Moniulotteinen relevanssiarviointi
Hannele Luomanen
Tampereen Yliopisto
Informaatiotutkimuksen laitos Pro Gradu- tutkielma
maaliskuu 2008
TAMPEREEN YLIOPISTO Informaatiotutkimuksen laitos
LUOMANEN, HANNELE: Moniulotteinen relevanssiarviointi Pro gradu -tutkielma, 44 s.
Informaatiotutkimus Maaliskuu 2008
TIIVISTELMÄ
Tutkimuksen tarkoituksena on selvittää moniulotteisen relevanssikorpuksen ominaisuuksia ja vertailla moniulotteisia relevanssiarvioita suhteessa yksiulotteiseen relevanssiin eli binäärisiin ja moniportaisiin relevanssiarvioihin. Lisäksi tutkitaan sitä kuinka paljon sisällöllistä päällekkäisyyttä esiintyy relevanttien dokumenttien joukossa. Tarkemmin tutkitaan pystytäänkö moniulotteisten relevanssiarvioiden perusteella ennakoimaan dokumenttien sisällöllistä päällekkäisyyttä.
Aineistona on käytetty Informaatiotutkimuksen laitoksen tiedonhakulaboratorion TUTK- kokoelmasta 26 hakutehtävää, joista oli tehty neliportaiset relevanssiarviot, ja jotka arvioitiin uudelleen käyttäen moniulotteista relevanssiarviointia. Lisäksi tehtiin erillinen sisällönanalyysi artikkelipareittain, jotta saataisiin selville kuinka paljon todellista sisällöllistä päällekkäisyyttä esiintyy.
Tutkimuksessa havaittiin, että moniulotteiset relevanssiarviot korreloivat perinteisten relevanssiarvioiden kanssa. Teemapäällekkäisyyden ennustettavuus on suurinta yleisempien teemojen osalta ja sisällöllisen päällekkäisyyden toteaminen on todennäköisintä erittäin relevanttien dokumenttien joukossa. Dokumenttiparien vertailu osoitti, että teemojen avulla pystytään ennakoimaan myös sisältöjä, mutta teemojen ja sisältöjen suhde ei ole täysin suoraviivainen.
(Avainsanat: relevanssi, moniulotteinen relevanssi)
Sisällysluettelo
1. Johdanto………..1
2. Peruskäsitteet ja aikaisempi tutkimus……….………....2
2.1. Relevanssi tiedonhankintatutkimuksen valossa...3
2.2. Testikokoelmat ja relevanssin operationalisointi……….7
2.3. Testikokoelmanäkökulman kritiikki relevanssitulkinnan osalta………..9
2.4. Päällekkäisyyden huomiointi vuorovaikutteisen tiedonhaun tutkimuksessa..12
3. Moniulotteinen relevanssiarviointimalli………..14
3.1 Menetelmän perusideat………...14
3.2 Moniulotteisen datan esittäminen………...15
3.3 Moniulotteisen relevanssidatan arviointiprosessi………17
4. Tutkimustehtävä, aineistot ja menetelmä………...17
4.1 Tutkimuskysymykset………...18
4.2 Tutkimusaineisto………. …………19
4.2.1 Testikokoelma ……..………..………19
4.2.2 Arvioitavat dokumentit ………..19
4.2.3 Relevanssiarviot………...19
4.3 Aineiston analysointi………...20
4.3.1 Relevanssikorpuksen ominaisuudet……….20
4.3.2 Sisällönanalyysi artikkelipareittain………..21
5. Tulokset……….….………....22
5.1 Relevanssikorpuksen ominaisuudet...22
5.2 Teemarelevanssi vs. perinteinen relevanssi...23
5.3 Suhteellinen teemapäällekkäisyys...25
5.4 Suhteellinen informaatiopäällekkäisyys...30
5.5 Poikkeustapausten analyysi………. ………..35
6. Johtopäätökset …..………37
7. Lähteet……….………..……….39
1
1. Johdanto
Tiedonhaun tutkimuksen testikokoelmissa on perinteisesti käytetty yksiulotteista relevanssia, jossa dokumenttien sisällöllistä vastaavuutta hakuaiheeseen on kuvattu yhdellä luvulla.
Yksiulotteista relevanssia on kritisoitu sen realistisuuden puutteesta. Tiedonhakua ja – hankintaa koskevat empiiriset tutkimukset osoittavat, että relevanssi on moniulotteinen ja dynaaminen ilmiö (Schamber, 1994).
Tutkimuksen tarkoituksena on selvittää moniulotteisen relevanssikorpuksen ominaisuuksia. Työn tarkoituksena on myös vertailla moniulotteisia relevanssiarvioita suhteessa yksiulotteiseen relevanssiin eli binäärisiin ja moniportaisiin relevanssiarvioihin. Tarkemmin on tarkoituksena tutkia pystytäänkö moniulotteisten relevanssiarvioiden perusteella ennakoimaan dokumenttien sisällöllistä päällekkäisyyttä.
Uudella lähestymistavalla on tarkoituksena ylittää perinteisen relevanssin rajoitukset, jossa oletetaan, että kokoelman dokumentti on itsenäinen ja riippumaton kokoelman muista dokumenteista. Moniulotteisen relevanssin avulla on helpompi huomioida esimerkiksi dokumenttien sisällöllisiä päällekkäisyyksiä. Moniulotteisen relevanssin käyttö tiedonhaun tutkimuksissa ja testikokoelmissa on suhteellisen uusi asia, jota ollaan vasta kehittämässä.
Aikaisemmin aiheeseen liittyviä kokeellisia asetelmia on ollut käytössä mm. vuorovaikutteisessa TREC:ssä. (Over, 2001.)
Relevantin informaatiosisällön päällekkäisyyttä tai täydentävyyttä ei voida päätellä perinteisestä yksiulotteisesta relevanssikorpuksesta. Käyttäjälle olisi kuitenkin hyödyllisempää saada hakutuloksiin dokumentteja, jotka käsittelevät aihetta laajasti ja sen lisäksi mahdollisimman monipuolisesti eri näkökulmista ja aiheen eri osa-alueilta. Moniulotteisessa relevanssiarvioinnissa on mahdollista huomioida myös hakuaiheen sisällöllinen jakautuminen potentiaalisesti relevanttien dokumenttien joukossa ja näin ollen se on myös käyttäjälähtöisempi ja realistisempi lähtökohtana kuin dokumenttien yksiulotteinen arviointi.
2
2. Peruskäsitteet ja aikaisempi tutkimus
Relevanssi on tärkeä käsite tiedonhankintatutkimuksessa ja tiedonhakujärjestelmien arvioinnissa.
Relevanssin määrittelyssä on kaksi pääsuuntaa: aiherelevanssi ja käyttäjärelevanssi (Järvelin &
Sormunen, 1999). Aiheenmukainen relevanssi on yleisin ja selvin määritelmä relevanssista ja sitä mitataan perinteisessä tiedonhaun systeemien evaluoinnissa. Aiheenmukainen relevanssi on kontekstista vapaa ja mittaa vain sen kuinka hyvin haku sopii löydetyn informaation sisältöön (Borlund & Ingwersen, 1998).
Aiherelevanssi tarkoittaa, että dokumentti käsittelee hakupyynnön määrittelemää aihetta.
Käyttäjärelevanssi huomioi dokumentin aiheen lisäksi tiedon käyttäjästä riippuvia tekijöitä.
Käyttäjän arvioon voivat vaikuttaa mm. tiedontarpeen aiheuttavan tehtävän luonne, dokumenttien kieli, ulkoasu ja tuttuus käyttäjälle. Tiedontarve voidaan määritellä tiedontarvitsijan kokemukseksi tilanteensa ja ympäristönsä epävarmuudesta ja tiedon hyödyllisyydestä kyseessä olevassa tilanteessa. Tilanteen hallinta edellyttää menneiden, nykyisten ja tulevien tilanteiden ymmärtäminen. Relevanssiarviot ovat tällöin tilannesidonnaisia ja dynaamisia (Järvelin &
Sormunen, 1999).
Tämän perusteella Järvelin & Sormunen (1999) antavat relevanssille seuraavan määritelmän:
Relevanssilla tarkoitetaan informaation arvioitua käyttökelpoisuutta tietyissä käyttötilanteissa ottaen huomioon käyttäjän
tavoitteet, arvot ja odotukset.
Käyttäjäsuuntautuneessa tiedonhakututkimuksessa tiedonhakijalta pyydetään löydetyistä dokumenteista relevanssiarvio, joka voi perustua edellä esitetyn määritelmän mukaisiin, tilannekohtaisiin käyttökelpoisuuskriteereihin (Harter & Hert 1997). Tuloksellisuuden arviointi perustuu käyttäjäsuuntautuneessakin tiedonhakututkimuksessa yksiulotteisen relevanssin käsitteelle.
3
Yksiulotteisessa relevanssiarvioinnissa dokumentin relevanssia kuvataan yhdellä luvulla, joka kuvaa yhtä dokumentin ominaisuutta. Binäärisessä relevanssiarvioinnissa dokumentti saa relevanssiarvoksi joko arvon 0 (ei relevantti) tai 1 (relevantti). Dokumentti on määritelty joko relevantiksi tai ei relevantiksi, huomioimatta lainkaan sitä kuinka laajasti ja kuinka monesta eri näkökulmasta dokumentti hakuaihetta käsittelee.
Tiedonhakijan kannalta relevanteiksi määritellyt dokumentit saattavat olla hyvinkin eritasoisia ja niiden hyödyllisyys vaihdella laajasti, jolloin käyttäjälle tärkeitä dokumenttiattribuutteja jätetään huomioimatta binäärisessä hakuaihearvioinnissa. Käyttäjälle olisi useimmiten hyödyllisintä löytää dokumentteja, jotka käsittelevät hakuaihetta laajasti (Sormunen, 2002).
Moniportaisissa relevanssiarvioinneissa on tyypillisesti käytetty kolmi- tai neliportaista asteikkoa, jolloin on jo selvemmin arvioitavissa kuinka laajasti hakuaihetta dokumentissa käsitellään. Kuitenkaan relevantin informaation päällekkäisyyttä ei voida päätellä relevanssikorpuksesta. Käyttäjälle olisi kuitenkin hyödyllisempää saada hakutuloksiin dokumentteja, jotka käsittelevät aihetta laajasti ja sen lisäksi mahdollisimman monipuolisesti eri näkökulmista ja aiheen eri osa-alueilta (Kekäläinen & Järvelin, 2002).
