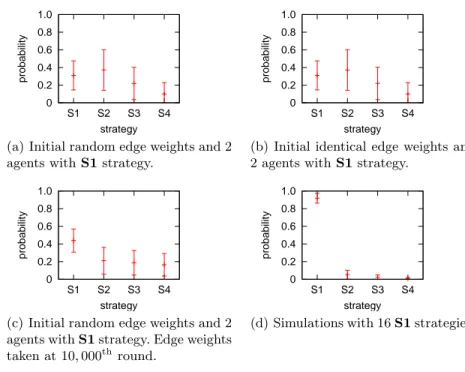
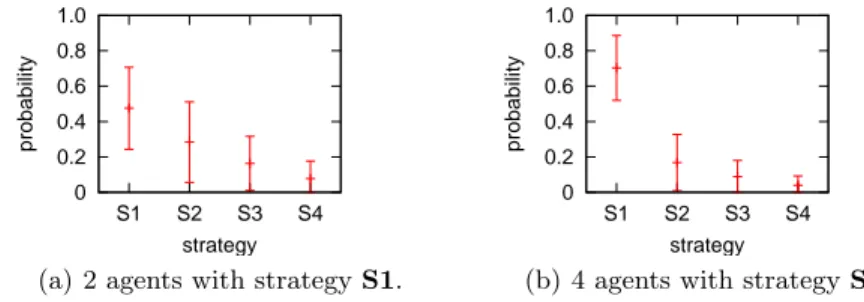
How to build the network of contacts : selecting the cooperative partners
Texto
Imagem

Documentos relacionados
The probability of attending school four our group of interest in this region increased by 6.5 percentage points after the expansion of the Bolsa Família program in 2007 and
Desta forma, diante da importância do tema para a saúde pública, delineou-se como objetivos do es- tudo identificar, entre pessoas com hipertensão arterial, os
This log must identify the roles of any sub-investigator and the person(s) who will be delegated other study- related tasks; such as CRF/EDC entry. Any changes to
A segunda parte apresenta o crowdfunding como uma alternativa ao modelo de financiamento atual, apesar das limitações impostas pela Lei das Eleições (Lei nº 9.504/1997), e como
Numa análise alinhada com às observações teóricas da escola culturalista, acerca das possibilidades entre cultura e linguagem, Robin expõe em seu texto as
pelos médicos e enfermeiros e como essa integração pode determinar uma maior e melhor adequação das práticas destes profissionais na educação para a saúde
É importante destacar que as práticas de Gestão do Conhecimento (GC) precisam ser vistas pelos gestores como mecanismos para auxiliá-los a alcançar suas metas
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
