Proposta para previsão de evasão baseada
em padrões de acesso de usuários em jogos
online
Tese apresentada à Escola Politécnica da Universidade de São Paulo como requisito para obtenção do Título de Doutor em Engenharia.
Proposta para previsão de evasão baseada
em padrões de acesso de usuários em jogos
online
Tese apresentada à Escola Politécnica da Universidade de São Paulo como requisito para obtenção do Título de Doutor em Engenharia.
Área de concentração:
Engenharia de Controle e Automação Mecânica
Orientador:
Prof. Dr. Marcos de Sales Guerra
Tsuzuki
original, sob responsabilidade única do autor e com a anuência de seu orientador.
São Paulo, 11 de julho de 2011.
Emiliano Gonçalves de Castro
Prof. Dr. Marcos de Sales Guerra Tsuzuki
Ficha Catalográfica
Castro, Emiliano Gonçalves de
Proposta para previsão de evasão baseada em padrões de acesso de usuários em jogos online. São Paulo, 2011. 76 p.
Tese (Doutorado) — Escola Politécnica da Universidade de São Paulo. Departamento de Engenharia Mecatrônica e de Sistemas Mecâ-nicos.
O impulso responsável pela realização deste trabalho veio do ambiente altamente estimulante e desafiador que sempre encontrei junto aos meus colegas da indústria de jogos eletrônicos. Agradeço a todos aqueles que contribuíram, de uma forma ou de outra, para aguçar a minha curiosidade sobre o tema desta pesquisa.
Agradeço especialmente ao Júlio Vieitez, da Level Up! Games, pelas conver-sas a respeito deste trabalho e pela gentileza em compartilhar os dados brutos utilizados nesta pesquisa. Sem a sua contribuição, nenhuma análise teria sido possível.
Sou grato também aos meus colegas da Escola Politécnica da USP, parti-cularmente ao Prof. Thiago Martins, por todo o apoio nas discussões sobre a metodologia empregada e sobre a pesquisa de uma forma geral; ao Prof. Romero Tori, pelas valiosas sugestões e críticas na fase de qualificação deste trabalho; ao André Sato Kubagawa e à Christiane, pela atenciosa ajuda na revisão do texto.
O mercado de jogos eletrônicosonline tem crescido em ritmo acelerado nos últimos anos, particularmente a partir do surgimento do modelo de negócio baseado em serviços. Como consequência, as publicadoras destes jogos passaram a compartilhar problemas comuns na área de serviços, como a erosão do lucro causada pela evasão de usuários. Modelos preditivos têm sido utilizados no combate à evasão em mercados como os de telefonia móvel e de cartões de crédito, setores que detêm um grande volume de informações demográficas e econômicas a respeito dos seus consumidores. Já os publicadores de jogos muitas vezes só possuem o endereço eletrônico dos jogadores.
O objetivo deste trabalho é propor um modelo de previsão de evasão com base exclusivamente nos padrões de acesso de usuários em jogosonline, onde estes registros temporais são submetidos a um conjunto de operadores que analisam os dados no domínio do plano tempo-frequência, utilizando a Transformada Discreta de Wavelet. Sua principal contribuição está na proposta de parametrização dos dados de entrada para classificadores probabilísticos baseados no algoritmo k-Nearest Neighbors.
Testados com dados reais de acessos de usuários ao longo de alguns meses em um jogo online, os classificadores foram avaliados com o uso de curvas ROC (Receiver Operating Characteristic) e de elevação. A abordagem proposta nesta tese, baseada na análise no domínio do plano tempo-frequência, apresentou resul-tados satisfatórios. Não apenas superiores se comparados com as abordagens no domínio do tempo ou da frequência, mas também comparáveis aos desempenhos encontrados por modelos com centenas de variáveis preditivas utilizados em outros mercados.
The online gaming market has rapidly grown in recent years, particularly since the rise of the service-based business model. As a result, the publishers of these games have started to share usual problems from the services business, like the profit erosion caused by customer churn. Predictive models have been used to address the churn problem in the mobile phones and credit cards markets, where companies have a huge volume of demographic and economic data about their customers. While game publishers often have only their users’ email addresses.
The goal of this study is to propose a model for churn prediction based solely on the online games users’ access patterns, where these time entries are fed into a set of operators that are able to analyze the data in the time-frequency plane domain, using the Discrete Wavelet Transform. Its main contribution is the input data parameterization proposed for the probabilistic classifiers based on the k-Nearest Neighbors algorithm.
Tested with real data from an online game users’ access over a few months, the classifiers were evaluated using ROC (Receiver Operating Characteristic) and lift curves. The approach proposed in this thesis, based on the analysis of the time-frequency plane domain, has shown satisfactory results. Not only higher when compared with approaches based on both time or frequency domains, but also comparable to performances found on models with hundreds of predictive variables used in other markets.
Lista de Figuras
Lista de Tabelas
Lista de Símbolos
Lista de Abreviaturas
1 Introdução 1
1.1 Contexto . . . 1
1.2 Motivação . . . 4
1.2.1 Vantagem Competitiva da Previsão . . . 6
1.2.2 Impacto Econômico . . . 8
1.2.3 O Problema da Falta de Informações . . . 11
1.3 Objetivos e Contribuições . . . 13
1.4 Revisão Bibliográfica . . . 14
1.5 Organização da Tese . . . 18
2 Conceitos Básicos 19 2.1 Transformada Discreta de Wavelet . . . 19
2.1.1 Transformada de Fourier de Curta Duração . . . 19
2.1.2 Transformada de Wavelet . . . 21
2.1.3 A Base Wavelet Haar . . . 23
2.1.4 Decomposição por Pacote de Wavelet . . . 23
2.1.5 Análise de Frequência . . . 26
2.2.1 Matriz de Confusão . . . 29
2.2.2 Curvas ROC . . . 32
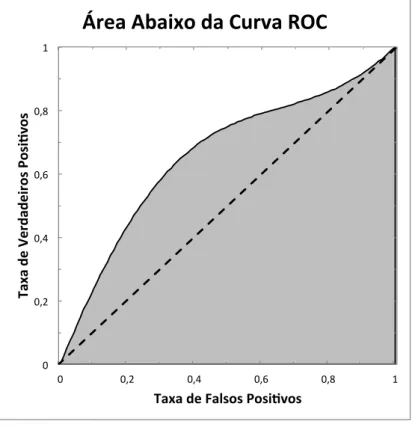
2.2.3 Área Abaixo da Curva ROC (AAC) . . . 36
2.2.4 Curvas de Elevação . . . 37
2.2.5 Elevação no Primeiro Decil (EPD) . . . 39
3 Metodologia 41 3.1 Definição do Problema . . . 41
3.2 Configurações de Testes . . . 42
3.3 Extração de Dados . . . 44
3.4 Pré-processamento . . . 44
3.5 Parametrizações da Entrada das Amostras . . . 45
3.5.1 Proporção de Dias com Atividade (PDA) . . . 46
3.5.2 Espectro de Potência (ESP) . . . 47
3.5.3 Plano Tempo-Frequência (PTF) . . . 47
3.6 Categorização das Amostras . . . 48
3.7 Função de Saída das Amostras . . . 49
3.8 Construção dos Conjuntos de Treinamento e Teste . . . 49
3.9 Classificação por k-Nearest Neighbors . . . 50
3.10 Avaliação da Classificação . . . 52
3.11 Aplicação dos Classificadores . . . 53
4 Resultados 54 4.1 Configuração PDA . . . 54
4.2 Configuração ESP16 . . . 56
4.3 Configuração ESP64 . . . 58
4.4 Configuração PTF16 . . . 59
4.7 Discussão dos Resultados . . . 65
5 Conclusões e Considerações Finais 67
5.1 Conclusões . . . 67
5.2 Trabalhos Futuros . . . 69
5.3 Considerações Finais . . . 71
2.1 Estrutura de resoluções de tempo e frequência para a TFCD. . . . 21
2.2 Estrutura de resoluções de tempo e frequência para a TW. . . 22
2.3 Esquema do Pacote de Wavelet. . . 25
2.4 Coeficientes da Transformada Discreta de Wavelet. . . 26
2.5 Pacote de Wavelet (ordem normal). . . 28
2.6 Pacote de Wavelet (ordenado por frequência). . . 29
2.7 Plano Tempo-Frequência. . . 29
2.8 Matriz de Confusão. . . 31
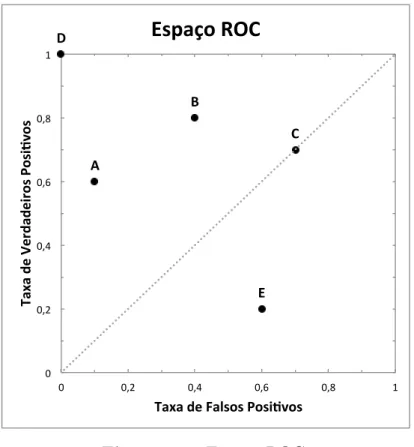
2.9 Espaço ROC. . . 32
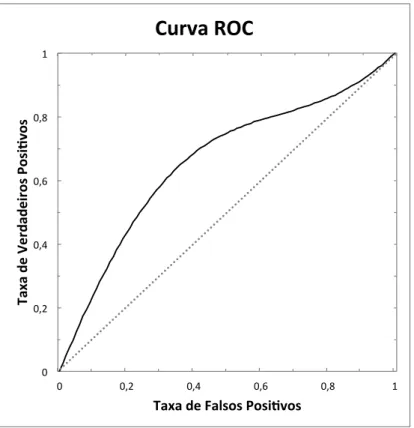
2.10 Exemplo de curva ROC. . . 34
2.11 Área Abaixo da Curva ROC. . . 36
2.12 Curva de Elevação. . . 38
4.1 Curva ROC para a configuração PDA. . . 55