Perinteisen relevanssiarvioinnin tarkoituksena on hakuaiheen ja dokumentin vastaavuuden arviointi, kun taas moniulotteisen relevanssiarvioinnin tarkoituksena on dokumentin ja kunkin hakuaiheen teeman vastaavuuden arviointi. Moniulotteinen relevanssiarviointi antaisi mahdollisuuden tunnistaa sisällöllisesti päällekkäistä informaatiota sisältävät dokumentit, jolloin käyttäjän kannalta olisi mahdollista karsia hakutuloksista jo kertaalleen löydettyä informaatiota, josta käyttäjälle ei enää olisi hyötyä ja tuoda hakutuloksiin lisää relevanttia informaatiota hakuaiheen eri aspektien osalta.
2.1 Relevanssi tiedonhankintatutkimuksen valossa
Tiedonhankintatutkimuksessa esiintyy erilaisia relevanssitulkintoja. Relevanssi voidaan jakaa kahteen pääluokkaan: objektiiviseen tai systeemiperusteiseen relevanssiin ja subjektiiviseen tai käyttäjäperusteiseen relevanssiin. Tiedonhankintatutkimuksessa esiintyy nämä kaksi eri
4
lähestymistapaa: systeemiorientoitunut lähestymistapa ja käyttäjälähtöinen lähestymistapa.
Systeemilähtöinen lähestymistapa käsittelee relevanssia staattisena ja objektiivisena käsitteenä ja käyttäjälähtöinen lähestymistapa subjektiivisena yksilöllisenä kokemuksena, johon liittyy kognitiivista toimintaa. (Borlund, 2003b.)
Borlund (2003b) erottaa artikkelissaan erilaisia relevanssityyppejä lähtien systeemi- ja käyttäjäperustaisista lähestymistavoista. Erilaiset relevanssityypit viittaavat erilaisiin suhteisiin, joita on löydetyn informaation, hakutehtävän, tiedontarpeen tai tiedontarpeen luovat tilanteen taustalta. Kuvassa 1 on esitetty perinteinen tulkinta eri relevanssityypeistä ei-interaktiivisessa tiedonhakutilanteessa.
Kuva 1. Borlundin malli relevanssin tyypeistä. (Borlund. 2000. p. 29)
Algoritminen relevanssi (A) kuvaa kyselyn ja dokumenttikokoelman suhdetta kyselyssä löydettyihin dokumentteihin. Aiheenmukainen relevanssi voidaan määritellä sen mukaan kuinka hyvin löydetyn informaation aihe vastaa hakutehtävää. Dokumentti on objektiivisesti relevantti, jos se käsittelee hakutehtävän aihetta. Relevanssi käsitetään kontekstivapaaksi, jolloin käyttäjää ei oteta huomioon ja lisäksi arvioinnissa käytetään usein binääristä asteikkoa eli dokumentti joko on relevantti tai ei ole. Borlund (2003b) pitää algoritmista relevanssia kaikkein yleisimpänä ja
5
selkeimpänä relevanssin määritelmänä ja sitä käytetään perinteisessä tiedonhakujärjestelmien evaluoinnissa.
Intellektuaalinen aiheenmukaisuus (IT) on kytkeytynyt käyttäjään ja dokumentin relevanttius riippuu siitä kuinka arvioitsija kokee informaation vastaavan annettua hakuaihetta ja kuvailtua tiedontarvetta. Relevanssitulkinnassa otetaan huomioon eriasteiset ihmisten tekemät intellektuaaliset tulkinnat dokumentin relevanssista. Relevanssi käsitteenä voi viitata löydetyn dokumentin hyödyllisyyteen tai käytettävyyteen suhteessa hakijan tavoitteiden täyttymiseen tai hakutehtävän ratkeamiseen. Relevanssi on siten kontekstiriippuvainen. (Borlund, 2003b.)
Käyttäjärelevanssi (P) on informaation tarpeen ja informaatio objektien välinen suhde, jonka käyttäjä luo hakutilanteessa. Tämä sallii dynaamisen informaatiotarpeen olemassaolon. (Borlund, 2003b.)
Perinteisissä tiedonhauntestikokoelmissa (esim. Cranfield ja TREC) relevanssi on tulkittu algoritmiseksi relevanssiksi tai intellektuaaliseksi aiheenmukaisuudeksi eli informaatio-objektien ja kyselyn tai hakupyynnön väliseksi suhteeksi (Borlund, 2003b). Toisaalta tiedonhankintatutkimuksessa on noussut esille useita erilaisia oikeiden käyttäjien relevanssikriteereitä. Relevanssin yksinkertaistamista aiheenmukaisuuteen on kritisoitu käyttäjälähtöisen tiedonhakututkimuksen puolelta (Schamber 1994, Borlund & Ingwersen 1998).
Tiedonhankintatutkimuksen näkökulmasta oikeat tiedonhakijat käyttävät monia relevanssikriteereitä.
Monissa empiirisissä tiedonhankintatutkimuksissa tutkijat ovat tunnistaneet laajan kirjon subjektiivisia ja dynaamisesti muuttuvia relevanssikriteereitä, joita käytetään dokumenttien arvioimiseen (esim. Greisdorf 2003, Maghlaughlin & Sonnenwald 2002, Rieh 2002). Toisaalta monet käyttäjätutkimukset ovat myös osoittaneet, että dokumentin informaatiosisältö ja aiheenmukaisuus ovat kriteerejä, jotka tyypillisesti kaikki käyttäjät jakavat (Schamber 1994, Maghlaughlin & Sonnenwald 2002).
6
Greisdorf (2003) kiinnitti huomiota relevanssin dynaamiseen luonteeseen ja totesi, että käyttäjillä on monia erilaisia kriteerejä, joiden perusteella he tekevät päätöksiä tietokannasta löydetyn dokumentin informaation relevanssin suhteen. Hän selvitti tutkimuksessaan miten käyttäjät evaluoivat informaatiota ja millaisia relevanssikriteereitä he käyttävät. Hän on tunnistanut evaluointikriteereinä mm. aiheenmukaisuuden, hyödyllisyyden, motivaation ja systemaattisuuden.
Maghlaughlin & Sonnenwald (2002) tutkivat relevanssikriteereitä, joita hakijat käyttivät relevanssiarviointiin arvioitaessa kolmiportaisella asteikolla relevantteja, osittain relevantteja ja ei-relevantteja dokumentteja, keskittyen erityisesti kriteereihin, joita käytettiin arvioitaessa dokumentti osittain relevantiksi. Tulokset osoittivat, että käyttäjillä on monia erilaisia kriteerejä relevanssiarvioita tehtäessä ja useimmilla kriteereillä voi olla joko positiivinen tai negatiivinen vaikutus dokumentin relevanssille. Maghlaughlin & Sonnenwald löysivät kaiken kaikkiaan 29 erilaista kriteeriä.
Internetin kontrolloimaton ympäristö on haasteellinen käyttäjille, jotka arvioivat informaation hyödyllisyyttä. Rieh (2002) tutki internetin hakukäyttäytymistä ja käyttäjien arvioiden tekemistä löydetystä informaatiosta. Rieh keskittyi erityisesti kahteen asiaan, jotka ovat esiintyneet useissa tutkimuksissa: löydetyn informaation laatuun ja auktoriteettiin, joiden on todettu olevan kaikkein tärkeimpien relevanssikriteerien joukossa etenkin internetin kaltaisissa kontrolloimattomissa hakuympäristöissä ja havaitsi, että Web ympäristössä käyttäjät käyttävät vielä useampia kriteereitä kuin perinteisissä tiedonhakuympäristöissä.
Laadun ja auktoriteetin määrittelemisessä käytettiin myös monia erilaisia tekijöitä. Esim. laadun määrittelemisessä vaikutti informaation ajantasaisuus, tarkkuus ja hyödyllisyys. Erilaisten relevanssikriteerien ja niitä määrittävien tekijöiden lisäksi käyttäjien arviointiin vaikuttaa myös tulosjoukossa muualla esiintyvät dokumentit (Rieh, 2002).
Kekäläinen & Järvelin (2002) tuovat esille relevanssiarvioiden dynaamisen luonteen.
Relevanssiarviot ovat dynaamisia ja ne muuttuvat tiedonhakuprosessin kuluessa.
Relevanssiarvioinnissa tulisi ottaa huomioon muitakin tekijöitä kuin vain aiheenmukaisuus. Se
7
mikä on alussa relevanttia voi olla myöhemmin epärelevanttia tai jo tiedossa olevaa päällekkäistä informaatiota. Heidän mielestään olisi tärkeää pystyä tunnistamaan nämä tekijät informaatio- objekteista.
2.2 Testikokoelmat ja relevanssin operationalisointi
Kokeellisella tiedonhaun tutkimuksella on pitkä historia. Nykyiset tiedonhakututkimuksen testikokoelmat perustuvat malliin, joka kehitettiin 1960-luvun alussa Cranfield -projekteissa.
Cranfield-testikokoelma sisälsi 1400 dokumenttia ja 225 kyselyä ja se oli pitkään vallitseva testikokoelma tutkijoiden käytössä sen jälkeen. Cranfield osoitti testikokoelmien luomisen tärkeyden ja niiden käyttämisen vertailevaan evaluointiin.
Myös muita kokoelmia on rakennettu, kuten CAMC kokoelma ja NPL kokoelma (Harman, 1993). Testikokoelmissa käyttäjällä ja käyttäjän ja informaation välisellä vuorovaikutuksella pieni rooli. Testikokoelman hakuaiheen ja yksittäisten dokumenttien välillä on tällöin staattinen suhde. Cranfield kokoelmassa dokumentit arvioitiin käyttäen viisiportaista relevanssiasteikkoa ja arvioinnissa huomioitiin aiheen lisäksi informaation potentiaalinen hyödyllisyys käyttäjälle.
(Cleverdon, 1967.)
Viime vuosina TREC konferenssit ovat olleet mittavin tutkimusfoorumi, joka perustuu laboratoriomallille. TREC:ssä on alkuperäisenä tavoitteena on ollut se, että tuloksia on mahdollista myös vertailla tutkimusryhmien välillä käyttämällä samoja dokumenttikokoelmia ja evaluointimenetelmiä. TREC on suunniteltu rohkaisemaan laajojen testikokoelmien käyttöä tiedonhauntutkimuksessa. TREC onkin tuonut tutkimukseen laajemmat ja realistisemmat testikokoelmat sekä pyrkimyksen käyttäjälähtöisempään suuntautumiseen. (Harman, 1993.)
