Estimation of human posture under cloth-like objects from depth images using a cloth simulation synthetic image dataset. In this paper, we propose a method for estimating human posture when the human body is largely covered by a cloth-like object such as a blanket from a single depth image. However, many methods of estimating human pose are difficult to use when the human body is largely closed.
The people to be monitored are often in bed and the situation makes estimating human pose challenging due to the wide variety in the shape of the covering objects. For real-world evaluation, the human pose estimation model, OpenPose was used to estimate key points, which were used as pseudo-ground truth.
Background
Outline of Thesis
Gradient Descent Method To map the input to the output, one of the most common approaches to train the network is the gradient descent method. In the method, the local gradient of the error function with the vector parameter θ is calculated and updated following the direction of. The difference between the gradient descent method and SGD is that it uses a randomly selected data instead of all data for a parameter update.
This method solves the problem of convergence to the local optimum by randomly selecting samples, which is called a mini batch, for each parameter update. The Momentum term increases the parameter update towards the dimension where the gradient is heading in the same direction.
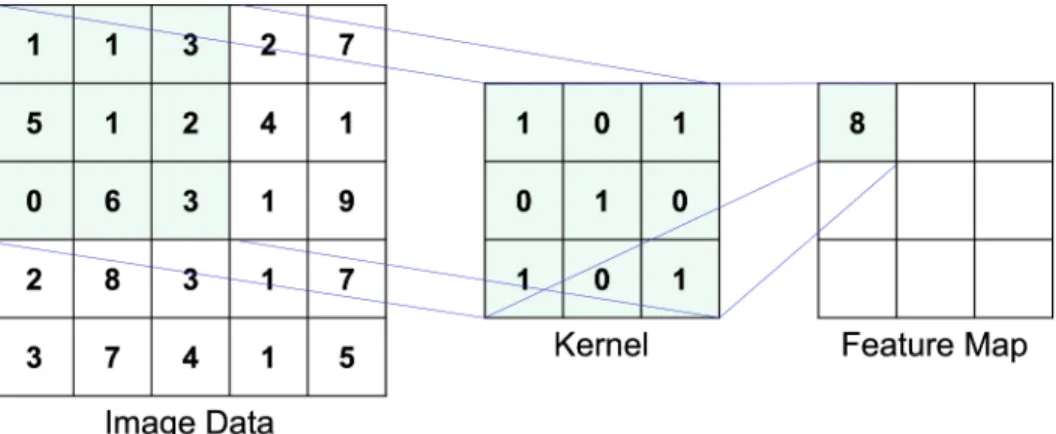
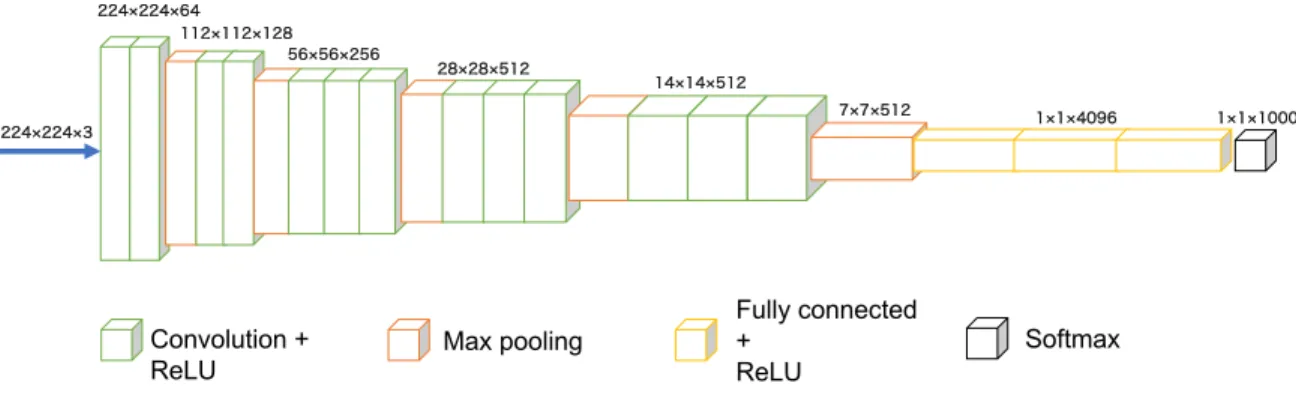
Convolutional Neural Networks
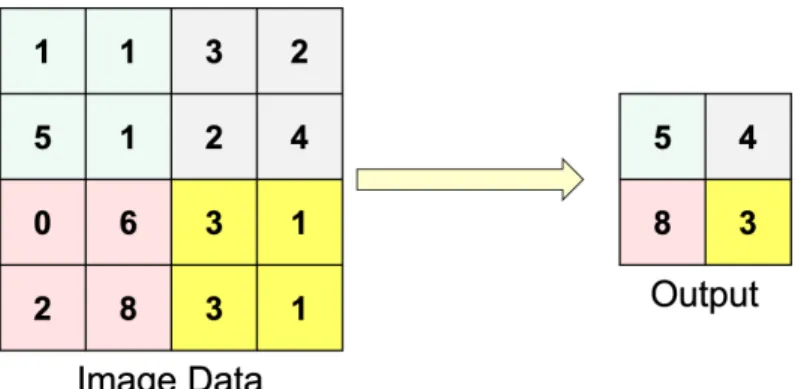
Convolution layer applies a convolution operation (Fig. 3) to the input and passes the result to the next layer. Pool layer is used together with the convolution layer and is trained by using an activation function and adding bias. A large degree of freedom from human structure and frequent closures sometimes make the pose estimation a difficult task.
