecidas baseada no perfil do visitante e com base na carga da bateria.
Algumas aplicações podem ser desenvolvidas a partir da LPSSC Mobiline, entre elas pode-se citar, por exemplo, guias de visitas para museus, laboratórios ou pontos turísticos. Um produto gerado pela Linha é o GREat Tour que, conforme mencionado na Seção 2.1, tem como intuito guiar os visitantes dentro do laboratório GREat, indicando textos, imagens, vídeos e pessoas alocadas em cada ambiente visitado.
2.3 Conclusão
Neste capítulo foram apresentados os conceitos de aplicações sensíveis ao contexto e Linhas de Produtos de Software Sensível ao Contexto.
No tocante à aplicações sensíveis ao contexto, além dos conceitos, também foi apre-sentada uma arquitetura de referência encontrada na literatura, a qual descreve os componentes necessários, como um componente para descoberta de serviços existentes no ambiente. Também foram abordados os conceitos de aplicações móveis e sensíveis ao contexto.
3 GERAÇÃO DE CASOS DE TESTE A PARTIR DE CASOS DE USO
Neste capítulo são apresentados primeiro os conceitos associados a teste de software, casos de uso, além de linguagem natural controlada para especificação de casos de uso.
Em seguida, são apresentados os métodos existentes na literatura que possuem como objetivo a geração de casos de teste ou cenários de teste para aplicações convencionais e para linhas de produtos de software, bem como para LPSSC. Trabalhos relacionados que, para alcançar esse objetivo de geração de casos de testes, definem uma LNC para gerar testes também são descritos. Todos esses trabalhos foram encontrados após serem realizadas pesquisas na literatura que definissem métodos para geração de testes a partir de casos de uso ou que definissem uma LNC. Assim, neste capítulo são descritos os trabalhos de (NEBUTet al., 2006), (GOISet al., 2010), (CHEN; LI, 2010), (SIQUEIRA, 2010), (BERTOLINO; GNESI, ), (NETO, 2011) e (SANTOS, 2013) definem métodos para geração de testes, além do trabalho de (BARROSet al., 2011) que define uma LNC para gerar testes.
Para isso, este capítulo se encontra assim dividido: na Seção 3.1 são apresentados os conceitos de teste de software; na Seção 3.2 casos de uso são conceituados; na Seção 3.3 é definido o conceito de Linguagem Natural Controlada, bem como uma LNC pode ser utilizada em um caso de uso; a Seção 3.4 contém os trabalhos que propõem um método para geração de testes ou definem uma LNC; na Seção 3.4.8 é apresentada uma análise comparativa desses trabalhos; e a Seção 3.5 apresenta as conclusões deste capítulo.
3.1 Teste de Software
O teste de software é uma atividade fundamental para garantir a qualidade dos siste-mas [Liu et al. 2005] e está focado em revelar erros em um sistema para assegurar confiabilidade ao mesmo (CHEN; LI, 2010). É importante ressaltar que o teste é uma das atividades mais caras e que mais consome tempo durante o desenvolvimento de software (SHAMSODDIN-MOTLAGH, 2012; SANTOSet al., 2011), chegando a 50% do tempo gasto no desenvolvimento (MYERS et al., 2011) e a 50% dos custos da produção de um software (MYERSet al., 2011; LIUet al., 2005; HIERONSet al., 2009).
acordo com os requisitos.
A criação dos testes em etapas iniciais do desenvolvimento de software traz alguns benefícios como a descoberta de defeitos ainda na fase de especificação que é importante tanto para o desenvolvimento da aplicação em si como para a atividade de testes servindo de referência para os mesmos (POHL, 2010). Facilitando, assim, a identificação da conformidade do software com os requisitos. Além disso, os custos associados com a definição, implementação, quando possível, e execução dos testes podem ser reduzidos.