Kuten perinteiset testikokoelmat yleensä TREC:n testikokoelma koostuu kolmesta erillisestä osasta: dokumenttikokoelmasta, hakuaiheiden joukosta ja relevanssikorpuksesta. TREC:in dokumenttikokoelma koostuu pääasiassa uutisartikkeleista ja lyhennelmistä. Dokumenttien valintaan vaikuttaa mm. dokumenttien tyyppi, pituus, kirjoitustyyli, editointi ja sanasto.
8
Hakuaiheiden on tarkoitus olla mahdollisimman todentuntuisia ja käyttäjien oikeiden tiedontarpeiden mukaisia. Hakuaiheet saattavat sisältää myös kuvauksen minkälainen tieto on relevantti. Hakuaiheet TREC:ssä on pyritty valikoimaan käyttäjän tarpeita kuvaaviksi lauseiksi, sen sijaan, että käytössä olisi perinteisempi kysely. Aiheen kuvauksessa pyritään usein kuvaamaan todellisen käyttäjän tarpeita ja informaation mahdollisia käyttötilanteita.
Relevanssiarviot ovat testikokoelman tärkeä osa. Jokaisella hakuaiheella täytyy olla mahdollisimman täydellinen lista relevanteista dokumenteista. TREC:ssä käytettiin relevanssiarvioitavien dokumenttien kartoittamisena pooling- menetelmää, joka on käytössä muissakin kokoelmissa. Metodissa eri hakujärjestelmillä haetaan tietty määrä relevantteja dokumentteja jokaisesta hakuaiheesta, tulosjoukot yhdistetään, duplikaatit poistetaan ja jäljelle jääneistä uniikeista dokumenteista arvioitsijat tekevät relevanssiarviot.
Vertailtavien hakumenetelmien paremmuutta mitataan suorittamalla kyselyt kokoelmassa kullakin hakuaiheella ja laskemalla hakutulosten keskimääräiset tuloksellisuusluvut relevanssikorpuksen perusteella. Testikokoelmissa on perinteisesti käytetty evaluointimetodina tarkkuutta ja saantia, joita myös TREC:ssä käytettiin. (Harman, 1995.)
Cranfieldin lähestymistapaa käyttävistä kokoelmista vallitsevin on tällä hetkellä TREC.
Samanlaista lähestymistapaa ovat käyttäneet myös CLEF consortium for Cross-Language IR (ks.
http://www.clef-campaign.org/), sekä yksittäiset tutkimusryhmät (esim. Kluck 1998, Sormunen 2000).
Relevanssiarviot ovat kriittisen tärkeitä testikokoelmassa. Nykyisten testikokoelmien relevanssitulkintaa on kritisoitu realismin puutteesta. Testikokoelmissa relevanssi on usein operationalisoitu. Käytössä on ollut binaariset relevanssiarviot, jotka määrittelevät dokumentin joko aiheenmukaiseksi tai ei. TREC:n ohjeissa dokumentti määritellään relevantiksi mikäli joku osa dokumentista on relevanttia huomioonottamatta sitä kuinka suuri tai pieni osa dokumentista on relevanttia. (Sormunen, 2002.)
9
TREC:n tyyppiset testikokoelmat sopivat liberaaleine relevanssiarvioineen varsin heikosti monipuoliseen hakujärjestelmien testaukseen. Ottamalla käyttöön moniportaiset relevanssiarviot voidaan paremmin tutkia esimerkiksi hakumenetelmien selektiivisyyttä löytää parhaiten relevantteja dokumentteja. Tiedonhaun vielä monipuolisempaan informaation päällekkäisyyden tutkimiseen tarvitaan laajempia relevanssiskenaarioita. (Sormunen, 2002.)
2.3 Testikokoelmanäkökulman kritiikki relevanssitulkinnan osalta
Testikokoelmien perinteinen relevanssiarviointi perustuu rajoittavalle oletukselle, että kokoelman dokumentti on itsenäinen ja riippumaton kokoelman muista dokumenteista (Robertson, 1977).
Uudemmissa relevanssimääritelmissä on otettu huomioon relevanssin dynaaminen luonne mukaan lukien sisällöllisen päällekkäisyyden mahdollisuus. Relevanssin operationalisoinnissa ei kuitenkaan ole laajalti sovellettu käsitystä sisällöllisen päällekkäisyyden mahdollisuudesta.
Relevanssin käsite on paljon käsitelty ja väitelty tiedonhaun tutkimuksessa ja artikkeleissa on tuotu esiin useita tulkintoja ja määritelmiä relevanssista. Relevanssin on todettu olevan monipuolinen ilmiö, eikä pelkästään viittaa aiheenmukaisuuteen käyttäjän arvioidessa löydettyä informaatiota (Borlund, 2003b). Tiedonhakua ja – hankintaa koskevat empiiriset tutkimukset osoittavat myös, että relevanssi on moniulotteinen ja dynaaminen ilmiö (Schamber, 1994).
Usein perinteisissä testikokoelmissa on käytetty binaarista relevanssiarviointia, jolloin relevanssi on operationalisoitu voimakkaasti yksinkertaistavalla tavalla. Sormunen (2002) tutki moniportaista relevanssia tekemällä osalle TREC 7 ja 8:n hakuaiheista neliportaisia relevanssiarvioita. Alkuperäisten binääristen ja tutkimuksessa tuotetun moniportaisen relevanssikorpuksen vertailu osoitti, että relevanssin kynnys on matala TREC:ssä.
Marginaalisesti hakuaihetta käsittelevät dokumentit dominoivat relevanssikorpuksessa.
Borlundin (2003b) mukaan dynaaminen relevanssi viittaa siihen, kuinka saman käyttäjän relevanssituntemukset voivat vaihdella yhden hakutehtävän aikana. Borlundin (2003b) ehdottama malli tilannerelevanssista (situational relevance) interaktiivisen tiedonhaun tutkimuksessa osoittaa hyvin käyttäjärelevanssin dynamiikan.
10
Borlundin malli
Borlund (2003a) ehdottaa vaihtoehtoista lähestymistapaa interaktiivisen tiedonhakujärjestelmien evaluoinnille (IIR evaluation model). Borlund esittää mallin vaihtoehtona systeemisuuntautuneella Cranfieldin mallille, joka on edelleen vallitseva lähestymistapa tiedonhaun tutkimuksessa. Tavoitteena on mahdollisimman realistinen interaktiivisen tiedonhaun arviointi ja hakujärjestelmän suorituksen laskeminen ottamalla huomioon relevanssiarvioiden ei- binaarinen luonne.
Borlundin mallissa tarjotaan kehys tiedonhaun datan keräämiselle ja analyysille. Tavoitteena on tiedonhakujärjestelmien evaluointi mahdollisimman realistisesti todellisen tiedonhakuprosessin mukaisesti suhteellisen kontrolloidussa evaluointiympäristössä. Tarkoituksena on myös järjestelmän suorituskyvyn mittaaminen siten, että relevanssiarvioiden ei-binaarinen luonne voidaan ottaa huomioon. (Borlund, 2003a.)
Borlundin mallin keskeisenä tarkoituksena on käyttää realistisia skenaarioita, simuloituja hakutehtäviä (simulated work task situations) ja vaihtoehtoisia tuloksellisuuden mittareita.
Simuloitujen hakutehtävien tarkoituksena on luoda pohjaa realistiselle tiedontarpeelle ja sen tunnistamiselle. Simuloidut hakutehtävät sisältävät lyhyen johdannon, joka kuvailee tilannetta, jossa hakijan on tarve käyttää tiedonhakujärjestelmää. Simuloidut hakutehtävät takaavat kokeelle myös riittävästi kontrollia. Vaihtoehtoisiksi tuloksellisuuden mittareiksi Borlund ehdottaa suhteellista relevanssia (relative relevance, RR) ja ranked half-life (RHL). Lisäksi hän mainitsee Järvelinin ja Kekäläisen (2002) ehdottaman kumulatiivisen hyödyn (Cumulated Gain, CG) ja diskontatun kumulatiivisen hyödyn (Discounted Cumulated Gain, DCG). (Borlund, 2003a.)
Borlundin mielestä tiedonhauntutkimuksessa tiedontarpeen määrittely tulisi olla yksilöllisten tiedonhakukokemusten ja käsitteiden dynaamisen luonteen mukainen. Hänen mielestään Cranfieldin malli ei ota huomioon dynaamista tiedontarvetta vaan käsittelee tiedontarvetta staattisena käsitteenä, jota hakulauseke kuvastaa. Yhteenvetona Borlund toteaa, että Cranfielden malli ei sovellu interaktiivisten tiedonhakujärjestelmien evaluoimiseen, jos se suoritetaan niin
11
realistisesti kuin mahdollista. Realismi vaatii interaktiivisuutta, potentiaalisesti dynaamista tiedontarpeen tulkintaa ja moniulotteista ja dynaamista relevanssitulkintaa.
Käyttäjäsuuntautuneessa tiedonhaun tutkimuksessa on Borlundin (2003a) mukaan myös puutteita. Käyttäjäsuuntautunut lähestymistapa määrittelee tiedonhakujärjestelmän laajemmin ja näkee tiedontarpeet ja hakuprosessin kokonaisuutena. Evaluointiprosessissa kiinnitetään huomiota siihen miten hyvin käyttäjä, tiedonhakumekanismi ja tietokanta toimivat keskenään todellisista operationaalisissa tilanteissa.
Tässä lähestymistavassa alkuperäinen käyttäjä tekee relevanssiarviot suhteessa omaan tiedontarpeeseensa, joka voi vaihdella hakutehtävän aikana. Oletuksena tässä on, että relevanssiarviot edustavat tietyn käyttäjän tietyssä tilanteessa tekemiä arvioita, joten relevanssiarvion voi tehdä vain käyttäjä sillä hetkellä. Relevanssitulkinta on silloin subjektiivinen, ei-binaarinen tilannerelevanssi. Näillä perusteilla realismin vaatimus olisi saavutettu. Borlund kritisoi kuitenkin käyttäjälähtöisen lähestymistavan tapaa mitata suoritustehokkuutta saanti- ja tarkkuuslukuina huolimatta siitä, että kerätään ei-binaariset relevanssiarviot. (Borlund, 2003a.)
Borlund tuo ilmi tarpeen kehittää realistisempia koeasetelmia ja korostaa relevanssin dynaamista ja moniulotteista luonnetta, mutta häneltä puuttuvat ehdotukset siitä, kuinka testikokoelmien relevanssiarviointien esittämistä tulisi käytännössä kehittää. Lisäksi Borlund ei tarkastele dokumenttien sisältöjä tai niiden päällekkäisyyksiä, vaikka tarkastelee relevanssia dynaamisena ilmiönä.
