Marcelo Mendes Marinho
Localização de Casos de Uso: Uma Abordagem
para a Compreensão de Software
Dissertação apresentada ao Programa de Pós-Graduação em Gestão do Conhecimento e da Tecnologia da Informação da
Universidade Católica de Brasília como requisito parcial para obtenção do grau de Mestre em Gestão do Conhecimento e da Tecnologia da Informação
Orientador: Prof. Nicolas Anquetil
Agradecimentos
Agradeço a todos aqueles que contribuíram para a realização deste
trabalho, direta ou indiretamente. Correndo o risco de não incluir todas as pessoas que merecem destaque, agradeço em especial:
Ao Prof. Nicolas, pela paciência, pelas idéias, pela orientação.
Ao pessoal do trabalho que além de cobrir as ausências necessárias mantiveram o apoio ao projeto o tempo todo.
À minha família, por me ensinar pelo exemplo o valor da educação, não apenas na vida profissional, mas para sermos pessoas sempre melhores.
Resumo
Abstract
Índice
CAPÍTULO 1– INTRODUÇÃO ...ERROR! BOOKMARK NOT DEFINED. 1.1. MOTIVAÇÃO E TEMA...ERROR!BOOKMARK NOT DEFINED. 1.2. OBJETIVOS...ERROR!BOOKMARK NOT DEFINED. 1.3. METODOLOGIA...ERROR!BOOKMARK NOT DEFINED. 1.4. ESTRUTURA DA DISSERTAÇÃO...ERROR!BOOKMARK NOT DEFINED. 1.5. OUTRAS CONSIDERAÇÕES...ERROR!BOOKMARK NOT DEFINED.
CAPÍTULO 2– DESAFIOS DA MANUTENÇÃO DE SOFTWAREERROR! BOOKMARK NOT DEFINED.
2.1. MANUTENÇÃO DE SOFTWARE...ERROR!BOOKMARK NOT DEFINED. 2.1.1. Papel da Documentação ...Error! Bookmark not defined.
2.2. DESAFIOS DA MANUTENÇÃO DE SOFTWARE...ERROR!BOOKMARK NOT DEFINED. 2.3. PROCESSO DE MANUTENÇÃO...ERROR!BOOKMARK NOT DEFINED. 2.4. CONSIDERAÇÕES SOBRE O CAPÍTULO...ERROR!BOOKMARK NOT DEFINED.
CAPÍTULO 3– COMPREENSÃO DE PROGRAMAS...ERROR! BOOKMARK NOT DEFINED.
3.1. IMPORTÂNCIA DA COMPREENSÃO DE PROGRAMAS...ERROR!BOOKMARK NOT DEFINED. 3.2. ODESAFIO DA COMPREENSÃO DE PROGRAMAS DE COMPUTADORERROR!BOOKMARK NOT DEFINED. 3.3. MODELOS COGNITIVOS...ERROR!BOOKMARK NOT DEFINED.
3.3.1. Modelo de Brooks...Error! Bookmark not defined.
3.3.2. Modelo de Letovsky ...Error! Bookmark not defined.
3.3.3. Integrated Metamodel (Mayrhauser e Vans)...Error! Bookmark not defined.
3.3.4. Modelo de Xu ...Error! Bookmark not defined.
3.4. SUPORTE A COMPREENSÃO DE PROGRAMAS...ERROR!BOOKMARK NOT DEFINED. 3.4.1. Engenharia Reversa ...Error! Bookmark not defined.
3.4.2. Slicing...Error! Bookmark not defined.
3.4.3. Ontologias ...Error! Bookmark not defined.
3.4.4. Visualização de Software ...Error! Bookmark not defined.
3.4.5. Análise de Programas: Estática e Dinâmica ...Error! Bookmark not defined.
3.5. CONSIDERAÇÕES SOBRE O CAPÍTULO...ERROR!BOOKMARK NOT DEFINED. CAPÍTULO 4– LOCALIZAÇÃO DE CONCEITOS ...ERROR! BOOKMARK NOT DEFINED.
4.1. CONCEITOS HUMANOS X LINGUAGENS DE PROGRAMAÇÃOERROR!BOOKMARK NOT DEFINED. 4.2. SOLUÇÕES PARA A LOCALIZAÇÃO DE CONCEITOS...ERROR!BOOKMARK NOT DEFINED.
4.2.1. Abordagens baseadas em Análise Estática ...Error! Bookmark not defined.
4.2.2. Abordagens baseadas em Análise Dinâmica...Error! Bookmark not defined.
4.3. LIMITAÇÕES DAS SOLUÇÕES...ERROR!BOOKMARK NOT DEFINED. 4.3.1. Análise das Funcionalidades...Error! Bookmark not defined.
4.4. CONSIDERAÇÕES SOBRE O CAPÍTULO...ERROR!BOOKMARK NOT DEFINED. CAPÍTULO 5– CASOS DE USO...ERROR! BOOKMARK NOT DEFINED.
5.1. AESTRUTURA DOS CASOS DE USO...ERROR!BOOKMARK NOT DEFINED.
5.2. APLICAÇÃO DOS CASOS DE USO NA COMPREENSÃO DE PROGRAMASERROR!BOOKMARK NOT DEFINED. 5.3. CRIANDO CASOS DE TESTES A PARTIR DE CASOS DE USOERROR!BOOKMARK NOT DEFINED.
5.4. CONSIDERAÇÕES SOBRE O CAPÍTULO...ERROR!BOOKMARK NOT DEFINED. CAPÍTULO 6– LOCALIZAÇÃO DE CASOS DE USO ...ERROR! BOOKMARK NOT DEFINED.
6.1. VISÃO GERAL DA PROPOSTA...ERROR!BOOKMARK NOT DEFINED. 6.2. CRIAÇÃO DOS CASOS DE TESTE...ERROR!BOOKMARK NOT DEFINED. 6.3. INSTRUMENTAÇÃO DO SISTEMA...ERROR!BOOKMARK NOT DEFINED. 6.4. EXECUÇÃO DOS CASOS DE TESTE...ERROR!BOOKMARK NOT DEFINED. 6.5. ANÁLISE DOS RASTROS COLETADOS...ERROR!BOOKMARK NOT DEFINED. 6.6. OECOSSISTEMA DOS CASOS DE USO...ERROR!BOOKMARK NOT DEFINED. 6.6.1. Automação da Execução dos Casos de Teste ...Error! Bookmark not defined.
7.1. PROTÓTIPO DO AMBIENTE DE LOCALIZAÇÃO DE CASOS DE USOERROR!BOOKMARK NOT DEFINED. 7.1.1. Base de Rastros ...Error! Bookmark not defined.
7.1.2. Instrumentador ...Error! Bookmark not defined.
7.1.3. Gerenciador de Rastreamento e Interface do Executor ...Error! Bookmark not defined.
7.1.4. Automação da Execução dos Casos de Teste ...Error! Bookmark not defined.
7.1.5. Analisadores...Error! Bookmark not defined.
7.2. PRIMEIRO ESTUDO DE CASO:ADVENTURE BUILDER...ERROR!BOOKMARK NOT DEFINED.
7.2.1. Criação dos Casos de Uso ...Error! Bookmark not defined.
7.2.2. Criação dos Casos de Teste ...Error! Bookmark not defined.
7.2.3. Instrumentação do Código Fonte...Error! Bookmark not defined.
7.2.4. Execução dos Casos de Teste ...Error! Bookmark not defined.
7.2.5. Análise dos Rastros Coletados ...Error! Bookmark not defined.
7.3. SEGUNDO ESTUDO DE CASO:SIGEP ...ERROR!BOOKMARK NOT DEFINED. 7.3.1. Revisão dos Casos de Uso...Error! Bookmark not defined.
7.3.2. Criação dos Casos de Teste ...Error! Bookmark not defined.
7.3.3. Instrumentação do Código Fonte...Error! Bookmark not defined.
7.3.4. Execução dos Casos de Teste ...Error! Bookmark not defined.
7.3.5. Análise dos Rastros Coletados ...Error! Bookmark not defined.
7.4. CONSIDERAÇÕES SOBRE O CAPÍTULO...ERROR!BOOKMARK NOT DEFINED. CAPÍTULO 8– CONCLUSÕES ...ERROR! BOOKMARK NOT DEFINED.
Capítulo 1
–
Introdução
1.1.
