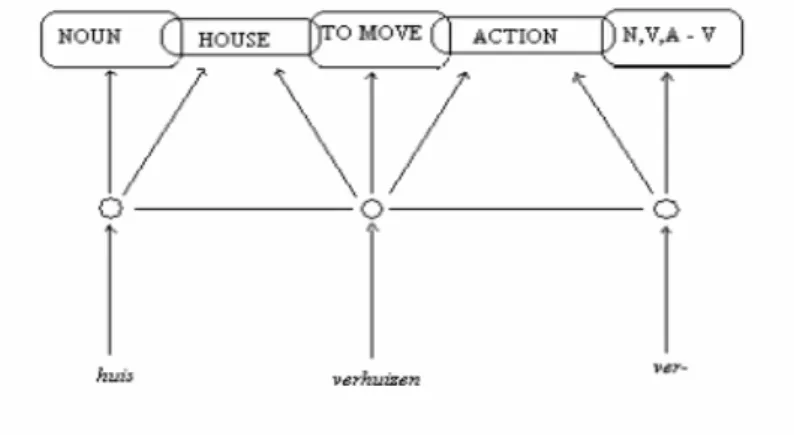
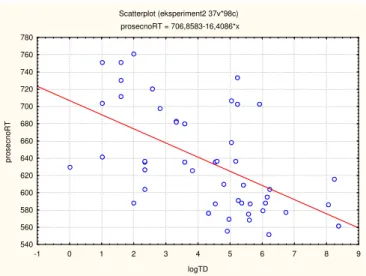
The effect of family size on processing Serbian nouns
Texto
Imagem


Documentos relacionados
Rekons- truisani 3D model pruža prave informacije i za donošenje odluke o mogu ć nosti i prihvatljivosti hirurško-ortodontskog izvla č enja impaktiranog zuba, jer se kost na modelu
nih karakteristika ć elija u njenom sastavu, sugerišu da se kao najzna č ajniji faktori koji doprinose rupturi aneurizme mogu izdvojiti: prisustvo nestabilnog,
Na zahtev kupaca postoje ć i komunikacioni sistem može se zameniti savremenom radio- opremom, uklju č uju ć i interfon, uz obezbe đ enu zaštitu od ometanja (radio-komunikacija
Sa druge strane su autori č ija istraživanja demonstriraju jedinstvenost strukture formalnih operacija i koji smatraju da horizontalno pomeranje nije u suprotnosti sa Pijažeovim u
Ovo neslaganje u rezultatima može biti posledica razli č ite etio- logije ciroze jetre, ali i malog broja bolesnika bez splenomega- lije koji je bio obuhva ć en našim
Uopšte govore ć i, rezultati dobijeni pomo ć u primene bilo kojeg instrumenta za istraživanje kvaliteta života zavise od klini č kog stanja ispitanika u momentu ispitivanja (naro-
Rezultati koji su dobiveni mjerenjem visinskih razlika, a i nakon mjerenja visinskih razlika nivelmanske mreže digitalnim nivelirom LEICA DNA03 i opti č kim nivelirom KONI 007, dali
Na taj na č in, analiziraju ć i konstrukcionu šemu va- kuum kristalizera sa recirkulacijom suspenzije u kome se obavlja kristalizacija NaCl iz vodenih rastvora, može se