4.2 Curva de Elevação para a configuração PDA. . . 55
4.3 Curva ROC para a configuração ESP16. . . 56
4.4 Curva de Elevação para a configuração ESP16. . . 57
4.5 Curva ROC para a configuração ESP64. . . 58
4.6 Curva de Elevação para a configuração ESP64. . . 59
4.7 Curva ROC para a configuração PTF16. . . 60
4.8 Curva de Elevação para a configuração PTF16. . . 60
4.9 Curva ROC para a configuração PTF64. . . 61
4.10 Curva de Elevação para a configuração PTF64. . . 62
3.1 Parâmetros de configuração dos testes . . . 43
3.2 Configurações de testes para os classificadores . . . 52
4.1 Resultados da configuração PDA . . . 56
4.2 Resultados da configuração ESP16 . . . 57
4.3 Resultados da configuração ESP64 . . . 58
4.4 Resultados da configuração PTF16 . . . 60
4.5 Resultados da configuração PTF64 . . . 61
4.6 Comparação entre os resultados dos testes . . . 62
4.7 Comparação entre ganhos no lucro de uma campanha de retenção 65
A Custos administrativos fixos . . . 9
AAC Área Abaixo da Curva . . . 36
br Vetor binário, de dimensão r . . . 46
bT 0 Vetor binário, de dimensão T0 . . . .46
bT 2 Vetor binário, de dimensão T2 . . . .48
C Categoria de uma amostra . . . 48
c Custo de oferta de incentivo . . . 9
CAU Custo de Aquisição de Usuário . . . 3
d Distância Euclidiana entre dois vetores . . . 51
EP D Elevação no Primeiro Decil . . . 39
k Quantidade de vizinhos considerados no k-NN . . . 51
N Número total de usuários ativos . . . .8
N Btre Número de subconjuntos da Base de Treino . . . 43
N Btes Número de subconjuntos da Base de Teste . . . 43
r Resolução temporal para pré-processamento em T0 . . . 43
T0 Período de observação de acessos passados . . . 42
T1 Período de não-observação . . . 42
T2 Período de observação de acessos futuros . . . .42
t0 Início do período de observação de acessos passados . . . 41
t1 Momento presente . . . 41
t2 Início do período de observação de acessos futuros . . . .41
t3 Final do período de observação de acessos futuros . . . 41
T Btre Tamanho da Base de Treino . . . 43
T Btes Tamanho da Base de Teste . . . 43
T V M Tempo de vida médio dos usuários . . . 8
V Conjunto dos k vizinhos mais próximos de uma amostra . . . 51
V T V Valor do tempo de vida do usuário . . . 3
w Tripla ordenada de uma amostra . . . 49
w′ Quádrupla ordenada de uma amostra de teste completa . . . 51
x Vetor de entrada de uma amostra . . . 49
y Função de saída de uma amostra . . . 49
β Fração dos usuários-alvo da campanha que irão evadir . . . .8
β0 Fração total dos usuários que irão evadir . . . 9
γ Taxa de sucesso da campanha de retenção . . . .8
δ Custo do incentivo individual . . . 8
λ Elevação de uma dada proporção de usuários . . . 9
Π Lucro gerado pela campanha de retenção . . . .9
ˆ π Proporção de positivos em todo o grupo de teste . . . 37
ˆ πm Proporção de positivos num grupo formado por m elementos . . 38
ρF P Taxa de falsos-positivos dentro do total de negativos . . . 31
ρV P Taxa de verdadeiros-positivos dentro do total de positivos . . . 30
ΨESP Operador Espectro de Potência . . . 47
ΨP DA Operador Proporção de Dias com Atividade . . . 46
AAC Área Abaixo da Curva
CAU Custo de Aquisição de Usuário
DPW Decomposição por Pacote de Wavelet
EPD Elevação no Primeiro Decil
FN Falso-negativo
FP Falso-positivo
k-NN k-Nearest Neighbors
MMO Massively Multiplayer Online
MMORPG Massively Multiplayer Online Role-Playing Game
ROC Receiver Operating Characteristic
TDW Transformada Discreta de Wavelet
TF Transformada de Fourier
TFCD Transformada de Fourier de Curta Duração
TVM Tempo de Vida Médio
TW Transformada de Wavelet
VN Verdadeiro-negativo
VP Verdadeiro-positivo
1
Introdução
1.1
Contexto
O mercado de jogos eletrônicos online1 tem demonstrado um vigoroso crescimento desde o seu surgimento. Composto basicamente por jogos Massively Multiplayer Online (MMO)2, casuais3 e, mais recentemente, jogos sociais4, em 2009 este mercado apresentou um faturamento global estimado em 19 bilhões de dólares americanos, cerca de um terço (32%) de todo o faturamento da indústria mundial de jogos eletrônicos[1]. Projeções[1] apontam que esta proporção chegará a 50% em 2014.
Além da dimensão econômica, estes jogos estão cada vez mais presentes no nosso cotidiano. Uma recente pesquisa de mercado conduzida entre internautas americanos[2] apontou que os jogos online ultrapassaram até o uso de e-mail e se tornaram a segunda atividade em tempo gasto na internet (10,2%), atrás apenas do uso de redes sociais (22,7%).
A inovação tecnológica tem sido o grande motor deste mercado ao contornar limitações técnicas que dificultavam a participação simultânea de muitos jogadores, e ao proporcionar entretenimento de qualidade mesmo para plataformas simples, permitindo assim que jogos sejam executados diretamente nos navegadores de internet. Mas além das inovações na área de desenvolvimento, há muito espaço também para o uso de tecnologia na publicação destes jogos. E um bom candidato para merecer atenção especial da tecnologia é o problema da evasão dos usuários5.
No mercado de jogos online tem se tornado cada vez mais popular o modelo de serviços, no qual ao invés de cobrar pela licença do jogo as empresas cobram
1
Jogos eletrônicos que utilizam de alguma forma uma rede de computadores, tipicamente a internet.
2
Jogos capazes de suportar centenas ou milhares de usuários jogando simultaneamente.
3
Jogos mais simples de serem jogados, que não dependem de muito tempo e dedicação por parte dos jogadores.
4Jogos que têm como plataforma redes sociais como o Facebook e o Orkut.
5Os consumidores finais no mercado de jogosonline. Neste trabalho, o termo “usuário” foi
pelo direito de jogar em seus servidores, que vem aos poucos substituindo o tradicional modelo de produtos6 da indústria de jogos eletrônicos. Por conta desta característica, os publicadores7 de jogos online passaram a compartilhar alguns dos problemas comuns encontrados em mercados como os de telefonia móvel, telefonia fixa, cartões de crédito e operadoras de TV a cabo.
Nestes mercados são famosas as “ilhas de retenção” das empresas, unidades de negócio focadas em fazer com que os usuários que decidiram abandonar o serviço8 mudem de idéia. Qualquer pessoa que já tenha passado pela experiência de tentar cancelar a assinatura de uma operadora de telefonia móvel ou TV a cabo, teve a chance de notar a persistência dos profissionais que trabalham nestas unidades, empenhados em manter o cliente dentro da base de usuários ativos9 a (quase) qualquer custo. De certa forma, a própria existência destas “ilhas” demonstra o valor que a retenção de usuários tem para estas empresas.
A evasão é um evento formal e muito bem definido nesses mercados, e envolve uma ação voluntária do usuário de entrar em contato com a empresa e solicitar o cancelamento do serviço. E isso só acontece porque existe este tipo de vínculo, na maioria das vezes na forma de um compromisso de pagamento na relação entre o usuário e a empresa prestadora do serviço.
Mas existe um mercado cada vez mais expressivo de jogos online que são gratuitos10. Jogos que não cobram nenhum tipo de assinatura11, e que são viabilizados economicamente pela venda de itens, que são comprados geralmente por uma pequena parcela de jogadores, os jogadores pagantes12. A venda de itens é um modelo de negócios onde os jogadores podem comprar, através de
6Modelo onde as empresas vende licenças de uso do jogo.
7A empresa publicadora é a responsável pela comercialização de um jogo, o que envolve os
aspectos de licenciamento, marketing, gestão de comunidade, suporte técnico, infra-estrutura operacional (servidores), etc.