Motivação e Tema
A importância da tecnologia da informação para os negócios vem crescendo desde que os computadores passaram a fazer parte do dia-a-dia das operações das empresas há algumas décadas. No centro desta importância estão os programas que implementam os controles, lidam com os dados cada vez mais volumosos e suportam a execução dos processos de negócio. Desde o surgimento da Internet nos anos 1990, mais que uma atividade de suporte, muitos negócio passaram a depender da tecnologia a tal ponto que muitas vezes é difícil separar o que é processo de negócio e o que é solução tecnológica. Atualmente, empresas inteiras se baseiam em suas soluções de software: comércio eletrônico, entretenimento e telecomunicações são apenas algumas das atividades econômicas nas quais isso fica mais evidente.
A pressão pela inovação constante a que estão submetidas as organizações no mundo atual faz com que novas soluções tecnológicas sejam criadas e disponibilizadas o tempo todo. Esse processo cria uma impressão de que tudo que existe em termos tecnológicos é jogado fora e recriado em ciclos de poucos anos. Se por um lado isso é verdade quando se fala de equipamentos físicos, as antigas soluções de software, por outro lado, não estão perdendo sua importância (LEHMAN, 1998). É comum que sistemas importantes de grandes organizações tenham algumas décadas de idade. Um produto de software pode levar alguns anos para ficar pronto e quando ele entra em atividade espera-se que ele permaneça muito tempo em funcionamento. O caso do bug do milênio é bastante ilustrativo, pois mostrou que sistemas que tinham sido desenvolvidos sem uma expectativa de vida longa acabaram surpreendendo muitas empresas quando estas descobriram que eles não estavam preparados para a chegada do ano 2000. O bug do milênio mostrou mais duas coisas interessantes: que os sistemas mesmo sendo antigos eram muito importantes e que não seria fácil substituí-los por programas novos.
muito desafiadora do ciclo de vida do software. Entre estes motivos estão: falta de documentação adequada, complexidade intrínseca do produto de software, ausência dos projetistas e programadores originais e inexperiência da equipe responsável. Estas questões são ainda agravadas pela pressão por qualidade e cumprimento de prazos e custos cada vez mais restritos.
Os problemas que afetam a manutenção de software podem ser relacionados a uma questão fundamental: a compreensão adequada do software. Estimativas a respeito da composição dos custos de manutenção apontam que o tempo gasto pelos mantenedores para entender como um sistema está implementado e de que forma eles devem proceder para realizar uma determinada mudança está entre 40% e 90% do tempo total (LUCIA et al, 1998). Para Rajlich e Wilde (2002) a “compreensão de programas é uma parte essencial da evolução e manutenção de software”, pois “programas que não podem ser compreendidos, não podem ser mudados”.
Com isso, a compreensão de programas se tornou um importante campo de estudo. Alguns autores se dedicaram à tarefa mais teórica de tentar descrever o processo mental pelo qual os engenheiros de software compreendem um sistema ou programa no qual precisem trabalhar: desenvolvendo os chamados modelos cognitivos (BROOKS, 1982) (MAYRHAUSER e VANS, 1995) (XU, 2005). Outros autores adotaram um caminho mais prático e passaram a desenvolver métodos, técnicas e ferramentas que ajudassem na compreensão de diferentes maneiras, tais como engenharia reversa, visualização e navegação de código fonte, slicing e análises estáticas e dinâmicas. Entre estas linhas de pesquisa está a localização da implementação de conceitos no código fonte, ou simplesmente localização de conceitos.
é inexistente ou está desatualizada, este trabalho precisar ser realizado tendo apenas a requisição do usuário e o código fonte como insumos principais.
Biggerstaff et al (1993) foram pioneiros na formalização da localização de conceitos. Eles introduziram a noção de que os termos do domínio da aplicação, expressos em linguagem natural, são conceitos humanos, e portanto, imprecisos e sujeitos à ambigüidade; enquanto as linguagens de programação são baseadas em expressões determinísticas e não-ambíguas. A principal conseqüência desta diferença de naturezas é que é muito difícil descobrir relações entre estes conceitos e o código fonte de programas através de abordagens algorítmicas. Eles chamaram esta questão de problema de associação de conceitos – “concept assignment
problem”, em inglês.
Os trabalhos da área que se seguiram à definição do problema de associação de conceitos buscaram ajudar na localização da implementação de conceitos humanos através de diferentes estratégias: busca por padrões de texto, inteligência artificial e técnicas de data
mining, entre outras. Contudo, ainda falta às abordagens propostas um tratamento mais
cuidadoso desses conceitos. Com identificá-los? De que forma eles devem ser expressos? Como estruturar as relações entre eles? Nenhum dos trabalhos procura responder tais perguntas. A própria terminologia para se referir aos conceitos é difusa; além de conceito, são usados os termos “funcionalidade”, “cenário de uso” e “caso de uso”.
Paralelamente, processos modernos de desenvolvimento de software (RUP, 2007) advogam os casos de uso (JACOBSON et al, 1992) como a forma preferencial de se representar as funcionalidades dos produtos de software que estão sendo desenvolvidos. Como características fundamentais dos casos de uso estão: uma estrutura razoavelmente definida em fluxos de eventos e ações; e um nível de abstração que está ligado a “resultado de valor observável” para quem usa o sistema (KRUCHTEN, 2001). Essas características indicam que os casos de uso podem ajudar a reduzir as limitações das soluções de localização de conceitos, conferindo a elas mais estrutura no tratamento dos conceitos e favorecendo um nível de abstração mais alto que facilita o entendimento (ZHANG et al, 2006).
software e incentiva o reuso de artefatos produzidos no desenvolvimento das atividades de manutenção.
1.2.
Objetivos
O objetivo deste trabalho é estruturar e propor uma abordagem para a aplicação de Casos de Uso na localização de conceitos. Esta abordagem deve utilizar a estrutura dos fluxos de eventos para criar uma forma mais clara de se obter e representar os conceitos, para obter informações que não eram apresentadas em outras técnicas e para aproximar a localização de conceitos do restante dos processos e ferramentas do ciclo de vida do software.
Os objetivos específicos do trabalho são:
Fazer uma revisão bibliográfica sobre compreensão de programas e sistemas em fase de manutenção, identificando algumas limitações que ainda não tenham sido resolvidas;
Estruturar uma abordagem baseada em técnicas e tecnologias estabelecidas, que favoreçam sua adoção;
Desenvolver análises específicas para os dados coletados baseadas na estrutura dos casos de uso;
Implementar um protótipo de ferramenta para suportar a aplicação da abordagem; Validar a aplicabilidade da abordagem proposta através de estudos práticos.
1.3.
Metodologia
Esse trabalho de pesquisa tem como objetivo definir uma abordagem para suportar a compreensão do código-fonte de sistemas com base em especificações de caso de uso, através de análise dinâmica.
1.4.
Estrutura da Dissertação
Capítulo 2 – são tratados os principais problemas que envolvem a manutenção de software.
Capítulo 3 – introduz-se a compreensão de programas, sua correlação com os problemas da manutenção, a teoria dos modelos cognitivos e prática das soluções propostas.
Capítulo 4 – apresentam-se as soluções de localização de conceitos e suas limitações. Capítulo 5 – aborda a estrutura dos casos de uso e sua aplicabilidade à compreensão de programas.
Capítulo 6 – a proposta de abordagem, foco deste trabalho, é apresentada.
Capítulo 7 – são mostrados casos de aplicação prática da abordagem sobre dois sistemas.
Capítulo 8 – apresenta as conclusões e trabalhos futuros.
1.5.
Outras Considerações
As expressões programa, programa de computador, sistema, sistema de informação e
software são usadas livremente como sinônimos ao longo do texto, apesar de ser possível
encontrar diferentes definições para cada uma delas na literatura. Da mesma forma,
manutenção, manutenção de software e manutenção de sistemas também podem ser
Capítulo 2
–
Desafios da Manutenção de Software
2.1.
Manutenção de Software
Desde seu surgimento na década de 60 os computadores e seus programas aumentam sua importância na sociedade (LEHMAN, 1998). Alguns exemplos recentes são computadores de bordo de carros, celulares, agendas eletrônicas, sistemas bancários acessados via internet e
vídeo-games. Apesar da visibilidade deste tipo de software existem outros exemplos menos
evidentes, como os sistemas que são utilizados dentro das empresas, suportam seus processos de negócio e possibilitam que os negócios continuem funcionando e crescendo.