É importante ressaltar que os testes podem ser categorizados em duas categorias principais: quanto ao objetivo e quanto ao nível. Neste trabalho focamos na classificação quanto ao nível que podem ser de três tipos: (i) teste de unidade; (ii) teste de integração; e (iii) teste de sistema. O teste de unidade representa o processo de teste para partes menores de um programa como sub-rotinas, subprogramas ou procedimentos em um programa (MYERS et al., 2011). O teste de integração exercita o mesmo código que o teste de unidade, porém verificando a comunicação e as ações entre as unidades (RUBINOV, 2010). O teste de sistema verifica se o sistema atende aos objetivos (MYERSet al., 2011).
Existem ainda outros termos utilizados na parte de teste de software que é em relação à classificação no que concerne à especificação do teste. Assim, podemos ter uma especificação menos concreta sendo em um nível mais alto ou uma especificação mais detalhada ou ainda as etapas a serem executadas durante o teste. Esse último tipo de especificação é melhor detalhado nas subseções seguintes.
3.1.1 Cenário de Teste
Um cenário de teste, segundo (SOMÉ; CHENG, 2008), é uma representação abstrata do teste. Logo, o cenário não deve conter informações detalhadas dos testes a serem executados. Por exemplo, ele não contém os valores a serem utilizados e nem os passos a serem executados detalhadamente. A Figura 5 apresenta um exemplo de cenário de teste.
apresentado na Seção 3.1.3.
Figura 5 – Exemplo de cenário de teste para o GREat Tour
Fonte: O autor.
3.1.2 Caso de Teste
Um caso de teste contém as entradas a serem utilizadas no teste, as saídas esperadas e o procedimento de teste a que se refere. A necessidade de se identificar os valores de entrada e saída é relevante em caso de erros, pois permite reproduzir o teste novamente de maneira igual a fim de verificar os erros encontrados e corrigi-los. Após a correção ou em caso de sucesso, garante que em determinadas condições o sistema executa conforme o esperado.
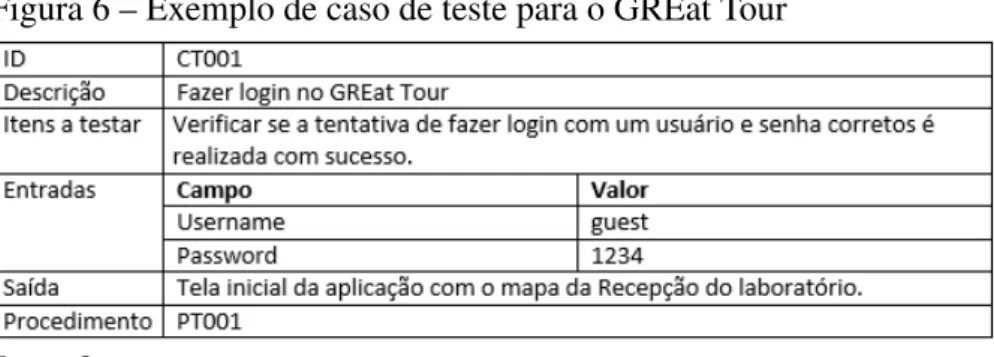
A Figura 6 apresenta um exemplo de caso de teste para a aplicação GREat Tour. Nesse caso de teste é possível identificar o objetivo do mesmo, que é a realização da autenticação através de login na aplicação. Como entradas, tem-se que para o campo “username” é usado o valor “guest” e no campo “password” é utilizado “1234”. Como saída esperada, tem-se definida a tela inicial da aplicação com o mapa da Recepção do laboratório. Esse caso de teste está associado ao procedimento de teste “PT001”.
Figura 6 – Exemplo de caso de teste para o GREat Tour
Fonte: O autor.
3.1.3 Procedimento de Teste
testar várias situações. Um exemplo de procedimento de teste para o GREat Tour é apresentado na Figura 7.
Na Figura 7, é possível ver que os passos para se realizar o login GREat Tour são definidos. O primeiro passo é o preenchimento do campo “username”. Em seguida, ocorre o preenchimento do campo “password”, e, por fim, há o clique em “Login”. Assim, esse proce-dimento pode ser utilizado em várias situações de teste, que podem ser entradas consideradas válidas (e.g., senha tem que ter entre 6 e 13 caracteres contendo caracteres especiais) ou valores que representam entradas inválidas.