In both methods, a highly accurate position estimation is achieved by training the network using a large amount of data. Therefore, we propose a method for estimating human posture that only requires a single depth image as input.
Depth-based human pose estimation
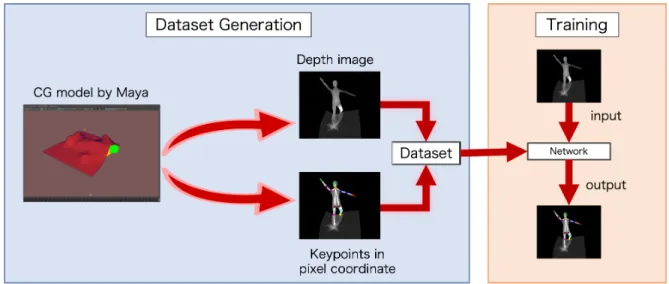
Outline of Dataset Generation
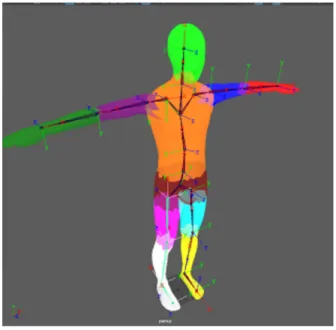
We use a computer graphics platform, Maya [32], to generate the dataset, following the steps in our previous work [8]. The human model has 14 trackers (Fig. 10) on its body so that the locations of each joint can be extracted. The depth values are normalized to [0,1] with the farthest point being 1 and the nearest point being 0.
There are 14 body joints: nose, neck, left/right wrists, left/right elbows, left/right shoulders, left/right hips, left/right knees, left/right ankles. When rendering the depth data, the locations of these trackers are also obtained in pixel coordinates.
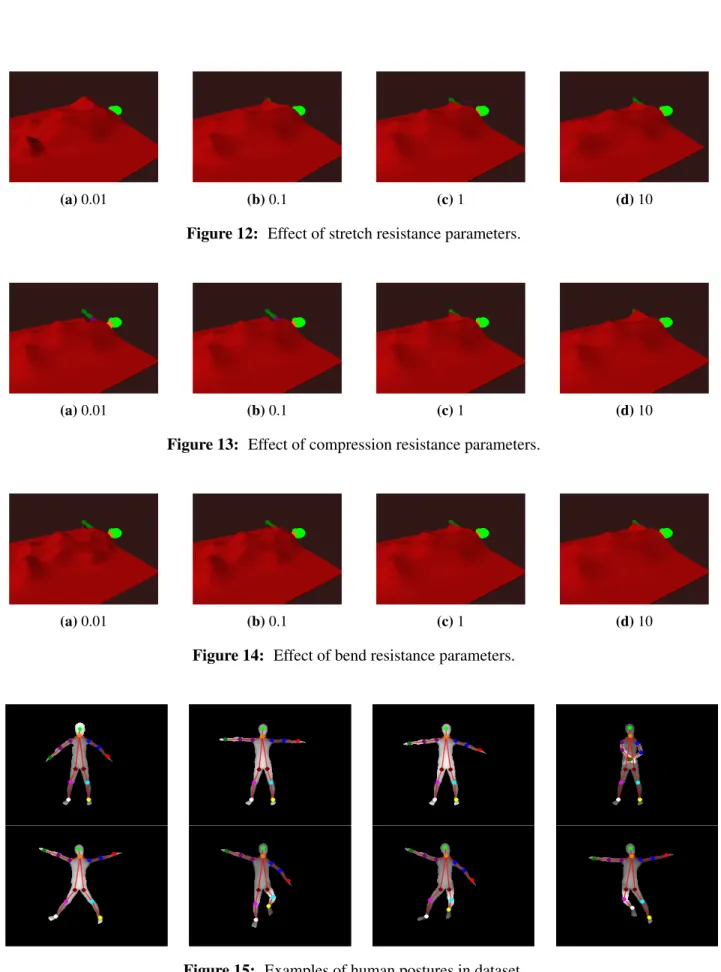
Simulation of Cloths
When the depth data is displayed, the locations of these trackers are also obtained in pixel coordinates. a)nCloth object components (b)nCloth particle network components Figure 11: nCloth components. To apply a cloth to the human body, we place a cloth 50 [cm] above the human body and let it fall freely while we start the dynamic simulation. When the movement of the canvas converges, we stop the simulation and extract the shape of the canvas surface.