Quando um correntista de banco faz o pagamento de uma conta através de em um caixa-eletrônico, ele pode não saber, mas aquele programa de layout moderno não executa realmente a operação desejada. O real responsável é provavelmente algum programa obscuro, de algumas décadas de idade, executado em um computador trancado em uma sala-cofre, conhecido por uns poucos analistas de sistema e com o qual o caixa-eletrônico – ou o website
– se comunica para requerer a operação. O cenário exposto acima serve para ilustrar um
fenômeno importante a respeito dos programas de computadores: não importam quantos novos programas sejam criados, os programas antigos – também chamados de sistemas legados – não estão sendo aposentados e nem mesmo estão perdendo a importância. Ao contrário, os programas existentes estão se tornando mais complexos e mais amplos em funcionalidade (LEHMAN, 1998).
O fato de um sistema ter sido escrito há alguns anos ou décadas, não significa que ele continua sendo exatamente o mesmo produto que era no dia em que entrou em operação pela primeira vez. É bastante provável que o programa venha sofrendo diversas mudanças no curso dos anos. Um sistema de informação só continua sendo útil ao longo do tempo se ele sofrer mudanças, correções e adaptações (LEHMAN, 1996). O fim do projeto de desenvolvimento de um sistema de informação, por mais bem sucedido que tenha sido, não é o fim da necessidade de mudanças. Corbi (1989) ressaltou que realizar mudanças nos sistemas não é uma opção para as organizações e sim um fato inevitável.
define manutenção de software como sendo a modificação de um sistema ou componente de software após a sua entrega, a fim de corrigir erros, melhorar o desempenho, adicionar novas capacidades ou se adaptar a um novo ambiente.
A manutenção de software pode ser incorretamente vista simplesmente como a correção de defeitos (SWEBOK, 2004). Apesar da atividade de corrigir defeitos ser realmente importante na fase de manutenção, ela não trata apenas disto. Como destacou Pressman (1994), não é razoável imaginar que os testes realizados durante o desenvolvimento sejam capazes de encontrar todos os possíveis erros no código fonte de um software. Mas, Lientz e
Swanson (1980 apud SOMMERVILLE, 1995, p. 660) estimam que apenas 17% do custo total
de manutenção referem-se à correção de defeitos e que o restante está ligado a outros fatores, tais como (SWEBOK, 2004):
• Endereçar novos requisitos
• Melhorar o design e/ou o desempenho
• Integrar-se com novos programas
• Explorar novos recursos de hardware, software e telecomunicações
Como exemplos práticos de motivadores que levaram a mudança em um grande número de sistemas em diversos países do mundo estão a chegada do ano 2000 (SWEBOK, 2004) (POLO et al, 2003), que obrigou ajustes nos formatos das datas, e a adoção do Euro pela Comunidade Européia (LEHMAN, 1998) (POLO et al, 2003). Fica claro que as novas situações – o novo ano e nova moeda – estavam fora do controle das organizações envolvidas com estas questões que, portanto, não tiveram outra opção a não ser atualizar seus sistemas.
A variedade de fatores que motivam a manutenção de sistemas faz com que diversos autores (CORBI, 1989) (PRESSMAN, 1994) (SOMERVILLE, 1995) (BENNETT E
RAJLICH, 2000a) (POLO et al, 2003) (SWEBOK, 2004) adotem a divisão das atividades de
manutenção de software proposta inicialmente por Lientz e Swanson (1980 apud
PRESSMAN, 1994) em ao menos 3 tipos. Estes tipos de manutenção estão presentes na própria definição do termo manutenção de software, no Glossário de Engenharia de Software do IEEE (2005):
• Manutenção adaptativa é aquela motivada pelas mudanças no ambiente operacional
dos sistemas já existentes, novos periféricos, atualizações de hardware e assim por diante (PRESSMAN, 1994, p. 676).
• Manutenção corretiva é aquela que compreende o diagnóstico e a correção de erros
de programação (PRESSMAN, 1994, p. 676).
• Manutenção perfectiva é motivada pelas requisições de mudanças feitas pelos usuários e outros envolvidos que visam à implementação de novos requisitos funcionais ou não funcionais (SOMMERVILLE, 1995, p. 660).
A distinção entre os tipos de manutenção pode não ser tão clara na prática (SOMMERVILLE, 1995, p. 660) e alguns autores acrescentam uma quarta classe de atividades – comum nos projetos de sistemas de hardware – chamada de preventiva (CORBI,
1989) (PRESSMAN, 1994) (POLO et al, 2003) (SWEBOK, 2004). O objetivo de atividades
preventivas é melhorar a manutenabilidade e a confiabilidade do sistema a fim de facilitar a implementação de novas mudanças no futuro.
2.1.1. Papel da Documentação
Durante o desenvolvimento inicial, que dá origem à primeira versão do software, muito conhecimento do domínio do problema é adquirido pelos desenvolvedores que também definem a arquitetura do software e seus detalhes de implementação, entre eles o código fonte (BENNET e RAJLICH, 2000b). Os artefatos produzidos são variados e de diversas naturezas, como as próprias atividades características deste primeiro estágio do ciclo de vida.
A NBR ISO/IEC 12207 inclui, entre as atividades do Desenvolvimento, elicitação e análise de requisitos, projeto arquitetural e projeto detalhado, codificação e testes de software. No SWEBOK (2004) requisitos, projeto, construção e testes também são áreas de conhecimento da engenharia de software. Os artefatos produzidos nestas atividades, tais como especificações de requisitos, modelos, documentos e casos de testes, expressam parte do conhecimento adquirido pela equipe de desenvolvimento que deve ser repassado à equipe de manutenção.
desempenho satisfatório das atividades de manutenção, conforme será detalhado no tópico a seguir.
2.2.
Desafios da Manutenção de Software
A importância os sistemas de software têm para as organizações não torna mais fácil a tarefa de mantê-los. Diversos problemas envolvem as atividades do dia-a-dia das organizações responsáveis pela manutenção de sistemas em fase de manutenção e muitas vezes as restrições de prazo e pessoal habilitado agravam ainda mais o tratamento das questões técnicas. Entre estes problemas podemos citar:
• É muito difícil rastrear e documentar o processo pelo qual o software foi criado e as mudanças que foram implementadas nas diversas versões que se seguem. É comum que mesmo a documentação existente se degrade ao longo do processo de manutenção (CORBI, 1989) (PRESSMAN, 1994, p. 680) (SOMMERVILLE, 1995, p. 661) (LETHBRIGDE et al, 2003).
• Novos problemas podem ser criados pelas próprias atividades de manutenção, o que leva a necessidade de novas mudanças, e quanto mais complexo for o sistema em questão, maior a dificuldade em avaliar previamente o impacto que as mudanças podem ter sobre seu funcionamento geral (SOMMERVILLE, 1995, p. 661).
• É muito difícil lidar com código fonte escrito por outras pessoas. É comum que o
projeto original do sistema tenha preocupado-se mais com otimização e eficiência do que com técnicas de engenharia de software para criar uma estrutura que facilite mudanças e favoreça a compreensão por outras pessoas (CORBI, 1989) (PRESSMAN, 1994, p. 680) (SOMMERVILLE, 1995, p. 661).
• A rotatividade dos profissionais de software é grande. Dificilmente os autores originais dos programas estão disponíveis para explicar como o programa funciona. E o aumento da complexidade que ocorre com as mudanças sucessivas (LEHMAN, 1996) cria um ciclo de retro-alimentação que torna o problema cada vez mais grave. Bennett e Rajlich (2000a) chamam isto de “decaimento”do código.
• A manutenção de software é normalmente vista pelos profissionais e mesmo pelos
de recursos e que deve ser evitada e coibida (CHAPIN, 2003) (PRESSMAN, 1994, p. 680) (SOMMERVILLE, 1995, p. 661).
Para entender os desafios que envolvem o processo de manter sistemas de software, as Leis da Evolução do Software de Lehman (1996) – resumidas na Tabela 1 – são de fundamental importância O trabalho de Lehman encontra suporte em diversos autores e a experiência prática, aparentemente confirma as suas observações1.
Tabela 1 – Leis da Evolução do Software de Lehman.
Lei Descrição
Mudança Contínua Um programa utilizado em um ambiente real precisa ser adaptado continuamente ou ele deixa de ser útil.