8
Decisão feita muitas vezes em favor de um concorrente.
9
Nos jogosonline, usuário ativo é aquele que fez pelo menos um acesso (uma sessão de jogo)
em determinado período. É prática de mercado considerar este período como sendo os últimos 30 dias.
10
Jogos free-to-play, expressão em inglês que ficou tão popular no mercado que quase se
confunde com um gênero, mas na prática apenas indica que o jogo faz parte de um modelo de negócio onde o usuário não precisa comprar o jogo e nem pagar para jogar.
11Pagamento que estabelece uma relação de consumo entre o usuário e o publicador. Envolve o
pagamento de uma taxa, geralmente mensal, que dá ao usuário o direito de permanecer jogando nos servidores do publicador.
12No caso dos jogos baseados em venda de itens, usuário pagante é aquele que já contribuiu
microtransações13, pequenos pacotes de itens virtuais (roupas para o seu avatar14, veículos, armas, etc.) ou pacotes de conveniência (como mudança no nome do seu avatar, seguro do inventário do jogador, etc.). Outro tipo de receita utilizada por estes jogos gratuitos é o da publicidade in-game15.
No caso dos jogos gratuitos não há formalidade no cancelamento do serviço, simplesmente por não haver compromisso de pagamento: o usuário simplesmente pára de acessar16 o jogo. Não precisa comunicar para a empresa a sua decisão de abandonar o serviço.
Esta característica é particularmente desfavorável para os publicadores, pois se os jogadores entrassem em contato as empresas teriam ao menos esta oportunidade para tentar reverter a situação. E existe uma excelente razão para que a empresa realmente se esforce em tentar dissuadir seus usuários a respeito da decisão de cancelamento: o custo de retenção é geralmente muito menor do que o custo de aquisição de um novo jogador[3]. No setor de telecomunicações, reter um usuário custa aproxidamente cinco vezes menos do que adquirir um usuário novo[4].
Uma forma bastante sintética e superficial de entender a rentabilidade deste mercado pode ser expressa da seguinte forma:
Lucro= (VTV−CAU)·Escala (1.1)
Onde VTV significa o Valor do Tempo de Vida17 do usuário, CAU representa o Custo de Aquisição de Usuário18 e Escala significa o volume de jogadores.
No esforço de reduzir ao mínimo a taxa de evasão19 (ou, em outras palavras, maximizar a taxa de retenção20), muitas vezes as empresas buscam se antecipar ao processo de evasão, utilizando modelagem preditiva. A partir destas previsões,
13
Compra de um pacote de créditos através de cartão de crédito, boleto bancário ou algum outro meio de pagamento, normalmente envolvendo o uso de alguma moeda virtual, própria do jogo ou do publicador.
14
Representação visual do usuário dentro do jogo.
15
Anúncios publicitários feitos antes, durante ou depois das sessões de jogo. Podem representar
desdebanners descontextualizados até ações demerchandising dentro do ambiente do jogo.
16
Neste trabalho, “acesso” é definido como a atividade por parte do jogador em iniciar uma sessão de jogo. Em muitos casos, o termo sessão de jogo foi utilizado com o mesmo significado.
17
Valor líquido presente do total de receitas originadas na relação com determinado consumidor.
18Total de investimento em marketing para atrair um usuário para o jogo. Calculado geralmente
a partir de uma média considerando investimentos e número de novos jogadores num determinado período.
19Também conhecida como taxa de atrito ouchurn-rate. Proporção de usuários que deixaram
de ser considerados ativos num determinado período. No mercado de jogos, uma base de tempo muito utilizada é a mensal.
20
as empresas tomam medidas ativas para aumentar a retenção, investindo parte do orçamento de marketing no oferecimento de incentivos aos usuários apontados pelo modelo preditivo como sendo os mais propensos a se tornarem evasores21.
Assim, ao invés de disseminar o incentivo por toda a base de usuários de forma indiscriminada, as empresas direcionam estas ações de retenção àqueles que aparentemente têm maior probabilidade de evasão. Potencialmente economizando o investimento que seria desperdiçado com incentivos para usuários que não precisariam recebê-los[5]. E a capacidade de apontar com precisão os usuários que estão no grupo de risco tem impacto direto na lucratividade destas operações. Esta capacidade se torna mais importante à medida que o mercado fica mais competitivo e dependente de economia de escala, de grandes volumes de usuários.
1.2
Motivação
A estratégia de utilizar modelagem preditiva de evasão para executar campanhas de retenção de usuários com alvos mais precisos já é familiar a alguns mercados. Mas o mercado de jogos eletrônicos online tem algumas peculiaridades que fazem com que grande parte deste know-how não seja aplicável.
A responsável por esta incompatibilidade de know-how está, mais uma vez, na natureza do modelo de negócio. Ao contrário dos outros mercados aqui citados, onde cada novo usuário traz custos não desprezíveis de instalações, equipamentos, infra-estrutura, risco financeiro, etc., no mercado de jogos estes custos são geralmente marginais. Foi isso inclusive que permitiu a ascensão do modelo free-to-play, cada vez mais popular.
Esta diferença fundamental acabou permitindo que os publicadores de jogos fossem reduzindo ao mínimo as barreiras de entrada, para permitir que o maior número possível de potenciais usuários que tenham contato com o jogo não se percam pelos labirintos de cadastros e confirmações e se tornem logo jogadores ativos. E esta decisão traz uma série de implicações e dificuldades para a previsão de evasão de usuários.
Em primeiro lugar, estas barreiras de entrada insignificantes22, e no caso dos jogos free-to-play existe também o poder incrível da palavra “grátis”, trazem para dentro da base de usuários muitos jogadores que em condições normais
21
Jogadores que, ao contrário dos usuários ativos, não tiveram nenhuma sessão de jogo registrada nos últimos 30 dias.
22Muitas vezes compostas de um cadastro mínimo (apenas um e-mail), e no caso dos jogos
jamais teriam se tornado usuários23. Entretanto, a mesma estratégia que facilita a entrada possui um desdobramento, pois ela também é comumente apontado pelos profissionais da área como uma das principais causas das elevadas taxas de evasão encontradas neste mercado.
Um segundo desdobramento importante diz respeito à importância desta grande quantidade de jogadores que apenas passam rapidamente pela base de usuários ativos, que não se identificam ou se engajam suficientemente com a experiência do jogo, e são grandes responsáveis pelas altas taxas de evasão. Ocorre que mesmo estes usuários, mesmo os que nunca tenham ativamente contribuído economicamente com a publicadora através de microtransações, têm às vezes valor como audiência publicitária, modelo de negócio que tem se tornado cada vez mais comum.
Se não parece clara a importância econômica de manter jogadores que não pagam dentro da base de usuários, consumindo recursos operacionais, vale lembrar que muitos jogos multiplayer24, particularmente os MMO, são projetados para que a experiência de jogo seja otimizada para um determinado volume mínimo de jogadores. Simultâneos ou não, dependendo de cada caso. Há portanto um valor intangível de cada usuário não-pagante para garantir uma boa experiência para os usuários pagantes. Assim, embora eles não tragam receitas diretas são importantes para manter o ecossistema econômico da operação.
Um terceiro desdobramento está relacionado à interação entre os usuários. Embora isto ocorra somente nos jogos multiplayer, o fato é que estudos apontam que a evasão de um jogador exerce influência sobre outros jogadores diretamente ligados a ele[3]. Nos mercados em que a relação entre o usuário e a empresa prestadora de serviço não interfere na relação da mesma empresa com outros usuários (caso do mercado de telefonia móvel, cartões de crédito, etc.), a evasão dos usuários não tem efeito viral. Já nos jogos multiplayer, esta capacidade de difusão torna a evasão um efeito ainda mais devastador.
O quarto e último desdobramento está associado à motivação deste trabalho. A redução das barreiras de entrada implica na indisponibilidade de informações detalhadas a respeito dos usuários.
Enquanto nos outros mercados citados aqui existe um cadastro detalhado formalizando a relação de consumo, no mercado de jogos online esta relação é bastante informal. No caso particular dos jogos gratuitos, é comum que nem
23Em muitos casos, um investimento financeiro mínimo por parte do usuário funciona como
barreira quase intransponível.
mesmo o e-mail do jogador seja verificado.
Os modelos preditivos tradicionais das indústrias de telefonia, seguradoras, cartões de crédito, etc. têm a sua disposição dezenas ou mesmo centenas de informações sobre os usuários[5]. Já no mercado de jogos online quase nada se sabe sobre o usuário em termos de informações demográficas e econômicas. Esta falta de informações é um problema intrínseco deste mercado, e é a principal motivação para o desenvolvimento deste trabalho.
Antes de evoluir na direção de qualquer proposta para solucionar este problema, convém refletir sobre as seguintes questões:
1. A natureza da modelagem preditiva, de antecipar a informação sobre quais usuários vão ou não vão deixar de ser ativos com determinado nível de confiança, traz alguma vantagem competitiva para o mercado de jogos online?