Tiedontarpeen dynaamisen luonteen tunnistaminen tutkimuksissa on haasteellista interaktiiviselle tiedonhauntutkimukselle. Tietoisuus relevanssin moniulotteisuudesta ja vaihtelevuudesta on muuttanut käsitystä siitä kuinka tiedonhakujärjestelmiä tulisi arvioida ja viimeaikoina testaamisessa on tapahtunut muutoksia interaktiiviseen käyttäjälähtöiseen suuntaan. (Borlund &
Ingwersen, 1998.)
12
Simuloidut hakutehtävät kuvailevat tiedontarveskenaarion ja varmistavat, että evaluointi on hallittavissa ja relevanssiarviot ovat vertailukelpoisia. Menetelmä kaventaa kuilua subjektiivisen ja objektiivisen relevanssin välillä ja on käyttäjälähtöisempi näkökulma. Kaikki mittaustavat tuottavat hiukan erilaiset arvioinnit samoille objekteille. (Borlund & Ingwersen, 1998.)
Tiedonhakututkimuksessa päähuomio on vuosien kuluessa siirtynyt aiherelevanssista kohti käyttäjärelevanssia. Tämä ei kuitenkaan tarkoita sitä, että tutkimuksessa tulisi tai edes aina voitaisiin käyttää käyttäjärelevanssiin perustuvaa hakutuloksen arviointiperustaa aiherelevanssin sijasta. Monissa järjestelmäkeskeisissä tutkimusasetelmissa aiherelevanssi antaa yksinkertaisemman toteutustavan ja riittävän pohjan hakujärjestelmän arvioinnille. Valinta riippuu tutkittavasta ongelmasta. (Järvelin & Sormunen, 1999.)
Käyttäjän relevanssitulkintaan voisivat myös vaikuttaa samantapaiset tai päällekkäiset dokumentit, jotka ovat esiintyneet aiemmin tulosjoukossa. Kekäläinen ja Järvelin (2002) ovat tulleet siihen tulokseen, että aiheenmukainen relevanssi on riittävä evaluointitarkoitukseen, jos se kohtaa evaluoinnin tarkoituksen eli hakutehtävän, johon algoritmi, jota testataan on suunniteltu.
Kokeellisen tutkimuksen tavoite on luoda kontrolloitu ympäristö, jossa tutkittavaa ilmiötä voidaan testata. Testikokoelmia, jotka perustuvat realistiseen dokumenttikokoelmaan, määriteltyihin simuloituihin hakutehtäviin (Borlund 2003) ja moniportaisiin aiheenmukaisiin relevanssiarvioihin (Sormunen 2002, Kekäläinen 2005) voidaan edelleen pitää luotettavina työkaluina kokeellisessa tiedonhaun tutkimuksessa. Kuitenkin, uudenlaisia lähestymistapoja täytyy kehittää, jos uusia tai laajempia evaluointiskenaarioita sovellettaisiin (Kekäläinen &
Järvelin 2002).
2.4 Päällekkäisyyden huomiointi vuorovaikutteisen tiedonhaun tutkimuksessa
Päällekkäisen informaation ongelma on tiedostettu tiedonhaun tutkimuksessa, mutta sen ratkaisemiseksi ei ole vielä tehty kovin paljon. Moniulotteisen relevanssin varsinainen käyttö tiedonhaun tutkimuksissa ja testikokoelmissa on suhteellisen uusi asia, jota ollaan vasta kehittelemässä.
13
Aiheeseen liittyviä kokeellisia asetelmia on ollut käytössä mm. TREC:ssä.
Interaktiivisen TREC:in kokemukset ovat osoittaneet, että perinteiset testausmenetelmät, jotka perustuvat binääriseen yksiulotteiseen relevanssiarviointiin, eivät anna kunnollista pohjaa tutkia interaktiivista tiedonhaun ilmiötä. TREC:n interaktiivisen tiedonhaun kokeet ovat osoittaneet myös päällekkäin menevän informaation ongelman tärkeyden. Käyttäjälle tai systeemille, joka löytää päällekkäistä informaatiota, ei tulisi antaa tehokkuusvertailussa perusteetonta etua.
TREC:ssä on ollut mukana interaktiivisen tiedonhaun tutkiminen alusta alkaen. TREC 1:ssä ja TREC 2:ssa tutkittiin jo myös tiedonhaun interaktiivista puolta. Kokeet kuitenkin kärsivät hakuaiheiden epärealistisesta luonteesta (Beaulieu et al. 1996). TREC 3:ssa ja TREC 4:ssä mukaan otettiin erilliset interaktiiviset tiedonhaun kokeet, joissa käytettiin kuitenkin vielä samoja hakuaiheita.
TREC 6 perinteiset relevanssiarviot korvattiin aspektuaalisilla arvioinneilla ja myös saanti ja tarkkuus korvattiin aspektuaalisella saannilla ja tarkkuudella (aspectual precision and recall).
TREC 7:ssä termi aspekti (aspect) korvattiin termillä instanssi (instance). Viimeisimmissä kokeissa aiheet on kehitetty interaktiivista tiedonhaun tutkimusta varten ja instanssisaantia ja - tarkkuutta on käytetty mittaamisen välineinä.
Interaktiivisessa TREC:ssä käytettiin erikoishakutehtäviä, joissa tehtävänä oli löytää tietyn ajan sisällä mahdollisimman monta hakuaiheen eri instanssia käsittelevää dokumenttia. Hakutehtävänä voi olla esimerkiksi eri hoitokeinot sydänsairauksiin, joista kustakin tuli löytää informaatiota (TREC 5). Hakijan piti löytää informaatiota mahdollisimman monesta hoitokeinosta, mutta joukossa ei saanut olla päällekkäistä informaatiota. Päällekkäisen informaation löytämisestä ei annettu pisteitä tuloksellisuuden mittaamisessa. (Over, 2001.)
Todellisessa hakutilanteessa käyttäjän tarkoituksena ei ole kuitenkaan luoda optimaalista kyselyä, vaan löytää informaatiota sisältäviä dokumentteja, lisäksi todellisessa hakutilanteessa kysely todennäköisesti kehittyy dynaamisesti (Beaulieu et al. 1996). TREC:ssä kehitetty relevanssiarviointi menetelmä ei ole yleiskäyttöinen, vaan sopii paremmin tietyntyyppisiin
14
hakutehtäviin, koska useimmiten hakutilanteissa ei ole tarkoituksena hakea instansseja vaan tiettyyn aiheeseen liittyvää informaatiota Borlund (2000).
3. Moniulotteinen relevanssiarviointimalli
Moniulotteisen relevanssiarviointimallin perusajatus on sisällöllisen päällekkäisyyden arvioiminen tietyn hakuaiheen relevanteista dokumenteista. Malli perustuu siihen, että hakuaihetta käsittelevät dokumentit jaetaan erilaisiin teemoihin sisällönanalyysin kautta.
Teemoihin liittyvä informaatiosisältö arvioidaan perinteisin binaarisin tai moniportaisin relevanssiarvioiden. Eri teemoissa toisiaan täydentävien tai päällekkäisten dokumenttien tunnistamiseen voidaan käyttää taulukkona esitettyä relevanssidataa.
3.1 Menetelmän perusideat
Sormusen (2006) esittämä malli perustuu seuraaville taustaolettamuksille: Moniulotteisten relevanssiarviointien luomisessa tietokannan informaatiosisältö on oleellinen suhteessa tarkasti määriteltyyn tai simuloituun hakutehtävään. Potentiaalisesti relevantit dokumentit ovat relevanssiarvioiden tarkastelun kohteena. Jokainen dokumentti potentiaalisesti relevanttien dokumenttien joukossa saattaa tarjota relevanttia informaatiota käyttäjälle, joka suorittaa hakutehtävää.
Tämä potentiaali arvioidaan ja esitetään moniulotteisella relevanssikorpuksella. Kriittinen kysymys on kuinka hyvin moniulotteinen relevanssidata auttaa arvioimaan minkä tahansa dokumentin uniikkia ja muiden dokumenttien kanssa päällekkäistä sisältöä. Moniulotteinen relevanssikorpus voi sisältää myös tietoja ei-aiheenmukaisista dokumenttiattribuuteista.
Moniulotteisessa relevanssiarvioinnissa dokumentin relevanssia voidaan kuvata useilla luvuilla, joista kukin edustaa yhtä dokumentin ominaisuutta. Moniulotteisessa relevanssiarvioissa voidaan käyttää kunkin ominaisuuden osalta binäärisiä tai moniportaisia relevanssiarvoja. Jos moniulotteisessa relevanssiarvioinnissa keskitytään hakuaiheeseen, dokumentit arvioidaan hakuaiheesta tunnistettujen teemojen vastaavuuden perusteella.
15
Moniulotteisessa relevanssiarvioinnissa pyritään ottamaan huomioon enemmän myös sitä mihin aihealueeseen dokumentit sisällöllisesti jakautuvat. Sisällöllisesti päällekkäiset dokumentit voivat sisältää samaa informaatiota, jolloin toiseen kertaan löydetty informaatio ei tuo enää lisäarvoa käyttäjälle.
Testikokoelmien moniulotteisten relevanssiarviointien tarkoituksena on tukea tutkimusta, jossa voidaan ottaa huomioon dokumenttien sisällön päällekkäisyys tai täydentävyys. Interaktiivinen tiedonhaun tutkimus, käyttäjiä koskeva tutkimus ja samantapaiset tutkimustarpeet voisivat hyötyä rikkaammasta relevanssidatasta kontrolloiduissa kokeissa.
3.2 Moniulotteisen datan esittäminen
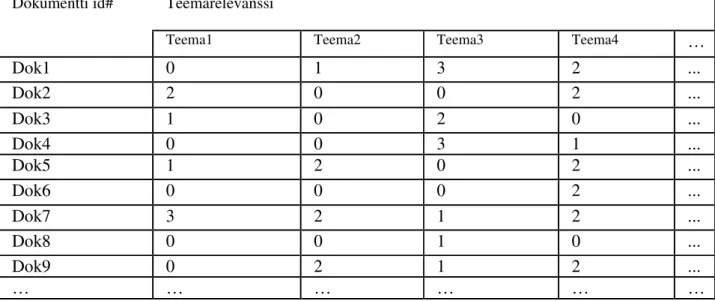
Taulukko 1 on esimerkki moniulotteisen relevanssidatan esittämisestä. Testikokoelman hakuaiheet on jaettu teemoihin. Teemoilla on sama rooli kuin instansseilla interaktiivisessa TREC:ssä (Over 2001), mutta ne ymmärretään yleisemmällä tasolla. Teemoille voidaan antaa eri rooleja erilaisissa hakuaiheissa ja aineistoissa. Uutismateriaalissa teemat voivat liittyä uutisjutun raportoinnin eri vaiheisiin. Esimerkiksi teemat, jotka liittyvät aiheeseen "Junaonnettomuus Jyväskylässä" voidaan jakaa seuraavasti: onnettomuus (mitä tapahtui), seuraukset (kuolleet, loukkaantuneet), henkilökohtaiset kokemukset (haastattelut), onnettomuustutkinta, oikeudenkäynti, onnettomuuden synnyttämä kirjoittelu rautateiden turvallisuudesta yleensä.