Complexidade Crescente As mudanças sucessivas levam os programas a se tornarem mais complexos com o passar do tempo. Esta tendência só é revertida se for realizado trabalho com o objetivo específico de simplificação. Auto-Regulação A evolução do software é um sistema auto-regulado, onde as
medidas dos diversos atributos de produto e processo apresentam uma distribuição normal.
Taxa de Trabalho Invariante O esforço gasto com a evolução de um sistema não é totalmente determinado por decisões gerenciais; a tendência é de estabilização em torno de um valor constante.
Conservação da Familiaridade De uma versão para outra as mudanças incorporadas em um sistema são aproximadamente constantes.
Crescimento Contínuo O escopo de funcionalidades cobertas por um sistema deve crescer ao longo do tempo para manter a satisfação dos usuários.
Qualidade Decrescente A qualidade percebida de um sistema tende a se reduzir a menos que ocorra manutenção para adaptá-lo às mudanças no contexto operacional.
Sistema de Retro-Alimentação Os processos envolvidos na evolução de software são sistemas dotados de retro-alimentação.
A complexidade do problema exposta nas leis de Lehman, somada a todos os desafios relacionados e ao volume de alterações que são cotidianamente necessárias nos sistemas fazem
1 As “leis” de Lehman se baseiam em observações de curvas de dados de alguns projetos reais. Por isso,
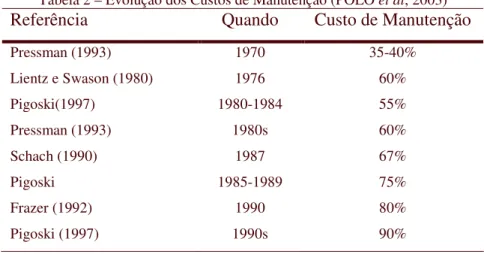
com que o custo da fase de manutenção seja muito significativo em relação ao custo total do ciclo de vida de um sistema. A Tabela 2 mostra como este porcentual foi estimado por diversos autores para épocas diferentes. Basta notar que apenas uma das linhas tem valor abaixo de 50%, e o mesmo autor atribui 60% na década seguinte. Em resumo, a fase de manutenção sozinha pode ter um custo superior a todo o projeto de desenvolvimento de um software. O tratamento de problemas em sistemas legados tem o potencial de impactar de tal forma a capacidade produtiva da organização de TI que Pressman (1994, p. 675) chega a imaginar uma organização impedida de investir em novos projetos de desenvolvimento. Por outro lado, sistemas que não são mantidos adequadamente representam riscos para próprio negócio devido a forte relação entre estes e aqueles (CHAPIN, 2003).
Tabela 2 – Evolução dos Custos de Manutenção (POLO et al, 2003)
Referência Quando Custo de Manutenção
Pressman (1993) 1970 35-40%
Lientz e Swason (1980) 1976 60%
Pigoski(1997) 1980-1984 55%
Pressman (1993) 1980s 60%
Schach (1990) 1987 67%
Pigoski 1985-1989 75%
Frazer (1992) 1990 80%
Pigoski (1997) 1990s 90%
2.3.
Processo de Manutenção
Apesar de não existir uma visão unificada do que é o processo de manutenção de software e diversos autores optarem por uma visão própria, existem muitas características em comum nas metodologias e modelos de processo adotados na literatura (POLO et al, 2003)
(ARTHUR, 1988 apud SOMMERVILLE, 1995, p. 662) (IEEE 1219) (ISO 14764) (YAU,
1978 apud BENNETT e RAJLICH, 2000a) (PRESSMAN, 1994). Através destes modelos é possível ter uma visão geral de como devem desenrolar-se as manutenções no dia-a-dia das organizações.
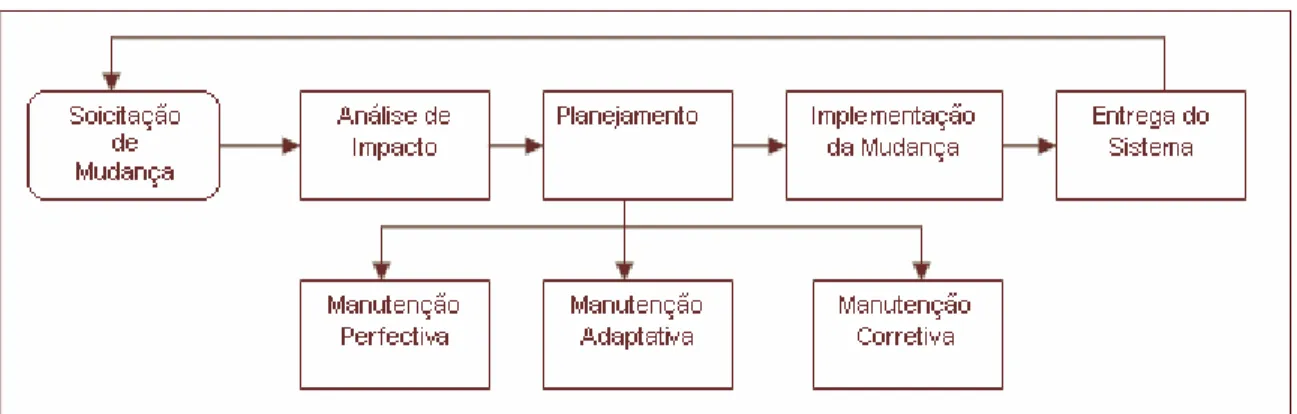
qualquer manutenção se inicia quando alguém requer que uma mudança seja feita no sistema. Estas requisições normalmente têm origem em pedidos realizados pelos usuários finais que identificam defeitos no sistema, falta de funcionalidades ou mesmo a necessidade de se adaptar a uma nova situação do negócio. A Figura 1 apresenta a visão geral do processo de
manutenção como descrito por Arthur (1988 apud SOMMERVILLE, 1995).
Figura 1 - Visão Geral do Processo de Manutenção (ARTHUR, 1988 apud SOMMERVILLE, 1995)
Outra característica comum é a existência de algum nível de especialização do processo para os tipos de manutenção. Esta preocupação em acomodar subprocessos específicos para cada manutenções adaptativas, corretivas e perfectivas é compartilhada por Arthur (1988), Polo et al (2003) e Pressman (1994, p.685), entre outros.
Praticamente todos os modelos de processo de manutenção prevêem uma análise de impacto que deve descrever que forma a mudança requerida afetará o sistema como um todo e então estimar custo e prazo para a implementação (SNEED, 2003). A análise de impacto é também ponto de decisão para que a organização de manutenção defina, possivelmente em conjunto com o cliente requisitante, a prioridade de implementação da demanda ou até mesmo a sua rejeição. Normalmente, a responsabilidade de tomar este tipo de decisão é da gerência de
manutenção – Maintenance Management – e do Comitê de Controle de Mudanças – Change
Control Board (CCB) – composto de gestores seniores. Pressman (1994) chama a atenção para
Para Chapin (2003), há uma forte relação entre o desempenho das organizações e a qualidade e eficiência de seu processo de manutenção de software. Quando a gerência de uma organização decide fazer mudanças na estrutura ou nos processos normalmente o objetivo é melhorar o desempenho operacional. Muitas vezes, como já foi citado, o estímulo para tal mudança é algum fator externo, fora de seu controle. A dependência que os processos de negócio têm dos sistemas que os suportam faz com que a necessidade de mudar o negócio seja uma das principais razões para que os sistemas de informação também sofram mudanças. A distância entre o que processo de negócio deveria ou poderia ser, segundo as intenções da gestão da organização, e os recursos oferecidos pelos sistemas de informação significa que a organização está desempenhando abaixo de suas reais possibilidades e necessidades. Por isso, um processo de manutenção organizado, controlado e eficiente é muito importante. Gestores que deixam a manutenção de software ocorrer de forma ad hoc e não a reconhecem como parte do processo de realizar mudanças organizacionais colocam em risco a própria capacidade operacional (CHAPIN, 2003).
2.4.
Considerações Sobre o Capítulo
A manutenção de software é etapa importante do ciclo de vida do software. Ela está diretamente relacionada às adaptações exigidas pelas mudanças do negócio. As limitações de prazo e de recursos impedem que os sistemas sejam recriados do início toda vez que um processo de negócio sofre uma mudança e precisa que seu suporte tecnológico seja atualizado. A perda de conhecimento, que ocorre quando a equipe que trabalhou no desenvolvimento se dispersa, se torna um potencial risco de negócio, na medida em que pode atrasar ou mesmo impedir que uma nova idéia seja colocada em prática por falta de quem atualize os sistemas de informação da organização à nova realidade.