2. Campanhas de retenção em jogos que utilizam previsão de evasão têm impacto econômico significativo nas operações deste mercado?
3. Até que ponto a falta de informações a respeito dos usuários prejudica a modelagem preditiva de evasão?
Estas questões serão discutidas nas próximas seções.
1.2.1 Vantagem Competitiva da Previsão
Quanto à primeira pergunta, é bem provável que a previsão de evasão seja tão ou mais importante no mercado de jogosonline do que nos mercados mais tradicionais, em particular no caso dos jogos gratuitos.
Isto porque, conforme já explicado aqui, nos serviços baseados em assinatura a iniciativa de evasão deve ser claramente informada pelo usuário, que anuncia à empresa sua intenção de cancelar o pagamento dos serviços25. Neste momento a empresa tem a sua chance de tentar entender as razões da evasão e, se possível, convencer o usuário a permanecer dentro da sua base de usuários. A modelagem preditiva, nesses casos, é um reforço para tentar antecipar a informação sobre este tipo de decisão e permitir à empresa realizar alguma ação antes que a evasão seja verificada.
25
Já nos jogosonline não baseados em assinatura, o jogador não precisa anun-ciar que vai parar de jogar. Como não há nenhum compromisso de pagamento recorrente, ele simplesmente cessa suas atividades, sem aviso prévio. É por isso mesmo que é prática de mercado só considerá-lo como inativo depois de 30 dias sem nenhuma atividade, pela ausência de uma definição mais clara de quando a evasão ocorre.
O fato de que um usuário só é considerado inativo após 30 dias sem atividade representa uma diferença fundamental entre estes mercados: por conta desta definição, os publicadores de jogos gratuitos em geral só conhecem a evasão de um jogador 30 dias após ele ter realizado sua última atividade dentro do jogo.
Saber que um usuário evadiu pode, por exemplo, levar a empresa a disparar um e-mail com uma promoção ou algum outro tipo de incentivo para trazê-lo de volta. Quanto mais tempo demorar para a empresa entrar em ação, menor pode ser o sucesso da iniciativa. Ou seja: quanto antes, melhor.
O cenário ideal seria a empresa detectar os usuários que estão prestes a serem considerados evasores ainda antes de eles efetivamente ficarem 30 dias sem nenhuma atividade. Melhor ainda, antes até de terem jogado pela última vez. E ter acesso a esta informação com alguma antecedência mínima para que a empresa possa executar suas ações de retenção.
Embora possa parecer sutil, a diferença entre prever a evasão e prever a iminência de evasão tem uma consequência dramática. Ao identificar um grupo como tendo alto risco de só jogarem por, digamos, mais uma última semana, a empresa passa a ter a possibilidade de atuar não apenas nos canais de marketing, mas influenciando diretamente na experiência do usuário dentro do jogo. Alterando as reações do jogo que seriam, em tese, as suas últimas experiências. É como se a empresa tivesse uma última chance com estes jogadores, uma última tentativa de engajar ou reengajar aqueles que estão na iminência de abandonar a base de usuários ativos.
Esta seria ainda uma ação de marketing, em sua essência. Mas ao estar “embrulhada” e disfarçada dentro da própria experiência do jogo, teria a chance de impactar o usuário num momento em que a própria decisão de abandonar o jogo talvez ainda não tenha sido definida. Ou, se foi, ainda não foi consolidada.
uma relevante vantagem competitiva. Porque no mercado de jogos online, este tipo de previsão muitas vezes não significa enxergar o futuro, como pode parecer à primeira vista. Mas sim enxergar com maior nitidez o próprio presente, antes que este se torne um irremediável passado.
1.2.2 Impacto Econômico
A equação (1.1) apresenta o ponto de partida para o entendimento do impacto da taxa de evasão. E quanto maior a taxa de evasão, menor é o Valor do Tempo de Vida (VTV) médio e, consequentemente, o lucro. Isto porque o VTV depende do Tempo de Vida Médio (TVM), que representa a receita acumulada ao longo do tempo de vida. O Tempo de Vida Médio pode ser expresso na seguinte forma:
TVM= 1
taxa de evasão (1.2)
A partir de uma previsão de evasão, o publicador pode planejar uma campanha de retenção direcionada aos usuários que, de acordo com a previsão, são os mais propensos a se tornarem evasores. A natureza da campanha depende fortemente do gênero do jogo e de uma série de outros fatores. Pode ser simplesmente presentear o jogador com algum item especial (veículo, magia, arma, etc.). A idéia é que este presente pode servir como incentivo para que ele passe mais algumas horas no jogo, e talvez reverta a sua decisão de parar de jogar.
O impacto econômico de uma campanha de retenção que utiliza um modelo preditivo de evasão foi detalhadamente apresentado por Neslin et al.[5]. A rentabili-dade de uma única campanha de retenção como função da habilirentabili-dade do modelo preditivo para identificar usuários que irão evadir pode ser expressa a partir dos parâmetros:
N : número total de usuários ativos;
α : fração dos usuários ativos que serão alvos da campanha de retenção;
β : fração dos usuários-alvo da campanha que irão evadir;
δ : custo do incentivo individual (para cada usuário-alvo) da campanha de retenção;
c : custo de comunicação com cada usuário-alvo para oferecer o incentivo da campanha de retenção;
V T V : Valor do Tempo de Vida (Customer Lifetime Value): valor líquido pre-sente do total de receitas originadas na relação com determinado consumidor;
A : custos administrativos fixos de execução da campanha de retenção.
Com base nas definições acima, o lucro (Π) gerado por uma única campanha de retenção, conforme apresentado por Neslin et al.[5], pode ser expresso como:
Π =N α︁βγ(V T V −c−δ) +β(1−γ)(−c) +
+ (1−β)(−c−δ)︁−A
(1.3)
Os três termos dentro dos colchetes apresentam, respectivamente, as seguintes contribuições para o lucro:
∙ contribuição para o lucro da fraçãoβγ dos usuários que iam evadir e decidi-ram continuar ativos por conta da campanha de retenção;
∙ custo da comunicação com os β(1−γ) dos usuário que irão evadir e que portanto nem gastam os incentivos da campanha de retenção;
∙ custo da fração (1−β)de usuários que foram alvo da campanha, não iam evadir mas aceitam os incentivos da campanha.
O termo β reflete o desempenho26 do modelo preditivo:
β0 : fração de usuários que irão evadir dentro de toda a base de usuários ativos;
λ : indica quantas vezes maior é a proporção de usuários que irão evadir dentro do grupo alvo em relação à mesma proporção dentro da base total de usuários ativos. Assim,λ = 1significa que o modelo não tem nenhum poder preditivo, o que só acontece quando λ >1. Este termo também é chamado de “elevação”.
Desta forma, β pode ser expresso como:
26A seção 2.2 apresenta em maior profundidade as métricas de desempenho dos modelos
β =λβ0 (1.4)
Substituindo a equação (1.4) na equação (1.3) obtemos, após alguma manipu-lação algébrica:
Π =N α
︂ ︁
γV T V +δ(1−γ)︁β0λ−δ−c
︂
−A (1.5)
Tomando como referência uma escolha aleatória27 dos N α usuários como alvo para a campanha de retenção, o ganho incremental no lucro em função de λ pode ser expresso como28:
Ganho= (λ−1)N α
︂ ︁
γV T V +δ(1−γ)︁β0
︂
(1.6)
Esta equação apresenta, assim, a relação direta entre o acréscimo no desempe-nho do modelo preditivo e o aumento numa componente de lucro da operação de publicação de um jogo online.
Isto significa que, dada uma mesma configuração de custos e retorno (termos dentros dos colchetes), o lucro da campanha é diretamente proporcional à taxa de evasão na base como um todo (β0) e ao tamanho do grupo alvo da campanha (N α).
O tamanho do grupo alvo é certamente uma decisão da publicadora29. Assim, a grande responsável pela justificativa econômica da utilização destas campanhas é a elevada taxa de evasão encontrada nos jogos online, reportada como variando entre 20% a 50% ao mês[6]. Enquanto, por exemplo, no mercado de telefonia celular, foram encontradas taxas da ordem de 2% a 3% ao mês[4, 7, 8].
Mas o que realmente nos importa na equação (1.6) é o fato de que o lucro da campanha é diretamente proporcional ao termo (λ−1), ou seja, a elevação descontada de uma unidade. O que significa que basta que a taxa de evasão no grupo selecionado pelo modelo preditivo seja 10% maior do que a taxa de evasão na base geral (ou seja, λ = 1,1) para que o ganho no lucro da campanha aumente em 10%. Isto responde à segunda pergunta, deixando claro que o impacto econômico deste tipo de previsão é relevante e pode ser avaliado com clareza.
27Numa seleção aleatória,
λ= 1.
28A formulação original do ganho proposta por
Neslin et al.[5]trata apenas do ganho incremental
proporcionado pelo aumento em uma unidade na elevaçãoλ.