Figura 7 – Exemplo de procedimento de teste para o GREat Tour
Fonte: O autor.
3.1.4 Teste em Aplicações Sensíveis ao Contexto
Segundo (LOKE, 2006), o teste se torna mais difícil e têm o custo aumentado devido ao aumento da complexidade e da criticidade das aplicações ou quando elas se tornam pervasivas. Ainda segundo (LOKE, 2006), essas são aplicações sensíveis ao ambiente que processam a informação recebida do meio e agem de acordo com o resultado do processamento. Assim, esse tipo de aplicação é o que foi chamado neste trabalho de aplicações sensíveis ao contexto.
É importante lembrar que mudanças no contexto podem ocorrer e afetar o compor-tamento da aplicação em qualquer momento durante a execução (WANG et al., 2007). Isso ocorre devido a alta dinamicidade do contexto (e.g., força do sinal), dados aproximados (e.g., localização) ou ainda dados contraditórios (e.g., sensores percebem eventos diferentes em um mesmo momento) (WANG et al., 2007). (LU, 2007) identificou alguns desafios associados ao teste em aplicações sensíveis ao contexto, como a incerteza da computação que diz que as aplicações interagem com o ambiente em mudança e isso é difícil de reproduzir em um teste.
1. Identificar os pontos chaves onde uma informação de contexto pode afetar o comporta-mento da aplicação;
2. Gerar potenciais pontos de variação para cada caso de teste que devem explorar a execução de diferentes sequências de contexto; e
3. Direcionar a aplicação para uma sequência de contexto gerada.
Quando se trata de aplicações sensíveis ao contexto, executando em dispositivos móveis, existem outros desafios a serem solucionados. (MYERS et al., 2011) identificaram que existem mais desafios para o teste em aplicações móveis do que em qualquer outro tipo de aplicação ou plataforma exigindo, assim, um esforço adicional em relação ao processo de teste tradicional (DANTAS, 2009).
(MYERSet al., 2011) também identificaram que mais do que as próprias aplicações, os desafios são inseridos pelo ambiente e pelos dispositivos. Assim, é preciso considerar alguns desafios ao se testar aplicações móveis. São exemplos de alguns desses desafios:
• Variedade de dispositivos: devido à grande variedade de dispositivos, é difícil garantir que uma mesma aplicação execute corretamente em todos eles;
• Restrições de hardware: apesar dos avanços no hardware dos dispositivos móveis, ainda existem limitações na memória ou processador como também há o tamanho reduzido da tela; e
• Variedade de dispositivos de entrada: é preciso analisar a variedade de dispositivos de entrada, pois as informações podem ser fornecidas por teclados, botões, telas touch-screen, entre outros.
Além desses tópicos identificados por (MYERSet al., 2011), é possível identificar também a grande variedade de meios que o dispositivo pode interagir com o usuário para indicar uma resposta a uma solicitação feita por ele. Por exemplo, podemos ter o retorno háptico (vibração), sonoro, visual, entre outros. Tais modos de saída podem ser influenciados também diante das mudanças de contexto identificadas pela aplicação. Assim, tudo interfere na definição e execução dos testes.
3.1.5 Teste em LPS
devem ser executados ainda na fase de Desenvolvimento de Artefatos do Núcleo, e testes de aplicação, que devem ser executados na fase de Desenvolvimento do Produto.
Quando se trata do teste de domínio, é possível identificar defeitos nos artefatos gerados ainda na primeira etapa e também nos artefatos que podem ser reutilizados no teste da aplicação (POHLet al., 2010). Além disso, componentes reutilizáveis podem ser desenvolvidos e testados ainda nesse primeiro momento, não excluindo a execução posterior de testes na etapa referente ao desenvolvimento de produtos de modo que assegure o correto funcionamento do componente quando associado a outros componentes.