Encarar a manutenção como simples correção de defeitos, como se todas as mudanças de um software tivessem origem em erros de programação é como condenar o software à desativação. Lehman (1996) mostrou que sem manutenção e esforço dedicado a tendência do software é perder a utilidade até ser abandonado.
Capítulo 3
–
Compreensão de Programas
3.1.
Importância da Compreensão de Programas
Para desempenhar as atividades de manutenção efetivamente, os mantenedores responsáveis precisam compreender o software em questão (BROOKS, 1982) (GRUBB e TAKANG, 2003); sua estrutura, comportamento, inserção no ambiente operacional e etc. No SWEBOK (2004) o tempo necessário para que um engenheiro de software leva para compreender um programa que ele não desenvolveu é citado como uma das questões técnicas a serem consideradas na manutenção de software. Este entendimento é tão fundamental que Lucia et al (1996) afirmam que o tempo gasto para compreender o sistema, e como devem ser realizadas as mudanças necessárias, pode chegar a 90% do tempo total gasto.
Melhorar a manutenção de software passa por facilitar os processos cognitivos envolvidos em fazer com que os mantenedores entendam o problema e o sistema alvos de suas atividades (BROOKS, 1982) (MAYRHAUSER e VANS, 1994). Bennett e Rajlich (2000a) destacam que estudar métodos e ferramentas de apoio à compreensão de programas é uma das sete grandes áreas de pesquisa em manutenção de software.
Apesar de, normalmente, a compreensão não ser considerada como uma atividade no processo de manutenção, e sim um pré-requisito para o desempenho das atividades, Polo et al (2003) previram uma tarefa específica de aquisição de conhecimento em sua metodologia de gerência de manutenção de programas – MANTEMA. Nesta tarefa “o time de manutenção estuda a documentação existente sobre o software a ser mantido, incluindo o código fonte, esquema de banco de dados, etc. Entrevistas com usuários e atenção em como a organização de manutenção atual trabalha também são necessários”.
Corbi (1989) observa que o trabalho de compreender o programa que será mantido, além de crucial, não é uma tarefa executada apenas uma única vez. Para assegurar o sucesso de grandes modificações, os mantenedores precisam “examinar repetidamente a estrutura real” e “descobrir ou redescobrir e reunir partes detalhadas de informação” a respeito do código fonte do software mantido.
Para Biggerstaff et al (1993), “uma pessoa compreende um programa de computador
dos utilizados no código fonte do programa”. Lucia et al (1996) definiram a compreensão de programas como “o processo de abstrair descrições do sistema de nível mais alto – tipicamente aplicando termos e conceitos do domínio – a partir de níveis mais baixos”. De forma mais intuitiva, compreender um software significa saber responder perguntas importantes a respeito de seu código fonte e arquitetura (DEVAMBU et al, 1991), como: para modificar uma determinada funcionalidade do software que classes, linhas de código, estruturas de dados – ou qualquer outra unidade computacional envolvida dependendo da linguagem de programação – devem ser alteradas?
A compreensão de programas em si não é um fim, mas um passo necessário para o desempenho de várias outras atividades (CANFORA e CIMITILE, 1998). A Tabela 3 mostra como a compreensão do sistema – em diferentes níveis – é parte integrante de diversas tarefas do ciclo de vida de um software (MAYRHAUSER e VANS, 1995). No contexto atual de diversas organizações, o conhecimento adquirido sobre um determinado sistema se torna ainda mais importante devido a fatores como a rotatividade de profissionais (CORBI, 1989) e o controle de projetos de desenvolvimento sub-contratados.
Tabela 3 – Tarefas e atividades que requerem compreensão de código
Tarefas de Manutenção Atividades
Adaptativa Entender o sistema
Definir os requisitos de adaptação
Desenvolver projetos preliminares e detalhados Mudanças no código fonte
Depuração
Testes de regressão
Corretiva Entender o sistema
Criar e avaliar hipóteses sobre o problema Corrigir o código fonte
Testes de regressão
Perfectiva Entender o sistema
Diagnosticar e definir os requisitos de melhoria Desenvolver projetos preliminares e detalhados Mudanças e adições ao código fonte
Depuração
Testes de regressão
Reuso Entender o problema e encontrar uma solução baseada no melhor encaixe de componente re-usáveis
Alavancagem de código Entender o problema e encontrar uma solução baseada em componentes pré-definidos
Re-configurar a solução para aumentar as chances de uso de componentes pré-definidos
Obter e modificar componentes pré-definidos Integrar componentes modificados
É importante notar que, apesar da forte da relação entre compreensão de programas e as atividades de manutenção, entender como um sistema de informação funciona não é essencial apenas para a manutenção de software, mas também para diversas atividades do dia-a-dia dos projetos de software. Planejamento de testes, (SNEED, 2004), reuso (BASILI, 1990) (DERIDDER, 2002), re-engenharia e auditoria são outras atividades que necessitam que os profissionais envolvidos compreendam bem os programas nos quais estão trabalhando (GRUBB e TAKANG, 2003) (MAYRHAUSER e VANS, 1995).
As organizações responsáveis pela manutenção de sistemas internos de companhias ou de sistemas comerciais são obrigadas a contratar e treinar novos profissionais constantemente. A equipe designada para realizar a manutenção é muitas vezes composta primariamente de novatos (CORBI, 1989) (SOMMERVILLE, 1995) (CHAPIN, 2003). A primeira tarefa que comumente é designada para qualquer ingressante em uma posição de desenvolvimento é estudar um determinado sistema até entendê-lo, pois a compreensão é um pré-requisito para o desempenho de muitas outras atividades (CORBI, 1989).
3.2.
O Desafio da Compreensão de Programas de Computador
O processo de aprendizado que leva à compreensão se torna especialmente desafiador na medida em que vários fatores influenciam negativamente a capacidade dos indivíduos de entenderem um programa. Entre estes fatores pode-se citar:
• Programas de computadores são produtos de engenharia extremamente complexos.
Eles envolvem diversos elementos com inúmeras relações entre eles como algoritmos, componentes, estruturas de dados, interfaces com entidades externas, camadas, decisões de projeto, domínio de aplicação e etc.
• Cada programa de computador é uma solução única para um problema. Não
existem dois programas iguais, ainda que eles possam endereçar o mesmo domínio e ter características comuns. Mesmo que uma pessoa conheça muito bem o domínio de aplicação e a linguagem de programação utilizada na implementação de um programa específico, ela deve gastar um tempo razoável para entender como funciona outro programa similar. Corbi (1989) lembra que “mesmo programadores experientes podem enfrentar problemas quando mudam para projetos diferentes”.
• As “Leis da Evolução do Software” de Lehman (1996) indicam que os sistemas precisam sofrer mudanças para continuarem a ser úteis. Com isso, o conhecimento adquirido a respeito de um software é bastante volátil, podendo perder sua validade em pouco tempo em conseqüência destas mudanças.
• O mesmo ocorre com a documentação. Devido a pressões por cumprimento de prazos e orçamentos é comum que os mantenedores se descuidem de atualizar modelos, diagramas e outros documentos e com isso muitos sistemas não possuem uma documentação atualizada que descreva corretamente e compreensivelmente sua estrutura, seu comportamento e as decisões de projeto tomadas
(LETHBRIGDE et al, 2003). Em alguns casos a documentação do sistema não é
produzida nem mesmo durante o processo de desenvolvimento. Uma documentação desatualizada pode ser considerada ainda pior que uma documentação inexistente, uma vez que ela pode levar a uma compreensão errada do sistema (PRESSMAN, 1994, p 691) (CORBI, 1989) (SWEBOK, 2004).
atividades com o objetivo de controlá-la de tempos em tempos. Com o passar do tempo fica cada vez mais difícil compreender e, portanto, manter e gerenciar um sistema.
• A estrutura de um software está escondida – invisível para Brooks (1987) – durante a sua execução. Apenas o seu comportamento externo é visível em situações normais. Diferentemente de um engenheiro civil que pode investigar livremente a estrutura de um prédio a ser restaurado, por exemplo, o engenheiro de software precisa utilizar inúmeros artifícios para obter informações sobre a estrutura de um sistema de software.