29
1.2.3 O Problema da Falta de Informações
A terceira e última questão se refere ao fato de que, ao invés de ter à disposição dezenas ou centenas30 de variáveis para segmentar e identificar os usuários, as publicadoras de jogos online praticamente só têm à disposição informações sobre a atividade dos usuários dentro do jogo.
O cadastro geralmente não fornece nenhuma informação relevante para a modelagem preditiva, já que muitas vezes só possui como registro obrigatório um endereço eletrônico. Que nem sempre é verificado.
Por outro lado, a atividade dos usuários dentro do jogo pode ser monitorada num nível de detalhe incomparável em relação à maioria dos mercados mais tradicionais. Enquanto uma operadora de cartão de crédito consegue monitorar qual a data, valor pago em uma determinada transação e a localização da loja, num jogo seria em tese possível saber quanto tempo o jogador levou para efetivar a transação, qual foi o seu caminho até a transação, quais ações a antecederam ou sucederam, etc. Mas nem sempre estes dados são armazenados.
Embora se possa argumentar que este manancial de dados poderia embasar modelos preditivos bastante sofisticados, o fato é que isto produziria geralmente uma análise caso a caso. Cada jogo tem as suas peculiaridades, e não seria trivial encontrar paralelos imediatos entre métricas e variáveis de jogos distintos.
Para uma abordagem mais generalista, o foco deveria se concentrar no tipo de informação que é comum em todos os casos. Nem mesmo a compra de itens, ação relativamente comum, pode ser encontrada em todos os jogos. Mas uma informação que inevitavelmente existe em todos os jogos é o registro temporal de acesso31 dos jogadores.
Publicadores sempre armazenam a data e o horário das sessões de acesso dos seus jogadores. Por razões que vão desde a geração de métricas básicas de desempenho do jogo32 até pesquisas da equipe de suporte técnico, o fato é que é altamente improvável que um publicador deixe de armazenar estes dados, pelo menos por algum tempo.
Nos mercados das operadores de telefonia e cartões de crédito, este tipo
30
O Torneio de Modelagem de Evasão da Universidade de Duke oferecia 171 variáveis[5] para
a construção dos modelos preditivos. Alguns exemplos são: receita média mensal, média de minutos utilizados em contato com o serviço de atendimento ao consumidor, idade do usuário, renda estimada, estado civil, localização geográfica, crianças na casa (s/n), preço do aparelho atual, etc.
31
Data e horário de cada acesso, ou seja, de cada início de sessão de jogo.
32
de informação também é utilizada em modelagem preditiva, mas entra como uma variável entre dezenas ou centenas de outras. Muitas vezes processada e representada através da variáveis como “tempo decorrido desde o último evento”33.
Seja concentrada em uma única variável ou destrinchada em uma série de parâmetros, os registros temporais de acesso oferecem um único tipo de resposta: quando o usuário iniciou suas sessões de jogo. Pode-se extrair a partir daí respostas para perguntas como “há quantas semanas ele tem jogado?” ou “qual a frequência média de acesso?”, mas sempre respostas associadas a medidas de tempo, nunca a perguntas do tipo “como ele tem jogado?” ou “o que ele tem feito no jogo?”.
Muitos trabalhos[4, 8, 11, 12] sobre previsão de evasão busca avaliar o impacto de diversas variáveis independentes sobre a variável dependente (a probabilidade de evasão). Este tipo de análise favorece um entendimento mais profundo sobre a natureza do fenômeno de evasão. Mas no problema proposto neste trabalho só há um tipo de variável: os registros temporais das sessões de jogo. Perde-se, assim, este possível entendimento sobre as causas da evasão.
A reflexão sobre a falta de informações traz portanto um novo questionamento:
1. Seria possível que, ao deixarmos de lado as causas e nos concentrarmos nos sintomas34, podermos encontrar modelos preditivos de evasão mais simples, porém com boa capacidade preditiva?
2. A evasão apresenta algum tipo de sintoma prévio observável?
3. Seriam os registros de acessos bons indicadores deste tipo de sintoma, e poderiam apresentar boa capacidade preditiva?
Com relação à primeira pergunta, de acordo com Neslin et al.[5], “explicação
não significa previsão”. Este estudo apontou que isto é bastante claro no contexto de previsão de evasão, onde modelos de abordagens mais explanatória tiveram desempenhos ruins como ferramentas preditivas.
Um resultado importante apresentado porFeng, Brandt e Saha[9] e Chambers et al.[10]dá uma pista a respeito da segunda questão. Estes trabalhos mostraram que
os jogadores mudam seus comportamentos na iminência da evasão, particularmente no que diz respeito ao tempo entre sessões de jogo.
33
Onde “evento” pode significar um telefonema, uma compra, etc.
34
A terceira pergunta está relacionada com a resposta anterior: o tempo entre sessões foi apontado como uma variável com potencial preditivo. Mas o quão preditiva esta variável é, e qual a sua capacidade de suportar isoladamente um modelo preditivo são perguntas ainda a serem respondidas.
Esta é portanto a questão fundamental que este trabalho se propõe a responder: pode um sistema de previsão para evasão em jogosonline embasado exclusivamente nos registros temporais de acesso ter boa capacidade preditiva?
1.3
Objetivos e Contribuições
Este trabalho se propôs a construir e avaliar o desempenho de modelos preditivos de evasão simplificados: classificadores probabilísticos baseados no algoritmo de classificaçãok-Nearest Neighbors (k-NN), utilizando como dados de entrada apenas informações temporais do acesso de jogadores.
Trata-se de uma abordagem baseada em sintomas, sem oferecer contribuição direta para o entendimento das causas intrínsecas da evasão. Ou seja, indepen-dentemente de quais sejam os motivos de cada usuário, alguns deles passam a adotar um comportamento que pode ser em tese identificado como pertencente a um padrão de alto risco de evasão. E o objetivo dos classificadores construídos foi simplesmente tentar apontar da melhor maneira possível qual é o subconjunto de usuários com os maiores riscos.
Como diferentes alternativas foram testadas e foram avaliadas de forma compa-rativa, grande ênfase foi colocada na metodologia deste tipo específico de avaliação, em particular na definição das métricas de desempenho dos classificadores proba-bilísticos.
Foram utilizas neste trabalho diversas técnicas de diferentes áreas do conheci-mento, da mineração de dados ao processamento de sinais. Cabe destacar, aqui, onde exatamente ficou definido o foco da pesquisa e quais foram as suas principais contribuições.
k-NN foi escolhido justamente por ser um dos mais simples e populares no campo do aprendizado de máquinas.
O que este trabalho traz como contribuição é uma série de propostas práticas para aumentar a qualidade da previsão de evasão, considerando os registros temporais de acesso como única fonte de entrada. E descreve passo a passo a metodologia utilizada para atingir este objetivo.
Sua principal contribuição, no entanto, está na proposta de parametrização dos dados de entrada para o algoritmo de classificação. Uma vez que os registros temporais de acesso consistem na única informação oferecida aqui para associar os usuários às suas condições futuras de evasores ou não-evasores, foram analisadas três alternativas (implementadas através de três operadores matemáticos) para processar estes registros e transformá-los num conjunto de parâmetros. Estas três abordagens derivam das seguintes perguntas:
1. O quanto estes registros cobrem o domínio do tempo?
2. Como estes registros se traduzem quando transformados no domínio da frequência?
3. Qual o comportamento dos registros numa análise híbrida, combinando os domínios do tempo e da frequência?
Assim, com análises nos domínios do tempo, da frequência e do plano tempo-frequência, foi possível comparar o desempenho de previsões que utilizaram como base cada uma destas alternativas. E assim verificar se os registros temporais de acessos podem, sozinhos, fornecer informação suficiente para a modelagem preditiva de evasão.
A hipótese deste trabalho é que a terceira abordagem, combinando os domínios do tempo e da frequência, tem maior capacidade preditiva por permitir a análise da evolução temporal da frequência de acesso. Razão pela qual foi utilizada como ferramenta a Transformada Discreta de Wavelet, que conforme será apresentado na seção 2.1, permitiu este tipo de análise com algumas vantagens práticas.
1.4
Revisão Bibliográfica
ou ponderar as dezenas ou centenas de variáveis disponíveis. Mas a intersecção entre previsão de evasão e o domínio dos jogos eletrônicos online foi apenas superficialmente explorada até este momento.
Uma avaliação comparativa entre 44 modelos preditivos de evasão para o contexto de telefonia móvel foi apresentada porNeslin et al.[5], trabalho que resumiu os resultados de um torneio de previsão de evasão, oChurn Modeling Tournament, promovido pelo Teradata Center for Customer Relationship Management at Duke University - The Fuqua School of Business. Foi disponibilizado um banco de dados com 171 variáveis potencialmente preditivas a respeito de usuários anonimizados de uma operadora de telefonia móvel35. Por conta da natureza competitiva deste Torneio foram definidas métricas de desempenho para definir os melhores modelos. Uma análise detalhada do impacto econômico das campanhas de retenção também foi apresentada neste mesmo trabalho.