O teste de domínio possui dois objetivos principais. O primeiro deles refere-se à validação dos artefatos gerados na primeira fase onde os objetivos e escopo da linha são definidos. Assim, seria assegurada a concordância dos produtos com a linha permitindo uma rastreabilidade entre as etapas do processo de desenvolvimento. O segundo objetivo diz respeito à definição de um processo de teste geral e eficiente (POHL et al., 2010) para que os componentes e os produtos, compostos por aqueles, possam ser testados de maneira mais adequada, evitando, assim, retestes desnecessários, o que encareceria o projeto.
Na etapa de teste de domínio, os componentes ou funções desenvolvidas para serem utilizados por todos os produtos da linha podem ser testadas a partir de artefatos produzidos na especificação de requisitos ou artefatos de arquitetura ou design. Esses componentes também podem ser testados apenas nas partes comuns a todos os produtos deixando o teste para as partes variáveis para o teste de aplicação (POHLet al., 2010).
O teste da aplicação, por sua vez, compreende as atividades que verificam e validam uma aplicação contra sua especificação. Isso ocorre porque a aplicação é validada conforme as definições na primeira fase do desenvolvimento em uma LPS e também conforme os requisitos específicos do produto. Há também a reutilização de artefatos produzidos na etapa anterior para encontrar defeitos nas aplicações geradas a partir de uma LPS. Assim, essa etapa tem como objetivo garantir uma qualidade mínima para a aplicação sob teste (POHLet al., 2010). Para alcançar esses objetivos, algumas verificações devem ser realizadas:
• Verificar variantes que não devem estar presentes;
• Assegurar a presença das variantes que deveriam existir; e
3.1.6 Teste baseado em Requisitos
A partir de requisitos, é possível gerar testes de sistema, de aceitação (POHL, 2010), de unidade, funcionais, entre outros. Assim, é possível garantir uma maior qualidade aos sistemas desenvolvidos, pois serão verificados e validados de maneira que seja assegurada a conformidade dos mesmos em relação às necessidades dos clientes.
A geração de testes a partir de requisitos possui vantagens, sendo a primeira delas o fato de que os artefatos de requisitos são uma excelente base para a derivação dos testes. Isso ocorre devido a esses artefatos possuírem propriedades do sistema que são relevantes para o usuário (POHL, 2010).
Em segundo lugar, pode ser citada como outra vantagem o fato de que erros nos requisitos podem ser identificados durante a criação e execução dos testes. Essa situação pode ser identificada, porque, como apresentado anteriormente, é feita uma verificação do comportamento do sistema com o intuito de assegurar a sua conformidade em relação aos requisitos do usuário (POHL, 2010).
A terceira vantagem refere-se à identificação de falhas nos artefatos dos requisitos. Caso uma falha na especificação de requisitos não seja encontrada durante a verificação e validação dos artefatos, elas podem ser encontradas durante a derivação de testes a partir dos requisitos (POHL, 2010). Assim, enquanto os testes estão sendo criados, erros nos requisitos podem ser encontrados e os mesmos são corrigidos, contribuindo, assim, para a redução dos custos que estão associados com uma possível correção em um momento posterior.
Na geração dos testes podem ser utilizadas duas abordagens. A primeira delas é a derivação direta de casos de teste a partir dos artefatos de requisitos. Assim, os testes podem ser derivados de casos de uso, entre outros artefatos. A segunda maneira é a geração de testes a partir de modelos, abordagem conhecida como derivação de casos de teste baseada em modelos (POHL, 2010), sendo o foco deste trabalho a geração de testes a partir de casos de uso.
3.2 Caso de Uso
objetivos e das funcionalidades dos sistemas, permitindo uma geração de testes com uma maior qualidade.