• Os profissionais não são preparados para trabalhar com código existente. Nas instituições de ensino de ciências da computação que têm em seus currículos cadeiras de engenharia de software, os alunos aprendem a criar sistemas, mas raramente são preparados para lidar com sistemas já existentes (CORBI, 1989). A Tabela 4 é um resumo dos fatores negativos da compreensão de software que estão relacionados aos problemas da manutenção de software e vice-versa.
Tabela 4 – Resumo das relações entre Manutenção e Compreensão de Programas Problemas da Manutenção
de Software Questões da Compreensão de Programas
Profissionais Inexperientes Profissionais menos experientes levam mais tempo para compreender programas.
Rotatividade de Pessoal Alta rotatividade de pessoal prejudica a preservação do conhecimento adquirido. E aumenta o tempo necessário para avaliar o impacto e definir a execução das mudanças.
Falta de Documentação Sem documentação adequada é mais difícil entender todos os aspectos técnicos e não-técnicos de um sistema. A única fonte confiável de informação é o código fonte.
Projeto Não Intuitivo Arquiteturas complexas e difíceis de entender dificultam revisar a estrutura do software, acelerando o processo de aumento de complexidade e degradação da qualidade.
Complexidade e Tamanho do
Produto Com o passar do tempo o produto se torna maior e mais complexo e, portanto, mais difícil de ser compreendido no todo.
Para superar estas barreiras e ajudar os mantenedores na difícil tarefa de entenderem os programas de computador, é possível empregar vários processos, técnicas e ferramentas que de diferentes formas facilitam os processos cognitivos da compreensão de programas, como por exemplo: engenharia reversa (MÜLLER et al, 2000) (BOJIC E VELASEVIC, 2000b), análises estática (BIGGERSTAFF et al, 1993) e dinâmica (BALL, 1999) de código fonte,
recuperação de informação, visualização de programas (UMPHRESS et al, 2006) (STOREY
et al, 1998), slicing (LUCIA, 2001) e ontologias (DERRIDER, 2002). Boa parte destas
abordagens foi desenvolvida de forma intuitiva a partir da observação prática do dia-a-dia dos mantenedores e das tarefas por eles executadas (CANFORA E CIMITILE, 1998). No entanto, uma forma mais sistemática de abordar o problema é tentar explicar o processo pelo qual a compreensão de programas ocorre em primeiro lugar, para então propor técnicas e ferramentas interessantes ou melhorar as já existentes.
A forma pela qual se explica um processo de compreensão é chamada de modelo cognitivo. Os modelos cognitivos de compreensão de programas procuram descrever elementos estruturais, mapas mentais e atividades realizadas pelos mantenedores enquanto tentam entender os programas de computador. Com base nestes modelos é possível desenvolver melhores processos e ferramentas que atuem de forma mais decisiva na melhoria da compreensão de programas (MAYRHAUSER e VANS, 1995).
3.3.
Modelos Cognitivos
Diversos modelos cognitivos, que procuram descrever o processo pelo qual os mantenedores aprendem como funcionam os sistemas de informação foram propostos. Devido à forte influência das teorias construtivistas do aprendizado (RAJLICH, 2002), os modelos cognitivos da compreensão de programas apresentam diversas características em comum. Mayrhauser e Vans (1995) descrevem da seguinte forma as semelhanças entre os modelos cognitivos:
“A compreensão de programas é um processo que usa conhecimento existente para
adquirir conhecimento novo, até que finalmente atinge o objetivo de uma tarefa de cognição
de código. Este processo referencia ambos os conhecimentos, existentes e recém-adquiridos,
estratégias. Enquanto estas estratégias de cognição podem variar, todos eles formulam
hipóteses e então resolvem, revisam ou abandonam-nas.”
De forma mais estruturada, as características comuns entre os modelos podem ser relacionadas da seguinte forma:
• O conhecimento novo, adquirido no processo, tem origem em conhecimento
pré-existente. Este conhecimento pré-existente pode ser, por exemplo, conhecimento da linguagem de programação na qual o sistema em questão foi implementado, a respeito do domínio da aplicação, algoritmos (de ordenação, por exemplo) ou mesmo conhecimento a respeito de outros sistemas similares. O conjunto dos conhecimentos pré-existentes é chamado de base de conhecimento.
• Um componente fundamental de todos os modelos cognitivos é o mapa mental. Cada modelo descreve uma forma através da qual o conhecimento que o mantenedor tem e adquire a respeito do sistema estudado é organizado. Mas é importante notar que o produto final de um esforço de compreensão bem sucedido é um mapa mental que representa correta e suficientemente o programa alvo e que permite ao mantenedor executar a tarefa de manutenção – ou de outra natureza – necessária.
• A criação do conhecimento se dá por meio de formulação e testes de hipóteses, que podem ser confirmadas ou rejeitadas conforme o mantenedor obtém e avalia informações sobre o sistema em questão.
• As hipóteses são formuladas e testadas seguindo algum tipo de estratégia que pode ser sistemática – quando o código é lido linha por linha, por exemplo – ou oportunista – quando o mantenedor procura compreender apenas as partes do programa necessárias à execução de uma tarefa específica.
• Existem dicas no código que facilitam a associação de conceitos de mais alto nível de abstração às estruturas de implementação. Estes facilitadores normalmente são algoritmos conhecidos, padrões de codificação, nomes mnemônicos para variáveis e rotinas e comentários (BROOKS, 1987).
rapidamente, além de se beneficiar de conhecimento de outros sistemas com os quais ele teve contato antes (MAYRHAUSER e VANS, 1994b) (GRUBB e TAKANG, 2003).
• A identificação das estruturas para definir seqüências de atividades – planos – utilizadas pelos desenvolvedores em diferentes níveis de abstração. (RUGABER, STIREWALT, WILLS, 1995).
• O processo conhecido como Chunking representa a agregação de conceitos de nível mais baixo de abstração para formar conceitos de nível mais alto. Por exemplo, linhas de programa combinadas formam um algoritmo de cálculo de fatorial e um algoritmo de cálculo de fatorial associado a outros pode formar um cálculo probabilístico e assim por diante.
• Referências cruzadas também são elementos presentes em qualquer mapa mental descrito em modelos cognitivos. Elas representam o relacionamento entre conhecimentos em diferentes níveis de abstração. Por exemplo, a identificação de que uma determinada rotina implementa uma regra de negócio já conhecida.
Quanto à estratégia, é possível agrupar os modelos cognitivos em torno de 3 teorias da
compreensão: top-down, bottom-up e oportunistas (CORBI, 1989) (MAYRHAUSER e VANS,
1995) (CANFORA E CIMITILE, 1998) (GRUBB e TAKANG, 2003). Na estratégia top-down
os programadores procuram entender um programa criando hipóteses sobre a sua estrutura e então confirmam ou não estas teorias ao analisar as evidências encontradas no código. As hipóteses confirmadas passam a fazer parte do conhecimento a respeito do programa, as rejeitadas são descartadas. Os modelos que seguem a estratégia bottom-up se baseiam na idéia de que o mantenedor procura primeiro compreender pequenas partes do código e então reconhece e nomeia estas pequenas partes. Na medida em que combina estas partes e as associa a novos conceitos o mantenedor vai atingindo níveis mais altos de abstração. As duas estratégias não são excludentes e os modelos mais recentes advogam que o mantenedor procura alternar entre as abordagens top-down ou bottom-up conforme ele julgue ser mais interessante em um dado momento. Este tipo de estratégia é chamada de oportunista (MAYRHAUSER e VANS, 1994) (RAJLICH e WILDE, 2002) (GRUBB e TAKANG, 2003).
3.3.1. Modelo de Brooks
Seguindo uma abordagem totalmente top-down o modelo cognitivo de Brooks (1983
apud MAYRHAUSER e VANS, 1995) tem origem no próprio processo de desenvolvimento
de software, no qual, a partir do domínio de problema são criados mapeamentos em domínios intermediários até se chegar à linguagem de programação, que implementa o produto final. O processo de compreensão pode ser então descrito como a reconstrução do mapeamento do domínio do problema no domínio de programação através de níveis intermediários (BROOKS, 1982).