Tutkimusjulkaisujen kokoelmassa sopivat teemat olisivat erilaisia. Esimerkiksi aihe "Web- tiedonhaku käyttäytyminen" voitaisiin jakaa teemoihin: peruskäsitteet, mallit ja teoriat, tutkimusmetodit, empiiriset tulokset, yleiset ympäristöt ja spesifit ympäristöt (informaation tyypit, vrt. Vakkari 2001).
Teemojen valinta riippuu hakutehtävästä ja aiheenmukaisten dokumenttien sisällöstä. Teemojen täytyy käsitellä aiheenmukaisuuden eri aspekteja, jotka ovat tarkoituksenmukaisia tarkastelussa olevalle hakutehtävälle. Toisaalta sellaiset aiheenmukaiset aspektit, joita ei käsitellä yhdessäkään dokumenteista voidaan jättää huomioimatta teemojen valinnassa.
16
Jokaisen teeman sisällä dokumentin relevanssi voidaan arvioida käyttäen binääristä tai moniportaista asteikkoa. Saantia ja tarkkuutta voidaan käyttää tuloksellisuuden mittareina.
Dokumentin moniulotteiset relevanssiarvot voidaan myös muuntaa perinteisiksi yksiulotteisiksi relevanssikorpukseksi, jolloin voidaan tehdä tavanomaisia testejä. Moniulotteinen relevanssikorpus auttaa arvioimaan informaation täydentävyyttä dokumenteissa osoittamalla mitkä dokumentit käsittelevät eri teemoja. Kun dokumentit käsittelevät eri teemoja voidaan soveltaa vuorovaikutteisessa TREC:ssä kehitettyjä tuloksellisuusmittareita kuten instanssisaanti.
Kun dokumentit käsittelevät samoja teemoja, on mahdollista, että informaatiosisällöt ovat päällekkäisiä (redundantteja). Kuinka suuri informaatiosisältöjen redundanttisuuden todennäköisyys on teemojen ollessa päällekkäisiä on avoin tutkimuskysymys, johon tämän tutkielman empiirisen osuuden toivotaan antavan vastauksia.
Dokumentti id# Teemarelevanssi
Teema1 Teema2 Teema3 Teema4 …
Dok1 0 1 3 2 ...
Dok2 2 0 0 2 ...
Dok3 1 0 2 0 ...
Dok4 0 0 3 1 ...
Dok5 1 2 0 2 ...
Dok6 0 0 0 2 ...
Dok7 3 2 1 2 ...
Dok8 0 0 1 0 ...
Dok9 0 2 1 2 ...
… … … …
Taulukko 1. Moniulotteisen relevanssidatan esittäminen.
17
3.3 Moniulotteisen relevanssidatan arviointiprosessi
Perinteisen ja teemaperustaisen relevanssiarvioinnin suurin ero on siinä, että jälkimmäisessä arvioijan täytyy tuntea hakutehtävä hyvin. Arvioijan täytyy myös perehtyä aiheen käsittelyyn eri dokumenteissa kokonaisuutena, jotta teemojen valinta voi tapahtua mielekkäästi. Menetelmän haasteena on se, että varsinainen arviointi tehdään yksi dokumentti kerrallaan, jotta arvioija pystyy suoriutumaan tehtävästä. Kaikkien potentiaalisesti relevanttien dokumenttien rinnakkainen, yhtäaikainen vertailu ylittää arvioijan kapasiteetin.
Moniulotteisen relevanssidatan keräämisen vaiheet hakuaiheelle määritellään seuraavasti:
1. Valitaan hakuaihe ja tehdään testihakuja, jotta saadaan selville minkätyyppistä materiaalia on saatavilla ja onko sitä riittävästi. (Ei poikkea normaalista käytännöstä testikokoelmien rakentamisessa.)
2. Vaiheessa 1 valituille potentiaalisesti relevanteille dokumenteille tehdään alustava sisällönanalyysi (vähintään 10-15 dokumenttia, ainakin osa erittäin relevantteja) ja valitaan teemat. Kaikki teemat dokumentoidaan, jotta saadaan riittävä pohja relevanssiarvioille ja kokoelman ylläpitämiselle.
3. Suunnitellaan ja tehdään kyselyt, jotta löydetään mahdollisimman luotettavasti kaikki potentiaalisesti relevantit dokumentit. (Tämäkin vaihe normaalin testikokoelman mukaista.) 4. Arvioidaan dokumenttien relevanssi suhteessa valittuihin teemoihin.
5. Jos alkuperäisten teemojen määritelmiä pitää muuttaa tai liian laaja teema on jaettava osiin, kaikki tai osa dokumenteista joudutaan arvioimaan uudelleen määriteltyjen ja muokattujen teemojen mukaan. (Sormunen, 2006.)
4. Tutkimustehtävä, aineistot ja menetelmät
Moniulotteisia relevanssikorpuksia ei ole vielä käytetty tiedonhakujärjestelmien tutkimuksessa, mutta informaatiotutkimuksen laitoksella on tuotettu menetelmää soveltaen moniulotteinen korpus. Korpusta analysoimalla on mahdollista selvittää korpuksen ominaisuuksia ja arvioida sen käyttökelpoisuutta ajatellussa käytössä.
18
Uuden menetelmän kyky tunnistaa sisällöllistä päällekkäisyyttä edellyttää erillistä sisällönanalyysia samoista teemoista kertovista dokumenteista. Tällöin tarkastellaan sitä, kuinka paljon todellista päällekkäisyyttä eri dokumenteissa esiintyy. Vaikka dokumentti kertoo samasta teemasta, ei voida olla varmoja siitä ovatko dokumenttien informaatiosisällöt toisensa korvaavat.
Tässä tutkimuksessa pyritään saamaan selville kuinka hyvin tämä menetelmä pystyy kertomaan todellisesta sisällöllisestä päällekkäisyydestä dokumenttien välillä.
4.1 Tutkimuskysymykset
Moniulotteisesti relevanssiarvioitu aineisto antaa mahdollisuuden tutkia moniulotteisen relevanssikorpuksen ominaisuuksia, relevanttien dokumenttien sisällöllisiä päällekkäisyyksiä sekä perinteisten ja moniulotteisten relevanssiarvioiden yhteyksiä. Tässä relevanssikorpusta apuna käyttäen tutkitaan seuraavia kysymyksiä:
1. Moniulotteisten relevanssikorpuksien ominaisuudet: Kuinka monta teemaa on valittu hakutehtävää kohden? Kuinka monta teemaa eri relevanssitasoja edustavissa dokumenteissa keskimäärin esiintyy?
2. Perinteisten relevanssiarvioiden suhde teemakohtaisiin relevanssiarvioihin. Korreloivatko teemakohtaiset relevanssiarviot perinteisten relevanssiarvioiden kanssa?
3. Sisällölliseen päällekkäisyyteen liittyvä tarkastelu eli kuinka paljon päällekkäisyyttä esiintyy samoista teemoista kertovien dokumenttien sisällöissä. Miten relevantit dokumentit ovat päällekkäisiä ja täydentävät toisiaan? Lisäksi on tarkoituksena tehdä moniulotteisen relevanssikorpuksen päällekkäisyystarkastelu eli tarkastella kuinka suurta vaihtelua on päällekkäisyydessä eri hakutehtävien välillä.
4. Mikä on todellinen informaation sisällöllinen päällekkäisyys relevanteissa dokumenteissa, jotka käsittelevät päällekkäisiä/ei-päällekkäisiä teemoja? Kuinka paljon todellista informaatiosisältöjen päällekkäisyyttä tai täydentävyyttä esiintyy kahden eri dokumentin saman teeman eri relevanssitasojen välillä.
19
4.2 Tutkimusaineisto
4.2.1 Testikokoelma
Aineistona on TUTK- kokoelmasta 26 hakutehtävää, joista on tehty neliportaiset relevanssiarviot.
Informaatiotutkimuksen laitoksen tiedonhakulaboratorion TUTK- kokoelma sisältää kaiken kaikkiaan 54 000 vuosina 1988-1992 ilmestynyttä sanomalehtiartikkelia Aamulehdestä, Keskisuomalaisesta ja Kauppalehdestä. Aamulehden ulkomaan uutisosaston artikkeleita kokoelmassa on 25 000, kaikista Keskisuomalaisen osastoista 13 000 ja kaikista Kauppalehden osastoista 16 000. Koko tietokanta sisältää 12,5 miljoonaa sanaa.
Keskimääräinen artikkelinpituus on 202 sanaa, mediaanipituus 162 sanaa ja keskihajonta 155 sanaa. Kokoelman testikanta sisältää 445 erittäin relevanttia, 833 melko relevanttia ja 1002 marginaalisesti relevanttia dokumenttia (2280 relevanttia dokumenttia yhteensä). (Sormunen, 2000). Nämä artikkelit uudelleen arvioitiin käyttäen moniulotteista relevanssiarviointia.
4.2.2 Arvioitavat dokumentit
Dokumentit on valittu siten, että jokaisesta relevanssitasosta on valittu 5-10 dokumenttia kultakin relevanssitasolta (marginaalisesti, melko ja erittäin relevantit). Dokumentit on valittu 26 sellaisesta hakutehtävästä, joista löytyi vähintään viisi relevanttia dokumenttia kutakin relevanssitasoa kohti. Korkeintaan kymmenen dokumenttia otettiin mukaan kuhunkin relevanssitasoon, joten dokumenttien lukumäärä on 5-10 kutakin relevanssitasoa ja hakuaihetta kohti. Kaiken kaikkiaan moniulotteisesti arvioituja dokumentteja on noin 684 kappaletta 26 eri hakuaiheesta.