(ANTHONYSAMY; SOMÉ, 2008) definiram que um caso de uso captura os inte-resses dos stakeholders (pessoas que podem influenciar no desenvolvimento do software ou da linha a ser desenvolvida) bem como a interação entre o sistema e os atores (quem executa uma ação no sistema). Um ator representa uma pessoa ou sistema que interage com o sistema descrito nos casos de uso (BERTOLINOet al., 2002). Um ator pode ser classificado como primário ou secundário. Um ator primário é aquele que interage com o caso de uso, de forma que o dispara para ser executado. Um ator secundário interage com o caso de uso, mas não é responsável por iniciar a sua execução (BERTOLINOet al., 2002) aparecendo sua interação apenas no decorrer da execução do caso de uso.
Os casos de uso também podem ser representados graficamente. Isso permite que sejam feitas verificações nas interações entre o sistema e os atores identificando quem pode executar uma determinada ação. Além disso, é possível identificar as relações entre os diferentes casos de uso de um sistema, bem como o relacionamento dos casos de uso e dos atores (POHL, 2010).
Um caso de uso pode se relacionar de três formas com outro caso de uso. A primeira maneira é a “generalização” que diz que um caso de uso especializado “A” herda os passos de interação do caso de uso generalizado “B”. O segundo relacionamento diz que um caso de uso “A” estende sequências de interações de outro caso de uso “B”, modificando alguns passos dessas interações. O último relacionamento é o que inclui em um caso de uso “A” uma sequência de interações documentadas no caso de uso “B” que é dito incluso no caso de uso “A” (POHL, 2010).
Outro ponto importante quando se trata de casos de uso são os tipos de cenários que podem existir, sendo eles o cenário principal, o alternativo e o excepcional. O principal deve descrever uma sequência de interações que normalmente é executada no sistema. Um cenário alternativo documenta uma sequência de interações que podem ser executadas no lugar do cenário principal, mas que levam ao mesmo fim do cenário principal. Um cenário excepcional representa a execução do sistema quando um evento excepcional (e.g. lançamento de exceções) ocorre durante a execução de outro cenário incluindo a execução de um cenário excepcional.
2008). Assim, é importante lembrar que nos casos de uso devem ser inseridas informações referentes as variabilidades existentes na linha. Para facilitar a definição dessas informações, ao se modelar casos de uso podem ser utilizados templates.
Com base nisso, é possível encontrar na literatura alguns templates para modelar casos de uso tanto para aplicações tradicionais, como para linhas de produtos de software. (ANTHONYSAMY; SOMÉ, 2008) identificaram alguns trabalhos ([(JACOBSONet al., 1997; GOMMA, 2004; JOHN; MUTHIG, 2002)) que definiram templates para trabalhar com as variabilidades existentes nas linhas de produtos.
Outro trabalho encontrado na literatura, o de (SANTOS, 2013), além de definir um template próprio, identificou outros templates de caso de uso que representavam variabilidade de uma linha. Ele conseguiu identificar nove templates ([(ERIKSSONet al., 2004; BERTOLINO et al., 2002; GALLINA; GUELFI, 2007; CHOI et al., 2008; BONIFáCIO; BORBA, 2009; ARAúJO, 2010; GOMMA, 2004; JOHN; MUTHIG, 2002; ANTHONYSAMY; SOMÉ, 2008)). Como o foco deste trabalho não é propor um novo template de casos de uso será apresentado apenas o template que é utilizado como base para este trabalho. Na Tabela 3.1 é apresentado um caso de uso para a funcionalidade de autenticação de um produto da LPSSC Mobiline seguindo o template definidod por (SANTOS, 2013). É importante ressaltar que o template será melhor explicado na Seção 3.4.7.1.
3.3 Especificação de Caso de Uso utilizando Linguagem Natural Controlada
Uma linguagem natural controlada (LNC) pode ser denida como sendo um subcon-junto de uma linguagem natural completa (ou pura) com restrições sobre a gramática, vocabulário e estilo (SCHWITTER; TILBROOK, 2006). Ela ajuda a eliminar a ambiguidade e complexidade de uma linguagem natural pura (LU, 2010). Além disso, uma Linguagem Natural Controlada (LNC) pode resolver o problema de legibilidade, entendimento e tradução (CARDEYet al., 2008) de uma informação que deve ser compreensível, ao mesmo tempo, para humanos e máqui-nas. É importante ressaltar que uma sentença válida em uma LNC é uma sentença válida em uma linguagem natural (SCHNELTE, 2009). Porém, o inverso não é sempre verdadeiro (SCHNELTE, 2009).