Brooks (1982) diz que “esta construção ou reconstrução envolve a aquisição de dois tipos de informação”. Primeiro, dentro de cada domínio existe informação a respeito do conjunto básico de objetos, incluindo suas propriedades e relacionamentos, o conjunto de operações e a ordem na qual elas podem ocorrer. Segundo, haverá informação a respeito dos relacionamentos entre os objetos e operadores de um domínio e aqueles do domínio vizinho. Estes relacionamentos não precisam ser “um para um” e novas operações podem ser criadas em um domínio pela junção de objetos e operadores do domínio anterior”.
Em relação às hipóteses formuladas pelo mantenedor, Brooks descreve uma hierarquia através da qual as hipóteses são dividas em sub-hipóteses e estas também podem ser subdividas sucessivamente até o nível no qual as hipóteses podem ser testadas através da busca de evidências no código fonte ou na documentação disponível para confirmação ou refutação. Estas evidências são chamadas de beacons, que correspondem a construções, comentários ou descrições que possam levar o mantenedor a uma conclusão mais ou menos embasada sobre a hipótese.
3.3.2. Modelo de Letovsky
O modelo cognitivo proposto de Letovsky se baseia em um “processo de assimilação” que utiliza o código fonte, a documentação do sistema e o conhecimento pré-existente de uma “base de conhecimento”, sobre o domínio da aplicação, linguagens de programação, planos e regras de discurso, para atualizar o modelo mental (STOREY et al, 1998).
algoritmos, funções e estruturas de dados. Por último, o nível de Anotação relaciona os conceitos nos dois diferentes níveis (MAYRHAUSER e VANS, 1994b).
Letovsky, ainda classificou as hipóteses usadas pelo entendedor em três diferentes níveis de certeza (de incertos a quase certos) e em três diferentes tipos de conjecturas: por que uma determinada decisão de projeto-programação foi tomada, como a decisão foi tomada e o
que é aquela estrutura – uma função, uma variável (RUGABER, 1995).
3.3.3. Integrated Metamodel (Mayrhauser e Vans)
Tendo, como referências, diversos outros modelos cognitivos, Mayerhaurser e Vans (1994a) criaram um novo modelo que agregou características importantes, tornando-se um super-conjunto dos demais.
O modelo de Mayrhauser e Vans é divido em três sub-modelos que descrevem as possíveis estratégias e compartilham uma base de conhecimento. Em cada um destes componentes estão presentes os principais elementos dos demais modelos como a memória de curto prazo, os modelos de situação e programa, o processo de chunking, beacons e etc. Qualquer um dos processos de compreensão pode ser ativado a qualquer momento e eles podem compartilhar os diversos tipos de conhecimentos armazenados na base, ainda que cada sub-modelo tenha seus tipos preferenciais. A alternância entre os modelos é determinada pelos objetivos que o entendedor tem em mente a cada momento e novas descobertas em um modelo podem levar a novos objetivos e novas hipóteses a serem avaliadas. Por exemplo, a
descoberta de um algoritmo de ordenação através de um estudo bottom-up sistemático pode
levar a um novo objetivo de descobrir se a ordenação deve ser ascendente ou descendente e a qual funcionalidade ela está relacionada.
Além disso, diferentemente dos trabalhos anteriores que apresentavam estudos de
casos baseados em pequenos programas, o Integrated Metamodel foi observado em projetos
de manutenção de larga escala (MAYRHAUSER e VANS, 1996).
3.3.4. Modelo de Xu
compreensão de programas e como as diferenças entre novatos e especialistasse refletiam nas atividades realizadas.
O modelo de Xu se baseou na Teoria Construtivista do Aprendizado de Glaserfeld (1995 apud XU, 2005) que estendeu o trabalho de Piaget (1954 apud XU, 2005) sobre o desenvolvimento infantil. No modelo construtivista as atividades principais são: a assimilação, que é a forma como lidamos com novos conhecimentos; e a acomodação, que trata do conhecimento já existente.
As atividades da teoria construtivista foram especializadas em 4 atividades cognitivas (RAJLICH e XU, 2003): absorção e negação são especializações da assimilação e reorganização e expulsão são especializações da acomodação. Para cada atividade cognitiva existe uma lista de verbos que podem ajudar a identificar que tipo de atividade cognitiva uma determinada ação do mantenedor corresponde (Tabela 5).
Tabela 5 – Atividades Cognitivas e Verbos Exemplos (XU, 2005).
Atividade Verbos (exemplos) Comportamento (exemplos)
Absorção Adicionar, acreditar, escolher, concluir,
confirmar, considerar, criar, definir, demonstrar, identificar
Programador criar uma nova classe ou um novo caso de teste
Negação Declinar, desaprovar, rejeitar Programador rejeita conceito
para implementação
Reorganização Ajustar, alterar, quebrar, mudar, extrair, consertar, reagrupar
Programador quebra uma função em duas
Expulsão Remover, eliminar, apagar, matar,
excluir, jogar fora, expulsar
Programador elimina uma
variável e o conhecimento relacionado
Xu combinou a taxonomia do domínio cognitivo de Bloom (1956 apud XU e
RAJLICH, 2004) que é divida em seis níveis de abstração e dificuldade: conhecimento, compreensão, aplicação, análise, síntese e avaliação – dos mais baixos para os mais altos.
Unindo as atividades cognitivas descritas anteriormente aos níveis de conhecimento propostos por Bloom, Xu criou um modelo cognitivo divido em 3 componentes:
• processo de compreensão, composto pelas atividades cognitivas e pelos níveis de conhecimento; e
• saída, composto por um novo programa, documentos e conhecimento adquirido a
respeito do programa.
Enfim, o modelo de Xu descreve a compreensão de programas como sendo “um processo de aprendizado que permite a reconstrução do conhecimento do domínio do programa para os domínios de projeto e tarefas com quatro diferentes atividades cognitivas aplicada a diferentes níveis de aprendizado. A saída contém o programa com novas funcionalidades, nova documentação e novos conhecimentos a respeito do programa, ganhos durante o processo de aprendizado”.
3.4.
Suporte a Compreensão de Programas
Tendo em vista o contexto desafiador da manutenção de sistemas e mais especificamente do processo de compreensão de programas exposto anteriormente, diversos autores propuseram ferramentas e técnicas a fim de facilitar e aprimorar este processo.
Através dos modelos cognitivos pode-se perceber que a compreensão não se dá pela simples leitura do código fonte. Conceitos de diversos níveis de abstração estão envolvidos, hipóteses devem ser validadas ou rejeitadas, documentação precisa ser consultada, o código fonte é lido e analisado seguidas vezes sob diferentes pontos de vista e assim por diante. Além disso, tarefas diferentes exigem diferentes tipos e níveis de compreensão do programa alvo (CANFORA e CIMITILE, 1998) e vários modelos cognitivos mostraram que diferentes níveis de especialização levam às diferentes abordagens adotadas para entender o sistema em questão. Desta forma, as propostas de suporte ao processo de compreensão também são variadas, pois cada linha de solução dá ênfase a um determinado aspecto do processo ou ao uso de uma determinada abordagem.
abordadas algumas das principais linhas de atuação que propuseram formas de suportar o processo de compreensão.
3.4.1. Engenharia Reversa
As técnicas e ferramentas de engenharia reversa se confundem com o próprio conceito de compreensão de programas. Como descreveu Brooks (1982), “a tarefa de entender um programa para um programador se torna a de construir ou reconstruir informação suficiente a respeito dos domínios de modelagem que o programador original usou para ligar o problema a um programa em execução”. Reconstruir o mapeamento entre os domínios tem como resultado recuperar as abstrações adotadas pelo programador do software enquanto o construía. A rastreabilidade entre os artefatos do software – código fonte, modelos, documentação, descrições de regras de negócio, etc – é um suporte essencial para a reconstrução deste mapeamento (MÜLLER et al, 2000).
A engenharia reversa é definida como o processo de analisar um sistema e identificar seus componentes e inter-relações, resultando na criação de representações do sistema em níveis mais altos de abstração (CHIKOFSKY e CROSS, 1990). A forte ligação entre a engenharia reversa e a compreensão de programas pode ser observada nos seis objetivos que Chikofsky e Cross (1990) atribuem à engenharia reversa:
(i) lidar com a complexidade, criar visões alternativas – possivelmente gráficas; (ii) recuperar informações perdidas sobre o projeto dos sistemas,
(iii) detectar efeitos colaterais;
(iv) sintetizar níveis mais altos de abstração; e (v) facilitar o reuso.