4.2.3 Relevanssiarviot
Kaikista 26 hakutehtävästä on tehty moniulotteiset relevanssiarviot. Tässä mukana olevat 26 hakuaihetta on jaettu Informaatiotutkimuksen laitoksella teemoihin siten, että teemojen valinta on sidoksissa tiettyyn hakutehtävään ja siihen liittyvien dokumenttien sisältöön.
20
Relevanssiarviointiin perehtynyt tutkija Erkka Leppänen kehitti teemat ja suoritti relevanssiarvioinnin. Teemojen on tarkoitus luonnehtia eri aspekteja kullekin hakutehtävälle.
Hakuaiheesta riippuen teemoja on kolmesta yhteentoista hakutehtävää kohti. Keskimäärin 5.2 teemaa hakuaihetta kohti. TUTK- kokoelmassa alkuperäiset relevanssiarviot on tehty neliportaisesti (0,1, 2 ja 3). Teemoittaisessa relevanssiarvioinnissa käytettiin myös neliportaista asteikkoa ja samoja relevanssikriteereitä kuin alkuperäisissä TUTK- kokoelman dokumenttien relevanssiarvioinnissa. Relevanssikriteerit neljälle eri tasolle ovat seuraavat: (Sormunen, 2002).
(0) Dokumentti ei sisällä lainkaan informaatiota aiheesta.
(1) Dokumentti vain viittaa aiheeseen. Ei sisällä enempää tai lisäinformaatiota aihekuvaukseen nähden. Tyypillinen laajuus: yksi lause tai fakta.
(2) Dokumentti sisältää enemmän informaatiota kuin aihekuvaus, mutta aiheen käsittely ei ole syvällistä. Jos aiheeseen sisältyy useita fasetteja, vain osaa alateemoista tai näkökulmista käsitellään dokumentissa. Tyypillinen laajuus: yksi tekstikappale, 2-3 lausetta tai faktaa.
(3) Dokumentti käsittelee hakuaiheen teemoja syvällisesti. Jos aiheeseen sisältyy useita fasetteja, kaikkia tai useimpia alateemoista tai näkökulmista käsitellään dokumentissa. Tyypillinen laajuus:
useita tekstikappaleita, ainakin 4 lausetta tai faktaa.
4.3 Aineiston analysointi
4.3.1 Relevanssikorpuksen ominaisuudet
Keskimääräiset tunnusluvut on laskettu kullekin relevanssitasolle teemarelevanssien kokonaispistemäärästä, käsiteltävien teemojen määrästä, käsiteltyjen teemojen relevanssiarvosta ja teemarelevanssien maksimiarvosta.
Teemarelevanssin kokonaispistemäärässä on laskettu yhteen kunkin teeman saamat relevanssiarvot. Käsiteltävien teemojen määrässä on laskettu kuinka montaa teemaa kussakin dokumentissa käsitellään. Käsiteltyjen teemojen relevanssiarvo kertoo kuinka suuria relevanssiarvoja käsitellyt teemat ovat keskimäärin saaneet ja teemarelevanssin maksimiarvo
21
kertoo mikä on korkein relevanssiarvo minkä kukin dokumentti on saanut teemakohtaisessa arvioinnissa.
Vertailun kohteena on kaikki alkuperäisessä relevanssiarvioinnissa marginaalisesti (rel=1), melko (rel=2) ja erittäin (rel=3) relevanteiksi todetut dokumentit. Tarkasteltavana on kunkin dokumentin teemarelevanssiarvot, joita on vertailtu moniportaisen relevanssiarvioinnin eri relevanssitasoilla. Tunnusluvut on laskettu erikseen jokaiselta relevanssitasolta 1, 2 ja 3.
Tilastollisen testauksen menetelmistä käytettiin Pearsonin korrelaationtestiä mittaamaan alkuperäisten relevanssiarvioiden ja moniulotteisten relevanssiarvioiden keskinäistä riippuvuutta.
Suhteellinen teemapäällekkäisyys eli relevantit dokumentit samasta teemasta mittasi teemapäällekkäisyyttä. Tunnusluvut kertovat kuinka suuri osa relevanteista dokumenteista käsittelee valittua teemaa. Tunnusluvut on laskettu eri teemarelevanssitasoille.
4.3.2 Sisällönanalyysi artikkelipareittain
Todellisten sisältöjen päällekkäisyyksien arviointi edellytti erillistä sisällönanalyysia.
Suhteellinen informaatiopäällekkäisyys kertoo kuinka paljon on dokumentteja, joissa on sisällöllistä päällekkäisyyttä. Informaation päällekkäisyys arvioitiin artikkelipareittain.
Moniulotteisesta relevanssikorpuksesta valittiin kpl 226 artikkeliparia.
Dokumenttiparit valittiin käsin ja valintakriteereitä oli useita: tarkoituksena oli valita pareja niin monesta hakuaiheesta kuin mahdollista, tasoittaa otanta marginaalisesti, melko ja erittäin relevanttien dokumenttien välillä, sisällyttää valintaan sekä teemoittain päällekkäisiä että ei- päällekkäisiä artikkelipareja, saada vaihtelevuutta päällekkäisten teemojen lukumäärään ja välttää yksittäisten dokumenttien esiintyvyyttä useasti.
Kahdeksan opiskelijan joukko teki päällekkäisyysarvioinnit. Jokaisen artikkeliparin arvioi kaksi eri arvioitsijaa ja jokainen arvioitsija arvioi eri dokumenttipariryhmät. Hakuohjeissa arvioitsijoita pyydettiin tutustumaan hakuaihekuvaukseen, tutkimaan yhtä artikkeliparia kerrallaan ja merkitsemään artikkeleista lauseet, jotka käsittelevät hakuaihetta. Sen jälkeen arvioitsijoiden tuli verrata hakuaihetta käsitteleviä lauseita ja arvioida onko niissä samaa vai erillistä informaatiosisältöä, jonka jälkeen kirjattiin ylös päällekkäistä ja erillistä informaatiota sisältävien
22
lauseiden määrä. Kunkin artikkelin päällekkäiselle ja erilliselle informaatiosisällölle annettiin lisäksi relevanssiarvo.
Artikkeliparit jaettiin neljään eri ryhmään: 1) Teemat ja sisältö eivät ole päällekkäisiä 2) Teemat ja sisältö ovat päällekkäisiä 3) Teemat ovat päällekkäisiä, mutta sisällöt eivät ja 4) Teemat eivät ole päällekkäisiä, mutta sisällöt ovat. Kategorioissa 1 ja 2 sekä teemarelevanssit ja sisällönarviointi ovat yhdenmukaisia. Kategorioissa 3 ja 4 artikkeliparien sisällönanalyysi oli ristiriidassa moniulotteisen relevanssiarvioinnin kanssa. Joko samasta teemasta kertovat dokumentit eivät sisältäneet päällekkäistä informaatiota (kategoria 3) tai sisällössä oli päällekkäisyyttä vaikka relevanssikorpuksen mukaan artikkeliparilla ei ollut yhteisiä teemoja (kategoria 4). Kategorioiden 3 ja 4 dokumenttipareista tehtiin tarkentava sisällönanalyysi, jolla voitaisiin selittää poikkeamia.
5. Tulokset
5.1 Relevanssikorpuksen ominaisuudet
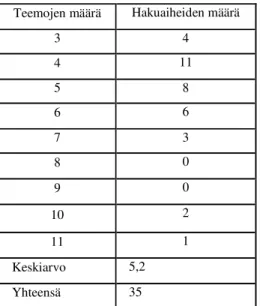
Taulukossa 2 on esitetty yhteenveto kuinka monessa hakuaiheessa arvioija oli valinnut tietyn määrän teemoja. Hakuaiheista oli tunnistettu 3-11 teemaa. Keskimäärin teemoja oli valittu 5,2 kappaletta.
Teemojen määrä Hakuaiheiden määrä
3 4
4 11
5 8
6 6
7 3
8 0
9 0
10 2
11 1
Keskiarvo 5,2
Yhteensä 35
Taulukko 2. Teemojen jakautuminen hakuaiheiden kesken.
23
5.2 Teemarelevanssi vs. perinteinen relevanssi
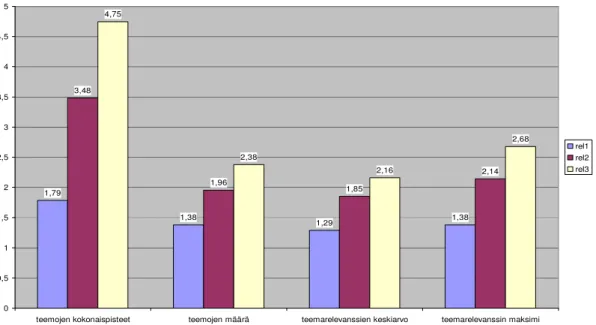
Kaaviossa 3 esitetään yhteenveto teemakohtaisten (eli moniulotteisten) relevanssiarvojen ominaisuuksista eritasoisesti relevanteissa dokumenteissa. Taulukossa on laskettu keskimääräiset tunnusluvut kullekin relevanssitasolle teemarelevanssien kokonaispistemäärästä, käsiteltävien teemojen määrästä, käsiteltyjen teemojen relevanssiarvosta ja teemarelevanssien maksimiarvosta.
Taulukosta käy ilmi, että erittäin relevantit dokumentit näyttäisivät saavan korkeampia arvoja kuin vähemmän relevantit dokumentit kaikkien neljän tarkastellun moniulotteisen relevanssikorpuksen tunnusluvun osalta.
1,79
1,38 1,29 1,38
3,48
1,96 1,85
2,14 4,75
2,38
2,16
2,68
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
teemojen kokonaispisteet teemojen määrä teemarelevanssien keskiarvo teemarelevanssin maksimi rel1 rel2 rel3
Kaavio 1. Teemakohtaisten relevanssiarvioiden eri ominaisuuksien jakautuminen eritasoisesti (erittäin, melko ja marginaalisesti) relevanttien dokumenttien kesken.
Teemakohtaiset relevanssiarviot näyttävät korreloivan perinteisen relevanssiarvioiden kanssa ja erittäin relevantit dokumentit saavat myös teemakohtaisesti korkeampia arvoja. Taulukosta ilmenee, että jokaisella lasketulla tunnusluvulla erittäin relevantit dokumentit saavat kaikkein korkeimmat arvot, melko relevantit saavat toiseksi korkeimmat arvot ja edelleen jokaisen teemarelevanssiarvon kohdalla marginaalisesti relevantit saavat matalimmat arvot. Kaikkien
24
teemarelevanssiarvojen kohdalla löytyi tilastollisesti merkitseviä eroja.