Figura 8 – Caso de Uso “Autenticação” baseado no template de (SAN-TOS, 2013)
Fonte: O autor.
também podem ser utilizados, pois são fáceis de serem compreendidos por um computador, mas são difíceis de serem usados por pessoas sem treinamento (SCHNELTE, 2009). Portanto, uma linguagem natural controlada seria a solução intermediária para os problemas apresentados pelas duas outras abordagens, e, por isso, é utilizada neste trabalho. Alguns exemplos são:
• PENG (Processable English): LNC definida para solucionar problemas que surgiam ao usar linguagens de Web Semântica;
• LiSe (Linguistic et Sécurité): LNC baseada em francês cujo objetivo é facilitar a tradução para LNCs definidas em outros idiomas;
• Linguagem de (SCHNELTE, 2009): essa linguagem foi criada para facilitar a especica-ção de requisitos para uma indústria automotiva; e
• ucsCNL: essa LNC, baseada no inglês, foi criada para descrever casos de uso para aplicações convencionais.
domínio para evitar que duas palavras possam representar a mesma entidade, além de evitar ambiguidade léxica (mesmo termo representa duas ou mais entidades) (BARROSet al., 2011). A gramática, por sua vez, é uma versão restrita de uma gramática de uma linguagem natural pura (SCHNELTE, 2009) e pode ser geral (“escrever frases curtas e simples”) ou mais formal que restringe a estrutura sintática aceita (BARROSet al., 2011). Em (PENG, 2014), é possível encontrar um exemplo de LNC que restringe a sintaxe:
Sentença->Sujeito+Predicado
Sujeito -> Determinante {+ Modificador pré-nominal} + Núcleo do Nome {+ Modificador pós-nominal}
Sujeito->Núcleo do Nome
Predicado->{Negação}+Núcleo Verbal+Complemento {+ Adjunto}
Nessa linguagem PENG (Processable ENGlish), uma sentença é composta, assim como em linguagem natural, de sujeito e predicado. O sujeito deve possuir um determinante (i.e. artigo), além de poder ter alguns modicadores. É obrigatória a presença do núcleo, que representa o próprio sujeito. “O mordomo” ou “A mãe do mordomo” ou ainda “Agatha” são exemplos de sujeitos aceitos pela linguagem. O predicado dessa linguagem pode conter uma negação além de possuir um núcleo verbal e um complemento para esse verbo. Esse complemento ainda pode possuir um adjunto. Por exemplo, “trabalha na mansão” ou “não trabalha na mansão” ou ainda “trabalha com todos os mordomos”.
Em (PENG, 2014), também é possível encontrar um exemplo que compara uma sequência de frases em linguagem natural e a representação da mesma frase utilizando a LNC denida por (SCHWITTER; TILBROOK, 2006). Um trecho dessa comparação é a frase descrita em linguagem natural: “Agatha, o mordomo e Charles vivem na Mansão Dreadsbury.”. Ao transformá-la para a linguagem de (SCHWITTER; TILBROOK, 2006) a frase é dividida em três outras frases. Por exemplo, “Agatha vive na Mansão Dreadsbury.”, “O mordomo vive na Mansão Dreadsbury.” e “Charles vive na Mansão Dreadsbury.”. Essa separação ocorre devido a restrições sintáticas da LNC como apresentado anteriormente, porém as frases se equivalem semanticamente. Essa comparação é apresentada na Tabela 1.
difícil determinar o quanto a ferramenta inuencia no entendimento da linguagem (KUHN, 2009). Para facilitar a validação de uma LNC, (KUHN, 2010) deniu um framework, que independe de ferramenta, chamado ontographs e representa gracamente expressões de uma LNC. Frases seguindo a estrutura da LNC devem ser criadas de maneira que possam ser comparadas com a representação na ontographs e se for possível declarar se uma frase é falsa ou não, assim a linguagem pode ser validada.