Dataset Details
Training
Training Condition
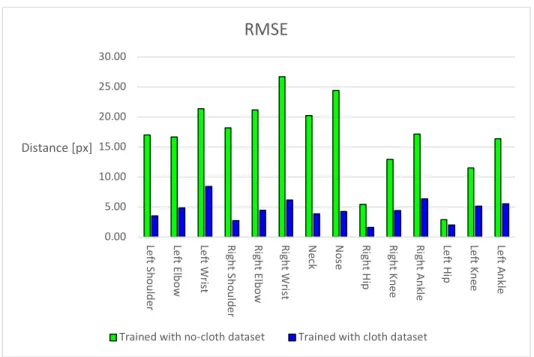
Figure 18 shows the results of the key point estimation on a test dataset with no canvas, with the model trained on a dataset with no canvas. However, for the other parts of the body, the output data is quite close to the attitude indicated by the ground truth. Figure 19 shows the estimation results of the synthetic test data with cloth, with the model trained without cloth.
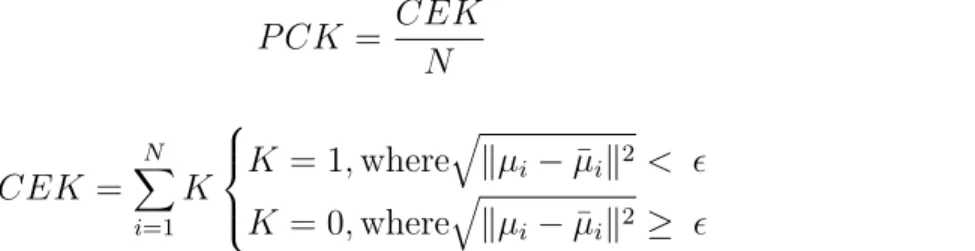
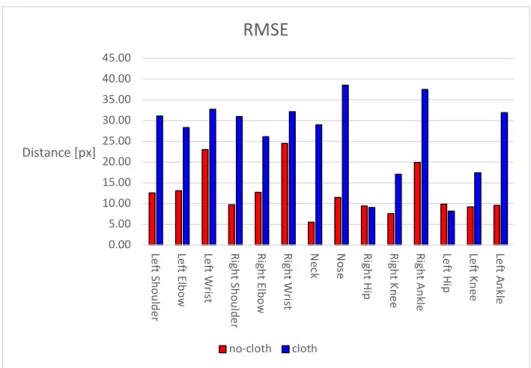
However, the estimation results are close to the ground truth even though most of the body surface is covered by the cloth. Half the diagonal length of the ground-truth head bounding box is commonly used as the threshold value in the 2D human pose estimation domain. 20 shows the evaluation results of pose estimation using test data sets with and without fabric, and evaluated using RMSE.
The accuracy of the cloth dataset decreased because there were fewer cues for pose estimation when the body was covered with cloth. In both datasets, the RMSE of the wrist and the ankle, which have a high degree of freedom of movement, were found to be larger in common. The RMSE of the hips was the smallest in both datasets, which is a good estimation accuracy because the human model is always placed in the center of the image.
21 shows the results of pose estimation on the data sets with and without fabric and evaluated at [email protected]. As observed in the RMSE evaluation, [email protected] for wrist and ankle was lower than the other regions and the estimation accuracy was low. However, the overall accuracy was more than 0.9 in both data sets, and it can be said that the trained network can estimate the human pose from a single depth image, even if the pose is unknown and the human body is covered by a cloth.