Teemarelevanssin kokonaispistemäärä eroaa huomattavasti erittäin relevanttien ja marginaalisesti relevanttien dokumenttien välillä. Erittäin relevantit saavat arvon 4,75 ja marginaalisesti relevantit arvon 1,79, joka tarkoittaa sitä, että keskimäärin teemoittain erittäin relevanteiksi arvioidut dokumentit myös sisältävät enemmän informaatiota hakuaiheen eri teemoista. Tästä johtuen voitaisiin myös olettaa, että erittäin relevanteissa dokumenteissa myös käsitellään aihetta laajemmin. Tilastollinen testaus osoittaa marginaalisesti ja erittäin relevanttien sekä marginaalisesti ja melko relevanttien välisen eron merkitseväksi (p>0,01).
Erittäin relevanteissa dokumenteissa käsitellään keskimäärin 2, 38 teemaa, melko relevanteissa 1, 96 ja marginaalisesti relevanteissa dokumenteissa keskimäärin 1, 38 teemaa. Tästä voidaan päätellä, että erittäin relevanttien dokumenttien joukossa käsitellään keskimäärin useampia teemoja, jotka käsittelevät hakuaihetta. Voidaan sanoa, että erittäin relevanteissa dokumenteissa asiaa käsitellään monipuolisemmin. Vain marginaalisesti relevanttien ja erittäin relevanttien välinen vertailu osoittautui tilastollisesti merkitseväksi (p>0,01).
Käsiteltävien teemojen relevanssiarvo kertoo minkä arvon käsitellyt teemat ovat keskimäärin saaneet. Teeman esiintyessä se myös saa keskimäärin korkeampia arvoja erittäin relevanttien dokumenttien joukossa. Erittäin relevantit saavat arvon 2,16, melko relevantit arvon 1,85, kun taas marginaalisesti relevantit saavat arvon 1,29. Erittäin relevanttien ja marginaalisesti relevanttien välinen ero osoittautui myöskin tilastollisesti merkitseväksi, kuten myös marginaalisesti ja melko relevanttien välinen vertailu.
Teemarelevanssin maksimiarvot ovat myös korkeampia erittäin relevanteissa dokumenteissa, joka tarkoittaa sitä, että erittäin relevantit dokumentit (rel=3) saavat useammin korkeimman arvon, keskiarvon ollessa 2,68. Marginaalisesti relevantit saavat arvon 1,38, joka kertoo myös siitä, että niissäkin esiintyy dokumentteja, jotka saavat ykköstä suuremman teemarelevanssiarvon. Tämä viittaa siihen, että myös marginaalisesti relevantit dokumentit saattaisivat sisältää hyödyllistä informaatiota. Toisaalta kyse voi olla myöskin arvioiden välisistä tulkintaeroista. Eri teemojen saamat teemarelevanssi maksimit vaihtelevat kuitenkin
25
hakutehtävän sisällä, joka tarkoittaa sitä, että jokin teema saattaisi olla tärkeämpi hakuaiheen kannalta. Myös tässä marginaalisesti ja erittäin relevanttien ja marginaalisesti ja melko relevanttien välinen ero oli merkitsevä.
Perinteisen ja moniulotteisen relevanssiarvioiden riippuvuutta tutkittiin Pearsonin korrelaatiotestillä. Pearsonin korrelaatiotesti osoittaa, että tunnusluvut korreloivat (rp=0,62 teemarelevanssien summalle, rp=0,59 teemarelevanssien maksimiarvoille, rp=0,37 teemojen määrälle ja rp=0,56 teeman relevanssin keskiarvolle). Korrelaatio on vahvinta teemarelevanssien summalle kohdalla (0,62) ja heikointa käsiteltävien teemojen määrän kohdalla (0,37). Tämä osoittaa, että teemarelevanssien summa heijastaa eniten perinteisiä relevanssiarvioita, mikä on luonnollista, koska teemarelevanssin summa nousee, jos teema saa korkeita relevanssipisteitä, sekä jos dokumentti käsittelee kahta tai useampaa teemaa . Kaikkien tulokset olivat tilastollisesti merkitseviä (p<0,001).
Tulokset viittaavat siihen, että erittäin relevantit dokumentit saavat keskimäärin korkeampia teemarelevanssiarvoja, mutta niissä ei välttämättä käsitellä asiaa aina monipuolisemmin eli useammista teemoista. Selkein korrelaatio perinteiseen relevanssiin on moniulotteisen relevanssikorpuksen teemarelevanssien taso. Kokonaisuutena tulokset osoittavat, että teemoittaisista relevanssiarvoista olisi pääteltävissä perinteisen relevanssiarvioiden tasot.
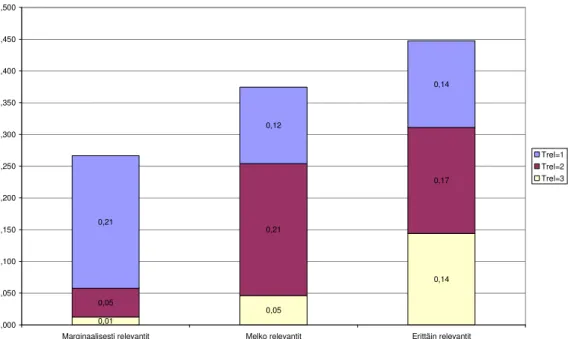
5.3 Suhteellinen teemapäällekkäisyys
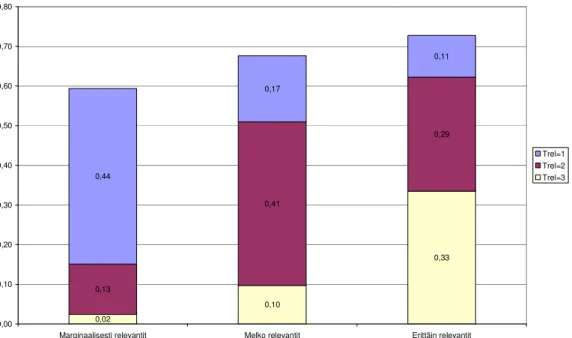
Kaaviossa 2 on esitetty relevanssikorpuksen marginaalisesti, melko ja erittäin relevanttien dokumenttien keskimääräinen suhteellinen teemapäällekkäisyys teemarelevanssitasoittain, kun tarkastelussa ovat kaikki teemat. Päällekkäisyysluvut kertovat siis sen, kuinka suuressa osassa relevanssikorpuksen dokumenteista puhutaan tietystä teemasta, joka voi olla mikä tahansa relevanssiarvioijan nimeämä aiheen teema (siis tyypillinen tai keskimääräinen teema).
26
0,01
0,05
0,14
0,05
0,21
0,17
0,21
0,12
0,14
0,000 0,050 0,100 0,150 0,200 0,250 0,300 0,350 0,400 0,450 0,500
Marginaalisesti relevantit Melko relevantit Erittäin relevantit
Trel=1 Trel=2 Trel=3
Kaavio 2. Keskimääräinen suhteellinen teemapäällekkäisyys marginaalisesti, melko ja erittäin relevanttien dokumenttien joukossa teemarelevanssitasoilla 1, 2 ja 3 (26 hakutehtävää, 684 dokumenttia per relevanssitaso).
Kaavio 2 kertoo selkeästi sen, että mitä korkeamman relevanssitason dokumentista on kyse, sitä suuremmassa osassa dokumentteja käsitellään samoja teemoja. Kun otetaan huomioon kaikki teemarelevanssin tasot (ei väliä kuinka paljon tai vähän teemasta puhutaan), suhteellinen teemapäällekkäisyys kasvaa marginaalisesti relevanttien dokumenttien 27 prosentista (0,01+0,05+0,21) erittäin relevanttien dokumenttien 45 prosenttiin (0,14+0,17+0,14). Toisin sanoen saman teeman käsittely on näin mitaten lähes kaksi kertaa yleisempää erittäin relevanteissa kuin marginaalisesti relevanteissa dokumenteissa.
Toinen selkeä trendi on dokumentin kokonaisrelevanssin ja teemarelevanssien asteen välinen riippuvuus. Marginaalisissa dokumenteissa on kaikista tavallisinta teemapäällekkäisyys tasolla TREL=1 (0,21) eli marginaalisissa dokumenteissa teemallinen päällekkäisyys liittyy pääosin marginaaliseen teemainformaatioon. Vastaavasti melko relevanteissa dokumenteissa tavallisin päällekkäisyys liittyy tasoon TREL=2 (myös 0,21). Sinänsä tulos ei ole yllätys, koska varsin suuri osa relevanssikorpuksen dokumenteista oli yksiteemaisia (vrt. aiemmat tulokset). Sekä kokonaisrelevanssia että teemakohtaista relevanssia arvioineet henkilöt ovat tehneet yhdenmukaisia arvioita (REL=TREL).
27
Erittäin relevanteissa dokumenteissa teemapäällekkäisyys jakaantuu tasaisemmin kaikille kolmelle teemarelevanssitasolle (TREL=1…3: 0,14/0,17/0,14). Tämäkin tulos on linjassa aiempien tulosten kanssa. Erittäin relevantit dokumentit käsittelivät keskimäärin useampia teemoja kuin melko ja erityisesti marginaalisesti relevantit dokumentit (vrt. aiempi tulos). Kun dokumentti käsittelee useampia teemoja, on todennäköistä että teemarelevanssin taso vaihtelee teemasta toiseen. Sivumennen käsitellyt teemat saavat alhaisen relevanssiarvon.
Voidaan olettaa korkean teemarelevanssin asteen (TREL=3) perusteella havaittu teemapäällekkäisyys voi olla käyttäjän kannalta kriittisempää kuin matalaan teemarelevanssiin (TREL=1 tai 2) liittyvä. Korkean relevanssiasteen (TREL=3) teemapäällekkäisyyttä esiintyy hyvin harvoin marginaalisissa dokumenteissa (1 %), jonkin verran melko relevanteissa (5 %) mutta jo melko yleisesti erittäin relevanteissa dokumenteissa (14 %).
Jos teemarelevanssivaatimusta nostetaan tasolle TREL=2-3, niin teemapäällekkäisyys jää marginaalisissa dokumenteissa melko alhaiseksi (6 %). Melko relevanteissa dokumenteissa teemapäällekkäisyys nousee reippaasti tasolle 26 prosenttia ja ero erittäin relevantteihin dokumentteihin kutistuu melko pieneksi (5 %). Tuloksista voidaan päätellä, että marginaalisesti relevanteissa dokumenteissa myös teemaapäällekkäisyys liittyy marginaaliseen teemainformaatioon. Erittäin relevanteissa dokumenteissa teemapäällekkäisyys liittyy huomattavasti (noin kuusi kertaa) useammin merkittävämmäksi arvioituun teemainformaatioon.