A equipe vencedora do Torneio, Cardell, Golovnya e Steinberg[8], apresentou a metodologia que utilizaram, aplicando uma técnica baseada em árvores de decisão36 para selecionar automaticamente os parâmetros relevantes para a modelagem preditiva.
Ainda a respeito de técnicas de seleção de parâmetros, máquinas de vetores de suporte foram utilizadas por Coussement e Poel[11] para encontrar as variáveis
com maior impacto na modelagem preditiva, neste caso no contexto de assinatura de jornais. Na mesma linha, Mozer et al.[4] utilizaram técnicas de aprendizado de
máquina como regressão logística, árvores de decisão e redes neurais para detectar os parâmetros preditivos mais relevantes. Eles utilizaram ainda curvas ROC para comparar o desempenho das diferentes abordagens.
O conjunto de variáveis de entrada é reduzido no trabalho apresentado porWei
e Chiu[12], que foca apenas nos detalhes de chamadas telefônicas numa aplicação do
mercado de telefonia móvel, onde não estavam disponíveis informações demográfi-cas sobre os usuários. Neste trabalho foram utilizadas curvas de elevação como ferramenta de análise e comparação.
Técnicas específicas para aumentar o desempenho de classificadores foram apresentadas por Lemmens e Croux[7]. Como as taxas de evasão no mercado de telefonia móvel (da ordem de 2%) tornam a evasão um fenômeno relativamente raro, o trabalho apresenta alguns métodos de balanceamento para evitar que esta raridade prejudique a capacidade de previsão de alguns tipos de modelos.
35O nome da operadora que forneceu os dados utilizados no Torneio não foi revelado.
36Técnica que utiliza uma estrutura em forma de árvore para modelar decisões e suas possíveis
O comportamento viral da evasão em redes sociais foi estudado por Karnstedt
et al.[13], onde uma taxonomia específica para a aplicação de modelagem preditiva
de evasão em redes sociais foi construída para analisar a influência da difusão de comportamento entre usuários que têm ligações uns com os outros. A influência dos laços sociais também foi analisada no trabalho de Dasgupta et al.[14], que teve
como foco o mercado de telefonia celular.
No domínio dos jogos eletrônicos, alguns estudos analisaram o comportamento dos usuários a partir da mineração de dados a respeito de suas ações realizadas dentro do jogo, mas não abordaram o problema da evasão. O impacto da jogabili-dade em grupo no jogo World of Warcraft37[16] sobre a evolução de nível no jogo foi examinado por Ducheneaut et al.[17] e Ducheneaut et al.[18].
Ainda utilizando o jogo World of Warcraft como referência, uma detalhada análise da evolução populacional e seu impacto sobre a carga nos servidores38 foi apresentada porPittman e Gauthierdickey[19]. A evasão é uma das medidas analisadas neste trabalho, mas não foi feita nenhum tipo de modelagem preditiva.
Um estudo que analisou a relação entre informações de acesso dos usuários e carga nos servidores foi relatado por Feng, Brandt e Saha[9], a partir de dados
coletados do jogo EVE Online39[20]. Foram também encontrados indícios de que a taxa de evasão aumentou à medida que o jogo amadureceu, e de que o tempo entre sessões seria um bom discriminante para determinar jogadores prestes a abandonar o jogo. Mas neste trabalho também não foi feita nenhuma modelagem preditiva.
Uma análise semelhante foi realizada por Chambers et al.[21], onde a atividade
de usuários de jogos first-person shooters40 foi estudada com o objetivo de avaliar o impacto sobre a carga nos servidores. Problema também investigado por Chen,
Huang e Lei[22] e Chambers et al.[10]. Além de avaliar a previsibilidade da carga
nos servidores, Chambers et al.[10] também apontaram interessantes conclusões a
respeito de sincronias e periodicidades nos padrões de atividades dos jogadores. Um resultado importante encontrado foi que os jogadores, observados de forma agregada, mudam seus comportamentos na iminência da evasão.
Para o caso específico dos MMORPGs, uma interessante abordagem que
37
Massively Multiplayer Online Role-Playing Game (MMORPG) baseado em assinatura mais
popular do mercado: 12 milhões de assinantes em outubro de 2010[15].
38
Genericamente, recursos dehardware,software e rede necessários para manter uma
experi-ência de jogo razoável para cada usuário[10]. Diretamente ligada ao custo variável do publicador,
razão pela qual seu provisionamento tem relevante impacto econômico na operação.
39
Popular MMORPG de ficção científica e temática espacial baseado em assinatura.
40
inclusive envolveu previsão de evasão foi relatada por Kawale, Pal e Srivastava[3]. A
probabilidade de evasão foi tratada como uma função tanto da influência social quanto do engajamento pessoal41 num estudo sobre o jogo EverQuest II42[23]. Um modelo de difusão foi adaptado para representar a propagação das influências dos jogadores ao longo das suas redes de relacionamentos dentro do jogo43.
De uma forma geral, o número de pesquisas que envolvem informações sobre a atividade dos jogadores coletadas no lado do servidor é muito pequeno, conforme apontado porFeng, Brandt e Saha[9]eChambers et al.[10]. E este tipo de informação é a
matéria-prima, o ponto de partida de qualquer estudo que se proponha a modelar a evasão de usuários.
Outro aspecto importante é que, como campo de estudo, a mineração de dados nos jogos eletrônicos online é uma área de pesquisa bastante nova. O artigo mais antigo encontrado que envolvia análise de dados em jogos online foi publicado em 2005, e a maioria dos artigos sobre este assunto foi publicada nos últimos três anos.
O uso de Wavelets em análise estatística de dados para mineração de dados já foi amplamente pesquisado, sendo alguns exemplos os trabalhos de Ogden[24] eLi et al.[25]. Mais especificamente, o uso de Wavelets na análise de séries temporais foi
explorado em diversos trabalhos, sendo alguns exemplos os trabalhos de Percival e
Walden[26],Nason e Sachs[27]eSharifzadeh, Azmoodeh e Shahabi[28]. Algumas aplicações de
usos mais particulares de Wavelets na análise de séries temporais foram relatadas
por Goodwin[29], que analisou dados de sismógrafos e tomógrafos.
Análise de séries temporais com aplicações em domínios mais próximos ao considerado neste trabalho foram relatadas por You e Chandra[30], que analisou
modelagem de tráfego de internet. A previsão de séries temporais num domínio de internet foi estudada por Olej, Hájek e Filipová[31]. Os trabalhos de Hofgesang
e Patist[32] e Hofgesang e Patist[33] focaram em retenção de usuários utilizando o
monitoramento individual de páginas na internet.
41
Definido neste estudo como o tempo total gasto no jogo pelos usuários.
42
O jogo Everquest II oferece hoje, além do modelo de assinaturas, também um formato gratuito porém mais limitado, seguindo uma tendência de migração dos jogos baseados em assinaturas.
43
Neste trabalho só foram considerados jogadores que preferem jogar em grupo, já que o jogo
1.5
Organização da Tese
Após ter contextualizado o mercado de jogos eletrônicos online e apresentado as motivações e objetivos deste trabalho no Capítulo 1, os principais conceitos básicos utilizados neste trabalho são descritos no Capítulo 2: Transformada Discreta de Wavelet e técnicas de análise de frequência e de plano tempo-frequência. O Capítulo 2 também introduz métodos de avaliação de classificadores, em particular os classificadores probabilísticos e algumas métricas indicadas para a sua análise.
O desenvolvimento da proposta para previsão de evasão é descrito no Capítulo 3. Todas as fases da metodologia são apresentadas, com detalhamento especial nas fases que representam as principais contribuições deste trabalho. Também é descrito o ambiente de testes construído para esta pesquisa.
2
Conceitos Básicos
Neste Capítulo são apresentados os principais conceitos fundamentais utilizados neste trabalho. As Wavelets e suas Transformadas Discretas são introduzidas, ressaltando sua vantagem prática sobre a análise de Fourier para o tipo de aplicação desta pesquisa. Na sequência, são descritas técnicas de análise nos domínios da frequência e do plano tempo-frequência.
Uma metodologia para avaliação de classificadores também é apresentada, com foco para o caso particular dos classificadores probabilísticos. As curvas ROC e de elevação, assim como suas principais métricas, são introduzidas no final do Capítulo.
2.1
Transformada Discreta de Wavelet
Neste trabalho, a Transformada Discreta de Wavelet (TDW) foi utilizada como ferramenta para a análise dos registros temporais de acessos dos jogadores nos domínio da frequência e do plano tempo-frequência. Wavelets têm sido largamente utilizadas em engenharia, com aplicações em campos variados como astrofísica, análise de DNA, climatologia e mecânica quântica. Particularmente na área de análise estatística, têm como aplicações mais comuns o processamento de sinais, a análise de imagens e a compactação de dados[24].
Para uma compreensão adequada do tipo de análise proporcionado pela TDW, as Wavelets serão brevemente conceituadas nesta seção, seguidas de uma compacta apresentação de técnicas de análise no domínio da frequência e do plano tempo-frequência.