Training with Without-cloth Dataset and Test on With-cloth Dataset
Trained with cloth-free dataset (Training dataset: Synthetic dataset without cloth. Test dataset: Synthetic dataset with cloth.). Trained with cloth data set (Training data set: Synthetic cloth data set. Test data set: Synthetic cloth data set.). Trained with cloth data set (Training data set: Synthetic cloth data set. Test data set: Synthetic cloth data set.).
Real-world evaluation experiments will be conducted to determine whether the network can be applied to real-world data. In this section, we describe how to generate evaluation data in a real scene, and the results are presented in the following Section 6.2. Data for real-world evaluation are generated with a ceiling-mounted Azure Kinect [38].
A set of images is taken with the cloth covered and removed with an RGB-D camera. The RGB image taken with the cloth removed is imported into OpenPose to obtain a pseudo-ground truth. Then the depth image of the person covered by a cloth is fed to the trained network and the output is compared with the output of OpenPose.
To obtain the same angle of view and image size as the depth images in the synthetic dataset, the captured images were scaled and cropped to 256×212. The dataset is completed by rotating the depth images 360 degrees in 5-degree intervals, yielding 72 images for each attitude. In section 6.3 we describe the results of training the network using this real-world dataset.
Results
Test dataset: Real data without cloth. a)input (b)output (c)pseudo ground truth Figure 29: Estimation leads to actual scene (cloth). Left Shoulder Left Elbow Left Wrist Right Shoulder Right Elbow Right Wrist Nose Right Hip Right Knee Right Ankle Left Hip Left Knee Left Ankle Distance [px]. Left Shoulder Left Elbow Left Wrist Right Shoulder Right Elbow Right Wrist Nose Right Hip Right Knee Right Ankle Left Hip Left Knee Left Ankle.
Training with Real-world Data
Modification in Keypoints of Synthetic Dataset
Training Only on Real-world Dataset
5 poses (Training dataset: 5 poses of real data with cloth. Test dataset: Real data with cloth.). 10 poses (Training dataset: 10 poses of real data with cloth. Test dataset: Real data with cloth.). 20 poses (Training dataset: 20 poses of real data with cloth. Test dataset: Real data with cloth.).
Training on Synthetic Dataset + Real-world Data
Therefore, it can be said that it is effective to use not only the real data but also the synthetic data set as the training data set to improve the accuracy of human position estimation under object-like objects from a single depth image. a) input (b) real data only (c) real data + synthetic (d) pseudo ground truth Figure 36: Evaluation results in real scene. 5 poses (Training data set: 5 poses of real cloth data + synthetic cloth data set. Test data set: real cloth data.). 10 poses (Training data set: 10 poses of real cloth data + synthetic cloth data set. Test data set: real cloth data.).
This thesis describes a method for estimating the pose of people under clothing-like objects such as carpets. We use depth images as input to avoid sensitivity to lighting conditions and privacy issues. We use a cloth deformation simulation to generate pairs of depth images of people under cloth and locations of common key points in pixel coordinates.
The performance evaluation using synthetic test data shows a potential ability of the proposed method for estimating human pose among dust-like objects. Even though the postures in the input data are unknown or the human body is covered with cloth-like objects, the network successfully estimates the human posture. As mentioned above, the difference between synthetic and real data makes reliable estimation difficult.
To alleviate the reality gap, we added real data to the training data for training. The network was trained using the synthetic dataset with some real depth images that have 20 kinds of postures, and the results showed that the RMSE and PCK were 7.061 and 0.841, respectively. It is expected that this accuracy can be further improved with more variations of postures in the synthetic data set.
Future Work
In particular, adding noise to an image can help alleviate the reality gap between the synthetic dataset and the real data. It can be assumed that the position of each key joint point can be used as an important sign to detect such abnormal posture. In addition to my supervisors, I would also like to thank Professor Yasushi Kanazawa and Senior Researcher Ville Hautamäki as co-investigators for their kind comments and suggestions on this thesis.
Finally, I must express my deep gratitude to my parents and my friends for giving me unceasing support and continuous encouragement throughout my years of study and throughout the process of researching and writing this dissertation.
![Figure 5: Joint position estimation (figure taken from [6])](https://thumb-eu.123doks.com/thumbv2/9pdfco/1891421.267587/13.918.329.591.228.437/figure-joint-position-estimation-figure-taken-from.webp)
![Figure 6: Body part segmentation (figure taken from [22])](https://thumb-eu.123doks.com/thumbv2/9pdfco/1891421.267587/13.918.227.675.713.904/figure-body-segmentation-figure-taken.webp)