Tabela 1 – Comparação entre uma Linguagem Natural e uma LNC
Fonte: Adaptado de Peng (2014).
3.4 Métodos para Geração de Testes
3.4.1 Trabalho de Nebut et al. (2006)
(NEBUTet al., 2006) propuseram uma abordagem para automação da geração de cenários de teste a partir de casos de uso no contexto de software embarcado orientado a objeto. O método desenvolvido por (NEBUTet al., 2006) é baseado em um modelo de casos de uso que permite que sejam descobertas ambiguidades nos requisitos descritos em uma linguagem natural. Esse método foi construído com base em caso de uso UML (UML, 2014) aprimorado com contratos, que ajudam a inferir a ordenação parcial correta das funcionalidades que o sistema deve oferecer (NEBUT et al., 2006). A Figura 9 apresenta o funcionamento da proposta de (NEBUTet al., 2006).
Figura 9 – Funcionamento da proposta de [Nebut et al. 2006]
Fonte: Adaptado de Nebutet al.(2006).
3.4.2 Trabalho de Gois (2010)
(GOISet al., 2010) propôs a criação de um diagrama para geração de scripts de teste, o Test Script Diagram (TSD). Este diagrama possui uma representação gráca dos uxos de casos de uso e permite associar dados de teste com as respectivas etapas em que são utilizados (GOIS et al., 2010). Além disso, o autor deniu um método para geração de casos de teste a partir do TSD.
O TSD possui 6 elementos, os quais foram descritos utilizando a Forma Normal de Backus Naur (BNF). Esses elementos foram assim definidos:
• Passo: descreve uma ação ou uma verificação de um caso de teste, possuindo uma ação descritiva que pode conter variáveis utilizadas para associar um passo a um dado de teste. Pode conter as seguintes definições para diferenciar as ações e verificações de casos de teste: «Ação» e «Vericação». Ele é representado por um retângulo e contém a expressão que descreve o passo, e, por isso, não pode ser vazio.
• Fluxo: é formado por um conjunto de "Passo", "Sub-diagrama", "Filtro"e "Loop", e é representado por um retângulo não-contínuo. O objetivo é representar os uxos de casos de uso.
• Seta do Fluxo: representada por uma seta contínua que indica a sequência de ações e vericações. Ele pode relacionar um "Passo"a outro, ou um "Passo"a um "Sub-diagrama", ou um "Sub-diagrama"a um "Passo", entre outras possibilidades.
associada a ele. Ele é representado por um triângulo, que possui um dos vértices voltado para o uxo, e uma expressão que descreve as classes de equivalência;
• Sub-diagrama: representado por dois retângulos sobrepostos que indicam que outro diagrama foi encapsulado. O objetivo é reutilizar diagramas previamente criados e reduzir a complexidade do diagrama; e
• Loop: interliga um "Passo"do uxo à um "Passo"anterior a ele. Possui um nome que o identica e é representado por uma seta não-contínua.
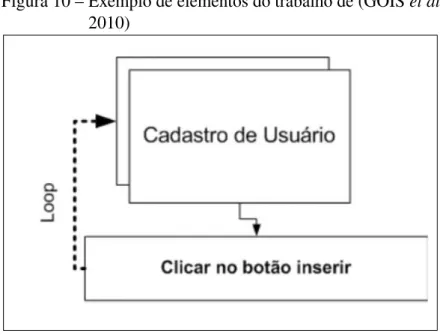
A Figura 10 apresenta um exemplo de uso para os elementos que podem ser utilizados na descrição do Test Script Diagram. Nessa figura, é possível ver um subdiagrama (Cadastro de Usuário), um passo (Clicar no botão inserir), uma seta de fluxo que liga o subdiagrama ao passo, além do elemento loop que indica que após a execução do passo, a execução do teste deve retornar para a etapa de cadastro de usuário.