2.1.1 Transformada de Fourier de Curta Duração
f(x) = a0
2π +
1 π ∞ ︁ n=1 ︀
ancos(nx) +bnsin(nx) ︀
(2.1)
onde
an= ︁ 2π
0
f(x)cos(nx) dx (2.2)
bn= ︁ 2π
0
f(x)sin(nx) dx (2.3)
As funções senoidais (senos e cossenos) são localizadas na frequência, mas não no tempo. Razão pela qual uma função com descontinuidades precisaria de um grande número de termos para ser adequadamente representada[29].
Embora seja possível, com a expansão de Fourier, encontrar todas as frequên-cias presentes num sinal, não é possível determinar onde elas estão localizadas no tempo. Só é possível analisar no domínio da frequência, e não no domínio do tempo.
A TF também não é indicada para sinais não-estacionários1. A Transformada de Fourier de Curta Duração (TFCD), adaptada a partir da TF, divide o sinal em pequenos segmentos para poder assumir que, em cada segmento, o sinal é praticamente estacionário. Desta forma é possível obter uma representação do sinal nos domínios do tempo e da frequência. Mas o Princípio da Incerteza de Heisenberg2 torna a definição do tamanho destes segmentos um dilema[25].
Neste contexto, este Princípio formula que não é possível obter simultane-amente boas precisões para tempo e frequência. Com a TFCD, ao fixar um segmento, fixa-se uma resolução3. E segmentos de tempo grandes produzem resoluções boas para a frequência e ruins para o tempo, enquanto segmentos mais curtos produzem resoluções ruins para a frequência e boas para o tempo. Esta resolução fixa é apresentada na Fig. 2.1.
Conforme pode ser observado na Fig. 2.1, as localizações de tempo e frequência são independentes. Como resultado, as células da estrutura apresentada são sempre quadradas[25].
1
Sinais onde a frequência varia com o tempo.
2Estabelece que certos pares de propriedades não podem ser medidas ao mesmo tempo com
precisões arbitrariamente altas. Quanto mais precisamente uma delas é medida, menos precisa fica a medição da outra. O exemplo mais conhecido é da Mecânica Quântica, com relação às grandezas posição e momento.
3Neste caso, ao fixar uma resolução para o tempo fixa-se automaticamente uma resolução
! "
#$
%
&'(
)*
+,
-%./0
"
!
1
2
2 1
Figura 2.1: Estrutura de resoluções de tempo e frequência para a TFCD.
2.1.2 Transformada de Wavelet
Conforme bem observado emGoodwin[29], “Wavelet é uma onda pequena e localizada, projetada para ter propriedades atraentes não desfrutadas por ‘ondas grandes’.”.
Wavelets são funções básicas, blocos de construção para representar sinais nos domínios do tempo e da frequência simultaneamente. Transformada de Wavelet (TW) servem para aproximar um sinal da mesma forma que a Transformada de Fourier, com a vantagem de poderem lidar com uma gama de sinais mais ampla do que a análise de Fourier, pelo fato de serem localizadas não só na frequência mas também no tempo[25].
Dada a impossibilidade computacional de analisar um sinal utilizando todos os coeficientes possíveis das Wavelets. Uma forma eficiente de calcular coeficientes para uma série discreta é obtida com o uso da TDW. A idéia básica é filtrar a série utilizando filtros passa-alta e passa-baixa associados a uma base Wavelet para obter estes coeficientes[29]. A Wavelet principal, também chamada de Wavelet mãe é, neste caso, calculada pela expressão:
ψ(x) = ︁ k∈Z
gk
√
2φ(2x−k) (2.4)
onde os componentes gk fazem o papel do filtro passa-alta. Já a função φ(x)é
φ(x) =︁ k∈Z
hk
√
2φ(2x−k) (2.5)
onde os componentes hk fazem o papel do filtro passa-baixa. Uma base4
Wavelet pode ser formada por translação e dilatação da função Wavelet mãe.
Ao contrário da Transformada de Fourier de Curta Duração, a Transformada Discreta de Wavelet não tem resolução fixa. Ela produz resoluções boas para o tempo e ruins para a frequência para as altas frequências, e resoluções ruins para o tempo e boas para a frequência para as baixas frequências. O esquema de resoluções para a WT é apresentado na Fig. 2.2.
! !
"
#
$
%
&
'
& % $ # "
()*+,
-'
./
)
012
34
56
Figura 2.2: Estrutura de resoluções de tempo e frequência para a TW.
No caso da TW, ao invés de seguir uma resolução fixa, as divisões de tempo e frequência seguem uma evolução logarítmica, e enquanto uma aumenta a outra diminui, como podemos observar na Fig. 2.2. O Princípio da Incerteza de Heisenberg fica ilustrado aqui pelo fato de que nesta figura os blocos não têm um formato único (como na Fig. 2.1), mas têm todos a mesma área.
Este esquema de resolução adaptativa é muito útil em várias aplicações práticas, que têm componentes de alta frequência de curta duração (explosões) e componentes de baixa frequência de longa duração (tendências)[25].
4
2.1.3 A Base Wavelet Haar
A primeira TDW foi inventada pelo matemático húngaro Alfréd Haar, e é formada provavelmente pela mais simples família de funções que pode ser utilizada como base Wavelet[29]. Tem como formulação para a Wavelet mãe e Wavelet pai as seguintes expressões:
ψ(x) = ⎧
⎪ ⎪ ⎨
⎪ ⎪ ⎩
1 0≤x <0,5
−1 0,5≤x <1
0 outros valores de x
(2.6)
φ(x) = ︃
1 0≤x <1
0 outros valores de x (2.7)
Os filtros passa-alta � e passa-baixa ℋ para a base Wavelet Haar são repre-sentados pelos seguintes valores:
�= (g0, g1) = (1/
√
2,−1/√2) (2.8)
ℋ= (h0, h1) = (1/
√
2,1/√2) (2.9)
2.1.4 Decomposição por Pacote de Wavelet
Na TDW, uma série de dados é decomposta em coeficientes utilizando progressi-vamente um filtro Wavelet em vários passos. O resultado de cada passo do filtro é a entrada para o passo seguinte. Se a série de dados inicial tem n elementos, os passos seguintes operam sobre n/2i, com i variando entre 1 e (log
2n)−1. Se a série inicial tiver 64 elementos, por exemplo, a TDW terá 6 passos sobre 64, 32, 16, 8, 4 e 2 elementos.
Enquanto a TDW só aproveita os coeficientes da função Wavelet pai, a Decomposição por Pacote de Wavelet (DPW) utiliza tanto os coeficientes da Wavelet pai quanto os da Wavelet mãe. Em algumas aplicações (e a análise combinada no domínio do tempo e da frequência é uma delas) esta decomposição mais completa é necessária.
Algoritmo 1 Decomposição por Pacote de Wavelet de Haar usando Lifting Scheme
Entradas: S, série de dados para a decomposição, contendo um número de elementos que é uma potência de 2.
Saída: S′, coeficientes da função Wavelet pai, e
D′, coeficientes da função Wavelet
mãe.
1: function LIFTING_SCHEME (S)
2: n← número de elementos de S
3: S′
← ⟨⟩
4: D′
← ⟨⟩
5: i←1
6: while i≤n/2 do
7: pos1←2i−1
8: pos2←2i
9: insira (S[pos1] +S[pos2])/2 em S′ 10: insira (S[pos1]−S[pos2])/2em D′ 11: end while
12: return [S′
, D′ ] 13: end function
As funções Wavelet mãe e pai de Haar aparecem no algoritmo nas linhas 10 e 9, respectivamente. Aplicando o filtro expresso na equação (2.8) na equação (2.4), a Wavelet mãe ficou resumida a um cálculo que é simplesmente a metade da diferença entre dois valores. Analogamente, a Wavelet pai foi simplificada como a metade da soma de dois valores, como resultado da aplicação da equação (2.9) na equação (2.5).
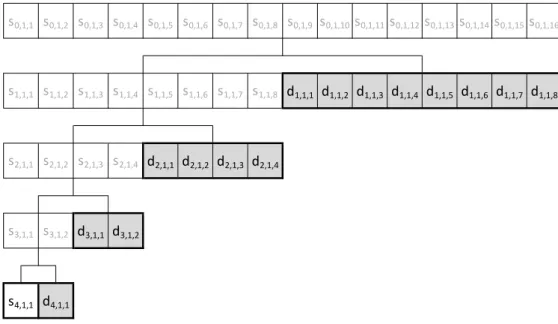
A Fig. 2.3 ilustra de forma esquemática a utilização recursiva do Algoritmo 1 numa série de dados. No exemplo ilustrado nesta figura, a série original de dados possui 16 elementos e ocupa a primeira linha, com os componentes s0,1,k, com k
variando de 1 a 16. Na segunda linha aparece o resultado na aplicação de um passo do Lifting Scheme, com os coeficientes da Wavelet pai agrupados do lado esquerdo (componentes s1,1,k, com k variando de 1 a 8), e os componentes da
Wavelet mãe agrupados do lado direito (componentes d1,1,k, comk variando de 1
a 8), estes últimos em células sombreadas. O número de elementos destes novos grupo é metade do número de elementos da série original (linha 6 do algoritmo), como consequência da amostragem realizada pela TDW.