Diversas abordagens podem ser adotadas para suportar a compreensão de programas através da engenharia reversa (TILLEY et al, 1996). Por exemplo, o trabalho em engenharia reversa de casos de testes de Sneed (2004) é particularmente interessante, pois dá uma visão diferente daquela que intuitivamente se associa ao termo engenharia reversa. Seu objetivo é recuperar as relações entre os casos de testes e o resto dos documentos de especificação do sistema, como processos, telas, relatórios, componentes, etc. Chikofsky e Cross (1990) apresentaram uma taxonomia da terminologia adotada nesta área, como por exemplo:
• Redocumentação é a forma mais simples e antiga de engenharia reversa.
abstração e normalmente se refere à criação de visões alternativas, como modelos de dados e fluxos de dados.
• Recuperação de Projeto – Design Recovery – é um tipo específico de engenharia reversa que procura criar ou recuperar representações do sistema em níveis mais altos de abstração e também suas ligações com o código fonte. É interessante notar a semelhança desta definição com a forma como Brooks (1982) define a própria compreensão de programas como a reconstrução do mapeamento do domínio do problema no domínio de programação através de níveis intermediários. A diferença é que o modelo cognitivo de Brooks se refere às representações mentais e a engenharia reversa se propõe a criar representações documentais destes diferentes níveis de abstração.
• Reestruturação corresponde a transformar uma representação em determinado nível
de abstração em outra no mesmo nível, sem mudar o comportamento externo do sistema. Normalmente está associada a melhorias arquiteturais, realizadas em nível de código fonte.
• Reengenharia trata-se de uma renovação ou re-desenvolvimento de um sistema. Normalmente envolve algum tipo de engenharia reversa, reestruturação e também a adição de novos requisitos na criação de um novo sistema.
Ferramentas CASE, tais como IBM® Rational Rose™, IBM® Rational Software Architect™, Borland® Together™, dotadas da capacidade de realizar engenharia reversa são comuns na indústria de software. Elas geralmente são capazes de analisar um código fonte e gerar modelos UML, com diagramas de classe, máquinas de estado, grafos de chamadas ou ainda gerar modelos lógicos a partir de esquemas de bancos de dados. Em todos esses casos o produto gerado tem um nível de abstração mais alto e, portanto, menos detalhes o que facilita a sua assimilação pela proximidade com conceitos de domínio humano. O trabalho de Bojic e Velasevic (2000a, 2000b) ilustra como é possível recuperar arquiteturas de sistemas a partir de ferramentas como estas.
compreensão de programas. Depois foram identificadas as atividades canônicas que compõem as atividades de engenharia reversa, são elas: coleta de dados, organização do conhecimento e exploração de informação. E por fim, foram definidas as dimensões para classificação de ferramentas e técnicas de engenharia reversa: domínios de aplicação, domínio de implementação e escalabilidade, suporte a tarefas específicas e extensibilidade.
É importante mencionar que os trabalhos ligados à recuperação de arquitetura e projetos, como o de Mendonça (1999), apesar de sua importância para a compreensão, não conseguem superar a barreira de aspectos técnicos do produto de software. Os níveis mais altos de abstração criados se referem, por exemplo, ao uso de algoritmos e estruturas de programação para implementar determinadas tarefas, como a comunicação e a organização entre processos em sistemas distribuídos. Contudo, é muito difícil atingir questões relacionadas ao domínio da aplicação do software em seu ambiente operacional, com os processos de negócio mencionados por Chapin (2003).
3.4.2. Slicing
O processo de slicing – fatiamento, em português – consiste na criação de subconjuntos do código fonte do programa original – as fatias – que sejam equivalentes ao programa original do ponto de vista de um determinado critério, normalmente um conjunto de variáveis um ponto do código fonte.
Weiser (1981) foi quem primeiro introduziu o conceito de slicing ao observar programadores durante a tarefa de depuração. Para ele, reduzir o programa a partes menores e consistentes segundo algum critério é a forma pela qual programadores entendem programas muito grandes. O trabalho de Weiser surgiu inicialmente quase como um modelo cognitivo, procurando não apenas descrever uma técnica, mas sim com o objetivo de explicar o processo de compreensão.
Apesar de ter surgido com o propósito de auxiliar a compreensão, as técnicas de slicing acabaram sendo usadas outros fins, como dividir linhas de processamento de um programa a serem alocadas para processadores paralelos, avaliação de conformidade, testes, suporte ao
reuso entre outros (HARMAN et al, 2003) (LUCIA, 2001) (FRANCEL e RUGABER, 2001).
original. De certo ponto de vista, é o mesmo que remover todas as linhas de código que de nenhuma forma afetam os valores armazenados nessas variáveis em qualquer situação. No
slicing dinâmico o programa original é substituído por rastros de execução específicos. Com
isso, potencialmente o tamanho do programa gerado reduz-se, o uso de ponteiros de memória para dados e funções é tratado de forma mais precisa. Por fim, o slicing quasi dinâmico procura fixar determinados valores de variáveis enquanto outras variáveis são livres para assumir qualquer valor. Se todas as variáveis são livres o slicing quasi dinâmico coincide com o slicing estático. Se, ao contrário, todas as variáveis forem fixadas teremos o mesmo resultado do slicing dinâmico.
Harman et al (2003), aplicaram um slicing com resultados menos formais em termos sintáticos com o objetivo de evitar a indecibilidade e dar respostas aproximadas a perguntas feitas na forma de critérios. Por exemplo, para determinar se o acesso a um vetor é seguro – no sentido de não ler ou escrever dados fora da área de memória alocada para ele. Villavicencio (2001) procurou aplicar slicing para realizar o reconhecimento automático de planos (ver Modelos Cognitivos). Com base em técnicas de slicing dinâmicos e quasi dinâmicos, Lucia et
al (2001) criaram o Slicing Condicionado como um framework para suportar a compreensão
de programas.
3.4.3. Ontologias
Ontologias estão tornando-se mais populares como ferramentas de apoio a diversas atividades relacionadas ao conhecimento. Uma ontologia é a especificação explícita de conceitos (GRUBBER, 1993). Na prática isso significa que as ontologias ajudam a reduzir a ambigüidade dos conceitos ao explicitar suas definições e suas relações. Trabalhos que utilizam ontologias como suportes à compreensão de programas chamam a atenção para a inconsistência entre os conceitos representados na documentação dos sistemas, a realidade de seu código fonte e o modelo mental do mantenedor envolvido na tarefa de compreensão
(DERIDDER, 2002) (ZHANG et al, 2006).
O que se pretende é que a ontologia seja usada como referência nos artefatos produzidos, criando um vocabulário comum e sem ambigüidade dentro da equipe envolvida no sistema. As principais motivações de Deridder (2002) para propor o uso de ontologias para suportar a compreensão de programas são:
• A natureza explícita da representação de conceitos evita que grande parte do conhecimento fica apenas na mente dos projetistas do sistema, a que se pode creditar grande parte da inconsistência da documentação do sistema citada anteriormente.
• A organização intrínseca que a ontologia provê aos conceitos representados, descrevendo suas propriedades e relacionando-os uns aos outros.
Preocupados com a evolução da arquitetura de websites, Zhang et al (2006) desenvolveram uma abordagem baseada em duas ontologias para reduzir a inconsistência entre os modelos mentais dos desenvolvedores e as representações tradicionais. A primeira ontologia é a ontologia de Código fonte, onde estão representados os conceitos de linguagens de programação orientada a objetos, como classes, métodos e pacotes. A segunda ontologia é a de documentação onde estão representados os conceitos encontrados na documentação do sistema com relação à arquitetura, como camadas e componentes.
Um terceiro componente da abordagem de Zhang é a mineração de texto que ajuda a identificar automaticamente os conceitos dentro dos documentos e criar a ontologia de documentação. A mineração de textos busca não apenas encontrar termos isolados, mas também dar a eles semântica o que os faz representáveis na forma de ontologia.
3.4.4. Visualização de Software
Diversas áreas do conhecimento humano que lidam com questões complexas usam representações visuais para facilitar o entendimento do objeto de estudo, tais como, plantas de engenharia civil, diagramas de circuitos eletrônicos e mapas cartográficos. Contudo a natureza digital do software – distante do espaço em três dimensões em que vivemos – faz com ele não tenha uma representação gráfica intuitiva e imediata (BROOKS, 1987) (UMPRHESS et al, 2006).