Figura 10 – Exemplo de elementos do trabalho de (GOISet al., 2010)
Fonte: Goiset al.(2010).
3.4.3 Trabalho de Chen e Li (2010)
representar:
• Cobertura de estados: Cada estado é acessado pelo menos uma vez; • Cobertura de transições: Cada transição ocorre pelo menos uma vez;
• Cobertura dos caminhos: Cada caminho é percorrido, também, pelo menos uma vez; e • Cobertura dos caminhos restritos: Cada caminho no IFA é percorrido pelo menos uma
vez com restrições onde cada transição é acessada n vezes.
De acordo com o critério escolhido para ser testado, um conjunto de caminhos no modelo será gerado. É importante ressaltar que, seguindo a ideia de autômatos, os caminhos têm um estado inicial e um estado nal. Com a cobertura de transição, cada uxo do caso de uso pode ser testado.
3.4.4 Trabalho de Siqueira (2010)
TaRGeT (Test and Requirements Generation Tool) é uma ferramenta criada por (SIQUEIRA, 2010) que tem como objetivo gerar cenários de teste a partir de casos de uso. Os cenários de teste são obtidos a partir de uma denição formal do sistema a ser testado. Um modelo para descrição de casos de uso foi denido, e, nele é possível descrever ações do usuário, do sistema e pré-condições para cada passo do caso de uso. É possível, ainda, descrever passos alternativos a passos já mapeados.
A ferramenta possui dois módulos principais. O primeiro, TaRGet Test Case Genera-tion, realiza a geração de suítes de teste que podem ser exportadas para diversos formatos, além de permitir a extensão dessa funcionalidade para novos formatos. O segundo módulo, TaRGeT On The Fly Generation, é um plugin que tem como objetivo gerenciar os casos de teste gerados pelo primeiro módulo. Esse gerenciamento corresponde a inserção de ltros e a exportação da suíte de testes para diversos formatos.
Com o intuito de evoluir esse trabalho e permitir que fossem gerados casos de teste para LPS, (BARROSet al., 2011) definiu uma LNC para descrever os casos de uso que servem de insumo para a TaRGeT. Essa linguagem é um subconjunto da língua inglesa, portanto, as restrições definidas são baseadas na estrutura sintática e no vocabulário dessa língua.
3.4.5 Trabalho de Bertolino e Gnesi (2003)
foi definida para permitir que sejam inseridas informações de variabilidade das linhas de produtos de software. Essa representação é possível devido ao uso de tags que definem três tipos de variações: alternativas, opcionais e paramétricas. Uma variação é dita alternativa quando se deve escolher uma opção entre várias. Ela é dita opcional quando pode estar ou não presente e é dita paramétrica quando está associada ao valor atual do parâmetro dos requisitos para o produto específico.
Os autores também definiram um método para geração de cenários de teste, o PLUTO (Product Line Use Case Test Optimization) (BERTOLINO; GNESI, ). Esse método utiliza o PLUC e a descrição em linguagem natural como insumos para a automação da geração dos cenários de teste. O PLUTO expandiu o método de partição de categorias (MYERSet al., 2011) para permitir a inserção de variabilidade e a instanciação de casos de teste para um produto específico da linha. Assim, ele gera testes com base nas categorias que são extraídas dos casos de uso.
3.4.6 Trabalho de Neto (2011)
(NETO, 2011) propôs uma ferramenta para gerar e gerenciar cenários de teste para Linhas de Produtos de Software. Ele utilizou um modelo de teste para gerar os artefatos de teste e suas dependências.
A geração dos testes se dá a partir de casos de uso. O método que faz a geração dividiu o objetivo de um caso de uso em sub-objetivos. Como resultado dessa operação, cenários de teste são criados para cada fragmento (sub-objetivo), assegurando, assim, a cobertura de um caso de uso.
3.4.7 Trabalho de Santos (2013)
![Figura 9 – Funcionamento da proposta de [Nebut et al. 2006]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15637871.618353/44.892.127.818.140.448/figura-funcionamento-proposta-nebut-al.webp)