A terceira linha da figura é resultado da aplicação do mesmo algoritmo nos dois grupos da segunda linha, ou seja, da aplicação da TDW de Haar usando Lifting Scheme tanto nos coeficientes das Wavelet pai quanto nos coeficientes da Wavelet mãe representados na linha anterior. É composta portanto pelos quatro grupos formados pelos componentes s2,j,k e d2,j,k, com j variando de 1 a 2 e k
!"#$#% &"#$#% !"#'#% &"#'#% !"#"#% &"#"#% !"#(#% &"#(#% !"#)#% &"#)#%
!*#"#% !*#"#+ &*#"#% &*#"#+
!"#%#% &"#%#% !"#+#% &"#+#% !"#*#% &"#*#%
&*#+#% &*#+#+ !*#*#% !*#*#+ &*#*#% &*#*#+
&+#+#% &+#+#+ &+#+#* &+#+#"
!*#%#% !*#%#+ &*#%#% &*#%#+ !*#+#% !*#+#+
&+#%#* &+#%#" !+#+#% !+#+#+ !+#+#* !+#+#"
&%#%#( &%#%#) &%#%#$ &%#%#'
!+#%#% !+#%#+ !+#%#* !+#%#" &+#%#% &+#%#+
!%#%#$ !%#%#' &%#%#% &%#%#+ &%#%#* &%#%#"
!,#%#%*!,#%#%"!,#%#%(!,#%#%)
!%#%#% !%#%#+ !%#%#* !%#%#" !%#%#( !%#%#)
!,#%#$ !,#%#' !,#%#- !,#%#%,!,#%#%%!,#%#%+
!,#%#% !,#%#+ !,#%#* !,#%#" !,#%#( !,#%#)
Figura 2.3: Esquema do Pacote de Wavelet.
grupo final é composto por apenas um único elemento.
Uma das vantagens da utilização do algoritmoLifting Scheme é claramente representada na Fig. 2.3, onde todas as linhas possuem exatamento o mesmo número total de elementos. Isto permite que, dependendo da aplicação5, seja utili-zada uma única estrutura de dados linear para armazenar todos os componentes, que vão sendo substituídos a cada passagem. Neste caso, cada par de elementos da entrada vai sendo substituído no mesmo lugar dentro da estrutura de dados por um coeficiente da Wavelet pai e outro da Wavelet mãe, portanto é necessário um rearranjo entre os elementos em cada etapa do algoritmo para garantir que eles fiquem organizados como na Fig. 2.3.
Cada elementosedfoi identificado no esquema com três índices, num sistema de endereçamento que obedece a seguinte convenção:
i : Número de passos já realizados pelo algoritmo. Na primeira linha os dados são originais, e portanto i vale zero. Na medida em que descem as linhas, i
vai incrementando. Se a série de dados temn elementos, o valor máximo de
i élog2n.
j : Identificação do par de grupo dentro da mesma linha. Um grupo é um conjunto de coeficientes de uma mesma Wavelet, e pode ser da Wavelet mãe ou da Wavelet pai. Um par de grupo representa o conjunto formado pelos coeficientes das Wavelets mãe e pai de uma mesma transformada. Só
começa a ser diferente de 1 a partir da terceira linha, pelo fato de que ela já apresenta resultados de duas transformações (feitas sobre os dois grupos da segunda linha). Em cada linha, o valor máximo de j é 2i−1.
k : Identificação de um coeficiente dentro do seu próprio grupo. Em cada linha, o valor máximo de k én/2i.
2.1.5 Análise de Frequência
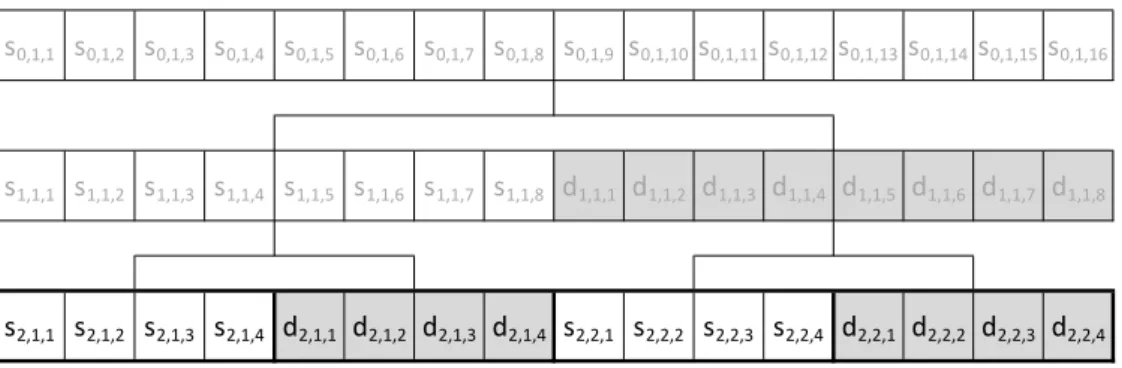
O esquema apresentado na Fig. 2.3 mostra a aplicação recursiva do algoritmo Lifting Scheme em todos os coeficientes, tanto nos da Wavelet mãe quanto nos da Wavelet pai, fazendo assim uma decomposição completa. Se a aplicação se concentrasse somente nos grupos da esquerda, que são resultantes do filtro passa-baixa, estaria atuando sobre basicamente amostras de decrescente resolução da série original. Este processo está ilustrado na Fig. 2.4, que destaca os coeficientes finais encontrados.
!"#$#%
!"#$#$ !"#$#& !"#$#' !"#$#( !"#$#) !"#$#$'!"#$#$(!"#$#$)!"#$#$%
!$#$#$ !$#$#& !$#$#' !$#$#( !$#$#) !$#$#%
!"#$#* !"#$#+ !"#$#, !"#$#$"!"#$#$$!"#$#$&
-$#$#) -$#$#% -$#$#* -$#$#+
!&#$#$ !&#$#& !&#$#' !&#$#( -&#$#$ -&#$#&
!$#$#* !$#$#+ -$#$#$ -$#$#& -$#$#' -$#$#(
!'#$#$ !'#$#& -'#$#$ -'#$#&
-&#$#' -&#$#(
!(#$#$ -(#$#$
Figura 2.4: Coeficientes da Transformada Discreta de Wavelet.
Estes coeficientes finais permitem uma análise no domínio da frequência da série original de dados. Na Fig. 2.4 o elemento s4,1,1 é o último coeficiente da Wavelet pai encontrado. No caso específico da base Wavelet Haar, este coeficiente equivale à média de todos os elementos da série original.
de 2 (1, 2, 4 e 8 no exemplo, que tem uma série original de 16 elementos e 4 grupos de coeficientes).
Os compontentes do espectro de potência da Wavelet são encontrados pelo cálculo da soma dos coeficientes de cada um destes grupo. Para efeito de análise, o grupo que corresponde ao último coeficiente da Wavelet pai (a média dos dados ao utilizarmos Wavelet de Haar) também é considerado[35]. Genericamente, os componentes podem ser expressos (seguindo a notação da Fig. 2.4) como:
Espectro[0] = (slog2n,1,1)
2 (2.10)
Espectro[i] =
2i−1 ︁
k=1
(d(log2n)−i+1,1,k)
2 (2.11)
onde i varia entre 1 e log2n. Portanto, o número total de componentes do espectro de potência de uma série de dados com n elementos vale (log2n) + 1.
2.1.6 O Plano Tempo-Frequência
Conforme podemos perceber pela Fig. 2.3, cada coeficiente de Wavelet é resultado do processamento de dois coeficientes da geração anterior. E pela análise do Algoritmo 1 percebemos que cada coeficiente é resultado de um processamento local e ordenado: s1,1,1 (assim como d1,1,1) é resultado exclusivamente do processamento de s0,1,1 e s0,1,2, s1,1,2 resulta de s0,1,3 e s0,1,4, e assim por diante. Desta forma, se os elementos da série original representarem uma série temporal, todos os grupos gerados com este algoritmo também estarão ordenados no tempo. Este fato permite que os dados sejam analisados também no domínio do tempo.
Combinando esta análise no domínio do tempo com a análise apresentada na seção anterior, é possível obter uma análise simultânea nos domínios do tempo e da frequência. Na primeira linha, no alto da Fig. 2.3, não foi realizada nenhuma TDW, e portanto não há nenhum componente de frequência para ser analisado. Mas os elementos da série estão todos registrados ali, na máxima resolução temporal.
Já na última linha da mesma figura, a DPW foi levada até o limite6, atingindo assim a máxima resolução para a frequência. Por outro lado, os grupos da última linha têm todos um único elemento, o que faz com que a resolução temporal seja mínima.
6