Edellä kuvatut tulokset on saatu tarkastelemalla kaikkien relevanssiarvioijan tunnistamien teemojen keskimääräisiä teemoja. Moniulotteisen relevanssiarvioinnin periaatteen mukaan valittujen teemojen yleisyys relevanssikorpuksen dokumenteissa vaihtelee kuitenkin varsin paljon. Sen vuoksi on syytä tarkastella erikseen kunkin hakuaiheen osalta yleisimmin dokumenteissa käsiteltyjä teemoja. Voidaan olettaa että niihin liittyvät päällekkäisyydet ovat evaluoinnin kannalta kaikkein olennaisimpia.
Kaaviossa 3 on esitetty relevanssikorpuksen marginaalisesti, melko ja erittäin relevanttien dokumenttien keskimääräinen suhteellinen teemapäällekkäisyys teemarelevanssitasoittain, kun tarkastelussa on jokaisesta hakuaiheesta yleisimmin esiintyvä teema.
28
0,02
0,10
0,33
0,13
0,41
0,29
0,44
0,17
0,11
0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80
Marginaalisesti relevantit Melko relevantit Erittäin relevantit
Trel=1 Trel=2 Trel=3
Kaavio 3. Hakuaiheen relevanssikorpuksessa yleisimmin esiintyvän teeman keskimääräinen suhteellinen teemapäällekkäisyys marginaalisesti, melko ja erittäin relevanttien dokumenttien joukossa teemarelevanssitasoilla 1, 2 ja 3 (26 hakutehtävää, 684 dokumenttia per relevanssitaso).
Kussakin hakuaiheessa yleisimmin esiintyvällä teemalla mitattu teemapäällekkäisyyden arvo luonnollisesti kasvaa (jo määritelmän mukaan) eri relevanssitasoja edustavissa dokumenttiryhmissä. Marginaalisesti relevanteissa dokumenteissa teema päällekkäisyys kaksinkertaistuu eli nousee 59%:iin (0,02+0,13+0,44). Relevanteimmissa dokumenteissa yleisimmän teeman perusteella laskettu teemapäällekkäisyys nousee hieman hillitymmin.
Esimerkiksi erittäin relevanteissa dokumenteissa teemapäällekkäisyys kasvaa 1,6-kertaiseksi tasolle 73 % (0,33+0,29+0,11). Eli tärkein teema ainakin mainitaan kolmessa neljästä erittäin relevantista dokumentista.
Yleishuomiona kaaviosta 3 voidaan todeta, että eri relevanssitasoja edustavien dokumenttien teemapäällekkäisyyden erot ovat selvästi pienempiä kuin kaaviossa 2, kun laskentaperusteena käytetään kaikkia teemarelevanssitasoja. Kun huomioidaan teemat, joita dokumentit käsittelevät laajemmin kuin maininnan verran (TREL=2 tai 3), olennaiset erot tulevat esiin.
Tärkeintä teemaa käsitellään melko tai erittäin paljon keskimäärin 51 %:ssa melko relevantteja ja 62 %:ssa erittäin relevantteja dokumentteja. Vastaava teemapäällekkäisyys on vain 15 %
29
marginaalisesti relevanteissa dokumenteissa. Kun tarkastellaan vain erittäin paljon teemaa käsitteleviä dokumentteja, teemapäällekkäisyys putoaa 33 %:sta (erittäin relevantit) 10 %:n kautta (melko relevantit) 2 %:iin (marginaalisesti relevantit).
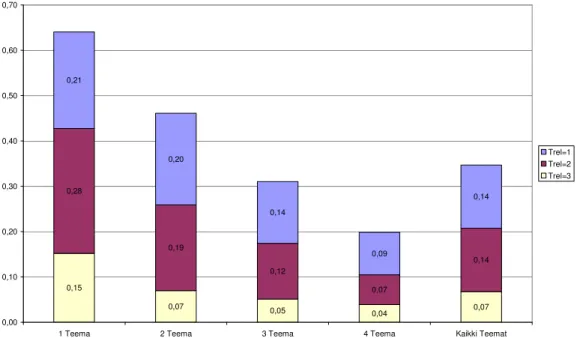
Kaaviossa 4 on esitetty relevanssikorpuksen keskimääräinen suhteellinen teemapäällekkäisyys teemarelevanssitasoittain, kun tarkastelussa on neljä yleisemmin esiintyvää teemaa ja kaikkien teemojen keskiarvo. Teemapäällekkäisyys putoaa nopeasti siirryttäessä vähemmän yleiseen teemaan.
0,15
0,07 0,05 0,04 0,07
0,28
0,19
0,12
0,07
0,14 0,21
0,20
0,14
0,09
0,14
0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70
1 Teema 2 Teema 3 Teema 4 Teema Kaikki Teemat
Trel=1 Trel=2 Trel=3
Kaavio 4. Hakuaiheen relevanssikorpuksessa neljän yleisimmin esiintyvän teeman ja kaikkien teemojen keskiarvon keskimääräinen suhteellinen teemapäällekkäisyys teemarelevanssitasoilla 1, 2 ja 3 (26 hakutehtävää, 684 dokumenttia per relevanssitaso).
Yleisimmän teeman teemapäällekkäisyys huomioitaessa kaikki teemarelevanssitasot on 64%
(0,15+0,28+0,21) ja pienenee neljäsosalla 46%:iin (0,07+0,19+0,14) siirryttäessä toiseksi yleisimpään teemaan, kolmas teema pienenee jo hieman alle puoleen 31%:iin (0,05+0,12+0,14) verrattuna yleisimpään teemaan.
Teemarelevanssitason 3 dokumenttien osuus on yleisimmän teeman kohdalla 15 % ja putoaa 2.
teeman kohdalla 7%:iin ja 3.teeman kohdalla 5%:iin. Teemarelevanssitason 3 dokumenttien suhteellinen osuus kaikista teeman dokumenteista pienenee siirryttäessä yleisimmästä teemasta
30
neljänneksi yleisimpään, joka osoittaa sen, että yleisimmän teeman merkitys on erityisen suuri ja myös TREL=3 edustava päällekkäisyys on suurempaa yleisimmän teeman kohdalla. 4.
yleisimmän teeman TREL=3 tason dokumentteja esiintyy enää 4 %, jolloin teemapäällekkäisyyden ennustettavuus heikkenee melko pieneksi. Vain 2-3 yleisintä teemaa ovat olennaisia päällekkäisyystarkastelussa, joissa päällekkäisyyden pitäisi ilmetä, jos sitä esiintyy.
5.4 Suhteellinen informaatiopäällekkäisyys
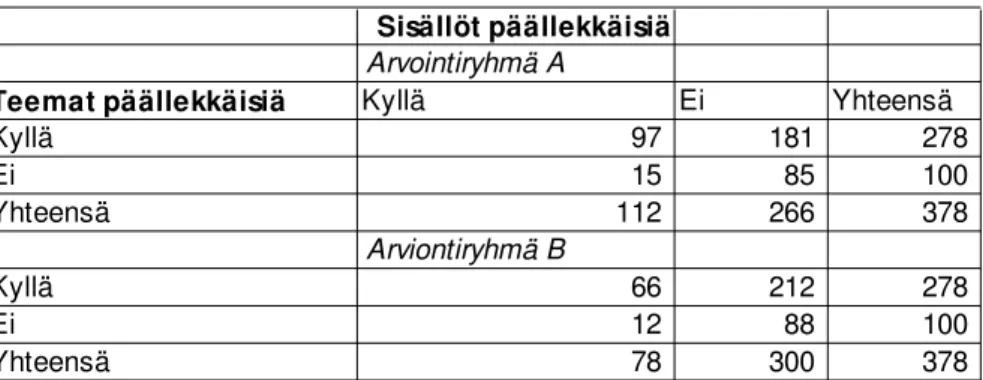
Tarkoituksena on selvittää kuinka paljon teemojen päällekkäisyys viittaa informaatiosisältöjen päällekkäisyyteen. Sen selvittämiseksi tehtiin dokumenttien pareittainen sisällöllinen vertailu, jossa dokumenttipareja oli yhteensä 226. Artikkelit määriteltiin päällekkäisiksi, jos niissä oli vähintään yksi lause, joka sisältää samaa informaatiota.
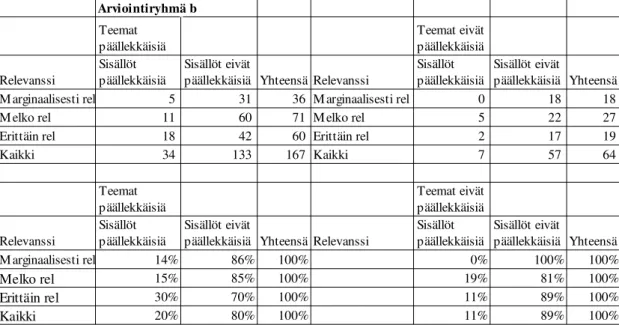
Taulukossa 3 on esitetty tuloksia päällekkäisyysvertailusta. Artikkelipareilla, jotka eivät käsittele samaa teemaa (Teemat päällekkäisiä = Ei), ei pitäisi myöskään olla päällekkäistä informaatiosisältöä (Sisällöt päällekkäisiä = Kyllä, pitäisi olla tyhjä) ja vastaavasti artikkelipareilla, jotka käsittelevät samaa teemaa (Teemat päällekkäisiä = Kyllä) tulisi olla myös päällekkäistä sisältöä (Sisällöt päällekkäisiä = Kyllä).
Sisällöt päällekkäisiä Arvointiryhmä A
Teemat päällekkäisiä Kyllä Ei Yhteensä
Kyllä 97 181 278
Ei 15 85 100
Yhteensä 112 266 378
Arviontiryhmä B
Kyllä 66 212 278
Ei 12 88 100
Yhteensä 78 300 378
Taulukko 3. Artikkeliparien vertailu: teemoittaisesti ja sisällöllisesti päällekkäisten ja ei- päällekkäisten dokumenttien osuudet.
Arviointiryhmällä B on ollut ryhmää A ankarammat kriteerit hyväksyttäessä sisältöjä päällekkäisiksi ja he löysivät vähemmän dokumenttipareja, joissa on päällekkäistä informaatiota (78 vs. 112). Ryhmä A havaitsi 97 (ryhmä B 66) samaa teemaa käsittelevää artikkelia myös